
Abstract
Background
Traditional tongue inspection relies on visual assessment by practitioners, which introduces subjectivity and compromises reproducibility. Existing solutions often rely on enclosed, dedicated acquisition instruments with nontrivial operation, whereas mobile self-capture approaches are more accessible but sensitive to environmental variability, making reliable analysis challenging in real-world use.
Objective
To develop a portable non-contact tongue imaging and automated analysis system that is robust to real-world acquisition variability.
Methods
We designed a portable acquisition terminal that integrates a camera, touchscreen preview, touch-initiated capture with voice prompts, and supplementary illumination for acquisition assistance. For automated analysis, we developed TongueSegNet (TSegNet) for tongue segmentation, incorporating stage-dependent residual modulation, deep-stage attention enhancement, and gated skip-pathway feature fusion to improve feature representation and boundary delineation. For fissured-tongue feature recognition, we developed Residual Kolmogorov-Arnold Network (ResKAN), which combines a convolutional neural network feature extractor with a Kolmogorov-Arnold Network–based head to improve modelling capacity for fine-grained texture patterns.
Results
On tongue images acquired under unconstrained conditions, TSegNet achieved mean Dice of 98.16%, mean intersection over union of 96.42%, and mean pixel accuracy of 98.31%, outperforming representative baselines. ResKAN achieved mean accuracy of 92.48%, sensitivity of 92.67%, specificity of 92.31%, and a fissured-class F1 score of 92.34%.
Conclusion
The proposed system enables reliable non-contact tongue imaging with automated server-side analysis under unconstrained conditions. These findings support the feasibility of this integrated approach as an initial step toward more accessible automated tongue-image analysis in community and home settings.
Keywords
Introduction
With the growing global emphasis on preventive healthcare, there is a rising public demand for continuous and personalized health assessment.1,2 Traditional Chinese Medicine (TCM) emphasizes individualized assessment and preventive treatment, aligning naturally with these goals.3–5 Tongue inspection is a key non-invasive diagnostic method in TCM for assessing health status through observation of tongue morphology and appearance.6–8 Among these features, fissure patterns are representative and meaningful morphological signs characterized by grooves or cracks on the dorsal surface of the tongue, and they are often interpreted in relation to internal conditions such as syndrome-related hotness, blood deficiency, and spleen insufficiency.9,10 Emerging clinical evidence also suggests that fissured tongue may have observational value in modern clinical settings. For instance, a hospital-based cross-sectional study reported that fissured tongue was independently associated with upper gastrointestinal precancerous lesions. 11 These findings indicate that fissured tongue is a meaningful tongue feature warranting further investigation.
However, conventional tongue inspection still relies heavily on manual assessment by experienced practitioners. This reliance on individual expertise and subjective judgment may limit diagnostic reliability and objectivity.12,13 In addition, proficiency in tongue diagnosis requires substantial training and accumulated clinical experience, which limits the availability of qualified practitioners and constrains service scalability. 14 These limitations highlight the need for more objective and automated tongue analysis. Furthermore, reliance on in-person assessment may introduce operational barriers, including patient scheduling difficulties, uncertain waiting times, and repetitive manual workloads for clinicians. 15 In this context, portable digital health approaches that can be deployed in community and home settings may help extend access to tongue assessment beyond conventional clinical environments.16,17 As a representative and visually recognizable morphological sign within tongue diagnosis, fissured tongue provides a practical initial target for developing and evaluating accessible automated assessment approaches.
Reliable automated tongue analysis begins with tongue image acquisition.18,19 Existing acquisition solutions can be broadly categorized into dedicated imaging devices and mobile approaches. Dedicated imaging devices typically rely on constrained setups to provide relatively controlled imaging conditions, but their limited portability may restrict deployment outside clinical or laboratory environments.20,21 Mobile approaches, particularly smartphone-based solutions, have been investigated to improve accessibility and enable more flexible use.22–24 However, these methods remain susceptible to environmental variations, which may degrade image quality and affect subsequent analysis. 25 Moreover, self-capture typically requires active manual operation and may therefore present usability challenges for some users, especially older adults and individuals with limited digital literacy or sensorimotor capability.26–28 A portable acquisition solution that improves imaging consistency while remaining simple to operate is therefore important for community and home use.
Tongue image segmentation is a fundamental step in automated tongue image analysis because it isolates the tongue region from surrounding structures, such as the lips, teeth, and facial skin, and provides a reliable basis for subsequent feature extraction and quantitative assessment. 29 Early studies primarily employed traditional image processing methods, including edge detection, thresholding, and region-growing techniques.30–33 These approaches depended heavily on handcrafted features, required laborious parameter tuning, and were often sensitive to illumination changes and background interference. Deep learning-based methods have since substantially advanced tongue segmentation performance. Representative studies, such as TongueNet, TU-Net, and RTC TongueNet, have improved segmentation accuracy through enhanced shape modeling, feature representation, and contextual learning.34–36 Despite these advances, tongue images acquired in real-world settings often exhibit substantial appearance variability and background complexity, whereas many existing segmentation models have been developed and evaluated on datasets acquired under relatively controlled conditions, such as uniform illumination and clean backgrounds.37–39 This mismatch may reduce model robustness and generalizability when such methods are deployed in real-world settings.
Existing studies on fissured-tongue feature recognition have mainly formulated the task as image-level classification and have relied on transfer learning with pre-trained convolutional neural networks (CNNs) to extract discriminative representations. 40 Although these approaches have shown promising results, most of them still employ conventional linear or multi-layer perceptron (MLP)-based heads on top of CNN features. The potential value of more expressive classifier designs for fissured-tongue feature recognition therefore remains insufficiently explored.
Kolmogorov-Arnold Networks (KANs) have recently been proposed as an alternative to MLPs by replacing fixed node-wise activation functions with learnable univariate functions on edges, which may provide greater functional flexibility and improved interpretability. 41 However, directly applying pure KAN architectures to high-dimensional image data remains challenging because of their computational and optimization burdens. A practical strategy is therefore to combine CNN-based feature extraction with KAN-based nonlinear modeling.42–45 Nevertheless, the utility of such hybrid architectures for automated fissured-tongue feature recognition has not yet been adequately investigated.
To address these challenges, this study proposes an integrated tongue analysis system combining a custom-designed acquisition terminal with an advanced deep learning framework. Our main contributions are summarized as follows:
We design a portable tongue image acquisition prototype with supplementary illumination and multimodal interaction (touch initiation with voice guidance) to facilitate reliable data collection and ease of use.
We propose TongueSegNet (TSegNet) for robust tongue image segmentation in unconstrained conditions. The model incorporates stage-dependent residual modulation, deep-stage attention enhancement, and gated skip connections to improve feature representation and boundary delineation under complex backgrounds and illumination variations.
We develop Residual Kolmogorov-Arnold Network (ResKAN), a hybrid architecture combining a CNN feature extractor with a KAN-based head for fissured-tongue feature recognition. This design enhances the model’s non-linear modelling capacity, enabling more effective recognition of fine-grained texture patterns.
