
Abstract
In uncontrolled environments, facial expression recognition encounters challenges such as poor image quality, uneven lighting, facial occlusions, and head pose variations. To address the challenges of facial occlusions and head pose variations, this paper introduces the Feature Segmentation-Based Dual-Stream Network (FS-DSN). The network consists of four components: a feature pre-extraction module, a feature segmentation module, a global feature extraction module, and a local feature extraction module. The pre-extraction module extracts mid-level features from facial expression images, which are then segmented into three areas: left eye, right eye, and mouth. The global feature extraction module uses the full set of features to extract global expression features, while the local feature extraction module focuses on the segmented regions. This dual-stream approach captures both broad and subtle expression changes, enhancing the semantic interpretation of facial expressions. Empirical tests show FS-DSN's robust performance, achieving accuracies of 88.82%, 60.09%, 78.33%, and 74.17% on the RAF-DB, SFEW 2.0, FED-RO, and FER-2013 datasets, respectively.
Keywords
Introduction
In interpersonal communication, facial expressions convey up to 55% of emotional information (Mehrabian and Ferris, 1967), making them the most potent medium for expressing emotional states. The study of facial expressions as a natural human physiological phenomenon dates back to Darwin's research on the expressive features of humans and animals (Darwin, 2009). Darwin used facial expressions as a starting point to elucidate the connections and evolutionary aspects between humans and animals, marking profound significance in research. With the significant advancements in deep learning technology, Facial Expression Recognition (FER) has emerged as a prominent research direction within the field of computer vision. Furthermore, FER holds extensive application value in areas such as fatigue driving detection (Jeong and Ko, 2018), intelligent learning (Li et al., 2019a; Singh and Ramanujam, 2025), medical assistance (Irani et al., 2015; Li et al., 2019b; Sripian et al., 2021), and human–computer interaction (Starostenko et al., 2015).
In recent years, the advancement of deep learning has led to an abundance of solutions for FER tasks, achieving notable success (Guo et al., 2025; Li et al., 2020; Qian et al., 2023). However, these achievements often rely on datasets from controlled laboratory environments, such as CK+ and Jaffe (Lucey et al., 2010; Lyons et al., 1998). Real-world FER applications, conversely, operate under uncontrolled conditions where factors like uneven lighting, facial occlusions, and head pose variations (Liao et al., 2022) negatively affect feature detection and extraction, posing significant challenges. Farzaneh and Qi (2021) introduced a method that enhances recognition by adaptively selecting subsets of crucial feature elements using a deep attention-based center loss to enhance class compactness and separation. Xie et al. (2022) proposed improving model compactness and class separation by optimizing the loss function. These approaches, however, do not account for partial facial occlusions and head pose variations, thus limiting their effectiveness.
Cognitive science and psychology research suggest that human facial perception processes details from a holistic to a more granular, part-based approach (Roberson et al., 2012), with global and local facial features possessing distinct granularities. Therefore, extracting features globally and locally is an effective method. Liao et al. (2022) selected 16 key landmarks out of 68 facial landmarks, integrating local feature information through a classification module. Li et al. (2019c) focused on 24 landmarks, including the eyes, nose, and cheeks, applying an attention mechanism for differential weighting of these patches. Liu et al. (2021) retained 38 of 68 facial landmarks, connecting feature vectors with Gabor (Luan et al., 2018) and HOG (Dalal and Triggs, 2005) filters to form a comprehensive set of local texture features. This approach, while effective in unobstructed environments, faces inaccuracies in landmark positioning under occlusions. Li et al. (2023) proposed generating patches by sliding a fixed number of pixels along the image's x-axis, efficiently capturing local features. However, due to the excessive number of patches and fixed pixel shifts, this method lacks specificity for key areas and is inefficient in feature extraction.
Experiments by Widen et al. (2011) demonstrated that the human visual system tends to focus more on the eye and mouth regions when performing FER. To more accurately extract local features of facial expressions, Zhao et al. (2021) divided facial expression images into four equal regions using spatial axes, then extracted local features with a CBAM (Woo et al., 2018)-enhanced module. Wang et al. (2020) devised three methods for dividing local regions: fixed-position cropping, random cropping, and landmark-based cropping. Ding et al. (2020) segmented global features into m × n irregular, non-overlapping blocks, merging predictions from each to form a final outcome. Weng et al. (2021), noting facial symmetry, focused solely on one eye after defining the eyes, nose, and mouth. Liu et al. (2022a) divided faces into four sub-regions (upper left, upper right, lower left, and lower right) using a pose segmentation and filling method, ensuring effective feature segmentation under occlusions.
Wang et al. (2019) showed that occluding the eyes and mouth significantly reduces the ability to decode facial expressions, thus, recognizing facial expressions hinges on these crucial areas. Based on this, we propose a Feature Segmentation-Based Dual-Stream Network (FS-DSN), separately extracting global and local features. FS-DSN comprises feature pre-extraction, segmentation, global feature extraction, and local feature extraction modules. In the segmentation module, intermediate feature maps are divided into non-overlapping regions for the left eye, right eye, and mouth. The global feature extraction module adapts to feature map reductions, and the local feature extraction module targets the segmented features for more precise extraction. Finally, a fusion decision combines global and local features for the final recognition result.
The main contributions include:
A dual-stream network method based on feature segmentation is proposed to extract overall and partial expression features comprehensively to take into account both global and detailed features of facial expressions, so as to improve the robustness of the network. A facial feature segmentation method inspired by human perception mechanisms and psychology is designed to efficiently delineate feature regions, extracting potential information from each. A two-stream network is designed to more effectively target global and local feature extraction. Experimental results on uncontrolled datasets demonstrate that FS-DSN outperforms previous methods, achieving higher recognition accuracy and stronger robustness.
Dual-stream network for FER
FER methods based on dual-stream networks typically divide the face into global and local regions, with separate branches for extracting features. These features are then fused to generate a comprehensive expression feature. Previous approaches, such as Zhao et al. (2021), employed a dual-stream network where the global branch used an attention module like CBAM (Woo et al., 2018), and the local branch applied multi-scale extraction to capture detailed local features. The global and local features are then fused to produce a comprehensive recognition result. Building on this architecture, Liu et al. (2022b) proposed a dual-stream network with a specialized Gate-OSA module in the global branch, enhancing global facial feature extraction. Weng et al. (2021) utilized three sub-networks to extract features, focusing on aligned facial images. The local branch relied on several key facial landmarks, including the eyes, nose, and mouth, to extract regional features, which were then fused with the global features for final classification. Li et al. (2023) presented a dual-stream approach that segments the feature map into patches along horizontal and vertical axes, with each patch processed by the local branch, while the entire feature map flows through the global branch. Their approach emphasizes the importance of patch-level feature extraction and fusion. Similarly, Li et al. (2019c) and Ding et al. (2020) proposed methods where local regions, based on facial landmarks, were either segmented into fixed or dynamic blocks for local feature extraction, which were later fused with global features at different levels. Other works incorporate dual-stream CNNs combining RGB data and texture descriptors with multi-feature fusion layers (Tiong et al., 2020), fine-grained bilinear CNNs modeling second-order interactions between local and global features (Shabbir and Rout, 2023), and dual attention networks to capture local and global facial micro-expression cues (Takalkar et al., 2021). Additionally, some methods employ 3D landmark-based attention masks to enhance focus on salient regions (Shahid and Yan, 2023) or utilize dual-stream super-resolution combined with recurrent neural classifiers to improve recognition on low-resolution images (Ullah et al., 2022).
