
Abstract
To address the issues of neglected review information and insufficient personalization in product recommendations, we developed a recommendation approach combining Quality Function Deployment (QFD) with user profiling. Our method employs data mining and TF-IDF algorithms to extract product feature words from consumer reviews, constructs preference vectors for product attributes and builds both “consumer-product attribute” and “product-product attribute” house of quality models. Additionally, we incorporate user profile labels to optimize recommendation rankings. Validation using lipstick review data from the Tmall platform confirms the model's feasibility. Results demonstrate that this approach offers a novel solution to the personalized ranking challenges while expanding the application scope of Quality Function Deployment (QFD), providing a foundation for developing interpretable recommendation systems.
Keywords
Introduction
According to Star Chart data monitoring, the total sales of integrated e-commerce platforms reached 614.3 billion yuan during the 618 shopping festival in 2023, with Tmall occupying the top position. Among popular sales categories, the beauty and skin care category was relatively weak, with sales of 30 billion yuan. Perfume and makeup maintained their growth rate, with total sales of 10.6 billion yuan. Food and oil seasonings, as essential products, showed sustained sales growth, with total sales of 10.5 billion yuan. Casual snacks grew slightly, with sales of 6.6 billion yuan during ‘618’. Given the wide variety of products, consumers often find it difficult to make purchasing decisions. A product recommendation ranking method can realize the rapid selection of products suitable for consumers’ needs, improve consumer experience, increase sales, and optimize the product operation of enterprises. In view of this, we construct a product recommendation ranking method based on Quality Function Deployment (QFD) and a product recommendation ranking optimization method based on user profile. This paper aims to construct a novel, interpretable personalized product recommendation ranking framework. Unlike research focused on improving the performance of individual algorithms, the core contribution of this study lies in the integration and validation of cross-domain methodologies. We creatively combine Quality Function Deployment (QFD) theory—originally from systems engineering—with user profiling techniques and sentiment analysis of online reviews. This framework employs a two-level Quality House model to systematically transform ambiguous, subjective online review data into a clear “consumer demand-product attribute” relationship network. This provides both theoretical foundations and operational pathways for achieving structured, interpretable recommendations. This paper comprehensively demonstrates the feasibility of this integrated framework for the first time and validates its effectiveness through real e-commerce data cases.
The remainder of this paper is structured as follows: Section 2 reviews relevant literature; Section 3 details the proposed Quality House-based recommendation ranking method and its extension path to fuzzy systems; Section 4 presents a case study and analysis using lipstick reviews from the Tmall platform; Section 5 concludes the paper, discussing theoretical contributions, research limitations, and future directions.
Related literature
With the rapid development of e-commerce platform, how to realize product recommendation ranking has become a hot issue for scholars. By reviewing the current relevant literature, the exiting research on product recommendation ranking mainly focuses on the information mining of product online reviews, considering the product feature weight and considering consumer preferences.
Online reviews are the evaluations that consumers post for a product or service after making a product purchase on an e-commerce platform. 1 As an important bridge among enterprises, consumers and third-party shopping platforms, online reviews are also an effective reference for potential consumers to understand products and make purchase decisions. 2 By mining consumers’ online reviews to obtain effective information, we can complete a reasonable match between consumers and products and provide consumers with more personalized product recommendations. Najmi et al. combined sentiment analysis and usefulness analysis to propose a ranking method based on the latest reviews and product descriptions. 3 Yang et al. proposed a new product ranking method based on four types of online review information to help consumers compare and select multiple available products and make appropriate purchase decisions. 4 Liu et al. proposed an intuitionistic fuzzy number based on the emotional features of online reviews in conjunction with PROMETHEE-II to obtain ranking results for alternative products. 5 Hao et al. combined the sentence structure analysis in online reviews with the matching relationship of feature opinions and proposed a product recommendation model using dynamic window to extract feature opinions. 6 Morente et al. combined sentiment analysis to propose a method for identifying statements related to product attributes in review information and constructed a product preference matrix. 7 Cui et al. took PLTS as a statistical tool to describe user review information and proposed a hotel recommendation algorithm. 8 Qin et al. proposed a product ranking based on the multi-criteria decision-making method considering the evidence reasoning (ER) theory and random dominance (SD) rule. 9 You et al. proposed a hotel ranking model based on sentiment analysis of online text reviews for hotel selection, considering the differences in the number of reviews from different aspects. 10 Anand et al. proposed graph neural network (GNN) significantly improved recommendation systems by effectively modeling graph-structured data, including text reviews. 11 The above research establishes a recommendation system by mining product online review information, which can provide consumers with personalized product recommendations and improve user experience and purchase satisfaction.
