
Abstract
Objective
Early recognition of skin lesions, including diverse abnormalities and life-threatening skin cancers, is critical for effective treatment and improved clinical outcomes. However, existing skin lesion datasets exhibit significant class imbalance, and there is no standardized guideline for optimal data augmentation strategies. This study aims to establish a robust and interpretable framework that addresses these limitations while enhancing diagnostic performance.
Methods
We propose a novel transfer learning-based framework termed Tri-Path Attention Stacked Ensemble (TASE), which integrates multiple EfficientNetV2 backbones through three distinct stacking strategies: TASE: Independent TA, TASE: Serial Stacked TA, and TASE: Parallel Stacked TA. Here, TA refers to the Triple-Attention mechanism, comprising soft attention integration, channel attention integration, and squeeze-excitation attention integration. To optimize ensemble prediction fusion, we introduce an advanced aggregation method—Cohen’s Kappa Proportioned Averaging (CKPA)—which is further extended into a Multi-Layer CKPA (ML-CKPA) framework to enhance weight distribution across hierarchical model outputs. Additionally, four augmentation strategies were systematically evaluated to determine the most effective ensemble configuration.
Results
Experimental validation on the HAM10000 dataset demonstrated that the proposed framework achieved a superior accuracy of 94.44%, outperforming several state-of-the-art methods. Grad-CAM visualizations were employed to enhance interpretability by highlighting lesion-relevant regions, thereby improving model transparency and reliability.
Conclusion
The proposed TASE framework delivers enhanced diagnostic accuracy while effectively mitigating challenges related to class imbalance, dataset variability, and computational efficiency. By combining hierarchical triple-attention mechanisms with multi-layer ensemble weighting, it offers a reliable and interpretable solution for early and precise skin lesion classification, supporting real-world dermatological applications and improved patient care.
Keywords
Introduction
Skin lesions refer to abnormal changes in the skin’s structure or visual appearance and are linked to a broad spectrum of dermatological conditions. These conditions range from minor issues, such as acne, to severe and potentially fatal diseases like skin cancer. Although skin disorders manifest in various forms, they are not defined solely by the presence of lesions. Such abnormalities may arise from multiple causes, including infections, inflammatory reactions, allergic responses, malignancies, insect bites, trauma, autoimmune disorders, genetic predispositions, environmental influences, vascular irregularities, warts, and cysts. 1 Based on clinical severity, skin lesions are generally categorized into two principal types. Benign lesions, including moles, skin tags, warts, seborrheic keratoses, and hemangiomas, are typically non-cancerous and pose minimal medical risk. In contrast, malignant lesions, such as basal cell carcinoma, squamous cell carcinoma, and melanoma, are cancerous and possess the ability to metastasize, representing a significant threat to human health. 2
Accurate detection and timely management of skin disorders have traditionally relied on clinical examination and diagnostic procedures. Delayed diagnosis or neglect of symptoms can result in serious outcomes, particularly in the case of skin cancer, which remains one of the most prevalent cancers worldwide. Although melanoma is less common than other forms of skin cancer, it accounts for the majority of skin cancer-related deaths. 3 Recent statistics indicate that approximately 2.2% of individuals may develop melanoma during their lifetime, with nearly 97,610 new cases and 7,990 deaths reported in the United States in 2023. Moreover, more than 1.4 million people in the U.S. were living with melanoma, highlighting its considerable public health burden. 4
Early identification plays a crucial role in preventing skin lesions from progressing to more advanced and life-threatening stages. However, many individuals remain unaware of underlying abnormalities due to the cost and complexity associated with conventional diagnostic procedures. Dermatoscopy, a non-invasive imaging technique that employs magnification and illumination, assists clinicians in evaluating suspicious lesions and supports early cancer detection. Despite its clinical value, the diagnostic accuracy of dermatoscopy is highly dependent on practitioner expertise, thereby introducing the possibility of human error. 5
Artificial intelligence (AI), particularly through machine learning (ML) and deep learning (DL) paradigms, has demonstrated substantial potential in automating the analysis of medical images for skin lesion detection. These approaches enable rapid and precise interpretation of dermoscopic images, facilitating early diagnosis and improved treatment outcomes. Nevertheless, significant challenges persist. Many existing techniques exhibit bias toward classes with abundant training samples, struggle to extract high-level representations from transfer learning (TL) models without adequate fine-tuning, and encounter difficulties when integrating multiple architectures effectively. Additionally, limited interpretability and biases resulting from overlapping validation and testing datasets restrict their clinical applicability. Popular TL architectures such as DenseNet and ResNet also face constraints related to fixed scaling parameters, manual architectural configurations, and considerable computational demands, limiting adaptability and efficiency in resource-constrained environments. 6
To address these limitations, researchers have explored convolutional neural networks (CNNs) combined with ensemble learning strategies. While these methods attempt to overcome the weaknesses of individual models, traditional ensemble approaches—such as majority voting, softmax averaging, and conventional weighted averaging—often fail to account for the relative contribution of each predictor, leading to suboptimal results. Furthermore, reliance solely on post-prediction ensembling may be inadequate when handling highly variable images, as no single model consistently achieves accurate classification. This limitation underscores the importance of incorporating pre-prediction stacking mechanisms to enhance feature representation and improve overall predictive robustness.
Our proposed methodology was systematically designed to confront the aforementioned challenges in skin lesion detection and to address the following research questions (RQs), which guided the architectural development of our framework:
How can severe class imbalance be effectively reduced, and which strategy yields optimal generalization performance?
- The pronounced imbalance in skin lesion datasets often biases models toward dominant classes. Although data augmentation and generative adversarial networks (GANs) offer potential solutions, identifying the most reliable augmentation strategy for unseen data remains a key objective.
7
How can Transfer Learning (TL) models be efficiently adapted for domain-specific tasks?
- Selecting and fine-tuning the most suitable TL architecture is challenging, particularly when pretrained models (e.g., ImageNet-based models) possess fixed structures that may not align with specialized dermatological datasets. Effective customization is essential for achieving superior performance.
8
Which techniques can accurately highlight the most informative regions within dermoscopic images?
- Since not all image regions contribute equally to classification, emphasizing critical areas while suppressing redundant information is vital for enhancing predictive accuracy.
9
Is reliance on a single algorithm sufficient, or is Ensemble Learning (EL) required? If so, which ensemble strategy is most effective?
- A single model may be insufficient for handling complex image distributions. Although EL improves stability and performance, conventional aggregation strategies often lack dynamic weighting mechanisms, reducing their effectiveness.
10
What are the limitations of post-prediction ensembling alone, and how can pre-prediction stacking improve model robustness?
-Post-prediction fusion may struggle with high-variance samples where no individual model consistently performs well. Integrating a pre-prediction stacking approach strengthens feature learning and enhances classification reliability.
11
These research questions shaped the foundation of our work and led to the following key contributions: • • • • • •
The remainder of this paper is structured as follows. Section 2 reviews related work to contextualize the study. Section 3 details the proposed framework and experimental design. Section 4 presents and evaluates the performance outcomes. Section 5 discusses practical implications and potential enhancements. Finally, Section 8 summarizes the principal findings and contributions of the research.
Literature review
Skin lesion classification has attracted substantial interest in medical imaging and artificial intelligence research. Although significant progress has been made, persistent challenges such as class imbalance, limited dataset-specific adaptation, and suboptimal integration of attention mechanisms continue to affect performance. This section critically examines prior studies, outlining their contributions and limitations to contextualize the proposed framework.
Wang et al. 12 employed DenseNet-121 and VGG-16 to extract multiscale features, achieving an accuracy of 91.24%. However, the lack of dataset-specific fine-tuning reduced adaptability to domain-specific variations. Mahbod et al. 13 investigated the impact of image resolution on transfer learning-based classification and reported a balanced accuracy of 86.2%, though the increased computational cost limited real-time applicability.
Transfer learning (TL) remains one of the most widely adopted strategies for skin lesion analysis. Tajerian et al. 14 utilized EfficientNet-B1 and achieved 84.30% accuracy, demonstrating its capability in detecting pigmented lesions. Nonetheless, dependence on generalized pretrained features constrained dataset-specific optimization. Similarly, Hosny et al. 15 applied AlexNet for melanoma and nevus classification, reporting high accuracy but without integrating attention mechanisms to enhance discriminative feature extraction. Popescu et al. 16 combined TL with collective intelligence, reaching 86.71% accuracy; however, the absence of validation on an independent test set raised concerns regarding generalization.
Hybrid models integrating convolutional neural networks (CNNs) with transformer architectures have shown promise in capturing both local and global contextual information. Khan et al. 17 introduced SkinViT, merging outlook attention with transformers and achieving 91.09% accuracy. Despite strong performance, its high computational complexity limited scalability. Dong et al. 18 proposed TC-Net, effectively combining CNN and transformer features to enhance segmentation, though model complexity hindered practical deployment. Nie et al. 19 developed a hybrid CNN-transformer framework with focal loss, achieving 89.48% accuracy, but the approach struggled to extract deeper representations for more challenging cases.
Attention mechanisms have increasingly been adopted to emphasize critical image regions. Singh et al. 20 integrated Bayesian MultiResUNet with DenseNet-169 for segmentation and classification, attaining 86.67% accuracy, yet encountered difficulties in handling complex lesion patterns. Khan et al. 21 proposed an entropy-optimized attention module within a deep learning framework, achieving over 90% accuracy, though robustness on independent datasets was not thoroughly validated. Saarela and Georgieva 22 improved interpretability using Bayesian inference, achieving 80% accuracy, but their classification performance lagged behind competing approaches.
Nidhi et al. 23 and Abir et al. 24 employed the PAD-UFES-20 dataset for lesion classification using a single transfer learning approach without incorporating ensemble techniques. Similarly, Ahmmed et al. 25 adopted the same strategy with the PH2 dataset.
Additional attention-based strategies have been explored to improve discriminative capability. Nguyen et al. 26 incorporated deep learning with soft attention integration, reporting 90% and 86% accuracy across different models, though comparative evaluation with alternative attention mechanisms was not conducted. Datta et al. 27 implemented soft attention and achieved 93.4% accuracy; however, challenges in optimizing color channel weighting limited generalization performance.
Ensemble learning (EL) approaches have also been investigated to enhance predictive robustness. Gouda et al. 28 improved image quality using ESRGAN prior to classification, achieving 83.2% accuracy, but persistent class imbalance remained unresolved. Ajmal et al. 29 applied fuzzy entropy optimization within an ensemble framework, demonstrating strong performance on HAM10000 and ISIC 2018 datasets; nevertheless, high computational requirements and limited real-world validation reduced applicability. Rahman et al. 30 combined five deep networks into an ensemble, achieving 88% accuracy, though dataset-specific optimization was not incorporated.
Studies31–34 utilized augmentation techniques on the ISIC2017–2020 datasets in conjunction with transfer learning; however, they did not investigate the use of ensemble methods.
Data augmentation has played a vital role in mitigating imbalance. Sun et al. 35 utilized augmented datasets with supplementary metadata, attaining 89.5% accuracy, yet the augmentation methodology lacked sufficient transparency for reproducibility.
Studies36–48 have also analyzed related machine learning and deep learning approaches across various domains, including medical image analysis and classification tasks.
Despite these advancements, many existing approaches remain constrained by limited dataset-specific fine-tuning, insufficient independent validation, computational inefficiency, and suboptimal ensemble weighting strategies. Conventional ensemble techniques frequently fail to dynamically assign appropriate weights to individual predictors, thereby limiting overall effectiveness.
Motivated by these gaps, our study introduces a comprehensive framework aimed at overcoming current limitations. An effective augmentation strategy is first identified to address class imbalance. Triple-Attention mechanisms are incorporated within serial, parallel, and independent stacking configurations to enhance feature extraction and emphasize lesion-relevant regions. Transfer learning models are carefully fine-tuned to capture skin-specific characteristics rather than relying solely on generalized ImageNet representations. Furthermore, a dynamic ensemble strategy based on Cohen’s Kappa Proportioned Averaging (CKPA) is introduced to compute optimal prediction weights, ensuring consistent and robust performance across diverse datasets. Collectively, these contributions advance the reliability, interpretability, and practical applicability of automated skin lesion classification systems.
Materials and methods
Dataset description
This study utilized a publicly available dermatoscopic dataset to ensure a comprehensive and diverse evaluation of skin lesion classification performance.
The dataset, Human Against Machine (HAM10000), was collected from the Harvard Dataverse repository. 49 It comprises 10,015 carefully curated dermatoscopic images in JPG format, categorized into seven distinct classes.
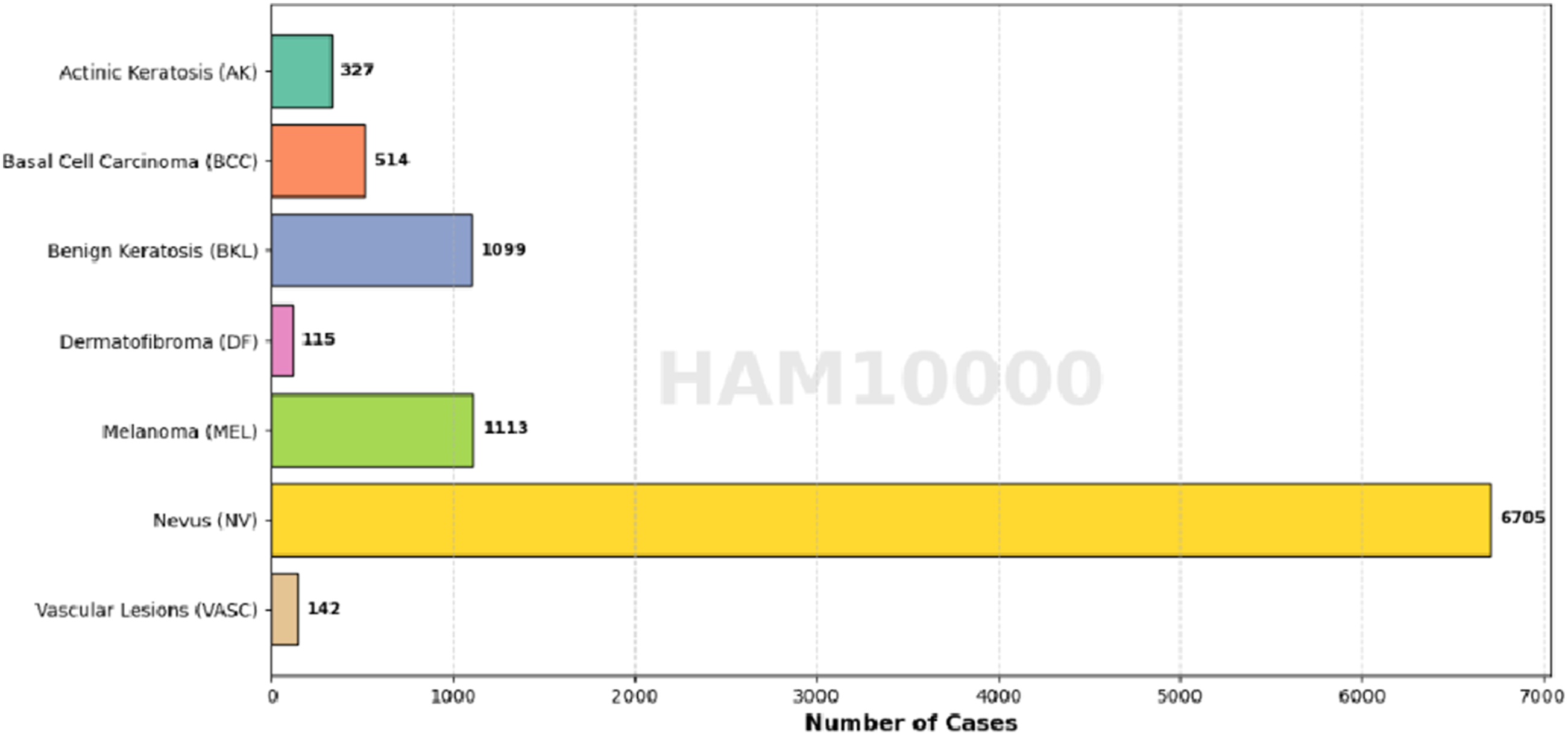
The seven lesion categories included in the dataset are Melanoma (MEL), Nevus (NV), Vascular Lesions (VASC), Actinic Keratosis (AK), Basal Cell Carcinoma (BCC), Benign Keratosis (BKL), and Dermatofibroma (DF). Among these categories, MEL, AK, and BCC are classified as malignant lesions, whereas NV, BKL, and DF are considered benign. Certain types of VASC may also demonstrate malignant characteristics.
