
Abstract
Introduction
Artificial intelligence (AI) tools offer promising opportunities to support evidence synthesis at scale. This study presents a novel AI-human hybrid screening approach to a large-scale bibliometric analysis of technologies promoting physical activity.
Methods
Records (n = 28,957) were retrieved from electronic databases and screened using ASReview, an open-source machine learning tool. Over 100 seed articles trained the model. Screening followed the SAFE framework across four phases, including (1) initial random screening to inform stopping rules, (2) active learning with human reviewers, and multi-model rescreening of (3) unlabelled and (4) excluded records to minimise risk of missed studies.
Results
In Phase 1, a random 1% sample (n = 290) was screened, identifying 20 relevant records. In Phase 2, 3,994 records were screened using active screening, identifying 2,904 relevant studies. In Phase 3, re-screening of unlabelled records (n = 410) identified 53 additional studies, while Phase 4 re-evaluation of excluded records yielded a further 226 studies. Across all phases, 3,183 records were identified as relevant, with 2,985 retained for analysis following post-screening exclusions (n = 598). Only 18% of records required manual screening, saving an estimated 592 hours.
Conclusion
AI-assisted screening offers a feasible and efficient approach for large-scale evidence synthesis when supported by structured workflows and safeguards. While methods like careful seed selection and stopping rules improve rigour, challenges remain—particularly residual risks and reliance on manual data extraction. Future work should focus on extending AI to downstream tasks and embedding human-in-the-loop approaches to ensure it serves as a reliable, transparent partner in evidence synthesis.
Keywords
1. Introduction
The exponential growth of the scientific literature presents a major challenge for researchers conducting large-scale evidence syntheses. Systematic reviews, scoping reviews, and bibliometric analyses now frequently require the screening of tens of thousands of records, particularly in fast-moving, interdisciplinary fields such as public health.1–3 This scale of work, while essential for comprehensive and policy-relevant syntheses, places substantial pressure on review teams in terms of time, resources, and consistency. Manual screening at this magnitude introduces risks such as reviewer fatigue, inconsistency in applying eligibility criteria in large teams required to complete large scale reviews, and lengthy delays that undermine the timely delivery of actionable evidence. In practice, these challenges often create incentives to narrow review scope or adopt stricter exclusion criteria simply to keep projects manageable, which can result in syntheses with a more limited focus and reduced generalisability.
In response to these growing challenges, the use of artificial intelligence (AI) and machine learning (ML) tools in evidence synthesis has gained significant attention.4,5 Several AI tools have been developed to automate or semi-automate key stages of the review process, including title and abstract screening. 6 These tools, particularly those employing active learning algorithms, aim to optimise the screening process by continuously reprioritising records based on human feedback. Such AI-assisted approaches hold the potential to enhance efficiency while preserving accuracy and reproducibility. 7 Consistent with broader developments in AI-assisted decision-making, there is increasing recognition of the importance of human-in-the-loop systems, where algorithmic predictions are integrated with domain expertise to support transparent and accountable decision-making. 8 In the context of evidence synthesis, such approaches are particularly important to ensure that efficiency gains do not come at the expense of methodological rigour. Rather than replacing human judgement, AI-assisted systems are increasingly conceptualised as decision-support tools that must be embedded within structured, safe, ethical, and accountable processes. 9
A 2024 letter published in Systematic Reviews highlights this shifting paradigm, asserting that “AI is no longer an experimental adjunct but a core consideration for modern review workflows”. 10 The authors emphasised the opportunity to leverage AI tools such as ASReview to reduce reviewer burden and accelerate synthesis timelines while sustaining methodological rigour. However, they also caution that “real-world applications remain underreported”, particularly in the context of very large reviews where AI’s potential advantages are most needed. Indeed, while a number of studies have proposed conceptual frameworks for integrating AI into evidence synthesis workflows, 8 relatively few have reported detailed real-world implementation in large-scale review contexts. Previous studies of active learning tools such as ASReview have reported high recall alongside substantial reductions in screening workload5,11,12; however, much of this evidence remains confined to simulated environments11,12 or relatively small-scale datasets within systematic reviews.5,12 As such, there is limited understanding of how these tools perform in large, heterogeneous review contexts, particularly with respect to workflow design, stopping decisions, and the balance between efficiency and methodological rigour in real-world applications. This underscores the need for detailed methodological case studies that assess the feasibility, advantages and limitations, and practical realities of applying AI-assisted screening in applied, high-volume review settings.
