
Abstract
Background
Critical appraisal of the studies included in a systematic review is essential to ensure that results of the review are properly interpreted. Critical appraisal is also one of the most difficult steps in research reviews. Structured risk of bias (ROB) tools can facilitate critical appraisal, but these tools vary in content and structure, and there are unresolved issues in applications of these tools. Assessment of risk of reporting biases, such as outcome reporting bias (ORB) and analysis reporting bias (ARB), is especially difficult, given the lack of availability of the raw materials (such as prospectively registered protocols or analysis plans) needed to properly assess the risk of selective reporting and selective non-reporting of outcomes and analyses.
Objectives
To identify methods used in recent Campbell systematic reviews of intervention effects to assess the risk of selective reporting biases in included studies.
Search Methods
We searched the Campbell Library website, using a structured online form developed for this purpose, with filters for publication dates (all dates in 2020 through April 2023) and type of document (completed reviews only).
Selection Criteria
We included systematic reviews (SRs) of primary studies of intervention effects published in Campbell Systematic Reviews between 1 January 2020 and 30 April 2023.
Data Collection and Analysis
Of the 59 SRs published from 2020 through early 2023, 51 were eligible for our review. Forty-nine of these reviews included relevant studies of intervention effects. From these 49 reviews, we extracted data on methods used to assess risk of reporting biases (ORB and ARB), broader risk of bias (ROB) or study quality assessments, and adherence to 12 mandatory methodological standards. Data extraction and coding were performed in duplicate, by pairs of team members who worked independently, and any discrepancies were resolved by coders or by the review team. Results were compiled in a spreadsheet, which was used to generate tables, graphics, and a narrative summary.
Main Results
Reporting biases were defined and assessed in diverse and sometimes idiosyncratic ways in recent Campbell systematic reviews of intervention effects. Most (40 of 49) reviews conducted some structured assessment of reporting biases, but many did not report results of these assessments. Explanation and documentation of ORB and ARB assessments was missing in more than half (28) of the reviews. Only 12 reviews provided full documentation for their ORB/ARB assessments.
Overall, we found that reviewers’ descriptions of their assessments of reporting biases were often incomplete and inconsistent across studies. In many cases, these assessment practices did not reflect current understanding of the prevalence of selective reporting and ways in which these biases can undermine the validity of and confidence in results of research reviews. This observation is consistent with the fact that most reviews did not consider the potential impacts of risks of bias on the credibility of their results.
None of the recent reviews appeared to meet all (12) of the mandatory methodological standards we assessed. On average, these reviews failed to meet 4.9 of these standards (SD = 2.3); almost three-quarters (35) of the reviews failed to meet four or more standards.
Authors’ Conclusions
Recent Campbell reviews did not consistently appraise or document risks of reporting biases in the studies they included. Assessment of risk of reporting biases is difficult, given the lack of availability of prospective, public protocols or analysis plans for most studies.
Reviewers’ failure to adhere to Campbell’s mandatory methodological standards and editors’ apparent inability to enforce these standards can be understood as functions of the contexts in which systematic reviews are highly desirable, highly cited, and under-resourced.
We provide a decision tree to guide reviewers’ assessments of reporting bias, along with nine recommendations for improving these practices in systematic reviews of intervention effects. Our recommendations include more deliberate use of eligibility criteria to eliminate studies that cannot provide valid answers to review questions, thorough documentation of reviewers’ assessment processes and ROB ratings, and explicit use of ROB ratings in interpretation of results.
Plain Language Summary
Selective reporting bias occurs when researchers report some outcomes or analyses but not others, often favoring statistically significant or positive results. This includes outcome reporting bias, where some measured outcomes are not reported, and analysis reporting bias, where only selected analyses are reported. These practices can distort the evidence base and may lead to biased conclusions in systematic reviews.
This review examines how recent Campbell systematic reviews of intervention effects assess the risk of selective reporting bias in included studies. It also examines whether these reviews adhere to Campbell’s mandatory methodological standards related to risk of bias.
Note: the first draft of this summary was generated by ChatGPT (version GPT 5.2 Instant, January 20, 2026, OpenAI, https://chat.openai.com) then edited by the authors.
Keywords
Background
The Problem
Systematic reviews analyze and synthesize results of relevant research to inform policy, practice, and further research. When these reviews include studies with incomplete, unreliable, or invalid data, the synthesis may produce information that is biased and misleading. This problem – often termed “garbage in, garbage out” – can be addressed in several ways.
First, reviewers can set clear a priori study eligibility criteria that limit inclusion in the review to studies that have the methodological qualities needed to produce reliable and valid data in relation to a specific review question. At this stage, reviewers should be careful not to systematically exclude studies due to incomplete reporting, because this can introduce reporting bias into the review.
Second, reviewers are expected to systematically assess key methodological characteristics and risks of bias within the studies included in a review in order to gauge the credibility and certainty of the evidence these studies provide (Higgins et al., 2019; Page et al., 2019, 2021, 2021b, Sterne et al., 2016, 2019, The Methods Group of the Campbell Collaboration, 2019a, The Methods Group of the Campbell Collaboration, 2019b).
Third, reviewers can conduct post hoc sensitivity and/or moderator analyses to see whether and how certain study qualities or risks of bias may influence results. Then reviewers may wish to emphasize more credible results obtained by rigorous studies.
Here, we are primarily concerned with the second task described above; that is, with the assessment of risk of bias in studies included in a review and, more specifically, with assessment of the risk of selective reporting or non-reporting of results in studies of intervention effects. We begin with a brief overview of what is known about (a) selective reporting in primary studies, (b) the threat this bias poses to the validity of systematic reviews, and (c) methods to detect reporting biases.
Reporting Biases in Primary Studies Are Common
In contrast to publication bias, which refers to the selective publication or nonpublication of entire studies (Rothstein et al., 2005; Bartoš et al., 2024), reporting bias involves the selective reporting of outcomes, endpoints, and/or analyses within published or unpublished studies.
There is a large body of empirical literature demonstrating that positive results (those that confirm prior expectations) and statistically significant results are more likely to be fully reported--in both unpublished and published papers--compared with equally valid negative and null results (Dwan et al., 2008, 2013; Norris et al., 2012; Song et al., 2009, 2010). For example, in a study of educational interventions, Pigott and colleagues (2013) compared 79 publications to the dissertations upon which they were based; only 24% (19 publications) included all the outcomes described in the dissertation, and the odds of publication were 2.4 times greater for statistically significant versus non-significant outcomes. Similarly, O’Boyle et al. (2014) found that the ratio of supported to unsupported hypotheses more than doubled in journal articles derived from 142 dissertations in management research.
Outcome reporting bias (ORB) is the selective reporting of outcomes, based on their direction and/or statistical significance. Most evaluation studies include multiple outcomes and endpoints; hence, they have multiple results. Some results may be fully reported (with sufficient information to support meta-analysis), while other results may be under-reported (with missing information), and some results may not be mentioned at all.
Analysis reporting bias (ARB) occurs when studies conduct multiple analyses (e.g., using different comparisons, subgroups, control variables, and/or statistical models) but selectively report only a subset of these analyses. ARB occurs when researchers fully report results of statistically significant analyses or those that appear to confirm a priori hypotheses, and under-report null or negative findings. ARB is sometimes called “bias in selection of the reported result” (Page et al., 2018).
Chalmers (1990) argued that under-reporting of research results is form of scientific misconduct, yet Smyth and colleagues found that many clinical trial investigators “seemed generally unaware of the implications for the evidence base of not reporting all outcomes” (Smyth et al., 2011, p. 1). Trained to view statistical significance as an indicator of important or noteworthy results, some researchers may not understand that selective reporting introduces bias into the literature and impedes access to important unreported and under-reported empirical results. Indeed, Song and colleagues (Song et al., 2009, 2010) found that investigators are the main source of reporting bias, because this bias tends to arise early in the dissemination process, before results are submitted for publication. Peer reviewers and journal editors are other potential sources of influence on reporting (Mahoney, 1977), but these influences are poorly understood (Tennant & Ross-Hellauer, 2020). Song and colleagues (Song et al., 2009, 2010) found little evidence that selection bias occurred after manuscripts were submitted to journals, although Goldacre and colleagues (2019) found that some journal editors do not understand ORB well and some are reluctant to correct misreporting.
To improve transparency and facilitate later detection of publication and reporting biases, trialists have been encouraged to deposit detailed protocols, describing all planned outcome measures, endpoints, and analyses into a public registry before enrollment into the study begins. Some funders and journals require prospective public registration of studies as a condition of funding or publication (De Angelis et al., 2004), but enforcement is weak and prospective registration is uneven (Alayche et al., 2022; Al Durra et al., 2020; Chan et al., 2017; Lamberink et al., 2022; Serghiou et al., 2023; Silva et al., 2024). Many protocols are not public, trial registrations often occur after studies are completed, primary outcomes are frequently changed in registration records, and study reports do not consistently mention trial registration (Bradley et al., 2016; Norris et al., 2012; Schönenberger, Griessbach, & Taji Heravi, 2022; Taylor & Gorman, 2022). Public registration has not been sufficient to ensure adequate documentation and full reporting of trials in medicine (Goldacre et al., 2019; Rasmussen et al., 2009) and prospective registration is relatively uncommon in the social sciences and for non-experimental studies (Boccia et al., 2016; Leducq et al., 2024).
Reporting Biases Threaten the Validity of Systematic Reviews
ORB and ARB pose potential threats to the validity of systematic reviews (SRs) and meta-analysis (MA), because they introduce bias in the selection of results that are available from included studies. When results are fully reported (for example, with valid Ns, means and standard deviations or proportions for all subgroups), they can be included in meta-analysis. Partial reporting of results (e.g., simply stating that a finding was not statistically significant and providing little or no additional information beyond this) and non-reporting of results (failure to mention nonsignificant or negative results at all) makes their inclusion in meta-analysis impossible without additional information from the authors or assumptions by the meta-analysts. At best, this represents a loss of information that could contribute to more powerful tests of hypotheses, including moderator analyses, for which statistical power tends to be low (Hedges & Pigott, 2004; Valentine et al., 2010). At worst, the results of the SR and MA will be biased, usually by inflating estimates of beneficial effects and underestimating potential harms.
There is empirical evidence that reporting biases affect results of systematic reviews (Song et al., 2010). Kirkham and colleagues (Kirkham et al., 2010) found that more than half (157) of 283 Cochrane reviews published in 2007 did not include all outcomes of interest from all eligible trials, and one-quarter (70 reviews) were missing at least 50% of the relevant data. Sensitivity analysis showed that the treatment effect was overestimated by 20% or more in almost one-fourth (19) of the 81 reviews that had only one meta-analysis. Almost one-fifth (8) of 42 meta-analyses with a statistically significant effect became non-significant after adjustment for ORB (Kirkham et al., 2010). Thus, while reporting biases tend to overestimate treatment effects overall, this bias may be small in some reviews and quite large and consequential in others. Reporting biases may be even more pronounced in reviews of adverse effects; for example, most (79 of 92) Cochrane reviews published in 2013 did not include all the data on the main harm outcome of interest (Saini et al., 2014).
Methods to Detect Reporting Biases
Ideally, systematic reviews would (1) obtain a prospectively registered protocol for each included study, (2) check to see if the protocol was completed before enrollment into the study began (or before unblinded data became available for analysis), (3) compare the pre-specified measures, endpoints, and analyses described in the protocol with results reported in subsequent papers, and (4) determine whether some or all outcome measures, endpoints, and analyses were fully reported. If all prespecified measures and analyses are fully reported at all endpoints, and there are no additional (unplanned) or changed measures or analyses, then the risk of selective reporting is very low. The potential for reporting bias arises when study reports only include a subset of the pre-specified outcomes and/or analyses, some endpoints are not reported, unspecified outcomes are added, or insufficiently justified changes are made in measurement or analysis plans. As the number of differences between pre-planned and reported results increases, the potential risk of reporting bias increases.
Of course, it would be relatively easy to detect ORB and ARB if every study had a detailed protocol or list of pre-registered outcomes, endpoints, and analyses (Hardwicke & Wagenmakers, 2023; Humphreys et al., 2013; Wagenmakers et al., 2012). However, the practice of prospective protocol registration is not well-established in most disciplines, and the majority of studies in most disciplines do not have prospectively registered or publicly available protocols or analysis plans. Below, we use the term “protocols” broadly, to include pre-registrations and public, a priori lists of planned analyses and outcomes. Many existing protocols are not written at an operational level (i.e., specific measurement instruments, timings, sources of data, and analyses are not all pre-specified) and, as mentioned above, protocols are sometimes registered retrospectively or altered after initial plans change (Fleming et al., 2015; Harriman & Patel, 2016; Taylor & Gorman, 2022; van Lent et al., 2015).
