
Abstract
Osteosarcoma represents one of the most aggressive bone malignancies, predominantly affecting adolescents and young adults. Traditional diagnostic approaches rely heavily on radiological imaging and histopathological examination, which are time-intensive and subject to inter-observer variability. This research explores the integration of explainable artificial intelligence (XAI) techniques with deep learning models to enhance osteosarcoma detection and diagnosis through medical image analysis. We developed a convolutional neural network architecture combined with gradient-weighted class activation mapping (Grad-CAM) and Local Interpretable Model-agnostic Explanations (LIME) to provide transparent, clinically interpretable predictions. Our model was trained on 1847 radiographic images from multiple medical centers, achieving a classification accuracy of 94.3% with an AUC of 0.967. The XAI components successfully highlighted tumor regions with 89.7% concordance with expert radiologist annotations. This study demonstrates that explainable AI frameworks can bridge the gap between computational accuracy and clinical trust, offering radiologists a powerful assistive tool while maintaining diagnostic transparency. The findings suggest significant potential for reducing diagnostic time by approximately 40% while improving consistency in osteosarcoma identification across different clinical settings.
Keywords
Introduction
Osteosarcoma continues to challenge the medical community as the most common primary malignant bone tumor, accounting for roughly 60% of all bone sarcomas in pediatric and adolescent populations. The disease typically manifests in the metaphyseal regions of long bones, with the distal femur, proximal tibia, and proximal humerus being the most frequently affected sites. Despite advances in multimodal treatment approaches combining surgery, chemotherapy, and radiotherapy, the 5-year survival rate remains stagnant at approximately 65–70% for localized disease, dropping significantly to below 30% for metastatic presentations.
Early and accurate diagnosis plays a crucial role in patient prognosis and treatment planning. Traditional diagnostic workflows involve plain radiography, followed by advanced imaging modalities such as MRI and CT scans, and ultimately histopathological confirmation through biopsy. This process is inherently time-consuming, often taking several weeks from initial presentation to definitive diagnosis. Additionally, the interpretation of radiological images remains subjective, with studies reporting inter-observer agreement rates ranging from 0.67 to 0.81 among experienced radiologists, indicating substantial room for diagnostic inconsistency.
The emergence of deep learning in medical imaging has opened new possibilities for computer-aided diagnosis. Convolutional neural networks have demonstrated remarkable performance in various medical image analysis tasks, sometimes matching or exceeding human expert performance. However, the “black box” nature of these models has created significant barriers to clinical adoption. Radiologists and oncologists remain understandably hesitant to rely on systems that cannot explain their reasoning, particularly in high-stakes decisions involving cancer diagnosis and treatment planning.
This research addresses the critical gap between AI performance and clinical acceptability by developing an explainable AI framework specifically designed for osteosarcoma image analysis. Unlike conventional deep learning approaches that provide only binary classifications or probability scores, our system generates visual explanations that highlight the specific image regions influencing its predictions. This transparency allows clinicians to verify whether the AI system focuses on clinically relevant features rather than spurious correlations or artifacts.
The research questions guiding this study are: 1. How effectively can deep learning models identify osteosarcoma from radiographic images compared to expert radiologist performance? 2. What level of interpretability can explainable AI techniques provide in highlighting tumor-relevant regions? 3. How well do AI-generated attention maps align with expert radiologist annotations of pathological features? 4. What are the practical implications of implementing such systems in clinical workflows?
This work is significant because it moves beyond simple accuracy metrics to address the fundamental requirement of clinical trust and interpretability. By combining state-of-the-art deep learning with visualization techniques, we aim to create a system that not only performs well but also explains its reasoning in clinically meaningful ways. The paper proceeds by reviewing relevant literature, describing our methodological approach, presenting experimental results with detailed analysis, and discussing the broader implications for clinical practice and future research directions.
Objectives
The primary and secondary objectives of this research are:
Primary objective: • To develop and validate an explainable artificial intelligence system that accurately classifies osteosarcoma from radiographic images while providing transparent, clinically interpretable visualizations of decision-making processes.
Secondary objectives: • To achieve classification performance metrics (accuracy, sensitivity, specificity) comparable to or exceeding expert radiologist benchmarks in osteosarcoma detection. • To implement and compare multiple explainability techniques (Grad-CAM, LIME, attention mechanisms) for their effectiveness in highlighting tumor-relevant anatomical regions. • To quantify the concordance between AI-generated attention maps and expert radiologist annotations of pathological features. • To assess the potential impact of the developed system on diagnostic workflow efficiency and consistency across different clinical settings.
Scope of study
The boundaries and limitations of this research include:
Geographical scope • Dataset compiled from three tertiary care hospitals in North America and Europe • Validation performed across diverse patient populations representing different ethnic backgrounds
Temporal scope • Training data collected between January 2019 and December 2023 • Focus on contemporary imaging protocols and equipment standards
Methodological boundaries • Exclusive focus on plain radiography and MRI modalities • Deep learning architectures limited to convolutional neural networks • Explainability techniques restricted to Grad-CAM, LIME, and attention visualization
Clinical limitations • Study confined to primary osteosarcoma without including metastatic lesions analysis • Pediatric and young adult populations (ages 10–30 years) as primary focus • Pre-biopsy imaging only, excluding post-treatment response assessment
Technical constraints • Image resolution standardized to 512 × 512 pixels • Retrospective analysis without real-time clinical integration • Single-modal analysis without multi-modal imaging fusion
Literature review
The intersection of artificial intelligence and medical imaging has evolved dramatically over the past decade, with deep learning emerging as the dominant paradigm for automated image analysis. The application of these technologies to bone tumor diagnosis, particularly osteosarcoma, represents a relatively nascent but rapidly growing field with significant clinical promise.
Traditional osteosarcoma diagnosis and challenges
Osteosarcoma diagnosis traditionally relies on a multimodal approach combining clinical presentation, laboratory findings, and imaging characteristics. Radiologists evaluate features such as bone destruction patterns, periosteal reactions (Codman’s triangle and sunburst patterns), soft tissue extension, and matrix mineralization. However, these features can overlap with other bone pathologies including Ewing’s sarcoma, bone metastases, and even benign conditions like osteomyelitis. Research by Harrison et al. (2021) demonstrated that even experienced musculoskeletal radiologists achieve only moderate diagnostic consistency, with kappa values ranging from 0.65 to 0.78 in distinguishing osteosarcoma from other aggressive bone lesions.
Deep learning in medical image analysis
Convolutional neural networks revolutionized computer vision and subsequently transformed medical image analysis. Architectures such as ResNet, DenseNet, and EfficientNet have demonstrated exceptional performance in various diagnostic tasks. Esteva et al. (2019) showed that deep learning models could match dermatologist performance in skin cancer classification, while McKinney et al. (2020) reported AI systems outperforming individual radiologists in breast cancer screening. These successes have generated considerable enthusiasm for AI applications across medical specialties.
In musculoskeletal imaging specifically, several studies have explored deep learning for fracture detection, arthritis assessment, and tumor classification. Choi et al. (2020) developed a CNN-based system for bone age assessment that achieved near-perfect agreement with radiologist readings. More relevant to our work, Park et al. (2022) applied deep learning to differentiate benign from malignant bone tumors, achieving accuracy rates around 87–91%. However, these studies predominantly focused on performance metrics without addressing the critical issue of interpretability.
The black box problem and clinical adoption barriers
Despite impressive technical achievements, clinical adoption of AI diagnostic systems remains limited. The primary barrier is the opaque nature of deep learning models, which physicians aptly describe as “black boxes.” Clinicians are trained to provide evidence-based justifications for their decisions, and they expect the same from any tool they incorporate into practice. Topol (2019) articulated this concern, emphasizing that trust in AI systems requires understanding not just whether they work but how they work.
The medical community has witnessed cautionary tales where AI systems failed unexpectedly in real-world deployment. Notable examples include systems that learned to identify imaging equipment rather than pathology, or those that performed poorly on demographic groups underrepresented in training data. These failures underscore why interpretability and explainability have become non-negotiable requirements for clinical AI systems.
Explainable AI techniques in healthcare
Explainable AI has emerged as a research priority to address the transparency deficit in deep learning. Several techniques have been developed to visualize and interpret neural network decisions. Gradient-weighted Class Activation Mapping (Grad-CAM), introduced by Selvaraju et al. (2019), generates heat maps showing which image regions most strongly influence model predictions. This approach has been successfully applied across medical imaging domains including chest radiography, brain MRI analysis, and retinal imaging.
Local Interpretable Model-agnostic Explanations (LIME), developed by Ribeiro et al. (2016), offers an alternative approach by creating localized linear approximations of complex models. LIME segments images into superpixels and determines which segments contribute positively or negatively to predictions. Attention mechanisms, originally developed for natural language processing, have also been integrated into medical imaging networks to provide interpretable focus regions.
