
Abstract
Background
Cochlear implant (CI) users require long-term auditory-speech rehabilitation to achieve optimal outcomes, yet access to continuous and structured rehabilitation remains limited. Mobile health technologies offer a potential approach to improve the accessibility and continuity of rehabilitation services.
Objective
This study aims to develop a WeChat-based auditory-speech rehabilitation system for Mandarin-speaking CI users and to conduct a preliminary validation of its usability and measurement consistency.
Methods
Guided by a goal-oriented digital design framework, a WeChat-based system was developed to assess six domains of auditory and speech rehabilitation. A total of 20 Mandarin-speaking CI users were recruited from Shanghai Sixth People’s Hospital. Usability and app quality were assessed using the System Usability Scale (SUS) and User Version of the Mobile App Rating Scale (uMARS), respectively. Measurement consistency was evaluated using the intraclass correlation coefficient (ICC), weighted Cohen’s kappa (κ), and Bland-Altman analyses.
Results
20 Mandarin-speaking CI users completed the study. Usability assessment demonstrated favorable ratings (SUS = 71.50, SD = 13.58; uMARS = 4.19, SD = 0.50). The system-generated Categories of Auditory Performance classification showed excellent agreement with the rater (weighted κ = 0.97, 95% CI: 0.93-1.00). Articulation intelligibility scores demonstrated high consistency with rater assessments (system vs. rater 1: ICC = 0.97; system vs. rater 2: ICC = 0.94), with minimal bias observed in Bland-Altman analysis.
Conclusion
This WeChat Mini Program provides preliminary support for the feasibility of a digital auditory-speech rehabilitation approach for Mandarin-speaking CI users. Further studies are needed to validate its broader applicability and effectiveness in out-of-hospital rehabilitation.
Keywords
Introduction
Hearing loss has been recognized as one of the major contributors to the global burden of disability. 1 It is estimated that by 2050, approximately 2.5 billion people worldwide will be affected by hearing loss. 2 In China, approximately 115 million individuals had moderate to profound hearing loss in 2015, and this number is projected to increase to 242 million by 2060.3,4 The burden of disease at this scale is first reflected in limitations to daily communication and frustration in social participation. 5 Prelingual deafness directly leads to speech impairment, whereas in individuals with postlingual deafness, long-term auditory deprivation induces plastic changes in central auditory and language-related brain regions, ultimately impairing speech perception and production. 6 Cochlear implantation is currently the main intervention for individuals with severe to profound sensorineural hearing loss,7,8 and the benefits of cochlear implant (CI) depend heavily on high-quality postoperative auditory-speech rehabilitation. 9 However, the accessibility and continuity of rehabilitation services remain limited due to constraints in resources, time, and geography. 10
Recent studies have shown that digital remote rehabilitation is a feasible and effective approach for postoperative training in CI users.11–14 These approaches include mobile applications 15 and computer-based platforms for auditory training, 16 speech perception, 17 and communication support. 18 However, existing applications are often dominated by communication-support functions, while structured rehabilitation-oriented interventions remain limited. Most existing studies focus on auditory perception, with relatively few addressing speech production. 12 In addition, many tools are designed for pediatric users and emphasize gamified or story-based training.19,20 As a result, integrated and individualized auditory-speech rehabilitation systems for adult CI users are still lacking. Furthermore, tools tailored to Mandarin remain limited due to its unique phonological and tonal characteristics. 21 Therefore, there is a need to develop a Mandarin-speaking auditory-speech rehabilitation system supports home-based use and individualized adjustment. 22
WeChat is the most widely used social and information platform in China and has become an important infrastructure for telemedicine delivery and patient health data generation.23,24Compared with standalone applications, WeChat Mini Programs offer lower entry barriers, lower development costs, and better integration into daily use, which may support sustained engagement and continuous data collection. 25 Given these platform-related advantages and the existing clinical needs for accessible and individualized auditory-speech rehabilitation, this study aimed to develop and preliminarily validate the “Miao Yan Hui” Mini Program as an integrated auditory-speech rehabilitation and assessment system for adult Mandarin-speaking CI users. The system was intended to support individualized rehabilitation and provide preliminary methodological support for future clinical studies.
Methods
Study design and participants
This study was a preliminary validation study conducted at Shanghai Sixth People’s Hospital, China, in 2025. A total of 20 Mandarin-speaking CI users were recruited. As this was a preliminary feasibility study, no formal a priori sample size calculation was performed. The sample size was determined based on feasibility and the availability of eligible participants, and was considered appropriate for the exploratory aims of the present study.26,27 Participants were eligible if they had undergone cochlear implantation, were able to use the WeChat Mini Program, and had completed at least one baseline assessment. Individuals unable to complete the study procedures or with conditions that could interfere with participation in auditory-speech rehabilitation tasks were excluded.
Overall system design
An interdisciplinary team of six members was established, including two senior software engineers (responsible for modular architecture design and system maintenance), two speech therapists (responsible for formulating rehabilitation prescription logic and training content), and two otolaryngologists (responsible for providing medical feedback on clinical needs and issues). Based on an initial literature review and expert consultation, the team adopted an iterative process to optimize the prototype content and user interaction, followed by entry into the systematic development stage.