In the absence of a fully prespecified protocol, reviewers must rely on retrospective protocols or descriptions of outcomes, endpoints, and analyses provided in the methods sections of study reports. These sources are often inadequate for assessing reporting biases as there is no way to determine (a) if they were written before study data were analyzed or (b) whether they represent a complete accounting of the researchers’ original plans.
Convincing evidence of reporting bias is sometimes found in (a) researchers’ explicit statements that their reports focus on statistically significant and/or positive results, or in (b) patterns of reporting that differ for significant versus nonsignificant (or positive versus other) results. For example, some reports provide full statistical details for significant results but only mention nonsignificant results in the text or partially report these results in tables.
It is sometimes possible to detect selective reporting by comparing results reported in different papers from the same study (see, for example, Gorman, 2017; van der Zee et al., 2017). In some cases, data dredging and selective reporting data are evident in one or more reports. However, comparisons of multiple reports from the same study are not sufficient to detect reporting biases. While discrepancies in reporting across different papers can suggest reporting biases, consistency in reporting across papers does not suggest the absence of selective reporting. The latter can only be demonstrated by comparing information on all outcomes that were measured and all analyses that were conducted with the reported results.
Therefore, investigating the plausibility of reporting biases in most cases requires relying on clues left in the paper trail, triangulating across multiple reports of the same study, and employing professional judgment regarding the likelihood that a particular outcome was indeed measured. These are high-inference tasks that will usually not support confident judgments about the presence or absence of reporting biases. Indeed, reporting biases can, in some cases, be impossible for individuals outside of the research team to detect.
Finally, there are gaps and ambiguities in guidance on the use of study protocols and trial registries in systematic reviews (Boden et al., 2017). And there is little information on how reviewers handle different sources of evidence on reporting biases.
Below, we describe structured assessment of risk of reporting biases, broader risk of bias (ROB) assessments, and the Methodological Expectations for Campbell Collaboration Intervention Reviews (MECCIR standards).
Structured Assessment of Risk of Reporting Biases
Page et al. (2018) identified 18 tools designed to assess risk of reporting biases in the studies, outcomes, specific results, and/or syntheses included a systematic review. Fifteen of these tools assess selective non-reporting of outcomes in primary studies (ORB), and all 15 “suggest that the risk of bias is ‘high’ when it is clear that an outcome was measured but no results were reported” (Page et al., 2018, p. 6). Eight tools assess “selection of the reported result” (ARB), using different criteria for “high risk” ratings, including the post hoc addition of new outcomes and selection of reported results from multiple outcomes and/or multiple analyses within an outcome domain.
Outcome Reporting Bias In Trials (ORBIT) is possibly the most elaborate system for assessing ORB (see https://outcome-reporting-bias.org). Dwan, Kirkham, and colleagues (Dwan et al., 2010; Kirkham et al., 2018) published tutorials for using ORBIT tools. Separate ORBIT classifications systems were developed for benefits and adverse effects. The former assesses “risk of bias arising from the lack of inclusion of non-significant results…” For adverse outcomes, high risk of bias occurs when “data were presented or suppressed in a way that would mask the harm profile of particular interventions” (https://outcome-reporting-bias.org/HarmOutcomes).
Some users reported difficulties using the ORBIT approach. Norris and colleagues (2012) noted that ORBIT (1) does not classify outcomes that were pre-specified and fully reported (these should be classified as low risk or no risk) and (2) does not cover some types of ORB, such as (a) reporting of outcomes that were not prespecified and (b) changes in data measurement or analysis plans (including “data dredging”). ORBIT focuses on reasons for non-reporting.
The ORBIT tool requires high-inference judgments (including clinical judgments). It appears to emphasize discrepancies within study reports, rather than comparisons between study protocols and reports. We found no information on inter-rater reliability of ORBIT ratings.
ROB-ME (risk of bias due to missing evidence) is a newer tool that assesses missing evidence at the synthesis (meta-analysis) level (Page et al., 2023). The rationale for synthesis-level assessment is that factors related to reporting biases (e.g., comprehensiveness of the search, missing studies due to publication bias, and unreported or under-reported outcomes) are often “fragmented” in reviews (Page et al., 2018, p. 13).
Reporting biases also arise within SRs, when reviewers report their own result selectively (Shah et al., 2020). The present review focuses on whether and how reviewers assessed ORB and ARB in the studies included in their systematic reviews, not on whether the results of these reviews were selectively reported.
Structured Risk of Bias (ROB) Tools
Reporting biases are usually assessed in SRs as components of a larger set of structured assessments of risks of multiple sources or domains of bias (e.g., selection bias, detection bias, performance bias, attrition bias). Of the 18 reporting bias assessment tools identified by Page et al. (2018), 13 covered multiple sources of bias.
In the past, this type of work was often termed study quality assessment (or methodological quality assessment). Risk of bias (ROB) rubrics now focus more clearly on issues that may affect the credibility of conclusions that can be drawn from individual studies and SRs. The structured critical appraisal of included studies is an important feature of systematic reviews.
Many ROB tools have been developed for use in SRs (see https://osf.io/dmrq6). As indicated above, ROBs can be assessed at the study level, at the outcome level (for outcome domains or specific numerical results), and at the synthesis level (Page et al., 2018). Because most ROB tools require high-inference judgments, they are often conducted by two trained raters who work independently, compare notes, and resolve any discrepancies.
Cochrane’s initial ROB tool (RoB1; Higgins & Green, 2011) and its successor (RoB2; Higgins et al., 2019; Sterne et al., 2019) were designed to assess risks of bias in randomized controlled trials (RCTs). These tools assess ROB in several domains, including selection (biases in the randomization process), detection (blinding), performance (confounding), deviations from intended interventions, missing outcome data (attrition), outcome measurement, and selective reporting. A series of signaling questions is used in each domain, with response options of Yes, Probably Yes, Probably No, No, and No Information. In RoB2, algorithms are used to suggest domain-specific ratings and an overall ROB rating.
Cochrane RoB1 and RoB2 are widely used in non-Cochrane reviews of interventions, although they tend to be poorly implemented (Babić et al., 2024) and have poor to moderate interrater reliability (Armijo-Olivo et al., 2014; Hartling et al., 2009, 2011, 2013; Minozzi et al., 2020). The same studies are rated differently in different reviews that use RoB1 (Jordan et al., 2017) and agreement between RoB1 and RoB2 ratings of the same studies is low (Viana et al., 2025).
ROBINS-I (Sterne et al., 2016) assesses ROB in non-randomized studies (NRS) of interventions. Like other Cochrane tools, ROBINS-I uses signaling questions within domains, response categories that may require high inference judgments (e.g., Probably Yes, Probably No), and algorithms that suggest domain-specific and overall ROB ratings. One study showed that the interrater reliability of this instrument was low and evaluator burden was high (average 49 minutes per study to complete and resolve discrepancies in ROBINS-I ratings; Jeyaraman et al., 2020).
Several groups developed tools that use different criteria for assessing ROB in studies that have different research designs. When diverse study designs are included in a single review, these ROB assessments yield ratings that are not comparable across studies. For example, Cochrane’s EPOC group developed an ROB tool with (1) nine criteria for studies that use control groups and (2) seven criteria for interrupted time series (ITS) designs (EPOC, 2017). The 3ie (International Initiative for Impact Evaluation) ROB tool uses different signaling questions for different research designs (Hombrados & Waddington, 2012a, 2012b; Waddington et al., 2012) and applications of this tool conflate selective reporting with unrelated “requirements for specific methods of analysis” (e.g., Castle et al., 2021, Appendix 3). We found no information on interrater reliability of the EPOC or 3ie ROB tools.
For assessments of ORB and ARB, the most prominent ROB tools (RoB2, ROBINS-I) refer to the presence of an a priori, public (pre-registered or published) protocol for the study, including a list of outcomes and/or a pre-analysis plan. But these tools do not provide guidance for reviewers about how to (1) determine if such plans exist; (2) find these plans; (3) discern whether plans were prospective or retrospective, or if they were altered after data was available for analysis; or (4) compare plans to research reports to identify ORB and/or ARB.
Methodological Expectations for Campbell Collaboration Intervention Reviews (MECCIR)
The Campbell Collaboration developed standards for the conduct and reporting of results of systematic reviews of intervention effects. There are 79 standards for conducting such reviews and 108 standards for reporting them. Of these 187 standards, 113 (60%) are “mandatory,” which “means that a new review will not be published if this standard is not met,” while others standards are relevant “if applicable,” or are “highly desirable,” or “optional” (The Methods Group of the Campbell Collaboration, 2019a, 2019b).
The MECCIR standards indicate that assessment and documentation of study-level ROB is mandatory in Campbell reviews on interventions, but the components of these ROB assessments are not specified (The Methods Group of the Campbell Collaboration, 2019a, 2019b). Thus, Campbell reviews may use assessment tools that do not cover selective reporting biases. A study of 96 Campbell reviews published from 2011 through 2018 showed that: • 82% (79) of the reviews described the tool used for ROB assessments, • 63% (60) described the methods used to assess ROB, • 79% (76) reported results of ROB assessments, and • 73% (70) took ROB into account in interpretation of results (Wang et al., 2021).
To our knowledge, there are no systematic studies of methods used to assess reporting biases in Campbell reviews.
Why it is Important to do This Review
Selective reporting of research results is a pernicious problem in the scientific literature. Reporting biases can affect results of SRs and appears to be one of the most difficult sources of bias to assess. Knowledge about whether and how reviewers attempted to assess reporting biases could lead to recommendations for improving assessments in future SRs.
There are no systematic reviews of methods used to assess ORB in Campbell reviews. Wang and colleagues (Wang et al., 2021) considered whether and how Campbell reviews assessed risks of bias but did not examine assessment of risks of specific types of bias, such as ORB and ARB.
ORB ratings appear to be perfunctory in some reviews, indicating that there is room for improvement in methods of assessing reporting biases. For example, a prominent Campbell review (Gaffney et al., 2021) assessed risk of ORB as “low” in most included studies but provided no support for these ratings. Independent attempts to replicate these ratings (using the review’s stated criteria) with 41 studies showed very low (7%) agreement (kappa = 0.003; Littell & Gorman, 2022). A similar problem was identified in a recent Cochrane review of Alcoholics Anonymous (Kelly, Abry, et al., 2020; Kelly, Humphreys, & Ferri, 2020). While reviewers rated all 27 included studies “low risk” for reporting bias, only one protocol and five registry entries existed; moreover, only two of the five entries were registered before the study started and four subsequently changed outcomes (Gorman, 2022).
Objectives
To identify methods used in recent Campbell systematic reviews of intervention effects to assess the risk of reporting biases in included studies, we attempted to answer the following questions that were posed in our protocol (Littell et al., 2023) or arose during our review. 1. To what extent did reviewers avoid introducing reporting biases into the review (e.g., by including studies regardless of their publication status and adequacy of reporting on relevant measured outcomes)? 2. How did reviewers assess ROB? What tools, signaling questions, and response categories did they use? 3. What proportion of reviews assessed risks of reporting biases? 4. How did reviewers assess risks of reporting biases? That is, what questions did reviewers ask, what specific issues were considered, and what ROB tools and rating criteria were used? 5. To what extent and how did reviewers use study protocols as sources of data to assess risks of ORB/ARB? 6. To what extent and how did reviewers assess interrater reliability of ORB/ARB ratings? 7. To what extent and how did reviewers document reasons for their ORB/ARB judgments? 8. What proportion of reviews used overall ROB (or study quality) ratings? 9. To what extent and how were issues of ROB and selective reporting considered in the abstract, plain language summary, discussion, and conclusions? 10. To what extent did reviewers meet relevant, mandatory MECCIR standards?
Methods
Criteria for Considering Studies for This Review
We included all systematic reviews (including newly updated reviews) that • focused on primary studies of intervention effects, and • were published in Campbell Systematic Reviews between 1 January 2020 and 30 April 2023.
We defined reviews of intervention effects as those that focused on the outcomes of a manipulated variable. We limited the focus to reviews of primary studies of intervention effects, because (a) most of the tools for assessing reporting biases were developed for these kinds of reviews and (b) Campbell has guidelines for the conduct and reporting of these types of reviews, but not for other kinds of reviews (The Methods Group of the Campbell Collaboration, 2019a, 2019b). We excluded overviews of reviews, in which the primary unit of analysis is the review.
