
Abstract
Despite the exponential growth in academic publications and industrial investments in artificial intelligence (AI) in medical imaging, clinical translation remains disproportionately low. Notably, the absence of internationally recognized guidelines for evaluating AI model performance and ethical considerations creates a critical gap in current practices. In this regard, we aim to offer a practical concise perspective exploring performance challenges to implementation while focusing on their mitigation. The dialog continues in subsequent work (part 2) which focuses on ethical issues. In this part, we explore the challenges inherent to the performance evaluation of AI in radiology, focusing on data heterogeneity, the choice of performance metrics and their interpretability, and data access. By shedding light on these issues and discussing potential opportunities, this work contributes to the ongoing dialog surrounding the practical integration of AI in clinical settings. It highlights the imperative need for established guidelines to ensure the safe and efficient deployment of AI technologies in medical imaging, ultimately bridging the gap between theoretical potential and practical implementation.
Keywords
Introduction
The computer-based nature of radiology provides an expansive space for leveraging machine intelligence solutions to enhance administrative processes and diagnostic capabilities. This technological evolution is reflected in the exponential rise of academic publications dedicated to medical imaging artificial intelligence (AI).1,2 Despite the convergence of interests between the healthcare and industrial stakeholders in the potential of AI applications in radiology, there remains a disproportionate gap between theoretical advancements and their practical adoption.3,4 In the United States, the Food and Drug Administration (FDA) serves as the regulatory authority responsible for the approval process of pre-market AI models after initial testing.3–6 Despite its concerted efforts to define performance criteria, recent analysis of FDA-approved models has revealed deficiencies in performance assessment, which resulted in apprehensions regarding the generalizability and safety of FDA-approved AI tools impeding their seamless deployment into radiology.3,7–9
Pre-clinical and post-clinical performance assessment plays a pivotal role in establishing confidence in AI models’ use in the clinical settings in radiology.6,8 This step involves comparing the model’s predicted and observed outcomes within the target population of its deployment. 6 In order to do this, the availability of a data set representative of the real-world target population is crucial, which ideally requires multiple test sets of authentic, unseen well-curated data across diverse clinical sites. 10 In radiology, this often constitutes a major challenge partly due to variability in imaging data acquisition and handling, the nuanced selection of performance metrics, and data access limitations.11,12
This article constitutes the first half of a two-part perspective that aims to concisely discuss mitigating challenges associated with the implementation of AI in radiology. In part I, we tackle performance evaluation, encompassing issues related to handling data heterogeneity, performance metric selection, and data access. In part II, we address ethical issues to enable AI adoption including data bias, fairness, patient privacy, and data security.
Discussion
Addressing data heterogeneity
Heterogeneity is an inherent and distinctive feature of healthcare data, given the unique biology and pathology of each patient. While most AI models leverage these differences as discriminatory features, unwanted heterogeneity pertaining to variations in data distribution, collection, and handling introduces biases compromising the performance of AI models.11,12 In medical imaging, variabilities related to scanner differences, image parameters, acquisition protocols, pre-processing and processing practices, and ground truth collection constitute additional layers of heterogeneity. 13 Especially in smaller data sets, these differences become pronounced resulting in dangerous prediction inaccuracies after clinical deployment if missed in pre-market assessment. 14 Recognizing and appropriately addressing these variations as early as project planning is feasible and necessary for reducing unwanted model biases and improving model generalizability.
Although population distribution variations may be difficult to overcome, various techniques have been successful in reducing the weight of technical variabilities in imaging data. Several methods can be employed to enhance the similarity between the training, performance evaluation, and real-world population datasets to counteract unwanted heterogeneity. These methods mostly aim at minimizing the inherent and introduced data biases. In this section, we provide an overview of some of the most popularly investigated techniques, which are extensively discussed in the literature. It is important to note that these methods are not without drawbacks, and their ideal applications and handling require experienced individuals.