Methods
Overall system workflow
As illustrated in Figure 1, the system employs a client-server architecture. The terminal focuses on tongue image acquisition and interaction, while computationally intensive inference is performed on the server. Overall system workflow. The acquisition terminal captures and transmits a tongue image to the server. The server performs tongue-body segmentation for region of interest (ROI) extraction and then applies ResKAN for fissured-tongue recognition. The resulting report is returned to the terminal for visualization.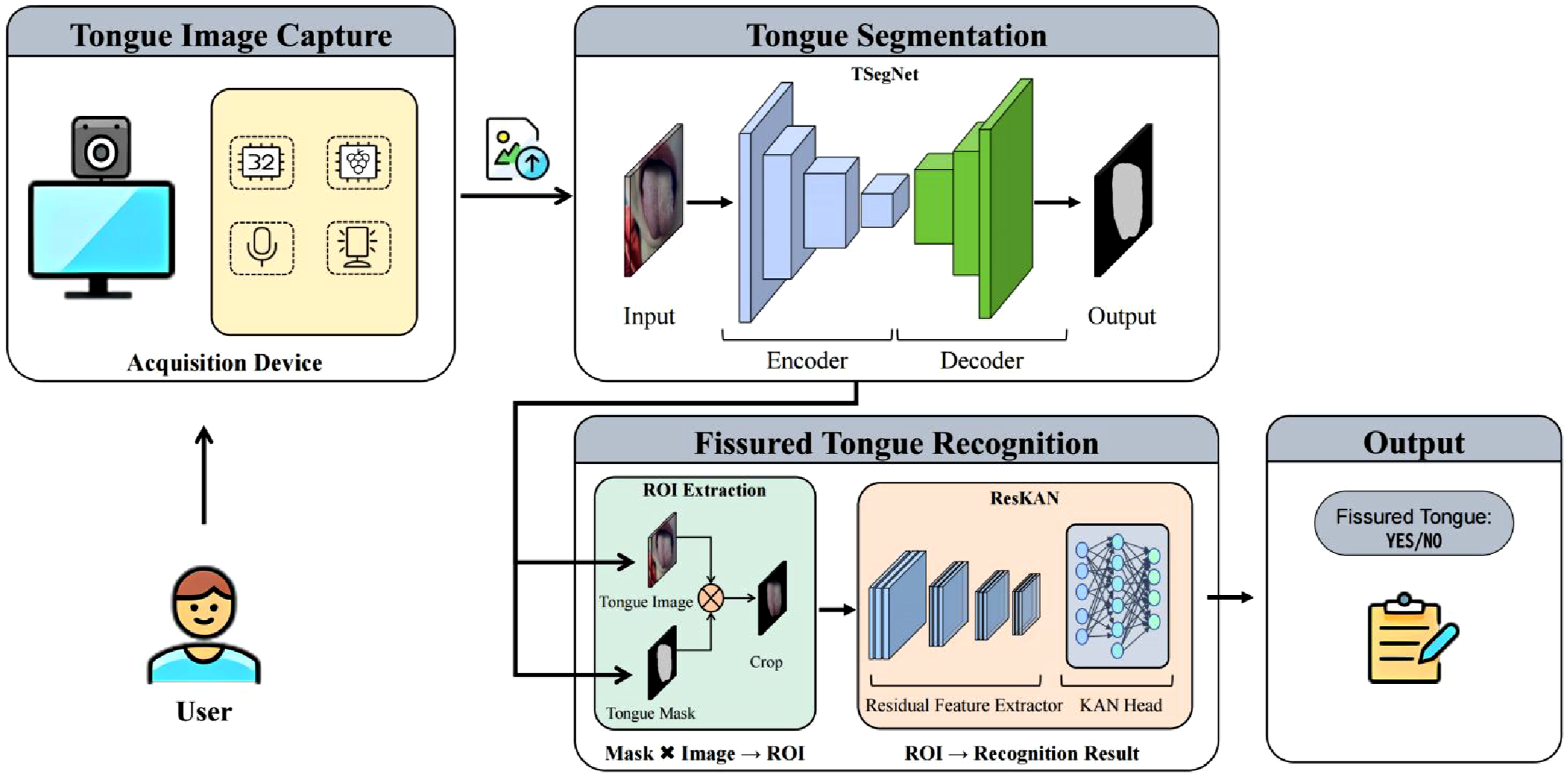
Specifically, the process begins with the user interacting with the acquisition device. Under controlled illumination, the terminal captures the tongue image and transmits it to the server. Upon receiving the image, TSegNet first performs tongue segmentation to generate a binary segmentation mask, which separates the tongue region from non-tongue pixels. The mask is further used analysis result is returned to the terminal and presented as a user-facing report.
Acquisition terminal
The acquisition terminal is a standalone and portable unit for non-contact tongue image acquisition in public and home environments.As shown in Figure 2, it integrates a camera, a touchscreen interface for on-device visualization, and internal control electronics. Acquisition terminal design and prototype. (a) Schematic illustration of the mechanical layout and the A–A sectional view, with key components labeled, including the camera, touchscreen, illumination module, raspberry Pi 4B, printed circuit board, and power supply; (b) Photographs of the assembled prototype from multiple views: front (top-left), side (top-right), rear (bottom-left), and oblique (bottom-right).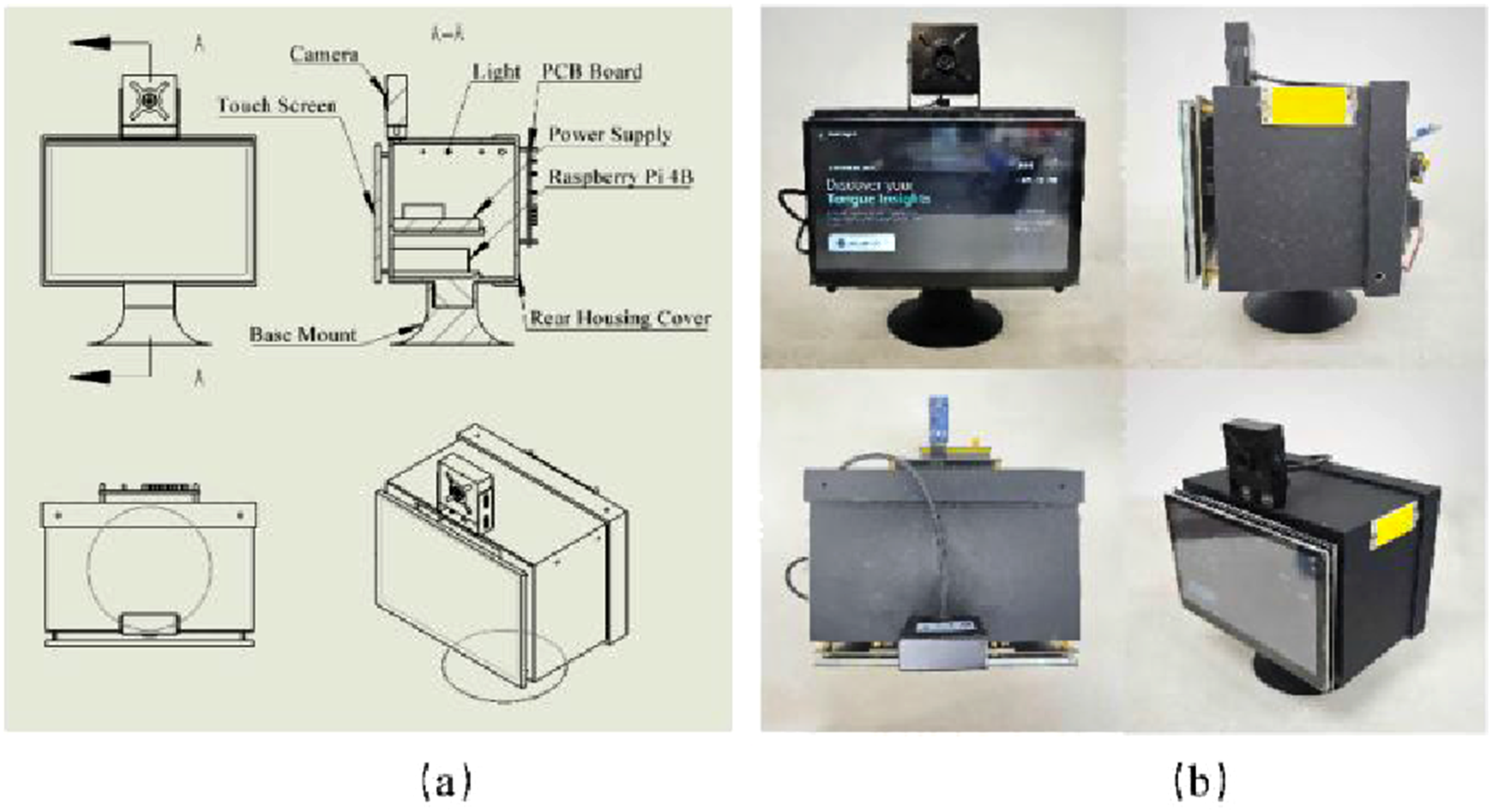
Hardware configuration of the acquisition terminal.

Abbreviations: CMOS, complementary metal-oxide-semiconductor; IPS, in-plane switching; LED, light-emitting diode; CCT, correlated color temperature; PLA, polylactic acid.
TongueSegNet
To address challenges in tongue image segmentation under unconstrained acquisition conditions, including complex backgrounds, blurred edges, and variable object shapes, we propose TSegNet. The encoder is organized into four stages with stage-dependent residual modulation. The two shallow stages use plain residual units to preserve local details, whereas the two deep stages incorporate attention enhanced residual modulation to strengthen semantic discrimination and suppress background-induced false positives. In addition, a gated feature fusion mechanism is introduced into the intermediate skip pathways before feature concatenation to reduce noise propagation and alleviate the semantic gap between encoder and decoder features. The overall architecture is shown in Figure 3. Overall architecture of TSegNet. The encoder has four stages: shallow stages use residual blocks (ResBlock) to preserve boundary details, while deep stages use ResEMA (residual block with EMA attention) for semantic refinement. CSAF-Gate (channel-spatial attention fusion gate) is applied to the intermediate skip connections before concatenation to suppress background-dominant responses. Down-sampling is performed by max pooling and up-sampling by transposed convolution followed by convolutional refinement.