While these two-stream architectures have made notable progress in FER, many global branches focus on limited scales. They often rely on coarse segmentation strategies, which can result in incomplete feature extraction. To address these limitations, we propose a more flexible and precise Feature Segmentation-Based Dual-Stream Network (FS-DSN). FS-DSN uses 9 × 9 and 7 × 7 convolution kernels in the backbone's first two layers to capture detailed intermediate features across multiple scales. The global branch refines this with 5 × 5 and 3 × 3 kernels to extract finer semantic details. We also incorporate CBAM in the global branch to allow the network to focus on the most informative facial regions for expression recognition. The local branch divides the facial feature map into three regions—left eye, right eye, and mouth—each processed by a sub-branch with 3 × 3 kernels. We also integrate Coordinate Attention into the local branch to enhance spatial relationships within each region. By combining multi-scale global extraction with targeted local features, FS-DSN improves upon traditional networks, enabling more accurate and reliable FER, especially in uncontrolled conditions.
Feature segmentation for FER
FER in uncontrolled environments often requires dividing the face into regions and employing specialized extraction methods for these areas. Many existing methods, such as Liao et al. (2022), rely on facial landmark segmentation, where key points are selected from a set of 68 facial landmarks, and a classification module integrates the local feature information. Similarly, Ding et al. (2020) segmented the face into 16 regions based on facial landmarks, dividing the global feature map into irregular, non-overlapping blocks to learn useful contextual information. Li et al. (2019a) introduced a regional decomposition and occlusion-aware method, recalculating 24 facial landmarks and dividing the face into 24 patches, using patch gating units to account for occlusions and focus on unobscured patches. Other methods, like Li et al. (2023), employed a sliding patch technique to extract local features by sliding a fixed-size block across the facial feature map, while Zhao et al. (2021) used a spatial axis-based segmentation method to divide the map into non-overlapping blocks. Similarly, Liu et al. (2022a) introduced a facial attribute-based LP module, dividing the face into four sub-regions and assigning facial organs to each region for effective feature extraction, especially under occlusion. Wang et al. (2020) explored cropping methods such as fixed-position, random, and landmark-based cropping, focusing on key facial landmarks like the eyes, nose, and mouth corners. Islam et al. (2018) proposed segmenting the face into four expression regions and extracting fused HOG and LBP features, followed by multiclass SVM classification. Mohseni et al. (2014) developed an anatomy-based facial graph modeling facial muscles via geometric facial points and graph edges, extracting robust features under pose variation. Dillague et al. (2024) demonstrated that incorporating eyebrow features alongside eyes and mouth improves accuracy using neural network classifiers. Rathod et al. (2023) applied super-resolution and multi-scale deep feature extraction techniques on local facial regions to enhance group emotion recognition. Aquib et al. (2024) proposed to capture the global dependencies of each local region of the face through a modified nonlocal convolutional neural network combined with an attention mechanism, which effectively enhances the local feature interaction.
While these methods achieve success in segmenting facial regions, they generally rely on pre-calibrated key points or equally divide the facial region without targeting specific features, which may fail to capture subtle changes in facial expressions due to occlusions or pose variations. FS-DSN addresses these limitations by segmenting the face into three key regions: left eye, right eye, and mouth. This targeted segmentation method enables more accurate local feature extraction. By combining fine-grained segmentation with multi-scale global feature extraction, FS-DSN overcomes the shortcomings of previous segmentation-based methods. It not only focuses on critical regions but also performs better in handling occlusions and pose variations. This enhanced segmentation and attention mechanism makes FS-DSN an effective solution for FER, especially in uncontrolled environments with partial occlusion of faces.
Proposed method
Overview
We introduce a Feature Segmentation-Based Dual-Stream Network for FER tasks in uncontrolled environments, as depicted in Figure 1. This network comprises two branches and four main components: the feature Pre-Extraction module (PE Module), Feature Segmentation module (FS Module), Global Extraction module (GE Module), and Local Extraction module (LE Module). Initially, layers Conv1 to Conv3 from ResNet-18 (He et al., 2016) serve as pre-extractors to derive shallow image features, resulting in feature maps of dimensions 128 × 3 × 3. Subsequently, these pre-extracted shallow features are divided into two branches for the extraction of global and local region features, respectively. Finally, feature-level fusion is utilized on the extracted global and local features to produce the final recognition result.
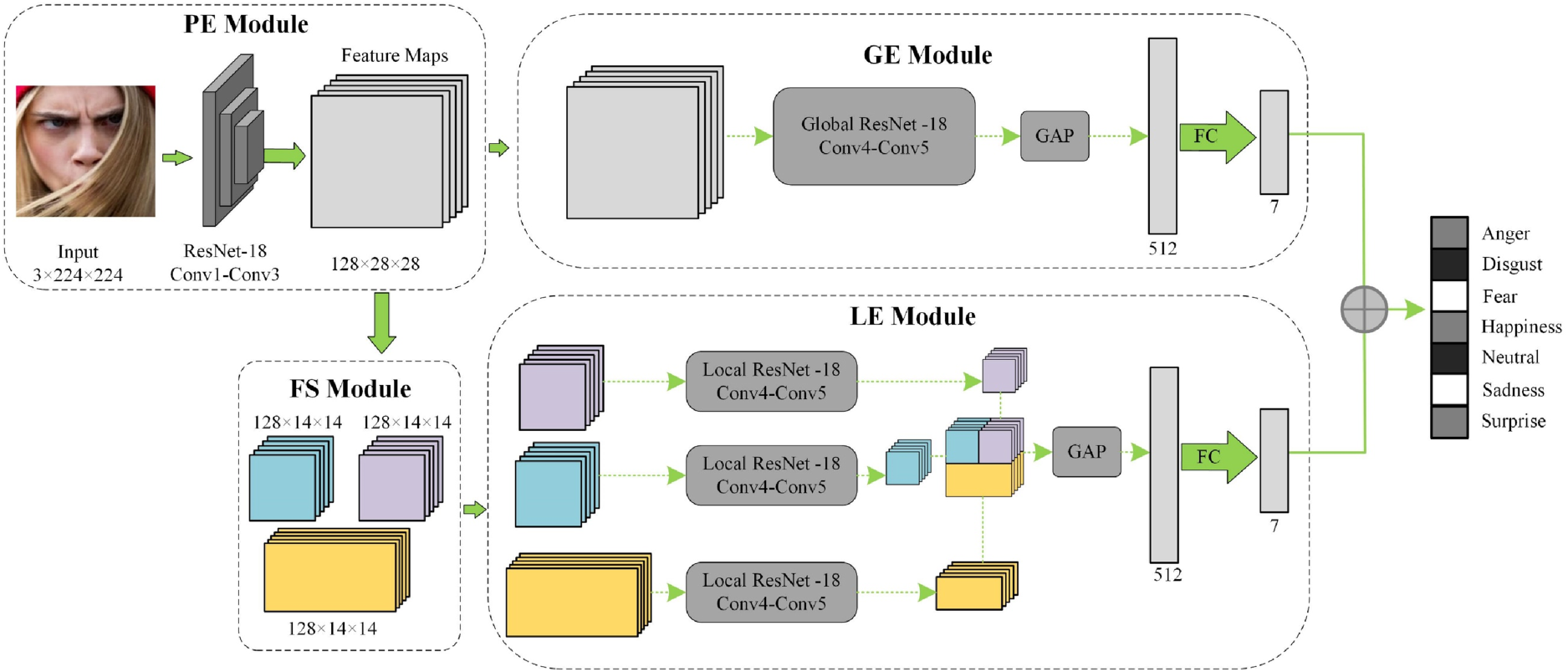
Structure of the proposed method. PE = the pre-extraction feature module; GE = the global feature extraction module; FS = the feature segmentation module, and LE is the local feature extraction module; GAP = global average pooling; FC = a fully connected layer.
