
Abstract
Introduction:
Type 1 diabetes mellitus (T1D) requires precise carbohydrate estimation to manage blood glucose and prevent chronic and acute complications to hyperglycemia or hypoglycemia. This study evaluates the accuracy of ChatGPT in estimating carbohydrate content in images of meals, compared with the considered gold standard of manually counting carbohydrates.
Method:
Carbohydrate content of 60 fruits and vegetables (F&V) and 60 composite meals was manually counted as the reference standard. Images (n = 240), with and without a size reference, were uploaded to ChatGPT-4o with a standardized prompt in separate sessions. ChatGPT’s estimates were then compared with the manual counts to assess accuracy.
Results:
The performance of ChatGPT-4o compared with the manual calculation was assessed primarily using mean absolute error, percentage of agreement (PoA), and Bland-Altman analysis. ChatGPT-4o achieved a PoA of 93.3% for F&V’s estimates, increasing to 95% with a size reference, while composite meal estimates yielded a PoA of 46.7%, reducing to 43.3% with a size reference, based on a ±10 g carbohydrates limit. Bland-Altman analysis showed a slight bias tendency in both ChatGPT-4o’s estimates of F&V and composite meals with a size reference. ChatGPT-4o’s estimate for F&V and composite meals without a size reference exhibited a systematic bias, with both overestimation and underestimation of the carbohydrate content.
Conclusion:
This study suggests that adolescents living with T1D should employ ChatGPT-4o for carbohydrate estimating with caution. ChatGPT-4o showed inaccuracies in its application to composite meals, increasing the risk of inaccurate insulin administration and potentially causing postprandial hyperglycemia or hypoglycemia.
Keywords
Introduction
Type 1 diabetes mellitus (T1D) is a chronic illness characterized by elevated blood glucose levels due to insufficient insulin production. 1 Type 1 diabetes mellitus is mainly associated with diagnosis at an early age, with large representation in children and adolescents. 2 An estimated 108 300 children under the age of 15 are diagnosed each year, rising to nearly 150 000 when including those under 20 years of age. 3
Treatment focuses on achieving stable blood glucose levels through insulin replacement therapy and nutritional management. 4 As recommended by the International Society for Pediatric and Adolescent Diabetes, maintaining a nutritious diet is important to sustain a healthy weight and growth, as well as avoiding acute and chronic complications. 5 The postprandial glycemic response is modulated by different macronutrients in food, although carbohydrates play the predominant role. 6 It is essential that children and adolescents diagnosed with diabetes (or the one in charge of their diabetes treatment) accurately perform carbohydrate counting (CC) to estimate the necessary insulin dose before meals. 7 Manual CC is considered the gold standard and can be done manually or using applications.8,9 Manual CC requires weighing food and calculating carbohydrate content. Apps automate carbohydrate calculations based on selected items, but the food must still be weighed. 9 Although these methods are viable options, CC is a difficult task for people with T1D, causing them to often make mistakes in calculations, potentially causing postprandial hyper- or hypoglycemia. 10 Hypoglycemia is especially dangerous as it can cause seizures, dizziness, and loss of consciousness. 11 In addition, adolescents find it particularly difficult to perform accurate CC in social settings. 12 This presents a growing need for alternative tools that can simplify the process, potentially alleviating some of the difficulties encountered by children and adolescents with T1D.
Children and adolescents with T1D face substantial daily challenges, including insulin administration, dietary restrictions, and psychosocial stressors, such as feeling different from peers. 13 As they enter adolescence, their increasing autonomy can affect how willing they are to take in guidance from others. 14 To ensure a smooth and easy transition to adolescent independence in managing their T1D, solutions might be found in what most adolescents always have at hand: a smartphone.
The use of electronics and apps among children and teenagers has increased significantly, making young people more susceptible to using and adapting to emerging technologies, such as generative
Artificial intelligence (AI), compared with elders.15,16 One of the most well-known, available, and widely used AI assistants is ChatGPT by OpenAI, which generally uses a large language model (LLM).17,18 Newer versions of ChatGPT (ChatGPT-4V, ChatGPT-4-turbo, and ChatGPT-4o) now include visual recognition, 17 marking a shift toward multimodal capabilities (MLLM), potentially enabling simplified carbohydrate estimation for self-management. While these AI models cannot directly measure biochemical substances, they can classify foods in images and combine this with knowledge of macro nutritional composition, providing estimated carbohydrate values. Such capabilities are increasingly leveraged in commercial applications, including dietary assessment tools for people with diabetes (eg, the SNAQ app), potentially enabling simplified carbohydrate estimation for self-management.8,19,20
Recent advances in MLLMs have shown promise in improving nutritional estimation from food images. A study by Lo et al 21 found that ChatGPT-4V’s visual recognition could identify food items, portion sizes, and convert estimated weight of food items into nutritional components. A separate study by Khlaisamniang et al 22 introduced a two-step MLLM framework that improved nutritional estimation by separating dish analysis from macronutrient calculation. While these studies demonstrate a general progress in nutritional estimation, the multimodal capabilities of ChatGPT have yet to be fully explored in the context of T1D management. Moreover, limited research on Nordic cuisine highlights the need to explore ChatGPT’s accuracy in carbohydrate estimates in culturally specific meals.