Stage-dependent residual modulation with efficient multi-scale attention
In open environments, tongue image segmentation faces two challenges at shallow and deep feature levels. In the shallow stages, varying illumination often degrades the contrast of tongue boundaries, so the network needs to preserve local details such as edges and textures. Conversely, in deeper stages, complex backgrounds and surrounding tissues may induce false positives, which calls for stronger semantic context to distinguish the tongue region.
To meet these requirements, we employ a hierarchical encoder with stage-dependent feature modulation. Let 
In shallow high-resolution stages (
This configuration reduces the block to a standard residual unit. This identity shortcut facilitates gradient propagation and helps preserve low-level boundary cues during downsampling.
46
As the network deepens (
Accordingly, the deep-stage block becomes: Structure of the ResEMA module. ResEMA applies a residual convolutional transform followed by efficient multi-scale attention (EMA) for feature modulation. EMA first groups channels into 

Gated skip connection with channel-spatial attention fusion
Direct skip concatenation in U-Net may propagate background-dominant low-level activations (e.g., lips, teeth, or shadows) to the decoder, which can hinder mask reconstruction under unconstrained acquisition conditions. To mitigate this issue, we introduce a lightweight Channel-Spatial Attention Fusion gate (CSAF-Gate) into the skip pathways (Figure 5). Drawing inspiration from attention gating protocols and dual-domain feature refinement, the CSAF-Gate functions as a dynamic filter, which explicitly suppresses irrelevant background responses by recalibrating features along both channel and spatial dimensions before feature fusion.48,49 Structure of the CSAF-Gate. Channel attention is computed using global average pooling (GAP) and global max pooling (GMP), followed by a shared MLP. Spatial attention utilizes channel-wise pooling and convolution to highlight informative regions. The final gated feature is obtained by element-wise summation of the two reweighted streams.
Given an encoder feature map 
The channel-attention branch is designed to explicitly model inter-channel dependencies by aggregating global context via both global average pooling and global max pooling, followed by a shared two-layer MLP: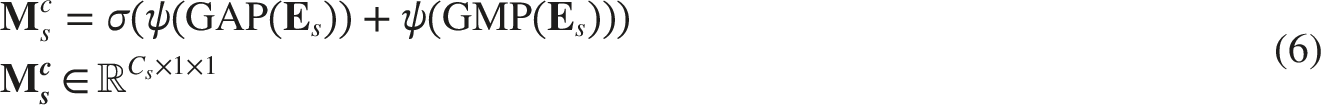
The spatial attention branch highlights informative locations by pooling along the channel dimension and applying a lightweight convolution:
The gated skip feature
Composite loss function
In addition to the network architecture, the loss function is critical for effective optimization. In open-environment tongue images, the tongue region typically occupies a relatively small portion of the image. This leads to class imbalance, which can result in incomplete or inaccurate segmentation of tongue boundaries.
The Dice Similarity Coefficient (DSC) loss is a region--based criterion that directly measures the overlap between the predicted segmentation and the ground-truth mask, making it robust to the imbalance between foreground and background pixels.
50
It is defined as:
However, DSC loss alone may exhibit unstable gradients and optimization difficulty, especially at the early training stage or when the initial overlap between prediction and ground truth is very low. To complement this behavior, we additionally employ the Cross-Entropy (CE) loss, a distribution-based loss criterion that measures the difference between the model’s predicted probability distribution over classes and the true probability distribution.
51
It is mathematically expressed as:
To tackle the challenge of class imbalance in tongue segmentation while ensuring training stability, we adopt a composite loss function:
Fissured-tongue feature recognition
Following the segmentation of the tongue region, the system proceeds to the recognition of specific morphological features. In this study, we focus on the automated identification of the fissured-tongue feature. We propose the ResKAN, a hybrid architecture that integrates the robust feature extraction capabilities of ResNet with the adaptive non-linear modeling of KANs, as illustrated in Figure 6(a). Architecture of ResKAN for fissured-tongue feature recognition. (a) The overall pipeline comprises a convolutional stem, four residual stages, a global average pooling (GAP) extracts a compact descriptor, and a two-layer KAN head; (b) The downsampling bottleneck block uses a 1×1 convolution with stride 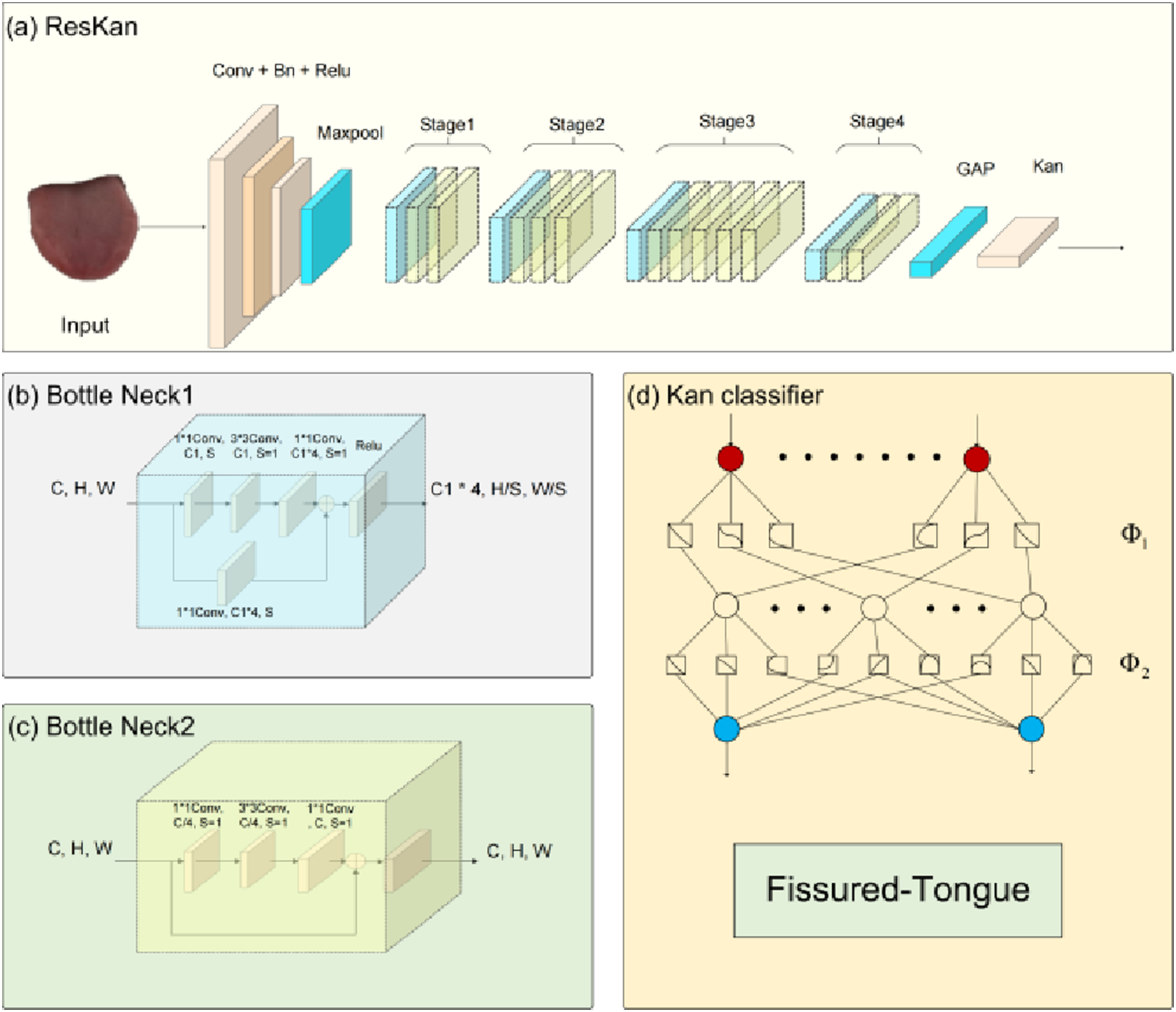
Feature extraction backbone
We employ a ResNet-50 backbone to extract high-level semantic representations from the input images. The backbone comprises a sequence of residual bottlenecks, including downsampling blocks for dimension reduction (Figure 6(b)) and identity blocks for depth expansion (Figure 6(c)) that effectively mitigate the vanishing gradient problem, enabling deep hierarchical feature learning.