Product feature weight refers to consumers’ preference for a certain feature among all features of a given product. Hierarchical analysis process is usually used to process the ratings of experts in the authoritative field to get the product feature weights, which can effectively improve the credibility of the recommendation ranking Bi et al. proposed a product feature performance evaluation method based on consumers’ emotional intensity by combining stochastic approximation of ideal point ranking method. 12 Cao et al. introduced a product attribute model and a new recommendation ranking formula to implement a novel recommendation method that utilizes product attributes to improve recommendation efficiency. 13 Beleveslis et al. proposed an efficient content-based (CB) product recommendation method that promotes product diversity and can match recommendations by adjusting appropriate feature weights. 14 Wang et al. investigated a new colony-based feature selection algorithm to improve customer classification accuracy for personalized product recommendation. 15 Gupta et al. considered product multiple attributes and recommended the most appropriate product to the consumer based on their expectations of attribute satisfaction. 16 Considering the cost and risk, Bigorra et al. proposed a customer demand development method based on the quality house model and analytic hierarchy process to link customer satisfaction with product design requirements. 17 Abuzid utilized the Quality Function Deployment (QFD) tool system to design and develop instructional strategies to meet customer need. 18 Dumilah et al. provided consumers with digital product recommendation content based on two levels of QFD analysis involving interviews and discussions. 19 In the case that business developers lack key information and the efficiency and accuracy of new product development cannot be guaranteed, Huang et al. used text mining method to obtain users’ online comment information and convert it into data to drive product development by input interval grey number Quality Function Deployment (QFD). 20 Huang et al. integrated Quality Function Deployment (QFD) into human-LLM collaborative conceptual design to reduce reliance on human resources. 21 Park et al. developed a data-driven QFD methodology utilizing customer reviews and product manuals. 22
At the same time, consumers’ personal preferences will directly affect their demand for products and purchase decisions. Vatani et al. proposed a probabilistic product recommendation algorithm for social networks based on personality and trust perception. 23 Tian et al. proposed a price-aware recommendation method based on a matrix decomposition model, considering that each consumer's preference for product price is specific. 24 Tian et al. argued that integrating group information for personalized recommendations is necessary. 25 Zheng et al. proposed a personalized recommendation model by calculating the content interest affinity and semantic interest affinity between user profiles. 26 Dhelim et al. proposed Meta-Interest, a personality-aware product recommendation system based on user interest mining and meta-path discovery. 27 Gupta et al. developed an effective product recommendation method to generate more user-friendly results by grouping related products and recommending similar products to interested users. 28 Chen et al. created two lists of movies for each user, which were the movies that the user liked and disliked. Based on these two movie lists, a user positive profile and a user negative profile were created to recommend movies to users. 29 Raj et al. proposed large language models excel in capturing complex user preferences. 30 Wang et al. proposed a Large Language Model (LLM) enhanced Cross-Domain Sequential Recommendation Algorithm. By leveraging LLM to generate cross-domain user profile embeddings that transfer preference information, it employs a semantic fusion layer to integrate semantic and ID embeddings. Utilizing a contrastive loss function to align feature spaces, the algorithm outperforms existing cross-domain sequence recommendation models on real-world datasets. 31
Based on the above discussion and analysis, existing literature still exhibits the following limitations: (1) Research on online review information mining has largely focused on three areas: feature analysis, key technological studies, and factors influencing consumer purchasing behavior. Research leveraging information mining techniques to utilize useful information from online reviews for product recommendation ranking remains relatively scarce. (2) Within the product recommendation domain, current research primarily emphasizes product attributes and their weighting, alongside product evaluation methodologies. Most approaches enhance the accuracy of product attribute extraction through common recommendation algorithms—such as utility-based, association rule-based, or collaborative filtering—or by refining traditional ranking methods. Further research is needed on integrating online review data to improve product recommendation effectiveness with the goal of enhancing customer satisfaction. (3) Quality function deployment (QFD) is currently applied in evaluation systems across diverse fields such as defense technology, traditional manufacturing, railway passenger services, maintenance support equipment, and shipping. Few studies have explored integrating online reviews with QFD models to address product recommendation challenges. To deal with these problems, we establish a product recommendation model.
A product recommendation ranking method based on quality house
According to the numerous studies on e-commerce consumer behavior, before purchasing a desired product, potential consumers tend to search for the product on the platform and judge whether to make a purchase based on the content of existing reviews. Therefore, how to determine the product recommendation ranking that match consumers based on online review information is the priority problem to be addressed in this paper. The purpose of this paper is to build a product recommendation ranking model based on quality house, to achieve a product recommendation ranking for different consumer groups by mining online review information to measure the matching degree between products and consumers, and to build a product recommendation ranking optimization method based on user profile while considering consumer personalization.
Problem description
There is a set of candidate products from different brands determined by consumers who want to purchase a certain type of product through search and comparison, denoted as
After purchasing a product, consumers try it out and post comments on the shopping platform based on their own experience. At the same time, it is assumed that the comments on the platform are authentic and valid after processing. Let
Assuming that potential consumers who want to purchase the product have the same preferences as existing buyers, that is, based on existing online reviews on the shopping platform, all consumers can be divided into several customer groups, and any potential consumer can be placed in a certain customer group. Let
By mining online reviews of candidate products, we can more accurately understand different consumers’ evaluations and preferences of products. Accordingly, divide consumers into different groups, so that we can recommend products suitable for different groups in a targeted manner. The specific operation steps are: Firstly, clean and pre-process the collected online reviews; secondly, use the TF-IDF algorithm to extract product feature words; then, construct the spatial vector of consumer product attribute preference based on sentiment analysis; finally, utilize the improved two-step clustering algorithm to classify the consumer groups. Compared with the traditional recommendation method, the quality house model can realize the product recommendation ranking for different consumer groups to meet the personalized needs of users and improve the shopping experience of users. Therefore, combine the divided consumer groups, build two quality house models of “consumer-product attribute” and “product-product attribute”, and get the preliminary product recommendation ranking results. Then, through the consumer and candidate product matching degree matrix, we can further realize the accurate recommendation for each consumer group through the matching matrix of consumers and candidate products.
The following requirements need to be met before building a quality house model:
Product attributes mainly include external physical attributes such as function and appearance, and service attributes such as quality and after sale service. These attributes exist objectively and are not changed by consumers’ preferences. At the same time, consumers’ preferences for product attributes are based on real needs, and there is no “irrational demand”. The preference value of consumer groups for each product attribute is a natural number within 10, which is given by the QFD group based on consumer preferences and shopping platform information and is accurate. The matching value of each product attribute of a certain product is a natural number within 100, which is analyzed by the QFD team and has accuracy.
According to the candidate product set
After data cleaning, the reviews are word-sorting and lexical annotation. The online reviews about the candidate products were input into ICTCLAS Chinese word separation system, and the system automatically obtained the word separation and lexical annotation results for each review text in the online review set
Extract product feature word based on TF-IDF algorithm
In this section, we apply the TF-IDF algorithm to extract keywords for the online review information of the studied products. TF-IDF is a statistical method to assess the importance of words to one of the documents in a document set or a corpus. A word or phrase is considered to have good category differentiation ability if it appears with high TF frequency in one document and rarely in other documents. The online comment set The frequency of each word
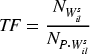
Where, According to formula (2), the inverse document frequency IDF of the feature term
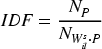
Where, The formula for the TF-IDF value of the feature term After calculating the TF-IDF value of each word in the comments and, the words are arranged in descending order, and the top word can be selected as the extracted keywords according to the need.
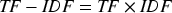
When consumers make post-purchase evaluations on the platform, the potential information contained in the content of their reviews can reflect consumers’ demand preferences for product attributes. In order to classify consumer groups based on consumers’ demand preferences for product attributes, this paper further classifies the extracted product feature words by combining word co-occurrence relationship and semantic similarity. And quantifies consumers’ preference degree by sentiment tendency analysis to construct a spatial vector of consumers’ product attribute preference for the following consumer group classification.