The rehabilitation workflow for participants using the Mini Program was as follows. Initially, participants accessed the system after completing account registration and identity verification. All accounts were managed using de-identified IDs, and all data were kept strictly confidential. Participants then underwent a baseline auditory–speech assessment to determine their initial functional level, which served as the basis for subsequent rehabilitation training. The baseline assessment was completed in a single session at first use, after which the system generated individualized daily training plans according to baseline results and predefined rules. Participants logged in daily to complete training tasks according to the prescribed rehabilitation plan. Each training cycle lasted approximately four weeks, after which a re-evaluation was conducted. Based on re-evaluation results, the training plan was adaptively adjusted, and training levels were updated, forming a closed-loop process of baseline assessment, individualized training, and re-evaluation, to progressively improve speech-related abilities (Figure 1). Schematic workflow of the “Miao Yan Hui” Mini Program, including user registration and login, server-side and therapist tasks, and the training pathway from baseline assessment to training and re-evaluation.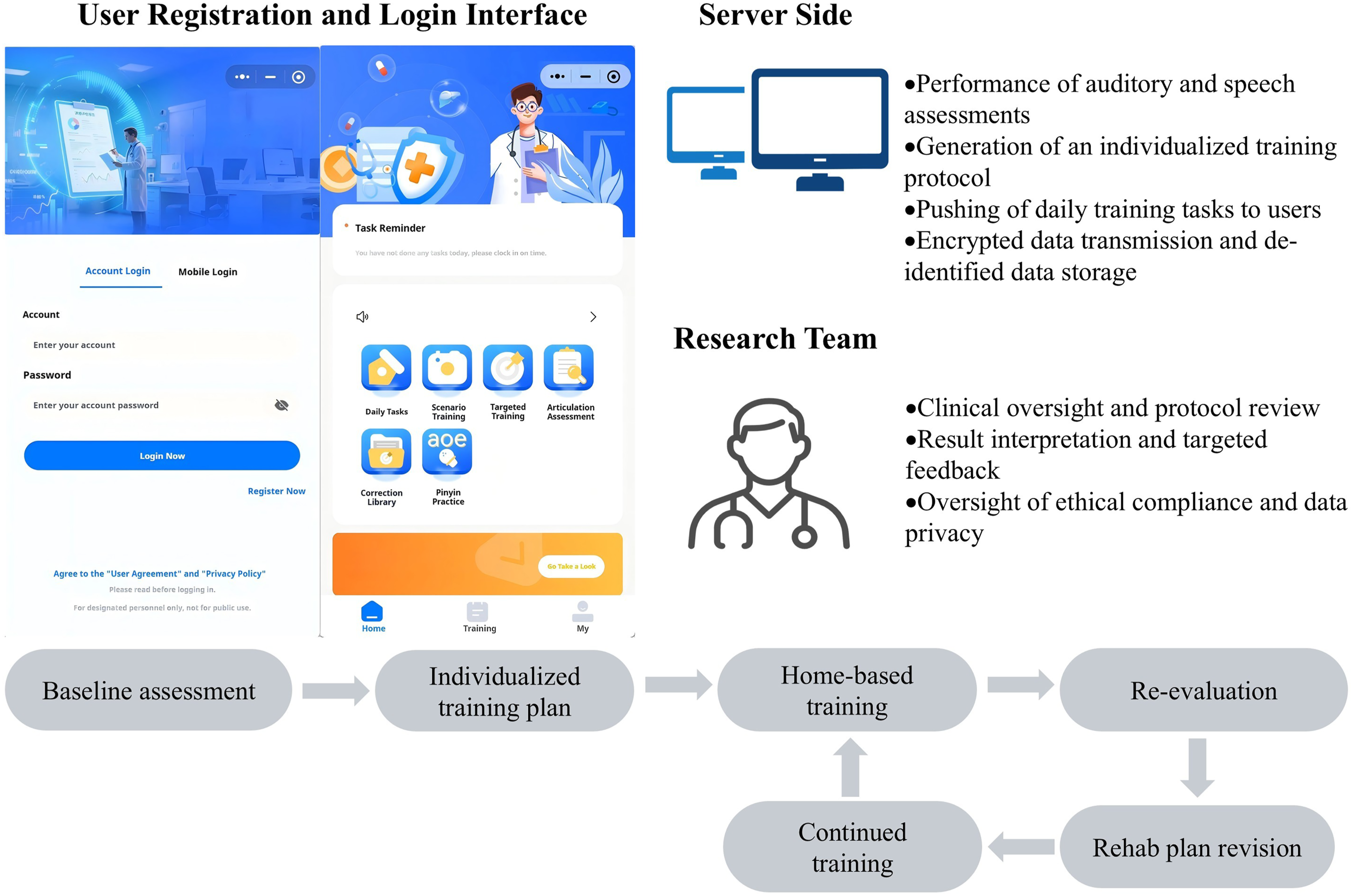
Assessment module
This study established a multidimensional auditory and speech assessment framework within a Mini Program, covering six domains: auditory function, respiratory function, vocal function, resonance function, articulation function, and language function
28
(Figure 2). Assessment tasks were completed using mobile devices in a relatively quiet environment. Participants were instructed to use the built-in microphone of the device while maintaining a stable speaking position and, as far as possible, a consistent distance from the device. However, variations in device type and recording conditions could not be fully eliminated. Structural overview of the assessment modules, showing the six functional domains of auditory, respiration, phonation, resonance, articulation, and language, along with their corresponding evaluation tasks.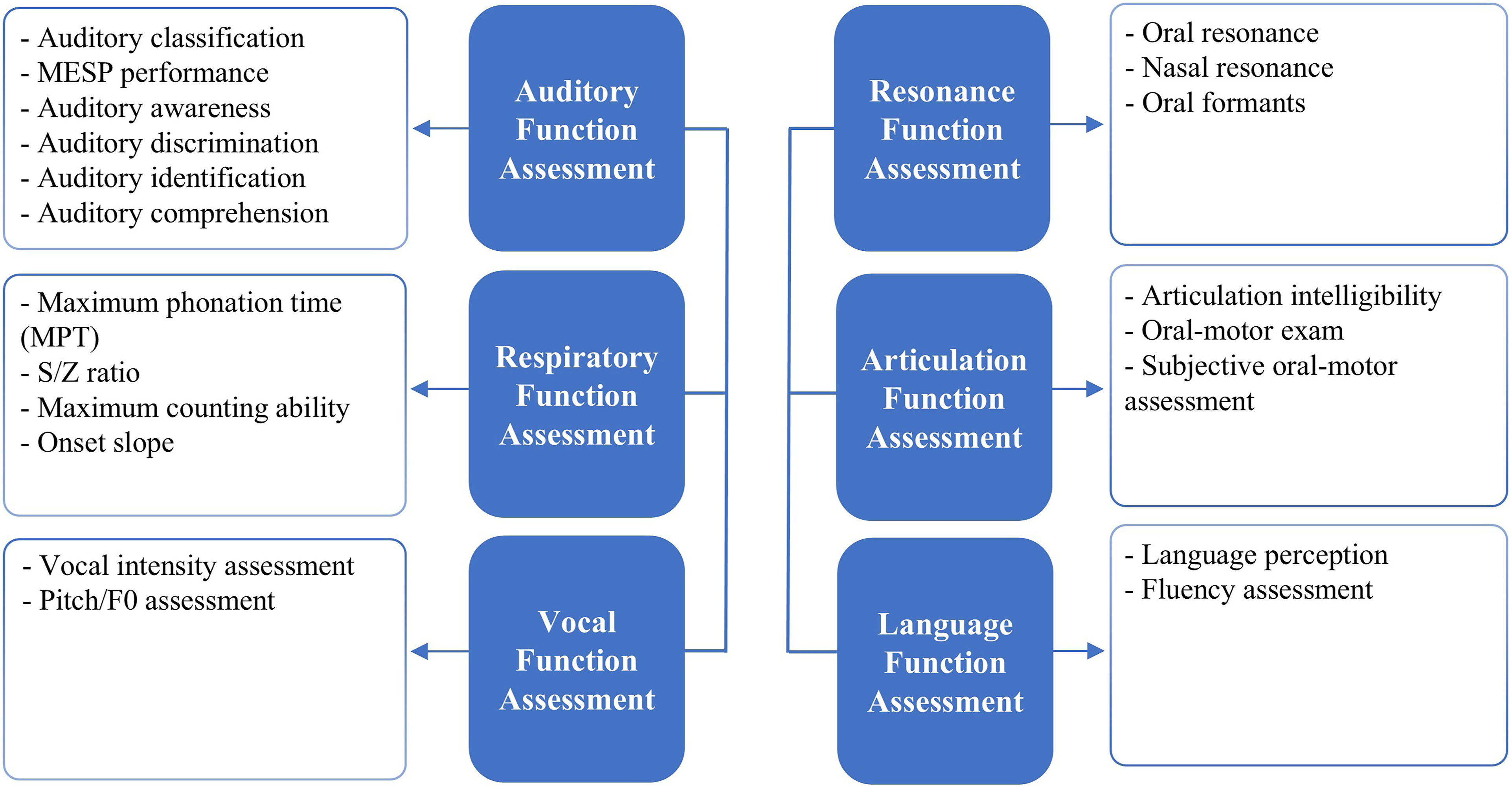