46
Finally, GAP aggregates the spatial feature maps into a compact descriptor
KAN-based recognition head
Instead of the standard linear fully-connected classifier, we employ a two-layer KAN head to map the global descriptor to recognition logits (Figure 6(d)). Different from conventional MLP heads that use fixed node activations with scalar edge weights, KAN parameterizes each edge by a learnable univariate function, typically implemented with spline bases, while nodes mainly perform summation.
Given the global feature vector 

Qualitative interpretability analysis
To provide qualitative interpretability analysis of the recognition model, Gradient-weighted Class Activation Mapping (Grad-CAM) was applied to visualize the image regions contributing most to ResKAN predictions. 52 Heatmaps were generated from the final convolutional feature maps to support qualitative inspection of whether the model focused on fissure-related regions.
Dataset construction
Image source and acquisition setting
The tongue images used in this study were captured using smartphones by clinicians during routine diagnosis and treatment at Maoming Hospital of Traditional Chinese Medicine. Images were acquired in routine clinical settings using smartphones, rather than under fully standardized imaging equipment or tightly controlled acquisition conditions.
Annotation protocol
For tongue segmentation, 1012 images were manually annotated by experienced researchers at Guangzhou University of Chinese Medicine using the LabelMe tool. For each image, a closed polygon was drawn along the tongue boundary to delineate the tongue region of interest (ROI), as illustrated in Figure 7. Illustration of the tongue annotation process. (a) Original tongue image; (b) Manual polygon-based annotation of the tongue boundary; (c) Extracted tongue region after annotation.
Based on the extracted tongue ROIs, a subset of 684 samples was selected to construct the fissured-tongue feature recognition dataset, comprising 336 images with fissured-tongue features and 348 without fissured-tongue features. The labeling of fissured-tongue features was performed according to the Chinese National Standard GB/T 40665.1-2021. Three professional TCM physicians participated in a consensus-based labeling procedure. One physician first assigned the preliminary label, and the other two physicians then independently reviewed it. Samples with discordant opinions were excluded from the final classification dataset. The retained labels were further reviewed and confirmed by senior experts from Maoming Hospital of Traditional Chinese Medicine.
Data splitting For each task, the corresponding dataset was randomly split into training, validation, and test sets at a ratio of 0.70:0.15:0.15 using each random seed in {3, 33, 42}. The reported results were averaged across the three runs.
Experimental setup
Tongue segmentation experiments
Tongue segmentation was conducted on a workstation equipped with an NVIDIA Quadro RTX 5000 GPU, an Intel Xeon Silver 4210R CPU, and 128 GB RAM, running Ubuntu 22.04 with Python 3.10.14 and CUDA 12.1.
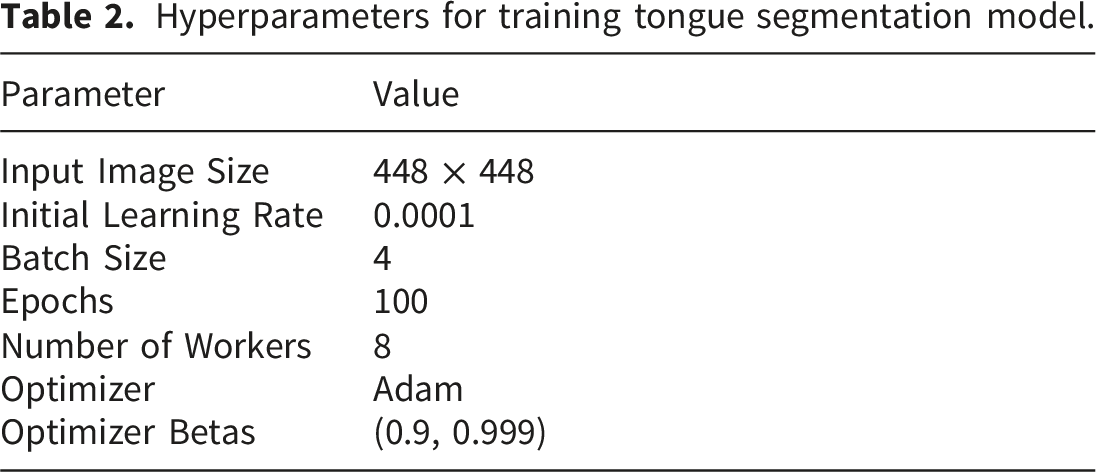
Hyperparameters for training tongue segmentation model.
Fissured-tongue feature recognition
The fissured-tongue recognition experiments were run on a separate machine equipped with an NVIDIA RTX 3090 GPU, an AMD EPYC 7K62 48-Core CPU, and 60 GB RAM, running Ubuntu 22.04 with Python 3.12.4 and CUDA 12.9.
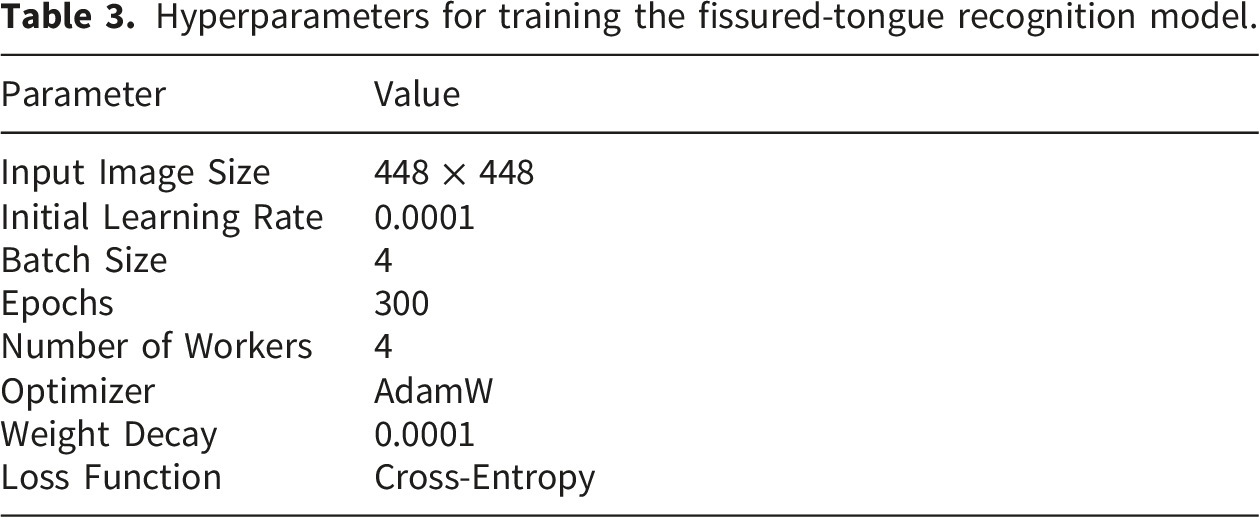
Hyperparameters for training the fissured-tongue recognition model.
During training, we applied data augmentation including random horizontal flipping and color jittering (brightness/contrast/saturation), as well as random sharpness adjustment to improve robustness to illumination and appearance variations.
Evaluation metrics
To comprehensively evaluate the performance of our system, we employed distinct sets of standard metrics for the segmentation and recognition tasks, respectively.
Metrics for tongue segmentation
The performance of our tongue segmentation model was quantified using three widely-adopted metrics. These metrics are calculated based on the number of pixels correctly or incorrectly classified: True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN). •



Metrics for fissured-tongue feature recognition
For the downstream fissured-tongue feature recognition task, the model’s performance was evaluated at the image level. We treat fissured tongue as the positive class and normal tongue as the negative class. Accordingly, TP, FP, TN, and FN are defined as follows:
Based on these counts, we report the following metrics:





Results
Tongue segmentation results
Comparison with representative models
To evaluate our model, we compared TSegNet with representative segmentation models, including U-Net, U-Net++, U2-Net, DeepLabV3+, TransUNet, and Swin-Unet.
Comparative segmentation performance (mean ± std over three random seeds).