When reviews of intervention effects also address other (descriptive or correlational) review questions, they may use different types of studies (e.g., qualitative and survey research) for these purposes. To ensure that we compared similar types of data and analyses across systematic reviews, we focused solely on the portions of these reviews that related to intervention effects and the studies they used for this purpose.
We limited inclusion to systematic reviews published after the release of new guidance for the assessment of reporting biases (Higgins et al., 2019; Sterne, et al., 2016, 2019) and revisions in Campbell’s MECCIR standards (The Methods Group of the Campbell Collaboration, 2019a, 2019b). This is why we excluded reviews published before 2020.
Search Methods for Identification of Reviews
On 1 May 2023, we searched the Campbell Library website, using a structured online form developed to facilitate searching on that site. (We note that this form is no longer available on that site.)
As shown in Appendix 1, we used available filters to select: • publication dates (from 1 January 2020 through 30 April 2023) and • type of document (Reviews).
Data Collection and Analysis
Bibliographic data were stored in Zotero and imported into MetaReviewer (beta version) for screening and eligibility decisions.
Selection of Reviews
Reasons for Exclusion for All Excluded Reviews (k = 8)

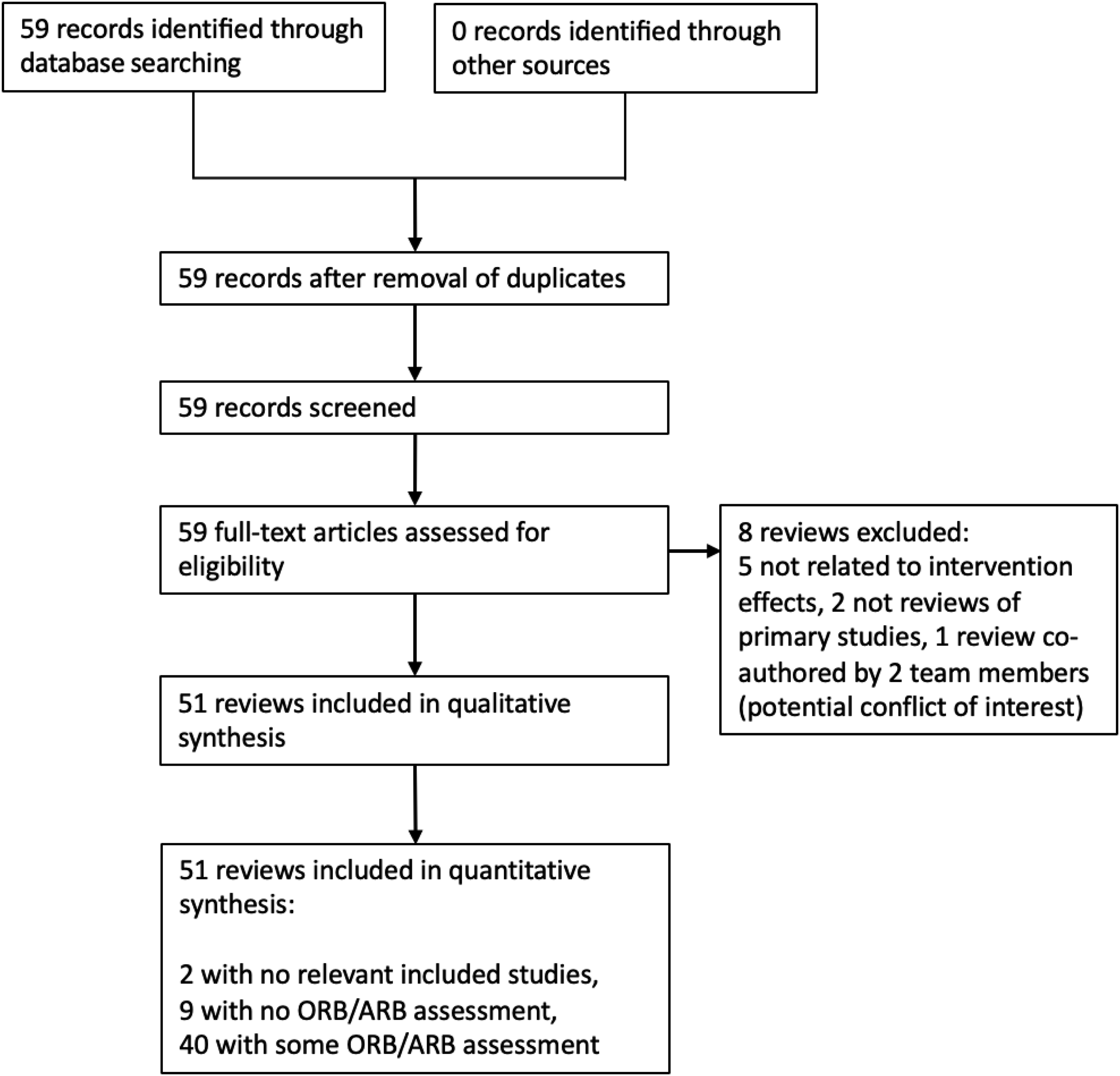
PRISMA Flow Chart
Data Extraction and Management
For each included review, data extraction was conducted by two team members who were not co-authors of the review in question. All coders independently pilot tested the data extraction form and revisions were made as needed.
Data extraction began in June 2023 with a Word codebook and an Excel coding sheet based on the data extraction forms shown in our protocol (Littell et al., 2023). After we extracted data from the first 10 reviews, pairs of reviewers compared results, and it became clear that much of the information we sought could not be reliably extracted from review reports. With this in mind, we documented problems encountered in coding the next set of 10 reviews in greater detail. Based on their published reports, we could not reliably extract information on the number of studies included in each of these reviews. Nine of the 10 reviews contained conflicting information on the number of included RCTs and NRS, due to post hoc exclusions of eligible studies from some or all qualitative and quantitative analyses and/or inconsistent statements in figures, tables, and text. Lacking reliable information on the number of included studies, we could not analyze data on the proportion of included studies that received various ROB ratings.
Our data extraction forms were revised by JCV and JHL. The second and third versions of these forms relied on Google forms for data entry and reconciliation of disagreements between raters was conducted with spreadsheets generated from those forms. Changes are described below, and the final version of our data extraction form is shown in Appendix 3. The final version of each question was applied consistently to all reviews.
Throughout the data extraction process, coders added comments to coding sheets to clarify and document their answers. In reviewing these comments, disagreements between raters became clearer: it was often the case that one reviewer would find an answer to a question in one portion of a review and another reviewer would find a different (contradictory) answer to the same question in another portion of the review. We documented these conflicts in a spreadsheet (see Littell et al., 2025; https://osf.io/58bys).
Our initial questions focused on how reviewers conducted their work, but we found that descriptions of some review methods were opaque, contradictory, or missing in many reviews. So, instead of trying to make high-inference judgments about the conduct of these SRs, we altered our data extraction forms to focus on reviewers’ statements about whether and how they conducted various tasks and information reported in the review.
Some of the newer ROB instruments combined assessments of risk of ORB and ARB and (sometimes) selective reporting on subgroups; and some provided instructions for calculating an overall ROB rating or score. We added questions on these topics.
If reviewers stated that they used a specific ROB tool but did not present the items they used for ROB assessment, we assumed they used these tools as they were written. We usually could not tell whether or how ROB instruments had been adapted and/or implemented.
We documented instances where mandatory MECCIR standards were not followed, focusing on 12 standards related to ROB assessment (see Littell et al., 2025, columns CB to CM). These standards were assessed consistently across reviews using verbatim excerpts from the standards. When other apparent violations of mandatory MECCIR standards were identified, those were noted as well.
The data file was cleaned by JHL, who checked rows and columns to make sure that codes were clear and consistent within and across reviews, and that all totals and subtotals were correct. In some cases (e.g., when comments on one entry conflicted with comments on another entry on the same review), previously reconciled codes were changed to reflect inconsistencies in the review; these cases were documented with quotations from the review in question.
Unit of Analysis Issues
The primary unit of analysis is the systematic review (SR). We collected and analyzed data on reviewers’ coding and classification of included studies related to assessment of intervention effects.
Dealing With Missing Data
We had planned to contact review authors to request missing or incomplete information. After we realized that there was a great deal of information that was missing or unclear in these reviews, and that we could not reliably extract data from SRs to answer some of our research questions, we focused on what readers could and could not glean from the published reports. For this reason, we did not contact review authors for additional information.
Data Synthesis
We used descriptive statistics (frequencies and percentages) to summarize characteristics of included reviews and the methods they used to assess reporting biases. Aggregated data are presented in tables and graphs.
As we did not synthesize effect sizes, we did not perform meta-analysis.
Subgroup Analysis and Investigation of Heterogeneity
We planned to report differences between systematic reviews that limited included studies to RCTs versus those that included other study designs (perhaps in addition to RCTs), because RCTs are more likely to have pre-registered protocols than other kinds of studies. However, all but two SRs included both RCTs and NRS designs.
If sufficient data were available, we planned to report results separately for each Coordinating Group (CG). CGs produce systematic reviews in different substantive domains within the Campbell Collaboration (e.g., Crime and Justice, Education, Social Welfare, International Development), and their reviews may reflect different research norms in different substantive fields and/or evolving traditions and norms within CGs. We did not have enough reviews in this study to support separate reports for each CG or quantitative comparative analyses. We were able to identify a couple of consistent patterns within two groups.
Treatment of Qualitative Research
We extracted quotations from included reviews to capture reviewers’ definitions and descriptions of their methods verbatim. We used quotations from reviews to document our coding and illustrate different approaches.
Development of Recommendations
We used information gleaned in this review to develop a set of recommendations for improving assessments of selective reporting bias (and ROB in general). We developed a decision tree to illustrate proper use of protocols (pre-registration or a prior plans) in assessments of reporting bias. The decision tree was conceived by DMG, revised by JHL, and developed by agreement among all co-authors.
Summary of Findings and Assessment of the Certainty of the Evidence
We summarized findings in tables, graphs, and narratives. We attended to the consistency of evidence within and across SRs, documented inconsistencies within reviews, and rated evidence as Unclear when it was uncertain. (We did not use the GRADE rubric or a Summary of Findings table because we did not synthesize effect sizes.)
Results
Results of the Search
Our search identified 59 Campbell reviews of intervention effects published between 1 January 2020 and 30 April 2023 (see Figure 1).
All screening and eligibility decisions were conducted by two reviewers working independently. There was initial agreement on the eligibility status of 57 of the 59 reviews; the remaining two reviews were discussed and resolved by the review team. Fifty-one reviews met our inclusion criteria and eight were excluded.
Description of Reviews
Excluded Reviews
Two reviews did not include any primary studies (they were reviews of reviews) and five did not focus on intervention effects. Another review was excluded because it was co-authored by two of the four members of our review team; this was considered a potential conflict of interest because, given the size and organization of our team, it was impossible for us to avoid involving co-authors of this review in the coding and cleaning of data. Specific reasons for exclusion for each of the eight excluded reviews are shown in Table 1.
Included Reviews
Characteristics of 51 Included Reviews

aLetters in parens refer to columns in the supplemental data file (Littell et al., 2025).
bThese categories are not mutually exclusive (total > 100%). Three reviews were jointly registered with the International Development and Social Welfare groups, two with International Development and Nutrition, and one with the Education and Disability groups.
As noted in the previous section on Data Collection and Analysis, we could not reliably extract data on many important characteristics of reviews, such as the number of studies included in each review.
Most reviews considered both RCTs and non-randomized studies (NRS) eligible for synthesis of data on intervention effects. One review indicated that only RCTs were eligible (Table 2, item 4) and reviewers noted that this was a deviation from their protocol (Mugellini et al., 2021). Some reviews had planned to include more diverse study designs but only found RCTs (6 reviews) or NRS (4 reviews) that met their eligibility criteria (Table 2, item 5).
Two reviews (Kumah et al., 2022; Zych & Nasaescu, 2022) found no eligible studies related to intervention effects. Further analysis (below) focuses on the remaining (49) reviews with relevant included studies.
Analysis and Synthesis of Data
In this section we address the questions posed above, in the section on Objectives. We show aggregate data in Tables 3 to 6, and information on each review is provided in Table 7.
