
Abstract
As fake news and disinformation continue to proliferate in digital journalism, the development of artificial intelligence (AI) analytics to identify synthetic content inconsistencies is increasingly important. This study explores trained AI analytics’ struggle to detect semantic gaps within AI-generated media. Findings reinforce human semantic capabilities and a direction for detection tools. AI analytics designed for semantic detection-related tasks are evaluated through the application of the Theory of Content Consistency, with insights for combatting social media news truth erosion.
Artificial intelligence (AI)-driven algorithms operate on both sides of the journalistic coin. Through proprietary algorithms used by news organizations they play a role in how news is produced and shared, and on the flip side, they also generate misinformation and disinformation, disrupting traditional news cycles and undermining journalistic credibility (Tandoc et al., 2020). As fake news becomes more sophisticated, it is increasingly harder for humans to distinguish real from false information (Rudin & Radin, 2019). To address this, training AI analytics to detect and mitigate misinformation, is an important tool in protecting the integrity of digital and social media journalism. AI models rapidly become more adept at creating seamless, multimodal content, the need also increases for AI detection tools at scale where humans have a chance of keeping pace with AI's evolving sophistication.
This study focuses on AI detection methods regarding semantic understanding, likely among the most challenging for AI analytics to achieve. As semantics involve understanding the connections between words, images, and concepts, the challenge for AI lies in bridging the gap to comprehend and derive meaning from certain expressions. This approach is important for journalism researchers, digital journalism professionals, and multimedia news organizations to understand both the strengths and limitations within AI. AI is not inevitable nor neutral (Buolamwini, 2023). When weaknesses present themselves, the humans involved in creating responsible AI practices—with transparency and accountability at the forefront—can look to use this identification as an opportunity to build tools with which to fight fire with fire, or in other words, to use AI to fight AI.
Using AI analytics in semantic gap experiments uncovers an area where AI is not yet strong, as it underperforms in emotional meaning-making between words and phrases, though the technology is rapidly catching up (Parekh et al., 2021; Xue et al., 2021). Exposing these semantic gap inconsistencies can offer clues into AI content that is synthetically created for the purposes of mis- and disinformation. This research employs the theoretical framework of the Theory of Content Consistency (ToCC) to evaluate the capabilities and limitations of various AI analytics designed for semantic detection-related tasks in multimodal media assets (MMAs). This study is relevant to digital journalism research as the MMAs used are similar to the text/caption and photo usage of a digital news post or of social media news content, and the findings provide direction for AI detection and fake news mitigation strategies in digital and social media journalism at large.
The ToCC is a multilevel framework that was developed to support AI detection research by mirroring traditional news production processes. It aligns with established journalistic roles, routines, and production cycles, structuring content analysis to identify inconsistencies and confirm alignment with news standards (Reese & Shoemaker, 2018; Schudson, 2001). Developed through an analysis of news content, websites, and media kits from leading outlets in top markets across the United States, the ToCC organizes detection measures into specific analytic domains, enabling researchers to assess the efficacy of AI-driven misinformation detection across different contexts and content types.
Mis- and disinformation detection is not a simple true-false task; it requires balancing multiple measures of evidence. ToCC facilitates this by structuring its analysis into five discrete levels, each generating an evidence vector—a structured set of parameters used in neural network algorithms. These vectors, when combined, allow machine learning models to refine their accuracy over extended training cycles. Machine learning is a subset of AI that enables systems to learn from data, identify patterns, and make decisions with minimal human intervention (Aljabri et al., 2023). By neural network algorithm we are referring to a machine learning model inspired by the human brain, designed to recognize patterns and process complex data by passing information through interconnected layers of artificial neurons (Agarwal et al., 2020). Given this level of complexity, by examining multiple measures in a structured framework, ToCC enhances the ability to isolate falsifications and optimize future detection algorithms, strengthening AI's capacity to distinguish authentic news from misinformation.
This research comes at a pivotal moment as many people access news through social media platforms, and generative AI models are capable of creating multimodal media akin to real social media content including text, image and audio (Cao et al., 2018; Gottfried, 2024). AI-generated content (AIGC) generally outpaces the capabilities of AI detection analytics, especially in natural language generation models that quickly develop language fluency close to human language patterns (Comito et al., 2023; Heikkilä, 2023). This allows for the easy creation of GAI multimodal propaganda, whereby news images and text can be combined to create and distribute manipulated messages, without the necessity of active human input (Ng & Li, 2023).
Frameworks emerging in AI journalism research like the Multimodal Consistency Neural Network (MCNN) and the ToCC argue that AI detection models must evaluate the features contained in multimodal media to inform its judgements (Xue et al., 2021; Masiclat & Luttrell, 2020; Yang & Luttrell, 2022). This means that to accurately detect misinformation, AI analytics must identify inconsistencies within a single type of media (like text or images) and also recognize patterns across different media types (such as text, images, and video) to understand how they relate within the same piece of content (Parekh et al., 2021). This can be challenging for AI analytics because the technology struggles to grasp the implicit rules and relationships that shape human language and meaning. This is why this application of theory via ToCC, tested with empirical data via the semantics synthetic AI detection task, are important as together, they provide a structured framework for analyzing news (real or fake) content, helping AI analytics identify inconsistencies across multimodal media and improving the detection of mis- and disinformation in a disruptive digital news environment.
Literature Review
Social Media as A Primary News Source
Social media platforms, including Facebook (Meta), Instagram, X, and TikTok, have emerged as primary conduits of communication in the United States, embedding themselves into the fabric of daily life over the past two decades (Ahmed, 2023; Aljabri et al., 2023; Gottfried, 2024; Neumann & Rhodes, 2024). As Aljabri et al. advance, social media “… radically impacts daily human social interactions where users and their communities are the base for online growth, commerce, and information sharing” (2023, pp. 19–20), as Ahmed supports, “Social media platforms have evolved from being a means to communicate personal news and information within one's social network to becoming the primary source of news information to its users,” (2023, p. 1108). Finally, Neumann and Rhodes concur, “Social media platforms have been adopted rapidly into our current culture and affect nearly all areas of our everyday lives” (2024, p. 1096). While these platforms have played a pivotal role in fostering connections, they simultaneously serve as the main vectors for the spread of misinformation and disinformation.
This duality highlights the increasing dependence on social media. Juxtaposed with news audiences’ vulnerability to the false narratives it perpetuates, it underscores the complex relationship between digital connectivity and information integrity. Ahmed supports, “… recent research suggests that social media also hastens the spread of rumors, fake news, and disinformation, which work to undermine democratic ideals’‘ (2023, p. 1108). Deepfakes, understood as the use of machine learning AI to produce images, video, and audio of actual people doing things that are not true, are some of the most concerning content in semantics and meaning-making, in their potential to erode or redefine what humans collectively understand as truth (Ahmed, 2023; Masood et al., 2023; Mirsky & Lee, 2021). The stakes could not be higher, with increased mis- and disinformation plus deepfakes rolling out at higher rates with more dangerous consequences.
