
Abstract
Introduction:
Precise sample identification is crucial for the success of any biomedical research project. To ensure quality, biobanks follow best practices standards. However, errors such as mislabeling, sample switching, and other mishandling issues can still happen at various stages of the sample lifecycle at collection sites, within the biobank, in research laboratories, or during data management and analysis.
Objective:
To ensure sample integrity, the biobank at the Chan Soon-Shiong Institute of Molecular Medicine at Windber maintains detailed and accurate documentation throughout all sample handling stages. The biobank also develops additional quality tools to thoroughly investigate and correct discrepancies such as sample misidentification.
Methods:
Between 2018 and 2020, the biobank recorded a total of four misidentifications out of 284 sample isolations, resulting in a 1.4% misidentification rate. Alongside effective quality documentation procedures, a flowchart was created to trace and identify potential causes of reported sample discrepancies, followed by a decision tree outlining the steps to resolve the observed issues.
Results and Conclusion:
Here, we report how record documentation, a flow chart, and decision tree helped the successful resolution of sample misidentifications. In the reported case studies, these tools allowed us to conclude, in one case, that the source of error most likely occurred outside the biobank, while the other pointed to a sample switch during batch DNA processing within the biobank. All outcomes were confirmed by short tandem repeat analysis. These quality assessment tools ensure efficient biobanking that promotes research integrity.
Keywords
Background
The biobank at the Chan Soon-Shiong Institute of Molecular Medicine at Windber (CSSIMMW) is accredited by the College of American Pathologists (CAP) and serves as the central repository for numerous government-funded cancer research programs. Currently a variety of human biological samples (blood, blood products, solid tissue, and other human body fluids) are shipped from over 15 sample source sites across the United States to the biobank for sample processing, long-term management, and distribution.
Biobanks play a vital role in translational research, ensuring the proper handling of samples to preserve their quality and integrity for downstream projects. 1 The crucial role of biobanks has led to a rapid growth in their numbers over the past 20 years, with two-thirds of U.S. biobanks established in the last two decades.2,3 Quality standards for biobanking have been promoted through efforts like the International Society for Biological and Environmental Repositories (ISBER) Best Practices,4–6 and accreditation programs such as CAP Biorepository accreditation 7 and the International Organization for Standardization 20387 General Requirements for Biobanking. 8 Despite these measures, errors such as sample mislabeling can still occur at any stage of the sample’s lifecycle. These errors may be detected through routine authentication procedures or unintentionally revealed during data analysis or when comparing clinical pathology information with molecular data. The circumstances surrounding these misidentifications vary, making it difficult to compare sample misidentification rates across biobanks and laboratories, although a few publications have reported differing rates in relation to their operations.9–12 Up to a 1.5% sample identity error rate in existing biobanks have been reported, and more than 98% of errors are reported to occur during sample collection. 13
The most effective way to detect sample misidentification is by routine sample authentication before using samples for downstream research. Several technologies are available for sample authentication, including commercial single-nucleotide polymorphism (SNP) panels like SNPTrace, Agena iPLEX Sample ID panels, and others.11,14–16 DNA fingerprinting using a double ALU insertion/deletion genotyping panel has been developed for the traceability of a sample, certifying its uniqueness and ensuring the identification of potential sample contamination. 17 Short Tandem Repeat (STR) fragment analysis has been utilized in forensic DNA fingerprinting. It is a valuable tool for quality control in biobanking, as it can be applied to various specimen types, including blood, tissue, and cell lines.18,19
Since these technologies are costly, it is unlikely that many biobanks or research laboratories will use them routinely. Consequently, biobanks must adopt effective quality management systems that help reduce the occurrence of such errors while maintaining traceability to identify the root cause when mistakes occur and are identified.
Sample identity errors negatively impact research outcomes and cannot be overlooked. When a sample is identified as mislabeled, it is often possible to trace its origin and correct the mistake; however, this can be difficult without a structured and systematic workflow. Therefore, biobanks need to establish efficient processes and procedures aimed at preventing or minimizing the effects of such sample mix-ups. Although many publications detail analytical methods for detecting sample mix-ups, they often lack guidance on how to resolve the misidentification or address the root causes behind such errors. Resolving these issues promptly provides an opportunity to implement corrective and preventive measures, thereby improving overall quality management within the biobank. Drawing on extensive biobanking experience, the CSSIMMW biobank developed a method that uses a step-by-step approach to investigate and resolve each case of sample misidentification, while also identifying potential underlying causes.
Materials and Methods
Ethical considerations
All samples used for this study were duly consented to, under an active Institutional Review Board-approved protocol (WRNMMC-2018-0147) of the Walter Reed National Military Medical Center (WRNMMC). All research activities complied with ethical regulations.
