
Abstract
Objective
To develop an interpretable machine-learning framework for supporting quality-of-life (QoL) assessment and stratification in patients with knee osteoarthritis (OA) by integrating linear and nonlinear modelling strategies.
Methods
This retrospective study utilised de-identified clinical data from 1,102 patients with knee OA collected at a university hospital in South Korea between September 2013 and January 2022 and made available via the AI Hub platform. QoL was assessed using the EuroQol-5 Dimensions (EQ-5D) index and dichotomised at 0.7. A residual ensemble model combining logistic regression (LR) and a Random Forest residual learner was developed and evaluated using stratified train–test split and three-fold cross-validation. Model performance was assessed using accuracy, F1-score, ROC-AUC, and PR-AUC. Model interpretability was examined using LR coefficients and SHAP analysis.
Results
The proposed model achieved superior performance on the independent test set (accuracy = 0.88, precision = 0.85, recall = 0.83, F1 = 0.84, ROC-AUC = 0.93, PR-AUC = 0.91), outperforming individual baseline models. Key predictors included functional limitation (WOMAC), pain severity (VAS), and surgical history (TKA). Incorporating interaction features further improved accuracy to 0.89 without compromising interpretability.
Conclusions
The proposed residual ensemble framework effectively balances predictive performance and interpretability, providing a clinically meaningful framework for QoL assessment and risk stratification in knee OA. This approach supports the development of explainable decision-support tools in digital musculoskeletal health.
Keywords
Introduction
Knee osteoarthritis (OA) is one of the most prevalent musculoskeletal disorders in older adults and a leading cause of chronic pain, functional limitations, and reduced quality of life (QoL). 1 In South Korea, its prevalence continues to rise with population ageing, affecting more than one-third of adults aged 65 years or older. 2 Globally, knee OA contributes substantially to disability, healthcare costs, and caregiver burden. 3 Patient-reported measures of QoL, such as the EuroQol-5 Dimensions (EQ-5D) and Western Ontario and McMaster Universities Osteoarthritis Index (WOMAC), are widely used to assess disease burden and monitor rehabilitation outcomes.4–6 Given these clinical and socioeconomic challenges, developing reliable and interpretable frameworks for assessing and stratifying QoL status in patients with knee OA remains an important step towards individualised and data-informed rehabilitation planning.
QoL outcomes in patients with knee OA are shaped by interrelated physical, psychological, and social factors, including pain intensity, mobility restriction, obesity, depression, and comorbid conditions.7–9 These multidimensional influences often interact in nonlinear ways, which traditional statistical models cannot fully capture. Although logistic regression (LR) and other linear models are valued for their calibration stability and coefficient-level interpretability, they are limited in representing threshold effects—such as a sharp decline in QoL beyond a certain pain level—or higher-order interactions between factors, such as body-mass index and functional measures.10–12
Tree-based ensemble methods, including Random Forests and gradient boosting machines, have shown strong predictive capacity in tabular clinical datasets. Compared with deep-learning architectures, they are computationally efficient, perform robustly with moderate sample sizes, and offer feature-importance measures that facilitate interpretability.13–15 Deep-learning models provide greater flexibility in capturing complex feature interactions; however, their interpretability remains limited, and their computational demands may restrict clinical applicability.16,17 In QoL assessment and stratification, both accuracy and transparency are critical; clinicians and patients must be able to understand the rationale behind model outputs to trust and act upon them.
Recent advances in explainable artificial intelligence, such as Shapley Additive Explanations (SHAP), have improved the interpretability of complex models. However, most knee OA-related applications have focused on diagnosis or disease progression rather than patient-reported outcomes.18–20 To address this gap, the present study proposes a residual ensemble framework that integrates the interpretability of a logistic-regression baseline with the nonlinear adaptability of a Random Forest residual learner. Using real-world hospital data from 1,102 patients with knee OA, this study pursued three objectives: (1) to develop an interpretable framework for integrating multidimensional clinical and patient-reported information associated with QoL status; (2) to evaluate a residual logistic–forest ensemble; and (3) to interpret both linear and nonlinear contributions using explainable AI techniques.
By extending model evaluation from prediction to interpretation, this study seeks to provide practical insights into computer-aided QoL management and digital decision support for musculoskeletal rehabilitation. This integrative framework aims to contribute to the development of explainable, data-driven tools that enhance personalised care and support the broader goals of digital health transformation.
Methods
Study population and dataset
This study is a retrospective observational study based on de-identified clinical data collected at Jeju University Hospital in South Korea between September 2013 and January 2022 and subsequently released through the AI Hub platform as part of a government-supported AI development initiative. The dataset comprised 1,102 patients diagnosed with knee osteoarthritis (OA), confirmed by ICD-10 codes and radiographic evidence. The dataset was accessed through the AI Hub platform following a formal application and approval process and was used in accordance with the platform’s data usage policies.
Description of input features used for model development.

WOMAC, Western Ontario and McMaster Universities Osteoarthritis Index.
The target variable was the EQ-5D index score, a validated measure of health-related QoL developed by the EuroQol Group. The EQ-5D comprises five domains—mobility, self-care, usual activities, pain/discomfort, and anxiety/depression—each assessed on a three-point scale. Responses were converted into a single index ranging from zero (worst imaginable health state) to one (perfect health state). For modelling, the EQ-5D index was binarised using a threshold of 0.7, consistent with prior work identifying EQ-5D utility values below 0.7 as indicative of treatment failure in OA. 21 Scores below 0.7 were assigned to Class 0 (lower QoL), and scores ≥ 0.7 to Class 1 (higher QoL). This resulted in an imbalanced distribution, with 705 patients (64.0%) in Class 0 and 397 patients (36.0%) in Class 1. During model training, class weights were applied to mitigate imbalance; no artificial resampling or data augmentation techniques were used.
The Institutional Review Board (IRB) of Korea University Anam Hospital approved the study protocol (IRB No. 2022AN0110). All data were fully anonymised before release to the AI Hub, and the requirement for informed consent was waived by the IRB in accordance with national ethical and legal guidelines.