An example of these consequences is the January 2024 release of fake pornographic images of Taylor Swift, which circulated rapidly on X, demonstrating the alarming virality of deepfakes and the urgent need for more sophisticated detection methods to keep pace with AI-generated content on social media. Despite efforts by fans to have these images removed and accounts blocked, the AI-generated fakes were viewed by millions, highlighting the platform's struggle to effectively manage and prevent the spread of such content. This difficulty is exacerbated by the dismantling of X's trust and safety team, which has hindered the platform's ability to enforce content moderation rules effectively (Ingram, 2024). The spread of deepfake images—whether of a musical artist or a news event—raises significant concerns about privacy, consent, and the broader issue of AI's role in generating nonconsensual imagery. The necessity for news organizations, social media platforms and tech companies to develop and implement more robust AI detection mechanisms is foregrounded, particularly to maintain a common shared conception of truth, as “… deepfakes may cultivate the assumption that a basic ground of truth cannot be established” (Vaccari & Chadwick, 2020, p. 3).
Algorithmic Journalism
The transition of news consumption to online and social media platforms, while offering unprecedented access and control over the flow of news, presents significant challenges to the maintenance of traditional journalistic standards, such as those that serve as the foundation of the ToCC, including the critical process of fact-checking. The inherent features of the internet, such as its boundless connectivity and the relative absence of regulatory control, create a landscape vastly different from that of conventional news media (Tsfati, 2010). This environment can offer audiences access to a more diversified range of news items and political information, offering perspectives beyond the somewhat homogenized viewpoints prevalent in mainstream media (Moon & Lewis, 2024; Rhodes, 2022). As a result, individuals who hold mistrust towards mainstream outlets may find online and social media platforms more appealing for their news consumption due to the diversity and directness of information available (Heim & Craft, 2020; Tsfati, 2010). As Tandoc Jr. posits, “Not only did social media change news distribution, it has also challenged traditional beliefs of how news should work” (Tandoc et al., 2019, p. 139).
This shift raises concerns about the credibility of news disseminated through these channels. Despite the internet being perceived by some cohorts as a more credible source of news compared to traditional media, this perception is paradoxical given the lack of stringent editorial oversight online (Fletcher et al., 2020; Li, 2023; Tandoc, 2019). Research by Metzger et al. points to a significant erosion of authority in online news texts due to the absence of rigorous factual verification processes once served as a hallmark of traditional journalism (2003). This discrepancy suggests that while the diversity and accessibility of information on the internet and social media may contribute to its perceived credibility, the lack of editorial standards potentially undermines the trustworthiness of the news (Rhodes, 2022). As news distribution increasingly moves onto social media platforms, the rapid and wide dissemination of potentially incorrect information poses a challenge to the integrity of public discourse, emphasizing the need for actionable AI tools.
Another factor in the potential for misuse is the use of algorithms in digital and social media journalism. An algorithm is a sequence of actions carried out to solve a specific issue or achieve a predetermined result (Diakopoulos, 2013; Luttrell et al, 2025). The larger implications of algorithms making decisions on behalf of humans lies in risks associated with bias and the potential for grave mistakes in classification and association tasks. As Diakopoulus states, “Operating at scale and often impacting large swaths of people, algorithms can make consequential and sometimes contestable … decisions. Algorithms, animated by piles of data, are a potent new way of wielding power in society” (Diakopoulos, 2019, para. 3).
AI algorithms are increasingly used in journalism through proprietary systems within major news organizations, driving news production and distribution. However, there is a growing push for greater accountability and transparency in how these algorithms operate. This is because many AI algorithms operate in what is referred to as a black box. A black box in AI is a system whose internal machine-learning processes have progressed to the point where they are not visible or easily understood by humans, making it difficult to explain how decisions are made (Rudin & Radin, 2019). The challenge of the black box is twofold: One, proprietary algorithms inside of large news and social media organizations control how the news is given to the public, yet the public will never be able to access the AI making those decisions; and two, as AI advances in sophistication its decision-making will outpace that of humans (Diakopoulos, 2013). Humans are thereby called to stay “in the loop” as “human-in-the-loop” (HITL) responsible AI practices call for (Mosqueira-Rey et al., 2023). HITL requires milestone checkpoints and systems where the humans in charge are involved in the decision-making processes of the AI so that when a mistake is made, or the algorithm diverges in some way, a human brain is up-to-date on where the algorithm's logic and thinking are in order to help fix or redirect it.
Diakopoulos (2013) sums up this issue, “What we generally lack as a public is clarity about how algorithms exercise their power over us” (para. 5). If platforms do not know the process by which the news is selected by their own algorithms, the black box problem described here is exacerbated, and the risk of AI mistakes can lead to the increased spread of mis- and disinformation.
Skepticism is Not Enough
The rapid pace at which AI and social media now operate undermines the usefulness of media skepticism and literacy as strategies for dealing with online misinformation and disinformation. The sheer volume and speed at which information is disseminated make it virtually impossible for individuals to critically engage with and discern the credibility of every piece of content they encounter. Research into news consumption patterns reveals a complicated relationship between media skepticism and the sources from which individuals choose to get their news (Ahmed, 2023; Li, 2023; Vraga & Tully, 2021). Tsfati and Cappella demonstrated that individuals who are skeptical about mainstream media are more inclined to seek out alternative news sources, suggesting a deliberate avoidance of traditional news outlets due to mistrust (2003). This skepticism stems from a desire to obtain accurate information, leading people to selectively ignore news that does not meet their criteria for reliability. Conversely, a higher level of trust in traditional media correlates with a greater likelihood of consuming news from these sources (Tsfati & Cappella, 2003).
However, in the context of social media, the dynamics of trust and skepticism appear to follow a different pattern. Goyanes (2020) found that frequent use of social media for news is positively associated with trust in these platforms as a news source. This indicates that, despite the known issues with misinformation and the rapid dissemination of AI-generated content on social media, users who heavily rely on these platforms for news develop a certain level of trust in them. Speaking to the psychological theory of familiarity effect, influencers wield considerable influence across various domains, as their consistent presence on social media fosters a sense of trust and recognition among their followers, who come to know them through daily exposure (Krueger, 1975). This highlights the difficulty in employing media skepticism in the digital age, where skepticism alone may not be sufficient to navigate the challenges posed by powerful algorithms set to users’ preferences and AI-generated content. Tangible tools and strategies such as the ToCC that go steps further than skepticism to critically assess and verify the news content encountered on social media, ensure the means by which the public will be able to discern between authentic and synthetic media effectively will be available.
In advancing beyond media skepticism and literacy, the imperative shifts towards more tangible domains. Simply urging individuals to enhance their literacy and skepticism is no longer realistic; it is essential to provide practical tools for assistance. Even the task of human-led fact-checking is increasingly becoming obsolete and unsustainable, especially when confronted with the quick and viral pace at which machine learning and AI can generate and disseminate mis- and disinformation, as Aïmeur et al., posit, “… fact-checking organizations cannot keep up with the dynamics of propagation as they require human verification, which can hold back a timely and cost effective response” (2023, p. 30).
AI Semantic Inconsistency Detection
The detection of inconsistencies in image, text, and MMAs serves as a foundational strategy for identifying AI-generated synthetic content. The uncovering of semantic inconsistencies—areas where AI struggles to identify the nuanced interplay of emotions, meanings, and relationships between words, phrases, and images—signals a vulnerability in AI's current capabilities. When synthetic AI is utilized for propaganda and spreading misinformation, the creation of multimodal assets makes the disinformation far more impactful and memorable. Disinformation campaigns rarely rely on single modalities; instead, they often employ multiple modes of communication, resulting in messaging that is significantly stronger, more targeted, and purposeful. The inability of trained AI analytics to detect these inconsistencies, with prompts mirroring the digital news distributed online and via social media content, not only flags a significant gap for AI detection technologies but also opens a pathway for developing advanced tools aimed at understanding and exploiting these semantic challenges. Recognizing that AI's comprehension of emotional and conceptual subtleties is still evolving, this area of research represents a marathon approach, continually innovating detection techniques to keep pace with the sophisticated evolution of AI-generated misinformation and disinformation tactics (Fahad et al., 2012; Hollenstein et al., 2016; McCrae et al., 2022).