Brief information of the HAM10000 dataset.

Figure 1 presents representative examples from each class, illustrating one sample per category. The pronounced class imbalance within the dataset is further demonstrated through the class distribution visualization in Figure 2. Sample images from the HAM10000 dataset. Sample distribution for each class in the HAM10000 dataset.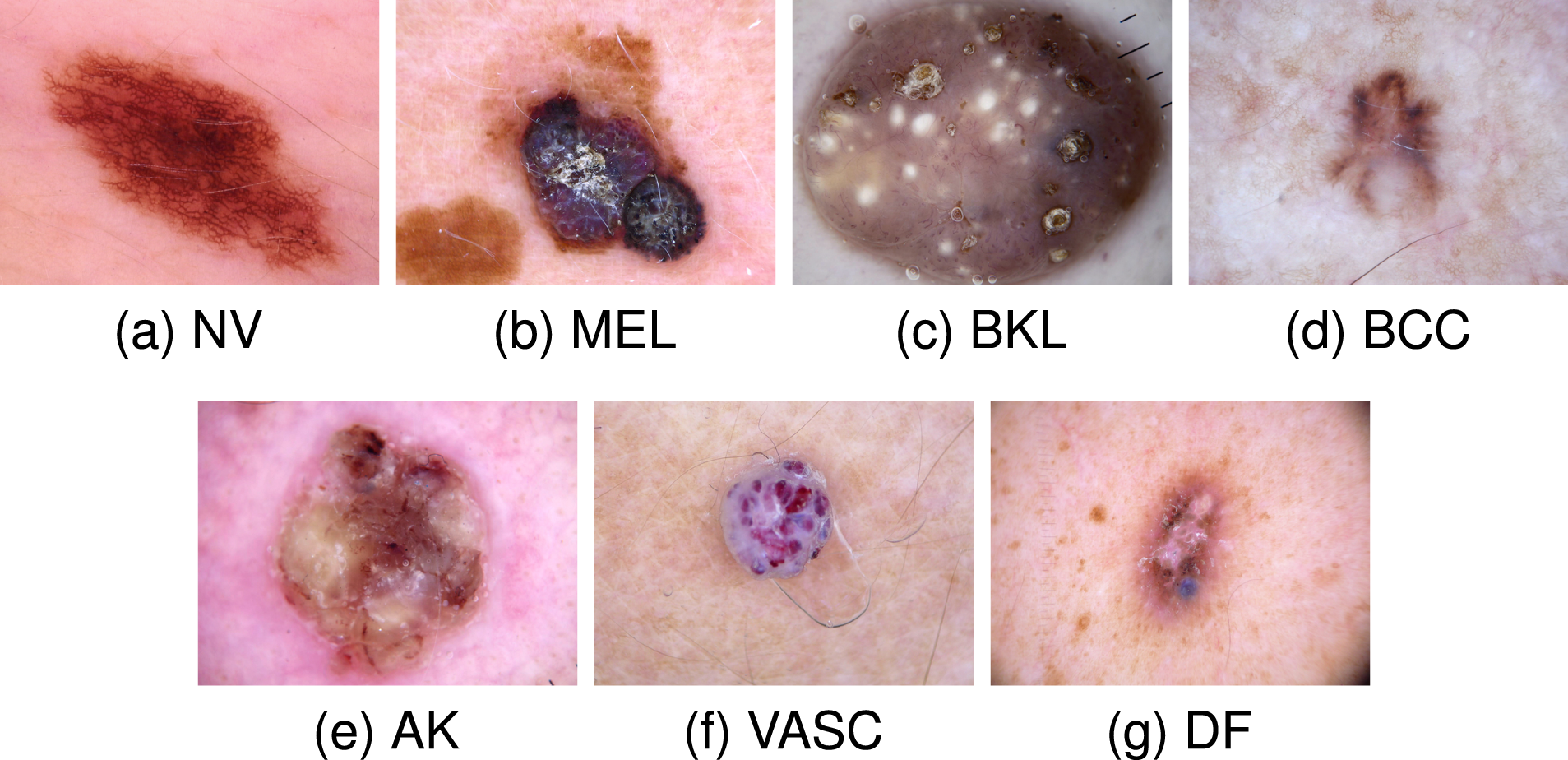
The dataset was carefully preprocessed to meet the requirements of our study. Additional details regarding the exact versions used can be found in HAM10000. 50
Methodological approach
The methodological framework of this study started with dataset acquisition, followed by comprehensive data preprocessing. The datasets were subsequently divided into two primary subsets: a main training set and an independent testing set. The independent testing set was completely held out during training and validation, providing truly unseen data for final evaluation.
To mitigate class imbalance, four distinct data augmentation strategies were employed: • No Augmentation (NA): Only the original dataset was used, without generating any synthetic images. • Prior Augmentation (PiA): Synthetic images were created prior to data splitting, which could result in overlap, where both original and augmented images from the same source might appear in training, validation, and testing sets. • Training Data Augmentation (TA): Augmentation was applied solely to the training data, keeping validation and testing sets independent and unchanged. • Posterior Augmentation (AP): Each subset—training, validation, and testing—was augmented after splitting, increasing the dataset size across all partitions.
The most effective augmentation strategy was identified by training a customized network based on EfficientNetV2 variants, followed by evaluation on the independent testing set to determine performance on entirely unseen data.
Next, the data was processed within the Tri-Path Attention Stacked Ensemble (TASE) framework. TASE combined architectures trained on the training set and validated on the validation set. It incorporated models using three Triple Attention (TA) configurations, which included Soft Attention Integration, Channel Attention Integration, and Squeeze-Excitation Attention Integration: TASE: Independent TA, TASE: Serial Stacked TA, and TASE: Parallel Stacked TA.
Predictions from each model were then fused using the Multi-Layer Cohen’s Kappa Proportioned Averaging (ML-CKPA) method, applied across multiple layers to boost performance. This ensemble technique enabled optimal weighting of predictions and improved generalization.
For interpretability, Grad-CAM visualizations were employed, providing insights into model behavior by highlighting critical regions of the input images. A schematic of the sequential steps in this methodology is presented in Figure 3. Sequential representation of methodology.
Preprocessing and data augmentation
To prepare the dataset for effective training, images were first grouped according to their lesion IDs to ensure proper organization at the lesion level. This grouping strategy was explicitly used to enforce lesion-level separation during dataset splitting, preventing any images from the same lesion appearing across different subsets. Careful sampling was then conducted to create distinct subsets for training, validation, and testing. Specifically, 15% of the images were allocated to the independent testing set, while the remaining 85% formed the primary training set. The independent testing set was strictly separated prior to any augmentation process and was fully preserved as unseen data for final evaluation.
Lesion-level separation was strictly enforced during dataset splitting, ensuring that images from the same lesion did not appear across training, validation, or independent testing sets. Furthermore, data augmentation was applied strictly after the splitting process and only to the training set, while the validation and independent testing sets were kept entirely unchanged. This strategy prevents any form of data leakage and ensures a fair and reliable evaluation of the proposed models.
Figure 4 depicts the four data augmentation strategies implemented to address class imbalance: • No Augmentation (NA): Only the original dataset was used, without generating any synthetic images. • Prior Augmentation (PiA): Synthetic images were created prior to data splitting, which could result in overlap, where both original and augmented images from the same source might appear in training, validation, and testing sets. • Training Data Augmentation (TA): Augmentation was applied solely to the training data, keeping validation and testing sets independent and unchanged. • Posterior Augmentation (AP): Each subset—training, validation, and testing—was augmented after splitting, increasing the dataset size across all partitions. Illustration of four data augmentation strategies.

To address class imbalance, roughly 8,000 synthetic images were generated for each class. The primary training dataset was subsequently split into training, validation, and testing subsets in a 70:15:15 ratio, respectively.
Augmentation was carried out using TensorFlow’s
Figure 5 presents examples of original, contrast-enhanced, and augmented images, illustrating a sample from the Actinic Keratosis (AK) class along with its augmented variants. Images of the augmented samples.
Tables 5 and 6 show the comparison of all augmentation strategies in both testing and independent testing data. Accordingly, all primary performance comparisons and conclusions in this study are drawn based on results obtained using the TA strategy.
Development of Tri-Path Attention Stacked Ensemble (TASE) architectures
The TASE framework utilized customized EfficientNetV2 models, fully leveraging Transfer Learning. Specifically, seven pre-trained architectures, including various EfficientNetV2 variants with input dimensions of 299x299x3 and 224x224x3, were fine-tuned. Since these models were originally trained on unrelated datasets, fine-tuning allowed adaptation to our dataset, enabling the extraction of both shallow and deep features effectively. To further improve performance, Triple-Attention (TA) was incorporated in three configurations: Serial Stacked, Parallel Stacked, and Independent Attention. A schematic of the complete architecture is illustrated in Figure 6. Overview of the TASE architecture.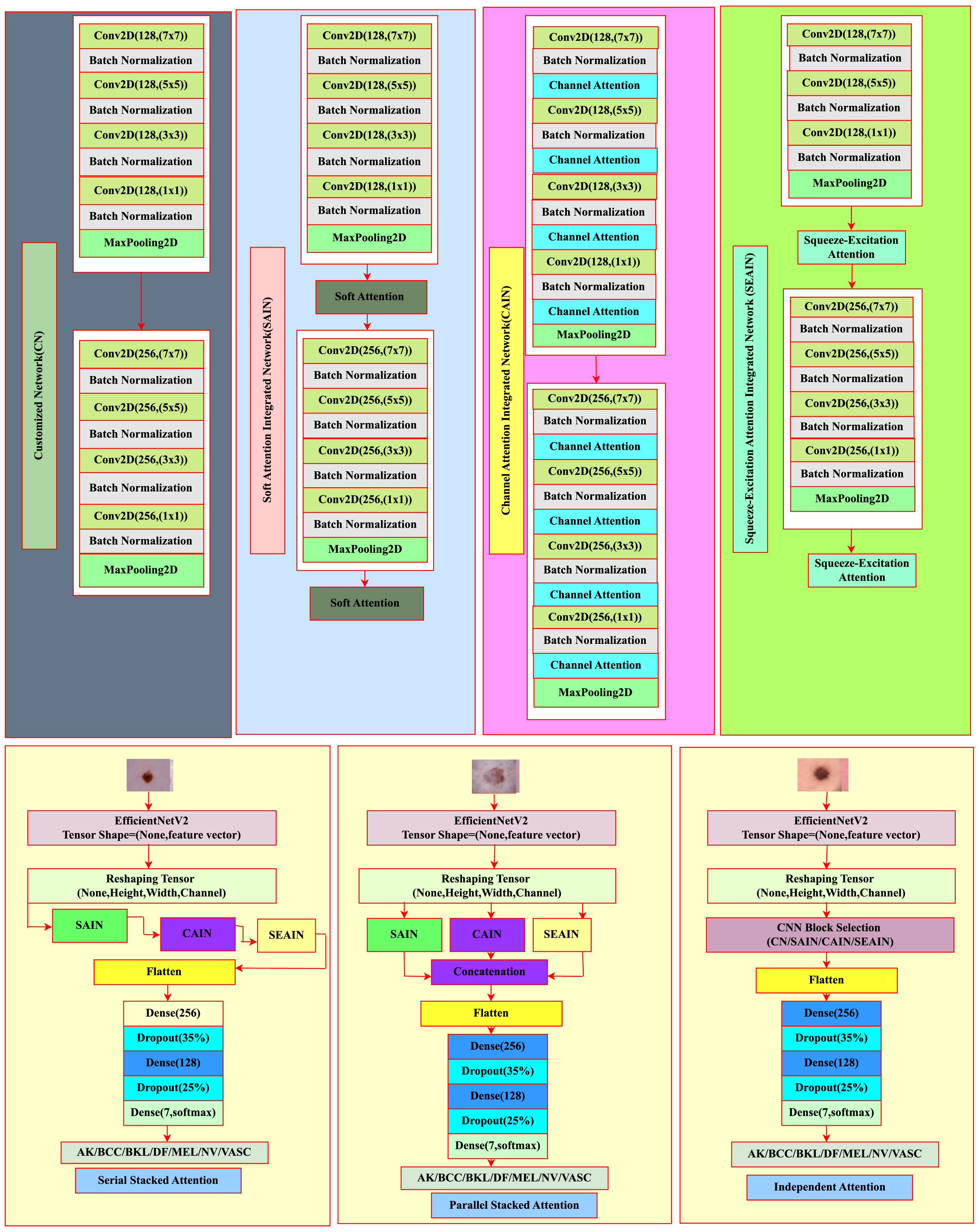
The integration process started by importing pre-trained models from the
Three customized CNN architectures incorporating TA were developed: 1. Soft Attention Integrated Network (SAIN): Targeted fine-grained spatial features. 2. Channel Attention Integrated Network (CAIN): Enhanced feature representation by emphasizing significant channels. 3. Squeeze-Excitation Attention Integrated Network (SEAIN): Calibrated channel-wise responses to capture hierarchical features more effectively.
The TA modules were selectively integrated into these networks. For SAIN and SEAIN, TA modules were inserted after each convolutional block, while CAIN incorporated channel attention after every
The convolutional backbone consisted of two convolutional blocks, each containing four
The three TASE configurations—Serial Stacked, Parallel Stacked, and Independent Attention—are described as follows.
TASE: Serial stacked attention network
In the Serial configuration, outputs from SAIN, CAIN, and SEAIN were integrated in a sequential manner. Following the reshaping of the pre-trained model’s output tensor, the SAIN network processed the features first, followed by CAIN, and finally SEAIN. Each network further refined the features extracted by the preceding one, producing progressively enhanced representations. These features were flattened into a one-dimensional tensor and fed through three fully connected layers with sizes 256, 128, and 7, corresponding to the number of classes. ReLU activation was applied to the first two layers, while the final layer used softmax to produce class probabilities. Dropout layers with rates of 35% and 25% were included after the first two dense layers, respectively, to reduce overfitting.
TASE: Parallel stacked attention network
In the Parallel configuration, outputs from SAIN, CAIN, and SEAIN were computed concurrently. Each network independently processed the reshaped pre-trained output, extracting features in parallel. The resulting feature maps were then concatenated to merge complementary information from all attention mechanisms. The combined tensor was flattened and passed through the same fully connected layers and dropout setup as in the Serial configuration. This design facilitated the integration of diverse feature representations, enhancing model generalization.
TASE: Independent Attention network
In the Independent configuration, SAIN, CAIN, and SEAIN functioned completely independently. Each network extracted features separately from the reshaped pre-trained model output. The outputs were flattened into one-dimensional tensors and passed through their respective fully connected layers. Each network generated its own predictions, maintaining independence of the extracted features. This setup allowed each attention mechanism to focus solely on its specialized feature extraction, which could later be combined during ensemble evaluation.
The study utilizes seven pretrained EfficientNetV2 variants, each of which is fine-tuned independently. Specifically, every model is trained separately and consistently incorporated across all three proposed architectures—SSA, PSA, and ISA—without omission in any stage. During fine-tuning, only the final classification layer, which represents the number of target classes, is kept frozen, while all remaining layers are allowed to update their weights. In terms of training strategy, a fixed number of epochs is not strictly enforced; instead, a maximum limit of 120 epochs is set. Early stopping is employed to prevent overfitting, allowing training to terminate automatically once the model converges, ensuring both computational efficiency and robust performance.
The careful design of these three TASE configurations ensured effective utilization of attention mechanisms, enabling robust feature extraction and improving model performance across varied input scenarios.
Justification of the proposed architecture and improvements over state-of-the-art methods
Most existing state-of-the-art methods are not specifically designed for skin lesion analysis; instead, they are primarily developed and pre-trained on large-scale datasets such as ImageNet. Therefore, the first key improvement of the proposed framework lies in its domain-specific fine-tuning, where the models are explicitly adapted for skin lesion classification tasks. Moreover, beyond fine-tuning, many existing approaches do not fully exploit advanced attention mechanisms. In contrast, this work incorporates three distinct attention modules—Channel Attention, Squeeze-and-Excitation Attention, and Soft Attention—each contributing uniquely to improving feature representation and model performance. These attention modules are further utilized in three different stacking strategies: Serial (SSA), Parallel (PSA), and Independent (ISA), enabling a more comprehensive and effective feature extraction process compared to conventional methods. Unlike typical state-of-the-art approaches that rely on a single model, this study recognizes that a single architecture may be insufficient for achieving high performance due to risks such as bias and overfitting. To address this limitation, multiple models are combined in both pre-training and post-training stages. Specifically, attention-based stacking is applied before training, while post-training integration is performed using the proposed Cohen’s Kappa Proportioned Averaging (CKPA) ensemble method. This multi-stage integration enhances robustness, reduces bias, and improves overall generalization performance.