The primary function of the global feature extraction module is to extract complete facial features, focusing on the positional relationships among various features. Specifically, we designed a ResNet network with different convolution kernel sizes to accommodate changes in the size of feature maps, as illustrated in Figure 2(a). Within the four layers of ResNet, we have modified the inherent convolutional kernels of size 3 × 3 to sizes of 9 × 9, 7 × 7, 5 × 5, and 3 × 3, respectively. The original image, after being processed by the feature pre-extraction module, is resized to 128 × 28 × 28, and then input into the ResNet with varying sizes of convolutional kernels for global feature extraction. The features extracted by the global feature extraction module are comprehensive, and as the input progresses deeper into the layers of ResNet, the feature maps gradually decrease in size. Larger convolutional kernels are generally more adept at handling higher-order information, making the extraction of global features more comprehensive, whereas smaller kernels can extract texture information from the images more effectively. Therefore, modifying the size of the convolutional kernels at each layer of ResNet is essential. Furthermore, within each residual block, the feature map undergoes two convolution operations before being fed into the CBAM module, which considers the image from both spatial and channel dimensions. This attention mechanism involves sequentially multiplying the attention maps by the spatial and channel maps. The spatial and channel feature maps can be defined as follows:
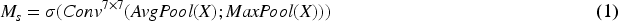
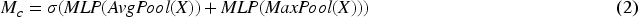

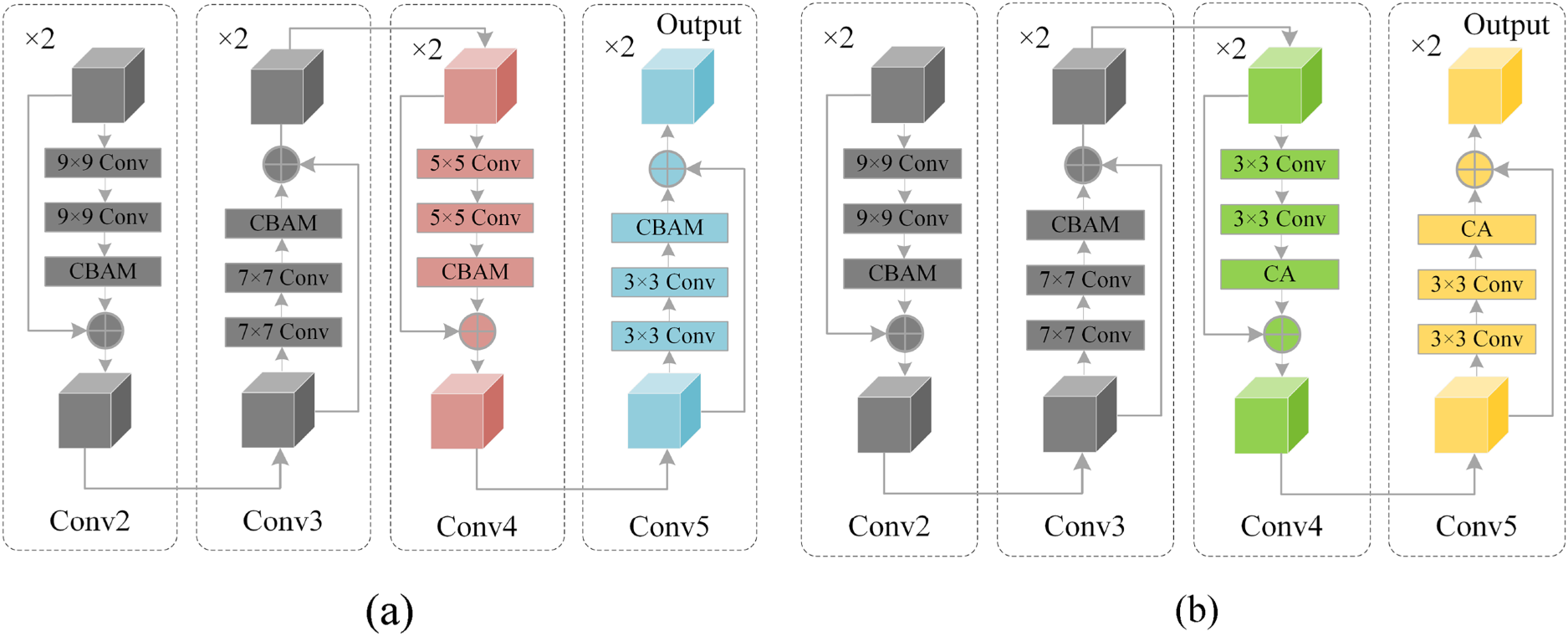
FS-DSN uses a global feature extraction module and a local feature extraction module: (a) Global ResNet and (b) Local ResNet.
After processing through the ResNet module with varying convolutional kernel sizes, the output is passed into a Global Average Pooling (GAP) layer, resulting in a feature vector of size 512. This step is crucial for condensing the spatial dimensions of the feature maps into a compact representation, while preserving essential global information conducive to the task at hand. The employment of different kernel sizes throughout the ResNet layers not only facilitates the extraction of features at various scales but also enhances the network's adaptability to the dynamic nature of facial expressions in uncontrolled environments. Subsequently, the GAP layer's role in aggregating these features ensures that the final feature vector is both comprehensive and succinct, making it well-suited for the subsequent recognition processes.
In the context of FER in uncontrolled environments, challenges such as poor image quality, lighting effects, occlusions of facial regions, and changes in head posture can significantly affect the effectiveness of conventional feature extraction methods, often leading to loss of features or incomplete feature extraction. To address these issues, we adopt a simultaneous global and local feature extraction approach, which ensures comprehensive capture of the facial expression features while also enabling targeted extraction of local features that significantly influence facial expressions. Specifically, traditional methods of local feature segmentation, which divide the facial expression image into several regions of equal or unequal sizes, typically do so without specific focus, leading to less effective feature extraction. Therefore, prior to local feature extraction, we devised a more efficacious feature segmentation method. This involves defining specific local areas for targeted extraction, followed by conducting further in-depth feature extraction on the local feature maps obtained from these areas. This approach not only enhances the accuracy of FER by ensuring that critical local features are not overlooked but also improves the robustness of the recognition system against the various challenges present in uncontrolled environments.
Before initiating the local extraction process, the Feature Segmentation module divides the intermediate layer feature maps. Specifically, after the input image is processed through the feature PE module, it segments the intermediate layer feature maps along the horizontal and vertical spatial axes into three local feature maps
The ResNet with Attention, as illustrated in Figure 2(b), integrates Coordinate Attention (CA) (Hou et al., 2021) into each residual block of ResNet-18. CA meticulously evaluates each pixel across both horizontal and vertical dimensions of the image, amplifying the focus on key regions. The purpose of incorporating local feature extraction is to capture finer details within each localized facial region (such as the twitching of the eye corners, or the upturning or downturn of the mouth corners). CA can seamlessly integrate into the ResNet architecture, enhancing its ability to focus on and extract detailed information from specific areas of interest. This incorporation of CA ensures that the network not only recognizes broader facial expressions but also pays close attention to subtle changes in facial features, which are critical for accurate expression recognition.
In the local extract module, the output can be written as:

In the local extraction module, the input feature maps for the left and right eye regions are sized at 128 × 14 × 14, while the input for the mouth region is 128 × 14 × 28. After processing through the local extraction module, the outputs are two feature maps of size 512 × 7 × 7 for the eyes and one feature map of size 512 × 7 × 14 for the mouth. These feature maps are then concatenated along the spatial axis—first, the feature maps of the left and right eyes are concatenated, and this concatenated map is subsequently concatenated with the feature map of the mouth region. This concatenation results in a composite feature map of dimensions 14 × 14 × 512. When this composite feature map is input into a Global Average Pooling (GAP) layer, it produces a feature vector of size 512.
Figure 3 displays the outcomes of the facial feature segmentation method under three distinct conditions: standard, facial occlusion, and head pose variations. Despite these uncontrolled environments, the Feature Segmentation (FS) module successfully divides the facial regions into corresponding local areas for the left eye, right eye, and mouth, ensuring the accuracy of feature segmentation. This capability highlights the robustness of the FS module, demonstrating its effectiveness in accurately identifying and segmenting key facial regions even in challenging scenarios. Such precision in feature segmentation is crucial for maintaining the performance of FER systems, as it allows for consistent extraction of relevant features across varying conditions.

Feature segmentation module, the three purple boxes represent the left eye, right eye, and mouth regions, respectively. The first, second, and third rows are facial expression images representing normal, facial occlusion, and head posture changes acquired on the RAF-DB, FED-RO, and SFEW 2.0 datasets, respectively.