As an example, Figure 1 contains an intramodal inconsistency, meaning that an inconsistency is apparent within a singular media modality. The type of inconsistency contained in Figure 1 (the red arrows and close up inset photos on the left and right bottom corners point to the woman's earrings being different on each ear) exemplifies a common feature in AIGC. Add another descriptive sentence with arrows, etc. It is typically easier for analytics to focus on one modality to detect inconsistencies, as the addition of multiple modalities changes the available features an analytic uses to inform its judgements. This means broader detection goals are typically informed by a suite of AI analytics, rather than a singular AI model. However, advances in image generation technology are swiftly reducing the occurrence of semantic errors, making visual inconsistencies within a single modality increasingly rare.

Image Inconsistency. Note. Turek, 2019.
Image detection tasks are generally easier than text or audio-based tasks. Various model approaches to image inconsistency detection exist, such as discrete cosine transformation, using a histogram of oriented gradient, local binary detection, or even assessing self-consistency (Hilal et al., 2017; Huh et al., 2018; Mahale et al., 2017; Mahale et al., 2019). Text-based approaches include BERT for general text classification, GLTR which localizes synthetic text, and OpenAI's classifier released in late 2022 (Guerrero & Alsmadi, 2022). Multimodal approaches must examine not only the intramodal features of a media asset, but also compare the intermodal features present in a singular multimodal asset to make a judgment about that media. An example of this type of asset is showcased in Figure 2, which contains two modalities in the text in both the caption and article as well as a photo. Further, leveraging transformers has allowed for the joint processing of both text and imagery or even text and video (McCrae et al., 2022). These cross-modal transformers allow for a comparative analysis of multiple forms of media for an AI analytic to make broader judgments with more features. Aligning with the digital and social media news focus of this study, the most common form of multimodal detection tends to compare news article captions and images (McCrae et al., 2022; Shekhar et al., 2017; Tan et al., 2020).
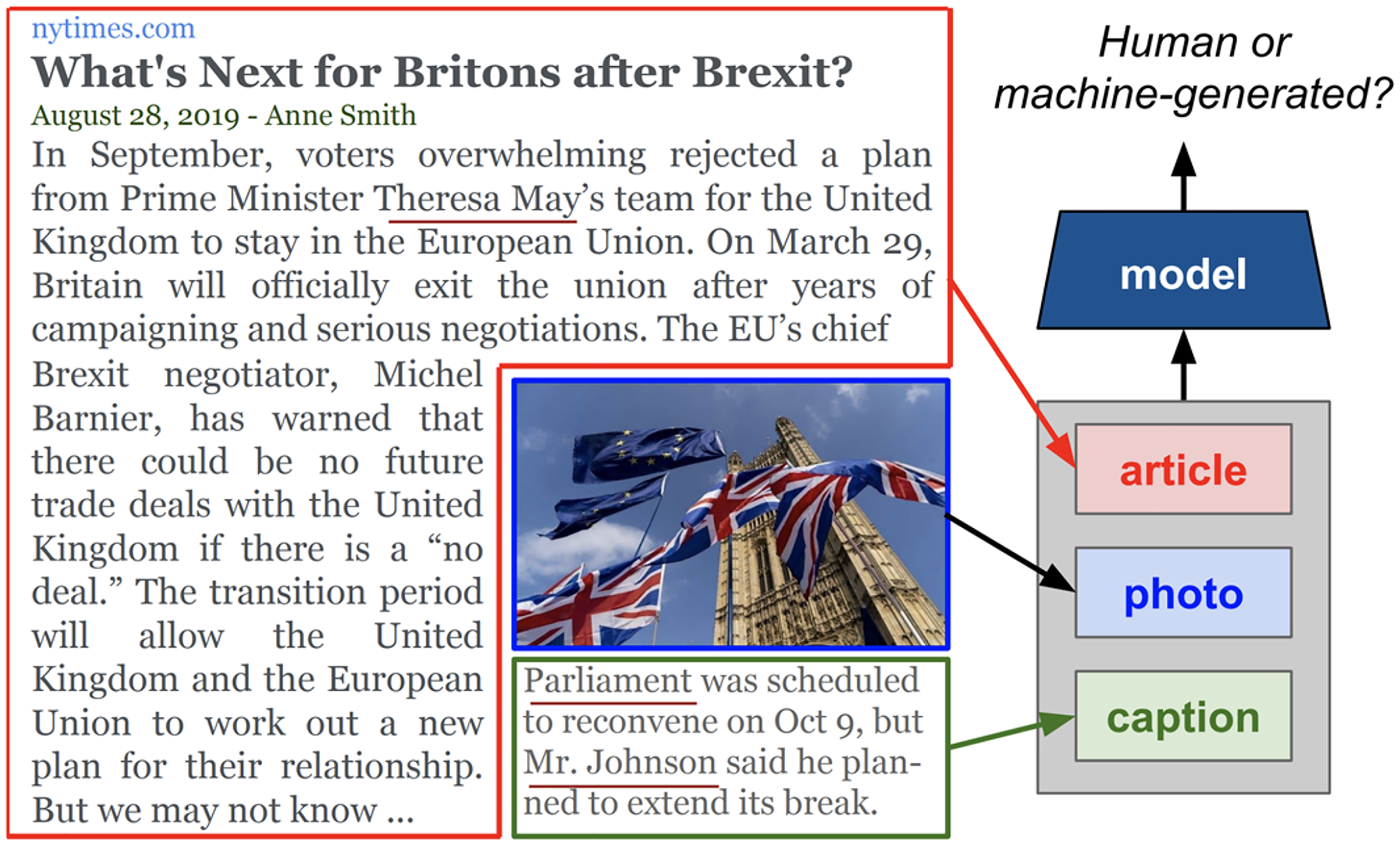
Multimodal Inconsistency. Note. From Tan et al. (2020).
The Theory of Content Consistency
Having explored the landscape of AI-driven misinformation, disinformation, and detection methods, we can now delve deeper into the ToCC, examine its levels of analysis, and discuss its application to research in this field.
To review, the ToCC provides a multilevel framework that mirrors traditional news production processes, enhancing AI-driven misinformation detection by aligning with journalistic standards. It structures content analysis into five discrete levels, generating evidence vectors to refine machine learning models and improve detection accuracy. This approach strengthens AI's ability to distinguish authentic news from misinformation by incorporating multiple measures of evidence in a structured framework. In this study, the research team focused on validating the Journalistic Domain and Creator Levels as they most related to the subject and task at hand in exploring semantic (creator) inconsistencies in AI-generated content that looks and feels like digital news (journalistic).
