
Abstract
Background
Machine learning (ML) has become a transformative force in clinical research, offering predictive precision and data-driven decision-making across diverse medical domains. Despite this rapid adoption, a comprehensive informatic-based synthesis of ML applications in clinical trials remains lacking. This study systematically maps the scientific landscape, thematic evolution, and emerging directions of ML-related clinical trial research.
Methods
The analysis was conducted on PubMed-indexed clinical trials (1995–2025) using Bibliometrix R package, VOSviewer, and Microsoft Excel 2021 (Microsoft Corp., USA). Temporal trends were modeled using ARIMA(5,1,0) forecasting and additive time-series decomposition. Collaboration networks, productivity patterns (Lotka’s Law), journal dispersion (Bradford’s Law), keyword co-occurrence, and thematic mapping (Walktrap clustering, Callon’s centrality/density) were analyzed to identify conceptual structures and research frontiers.
Results
A total of 1,195 publications across 563 journals were identified, showing exponential growth after 2018 and a forecasted stabilization by 2030. The USA (24.8%) and China (19.5%) led global output, reflecting strong North American–Asian collaboration. Keyword co-occurrence revealed eight clusters centered on machine learning, artificial intelligence, and radiomics, transitioning toward deep learning, precision medicine, and mHealth. Bradford’s Law identified 36 core journals, including Scientific Reports, BMJ Open, and PLOS ONE. Thematic evolution showed a shift from algorithmic and retrospective studies to clinically grounded themes such as cognitive behavioral therapy and telemedicine. Emerging topics emphasized translational and patient-centered applications.
Conclusion
This study delineates the dynamic evolution of ML in clinical trials, highlighting its growing integration into precision medicine. Future research should prioritize inclusivity, real-world implementation, and ethical frameworks to sustain equitable and clinically impactful innovation.
Keywords
1. Introduction
Machine Learning (ML) is increasingly applied across all phases of clinical trials to enhance efficiency, patient-centeredness, and overall success. 1 ML algorithms analyze large, diverse datasets to uncover patterns and predict outcomes, improving trial design, execution, and analysis. 2 A key application is accelerating patient recruitment. Natural language processing (NLP) models screen electronic health records to identify eligible patients much faster than manual methods, 3 reducing recruitment time. By automating eligibility checks and matching, ML helps trials enroll participants more efficiently, potentially reducing recruitment time. 4 During trials, ML enables real-time data monitoring and risk assessment. For example, ML models predict adverse events and treatment outcomes by analyzing patient data trends, allowing proactive safety interventions. 5 These algorithms also identify subgroups most likely to benefit from an experimental therapy. 6 After trials, ML-driven analytics extract insights from complex data such as genomics or imaging, enhancing result interpretation. 7 Collectively, these applications highlight ML’s potential to streamline clinical trials—making them faster, more cost-effective, and more successful in bringing new therapies to patients.
Clinical applications of machine learning.
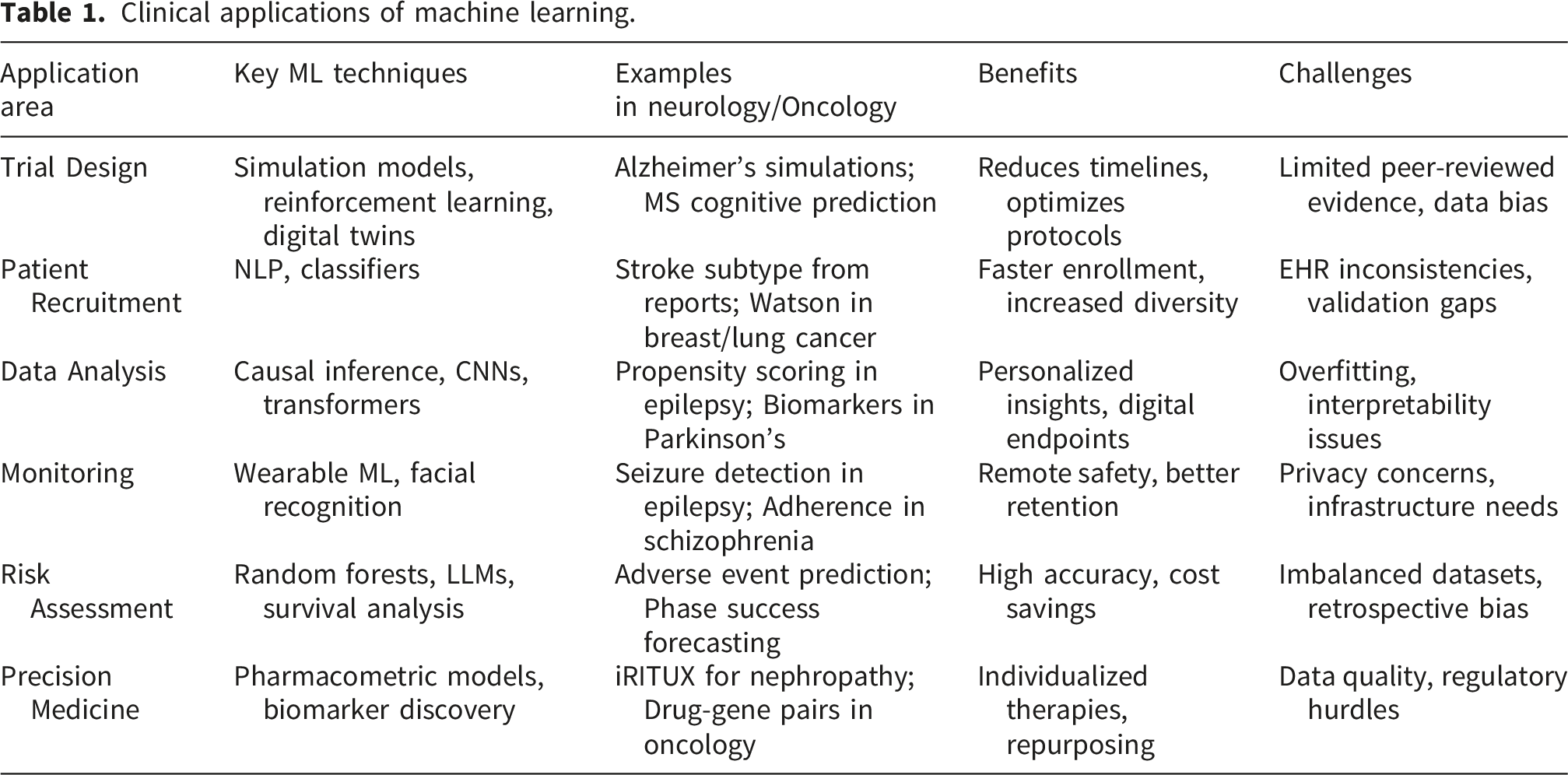
Despite rapid progress, clinical research applying ML faces several gaps. Current studies remain fragmented, often confined to single diseases such as oncology or neurology, without a comprehensive synthesis across diverse clinical domains.18,19 Limited attention has been given to ML applications in trial design optimization, adaptive protocols, and regulatory acceptance, leaving critical translational gaps. 1 Collaboration patterns also remain underexplored, particularly the imbalance between high-income and low-/middle-income countries. 13 Moreover, ethical and fairness concerns such as bias, transparency, and explainability are rarely addressed in bibliometric assessments. 15 The novelty of this bibliometric study lies in providing the first large-scale mapping of ML in clinical trials across all phases—recruitment, monitoring, and outcome prediction—integrating cross-disease insights, global collaboration trends, and thematic evolution to identify emerging frontiers and guide future research directions (Li et al., 2025; Watkins et al., 2025). This study aims to provide a comprehensive bibliometric analysis of ML in clinical research, mapping its applications across all trial phases. It seeks to identify knowledge structures, collaboration patterns, global disparities, and underexplored areas such as trial design and ethics, ultimately highlighting emerging frontiers and guiding future ML-driven clinical research.
2. Methods
2.1. Database selection
PubMed, maintained by the U.S. National Library of Medicine, is a leading biomedical database with over 36 million citations covering medicine, life sciences, and clinical research. It provides access to MEDLINE, PubMed Central, and linked resources, offering specialized filters for clinical trial phases, protocols, and randomized studies. Its use of Medical Subject Headings (MeSH) enhances precision and reproducibility in searches, while integration with ClinicalTrials.gov improves transparency by connecting trial registrations and outcomes. Overall, PubMed is a reliable platform for retrieving peer-reviewed clinical trial literature and supporting evidence-based research.
20
The PubMed database was systematically searched, and all records were retrieved on
2.2. Search strategy
In the present study, a targeted PubMed search strategy was employed to identify clinical trial publications involving ML. The query combined title/abstract keyword searching with multiple PubMed filters to maximize coverage: (“machine learning”[Title/Abstract]) AND ((excludepreprints[Filter]) AND (clinicaltrial[Filter] OR clinicaltrialprotocol[Filter] OR clinicaltrialphasei[Filter] OR clinicaltrialphaseii[Filter] OR clinicaltrialphaseiii[Filter] OR clinicaltrialphaseiv[Filter] OR controlledclinicaltrial[Filter] OR randomizedcontrolledtrial[Filter])) AND (humans[Filter]) AND (english[Filter]). This approach ensured the retrieval of human studies published in English, spanning all clinical trial phases and designs while excluding preprints, thereby providing a focused and high-quality dataset of clinical trial literature relevant to machine learning applications. No time frame was applied. All data were extracted from PubMed on 3 October 2025.