To address the gap in existing literature, this study aims to evaluate the accuracy of ChatGPT when estimating carbohydrates in images of Nordic cuisine compared with manual calculations, aiding in T1D management for adolescents.
Method
This comparative study analyzed differences between manual and ChatGPT-based carbohydrate estimations from images to asses ChatGPT’s potential as a tool for young people with diabetes to estimate carbohydrate content without a digital scale. As illustrated in Figure 1, manual calculations were compared with ChatGPT estimates for both composite meals (two or more ingredients) and fruits and vegetables (F&V). A standardized size ratio (85.50 mm × 54 mm × 0.76 mm) 23 was also provided to ChatGPT to assist in accurate meal size estimates. 21
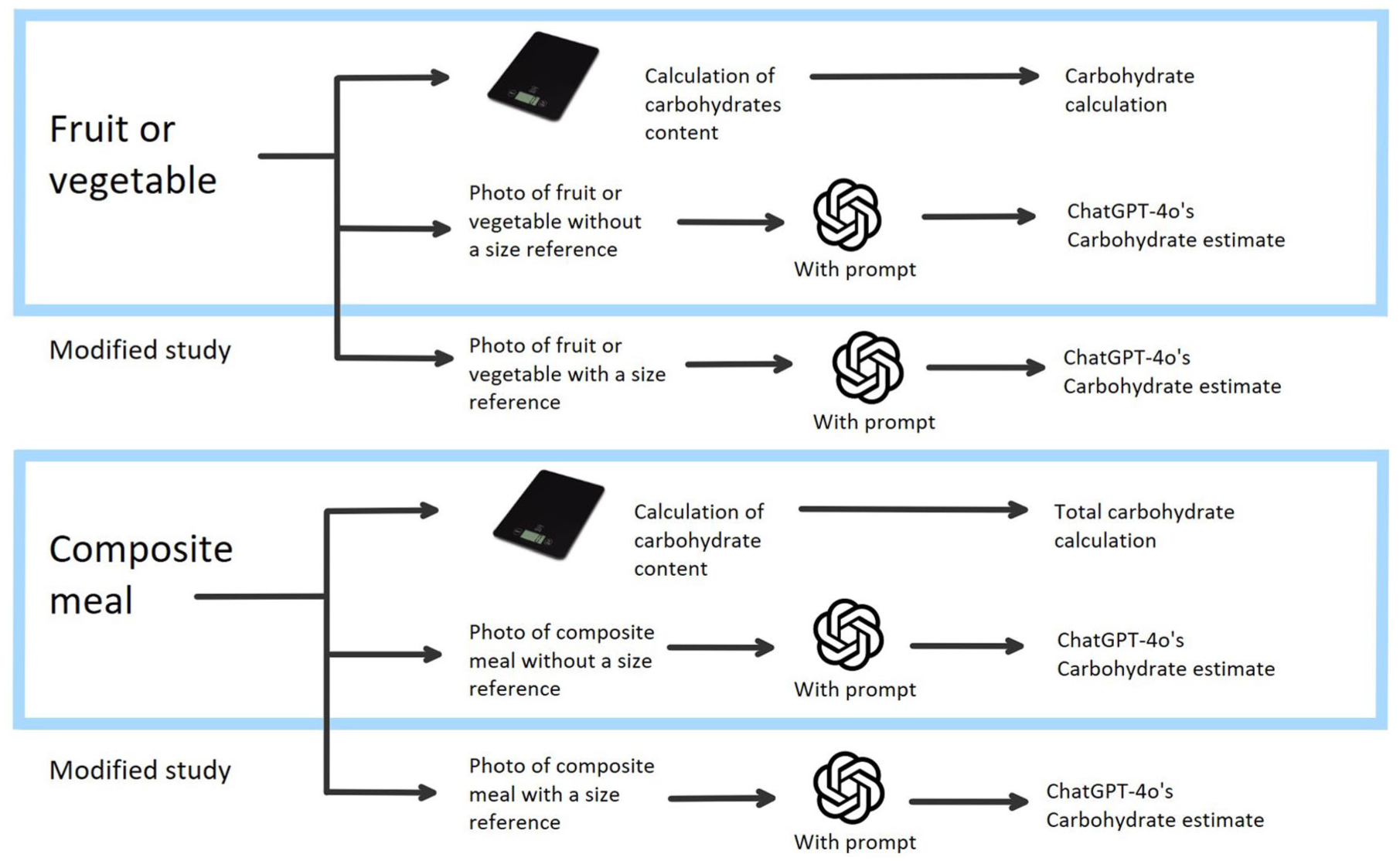
The figure illustrates the overall design of the study. The blue square represents the general framework, which includes a simple model with simple food items and a meal model (composed of more complex elements). Within the framework, each model’s respective manual CC was compared with its ChatGPT-4o estimate. Outside the framework, a modification of both models is shown. The modification consists of the application of a standard-size reference in the image—a card (library card, student-ID card, etc.).