Differences in magnetic resonance imaging (MRI) acquisitions can be classified into two main categories: intensity and scanner effects. Voxel intensity variations are inevitable and seen even when scanning the same patient in the same position using the same parameters in the same scanner.15,16 By correcting intensity variations, intensity normalization techniques may improve model performance enhancing repeatability, reproducibility, and generalizability. Foltyn-Dumitru et al. evaluated the impact of intensity normalization techniques on the radiomic features extracted from the glioblastoma region of interest (ROI) on T2-fluid attenuated inversion recovery (FLAIR) MRI scan-rescan. Both z-score and histogram intensity normalization techniques showed similar significant improvement in intensity and texture radiomic features repeatability and reproducibility between the two scans. Depending on the context of the application and the appropriateness of the techniques applied, different techniques have variable effects occasionally introducing negative effects harmful to image standardization.17,18 Data harmonization is another technique that applies mathematical concepts that minimize scanner variabilities.16,18,19 The efficacy of this method was evaluated by using a ML classifier trained to identify imaging sites using raw versus harmonized brain MRIs. This classifier prominently predicted the actual source of the data prior to harmonization, but weakly performed (mostly predicted the same source of data different from its actual source) when tested after harmonization. 19 Careful experienced application and transparent detailed reporting of pre-processing techniques including normalization and harmonization are paramount.
Overfitting poses another major challenge in performance assessment, resulting in inaccurate predictions when the model is tested on new unseen data. This phenomenon occurs when a machine learning model overly learns the training data, including recognizing non-biological aspects related to acquisition protocols which are magnified in small non-diverse datasets. Data augmentation offers a way that involves manipulating imaging data and applying various modifications to create additional samples. This process aims to mimic variations in patient anatomy and imaging acquisition, thereby enhancing the diversity of the dataset. 20 By artificially creating new samples through operations like rotation and flipping, the model becomes more robust to variations in imaging quality, thereby mitigating the impact of data heterogeneity.20,21 For example, Sanford et al. used a data augmentation strategy called deep stacked transformation in their study. 22 This strategy was combined with transfer learning and a fine-tuning approach to improve the model’s generalization to multiple external centers. This method increased the Dice similarity coefficient (DSC), with the model trained with DST data augmentation achieving 91.0 for whole prostate segmentation and 88.1 for transition zone segmentation, representing a 2.2% and 3.0% improvement over models not trained using these methods. Despite the appeal of this approach, it’s essential to recognize that it has the potential to propagate biases or errors present in the original dataset.23,24
Domain adaptation is another potent technique for counteracting the effect of bias inherent to limited data availability. This method works by leveraging the knowledge gained by a model trained on reasonably sized labeled data to a target domain with only limited annotated dataset available.25,26 Different domain adaptation techniques may be carefully utilized to address context-relevant data deficiencies. 27 Ouyang et al. compared the performance accuracy of cardiac CT image segmentation using a novel data-efficient unsupervised domain adaptation technique for cross-modality segmentation to an unadapted baseline and other segmentation tools including a state-of-art model. The proposed technique showed significant improvement compared to the unadapted baseline achieving a mean DSC of 72.18% and 52.15%, respectively. Compared to the state-of-art method, the proposed technique achieved close results while requiring only a sixth of the target data. 28
Image segmentation stands as one of the most essential tools in image pre-processing and processing, crucial for model training, ground truth generation, and performance assessment.29,30 Presently, manual, and semi-automatic segmentations are predominant techniques for constructing databases of normal tissue and pathology, significantly influencing data reproducibility. 30 While some advocate for mitigating this using automatic segmentation tools to enhance model reproducibility, recent data indicates that these algorithms are not immune to biases.29,31 Additionally, beyond the challenges posed by intra- and inter-operator variability, the clarity of instructions regarding the segmentation process details and image pre-processing profoundly affects outcomes. A practical example of this challenge was encountered in our laboratory’s validation of perfusion analysis conducted at another center. Upon investigating the cause of conflicting results, it appeared that the two institutions treated ROIs segmentation differently, lacking sufficient methodologic details and relying on each laboratory’s best practice segmentation definitions. Our institution segmented the contrast-enhancing tumor ROI using raw contrast-enhanced T1-weighted MRI and segmented normal-appearing white matter (NAWM) as a single ROI of similar volume on the contralateral normal brain, the other institution used contrast subtraction method prior to performing the enhancing tumor segmentation and segmented the NAWM as multiple rounded ROIs. 32
The optimal source of data for model training and evaluation is that of real-world patient data representative of population diversity and distribution. Thus, multi-institutional collaborations and data sharing are crucial in generating larger, more diverse datasets that effectively address data heterogeneity. 29 Early communication with potential collaborators is essential to ensure the availability and quality of multi-source performance evaluation datasets that align with the population of the model deployment. Careful transparent curation with consideration of structuring, institutional standard parameters, and metadata practices, including ground truth, at collaborating facilities- is necessairy element that needs to be considered. To facilitate robust institutional data sharing, data governance frameworks, and implementing rigorous control measures throughout the data lifecycle, covering aspects like data collection, annotation, feature elimination, and engineering, is necessary.33,34 More studies should focus on the data elements that may introduce errors and agreement on image acquisition standards for best practices to minimize future heterogeneity.