The assessment of auditory function included six domains: auditory classification, Mandarin Early Speech Perception (MESP) performance, auditory awareness, auditory discrimination, auditory identification, and auditory comprehension. Among these, Categories of Auditory Performance (CAP) scale 29 and MESP test 30 were used as assessment tools to characterize auditory performance and speech perception ability, respectively, thereby providing indirect information on auditory function. In addition, auditory awareness, discrimination, identification, and comprehension were evaluated as specific aspects of auditory function. 31 For CAP-based auditory classification, the system used a series of standardized auditory behavior items and automatically assigned a CAP level (0-8) through a predefined rule-based decision-tree algorithm. The system also recorded performance in the remaining subdomains to generate an overall auditory profile and identify individual areas of deficit.
The assessment of respiratory function included parameters with established physiological and clinical relevance, such as maximum phonation time (MPT), 32 the s/z ratio, 33 maximum counting ability, 34 and voicing onset. 35 These measures are commonly used to reflect respiratory support for speech production and phonatory efficiency, as well as the coordination between respiration and phonation during speech. 36 In the present study, they were used to provide preliminary information on speech breathing performance and to support follow-up and monitoring.
The assessment of vocal function focused on loudness and pitch control, which are key acoustic features related to phonatory stability and vocal control during speech production. 28 This module extracts average speech intensity and its stability across four contexts: sustained vowel/a/, short sentence reading, natural conversation, and counting. In addition, fundamental frequency (F0), together with its variability and range, was measured to characterize vocal pitch regulation. 37 These parameters were used to provide quantitative information on vocal performance.