This paper aims to address these gaps by exploring the practical implementation of an AI-assisted screening workflow in a large-scale bibliometric review of technologies used to promote physical activities containing nearly 29,000 articles. This work is presented as a methodological case study of applied implementation in a real-world context, rather than a formal validation of model performance. Using ASReview and the SAFE framework, 13 this study provides a detailed account of workflow design, including model training, stopping rules, and safeguards to minimise error.
2. Methods
All records (n = 32,237) were exported from Scopus (n = 24,596) and SportDiscus (n = 7,641) databases on March 13, 2024, using a predefined search strategy (Supplementary Table 1). Duplicates (n = 3,280) were initially removed using the Covidence built-in deduplication tool and later verified during data extraction. A total of 28,957 remaining records were uploaded for screening.
2.1. Eligibility criteria
Screening was performed at the title and abstract level only, consistent with the bibliometric aims of the paper and large volume of records accessed. 14 The search covered studies published from January 1953 to December 2025, with the start date selected to align with the emergence of modern physical activity and health research following early foundational epidemiological work. 15 Technologies promoting physical activity were defined as digital or device-based tools designed to support, encourage, or facilitate physical activity participation, including mobile applications, wearable devices, sensors, and interactive technologies. Records were considered “relevant” if they reported empirical evidence where a digital or device-based technology (e.g., mobile apps, wearables, sensors, exergaming, prompts) was used to promote, support, or intervene on physical activity. Records were excluded if they were reviews, study protocols, or validation studies; qualitative studies conducted solely for technology development or to explore general perceptions rather than intervention evaluation; studies in which technology was used exclusively to measure physical activity or to enhance performance (rather than participation); and studies lacking an explicit reference to physical activity. Screening decisions were initially made by three authors (GT, SA, MB) within each phase. Disagreements or uncertainties were resolved through discussion, and a fourth author (NG) adjudicated if consensus could not be reached. The wider research team comprised expertise across public health, digital health, and behavioural science.
2.2. AI screening configuration and workflow