Tool development: A flowchart and decision tree to investigate misidentifications reported to the biobank
A flowchart was created (Fig. 1) to identify potential steps in the sample lifecycle where errors, such as sample misidentification or mishandling, could occur. These steps are shown in Figure 1, steps 1–5. The collection site represents the earliest point where mishandling and errors could be introduced (Fig. 1, step 1). Subsequent activities within the biobank, specifically sample receiving and processing (Fig. 1, steps 2 and 3), are other points where a sample could be mishandled, leading to misidentification. In addition, instances of sample mishandling could occur outside the biobank at the investigator’s research laboratory (Fig. 1, step 4) or during data analysis (Fig. 1, step 5). A mislabeling at the collection site, if undetected, can pass through all stages of the sample workflow, from storage in the biobank to research use. The same risk exists if mislabeling occurs within the biobank. Samples can be mislabeled or switched during receipt or processing, such as during nucleic acid extraction or sample aliquoting (Fig. 1, steps 2–3). These errors could lead to the distribution of incorrect samples for research and the publication of unreliable data (Fig. 1, steps 4–5).
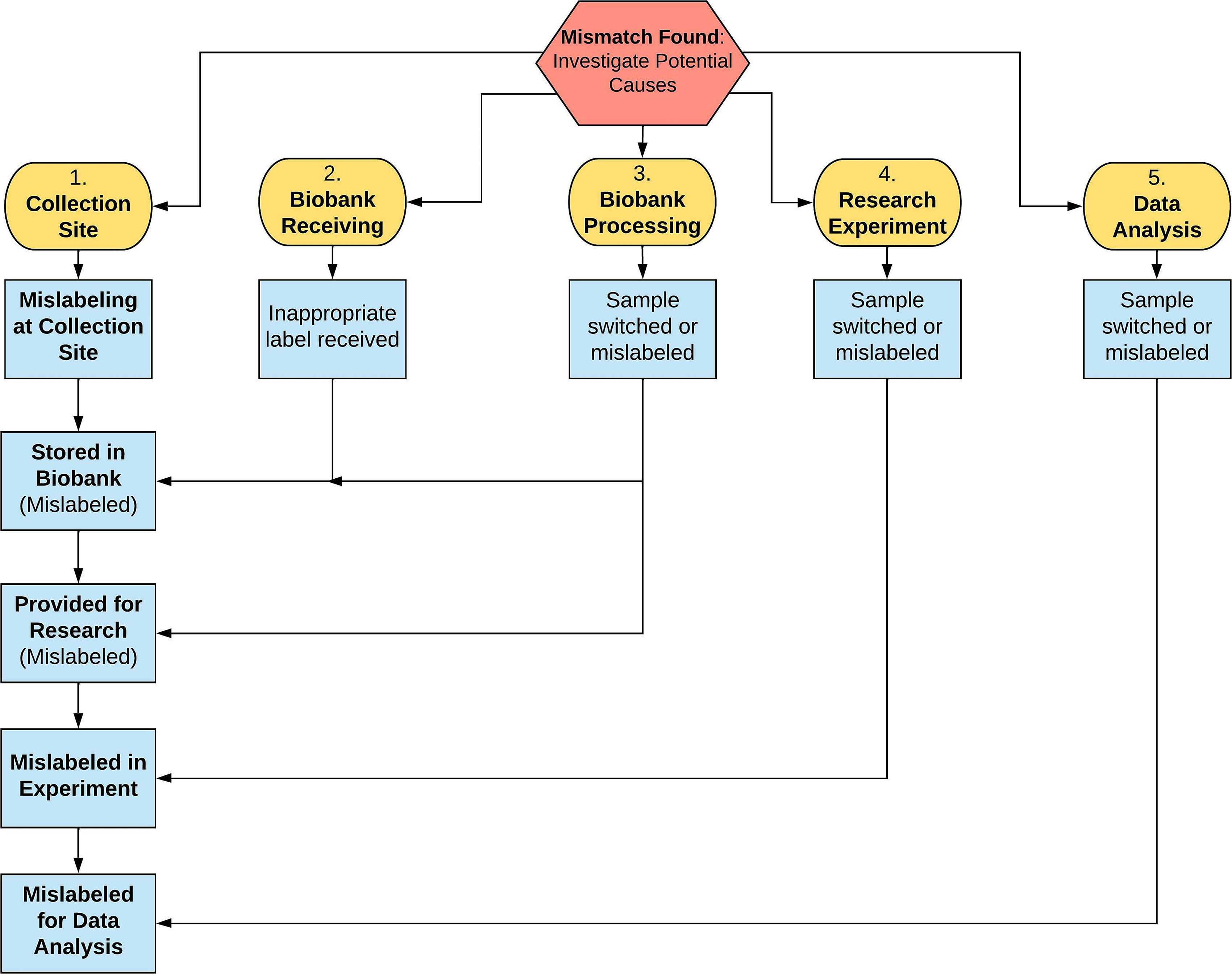
Flowchart showing potential areas where errors can occur across the biobanking and research pipeline, leading to sample misidentification. These include: (1) collection site, (2) biobank receiving, (3) biobank processing, (4) research experiment, and (5) data analysis. Examples of potential failure modes at each stage include mislabeling, specimen switching, or use of incorrect identifiers. Blue boxes denote downstream consequences in which specimens may be stored, distributed, or analyzed under incorrect labels from upstream activities. When a mismatch is identified, a centralized investigation is initiated to assess these workflow stages using biobank audit trails and quality assurance records to determine the most likely source of error.