Modelling framework
A stepwise modelling framework was designed to balance interpretability and predictive performance, as illustrated in Figure 1. LR was employed as the linear baseline to capture direct and interpretable relations between clinical features and QoL outcomes. LR was chosen for its statistical efficiency, calibration stability, and coefficient-level interpretability, enabling clinically meaningful associations between predictors and outcomes to be readily identified. All input features were standardised using StandardScaler prior to model training. The scaler was fitted on the training data and applied consistently to the validation and test sets within a pipeline framework to prevent data leakage. Stepwise workflow of the proposed QoL assessment and stratification framework.
To address limitations of the linear specification, several nonlinear learners with strong predictive capacity for tabular clinical data were considered, including Random Forest, XGBoost, LightGBM, CatBoost, and TabNet.
All these standalone nonlinear models were trained using the original feature set for comparative evaluation. In contrast, for the residual ensemble model, the nonlinear learner was trained on an extended feature set that included both the original features and the engineered interaction terms.
Each model was independently optimised and evaluated using three-fold cross-validation on the training data. Based on overall performance and stability, the best-performing model was selected for residual learning.
After fitting the LR baseline, predicted probabilities were obtained for each sample, and residuals were defined as the difference between the observed binary labels and the LR-predicted probabilities (residual = y − p_LR). The selected nonlinear model was then trained to predict these residuals, thereby learning a nonlinear correction term for the LR baseline rather than directly performing classification.
For the residual ensemble model, feature engineering was performed independently of residual modelling. Guided by both the LR coefficient analysis and clinical plausibility, three influential variables—WOMAC function, VAS pain score, and TKA surgical site—were selected, and pairwise interaction terms were constructed. These interaction features were appended to the original feature set to enhance the model’s ability to capture higher-order relationships.
Although some degree of collinearity may exist among clinical variables, particularly those related to pain and functional status, the use of L1-regularised logistic regression helps mitigate its impact by promoting sparse coefficient estimates. Furthermore, the tree-based residual learner is less sensitive to collinearity, as it relies on hierarchical feature partitioning rather than linear assumptions.
The final prediction was computed using a residual correction scheme:
Finally, the proposed residual ensemble operates through the residual correction scheme described above, rather than through conventional averaging or stacking of model outputs.
Model training and evaluation protocol
The dataset was randomly partitioned into a training set (80%) and a test set (20%), with stratification to preserve class distribution. During training, three-fold cross-validation was applied across the LR baseline and all nonlinear learners to mitigate overfitting and identify the best-performing nonlinear model for residual integration. Model performance was primarily assessed on the independent test set using the following standard classification metrics: accuracy, precision, recall, F1-score, area under the receiver operating characteristic curve (ROC-AUC), and area under the precision-recall curve (PR-AUC). To address class imbalance in the target variable, class-weight adjustments were applied during training to penalise misclassification of the minority (high-QoL) class. In this study, the F1-score was adopted as the primary selection criterion because it balances precision and recall, thereby reflecting the clinical priority of accurately identifying patients at risk of poor QoL, whereas accuracy alone could be misleading under class imbalance.
Interpretability and clinical translation
To enhance interpretability, a dual-layer explanation strategy aligned with the framework’s hybrid design was employed. First, the LR baseline provided coefficient estimates that could be directly translated into odds ratios, thereby offering global and clinically intuitive insights into risk and protective factors influencing QoL in patients with knee OA. These estimates highlighted transparent associations among demographic, functional, and biomechanical variables and the likelihood of reduced QoL.
Second, for the nonlinear residual component, a SHAP-based analysis was applied to quantify and visualise feature contributions to the residual corrections. This approach enabled the identification of complex interactions and higher-order effects that could not be captured by the linear model alone. Together, these complementary interpretive layers—global coefficients from the linear baseline and localised SHAP explanations from the residual learner—provide both trustworthy and actionable insights, supporting clinical decision-making in QoL management.
Statistical analysis
Descriptive statistics were used to summarise the class distribution of the study population. The positive class was defined as Class 1 (high QoL) for the calculation of class-specific performance metrics. Accordingly, precision, recall, F1-score, and PR-AUC were computed with respect to the high-QoL class.
Cross-validation results are presented as mean ± standard deviation across folds. Odds ratios were calculated as exp(β) from logistic regression coefficients.
In addition to discrimination metrics, calibration performance was assessed using Brier score and log loss to evaluate the agreement between predicted probabilities and observed outcomes. Calibration curves were visually inspected on the independent test set.
Decision-curve analysis (DCA) was performed to evaluate the potential clinical utility of the proposed models by estimating net benefit across a range of threshold probabilities. No formal hypothesis testing was conducted, as the primary objective of this study was predictive modelling and model evaluation rather than inferential statistical comparison.
Results
Baseline performance: LR
Model comparison using three-fold cross-validation on the training dataset.

ROC-AUC, area under the receiver operating characteristic curve; PR-AUC, area under the precision-recall curve; LR, logistic regression.
Performance of nonlinear models
Model comparison using three-fold cross-validation on the training dataset. All models were trained using the original feature set.