Key methodological parameters of the AI-assisted screening workflow.
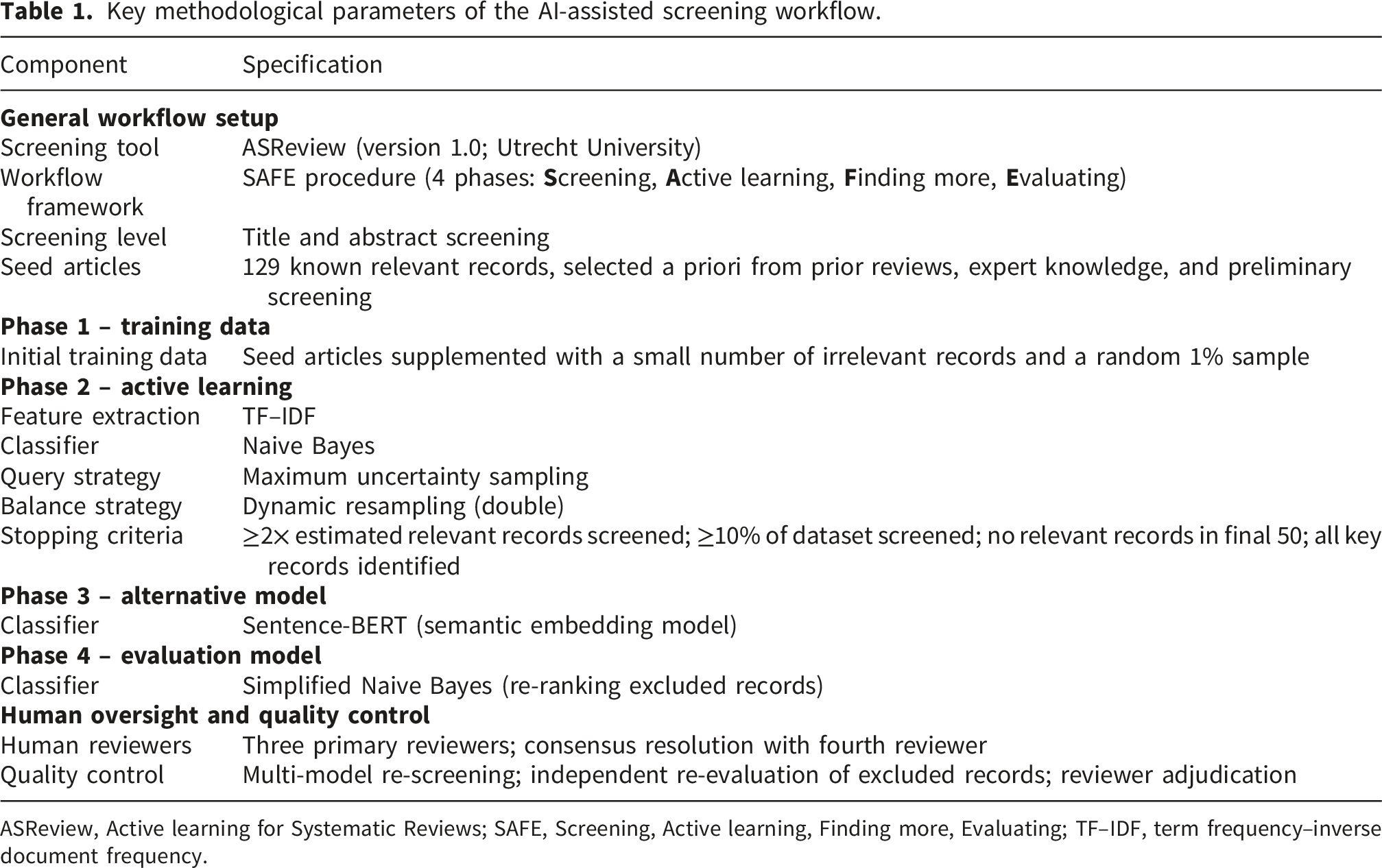
ASReview, Active learning for Systematic Reviews; SAFE, Screening, Active learning, Finding more, Evaluating; TF–IDF, term frequency–inverse document frequency.
2.2.1. Phase 1 (S): Screening a random set for training data
In Phase 1, it is necessary to provide training data (prior knowledge) containing at least one relevant and one irrelevant record. 13 In this review, additional prior knowledge were added to improve early prioritisation of relevant records and efficiency of the active learning process. 6 This included the review team identifying a set of 129 seed articles known to be relevant to the topic area (positive examples). These articles were selected a priori and were drawn from multiple sources to ensure they represented conceptually important and clearly eligible studies within the field. Specifically, these articles were identified from: (1) studies included in previous scoping and umbrella reviews on technology and physical activity, (2) highly cited and seminal papers identified through expert knowledge within the research team, and (3) key studies identified through preliminary manual screening and reference list checking. In addition, a smaller number of records from the dataset were labelled irrelevant to serve as negative examples. Then, one reviewer (GT) screened a random 1% of records from the total dataset (n = 290) which allowed calibration of the inclusion/exclusion criteria and further establish the training dataset. The fraction of relevant records (FRRt) was calculated by dividing the number of relevant records in the training set by the total number of records screened in Phase 1. This estimate was then extrapolated to approximate the total number of relevant records in the dataset (RRt), which informed the heuristic stopping rules applied in Phase 2.
2.2.2. Phase 2 (A): Applying active learning
In Phase 2, ASReview was configured to use a term frequency–inverse document frequency (TF–IDF) feature extraction technique, which converts words in titles and abstracts into numerical weights that reflect their importance across the dataset. These features were processed with a Naive Bayes classifier, a simple algorithm that estimates the probability of a record being relevant. To ensure the model continually learned from the most informative examples, a Maximum query strategy (prioritising records with the greatest model uncertainty) and Dynamic resampling (double) balance strategy was applied, which rebalanced relevant and irrelevant records to reduce bias.