The ToCC domain levels function independently from each other, but can also work in tandem when necessary. This theoretical framework is intended to provide a structure for further studies in the mis- and disinformation research discipline and provide a way to identify inconsistencies in alignment with journalistic norms. Each level of the ToCC is designed to stand alone, offering targeted analytical insights that support the HITL approach in AI detection. Depending on the research focus or the type of media under review, individual levels can be applied separately to highlight specific inconsistencies or patterns. At the same time, the levels are built to operate in an overlapping and complementary manner, allowing for a more holistic evaluation when needed. This layered approach is particularly useful when analyzing complex or multimodal content, as different media types may call for varied analytic strategies—each of which is addressed within the appropriate ToCC category.
There are also instances when not all layers of information are available for analysis. The ToCC is designed with this in mind—it allows each level to be used independently when needed, while still providing meaningful insights. This flexibility ensures that even when certain data (such as authorship or metadata) is missing, researchers can still apply the framework to identify inconsistencies and evaluate content using the available layers.
For instance, consider content that lacks an accompanying image or metadata. In this case, there would be a disconnect between the Presentation and Network levels of the ToCC and the top three levels—Journalistic, Author, and Creator—because essential context is missing. Another example is when an article is published without an author name, or under a fabricated name claiming affiliation with a well-known journalistic organization. This scenario disrupts the Author level of analysis, as there is no established body of work to compare against, making it difficult to assess consistency in style, credibility, or authorship.
Each level is outlined further below, and also highlighted in Figure 3.
Network Level: Vetted and edited news stories propagate across social networks at measurably different rates and in qualitatively different ways than false or misinformation. Display or Presentation-tier Level: Digital news stories are published as multimodal collections (i.e., text, images, video, etc), and each of these elements have information-containing features (i.e., meta-data, compression artifacts, etc) which can be forensically assessed in multiple ways to discern adherence to or deviance from baseline measures of acceptable manipulation. This is a non-trivial computation problem requiring a machine to both correctly associate items based on their relative positions, and then reason about the consistency between associated elements. Journalistic Domain Level: Any media purporting to be news or journalism will conform to discernable, measurable categorical industry norms for the creation of the elements that form that news story. These norms derive from the long tradition, supported by a formal educational system and professional ethics and guidelines, for the gathering, recording, attributing, fact-checking, editing, and presentation of information characterized as journalism. Platform Level: Through the consistent use of corporate or in-house style guides, different publications, hereafter referred to as platforms, will exert measurable influences on key text dimensions. Creator Level: Systematic analysis of a given author's collected works will exhibit consistent and measurable tendencies in their word choices, and semantic constructions in accordance with measures previously established in stylometry literature. In addition, when authors move from one news subspecialty to another (e.g., from covering municipal activities to covering state or federal-level administrations) there are discernable, measurable, and categorical differences in their word uses and stylistic measures.
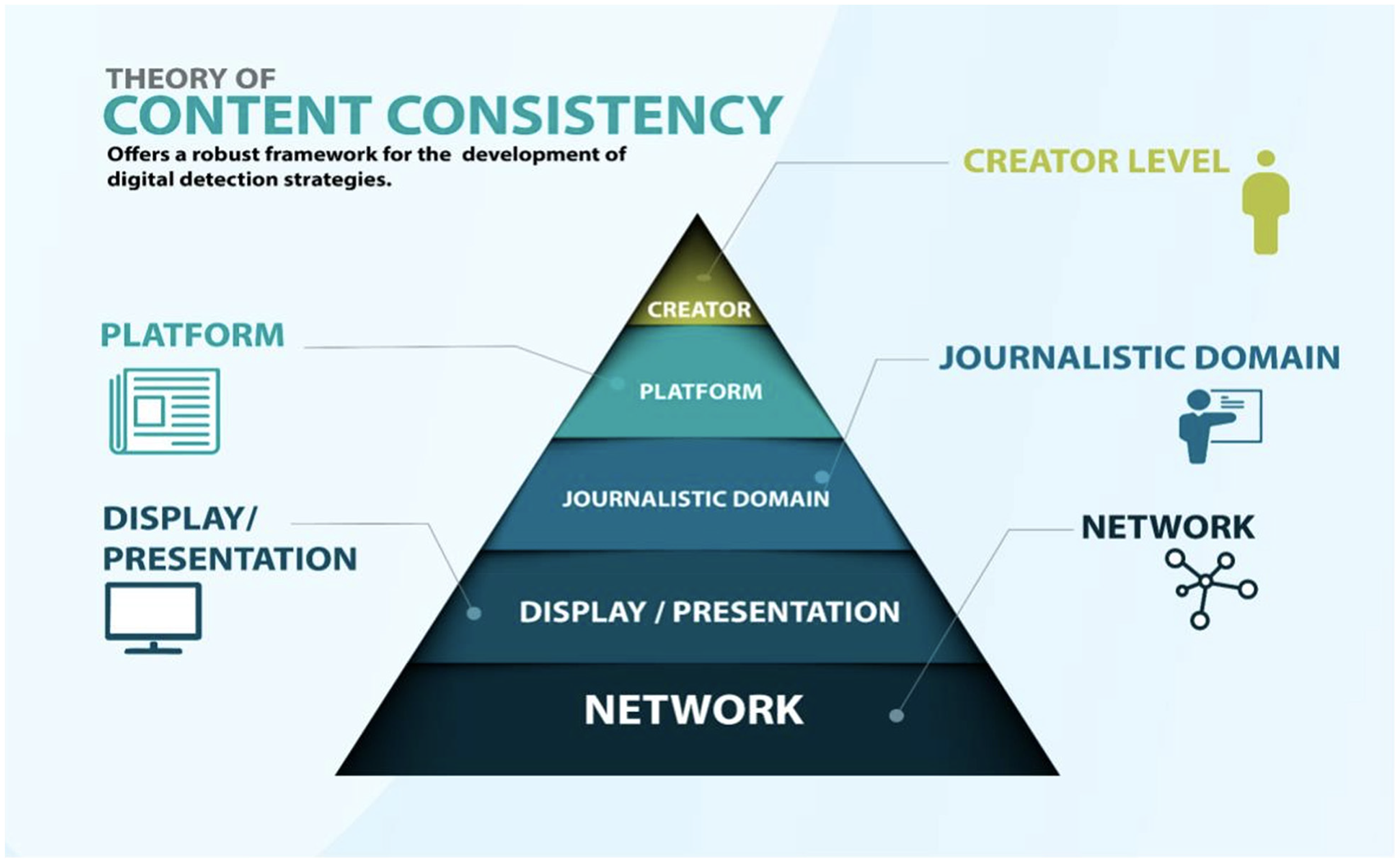
The Theory of Content Consistency. Note. Masiclat & Luttrell, 2020.
From an ethical standpoint, one of the most compelling reasons to adopt frameworks such as the ToCC is their potential to address the opacity and accountability challenges posed by black-box AI systems. As black boxes “are created directly from data by an algorithm, meaning that humans, even those who design them, cannot understand how variables are being combined to make predictions” (Rudin & Radin, 2019, p. 3). This conundrum highlights what AI and algorithmic journalism researchers describe as a “clear trade-off between the performance of a machine learning model and its ability to produce explainable and interpretable predictions” (Linardatos et al., 2020, p. 1; Sheu, 2020). While black box models perform well on large sets of data, transparent functioning—and clear human understanding of how these algorithms arrive at their outputs—is critical for the responsible, ethical and legal integration of AI systems: “From an ethical point of view, the ability to explain can help to identify and defuse problematic biases” (Asatiani et al., 2020, p. 260).