To improve the ability to re-identify samples, electronic tracking methods for documenting and investigating discrepancies are recommended. This includes audit trails within inventory management systems—whether commercial or custom-built—and other internally developed quality assurance (QA) databases. For the samples discussed here, all collection sites used an in-house built data tracking system (DTS) that integrates clinical, demographic, and pathological information.20,21 Biospecimen data include collection date, sample type, and number of aliquots, among other relevant information. At the biobank, the samples are received by scanning barcodes into the DTS, which has features to verify each shipment and identify and report shipment discrepancies. The DTS interfaces with the commercial sample inventory database, Freezerworks (Ascent edition, v14.01.03; www.freezerworks.com), which records aliquot numbers, freeze–thaw cycles, batch processing activities, among other relevant data, including an audit trail, which enhances traceability across the entire sample lifecycle. These databases enable detailed documentation and tracking of samples throughout their lifecycle, allowing the biobank to easily access information from collection to distribution.
The decision tree (Fig. 2) was created to guide the steps for resolving a reported misidentification. In cancer research, it is common to analyze both germline and tumor samples at the molecular level. When molecular profiles of germline and tumor samples from the same person do not match, the next step is to evaluate whether an error might have occurred at one of the five steps shown in Figure 1. If the profile of the sample in question matches the profile of another sample within the tested set (batch), the decision tree (Fig. 2) recommends testing additional representative samples available in the biobank. The decision tree guides the user through sequential elimination steps based on a series of “Yes”/“No” responses (Fig. 2). The tools described in Figures 1 and 2 help identify the root cause of any misidentifications and the actions needed to resolve the issue, which may include: (1) verifying and/or confirming sample identity or (2) discarding the samples if the investigation cannot lead to a conclusion.
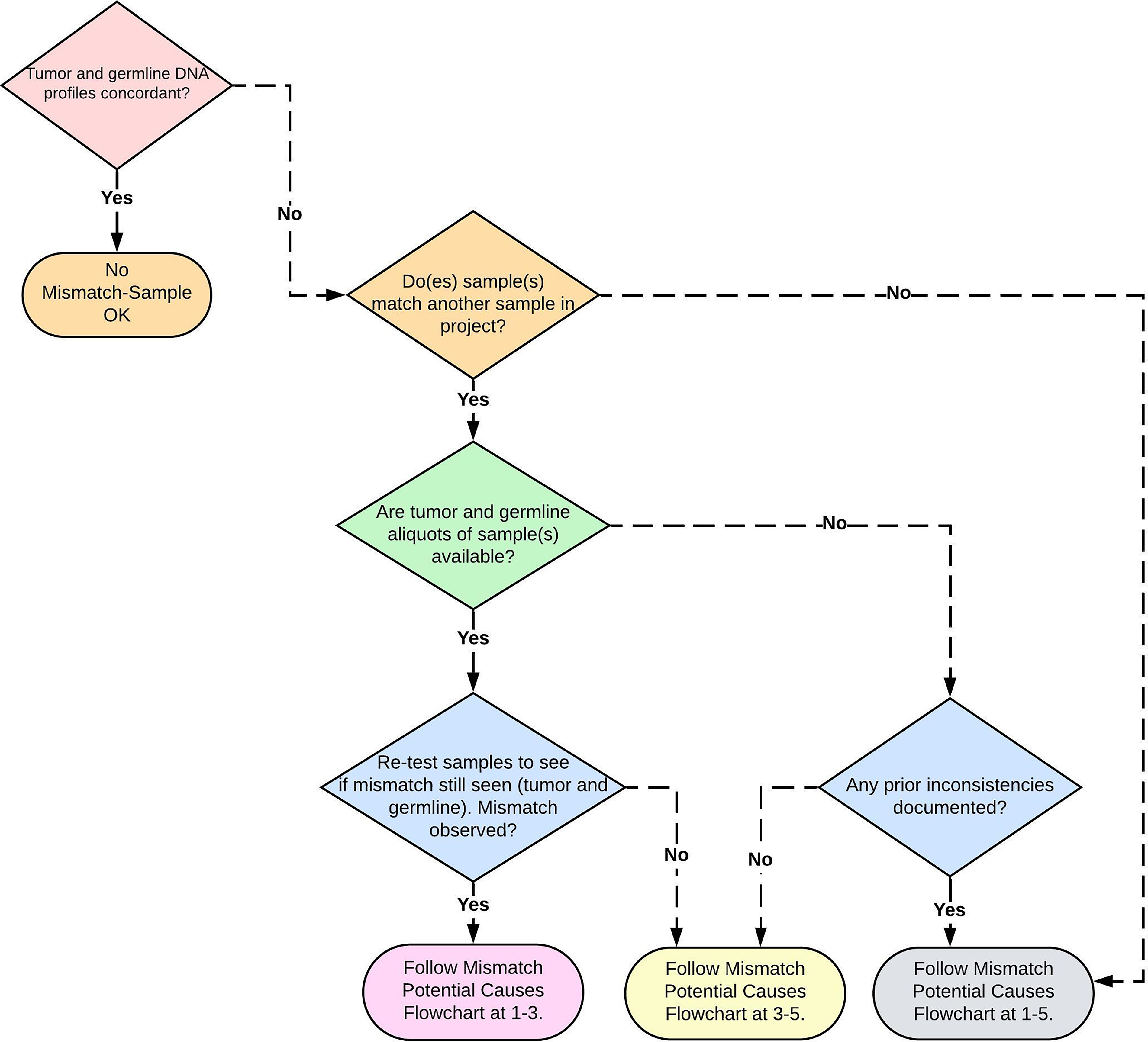
A decision tree to aid in the determination of the root cause of a reported sample misidentification. The decision tree refers back to steps within the flowchart (Fig. 1) where potential errors could occur during sample handling.