Using this configuration, three reviewers (GT, SA, MB) screened records using active learning. All screeners had extensive prior experience with systematic review screening. Screening continued until a four-fold rule was met 13 : (i) all key records identified; (ii) at least twice the estimated number of relevant records screened (iii) at least 10% of the was dataset screened; and (iv) no relevant records were found in the final 50 screened.
2.2.3. Phase 3 (F): Finding more relevant records with a different model
In Phase 3, safeguards against missed inclusions were applied using a more advanced fully connected neural network with Sentence-BERT (Bidirectional Encoder Representations from Transformers) feature extraction. Unlike TF–IDF, which focuses on word frequency, Sentence-BERT captures the semantic meaning of whole sentences, allowing the model to identify conceptually similar records even if different terms are used. This approach helped to identify additional relevant studies in the unlabelled (unscreened) dataset.
2.2.4. Phase 4 (E): Evaluating screening
In Phase 4, a simplified Naive Bayes classifier was applied to re-rank records previously excluded (labelled irrelevant) by a reviewer, which were screened by two independent reviewers (SA, MB). This final step acted as a safeguard to minimise the risk of false exclusions. Screening continued until no additional relevant records were identified in the final 50 screened.
In addition to applying the SAFE procedure, several safeguards were implemented to mitigate automation bias. First, multi-model re-checks in Phases 3 and 4 were conducted to validate the active learning results. Second, reviewers retained the option to override model suggestions based on domain expertise.
2.2.5. Post-screening exclusions and final dataset
All records meeting initial inclusion criteria were exported into an Excel workbook for structured coding. Extraction fields included publication metadata (e.g., author, year, country, journal), study characteristics (e.g., design, sample size, population), technology type, measures of physical activity, and study outcomes. Records were further assessed for eligibility during data extraction, and exclusions were applied where necessary. Reasons for exclusion at this stage included duplicate entries not identified during earlier deduplication, studies in which technology was used exclusively to measure physical activity, and studies with no technology included.
2.2.6. Human oversight and quality control
Human reviewers remained central throughout the screening process. Their roles included seed article selection, screening adjudication, and verification of model outputs. Disagreements were resolved through discussion, with escalation to a fourth reviewer where required. To minimise the risk of missed studies, multiple quality control steps were implemented. These included re-screening of unlabelled records using an alternative model (Phase 3) and independent re-evaluation of previously excluded records (Phase 4). These steps were designed to mitigate automation bias and enhance confidence in the final dataset.
3. Results
3.1. Screening outcomes across phases
Across the four screening phases, a total of 28,957 records were processed using the AI-assisted workflow. In Phase 1, a random 1% sample (n = 290) was screened, of which 20 records were labelled relevant, informing an estimated 1,997 relevant records in the dataset. In Phase 2, three reviewers screened 3,994 records using active learning, identifying 2,904 relevant studies. This represents a high proportion of relevant records identified during active learning, indicating effective prioritisation of relevant studies. In Phase 3, re-screening of unlabelled records (n = 410) using an alternative model identified an additional 53 relevant studies, increasing the cumulative total to 2,957. In Phase 4, re-evaluation of previously excluded records yielded a further 226 relevant studies, resulting in a total of 3,183 records identified as relevant across all phases. Following post-screening exclusions (n = 598), the final dataset comprised 2,585 records retained for analysis.
Across phases, the majority of relevant records were identified during the active learning stage (Phase 2), with additional gains achieved through subsequent multi-model re-screening. Notably, Phases 3 and 4 contributed an additional 279 relevant records, highlighting the value of iterative screening and complementary model approaches in improving recall.