The assessment of resonance function combined perceptual evaluation with acoustic analysis. 28 Oral resonance was examined using vowel productions (/a, i, u/) with the first and second formant frequencies (F1 and F2) extracted as acoustic indicators of vocal tract resonance. 38 Nasal resonance was evaluated by comparing habitual speech with speech produced during nasal occlusion to identify possible hypernasality or hyponasality.39,40 The system outputs resonance-related measures, including resonance categories, F1/F2 values, and nasal contrast metrics, to support preliminary characterization of resonance patterns.
The assessment of articulation function focused on speech intelligibility, a key indicator of functional speech production in CI users. 41 A 50-item monosyllabic word list covering 21 Mandarin initial consonants was used to evaluate production accuracy, based on which intelligibility scores and word-level performance profiles were generated; interpretation of whether the observed errors were primarily related to auditory perception or articulatory impairment was made in conjunction with the other assessment modules and clinical history. Automated scoring was based on a Mel-frequency cepstral coefficient (MFCC)- and dynamic time warping (DTW)-based template-matching framework combined with a predefined phoneme knowledge base and a rule-driven clinical logic engine, which enabled identification of specific error patterns. In addition, acoustic analysis of sustained vowels (/a/,/i/,/u/,/ü/) was performed by extracting F1 and F2 to characterize vowel production and overall vowel space distribution. 42 These objective measures were supplemented with a perceptual assessment of oral motor function, including lip and tongue strength, flexibility, and coordination.
The assessment of language function focused on comprehension across linguistic levels, from words to connected discourse, as well as oral fluency, which are essential components of functional language ability in CI users. 43 Language comprehension was evaluated using auditory identification tasks at the words, phrases, and sentences, followed by short passage comprehension. Accuracy and response characteristics were recorded to reflect semantic mapping and syntactic processing abilities. Oral fluency was assessed through spontaneous responses to standardized prompts, with performance jointly evaluated by the system and the rater.
Training module
The Mini Program adopts a closed-loop framework consisting of baseline assessment, individualized training, and re-evaluation. After participants complete the baseline assessment at first use, the system automatically generates individualized training plans based on the identified weaknesses and functional levels and delivers them to the user interface as daily tasks. The rule-based process by which assessment findings were matched to corresponding training modules is illustrated in an anonymized example provided in Supplementary File 1. The assigned training content may include auditory discrimination and comprehension practice, breathing and vocal coordination exercises, loudness and pitch regulation, resonance-related practice, articulation training targeting consonants, vowels, tones, and syllable structure, as well as language-oriented tasks for comprehension and oral expression. Users complete their training sessions by accessing the “Daily Tasks” module. Each training stage consists of approximately 30 minutes per session, 5 days per week, for 4 consecutive weeks. At the end of each stage, a re-evaluation is conducted, and training plans are dynamically adjusted based on updated assessment results.
The training system comprises several modules, including Daily Tasks, Scene Training, Targeted Training, Pinyin Practice, and Correction Library (Figure 3). Daily Tasks represent the core training pathway. The scene training component was designed with potential applicability to broader user groups, including pediatric users; however, the present study focused on adult participants. Targeted Training is for each of the six functional domains-auditory, respiratory, vocal, resonance, articulation, and language-corresponding training modules are provided. Users may select training content based on system recommendations and their individual areas of weakness. Pinyin Practice provides systematic training focusing on Mandarin initial consonants, vowels, tones, and syllable structure.The Correction Library includes exercises targeting mandibular, oral, and tongue movements, basic resonance training, and directed exercises for hypernasality and hyponasality. Training task interface.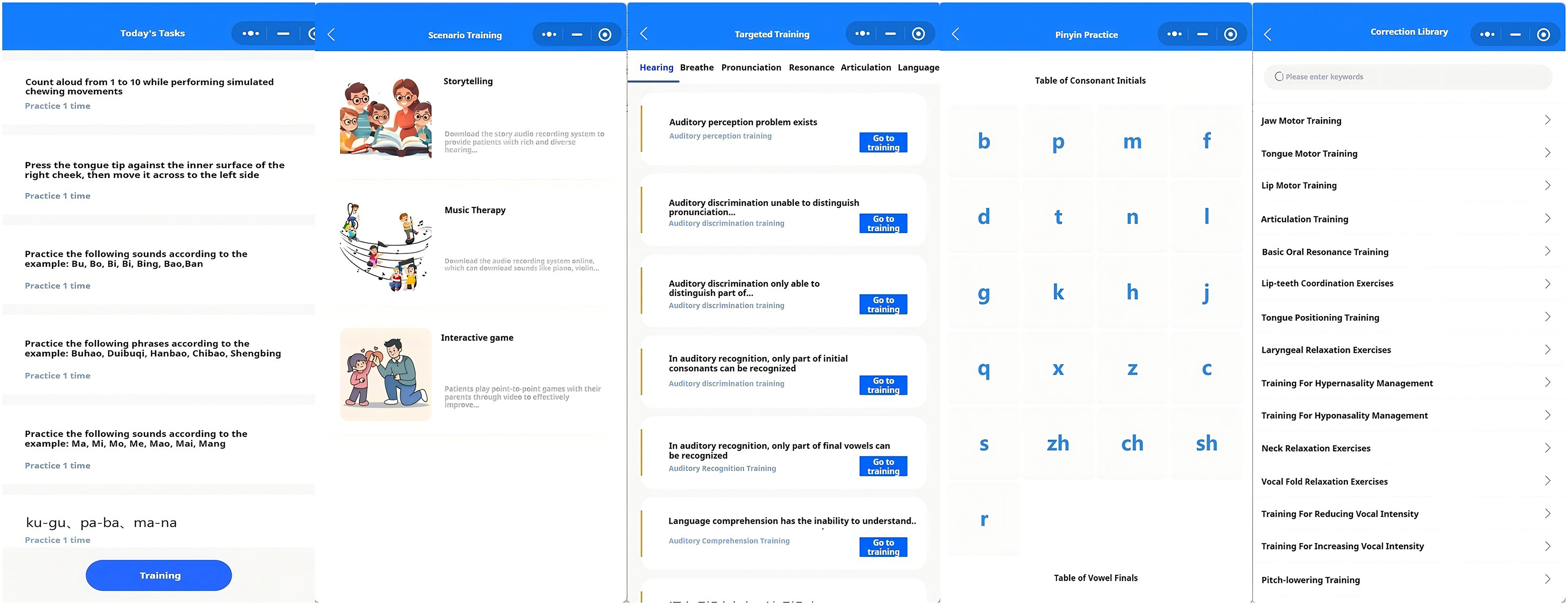
Usability and app quality evaluation
Two standardized instruments were administered via online questionnaires. Usability was assessed using the System Usability Scale (SUS), 44 a 10-items measure rated on a 5-point Likert scale and converted to a total score ranging from 0 to 100, with higher scores indicating better usability. App quality was evaluated using the user version of the Mobile App Rating Scale (uMARS), 45 which includes 26 items across five subscales: engagement, functionality, aesthetics, information, and subjective quality, each rated on a 5-point scale. The objective quality score was calculated as the mean of the four subscales. The SUS and uMARS questionnaires used in this study are provided in Supplementary File 2.