2.3. Inclusion and exclusion criteria
The inclusion criteria comprised peer-reviewed clinical trial publications that explicitly applied machine learning, restricted to human studies and English language articles. Eligible records covered all clinical trial phases (I–IV), protocols, randomized controlled trials, and controlled clinical trials. Exclusion criteria included non-human studies, non-English publications, preprints, conference abstracts, reviews, editorials, and commentaries. By applying these criteria, the dataset was limited to high-quality, original clinical trial research directly relevant to machine learning applications in healthcare. This study was conducted and reported in accordance with the BIBLIO (Bibliometric Reviews of the Biomedical Literature) reporting guidelines,
21
and the completed BIBLIO checklist is provided as Supplementary Material 1. Figure 1 presents a flow diagram summarizing the literature retrieval and selection process, from the initial PubMed search to the final inclusion of 1,195 machine learning–related clinical trial publications used for bibliometric mapping and forecasting analyses. Flow diagram illustrating the PubMed search and study selection process for machine learning–related clinical trial publications. A total of 218,904 records were initially retrieved using the keyword “Machine Learning.” After applying clinical trial–related filters and excluding non-human studies, non-English publications, and preprints, 1,195 eligible records were retained for bibliometric and time-series analyses. All data were extracted from PubMed on 3 October 2025. The figure summarizes the sequential screening, eligibility assessment, and inclusion steps leading to the final dataset analyzed in this study.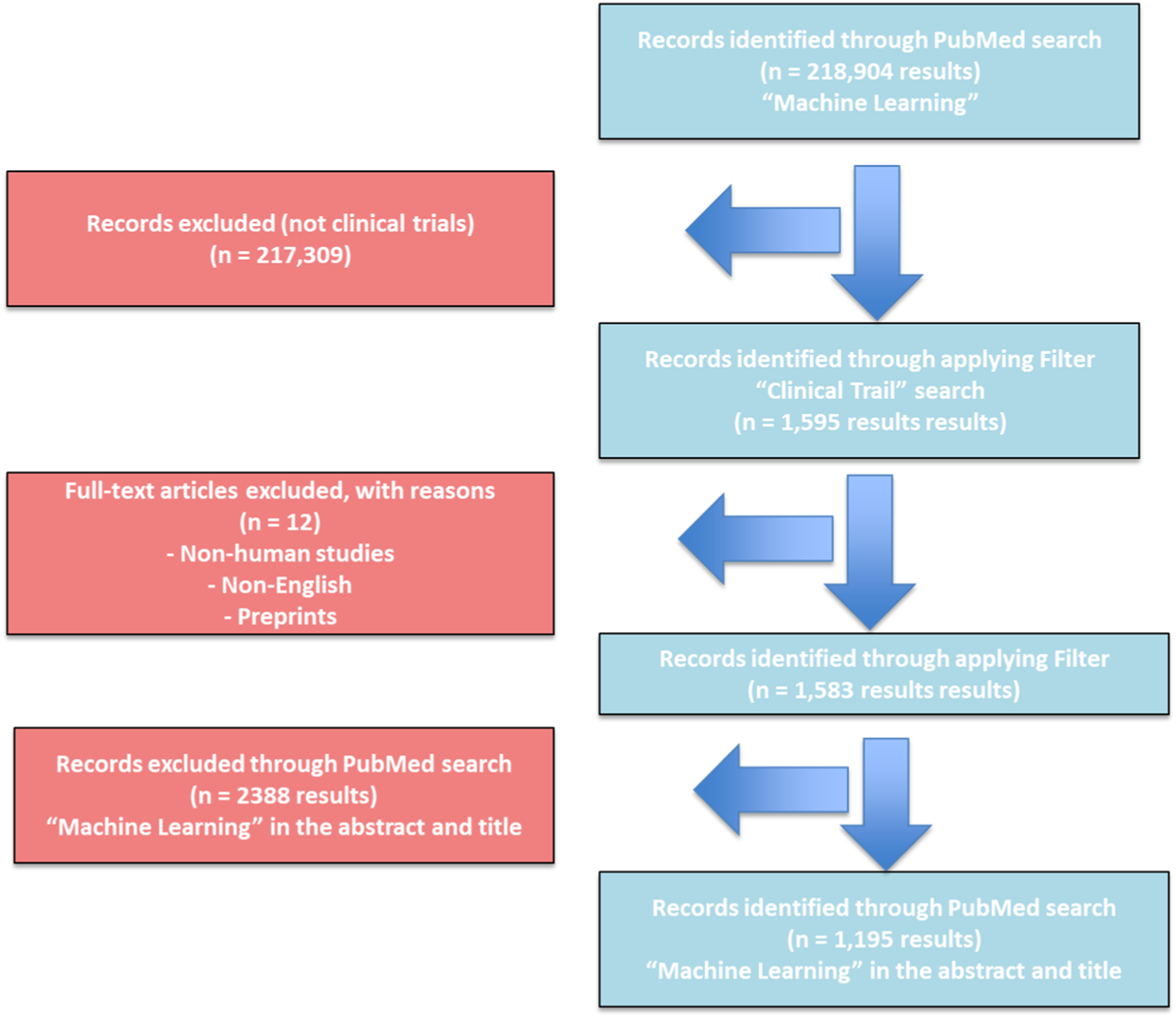
2.4. Data extraction and characteristics
All search results retrieved from PubMed were exported using the built-in “Save” function. The option “All results” was selected to ensure the complete dataset was downloaded, and the output format was set to PubMed. The file generated included essential bibliographic information such as titles and abstracts, which were later used for text-based analyses and map construction. The dataset spans publications from 1995 to 2025, encompassing 1,195 documents across 563 journals, with an annual growth rate of 18.26%, reflecting rapid expansion of the field. The average document age is 3.76 years, and both Keywords Plus and Author’s Keywords contributed 4,058 terms, indicating a broad thematic coverage. In terms of authorship, 9,607 authors contributed, but only 4 authors produced single-authored documents, resulting in 5 single-authored papers. Collaboration is high, with an average of 9.85 co-authors per document and 30.13% international co-authorships, highlighting strong global partnerships.
2.5. Data quality, sensitivity, and de-duplication
Data quality assurance was conducted through several steps to ensure accuracy and reproducibility. The PubMed search strategy was re-executed to verify reproducibility, and retrieved records were checked for completeness of metadata, including author names, abstracts, and DOIs. Sensitivity was assessed by testing alternative keywords to confirm that key studies were not omitted, while specificity was evaluated by screening random samples for relevance. Duplicate records were identified using bibliometric software and reference managers, then manually confirmed and removed. All processes were documented, including search dates, filtering, and exclusion logs.
2.6. Times series analysis
The time series analysis employed several statistical techniques to evaluate publication trends in machine learning–related clinical trials. An ARIMA (5,1,0) model was selected after testing multiple parameter combinations, incorporating five autoregressive terms, one differencing step to ensure stationarity, and no moving average terms. The model was fitted using the maximum likelihood method, with diagnostic checks including residual analysis and information criteria (AIC, BIC) confirming adequacy. Forecasts for 2026–2030 were generated with prediction intervals to quantify uncertainty. Additionally, additive time series decomposition was applied to separate trend, seasonal, and residual components. Given the annual nature of the data, seasonal effects were minimal, and the focus was placed on long-term trends and irregular fluctuations. All analyses were performed in Python 3.11 using pandas for data management, matplotlib and seaborn for visualization, and statsmodels for time series modeling. Publication counts for 2024 and 2025 should be interpreted cautiously, as PubMed indexing delays and journal embargo periods may result in partial coverage for the most recent years.
2.7. Visualization and clustering
The analysis was conducted using three complementary software tools to ensure robust visualization and statistical mapping of publication trends, collaborations, and conceptual structures. Bibliometrix R package (version 4.2.3; University of Naples Federico II, Naples, Italy) and its web interface Biblioshiny 22 were used for descriptive bibliometric indicators, thematic evolution, and conceptual mapping based on Callon’s centrality and density. VOSviewer (version 1.6.20; Centre for Science and Technology Studies, Leiden University, Leiden, Netherlands) was employed for constructing and visualizing co-authorship and keyword co-occurrence networks, 23 while Microsoft Excel 2021 (Microsoft Corp., Redmond, WA, USA) was used for bilateral collaboration matrices and data tabulation. A full counting method was applied in all VOSviewer analyses, and documents with more than 25 co-authors were excluded to minimize bias from large consortium papers. For co-authorship analysis, the unit of analysis was set to “authors,” with a minimum threshold of five documents per author, yielding 92 eligible authors out of 8,832. The resulting network comprised 92 items, 641 links, and a total link strength of 823, forming 11 distinct clusters. For country-level collaborations, fractional counting was used to normalize contributions, while for keyword co-occurrence networks, a minimum occurrence threshold of five terms was applied, identifying 103 terms, 546 links, and a total link strength of 1,164, distributed across eight thematic clusters. Lotka’s and Bradford’s bibliometric laws were applied through Bibliometrix to examine author productivity and source dispersion, respectively. Lotka’s Law analysis used the power-law model with goodness-of-fit (R2 = 0.94) to estimate author productivity (exponent = 2.86). Bradford’s Law categorized journals into three productivity zones, with Zone 1 consisting of 36 core journals accounting for 398 documents. The thematic evolution and conceptual structure analyses employed the Walktrap community detection algorithm and Multiple Correspondence Analysis (MCA) within Biblioshiny, 22 classifying clusters into motor, basic, niche, and emerging/declining themes. The threshold for inclusion was set to five keyword occurrences and a minimum of 50 documents per period to ensure stability across time segments. Finally, trend topic and emerging term analyses were performed using Bibliometrix R (biblioshiny::trendTopics) with n-gram tokenization for unigram, bigram, and trigram term extraction from article titles. These were visualized chronologically to capture thematic trajectories and the rise of emerging terms such as “machine learning models,” “clinical decision support,” and “prospective cohort study.” Collectively, these methods provided a multidimensional overview of machine learning–related clinical trial research, encompassing productivity, collaboration, and conceptual evolution across the 1995–2025 period.
