
Abstract
Background:
Studies have demonstrated that 50% to 80% of patients do not receive an International Classification of Diseases (ICD) code assigned to their medical encounter or condition. For these patients, their clinical information is mostly recorded as unstructured free-text narrative data in the medical record without standardized coding or extraction of structured data elements. Leumit Health Services (LHS) in collaboration with the Israeli Ministry of Health (MoH) conducted this study using electronic medical records (EMRs) to systematically extract meaningful clinical information about people with diabetes from the unstructured free-text notes.
Objectives:
To develop and validate natural language processing (NLP) algorithms to identify diabetes-related complications in the free-text medical records of patients who have LHS membership.
Methods:
The study data included 2.3 million records of 41 469 patients with diabetes aged 35 or older between the years 2012 and 2017. The diabetes related complications included cardiovascular disease, diabetic neuropathy, nephropathy, retinopathy, diabetic foot, cognitive impairments, mood disorders and hypoglycemia. A vocabulary list of terms was determined and adjudicated by two physicians who are experienced in diabetes care board certified diabetes specialist in endocrinology or family medicine. Two independent registered nurses with PhDs reviewed the free-text medical records. Both rule-based and machine learning techniques were used for the NLP algorithm development. Precision, recall, and F-score were calculated to compare the performance of (1) the NLP algorithm with the reviewers’ comments and (2) the ICD codes with the reviewers’ comments for each complication.
Results:
The NLP algorithm versus the reviewers (gold standard) achieved an overall good performance with a mean F-score of 86%. This was better than the ICD codes which achieved a mean F-score of only 51%.
Conclusion:
NLP algorithms and machine learning processes may enable more accurate identification of diabetes complications in EMR data.
Introduction
Diabetes mellitus (DM) is one of the significant causes of morbidity and mortality and the most common noncommunicable disease worldwide. 1 DM is associated with a range of macrovascular and microvascular complications, including coronary heart disease, cerebrovascular disease, heart failure, peripheral vascular disease, chronic renal disease, diabetic retinopathy, and cardiovascular autonomic neuropathy. These complications have a profound impact on quality of life, disability, and premature mortality among individuals with diabetes. 2 Effective management of diabetes is paramount to enhancing patient health outcomes and overall well-being. 3
The widespread implementation of electronic medical records (EMR) and other health care information technologies has led to an exponential growth in health data. 4 Analyzing EMR data offers numerous potential applications, such as identifying complications, predicting mortality, and influencing health care economics, all of which ultimately affect patient care. 5 Furthermore, the full disclosure of a patient’s complications to attending physicians and specialists holds significant importance, as it enables them to gain a comprehensive understanding of the disease’s progression. This knowledge consequently empowers health care providers to develop and implement more effective treatment strategies for individuals with DM. 6
The International Classification of Diseases and Related Health Problems (ICD)-10 provide a translation of health care diagnoses and procedures into universal codes. 7 However, it is estimated that approximately 50% to 80% of all health care data are captured as unstructured, mostly free-text, narrative data. 8 This raises significant challenges since busy clinicians are currently required to go through many narrative notes about a patient to understand their medical history and diagnose their conditions correctly. A possible solution to this problem is natural language processing (NLP) technology which aims to extract meaning from narrative data. 8 Applied to physician visit reports, NLP techniques can enable automatic identification and extraction of essential information, including the patient’s diagnoses, procedures history, and complications. 9
For example, Sheikhalishahi et al 10 reviewed 29 studies using NLP on clinical notes for chronic diseases including diabetes. Rule-based methods alone in these studies achieved complication F1 scores ranging from 60% to 80% on average due to variability in note documentation. Hybrid rule-based/machine learning approaches emerged to better address this variability by combining linguistic and contextual interpretations. 10
Specifically for DM, there has been significant research exploring NLP and machine learning approaches for automated identification of diabetes complications from electronic health records. Early rule-based systems achieved varying success extracting explicit complication mentions.11-13 However, rules struggle with contextual inferences and variability in clinical documentation.