Data Material
Data collection involved one manual CC and one ChatGPT estimate for each composite meal, fruit, or vegetable, with total carbohydrates in grams as the outcome. To ensure adequate statistical power, a sample size calculation was performed based on a two-sided significance level of .05, a power of 80%, and a predefined minimal difference of 5 g of carbohydrates. This represents the smallest unit of insulin administered through injection therapy, allowing a more precise dosage and preventing hypoglycemia or hyperglycemia.24,25 The assumed standard deviation was ±13 g of carbohydrate. This resulted in 60 composite meals, representing Nordic cuisine, and 60 F&V for analysis, all purchased in Danish supermarkets.
Images of composite meals and F&V were captured from a bird’s eye view with a uniform background and natural lighting using smartphones, iPhone 11, 11 Pro, 12 (Apple, Cupertino, California), and a Samsung Galaxy A54 (Samsung, Suwon, South Korea) equipped with a 12-megapixel camera or higher. Each of the four authors captured 30 paired images, to introduce varied perspectives to reflect real-life variation. Four different digital weighing scales (SD ± 1 g) were used (Aldente, Cook&Baker, Schou Company A/S, and OBH Nordica 9814).
Carbohydrate Estimation
For manual CC, each ingredient of composite meals was weighed, and carbohydrate content per 100 g was obtained from the nutritional label. For food items without a label (eg, fruits), reference values were retrieved from the Danish National Food Institute’s public food database (FRIDA). 26 FRIDA provides nutrient composition data based on analytical methods adhering to standard protocols from international organizations and ISO 17025, ensuring reliable micro- and macronutrient reference values for commonly consumed foods in Denmark. 26 Components within composite meals were measured separately to ensure accuracy. However, the images of composite meals may represent either a homogeneous dish, where the individual components cannot be distinguished (eg, soups or stews), or a dish where components are visually separated on the plate. Total carbohydrate content of F&V was calculated from the weight of the edible part of the fruit or vegetable and the carbohydrate content per 100 g.
This study utilized ChatGPT-4o (OpenAI, San Francisco, California) with the memory function turned on, accessed through a ChatGPT Plus subscription on August 6, 2025.ChatGPT-4o is OpenAI’s latest flagship model, featuring multimodal capabilities and state-of-the-art performance in visual recognition and text evaluation, making it suitable for the objective of this study. 17
ChatGPT-4o was configured with few-shot prompting to enhance step-by-step problem-solving and task understanding. 27 In this approach, the model received example interactions and was instructed to act and respond as an endocrinologist with a subspecialty as a dietitian, guiding it to calculate carbohydrate content in composite meals according to T1D nutritional guidelines (see Supplemental Appendix 1 and Figure 2). A zero-shot prompt was initially used only as a baseline to help develop the few-shot prompt. For the few-shot interactions, ChatGPT-4o provided only an estimate of carbohydrates along with the standard deviation.
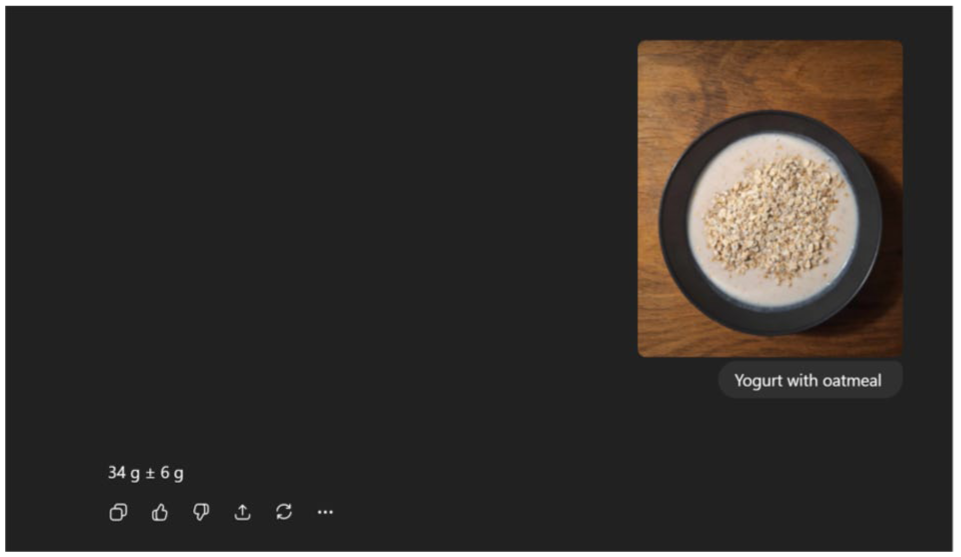
Example of a ChatGPT-4o interaction showing the input prompt “Yogurt with oatmeal” accompanied by a corresponding image. The model provides an estimated carbohydrate content of 34 ± 6 g. The response is based on a prompt that was developed using a few-shot approach.