The examples below illustrate case studies where these in-house developed tools were used to resolve misidentifications reported to the biobank. Cases of suspected sample misidentification reported to the biobank were quarantined until reaching definitive resolutions.
Laboratory procedures
Tumor DNA was isolated from OCT-embedded tissue sections using the Qiagen QIAamp DNA Mini kit (Hilden, Germany). Germline DNA was obtained from either blood clots collected after serum processing or red blood cell/buffy coat mix obtained after plasma processing from sodium heparin (green top) or K2 ethylenediaminetetraacetic acid (EDTA, purple top) vacutainer tubes. DNA extraction was carried out with the Qiagen Gentra Puregene Blood Kit for blood clots and the Qiagen QIAamp DNA Blood Midi Kit for red blood cell/buffy coat mix. Manufacturer’s protocols were followed for all extractions with minimal modifications, including serial ethanol washes to remove OCT from OCT-embedded tissues before DNA isolation. For the serial ethanol washes, 1200 µL of 80% freshly prepared ethanol stored at −20°C was added to the OCT specimens and vortexed vigorously. The OCT specimens were then centrifuged at ≥20,000 × g for 5 minutes. The resultant supernatant was removed. The samples were then incubated at room temperature for 15 minutes with the sample tubes open to evaporate any remaining ethanol. DNA isolation was then completed using the QIAamp DNA Mini manufacturer’s protocol.
STR analysis was performed with the PowerPlex Fusion System using the manufacturer’s protocol (Promega, Madison, WI, USA). The panel covers 24 loci and provides a Probability of Identity value (PI) of 6.58e-29. 22 A 25 µL total reaction volume containing 1 ng of DNA template and the appropriate kit components was prepared for each sample. Amplified fragments containing the repeated regions were separated and imaged with the 5-dye/96-capillary 3730xl Genetic Analyzer (ThermoFisher Scientific, Waltham, MA, USA) to generate STR profiles. Data were analyzed using GeneMapper ID v3.1 software (ThermoFisher Scientific). In each STR run, negative and positive controls were included and reviewed before interpretation. A no-template negative control (extraction blank) was carried through extraction, PCR amplification, and capillary electrophoresis to monitor contamination. A positive control consisting of control DNA from a commercially available kit was amplified (in duplicate) to confirm assay performance. Runs were accepted only if the positive control produced an expected STR profile, and the negative control showed no peaks at or above the analytical threshold (50 RFU); failed controls triggered run rejection and investigation prior to reporting. Concordance between STR profiles for tumor DNA and the corresponding germline DNA was used to confirm that samples were from the same donor.
When a profile misidentification was reported, the flowchart (Fig. 1) and decision tree (Fig. 2) were used to identify the possible cause of the misidentification.
Results
Case #1
Whole genome sequencing (WGS) results showed that the tumor DNA of donor A did not match its respective germline DNA. However, the WGS results of this tumor matched another tumor/germline pair from donor B within the same data set. Based on this outcome, the next step on the decision tree (Fig. 2) was to determine the availability of all samples in the biobank from donors A and B for testing. In both cases, the only samples remaining in storage for DNA isolation were the original OCT blocks that had already been used for prior DNA extraction. From the OCT blocks, sections were cut for DNA extraction. The newly extracted tumor DNA for donor A and donor B was subjected to STR analysis and compared with the respective germline DNA samples available in the biobank (Table 1).