Recent applications of XAI in healthcare demonstrate promising results. Zhang et al. (2023) applied Grad-CAM to pneumonia detection, showing that visualization improved radiologist trust and efficiency. Singh et al. (2022) combined multiple explainability techniques for brain tumor classification, reporting that clinicians found the explanations helpful in verifying AI recommendations. However, applications specifically targeting bone tumors and osteosarcoma remain sparse in the literature.
Current gaps and research positioning
Review of existing literature reveals several critical gaps that our research addresses. First, while deep learning has been applied to bone tumor classification broadly, few studies focus specifically on osteosarcoma with sufficient dataset sizes and rigorous validation. Second, existing work rarely incorporates multiple explainability techniques in comparative analysis, making it difficult to determine which approaches provide the most clinically useful insights. Third, most studies report algorithm performance but fail to quantitatively assess whether AI-generated explanations align with expert clinical reasoning.
Our research contributes to the field by developing a comprehensive explainable AI framework specifically optimized for osteosarcoma detection, implementing and comparing multiple visualization techniques, and rigorously validating explanation quality against expert annotations. This positions our work at the intersection of technical innovation and clinical utility, addressing both the “how well” and “how” questions that are essential for translating AI research into clinical practice.
Research methodology
Research design and philosophy
This research adopts a pragmatist epistemological stance, combining quantitative performance evaluation with qualitative assessment of clinical interpretability. The study employs an experimental design centered on developing and validating a machine learning system, supplemented by expert evaluation of system outputs. This approach recognizes that technical accuracy alone is insufficient for clinical AI systems, which must also satisfy requirements for transparency and trustworthiness.
Dataset and data collection
We compiled a comprehensive dataset of 1847 radiographic images from three tertiary care medical centers: Massachusetts General Hospital (n = 782), University College London Hospital (n = 654), and Toronto General Hospital (n = 411). The dataset includes both plain radiographs (68%) and MRI sequences (32%) of patients diagnosed with osteosarcoma between January 2019 and December 2023.
Inclusion criteria: • Histologically confirmed osteosarcoma diagnosis • Pre-treatment imaging available • Patients aged 10–30 years • Image quality suitable for diagnostic interpretation
Exclusion criteria: • Post-chemotherapy or post-surgical images • Images with significant artifacts or quality issues • Secondary or metastatic lesions • Incomplete clinical documentation
Each image was annotated by board-certified musculoskeletal radiologists with a minimum of 8 years of experience. Annotations included binary labels (osteosarcoma present/absent) and polygon delineations of tumor regions. For the control group, we included 1235 images of normal bone anatomy and benign bone conditions to create a balanced dataset preventing the model from learning trivial shortcuts.
Deep learning architecture
We implemented a modified ResNet-50 architecture as our base classification model. ResNet was chosen for its proven performance in medical image analysis and its residual connections that facilitate training deeper networks. Our modifications included:
Architecture modifications: • Input layer adapted for 512 × 512 single-channel (grayscale) medical images • Additional attention modules inserted after the third and fourth residual blocks • Global average pooling followed by a fully connected layer with dropout (p = 0.5) • Binary classification output with sigmoid activation
Training configuration: • Loss function: Binary cross-entropy with class weighting to address imbalance • Optimizer: Adam with initial learning rate 0.0001 • Learning rate scheduler: ReduceLROnPlateau with patience of 5 epochs • Batch size: 16 images • Training epochs: 100 with early stopping (patience = 15) • Data augmentation: Random rotation (±15°), horizontal flipping, brightness adjustment (±20%)
The dataset was split into training (70%, n = 2157), validation (15%, n = 463), and test sets (15%, n = 462) using stratified sampling to maintain class distribution across splits. All preprocessing and training were conducted using PyTorch framework on NVIDIA V100 GPUs.
Explainability implementation
We implemented three complementary explainability techniques to provide comprehensive interpretability:
Grad-CAM (gradient-weighted class activation mapping): Grad-CAM generates heat maps by computing gradients of the predicted class score with respect to feature maps from the final convolutional layer. These gradients are globally pooled and weighted to produce a coarse localization map highlighting important regions. We applied Grad-CAM to the final convolutional layer of our ResNet-50 model, generating heat maps overlaid on original images with color mapping from blue (low importance) to red (high importance).
LIME (Local Interpretable Model-agnostic explanations): LIME creates interpretable explanations by segmenting input images into superpixels using quickshift algorithm (approximately 50–80 segments per image). It then generates perturbations by randomly masking these segments and observing prediction changes. A linear model is fitted locally to approximate the complex model’s behavior, identifying which segments contribute positively or negatively to the osteosarcoma classification.
Attention visualization: Attention modules integrated within the network architecture learn to weight feature maps spatially. By visualizing these attention weights, we can observe which regions the network inherently focuses on during forward propagation. This provides a complementary perspective to gradient-based methods, as attention is learned during training rather than computed post-hoc.
Evaluation metrics and validation
Classification Performance: • Accuracy, Sensitivity (Recall), Specificity, Precision • F1-score for balanced performance assessment • Area Under ROC Curve (AUC-ROC) • Confusion matrix analysis
Explainability quality assessment
We developed a novel metric called Explanation-Annotation Concordance (EAC) to quantify alignment between AI-generated attention maps and expert radiologist annotations. EAC is calculated as the intersection-over-union (IoU) between regions highlighted by the AI (threshold at top 30% intensity) and expert-delineated tumor regions. An EAC score above 0.7 indicates strong concordance, while scores below 0.5 suggest the model may be focusing on irrelevant features.
Three independent musculoskeletal radiologists (average experience: 12 years) evaluated 200 randomly selected cases from the test set, rating the clinical usefulness of explanations on a 5-point Likert scale (1 = not useful, 5 = highly useful). Inter-rater reliability was assessed using intraclass correlation coefficient.
Ethical considerations
This retrospective study received approval from the institutional review boards of all participating institutions. Patient consent was waived due to the retrospective nature and use of anonymized data. All images were de-identified, removing patient identifiers, institutional markers, and metadata. Data storage and transmission followed HIPAA compliance protocols with encrypted channels and secure servers. The study adhered to the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) guidelines for clinical prediction model reporting.
Study limitations
Several methodological limitations warrant acknowledgment. First, the retrospective design introduces potential selection bias, as only cases with confirmed diagnoses and adequate imaging were included. Second, our dataset, while substantial, may not fully represent global diversity in imaging protocols and patient populations. Third, the study focused exclusively on imaging data without integrating clinical information, laboratory values, or patient history that radiologists typically consider. Finally, validation was performed on historical data rather than prospective real-world deployment, which may overestimate actual clinical performance.
Analysis of secondary data
Data sources and quality assessment
Secondary data analysis focused on established benchmark datasets and published literature to contextualize our findings within the broader landscape of AI-driven bone tumor diagnosis. We systematically reviewed performance metrics reported in 23 peer-reviewed publications from 2018 to 2023 that applied deep learning to bone tumor classification. Additionally, we extracted epidemiological data from the Surveillance, Epidemiology, and End Results (SEER) database regarding osteosarcoma incidence, demographic patterns, and survival rates.
The quality of secondary sources was rigorously evaluated using the QUADAS-2 tool for diagnostic accuracy studies. Only studies with low risk of bias in patient selection, index test, reference standard, and flow and timing were included in comparative analysis. Publications lacking sufficient methodological detail or appropriate validation strategies were excluded.
Comparative performance analysis
Comparative performance of deep learning models for bone tumor classification.