All the pictures were uploaded in four separate sessions with their corresponding prompt. See Supplemental Appendices 2 and 3 for the original prompts in Danish and an English version.
Statistical Assessment
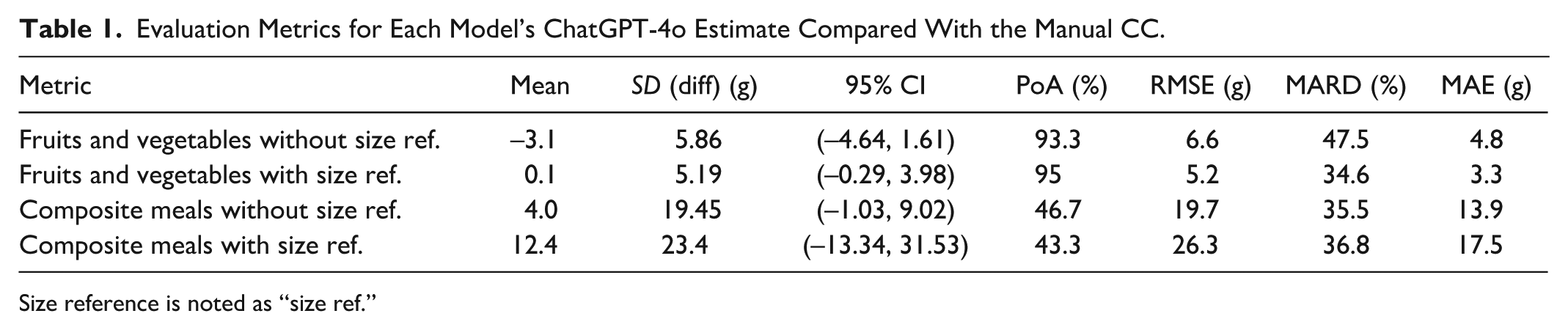
Several evaluation metrics were used to assess the accuracy and precision of the ChatGPT-4o’s estimate compared with the manual carbohydrate content. The metrics are presented in Table 1 with mean absolute error (MAE) (g), root mean squared error (RMSE) (g), mean absolute relative difference (MARD) (%), and mean difference (g) ± SD.28,29 Furthermore, the percentage of agreement (PoA) was calculated with an acceptable range of carbohydrate estimate within ±10 g carbohydrates. 24
Evaluation Metrics for Each Model’s ChatGPT-4o Estimate Compared With the Manual CC.
Size reference is noted as “size ref.”
Statistical analyses were performed in Stata 18 (StataCorp, 2023). 30 A Bland-Altman analysis assessed agreement between manual CC and ChatGPT-4o estimates, evaluating systematic bias and acceptable variation between the methods.
Results
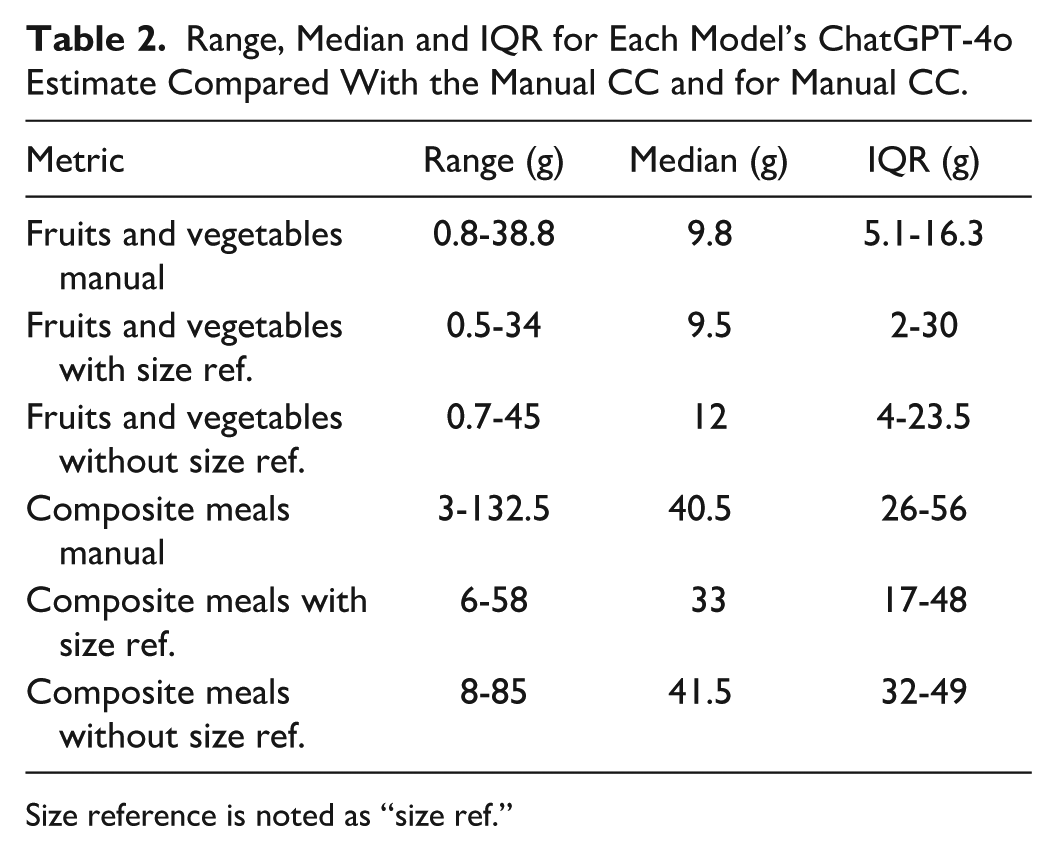
Sixty images of F&V and 60 images of composite meals were analyzed with and without a size reference, resulting in a total of 240 images. Table 2 and Figure 3 display the range, median, and interquartile range (IQR) of carbohydrate content estimates (in grams) for each of the four models compared with manual CC as baseline. A more detailed description of the images and results can be accessed and found online. 31
Range, Median and IQR for Each Model’s ChatGPT-4o Estimate Compared With the Manual CC and for Manual CC.