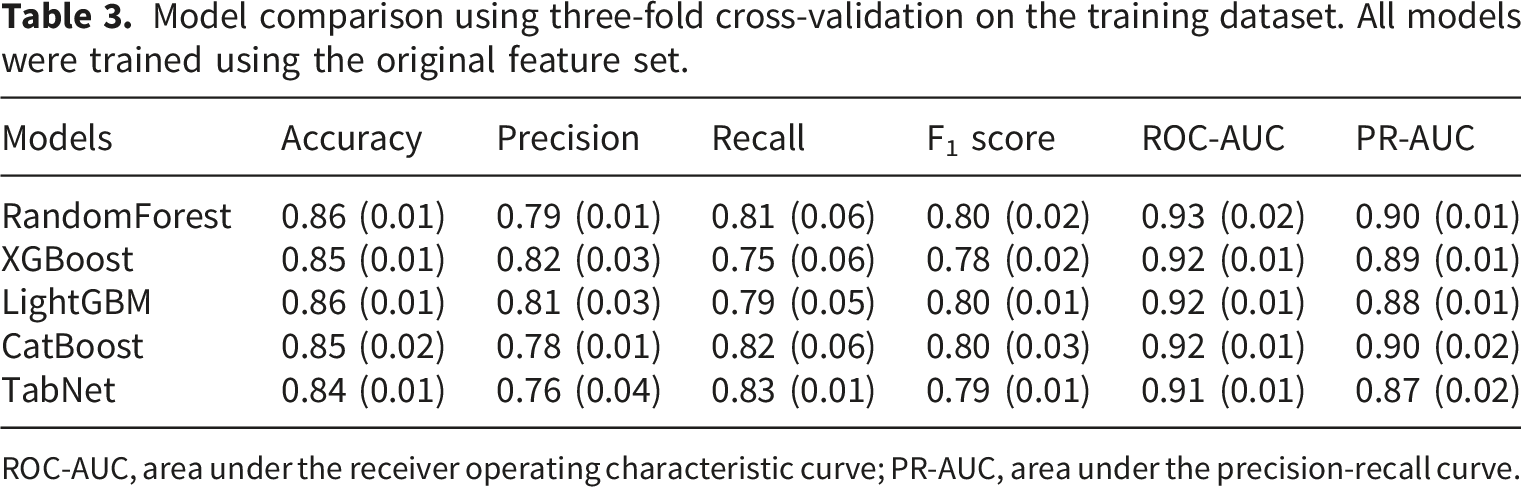
ROC-AUC, area under the receiver operating characteristic curve; PR-AUC, area under the precision-recall curve.
Among the candidates, the Random Forest demonstrated the most favourable balance between performance and stability. It achieved the highest ROC-AUC (0.93 ± 0.02) and PR-AUC (0.90 ± 0.01) while maintaining consistent F1 performance (0.80 ± 0.02) with relatively low variance across folds. By contrast, gradient boosting variants (XGBoost, LightGBM, and CatBoost) achieved comparable average metrics but exhibited slightly greater variability in recall, whereas TabNet, despite strong recall (0.83 ± 0.01), demonstrated lower precision (0.76 ± 0.04) and overall discrimination.
Based on its combination of robust discrimination, low variance, and interpretability through straightforward feature-importance measures, the Random Forest was selected as the nonlinear learner for integration into the residual ensemble with the LR baseline. This selection ensured that the ensemble captured nonlinear interactions while preserving stability and interpretability for clinical translation.
Hyperparameter optimisation
Optimised hyperparameters for each predictive model obtained.
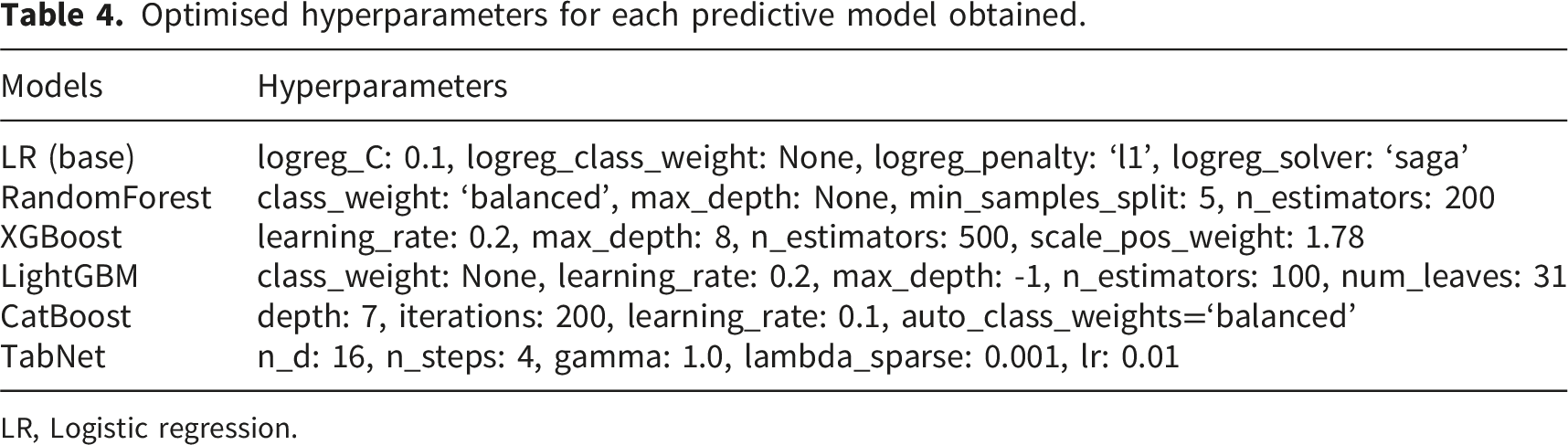
LR, Logistic regression.
Proposed ensemble model performance
The proposed model was evaluated using both the original features and engineered interaction features within the residual learning framework.
Model comparison using three-fold cross-validation on the training dataset. The proposed model was trained using both the original features and engineered interaction features within the residual learning framework.
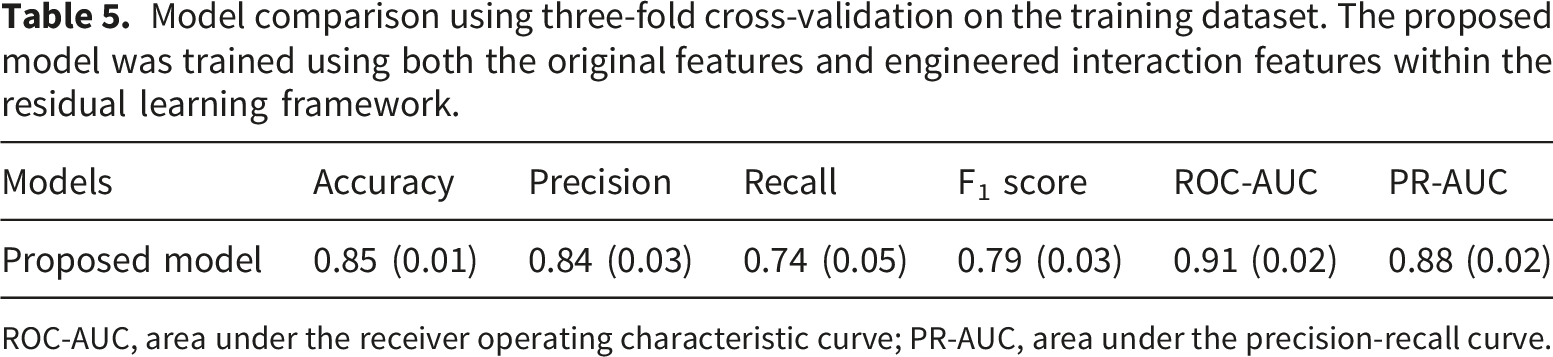
ROC-AUC, area under the receiver operating characteristic curve; PR-AUC, area under the precision-recall curve.