Concordance analysis
Comparisons between system-generated scores and rater-based ratings were conducted among participants who completed the corresponding assessments, with the assessment order randomly assigned. Concordance analysis was limited to the auditory and articulation modules, as these measures can be evaluated by both the system and human raters using comparable criteria. Auditory ability classification was evaluated using the CAP scale, 46 corresponding to the auditory grading results generated by the Mini Program. Articulation ability was assessed using a 50-item monosyllabic word list, with intelligibility defined as the percentage of correctly produced words. Two raters independently evaluated all recordings, and inter-rater reliability was first examined. System-generated scores were then compared with each rater’s scores to assess system–rater consistency.
Statistical analysis
All statistical analyses were performed using SPSS version 26.0. SUS and uMARS scores are presented as mean ± standard deviation. Agreement between system and rater assessments was evaluated using weighted Cohen’s kappa (κ) for categorical variables and the intraclass correlation coefficient (ICC) for continuous measures. Method agreement was further examined using Bland–Altman analysis. Bland–Altman plots were generated using GraphPad Prism version 9.5.0 to visualize the relationship between measurement differences and their corresponding means.
Results
Participant characteristics
Demographic and clinical characteristics of participants.
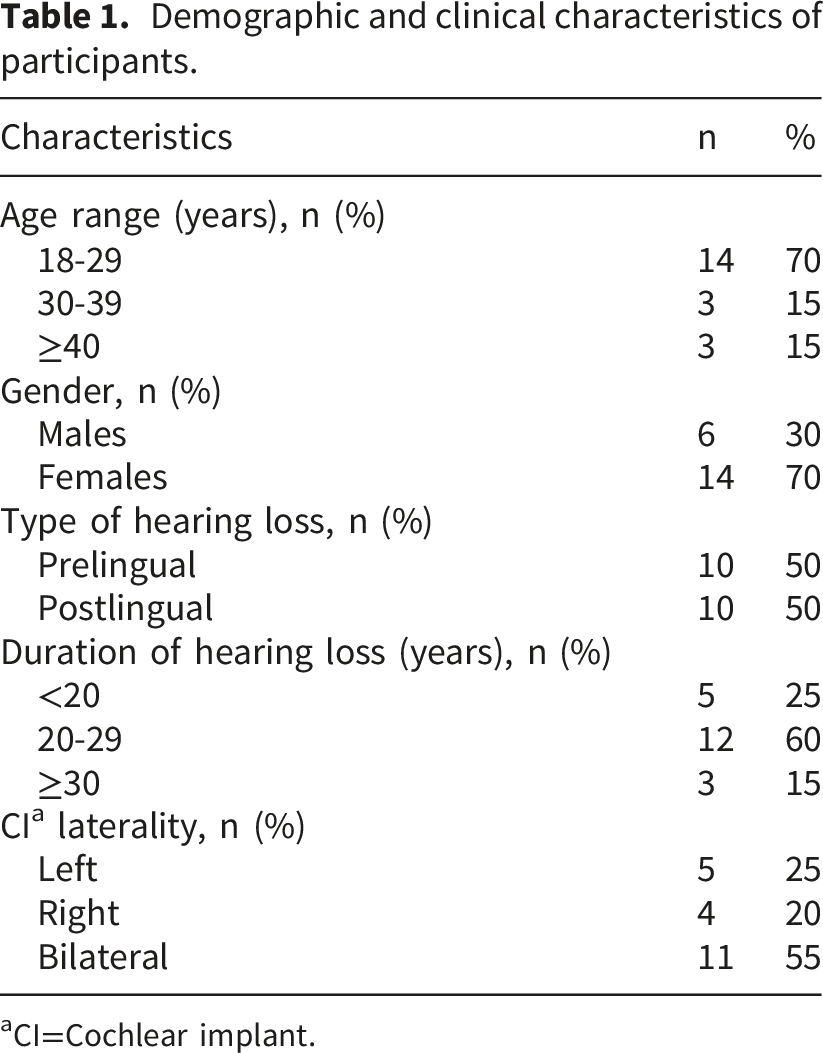
aCI=Cochlear implant.
