
Abstract
Objective
This study aimed to develop and evaluate machine learning and deep learning models for the early prediction of dataset-defined myocardial infarction/heart disease risk using structured demographic, clinical, electrocardiographic, exercise-testing, and angiographic-related variables. The study also aimed to improve the clinical interpretability and methodological transparency of artificial intelligence-based cardiovascular risk prediction.
Methods
A retrospective computational modeling design was applied to a merged public heart disease dataset containing 1,888 records and 14 variables. The outcome was the original binary dataset label indicating higher versus lower likelihood of heart disease/heart attack risk. Data preprocessing included missing-value management, categorical encoding, normalization of continuous variables, and stratified model evaluation. Three models were compared: Random Forest, Support Vector Machine, and a multilayer perceptron deep neural network. Model performance was assessed using accuracy, precision/positive predictive value, recall/sensitivity, F1-score, ROC-AUC, and class-wise support. A separate statistical analysis section was added to report descriptive analysis, outcome distribution, feature correlation, and clinically relevant evaluation metrics.
Results
The Random Forest model achieved the strongest overall performance, with 97.0% accuracy, 96.0%-97.0% class-wise precision, 96.0%-97.0% class-wise recall, 97.0% F1-score, and ROC-AUC of 0.97. The deep neural network achieved 92.3% accuracy and ROC-AUC of 0.94, whereas the Support Vector Machine achieved 87.0% accuracy and ROC-AUC of 0.87. The balanced distribution of the dataset supported internal model training but may not reflect the lower prevalence of myocardial infarction in real-world healthcare settings.
Conclusion
The findings suggest that Random Forest can provide strong internal predictive performance for structured cardiovascular risk classification. However, the outcome represents a dataset-defined surrogate classification rather than independently adjudicated acute myocardial infarction. Therefore, external validation, calibration, comparison with validated clinical risk scores, and prospective evaluation in real-world clinical populations are required before clinical deployment.
Keywords
1. Introduction
Myocardial infarction (MI) is a major cardiovascular emergency caused by an acute reduction or interruption of coronary blood flow, commonly following atherosclerotic plaque rupture and thrombus formation. Early identification of individuals at increased cardiovascular risk is essential because timely preventive measures, diagnostic evaluation, and treatment can reduce morbidity, mortality, and healthcare burden.1–3
Risk assessment for MI and related coronary heart disease commonly depends on a combination of demographic factors, symptoms, cardiovascular risk factors, physiological measurements, electrocardiographic findings, and, in selected clinical pathways, exercise-testing or angiographic information. These variables are not all collected at the same stage of care. Baseline variables, such as age, sex, blood pressure, cholesterol, and fasting blood sugar, are usually available during screening or routine clinical encounters. In contrast, exercise-induced angina, ST-segment depression, and angiographic indicators are usually obtained after further diagnostic evaluation. This distinction is clinically important when interpreting artificial intelligence models developed from aggregated datasets.
Machine learning (ML) and deep learning (DL) methods have increasingly been applied to cardiovascular risk prediction because they can model complex nonlinear relationships among clinical variables. Algorithms such as Random Forest, Support Vector Machine, Logistic Regression, and neural networks have been used for heart disease prediction with promising performance.4–8 These approaches may support clinical decision-making by identifying high-risk individuals, prioritizing diagnostic evaluation, and improving resource allocation in digital health systems.
Despite promising results, several barriers limit the translation of ML-based cardiovascular risk models into clinical practice. First, many public datasets use surrogate labels such as “heart disease presence” or “heart attack risk” rather than prospectively adjudicated MI according to contemporary clinical definitions. Second, models are often evaluated mainly using accuracy, even though accuracy can be misleading when disease prevalence is low. Clinically meaningful metrics, such as sensitivity, specificity, precision/positive predictive value, F1-score, ROC-AUC, and PR-AUC, are required to interpret performance more appropriately. Third, many studies lack external validation and comparison with established clinical risk scores, which makes it difficult to determine whether a new model adds value beyond existing standards of care.
The objective of this study was to evaluate three predictive models--Random Forest, Support Vector Machine, and a multilayer perceptron deep neural network--for the prediction of dataset-defined myocardial infarction/heart disease risk using a merged public heart disease dataset. The revised study explicitly clarifies the dataset context, outcome definition, preprocessing pipeline, model parameters, statistical analysis, clinical interpretability, and limitations related to generalizability.
2. Literature review
Summary of previous machine learning and deep learning studies for cardiovascular risk prediction.