1. To what extent did reviewers avoid introducing reporting biases into the review?
Avoided Introducing Bias at the Outset by Including Studies in the Review Regardless of Whether They Provided Useable Effect Sizes (k = 49 Reviews With Relevant Included Studies)

aLetters in parens refer to columns in the supplemental data file (Littell et al., 2025).
bSystematic exclusion of otherwise-eligible studies that collected but did not report data on key outcomes and/or lacked data sufficient to compute effect sizes. This judgment is based on reviewers’ statements and assessments shown in questions 2a, 2b, and 2c (more details are provided in our dataset (Littell et al., 2025; https://osf.io/58bys) and in Table 7.
cIncludes three reviews that did not have a table of characteristics of included studies.
dNA means there were no studies omitted from meta-analysis due to missing data on effect sizes; in most of these cases, reviewers obtained missing data from study authors.
Eleven reviews (22%) avoided introducing ORB, often by contacting study authors to retrieve missing data. We assessed the inclusion of studies with missing data by examining whether reviewers identified and included these studies in tables and narrative portions of the review.
In most cases (28 SRs), it was unclear whether reviewers had included otherwise-eligible studies that did not report or fully report relevant outcomes (Table 3, question 1 (q1)). We found no clear statements about the potential effects of underreporting of relevant outcomes on the magnitude of effects (Table 3, question 2d (q2d)).
2. How did reviewers assess ROB (or study quality)? What tools, signaling questions, and response categories did they use?
Most reviews relied on definitions and categorical schemas developed by authors of ROB tools, with or without modifications. Given the diversity of tools used for this purpose, and some lack of transparency about their modifications and uses in these SRs, it was not possible to conduct a systematic analysis of the concepts and categories reviewers used to assess ROB.
Risk of Bias (ROB) or Study Quality Assessment Tools Used in 49 Reviews With Included Studies

See study-level data in supplemental data file (Littell et al., 2025), columns S, T, U, and V.
3ie = International Initiative for Impact Evaluation, EPOC = Effective Practice and Organization of Care, EPHPP = Effective Public Health Practice Project, ESRC = Economic and Social Research Council, NRSMG = NonRandomized Study Methods Group, NTACT = National Technical Assistance Center on Transition, ROB = Risk of Bias, ROBINS-I = Risk Of Bias In Non-randomized Studies of Interventions, SCD ROB = Single Subject Design ROB.
aApplications of the 3ie tool (Hombrados & Waddington, 2012a, 2012b; Waddington et al., 2012) use different signaling questions for different research designs.
bThe EPOC tool uses different ROB items for studies with separate control groups (RCTs, NRS) versus interrupted time series (ITS) designs.
cOne review used RoB2 to assess RCTs but switched to ROBINS-I to assess those RCTs “where there is evidence that the randomisation has gone wrong or is no longer valid” (Filges et al., 2022a, pp. 12, 24).
A more diverse set of approaches was used to assess ROB in NRS. ROBINS-I was the most common tool, used in 12 (28%) of 43 reviews that assessed NRS. Reviewers who used ROBINS-I routinely stopped assessing risks of bias for a study after they recorded one Critical risk in any one ROB domain, and these studies were routinely excluded from further analysis. In some cases, this led to the post hoc elimination of hundreds of otherwise eligible studies from further quantitative and qualitative analysis, with incomplete documentation (see, for example, Dietrichson et al., 2020, 2021; Fong et al., 2021). Because selective reporting was the last ROB domain assessed, ORB/ARB ratings were not completed for many of these studies. In the Discussion section, we suggest that this practice may be the result of misinterpreting the guidance in ROBINS-I.
Assessment of ROB, ORB, and ARB

ARB = analysis reporting bias, NA = not applicable, ORB = outcome reporting bias, ROB = risk of bias.
aLetters in parens refer to columns in the supplemental data file (Littell et al., 2025).
Discussion and Analysis of ROB and ORB/ARB (k = 49 Reviews With Included Studies)

aLetters in parens refer to columns in the supplemental data file (Littell et al., 2025).
bThese categories are not mutually exclusive (total > 100%).
Key Characteristics of 51 Included Reviews

Abbreviations: 3ie = International Initiative for Impact Evaluation; ARB = analysis reporting bias; CG = Coordinating Group; CJ = Crime & Justice (Campbell CG); Dis = Disability (Campbell CG); Ed = Education (Campbell CG); EPOC = Effective Practice and Organization of Care (Cochrane group); EPHPP = Effective Public Health Practice Project; ESRC = Economic and Social Research Council; ID = International Development (Campbell CG); NRS = Non-Randomized Studies; NRSMG = NonRandomized Study Methods Group; NTACT = National Technical Assistance Center on Transition; Nut = Nutrition (Campbell CG); ORB = outcome reporting bias; QRCT = quasi randomized study; RCT = Randomized Controlled Trial; ROB = risk of bias; RoB1 = Cochrane ROB tool (Higgins & Green, 2011); RoB2 = Cochrane ROB 2.0 tool (Sterne et al., 2019), ROBINS-I = Risk Of Bias In Non-randomized Studies of Interventions (Sterne et al., 2016.); SCD ROB = Single Case Design ROB (Reichow et al., 2018); SW = Social Welfare (Campbell CG).
aPage numbers refer to pdf documents downloaded from the Campbell Systematic Reviews journal website.
bMandatory standards for the conduct or reporting of reviews from Methodological Expectations of Campbell Collaboration Intervention Reviews (MECCIR) reviews (The Methods Group of the Campbell Collaboration, 2019a, 2019b):
C12: “Include studies irrespective of their publication status, and their electronic availability.”
C40: “Include studies in the review irrespective of whether measured outcome data are reported in a ‘usable’ way.”
C51: “Assess the risk of bias/study quality for each included study, regardless of the study design or randomization type.” “Campbell reviews should not use composite scales, indices, or other measures that conflate multiple measures of risk of bias/study quality into a single score.”
R11: In the Abstract, “Provide a comment on the findings of the risk of bias/quality assessments.”
R32: “Studies should never be excluded from a review solely because no outcomes of interest are reported.”
R46: “State the tool(s) or coding strategies used to assess the primary study quality/risk of bias for included studies, how the tool(s) or coding strategies were implemented, and the criteria used to assign studies, for example, to judgments of low risk, high risk, and unclear risk of bias; low quality or high quality.”
R49: “Describe how studies with low quality or high/variable risks of bias are addressed in the synthesis.”
R57: “List key excluded studies (i.e., those a reader might reasonably have expected to find) and provide justification for each exclusion.”
R72: “Present a ‘Risk of Bias’ and/or ‘Study Quality’ table for each included study, with judgments about risks of bias, and explicit supports for these judgments.”
R74: “Provide a brief narrative summary of the quality/risks of bias among the included studies.”
R89: “Comment on the potential impact of studies that apparently measured outcomes but did not contribute data that allowed the study to be included in syntheses.”
R100: In the Discussion section, “Discuss…the implications of any study-level or outcome-level risk of bias/quality assessments on the review findings.”
Two reviews provided full descriptions of the ROB tools they used, including information on their items and rating criteria (Keenan et al., 2021; Psaki et al., 2022). We consider these examples of best practice in reporting on ROB tools used (for details, see Table 7).
In some cases, it was clear that reviewers did not follow instructions in the ROB tools they cited. For example, one review stated that they used the RoB2 tool, but considered issues related to sample size and baseline similarity as evidence of risk of selective reporting (Emezue et al., 2022, pp. 34, 39). Reviewers who used RoB2 and/or ROBINS-I did not apply the signaling questions to a specific “reported result,” as instructed; instead, reviewers applied these questions to whole studies or to a specific outcome domain.
Eight reviews used unique (nonstandard) tools for assessment of ROB in RCTs and 7 used unique tools for assessment of NRS. These tools reflected widely varying conceptualizations of ROB. For example, Mugellini et al. (2021) used two highly unusual approaches to “study quality” assessment: (1) studies were rated on four dichotomous variables: external validity as declared by study authors, external validity as judged by coders (who classified RCTs as field or lab experiments), internal validity, and “good quality;” and (2) reviewers used overall “quality” scores based on the 10-year Simple Impact Factor of the journal or working paper series in which the study appeared (p. 19; these scores were used in meta-regressions). Regarding the first approach, we think it is a mistake to view external validity, internal validity, and study quality as dichotomous variables. Regarding the second approach, impact factor may have little or nothing to do with study quality (Saginur et al., 2020) and it is therefore not a surprise that the reviewers concluded that there was no relationship between “study quality” and effect size.
Hinkle et al. (2020) used 5 unique items to assess ROB: “(a) Were any sources of nonequivalence or bias reported or implied in the application of the intervention or its analysis (i.e., threats to internal validity)? (b) If yes, what sources of nonequivalence or bias were identified? (c) Did the researcher(s) express any concerns over the quality of the data? (d) If yes, explain. (e) If a quasi-experiment, how was matching of groups achieved?” (p. 31). Note that this review relied heavily on study authors’ expressions of “concerns over quality of data” (pp. 31, 82).
One review (Carthy et al., 2020) used the EPOC ROB tool to rate RCTs and rated all NRS as High ROB overall.
Some reviewers (e.g., Lum et al., 2020, p. 18) rejected the use of certain domains contained in the Cochrane ROB instruments, and argued that these issues (e.g., blinding of participants and assessors) were not relevant in their field of research. We think it is important to note that the fact that a practice, such as blinding, is rare or (perhaps) not possible in some situations does not mean that it is irrelevant as a potential risk of bias.
3. What proportion of reviews assessed risks of reporting biases?
More than half (29) of 49 reviews assessed ORB for all studies, 16% (8) assessed ORB for some studies, and 20% (10) did not assess ORB at all (Table 5, question 2 (q2)).
Less than half (15) of the reviews assessed ARB for all studies, and 6 assessed ARB for some studies.
Most (82%) reviews conducted some assessment of reporting bias, but nine reviews (18%) contained no assessments of reporting biases (Table 5, q4).
Of the nine reviews that did not assess reporting biases, some used the word “reporting” in idiosyncratic ways in their ROB assessments. For example: • Cohn et al. (2020) used three criteria to assess “reporting of results” (one of the 6 ROB domains they assessed): (1) “The main findings of the study are clearly described,” (2) “authors report uncertainty due to random variability (confidence intervals),” and (3) “appropriate statistical tests were used to assess the main outcomes reported (p-values)” (p. 47, Appendix G). • Using a modified version of a 3ie ROB tool (Hombrados & Waddington, 2012a), Alfaro-Serrano et al. (2021) “assessed the quality of the evidence in terms of the completeness of reporting in four categories: (1) reporting on key aspects of selection bias and confounding, (2) reporting on spillovers of interventions to comparison groups, (3) reporting on SEs, and (4) reporting on Hawthorne effect and collection of retrospective data” (p. 14). • Gross et al. (2020) appeared to use the term “reporting bias” to refer to overall study quality (p. 12) or risk of bias (p. 16). 4. How did reviewers assess risks of reporting biases?
Here, we focus on the 40 reviews that provided some assessment of risk of reporting biases ORB and/or ARB. These reviews tended to combine ratings of different types of selective reporting (as per RoB2 and ROBINS-I) or reported ORB separately (Table 5, q5).
Some reviews used one or two questions to assess reporting biases. For example, “Are reports of the study free of suggestion of selective outcome reporting?” (Dyreborg et al., 2022, online supplement). Or “Was the study free from selective outcome reporting?” and “Was the study free from selective analysis reporting?” (Castle et al., 2021, p. 12; also see Berretta et al., 2021).
Some reviewers conflated ORB and ARB with other issues, including concerns about study methods or statistical analyses (e.g., Alfaro-Serrano et al., 2021; Castle et al., 2021; Imdad et al., 2021; Lwamba et al., 2022; Gonzalez Parrao et al., 2021). This was common in reviews that used 3ie ROB tools, and those tools appear to be a source of this problem, because their criteria for assessing reporting bias include elements related to the appropriateness and credibility of estimation methods. For example, one 3ie ROB tool contains the following criteria assessing reporting bias in non-randomized studies: “a) A pre-analysis plan is published… “b) Authors use ‘common’ methods of estimation… “c) There is no evidence that outcomes were selectively reported (e.g., results for all relevant outcomes in the methods section are reported in the results section); [and] “d) Requirements for specific methods of analysis” were fulfilled (Hombrados & Waddington, 2012b, online Appendix C, p. 26–27).