Word co-occurrence relationship refers to the existence of relevance between keywords appearing simultaneously within a specified range of text. Commonly, the mutual information (MI) is used to measure the degree of relevance between keywords, and let
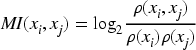
Where,
Semantic similarity measures the degree to which two words can be interchangeable in different texts without changing the semantic and syntactic structure of the original text. The result is usually a number between 0 and 1. The closer the value is to 1, the more similar the semantics of the two words are. Conversely, the greater the semantic gap between the two words is. Given the semantic similarity
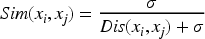
Where
To fully reflect the degree of association between product feature words, by combining mutual information and semantic similarity, the degree of association between feature word and feature word can be used. Let
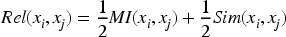
According to the above formula, the degree of association between feature terms is positively related to the value of
To quantify the degree of consumer preference for product attributes, we will analyze the sentiment words and sentiment modifiers in online reviews in this paper. Sentiment words contain positive, negative, and neutral words, which represent different emotional preferences of consumers towards product attributes, respectively. Sentiment modifiers are degree adverbs, which represent the degree of consumer preference. Among them, the review text contains negative words and sentiment modifiers assigned 1 point, negative words and no sentiment modifiers assigned 2 points, neutral words or not mentioned product attributes assigned 3 points, positive words and no sentiment modifiers assigned 4 points, positive words and sentiment modifiers assigned 5 points.
The sentiment analysis is carried out on the processed review word set
“Consumer-product attribute” quality house model
As shown in Figure 1, in the “consumer-product attribute” quality house, the left wall represents the consumer group
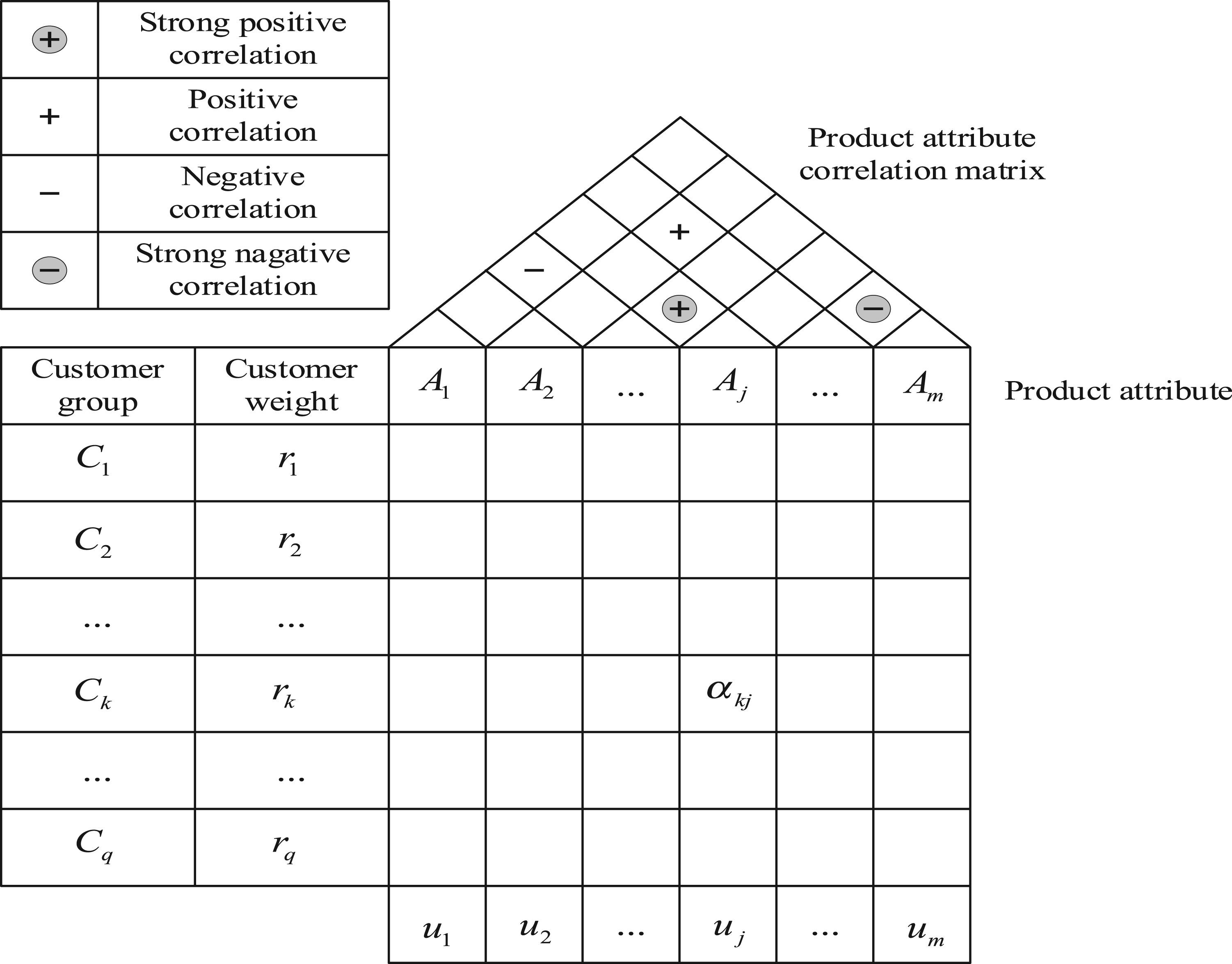
The quality house model of “consumer-product attributes”.