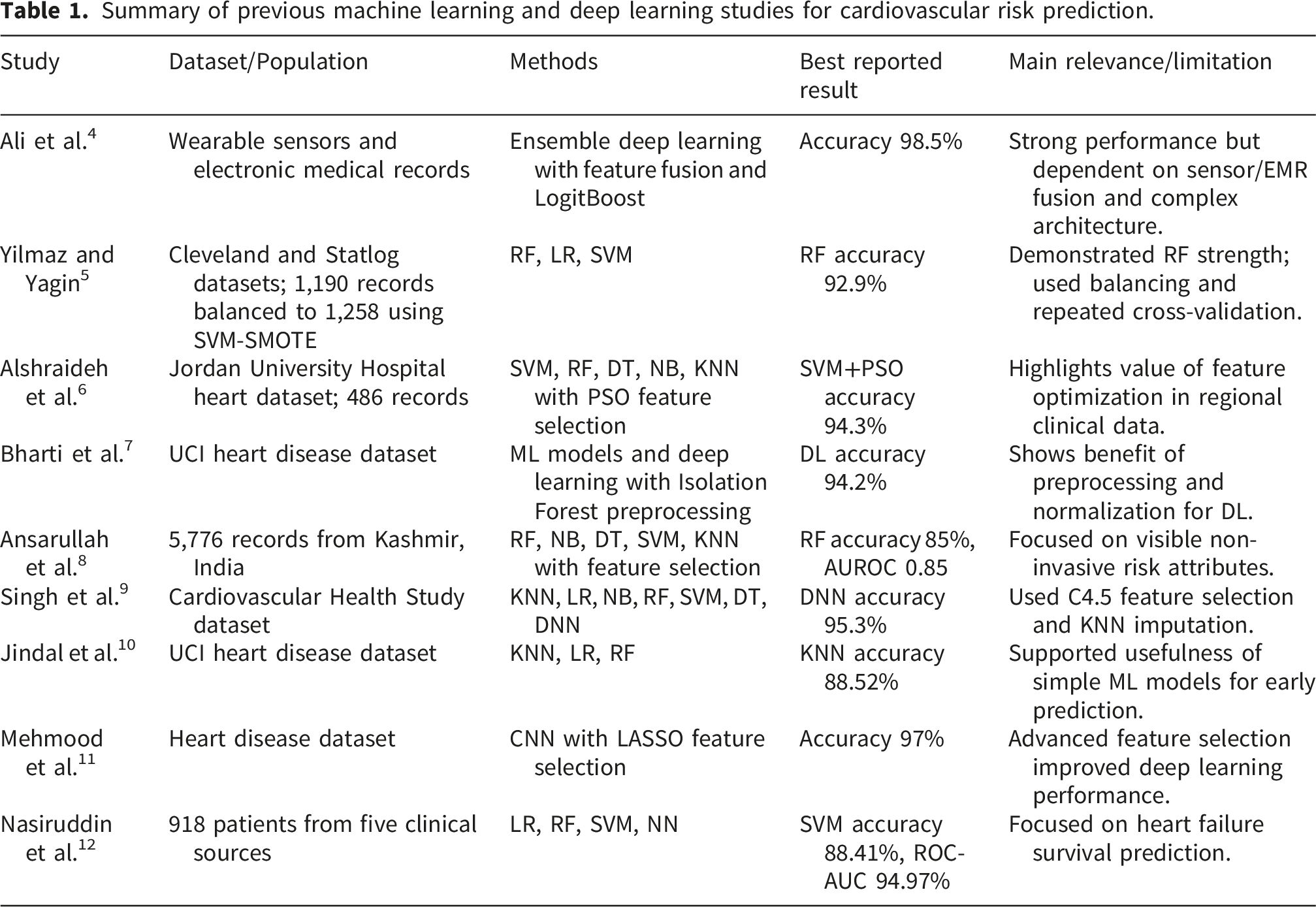
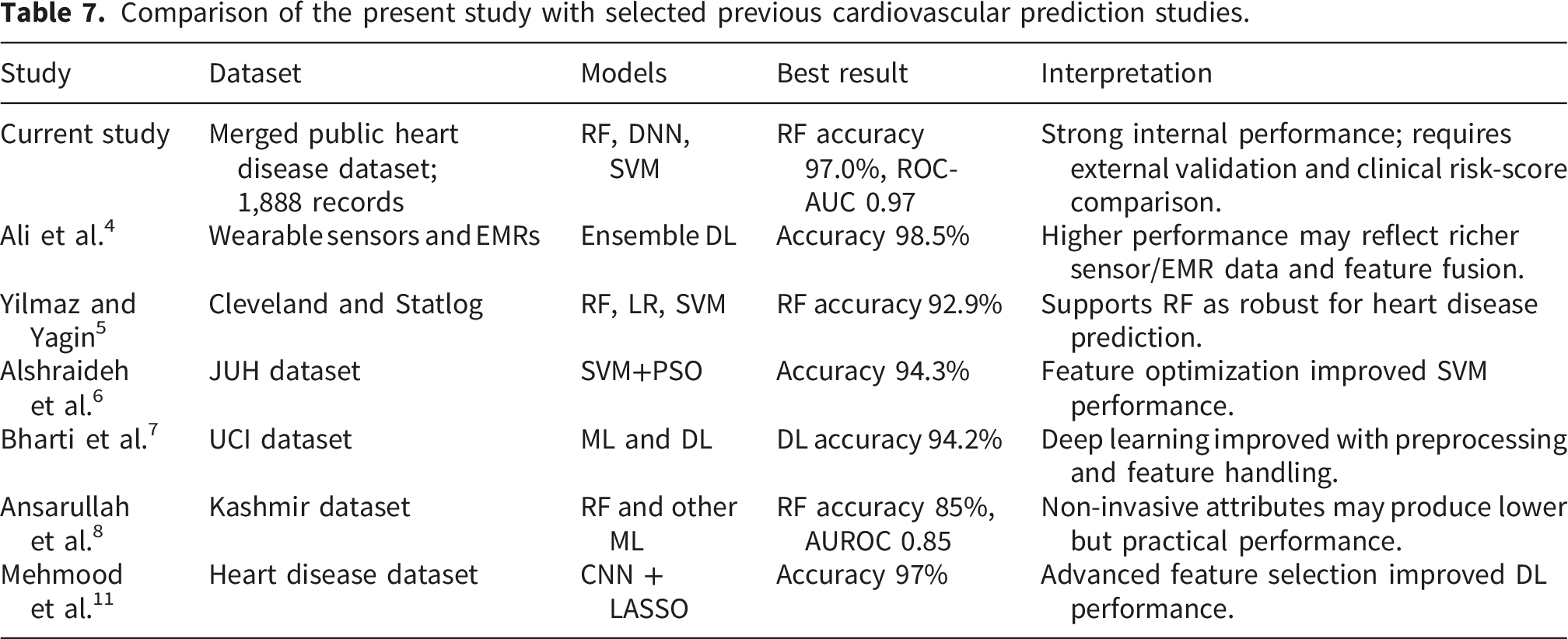
Table 1 shows that Random Forest, Support Vector Machine, and deep learning models frequently achieve strong performance in cardiovascular prediction tasks. However, most previous studies rely on internal validation and heterogeneous dataset-defined outcomes. Therefore, the present study positions its results as an internally validated computational model rather than a clinically deployable MI diagnostic tool.13–18
3. Methods
3.1. Study design, setting, and duration
This study used a retrospective computational modeling design based on secondary, publicly available heart disease data. No new patients were recruited, and no direct clinical intervention was performed. The analysis was conducted as a data-driven digital health study by researchers affiliated with Jadara University, Jordan, and Qassim University, Saudi Arabia. The computational analysis and manuscript revision were completed during 2026. The overall computational workflow is summarized in Figure 1. Proposed computational workflow for dataset-defined cardiovascular risk prediction.