To construct the ensemble, each component model was trained using previously optimised hyperparameters. This design choice ensured computational efficiency and reproducibility while avoiding the prohibitive cost of re-optimisation in a combined framework. By leveraging the best configurations from standalone model evaluations, the ensemble preserved the strengths of its constituents without incurring unnecessary overhead. Thus, the ensemble offers a balanced compromise among predictive accuracy, training efficiency, and interpretability, highlighting its potential for practical use in clinical QoL assessment and stratification.
Final evaluation on the independent test dataset
Model comparison on the test dataset. The proposed model was trained using both the original features and engineered interaction features within the residual learning framework.
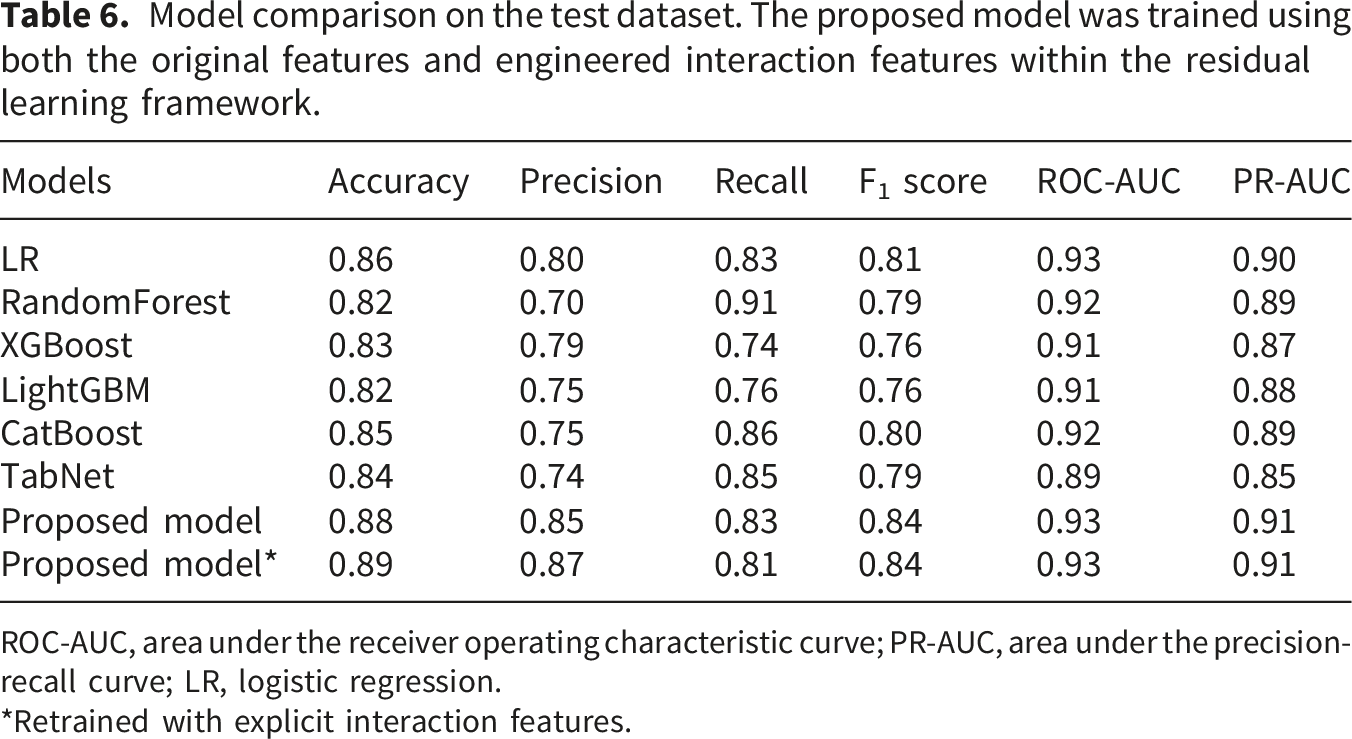
ROC-AUC, area under the receiver operating characteristic curve; PR-AUC, area under the precision-recall curve; LR, logistic regression.
*Retrained with explicit interaction features.
The proposed residual ensemble model outperformed the individual models, achieving the highest accuracy (0.88) and a strongly balanced performance across all metrics (precision = 0.85, recall = 0.83, F1 = 0.84, ROC-AUC = 0.93, PR-AUC = 0.91).
To evaluate the clinical reliability and practical utility of the proposed model, calibration and decision-curve analyses were conducted on the independent test dataset.
Calibration curves (Figure 2) showed that both the LR baseline and the proposed residual ensemble model produced reasonably well-aligned probability estimates relative to observed event rates. The proposed model achieved a slightly lower Brier score (0.0987 vs 0.0995) and log loss (0.3198 vs 0.3220) compared with the LR baseline, indicating marginal improvement in probability estimation while maintaining similar overall calibration characteristics. Calibration curves on the independent test set for the logistic regression (LR) baseline and the proposed residual ensemble model.