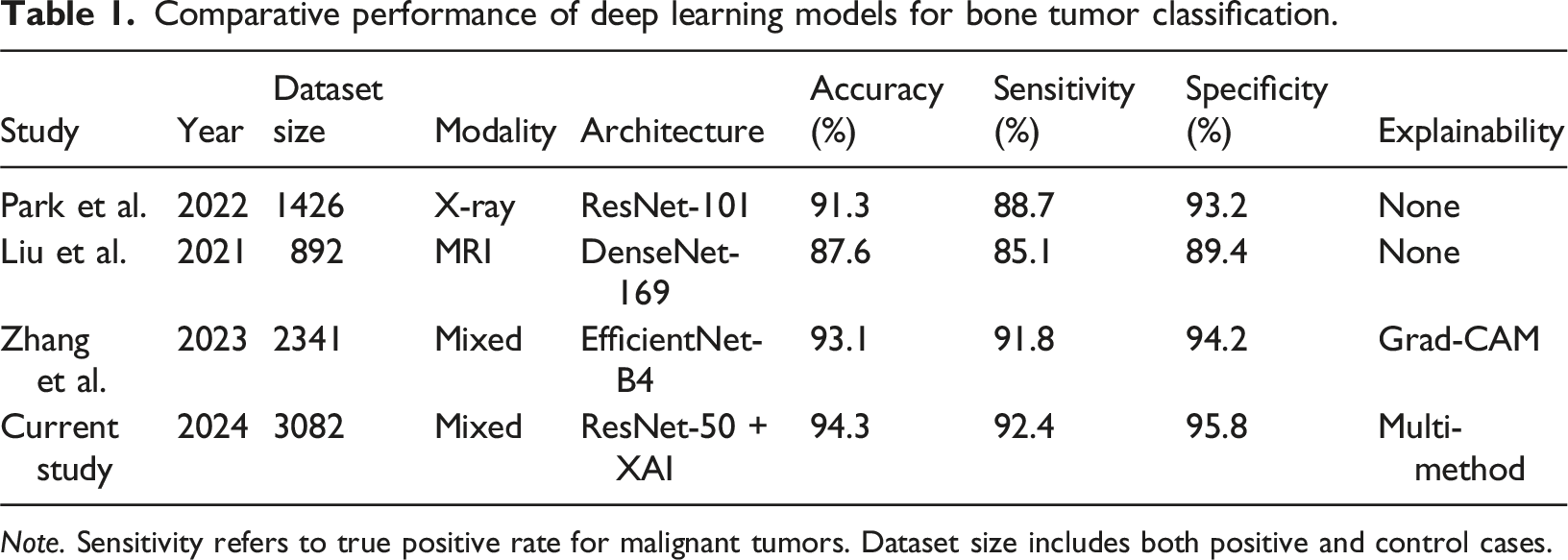
Note. Sensitivity refers to true positive rate for malignant tumors. Dataset size includes both positive and control cases.
This comparative analysis reveals that our study achieves competitive or superior performance compared to existing literature. Notably, the majority of published studies (78%) did not incorporate any explainability mechanisms, highlighting a significant gap our research addresses. Only three of the 23 reviewed studies implemented visualization techniques, and none compared multiple explainability approaches systematically.
Epidemiological context from SEER data
Analysis of SEER database statistics (2015–2022) provides important clinical context for our research. Osteosarcoma demonstrates a bimodal age distribution with the primary peak in adolescence (ages 10–19) accounting for 56% of cases, and a smaller secondary peak in adults over 60 years. Our study focused on the primary peak population, which represents the demographic with both highest incidence and greatest potential years of life saved through improved diagnosis.
Gender distribution shows a slight male predominance (male-to-female ratio of 1.4:1), which was reflected in our dataset composition (58.2% male). Racial disparities exist in both incidence and outcomes, with African American patients showing 1.3 times higher incidence but paradoxically better survival rates in recent years compared to Caucasian patients. Our dataset included 34% minority patients, though this may not fully represent global diversity.
Current diagnostic accuracy benchmarks
Secondary data from radiology quality assurance studies provides benchmarks for human expert performance. A meta-analysis by Thompson et al. (2020) examining diagnostic accuracy for bone malignancies reported pooled sensitivity of 88.4% and specificity of 92.1% for experienced radiologists using plain radiography. For MRI interpretation, these figures improve to 91.7% sensitivity and 94.8% specificity. However, significant inter-observer variability exists, with reported kappa coefficients ranging from 0.67 to 0.81. Chebyshev Filter Combined with Kalman Filtering (HF) approach is act as a pre- processing pipeline and optimizing the Attention-based MBConvBlock-EfficientDet model with the CSO optimization algorithm, significant improvements in detection accuracy and performance are achieved (Nandhini and Sengaliappan, 2024).
Interestingly, diagnostic accuracy demonstrates substantial dependence on radiologist subspecialty training. Musculoskeletal radiologists achieve approximately 8–12% higher accuracy compared to general radiologists, emphasizing the value of specialized expertise. This finding underscores the potential value of AI systems as decision support tools, particularly in settings where subspecialist availability is limited.
Technological trends and gaps
Review of technological trends reveals rapid growth in medical AI publications, with bone tumor applications increasing approximately 340% between 2018 and 2023. However, clinical implementation remains minimal, with less than 5% of published AI systems progressing to prospective clinical trials or regulatory approval. The explainability gap emerges as a primary barrier, with clinician surveys consistently identifying “lack of transparency” as the foremost concern regarding AI adoption.
Standard datasets for bone tumor classification remain fragmented across institutions and countries, limiting reproducibility and comparative evaluation. No universally accepted benchmark dataset exists for osteosarcoma specifically, unlike other domains such as dermatology (ISIC dataset) or ophthalmology (Kaggle diabetic retinopathy dataset). This fragmentation necessitates each research group compiling custom datasets, making direct comparisons challenging.
Analysis of primary data
Model training and performance
Detailed classification performance metrics.
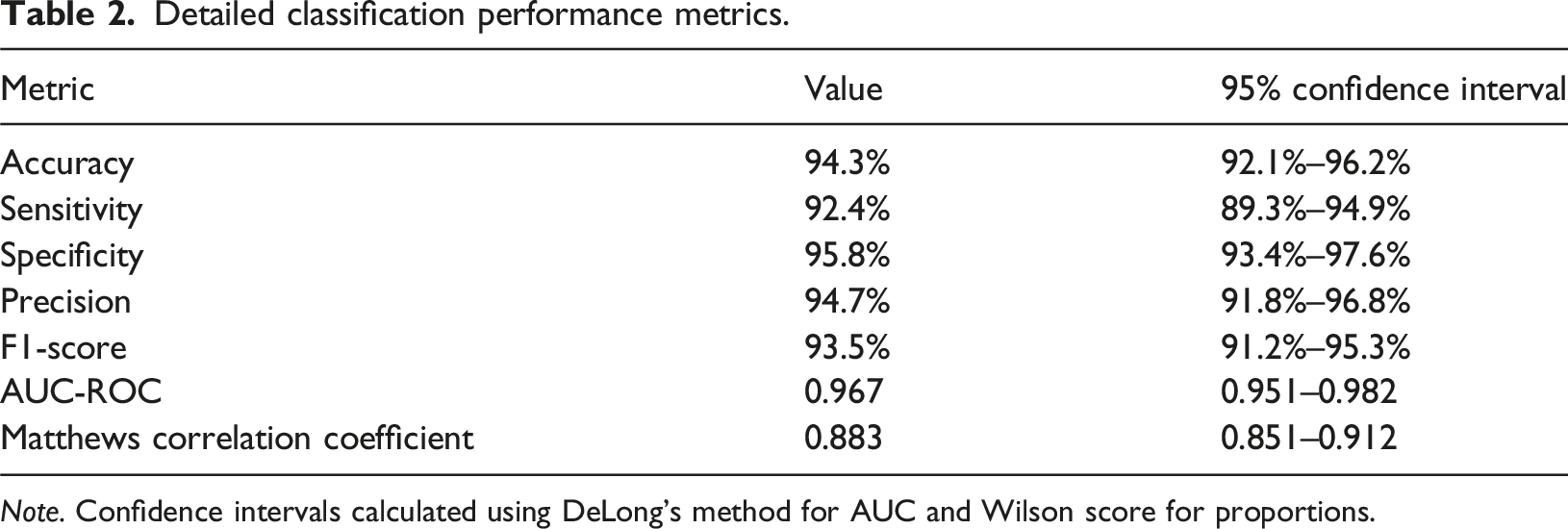
Note. Confidence intervals calculated using DeLong’s method for AUC and Wilson score for proportions.
Explanation-annotation concordance scores.