Figure 1 presents the flow of records across the AI-assisted screening workflow, including the number of records screened and retained at each phase. PRISMA-style flow diagram of records across the AI-assisted screening workflow using the SAFE procedure.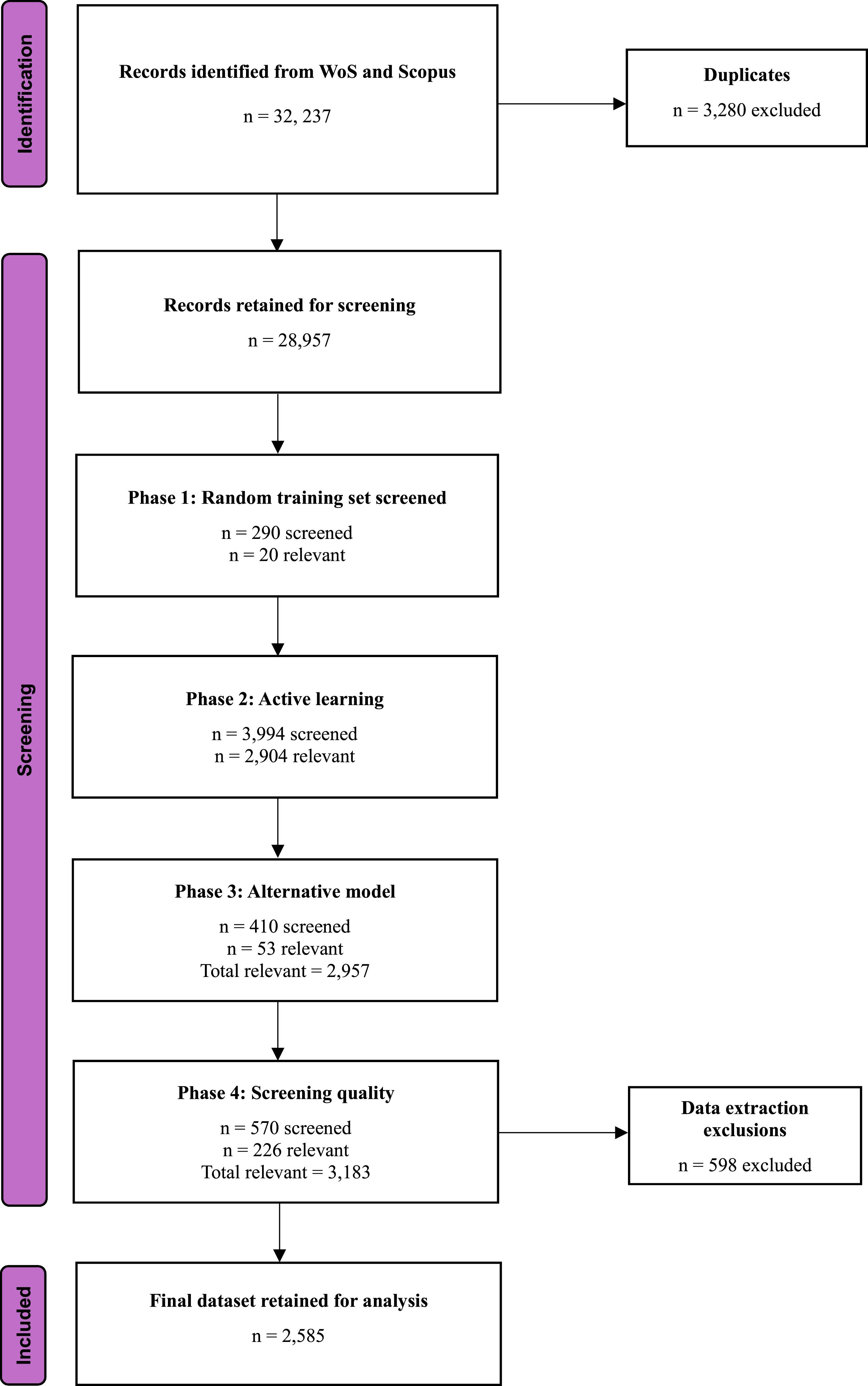
3.2. Efficiency of AI-Assisted screening
Only 18% of records (n = 5,264) required manual review, resulting in a substantial reduction in workload. Based on an average screening time of 90 seconds per abstract, calculated after pilot testing; this approach saved an estimated 592 hours, equivalent to approximately 74 full workdays (7.5-hour days).