3. Results
3.1. Temporal trends and time series analyses
The temporal analysis of clinical trials applying ML demonstrates a steady upward trajectory over recent years. As shown in Figure 2(a), the number of publications increased from 172 trials in 2021 to a peak of 224 in 2023, followed by 180 in 2024 and 154 in 2025. Although the most recent year shows a modest decline, the overall trend reflects sustained growth in the integration of machine learning within clinical research. Descriptive statistics showed a mean annual count of 58.08 (SD = 77.66), with values ranging from 1 in the early years to a maximum of 224 in 2023. The distribution was positively skewed (Figure 2(a)), with most years exhibiting low counts and a few recent years showing disproportionately high values, as illustrated by the histogram and boxplot (Figure S1 and S2). Time series visualization (Figure 2(a)) highlighted a prolonged period of minimal activity until around 2005, after which publication counts increased steadily, with marked acceleration after 2018. Autocorrelation analysis (Figure 2(b)) demonstrated strong temporal dependence (r = 0.95), supporting the use of autoregressive modeling. An ARIMA(5,1,0) model provided an adequate fit, as indicated by diagnostic tests and residual analysis (Figure 2(c)–(f)). Forecasting for 2026–2030 predicted fluctuating counts, with an initial decline from 145 in 2026 to 77 in 2029, followed by a modest recovery to 87 in 2030. Time series decomposition confirmed a strong upward trend with minimal seasonal influence. Overall, the findings indicate rapid adoption of machine learning in clinical trials, though future growth may stabilize, reflecting both maturation of the field and evolving publication dynamics. This pattern underscores both the rapid adoption of ML methodologies and their increasing recognition as valuable tools across diverse clinical trial domains. Publication counts for 2024 and 2025 should be interpreted cautiously, as PubMed indexing delays and journal embargo periods may result in partial coverage for the most recent years. (a): Temporal distribution of PubMed-indexed clinical trials applying machine learning (1995–2025). The number of trials remained minimal until 2012, followed by a marked increase from 2018 onward, peaking at 224 publications in 2023. A slight decline was observed in 2024 (n = 180) and 2025 (n = 154), though the overall trend demonstrates rapid growth in the application of machine learning across clinical research domains. (b): Heatmap showing the correlation between publication counts and their one-year lagged values, indicating strong temporal dependence. (c–f): Residual analysis of the ARIMA(5,1,0) model, including residuals over time, histogram, Q-Q plot, and autocorrelation function.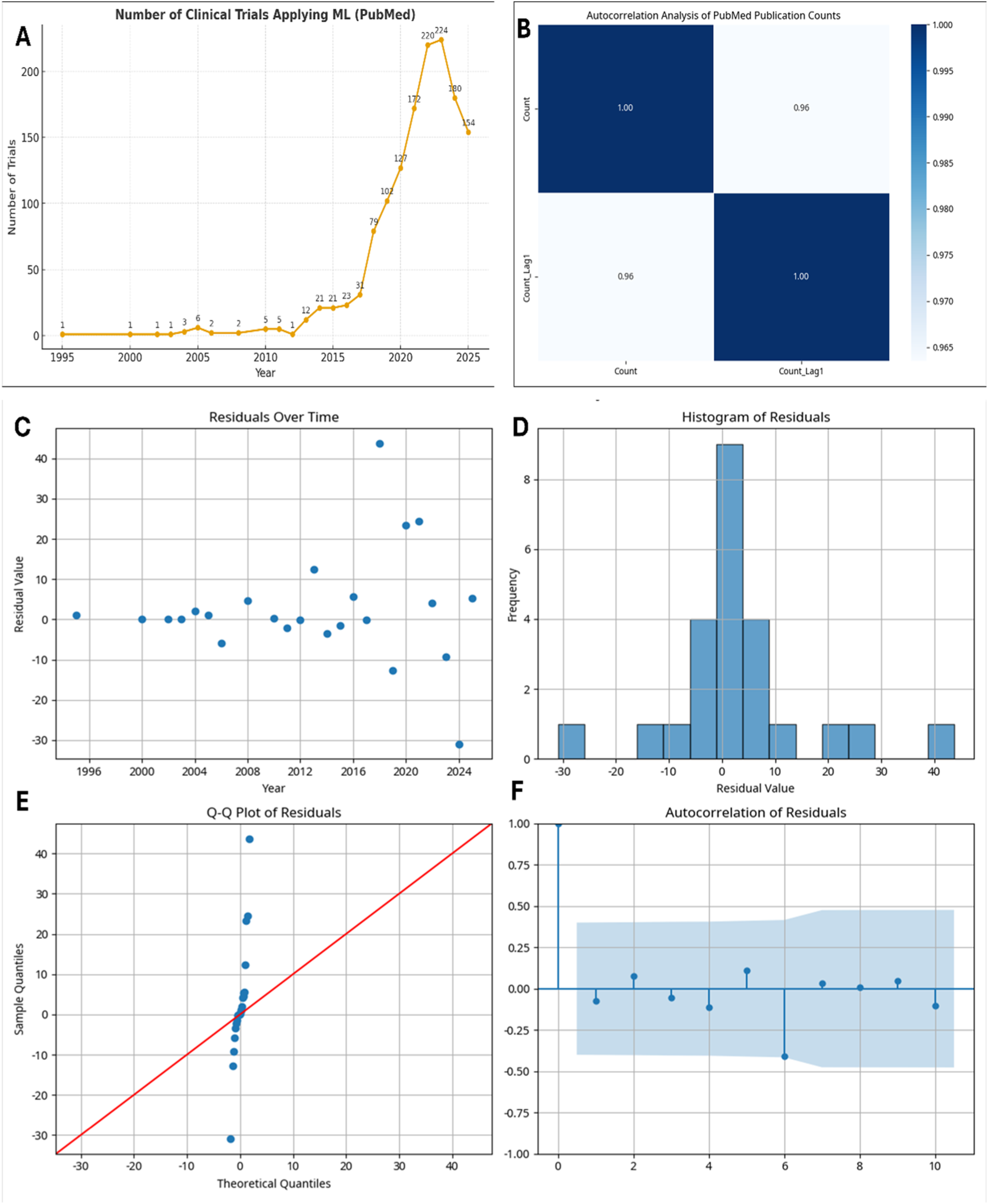
3.1.1. Forecasting
Using the fitted ARIMA(5,1,0) model, forecasts for PubMed publication counts were projected for the years 2026–2030 (Figure 3(a), Table 2). The model demonstrated a good fit, capturing the underlying temporal dynamics of publication growth. The forecast indicates a fluctuating trend over the next five years, with an initial decline followed by a mild recovery toward 2030. Specifically, the predicted publication counts are 145.48 (2026), 123.44 (2027), 88.56 (2028), 76.80 (2029), and 86.88 (2030). These results suggest a short-term contraction in output after the recent surge, potentially reflecting saturation effects or shifts in research priorities, before a modest rebound occurs. The differenced time series exhibited stable behavior with no remaining trend, supporting the appropriateness of the ARIMA(5,1,0) specification and the validity of the decomposition shown in Figure 3. (a) Time series plot with ARIMA forecast for PubMed publication counts from 2026 to 2030, showing the original data and the forecasted values. (b). Time series decomposition of PubMed publication counts into trend, seasonal, and residual components. Forecast for PubMed publication counts (2026-2030).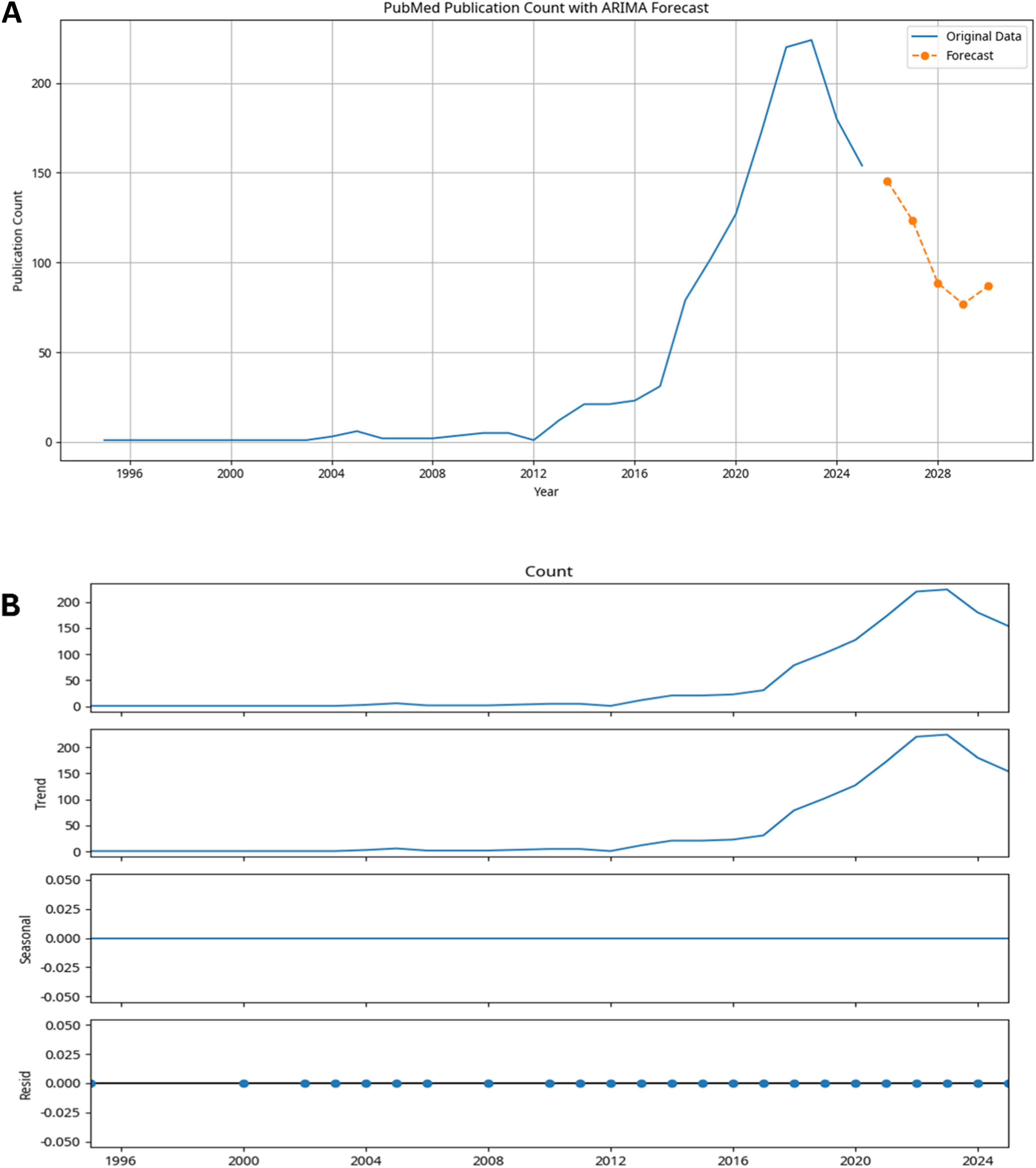
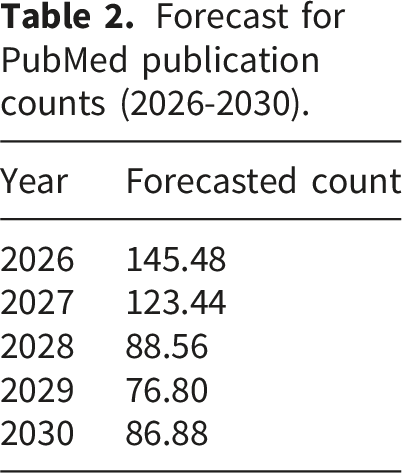
3.1.2. Time series decomposition
The time series decomposition analysis (Figure 3(b)) revealed three components—trend, seasonal, and residual. The trend component showed a consistent upward trajectory, confirming the long-term increase in research activity and highlighting accelerated growth in recent years. As the dataset comprises annual data, the seasonal component was minimal, consistent with the absence of cyclical annual effects. The residual component captured irregular fluctuations around the main trend, reflecting variations due to external factors such as policy changes or funding dynamics. Collectively, the decomposition underscores that the observed growth in publications is primarily driven by the strong and sustained upward trend. The forecast suggests a fluctuating pattern in publication counts over the next five years, with an initial decrease followed by a slight recovery toward the end of the forecast period.