Turchin and Florez Builes 9 conducted a systematic review of 24 studies applying NLP methods to EHR notes. Many studies used rule-based systems, reporting precision of 65% to 95% and recall of 60% to 90% for complication extraction. The review found later studies incorporating machine learning showed potential improvements. 9
Ding et al 14 specifically focused on predicting complications using machine learning. They developed a complete similarity enhanced Latent Dirichlet Allocation-based approach for diabetic complication prediction which includes a novel algorithm employing Support Vector Machines (SVM). Their experimental results demonstrated that this hybrid SVM-seLDA method achieved improved prediction performance over other representative seLDA-based models for automated identification of diabetes complications from electronic health records. 14
In summary, NLP technique has great clinical potential, but there are important challenges to its delivery into practice. 15 These challenges reflect data curation, model development, relevance to clinical practice, potential to introduce and amplify biases, the artificial intelligence (AI) tool’s transparency, evidence of accuracy, impact on outcomes, and cost-effectiveness. Indeed, the quality, quantity, and diversity of the data used to train such a machine learning model are critical to its utility in clinical practice. 16
Diabetes complications are a good example of clinically important events that are poorly documented in structured electronic data. A high-fidelity NLP tool that can identify documentation of diabetes complications, such as hypoglycemia in provider notes, could advance our understanding of its prevalence, risk factors, and consequences. However, the efforts to develop these tools appear disparate and uncoordinated. 17 Moreover, most studies to date have mainly focused on the English language,17,18 with limited results in other languages, including Hebrew.9,19,20 We therefore aimed in this study to develop and validate NLP algorithms to identify diabetes-related complications in free-text medical records of members of Leumit Health Services (LHS), a community health management organization (HMO). We also compared the algorithm performance to ICD classification extracted from the EMR.
Material and Methods
Study Setting
Leumit Health Services serves approximately 720 000 individuals in Israel with all members having similar general health insurance and equal access to health services. Leumit Health Services serves approximately 720 000 individuals in Israel with all members having similar general health insurance and equal access to health services. Leumit Health Services has a comprehensive computerized database, continuously updated concerning subjects. Leumit Health Services has a comprehensive computerized database, continuously updated concerning subjects’ demographics, medical visits, laboratory tests, hospitalizations, and medication prescriptions. Prescription records are available from 1998 and include those refilled and purchased per patient. Clinical diagnosis is established during each physician visit according to the International Classification of Diseases-9/10. The validity of diagnoses in the registry has been previously examined and confirmed as high. Leumit Health Services, in collaboration with the Israeli Ministry of Health (MoH), conducted the study using EMR to extract meaningful information of people with diabetes.