DCA (Figure 3) demonstrated that the proposed model provided comparable net benefit to the LR baseline across a wide range of threshold probabilities. Importantly, the proposed model consistently performed at least as well as the LR baseline, without evidence of reduced clinical utility. These findings suggest that the additional modelling complexity introduced by the residual ensemble does not compromise decision-making performance, while offering enhanced modelling flexibility. Decision-curve analysis (DCA) on the independent test set comparing the logistic regression (LR) baseline and the proposed residual ensemble model.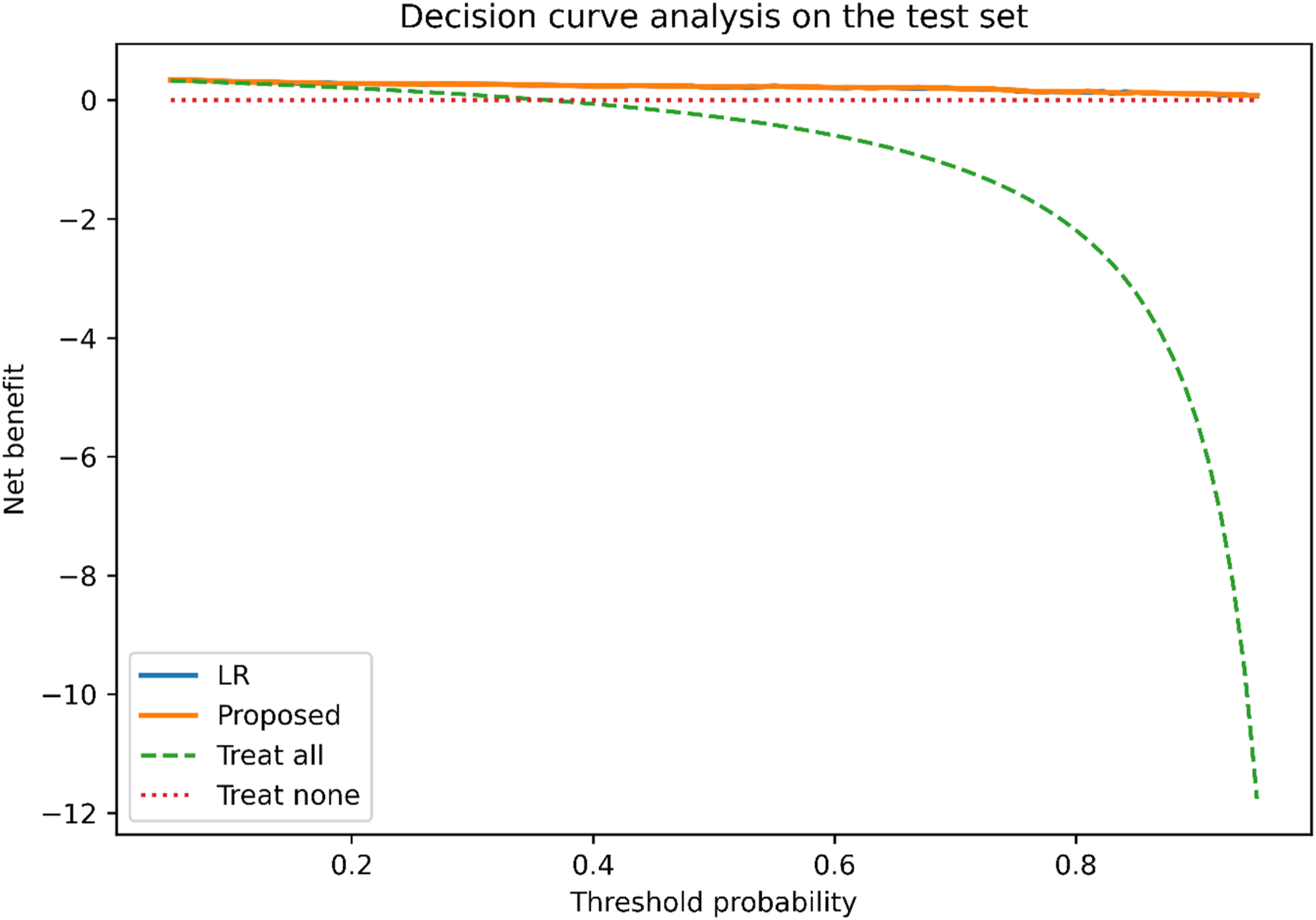
Logistic regression coefficients (standardised) and odds ratios (per +1 standard deviation) for the top 10 predictors of quality of life.
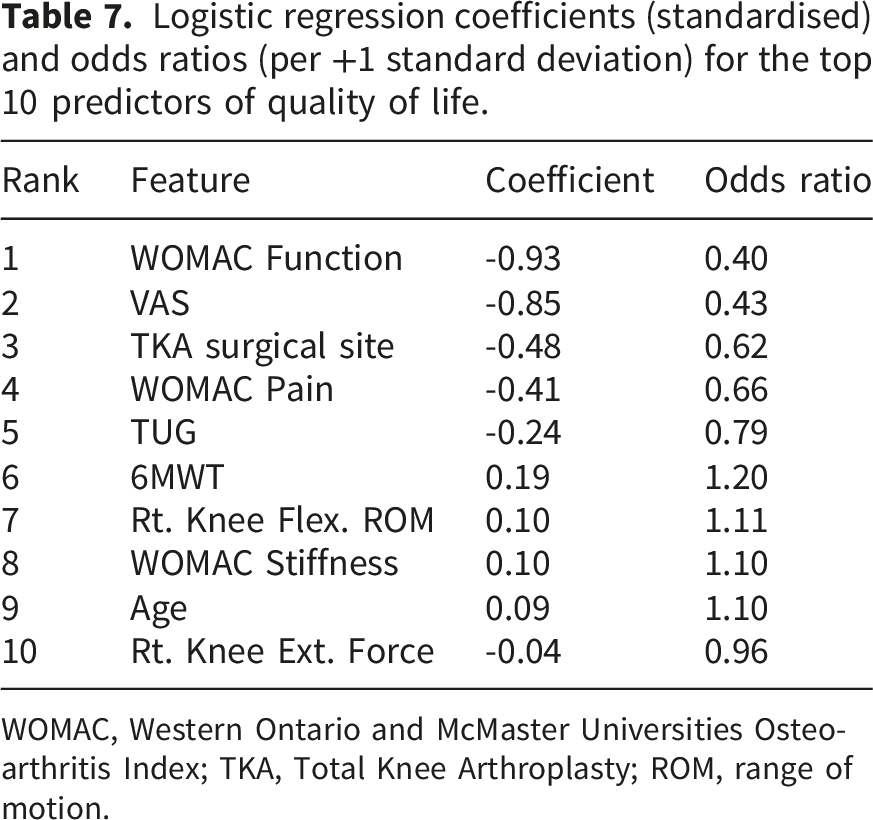
WOMAC, Western Ontario and McMaster Universities Osteoarthritis Index; TKA, Total Knee Arthroplasty; ROM, range of motion.