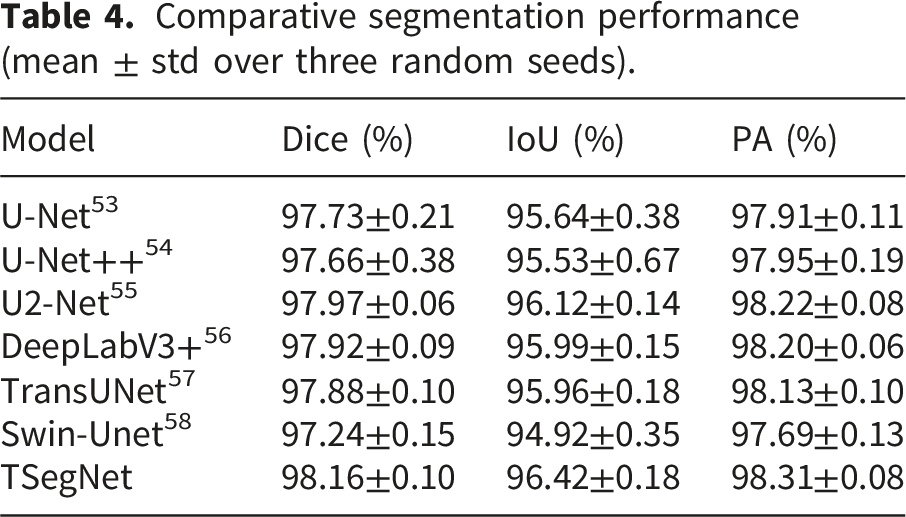
Figure 8 presents qualitative comparisons of tongue body segmentation results produced by different models, where panel (a) shows the input image and panels (b)-(h) show the predicted masks of U-Net, U-Net++, U2 -Net, DeepLabV3+, TransUNet, Swin-Unet, and our TSegNet, respectively. The red overlay denotes the predicted tongue region. Comparative visualization of tongue segmentation. (a) Input image; (b) U-Net; (c) U-Net++; (d) U2-Net; (e) DeepLabV3+; (f) TransUNet; (g) Swin-Unet; (h) TSegNet. The red overlay denotes the region predicted as the tongue body by each model.
The first two rows present scenarios where the tongue target occupies a dominant proportion of the image. In these samples, the tongue body shares similar chromatic characteristics with the surrounding lips and facial skin, creating low-contrast boundaries. Under these conditions, some baselines produce less coherent masks: for instance, TransUNet (col.∼f) in row 1 shows locally inconsistent predictions within the tongue region, while U-Net (col.∼b) in row 2 exhibits slight over-segmentation near the mouth boundary.
The third row illustrates a small-target scenario with background interference. In this case, Swin-Unet (col.∼g) produces noticeable false positives on the red clothing region, and several methods show minor spurious activations around facial areas, indicating sensitivity to contextual distractors.
The last two rows further demonstrate challenges under unconstrained geometric and lighting conditions. The fourth row depicts an oblique viewing angle where shadows blur the distinction between the tongue and surrounding tissues. Multiple baselines show mislocalized predictions near the upper lip region. In the fifth row, the low color contrast between the tongue and lower lip leads to boundary leakage for some models.
In contrast, TSegNet generates more complete masks with cleaner and more consistent boundaries across these challenging scenarios, indicating improved robustness for real-world tongue image segmentation.
Ablation study of TSegNet
Ablation study on loss functions for TSegNet (mean ± std over three random seeds).
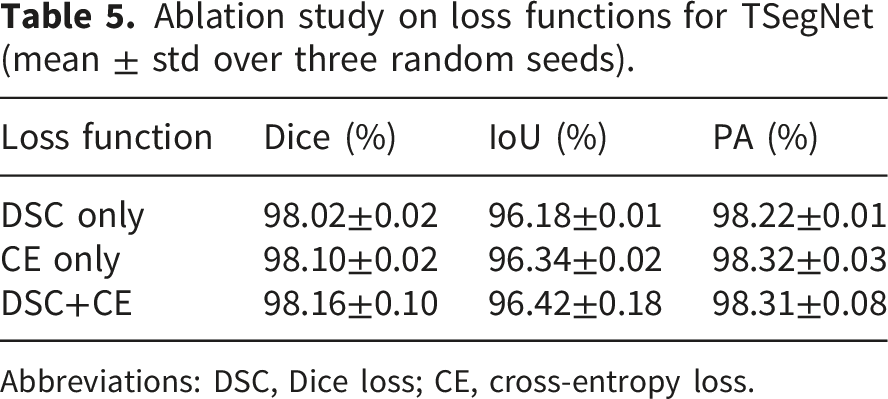
Abbreviations: DSC, Dice loss; CE, cross-entropy loss.
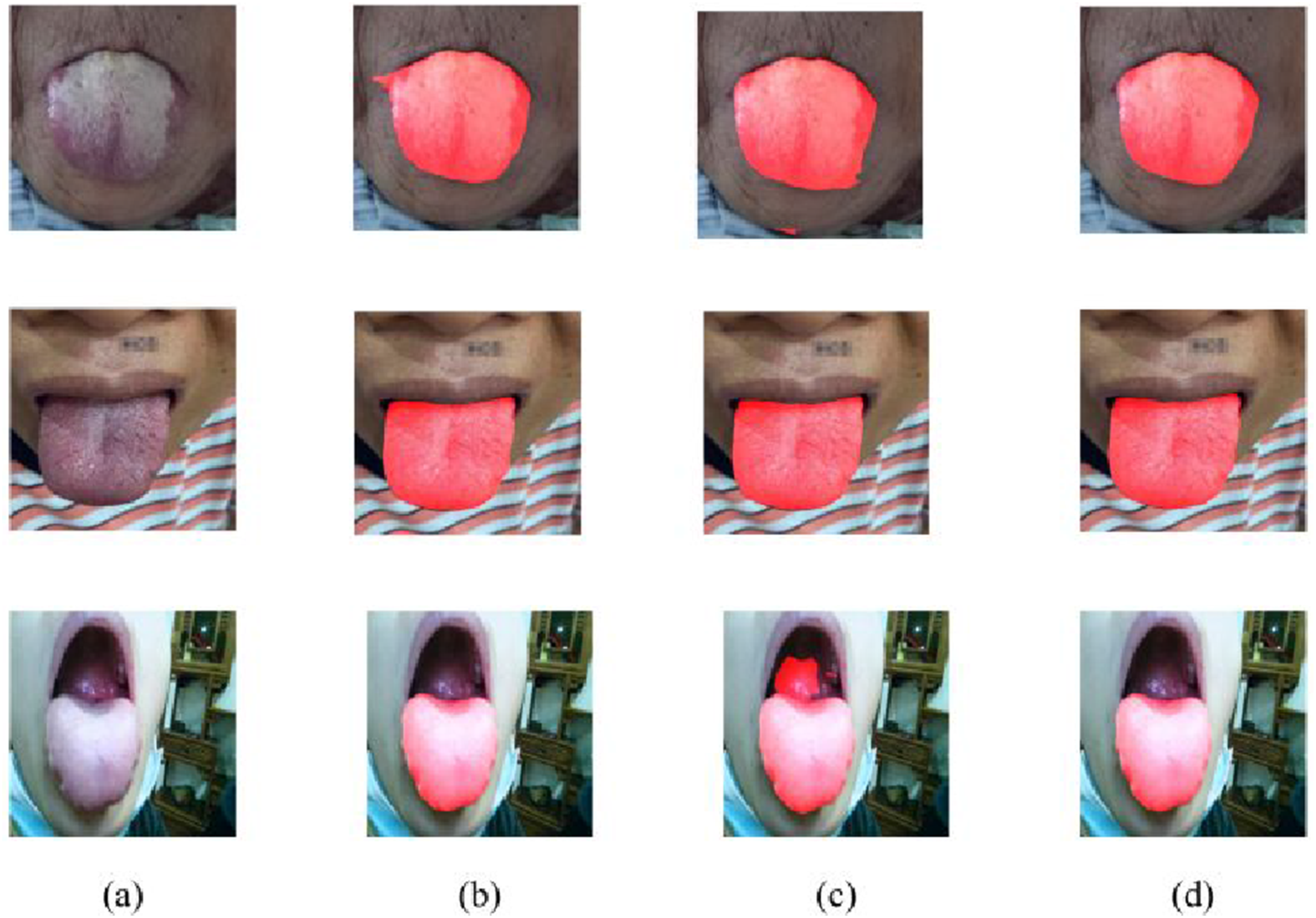
Qualitative comparison of segmentation results using different loss functions. (a) Input image; (b) Ground truth; (c) DSC loss only; (d) CE loss only; (e) Composite loss. The red overlay denotes the predicted tongue region.
Ablation study on attention mechanisms for TSegNet (mean ± std over three random seeds).