As shown in Figure 2, in the “product-product attribute” quality house, the left wall represents the set of product attributes that consumers care about, and the partitions represent the product attribute weights, which correspond to the floor (“consumer-product attribute” weights) in the model shown in Figure 1, indicating the importance of the m product attributes that consumers care about for that category of products relative to all consumers; the ceiling is a collection of candidate products after initial consumer screening; the roof remains the product-related matrix; each room of the quality house consists of an output matrix
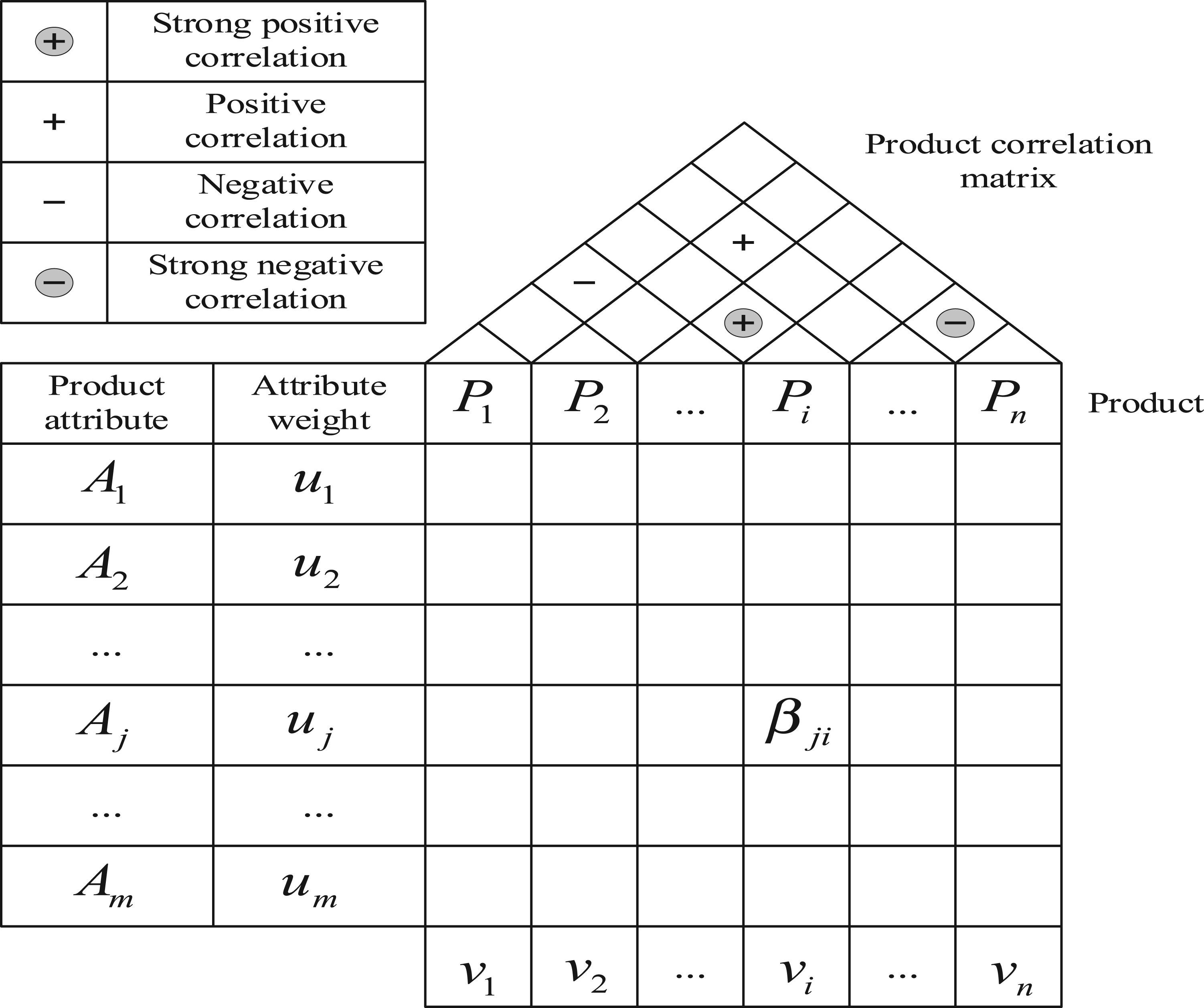
“Product-product attributes” quality house analysis model.
From the size ranking of
The above results use the improved two-step clustering to classify the consumer groups, whose multidimensional vectors represent the consumers’ product demand preferences, considering only the attribute of consumers’ demand preferences for products. In the actual online shopping, consumers usually consider their own income level, consumption habits, friends’ opinions, merchant service and after sale service when making purchase decisions. Now it is necessary to further consider consumer personality, achieve accurate positioning, and construct product recommendation ranking optimization method based on multidimensional user labels according to user profile.
Furthermore, we recognize that preferences expressed in online reviews are inherently fuzzy and uncertain. The current model's use of crisp values represents a beneficial simplification aimed at first validating the feasibility of the core integration framework. The framework's structure naturally supports extension toward a more rigorous fuzzy system, following these specific pathways: (1) Fuzzifying Inputs: Replace expert ratings from crisp values to triangular fuzzy numbers. (2) Fuzzy operations: Replace clear arithmetic operations with fuzzy number operation rules when calculating product attribute weights and overall product competitiveness. (3) Defuzzification and Ranking: Obtain the fuzzy competitiveness value for each product. Defuzzification methods such as the centroid method can be used to derive clear values for final ranking, or fuzzy numbers can be compared directly. This extension path enables more accurate modeling of uncertainty in human evaluations and represents a key direction for future research. The clear-valued model presented herein provides a validated, directly upgradeable foundational architecture for this purpose.
According to the above model and analysis, the decision steps of the proposed method are shown in Figure 3, and its detail steps are as follows:

The decision steps of the proposed method.
First, we establish the Problem Description & Model Assumptions to define the research scope and underlying premises. Second, Online Review Collection, Cleaning & Preprocessing is conducted to gather raw textual data from e-commerce platforms and prepare it for subsequent analysis. Third, Product Feature Extraction Based on TF-IDF is employed to automatically identify salient product attributes from the preprocessed reviews. Fourth, Construction of Consumer Product Attribute Preference Vectors quantifies individual consumer preferences toward specific product features. Fifth, Consumer Segmentation Based on Improved Two-Step Clustering is applied to partition heterogeneous consumers into distinct preference groups. Sixth, we perform Consumer-Product Matching Based on House of Quality to establish the relational mapping between consumer requirements and technical product characteristics. Finally, Recommendation Optimization & Ranking generates and refines personalized product recommendations for each consumer segment. This systematic pipeline integrates natural language processing, Quality Function Deployment (QFD), and clustering techniques to achieve data-driven personalized recommendation.
To verify the validity and rationality of the proposed model, a case of comment information of lipstick on Tmall platform for example analysis in this paper. This study analyzes consumer reviews of ten lipstick products on the Tmall platform. Data was collected using legitimate web scraping tools and underwent rigorous cleaning procedures, including removal of duplicate reviews, irrelevant spam comments, and system-generated content, to obtain a high-quality set of valid reviews. Subsequent preprocessing involved Chinese word segmentation, part-of-speech tagging, and stop-word removal.