Decision-level fusion refers to the fusion of recognition results from multiple sensors that have independently accomplished decision classification for the purpose of making optimal decisions. This method is efficiently compatible with the feature information of multiple sensors. In the FS-DSN network, the global feature extraction module and the local region feature extraction module focus on deep extraction of global features and features of local organs of the face, respectively, and each of them has unique advantages. Therefore, we adopt a decision-level fusion approach to fuse the global features and local minutiae features with equal weight allocation (50% each). In the global and local extraction module, the feature vectors of output 512 are obtained separately, using the

In Equation (5), N denotes the number of samples, C denotes the number of discriminated expression categories,
Finally, the final loss function is:

Datasets
We conducted performance evaluations of the Feature Segmentation-based Dual-Stream Network (FS-DSN) on four widely utilized facial expression datasets in uncontrolled environments: RAF-DB, FED-RO, SFEW 2.0, and FER-2013. These datasets are known for their diversity and complexity, encompassing a wide range of facial expressions captured under various uncontrolled conditions, such as different lighting, occlusions, and head poses.
RAF-DB (Li et al., 2017): This dataset is a facial dataset captured in natural settings, comprising 29,672 facial images. These images are annotated with both basic and compound expressions by 40 markers. In our experiments, we utilized images of the seven basic expressions, totaling 15,339 images. This subset is divided into 12,271 images for training and 3068 images for testing.
FED-RO (Li et al., 2019b): This dataset is the first of its kind, exclusively featuring facial expressions with occlusions in real-world environments. It consists of 400 images, each depicting one of the seven basic expressions. This dataset was compiled by mining images of occluded faces from Bing and Google search engines. Each image was annotated by three individuals to ensure the reliability of the expression classifications. Additionally, to maintain the dataset's uniqueness, any images that were also found in the RAF-DB and AffectNet (Mollahosseini et al., 2019) datasets were removed.
SFEW 2.0 (Dhall et al., 2012): The dataset comprises static facial expression images from natural environments, totaling 1766 pictures, obtained through keyframe extraction via facial point clustering from the AFEW dataset. SFEW 2.0 is a widely recognized benchmark dataset in the field, divided into training, validation, and test sets, each featuring seven basic expressions. For our research, we focus on the training and validation sets due to the unavailability of labels for the test set. This selection facilitates a clear and measurable assessment of our model, leveraging the accessible annotations for a precise comparison with other methodologies.
FER-2013 (Goodfellow et al., 2013): FER-2013 is a dataset previously utilized in a FER challenge hosted on Kaggle. It consists of grayscale images, totaling 35,887, featuring the seven basic expressions. This dataset is divided into 28,709 training images, 3589 validation images, and 3589 testing images. Given that these images are sourced from the internet, they are characterized by significant noise and lower image quality. For our study, we selected only the training and testing images for evaluation.
Implementation details
When preprocessing the datasets, we first employ RetinaFace (Deng et al., 2020) for face detection and alignment, subsequently cropping the images to a size of 224 × 224 pixels. We adopted distinct strategies for the training process across different datasets: For RAF-DB, FED-RO, and SFEW 2.0, we initially pretrained on the AffectNet-7 dataset, followed by fine-tuning. For the FER-2013 dataset, we pre-trained on the RAF-DB dataset before proceeding to fine-tuning. Experiments were conducted using PyTorch 1.11.0 on a GeForce RTX 2060 Super platform. For RAF-DB, FED-RO, and SFEW 2.0 datasets, we set the batch size to 256. For the FER-2013 dataset, the batch size was set to 128. We selected SGD as the optimizer, with a momentum decay set to 0.9 and an initial learning rate of 0.01. The learning rate was decreased by a factor of 10 every 20 epochs, with the training spanning a total of 100 epochs. This approach ensures a comprehensive and adaptable preprocessing and training methodology tailored to the specifics of each dataset, optimizing the performance of our FER model.
Ablation experiments
In this section, we conducted a series of ablation experiments on the proposed model to validate the effectiveness of the feature segmentation module and the dual-stream network.
Feature segmentation: for the feature segmentation part, we conducted experiments on two segmentation methods, namely, dividing the left and right eyes into the same region (as shown in Figure 4), and dividing the image into two parts according to the middle of the longitudinal axis direction as a one-time experiment; and dividing it into the left and right eyes and mouth regions (as shown in Figure. 5) according to the method proposed in this paper, which is a total of three regions as a one-time experiment. They were performed on four datasets, respectively, and the experimental results are shown in Table 1.

Divided into two areas.

Divided into three areas.
Comparison of the accuracy of the two segmentation methods on four datasets.
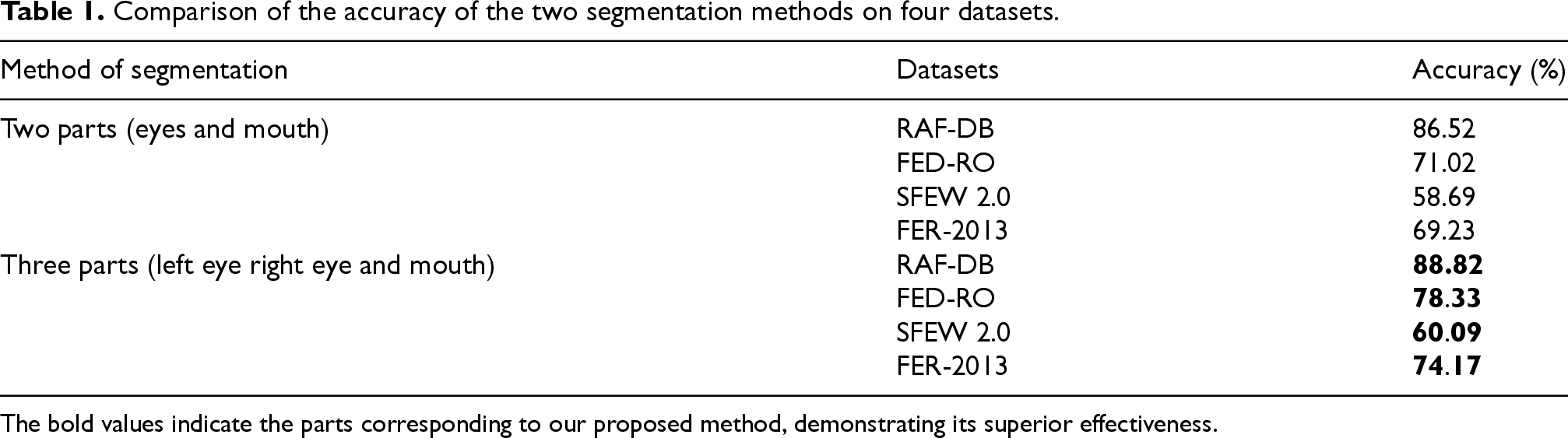
The bold values indicate the parts corresponding to our proposed method, demonstrating its superior effectiveness.
As demonstrated in Table 1, the three-part segmentation strategy exhibits superior performance over the two-part approach across all datasets, with accuracy improvements of 2.30% (from 86.52% to 88.82%) on RAF-DB, 7.31% (from 71.02% to 78.33%) on FED-RO, and modest yet consistent gains of 1.40% and 4.94% on SFEW 2.0 and FER-2013, respectively. These quantitative enhancements validate the effectiveness of our design, where independent modeling of left and right eye regions enables the capture of asymmetric muscle dynamics under occlusions (e.g., in FED-RO), while holistic eye modeling (two-part segmentation) risks losing fine-grained local textures. The observed improvements across diverse uncontrolled environments conclusively demonstrate the robustness and generalizability of our facial feature segmentation framework.