Case Study 1 STR Results
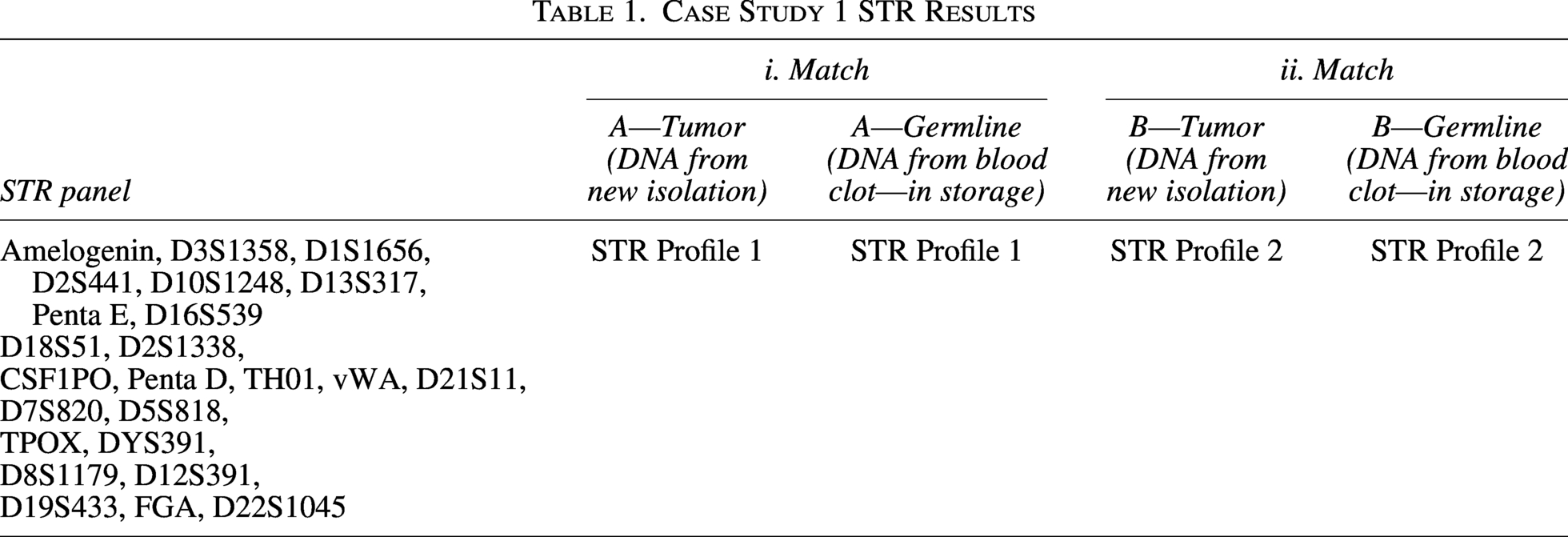
Comparison of the newly extracted tumor DNA from donors A and B with their corresponding germline STR profiles showed agreement between tumor and germline DNA (Table 1-i and ii). This confirmed the correct identities of samples A and B. Despite a few non-matching loci for sample A, the overall STR profile comparison resulted in a random match probability of 1 in 2.25e-24, indicating a highly consistent match. This verified that the newly isolated tumor DNA samples matched their respective germline DNA (Table 1). Therefore, tumors A and B stored in the biobank were correctly labeled, making a switch at the biobank unlikely.
The source of the problem was traced to the “aliquot” of tumor DNA used for WGS. Records and QA documents were reviewed, revealing that aliquots of tumor DNA A and B were shipped to a research laboratory. A review of the shipping manifest and matrix plate design showed these DNA samples were next to each other at well positions A2 and B2 (Fig. 3).
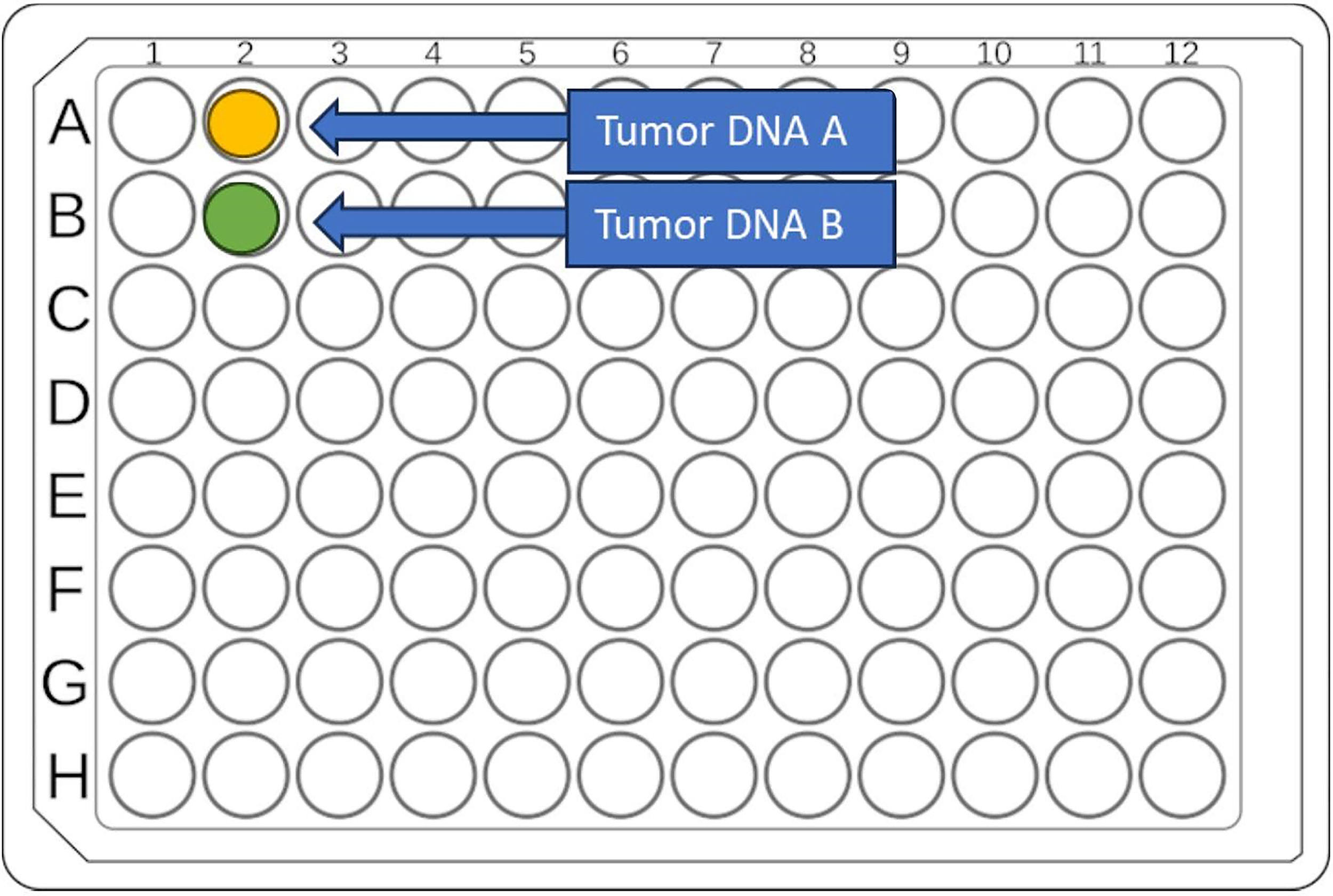
Case Study 1—Investigations revealed that the initial tumor DNA samples for donor A (which did not match its respective germline) and donor B (which matched its germline) were plated adjacent to each other (positions A2 and B2) on the microtiter plate shipped out of the biobank. Laboratory record documentation indicated the entire available tumor DNA aliquots for A and B was used for this shipment, leading to the elimination of sample mix-up occurring during pipetting at the biobank.