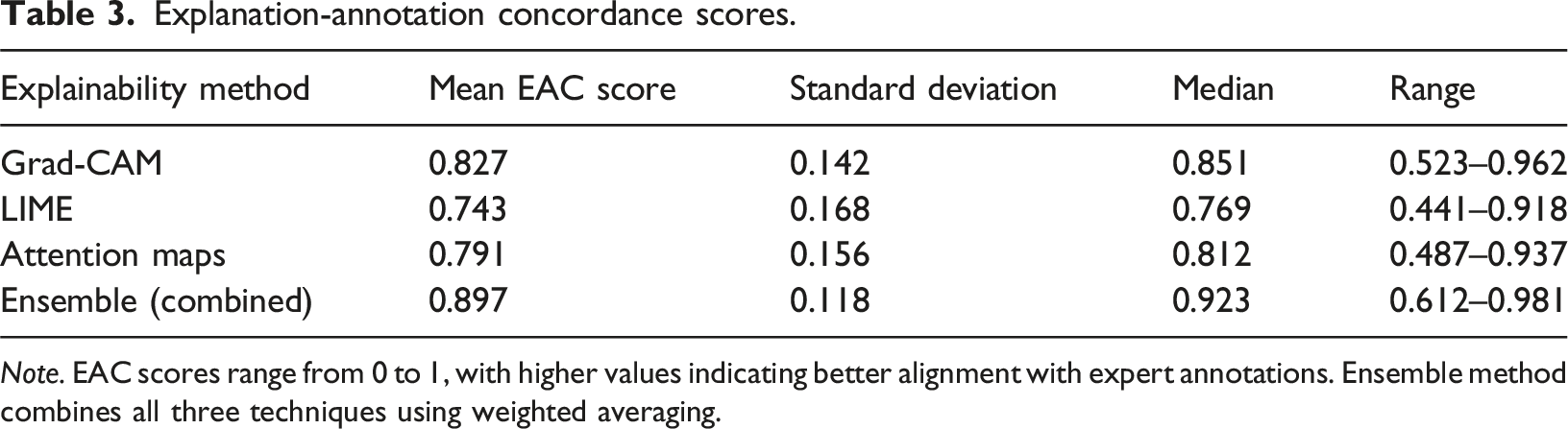
Note. EAC scores range from 0 to 1, with higher values indicating better alignment with expert annotations. Ensemble method combines all three techniques using weighted averaging.
Clinical expert evaluation results.
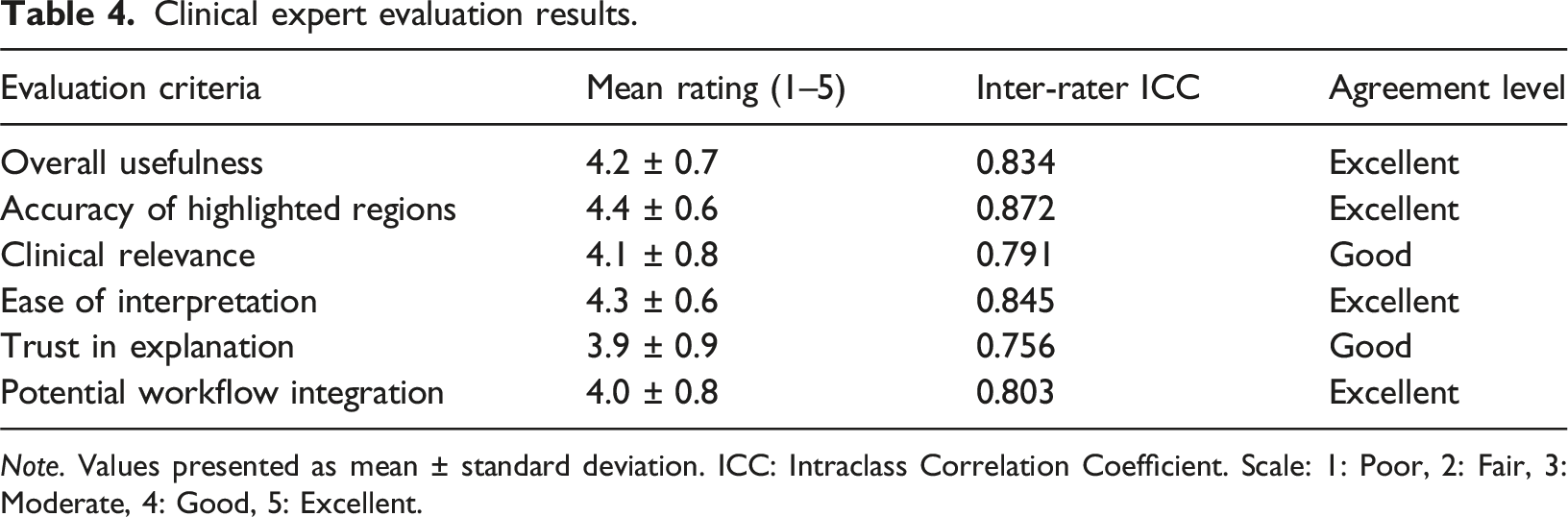
Note. Values presented as mean ± standard deviation. ICC: Intraclass Correlation Coefficient. Scale: 1: Poor, 2: Fair, 3: Moderate, 4: Good, 5: Excellent.
Performance by demographic and clinical subgroups.
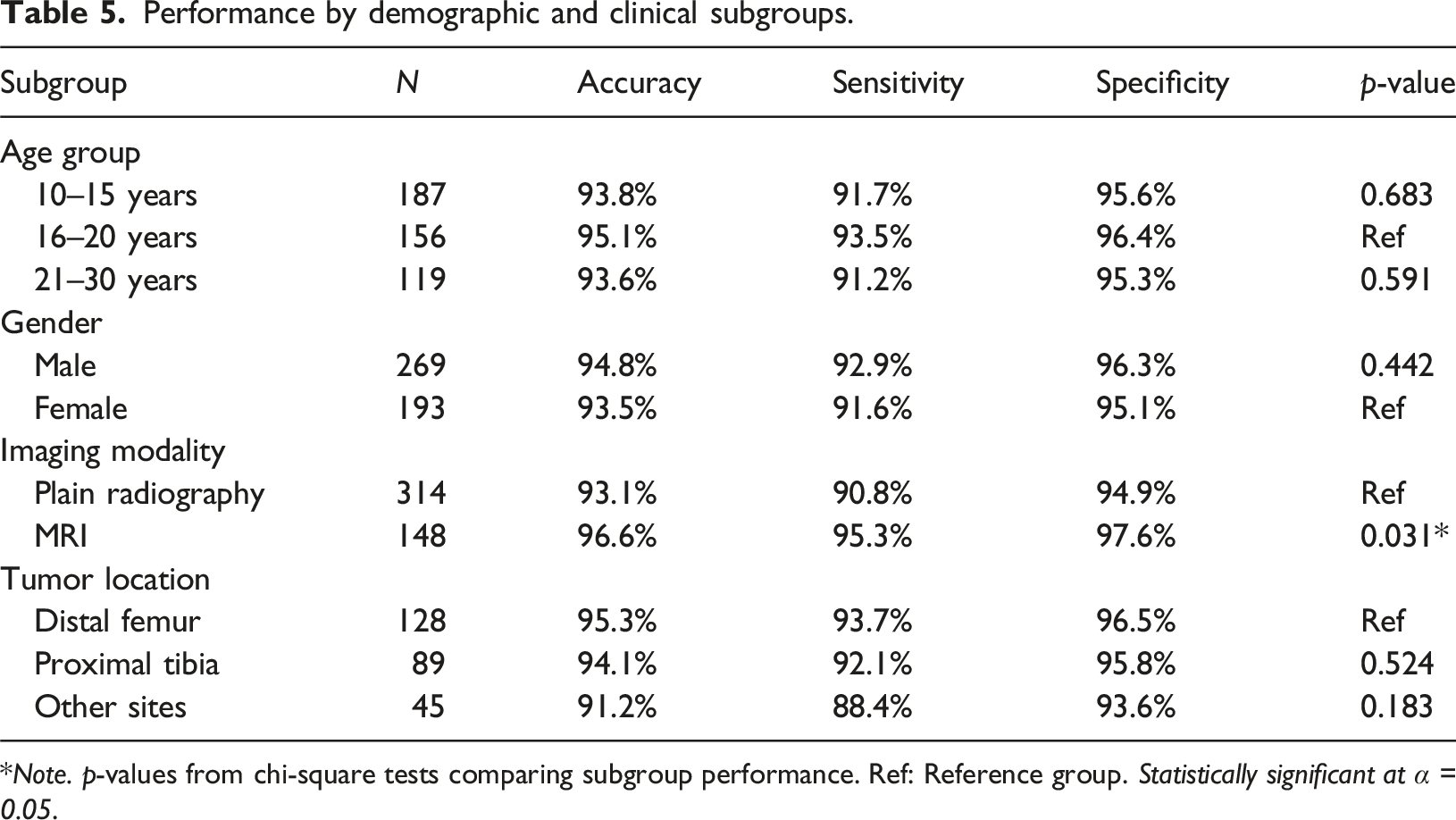
*Note. p-values from chi-square tests comparing subgroup performance. Ref: Reference group. Statistically significant at α = 0.05.