As an example of the last point (d), when using propensity score matching, the tool requires study authors to report a sensitivity analysis if more than 10% of participants are unmatched. In this and other examples, concerns about study design and analytic methods (items b and d above) are conflated with concerns about selective reporting bias (items a and c). These problems appeared in reviews in various ways. For example: • Lwamba et al. (2022) wrote, “Reporting bias is observed when authors of RCT studies do not discuss baseline balance between treatment and control groups… or when multiple treatment arms are not differentiated in the analysis…” (p. 62). One study was assessed as “having a high risk of bias because of reporting issues related to a lack of details provided on the matching methods used for identifying a valid comparison group” (Lwamba et al., 2022, p. 85). • Emezue et al. (2022) confused ORB with issues related to sample size and baseline equivalence. Small sample size was used as evidence of Unclear risk of reporting bias in one study (p. 34); baseline similarity was used as evidence of Low risk of reporting bias in another (p. 39). • Keats et al. (2021) conflated reporting bias with o participant enrollment and data collection (justification for an Unclear rating of risk of reporting bias: “Few of the final 200 women enrolled in the study were not included for analysis, since a subsample of 500 women was reached before the end of enrollment,” p. 147); o participant crossovers (justification for an Unclear rating of risk of reporting bias: “Women were switched into different treatment arms if they migrated to a different cluster area,” p. 167); and o publication status (justification for a Low rating of risk of reporting bias: “reports from the study are still being published,” p. 197). • Smith et al. (2022) conflated reporting bias with missing data due to attrition. Three studies “indicated high risk of bias based on selective outcome reporting due to missing data from participants withdrawing from the studies” (p. 23). • Imdad et al. (2021) used “minimal loss to follow-up” as justification for Low risk ratings of reporting bias for two studies (pp. 39–40).
In some cases, it was clear that reviewers did not address questions about reporting biases in the ROB tools they used, as when an ROB tool asked about information on prespecified outcomes and/or analyses and reviewers gave no indication that they searched for study protocols or pre-specified plans (e.g., Aventin et al., 2023; Castle et al., 2021; Lum et al., 2020). We discuss this issue in greater detail in the next section.
Criteria for risk ratings were often vague. For example, “a pre-analysis plan is published,” “authors use common methods of estimation,” and “there is no evidence that outcomes were selectively reported” (Castle et al., 2021, appendix 3). Some reviews used rating scales that were not fully anchored (e.g., Berretta et al., 2021; Dietrichson et al., 2020, 2021), leaving the meanings of some rating categories open to interpretation.
Several reviews provided explanations for rating ORB and/or ARB that demonstrated a fundamental lack of understanding of reporting biases. For example, “We rated a large majority of studies (and effect sizes) to be free of selective reporting, but this does not mean that they followed prespecified protocols or analysis plans” (Dietrichson et al., 2020, p. 26). As another example, Dyreborg et al. (2022, online supplement) scored ORB “Low risk if there is no evidence that outcomes were selectively reported (e.g., all relevant outcomes in the methods section are reported in the results section).” Emezue et al. (2022) used the observation that “negative findings were reported” to justify low risk ratings (pp. 34, 38, 40, 43). Imdad et al. (2021) justified low risk ratings with statements that studies “seem to report all the relevant outcomes,” “seem to report all the outcomes irrespective of their statistical significance,” and “do not seem to selectively report outcomes” or “most of the outcomes were reported” (pp. 28–59). Also see Carthy et al. (2020).
Some reviewers used the same criteria for different ORB ratings, so that ratings of Low risk and Unclear risk were virtually interchangeable (Das et al., 2020; Imdad et al., 2021).
Some reviews used consistent language in justifying assigning the same rating to different studies. For example, Birkenmaier et al. (2022) justified all Unclear ratings with the statement “study protocol was not found” (pp. 22–27).
Some reviews included inconsistent statements about their ORB/ARB assessments (e.g., Lassi et al., 2021a; McGinn et al., 2020; Salam et al., 2020; for details, see Table 7).
Some reviews provided opaque explanations for their ORB/ARB ratings. For example, Emezue et al. (2022) wrote, “The authors did not selectively report their findings” (p. 33), and “No selective reporting [was] suspected” (p. 37). It is unclear how reviewers arrived at these judgments.
It was helpful when reviewers described the documents they used in their ORB ratings. For example, “Insufficient information to permit judgement and no protocol was found” (Lassi et al., 2021a, p. 71) or “All outcomes presented in the methods section were reported in the paper” (Keats et al., 2021, p. 139).
Some reviewers seemed to use a default rating for ORB and/or ARB. In some reviews, the default rating was Unclear risk, especially if studies did not cite or reviewers could not locate an a priori protocol or plan. (We think this position is defensible.) In other reviews, especially those associated with the Crime and Justice Group, the default rating appeared to be Low risk, as studies were assigned to this category unless there was clear evidence of selective reporting within research reports. (Ten of 12 Crime and Justice reviews omitted assessment of ORB/ARB or rated these risks “low” or “no information” in > 80% of relevant included studies.)
1
For example, Gaffney et al. (2021) defined low risk for ORB as any reporting of a relevant outcome (Littell & Gorman, 2022). Hillman et al. (2020) reported that, “There was no evidence or suggestion of reporting bias in any of the studies” (p. 20), and all studies were rated low risk on this domain. Also, “Many of the studies reported results based on multiple analysis methods and reported all statistically significant and insignificant results for all outcome measures discussed, which implied a lower risk of bias due to selective analysis reporting” (Castle et al., 2021, p. 20, emphasis added). In these reviews, the absence of evidence of reporting biases was incorrectly used as evidence of the absence of these biases. 5. To what extent and how did reviewers use study protocols as sources of data on risks of ORB/ARB?
Ideally, assessments of risks of selective reporting bias involve comparisons between pre-registered protocols or pre-specified analysis plans and reported data on outcomes, endpoints, analyses, and subgroups (as per RoB2 and ROBINS-I). Based on information provided in the review reports, it was often impossible to tell whether or how reviewers searched for pre-specified plans for all studies. Dietrichson et al. (2020) included “two separate yes/no items asking reviewers whether they think the researchers had a prespecified protocol and analysis plan” (p. 13, emphasis added). Some reviews focused on whether studies cited a protocol or plan, using the presence or absence of a citation as evidence that an a priori plan did or did not exist. In many cases (21 reviews) it was unclear whether reviewers actually searched for protocols or plans and in 14 reviews it was clear that they did not do this (Table 5, q6).
One review included an item on study registration on the data extraction form, asking coders to: “Provide any details of study registration, including…registry IDs, and so forth” (Gonzalez Parrao et al., 2021, p. 75). We consider this an example of best practice (for details, see Table 7).
Eleven reviews used information about the availability of a priori plans in documenting their assessments of ORB/ARB for some or all studies (Table 5, q7). In the absence of a protocol, one review rated risk of reporting bias “not reported” or “no information” (Reith-Hall & Montgomery, 2023). Two reviews routinely rated risk of reporting bias as Unclear at best (High risk ratings were possible) in the absence of a protocol (Betts et al., 2022; Birkenmaier et al., 2022); we think these are examples of best practice in linking the absence of protocol to ORB/ARB ratings (for details, see Table 7).
Reviews did not question whether protocols and plans pre-dated unblinded analysis and reporting of results. In at least one review (Betts et al., 2022), an a priori protocol was defined as one that was public before the study report was published; such a protocol could have been created or changed after data analysis was completed. No reviews made clear distinctions between prospective and retrospective (or altered) plans (Table 5, q8).
In some reviews, the presence of an a priori published/registered/public protocol or analyses plan was a criterion for Low risk ratings, yet (a) there was no evidence of any search for such plans and (b) it was not clear why some studies were assigned Low risk ratings in the absence of these plans (see Table 7).
Other reviews reported that study protocols were used to assess ORB, but (a) it was not clear whether reviewers searched for a priori plans to assess all included studies or whether the search was restricted to a subset (e.g., a convenience sample) of studies that explicitly mentioned a plan (e.g., a registry entry), and (b) it was not always clear whether or how reviewers compared a priori plans to research reports (see Table 7).
Several reviews registered concerns about the absence of a priori protocols or analysis plans. This “may suggest that studies within this field are of lower quality than what would be expected” (Dalgaard et al., 2022c, p. 40). “Because the included studies did not have pre-registered protocols, it is difficult to assess reporting bias for incomplete outcome data for all outcomes or selective outcome reporting” (Birkenmaier et al., 2022, p. 49). 6. To what extent and how did reviewers assess interrater reliability of ORB/ARB ratings?
Most (31) reviews reported that they conducted independent double-coding for ORB/ARB assessments for all studies (Table 5, q9). No reviews provided information on initial agreement on (interrater reliability of) these ratings. 7. To what extent and how did reviewers document reasons for their ORB/ARB judgments?
Only 12 reviews (30% of the reviews that rated ORB/ARB) provided support or documentation for all ratings of ORB/ARB; another 12 (30%) provided support for some but not all of these ratings, and 16 reviews (40% of those that rated ORB/ARB) offered no support or documentation for these ratings (contrary to mandatory MECCIR item R72).
For examples of best practice in documenting support risk ratings judgments, see the risk of bias tables in the online supplemental appendix provided by Reith-Hall and Montgomery (2023). 8. What proportion of reviews used overall ROB (or study quality) ratings?
Most reviews (69%) used overall study ROB or quality ratings (Table 6, q1) sometimes (but not always) in addition to domain-specific ratings. On the surface, this might seem consistent with instructions in RoB2 and ROBINS-I, but contrary to MECCIR standard C51.
Reviews that used overall scores or ratings included those that used • unique summative scales (Gross et al., 2020; Lee et al., 2020; Mugellini et al., 2021) or ratings (Hunt et al., 2022; Saran et al., 2023; Windisch et al., 2022); • the 3ie ROB tool (Berretta et al., 2021; Castle et al., 2021; Gonzalez Parrao et al., 2021; Lwamba et al., 2022); • overall GRADE ratings (Carthy et al., 2020); • a tool similar to requirements of the ESRC (Cohn et al., 2020); • Rob1 and/or EPOC tools (Dyreborg et al., 2022; Gaffney et al., 2021).
Of the reviews that used RoB2 and/or ROBINS-I, most used the recommended weakest-link-in-the-chain approach to create overall ratings (e.g., Emezue et al., 2022, Filges et al., 2022a, 2022b; Reith-Hall & Montgomery, 2023). But some reviewers based their overall ratings on selected items from these tools (Petersen et al., 2022, 2023), others added new items (Psaki et al., 2022), and some didn’t report domain-level ratings at all (Strange et al., 2022).
Unfortunately, the practice of collapsing domain-specific ROB ratings into an overall rating or score often obscures further analysis and discussion of issues specific to selective reporting (and other specific ROB domains). 9. To what extent and how were ROB and reporting biases considered in the abstract, plain language summary, discussion, and conclusions of the review?
Discussion of overall ROB appeared in multiple sections of most reviews (Table 6, q3), while attention to reporting biases was far less common (Table 6, q5). Only one review mentioned reporting biases in the abstract, 14 reviews included comments about ORB/ARB in the discussion section, and 3 addressed these issues in their conclusions.
Most (31 of 40) reviews that assessed ORB/ARB provided a narrative summary of results (Table 6, q6). Five reviews conducted sensitivity or moderator analysis to explore whether and how reporting biases may have affected results (Table 6, q7), and no reviews discussed the potential impact of reporting biases on results (Table 6, q8).
Studies that used overall ROB ratings in moderator analyses tended to find no differences between studies with different overall ratings (e.g., Gonzalez Parrao et al., 2021, p. 93; Keenan et al., pp. 24–25). In contrast, moderator analyses that used individual ROB items may be more informative, showing that some risks (e.g., confounding) are associated with larger effect sizes and others are not (e.g., Dietrichson et al., 2020, p. 34).
More than one-third (18 or 37%) of reviews commented on the potential impact of missing data from studies that measured relevant outcomes but did not provide data sufficient to include effect size estimates in the synthesis (Figure 2, MECCIR R89 data from Table 7). Percent of Reviews that Did Not Meet Relevant Mandatory MECCIR Standards (k = 49)
Several reviews contained potentially misleading summary statements, which appeared to ignore or downplay the risks of bias they had identified in primary studies. For example, Mugellini et al. (2021) stated that their review “includes only high-quality experimental designs” (p. 31) and “(n)one of the included studies is of poor quality. Only one paper…presents low external and internal validity…” (p. 32). Wider variations in the reviewers own external validity ratings were not discussed, and there was no discussion of the overall quality scores reviewers derived from impact factors and used in moderator analysis. 10. To what extent did reviewers meet relevant, mandatory MECCIR standards?