Size reference is noted as “size ref.”
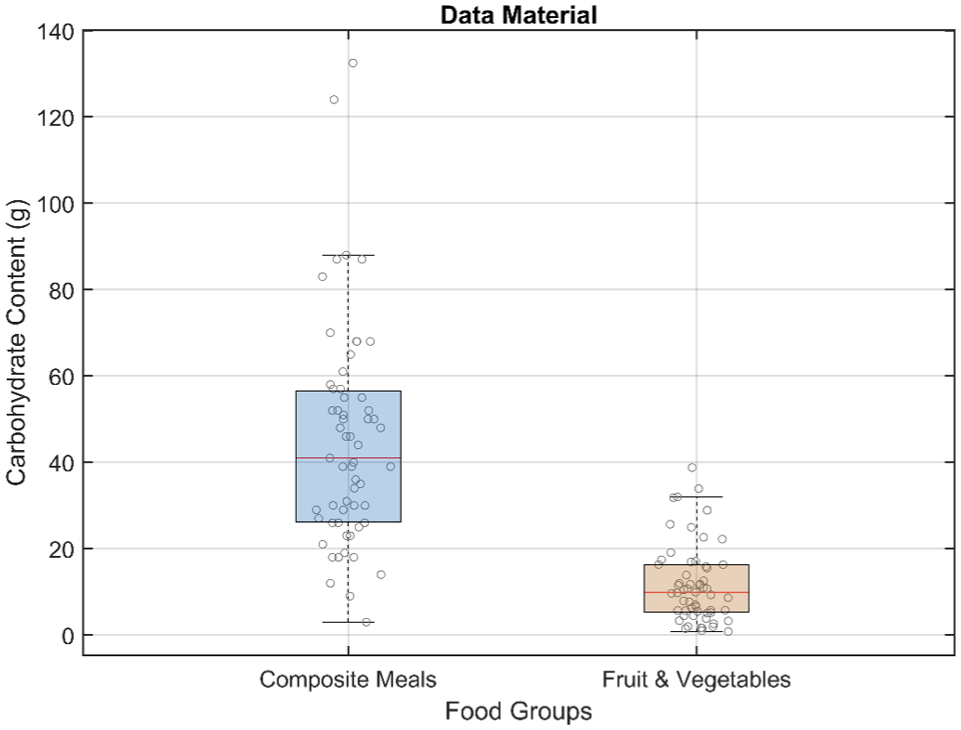
Distribution of carbohydrate content (g) in composite meals and F&V, displayed as notched boxplots. Notches indicate an approximate 95% CI for the median.
Table 1 demonstrates the statistical metrics of ChatGPT-4o carbohydrate estimates for each model with and without a size reference. For F&V without a size reference, the overall mean difference ± SD was −3.1 ± 5.86 g with a 95% confidence interval (CI) of (– 4.46, – 1.61). The data of F&V without size reference exhibit an RMSE of 6.6 g, MARD of 47.5%, and MAE of 4.8 g. The PoA was 93.3%
The mean difference was 0.1g ±5.19 g with a 95% CI of (–0.29, 3.98) when a size reference was included. The result was an RMSE of 5.2 g, MARD of 34.6%, MAE of 3.3 g, and PoA of 95%.