Furthermore, each model within the proposed framework was trained using distinct strategies corresponding to the respective stacking architectures. For the Independent Stacked Architecture (ISA), each model was trained separately to ensure independent feature learning. In contrast, for the Serial Stacked Architecture (SSA), models were trained sequentially in a stacked manner, allowing progressive refinement of learned representations. For the Parallel Stacked Architecture (PSA), models were trained concurrently using a parallel stacking approach to capture diverse feature interactions. To ensure stable convergence and prevent overfitting, early stopping was employed during training. Although the maximum number of training epochs was set to 120, the training process was automatically terminated once convergence was achieved, resulting in efficient and optimized model performance.
Feature extraction process
In our methodology, the TASE models were employed for effective feature extraction. The top fully connected layers were excluded (
The final classification probabilities are computed using the softmax function:
Feature visualization
Figure 7 illustrates the hierarchical feature extraction process within an Optimized InceptionV3 architecture. The figure shows activation maps at multiple stages of the transfer learning model, with each row corresponding to a different layer’s activations, providing a detailed view of the progressive transformation of input images: • Input Layer ( • Zero Padding ( • Convolution ( • Batch Normalization ( • ReLU Activation ( • Max Pooling ( • Concatenation ( • Dense Layer ( • Output Layer ( Feature extraction process illustrated by activation maps (sample visualization).

The visualization in Figure 7 illustrates up to five filters per layer using the
Demonstrated on a single sample and selected layers, this process highlights the systematic extraction of thousands of feature representations. These detailed features substantially enhanced overall model performance by providing deeper insights into how hierarchical patterns were captured across the architecture.
Triplet-Attention (TA)
To improve the model’s ability to focus on important input features while minimizing less relevant information, we employed three complementary attention mechanisms, collectively called Triplet-Attention (TA). This method integrates Channel Attention Integration (CAI), Squeeze-Excitation Attention Integration (SEAI), and Soft Attention Integration (SAI) to efficiently capture and emphasize critical patterns within the data. 51
Soft Attention Integration (SAI)
The Soft Attention Integration (SAI) module emphasizes assigning attention weights to individual elements of the input, enabling the model to prioritize regions according to their importance.
52
The attention mechanism can be expressed as:
Here, a i denotes the attention weight for the i-th input element, T is the total number of input elements, and e i represents the relevance score of the i-th element. 53
By assigning greater weights to the most important regions, the SAI module directs the model’s focus toward the most relevant portions of the input, thereby improving overall performance. 54
Channel Attention Integration (CAI)
The Channel Attention Integration (CAI) module emphasizes the significance of key channels within feature maps by computing attention weights across them. These weights are determined using statistical properties, such as the mean and standard deviation, of the input feature maps and are applied to enhance relevant features.
55
The functionality of the CAI module can be expressed mathematically as:

Here,
Squeeze-Excitation Attention Integration (SEAI)
The Squeeze-Excitation Attention Integration (SEAI) module emphasizes channel-wise attention, allowing the model to dynamically recalibrate feature maps.
56
The module carries out two main operations: aggregation of global spatial information and recalibration of features across channels. For an input feature map 


Here, GlobalAvgPooling performs global spatial information aggregation, and
Cohen’s Kappa Proportioned Averaging (CKPA)
We proposed a novel ensemble learning method called Cohen’s Kappa Proportioned Averaging (CKPA), which assigns optimal weights to predictions from multiple classifiers and combines them through weighted averaging. Unlike other metrics, CKPA leverages Cohen’s Kappa to evaluate the agreement between model predictions and the true labels, beyond what is expected by chance. Classifiers with higher Kappa scores are considered more reliable, as they demonstrate stronger consistency with the ground truth labels. By proportionally weighting classifiers according to their Kappa values, the CKPA method enhances both prediction quality and robustness. While CKPA introduces a reliability-aware weighting mechanism based on agreement beyond chance, it is not intended as a universal theoretical replacement for existing ensemble weighting strategies. Unlike calibration- or validation-based methods, CKPA prioritizes consistency between predictions and ground truth through Cohen’s Kappa.
However, agreement-based weighting may favor dominant class patterns in imbalanced datasets. To mitigate this, performance is evaluated using class-sensitive metrics such as precision, recall, F1-score, and specificity, ensuring balanced class-wise assessment.
Therefore, CKPA is positioned as an empirically motivated and practically effective weighting strategy rather than a purely theoretical advancement. The steps for implementing CKPA are outlined below.
Step 1: Evaluating classifier performance
The process begins by calculating the Cohen’s Kappa values for each classifier to assess their reliability. Cohen’s Kappa measures the degree of agreement between predicted and true labels, adjusted for the likelihood of random agreement. It is defined as:
Step 2: Computing ensemble weights
After obtaining the Kappa scores for each classifier, the raw scores are shifted to avoid negative or zero values. This ensures that all weights are positive and proportional to the relative reliability of the classifiers. The normalized weights are then computed as:
Step 3: Generating ensemble predictions
The final CKPA predictions are generated by performing a weighted average of the individual classifiers’ prediction probability distributions. Let P
i
= [pi1, pi2, …, p
in
] represent the probability predictions of classifier i for n instances. The ensemble prediction for the j-th instance is given by:
This CKPA method enhances ensemble performance by proportionally emphasizing classifiers with higher agreement beyond chance level, resulting in an accurate and robust ensemble output. The schematic illustration of this process is shown in Figure 8. Cohen Kappa-based weighted ensemble in layer L.
Multi-Layer CKPA
The Multi-Layer CKPA method extended the CKPA technique across two distinct layers, enabling a more refined and hierarchical emphasis on the strengths of individual models. This multi-layer strategy addressed a critical challenge in single-layer ensembling: the difficulty in adequately highlighting superior models due to relatively low individual classifier weights. By adopting a sequential “Layer-by-Layer” ensembling approach, this method progressively prioritized high-performing models at each layer, amplifying their influence in subsequent layers. A generic visual representation of the Multi-Layer CKPA framework is provided in Figure 9. Structure of the Multi-Layer CKPA framework.
CKPA in Layer 1
In the first layer, we ensembled the predictions to generate pre-final predictions using three core TASE approaches: TASE: Serial Stacked Attention (SSA), TASE: Parallel Stacked Attention (PSA), and TASE: Independent Stacked Attention (ISA). These approaches were applied to seven customized versions of pre-trained models, resulting in a total of 21 initial predictions. For the ISA approach specifically, a pre-layer combination step was introduced to aggregate the attention-integrated results for each model before proceeding to the ensembling process in Layer 1. This step ensured that the attention mechanisms were effectively integrated into the ensemble.
CKPA in Layer 2
The predictions from Layer 1, reduced to three consolidated outputs (SSA, PSA, and ISA), were further ensembled in Layer 2. This final ensembling step combined the strengths of the three TASE approaches, producing the ultimate prediction output, denoted as “TASE”. This hierarchical approach enhanced the robustness and accuracy of the ensemble by iteratively refining the influence of high-performing models across layers.
Pseudocode for CKPA

Numerical example of CKPA
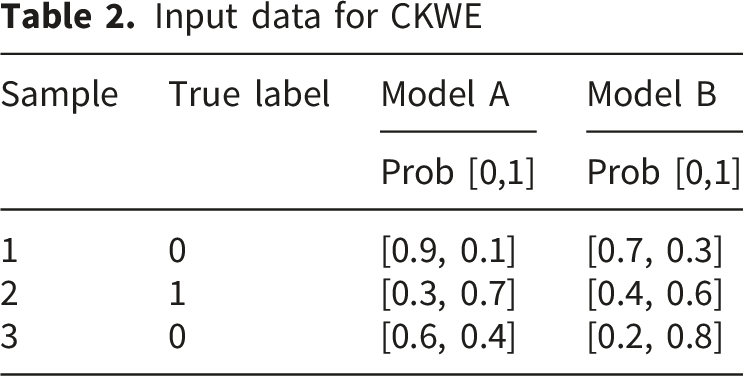
Consider a binary classification problem with 2 models and 3 test samples in Table 2.
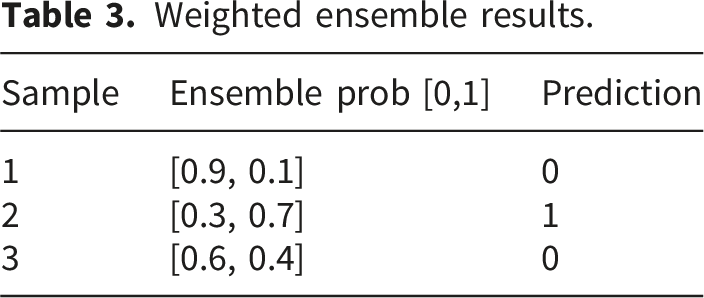
Input data for CKWE Weighted ensemble results.
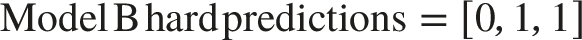
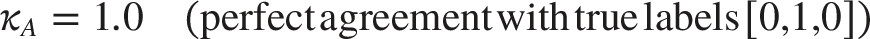

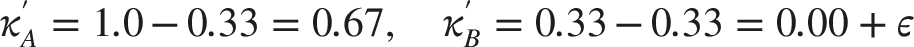
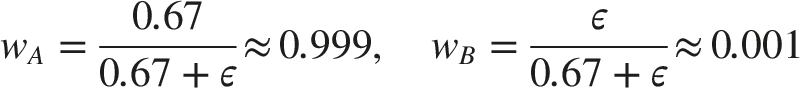
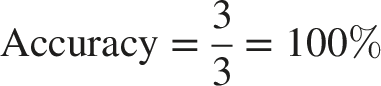
Experimental results and analysis
This section provides a detailed evaluation of the classification performance of our proposed methodology. The analysis included both quantitative metrics and visual interpretations to demonstrate the effect of applying CKPA on enhancing the predictive performance of TASE architectures. Through various experimental results, including multiple evaluation measures, graphical illustrations, and confusion matrices, we conducted a thorough comparison of the different approaches outlined in previous sections.
Performance evaluation metrics
To systematically evaluate our models, we used several key performance metrics: accuracy, precision, recall (sensitivity), F1-score, specificity, and ROC-AUC (Receiver Operating Characteristic Area Under the Curve).
58
These metrics provided essential insights into the classification effectiveness of the models. Each metric was calculated from the confusion matrix, which classified predictions into true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). The mathematical definitions for these metrics are as follows: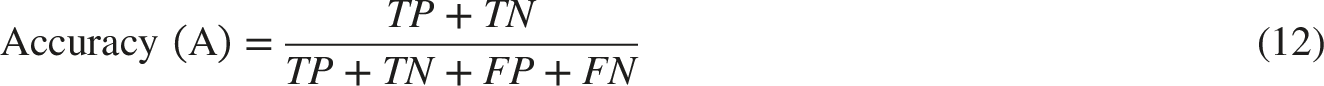


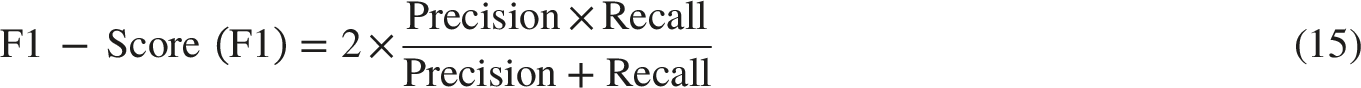

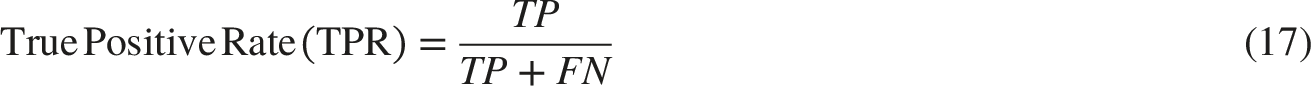
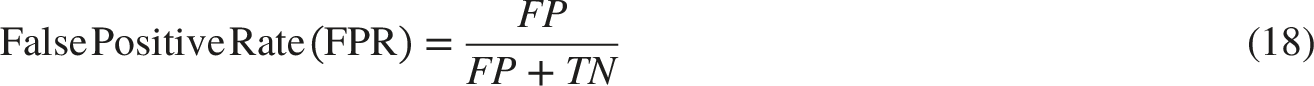
By utilizing these performance metrics, we obtained a comprehensive understanding of the models’ generalization capabilities across various classification tasks. This evaluation enabled the identification of each approach’s strengths and potential limitations, informing further improvements for practical deployment.
Experimental setup
The complete framework was executed within a Kaggle notebook environment, utilizing a GPU P100 and a dual-core Intel Xeon CPU with a processing speed of 690 ms/step. Lesion images were resized to (224, 224, 3) for models in the EfficientNetV2 family. The dataset was split into three subsets: 15% for validation, 15% for testing, and the remaining portion for training.
Model training was performed over 100 epochs with a batch size of 16. The optimization employed the Adam optimizer with an initial learning rate of 0.0001. Categorical cross-entropy was used as the loss function to facilitate effective multi-class classification. The loss function is defined as:
To prevent overfitting and improve generalization, early stopping was applied using the Reduce-on-Plateau method with a patience of 50 epochs.
This section covered both theoretical foundations and empirical results to evaluate classification performance. The primary aim was to demonstrate the effect of CKPA on enhancing the predictive accuracy of TASE architectures. Experimental results, including various evaluation metrics, ROC-AUC curves, and confusion matrices, provided a thorough comparison of the different methodologies presented in the previous sections.
Trainable parameters
Trainable parameters for each architecture.

Hyperparameter selection
Hyperparameter tuning is critical for maximizing model performance.60–62 In this study, a controlled manual tuning protocol was followed to ensure transparency and reproducibility. Key hyperparameters, including learning rate, batch size, kernel sizes, and activation functions, were systematically varied within predefined ranges while keeping other parameters fixed, allowing controlled observation of their impact on validation performance. Experiments were repeated with fixed random seeds to reduce stochastic variation and confirm stability of results.
A learning rate of 0.0001 with the Adam optimizer was selected based on consistent improvements in validation accuracy and loss convergence. Batch normalization was applied to stabilize training and accelerate convergence, while mitigating overfitting. The ‘he_normal’ kernel initializer maintained proper gradient flow, and the ReLU activation function captured non-linear patterns in the data, contributing to high classification accuracy. This structured approach ensured a balance between computational efficiency, model stability, and robust predictive performance.
Performance analysis of the four augmentation strategies to determine the optimal approach
As previously described, four data augmentation strategies were implemented to address class imbalance. No Augmentation (NA): The dataset remained unmodified, using only the original images without generating any synthetic samples. Prior Augmentation (PiA): Synthetic images were created before dataset splitting, which could result in overlaps where both original and augmented images from the same source appeared in training, validation, and testing subsets. Training Data Augmentation (TA): Augmentation was applied solely to the training subset, keeping the validation and testing sets fully independent. Posterior Augmentation (AP): Augmentation was carried out separately on each subset—training, validation, and testing—after splitting, thereby expanding the dataset size across all partitions.
Performance evaluation by four augmentation strategies on testing data.

Performance evaluation by four augmentation strategies on independent testing data.