A burgeoning responsible AI movement towards transparency within algorithmic development parallels the growing demand for clarity in algorithmic journalism, underscoring the necessity for openness about how information is processed and presented (Diakopoulos & Koliska, 2017; Heim & Craft, 2020). This push for transparency is not merely a matter of ethical best practice but a practical necessity; should something go awry, humans can intervene effectively, diagnosing and addressing issues. In news, where trust and credibility are paramount, the ability to provide clear answers about the workings and decisions of AI systems becomes indispensable (Chadha & Koliska, 2015). This aligns with the broader imperative for transparency in news dissemination, ensuring that the public can trust the information being provided, understanding not just what is being presented but how and why it is being presented in a particular way (Schudson, 2020: Tandoc et al., 2020).
While various theoretical approaches exist aimed at “opening” the black box, there is not yet a universal method to create this necessary transparency (Poon & Sung, 2021; Wischmeyer, 2020). The ToCC helps establish a theoretical framework to test how analytics search for these content inconsistency features. While feature localization may be an uphill process as AI analytics learn the basics of detection, attribution and characterization, the ToCC helps categorize where AI analytics will locate the features that inform their judgements.
Given the imperatives discussed, this study explores the application of the ToCC – on the Journalistic and Creator domain levels – in an assessment of AI analytics designed to detect modality inconsistencies within MMAs. The research questions ask:
Applying the ToCC to this data is a step toward understanding and opening the black box, helping researchers identify how detecting features like semantic inconsistencies can inform future best practices for developing AI detection tools.
Methods
The ToCC was developed and implemented in this study as a broad framework to guide the evaluative process of detection (Masiclat & Luttrell, 2020). Typically, the dissemination of AIGC is approached from a content moderation or propagation analysis approach, but the ToCC allows more space for the complex analysis necessary of multimodal assets. This framework establishes consistency as a key metric when assessing falsity, in addition to specific concrete concepts such as geospatial or temporal inconsistencies that help depoliticize the construction of datasets. Under this framework, semantic inconsistencies could include scenarios where a modality was (a) inconsistent with itself; (b) inconsistent with modality conventions; or (c) inconsistent with other modalities, such as an image that is inconsistent with associated text. The ToCC organizes these general inconsistency types into five levels for detection. These five axioms include the domain level, the creator level, the platform level, the display level, and the network level, under the premise that deviations within these levels are measurable and significant enough to allow AI detection analytics to locate falsified or manipulated content online.
The modality inconsistencies explored here refer to MMAs that included combinations of image and text that were inconsistent. The inconsistencies could have existed between captions and image, headlines and image, or body text and image and were created in MMA assets using one of two manipulation methods: either the text was directly manipulated such that it became inconsistent with the original image, or the image was manipulated (i.e. paste/splice operations, etc.) such that it became inconsistent with the original text. Audio and video modalities were not explored in this evaluation. The evaluation data for this task consisted of 616 pristine and 617 manipulated probes. Each probe was labeled according to the size of the semantic gap present between modalities. Table 1 displays the total probe count, along with an example of each semantic gap classification category.
Count of Probes for Semantic Gap Task.

To answer each research question, the analytics were scored based on the use of text-based content, pixel-based content for images, and metadata of MMA as represented in Figure 4. p(D) and false alarm rate (FAR) calculated across probes were the outcomes of interest. Modality inconsistencies were indicated in evidence graphs as one of five types: contextual, temporal, geospatial, tonal, and content. Each of these reflected a possible consistency check with an associated log-likelihood ratio (LLR). Metrics are computed by sorting classifications by LLR per performer for each analytic and for each task. The evaluation team dynamically set the LLR threshold at the point on the particular performer's receiver operating characteristic (ROC) curve where p(D) = 1 − FAR. Once this point was identified on the ROC curve, that LLR value was set as the performer's threshold to score individual probes. Thus, performers’ particular LLR thresholds for a positive versus negative classification will differ. Specific details regarding how these thresholds were calculated are outlined in Appendix A.

Evidence Graph Example. Note. Adapted from SemaFor Evaluation 1 Report.
Overall Evaluation
The equal error rate (EER) was employed to evaluate performance success, with an EER = 0 representing a perfect general score for an analytic. Figure 5 includes an image of the parameters for success. For example, an EER = 0.5 would signify the analytic is performing successfully as a random coin toss when determining falsity present in an MMA.
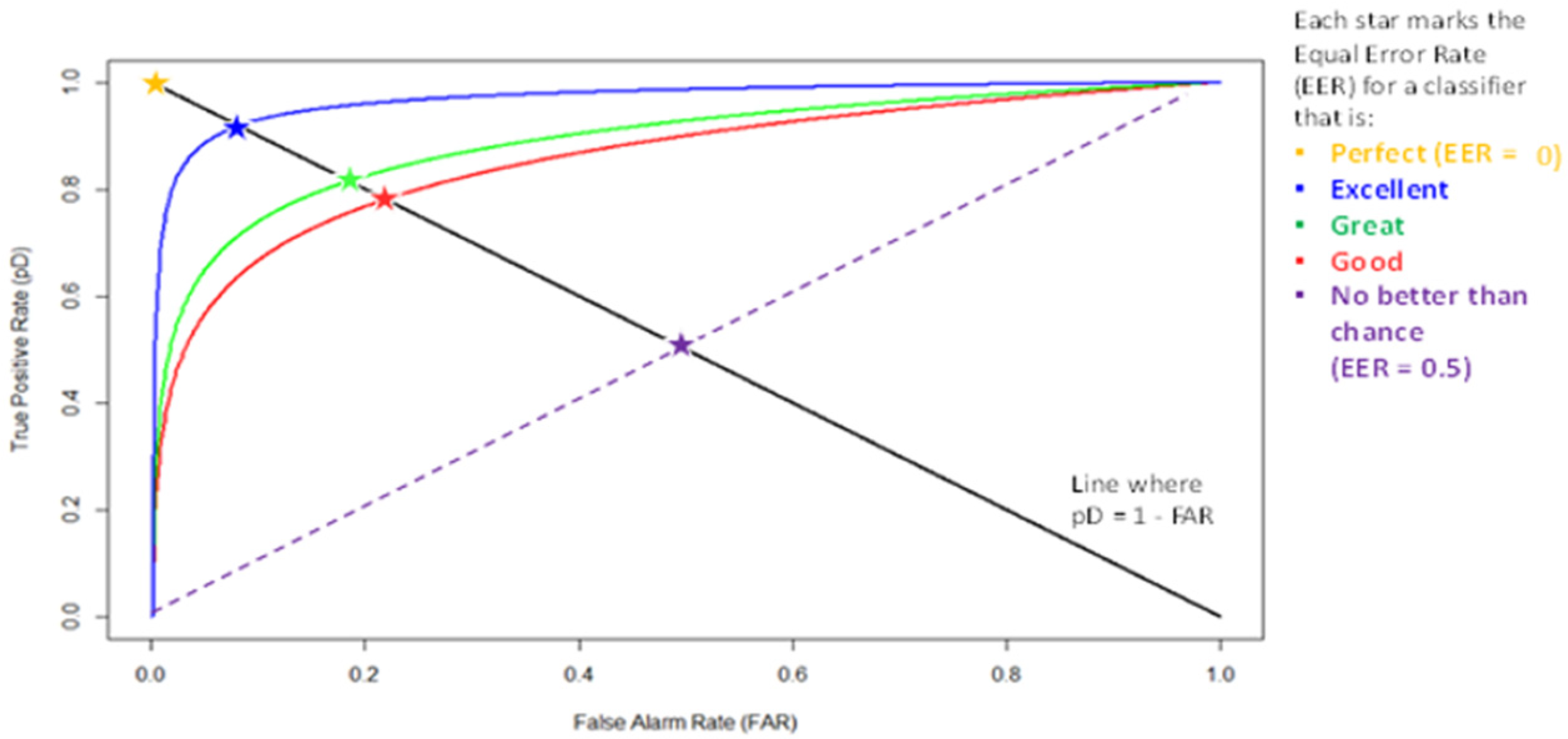
EER Classification. Note. Adapted from “Semafor Evaluation 1 Report” 2021 rate.