Build lipstick recommendation ranking
This study examines lipsticks priced under 500 yuan, specifically: Dior # Velvet 999- True Red (
Select the official flagship stores of each brand on Tmall platform as the data source and collect the online review information of candidate lipsticks by using Octopus collector. The candidate lipsticks online review sets
Consumer demand for lipstick preference categories.

Consumer demand for lipstick preference categories.
We process the product attribute preferences involved in each of the 69,264 online reviews of ten lipsticks with Python, assigning integers from 1 to 5 depending on the sentiment words contained in the reviews and whether they contain sentiment modifiers. If it contains multiple feature words of a category, we can determine the average value; if it does not contain any attribute of a category, it is considered to have a neutral attitude towards the attribute and is assigned a value of 3. Therefore, we obtain a spatial vector of consumer product attribute preferences, i.e., a four-dimensional vector of each lipstick consumer with the four lipstick demand preference categories of sensory experience, appearance & packaging, price & value and brand service as dimensions, namely, each lipstick consumer can be represented by a 4-dimensional vector
Based on the above spatial vector sample of lipstick consumers’ product attribute preferences, we can exploit a clustering analysis of lipstick consumer groups to classify customer groups by combining the improved two-step clustering algorithm with SPSS software. By using the BIC criterion as the clustering criterion for second-order clustering, we can divide lipstick consumers into five groups. The initial number of clusters is set to 5, and the maximum number of iterations with the system default value of 10 is selected, and obtain the clustering results as shown in Table 2.
69,264 × 4 Spatial vector K-means clustering results.

From the two clustering result tables, consumers of ten lipsticks can be divided into five groups according to their product demand preference categories. And then, the weight of each customer group is obtained by the population proportion of each group:
These consumers have high scores in both sensory experience preference and appearance & packaging preference. They usually pay more attention to product attributes such as lipstick color, color rendering effect and packaging design, and pursue fashion matching. Generally speaking, this group of consumers is highly concerned about their external image, hoping that using lipstick can bring them a more confident and beautiful image, and willing to try new products and styles, which is the largest group among all consumer groups.
Beauty enthusiasts
Consumers in this category have the highest scores in the appearance & packaging preference dimension. They tend to make purchase decisions simply because they are attracted by the shell color, packaging design and other lipstick's face value, and for them, the price and brand of the lipstick are relatively less important and account for a smaller proportion of the total.
Pragmatist
They pay more attention to practical attributes such as makeup persistence and comfort level, and usually make purchase decisions because of obvious effects, practicality and durability. Relatively speaking, they do not pay much attention to factors such as price and brand service. In their opinion, the sensory experience when using lipstick is the first shopping criterion, and the number of consumers ranks second among the five groups.
Value-for-money weigher
This group of consumers has the highest score in price preference dimension and has relatively high preference for sensory experience and brand service. They usually decide which lipstick to buy by considering various factors such as price, quality, brand service and usage experience. The decision criteria of this consumer group pay great attention to cost performance and will make decisions by comparing and analyzing various attributes and prices of different lipsticks, making more rational and comprehensive purchase decisions and considering more factors.
Shopping experience
These consumers have the highest scores in the brand service preference dimension, they pursue a good shopping experience, pay attention to logistics, after sale and other service attributes, and pay relatively less attention to price, appearance and other attributes, the purchase behavior of these consumers is relatively arbitrary, accounting for the least among all consumers.
The parameters required for the product recommendation method based on the quality house model have been obtained, and then customer groups and their weights and product attributes are filled into the left wall, partition and ceiling of the “consumer-product attribute” quality house model and observe the product attribute preference characteristics of each customer group. Score the “consumer-product attribute” preference matrix by the QFD expert panel to calculate the product attribute weights u, as shown in Table 3.
The “consumer-product attribute” preference matrix.
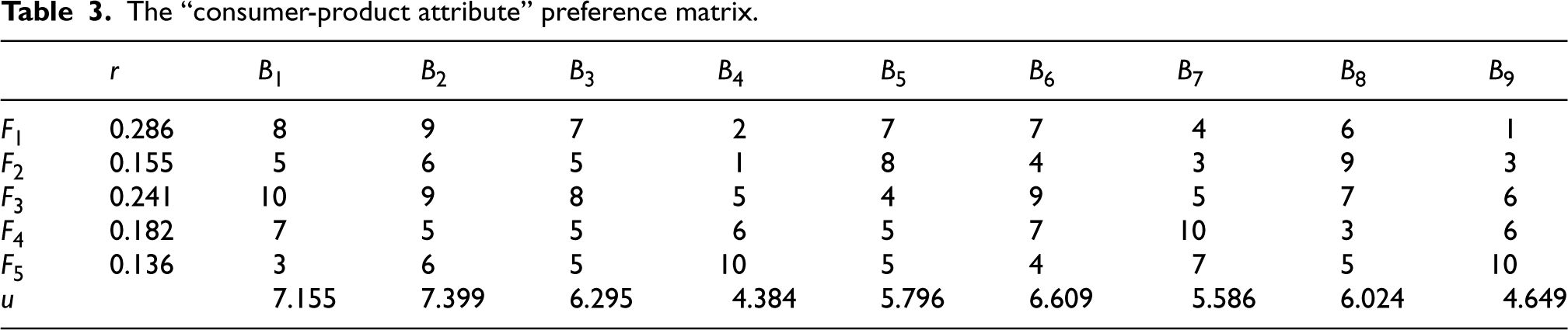
The “consumer-product attribute” preference matrix.