Effect of ResEMA and CSAF Gate. We quantify the contribution of ResEMA and CSAF–Gate in TSegNet by disabling each component while keeping all other settings unchanged. Specifically, we evaluate: removing the attention operation inside ResEMA (w/o ResEMA-attn), and removing CSAF–Gate from the skip connection (w/o CSAF–Gate).
Ablation study on TSegNet architecture (mean ± std over three random seeds).
Abbreviations: ResEMA-attn, residual modulation with deep-stage attention enhancement; CSAF-Gate, channel-spatial attention fusion gate; w/o, without.
Fissured-tongue feature recognition results
Quantitative performance comparison
Fissured-tongue feature recognition performance (mean ± std over three random seeds).
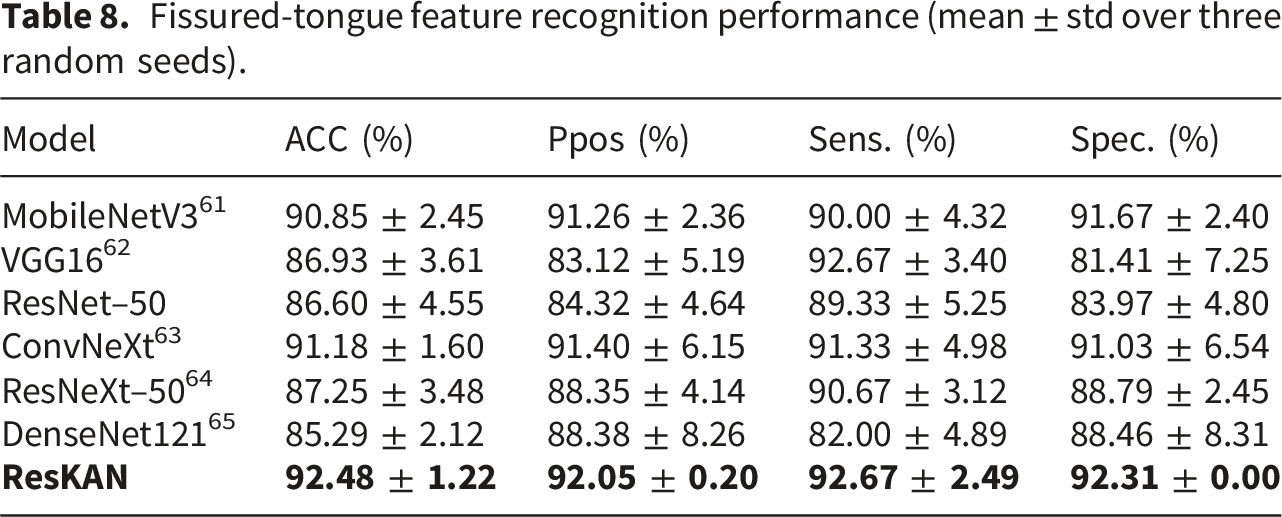
Overall, ResKAN achieves the highest accuracy (92.48%) and F1pos (92.34%), while maintaining a favorable balance between sensitivity (92.67%) and specificity (92.31%). Compared with ConvNeXt, ResKAN improves accuracy by 1.30 percentage points and F1pos by 1.29 percentage points, demonstrating stronger discrimination for fissure–related patterns. Notably, VGG16 attains a high sensitivity (92.67%) but a substantially lower specificity (81.41%), indicating a tendency to over–predict the positive (fissured) class and thus produce more false alarms. In contrast, ResKAN maintains a better balance between high sensitivity and high specificity. Relative to ResNet–50, ResKAN improves accuracy and F1pos by 5.88 and 5.62 percentage points, respectively. These results demonstrate the effectiveness and robustness of the proposed ResKAN for fissured–tongue recognition.
Error analysis and threshold-independent evaluation
To gain deeper insights into the error patterns of different models, we present the pooled, row-normalized confusion matrices across the three test splits. As shown in Figure 10, the matrices reveal two typical error modes. The first is a false alarm (FP), where a normal image is incorrectly predicted as fissured. The second is a missed detection (FN), where a fissured image is incorrectly predicted as normal. VGG16 shows a noticeably higher FP rate, misclassifying 29 normal samples as fissured, which is consistent with its lower specificity. Conversely, DenseNet121 suffers from a relatively high FN rate, missing 27 fissured cases (18.0%). ResKAN mitigates both error types, reducing FP to 12 (7.7%) and FN to 11 (7.3%), suggesting a more balanced behavior between sensitivity and specificity. Comparison of pooled confusion matrices. (a) MobileNetV3; (b) VGG16; (c) ResNet--50; (d) ConvNeXt; (e) ResNeXt--50; (f) DenseNet121; (g) ResKAN. For each model, confusion counts are aggregated over three random splits by summation, and each row is normalized by the number of samples in the corresponding true class. Each cell reports the pooled count and the corresponding percentage.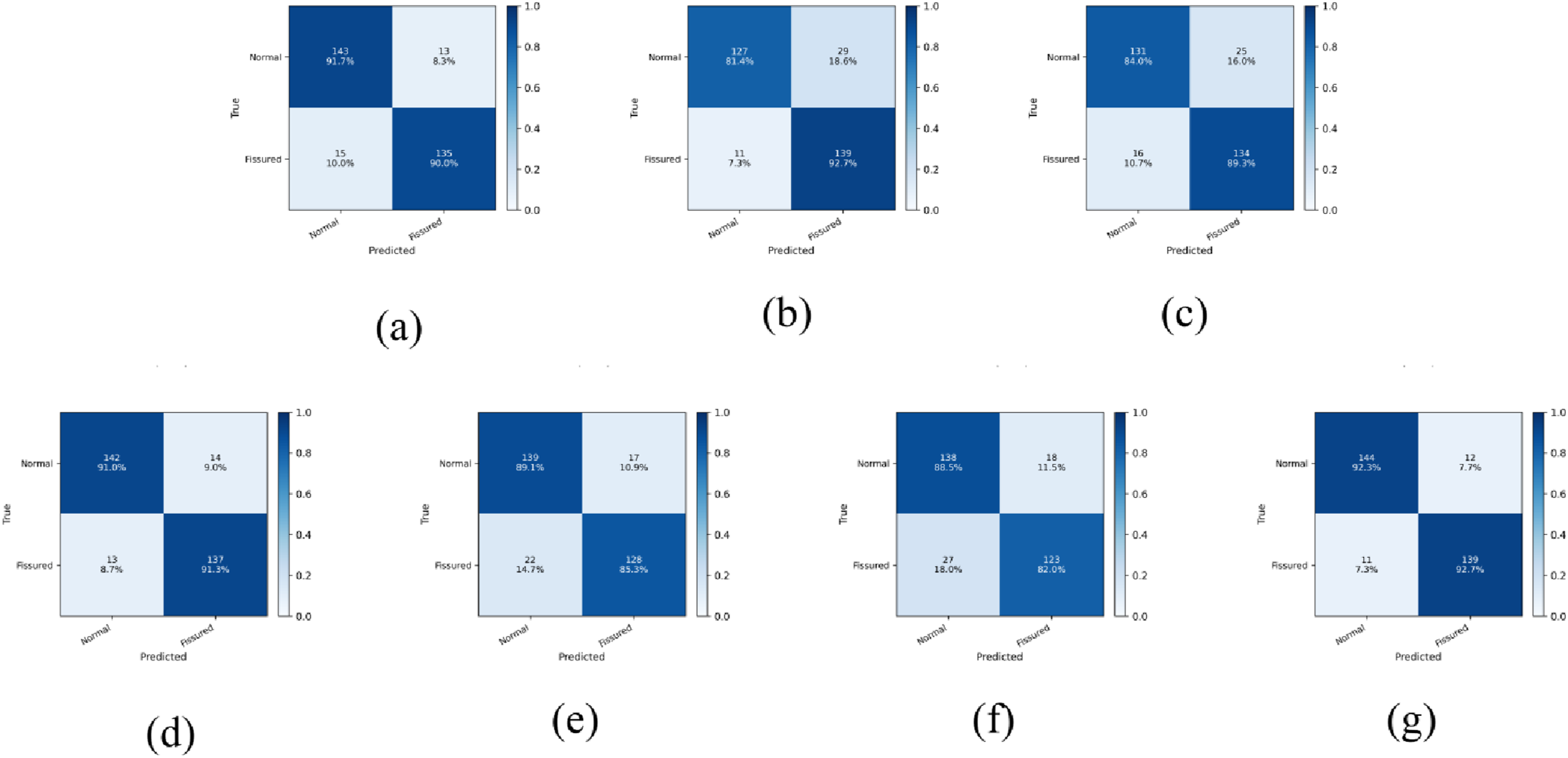
We further evaluate the threshold-independent discrimination capability using pooled receiver operating characteristic (ROC) curves in Figure 11. The ROC curve plots the trade-off between the true positive rate (TPR) and false positive rate (FPR) as the decision threshold varies. The Area Under the Curve (AUC) provides a scalar summary and can be interpreted as the probability that the model ranks a randomly chosen fissured sample higher than a randomly chosen normal sample. ResKAN achieves the highest AUC (0.968), indicating superior overall discrimination capability across various classification thresholds. ConvNeXt follows with an AUC of 0.955, while DenseNet121 lags at 0.900. The ROC-AUC results suggest that ResKAN’s performance advantage is robust and not dependent on a specific operating point. Comparison of ROC curves and AUC scores. The curves illustrate the trade--off between TPR and FPR across varying decision thresholds, and the AUC for each model is listed in the legend.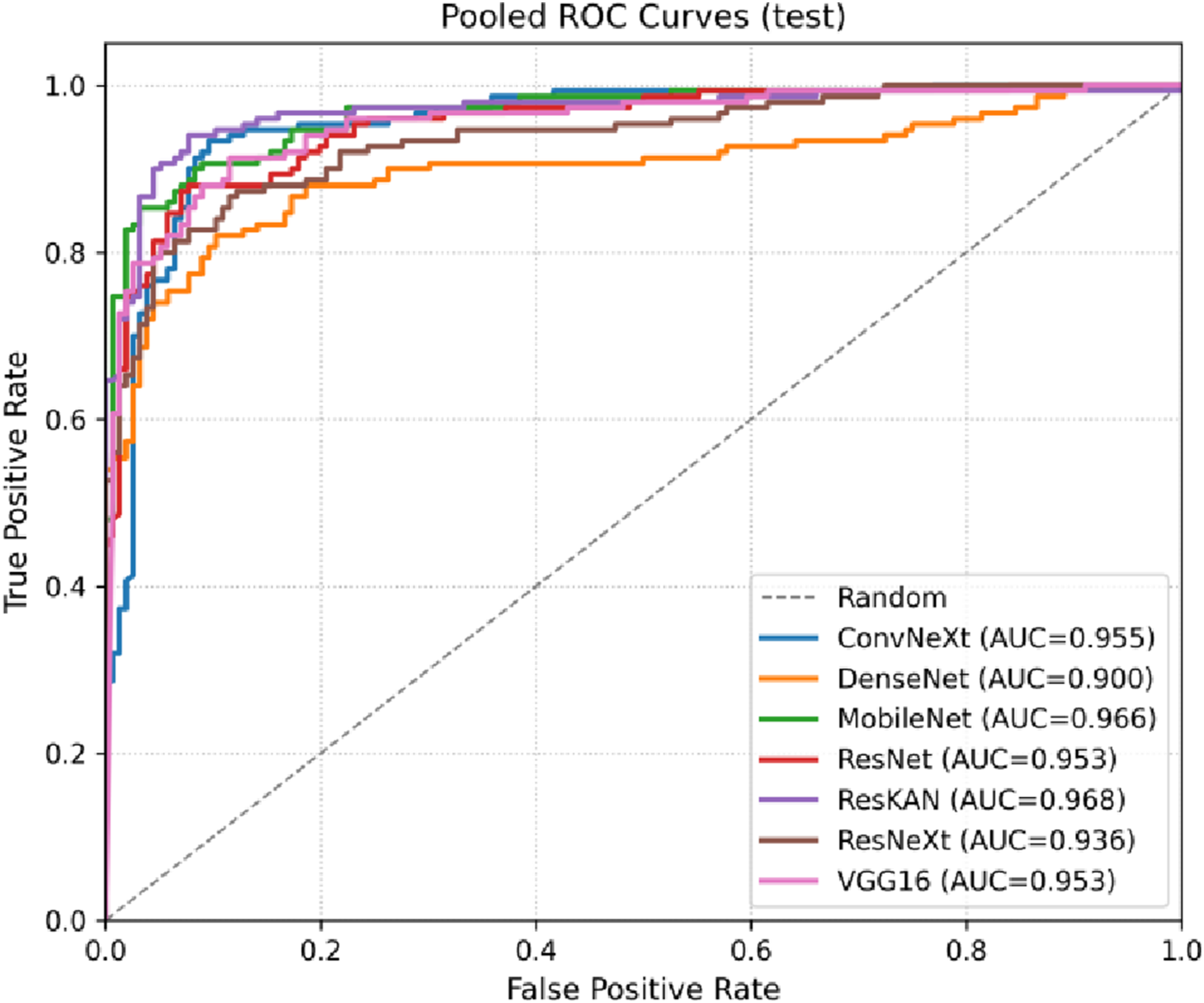
Grad-CAM visualization results