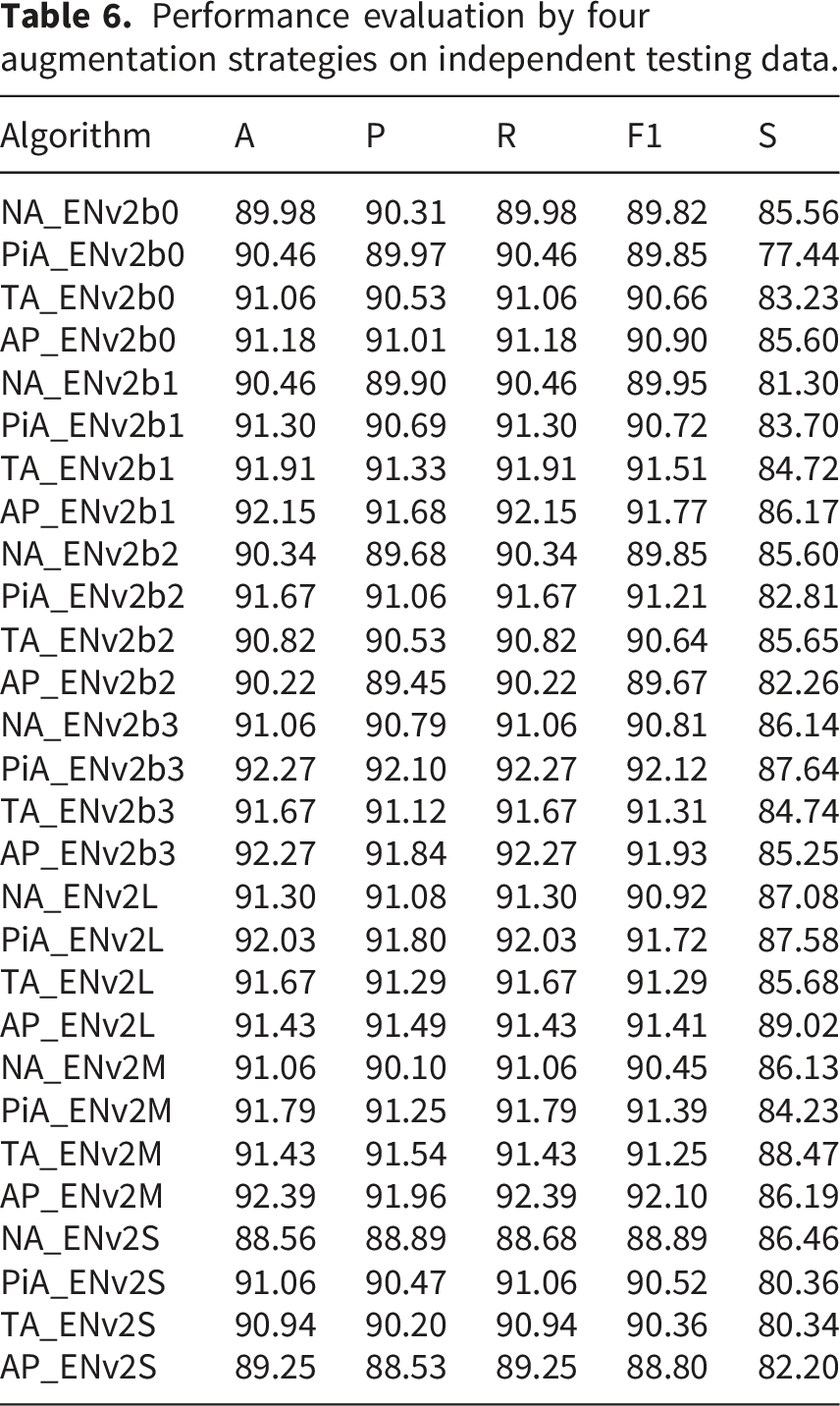
Although Prior Augmentation (PiA) achieved near-perfect test accuracies (e.g., PiA_ENv2b1: 98.58% on test data), its performance dropped considerably on independent testing data, exposing limitations in generalization. For example, PiA_ENv2b1 declined from 98.58% to 91.30% on independent testing—a decrease of 7.28%—whereas TA_ENv2b1 maintained 91.91%, demonstrating better robustness. Similarly, PiA_ENv2b3 decreased by 5.98% (98.25% → 92.27%), while TA_ENv2b3 improved from 90.13% to 91.67%, highlighting TA’s stability on unseen data. A comparable trend was observed for TA_ENv2b1 (89.37% → 91.91%).
Dominance of TA across architectures
TA consistently outperformed other augmentation strategies on independent datasets, even when test accuracies appeared lower. For instance, TA_ENv2b1 achieved 91.91% independent accuracy compared to PiA_ENv2b1’s 91.30%, despite PiA showing higher test accuracy (98.58% vs. 89.37%). TA_ENv2b3 improved from 90.13% (test) to 91.67% (independent), surpassing PiA_ENv2b3 (98.25% → 92.27%). A similar trend was observed for TA_ENv2L, which increased from 87.74% (test) to 91.67% (independent), while PiA_ENv2L declined from 96.35% to 92.03%.
These results emphasize TA’s ability to prevent overfitting, while PiA’s high test scores diminished when evaluated on independent data. Instances where TA’s independent accuracy exceeded its test accuracy (e.g., TA_ENv2b1: +2.54%) further confirm its superior generalization capability.
Limitations of PiA and AP strategies
The tendency of PiA toward overfitting was clearly reflected in its specificity values. For instance, PiA_ENv2b1 achieved an exceptionally high specificity of 99.76% on the test set, which declined notably to 83.70% on the independent data, indicating reduced ability to correctly identify minority classes. In contrast, TA_ENv2b1 maintained a more balanced outcome, with specificity improving from 91.60% to 84.72%, reflecting stronger class-wise generalization. Similarly, the AP strategies exhibited irregular performance patterns across datasets. For example, AP_ENv2b1 increased from 82.08% to 92.15% in accuracy (test → independent), but this inconsistency arose from the inclusion of augmented validation and testing samples, leading to biased evaluation and unstable model adaptation.
Although No Augmentation (NA) delivered moderate improvements compared to earlier baselines (e.g., NA_ENv2b1: 90.46% independent accuracy), TA consistently surpassed it across nearly all architectures. For example, TA_ENv2b1 exceeded NA_ENv2b1 by 1.45% on independent data (91.91% vs. 90.46%), with an even larger margin observed for TA_ENv2b3 (91.67% vs. NA_ENv2b3: 91.06%). Persistent class imbalance also impacted NA’s recall and F1-scores, as seen in NA_ENv2L (F1-score: 90.92% vs. TA_ENv2L: 91.29%), underscoring its weaker discriminative capacity.
Overall, these findings established TA as the most reliable augmentation technique among all evaluated methods. Although PiA achieved notably high test accuracies, its substantial reductions on independent data (e.g., PiA_ENv2b1: −7.28%) revealed limited generalization capability. Conversely, TA consistently sustained or even improved accuracy on unseen datasets, confirming its robustness and suitability for real-world deployment. By upholding evaluation fairness and mitigating the effects of class imbalance, TA exhibited stable and trustworthy performance, reaffirming its position as the most effective augmentation strategy for deep learning–based skin lesion classification.
Performance analysis of TASE architectures in multi layer CKPA
The Classifier-Kernel Probability Aggregation (CKPA) was applied to the outputs of all classifiers at each layer, denoted as CKPA L (with L representing the respective layer), to construct the Multi-Layer CKPA (ML-CKPA). This strategy incrementally refined predictions by utilizing a multi-stage ensemble approach.
TASE architectures in CKPA_Layer 1 on testing data
Performance evaluation of serial stacked attention on testing data in CKPA_Layer 1.

The SSA ensemble at CKPA_Layer 1 further enhanced performance, reaching an accuracy of 91.21%, precision of 91.10%, recall of 91.21%, and specificity of 91.62%, demonstrating that integrating multiple attention-based architectures improved robustness and generalization. These results underscore the SSA framework’s capability to leverage diverse backbone models for superior classification performance.
Performance analysis of TASE architectures in multi layer CKPA
The Ensembled Serial Stacked Attention (SSA) architecture at CKPA_Layer 1 demonstrated a marked improvement over individual models, achieving an accuracy of 91.21%, precision of 91.10%, recall of 91.21%, F1-score of 91.03%, and specificity of 91.62%. The balanced metrics, particularly specificity, highlighted the model’s effectiveness in correctly identifying negative samples. This enhanced performance illustrated that serial stacked attention integration effectively captured contextual information, resulting in more reliable and precise classification. The application of the CKPA ensemble further amplified these gains, confirming the SSA framework as a robust approach for complex classification tasks.
Performance evaluation of parallel stacked attention on testing data in CKPA_Layer 1.
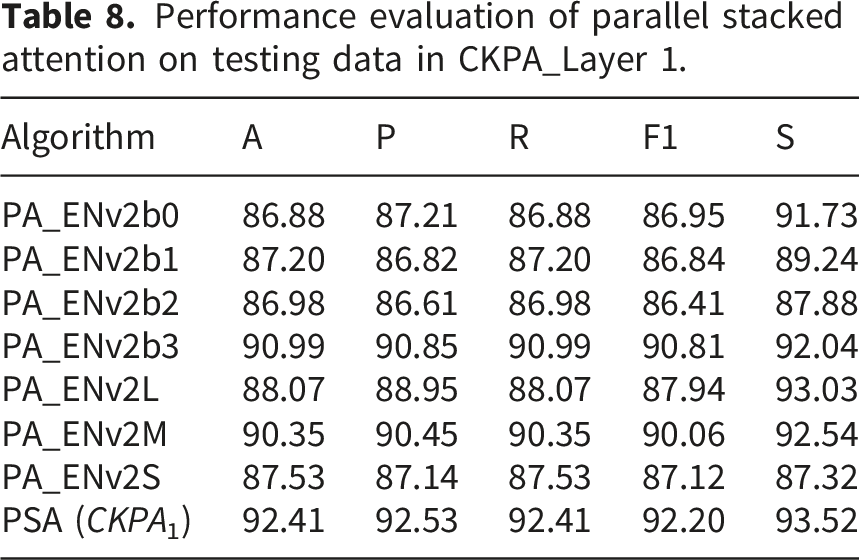
The PSA ensemble at CKPA_Layer 1 further improved performance, reaching an accuracy of 92.41%, precision of 92.53%, recall of 92.41%, F1-score of 92.20%, and specificity of 93.52%, illustrating the advantage of ensembling parallel attention-based architectures for enhanced robustness and classification performance.
The Ensembled Parallel Stacked Attention (PSA) architecture at CKPA_Layer 1 demonstrated superior performance compared to individual models, achieving an accuracy of 92.41%, precision of 92.53%, recall of 92.41%, F1-score of 92.20%, and specificity of 93.52%. The balanced metrics, particularly the specificity, highlighted the model’s ability to correctly classify negative samples. This improvement illustrated that parallel stacked attention effectively enhanced the model’s capacity to extract and utilize contextual information. Furthermore, the CKPA ensemble successfully integrated the strengths of individual architectures, resulting in overall performance gains. Consequently, the PSA configuration proved highly effective for improving classification performance in complex tasks.
Performance evaluation of independent attention on testing data in CKPA_Layer 1.
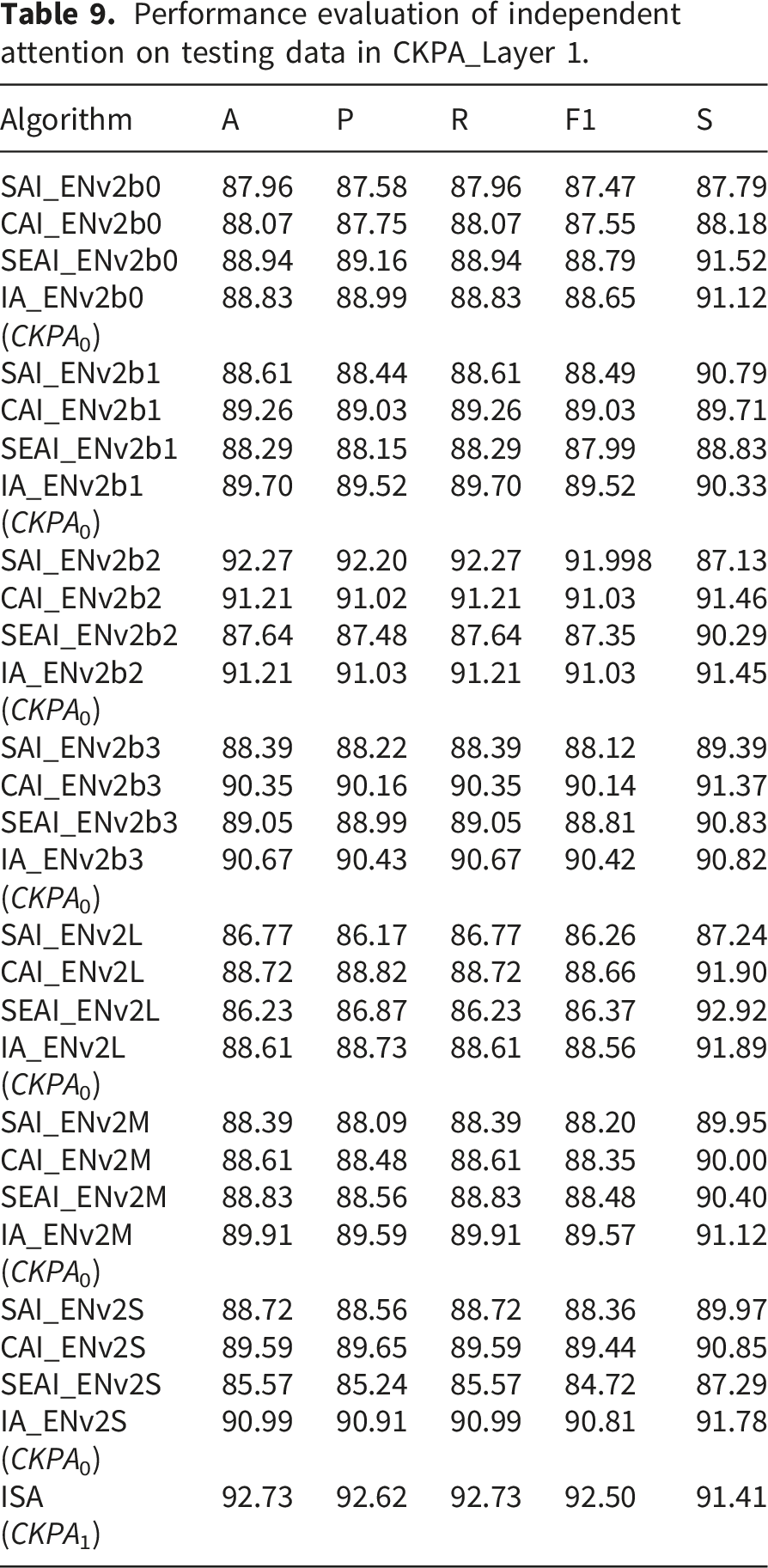
The table presents comparative results of the Triple-Attention modules and their corresponding ensemble configurations across the examined architectures. For example, IA_ENv2S (CKP A0) achieved an accuracy of 90.99%, precision of 90.91%, recall of 90.99%, F1-score of 90.81%, and specificity of 91.78%. Similarly, IA_ENv2b2 (CKP A0) and IA_ENv2b3 (CKP A0) recorded accuracies of 91.21% and 90.67%, respectively. The final ISA ensemble (CKP A1) consolidated these results, achieving an accuracy of 92.73%, precision of 92.62%, recall of 92.73%, F1-score of 92.50%, and specificity of 91.41%.
This evaluation illustrated that ensembling the Triple-Attention (TA) modules considerably boosted model performance, with the ISA architecture in CKPA Layer-1 achieving the highest results. By independently integrating attention mechanisms, the strengths of each architecture were effectively combined, resulting in enhanced overall performance. These findings underscore the robustness and efficacy of the ISA approach in managing complex classification challenges.
TASE architectures in CKPA_Layer 1 with independent testing data
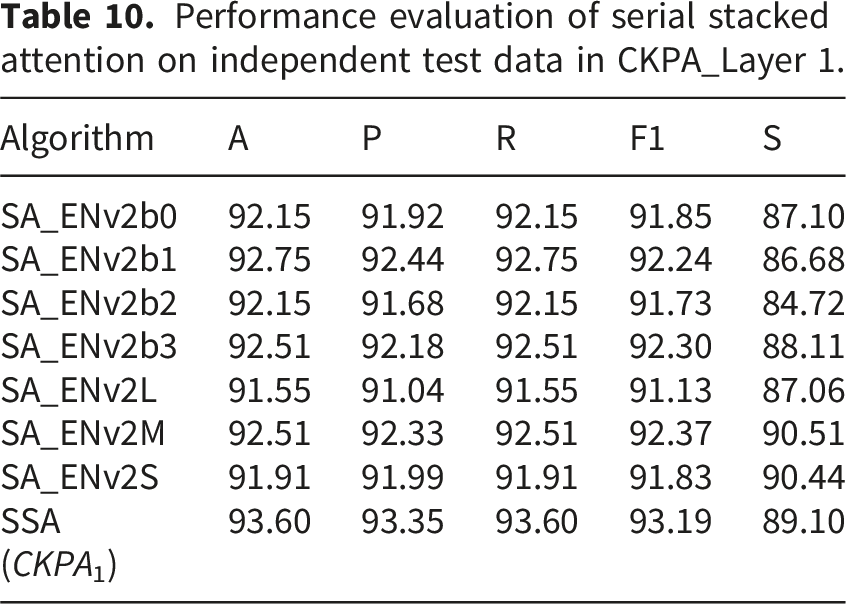
Performance evaluation of serial stacked attention on independent test data in CKPA_Layer 1.