Figure 4 illustrates the confusion matrix and ROC curve of Proposed model*. The confusion matrix showed that the model achieved a balanced classification with high true-positive and true-negative rates, indicating reliable discrimination between patients with lower and higher QoL. The ROC curve further confirmed the strong discriminative ability, with an AUC of 0.93, which is consistent with the cross-validation and test results reported in Tables 5 and 6. Final model performance evaluation.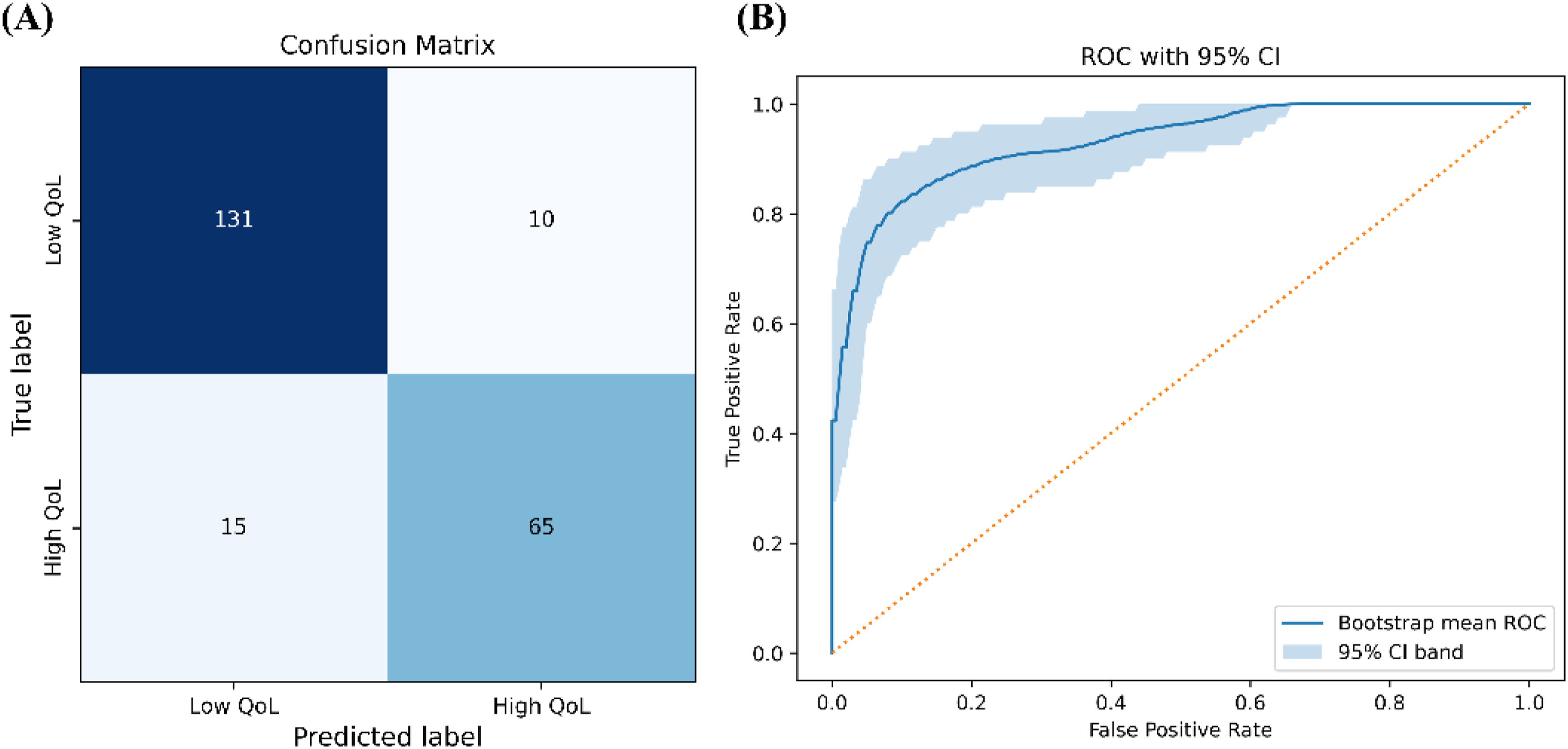
SHAP-based explainability of proposed model
Figure 5 summarises the SHAP-based interpretation of the proposed ensemble model. We found that WOMAC function, VAS score, TKA surgical site, pain, and TUG score were the most influential predictors of QoL, consistent with the LR analysis. The SHAP analysis further illustrates the direction of feature contributions at the individual patient level; higher Function and VAS scores (indicating greater disability and pain) were strongly associated with low predicted QoL (negative SHAP values), whereas high 6MWT and knee range of motion scores were positively associated. Notably, the TKA surgical site also emerged as an important nonlinear modifier, reinforcing the importance of considering surgical history in QoL assessment and stratification. Global feature importance based on Shapley Additive Explanations (SHAP) values.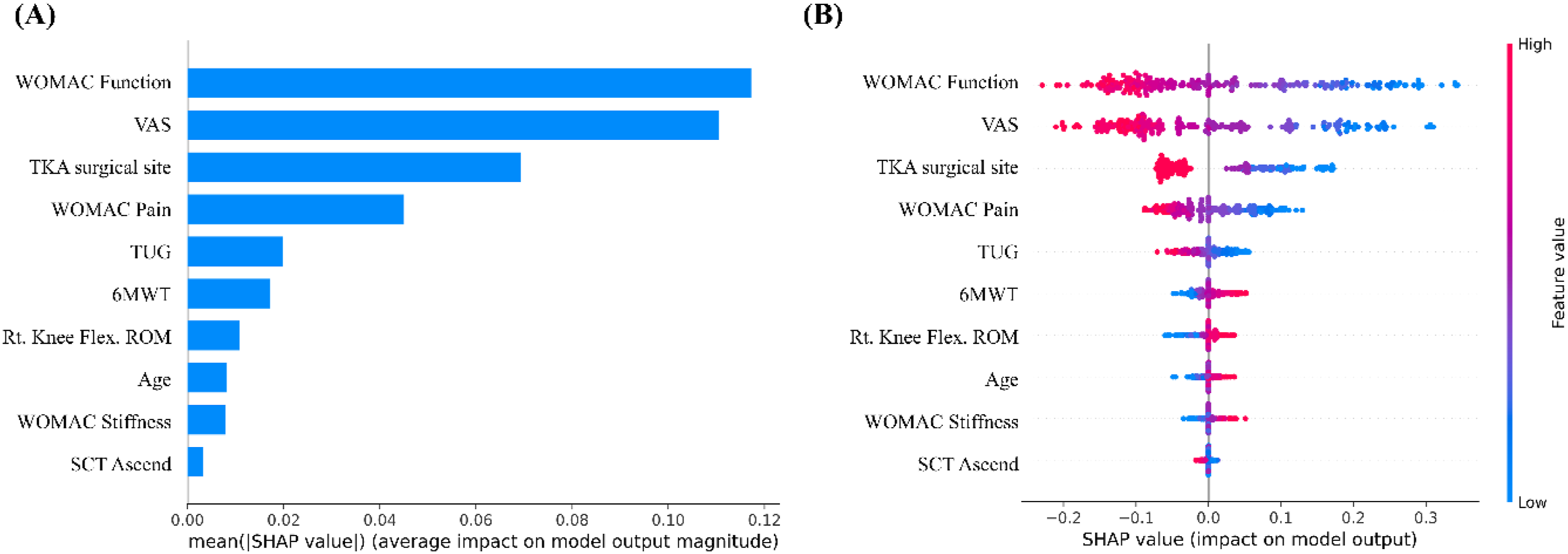
Discussion
This study proposes an interpretable residual ensemble framework designed to support QoL assessment and stratification in patients with knee OA by integrating multiple clinically relevant dimensions, including pain, functional limitation, and surgical history. Rather than identifying novel determinants of QoL, the primary contribution of this work lies in providing a transparent modelling framework capable of capturing both linear and nonlinear relationships among established clinical factors.
While key variables such as pain and functional limitation are well established, the proposed approach focuses on modelling their interactions and higher-order effects that are not adequately captured by conventional regression models. This allows the model to extend, rather than replace, traditional statistical approaches by providing additional explanatory power while preserving clinical interpretability.
By combining LR with Random Forest residual corrections, the framework achieved a balanced and robust predictive performance (accuracy = 0.88, ROC-AUC = 0.93, PR-AUC = 0.91) while maintaining coefficient-level interpretability.
Building on the coefficient analysis of the baseline model, clinically plausible interaction features, particularly among functional limitations, pain, and surgical history, were introduced to yield a refined version of the ensemble. This enhanced model achieved the highest accuracy (0.89) and precision (0.87) without loss of recall or discrimination, suggesting that data-driven refinement guided by clinical interpretability can improve model performance. Collectively, these results suggest that integrating linear reasoning with nonlinear correction provides a practical and explainable framework for individualised QoL assessment and risk stratification in knee OA.