This collaboration is a part of the Cross-Industry Standard Process for Data Mining (CRISP-DM), 21 a standardized process model utilized for data mining. It facilitates the exploration of databases to uncover patterns, trends, and correlations, with the objective of assisting health organizations in Israel to leverage data for the benefit of public health.
Procedure
A three-phase study was conducted to develop an algorithm to identify diabetes-related complications.
In the first phase, we collected a data set of Hebrew clinical notes focusing on diabetic cases. The text was preprocessed by eliminating stop words and tokenizing the free-text physician visit reports of patients who were members of Local Health System (LHS) between 2012 and 2017, resulting in a data set of 716 000 records (Figure 1). To enhance the text representations, we trained a Hebrew word embedding model on a substantial corpus.
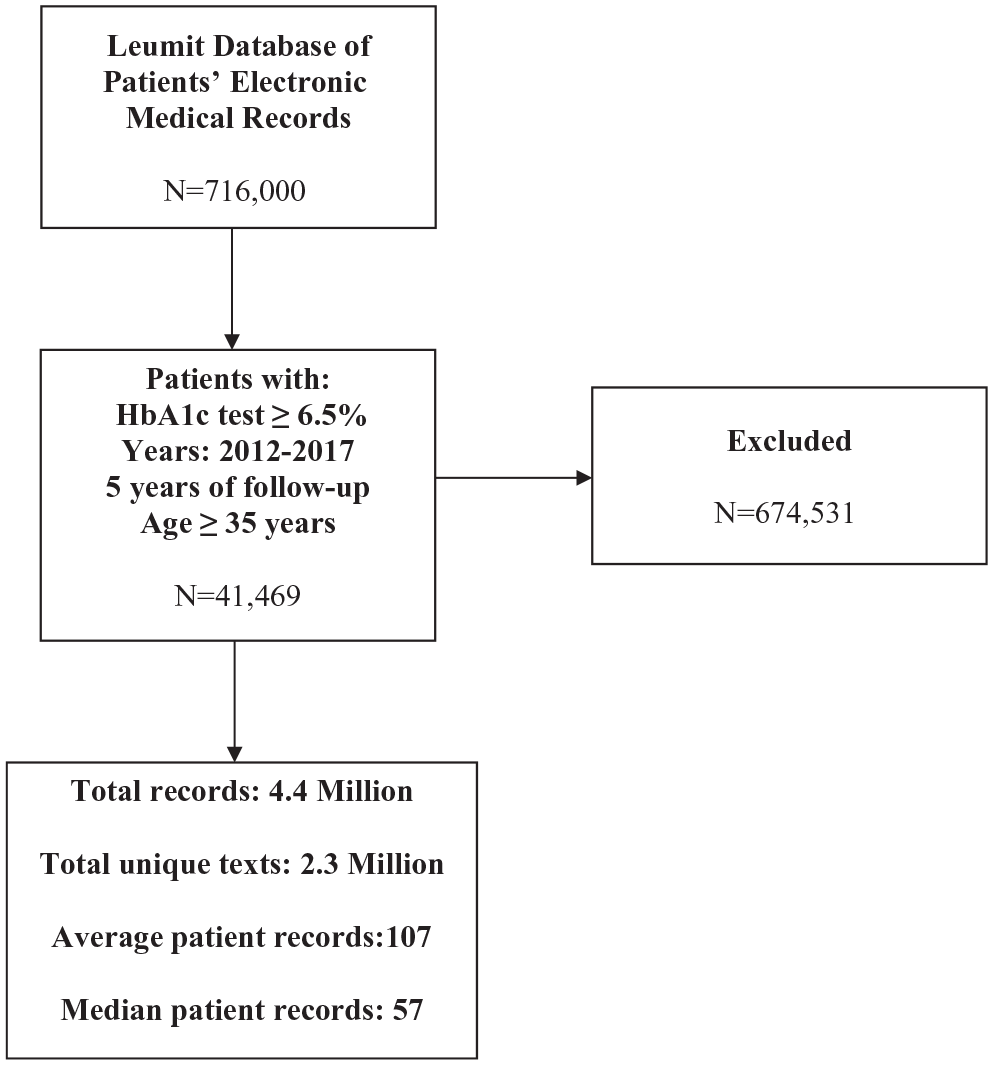
Study flow chart.
To identify a relevant patient cohort for our study, we conducted a search for patients with a comprehensive medical history spanning 5 years. The selected patients were required to be at least 35 years old and have an HbA1c test result ≥ 6.5%. Following this selection process, we obtained a sample size of 41 469 patients, encompassing a total of 2.3 million medical records.
Word embeddings
We trained word embeddings using the Word2Vec algorithm on a corpus of 500 million words extracted from online Hebrew news articles, Wikipedia pages and websites. 22 The model had hyperparameters of context window size: five words; minimum word count: 20; vector dimension: 300; negative sampling and 10 training epochs.
The embeddings were validated for semantic similarity on a word analogy task, achieving an accuracy of 65%.
Named entity recognition and classification models
Named entity recognition of medical concepts was performed using a bi-directional Long Short-Term Memory (BiLSTM) model with a Conditional Random Field (CRF) output layer. 23 Complication classification was conducted with a Logistic Regression classifier. Both models were developed in Python using the Scikit-Learn and Keras libraries.
Data Annotation and Model Training
Three board-certified physicians iteratively developed and adjudicated a diabetes complication vocabulary, obtaining a Cohen’s κ of 0.8 for inter-rater agreement.
Two independent nurses with PhDs then annotated the pool of random notes for entity and classification labels. The data were split into 70% train, 15% validation, and 15% test sets. Performance was evaluated on the test set for each complication type as well as averaged overall using precision, recall, and F1-score metrics.
Random sampling
For this study, we employed a random selection process to choose 2480 cases. These selected cases were then utilized for various crucial stages of our research, including training, tuning, and testing of our models.
During the training phase, we used these cases to teach our algorithms and models to recognize patterns and learn from the data. The tuning phase involved fine-tuning the parameters and settings of the models to optimize their performance. Finally, during the testing phase, we evaluated the models’ effectiveness and accuracy on this selected subset of cases to assess their overall performance.
This random selection of cases allowed us to obtain reliable and unbiased results, ensuring that our findings can be generalized to a broader population and are not limited to specific patterns found in the data. By employing a diverse set of cases in these critical stages, we aimed to develop robust and reliable models that can effectively handle various scenarios and contribute to the advancement of our research.