As presented in Table 1, composite meals without a size reference obtained a mean difference of 4.0 ± 19.45 g and a 95% CI of (–1.03, 9.02). Calculations for composite meals when not including a size reference achieved an RMSE of 19.7 g, MARD of 35.5%, MAE of 13.9 g, and a PoA of 46.7%
As for composite meals with a size reference, the mean difference was 12.4 ± 23.4 g, with a 95% CI (–13.34, 31.53). The results showed an RMSE of 26.3 g, while MARD and MAE were 36.8% and 17.5 g, respectively. Composite meals without size reference achieved a PoA of 43.3%
Bland-Altman plots were used to assess the agreement between manual CC and ChatGPT-4o estimates by plotting the differences against their means.
The mean difference for F&V was –3.1 g, with 95% limits of agreement ranging from –14.6 to 8.4 g. For F&V with a size reference, the mean difference was 0.1 g, with 95% limits of agreement ranging from –10.1 to 10.3 g. For composite meals without a size reference, the mean difference was 4.0 g with 95% limits of agreement ranging from –34.1 to 42.1 g and 12.4 g with 95% limits of agreement from –33.5 to 58.3 g for composite meals with a size reference.
Figure 4a shows a systematic tendency for lower carbohydrate estimates by ChatGPT-4o when the mean carbohydrate content was lower than 10 g. The opposite in Figure 4b shows an overall tendency for higher carbohydrate estimates when the mean carbohydrate content was around 20 to 40 g.
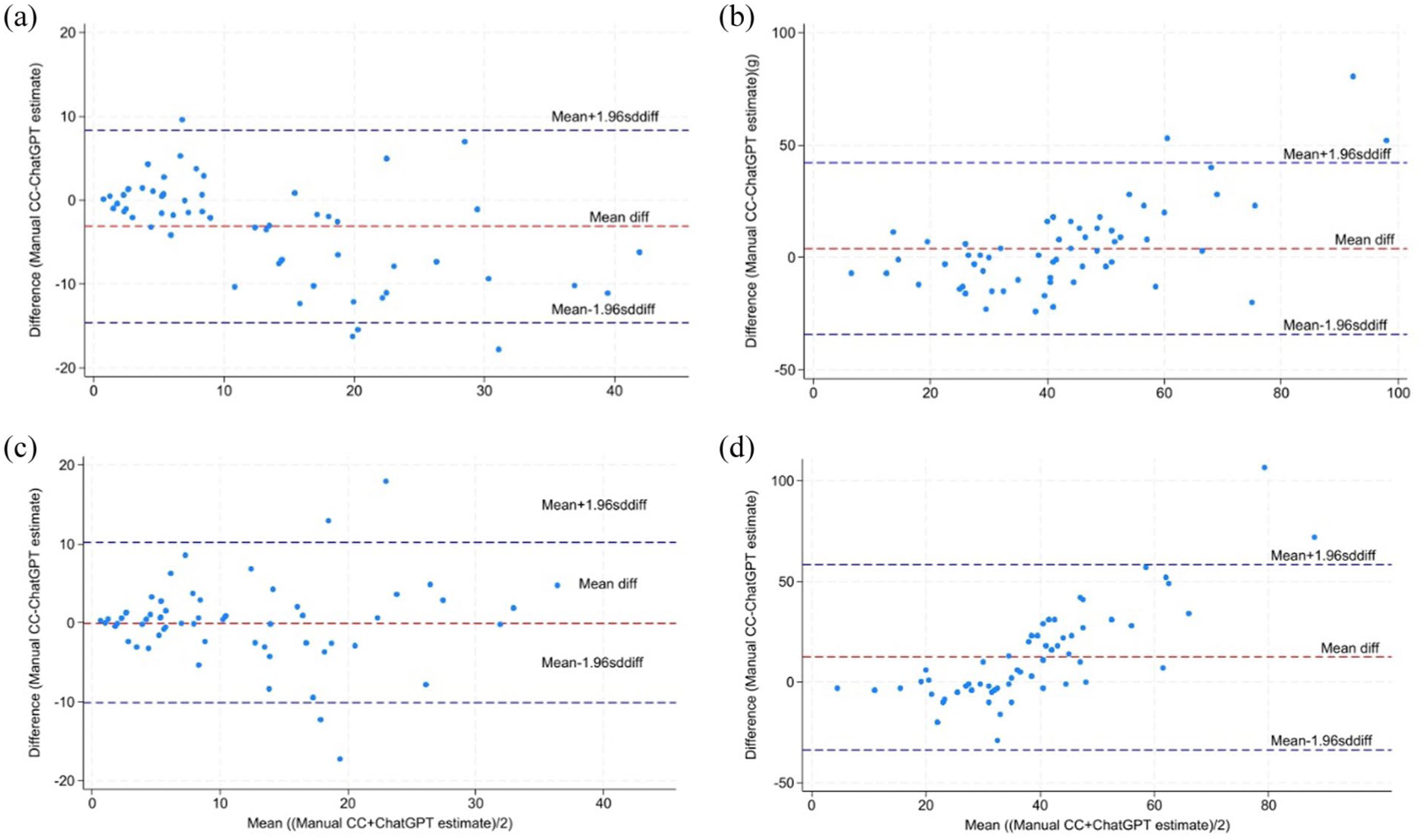
Bland-Altman plots for fruits and vegetables (F&V) and composite meals. (a) Bland-Altman plot for manual CC vs ChatGPT-4o estimates for F&V without a size reference. (b) Bland-Altman plot for manual CC vs ChatGPT-4o estimates for composite meals without a size reference. (c) Bland-Altman plot for manual CC vs ChatGPT-4o estimates for F&V with a size reference. (d) Bland-Altman plot for manual CC vs ChatGPT-4o estimates for composite meals with a size reference. Size reference is noted as “size ref.”