The ablation study on the dual-stream network rigorously evaluates the impact of multi-scale global feature extraction by varying convolutional kernel sizes in the global branch while maintaining a fixed local branch configuration (kernel sizes: [9,7,3,3]). As shown in Table 2, our adaptive kernel adjustment strategy (9→7→5→3) achieves superior performance across datasets, with notable improvements of 7.51% (from 81.31% to 88.82%) over the uniform 9 × 9 kernel configuration and 4.43% over the baseline ResNet-18 (3 × 3 kernels) on RAF-DB. Similar trends are observed on FED-RO, where adaptive kernels yield a 9.44% accuracy gain compared to the 7 × 7 kernel setup. This enhancement stems from a hierarchical feature capture mechanism: larger kernels in shallow layers extract broad contextual patterns (e.g., facial contours), while progressively smaller kernels in deeper layers refine fine-grained textures (e.g., wrinkles and muscle tensions). The synergy between dynamically scaled global features and fixed-scale local features validates the dual-stream architecture's capability to balance holistic and localized semantic representation, particularly under uncontrolled environments with occlusions or pose variations.
Accuracy of ResNet with different convolutional kernel sizes compared on four datasets.
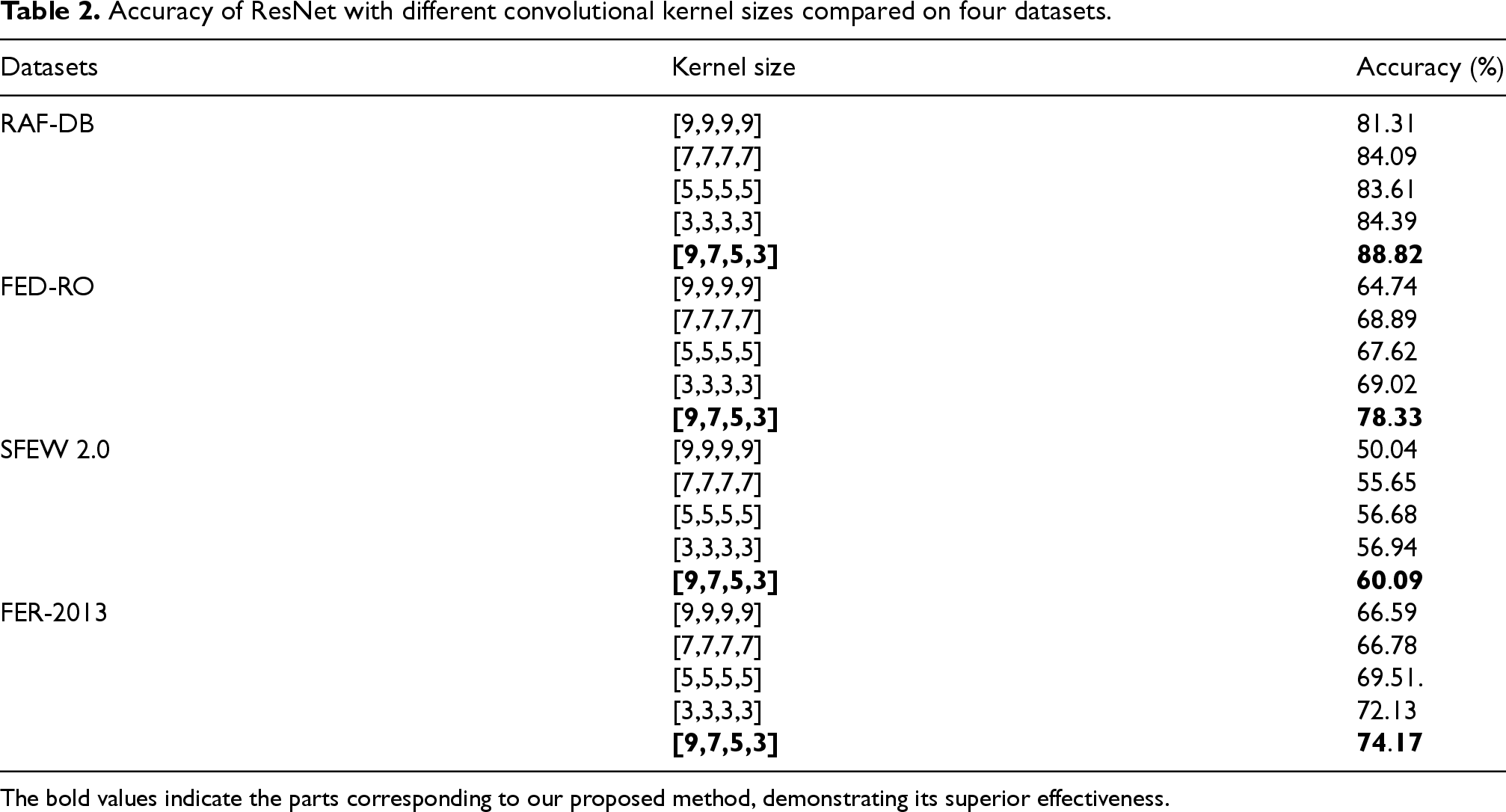
The bold values indicate the parts corresponding to our proposed method, demonstrating its superior effectiveness.
Figure 6 presents the Class Activation Mapping (CAM) (Zhou et al., 2016), where areas of high attention are indicated in red, with deeper colors signifying greater attention weight. From Figure 6(a), the Feature Segmentation (FS) approach demonstrates superior focus on critical areas compared to the Dual-Stream Network (DSN). However, the FS-DSN exhibits more accurate overall attention to the facial image, particularly concentrating on unobstructed facial regions, thus achieving higher recognition accuracy. Figure 6(b) shows the effect on the RAF-DB dataset. It is evident that FS-DSN prioritizes the eye and mouth regions, making the feature extraction more targeted and disregarding irrelevant and non-critical areas, which not only enhances recognition accuracy but also aligns with our anticipated goals.
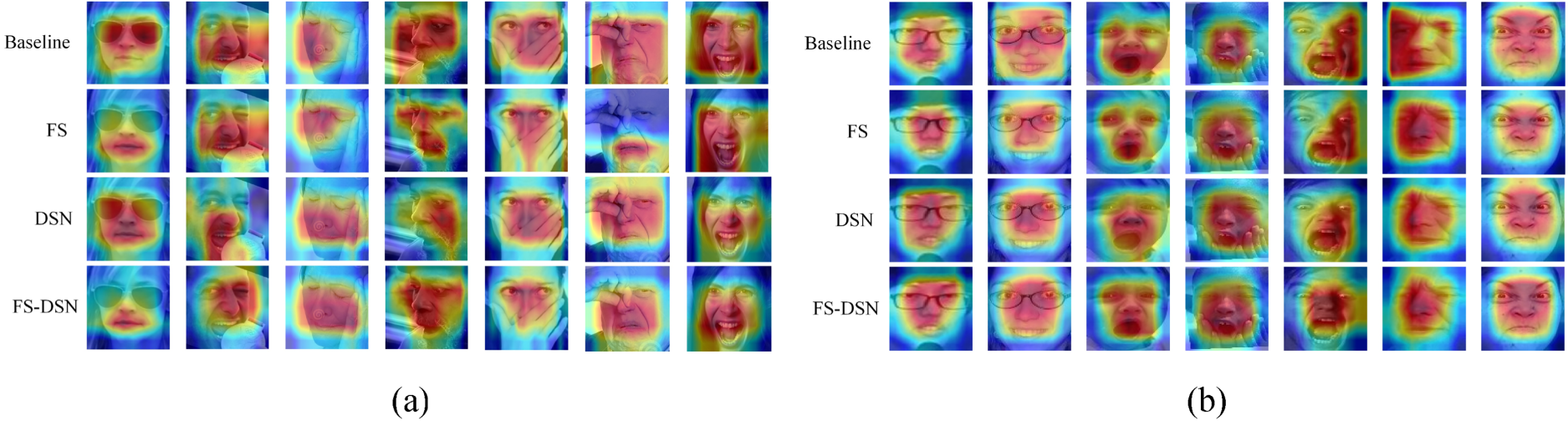
Comparison of class activation mapping (CAM) of baseline, feature segmentation, dual-stream network, and FS-DSN on FED-RO, SFEW 2.0 dataset: (a) On FED-RO and (b) On RAF-DB.