These efficiency gains enabled a substantial reduction in manual screening burden while maintaining broad coverage of the evidence base. In practical terms, this allowed the review team to screen a dataset of nearly 29,000 records within a feasible timeframe. While these estimates are based on pilot-derived screening times and should be interpreted with caution, they illustrate the potential of AI-assisted workflows to support large-scale evidence synthesis.
4. Discussion
This study provides a real-world demonstration of how AI-assisted screening can be integrated into large-scale evidence synthesis workflows, addressing a key methodological gap in the literature where existing evidence has largely been limited to simulated or smaller-scale applications. It highlights the practical trade-offs between efficiency and rigour, showing that while substantial workload reductions are achievable, careful workflow design and human oversight remain essential. The findings also suggest that AI-human hybrid approaches offer practical advantages in large-scale screening, reducing reviewer burden and enabling broader coverage than would be feasible through manual approaches alone. This increased efficiency may allow greater allocation of effort to downstream stages such as data extraction and analysis. However, screening represents only one step in the review pipeline, and substantial manual effort remains. More broadly, these results position AI not as a standalone solution, but as part of an evolving, hybrid approach to evidence synthesis, with future advances needed to support more integrated, end-to-end workflows. 7
4.1. Seed article curation is foundational to model performance
One of the most critical components of this review was the early inclusion of over 100 seed articles. These were selected based on team expertise and prior knowledge of the field, ensuring that the active learning model had access to a diverse and representative training set from the outset. Key seed articles were combined with a small set of ‘borderline’ irrelevant records and supplemented them with random screening to enhance diversity. This strategy helped mitigate the ‘cold start’ problem often encountered in machine learning workflows and appeared to support early prioritisation of relevant records. These observations are consistent with prior work suggesting that increasing the amount and diversity of prior knowledge may result in improved efficiency in active learning workflows. 6 However, this relationship was not directly tested in the present study and should be interpreted with caution.
Others have highlighted that the inclusion of key papers may bias the training set by reflecting the perspectives of those who selected them, and instead recommend only using them to validate screening results. 13 In addition, large or highly curated seed sets may increase the risk of overfitting, 17 whereby the model preferentially ranks records that resemble the initial training examples. To mitigate these risks, a diverse set of seed articles were combined with random screening and implemented multi-model re-screening and human oversight in later phases. Given that the purpose of the review was to map the development of technology use in physical activity promotion over time, capturing foundational studies early was essential. In this context, providing greater prior knowledge through seed articles was appropriate, as it ensured the model was trained on seminal work and enabled a more accurate and comprehensive mapping of historical and contemporary developments. Future review teams adopting AI-assisted screening should include members with diverse expertise to avoid bias and curate an initial training set that reflects variation in study design, publication year, and intervention type, with the extent of prior knowledge tailored to the review’s aims and design. Investing time in this phase may contribute to a more efficient screening process and greater time savings later in the review pipeline.
4.2. Pre-specified, multi-layered stopping rules increased rigour
Clear stopping rules are essential for transparency and reproducibility in AI-assisted workflows. The SAFE procedure 13 was applied to guide screening and stopping decisions, combining statistical estimation (e.g., expected number of relevant records) with performance-based thresholds (e.g., no relevant records in final 50). This four-criterion heuristic provided a structured and defensible rationale for when to stop screening. Beyond SAFE, alternative stopping approaches offer complementary strengths. For example, heuristic rules such as time-based thresholds or consecutive-irrelevant counts have been shown to capture most relevant studies with reduced workload, 18 while simulation studies emphasise that effectiveness depends strongly on dataset prevalence rather than the choice of learning algorithm. 19 Future research should systematically compare heuristic, statistical, and hybrid stopping strategies across fields, and develop benchmark datasets to enable reproducible evaluation of their performance.