We determined the diabetes-related complications list of terms using an adjudication committee composed of two physicians who are experienced, board-certified diabetes specialists. This list included cardiovascular disease (CVD), diabetic neuropathy, nephropathy, retinopathy, diabetic foot, cognitive impairments, mood disorders, and hypoglycemia. Then, two independent PhD registered nurses manually annotated each visit report based on the study findings and text for the presence or absence of diabetes complications. The nurses performed a binary classification task, labeling each patient record in the data set as either “high risk” or “not high risk” for the relevant complication. Inter-rater reliability between the two nurses who annotated the data was measured using Cohen’s kappa. 24 We observed substantial agreement of κ = 0.84, indicating that differences in nurses’ judgments were reasonably small.
Second, we developed a machine learning model that classified the patients’ complications according to the list of complications compiled by the two diabetes specialists.
As an initial exploratory analysis, we also trained a decision tree classification model on the extracted features to gain insights into variable importance. Decision-tree learning was used because it can explain the rules according to which decisions were made, where rules are the logical expressions related to the features used to partition patients into the branches and leaves of the decision tree. However, decision trees have limitations in capturing complex associations in clinical text. Therefore, the main focus of this study was to develop a deeper learning model.
To better model the hierarchical representations inherent in clinical notes, we employed a Convolutional Neural Network (CNN) model. 25 Unlike decision trees, CNNs can learn features directly from raw text without relying on feature engineering. This allows CNNs to discover intricate patterns in medical documentation that may not be evident using superficial keyword matching or shallow architectures.
The CNN architecture consisted of an embedding layer, 1D convolutional layer with 100 filters of size 3, maximum pooling with pool size 2, two dense layers with 128 and 64 units, respectively, and a single unit output layer with sigmoid activation. The CNN was trained for 10 epochs using Adam optimization, binary cross-entropy loss, and a batch size of 32. The training, validation and test sets comprised 70%, 15%, and 15% of annotated notes, respectively.
Hyperparameters were tuned on the validation set. Performance was assessed using precision, recall, and F1-score on the held-out test set.
In our study, we evaluated the model’s performance on both training and test data sets curated by expert nurses. These data sets contained de-identified physician visit notes for each patient. Rather than extracting predefined terms or concepts, the CNN model took the raw, unstructured physician visit notes as direct input. 26 This allowed the CNN to automatically learn meaningful feature representations from the text, without relying on manual feature engineering. The notes consisted of free-form documentation of physician examinations, including sections such as medical history, physical findings, diagnostic impressions, and treatment plans. Using the complete raw notes as input, the model was able to discover complex relationships between any terms or concepts described throughout the clinical documentation. This approach aimed to better capture the full context and nuances present in the physicians’ narratives compared with models relying on isolated terms alone.
During the third phase, we conducted a specific evaluation of the accuracy of our comprehensive pipeline. This pipeline begins with the CNN analyzing the raw physician visit notes to learn representations of medical concepts and pathologies mentioned, without any pre-defined extraction of terms.
The CNN analyzed the full unstructured notes end-to-end to identify pathologies and other clinical entities through its training, rather than relying on a separate named entity recognition step beforehand. We evaluated how well the learned features from the raw text allowed the overall pipeline to classify patients’ risk levels. Subsequently, the CNN model predicts the risk level for patients and generates decision rules based on analyzing the complete data set of physician notes.
The CNN takes as input the raw text notes for each patient. During training, it learns hierarchical representations of medical concepts, diagnoses, and other related information embedded within the notes. Using these derived features, the final layers of the CNN classify each patient into risk categories by calculating a probability distribution over the classes. 27 The category with the highest predicted probability is considered the model’s risk classification for that patient. After training on all available notes, the CNN is able to analyze new patient notes and predict their risk level based on the learned relationships between narrative content and outcome patterns from the training set.
Data Analysis
We performed both rule-based and machine learning techniques for NLP algorithm development. For the rule-based component, we developed lexical rules to identify common clinical concepts and their variants, such as symptoms, diagnoses, and medications. This involved writing rules to match concept keywords and synonyms against the text. For the machine learning component, a supervised machine learning algorithm was trained on a data set of physician notes that were manually annotated with clinical entity labels. This algorithm then learned to automatically recognize and label entities in new notes.
Precision, recall, and F-score were calculated to compare the performance of the NLP algorithm to the reviewers’ comments and the ICD codes to the reviewers’ comments for each complication.
Precision measures the ability of the model to identify only relevant instances. It is calculated as the number of true positives (correctly identified instances) divided by the total predicted positives (true positives + false positives).