It was documented in the laboratory records that the entire aliquot of tumor DNA for both A and B was used for this shipment. This information ruled out a mix-up during pipetting in the biobank. For all aliquoting activities, the remaining sample volume in the source tube and the number of freeze-thaw cycles are tracked in the DTS. This ensures specific project sample usage is easily accessible and accurately reflects the nucleic acid available for future studies. No action was necessary in the biobank, as the tumor and germline materials in the biobank all matched, confirming that the source of error lay outside the biobank.
Case #2
STR profiles from a breast tumor (C) and its corresponding germline DNA (extracted from a blood clot) did not match (Table 2-i). Since no other samples matched the profile in question, the recommended step on the decision tree was to consider the possibility of a sample handling error occurring at any step in Figure 1.
Case Study 2 STR Results
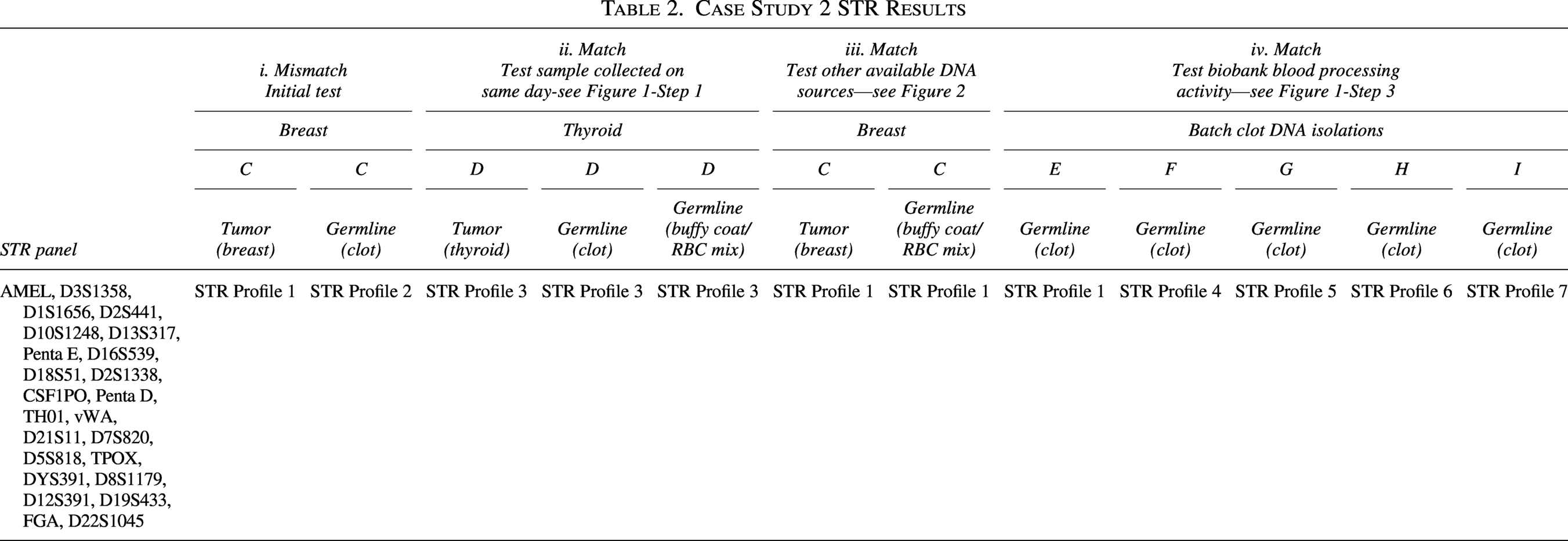
The collection site (Fig. 1, step 1) was examined to identify other samples collected on the same day as the breast sample. Reviewing the electronic DTS revealed that a thyroid tumor and blood samples were collected from donor D at the same site on the same day. The total samples available for STR analysis from donor D included thyroid tumor DNA and two germline DNA samples. One germline DNA for D was extracted from a blood clot, while the other was extracted from a buffy coat/blood cell mixture. The two germline samples for D were tested against tumor C (Table 2-ii).