4.3. Iterative multi-model approaches enhanced confidence and recall
One of the most important contributions of this study is the application of a multi-model, multi-pass strategy. After the primary screening phase, unlabelled records were re-ranked (Phase 3) using a Sentence-BERT neural network classifier and re-evaluated previously excluded records (Phase 4) using a simplified model. These additional phases identified 279 relevant records that would have otherwise been missed, demonstrating the value of iterative screening with different model configurations. Such approaches are especially useful in reviews where maximising recall (ensuring that as many relevant studies as possible are captured) is critical, such as systematic reviews informing clinical guidelines. In contrast, for a bibliometric mapping study like ours, the impact of missing a small number of papers is less severe, and efficiency may reasonably be prioritised over exhaustive recall. At the same time, the current findings show that AI-assisted multi-phase approaches do not completely eliminate error. Despite a Phase 4 screening quality check, 598 records that had initially passed screening were later excluded, illustrating that false positives can still slip through. This is not unique to AI; similar issues occur in conventional reviews, where irrelevant records are often only identified at the extraction stage. The key message is that while AI can substantially reduce workload, it is not flawless. This reflects a broader limitation of active learning–based systems such as ASReview, where probabilistic ranking and dependence on training data mean that relevant studies may still be deprioritised without iterative checks and human oversight. Review teams should therefore balance the efficiency gains against the risk of residual errors and allocate time for secondary checks to maintain confidence in the final dataset.
Taken together, these findings highlight that AI-assisted screening may not be appropriate in all review contexts. For example, in high-stakes systematic reviews informing clinical guidelines, where maximising recall is critical, reliance on AI-assisted prioritisation without full validation may introduce unacceptable risk. In such cases, AI should be used cautiously and in conjunction with comprehensive manual screening. Furthermore, external validation of AI-assisted workflows across different review types and domains remains necessary before widespread adoption.
4.4. Human reviewers remain central to AI workflows
Despite substantial efficiency gains, human reviewers remained essential across all phases of screening. Key roles included seed article identification, active screening of prioritised records, adjudication of uncertain or borderline cases, and verification of model outputs in later phases. Regular team calibration meetings helped maintain consistency in screening decisions, particularly where abstracts were incomplete, poorly structured, or lacking key contextual information. Consistent with Ge et al., 10 we caution against over-reliance on AI as a decision-maker. Rather, AI should be seen as a tool that augments, rather than replaces, human expertise. This aligns with the principle of human-in-the-loop design widely emphasised in the AI ethics literature, where machine predictions are embedded within, and guided by, domain expertise to support transparency and accountability. 8 Such hybrid approaches, anchored in active learning but safeguarded by human oversight, are particularly well suited for bibliometric and scoping reviews that span heterogeneous literatures.
4.5. Copyright issues
An important practical consideration for future reviews is the copyright status of abstracts used in AI-assisted screening. As highlighted by institutional copyright officers, many third-party tools require users to upload records to cloud-based platforms (e.g., AI Research Screener), 20 where terms and conditions may grant the vendor rights to use these texts for model training. Because most abstracts remain under publisher copyright, uploading them without explicit permission may breach both copyright law and publisher agreements, exposing researchers and institutions to infringement claims. This risk can be mitigated by restricting screening to open-access records, but this approach may bias reviews, particularly in longitudinal analyses. For example, in the current study, limiting to open-access records would have prevented a true reflection of technology use across decades, since open-access publishing was far less common in earlier periods. Locally installed tools, such as ASReview, offer a practical solution because they allow text mining without transferring copyrighted content to third-party servers. Nevertheless, reviewers should remain attentive to legal frameworks and institutional agreements when selecting AI screening software, and explicitly document the measures taken to ensure copyright compliance.
These considerations reflect broader debates across the AI field regarding the use of copyrighted material for model training and text mining. 21 As AI-assisted tools become more widely adopted in research workflows, there is a growing need for clarity around data ownership, licensing agreements, and the permissible use of published content. In health and research contexts, these issues are particularly salient, given the potential legal and ethical implications of data use.