Choice of performance metrics and clinical interpretability
Evaluating the performance of a machine learning (ML) model is essential to ensure its generalizability, that is, its ability to generate accurate and reliable predictions on a previously unseen dataset. 35 In order to do so, the choice of adequate performance tools is of particular importance and is not only dependent on the ML task in question but also on the clinical context of the problem being tackled.36,37 Performance evaluation is complex and requires an intricate collaboration among ML experts and radiologists. The following section addresses the performance evaluation of AI models in their pre-implementation phase; however, as populations evolve over time, and more data becomes available, it becomes essential to consistently monitor and update model performance after its deployment in clinical practice.
Classification tasks, whereby, for example, a computer vision algorithm detects the presence or absence of breast cancer on mammography, would be evaluated using simple metrics derived from the confusion matrix, that is, 2 x 2 matrix of actual versus predicted outcome. These metrics are widely popular in radiology and include sensitivity (or recall) and specificity, as well as positive predictive value (or precision). 8 While it is easier and more intuitive to interpret a single metric, assessing model performance based on a combination of metrics is necessary to minimize bias. For instance, if the goal is to screen for COVID-19 pneumonia on chest X-ray during a pandemic, it is important to select a highly sensitive model with high negative predictive value, as confirmation of diagnosis would require an ulterior, highly specific, scan. The choice of metrics, along with the choice of thresholds to determine whether the model is performing well enough, is guided by the clinical context. 36 Medical datasets also suffer from class imbalance, which encouraged ML experts to develop and use metrics combining different elements of the confusion matrix to tackle this issue. Examples of these tools include the F1 score, the area under the receiving operating characteristics curve, and the area under the precision-recall curve which is robust to massive class imbalance.38,39 This is the case when developing an MRI-based classifier detecting the presence or absence of glioblastoma, the most common and aggressive brain tumor which has an age-adjusted incidence rate of 3.27 per 100,000. 40
Segmentation is more complex than classification, as it involves localizing one or more than one structure of interest, whether normal or pathological, and then it outputs overlaying masks delimiting these structures. Taha et al. analyzed 20 evaluation metrics described in the literature and developed a strategy to adequately utilize these tools based on the specific segmentation task in question.
41
Similarity metrics are easily computed overlap-based metrics, with the Dice similarity coefficient being the most commonly reported metric in deep-learning-based segmentation tasks in a recent systematic review of radiology articles.
42
However, similarity metrics do not account for the distance between the edges of the predicted mask and the ground truth label. This issue is resolved when using distance metrics, such as the Hausdorff distance,
10
which additionally considers the shape of the output segmentation with respect to the ground truth (Figure 1). In this way, model A outputting a circular mask would have a better performance than model B outputting an elliptic mask of equal area, given that both models equally overlap with a circular metastatic brain lesion on an MR cross-section. These metrics are computationally expensive as they calculate pairwise distances between all voxels in a scan; in an era when 3D imaging is heavily relied upon for the accuracy of segmentation and volumetry, deriving such metrics requires special computational frameworks optimizing speed and memory usage.