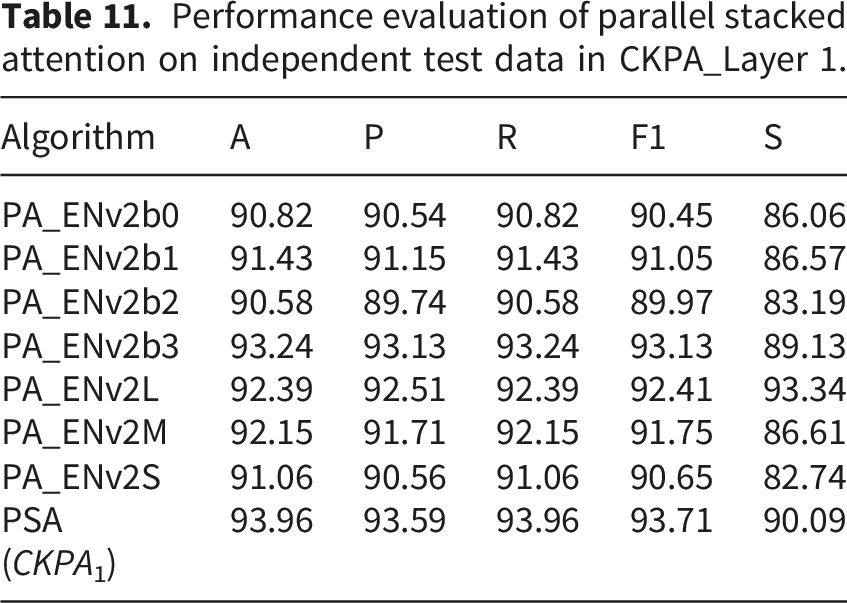
Performance evaluation of parallel stacked attention on independent test data in CKPA_Layer 1.
Performance evaluation of independent attention on independent test data in CKPA_Layer 1.
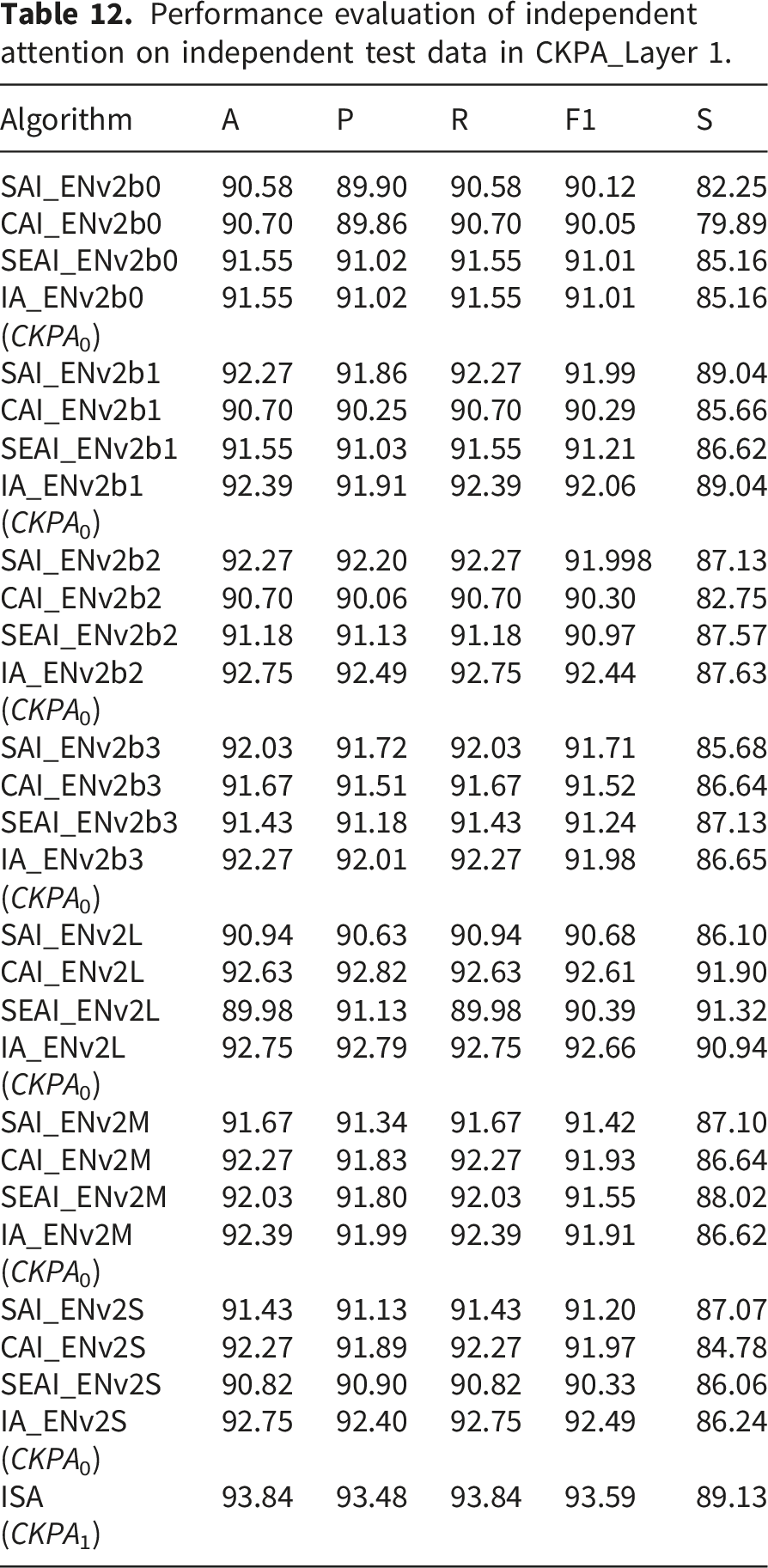
Table 10 showcases the performance of the SSA architectures across various models. For example, SA ENv2b1 achieved an accuracy of 92.75%, with precision and recall values of 92.44% and 92.75%, respectively. Similarly, SA ENv2M demonstrated strong performance with an accuracy of 92.51%, precision of 92.33%, and recall of 92.51%. The ensembled SSA mechanism in CKPA_Layer 1 (SSA (CKPA1)) achieved the highest accuracy of 93.60%, along with precision of 93.35%, recall of 93.60%, F1-score of 93.19%, and specificity of 89.10%. These results indicated that the SSA mechanism effectively leveraged serial stacked attention to enhance model performance on independent test data.
Table 11 presents the performance of the PSA architectures in CKPA_Layer 1 using independent test data. For example, PA ENv2b3 achieved an accuracy of 93.24%, with precision and recall values of 93.13% and 93.24%, respectively. Similarly, PA ENv2L demonstrated strong performance with an accuracy of 92.39%, precision of 92.51%, and recall of 92.39%. The ensembled PSA mechanism in CKPA_Layer 1 (PSA (CKPA1)) achieved the highest accuracy of 93.96%, along with precision of 93.59%, recall of 93.96%, F1-score of 93.71%, and specificity of 90.09%. These results indicated that the PSA mechanism, which processes attention in parallel, effectively enhanced model performance on independent test data.
Table 12 highlights the performance of the ISA architectures in CKPA_Layer 1, which effectively integrated the contributions of individual attention mechanisms. For example, IA ENv2b2 achieved an accuracy of 92.75%, with precision and recall values of 92.49% and 92.75%, respectively. Other IA variants listed in the table demonstrated similarly strong performance. The ensembled ISA mechanism in CKPA_Layer 1 (ISA (CKPA1)) achieved the highest accuracy of 93.84%, along with precision of 93.48%, recall of 93.84%, and an F1-score of 93.59%. These results underscore the effectiveness of the ISA framework in combining multiple attention strategies to enhance model performance on independent test data.
Evaluation of the TASE architectures using independent test data indicated that all three configurations—SSA, PSA, and ISA—exhibited strong performance. Among them, the ISA architectures achieved the highest accuracy and F1-score, underscoring the robustness of the CKPA framework in effectively integrating multiple attention strategies to enhance model generalization on unseen data.
TASE architectures in CKPA-Layer 2
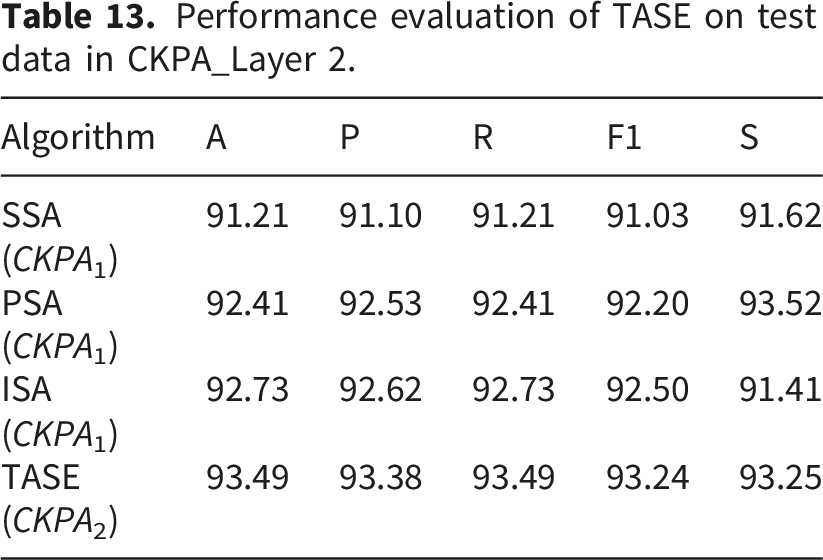
Performance evaluation of TASE on test data in CKPA_Layer 2.
Performance evaluation of TASE on independent test data in CKPA_Layer 2.
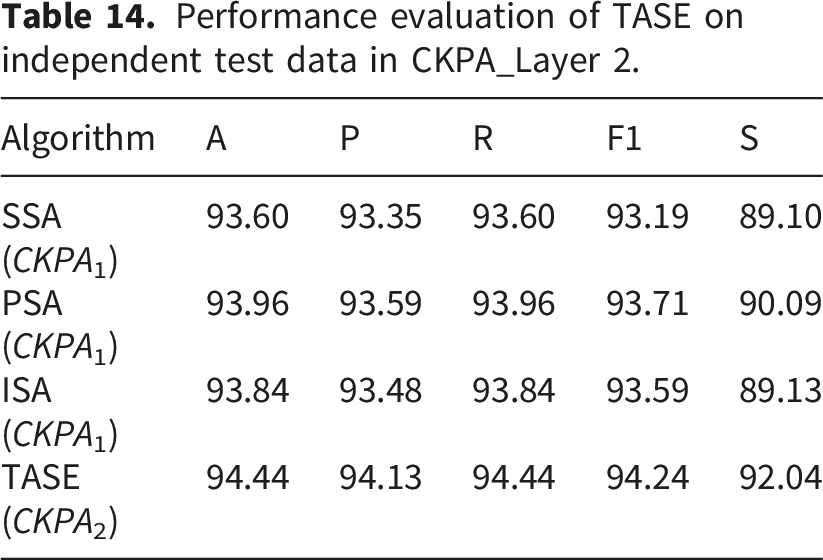
Table 13 reveals the comparative performance of the three pre-final architectures before final ensembling. The Serial Stacked Attention (SSA) achieved an accuracy of 91.21%, with precision of 91.10%, recall of 91.21%, F1-score of 91.03%, and specificity of 91.62%. The Parallel Stacked Attention (PSA) attained 92.41% accuracy, precision of 92.53%, recall of 92.41%, F1-score of 92.20%, and specificity of 93.52%. The Independent Stacked Attention (ISA) demonstrated competitive results with 92.73% accuracy, precision of 92.62%, recall of 92.73%, F1-score of 92.50%, and specificity of 91.41%. These metrics establish the baseline performance of individual components prior to their integration in the final ensemble layer.
The effectiveness of the TASE ensemble was evident as the combined architecture surpassed the performance of all preceding layer-specific models. The TASE (CKPA A2) ensemble on the test set improved upon pre-final results, attaining 93.49% accuracy (precision 93.38%, recall 93.49%, F1-score 93.24%, specificity 93.25%), demonstrating balanced classification performance and confirming the model’s ability to correctly identify the majority of samples.
Table 14 presents the performance of TASE architectures on independent test data, providing a rigorous assessment of generalization capability on completely unseen data. The pre-final architectures maintained strong performance, with SSA achieving 93.60% accuracy, PSA achieving 93.96%, and ISA achieving 93.84%. This consistency confirms the robustness of each attention mechanism when applied to unseen data.
The final TASE ensemble demonstrated the highest performance on independent data, attaining 94.44% accuracy, precision of 94.13%, recall of 94.44%, F1-score of 94.24%, and specificity of 92.04%. This represents a measurable improvement over any single attention mechanism, indicating that hierarchical ensembling effectively captures the complementary strengths of SSA, PSA, and ISA while maintaining balanced performance across all evaluation metrics.
These findings collectively illustrated that the CKPA framework’s hierarchical integration of attention mechanisms offered significant advantages. By systematically combining SSA, PSA, and ISA through layered ensembling, the final TASE architecture achieved superior results, outperforming any individual attention mechanism or standalone stacking configuration. The consistent performance observed across both validation and independent test sets confirmed the model’s robustness and generalization capability for complex classification tasks.
Importantly, the performance on unseen independent data exceeded that on standard test sets, demonstrating the architecture’s reliability and suitability for real-world skin lesion identification.
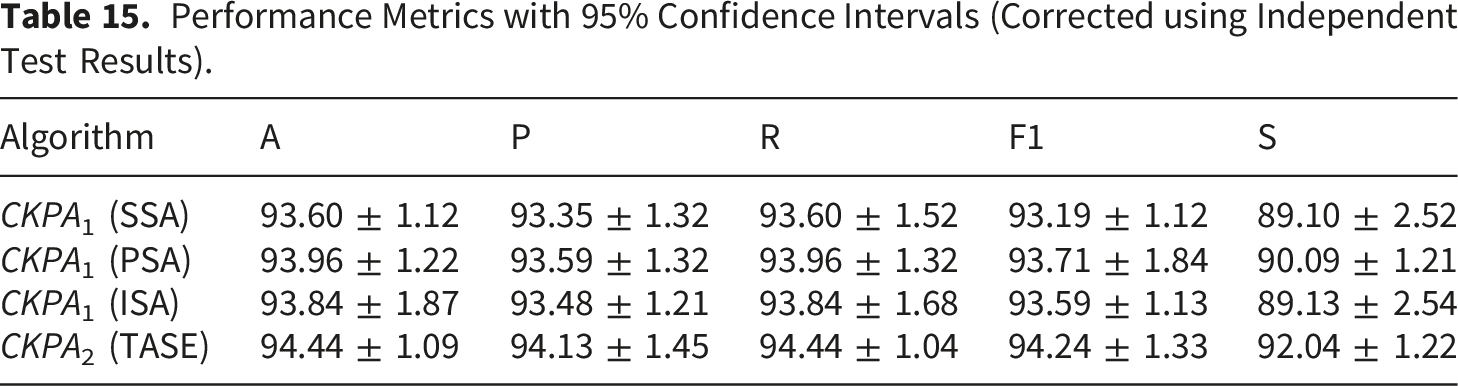
Results with confidence interval
Performance Metrics with 95% Confidence Intervals (Corrected using Independent Test Results).