We documented lack of adherence to 12 mandatory MECCIR standards that relate to assessments of ROB and reporting biases. This was a difficult task, because (a) some MECCIR standards (e.g., R32) can be interpreted in different ways and (b) reviewers’ descriptions of the conduct of these reviews were often opaque or internally inconsistent. Using two independent raters, we flagged failures to meet 12 standards across 49 reviews with relevant included studies. Our initial agreement on these items was only 66% (often due to inconsistent statements within reviews), but we resolved all initial discrepancies and extracted quotations from study materials to support final, agreed-upon judgments (see online datafile). Where there was clear evidence of failure to meet a mandatory standard, we provide this in Table 7.
Figure 2 shows the proportion of 49 recent Campbell intervention reviews that did not meet specific mandatory standards (a short summary of each of these standards is provided at the end of Table 7). The most common failures were as follows: • 80% failed to provide study-level ROB ratings and explicit supports for these judgments for each included study (R72), • 69% used overall (composite) ROB ratings or scores (contrary to MECCIR C51), • 67% failed to describe how coding strategies were implemented and/or criteria used to rate studies (R46), • 63% did not comment on the potential impact of studies that apparently measured outcomes but did not contribute data to the synthesis (R89), and • 57% failed to provide justifications for key excluded studies (R57).
Figure 3 shows that each of the 49 published Campbell reviews failed to meet at least one of the 12 mandatory standards we assessed. On average, these reviews failed to meet 4.9 of these standards (SD = 2.3). Almost three-quarters (35) of the reviews seemed to miss four or more mandatory standards. One review failed to meet all 12 of the standards we routinely assessed. Number of 12 Relevant Mandatory Standards Not Met Per Review (k = 49)
Compliance with mandatory standards was not much better when we looked at the nine reviews co-authored by a Campbell editor. These reviews missed an average of 4.7 of 12 standards (range = 2 to 8). 11. Other observations
Throughout our review, we tried to identify examples of best practices in this set of Campbell intervention reviews. Nine examples from eight reviews are mentioned above and these examples are highlighted in Table 7.
As mentioned above and documented in Table 7 and our supplemental data file (Littell et al., 2025), we found considerable amounts of missing and conflicting information in these reviews. For example, three reviews were missing tables of characteristics of included studies, 28 were missing information on excluded studies (e.g., reasons for exclusion), 39 reviews were missing reports and/or documentation of ROB ratings. We found inconsistent information on numbers of studies across the text and tables and graphs of six reviews; and seven reviews had inconsistent information on ROB ratings (criteria and/or results).
We also found many unclear and/or incorrect statements about reviewers’ methods. Consider these statements from one review: “The methodological process have [sic] been developed following the standards and principles of systematic reviews, in order to ensure accurateness, methodologically soundness, comprehensiveness, and control for risk of bias” (Mugellini et al., 2021, p. 13). “During the analysis, it emerged that the most important elements to be taken into consideration for evaluating the risk of bias were the internal and external validity” (Mugellini et al., 2021, p. 18). The same reviewers claimed that RCTs are internally valid (p. 18) and incorrectly asserted that non-RCTs are more likely to be affected by selective publication and p-hacking (p. 20).
Another review claimed that “standard methodological procedures expected of systematic reviews were used” (Lee et al., 2020, p. 3), but these reviewers provided no clear study inclusion criteria (p. 6), “the team drew only on published studies” (p. 10), and reviewers produced an “evidence map” that combined statistical significance of results with overall quality ratings (Figure 2). This review appeared to have violated at least 18 mandatory MECCIR standards (see Table 7).
Similarly, Strange et al. (2022) stated that they “used the standard methodological procedures as expected by The Campbell Collaboration” (p. 1), although this review did not appear to meet six mandatory MECCIR standards (Table 7).
Many reviews lacked clear criteria for rating risks of bias. In one such review, authors wrote, “the risk of bias assessment is refined, making it possible to discriminate between effect estimates with varying degrees of risk. This refinement is achieved with the addition of a 5-point scale for certain items….The refined assessment is pertinent when thinking of data synthesis as it operationalizes the identification of studies (especially in relation to nonrandomised studies) with a very high risk of bias” (Dietrichson et al., 2020, p. 13). This 5-point scale was only anchored with Low and High labels at the endpoints (Dietrichson et al., 2020, online appendix, pp. 56–58).
One review (Mazerolle et al., 2020) contained only one study, and the same study appeared in another review by the same author team (Mazerolle et al., 2021). Different CGs were involved in the publication of these two reviews.
Published SR reports included inconsistent and missing information, errors in grammar and syntax, and formatting and layout problems that made it difficult to understand the contents. Many reviews provided tables or appendices that were poorly organized, incomplete, or entirely empty (see, for example, Dalgaard et al., 2022c; Keenan et al., 2021; as described in Table 7). These issues undermine readers’ confidence in the conduct and reporting of SRs.
Discussion
Summary of Findings
Reporting biases were defined and assessed in diverse and sometimes idiosyncratic ways in recent Campbell systematic reviews of intervention effects. Most (40 of 49) reviews conducted some structured assessment of reporting biases, but 18% (9) did not.
Overall, reviewers’ descriptions of their assessments of risk reporting biases were incomplete and inconsistent. Explanations and support for reviewers’ judgments about risks of bias were often absent or unclear; and some explanations were illogical. In many cases, these assessment practices did not reflect current understanding of the prevalence of selective reporting and ways in which these biases can undermine the validity of and confidence in results of research reviews. This lack of understanding is underscored by the fact that most reviewers did not fully consider the potential impacts of risks of bias on the credibility of their results.
In our judgment, each of these reviews failed to meet at least one of Campbell’s mandatory standards (i.e., the standards that were in place at the time these reviews were published). It is important to note that we systematically assessed adherence to only 12 of the 187 MECCIR standards (there were 79 conduct standards and 108 reporting standards, not all of them mandatory). Our review focused only on mandatory standards related to assessment of ROB, so it is not a thorough assessment of compliance with MECCIR. Our results may seem to suggest more methodological quality and reporting problems in Campbell reviews than those reported by Wang et al. (2021), but Wang and colleagues used different criteria (they did not assess MECCIR standards). We acknowledge that the assessment of adherence to standards is complex and somewhat open to interpretation. Nevertheless, we report review results in great detail and provide study-level justifications for judgments.
We found many qualities of these reviews disappointing. However, we do not think that these reviews are unusual. A growing body of research is identifying problems in systematic reviews including limited or flawed ROB assessments and failure to incorporate ROB assessments into conclusions of reviews (Uttley et al., 2023, Table 2; also see Ayorinde et al., 2020; Minozzi et al., 2022). Campbell reviews have been considered among the most rigorous reviews in the social sciences and, while that may be true, our review suggests that there is ample room for improvement in the conduct and reporting of Campbell systematic reviews.
Below, we discuss central and unresolved problems in the assessment of reporting biases in studies included in recent Campbell intervention reviews. Then, to better understand the potential problems and promises of assessments of risk of reporting biases, we consider the contexts in which these assessments occur: in larger ROB frameworks, in the production of SRMAs, in diverse scientific communities, and within the larger sociology of science.
Concerns About Assessment of Reporting Biases
Introduction of Reporting Bias Into Reviews at the Outset
Some systematic reviews routinely exclude studies that lack sufficient data to calculate (or estimate) effect sizes. This introduces reporting biases into the review at the outset; that is, it increases the likelihood that the selection of results into the review will be affected by the direction and significance of the results. Reviewers may not want to code studies that do not yield “usable” effect sizes, but this practice increases the likelihood that review results will be affected by reporting biases, while impeding reviewers’ ability to detect these biases. As a result, treatment effects are likely to be overestimated, confidence intervals and prediction intervals may be underestimated, and this can lead to overconfidence in the results of a biased synthesis. We think reviewers should recognize this explicitly when interpreting their results.
Assessing ROB at the Level of the Study, Outcome Domain, or Numerical Result
Consistent with mandatory Campbell MECCIR standards C51, R72, and R74 (but not with nonmandatory standards C56, C57, and C58), most reviews assessed risks of bias at the study level, providing one set of ROB ratings for all study results. Some reviews provided separate ROB assessments for different outcome domains or comparisons (e.g., Filges et al., 2022a). In contrast, instructions for the RoB2 and ROBINS-I tools stipulate that ROB should be assessed separately for each “numerical result” (i.e., effect size) of interest. This is important because risks of bias may vary within studies and even within outcome domains (e.g., when some ES are adjusted for confounding variables and others are not). Similarly, Cochrane reviewers often applied ROB tools in ways the developers had not intended, by failing to identify effect sizes of interest and applying ROB tools to entire studies rather than to specific numerical results (Minozzi et al., 2022; Moore et al., 2023).
Exclusion of Studies With One or More “Critical” ROB Rating From Further Analysis
Most review teams that used ROBINS-I (12 reviews) excluded otherwise eligible studies from further analyses if the study had one “critical risk” rating in any ROB domain. This practice may reflect a misinterpretation of the ROBINS-I guidance. At first glance, it seems to be supported by guidance for ROBINS-I, which states that a critical risk of bias judgment means that “the study is too problematic to provide any useful evidence and should not be included in any synthesis” (Sterne et al., 2016, p. 4). However, the ROBINS-I guidance also makes it clear that (a) the tool is applied at the level of a specific numerical result (an ES) and (b) the term “synthesis” refers to a specific meta-analysis of treatment effects on a particular outcome (Sterne et al., 2016). This is important because ROB judgments can vary within and across outcome domains within the same study (e.g., depending on whether an ES was adjusted for certain confounders).
While ES with critical risks should be excluded from main estimates of treatment effects, these results could be included in subgroup, moderator, or sensitivity analyses to assess the magnitude and direction of potential biases--and validate “critical risk” ratings.
Furthermore, the core development team of ROBINS-I do not support the exclusion of entire studies from further qualitative or quantitative analysis on this basis, and they expect to see studies with critical risks of bias in tables of Characteristics of included studies, ROB tables, and narrative discussion of results (personal communication, J. P. T. Higgins & J. A. C. Sterne, 10 July 2025).
Some reviewers applied the (possibly misinterpreted) ROBINS-I principle of excluding results with critical risks to the studies they assessed with RoB2. “We added a critical level of risk of bias to the RoB 2 tool with the same meaning as in the ROBINS-I tool; that is, the study (outcome) is too problematic in this domain to provide any useful evidence on the effects of intervention and it is excluded from the data synthesis” (Dalgaard et al.. 2022c, p. 11).
Sometimes this practice was in accordance with the reviewers’ protocol (e.g., Filges et al., 2022a), although it appears to violate terms of the RoB2 copyright license which prohibits modifications (personal communication, J. P. T. Higgins, 10 July 2025).
In reviews that followed this practice, the study status appeared to be changed after one ROB item was judged to be “critical” or “too high.” Reasons for these status changes were not detailed in most of these reviews (for examples, see Dalgaard et al., 2022a, 2022b, 2022c; Dietrichson et al., 2020, 2021; Filges et al., 2022a, 2022b). In some SRs, this approach contributed to dramatic reductions in the number of included studies that were not available for further analysis (e.g., from 607 to 205 in Dietrichson et al., 2021). The status of these studies is confusing because, although they met initial inclusion criteria, they are not included in tables of Characteristics of included studies, detailed reports on ROB assessments, or discussion of results; instead, they are handled more like excluded studies, with a single row in a separate table (e.g., Dietrichson et al., 2021, Appendices A1, A4, and A5; Dietrichson et al., 2021, Appendices F and G).
In one review, this process was justified as follows. “The quality of the evidence in this review was enhanced by excluding studies assessed to be at critical risk of bias using the ROBINS–I tool from the data synthesis. We believe this process excluded those studies that are more likely to mislead than inform” (Filges et al., 2022a, p. 22).
Unfortunately, this practice is not supported by empirical evidence. It obscures study selection processes and prevents analysis of the potential effects of specific (and diverse) risks of bias on results. In our view, a more defensible approach involves revising the initial inclusion criteria to focus on a more manageable and well-defined set of studies. If reviewers wish to exclude studies that are so fundamentally flawed that they cannot provide reliable data (e.g., NRS that fail to control for important, pre-specified confounding variables and those with major study design flaws), then they should identify and apply relevant exclusion criteria a priori (i.e., when making study eligibility decisions based on reading of full texts). In some reviews, this could have saved reviewers a lot of time and strengthened the review. For example, in Dietrichson et al. (2021), 104 included studies were not included in meta-analysis for reasons related to study design (p. 25); some of the additional 257 studies that were identified as “too high” risk of bias could also have been excluded from the review for reasons related to study design (for example, studies with only one intervention and one comparison site could be excluded because this design confounds intervention status and school context; and studies in which intervention and control participants are drawn from different academic years, because this design confounds intervention status and time; see Dietrichson et al., 2021, Appendix G).