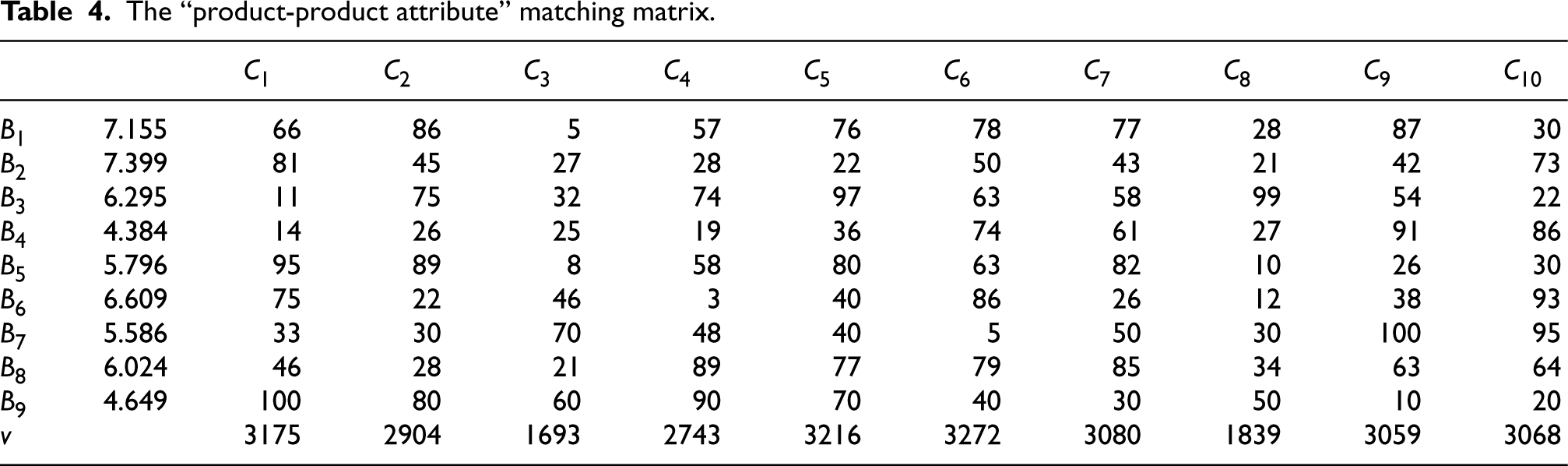
After obtaining u from the “consumer-product attribute” preference matrix, the product attributes and their weights and product types are filled into the left wall, partition and ceiling of the “product-product attribute” quality house, and the “product-product attribute” matching matrix is scored by the QFD expert team to calculate the product competitiveness value v, as shown in Table 4.
The “product-product attribute” matching matrix.
The construction of Tables 3 and 4 in this study relies on the evaluation of a panel of professional experts. To ensure the credibility and reproducibility of the scoring while adhering to confidentiality agreements, we adopted the following structured process: (1) To obtain multi-dimensional insights, we assembled a balanced panel of 5 experts, comprising 3 academic experts from management science and engineering or marketing departments of leading domestic universities, who have long been engaged in consumer behavior and decision analysis research and are well-versed in the QFD method, as well as 2 industry experts from product development or marketing departments of well-known cosmetics companies. (2) We established a structured scoring process employing a Delphi-style methodology: “independent-discussion-independent.” This involved training and calibration, independent back-to-back scoring, consensus meetings and revisions, and data synthesis. This approach aimed to effectively build consensus while minimizing individual subjective bias. Through this detailed process, we sought to maximize the objectivity and repeatability of the scoring while maintaining the confidentiality of the experts’ identities. Expert scoring, as the critical link converting textual sentiment into structured decision inputs, inherently carries subjectivity—a defining characteristic of this model. Its impact is discussed in Section 5.
The product competitiveness v in Table 4 is arranged in descending order:
By combining Table 3 and Table 4, we can obtain the consumer-product matching matrix shown in Table 5.
The consumer-product matching matrix.

Therefore, for each customer group that wants to make a purchase decision among the ten lipsticks, there is its corresponding recommendation ranking scheme. In other words, for fashion trendsetter, the platform's best recommended lipstick is Tom Ford # Matte 16- Scarlet (
Determine the user profile labels as: consumer gender (
A survey interview was launched to the publishers of the crawled and cleaned reviews to obtain the required labeling information, which eventually yielded 94, 88, 39, 55, 123, 47, 30, 63, 65, and 87 consumer messages with a sampling ratio of 1:100, respectively, for a total of 691 messages.
At the same time, the 691 texts obtained were quantified and processed. Referring to related studies, the basic attributes of lipstick consumers obtained through the weight pool network were statistically plotted to quantify the consumer gender
To convert textual sentiment into quantifiable preference scores, we designed a rule-based system integrating sentiment words and degree adverbs. This approach prioritizes operational feasibility and transparency under resource constraints. Rule definition: We consolidated authoritative resources such as the Hownet Sentiment Dictionary and established explicit mapping rules. For instance, when a comment features a combination of a “negative sentiment word + degree adverb” (e.g., “very dry”) regarding a specific attribute, it is assigned a value of 1 (strong dissatisfaction); a “positive sentiment word” (e.g., “beautiful color”) yields a value of 4; and if the attribute is not mentioned, a neutral value of 3 is assigned. Specific rules are clearly listed in tabular form. Automated Processing and Internal Validation: All reviews undergo automated processing according to this rule set. To assess the system's consistency, the research team randomly selected a portion of reviews for manual review, validating the reliability of the rule system within the study's context. We manually validated the rule-based sentiment assignment on a random subset of 200 reviews, achieving 87% agreement with manual labels (Cohen's κ = 0.81). We acknowledge that rule-based methods have limitations in understanding complex contexts and irony, providing a clear direction for future improvements through the adoption of deep learning-based fine-grained sentiment analysis models.
From this, a spatial vector of consumer attributes can be constructed. Then, based on this 691 × 6 spatial vector, a clustering analysis of lipstick consumer groups was performed to classify customer groups by combining the improved two-step clustering method with SPSS software. Similarly, the BIC criterion was used as the clustering criterion for second-order clustering, and lipstick consumers were divided into eight groups.
Based on K-Means clustering algorithm, the initial number of clusters could be set to 8, and then the maximum number of iterations with the system default value of 10 is selected, and then we can determine the results of the clustering part shown in Table 6.
691 × 6 spatial vector K-means clustering results.