3.2. Dataset source and permission for use
The study used a merged public heart disease dataset consisting of 1,888 records and 14 variables derived from five publicly available heart disease datasets. The dataset was used for academic research purposes. The data were anonymized and did not contain personally identifiable information. Because the dataset was publicly available and de-identified, additional institutional permission or individual patient consent was not required. Nevertheless, the analysis was conducted in accordance with responsible secondary-data research principles.
3.3. Dataset description
Description and clinical category of dataset variables used for prediction.

The merged dataset has a near-balanced target distribution, with approximately 910 records in class 0 and 978 records in class 1, as shown in Figure 2. This balance supports internal model training but does not reflect the lower prevalence of acute MI typically observed in real-world population-level screening settings. Source-level demographic details such as mean age, percentage of female participants, and prevalence of MI in each original dataset were not consistently available in the merged dataset file; this limitation is acknowledged in the Discussion. If original source-specific metadata are available, they should be reported in Table 3 before final submission. Distribution of the dataset-defined target variable in the merged heart disease dataset. Available dataset characteristics and source-level reporting status.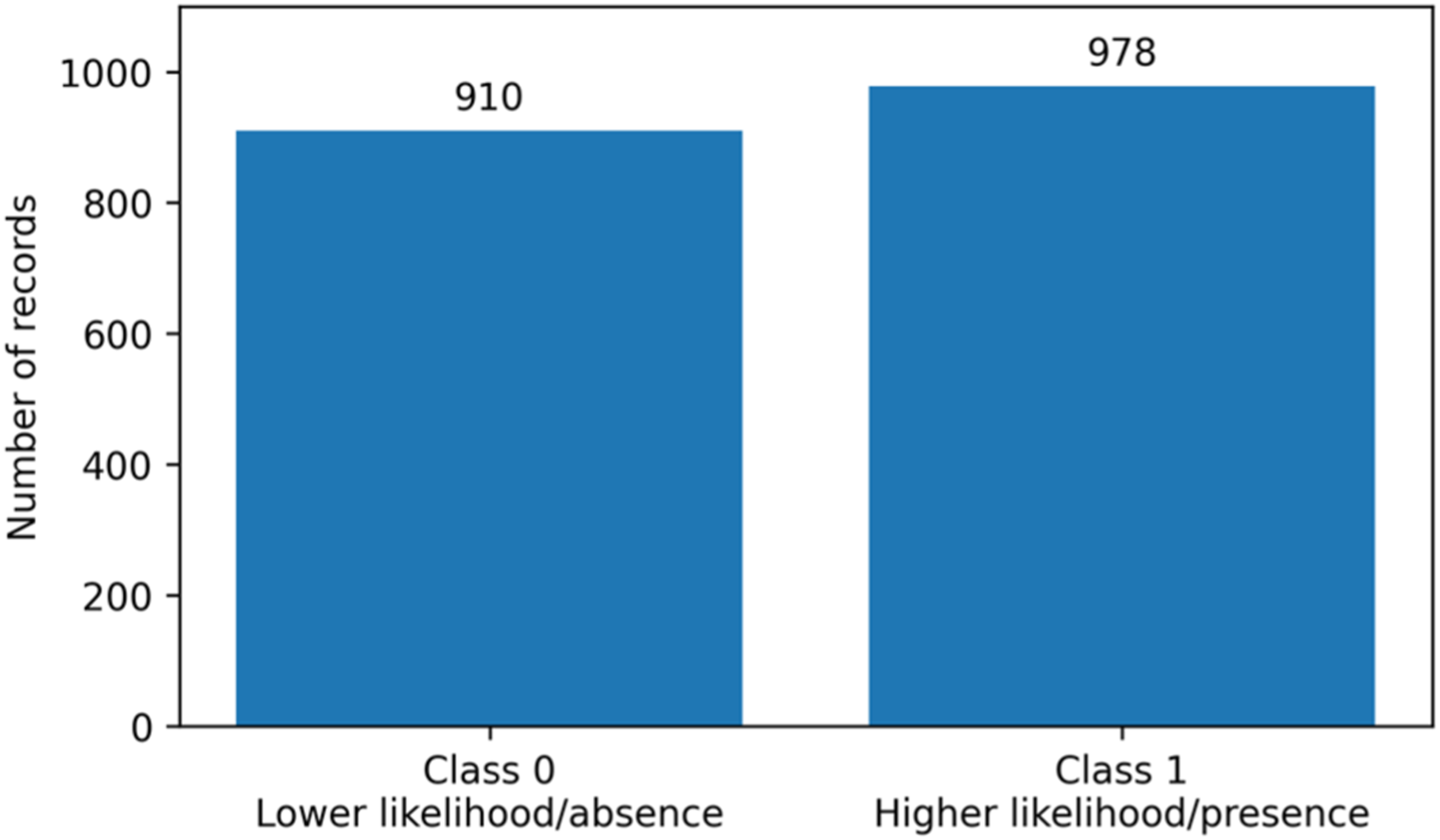
3.4. Outcome definition
Predictive models and hyperparameters used in this study.
Overall internal model performance comparison.
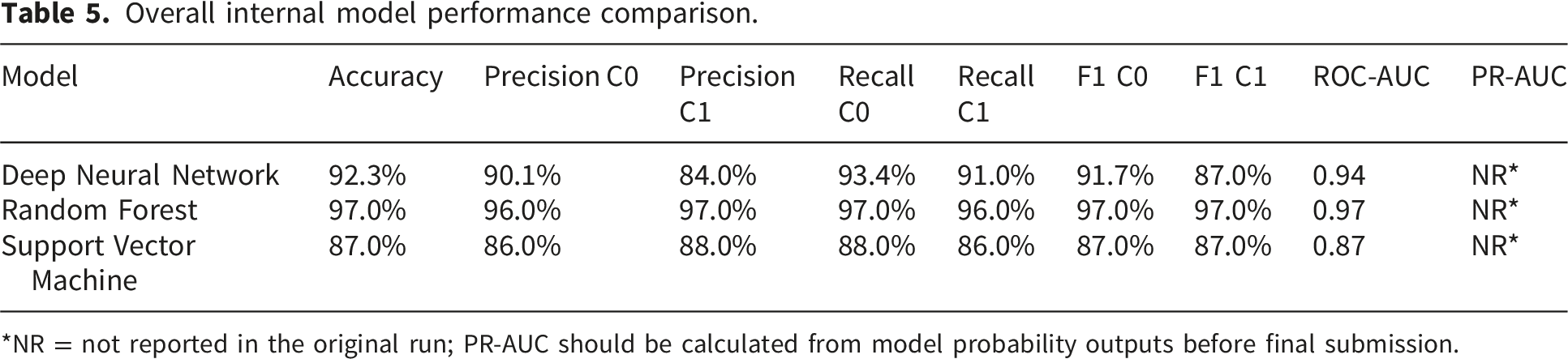
*NR = not reported in the original run; PR-AUC should be calculated from model probability outputs before final submission.