A score ranging between FAR ≤ 10% and a p(D) ≥ 80% is considered to be a success for the program. A total of 27 analytics were ultimately submitted for evaluation on the modality inconsistency task.
Results
Overall, 27 analytics were run against the data set and scored on their ability to detect the presence or absence of semantic inconsistencies between pairs of text and images at the various levels of semantic gap size. Figure 6 shows the performance of the top five modality inconsistency analytics on each level of inconsistency—small, moderate, and large. Overall, keeping in mind these results are framed within the Journalistic and Creator domain levels of the ToCC, analytics seemed to struggle with all three types of data, but the small semantic gaps appeared to be the most challenging to detect. This is expected, as intuitively, small subtle changes are generally less detectable than large discrepancies. However, it is important to note that the relative size of the semantic gap did not appear to correlate proportionally with human perceptions of the tasks. For example, inconsistencies in this task with large semantic gaps were designed to be generally trivial for human identification. Despite the anticipated simplicity of the task based on human semantic detection capabilities, analytics struggled to identify even large semantic gaps between modalities.
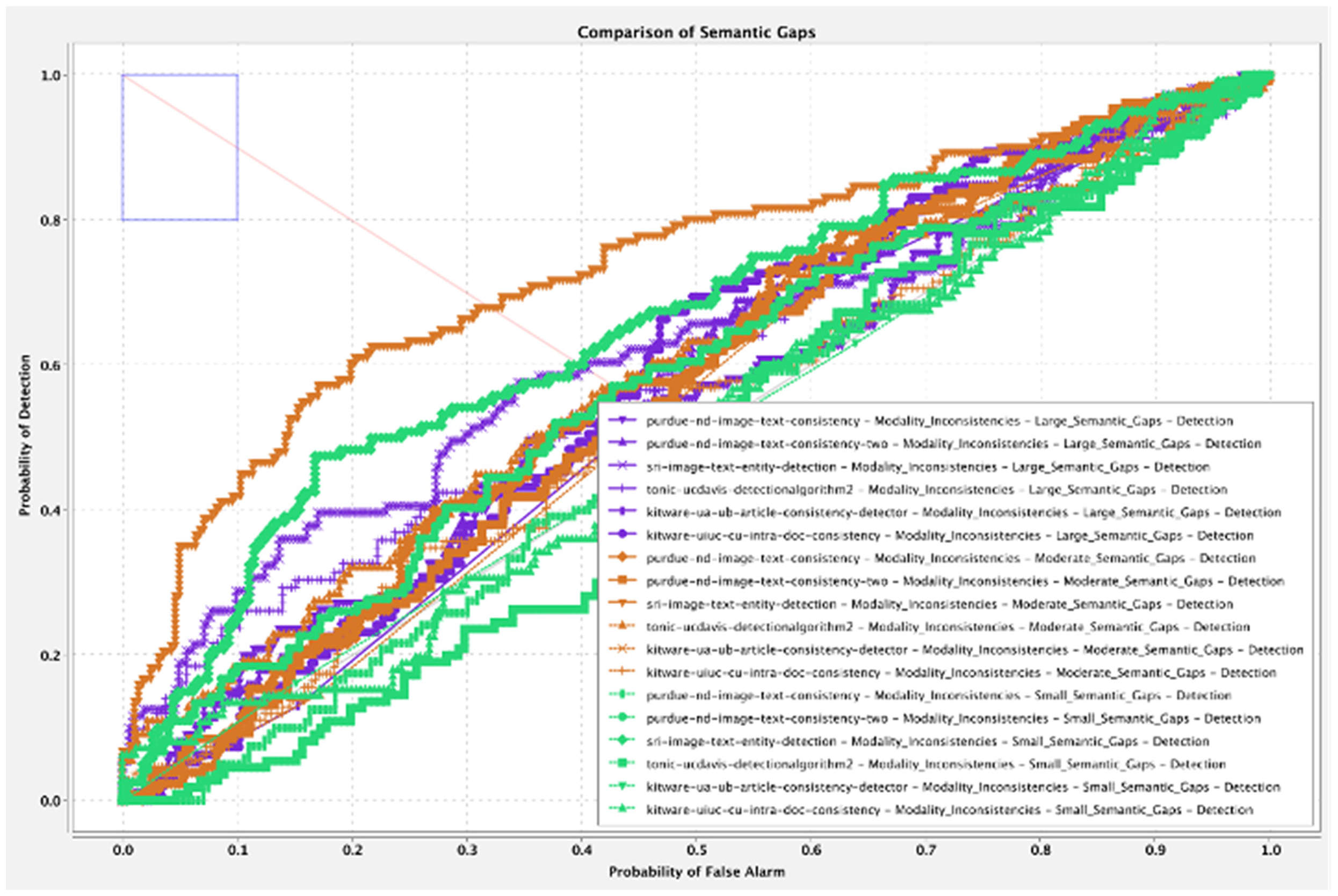
Semantic Gaps—Receiver Operating Characteristic (ROC) Curve. Note. Adapted from “Semafor Evaluation 1 Report” 2021.
This concept of designing evaluations that require analytics to perform reasoning between two different modalities is significant. The increased complexity created by requiring analytics to function across text and images may be an even more critical factor than the size of the semantic gap being analyzed, though the results of this evaluation show smaller gap size does still correlate to increased difficulty. The impact of this additional complexity is supported by results from previous evaluations where manipulations were limited to a single modality (i.e. is this image consistent with itself or is this text consistent with itself). In these unimodal evaluations, analytics performed detections at very high levels (routinely above 95%) despite the intentional creation of data with very small human detectable inconsistencies. However, unlike these earlier unimodal detection tasks, analytics in this evaluation needed to perform semantic processing of both the image and text content. The increased complexity required for this type of multimodal analysis could explain the lower overall performance.
When the same 27 analytics were evaluated on the full data set but allowed to use more conventional unimodal manipulation detection approaches, two were able to surpass 80% p(D), though none achieved a FAR lower than 10%. Table 2 showcases a detailed breakdown of their performance, and Figure 7 demonstrates analytic performance on a ROC curve.