Performance analysis by visualization
To streamline the analysis, confusion matrices were not presented for every classifier due to model diversity. Instead, we focused on the final layer of the CKPA model, with confusion matrices shown in Figures 10 and 11, highlighting per-class accuracy and misclassification patterns. Confusion matrix and ROC-AUC curve obtained by TASE architecture in CKPA-Layer 2. Confusion matrix and ROC-AUC curve obtained by TASE architecture in CKPA-Layer 2 on independent test data.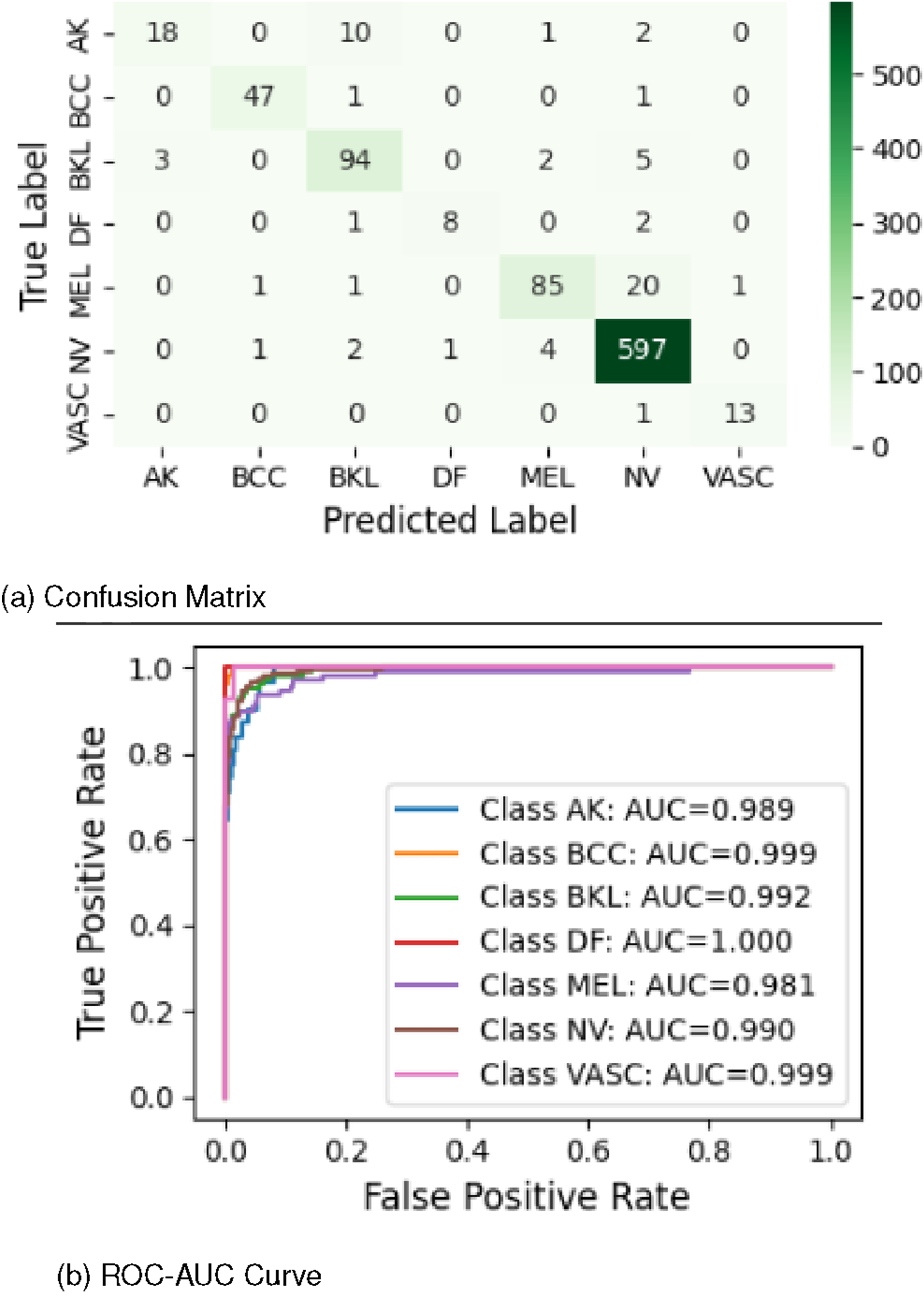
Similarly, ROC-AUC curves were analyzed to provide further insight into model performance. Following the same approach, ROC-AUC curves were presented only for the Multi-Layer CKPA model in Figures 10 and 11 for consistency.
The final TASE architecture (CKPA2) demonstrated strong performance across multiple classes. For example, the BCC class achieved perfect classification, correctly identifying all 49 samples, while the DF class correctly classified 8 out of 11 samples, with 3 misclassifications. The NV class performed exceptionally, correctly classifying 600 out of 605 samples, demonstrating robust handling of both majority and minority classes. In the AK class, 18 samples were correctly classified with 13 errors, whereas the VASC class achieved 12 correct predictions with 2 misclassifications. The BKL class correctly identified 93 out of 104 samples, and even the most challenging MEL class achieved 77 correct classifications, with 31 errors. Overall, TASE exhibited high accuracy and reliable performance across all categories.
The ROC-AUC scores further validated the effectiveness of TASE (CKPA2). The MEL class, with the lowest AUC, still achieved 0.973, indicating strong discriminative ability. The DF and VASC classes attained perfect AUC scores of 1, while the other classes maintained consistently high scores near 0.99. These consistently strong ROC-AUC values underscore the precision, stability, and robustness of the TASE architecture.
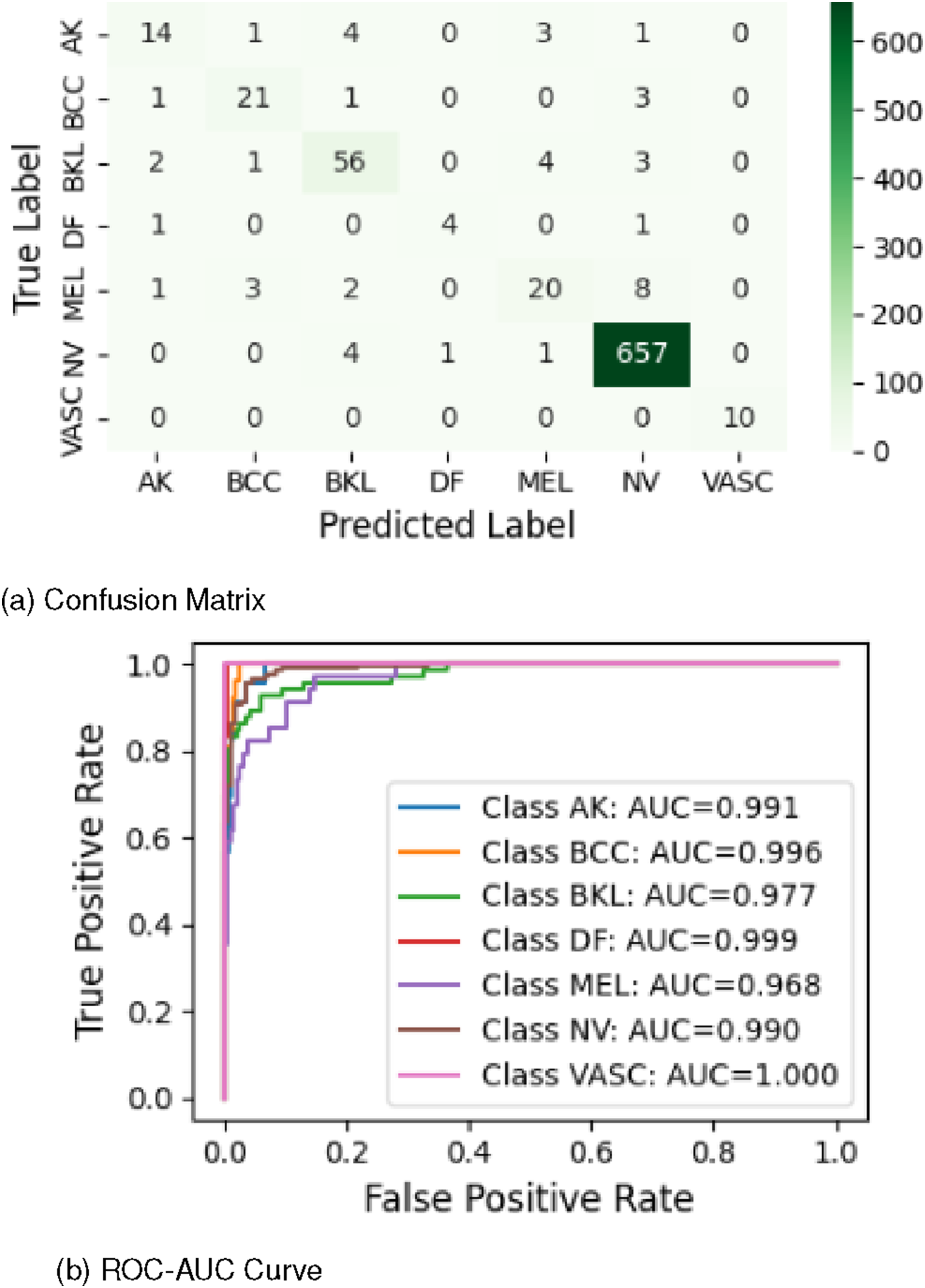
The TASE (CKPA2) architecture ultimately exhibited outstanding performance on independent test data, outperforming all preceding layers across every class.
For the VASC class, near-perfect classification was observed, with 8 out of 9 samples correctly identified, resulting in a single misclassification, and an AUC score of 1. The DF class also showed excellent results, accurately classifying 4 of 6 samples with 2 errors, achieving an impressive AUC of 0.992.
The AK class displayed a nearly balanced outcome, with 12 correct classifications against 11 misclassifications, while still maintaining a strong ROC-AUC score of 0.990. The NV class performed remarkably well, correctly identifying 658 out of 663 samples and achieving an AUC of 0.988, demonstrating reliable classification for both majority and minority class samples.
For the BKL class, 55 out of 66 samples were accurately classified, although it recorded the lowest AUC value of 0.977. The BCC class achieved similarly strong results, correctly identifying 21 of 26 samples and attaining a high AUC of 0.996.
The MEL class, which remained the most challenging, still managed 16 correct classifications out of 34 samples, with an improved AUC score of 0.980 compared to previous architectures.
In summary, the TASE (CKPA2) model exhibited exceptional accuracy and robustness, demonstrating consistent reliability and high effectiveness across all lesion categories.
Gradient class activation map (GradCAM) for interpretability
To enhance the interpretability of the proposed TASE model, Gradient-weighted Class Activation Mapping (GradCAM) was employed. GradCAM highlights the most critical regions of input images that drive the model’s predictions, providing insights into its decision-making process. The last convolutional layer was selected for generating activation maps, as it captures high-level spatial features essential for accurate classification.
The GradCAM procedure is illustrated in Figure 12. Gradients of class-specific outputs with respect to the chosen convolutional layer’s activations were computed using TensorFlow’s Step by step implementation of gradient class activation map.
The computed gradients were spatially pooled by averaging over each feature map channel, providing a measure of their importance for the target class. These pooled gradients were applied as weights to the activation maps of the final convolutional layer, and the resulting weighted activations were aggregated to generate a class-specific activation heatmap. The heatmap was normalized to a [0,1] range for clearer visualization and then overlaid on the original input image using a colormap, highlighting regions that most influenced the TASE (CKPA2) model’s classification decisions.
To assess model attention across different categories, GradCAM visualizations were produced for representative samples from each class. These heatmaps demonstrated that the model effectively focused on salient regions, such as lesions in medical images, confirming its ability to extract meaningful and discriminative features.
Despite its usefulness, GradCAM has limitations. Because it relies on model predictions, misclassifications can yield misleading heatmaps. Additionally, for complex or subtle patterns—such as ambiguous skin lesions—GradCAM may occasionally highlight irrelevant areas, potentially reducing interpretability. These limitations emphasize the importance of complementing GradCAM with rigorous quantitative evaluation to ensure reliable and actionable model insights.
In Figure 13, GradCAM visualizations are shown for all seven classes, demonstrating how the TASE (CKPA2) model focused on the most discriminative regions rather than the entire image. This targeted attention improved classification accuracy and illustrated the effectiveness of our approach. The figure displays the original image alongside the corresponding GradCAM and Region of Interest (ROI), enhancing interpretability of the model’s decisions. GradCAM visualization for each class.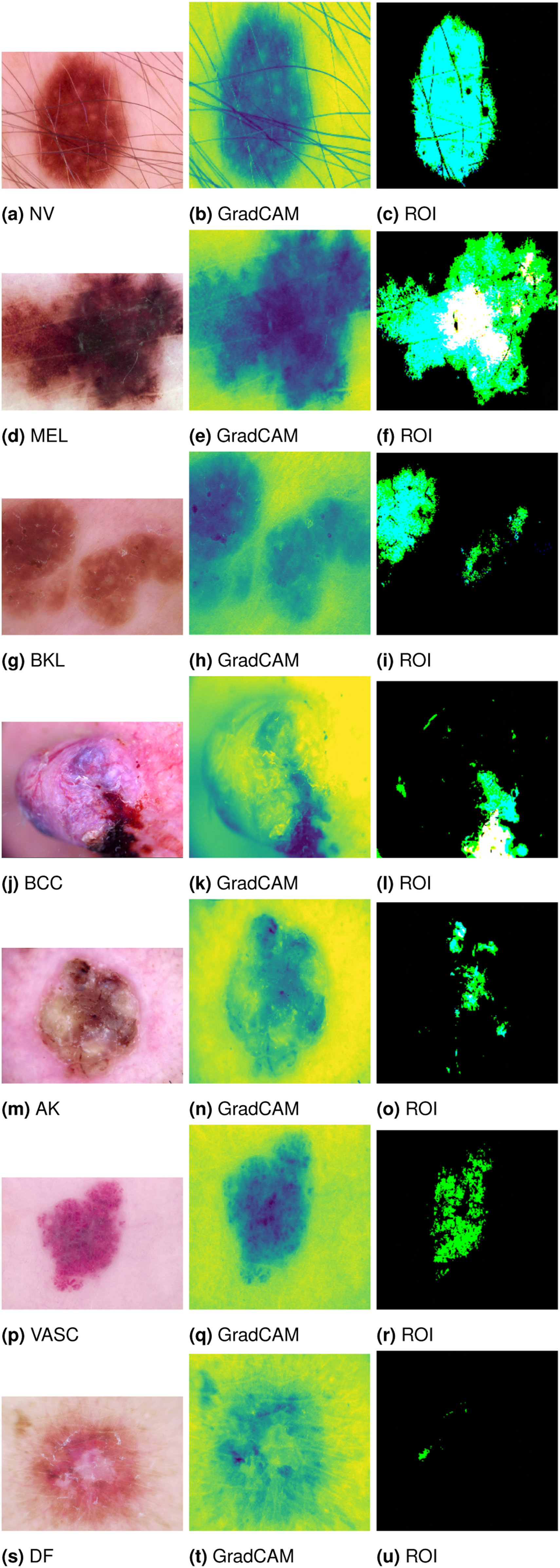
GradCAM also served as a tool to validate model reliability. When the heatmap aligned with the relevant region, it indicated accurate classification, whereas misaligned heatmaps often revealed misclassifications. By integrating multiple models in the CKPA ensemble, the final predictions achieved higher accuracy. The GradCAM visualizations confirmed that the ensemble effectively mitigated the limitations of individual classifiers, emphasizing the robustness of the Multi-Layer CKPA framework and its ability to produce precise predictions even in challenging cases, thereby reinforcing the strength of our methodology.
Ablation study
To demonstrate the superiority of our novel approach compared to state-of-the-art methods, we conducted a comprehensive ablation study focusing on two key innovations: Triple-Attention (TA) and Cohen’s Kappa Proportioned Averaging (CKPA). We evaluated the performance impact of these components by analyzing the results with and without their utilization.
Utilization of CKPA without TA
Performance metrics of CKPA without TA.
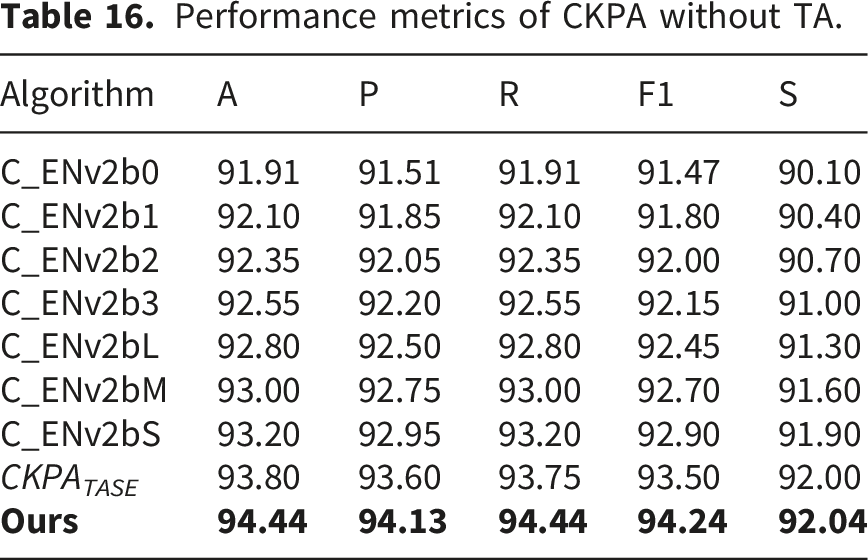
Our proposed Cohen’s Kappa Proportioned Averaging (CKPA) demonstrated superior performance when enhanced with Triple-Attention (TA) compared to traditional CKPA and other ensembling methods. By incorporating TA into CKPA, our approach, presented as “Ours” in Table 16, achieved the highest accuracy of 94.44%, surpassing the performance of all other configurations. This significant improvement underscores the efficacy of TA in refining CKPA’s ability to aggregate model predictions, leading to more accurate and reliable outcomes.