3.2. Global landscape
The global distribution of clinical trials applying machine learning was markedly concentrated in high-income countries (Figure 4(a)). The United States accounted for the largest share (24.76%), followed by China (19.51%) and Germany (8.34%). European countries such as the Netherlands (4.39%), France (3.81%), Italy (2.62%), Spain (2.53%), and Denmark (2.51%) collectively represented a substantial proportion of output. Other notable contributors included Canada (4.00%), Japan (3.22%), South Korea (2.63%), and Australia (2.50%). In contrast, contributions from low- and middle-income countries were relatively modest, with India (0.69%), Brazil (0.67%), and Mexico (0.41%) among the highest. African representation was limited, with South Africa (0.14%), Mozambique (0.14%), and a small number of single-digit contributors (e.g., Nigeria, Rwanda, Ghana, each ≤0.1%). Several emerging economies, including Turkey (0.18%) and Iran (0.29%), showed growing engagement despite lower absolute contributions. Overall, the geographical analysis highlights a dominance of the USA and China, together contributing over 44% of global publications, while many regions—particularly Africa, Latin America, and parts of Asia—remain underrepresented, emphasizing the need for greater inclusivity and international collaboration in the clinical application of machine learning. (a): Global distribution of clinical trials applying machine learning. Countries are shaded according to their percentage contribution of publications, with darker shades indicating higher output. Data were extracted from PubMed (1995–2025) and analyzed using country affiliation metadata. (b). Country production of machine learning–related clinical trial publications (1995–2025). The United States led with over 2,800 publications in 2025, followed by China (2,256) showing rapid recent growth. Germany (964), the Netherlands (507), and Canada (462) demonstrated steady increases. (c): Sankey diagram linking top authors, countries, and journals in machine learning–related clinical trial research. Most prolific authors (e.g., Wang Y, Li J, Zhang J) are primarily affiliated with China, followed by the USA and European countries. Key publication outlets include Scientific Reports, BMJ Open, Trials, eBioMedicine, and PLOS ONE. The flows highlight China and the USA as central hubs, with diverse dissemination across multidisciplinary and clinical journals. (d): Domestic (SCP) versus global (MCP) productivity of corresponding author countries in machine learning–related clinical trials. The USA and China lead in total output, while European countries and Canada show higher proportions of international collaboration. Data were sourced from PubMed and visualized using the Bibliometrix R package.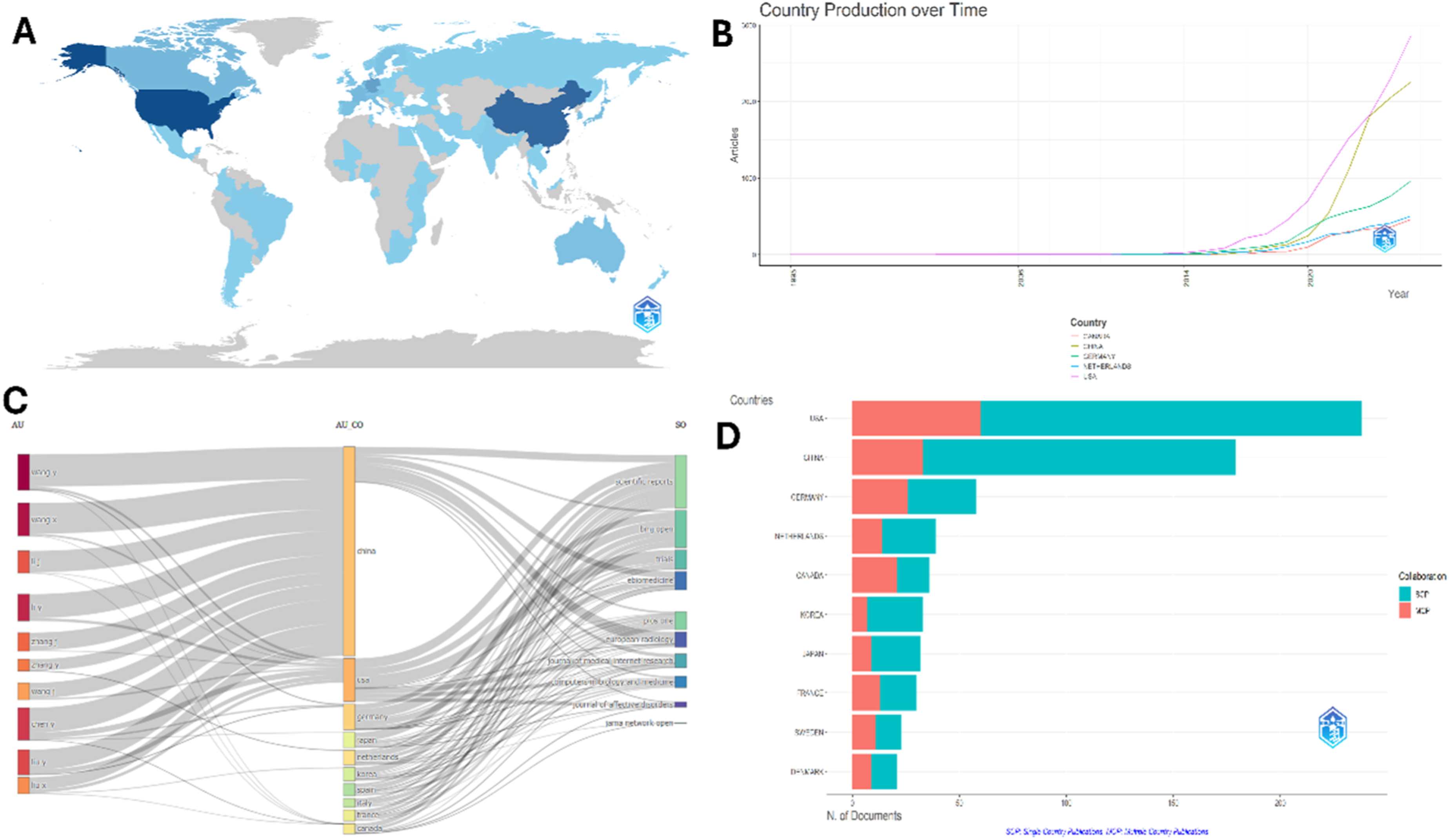
The temporal evolution of country-level contributions highlights distinct growth trajectories among leading nations (Figure 4(b)). The United States maintained dominance throughout the study period, exhibiting an exponential increase after 2015 and reaching 2,863 publications in 2025. China demonstrated the fastest acceleration, particularly after 2020, narrowing the gap with the USA and producing 2,256 publications in 2025. Germany showed steady, moderate growth, culminating in 964 publications, while Canada (462) and the Netherlands (507) reflected smaller but consistent upward trends. Collectively, these findings emphasize the rapid expansion of machine learning–related clinical trials, with the USA and China emerging as global leaders.
The Sankey diagram (Figure 4(c)) illustrates the relationship between leading authors, their affiliated countries, and target journals in machine learning–related clinical trial research. On the left (AU), highly productive authors such as Wang Y, Wang X, Li J, Li Y, Zhang J, and Chen Y are shown, with most linked to China. The middle section (AU_CO) highlights the dominance of China and the USA, followed by contributions from Germany, Japan, the Netherlands, Korea, Spain, Italy, France, and Canada. On the right (SO), major publishing outlets include Scientific Reports, BMJ Open, Trials, eBioMedicine, PLOS ONE, and European Radiology. The flows emphasize that Chinese and U.S. authors contribute heavily to high-impact multidisciplinary and clinical journals, with China emerging as the central hub of production. This visualization underscores the concentration of influential authorship in a few countries while showing the diversity of journal outlets for disseminating machine learning applications in clinical trials.
3.3. Domestic scholarly discourse
The analysis of corresponding author countries (Figure 4(d)) revealed the dominance of the United States (238 articles), with a strong balance between domestic publications (SCP = 178) and international collaborations (MCP = 60). China followed with 179 articles, of which the majority were domestic (SCP = 146), indicating a relatively lower proportion of global collaboration. Germany contributed 58 articles, showing a more balanced distribution between SCP (32) and MCP (26). Other European countries such as the Netherlands, France, Sweden, and Denmark exhibited smaller total outputs but relatively higher proportions of MCP, underscoring their stronger engagement in international partnerships. Canada produced 36 articles, with nearly equal contributions from domestic (15) and international collaborations (21), reflecting a collaborative research culture. Asian countries, including Korea (33 articles, largely domestic) and Japan (32, predominantly SCP), showed comparatively less global integration. Overall, the data highlight the USA and China as the most productive nations, though Europe and Canada demonstrate higher international research collaboration in machine learning–related clinical trials.
3.4. Lotka’s law
The analysis of author productivity using Lotka’s Law (Figure 5(a)) revealed a highly skewed distribution, with 88% (n = 8,450) of the 9,603 authors publishing only a single document, 8.1% (n = 779) publishing two, and progressively fewer contributing more than three publications. A very small group of core authors (≤0.1%) produced between 10 and 25 documents. The observed pattern closely followed Lotka’s theoretical distribution, with a strong fit (R2 = 0.94) and an estimated exponent of 2.86, slightly higher than the classical value of 2.0, indicating a steeper decline in productivity. These results confirm that research output in machine learning–related clinical trials is dominated by a small number of prolific contributors, while the majority of authors remain one-time or occasional participants. (a) Author productivity distribution analyzed using Lotka’s Law. The majority of authors contributed only one publication, while a small group of prolific authors produced multiple outputs. The observed distribution closely fits Lotka’s theoretical model. (b) Core sources identified through Bradford’s Law, highlighting a concentration of publications in a small set of journals (e.g., Scientific Reports, PLOS ONE, BMJ Open), which serve as the primary outlets for machine learning–related clinical trial research.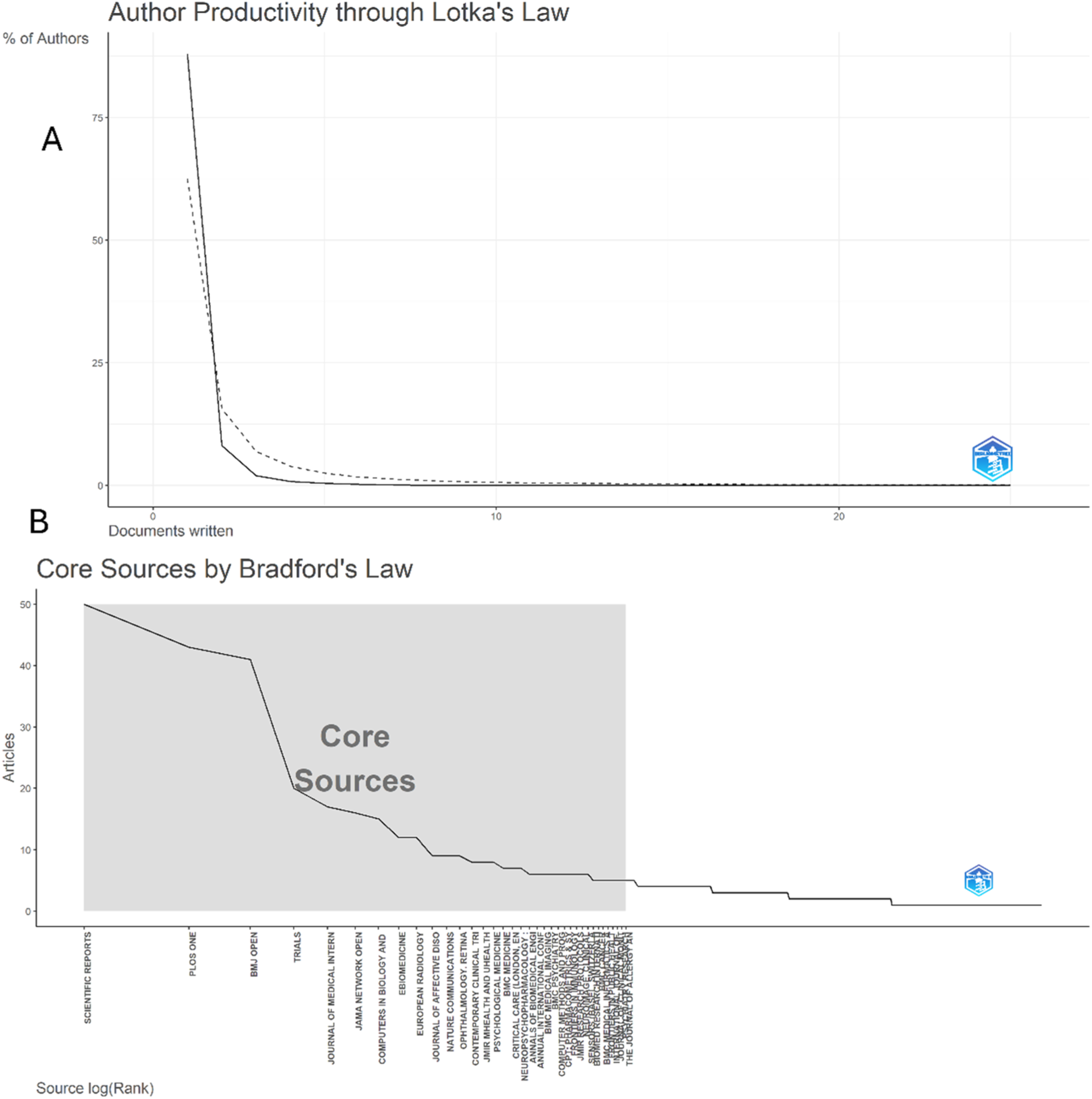
3.5. Leading sources: Bradford’s law
The application of Bradford’s Law identified a core group of journals (Zone 1) that published the majority of machine learning–related clinical trial research (Figure 5(b)). A total of 36 journals constituted this core, collectively accounting for 398 articles. Scientific Reports ranked first with 50 publications, followed by PLOS ONE (43), BMJ Open (41), and Trials (20). Other prominent sources included Journal of Medical Internet Research (17), JAMA Network Open (16), Computers in Biology and Medicine (15), and eBioMedicine (12). Several specialty and interdisciplinary journals, such as European Radiology, Journal of Affective Disorders, and Nature Communications, also appeared within Zone 1. The Bradford distribution indicates that while ML-related clinical trial research is dispersed across numerous outlets, a relatively small group of multidisciplinary and clinical journals serve as the primary sources of dissemination, forming the knowledge core of this field.