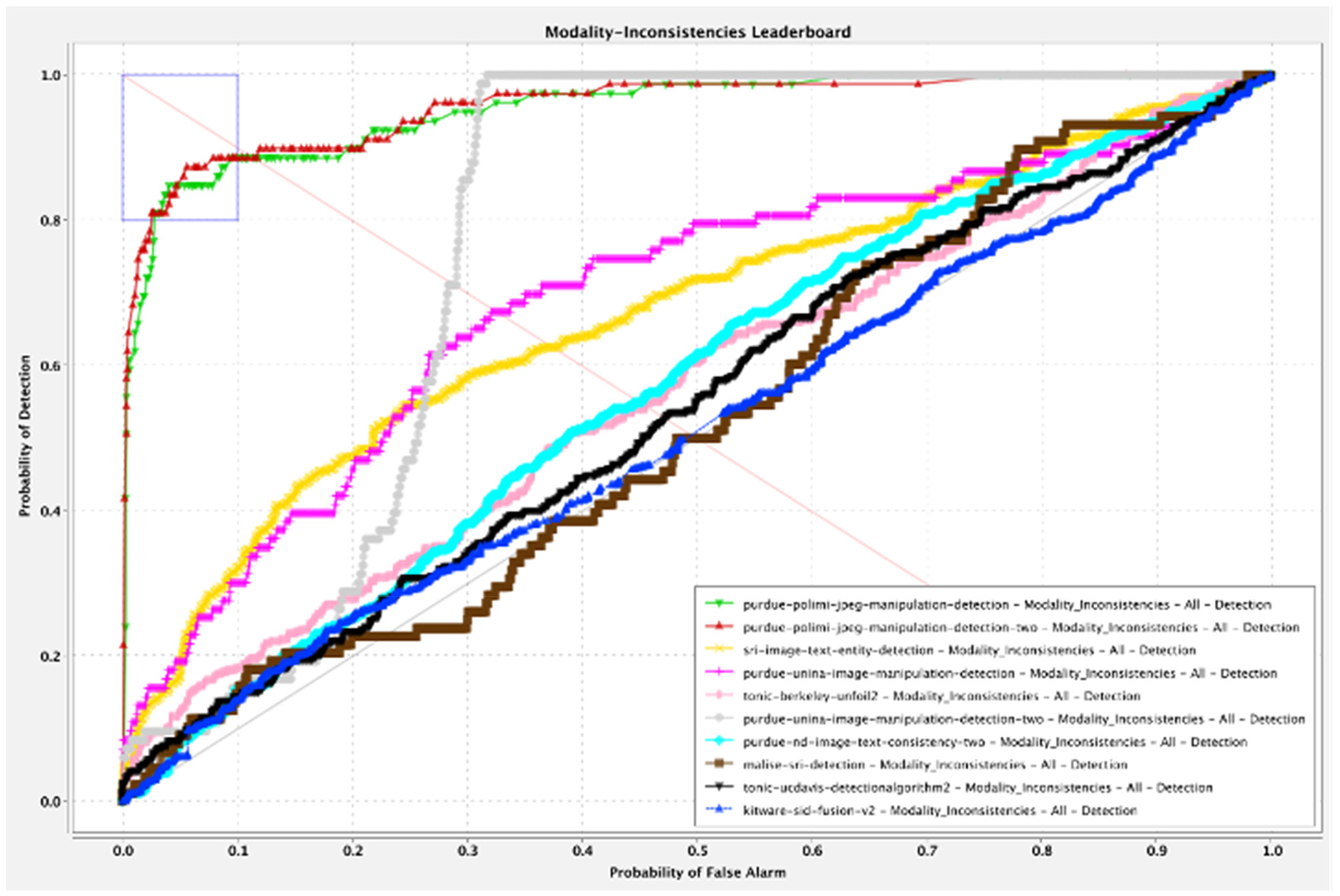
Modality Inconsistency— Receiver Operating Characteristic (ROC) for Top Performers. Note. Adapted from “Semafor Evaluation 1 Report” 2021.
Modality Inconsistency—Top 10 Performers.
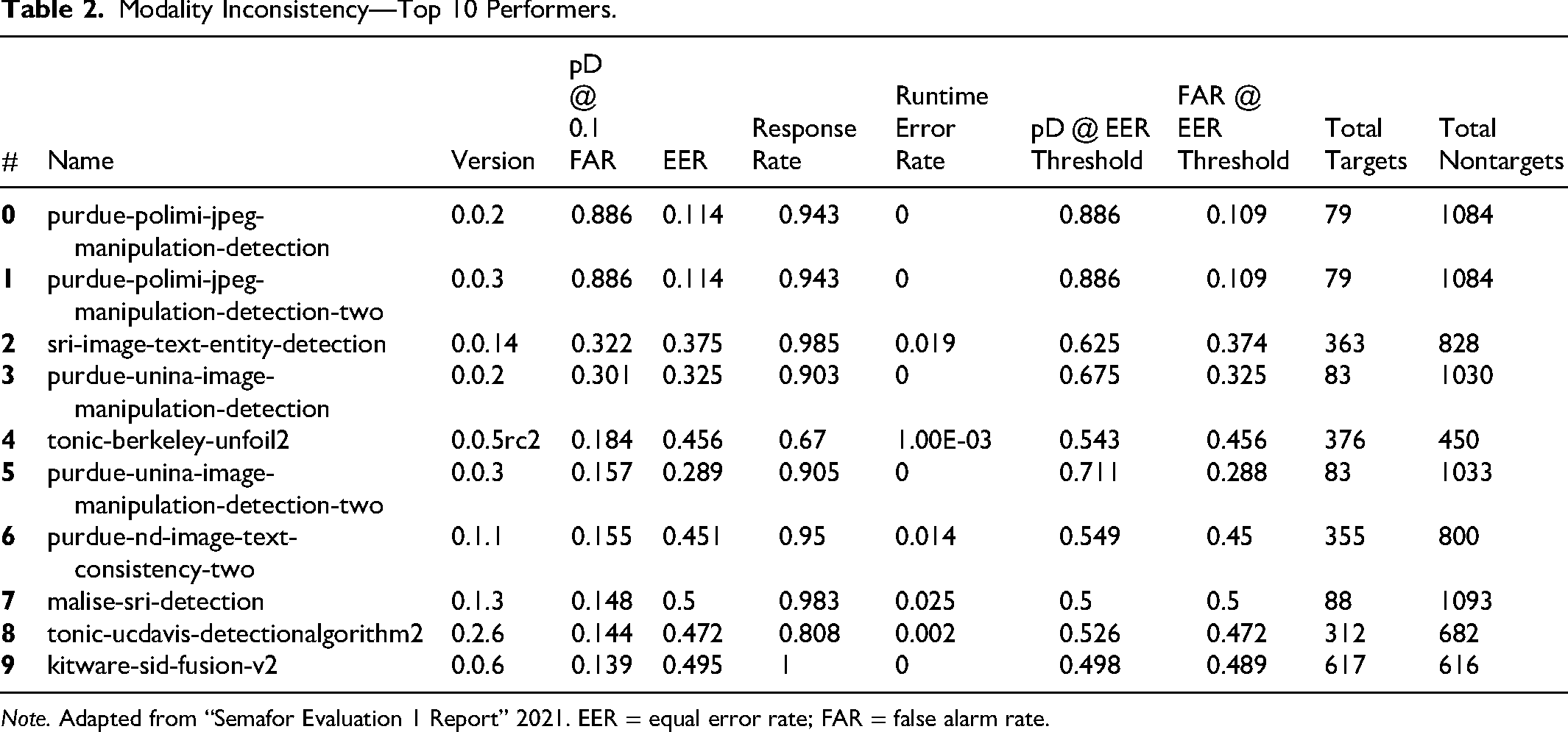
Note. Adapted from “Semafor Evaluation 1 Report” 2021. EER = equal error rate; FAR = false alarm rate.