Recall measures the ability of the model to find all relevant instances. It is calculated as the number of true positives divided by total actual positives (true positives + false negatives).
The F1 score calculates the weighted average of precision and recall, with scores ranging from 0 to 1 and higher values indicating better performance.
In addition, the ICD diagnosis codes documented for each EMR in the test set were also extracted for comparison. Precision, recall, and F1 scores were calculated to compare the NLP algorithm and ICD codes against the reviewers’ annotations for each complication.
These metrics are commonly used in evaluating classification models, particularly in tasks where class imbalance or misclassification costs need to be considered. 28
The data analysis was performed using Python (version 3.0).
The study protocol was approved by the Institutional Review Board and the Research Committee of the LHS and the Institutional Review Boards of Sheba Medical Center Ethics Committee.
Results
The study was composed of four different samples of patients with diabetes for training (Sample 1—N = 900, Sample 2—N = 836), validation (Sample 3—N = 372), and testing (Sample 4—N = 372).
Figure 2 depicts the success rates of the model by F score, for identifying target organ damage by sample.
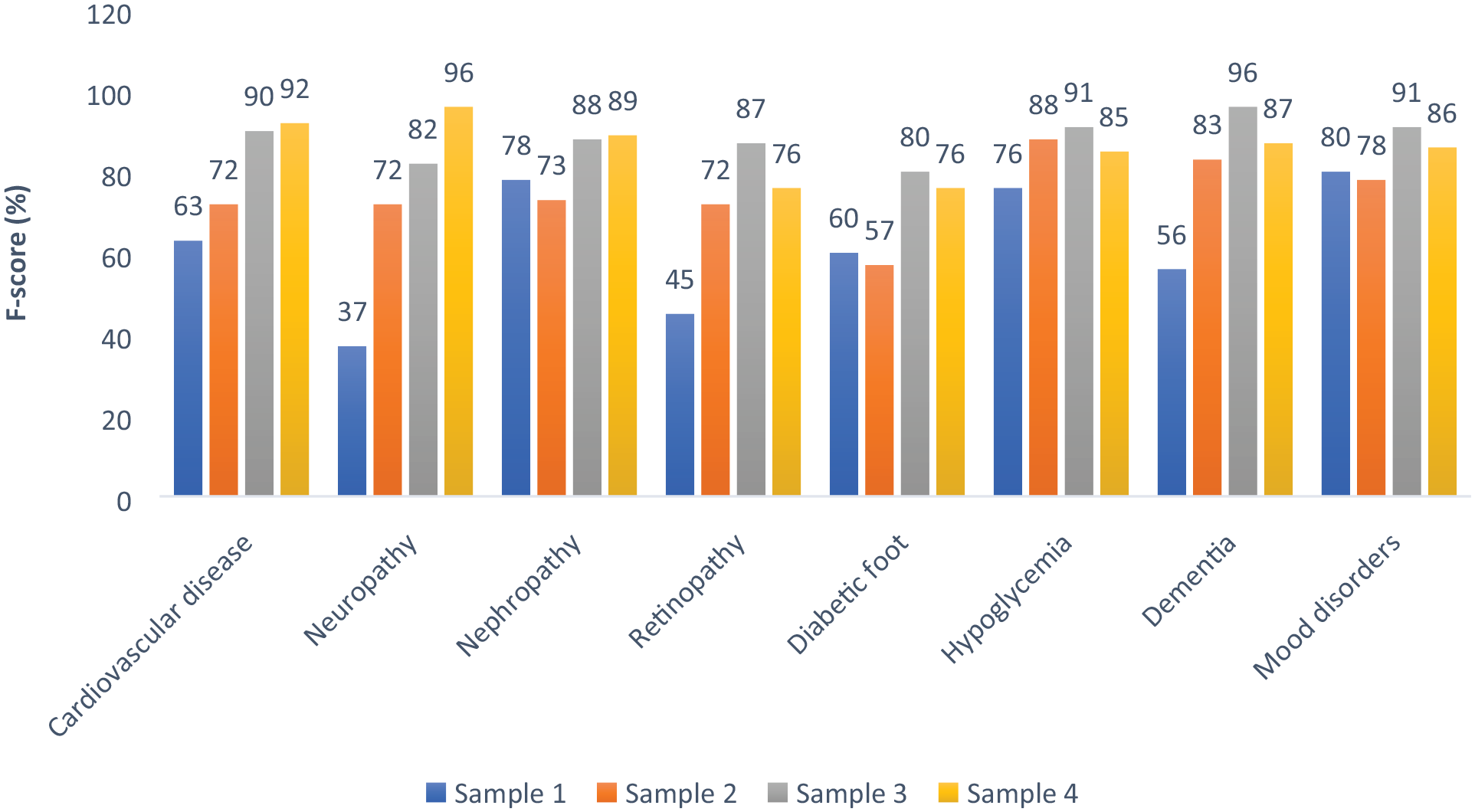
Success rates of the model for identifying target organ damage by sample.