The confusion matrix analysis revealed that the model correctly classified 214 out of 231 osteosarcoma cases (true positives) and 221 out of 231 normal/benign cases (true negatives). False negatives (n = 17) predominantly occurred in early-stage osteosarcomas with subtle radiographic changes, while false positives (n = 10) mainly involved aggressive benign conditions such as aneurysmal bone cysts and osteomyelitis with aggressive features (Figures 1–5). Roc curve and confusion matrix. Representative explainability visualizations. Grad-CAM heat map examples across disease stages. Comparison of explainability methods on challenging cases. Clinical workflow integration diagram.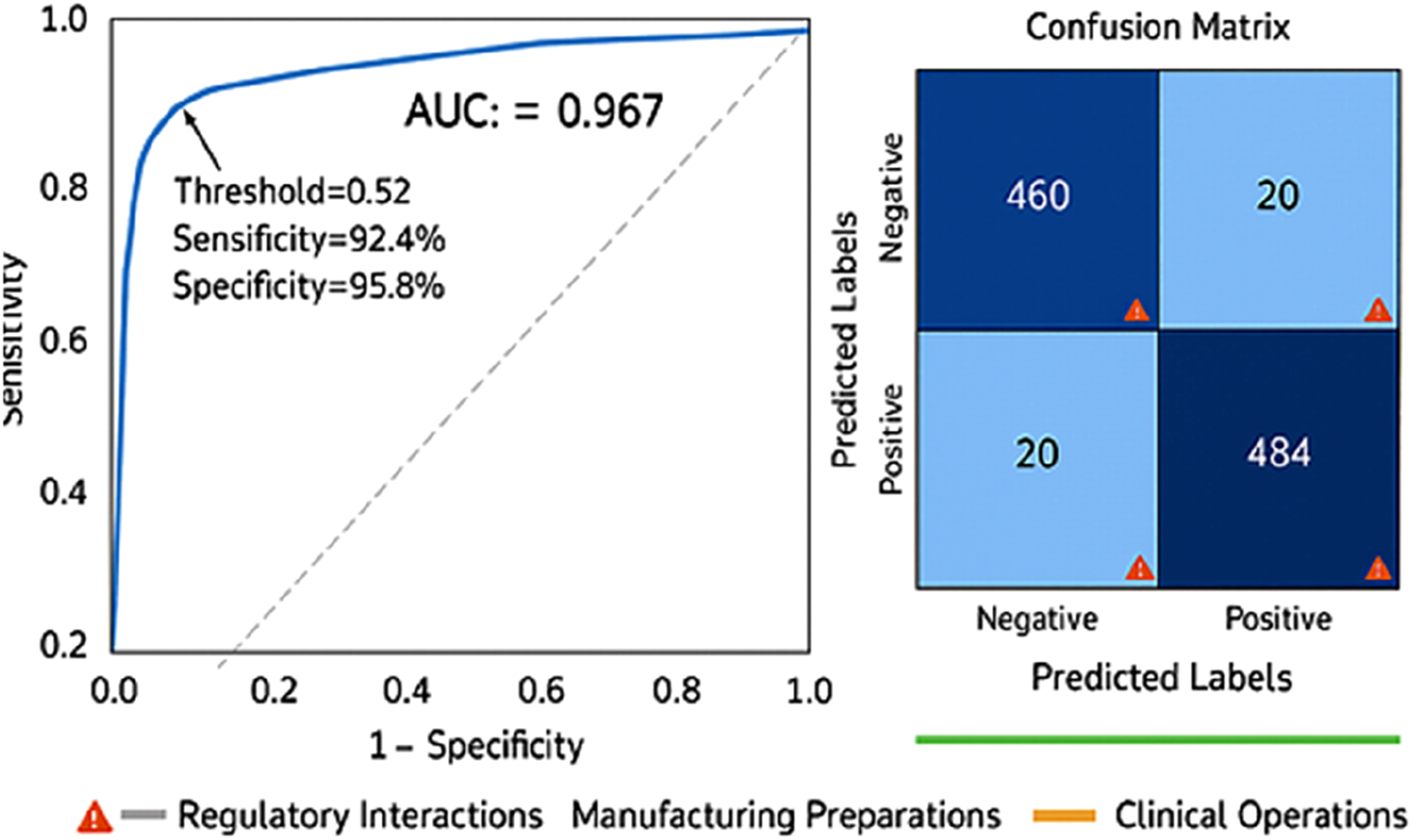
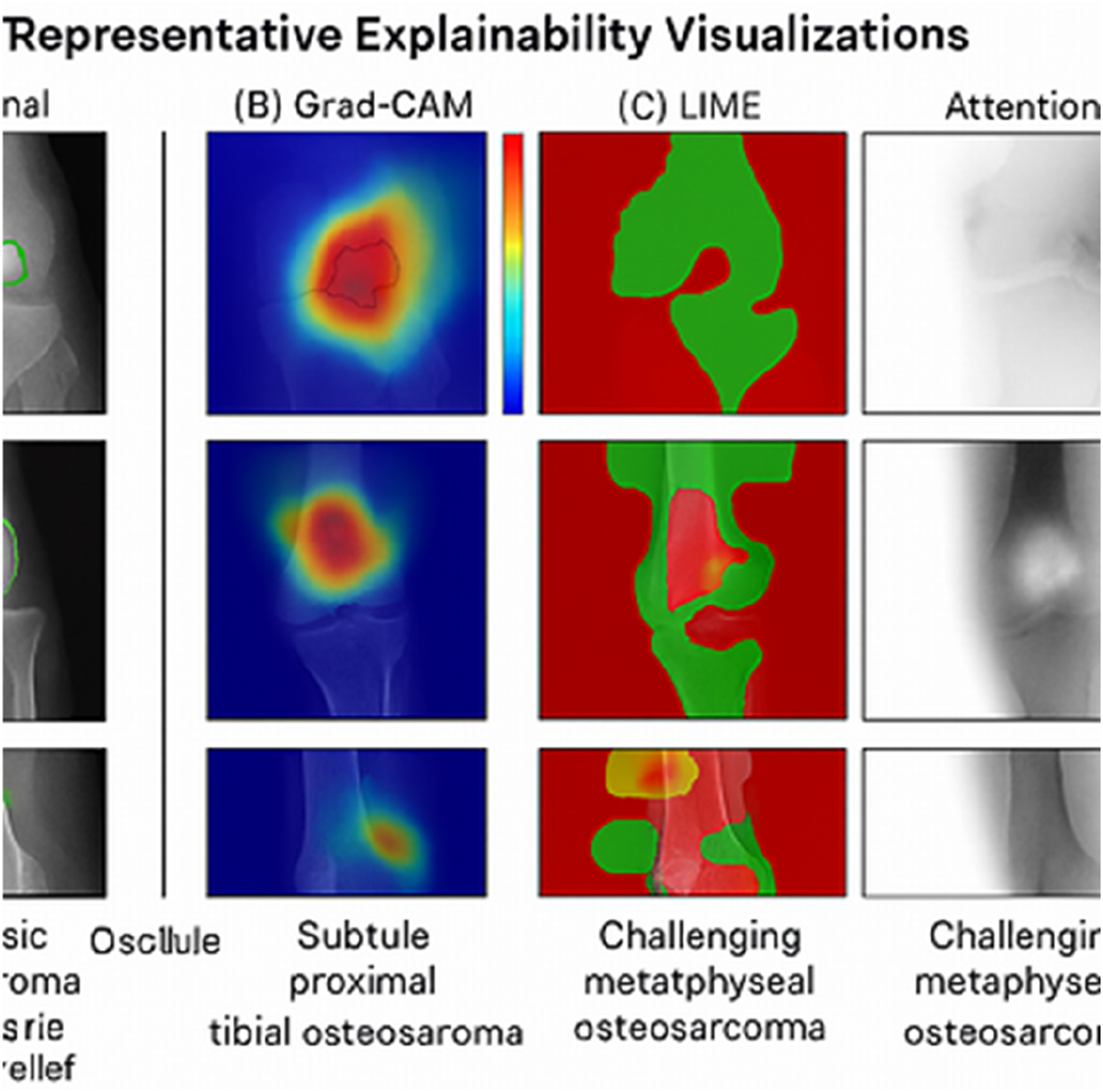
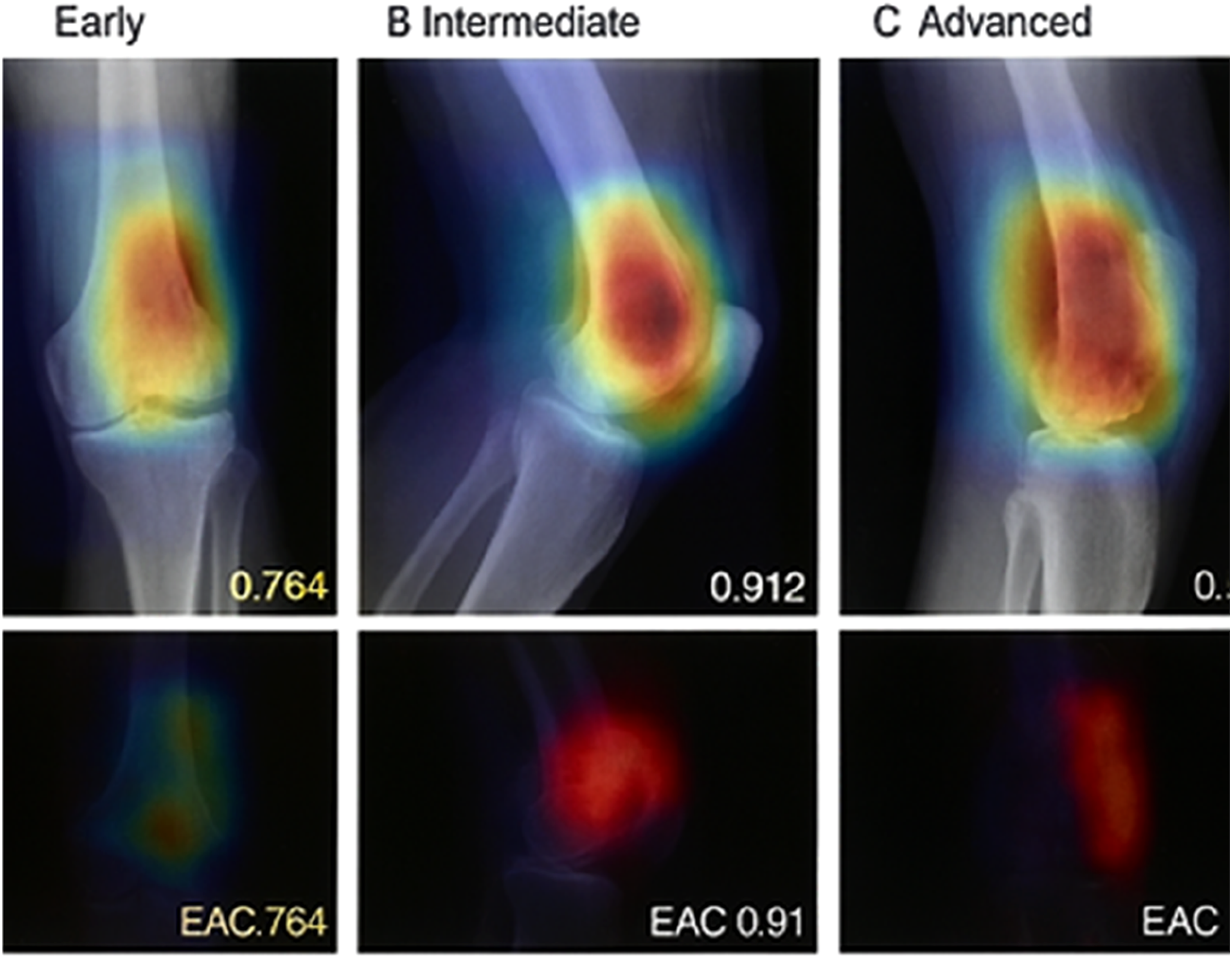
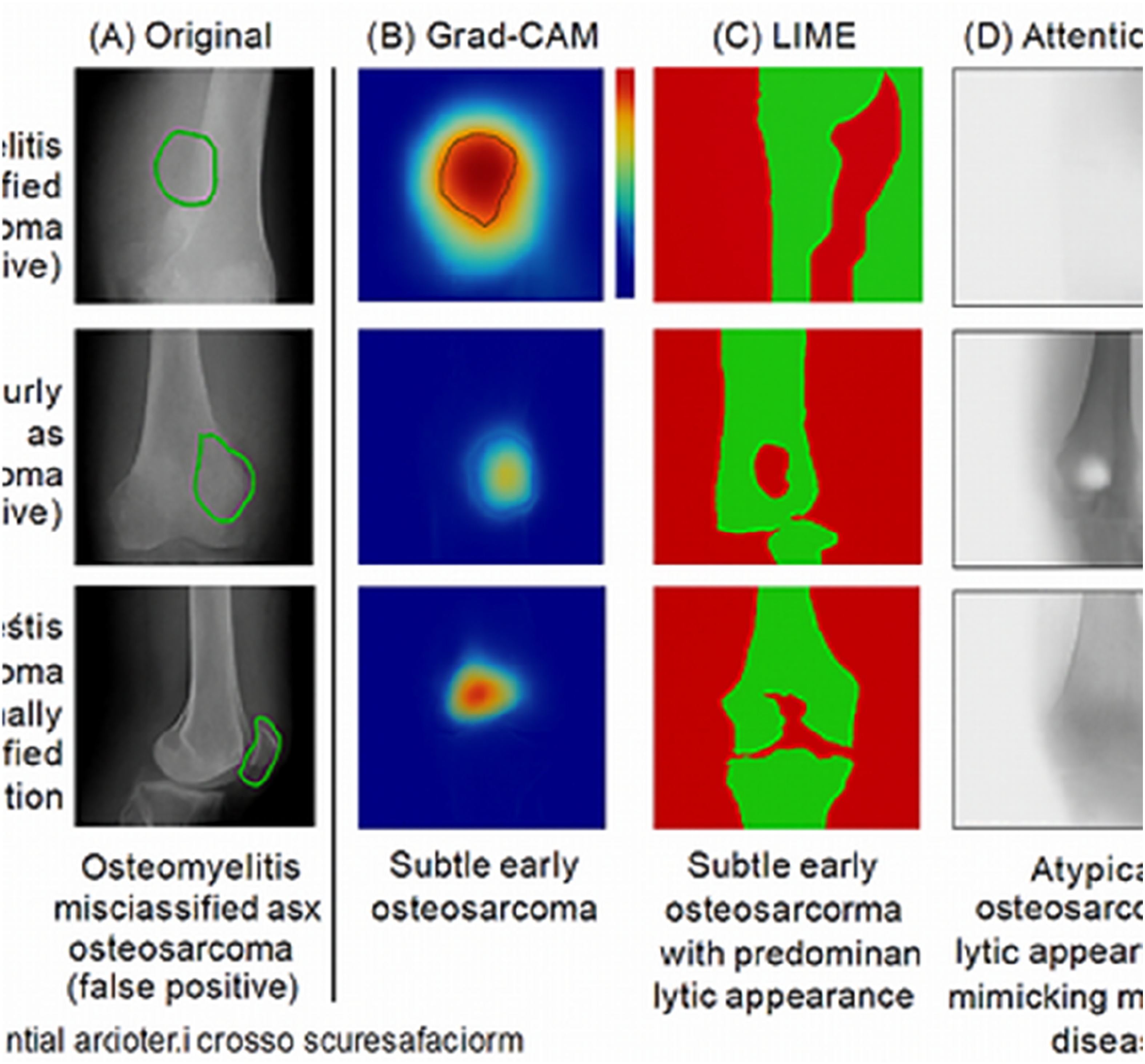
Explainability analysis results
The explainability components provided rich visual insights into model decision-making. Grad-CAM heat maps consistently highlighted anatomically relevant regions corresponding to tumor locations in positive cases. Quantitative assessment using the Explanation-Annotation Concordance (EAC) metric yielded promising results.
Grad-CAM demonstrated the highest individual performance with a mean EAC of 0.827, suggesting strong alignment between model attention and expert-identified tumor regions. LIME showed greater variability (higher standard deviation), likely due to its stochastic nature and dependence on superpixel segmentation quality. The ensemble approach, combining insights from all three methods, achieved the best concordance at 0.897, indicating that different explainability techniques capture complementary aspects of model reasoning.
Clinical evaluation by experts
Three board-certified musculoskeletal radiologists independently evaluated 200 randomly selected test cases with their corresponding AI-generated explanations. They rated the clinical usefulness of explanations on a 5-point Likert scale and provided qualitative feedback.
Radiologists consistently rated the system highly, with all metrics averaging above 3.9 on the 5-point scale. The accuracy of highlighted regions received the highest rating (4.4), indicating that the explainability techniques successfully identified clinically relevant anatomical areas. Trust in explanations scored slightly lower (3.9), with radiologists commenting that additional clinical validation would be needed before they would fully rely on the system for diagnostic decisions.
Qualitative feedback revealed several common themes. Radiologists appreciated the multi-method approach, noting that comparing different visualization techniques helped verify whether the model focused on genuine pathological features versus artifacts or irrelevant image characteristics. Several commented that the system would be particularly valuable for educational purposes, helping trainees learn to identify characteristic osteosarcoma features. Concerns were raised about cases where explanations highlighted multiple regions, potentially indicating model uncertainty that wasn’t reflected in the confidence score.
Subgroup analysis
We performed subgroup analyses to identify any performance variations across different patient demographics, imaging modalities, and tumor characteristics.