The top two performing analytics approached the task by focusing only on unimodal manipulation detection in the images portion of the probes rather than reasoning between the text and images for inconsistency. Of the top 10 analytics, five were from Purdue (four of which took the unimodal image analysis approach), while the two from Berkeley, two from SRI, and one from Kitware continued to approach the task using multimodal reasoning. These results exemplify the balance between an analytics overall performance on a task and its alignment with the specific focus of its algorithms approach and training data. In this case, initial attempts to build in the ability for a single algorithm to address the complexity of reasoning across text and images as well as inconsistency gaps were not as successful overall as an approach that solved a specific portion of the task with very high levels of competence. While continued improvements in performance for analytics capable of this type of multimodal reasoning can be expected over the longer term, fusion strategies that incorporate multiple analytics with high performance over specific portions of the task may be a more effective short-term approach.
Discussion and Limitations
In future research, the repeated training of AI analytics to advance their capabilities in detecting semantic inconsistencies would be beneficial in ongoing efforts to detect and combat fake news. While the potential exists, success in this endeavor will require a comprehensive and rigorous training approach. As demonstrated in the Results section, the intricacies of AI analytics discerning between various semantic gap sizes remains a challenge, and achieving proficiency may be contingent upon an overall enhancement in the holistic scores of inconsistency detection, especially between multimodal and unimodal approaches. Developing a more nuanced approach to the application of the ToCC and reflecting those categories in evaluation data will likely facilitate all aforementioned efforts.
When considering the general ability of analytics to successfully detect multimodal inconsistencies, it is clear to see there is a great disparity in performance amongst the analytics submitted to the task. Given that Purdue's top two analytics hover at a FAR at 0.114, the data confirms the task is not impossible, though is comparatively much more challenging than simple image or text detection, which similar detectors passed with flying colors. The disparity between this performance signifies that when presented with MMAs, analytics may approach feature detection differently than how they might approach a singular media asset. While the ToCC may provide insight at the network level to explain how an AI reaches these conclusions, it remains challenging to categorize where features may be extracted to make judgements in a real-world setting. Since researchers do not have access to how these analytical models were constructed, refining the ToCC and designing specific tests pertaining to each of its domains may prove useful to addressing the black box problem. An example of this may be limiting analytic access to metadata, or designing datasets that subscribe to a certain journalistic style guide.
Further, it may facilitate future evaluations as researchers aim to understand the disparity in performance as AI analytics approach various detection, attribution, and characterization-related tasks. For example, recent research exploring semantic labeling detection demonstrates AI may recognize concepts like people and firearms, however it fails to recognize fire, symbols, signs and vehicles. As AI still struggles with these basic semantic labels, analytics may need more development before graduating to multimedia inconsistency detection tasks.
Considering that analytics faced difficulties with tasks involving multimodal inconsistency, it is understandable that no significant discoveries were made in identifying the magnitude of semantic gaps in MMAs. Even the largest semantic gaps were still difficult for analytics to detect. While the majority of analytics hover around 50% accuracy in Figure 7, it should be noted that not a single large semantic gap was beneath the 50% line, along with moderate semantic gaps. Small semantic gaps were definitely most challenging, though the task was still generally difficult regardless of semantic gap size.
Applying these results to the ToCC's Journalistic Domain level, the human-led analysis would confirm that the semantic gaps represent deviations from journalistic norms. At the Creator level, if these examples were actually fake news articles used in a study like this, differences in how specific authors produce news would provide further insights into how the semantic inconsistencies do not align with the stylistic and stylometric patterns of individual journalists. Referring to the HITL provisions for responsible AI practice, this human-centered evaluation becomes even more important in fostering genuine transparency in both the development of AI detection tools and their use in opening the black box of proprietary algorithms.
A limitation of this research, beyond AI's ever-quickening evolution, lies in the definition of difficulty associated with the tasks administered to the analytics. The determination of what constitutes difficulty in identifying semantic inconsistencies introduces subjectivity, and this ambiguity can impact findings. Additionally, reliance on human levels of meaning as a benchmark for difficulty assessment poses challenges in establishing criteria. These limitations underline the need for further refinement in defining and evaluating the difficulty of the task. In detecting semantic inconsistency across multimodal media, none of the analytics submitted for evaluation were able to meet the parameters defined for successful detection. While two analytics met the required p(D), they did not meet the necessary FAR to achieve success. Similarly, analytics were unable to successfully detect semantic gaps of any size. However, the data still highlights valuable trends and insights that researchers can leverage in future evaluations.
Conclusion
Our research highlights the critical need for continuous development in detection technologies that can keep pace with the swift advancements in AI-driven misinformation and disinformation spread through digital and social media news platforms. Identifying and exploring the nuances in semantics and meaning-making through words and images offers a promising contribution to this area of journalism research in uncovering inconsistencies in AI-generated content, pointing towards innovative strategies that could augment human detection capabilities for fake news. This contribution has implications on both sides of journalism: it helps uncover what proprietary algorithms of news organizations may not reveal, while also aiding in the creation of detection tools that can quickly identify fake news at scale. This ensures that our news cycle, along with the journalistic norms that uphold the media's role as a fourth estate and a valuable check on our systems, remains intact.
The reliance on previous methods like skepticism, literacy, or fact-checking to approach the detection and mitigation of mis- and disinformation in social media news is increasingly inadequate in the face of sophisticated AI technologies capable of generating convincing synthetic content. As such, there is an urgent need for tangible, operationalized approaches that harness and amplify human analytical strengths in identifying semantic discrepancies. Our application of the ToCC offers a concrete framework to address this gap, aligning with established journalistic practices and refining AI detection strategies through multilevel content analysis. By incorporating human oversight at critical levels—in this case through the Journalistic Domain and Creator levels—we ensure that AI tools are not only more accurate but also aligned with ethical standards and transparency requirements, as emphasized by the HITL provisions for responsible AI.
The framework the ToCC provides assists in the fields of journalism and research, but will also help AI tool developers incorporate and design for explainability from the beginning rather than taking the black box approach and hoping statistical accuracy data will be enough to drive user adoption. The ToCC provides a framework for rational design in terms of integrating specific features of a piece of media that will enable AI tools to move beyond simple detection and into more complex analysis of attribution and characterization. It also allows developers to use a common language when describing the approach their tools are using, and to compare tools and understand if the tools offer complimentary approaches or are actually solving the problem in the same way. In the first case, there may be value in using multiple tools in a workflow while the second case only creates redundancy.
By investing in and developing tools that can effectively leverage these human insights at scale, journalism and news platforms can fortify their defenses against the tide of AI-generated mis- and disinformation. The ToCC's approach, which balances AI-driven detection with human judgment, is key to optimizing the detection of semantic inconsistencies and enhancing the capacity of AI tools to recognize and address misinformation across diverse contexts. In doing so, we not only protect the integrity of our news organizations and the systems by which they disseminate news but also preserve the foundational trust that underpins our collective belief in the authenticity and truthfulness of the news we share.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Defense Advanced Research Projects Agency
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.