SUS score
Mini Program usability scores.

uMARS score
This study used the uMARS to evaluate users’ subjective perceptions of the quality of the Mini Program. As shown in Figure 4, the overall objective quality score of the Mini Program, calculated as the mean of the four core dimensions, was 4.19 (SD = 0.50). The mean scores for each dimension were as follows: engagement, 3.71 (SD = 0.58); functionality, 4.38 (SD = 0.56); aesthetics, 4.40 (SD = 0.61); and information quality, 4.44 (SD = 0.51). Among these dimensions, Aesthetics and information quality had the highest mean scores. Mean uMARS scores across engagement, functionality, aesthetics, information, and overall objective quality. Error bars indicate standard deviations.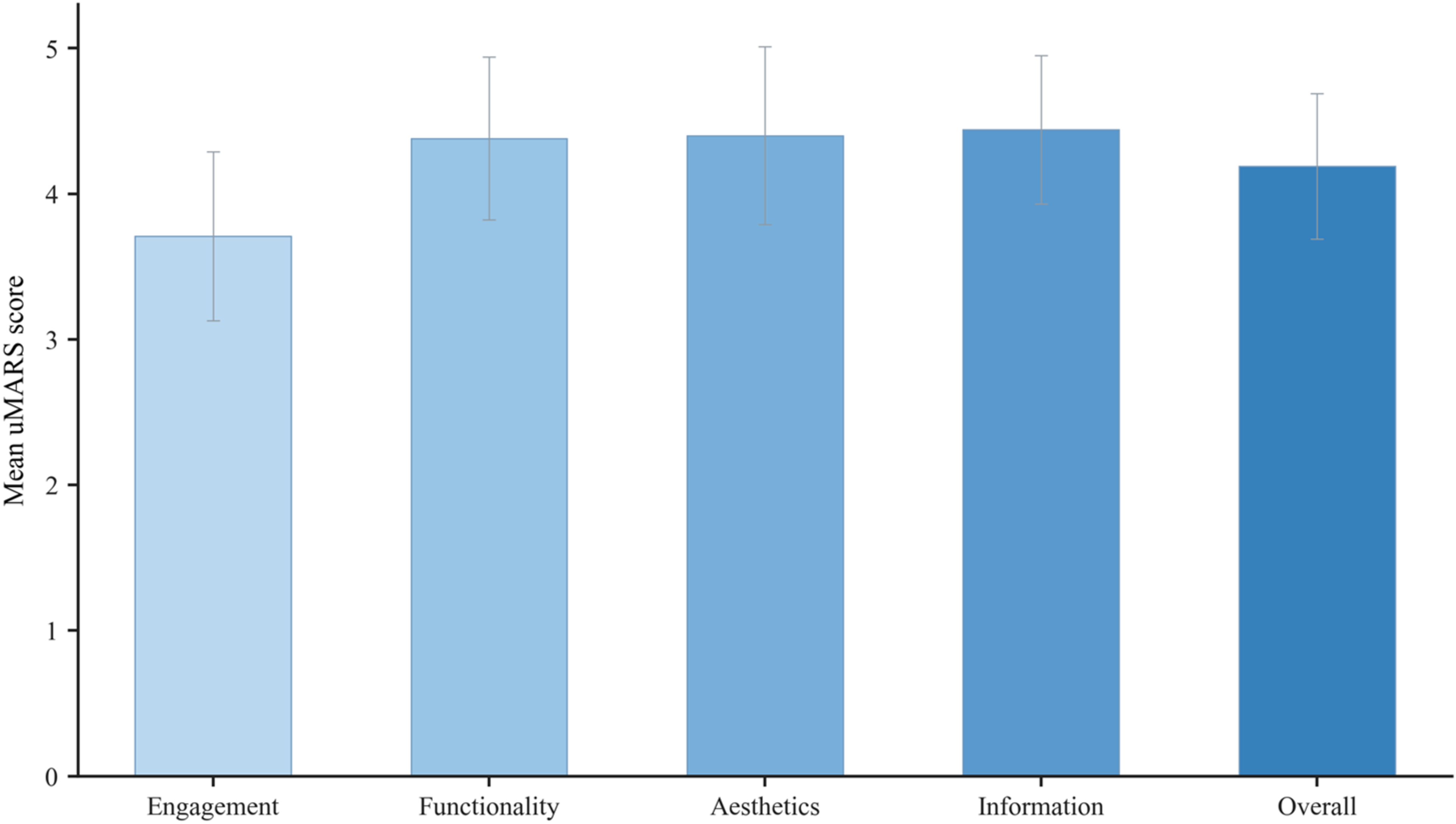
CAP ratings
Agreement between system-generated and rater-based CAP a assessments (weighted Cohen’s κ).

aCAP = Categories of Auditory Performance.
Articulation intelligibility scores
Intraclass correlation coefficients (ICCs) for system–rater and inter-rater agreement in articulation intelligibility scoring.