Grad-CAM heatmaps were used to qualitatively examine the image regions contributing to ResKAN predictions (Figure 12). In the generated heatmaps, warmer colors indicate greater contribution to the predicted class, whereas cooler colors indicate lower relevance. The visualizations show that ResKAN tends to focus on the fissure regions, including cases with varying illumination or subtle fissure presentations. These qualitative results suggest that ResKAN primarily relies on texture cues consistent with fissured-tongue features. Grad--CAM visualization of ResKAN for fissured-tongue feature recognition. Top row: input ROI images. Bottom row: Grad--CAM heatmaps, which highlight the regions of the input image that most influenced the prediction.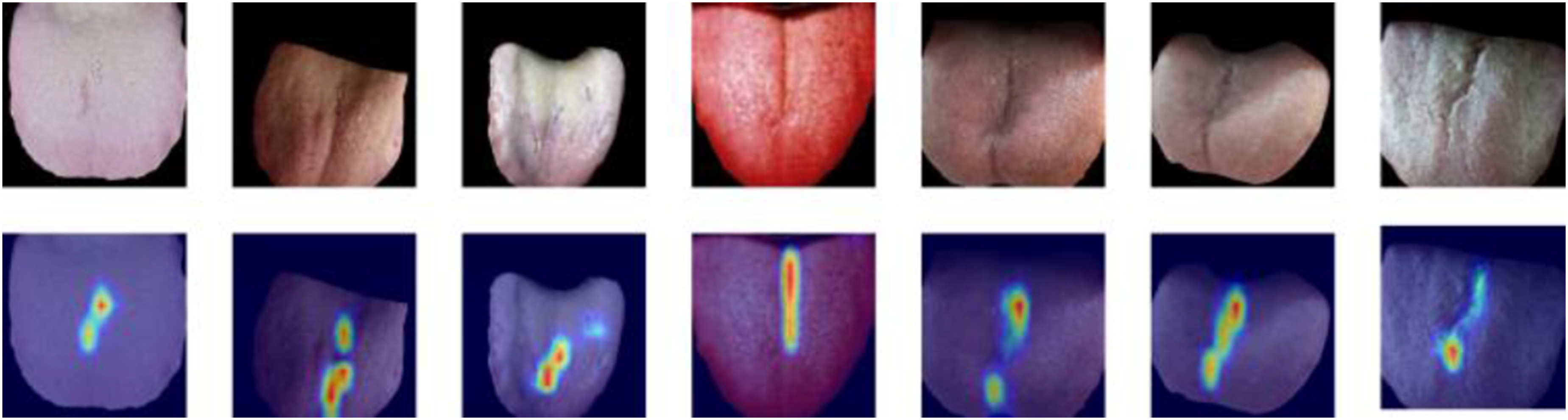
Integrated prototype demonstration
Figure 13 presents an end-to-end demonstration of the integrated prototype workflow. The prototype supports guided tongue-image acquisition at the terminal, followed by segmentation-based quality gating and server-side analysis. After image submission, TSegNet is first used to determine whether a valid tongue region can be extracted. Cases with a valid segmentation result proceed to the analysis dashboard for ROI visualization and fissured-tongue recognition, whereas unsuccessful cases are intercepted and returned with a recapture prompt. For valid cases, the system further provides user-facing feedback based on the predicted fissured-tongue feature status and confidence level. End-to-end demonstration of the integrated prototype workflow. (a) Guided image acquisition. The user completes profile setup and captures a tongue image through the guided interface; (b) Segmentation-based quality gate. TSegNet is used to verify whether a valid tongue region can be extracted. (1) If a valid tongue region is obtained, the system proceeds to the analysis dashboard, where the acquired image, segmented ROI, and model outputs are displayed. (2) If no valid tongue region is detected, the inference is interrupted and a recapture prompt is returned; (c) Confidence-stratified user feedback for valid cases. After valid segmentation, the ResKAN module performs fissured-tongue feature recognition and returns user-facing feedback with different confidence levels, including (1) feature-oriented feedback for high-confidence cases, (2) more cautious feedback for moderate-confidence cases, and (3) uncertainty-aware feedback for low-confidence or normal cases.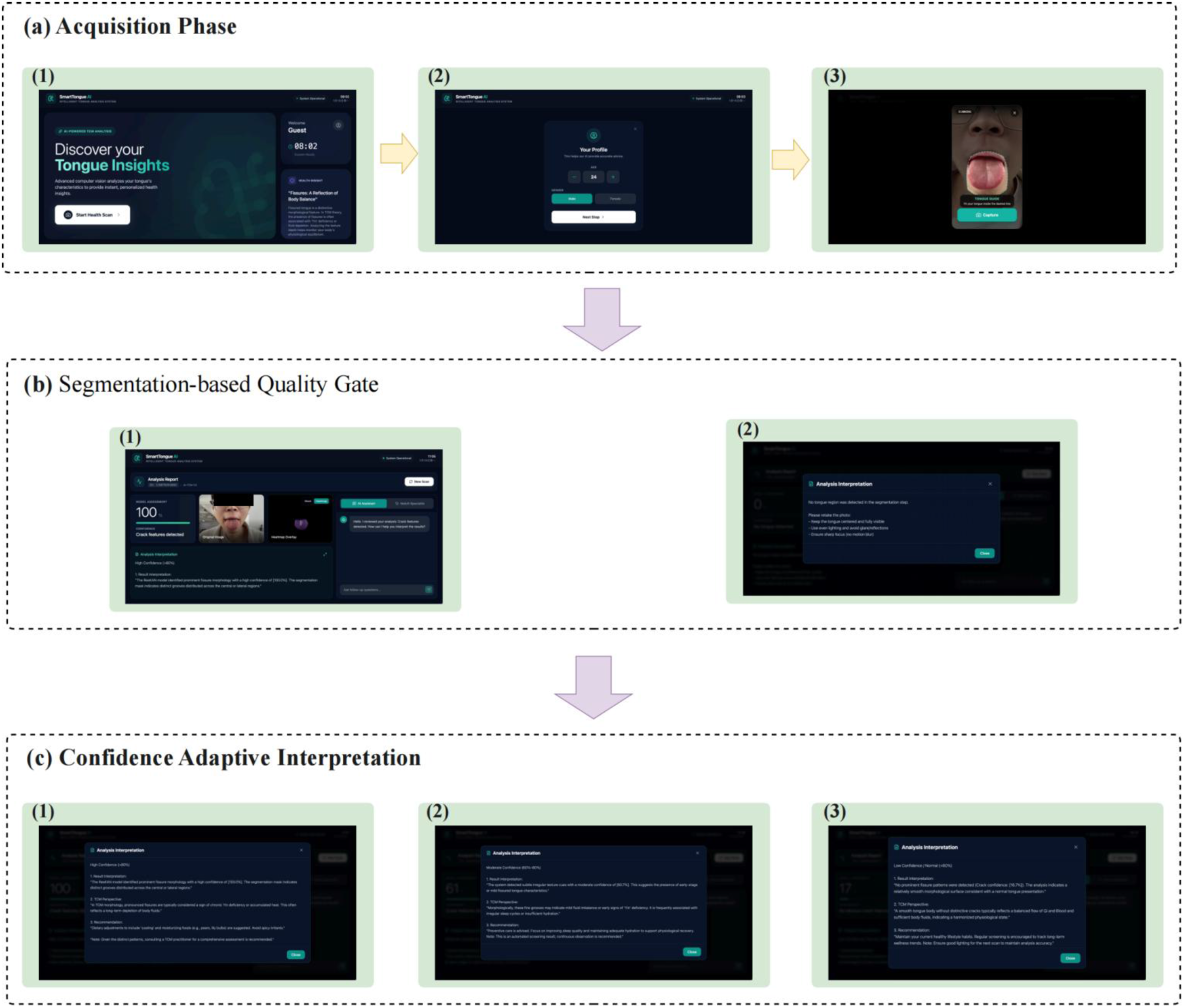
Discussion
Principal findings
This study developed an integrated portable system for non-contact tongue imaging and automated analysis in community and home settings. By combining a guided acquisition terminal with server-side deep learning models, the proposed framework supports image capture, tongue ROI extraction, fissured-tongue feature recognition, and user-facing feedback within a unified workflow. Taken together, these findings suggest that portable tongue-image analysis is technically feasible under relatively unconstrained acquisition conditions.
Interpretation of tongue segmentation performance
A notable finding of this study is the strong segmentation performance achieved by TSegNet on tongue images acquired in routine clinical settings rather than under highly standardized imaging conditions. Reliable tongue ROI extraction is an essential prerequisite for downstream analysis, particularly in portable deployment scenarios where background interference, pose variation, and illumination inconsistency may be more common. In this context, the quantitative and qualitative results suggest that the proposed segmentation strategy can provide a stable basis for subsequent analysis of tongue images acquired outside tightly controlled laboratory settings.
Interpretation of fissured-tongue feature recognition
The recognition results suggest that ResKAN is effective for the current recognition task targeting fissured-tongue features. Compared with the other evaluated models, ResKAN achieved the best overall mean performance and showed a more balanced error pattern in terms of false positives and false negatives. This may be related to the combination of residual feature extraction and KAN-based nonlinear modeling, which may help capture the subtle local texture variations associated with fissured-tongue features. In addition, the Grad-CAM visualizations provided qualitative support that ResKAN tended to attend to fissure-related regions, including cases with varying illumination and relatively subtle fissure presentations.