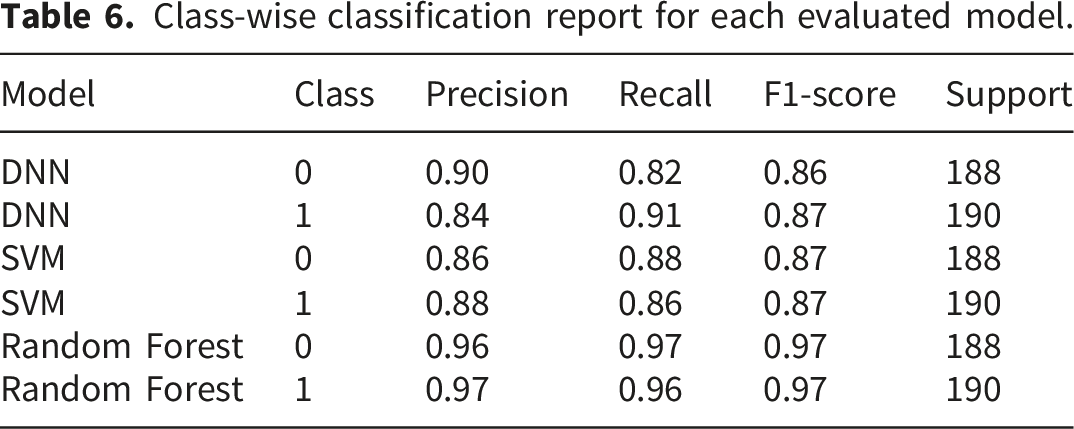
Class-wise classification report for each evaluated model.
Comparison of the present study with selected previous cardiovascular prediction studies.
3.5. Data preprocessing
Missing values: Missing entries were assessed before modeling. For numerical variables, median imputation was used because it is robust to skewed clinical measurements. For categorical variables, the most frequent category was used when missing values were present. Records with extensive missingness, if any, were excluded only when imputation was not clinically meaningful.
Encoding: Binary variables such as sex, fbs, and exang were retained as binary numeric variables. Ordinal or coded categorical variables such as cp, restecg, slope, ca, and thal were treated according to their dataset coding. For algorithms sensitive to categorical coding, one-hot encoding is recommended for non-ordinal variables; the final implementation should verify the encoding strategy used in the code.
Normalization: Continuous variables, including age, trestbps, chol, thalach, and oldpeak, were standardized using z-score normalization based on the training set parameters. The same transformation was then applied to validation and test data to prevent information leakage.
Data splitting: The dataset was divided into training and testing sets using an 80:20 stratified split to preserve class distribution. Where validation was required for hyperparameter tuning, it was derived from the training set. In addition, cross-validation was used to support more robust internal performance estimation.
Patient-level independence: The dataset was structured as one record per sample and did not provide longitudinal patient identifiers. Therefore, repeated measurements from the same patient could not be verified. Future work using hospital data should ensure patient-level splitting to prevent leakage between training and testing sets.
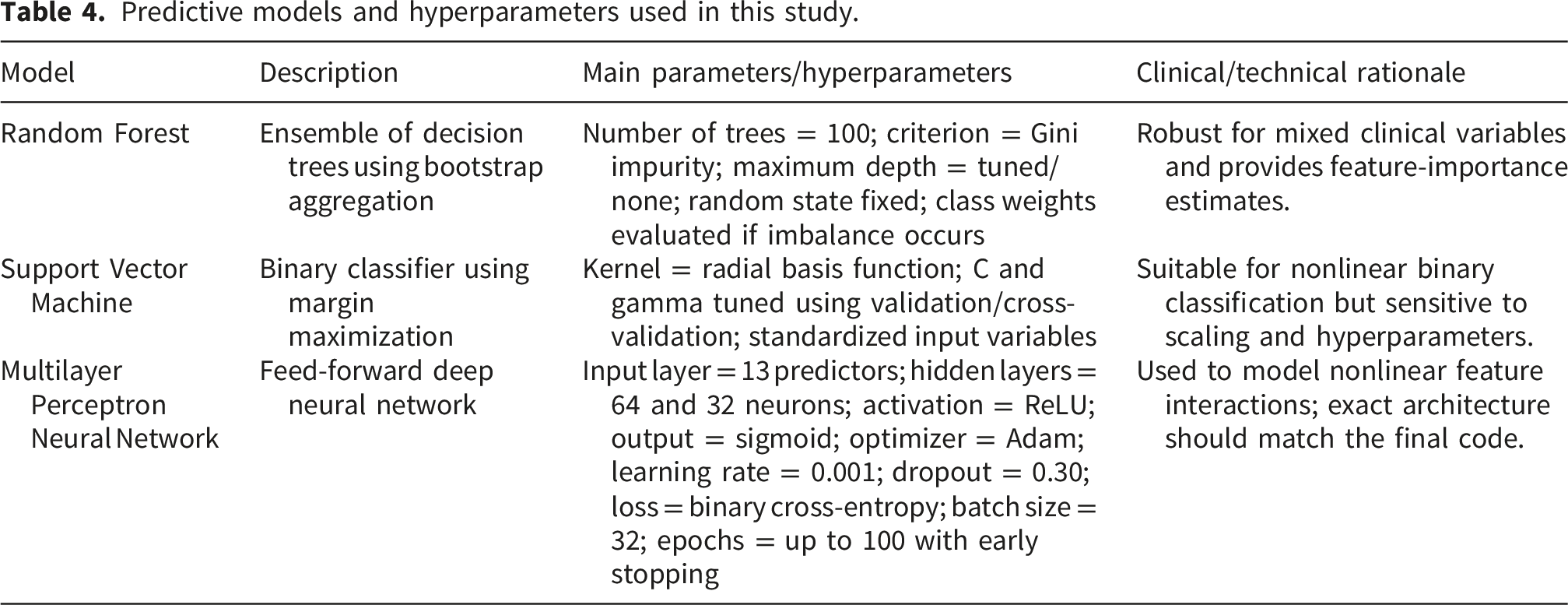
3.6. Predictive models and hyperparameters
Three supervised models were evaluated: Random Forest, Support Vector Machine, and a multilayer perceptron neural network. The model descriptions below were added to improve reproducibility. The final values should be checked against the original analysis script before submission.