Difficulty Locating Pre-Registered Protocols or a Priori Plans and Documenting Their Use
Prospective registration of study protocols has been promoted for at least 20 years (De Angelis et al., 2004). Yet, even in clinical medical research, where leading journals require prospective registration of studies, compliance with registration reporting requirements is uneven and prospective registration remains low (Al Durra et al., 2020; Serghiou et al., 2023; Silva et al., 2024). Prospective registration is rarely completed for observational studies and in disciplines outside of clinical medicine (Boccia et al., 2016; Leducq et al., 2024; Taylor & Gorman, 2022).
Thus, it is difficult to find protocols across multiple registries. The lack of availability of protocols, difficulty distinguishing prospective versus retrospective (or altered) protocols, and difficulty comparing protocols or analysis plans to reported results often hamper reviewers’ ability to assess reporting biases.
To help readers understand how reviewers handled protocols in assessing reporting biases, it is important for reviewers to clearly describe what they did and how they did this. In many reviews it was unclear whether reviewers actually searched for a priori plans or protocols. Some reviewers approached this issue by recording whether study authors mentioned or referenced such plans (e.g., Dalgaard et al., 2022a, 2022b). It was also not clear whether or how reviewers discerned (a) whether protocols or analysis plans were published, registered, or made publicly available before data collection began and (b) if and when these plans were changed.
Some ROB tools ask reviewers, “Was there an a priori protocol or analysis plan?” But it is not clear how reviewers are supposed to find such plans and there is little guidance on what reviewers should do with plans if they find them. A more straightforward approach focuses on whether study authors mentioned or referred to an a priori plan. This leaves reviewers with the task of assessing risks of reporting bias in the absence of essential information that can only be gleaned from a detailed, prospective protocol.
Given the difficulties involved in finding, assessing, and comparing protocols and study reports, and the need for better guidance for reviewers on this problem, we suggest that reviewers consider following the “Reporting bias decision tree” shown in Figure 4. Reviewers can use this decision tree as a guide to document the steps they took to assess reporting biases. This tree allows reviewers to rely solely on references to protocols (without searching for them) or to search for protocols. However, it constrains reporting bias ratings appropriately, so that Low risk ratings cannot be assigned in the absence of a prospective protocol with fully reported results. In the absence of a prospective protocol, the best possible rating for risk reporting bias is Unclear. This is similar to the approach taken by two review teams (Betts et al., 2022; Birkenmaier et al., 2022). Reporting Bias Decision Tree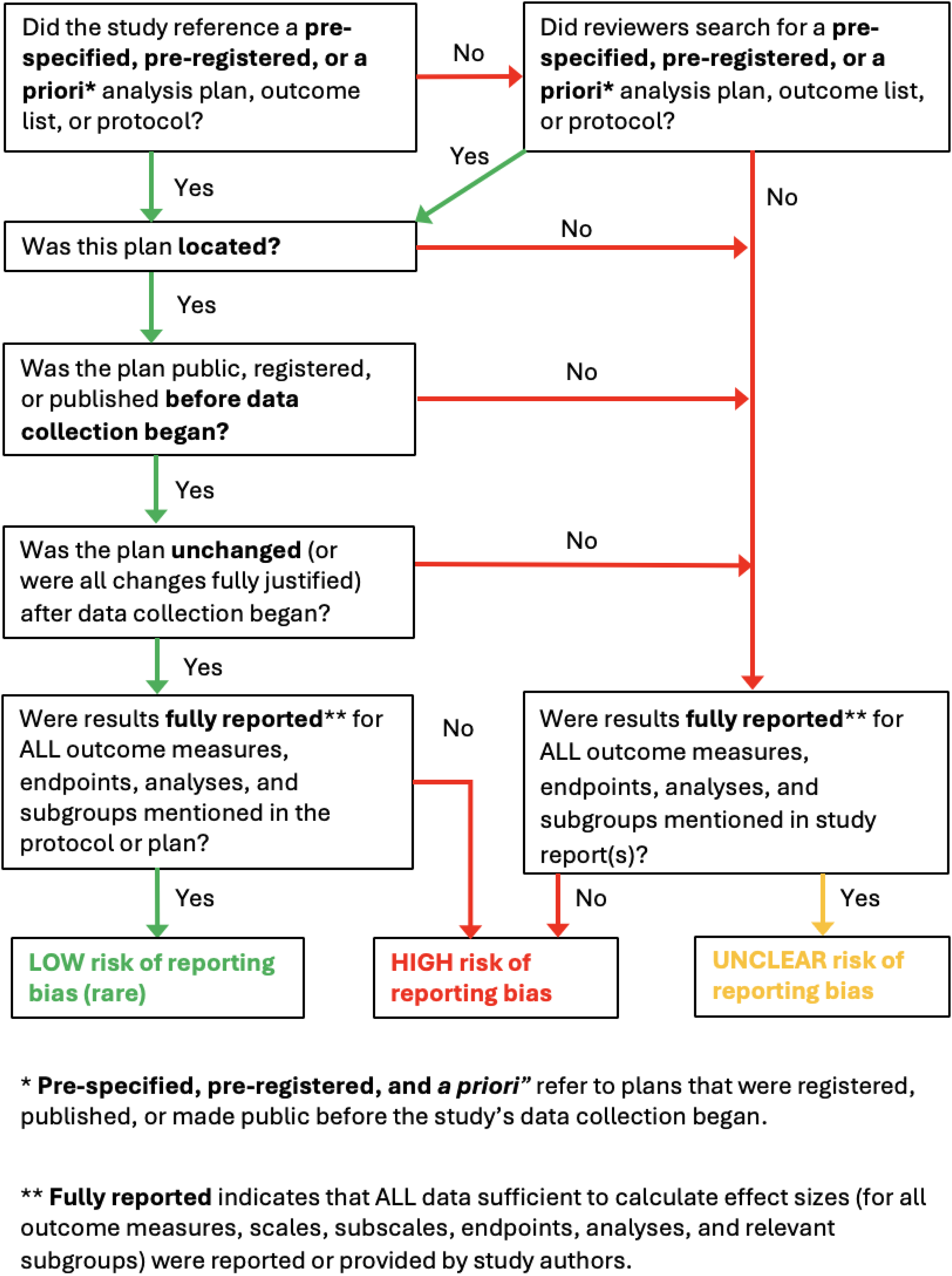
Concerns About the Construction of Prominent ROB Tools
The EPOC ROB tool instructs reviewers to “score ‘low risk’ if there is no evidence that outcomes were selectively reported (e.g., all relevant outcomes in the methods section are reported in the results section” (EPOC, 2017, p. 2). We think these instructions are insufficient to detect reporting biases, as there is no guarantee that the outcomes reported in the methods section are identical to those that specified at the start of the study.
Most ROB tools use unanchored or incompletely anchored response categories (e.g., “No” “Probably No” “Probably Yes” and “Yes”) which require the reviewer to make high-inference judgments. RoB2 and ROBINS-I use the “probably” modifier solely to signal that the review team has made a judgment, so in effect, these tools have two response categories, not four (“No” and “Probably No” have the same effect). The fact that considerable “guess work” is needed to answer some of these questions may explain why initial interrater agreement on these tools is low. This does not inspire confidence in ROB ratings. We encourage the use of more explicit, fully anchored response categories developed for the purpose of ROB assessments in specific reviews (for examples, see Littell et al., 2021, 2023). Alternatively, reviewers could begin with RoB2 or ROBINS-I and operationally define signaling questions and response categories to improve transparency for purposes of a specific review. In all cases, we strongly encourage routine use of quotes from the original papers that provide support for the reviewers’ judgments.
Approaches that use different ROB assessment questions for different study designs yield ratings that are not compatible across studies within a review. This is unfortunate and we think it unnecessary. Like threats to validity, which are not properties of study design or methods, risks of bias are properties of the inferences that can be drawn from data produced in a study.
We think that RoB2 and ROBINS-I articulate the domains of ROB assessments that should be required for all reviews of intervention effects. However, as the developers of those tools note, reviewers must translate standard signaling questions into items and response categories that are operationally defined to fit the purpose, content, context of a specific review. We think reviewers should report their operationalized items, response categories, and results, instead of (or in addition to) reporting responses to the formal signaling questions.
Use of Overall ROB Scores
Which risks of bias matter? How do these risks affect results? These are important empirical questions that cannot be addressed when ROB ratings are “rolled up” into an overall judgment. Nevertheless, prominent ROB scales have been modified to meet some consumers’ preferences for a single, overall ROB rating, even though much information is lost when multiple ROB items are combined into overall ratings or scores (Jüni et al., 1999, 2001; Wells & Littell, 2009).
One issue is that different elements that relate to study “credibility” probably do not operate in the same direction. In quantitative reviews, two ROB items may have opposite effects on an effect size. Some ROBs (e.g., selection bias, performance bias) tend to inflate effect sizes, biasing the effect estimate away from the null hypothesis, while others (e.g., intervention spillover effects) can deflate effects or bias results in favor of the null hypothesis.
Another issue is that there is very limited guidance on how much importance to attach different aspects of study credibility. ROB domains are often implicitly weighted equally, although this is almost certainly not correct. Different ROB domains are not well suited to formal or informal summing up, in part, because it is difficult to know how to weight different aspects appropriately.
Further, some ROB items are more important than others in some contexts. In some reviews there is little variation on some ROB items (e.g., blinding of participants), so weighting these noninformative items equally with those that make important distinctions between studies is illogical and obscures empirical investigation of relationships between potential sources of bias and results.
Recent Cochrane ROB tools provide algorithms for making overall, study-level ROB judgments, based on the highest risk rating assigned to any one ROB domain (Higgins et al., 2019, 2024; Sterne et al., 2016, 2019). Thus, a study with one High risk rating in any domain is considered High risk overall, a study with Moderate and Low risk ratings is considered Moderate risk overall, and a study with only Low risk ratings is considered Low risk overall. We strongly discourage use of overall (study-level) risk ratings, but we must note that the “weakest link in the chain” algorithms in Cochrane tools are preferable to more simplistic judgments about overall study quality, such as those based on overall research design (e.g., the Maryland Scientific Methods Scale; Farrington et al., 2002) or scales that create composite scores from unrelated study characteristics (e.g., the Methodological Quality Rating Scale; Miller & Willbourne, 2002; also see Vaughn & Howard, 2004).
Concerns About ROB Are Not Routinely Considered in Interpretations of Results
Risks of bias in included studies should always be considered explicitly in reviewers’ summaries of the results of their systematic reviews. These concerns raise questions about the extent to which readers can rely on reviewers’ assessments of ROB and, therefore, on published conclusions of SRs.
Understanding Assessment of Risks of Reporting Biases in Context
Risks of reporting biases are usually examined within broader, structured assessments of the qualities of studies within systematic reviews. Here we consider the research and social contexts that can facilitate or constrain these assessments.
ROB Assessments Are Inherently Difficult
Assessing the credibility of included studies is perhaps the most challenging intellectual task in systematic reviews. There are several interrelated reasons for this, all related to the fact that there are few (and potentially no) aspects of credibility that are universal across studies and reviews. To assess study qualities, credibility, and risks of bias, reviewers need a high degree of expertise in: • the substantive area (the “subject”) of the systematic review, • the methods used to answer questions that are relevant to the systematic review, and • the contexts in which the subject is studied.
Different considerations might apply in different contexts even if the study subject and methods are the same. For example, factors that affect the credibility of experiments on elementary school classroom reading programs (i.e., relevant confounders) can vary across school settings and cultures.
Given the complexity of the study “credibility” problem, and the near certainty that credibility issues are not the same across interventions, contexts, and methods, there is little empirical evidence on which to base credibility judgments (that is, to decide which items are good candidate to help us distinguish between more and less believable studies). In some areas, we can use statistical theory (for example, to express a preference for RCTs over NRS in intervention studies), but this only applies to a few aspects of credibility.
Therefore, we think it is important that systematic reviews of intervention effects begin with the ROB domains and signaling questions shown in RoB2 and ROBINS-I, operationalize these questions for purposes of a specific review, and report results in operationalized terms.
Systematic Reviews Are Highly Desirable, Highly Cited, and Under-Resourced
There are powerful incentives to produce SRMAs, including growing interests in synthesized evidence and the fact that published SRMAs tend to be very highly cited. These incentives are so strong that many reviewers are willing to conduct SRMAs without adequate funding. This puts pressure on researchers to conduct reviews quickly. There are real incentives to cut corners and few safeguards in place to ensure production of high-quality SRMAs.