3.6. Mapping of collaboration
The bilateral collaboration network (Figure 6(a)) revealed strong international partnerships in machine learning–related clinical trial research. Germany (n=37) and Canada (n=36) were the most frequent collaborators, followed by China (n=26), Switzerland (n=23), and the Netherlands (n=21). Other active partnerships included France, Japan, Italy, Spain, and Australia. These findings highlight the central role of European and North American countries in shaping global collaboration patterns, with Germany and Canada emerging as key hubs of cooperation. The network reflects a balanced mix of intra-European collaborations and transcontinental ties with North America and Asia, underscoring the globalized nature of the field. (a): Bilateral collaboration network in machine learning–related clinical trial research. Germany and Canada led with the highest number of partnerships, followed by China, Switzerland, and the Netherlands. Strong transcontinental ties and European hubs illustrate the globalized nature of research collaboration in this field. Data analyzed using MS Excel. (b). Network visualization of author collaboration in machine learning–related clinical trial research. The analysis was conducted using VOSviewer with full counting and a minimum threshold of five documents per author. The map includes 92 authors, 641 links, and a total link strength of 823 distributed across 11 clusters. Node size represents author productivity, while link thickness indicates collaboration strength. The color of each cluster reflects distinct co-authorship communities. An interactive version of this network is available at https://tinyurl.com/2aneyc8j.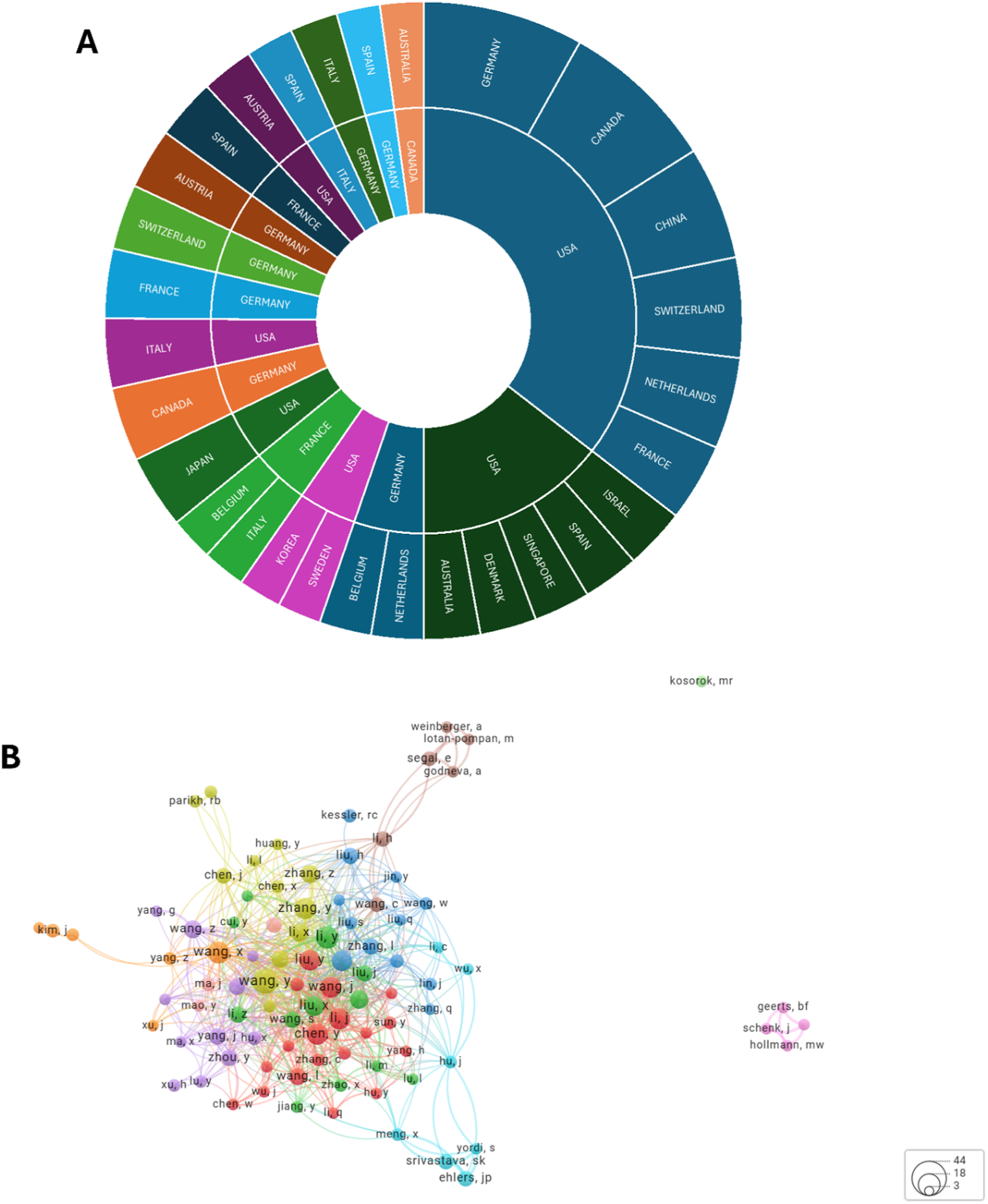
The co-authorship analysis, performed using VOSviewer with a minimum threshold of five documents per author, identified
3.7. Most frequent words: Unsupervised clustering and trajectory
The co-occurrence network analysis of author keywords identified 103 terms interconnected through 546 links, with a total link strength of 1,164, forming eight distinct thematic clusters (Figure 7(a)). The most frequent keywords included “machine learning” (n = 464), “artificial intelligence” (n = 60), “radiomics” (n = 49), “depression” (n = 37), and “prediction” (n = 32), underscoring the centrality of AI-driven methods in clinical research. The network revealed highly cohesive clusters linking clinical trial design, diagnostic imaging, mental health, and predictive modeling applications. The density visualization (Figure 7(b)) highlighted “machine learning,” “artificial intelligence,” and “radiomics” as dominant research hubs, reflecting their prominence and interconnectedness. Based on total link strength (TLS), “machine learning” (TLS = 587), “artificial intelligence” (TLS = 123), and “prediction” (TLS = 75) emerged as the most influential nodes, suggesting their key role in shaping research in ML (Figure 7(c)). The overlay visualization (Figure 7(d)) demonstrated a chronological evolution, with yellow-colored nodes such as “deep learning,” “precision medicine,” and “mHealth” representing emerging themes in recent years (2023–2025). Collectively, these findings indicate that research on machine learning in clinical trials has evolved toward integrative, patient-centered, and data-intensive paradigms, with growing attention to real-world clinical implementation and digital health applications. Keyword co-occurrence analysis of machine learning–related clinical trial publications visualized using VOSviewer. (a) Network visualization showing eight clusters representing thematic domains such as artificial intelligence, radiomics, clinical trials, and mental health. An interactive version of this figure is available at https://tinyurl.com/2a5qd9k4. (b) Density visualization highlighting frequently co-occurring terms; warmer colors indicate higher frequency. (c) Total link strength (TLS)–based density map emphasizing influential keywords in interconnections and research cohesion.(d) Overlay visualization illustrating temporal evolution, where yellow nodes represent emerging themes (e.g., deep learning, precision medicine, mHealth) from 2023–2025. Data source: PubMed (1995–2025).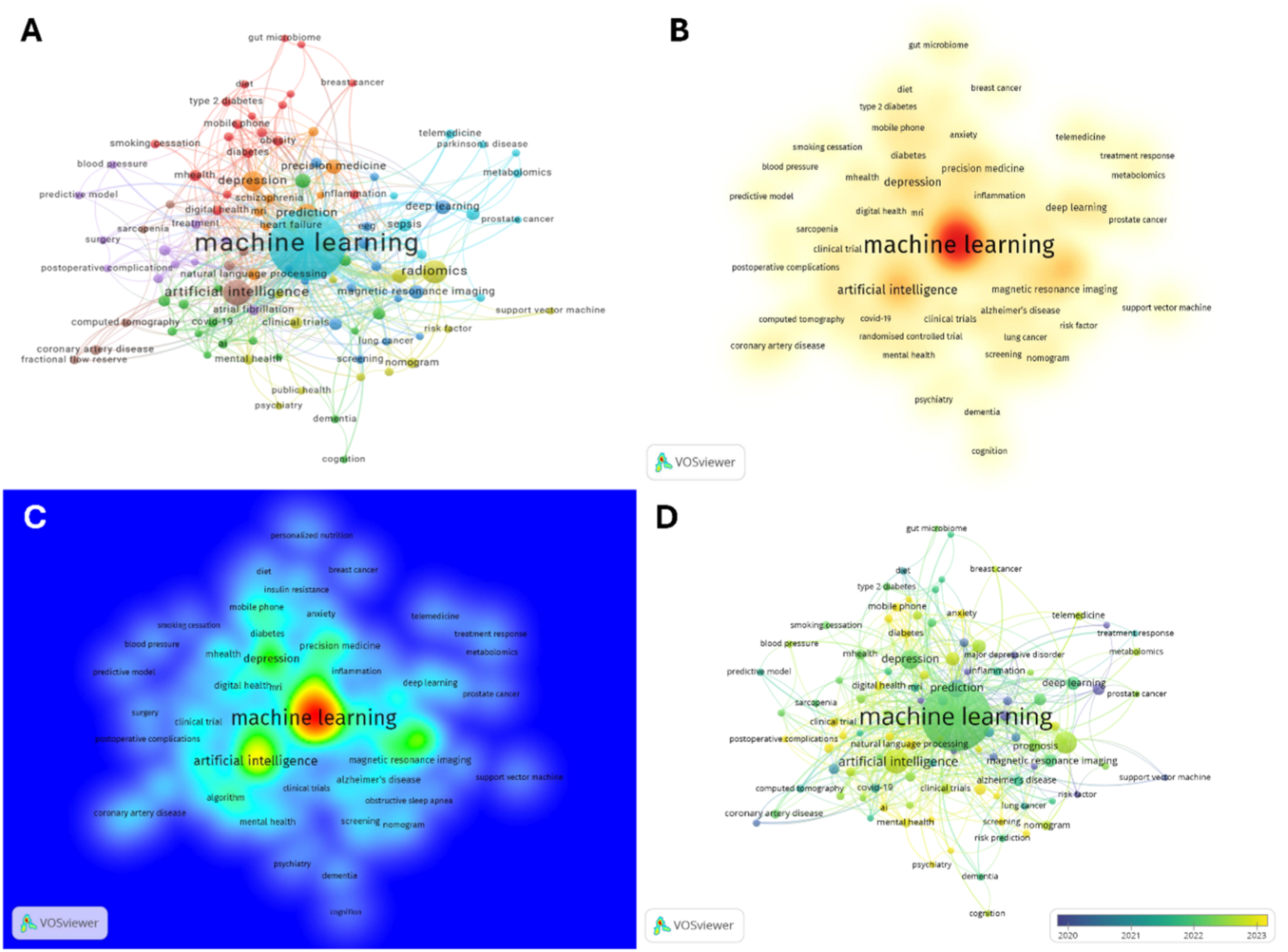
3.8. Thematic evolution and shifting research foci