3.7. Statistical analysis
Descriptive statistics were used to summarize the dataset. Continuous variables were summarized using mean and standard deviation or median and interquartile range depending on distribution. Categorical variables were summarized using frequencies and percentages. The target distribution was reported to assess class balance.
Correlation analysis was used to explore relationships among numerical and coded variables. The correlation heatmap was interpreted as exploratory and not as evidence of causal relationships. Because some model inputs were categorical codes, correlation findings were interpreted cautiously.
Model performance was evaluated using accuracy, precision/positive predictive value, recall/sensitivity, F1-score, ROC-AUC, and class-wise support. Because real-world MI prevalence can be low, accuracy was not treated as the only or primary clinical indicator. Precision/positive predictive value and recall/sensitivity were emphasized to provide a more clinically meaningful interpretation of false-positive and false-negative predictions. PR-AUC should be reported when probability scores are available from the final model run, particularly for future validation in low-prevalence populations.
Internal validation was performed using stratified train-test splitting and cross-validation. External validation was not performed because an independent real-world clinical cohort was not available. This limitation is discussed explicitly.
4. Results
4.1. Dataset distribution and exploratory analysis
The dataset contained 1,888 records, with an approximately balanced outcome distribution. Class 0 represented lower likelihood/absence of dataset-defined heart disease risk, and class 1 represented higher likelihood/presence of dataset-defined heart disease risk. The balanced distribution reduced the risk of major class imbalance during internal training. However, this distribution may overestimate real-world performance because MI prevalence is typically lower in many healthcare screening contexts.
Exploratory correlation analysis suggested that variables such as chest pain type, maximum heart rate achieved, ST depression, exercise-induced angina, and angiographic-related variables may provide useful predictive information. These findings were interpreted as exploratory associations rather than causal relationships.
4.2. Model performance
The Random Forest model achieved the strongest internal performance across all reported metrics. It reached 97.0% accuracy, class-wise precision of 96.0%-97.0%, class-wise recall of 96.0%-97.0%, F1-score of 97.0%, and ROC-AUC of 0.97. The DNN model achieved strong but lower performance, with 92.3% accuracy and ROC-AUC of 0.94. The SVM model achieved 87.0% accuracy and ROC-AUC of 0.87. Figure 3 visually compares the main performance metrics of the three evaluated models. Internal performance comparison of the evaluated models using accuracy, class 1 F1-score, and ROC-AUC.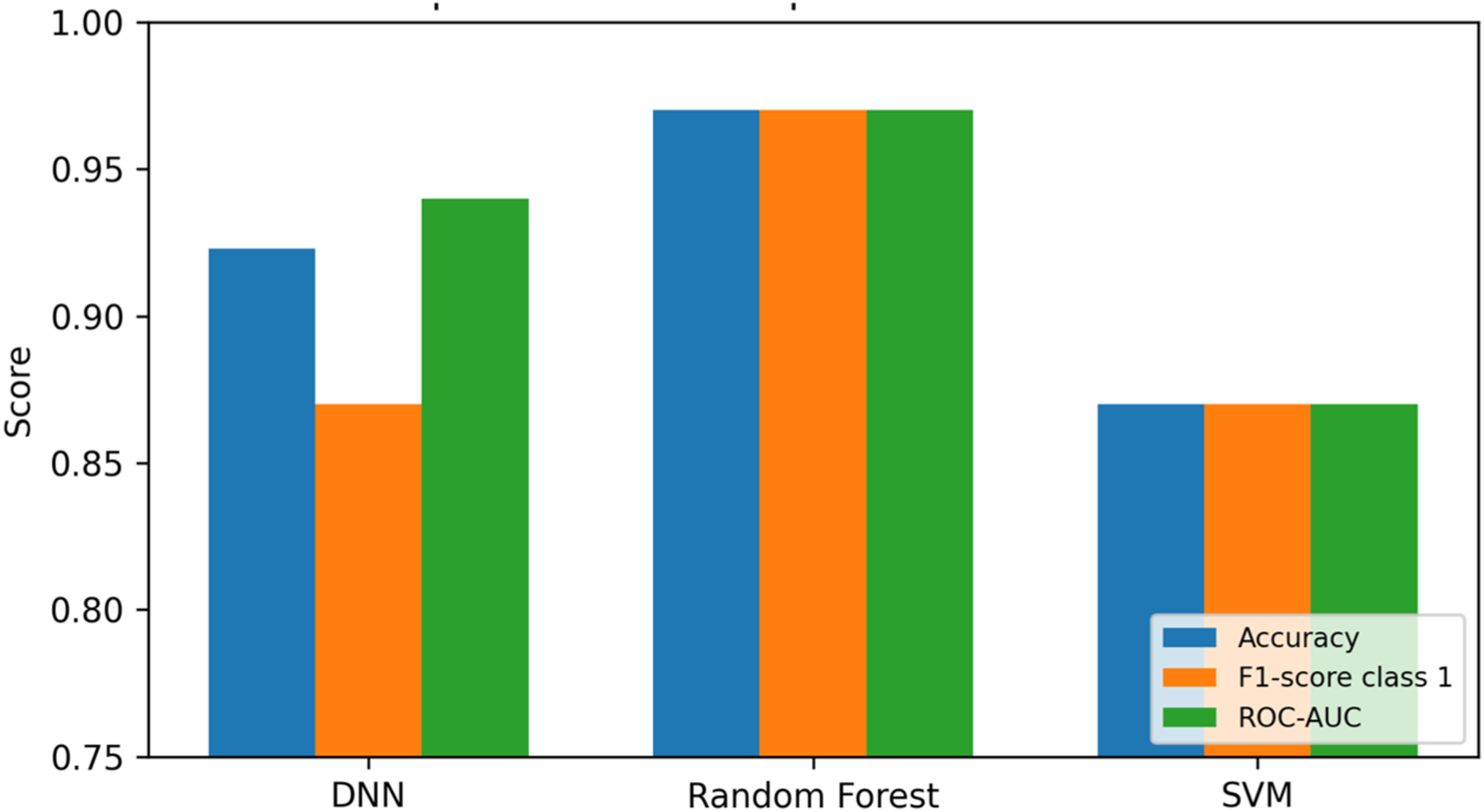