4.6. Impact on quality of evidence synthesis
Beyond efficiency gains, AI-assisted screening may also influence the quality of evidence synthesis. On one hand, prioritisation algorithms may enable more comprehensive coverage by allowing larger datasets to be screened within feasible timeframes. On the other hand, reliance on model-driven ranking introduces potential risks, including bias in study selection and the possibility of missing relevant studies. Previous studies of AI-assisted and data-driven approaches have reported improvements in efficiency, 11 and, in some cases, clinical decision-making 22 ; however, these findings are often derived from controlled or domain-specific applications and may not generalise to large, heterogeneous review contexts. In the present study, we did not directly evaluate whether AI-assisted screening improved the quality or completeness of the final dataset. As such, the integration of AI into evidence synthesis workflows requires careful consideration of both efficiency and methodological rigour, with appropriate safeguards to maintain confidence in the final dataset.
4.7. Limitations
This study has several limitations. First, the absence of formal performance metrics such as recall and precision represents an important limitation. Without a fully labelled dataset, it is not possible to quantify the proportion of relevant studies that may have been missed. Future studies should incorporate gold-standard datasets or parallel manual screening to enable formal evaluation of model performance. Second, the selection of seed articles and screening decisions were based on domain expertise and prior knowledge of the field, which introduces subjectivity and potential bias, and may reduce reproducibility across review teams. While efforts were made to include a diverse and representative set of studies, alternative seed selections may have influenced model behaviour and screening outcomes. Third, while multiple safeguards were implemented, there remains a risk that relevant studies were missed. Fourth, the study did not include a direct comparison with fully manual screening, limiting conclusions about relative performance. In addition, the estimated time savings were based on an average screening time derived from pilot testing and were not directly measured across all reviewers and phases, and should therefore be interpreted as an approximation. Finally, the findings of this study are based on an applied, real-world implementation and rely primarily on descriptive and qualitative observations rather than formal quantitative evaluation. As such, conclusions regarding performance, efficiency, and generalisability should be interpreted with caution.
5. Conclusion
In sum, this study shows that AI-assisted screening can deliver substantial efficiency gains at scale, but also that challenges remain. While careful seed selection, structured stopping rules, and iterative model passes enhance rigour and recall, residual risks, copyright constraints, and the persistence of manual data extraction highlight the limits of current approaches. The real potential of AI in evidence synthesis lies in extending beyond study selection to encompass downstream tasks such as data extraction, enabling true end-to-end efficiencies. Future work should therefore focus on building benchmark datasets, integrating semi-automated extraction tools, and embedding human-in-the-loop safeguards to ensure AI serves as a reliable, transparent partner in evidence synthesis. AI should be viewed not as a replacement for reviewers, but as a reliable, transparent partner in evidence synthesis.
Supplemental material
Supplemental material - Harnessing artificial intelligence for scalable evidence synthesis in reviews: Application in a bibliometric analysis of physical activity technologies
Supplemental material for Harnessing artificial intelligence for scalable evidence synthesis in reviews: Application in a bibliometric analysis of physical activity technologies by George Thomas, Stephanie Alley, Meighan Browne, Hannes Baumann, Mitch J Duncan, Corneel Vandelanotte and Nicholas D Gilson in Digital Health.
Footnotes
Author contributions
G.T. contributed to Conceptualization, Methodology, Software, Data curation, Formal analysis, Validation, Visualization, and Writing – original draft. N.G. contributed to Conceptualization, Project administration, Validation, Supervision, and Writing – review & editing. S.A. and M.B. contributed to Data curation, Formal analysis, Validation, and Writing – review & editing. M.J.D. and C.V. contributed to Validation, Visualization, Supervision, and Writing – review & editing. H.B. contributed to Validation and Writing – review & editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MJD is supported in part by The Commonwealth of Australia 2022 Effective Treatments and Therapies Grant (MRF2023434). CV is supported by a Future Fellowship from the Australian Research Council (FT210100234).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The software in this paper is available at https://asreview.nl/. The ASReview project files and processed datasets (including DOI lists of retained records) are openly available in OSF at ![]() .
.
Declaration of generative AI and AI-assisted technologies in the manuscript preparation process
During the preparation of this work the author(s) used ASReview in order to assist screening of title and abstracts. After using this tool/service, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the published article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.