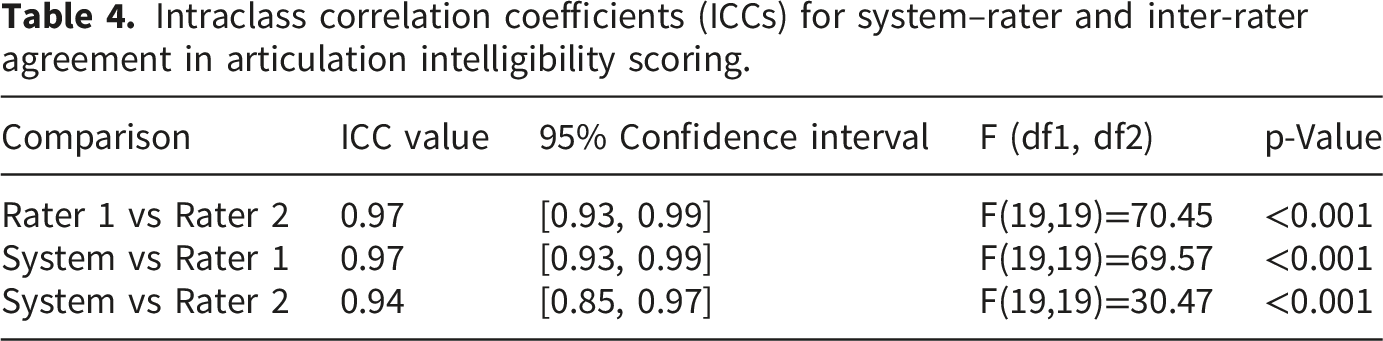
Bland-Altman analysis further examined the agreement between measurements (Figure 5). The 95% limits of agreement (LoA) between rater 1 and rater 2 were -6.67 to 6.17, with 95% of data points falling within this range. The 95% LoA between the system score and rater 1 were -7.31 to 4.81, with 90% of observations within the limits. The 95% LoA between the system score and rater 2 were -11.07 to 8.07, with 90% of observations within the limits. Bland-Altman plots of the number of articulation intelligibility scores between the system and raters. The solid line represents the mean difference. The area within 2 dashed lines represents the upper and lower 95% limits of agreement (LOA). (a) Bland-Altman plots of rater 1 vs rater 2. (b) Bland–Altman plots of system vs rater 1. (c) Bland-Altman plots of system vs rater 2.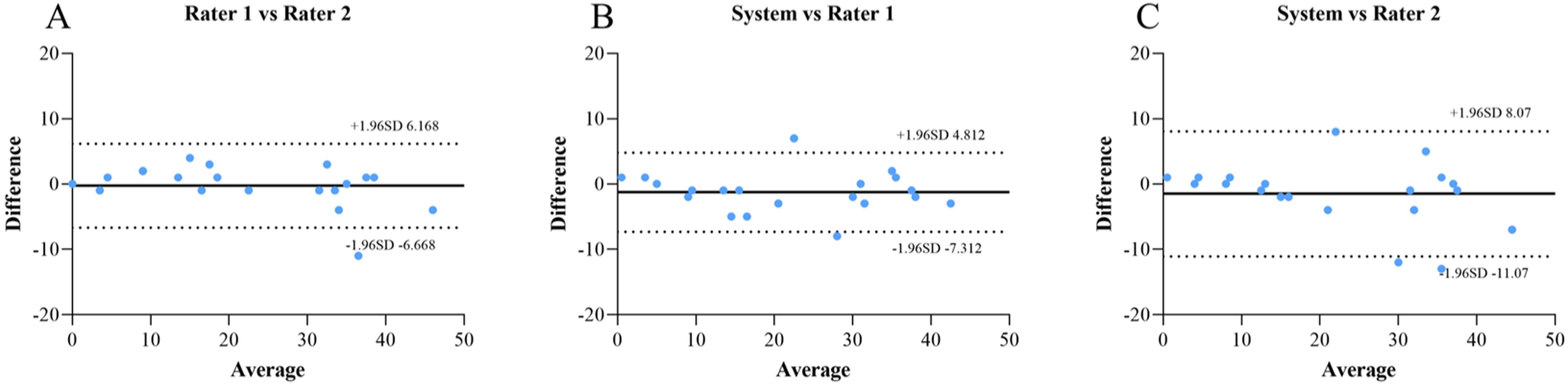
Discussion
This study developed and preliminarily validated a WeChat-based Mini Program for integrated auditory-speech rehabilitation in Mandarin-speaking CI users. The system combines multi-domain assessment with individualized training within a closed-loop digital framework. The findings showed good usability and promising agreement between system-based and rater-based evaluations for selected structured outputs, providing preliminary support for the feasibility of this Mini Program as a supplementary tool for auditory-speech rehabilitation.
From an accessibility perspective, the favorable user evaluations observed in this study likely reflect the combined influence of platform characteristics and system design choices. For adult CI users, rehabilitation needs tend to favor structured and goal-oriented training rather than highly gamified content. 49 In this study, targeted training modules and Pinyin practice enabled users to focus on individual deficits, thereby improving the precision and controllability of training. At the same time, the Mini Program emphasized clear functional organization, standardized task presentation, and explicit feedback, which may account for the high ratings in functionality and information quality while maintaining strong overall user acceptance. Taken together, these usability outcomes indicate not only positive user perception but also an effective alignment between platform design and the clinical characteristics of CI rehabilitation.
In addition to the favorable usability outcomes, the concordance findings provide preliminary support for the reliability of the Mini Program in selected auditory and articulation tasks. The high agreement in CAP classification is consistent with previous studies supporting CAP as a reliable functional auditory measure in CI users. 31 Similarly, the strong agreement in articulation intelligibility accords with earlier work showing that objective or automated speech assessment can correspond closely with human ratings.50–52 Together, these results suggest that the Mini Program not only achieved good user acceptance but also generated stable results in structured tasks with clearly defined scoring criteria. However, comparisons across studies should be interpreted cautiously because of differences in participant characteristics, speech materials, and analytic methods.