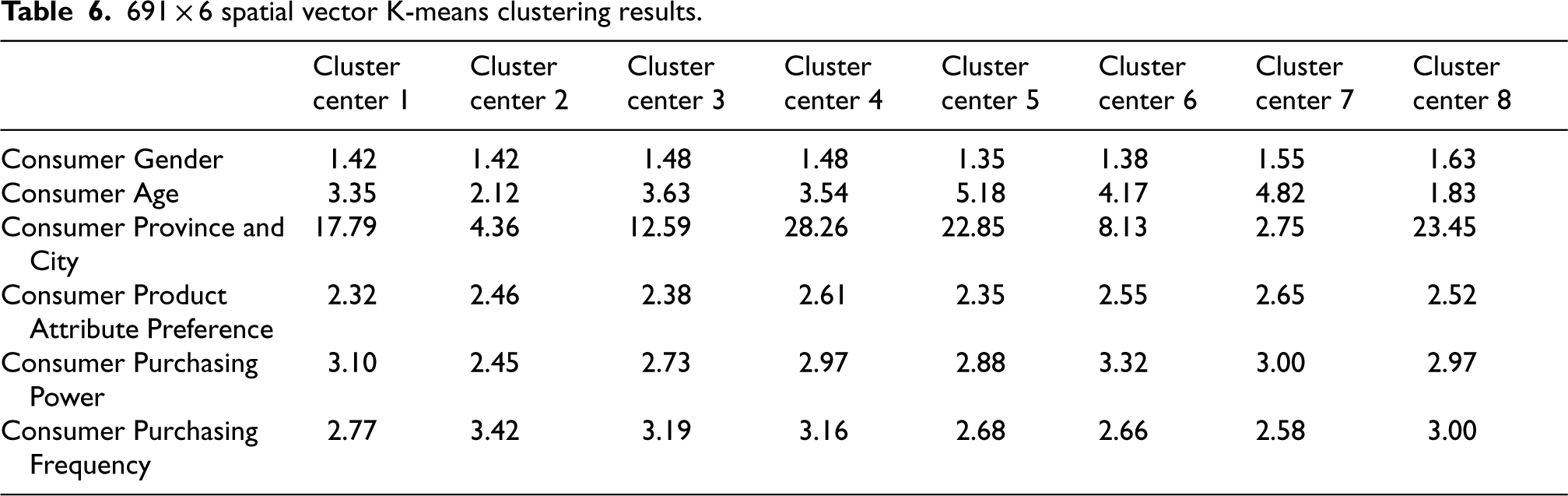
691 × 6 spatial vector K-means clustering results.
From the above two tables, based on the six-dimensional label of user profile, the consumers of ten lipsticks can be divided into 8 groups, and the consumer group weight
By substituting the obtained parameters in the proposed model, we can obtain the product competitiveness value v and the preliminary recommendation ranking result shown as follows:
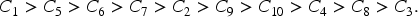
Compared to the recommended order provided by the Tmall platform:
Taking into account multi-dimensional attributes such as consumer behavior traits and consumption habits, Dior # Velvet 999- True Red (
On the Tmall platform, the recommended ranking of products is mainly based on comprehensive ranking, sales ranking, credit ranking, and price ranking. In the comprehensive ranking, it can be found that for the ten lipsticks selected in this paper, the top three recommended ranking orders are Dior # Velvet 999- True Red (
To provide a preliminary quantitative evaluation, we compare our QFD-based ranking against a simple popularity baseline using the same ten lipstick products. The ground-truth ranking is Tmall's comprehensive ranking from Section 4.2: P1 (Dior #999) > P5 (Armani #405) > P6 (Tom Ford #16) for the top-3 positions. The popularity baseline ranks products by total number of online reviews (higher is better). Review counts (from Section 4.1) are: P5 (24,681), P1 (18,850), P2 (17,600), P10 (15,745), P9 (10,067), P4 (9198), P8 (9039), P6 (5268), P3 (4936), P7 (3886). The popularity baseline top-3 is P5, P1, P2. Using NDCG@3, our model achieves a perfect score of 1.000 (since its top-3 exactly matches the ground-truth order, consistent with the Spearman correlation of 0.9515 reported in Section 4.2). The popularity baseline yields NDCG@3 = 0.8176. This demonstrates that the QFD model provides a more accurate ranking than a simple popularity heuristic. Full benchmark comparisons against collaborative filtering and deep learning methods are left as future work (see Section 5).
Further, we can obtain the consumer-product matching matrix shown in Table 7.
The consumer-product matching matrix.
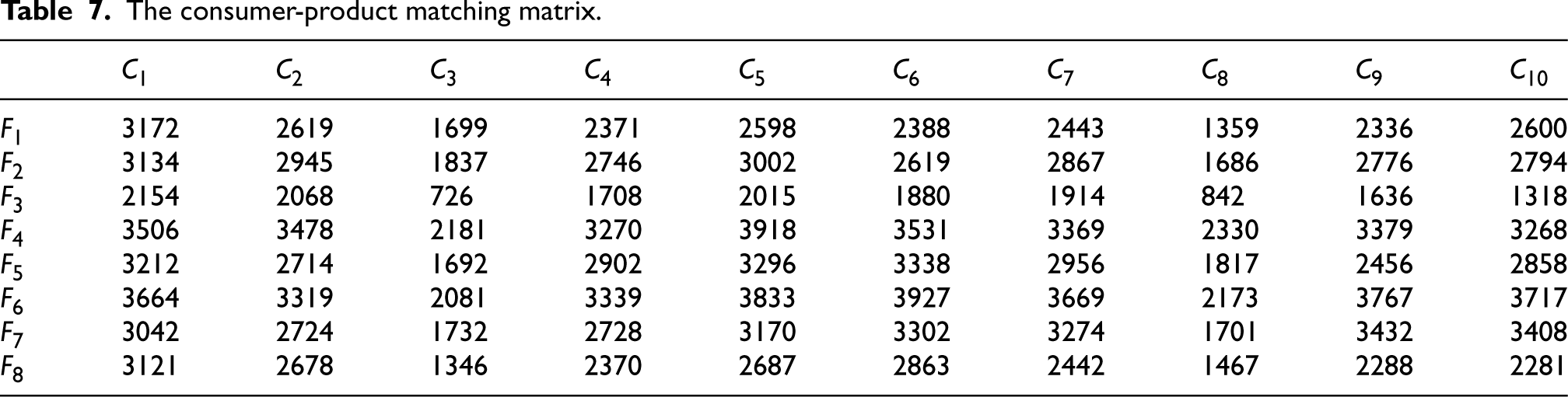
Therefore, considering the basic consumer attributes, behavioral characteristics, consumption preferences and other factors, there are corresponding recommendation ranking schemes for each customer group that wants to choose to buy one of these ten lipsticks. Among them, the optimized results are:
By applying the e-commerce platform product recommendation ranking method built based on quality house to the Tmall lipstick online review case, the competitive ranking of ten lipsticks and the optimal recommendation ranking results for each consumer group were obtained. The optimized product recommendation ranking is more realistic than the one before the optimization, thus providing consumers with better shopping experience and purchase suggestions. Compared with existing product recommendation methods, the method proposed in this paper demonstrates the potential to enhance product recommendation accuracy and user satisfaction by means of consumer online reviews, personalized recommendation, and consumer profile, offering a promising direction for e-commerce platforms seeking to improve user experience. Further validation through user studies would be necessary to confirm these potential benefits in practice.