The thematic evolution analysis (Figure 8(a)) revealed notable shifts in research focus across the study period. Between 1995 and 2022 (Figure 8(b)), dominant themes included humans, algorithms, randomized controlled trials, and retrospective studies, which served as foundational areas in machine learning–related clinical trial research. In the more recent period (2023–2025), these themes (Figure 8(c)) transitioned toward more specialized and clinically relevant directions, including case-control studies, cognitive behavioral therapy, double-blind methods, hemodynamics, intravitreal injections, and young adult populations. The thematic maps further demonstrated that while humans and randomized controlled trials persisted as basic themes, new methodological and clinical clusters emerged as motor themes, signaling evolving priorities in trial design, patient-focused research, and advanced computational approaches. This shift underscores the dynamic progression of the field from general foundations toward more targeted and applied clinical investigations. Thematic evolution and shifting research foci (1995–2025). (a) Sankey diagram illustrating the thematic evolution of machine learning–related clinical trial research from 1995–2022 to 2023–2025. Key themes such as humans, algorithms, randomized controlled trials, and retrospective studies transitioned into emerging topics including case-control studies, cognitive behavioral therapy, double-blind method, hemodynamics, intravitreal injections, and young adult. (b, c) Thematic maps for 1995–2022 and 2023–2025 based on Callon’s centrality and density, classifying clusters into motor, basic, niche, and emerging themes. This analysis highlights continuity in core themes while revealing emerging clinical and methodological directions in the recent period.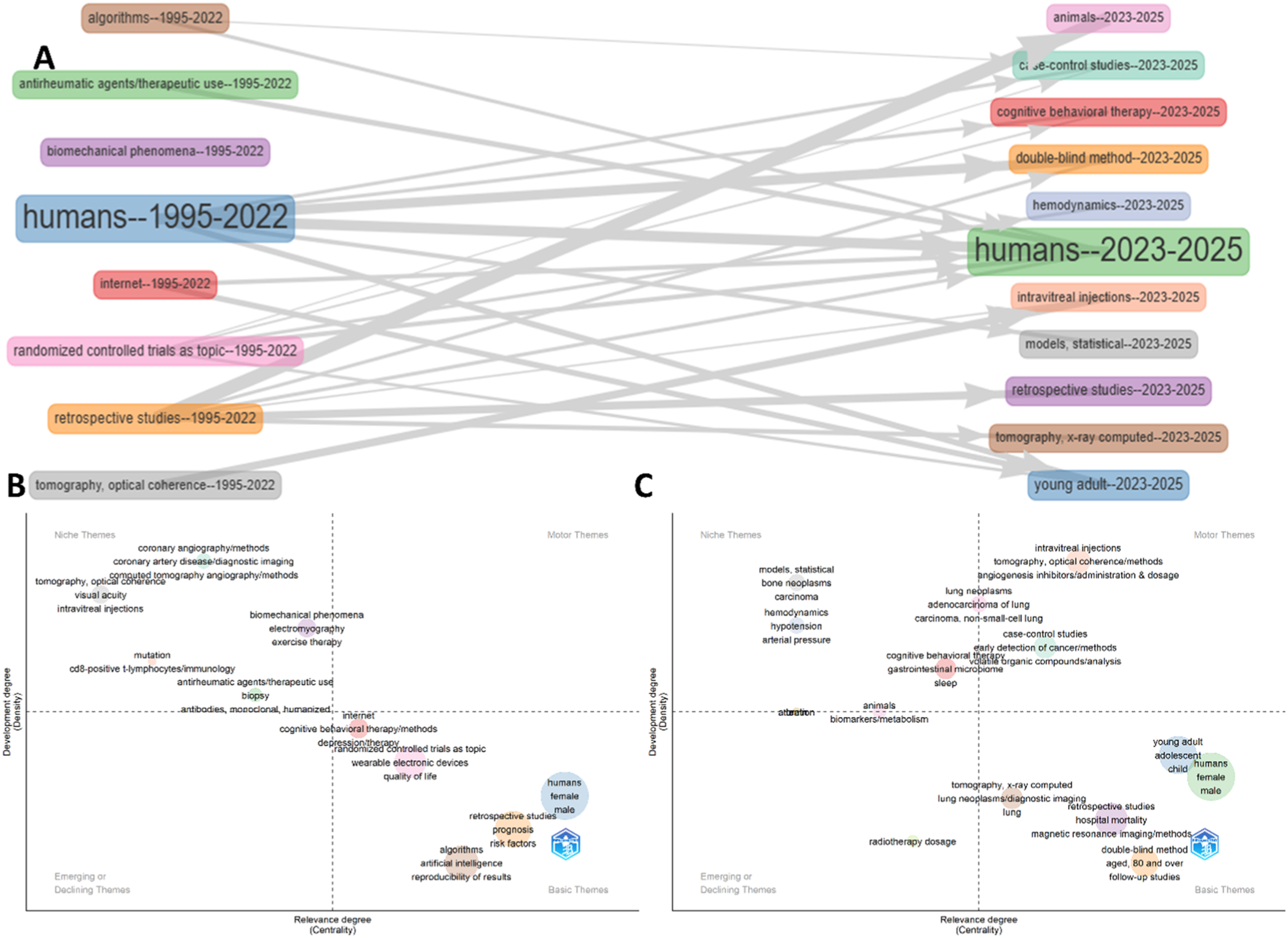
3.9. Conceptual mapping: Walktrap supervised clustering
The thematic map analysis (Figure 9 and Table 3), conducted using the Bibliometrix application, identified ten distinct clusters of research themes positioned across the four quadrants of centrality (relevance) and density (development). Basic themes included humans, algorithms, randomized controlled trials as topic, and aged, 80 and over, reflecting their high relevance but moderate developmental maturity. Motor themes, such as diet, blood glucose, and cognitive behavioral therapy/methods, demonstrated strong centrality and density, highlighting well-developed and influential topics. Niche themes, including intravitreal injections and pattern recognition, automated/methods, were characterized by strong specialization but lower relevance to the broader field. Emerging or declining themes, such as tomography, x-ray computed, showed limited centrality and development, suggesting either nascent or diminishing research focus. This distribution highlights the coexistence of foundational, specialized, and evolving directions in machine learning–related clinical trial research. Thematic map of machine learning–related clinical trial research generated using Bibliometrix. Themes were classified by Callon’s centrality (relevance) and density (development) into four categories: Motor (well-developed, central), basic (relevant but less developed), niche (specialized, peripheral), and emerging/declining (low centrality and density), highlighting the field’s evolving research priorities and knowledge structures. Clustered themes.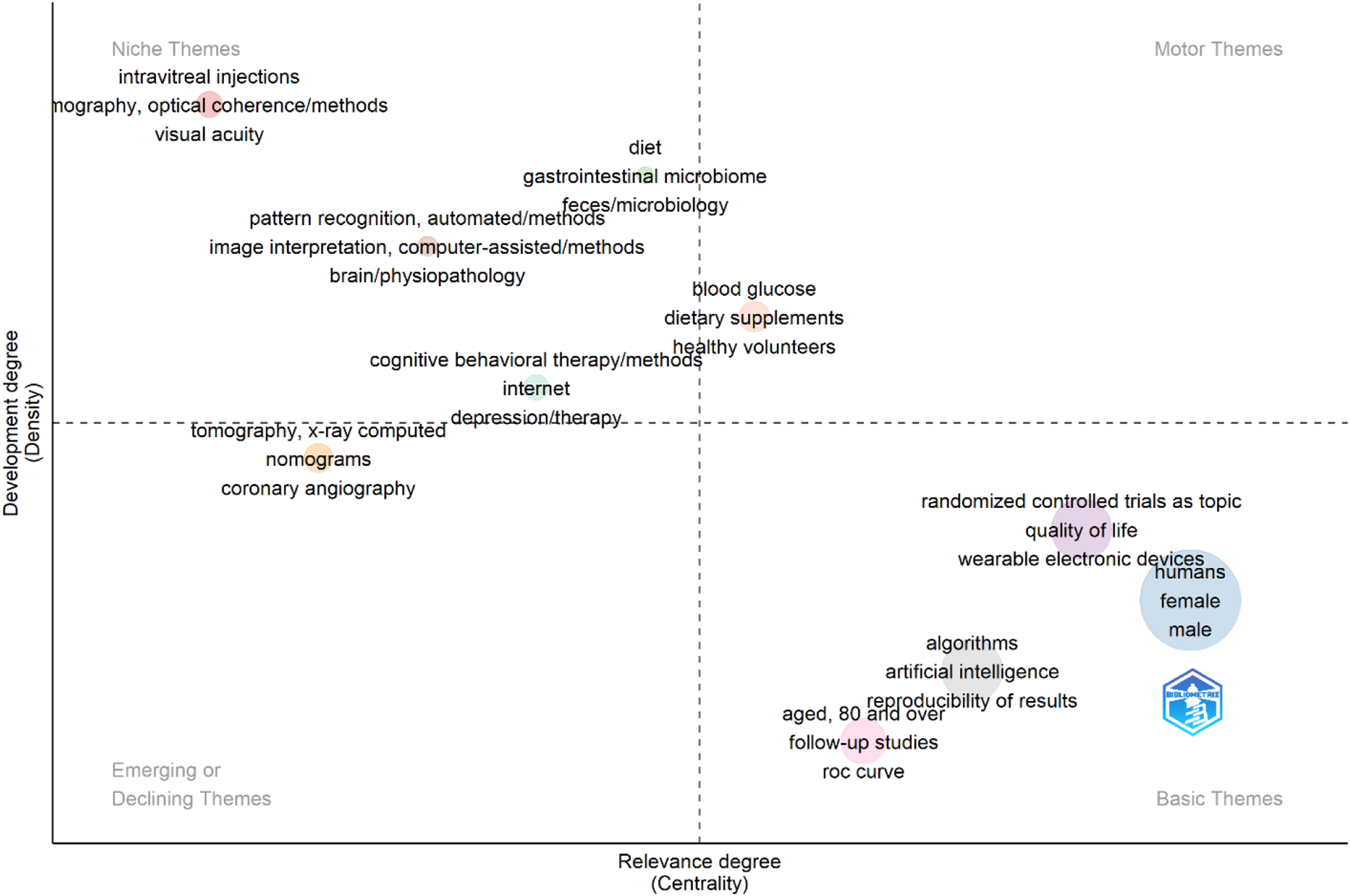
3.10. Analysis of emerging themes
The analysis of emerging themes was conducted using the Emerging themes.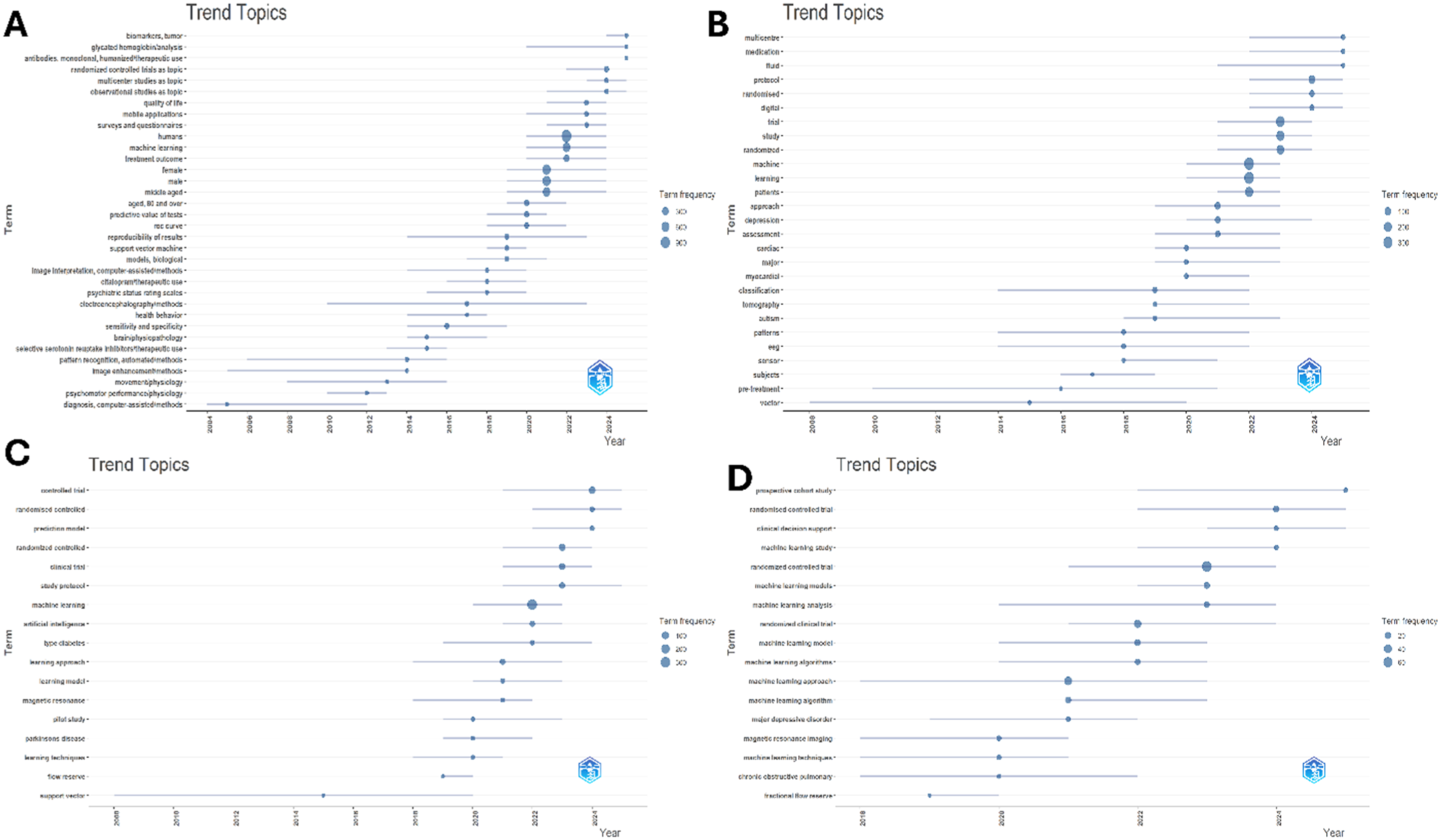
4. Discussion
This study provides the first comprehensive bibliometric and time series analysis of ML applications in clinical trials, revealing an exponential increase in research activity over the past decade. The findings confirm that the United States and China dominate global output, with expanding international collaboration networks. Keyword and thematic analyses highlight a clear shift from foundational algorithmic studies toward applied, patient-centered, and precision medicine approaches, underscoring the growing translational integration of machine learning into modern clinical research frameworks.
Our longitudinal analysis shows sustained expansion of ML–applied clinical trials since 2018, with a recent deceleration that remains consistent with global bibliometric trajectories documenting rapid growth of AI/ML in healthcare and clinical research.24–26 The modest dip in 2024–2025 should be interpreted cautiously: recent-year plateaus are a known artifact of indexing latency in bibliographic databases, particularly delays in PubMed/MeSH assignment and database ingestion, which can span several months.27–29 The strong autocorrelation we observe aligns with cumulative investments and learning effects in this domain and with the literature showing a rising—albeit still limited—number of randomized evaluations of AI/ML interventions: systematic reviews in 2022 identified few trials, but the pipeline accelerated markedly by 2024.30,31 Regulatory developments likely reinforced this trajectory; the U.S. FDA’s AI/ML SaMD Action Plan and the 2025 draft guidance on lifecycle management and marketing submissions provide clearer approval pathways, and the expanding list of authorized AI-enabled devices signals increasing translational readiness.32–34 Together, these forces help explain an overall upward trend, a positively skewed distribution concentrated in recent years, and forecasts that suggest stabilization rather than contraction. Methodologically, ARIMA-based projections are appropriate for such temporally dependent series but should be complemented by “real-time” bibliometrics to mitigate recency bias in rapidly evolving fields. 35 For the research community, the implication is clear: prioritize rigorous trial designs and reporting standards as the field shifts from exploratory modeling to decision-impacting evaluations, while accounting for indexing lags when interpreting near-term fluctuations. 36