Without TA, various levels of CKPA implementations using EfficientNet v2 variants yielded commendable results. Among them, C_ENv2bS stood out with a 93.20% accuracy, followed by C_ENv2bM at 93.00%. Despite their strong performances, none matched the enhanced accuracy achieved by incorporating TA. This comparison clearly illustrates that CKPA, when paired with TA, offers a more robust ensembling technique, pushing the boundaries of model performance and accuracy beyond existing methods.
Utilization of conventional ensemble methods instead of CKPA
As previously described, CKPA was applied at multiple levels using a distinct approach within the proposed framework. Predictions from different TASE variants incorporating Triple-Attention (TA) mechanisms were ensembled by determining optimal weights across all models as well as for the top-performing subset. Specifically, CKPA utilizing all classifiers at level i is denoted as CKPA i . To highlight the effectiveness of CKPA, its performance was compared with conventional ensemble methods, including Softmax Averaging (SA), Majority Voting (MV), and Weighted Averaging (WA) with randomly assigned weights. The comparative results are presented in this section.
Softmax averaging (SA)
Performance metrics of Softmax Averaging of all classifiers.
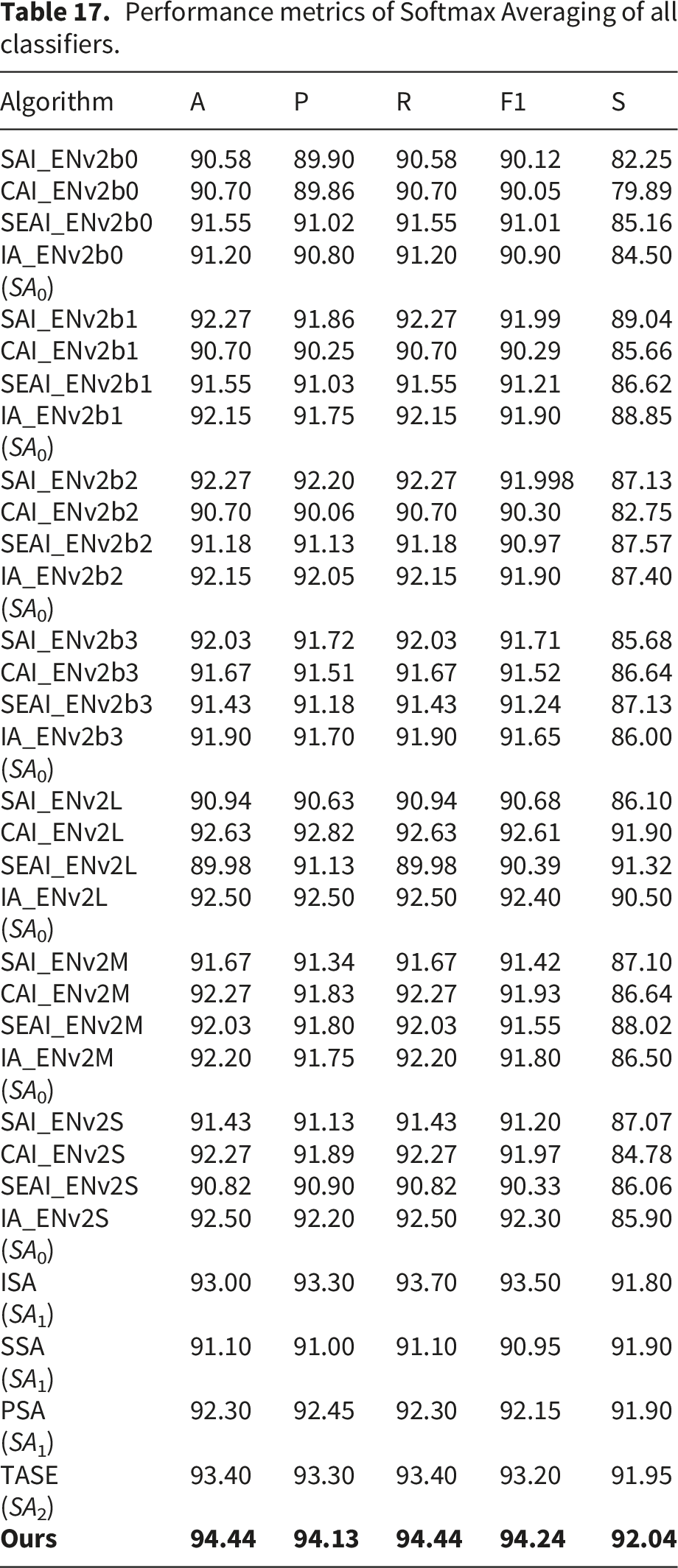
Table 17 presents the performance metrics of different classifiers using the Softmax Averaging (SA) technique at multiple levels, compared with the proposed Cohen’s Kappa Proportioned Averaging (CKPA) approach. The results clearly indicate that CKPA consistently outperforms SA across all levels and evaluation metrics, demonstrating the effectiveness of the proposed method.
In terms of accuracy, the highest result achieved by the SA-based approaches was 93.40%, obtained by the TASE model at the second level (SA2). In contrast, the proposed method achieved an accuracy of 94.44%, showing a clear improvement over the best SA-based performance.
A similar trend is observed for precision. The highest precision among the SA-based methods was 93.30%, while the proposed method achieved 94.13%, indicating improved reliability in positive predictions and reduced false positives.
For recall, the best SA-based performance reached 93.70% (ISA at SA1 level), whereas the proposed method achieved 94.44%, demonstrating its enhanced capability in correctly identifying positive instances.
The F1-score further confirms the superiority of the proposed approach. While the highest F1-score among SA-based methods was 93.50%, the proposed method achieved 94.24%, reflecting a better balance between precision and recall.
Overall, the proposed CKPA method consistently delivers superior performance compared to conventional Softmax Averaging. These results highlight the robustness and effectiveness of CKPA as an advanced ensemble strategy for improving classification performance.
Majority voting (MV)
Performance metrics of Majority Voting of all classifiers.
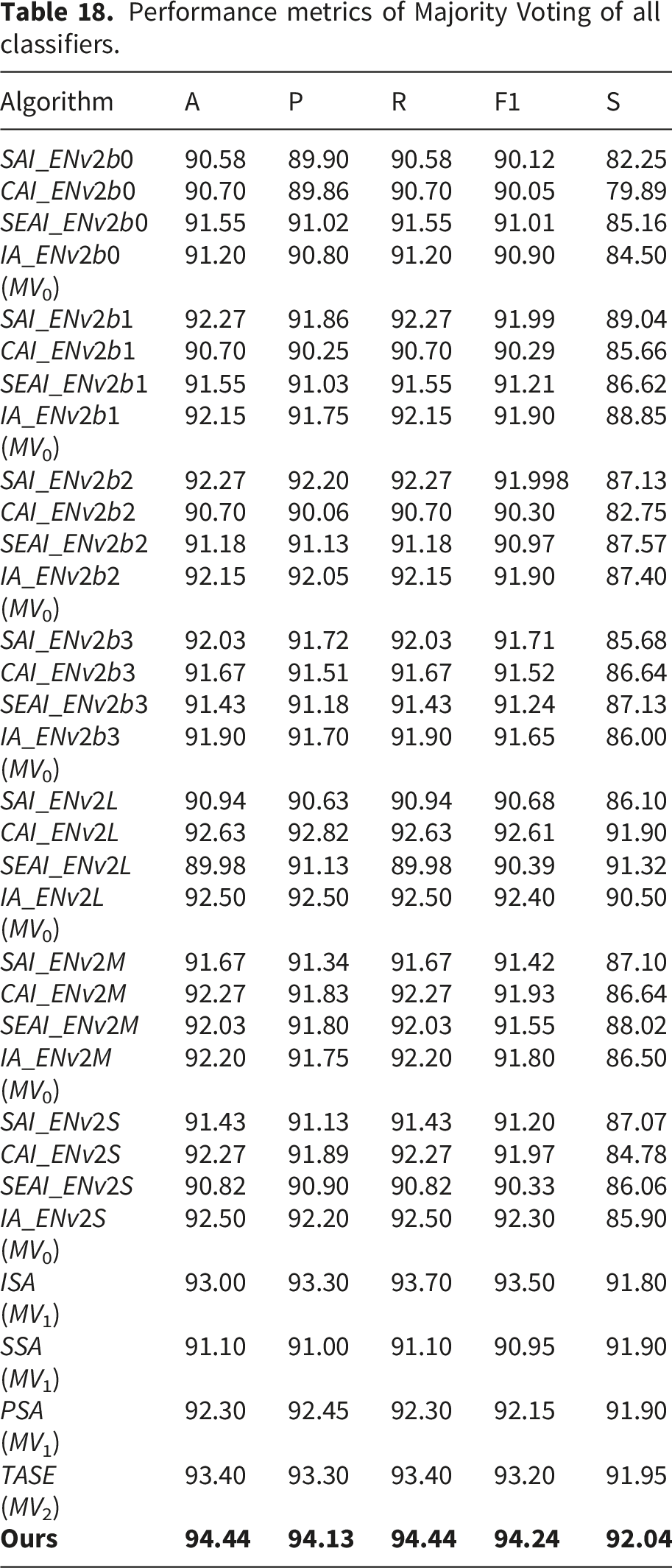
Table 18 presents the performance metrics of different classifiers using the Majority Voting (MV) technique at multiple levels, compared with the proposed Cohen’s Kappa Proportioned Averaging (CKPA) approach. The results clearly demonstrate that CKPA consistently outperforms MV across all levels and evaluation metrics, confirming the effectiveness of the proposed method.
In terms of accuracy, the highest result achieved by the MV-based approaches was 93.40%, obtained by the TASE model at the third level (MV2). In contrast, the proposed method achieved an accuracy of 94.44%, indicating a clear improvement over the best MV-based performance.
A similar trend is observed for precision. The highest precision among the MV-based methods was 93.30%, while the proposed method achieved 94.13%, demonstrating improved reliability in positive predictions and reduced false positives.
For recall, the best MV-based performance reached 93.70% (ISA at MV1 level), whereas the proposed method achieved 94.44%, showing its enhanced capability in correctly identifying positive instances.
The F1-score further highlights the superiority of the proposed approach. While the highest F1-score among MV-based methods was 93.50% (ISA at MV1 level), the proposed method achieved 94.24%, reflecting a better balance between precision and recall.
Overall, the proposed CKPA method consistently delivers superior performance compared to the conventional Majority Voting technique. These results emphasize the robustness and effectiveness of CKPA as an advanced ensemble strategy for improving classification performance.
Weighted averaging (WA)
Performance metrics of weighted averaging of all classifiers.
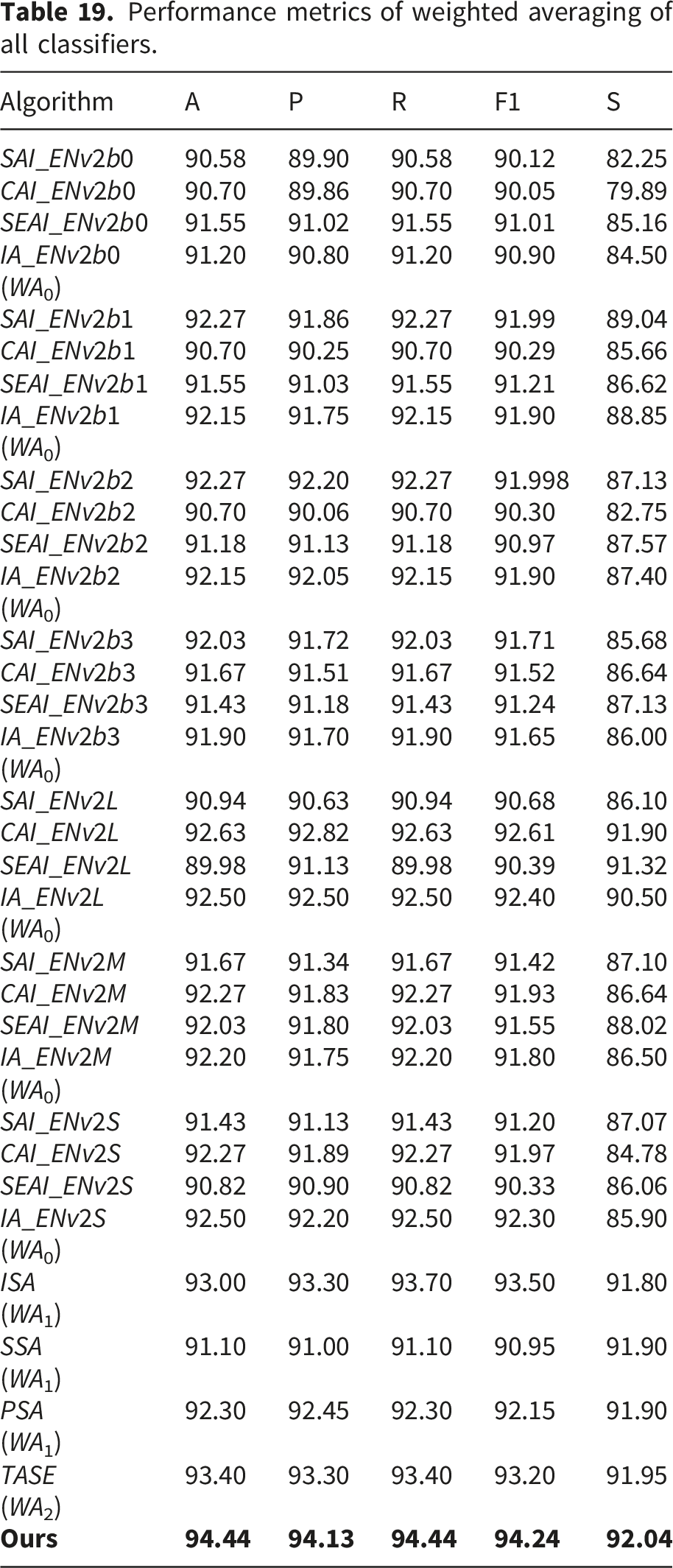
Table 19 compares the performance metrics of various classifiers using the Weighted Averaging (WA) technique at different levels with our proposed Cohen’s Kappa Proportioned Averaging (CKPA) approach. The results clearly show that CKPA consistently outperforms WA across all levels and evaluation metrics, demonstrating the effectiveness of the proposed method.
Regarding accuracy, the highest value achieved by the WA-based methods was 93.40%, obtained by the TASE model at the second level (WA2). In contrast, the proposed method achieved an accuracy of 94.44%, surpassing the best WA result. This improvement highlights the superior capability of CKPA in correctly classifying instances.
Precision also favors CKPA. The highest precision among the WA methods was 93.30%, achieved by the TASE model at the second level (WA2), whereas the proposed method achieved a precision of 94.13%. This indicates that CKPA is more effective in reducing false positives compared to conventional WA.
For recall, the best performance among WA methods was 93.70%, achieved by ISA at the first level (WA1). The proposed method achieved a recall of 94.44%, outperforming the best WA result, which reflects its improved ability to correctly identify positive instances.
The F1-score further demonstrates the superiority of the proposed method. While the highest F1-score among WA-based approaches was 93.50% (achieved by ISA at WA1 level), the proposed method achieved 94.24%, indicating a better balance between precision and recall.
In conclusion, the proposed CKPA approach consistently achieves superior performance across all evaluation metrics compared to the traditional Weighted Averaging technique. By addressing the limitations of WA, CKPA provides a more robust and reliable ensemble strategy for improving classification performance.
Based on the overall experimental analysis, it is evident that the integration of Triple-Attention (TA) and CKPA forms an effective and optimized architecture compared to existing ensemble methods.