Figure 7 showcases the accuracy curves from the ablation experiments. From Figure 7(a), it is evident that on the RAF-DB dataset, the accuracy curves of FS, DSN, and FS-DSN display a clear separation effect, indicating distinctive performance characteristics among the different configurations. Figure 7(d) reveals that on the FER-2013 dataset, FS-DSN initially exhibits lower accuracy compared to FS and DSN during the first 11 epochs, which can be attributed to the high noise levels inherent in the FER-2013 dataset. Subsequently, the recognition accuracy of FS-DSN rapidly increases, demonstrating its superior learning capability and robustness. This pattern underscores FS-DSN's ability to effectively adapt and improve over time, even in challenging conditions characterized by significant noise.
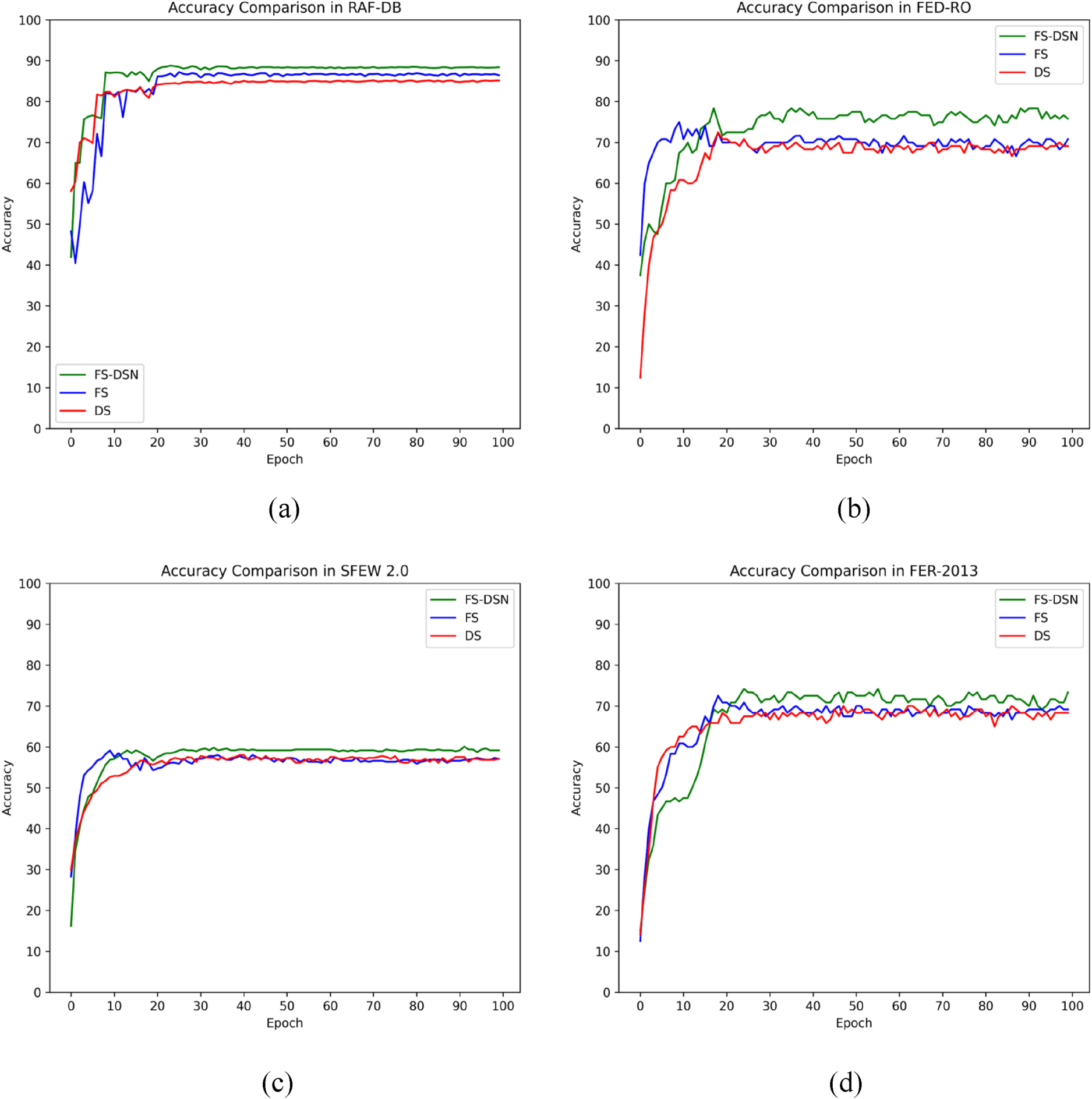
Accuracy curves for four datasets in uncontrolled environments: (a) On RAF-DB, (b) On FED-RO, (c) On SFEW 2.0, and (d) On FER-2013.
In this section, we compare the optimal experimental results obtained. The best experimental outcomes for FS-DSN are juxtaposed with the state-of-the-art (SOTA) results across the four datasets: RAF-DB, FED-RO, SFEW 2.0, and FER-2013. This comparison aims to highlight the performance of FS-DSN in relation to the current leading methodologies within the domain of FER, providing a comprehensive evaluation of its efficacy and advancements over existing approaches.
In comparison with the RAF-DB dataset, Table 3 presents the performance results of our network alongside current leading methods. As indicated in Table 3, FS-DSN achieved the highest recognition accuracy of 88.82%. Compared to the MA-Net approach, which divides the image into four equal regions, our proposed facial feature segmentation method resulted in a 0.42% improvement in accuracy on the RAF-DB dataset. Furthermore, the confusion matrix for the RAF-DB dataset, presented in Figure 8(a), shows that 14% of the “sad” samples were misclassified as “angry.” This misclassification can be attributed to the similarity between the facial expressions of sadness and disgust, both of which involve slight squinting of the eyes and contraction of the eyebrow area, potentially leading to confusion between the two emotions. Comparison with FED-RO: Table 4 showcases the performance comparison results of our network on the FED-RO dataset against current leading methods, achieving the highest recognition accuracy (78.33%). Our proposed FS-DSN network made significant improvements over other networks on this dataset. Given that the FED-RO dataset consists purely of occluded facial expressions, changes in head posture have minimal impact on recognition. This underscores our network's enhanced performance in classifying expressions under facial occlusion conditions. The confusion matrix from the FED-RO dataset, as seen in Figure 8(b), indicates substantial errors in distinguishing between anger and disgust, with each category being confused for the other more than 20% of the time. This confusion likely arises from the similarity in facial features between the two expressions, as both anger and disgust often involve open mouths and furrowed brows, making them susceptible to misclassification. In comparison with the SFEW 2.0 dataset, Table 5 presents the performance results of our network alongside current leading methods, with FS-DSN achieving the highest recognition accuracy of 60.09%. The image quality of the SFEW 2.0 dataset is generally low, and within the validation set, several samples from the “happy” and “surprised” categories suffer from poor image quality, including pure black images and zoomed-in sections of certain facial regions (e.g., head, eyes), leading to substantial noise interference. As shown in the confusion matrix in Figure 8(c), the “happy” and “surprised” expressions exhibit the lowest recognition accuracy, while “disgust” demonstrates the highest classification accuracy. This discrepancy may be attributed to the fact that the “disgust” images predominantly feature characters with tightly closed mouths and a skimming motion, a distinguishing feature that contributes to its relatively higher recognition accuracy. Table 6 presents a performance comparison of our network with current leading methods on the FER-2013 dataset. As shown in Table 6, FS-DSN achieved the highest recognition accuracy of 74.17%. The FER-2013 dataset consists of grayscale images, which are of lower quality and contain some inherent noise. The confusion matrix in Figure 8(d) indicates that the “fear” and “surprise” categories exhibit the lowest classification accuracy, with a notable proportion of misclassifications between the two. This misclassification may stem from the similarity in facial features associated with both emotions, as images of fear and surprise in the FER-2013 dataset typically depict characters with their mouths wide open, eye muscles contracted, and pupils dilated, thereby increasing the likelihood of confusion. Despite the challenges posed by the grayscale nature of the dataset, our model's superior performance suggests its ability to effectively capture discriminative facial expression features and demonstrates strong robustness.