The bibliometric findings reveal a highly uneven global distribution of ML clinical research, with the United States and China together accounting for nearly half of all publications—reflecting a concentration similar to that seen in general healthcare AI research. This “AI duopoly” aligns with global trends showing over 50% of AI-health publications emerging from fewer than ten countries, led by the US and China. 37 Meanwhile, contributions from low- and middle-income countries (LMICs) remain minimal, mirroring the limited AI research output from Africa, Latin America, and South Asia, which collectively account for under 5% of global publications despite carrying a disproportionate disease burden. 38 The exponential growth in ML-related clinical trials since 2015 corresponds with advances in deep learning, large-scale data availability, and strategic R&D investment—especially China’s Next Generation AI Plan (2017). 39 The COVID-19 pandemic further accelerated this growth, highlighting the value of AI for diagnosis, risk stratification, and decision support during healthcare crises. 40 However, much of this progress has occurred in high-income contexts, reinforcing global research inequities.
Collaboration patterns underscore these disparities. The US and China show strong domestic networks but relatively low international collaboration, contrasting with Europe and Canada, where cross-border co-authorship rates are markedly higher. 41 This imbalance limits knowledge exchange and risks perpetuating algorithmic bias, as datasets remain geographically and demographically narrow. 42 Research suggests that international collaboration enhances both quality and impact, with cross-country AI studies achieving higher citation influence and broader applicability. 43 To ensure the equitable translation of ML into clinical practice, there is an urgent need to expand research capacity, data representation, and cross-regional collaboration, particularly involving LMICs. 44 Policies that promote inclusive research partnerships and open data sharing are vital to avoid a global divide in AI-driven healthcare innovation and to ensure that ML-based tools are robust, fair, and beneficial across diverse patient populations. 45
The co-occurrence analysis highlights the dominance of AI-driven approaches in current clinical research, echoing global trends. “Machine learning” and “artificial intelligence” are central hubs, reflecting an exponential rise in AI publications. 25 Domain-specific keywords like “radiomics” and “depression” also feature prominently, indicating that imaging analytics and mental health are major frontiers. This aligns with bibliometric studies showing radiomics in a vigorous growth phase 46 and a strong focus on AI for depression in mental health. 47 The prominence of “prediction” underscores an emphasis on prognostic modeling, and the overlay of recent keywords (e.g. “deep learning,” “precision medicine,” “mHealth”) signals a shift toward data-intensive personalized care and digital health in clinical trials.25,48 These emerging themes mirror broader developments: AI is converging with precision medicine to tackle complex personalized care challenges, 49 and mobile health technologies are enabling more patient-centered, real-world data collection in trials. 48
The thematic map reveals a diverse landscape of mature and emerging topics. Foundational “basic” themes (e.g. humans, algorithms, randomized trials) are widely relevant but less internally developed. 50 In contrast, well-developed “motor” themes like diet & blood glucose (metabolic health) and cognitive behavioral therapy (mental health) are influential and central. Specialized “niche” themes (e.g. intravitreal injections in ophthalmology, automated pattern recognition methods) show high development within their domain but limited broader connectivity.22,51 Meanwhile, a topic such as “x-ray computed tomography” is weakly developed and marginal. This distribution indicates that the field balances core research themes with both well-established application areas and exploratory frontiers. Collectively, these patterns align with the wider evolution of medical AI – moving from algorithm-centric studies toward integrative, patient-centered and real-world implementations. Pandemic-driven digital health adoption 52 and global investment in AI for precision medicine 53 have likely accelerated these shifts. These shifts underscore the importance of interdisciplinary collaboration and real-world validation to translate AI innovations into improved clinical outcomes.