Investigating the potential errors within the biobank (Fig. 1, steps 2 and 3) revealed that another germline DNA source (buffy coat/red blood cell mix) for donor C was available (Table 2-iii). It also showed that the original germline DNA of donor C, (from a blood clot sample), which failed to match tumor C (Table 2-i), was processed as a batch with five other blood clot samples listed as E, F, G, H, and I. Germline DNA for E, F, G, H, and I was tested against the breast tumor DNA C (Table 2-iv).
Additionally, pathological review confirmed the histology of breast tumor C and thyroid tumor D, both collected on the same day from the same site.
The decision tree (Fig. 2) indicated the need to investigate steps 1–5 of the flowchart (Fig. 1). For step 1, the collection site, records retrieved from the electronic databases showed that only thyroid tumor D and representative blood samples were collected on the same day as breast tumor C. The STR results revealed that the thyroid tumor profile matched only its corresponding germline DNA profiles (Table 2-ii), confirming that there was no sample mix-up for this thyroid tumor donor at the collection site or biobank. To determine if the issue originated from the biobank, “newly” extracted germline DNA from the buffy coat/red blood cell mixture for the breast tumor donor C was tested against the breast tumor DNA. STR analysis showed a complete match between this “newly” extracted germline DNA and the breast tumor DNA (Table 2-iii).
This outcome indicated that the problem lies with the germline DNA (clot) of the breast tumor C. STR results from the batch DNA extractions of blood clots (E, F, G, H, and I), including that of C, showed that the germline DNA sample for E matched the DNA of tumor C. This indicated that the misidentification arose from a sample switch during batch DNA extraction within the biobank. This mistake was corrected by relabeling the samples and documenting accordingly (Table 2-iv).
Discussion
These two case studies highlight how sample misidentifications can arise at different points in the workflow, whether from an external source outside the biobank or internally during batch sample processing where labels are inadvertently switched. When samples are swapped or mislabeled at any point in the workflow (Fig. 1, steps 1–5), research reproducibility can be compromised. 23 Over a 2-year period, the biobank observed a 1.4% misidentification rate (four misidentifications out of 284 sample isolations), underscoring the importance of implementing systematic tools to identify and resolve such errors.
Other biobanks have created internal procedures and workflows to address general biobanking quality standards and prevent or reduce physical sample mix-up or misidentification. For example, the Beaumont Biobank and Core Molecular Laboratory developed a troubleshooting schema to resolve physical sample identification uncertainties. 24 In another report, DNA fingerprinting was used to resolve an observed sample misidentification that was observed from an “omics” technology research. 18 These examples show the uniqueness of each quality problem and resolution process. However, the importance of preventing misidentification is universal for researchers and biobanks, hence the development of a software application for the identification and management of such errors in multi-omics studies. 25
In recognition of the need to address quality issues within the biobank, a flowchart and decision tree are presented that can be used by any biobank with an efficient procedure to identify, investigate, and document nonconformities within the quality system which could allow resolution of reported sample misidentifications. The successful use of these tools is presented in the case studies. The flowchart identifies areas where sample misidentification could occur, and the decision tree offers step-by-step guidance toward a resolution, providing clarity to the investigation process (Figs. 1 and 2). In addition to these tools, other quality measures such as proper documentation of any observed deviations outside the stipulated standard operating procedures and established biobanking best practices are required. Using a system like the one described greatly increases the likelihood of accurately identifying and resolving sample misidentifications. The development and validation of robust tools are critical in biobanks, as they enable standardized processes, enhance sample management, optimize workflows, and support operations and quality management, essential for high-quality research outcomes.26–28
In case study #1, the misidentification was reported during data analysis, which is the most common way to detect a misidentified case, since not all research projects routinely perform sample authentication. For case study #2, the misidentification was reported after routine sample authentication by STR analysis (tumor DNA and matching germline DNA). Using these tools, along with the biobank’s quality plan, we determined that for case 1 the samples received and stored had been correctly collected and inventoried at the biobank, and the remaining representative samples in storage were authentic. For case 2, we identified the root cause, which was internal, and this was corrected by relabeling the affected germline DNA aliquots of “C” and “E” in the biobank.