The last two samples had a significant improvement compared with the first samples, with the last sample achieving a higher success rate compared with the third sample, in identifying cardiovascular disease, diabetic neuropathy, and nephropathy (92% vs. 90%, 96% vs. 82%, and 89% vs. 88%, respectively).
However, identifying complications of retinopathy, diabetic foot, hypoglycemia, cognitive impairments, and mood disorders was higher in the third running compared with the fourth (87% vs. 76%, 80% vs. 76%, and 89%, 91% vs. 85%, 96% vs. 87%, and 91% vs. 86%, respectively).
Concerning the specific organ damage, high rates of above 70% were observed consistently in each round in identifying diabetic nephropathy, hypoglycemia, and mood disorders.
Meaningful improvement of more than 30% was observed between the first and last rounds in identifying diabetic neuropathy (37% to 96%), retinopathy (45% to 76%), and cognitive impairments (56% to 87%).
The NLP algorithm versus the reviewers’ comments (gold standard) achieved good performance with a mean F-score of 86%. The algorithm result was better than the ICD codes, which achieved a mean F-score of 51%. Specifically, high success rates (≥85%) were observed in all measures (F-score, precision, and recall) in identifying CVD, neuropathy, nephropathy, cognitive impairments, and mood disorders. The highest sensitivity rate (98%) was found in detecting neuropathy (see Table 1).
Performance Comparisons of the Full NLP System, Rule-Based/ML Approaches, and ICD Codes Against Nurse Reviewers’ Annotated Gold Standard on Diabetes Complications. a
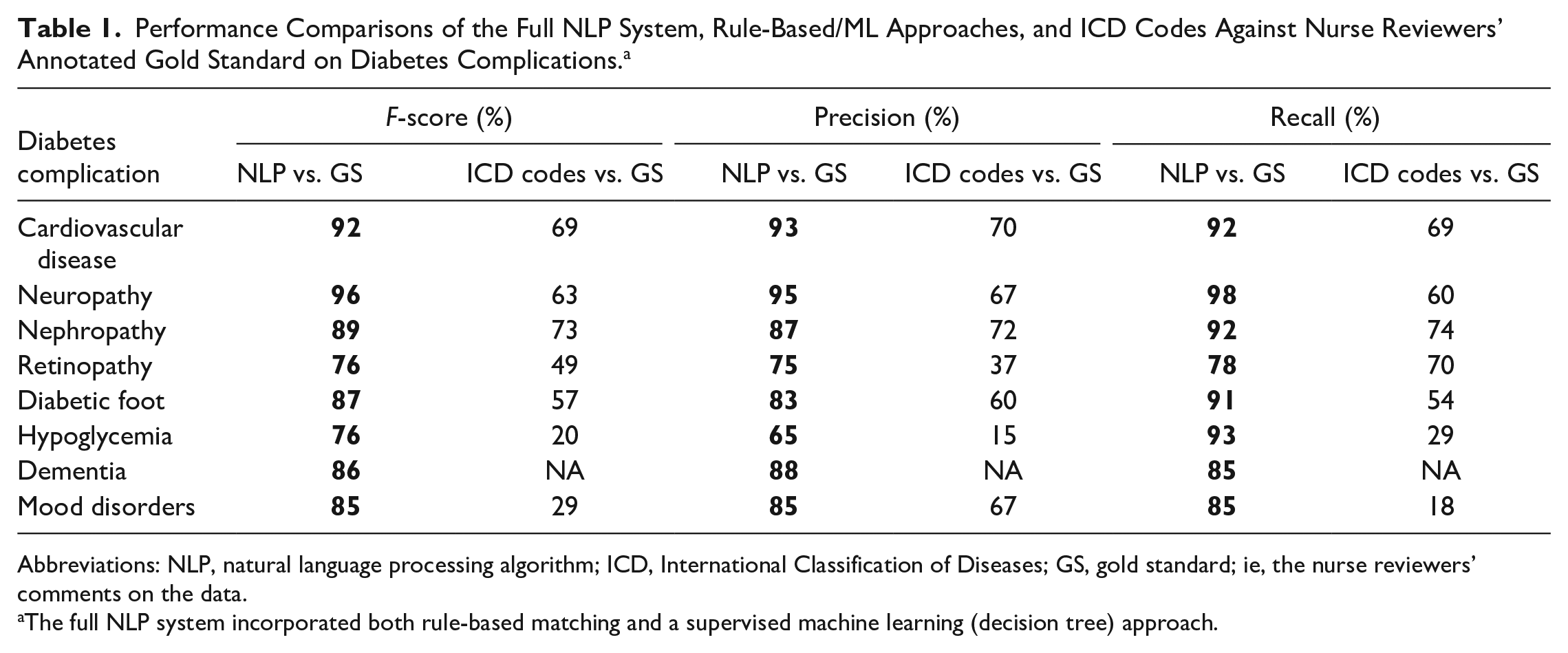
Abbreviations: NLP, natural language processing algorithm; ICD, International Classification of Diseases; GS, gold standard; ie, the nurse reviewers’ comments on the data.