Our thematic‐evolution analysis indicates that ML work in clinical trials has shifted from foundational foci (generic “humans/algorithms,” retrospective designs, and trial methodology) toward more specialized, patient-proximal applications and more rigorous prospective methods—namely case–control designs, double-blind procedures, and domain-specific themes such as cognitive-behavioral therapy (CBT), hemodynamics, and intravitreal injection care. This trajectory mirrors the wider field’s maturation from proof-of-concept studies to clinically embedded evaluations, catalyzed by reporting frameworks (SPIRIT-AI/CONSORT-AI) and a growing corpus of randomized and pragmatic trials of AI interventions.54,55 In mental health, emerging CBT-related clusters align with trials and reviews using ML to model heterogeneity of treatment effects and derive individualized treatment rules for internet-delivered CBT, underscoring a shift toward precision psychotherapy in youth and young-adult populations. 17 Ophthalmology’s rise (e.g., intravitreal injections) reflects imaging-dense workflows in which ML supports outcome prediction and treatment scheduling, echoing broader AI-enabled advances across drug development and retinal care.56,57 The hemodynamics theme coheres with fast-growing ML applications in cardiology, particularly CT-derived fractional flow reserve (FFR-CT), where meta-analytic evidence now spans thousands of vessels and shows robust diagnostic performance relative to invasive FFR.58,59 Methodologically, the persistence of randomized controlled trials as a “basic” theme alongside the emergence of double-blind and case–control clusters suggests normalization of trial-grade evaluation standards for AI/ML, reinforced by evolving device oversight (e.g., FDA’s AI/ML SaMD Action Plan) and global ethics guidance (e.g., WHO LMMs).60,61 Together, these shifts denote a field transitioning from algorithm-centric discovery to patient-centered, trial-ready ML with stronger causal inference and implementation ambitions—priorities that should guide future protocol design, reporting, and regulatory alignment.25,62
Consistent with our trend analysis, “clinical decision support” (CDS) has indeed emerged as a prominent theme in recent ML clinical research. This is evidenced by a surge of studies and systematic reviews focusing on ML-driven CDS across various medical domains, reflecting how researchers are increasingly exploring AI tools to aid clinical decision-making. For instance, a 2023 systematic review by Khosravi, M. et al. surveyed 121 studies on AI-based decision support for acute ischemic stroke, 63 demonstrating intensive research activity in that niche over the past several years. Similarly, Fernandes et al. (2020) examined 62 studies on intelligent CDS tools for emergency department triage, 64 highlighting the growing interest among clinicians and researchers in ML-driven decision aids for acute care. Michel et al. (2024) likewise identified 19 recent papers on AI-based CDS for telephone triage, 65 evidencing the extension of this trend into telehealth settings. Furthermore, Moazemi et al. (2023) reviewed 21 studies applying ML to patient monitoring in ICUs, 66 illustrating the push to integrate AI into critical care decision support. Taken together, the proliferation of these domain-specific CDS studies clearly indicates that leveraging ML for clinical decision support has become a central focus in contemporary clinical research and practice.
In recent years (2020–2025), major depressive disorder (MDD) has emerged as a prominent focus in machine learning (ML)–based clinical research. Numerous studies apply ML techniques—ranging from predictive modeling and deep learning to natural language processing—to improve the diagnosis, classification, and management of MDD. Several works have aimed to objectively differentiate MDD patients from healthy controls; for example, a large multi-site neuroimaging study (N=5365) reported ∼62% balanced accuracy for ML-based MDD vs healthy classification, 67 highlighting both progress and remaining challenges. Other efforts emphasize practical implementation and validation: one 2025 study developed an NLP model to infer depression severity (PHQ-9 scores) from clinicians’ notes, achieving high agreement with actual assessments (AUC ∼0.81) and markedly increasing available depression measures in real-world data. 68 Similarly, an AI system applied to speech from routine clinical interviews could detect MDD at ∼66% accuracy, 69 demonstrating feasible use of digital biomarkers. ML is also being leveraged for personalized treatment in MDD. A 2025 model using patient-reported data predicted treatment-resistant depression with about 78% accuracy, 70 potentially enabling earlier intervention for high-risk patients. Collectively, these studies reflect a clear trend of translating advanced ML methods into clinical depression care, with initial clinical validations showing promise for improved early diagnosis and tailored management.
The emergence of fractional flow reserve (FFR) as a machine learning (ML)–based theme reflects the field’s growing emphasis on noninvasive physiologic assessment in cardiology. Recent studies illustrate this trend: for example, a deep learning end-to-end model predicted angiography-based FFR values from imaging data, with promising performance metrics (AUC ≈ 0.81). 70 In addition, ML-enhanced CT-FFR techniques have shown superior diagnostic performance compared to traditional CCTA alone. 71 Moreover, externally validated models combining quantitative plaque features and ML algorithms accurately predicted invasive FFR–defined ischemia. 62 A recent proof-of-concept study directly compared AI-based FFR prediction to computational fluid dynamics–based CT-FFR in intermediate stenoses and found over 85% concordance. 72 Collectively, these works support our bibliometric finding that FFR-related ML applications are rapidly gaining traction. Importantly, ML-driven FFR estimation addresses critical clinical limitations of invasive FFR—namely cost, procedural risk, and workflow inefficiency—and is likely to influence future guideline-directed assessment of coronary lesions.
This study relied solely on PubMed-indexed records, potentially omitting relevant studies from other databases such as Scopus or Web of Science. The exclusion of non-English and preprint literature may also have limited comprehensiveness. Additionally, automated keyword normalization and author name disambiguation could introduce minor classification biases. The time series model assumes historical continuity, which may not fully capture emerging technological or policy-driven shifts. Publication counts for the most recent years (2024–2025) may be underestimated due to PubMed indexing delays and journal blackout periods, and therefore observed short-term declines should be interpreted cautiously rather than as definitive evidence of reduced research activity. Future research should integrate multiple bibliographic databases for broader coverage, incorporate non-English and gray literature to enhance inclusivity, and apply advanced NLP techniques for more accurate thematic extraction. Longitudinal analyses combining bibliometrics with funding data, clinical outcomes, and AI readiness indices could yield deeper insights into the translational impact of machine learning in clinical research.
5. Conclusions
This bibliometric study comprehensively mapped the global landscape, thematic evolution, and research trajectories of machine learning (ML) applications in clinical trials, revealing a rapidly expanding and maturing field. The analysis demonstrated a consistent upward trend in publications, led predominantly by the United States and China, underscoring their pivotal roles in advancing ML-driven clinical innovation. Collaboration networks showed increasing international partnerships, while Bradford’s and Lotka’s laws confirmed the dominance of a small core of journals and authors shaping this domain. Conceptual and thematic analyses identified “clinical decision support,” “precision medicine,” and “fractional flow reserve” as emerging themes, reflecting a shift from exploratory computational modeling toward applied, patient-centered, and decision-integrated clinical frameworks. Collectively, these findings highlight a transition from methodological exploration to translational implementation, where ML augments diagnosis, prediction, and therapeutic personalization. The study’s significance lies in providing a structured knowledge map that guides future research priorities, journal targeting, and interdisciplinary collaboration strategies. Practically, it underscores the necessity for cross-sector data integration, ethical AI governance, and clinical validation pipelines to translate ML outputs into meaningful healthcare outcomes. Future research should focus on explainable AI models, equitable dataset representation, and real-world clinical trials validating ML efficacy and safety. Ultimately, this work positions ML-enabled clinical research at the forefront of evidence-based digital medicine, offering a data-driven foundation for improving clinical decision-making, accelerating therapeutic innovation, and advancing precision health worldwide.
Supplemental material
Supplemental material - The landscape of machine learning in clinical applications: A thematic mapping of evolution, frontiers, and future opportunities
Supplemental material for The landscape of machine learning in clinical applications: A thematic mapping of evolution, frontiers, and future opportunities by Amir Mohamed Talib, Siddig Ibrahim Abdelwahab, Manal Mohamed Elhassan Taha, Yassine Daadaa, Fahad Omar Alomary, Essam Mohammed Obaid, Manam Ali Alhathli, Abullah Farasani, Jobran Moshi, Nizar Khamjan, and Haneen Hassan Al-Ahmadi in Digital Health.
Supplemental material
Supplemental material - The landscape of machine learning in clinical applications: A thematic mapping of evolution, frontiers, and future opportunities
Supplemental material for The landscape of machine learning in clinical applications: A thematic mapping of evolution, frontiers, and future opportunities by Amir Mohamed Talib, Siddig Ibrahim Abdelwahab, Manal Mohamed Elhassan Taha, Yassine Daadaa, Fahad Omar Alomary, Essam Mohammed Obaid, Manam Ali Alhathli, Abullah Farasani, Jobran Moshi, Nizar Khamjan, and Haneen Hassan Al-Ahmadi in Digital Health.
Footnotes
Author contributions
A.M.T. conceptualized and designed the study. S.I.A. supervised the project, performed data interpretation, and critically revised the manuscript. M.M.E.T. contributed to data collection, literature review, and manuscript drafting. Y.D. assisted with data analysis and visualization. F.O.A. contributed to methodological validation and manuscript editing. M.A.A. supported data curation and formatting. A.F. and J.M. participated in statistical analysis and figure preparation. N.K. assisted with manuscript review and final approval. All authors read and approved the final version of the manuscript.
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2601).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data are available on reasonable request.
Artificial Intelligence (AI) disclosure statement
The authors used OpenAI’s ChatGPT to assist with language refinement, editing, and manuscript organization. No AI tool was used to generate, analyze, or interpret the study data, nor to make scientific decisions. All bibliometric analyses, time-series modeling, data interpretation, and conclusions were independently performed, verified, and approved by the authors, who take full responsibility for the accuracy, integrity, and content of the work.
Supplemental material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.