An additional implication of the present findings lies in the multidimensional design of the Mini Program. Existing digital approaches have addressed some auditory-speech domains separately, but usually in a task-specific rather than integrated manner. For example, some tools have focused on language and literacy support for children with hearing loss, 19 whereas others have emphasized automated speech intelligibility or severity assessment.51,52 In CI research, vocal and articulatory domains have also often been investigated as separate outcomes, such as vocal pitch control, articulation, vowel space, intelligibility, or prosodic performance, rather than within a unified rehabilitation workflow.38,53 In addition, some of the specific measures incorporated in the present system, including maximum phonation time, the s/z ratio, 54 and sustained vowel-based acoustic features such as formant measures (F1/F2) and vowel space-related indices,55–57 have been applied in prior remote or technology-assisted assessment studies, supporting their methodological inclusion in the present system. Taken together, these studies suggest that existing digital approaches mainly support individual auditory-speech domains rather than integrating them within one closed-loop system. Against this background, the present Mini Program extends the literature by combining auditory, articulation, respiratory, vocal, resonance, and language-related components within a single WeChat-based platform linked to individualized training and re-evaluation.
From a clinical perspective, the present findings suggest that the Mini Program may provide a practical supplement to conventional auditory-speech rehabilitation by supporting accessible, home-based training. For users requiring frequency follow-up, the Mini Program also assist therapists by generating objective data from selected structured tasks to support progress monitoring and intervention adjustment. Although the system was primarily designed for CI users with severe to profound hearing loss, some core modules, such as auditory training and articulation clarity assessment, may also be adaptable to other populations after further validation. Importantly, the Mini Program is not intended to replace face-to-face rehabilitation, but to complement it by extending therapist-guided support into daily life.
Several limitations should be acknowledged. First, the sample size was small, and the cohort was relatively homogeneous, which may limit the generalizability of the findings to the broader CI population. Second, consistency analyses were conducted for selected key indicators, whereas other assessment domains have not yet undergone comprehensive validation. Third, although the system was designed for smartphone-based assessment, variation in device and recording conditions may have affected some acoustic measures, particularly in the respiratory, vocal, and resonance modules. Finally, the study design did not include randomized or longitudinal comparisons to evaluate therapeutic efficacy directly. Future studies with larger, more diverse cohorts and standardized, controlled designs are needed to further evaluate the measurement properties and clinical utility of the Mini Program.
Conclusion
This study developed a WeChat-based digital auditory-speech rehabilitation system for Mandarin-speaking CI users and provided preliminary support for its feasibility as a supplementary rehabilitation tool. By integrating multidimensional assessment with individualized training, the system offers a potential digital approach to support auditory-speech rehabilitation after cochlear implantation. Further studies with larger samples and more comprehensive validation are needed to confirm its broader applicability in out-of-hospital rehabilitation.
Supplemental material
Supplemental material - Development and preliminary validation of a WeChat-based auditory-speech rehabilitation system for Mandarin-speaking cochlear implant users
Supplemental material for Development and preliminary validation of a WeChat-based auditory-speech rehabilitation system for Mandarin-speaking cochlear implant users by Xuyuan Peng, Ran Cao, Pengjun Wang, Zheng Han, Yini Li, Jingjing Wang, Shujian Huang, Wen Lu, Yuli Hu, Jing Wang, Zhengnong Chen, Wendi Shi, Lihui Tao, Jun Zhan, Kun Ni, Dongzhen Yu, and Haibo Shi in Digital Health.
Supplemental material
Supplemental material - Development and preliminary validation of a WeChat-based auditory-speech rehabilitation system for Mandarin-speaking cochlear implant users
Supplemental material for Development and preliminary validation of a WeChat-based auditory-speech rehabilitation system for Mandarin-speaking cochlear implant users by Xuyuan Peng, Ran Cao, Pengjun Wang, Zheng Han, Yini Li, Jingjing Wang, Shujian Huang, Wen Lu, Yuli Hu, Jing Wang, Zhengnong Chen, Wendi Shi, Lihui Tao, Jun Zhan, Kun Ni, Dongzhen Yu, and Haibo Shi in Digital Health.
Footnotes
Acknowledgements
The authors would like to thank all the participants and staff who contributed to this study.
Ethical considerations
This study protocol was reviewed and approved by the Ethics Committee of the Shanghai Sixth People’s Hospital Affiliated to Shanghai Jiao Tong University School of Medicine (Approval No. 2025-199-(1)). Written informed consent was obtained from all participants prior to study initiation. All participant data, including personal information, audio recordings, and questionnaire responses, were kept strictly confidential and used solely for research purposes.
Author contributions
XP, RC, PW, and ZH: Conceptualization, Methodology, Software, Investigation, Data Curation, Formal analysis, Writing-Original Draft, Writing – Review & Editing, Visualization. YL, JW, SH, WL, YH, JW, ZC, and WS: Investigation, Writing-Review & Editing. LT, and JZ: Software, Resources, Product development, Writing-Review & Editing. KN, DY, and HS: Conceptualization, Methodology, Writing-Review & Editing, Supervision, Project administration, Funding acquisition. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Smart Healthcare Special Research Program of the Shanghai Municipal Health Commission (Grant No. 2025ZHYL025).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.