The full NLP system incorporated both rule-based matching and a supervised machine learning (decision tree) approach.
Discussion
This study aimed to develop and validate NLP algorithms for identifying diabetes-related complications within unstructured free-text medical records. The motivation behind this research stems from the fact that a significant portion of health data, ranging from 50% to 80%, lacks a diagnosis through the conventional ICD codes and is often recorded in narrative format without any evaluation.
The findings of this study revealed that the NLP algorithm achieved a mean F-score of 86% when compared with the reviewers’ assessments, which served as the gold standard. This performance was superior to using ICD codes alone, which only achieved a mean F-score of 51%. These findings suggest that relying solely on ICD codes for determining the prevalence of diabetes complications may result in underdiagnosis, as a substantial portion of health data remains uncategorized using this system (Table 2).
Comparison of Existing Knowledge and Contributions of the Study on Diabetes Complication Identification From EMR Data.

Abbreviations: ICD, International Classification of Diseases; NLP, natural language processing algorithm; EMR, electronic medical records; LHS, Leumit Health Services.
In line with a previous study, novel text classification methods were developed to identify mentions of diabetes in clinical notes written in Hebrew. The study’s results demonstrated the effectiveness of this approach in identifying diabetes mentions within Hebrew clinical notes, as evidenced by the CNN model’s high accuracy, precision, recall, and F1-score, effectively distinguishing between diabetic and nondiabetic cases in the Hebrew text. 19 There was some variation observed in the performance of our NLP models across different diabetes complication types. The success rates ranged from 92% for cardiovascular disease to 76% for foot complications. Several factors may have contributed to this difference. From a linguistic perspective, descriptions of cardiovascular problems tend to have more standardized terminology compared with foot complications, which exhibit more semantic heterogeneity. 12 This makes cardiovascular mentions easier to identify algorithmically. Clinically, specialists like cardiologists often document complications in a structured format adhering to organ-specific templates. In contrast, foot complications involve interactions between multiple body systems described across different specialties like podiatry, leading to greater unstructured variability in documentation patterns. 13
The phenotypic complexity of foot complications arising from neurological, vascular, and tissue-level interactions provides multiple avenues for ambiguous phenotypic manifestations in text. This intrinsic difficulty may underlie their lower classification accuracy. 11
While the majority of studies in the diabetes research domain have focused on English NLP systems, it is important to highlight the emerging trend of investigating NLP techniques specifically tailored for other languages, such as Hebrew.20,29 In line with this, our study sought to contribute to the growing body of knowledge by developing and evaluating a novel text classification approach for identifying diabetes mentions in clinical notes written in Hebrew. By collecting a data set of clinical notes in Hebrew and employing advanced techniques such as tokenization and Hebrew word embeddings, we successfully demonstrated the effectiveness of our approach in accurately classifying diabetic and nondiabetic cases. These results parallel the achievements of English NLP models.30,31 For example, Kavakiotis et al. explored the applications of machine learning and data mining techniques in diabetes research. The researchers reviewed various studies in the field and found that these methods have been effectively used for diagnosing diabetes, predicting complications, optimizing treatment plans, and managing patients. 32
The use of NLP algorithms in this study allowed for the extraction of meaningful information from unstructured free-text narrative data, which is commonly recorded in EMRs without thorough evaluation. By leveraging machine learning techniques and a vocabulary list of terms, the NLP algorithms successfully identified various diabetes-related complications, including CVD, diabetic neuropathy, nephropathy, retinopathy, diabetic foot, cognitive impairments, mood disorders, and hypoglycemia. This demonstrates the potential of NLP algorithms to automate and improve the accuracy of identifying diabetes-related complications.