4.3. Classification reports presented as tables
The classification reports were converted from screenshot-based Python outputs into editable journal-quality tables. This improves readability and allows the results to be indexed, formatted, and reviewed consistently.
4.4. Clinical interpretation of model outputs
From a clinical perspective, the Random Forest model is preferable not only because of its high performance but also because it can provide feature-importance estimates. Variables such as chest pain type, exercise-induced angina, ST depression, maximum heart rate achieved, and angiographic-related variables are expected to contribute meaningfully to model predictions. However, these variables may arise at different stages of care; therefore, predictions should be interpreted according to the clinical context in which the variables are available. For future implementation, model explainability methods such as SHAP or LIME should be used to provide patient-level explanations that clinicians can interpret at the point of care.
5. Discussion
This study evaluated Random Forest, Support Vector Machine, and a multilayer perceptron neural network for prediction of dataset-defined myocardial infarction/heart disease risk. The Random Forest model demonstrated the best internal performance. This finding is consistent with several previous studies showing that ensemble tree-based models are effective for structured clinical cardiovascular datasets.5,8,10
The high performance of Random Forest may be related to its ability to model nonlinear interactions, handle mixed variable types, and reduce variance through ensemble learning. In structured cardiovascular datasets, risk may be influenced by interactions among symptoms, blood pressure, cholesterol, ECG findings, exercise-induced changes, and angiographic indicators. Random Forest can capture such interactions more flexibly than linear models and may be less sensitive to feature scaling than SVM or neural networks.
However, the clinical interpretation of these results requires caution. The dataset combines baseline clinical characteristics, exercise testing variables, and angiographic-related variables. Therefore, the model does not represent a purely pre-test screening tool for the general population. Instead, it is better interpreted as an internally validated structured risk-classification model that may support decision-making after several diagnostic variables are already available.
The outcome also requires careful interpretation. The target variable is a dataset-defined label indicating higher versus lower likelihood of heart disease or heart attack risk. It is not an independently adjudicated acute MI outcome based on contemporary universal definitions. Therefore, the term “myocardial infarction prediction” should be understood in the context of dataset-defined cardiovascular risk classification.