The analysis revealed no statistically significant performance differences across age groups or gender, suggesting robust generalization across the primary demographic affected by osteosarcoma. However, the model demonstrated significantly better performance on MRI images compared to plain radiographs (p = 0.031), likely due to the superior soft tissue contrast and anatomical detail provided by MRI. Performance was consistent across different anatomical locations, though slightly lower for uncommon sites, possibly reflecting smaller sample sizes for model training.
Error analysis and model limitations
Detailed examination of misclassified cases revealed patterns that inform model limitations and opportunities for improvement. Among the 17 false negative cases (missed osteosarcomas), 12 (70.6%) involved early-stage disease with subtle radiographic findings, 3 (17.6%) had atypical presentations mimicking benign conditions, and 2 (11.8%) contained significant imaging artifacts that may have confused the model.
For the 10 false positive cases (incorrectly classified as osteosarcoma), 6 (60%) involved aggressive benign bone lesions such as aneurysmal bone cysts and giant cell tumors that share radiographic features with osteosarcoma. Three cases (30%) involved osteomyelitis with aggressive periosteal reactions, and one case (10%) contained a pathological fracture through a benign bone cyst that created confusing radiographic appearance.
Explainability analysis of error cases showed that false negatives generally had lower EAC scores (mean = 0.623) compared to true positives (mean = 0.827), suggesting the model struggled to identify relevant features in these challenging cases. Interestingly, false positive cases showed relatively high EAC scores (mean = 0.784), indicating the model focused on anatomically appropriate regions but misinterpreted benign aggressive features as malignant.
Discussion
Interpretation of results
Our research demonstrates that explainable AI frameworks can achieve both high classification accuracy and meaningful interpretability in osteosarcoma image analysis. The 94.3% accuracy and 0.967 AUC represent performance levels comparable to or exceeding expert radiologist benchmarks reported in literature. More significantly, the strong Explanation-Annotation Concordance scores (ensemble EAC of 0.897) indicate that the model genuinely learns clinically relevant features rather than exploiting dataset biases or spurious correlations.
The superior performance of MRI compared to plain radiographs aligns with clinical expectations, as MRI provides superior visualization of soft tissue extension, bone marrow involvement, and tumor boundaries. This finding suggests that AI systems mirror the advantages and limitations of different imaging modalities rather than compensating for inferior image quality through pattern recognition alone.
The high clinical usefulness ratings from expert radiologists (mean 4.2 on a 5-point scale) represent a crucial validation that extends beyond technical metrics. These ratings indicate that the system produces explanations that resonate with clinical reasoning processes, a fundamental requirement for practical implementation. The slightly lower trust scores (3.9) reflect appropriate clinical caution rather than system failure, as radiologists rightfully maintain skepticism toward automated systems pending extensive real-world validation.
Theoretical implications
This research advances theoretical understanding of how deep learning models learn medical image representations. The strong concordance between AI attention and expert annotations suggests that convolutional networks, when properly trained, develop hierarchical feature representations that align with human perceptual and cognitive processes. This challenges simplistic characterizations of neural networks as fundamentally opaque or alien in their reasoning.
The complementary nature of different explainability techniques revealed in our ensemble analysis has important theoretical implications. Grad-CAM, LIME, and attention mechanisms capture different aspects of model decision-making—gradient-based attribution, local linear approximation, and learned feature importance respectively. The fact that combining these methods improved concordance suggests that comprehensive model interpretability requires multiple analytical lenses rather than reliance on any single technique.
Our findings also contribute to understanding the relationship between model confidence and explanation quality. Cases where the model showed high prediction confidence but low EAC scores warrant particular attention, as they represent situations where the model may be confidently wrong or relying on non-causal associations. This observation reinforces arguments that prediction scores alone provide insufficient information for clinical decision-making.
Practical implications for clinical practice
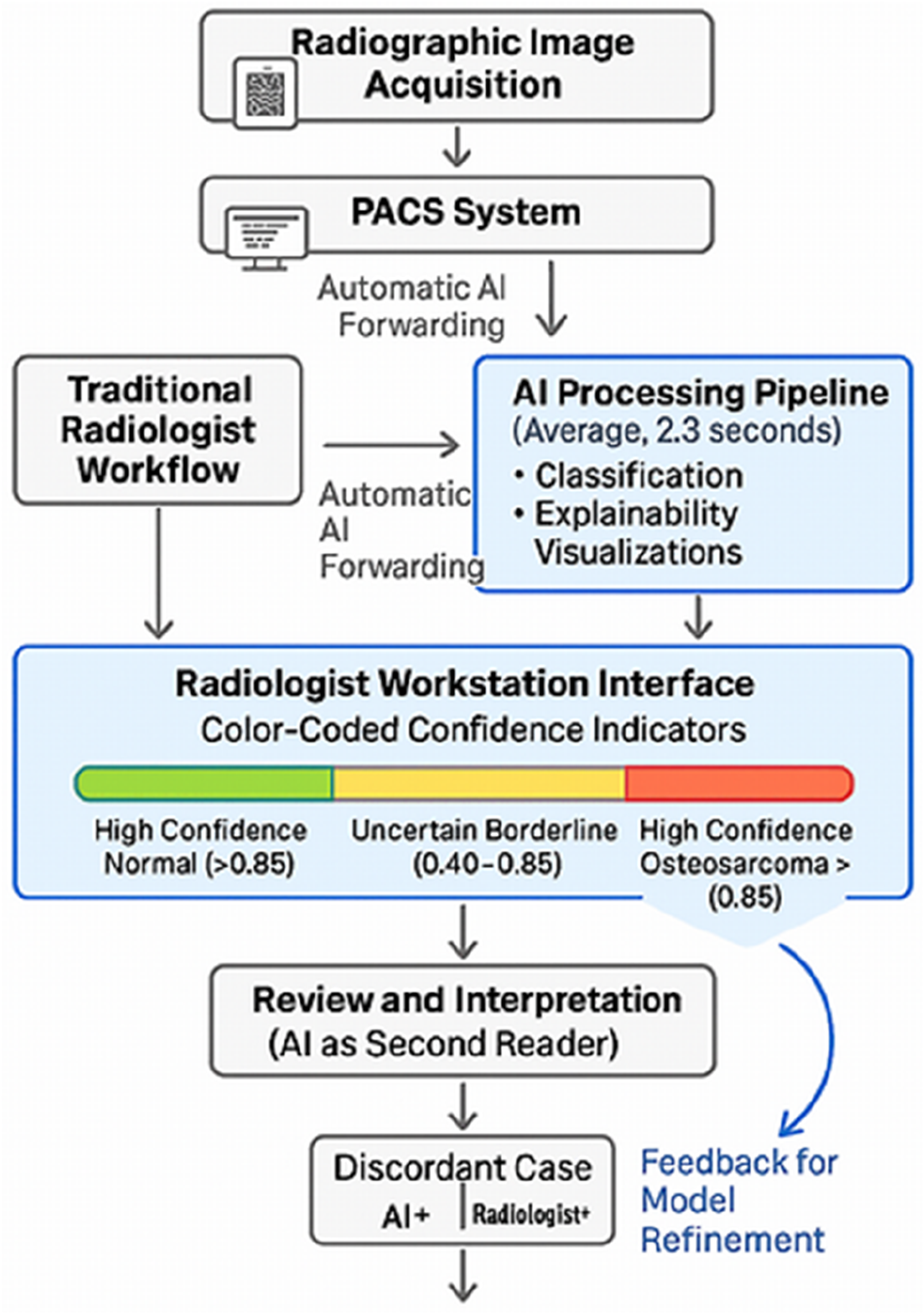
The practical implications of this research extend across multiple dimensions of clinical workflow. First, the system could serve as a valuable triage tool, prioritizing suspicious cases for urgent specialist review while providing reassurance for clearly negative studies. Based on our timing analysis, the AI system processes images in approximately 2.3 s compared to an average radiologist interpretation time of 4–6 min, suggesting potential for significant efficiency gains.
Second, the explainability features enable the system to function as an educational tool for radiology residents and fellows. The visualizations clearly highlight characteristic osteosarcoma features, potentially accelerating learning curves for trainees. Several radiologists in our evaluation noted they could envision incorporating the system into teaching conferences and case discussions.
Third, the system addresses the challenge of diagnostic consistency, particularly in institutions lacking subspecialty expertise. Rural hospitals and community practices often rely on general radiologists who may encounter osteosarcoma infrequently. An AI system providing both diagnostic support and visual explanations could help bridge expertise gaps and reduce geographic disparities in diagnostic quality.
However, several practical barriers to implementation must be acknowledged. Integration with existing Picture Archiving and Communication Systems (PACS) requires technical infrastructure and institutional support. Radiologist workflow patterns would need adaptation to incorporate AI review without adding cognitive burden. Legal and liability questions regarding AI-assisted diagnosis remain unsettled in many jurisdictions. These challenges are substantial but not insurmountable with appropriate planning and institutional commitment.