It is worth noting that the overall performance of the NLP algorithm was considered good. However, there is room for further improvements to enhance its accuracy and reliability. One potential approach is to enhance the data quality for the NLP algorithm, which could potentially lead to significant bias. 33 A previous study aimed to validate data obtained from an electronic data warehouse concerning diabetic ketoacidosis (DKA) by comparing it with information collected from medical records of patients diagnosed with DKA. Researchers identified a discrepancy between the two data sources, specifically noting inconsistencies in the documentation of DKA diagnosis and treatment details. 4 These inconsistencies underscore the importance of verifying and cross-referencing electronic data warehouse information with primary sources such as medical records. 31 Relying solely on electronic data warehouse information may lead to incorrect conclusions and erroneous interpretations and it should therefore be used with caution for studies related to diabetes complications, such as DKA. 4
Despite the need for further improvement, the findings of this study have substantial implications for both health care providers and researchers. By leveraging NLP algorithms, it becomes possible to harness valuable information from unstructured free-text narratives, thereby enhancing the identification and understanding of diabetes-related complications. The ability to extract meaningful data from such records may support clinical decision-making and improve patient care by identifying information relevant to diabetes related complications and their progression. The successful application of NLP algorithms in this study accordingly highlights the potential of these techniques for improving the identification and diagnosis of diabetes complications in EMR data. By automating the process and leveraging machine learning, health care providers can potentially benefit from more accurate and efficient diagnoses, leading to better patient outcomes.
Limitations
While the study demonstrated the effectiveness of NLP algorithms in this context, there are potential limitations to consider. First, the performance of the NLP algorithms heavily relies on the quality of the training data and the accuracy of the vocabulary list used. Second, only the presence rather than the severity or stage of complications was assessed. This is a limitation, as distinguishing severity levels such as background versus proliferative retinopathy has important clinical implications for treatment decisions and risk stratification. However, assessing severity was beyond the scope of this initial study, which aimed to develop and evaluate models for identification of complication types mentioned in the text. Future work will focus on enhancing our models to accurately classify not just the presence but also the severity of detected complications. This will allow a more in-depth examination of how severity information can be extracted and applied to improve clinical decision-making.
Third, the ability to generalize findings beyond the studied population is limited given reliance solely on internal randomization for validation without inferential analysis, as the reviewer pointed out. Further evaluation of model performance across diverse external data sets and patient groups is needed.
Conclusion
In conclusion, the study’s findings underscore the potential of NLP algorithms and machine learning techniques in accurately identifying diabetes-related complications within electronic medical record data. The ability to extract valuable information from unstructured narratives offers a promising avenue for improving health care outcomes and advancing our understanding of diabetes. Further research and development in this area can contribute to the ongoing efforts of leveraging technology to enhance medical data analysis and patient care.
Footnotes
Abbreviations
AI, artificial intelligence; BiLSTM, bi-directional Long Short-Term Memory; CNN, convolutional neural network; CRF, conditional random field; CVD, cardiovascular disease; DM, diabetes mellitus; EMR, electronic medical records; HMO, health management organization; ICD, International Classification of Diseases; LHS, Leumit Health Services; LHS, Local Health System; MoH, Ministry of Health; NLP, natural language processing; SVM, support vector machines.
Author Contributions
MS and ML performed analyses, prepared figures, and contributed to writing the first draft and revised the manuscript. IZ, SV, ACG, IL, and EM conceptualized the study and collected data. MU and AI conceptualized the study, provided insights on data interpretation, and performed the analysis. EM, SV, AGC, RE, IZ, and AI determined and validated the diabetes-related complications list. All authors approved the final manuscript and agreed to be accountable for all aspects of the work.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical Statement
This study protocol was reviewed and approved by the Institutional Review Board and the Research Committee of the LHS and the Institutional Review Boards of Sheba Medical Center Ethics Committee, which waived the need for informed consent, having received assurance of strict maintenance of participants’ anonymity during database analyses.
Data Availability Statement
Study data are not publicly available due to privacy and ethical restrictions. Interested parties can contact the corresponding author.