Figure 4c and d demonstrates the agreement between the manual CC and ChatGPT-4o estimates for F&V and composite meals with a size reference, showing a more even distribution around the mean difference.
The Bland-Altman plot reveals several outliers that fell outside the limits of agreement. The outliers are located above and below the limits of agreement, far from the mean difference. In Figure 4b and d, all outliers lie above the limits of agreement. One of the outliers was zucchini patties (see Figure 5). Manual CC attained a carbohydrate estimate of 132.5 g, whereas ChatGPT-4o provided an estimate of 52 g, resulting in a difference of 106.5 g. Figure 6 illustrates a whole-grain bun with eggs, where ChatGPT-4o provided an accurate estimate equal to the manual CC.

Image of meal nr. 48 from the database depicting a composite meal of zucchini patties, tzatziki, and potato slices with a size reference. The difference in carbohydrates was 106.5 g, making it an outlier compared with other meals.

Image of meal nr. 22 from the database depicting a composite meal of a whole-grain bun with eggs without a size reference. The difference in carbohydrates was 0 g.
Discussion
This study evaluated ChatGPT-4o’s ability to estimate carbohydrate contents in F&V and composite meals compared with manual CC to ease the management of T1D in adolescents.
The study found that the estimates for carbohydrates in F&V obtained an accuracy that met the predefined criteria of ±10 g carbohydrates, achieving narrow 95% CI and PoA of 93.3% and 95% with and without a size reference, respectively. The findings indicated that ChatGPT-4o could be used as a tool when eating F&V, as the estimates were within an acceptable margin of error. Therefore, insulin administration would be neither excessive nor insufficient, suggesting that adolescents with T1D would not reach postprandial hypoglycemic or hyperglycemic stages. However, it should be noted that the MARD’s for F&V with and without a size reference were 47.5% and 34.6%, respectively. The high MARD could be due to the general low carbohydrate content seen in F&V.
ChatGPT-4o did not achieve sufficiently accurate estimates of carbohydrates in composite meals. The PoA was 46.7% without a size reference and 43.3% with a size reference, indicating that ChatGPT4o only estimated within the given range of ± 10 g carbohydrates in approximately half of the cases. The Bland-Altman plot showed that ChatGPT-4o tended to estimate fewer carbohydrates than manual CC. Overall, the results for composite meals indicated considerable uncertainty in the use of ChatGPT-4o for carbohydrate estimates. Such use may increase the risk of excessive or insufficient insulin administration.
The results remained largely consistent with and without a size reference, suggesting it may not be effective for ChatGPT-4o under the given conditions. Although the evaluation metrics indicated a slight improvement in mean differences, the overall impact remained limited.
To our knowledge, the application of ChatGPT to estimate the carbohydrate content in images of meals for T1D management remains largely unexplored. However, some studies have examined the ability of ChatGPT to estimate macronutrients based on image input. One such study, conducted by O’Hara et al, 32 evaluated the use of ChatGPT to estimate the nutrient content in meal images derived from the National Adult Nutrition Survey. The study found a lack of precision in the general use of ChatGPT4V’s framework. This led to inconsistencies in precision when estimating macro-nutrition in composite meals. These findings align with the results of this study. Several studies have examined the use of designed applications or other constructed AI models within the same general concept of estimating macro-nutrition through images. 8 However, most of these studies have little or no regard for T1D management and mainly focus on machine learning models other than MLLM. The studies demonstrated adequately useful results, indicating that specialized pre-trained AI models or chatbots with image recognition systems can improve outcomes and be used to estimate the nutrient content of meals.33-35
Despite the above-mentioned limited quantity of existing literature within the same context, one study by Eskengren 36 aimed to evaluate the ability of MLLM (ChatGPT-4-Turbo) to estimate adequate insulin dosages and carbohydrate content through images of meals obtained from the Nutrition5k data set. Although the study has not been published in a peer-reviewed journal, it was carried out as part of a master’s program at the School of Electrical Engineering and Computer Science in Stockholm, Sweden. Similarly to the approach used in the present study, images were analyzed only from a bird’s eye view, and only a single image per meal was used. The study showed an MAE of 12.5 g, and revealed a bias of 8.54 g, indicating a general overestimation by ChatGPT-4-Turbo. 36 The study showed that ChatGPT-4-Turbo without fine-tuning could not be used for estimating carbohydrates and insulin predictions. Subsequently, external fine-tuning utilizing a separate software application was applied to ChatGPT-4-Turbo, attaining an MAE of 9.35 g, aligning with the predefined criteria of ±10 g carbohydrates. These findings align with previously mentioned studies that used pre-trained AI models or chatbots with image recognition systems. The results indicate that ChatGPT could be reinforced by fine-tuning, using a pre-trained model, or incorporating an external software application.