Previous studies on knee OA have primarily addressed disease diagnosis, radiographic grading, and surgical outcome prediction, with relatively limited attention paid to patient-reported QoL outcomes. 22 Moreover, most prior machine learning applications have relied on single-model approaches, such as LR, random forest, or gradient boosting, which tend to prioritise either interpretability or predictive flexibility. 23 This study extends this line of research by demonstrating that a hybrid residual ensemble can reconcile this trade-off. By coupling a transparent logistic baseline with a nonlinear residual correction, the framework captured threshold and interaction effects, such as the compounded influence of pain severity and functional limitation, which linear models alone cannot represent. Simultaneously, it maintained direct interpretability through coefficient estimates and SHAP-based explanations, addressing the common limitations of opaque deep or ensemble learning methods. This integrative design advances prior QoL modelling efforts by providing strong discrimination together with transparent and clinically interpretable decision support, supporting its potential use in data-driven rehabilitation and personalised digital care.
These findings suggest that a hybrid approach may assist clinicians in understanding and managing patient-reported QoL outcomes in patients with knee OA. LR analysis identified pain, functional limitations, and surgical history as key correlates of reduced QoL, whereas the residual component captured additional nonlinear interactions that may reflect complex recovery dynamics. 24
From a clinical perspective, this structure can help practitioners stratify patients according to the risk of QoL deterioration and tailor rehabilitation strategies accordingly. 25
For instance, patients exhibiting high levels of pain and poor functional scores could be prioritised for early and intensive intervention, whereas those with favourable function may benefit from maintenance-oriented programmes. 26
Furthermore, SHAP-based feature attributes provide a transparent visualisation of individual-level influences, supporting shared decision-making and enhancing patient engagement with their rehabilitation plans. 27
However, several considerations should be noted when interpreting these findings. Specifically, several input variables, such as WOMAC scores and functional measures, are closely related to the QoL outcome itself. While these variables reflect clinically relevant dimensions that contribute to QoL, their strong association with the outcome may limit the extent to which the model provides independent predictive information. Therefore, the proposed framework is best viewed as an approach for integrating multiple QoL-related domains within an interpretable assessment and stratification framework.
Future studies incorporating longitudinal data or less directly related predictors may provide additional insight into causal relationships and improve clinical applicability. Despite these limitations, the findings illustrate how interpretable ensemble modelling can complement existing clinical assessment tools in a data-driven yet transparent manner.