Editorial teams and peer reviewers at journals are also inadequately compensated for the difficult tasks of critical appraisal of SRMAs. As a result, we often see rather perfunctory critiques instead of thorough and constructive criticism and support.
Training and support for reviewers, editors, and peer-reviews is inadequate. Advanced trainings tend to focus on important issues in meta-analyses and rarely cover the many practical issues that reviewers face in conducting a SRMA.
We think this explains the apparent inability for reviewers to follow and editors to enforce Campbell’s MECCIR standards. Note that similar concerns were expressed about lack of adherence to formal guidance in recent Cochrane reviews (Minozzi et al., 2022; Moore et al., 2023).
Review Norms Develop Within Distinct Scientific Communities
Over the past 25 years, we have seen methods and norms for SMRAs evolve somewhat differently across disciplines and research communities. In Campbell, the Coordinating Groups (CGs) have developed norms which differ across groups. So we see consistent patterns in reviews produced by one group that are quite different from the practices in another group. The assessment of risks of reporting bias is a good example: “Low risk” judgments appear to be the norm in Crime and Justice CG reviews in which no evidence of bias is interpreted as evidence of no bias. As another example, concerns about statistical methods and competence only appear in ORB and ARB judgments in reviews produced in the International Development CG which use versions of the 3ie ROB tool.
How Can the Conduct and Reporting of SRMAs and ROB Assessments Be Improved?
The production of many low quality SRMAs is a growing source of research waste (Ioannidis, 2016; Uttley et al., 2023). We believe that fewer SRMAs should be conducted with much more training and support, and reviews should be held to clear, consistent, and high standards. Clearer methodological expectations and better adherence to stated expectations would be useful (Wang et al., 2021; Littell & Gorman, 2022; Young et al., 2024).
The Campbell Collaboration recently replaced the 2019 MECCIR standards with more “holistic” guidance (Aloe et al., 2024). The sheer number of MECCIR standards may have been overwhelming for reviewers and editors alike. Further, the opacity of some of these standards left room for doubt about whether or when they were followed. Nevertheless, we found evidence that recent Campbell reviews did not follow the mandatory MECCIR standards that were in place when these reviews were published (Table 7, Figures 2 and 3). Of course, the problem of nonadherence to standards can be vanquished by eliminating standards; but that represents an acceptance of the status quo and may have deleterious effects on the quality of future reviews.
The new Campbell “standards” (Aloe et al., 2024) do not provide clear expectations for authors or editors. Instead, there is more room for interpretation.
Regarding ROB assessment, the new Campbell guidance is limited to these general statements: • “Critical appraisal should be carried out with an appropriate risk of bias tool that includes assessment of domains such as selection bias, confounding, attrition [sic] that are appropriate for the study designs that are included. • “Choose and justify a critical appraisal tool that fits the purpose of the review. • “Describe data coding and critical appraisal process…and how these are designed to minimize bias. • “Conduct critical appraisal assessment (e.g., assessment of risk of bias or study quality fit for the purpose of the review)” (Aloe et al., 2024, p. 4).
Recommendations for Improving Assessment of Risk of Reporting Biases and Other Sources of Bias in Systematic Reviews of Intervention Effects

If conducted properly, the assessment of reporting biases involves a comparison study of protocols and registry records with reports of study results. Such studies are complicated and time consuming to conduct, and they can be published as stand-alone research reports (e.g., Fleming et al., 2015; Taylor & Gorman, 2022). If ORB/ARB assessments are to be done in anything other than a perfunctory manner in a SR, then it must be accepted that the time needed to complete the review will be greatly increased, as prespecified analysis plans will need to be thoroughly searched for and identified and the information in these compared to subsequent publications. In many cases, it is likely that protocols and pre-specified analysis plans will not exist or be inaccessible (Campbell et al., 2022), so ratings of ORB will likely be uncertain despite reviewers’ best efforts to obtain these.
As a practical matter, we suggest that reviewers follow the decision tree shown in Figure 4. When there is no prospectively registered protocol, prespecified list of outcomes, or prespecified analysis plan to compare to reported analysis and outcomes, the default rating for reporting biases should be “Unclear.” Under these circumstances, reviewers may find evidence of high risk of reporting biases within study reports, as when outcomes or analyses mentioned in the methods section are not reported or are under-reported in the study. For studies with no prospective or a priori protocol or analysis plan, low risk ratings cannot be justified.
Strengths and Limitations
This study provides a detailed examination of Campbell reviewers’ descriptions of their assessments of selective reporting and other ROB. It raises concerns about the transparency and integrity of many of these assessments and provides suggests for improving these assessments.
One of the strengths of this review is that extraction and coding of data from reviews was conducted in duplicate, using a pre-tested form (provided in Appendix 3). Another strength is all of the raw data used in this review are publicly available (at https://osf.io/58bys); this data file contains additional comments and relevant quotations from reviews.
Our study has several limitations. First, we relied solely on written reports (published reviews and online supplements), focusing on what readers could and could not glean from the available information. Where reporting was incomplete or incorrect, we could not capture the processes that reviewers actually used.
Second, we did not formally assess risks of bias in the included Campbell SRs per se. This would have required assessment of all aspects of the conduct and reporting of these SRs (including their search strategies, data extraction and coding methods, analytic methods, etc.), which was beyond the scope of this project.
Finally, the decision tree shown in Figure 4 is a heuristic device, meant to illustrate proper use of protocols (registrations, plans) in ORB/ARB assessment. It has not yet been pilot tested for reliability and feasibility. We believe it is an improvement on some existing tools, but further work is needed to clarify whether or when reporting bias ratings should be made at the study level or for different outcome domains or numerical results.
Authors’ Conclusions
Implications for Practice and Policy
More accurate and transparent reporting on the conduct of systematic reviews and meta-analyses can enhance credibility and confidence in these syntheses. We believe that fewer SRMAs should be conducted, with much more training and support per review. Additional support is needed for peer reviewers and editorial staff to ensure that published reviews meet the highest standards. These steps are essential to reduce research waste and ensure that decision makers have access to accurate information.
Implications for Research
Improve the Conduct and Reporting of Systematic Reviews of Intervention Effects
To improve assessment of risks of bias, we recommend the following steps for all systematic reviews of intervention effects.
Improve ROB Assessments and Use These Tools to Generate New Empirical Data
Further work is needed to improve the logic, ease of use, and psychometric properties (reliability and validity) of structured assessments of risks of reporting bias. Better understanding of the uses and limitations of structured instruments, such as RoB2 and ROBINS-I, is needed. These tools provide important guidance about topics that should be considered in assessing ROBs in intervention reviews, but (as indicated above) reviewers will need to operationalize items contained in these tools to fit specific review contexts and improve reliability and consistency in applications across studies. Guidance on how to operationalize standard signaling questions and additional examples would be useful.
Additional work is needed to clarify the critical hierarchical levels at which different ROBs operate. Current approaches suggest that ROB assessments can be conducted at the level of the “reported result” (i.e., a single effect size), outcome domain, primary study, meta-analysis (within a SRMA), or entire review. These are all potentially viable options, but further work is needed to specify how reviewers should assess specific ROBs at the “right” level. For example, concerns about the integrity of treatment assignments (e.g., selection bias, baseline equivalence) usually appear at the study level and do not need to be assessed for each ES or outcome domain. On the other hand, sometimes different analyses within a study (e.g., intent-to-treat versus per-protocol analyses) will have different ROBs related to treatment assignments. Similarly, different outcomes within a study may or may not share similar ROBs; outcomes collected via in-person interviews and those extracted from public administrative data will likely have different risks related to use of valid instruments, attrition, and blinding. To assess risks of reporting biases, reviewers need to consider analyses, outcome domains, and specific reported results. Clarification of the fit between levels of assessment and ROBs could improve the efficiency and accuracy of ROB assessments. Reviewers may need to map the relevant ROBs associated with different levels of assessment for purposes of a specific review. Some guidance on how to do this would be useful.
Improvements in ROB assessments can facilitate moderator analyses, which can lead to better understanding of potential impacts of different domains of risks of bias on the results of a synthesis. This will help us learn what works best for whom under what circumstances.
Extend Requirements for Prospective Protocols and Full Reporting for Primary Studies
Requirements for prospective protocol registration should be extended beyond randomized controlled trials to include non-randomized and observational studies. In many disciplines this can also be accomplished through the use of the Registered Reports (RR) publication procedure, in which the study methods are reviewed by a journal before data are collected in the form of a Stage 1 RR and, if accepted, the results reported in the Stage 2 RR must adhere to these methods or explain any significant deviations (Chambers & Tzavella, 2022; Lakens et al., 2024). Although such requirements for strict prespecification of study methods have not yet been successfully implemented in medical research and are currently rare in other disciplines, in principle, they are extremely important components of research integrity and open science (Spybrook et al., 2022). Without them it is almost impossible to detect reporting biases.
Finally, in the interest of science, researchers, reviewers, publishers, funders, and other stakeholders should always provide, support, and expect full and transparent reporting of all results from primary studies and reviews. This is feasible with current online repositories (e.g., osf.io) which can store de-identified datasets, data collection forms, statistical code, and other relevant supplementary materials.
Supplemental Material
Supplemental Material - Assessment of Selective Reporting Biases in Studies Included in Campbell Systematic Reviews: A Systematic Review
Supplemental Material for Assessment of Selective Reporting Biases in Studies Included in Campbell Systematic Reviews: A Systematic Review by Julia H. Littell, Jeffrey C. Valentine, Dennis M. Gorman and Therese D. Pigott in Campbell Systematic Reviews
Supplemental Material
Supplemental Material - Assessment of Selective Reporting Biases in Studies Included in Campbell Systematic Reviews: A Systematic Review
Supplemental Material for Assessment of Selective Reporting Biases in Studies Included in Campbell Systematic Reviews: A Systematic Review by Julia H. Littell, Jeffrey C. Valentine, Dennis M. Gorman and Therese D. Pigott in Campbell Systematic Reviews
Footnotes
Acknowledgements
We thank members of the Campbell Methods Group for feedback on the protocol for this review. We thank anonymous peer reviewers, Campbell Methods editors, and authors of several Campbell reviews for feedback on the completed review.
Author Contributions
All members of the review team have expertise in the content area, systematic review methods, statistical analysis, and information retrieval. JHL and DMG conceived the idea for this project. JHL drafted the protocol and final report; DMG, JCV, and TDP reviewed and commented on the protocol and final report. All authors participated in data extraction and coding.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: JHL, TDP, and JCV are co-authors of one or more published Campbell reviews. No member of the review team was involved in screening or extracting data from any reviews they co-authored.
Plans for Updating This Review
The review will be updated once every five years, if sufficient resources are available. All members of the review team will participate in updates, depending on their availability.
Differences Between Our Protocol and Review
In the protocol for this review, we stated that we would include reviews published through 31 December 2022. We extended this eligibility date through 30 April 2023, which allowed us to include four newer reviews.
We added potential conflicts of interest as a post-hoc exclusion criterion for reviews. Two of the four members of our review team were involved in the conduct of one review (Littell et al., 2021). Given the composition and structure of our review team, we could not avoid having one of those co-authors involved in the coding or cleaning of data from that review; thus, ![]() was excluded based on potential conflicts of interest.
was excluded based on potential conflicts of interest.
Changes in our initial data extraction forms were necessary, because we could not reliably extract data from included systematic reviews in relation to many of our initial questions. These changes are described in detail in the text (in the Methods sections on Data extraction and Management and Dealing with missing data) and the final data extraction form is shown in ![]() .
.
Changes in our objectives were needed to reflect important issues that arose during our review. First, we did not expect reviewers to introduce the likelihood of reporting bias into their review by systematically excluding unpublished studies or those with incomplete reporting on relevant measured outcomes; but, after we observed these issues in multiple reviews, we added Objective 1 along with data collection plans to support analysis of these issues. Second, we broadened Objectives 2 and 9 from a narrow focus on ORB assessment to broader consideration of methods of ROB assessment. Third, we did not expect reviews to use overall ROB scores or ratings (given MECCIR C51), but this was a common practice in reviews that used RoB2 and/or ROBINS-I; Objective 8 was added to capture this phenomenon. Finally, we added Objective 10 to formalize our assessment of relevant MECCIR standards (11 mandatory MECCIR standards were mentioned the online supplement to our protocol (Littell et al., 2023); we conducted formal assessment of adherence to 12 mandatory MECCIR standards related to our objectives).
We planned to use quotations from reviews to capture definitions of ORB but did not find definitions of ORB outside of the ROB tools that reviewers used. We use verbatim passages from reviews for purposes of clarification and to illustrate different approaches.
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.