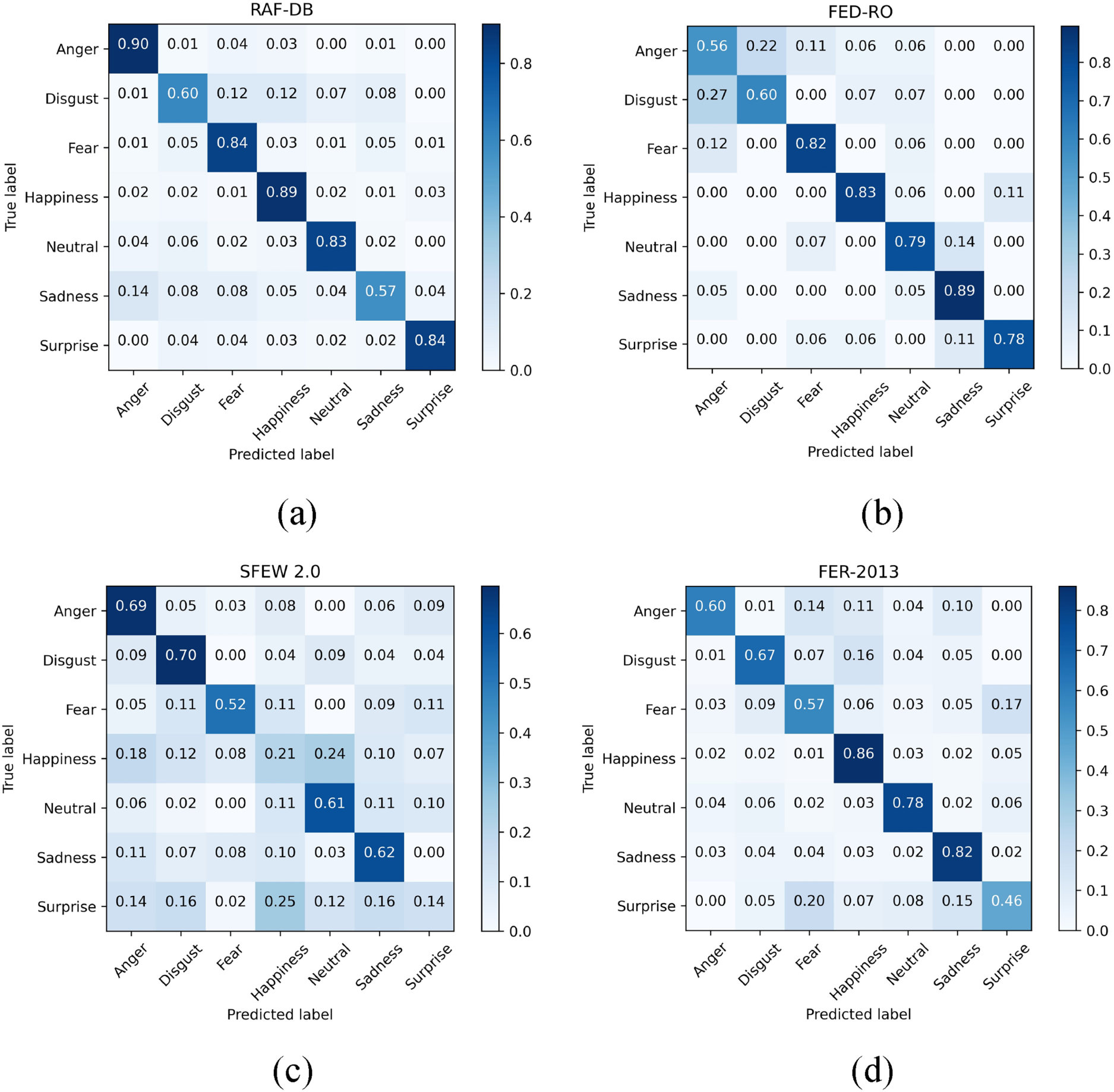
Confusion matrix of FS-DSN under four uncontrolled environment datasets: (a) On RAF-DB, (b) On FED-RO, (c) On SFEW 2.0, and (d) On FER-2013.
Comparison with SOTA on RAF-DB.

The bold values represent the results of our method, highlighting that it outperforms the other methods compared.
Comparison with SOTA on FED-RO.

The bold values represent the results of our method, highlighting that it outperforms the other methods compared.
Comparison with SOTA on SFEW 2.0.

The bold values represent the results of our method, highlighting that it outperforms the other methods compared.
Comparison with SOTA on FER-2013.
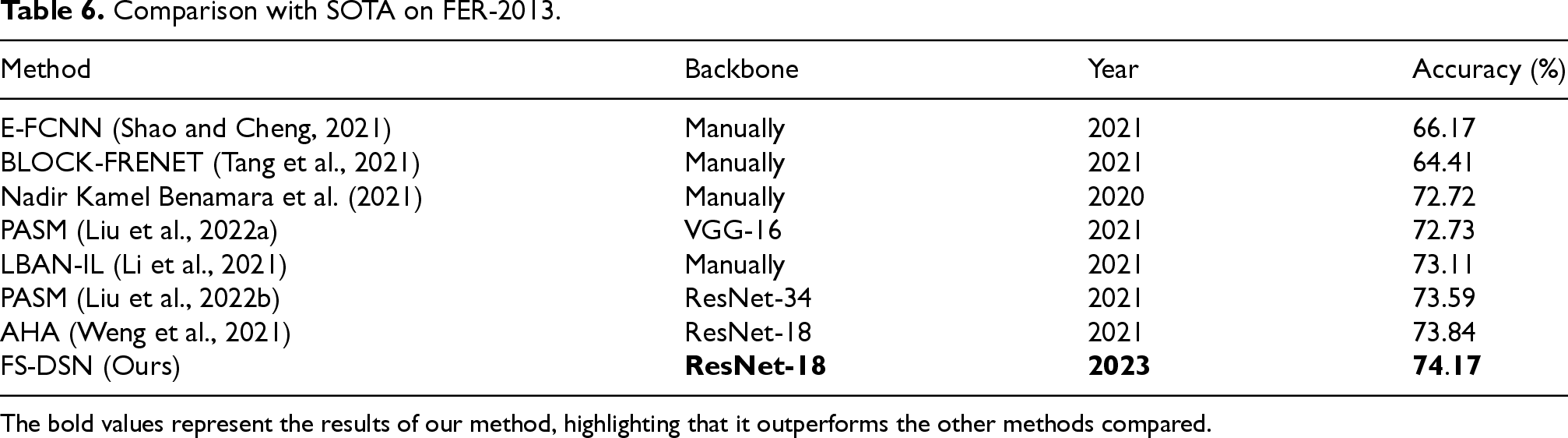
The bold values represent the results of our method, highlighting that it outperforms the other methods compared.