From a methodological standpoint, the proposed residual ensemble provides an interpretable pathway for enhancing predictive accuracy without compromising transparency. The linear baseline offers global interpretability through coefficient estimates and odds ratios familiar to clinicians and is aligned with traditional statistical reasoning.28,29 By contrast, the Random Forest residual learner captures localised nonlinear corrections, modelling higher-order interactions or threshold effects that the linear specification cannot represent. The combination of these paradigms helps bridge the gap between statistical inference and data-driven representation learning. SHAP-based analyses further enrich interpretability by decomposing predictions into feature-level attributes and clarifying the clinical variables that most strongly influence individual outcomes.30,31 Notably, the nonlinear residual corrections largely reinforced the relationships identified in the logistic baseline, such as the interplay between pain and function, suggesting that the residual layer added nuanced flexibility rather than unnecessary complexity. This layered transparency is particularly relevant in healthcare contexts, where trust, reproducibility, and interpretability are prerequisites for adoption. 32
Although the performance improvement over the logistic regression baseline was modest, particularly in terms of ROC-AUC, the proposed framework offers additional value by enabling the modelling of nonlinear interactions while preserving interpretability. Given the already strong discriminative performance of the baseline logistic regression model, substantial gains in conventional performance metrics were inherently difficult to achieve. Importantly, the objective of the proposed framework was not to maximise predictive accuracy through increasingly complex architectures, but to extend a transparent statistical model with a lightweight nonlinear correction mechanism. By combining coefficient-based interpretation from logistic regression with SHAP-based explanations of the residual learner, the framework retains clinical transparency while providing additional flexibility to capture nonlinear relationships among clinically relevant variables.
The proposed framework may serve as an interpretable decision-support tool for QoL assessment and risk stratification in patients with knee osteoarthritis. In routine clinical practice, clinicians often need to integrate multiple patient-reported and clinical factors, including pain severity, functional limitation, and treatment history, when determining management priorities and rehabilitation strategies. The proposed framework provides a transparent mechanism for synthesising these factors into a single QoL-related risk estimate, which may facilitate identification of patients at risk of poor QoL, prioritisation of follow-up, and personalised rehabilitation planning.
Importantly, the intended role of the framework is not to replace clinical judgement but to support clinical decision-making through explainable risk assessment. This perspective is consistent with emerging evidence suggesting that the primary value of artificial intelligence in knee osteoarthritis lies in supporting assessment standardisation, facilitating interpretation of complex clinical information, and enhancing clinical decision-making rather than functioning as a fully autonomous system. 33 Recent studies have highlighted the potential of AI-assisted approaches to improve consistency in osteoarthritis assessment and to support integration of evidence-based recommendations into routine clinical workflows. 34 Accordingly, the proposed framework should be viewed as an interpretable extension of existing patient assessment strategies that supports, rather than replaces, clinician expertise. Future studies should evaluate whether implementation of explainable QoL assessment models can improve clinical decision-making, resource allocation, rehabilitation planning, and patient outcomes in real-world healthcare settings.
This study had several limitations. First, the dataset was derived from a single university hospital, which may limit the generalisability of the findings. The absence of external validation prevents direct assessment of model performance across different clinical settings and patient populations. Future studies should incorporate independent multicentre datasets and temporal validation across different time periods to evaluate the robustness, transportability, and real-world clinical applicability of the proposed framework. Therefore, the present study should be interpreted as a proof-of-concept for an interpretable QoL assessment and stratification framework rather than a fully generalisable clinical prediction model. Second, the model used only static clinical features measured at a single time point. As QoL evolves with changes in pain, mobility, and psychosocial state, longitudinal or time-series modelling approaches may better capture patient-specific trajectories. Another limitation is the dichotomisation of the EQ-5D index using a threshold of 0.7. While this approach provides a clinically interpretable decision boundary, it may result in information loss compared with modelling QoL as a continuous outcome. The threshold-based formulation was selected to facilitate clinically interpretable risk stratification and to align with previously reported treatment-failure criteria in patients with OA. Nevertheless, continuous outcome modelling may better capture the full spectrum and granularity of patient-reported QoL. In addition, the selected threshold may not be universally applicable across different populations or clinical contexts. Future studies should explore regression-based approaches or alternative threshold definitions to better represent QoL variation and enhance generalisability. Finally, although the ensemble was designed to balance interpretability and efficiency, future studies could extend the feature representation to include imaging, wearable, or sensor-derived data, thereby enhancing the model’s scope for digital health integration. Continued investigations along these lines may strengthen both the scientific validity and real-world applicability of explainable ensemble learning for personalised QoL management.
Conclusion
This study developed a residual ensemble framework that combines the interpretability of a linear baseline with the flexibility of a nonlinear learner to support quality-of-life assessment and stratification in patients with knee OA. This approach achieved competitive predictive accuracy while maintaining transparency and clinical interpretability, suggesting that such hybrid architectures may provide a feasible balance between conventional statistical models and complex machine learning systems. By demonstrating how coefficient-based insights can inform data-driven refinement, this study outlined a practical pathway for explainable and clinically interpretable assessment and stratification of patient-centred outcomes. Although additional validation and methodological refinement are required, the proposed framework can serve as a foundation for integrating explainable AI tools into rehabilitation planning and QoL management for digital musculoskeletal health.
Footnotes
Acknowledgements
The results of the AI learning data construction project, led by the Ministry of Science and ICT and implemented by the National Information Society Agency, utilised AI learning data.
Ethical considerations
This study utilized AI learning data constructed as part of the AI Learning Data Construction Project led by the Ministry of Science and ICT and implemented by the National Information Society Agency. The Institutional Review Board (IRB) of Korea University Anam Hospital approved the study protocol (IRB No.: 2022AN0110).
Author contributions
Conceptualization, J.L. and S.O.; methodology, J.L.; software, S.O.; validation, J.C.; formal analysis, J.L.; investigation, J.L. and S.O.; resources, J.C.; data curation, J.L.; writing—original draft preparation, J.L.; writing—review and editing, B.K.; visualization, J.L.; supervision, B.K. and S.L.; project administration, B.K. and S.L.; funding acquisition, B.K. and S.L.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by Basic Science Research Program through the National Research Foundation of Korea (NRF) grant funded by the Ministry of Education (No. RS-2023-00275579), and in part by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2024-00336696).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.