Limitations
This study observed several outliers in composite meals giving rise to extreme values, potentially affecting the overall analysis of ChatGPT-4o. Meals, such as zucchini patties, dhal, and ravioli (image 48, 20 and 12, respectively, in the database), differed in carbohydrate estimates by 40 g of carbohydrates or more. This could be due to ChatGPT-4o’s inability to recognize specific ingredients in meals, where the ingredients are mixed or do not show clear outlines. 21 In addition, it could be caused by the specificity of the prompt. 37 The study did not explore and compare alternative prompting methods, and conclusions based on a single prompt may therefore not fully represent ChatGPT-4o’s broader potential. As previous studies have demonstrated, prompt optimization can significantly improve AI’s performance in nutrition estimation tasks, but with our case, it may also have hindered the ability to evaluate dishes, such as Zucchini patties, dhal, and ravioli, which were not listed in the databases, frida.fooddata.dk and diabetes.dk, potentially causing ChatGPT-4o to deviate from the prompt, resulting in less precise estimates. A study by Kocoń et al 38 showed that ChatGPT-4 sometimes did not stay within the prompt design. This questions whether ChatGPT-4 followed the prompt entirely or may have gotten information elsewhere than instructed.
The data set lacked a standardized structure for composite meals, likely causing errors in carbohydrate estimation due to poor separation of components. It also showed a skewed carbohydrate distribution, with few high-carb meals, limiting generalizability. Moreover, as the data represent only Nordic cuisine, findings may not extend to other food cultures. Using a more diverse data set, such as Nutrition5K, could improve inclusivity. Finally, reliance on ChatGPT Plus poses accessibility challenges, highlighting the need to explore open-source MLLM alternatives, though ChatGPT currently offers the most accurate text-based responses. 39
Further Investigation
The incorporated images in the prompt were taken from bird’s eye view, and a single image was used, which only allowed a 2D visualization of the meal to ChatGPT4o. A comprehensive survey regarding image-based food recognition and volume estimation by Tahir and Loo 40 stated that multi-image methods were more accurate than single-view-image methods when comparing volume estimations with the use of AI models. However, this approach is less user-friendly and might be too complex and time-consuming for adolescents. Therefore, further investigation might focus on potentially incorporating a multi-image method, providing ChatGPT with a multidimensional view of the meal.
Future research should aim to optimize prompt design and systematically evaluate the effects of ChatGPT’s inherent randomness in outputs. Comparing outcomes across different prompt formulations in ChatGPT and other MLLM models could provide insights into model reliability. Incorporating multiple meal images captured from various angles, as well as alternative size reference objects, could potentially further refine carbohydrate estimation accuracy. Building on the results obtained for F&V, a comparative study could be conducted to assess ChatGPT’s performance in estimating carbohydrates in more complex, processed foods and snacks. In addition, an efficiency study evaluating the practical use of ChatGPT among adolescents with T1D would provide valuable insights into its applicability in real-world diabetes management.
Conclusion
The findings of this study indicate that individuals living with T1D should use ChatGPT-4o to estimate carbohydrates with caution. In our data, ChatGPT-4o proved to be inaccurate when estimating carbohydrates in composite meals. On average, ChatGPT-4o estimated a higher carbohydrate content than manual CC for F&V, whereas composite meals attained a lower carbohydrate content. Therefore, individuals with T1D should be skeptical of their use of ChatGPT-4o for CC due to the risk of inaccurate insulin administration leading to postprandial hypoglycemia or hyperglycemia. However, more studies are needed to validate the findings in a broader and more representative data material.
Supplemental Material
sj-docx-1-dst-10.1177_19322968261424270 – Supplemental material for Evaluating Accuracy of ChatGPT-4o in Automated Carbohydrate Estimation From Images as a Self-Management Tool for Adolescents With Type 1 Diabetes
Supplemental material, sj-docx-1-dst-10.1177_19322968261424270 for Evaluating Accuracy of ChatGPT-4o in Automated Carbohydrate Estimation From Images as a Self-Management Tool for Adolescents With Type 1 Diabetes by Asta Risak Johansen, Isabella Kjær Laursen, Vár Jacobsen, Zacharias Henriksson Møller and Simon Lebech Cichosz in Journal of Diabetes Science and Technology
Footnotes
Abbreviations
CC, carbohydrate counting; F&V, fruits and vegetables; IQR, interquartile range; LLM, large language model; MAE, mean absolute error; MARD, mean absolute relative difference; MLLM, multimodal large language model; PoA, percentage of agreement; RMSE, root mean squared error; T1D, type 1 diabetes.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.