5.1. Comparison with previous studies
The comparative analysis indicates that the current Random Forest model performs similarly to or better than several previous models. Nevertheless, direct comparison must be interpreted cautiously because studies differ in dataset composition, outcome definition, validation strategy, disease prevalence, feature selection, and whether data were obtained from routine screening, diagnostic testing, or clinical records.
5.2. Clinical relevance and interpretability
For clinical adoption, predictive performance must be accompanied by interpretability, calibration, and evidence of incremental value over existing care pathways. In the present dataset, Random Forest feature importance can provide a first-level explanation of which variables drive predictions. However, global feature importance is not sufficient for individual patient care. Patient-level explanation methods, such as SHAP and LIME, should be used in future work to show how each variable increases or decreases the predicted risk for a specific patient.
The model may support clinicians by highlighting high-risk cases, guiding further evaluation, or prioritizing preventive counseling. However, it should not replace clinical assessment, biomarker testing, ECG interpretation, imaging, or established diagnostic criteria for acute MI. The model should be considered a decision-support tool that requires validation and integration into clinically appropriate workflows.
5.3. Comparison with established clinical risk scores
A limitation of the present study is that the dataset does not include all variables required to calculate established clinical risk scores such as Framingham Risk Score, SCORE2, TIMI, or GRACE. Therefore, direct comparison with these validated tools was not feasible. Future research should evaluate whether the proposed ML approach provides incremental predictive value beyond established risk scores using net reclassification improvement, decision-curve analysis, calibration plots, and external validation cohorts.
5.4. Limitations of the study
1. The dataset outcome is a public dataset-defined surrogate label and not an independently adjudicated acute MI diagnosis. 2. The dataset combines variables from different stages of the diagnostic pathway, including baseline, exercise-testing, and angiographic-related variables; therefore, the model does not represent a purely baseline screening tool. 3. Source-level demographic data, including mean age, percentage of female participants, and prevalence within each original dataset, were not consistently available from the merged dataset file. 4. The near-balanced target distribution does not reflect the lower prevalence of MI in many real-world healthcare systems, which may affect precision, PR-AUC, and clinical utility when deployed in low-prevalence settings. 5. No external validation was performed using an independent real-world clinical cohort. 6. The model was not compared directly with established clinical risk scores because the dataset did not contain all required variables for those scores. 7. Data leakage at the patient level could not be completely assessed because longitudinal patient identifiers were not available. 8. Calibration analysis, decision-curve analysis, and prospective clinical workflow evaluation were not performed and should be included in future research.
6. Conclusion
This study presented a revised and clinically contextualized evaluation of ML and DL models for predicting dataset-defined myocardial infarction/heart disease risk. Among the evaluated models, Random Forest achieved the best internal performance, with 97.0% accuracy and ROC-AUC of 0.97. The DNN and SVM models also showed acceptable performance but were less effective than Random Forest on the available dataset.
The findings support the potential of ensemble learning for structured cardiovascular risk classification. However, the results should be interpreted cautiously because the outcome is a dataset-defined surrogate label, the dataset combines variables from multiple diagnostic stages, and external validation was not performed. Before clinical deployment, the model should be validated in independent real-world cohorts, compared with established clinical risk scores, assessed using PR-AUC and calibration measures, and evaluated for interpretability and clinical workflow integration.
Footnotes
Acknowledgements
The researchers would like to thank the Deanship of Graduate Studies and Scientific Research at Qassim University for financial support (QU-APC-2026).
Ethical considerations
Not applicable. This study used publicly available anonymized data and did not involve direct human or animal participation.
Consent to participate
Not applicable. The dataset was anonymized and publicly accessible; therefore, individual informed consent was not required.
Consent for publication
Not applicable. This work does not include identifiable individual data, images, videos, or personal clinical details requiring consent for publication.
Author contributions
Conceptualization: Mohammad Subhi Al-Batah. Methodology: Mohammad Subhi Al-Batah and Abdullah Alourani. Data curation and analysis: Abdullah Alourani. Model development and validation: Mohammad Subhi Al-Batah. Writing - original draft: Abdullah Alourani. Writing - review and editing: Mohammad Subhi Al-Batah and Abdullah Alourani. Supervision and project administration: Mohammad Subhi Al-Batah and Abdullah Alourani. Funding acquisition: Abdullah Alourani. All authors have read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Qassim University (QU-APC-2026).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, 18 Sage UK House Style and/or publication of this article.
Data Availability Statement
The dataset used in this study was derived from publicly available heart disease datasets intended for academic and research use. The merged dataset contains anonymized records and does not include personally identifiable information. The processed data and analysis workflow are available from the corresponding author upon reasonable request, subject to the terms of the original public dataset source.
Trial registration
Clinical trial number: Not applicable. This study used secondary publicly available anonymized data and did not involve a clinical trial.