43
(Figure 1). Axial post-contrast 3D T1-weighted MRI of a 73-year-old female with a large lung-cancer metastatic lesion to the right frontal lobe (a). The contrast-enhancing component was segmented (b) manually by an expert neuroradiologist, and then semi-automatically using (c) a classification algorithm and (d) a thresholding algorithm after placement of five spherical initialization seeds. Compared with the ground truth (a), the classification algorithm (c) achieved a higher Dice similarity coefficient than the thresholding algorithm (d) (0.78 vs 0.66). This performance gap was more pronounced when Hausdorff distances were computed, with tumor edges located further from the ground truth for the thresholding algorithm (d) than for the classification algorithm (c) (22.8 vs 7.1). Hausdorff distances were computed in 2D for the displayed slice only, as 3D computations are memory-intensive.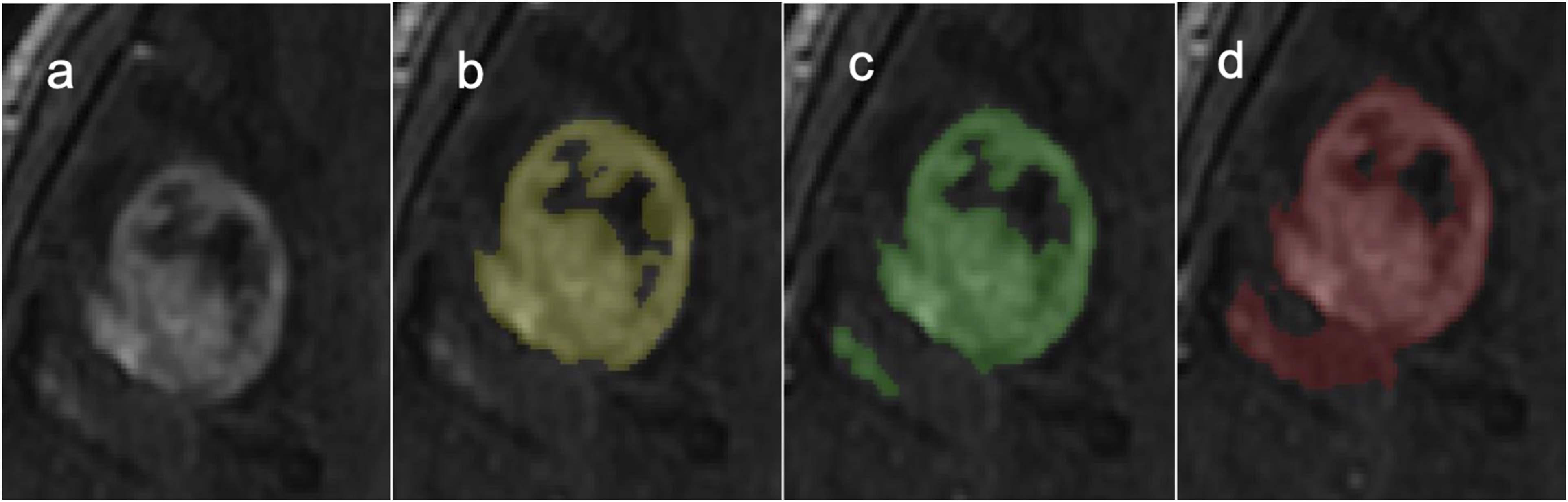
Data access and sharing
Large, diverse, and high-quality datasets mirroring a population of interest are required to develop accurate and reliable AI models. 44 Compared to other fields, it has been particularly challenging to build adequate datasets with such characteristics in healthcare, including in radiology. Although imaging data is growing exponentially by the day, utilization of such data for AI applications remains relatively low. For instance, the largest open-access dataset for Chest X-rays comprises 377,110 images, which combined with the nine other publicly available Chest X-ray datasets, “only” amounts to 1,010,530 open-access images. On the other hand, ImageNet, one of the largest annotated image repositories leveraged by ML scientists for computer vision tasks, currently contains over 14,000,000 labeled cases. 