After obtaining preliminary recommendation rankings and optimized rankings, we conducted further analysis to examine the validity of the results. (1) Correlation Analysis with Platform Rankings: To verify the consistency between model outputs and real-world consensus, we calculated the Spearman's rank correlation coefficient between the model-generated global product competitiveness rankings and Tmall's concurrent “Comprehensive Rankings.” This statistical analysis aims to provide an objective, quantitative external reference for the model's validity, rather than treating platform rankings as an absolute standard. (2) Discussion on Model Advantages and Positioning: Analysis indicates that the rankings generated by this model exhibit a trend-level consistency with the platform's comprehensive rankings, preliminarily validating the model's rationality. More importantly, this model provides deeper explanatory insights lacking in platform rankings. For example, it can explicitly indicate that a product is recommended to the “Fashion Leaders” group due to its significant advantage in the “Sensory Experience” attribute. This transparent reasoning process, grounded in attribute weighting and group preferences, constitutes the core value of this approach, facilitating the transition from “black-box” to “explainable” recommendations. (3) Impact Analysis of User Profile Optimization: Comparing recommendation outcomes before and after introducing multidimensional user profiles reveals significant differentiation in rankings across distinct demographic segments. This qualitatively demonstrates the effectiveness of integrated user profiles in achieving deep personalized recommendations. Simultaneously, we acknowledge that the user profile samples used for optimization (N = 691), though obtained through sampling, may exhibit potential self-selection bias due to their scale, potentially affecting their representativeness of overall user diversity. The primary objective of this phase was to validate the methodological proposition that “incorporating profile information optimizes ranking,” and the results unequivocally support this assertion. The application of large-scale, unbiased user behavior data will be crucial for future engineering deployment.
To address the problem of personalized recommendation ranking, we developed an integrated recommendation framework that incorporates the House of Quality (QFD), user profiles, and text mining. As a proof-of-concept study, we validated its feasibility through a case study of lipsticks on the Tmall platform. The main findings are as follows:
The proposed framework demonstrates the capability to utilize online review information to generate personalized product recommendation rankings for different consumer groups, offering a potential new approach to solving the problem of homogenization in recommendation results. The framework structures and visualizes the recommendation decision-making process through the House of Quality matrix, achieving built-in interpretability. This helps enhance user trust in the recommendations and offers a new paradigm based on systems engineering principles for developing explainable recommendation systems (XAI). This study successfully extends the application of QFD to dynamic, data-driven e-commerce recommendation scenarios, demonstrating its potential for handling unstructured big data and capturing group preferences, thereby enriching the theoretical extension of QFD.
However, as an exploratory framework validation study, this research still has several limitations, which point to directions for future work:
Limited case scope: The study is based on data from a single product category (lipsticks) and a single e-commerce platform (Tmall). The generalizability of the model to other product categories, different platforms, and cross-cultural contexts has yet to be validated. Subjectivity and static nature of model inputs: The core QFD matrix relies on expert ratings. Although we ensured consistency through rigorous procedures, subjectivity remains. Additionally, the user profile data sample size (N = 691) is relatively modest compared to industrial-scale datasets; although obtained through stratified sampling, its statistical significance and generalizability require further validation with larger and more diverse populations. Moreover, the current model is static and does not account for the dynamic evolution of user preferences and market trends. Simplifications at the technical implementation level: To prioritize validating the framework's feasibility, sentiment analysis employed a rule-based simplified method, which is less accurate than modern NLP models. Moreover, the model's validation relies primarily on alignment with platform rankings rather than rigorous quantitative benchmarking against standard recommendation algorithms using metrics such as Precision@K, Recall@K, and NDCG@K. Furthermore, the current model uses crisp values and does not fully capture the inherent fuzziness and uncertainty in review data.
Based on the findings and limitations of this study, future work will focus on the following areas:
Developing a fully fuzzified recommendation model: As the highest priority, the current crisp-value framework will be upgraded to a fuzzy QFD recommendation system based on triangular fuzzy numbers or intuitionistic fuzzy sets, following the approach outlined in Section 3.6. This will more fundamentally address the uncertainty in online reviews and enhance the theoretical rigor of the model. Cross-domain generalization validation and benchmark comparisons: Using public datasets such as Amazon and Yelp, the framework will be applied to multiple domains, including electronics, hotels, and books, to systematically evaluate its generalizability. Comprehensive benchmark performance comparisons with mainstream methods, such as collaborative filtering and deep learning-based recommendations, will be conducted using metrics like accuracy, recall, and NDCG. Upgrading key technical modules: Pre-trained language models (e.g., BERT) will replace rule-based methods for fine-grained sentiment analysis. Collaboration with e-commerce platforms will be explored to obtain large-scale, unbiased user behavior data for building more representative and dynamic user profiles. Deepening and extending the framework: Methods such as evidence theory and group decision-making will be integrated into the House of Quality to handle more complex uncertain information. Research on dynamic QFD models incorporating time series will be conducted to capture and adapt to user preference drift.
Finally, while our framework demonstrates theoretical soundness and feasibility, claims regarding improved user satisfaction or superiority over commercial systems would require validation through controlled user studies and A/B testing in real-world deployment scenarios, which represent important directions for future applied research.
Footnotes
Acknowledgements
This work is partially funded by the National Social Science Foundation of China (25FGLB111) ; Engineering Research Center of Integration and Application of Digital Learning Technology, Ministry of Education(1321005); National Statistical Science Research Program of China (2024LZ015) and Educational Planning Project of Jiangsu Province (ZYJN/2024/01) and, Jiangsu Higher Education Reform Research Project (2025JGYB099) and the Fundamental Research Funds for the Central Universities (JUSRP622047;JUSRP321016), and 2025 Jiangsu Social Science Application Research Project of Outstanding Engineering-Funding Project of Science and Technology Innovation Service and New Quality Productivity(25SXB-004) and the Tender Project from Wuxi Federation of Philosophy and Social Sciences (WXSK26-A-04). Even so, this work does not involve any conflict of interest.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, (grant number 71503103).
Conflict of interest statement
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and/or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.
Data availability statement
The data used to support the findings of this study will be considered by the corresponding author.