In addition to resolving reported misidentifications, these investigations highlighted opportunities to further reduce the risk of future errors through preventive measures within the biobank. Safeguards implemented to reduce sample misidentification errors included, when applicable, initiating sample processing early in the morning to minimize fatigue, requiring at least two identifiers on the source tube and all tubes used during processing, maintaining consistent sample order throughout labeling and processing, and establishing a maximum number of samples permitted per processing batch. Automated sample processing, which provides greater efficiency in the laboratory, is another potential solution if and when such technology can be instituted. Automation of key steps, including barcode-based sample labeling, electronic verification at receipt and processing, and automated plate and aliquot tracking, can substantially minimize manual handling errors. Since problems could occur during collection at the source site, regular training of staff to emphasize efficient sample labeling and steps to double-check sample collection entries are important. Any reported event should trigger an internal investigation and a determination of potential root cause, followed by training or retraining as appropriate. Standard operating procedures should be updated to include identified preventive measures across the laboratory and collection sites as needed. Regular internal audits and periodic review of quality metrics provide an additional safeguard by identifying process vulnerabilities before errors propagate. Together, these preventive strategies complement the flowchart and decision tree presented in this study, supporting both error resolution and continuous quality improvement in biobanking operations.
Conclusion
It is important to note that biobanking activities span beyond the collection and processing of human biosamples and include Ethical, Legal, and Social Implications (ELSI), which deal with research protocol design, participant recruitment, handling of biospecimens and data, research results, and incidental findings. 29 The focus of this article was directly related to the handling of samples, data, and laboratory/research results. All other areas of ELSI, which are equally relevant to the entire biobanking and research process, are outside the scope of this article and therefore not addressed. However, the biobank and all related research programs had the appropriate regulatory and ethical mechanisms in place to uphold standards in all relevant areas and included: ethics boards to approve study protocols/informed consents, ensure data protection, avoid discrimination and risk, as well as regulatory offices to manage material transfer agreements and other administrative agreements. 29 The in-house developed DTS also ensured appropriate tracking of data and biosamples from the clinic to the laboratory and included chain-of-custody considerations.
Although biobanks adhere to strict quality standards in all aspects of operation, including sample receiving, storage, tracking, processing, and distribution, errors can still occur. Therefore, it is essential to have plans in place to identify the causes of reported errors, correct them, or discard samples in unresolved cases. Documenting activities and maintaining audit trails are crucial. The reported cases were documented and investigated. For each case, appropriate recommendations were provided to avoid potential reoccurrence. The tools described here can be easily reproduced across other biobanks where there is a well-established quality system to identify nonconformities. The QA framework within a biobank should ensure sample integrity, traceability of the samples, and associated data as outlined in the ISBER biobanking Best Practices. Without such elements, it becomes difficult to confidently trace and identify the root cause of problems and provide a systematic approach toward their resolution.
Successful application of the described tools further emphasizes the importance of establishing a comprehensive quality management system within a biobank.
Ethical Considerations
All samples used for this study were duly consented for, under an active Institutional Review Board (IRB) approved protocol (WRNMMC-2018-0147) of the Walter Reed National Military Medical Center (WRNMMC). All research activities complied with ethical regulations.
Consent to Participate
Verbal or written informed consent for inclusion in this research was obtained from all participants. Those approached for consent were given the option to refuse or to opt out of the study at any time.
Authors’ Contributions
K.M. and H.L.B.: Tool conceptualization and design, article preparation and review (equal). S.M.S., L.A.S. and Z.G.: Experiments, data curation, article review (equal). B.D., J.K., M.C., and C.L.: Tool utilization for sample management, article review (equal). L.F-.C., N.L.W., J.L., J.M.W., C.L.D., and C.A.: Article review (supporting). M.D.W. and A.R.S.: Data curation (equal). H.H. and C.D.S.: Project administration, article review (equal). S.B.S.: Project conceptualization, administration, article preparation and review (lead).
Footnotes
Acknowledgments
The authors acknowledge all patients who participated in the study. They want to thank Lisa Malicki for her assistance with article preparation and review. They also thank Joseph Vockley for his program support.
Author Disclosure Statement
The authors declare no competing financial interests but the following competing non-financial interests: H.H. is a co-founder and shareholder of miRoncol Diagnostics, Inc. The contents of this publication are the sole responsibility of the author(s) and do not necessarily reflect the views, opinions, or policies of Uniformed Services University of the Health Sciences (USUHS), the Henry M. Jackson Foundation for the Advancement of Military Medicine, Inc., the Department of War (DoW) or the Departments of the Army, Navy, or Air Force. Mention of trade names, commercial products, or organizations does not imply endorsement by the U.S. government.
Funding Information
This work was supported with funds from the