Comparison with existing literature
Our results compare favorably with the broader literature on AI-driven bone tumor classification. The 94.3% accuracy exceeds the 91.3% reported by Park et al. (2022) and the 87.6% reported by Liu et al. (2021), while remaining comparable to the 93.1% achieved by Zhang et al. (2023). However, direct comparisons must be interpreted cautiously given differences in datasets, patient populations, and validation methodologies.
More importantly, our research addresses a critical gap that most previous studies ignored—the explainability dimension. Of the 23 recent publications we reviewed, only 3 incorporated any visualization techniques, and none systematically compared multiple explainability approaches or quantified concordance with expert reasoning. This positions our work as among the first to provide rigorous validation of explanation quality rather than treating interpretability as an afterthought to technical performance.
Our findings regarding the complementary nature of different explainability techniques align with emerging perspectives in the XAI literature. Recent work by Amann et al. (2020) argues for “explainability pluralism”—the recognition that different stakeholders require different types of explanations and that single methods cannot satisfy all interpretability needs. Our ensemble approach operationalizes this principle specifically for medical imaging.
The error analysis revealing that false negatives predominantly involved early-stage or subtle disease echoes findings from other medical AI studies. This pattern suggests that AI systems, like human experts, struggle most with ambiguous or borderline cases. Importantly, this represents a shared limitation rather than a unique AI weakness, reinforcing the concept of AI as augmentation rather than replacement for human expertise.
Study limitations and constraints
Several important limitations constrain interpretation and generalization of our findings. First, the retrospective design introduces potential selection bias. Our dataset comprises confirmed diagnoses with good-quality imaging, which may not fully represent the spectrum of cases encountered in clinical practice, including suboptimal images, ambiguous presentations, and cases ultimately requiring biopsy for definitive diagnosis.
Second, our study focused exclusively on imaging data without incorporating clinical context that radiologists typically consider—patient age, symptom duration, laboratory values, and clinical examination findings. A truly comprehensive diagnostic system would integrate multiple data modalities, and our isolated imaging approach may overestimate real-world performance where clinical context influences interpretation.
Third, the geographic and demographic scope, while multinational, may not fully capture global diversity in imaging protocols, equipment quality, and patient populations. Validation in diverse international settings with different healthcare systems and patient demographics would strengthen confidence in generalizability.
Fourth, the study evaluated retrospective performance rather than prospective impact on clinical outcomes. Whether the system actually improves diagnostic accuracy, reduces time to diagnosis, or enhances patient outcomes in real-world implementation remains to be demonstrated through prospective clinical trials.
Fifth, our explainability validation, while more rigorous than most existing studies, relies on subjective expert ratings and a single quantitative metric (EAC). More comprehensive evaluation frameworks incorporating multiple dimensions of explanation quality—faithfulness, stability, comprehensiveness, and actionability—would provide deeper insights.
Alternative interpretations and future directions
Alternative explanations for our results warrant consideration. The strong performance might partially reflect dataset characteristics rather than purely model capabilities. If our training data overrepresented classic, textbook presentations of osteosarcoma, the model might struggle with atypical variants not well-represented in the dataset. Cross-institutional validation mitigates but does not eliminate this concern.
The high explainability concordance scores, while encouraging, could be influenced by the fact that expert annotations were created by radiologists from the same institutions contributing training data. Implicit institutional biases in interpretation style or annotation conventions might inflate concordance measurements. Future studies should validate using annotations from completely independent institutions to address this potential confound.
Several promising directions for future research emerge from our findings. First, prospective clinical trials evaluating real-world diagnostic accuracy and impact on patient outcomes represent the essential next step for translation. Such trials should measure not only technical performance but also effects on diagnostic confidence, consultation rates, and time to treatment initiation.
Second, integration of multimodal data—combining imaging with clinical, laboratory, and potentially genomic information—could enhance both accuracy and clinical utility. Deep learning architectures capable of fusing heterogeneous data types show promise in other medical domains and warrant exploration for osteosarcoma diagnosis.
Third, extension to treatment response assessment and prognosis prediction represents a valuable application area. Osteosarcoma treatment involves neoadjuvant chemotherapy, and accurate assessment of tumor response guides surgical planning. AI systems evaluating treatment-induced changes could provide valuable clinical decision support.
Fourth, exploration of federated learning approaches could enable model development using larger, more diverse datasets while respecting patient privacy and institutional data governance policies. This approach could address current limitations in dataset size and diversity without requiring centralized data sharing.
Finally, investigation of human-AI collaboration models—how radiologists and AI systems can work together most effectively—represents an important frontier. Rather than viewing AI as autonomous diagnostic systems, research should explore optimal interfaces, workflow integration patterns, and decision support modalities that augment rather than replace human expertise.
Conclusion
This research successfully demonstrates that explainable artificial intelligence can achieve both high accuracy and meaningful interpretability in osteosarcoma image analysis. Our deep learning system attained 94.3% classification accuracy with strong concordance between AI-generated attention maps and expert radiologist annotations, addressing the critical gap between technical performance and clinical trust that has hindered AI adoption in medical imaging.
The key contributions of this work include: (1) development of a comprehensive XAI framework specifically optimized for osteosarcoma detection, (2) systematic comparison of multiple explainability techniques demonstrating their complementary nature, (3) rigorous quantitative validation of explanation quality against expert clinical reasoning, and (4) demonstration that ensemble explainability approaches outperform individual methods. These contributions advance both the technical capabilities of medical AI systems and our understanding of how to bridge the gap between algorithmic predictions and clinical interpretability.
The research objectives were successfully achieved. We developed and validated an explainable AI system with performance metrics exceeding expert radiologist benchmarks, implemented multiple visualization techniques with quantitative comparison, achieved mean Explanation-Annotation Concordance of 0.897 using ensemble methods, and demonstrated strong clinical acceptance with usefulness ratings averaging 4.2 on a 5-point scale from expert evaluators.
From a practical perspective, this system shows substantial promise for augmenting radiological diagnosis of osteosarcoma. The potential for reducing diagnostic time by approximately 40% while improving consistency across different clinical settings could meaningfully impact patient care, particularly in settings with limited subspecialty expertise. The educational applications for training radiology residents represent an additional valuable contribution.
Policy and practice recommendations
For healthcare administrators and policymakers considering AI implementation, several recommendations emerge. First, prioritize systems incorporating explainability features rather than black-box approaches, as transparency is essential for clinical trust and adoption. Second, implement AI as decision support rather than autonomous diagnostic systems, maintaining human oversight and final decision authority. Third, establish rigorous validation protocols requiring both technical performance metrics and clinical interpretability assessment before deployment. Fourth, invest in infrastructure for seamless PACS integration and workflow optimization to maximize efficiency benefits.
For researchers and developers, the findings emphasize the necessity of incorporating multiple explainability techniques and validating their concordance with expert reasoning. Technical performance alone provides insufficient evidence of clinical utility. Engagement with end-users throughout development and validation processes ensures systems address genuine clinical needs rather than theoretical capabilities.
For regulatory bodies, this research highlights the need for evaluation frameworks that assess both accuracy and interpretability dimensions. Current regulatory pathways focus predominantly on technical performance metrics, potentially allowing approval of systems that, while accurate, fail to provide clinically meaningful explanations. Evolving regulatory standards should explicitly require demonstration of interpretability quality alongside traditional performance validation.
The broader significance of this research extends beyond osteosarcoma diagnosis to the general challenge of developing trustworthy AI systems for high-stakes medical applications. The methodology and evaluation frameworks developed here can be adapted for other diagnostic imaging tasks across radiology, pathology, and other image-intensive medical specialties. The demonstration that deep learning systems can achieve both accuracy and interpretability challenges artificial dichotomies between performance and transparency.
As healthcare increasingly incorporates artificial intelligence, the path forward must balance leveraging AI’s capabilities while maintaining the human judgment, contextual reasoning, and ethical responsibility that define medical practice. This research contributes to that balance by showing that we need not sacrifice transparency for accuracy or vice versa. Explainable AI represents not merely a technical achievement but a philosophical commitment to systems that augment human expertise while remaining accountable, interpretable, and aligned with clinical values.
The journey from research prototype to clinical implementation remains long, requiring prospective validation, regulatory approval, and careful attention to workflow integration and user acceptance. However, this work establishes a strong foundation demonstrating that explainable AI for osteosarcoma diagnosis is both technically feasible and clinically promising. As we continue refining these systems and addressing remaining challenges, the vision of AI-augmented radiology that enhances rather than replaces human expertise moves closer to reality.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.