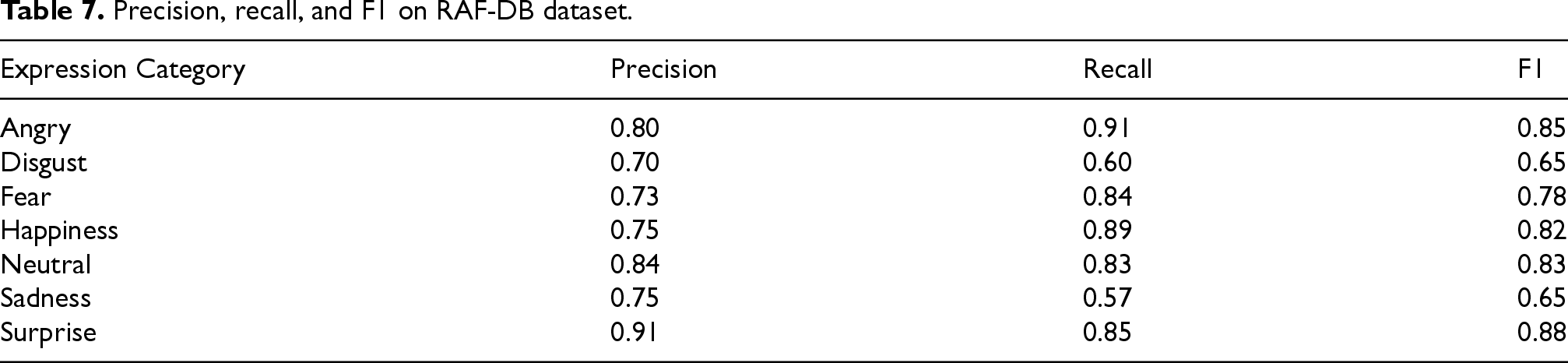
Precision, recall, and F1 on RAF-DB dataset.
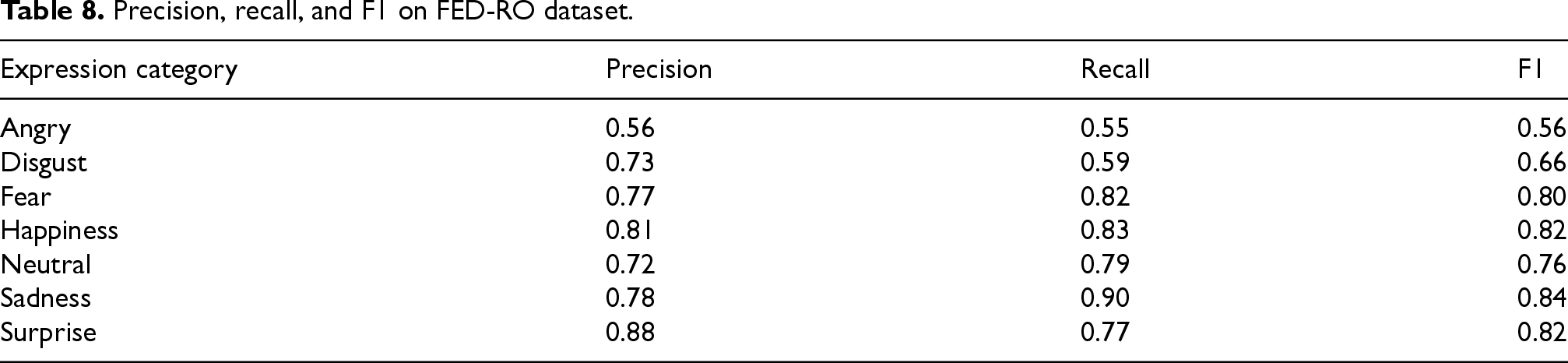
Precision, recall, and F1 on FED-RO dataset.
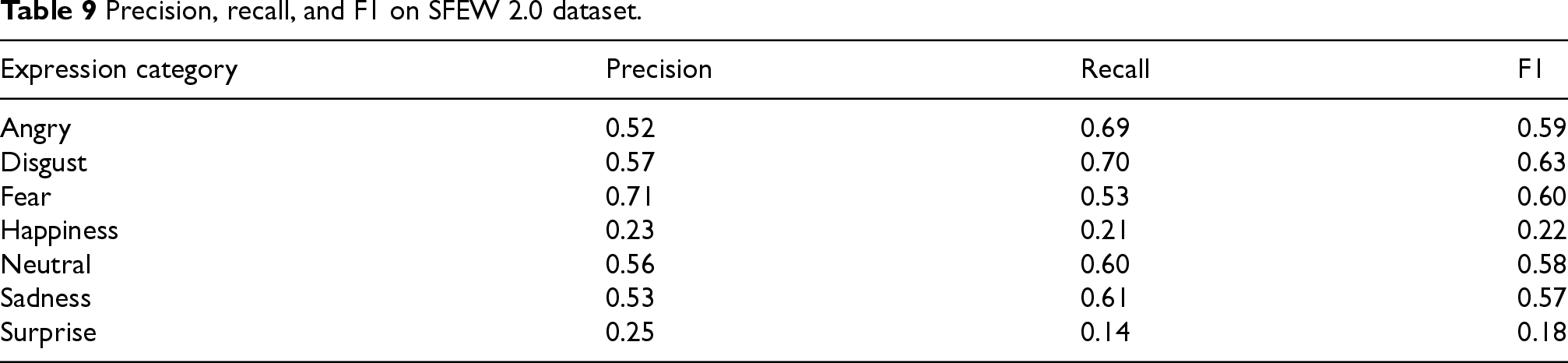
Precision, recall, and F1 on SFEW 2.0 dataset.
Precision, recall, and F1 on FER-2013 dataset.

In this section, we evaluate the performance of the model using precision, recall, and F1 scores across four different datasets: RAF-DB (see Table 7), FED-RO (see Table 8), SFEW 2.0 (see Table 9), and FER-2013 (see Table 10). These metrics provide a comprehensive view of how well the model identifies each expression category in the datasets, particularly in the presence of class imbalance.
In the RAF-DB dataset, the model performs well overall, particularly for the “Surprise” category, which achieves high precision (91%) and F1 score (88%). However, the “Sadness” category shows lower recall (57%), indicating that the model struggles to identify sadness effectively. Despite this, the model demonstrates stable performance across most categories, especially “Anger” (Precision: 80%) and “Happiness” (Recall: 89%), which both show strong F1 scores (85% and 82%, respectively).
In the FED-RO dataset, the model exhibits performance variation across categories. The “Sadness” category performs particularly well with an F1 score of 0.84, suggesting the model effectively recognizes sadness. On the other hand, the “Anger” category shows lower performance with both precision and recall below 60%, indicating that the model struggles to detect anger. Overall, “Happiness” shows a good balance, with an F1 score of 0.82.
The SFEW 2.0 dataset performs relatively poorly overall, especially in the “happy” (precision: 23%, recall: 21%) and “surprised” (F1: 0.18) categories. These poor results can be attributed to the poor quality of sample images in these categories, including pure black images. However, the “fear” category performs relatively well, with a precision of 71% and an F1 score of 0.60.
In the FER-2013 dataset, the model shows balanced performance, particularly in “Happiness” (F1: 0.74) and “Sadness” (F1: 0.74). However, the “Surprise” category has a low precision and recall, resulting in a low F1 score of 0.51. The “Angry” and “Disgust” categories perform well with precision scores of 0.82 and 0.71, respectively, but there is room for improvement in recall.
Conclusion
This paper introduces a dual-stream network based on facial feature segmentation. We designed branches for global and local feature extraction, fully leveraging the differences in the sizes and focal points of global and local feature maps. This approach enables the network to more specifically extract features from different perceptual domains, thereby ensuring the maximal capture of useful features while suppressing irrelevant noise interference, enhancing the network's robustness and adaptability. A series of ablation experiments and comparative tests have demonstrated that our proposed method exhibits exceptional performance on facial expression datasets in uncontrolled environments, particularly in cases of facial occlusion. Nevertheless, the method still faces the problem of performance degradation under extreme lighting conditions or when the face is heavily occluded. In addition, the current model is relatively heavy for deployment in real-time or mobile scenarios and relies only on visual information, which may be insufficient in the case of high blur or occlusion. In future work, we will explore the integration of illumination-invariant features, study lightweight network architectures for efficient deployment, and incorporate multimodal signals such as audio or physiological cues to further enhance its robustness in complex real-world environments.
Footnotes
Acknowledgements
This study was supported by the National Key Laboratory Fund SKLK22-11 and the Key Research and Development Project of Shaanxi Provincial Department of Science and Technology Project K20220022.
Author contributions
Daipeng Guo contributed to resources, methodology, and writing-original draft. Fei Xu contributed to writing-review and editing, investigation, funding acquisition, and conceptualization. Jing Mu contributed to visualization and formal analysis.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data will be made available on request.