45 In fact, ethical, technical, and data ownership concerns along with institutional, national, and regional policies46,47 safeguarding patient privacy and confidentiality constitute a major barrier to data sharing, 7 preventing researchers from building multi-institutional datasets with adequate disease frequency. Even within the same institution, interdepartmental data sharing is not as straightforward as one would expect. 34 These sample size limitations hinder the effective implementation of AI in radiology and stall the improvement in AI-assisted precision medicine. 48
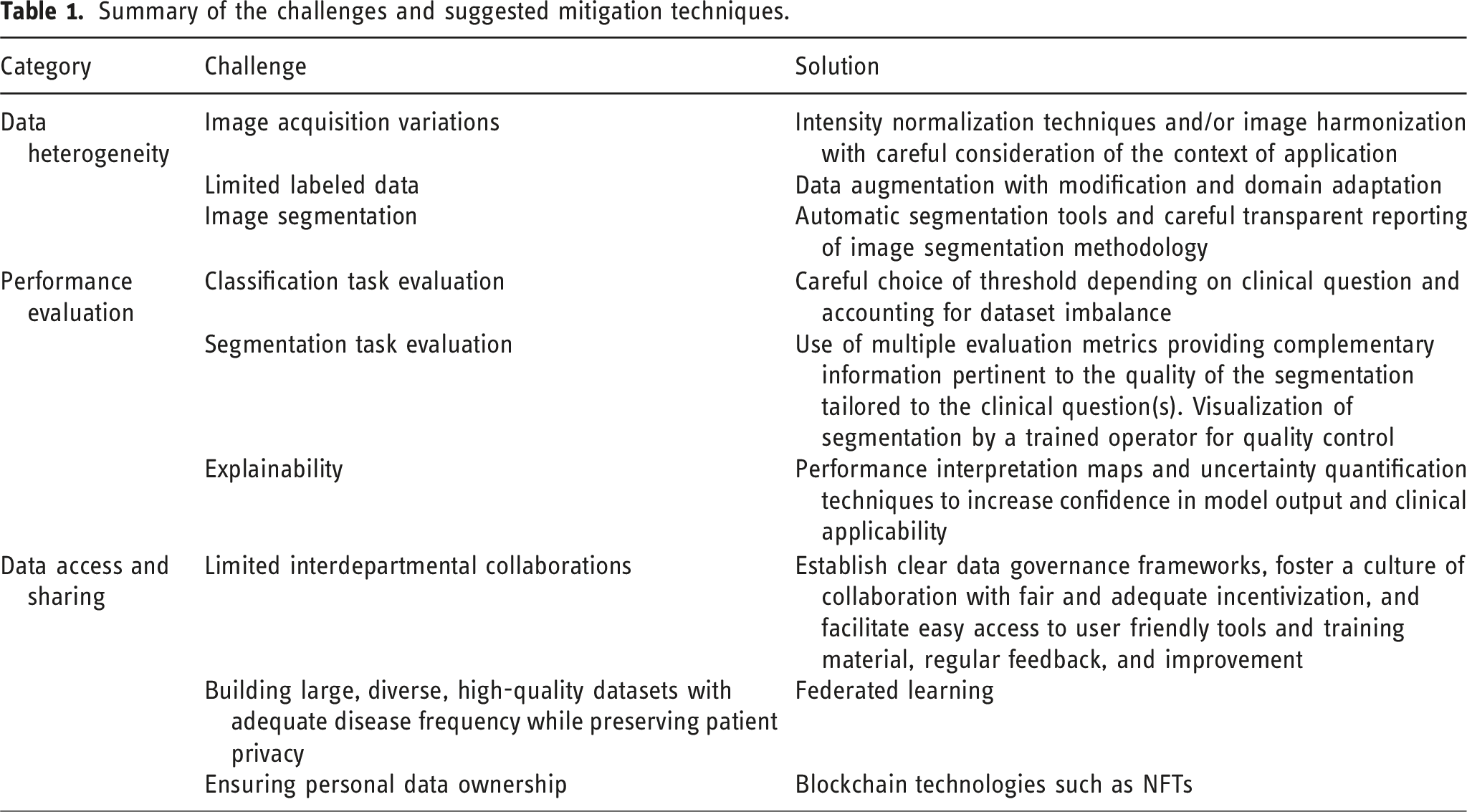
Summary of the challenges and suggested mitigation techniques.
Conclusion
In conclusion, the field of radiology is undergoing a transformative shift, marked by the integration of machine intelligence into medical imaging to address the surging demand for non-invasive diagnostic and prognostic techniques. However, despite the convergence of interests and the promising potential of AI applications in medical imaging, a notable gap exists between theoretical advancements and practical adoption in the clinical setting. There remain no clear guidelines for proper performance evaluation that allow safe and trustworthy deployment of AI models, even after receiving FDA approval. Ensuring rigorous and context-appropriate performance evaluation is essential, as inadequate assessment can undermine model reliability, delay clinical adoption, and ultimately affect patient care. Addressing the inherent heterogeneity in medical imaging data, emerges as a critical task, requiring collaborative efforts, robust data governance frameworks, and data sharing among institutions. Additionally, the choice of performance metrics and their clinical interpretability is essential for evaluating the generalizability and interpretability of AI models. Lastly, collaboration and stakeholder engagement are key elements in addressing these challenges, and continuous efforts toward transparency, standards, and guidelines can guide responsible AI adoption in healthcare, ultimately contributing to improved patient care and outcomes.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.