From a practical perspective, fissured tongue is a visually recognizable morphological sign and therefore provides a reasonable initial target for automated tongue-image analysis in portable deployment scenarios. Focusing first on a single and relatively explicit visual feature also allowed the feasibility of the overall workflow to be evaluated in a more controlled manner.
Limitations and future work
Despite these encouraging results, several limitations should be acknowledged. First, the usability and illumination robustness of the acquisition terminal require further quantitative validation across broader user demographics and diverse environments. Second, the current framework was limited to fissured-tongue feature recognition and did not jointly consider other tongue signs relevant to broader tongue analysis. In addition, the present model did not further characterize fissure-related properties such as severity, depth, number, or spatial distribution. Finally, several subject-related and acquisition-related factors may affect the visual appearance of tongue fissures, including hydration status, mouth breathing, smoking, oral hygiene, nutritional status, fungal infection, illumination, and tongue posture. These factors were not systematically controlled or analyzed in the present study. Accordingly, the current system should be interpreted as providing preliminary automated recognition of fissured-tongue imaging features rather than an independent clinical diagnosis.
Future work will therefore focus on broader real-world validation of the portable system and on extending the analytical scope of the framework. In particular, additional tongue signs, such as tongue body color, coating characteristics, and moisture, may be incorporated into a more comprehensive analysis pipeline. We will also investigate fissure-related morphology in greater detail, including finer-grained characterization of fissure severity and structural patterns through severity grading and quantitative morphological analysis.
Conclusion
This paper presents a portable non-contact tongue imaging system that integrates guided image acquisition with server-side automated analysis for community and home settings. The proposed framework combines TSegNet for tongue ROI extraction and ResKAN for fissured-tongue feature recognition, and the experimental results support the feasibility of this integrated approach under relatively unconstrained acquisition conditions. These findings provide an initial step toward more accessible and deployable automated tongue-image analysis.
Footnotes
Acknowledgements
The authors acknowledge Guangdong Polytechnic Normal University for providing the research platform and resources, and Guangzhou University of Chinese Medicine for its crucial data support.
Ethical considerations
This study was approved by the Ethics Committee of Maoming Hospital of Traditional Chinese Medicine (approval number: 2024061301). All participants provided informed consent before participating in the study.
Author contributions
The authors confirm contribution to the article as follows: Shaoyang Men, Peipei Zhou and Jiehan Wei did conceptualization; Jiehan Wei, Jun Song and Weiliang Lu did methodology; Jiehan Wei did software and writing---original draft; Jiehan Wei, Shaoyang Men, Peipei Zhou, Chuangquan Lin and Jun Song did writing---review and editing; Shaoyang Men and Peipei Zhou did supervision; Shaoyang Men did project administration; Peipei Zhou did funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (NSFC) (Grant Nos. 82575258 and T2341009).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are not publicly available due to ethical and privacy restrictions, but are available from the corresponding author upon reasonable request.