Answers to the research questions
Answer to RQ1
To address pronounced class imbalance, this study evaluated four augmentation strategies: No Augmentation (NA), which preserved the original dataset but risked underperformance on minority classes; Prior Augmentation (PiA), generating synthetic samples before dataset splitting, potentially introducing data leakage; Training Data Augmentation (TA), which augmented only the training set to maintain the independence of validation and test sets; and Posterior Augmentation (AP), which expanded all subsets but could bias evaluation metrics. Among these, TA proved most effective, synthesizing minority-class examples while keeping validation and test sets untouched, ensuring robust generalization. Integrating TA with TASE architectures further enhanced model performance, establishing it as the preferred strategy for handling imbalance while upholding strict evaluation integrity.
Answer to RQ2
To optimize Transfer Learning (TL) models for the target classification tasks, diverse variants of MobileNet and Inception were employed, enabling exploration of architectural strengths tailored to the dataset. Final layers were replaced and trained to align with task requirements, ensuring adaptability while preserving pre-trained feature extraction capabilities. Parameter quantization improved computational efficiency without sacrificing performance. Coupling TASE with Triple-Attention (TA) further strengthened model robustness. This dual strategy—leveraging architectural diversity for comprehensive feature representation and precise fine-tuning for task-specific optimization—ensured high adaptability and efficiency. Balancing pre-trained knowledge with domain-specific adjustments achieved superior results, demonstrating that optimal TL performance relies on strategic architecture selection, parameter-efficient training, and context-aware adaptation.
Answer to RQ3
The Triple-Attention (TA) mechanism integrated into the TASE model combined three complementary attention modules—Soft Attention Integration (SAI), Channel Attention Integration (CAI), and Squeeze-Excitation Attention Integration (SEAI)—to hierarchically capture and prioritize critical features. SA highlighted essential spatial regions in feature maps, focusing the model on discriminative local patterns. CA refined channel-wise importance, amplifying informative channels while suppressing irrelevant ones. SEA adaptively recalibrated channel responses through squeeze-and-excitation operations, enabling context-aware feature enhancement. Together, these modules mitigated the risk of overlooking hierarchical dependencies or overfitting. By synergistically balancing spatial focus, channel relevance, and cross-layer contextualization, the TA-equipped TASE model outperformed non-attention baselines in ablation studies, achieving precise localization of significant regions and robust feature discrimination, ensuring interpretable and generalizable feature extraction.
Answer to RQ4
Single algorithms were insufficient for skin lesion classification due to high inter-class similarity and intra-class variability, making Ensemble Learning (EL) essential. In this study, TASE architectures—custom CNNs fused with SAI, CAI, and SEAI modules, along with Transfer Learning (TL) models—were incorporated into three ensemble strategies: Serial Stacked, Parallel Stacked, and Independent Stacked. The final multi-layer ensemble effectively combined attention-driven feature representations, reducing bias and enhancing generalization. Aggregating predictions from heterogeneous architectures significantly improved accuracy and robustness on unseen data, demonstrating that EL is critical for complex medical imaging tasks where feature diversity and consensus are vital. A novel ensemble method, Cohen’s Kappa Proportioned Averaging (CKPA), was proposed to optimally weight predictions across multiple layers.
Answer to RQ5
Relying solely on post-prediction ensembling, such as CKPA, carries risks including redundant feature learning, error propagation from uncorrelated base models, and limited synergistic learning. Pre-prediction stacking—implemented through Serial, Parallel, and Independent Stacked Attention—integrates attention mechanisms during model training, enabling collaborative feature refinement. Serial stacking sequentially enhances attention-guided features across layers; Parallel stacking processes inputs via multiple attention pathways simultaneously; and Independent stacking maintains specialized attention modules for later fusion. By embedding attention at the architectural level, pre-prediction stacking minimizes redundancy, enhances feature complementarity, and allows end-to-end optimization of interactions. Experimental results confirmed that pre-prediction stacking outperforms post-prediction CKPA, particularly in complex tasks like skin lesion classification, where hierarchical feature refinement and synergistic learning improve discrimination and robustness.
Discussion and extended comparison
Our research demonstrated the advantages of combining TASE architectures with the Multi-Layer Cohen’s Kappa Proportioned Averaging (CKPA) ensemble framework to improve classification outcomes. Through systematic data preprocessing, targeted augmentation, and fine-tuning of pre-trained models, we effectively mitigated class imbalance issues and enhanced the extraction of discriminative features, leading to substantial improvements in overall model performance.
To optimize feature representation, we employed a Triple-Attention mechanism integrating Soft Attention Integration (SAI), Channel Attention Integration (CAI), and Squeeze-Excitation Attention Integration (SEAI). This mechanism was incorporated via three specialized stacking strategies: Serial Stacked Attention, Parallel Stacked Attention, and Independent Stacked Attention. By leveraging both low-level and high-level features, these approaches enabled the construction of a highly flexible and effective architecture. In addition to pre-prediction stacking, post-prediction ensembling across multiple layers further refined the model’s predictions, enhancing both accuracy and robustness.
The final evaluation at CKPA-Layer 2 highlighted the effectiveness of this hierarchical ensembling framework. The TASE model achieved a remarkable accuracy of 94.44%, outperforming prior approaches and validating the efficacy of our multi-layer CKPA design. Moreover, a high specificity of 92.04% confirmed the model’s capability to correctly identify non-target classes, ensuring consistent and reliable performance across diverse evaluation metrics.
These results affirmed the strength of our methodological framework, emphasizing the successful integration of advanced attention modules, stacking architectures, and multi-layer ensembling strategies. The observed improvements across performance metrics underscored the model’s ability to produce accurate and generalizable predictions, positioning it as a significant advancement in the domain of image classification.
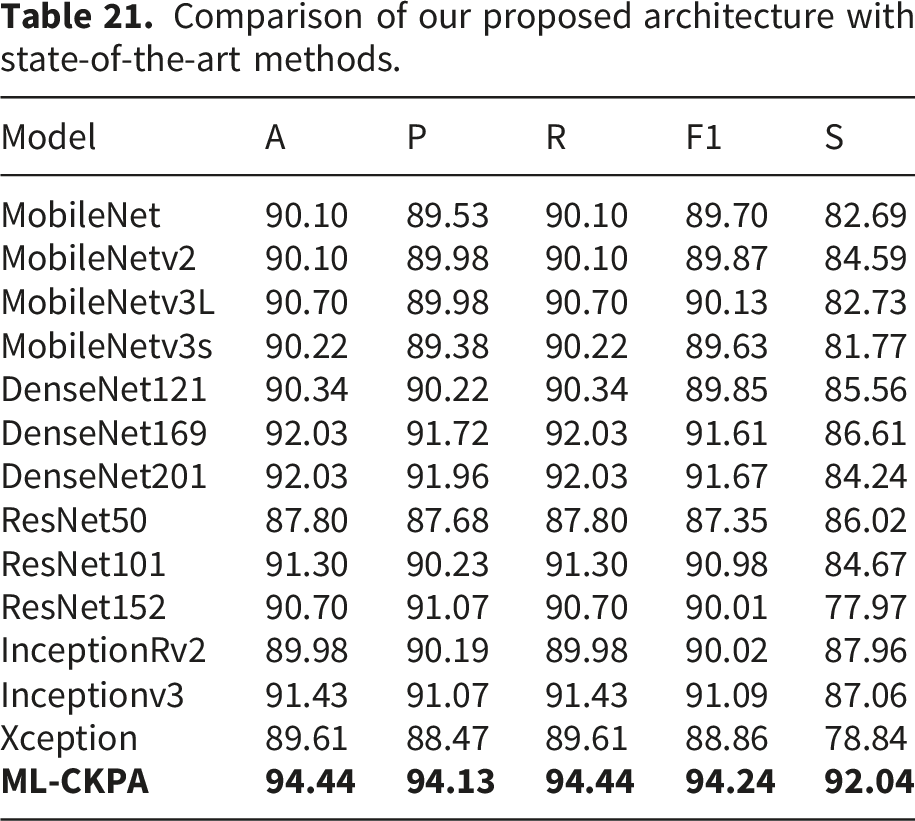
Comparison of our proposed architecture with existing others.
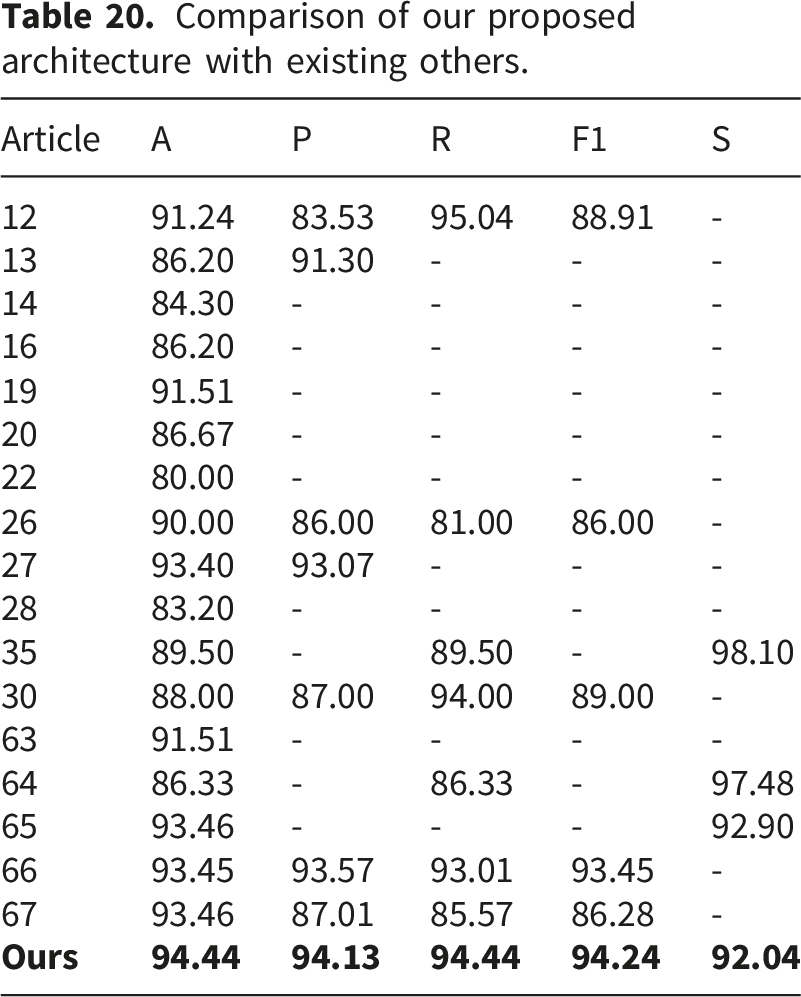
Comparison of our proposed architecture with state-of-the-art methods.
Threats to validity
Although the proposed methodology achieved notable success in image classification, certain limitations should be acknowledged to inform future improvements:
Computational overhead
The multi-layer CKPA framework, while effective, introduces considerable computational demands due to its reliance on multiple TASE architectures and iterative ensemble refinement. Both training and inference are impacted by the need to coordinate diverse attention modules and base classifiers, posing challenges for large-scale datasets or environments with limited computational resources.
Dependence on homogeneous base classifier
The success of CKPA depends on the diversity of its constituent models. Using homogeneous architectures may lead to overlapping feature representations, thereby limiting ensemble gains. Although this study leverages varied TASE forms (SSA, PSA, ISA) to mitigate this risk, incorporating additional architectural or algorithmic diversity could further improve robustness.
Dataset-specific generalization
The evaluation is based on a single benchmark dataset, which may contain domain-specific biases or distributional characteristics not representative of broader settings. Consequently, the model’s performance might decline when applied to cross-domain data, such as alternative imaging protocols or diverse lesion populations.
External validation limitation
Another limitation is the lack of external validation, as the proposed framework has been evaluated on a single benchmark dataset. This may restrict its immediate generalizability to real-world clinical settings. However, the primary contribution of this work is architectural, and future research will focus on validating the proposed model on multiple datasets as well as real-world clinical data to further assess its robustness and applicability.
Future work and research directions
The limitations highlighted in this study suggest several promising directions for extending the proposed framework’s applicability, efficiency, and robustness:
Optimizing computational efficiency
Future research could aim to reduce the computational demands of the multi-layer CKPA framework while preserving its ensemble advantages. Strategies may include knowledge distillation to compress multiple TASE architectures into more compact models, dynamic pruning of redundant classifiers during inference, and hardware-aware parallelization to maximize resource utilization. Additionally, adaptive ensembling depth—where the number of CKPA layers is determined based on dataset complexity—could provide a balanced trade-off between computational cost and performance, facilitating real-world deployment.
Enforcing base classifier diversity
The success of CKPA depends on the diversity of its underlying models. Automated approaches for promoting classifier heterogeneity could be explored, such as adversarial decorrelation losses to reduce redundant feature learning, and neural architecture search (NAS) to identify optimal combinations of attention modules and transfer learning backbones. Furthermore, hybrid ensembles that integrate CNNs with transformer-based or graph neural network models could enrich feature representations, particularly for rare or morphologically complex lesion subtypes.
Cross-domain generalization and robustness
To enhance the framework’s applicability beyond a single dataset, future work should focus on validating CKPA performance across multi-center datasets with diverse imaging protocols, patient demographics, and lesion distributions. Incorporating domain adaptation techniques and evaluating on heterogeneous datasets will help address distribution shifts and improve generalizability. Establishing collaborative benchmarking with clinical partners can create standardized evaluation protocols for real-world challenges, such as low-quality images or streaming data with class imbalance. Additionally, integrating uncertainty quantification into the CKPA ensemble weighting process could enhance reliability in ambiguous cases, supporting greater trust and adoption in clinical settings.
Conclusion
This study presents a comprehensive image classification framework that integrates TASE architectures with a Multi-Layer Cohen’s Kappa Proportioned Averaging (ML-CKPA) strategy. The process begins with systematic data preprocessing and the evaluation of four augmentation techniques, from which the most effective strategy is selected based on performance on an independent test set. This ensures efficient training and strong generalization capability of the TASE models.
To enhance feature representation and class discrimination, three attention-based stacking approaches—Serial Stacked Attention, Parallel Stacked Attention, and Independent Stacked Attention—are incorporated. Each configuration contributes unique strengths, and their outputs are combined using the proposed CKPA ensemble method to achieve improved predictive performance.
The ML-CKPA framework applies a two-stage sequential refinement mechanism that effectively leverages the complementary strengths of individual TASE models. This layered ensembling strategy results in a robust classification system, delivering notable gains in accuracy and consistency across all evaluation metrics.
Furthermore, GradCAM visualizations enhance the interpretability of the framework by identifying the regions influencing model decisions, thereby supporting its practical applicability. The proposed method demonstrates strong performance in transfer learning scenarios, particularly in medical imaging, and shows promise in facilitating early and accurate diagnosis of skin conditions, contributing to improved patient outcomes and accessibility to reliable diagnostic support.
Footnotes
Acknowledgements
The authors would like to express their sincere gratitude to their parents for their continuous support and encouragement.
Ethical considerations
This study was conducted in compliance with ethical standards, ensuring proper copyright adherence and attribution. The dataset used in this research is publicly available under the CC BY-NC-4.0 license, and it has been utilized with appropriate attribution. The study utilized the HAM10000 dataset, 50 which is a publicly accessible resource. The original authors of this dataset obtained the necessary ethical approvals and informed consent from all participants during the primary data collection process. Since this research is based on a retrospective analysis of a previously approved and publicly available dataset, further institutional ethics approval was not required.
Consent to participate
Informed consent was originally obtained from all individual participants by the creators of the dataset.
Consent for publication
All authors have provided their consent for publication in this journal (Digital Health, Sage). No additional consent is required beyond the authors’ approval.
Author contributions
All authors have read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data used in this study, including the augmented training dataset, are publicly available in the Kaggle repository: [HAM10000 Dataset].
50
(![]() ). The use of the HAM10000 dataset
49
complies with the Creative Commons Attribution-NonCommercial 4.0 International License. Proper attribution has been provided, and the recommended citation of the original dataset publication has been included, thereby fulfilling the license requirements. Furthermore, the dataset has been used strictly for non-commercial research purposes in accordance with the license terms. The source code developed for this study is available from the corresponding author upon reasonable request.
). The use of the HAM10000 dataset
49
complies with the Creative Commons Attribution-NonCommercial 4.0 International License. Proper attribution has been provided, and the recommended citation of the original dataset publication has been included, thereby fulfilling the license requirements. Furthermore, the dataset has been used strictly for non-commercial research purposes in accordance with the license terms. The source code developed for this study is available from the corresponding author upon reasonable request.
Guarantor
All authors accept full responsibility for the integrity of the data and the accuracy of the data analysis, and confirm that they had full access to all data used in the study.