
Abstract
Aim
To develop a Retrieval-Augmented Generation (RAG) question-answering system for stroke patients and family caregivers, and evaluate its performance and usability.
Methods
We constructed a localized knowledge base using clinical practice guidelines, consensus, expert opinion, textbooks, systematic review, evidence summary, and peer-reviewed literature. Three LLMs (GPT-4o, Claude3.7, and Qwen3) were first evaluated for accuracy using 184 exam questions under zero-shot and RAG configurations. Thirty open-ended stroke-related questions were assessed by three experienced clinicians across four dimensions. Usability testing was conducted with 20 stroke survivors and family caregivers using the best-performing model, measuring System Usability Scale (SUS) and Net Promoter Score (NPS).
Results
RAG integration improved accuracy, relevance, and completeness across all three LLMs, with GPT-4o under RAG configuration achieving the highest overall mean score. However, the addition of RAG slightly reduced understandability for Claude3.7 and Qwen3. Usability testing yielded high acceptance.
Conclusions
RAG can enhance the reliability of LLM-generated responses in stroke-related questions, offering trusted, guideline-based information. The high usability ratings suggest early feasibility for real-world deployment, while future research should assess its linguistic accessibility and long-term clinical benefits in real-world caregiving contexts.
Keywords
1. Introduction
Stroke continues to be a significant global health concern as the leading cause of death and permanent disability worldwide. 1 The burden is particularly high in China due to rising incidence and recurrence rates, especially among older populations and those with uncontrolled vascular risk factors. 2 Stroke is also a leading cause of death in China, with a mortality rate of 197.36 per 100,000 people. 1 Although acute-phase treatment is critical, effective stroke management extends well beyond the acute stage. 3 From emergency response to long-term rehabilitation and secondary prevention, patients and caregivers frequently face persistent gaps in receiving timely and accurate stroke-related health education information.
Large language models (LLMs), especially ChatGPT, 4 are examples of artificial intelligence technology that have advanced significantly in recent years and shown exceptional text generation and comprehension skills. These models show immense potential in healthcare, especially as intelligent question-answering systems,5,6 which are expected to provide stroke patients, their families and non-specialist medical staff with a convenient way to acquire knowledge, assist in education and decision support. 7 However, pure LLMs also reveal significant shortcomings when applied to medical scenarios that require extremely high accuracy. The biggest problem is that they might create hallucinatory information, 8 which is unacceptable in the medical field because it appears plausible but is false or fabricated. A significant challenge lies in their inability to continuously assimilate updated medical guidelines and care practices, alongside their struggle to offer authoritative and traceable advice for complex, specific care dilemmas. These factors critically impede the reliability and practical efficacy of deploying LLMs directly for caregiver assistance.
Retrieval-augmented generation (RAG) integrates an information retrieval component with a large language model, enabling the system to proactively retrieve pertinent, accurate, and up-to-date information from one or more external knowledge bases before to response generation.9,10 This architecture notably curtails the generation of factually incorrect information, leading to improved accuracy and robustness in the generated replies. It also strengthens information provenance, allowing caregivers to validate the sources for enhanced confidence. RAG technology is demonstrating transformative potential in healthcare, particularly in supporting patients and caregivers. Prior studies have demonstrated the utility of RAG frameworks in various clinical contexts, 11 including providing clinical decision support, 12 enhancing patient education, 13 and creating dynamic plans for both chronic disease management14–16 and personalized treatment.17,18 However, most of these studies have primarily focused on system-side evaluation, with limited empirical validation involving end users such as patients or caregivers. For stroke, most existing studies have concentrated on the application of LLMs in zero-shot scenarios, primarily supporting clinical decision-making processes or aiding in stroke diagnosis and prognostication.19–21 Although recent studies have begun to explore the integration of RAG with LLMs for stroke-related classification tasks, such as using GPT-4o to identify stroke subtypes within unstructured electronic health records, 22 the application of RAG-enhanced LLMs for interactive, patient- or caregiver-facing stroke education and support is an understudied topic. As a result, they have limited insights into usability and acceptability in the real world.
This study aims to develop and systematically evaluate a RAG question-answering system tailored for stroke-related queries. By constructing a localized knowledge base and comparing the performance of three leading large language models (GPT-4, Claude3.7, and Qwen3) under both zero-shot and RAG configurations, we assess technical performance, clinical validity, and end-user usability. The research seeks to address critical gaps in AI-assisted stroke care, providing a reliable, guideline-based information tool for patients and caregivers while exploring the potential of RAG to enhance LLM reliability in healthcare contexts.
This study makes multifaceted contributions by uniquely integrating AI technology, clinical needs, and end-user demands. Unlike prior research, our localized knowledge base combines diverse authoritative sources to ensure regional applicability, while our evaluation framework comprehensively assesses LLM performance through technical metrics (184 exam questions), clinician-led validation (30 open-ended questions), and end-user usability (SUS/NPS scales). This design provides novel insights into RAG’s potential to mitigate hallucination and improve traceability, while revealing trade-offs between performance enhancement and output understandability. For clinical practice, our work delivers a feasible, evidence-based solution for stroke management; for health policy, it lays the groundwork for AI integration in chronic disease care, emphasizing the balance between reliability and accessibility.
2. Methods
2.1. Study design
This study was conducted from May 2025 to January 2026, and adopted a comparative experimental design to evaluate the performance and usability of LLMs under both zero-shot and RAG settings. The usability component of this study was conducted to explore early feasibility and user acceptability of system. The study did not involve clinical intervention, diagnostic decision-making, or treatment modification. Figure 1 provides a schematic overview of the entire study. Architecture and evaluation pipeline of the retrieval-augmented generation framework for stroke knowledge.
2.2. Local stroke knowledge base
To build a robust knowledge base for stroke, we compiled textual data published from 2020 onwards from multiple authoritative sources. Chinese domestic sources included the China National Knowledge Infrastructure (CNKI), Wanfang Data, UpToDate, and official Chinese domestic guideline websites. Additionally, international sources were integrated to ensure guideline diversity and evidence depth, including PubMed, Web of Science, Cochrane Library, CINAHL (Cumulative Index to Nursing and Allied Health Literature), Joanna Briggs Institute (JBI) EBP Database, the American Heart Association (AHA), National Institute for Health and Care Excellence (NICE), World Health Organization (WHO), and European Stroke Organisation (ESO). These sources provided a comprehensive collection of guidelines, clinical practice documents, textbooks, systematic reviews, evidence summaries, and peer-reviewed literature (e.g., case analysis). The knowledge base was systematically reviewed every two months to identify newly released or updated clinical guidelines, and major guideline revisions were incorporated in a timely manner when identified. Before being added to the knowledge base, each newly identified piece of information was independently evaluated by two clinical experts. The criteria for selection included the authority of the source, the relevance of the content, the clinical validity, and the consistency with evidence-based practice. The final documents comprise over 300 full-text articles and 9,341 stroke-related structured abstracts were retrieved from PubMed.
2.3. Question set development
To evaluate the accuracy of the models through both objective and expert-based perspectives, we employed a dual assessment strategy. A total of 150 single-choice and 34 multiple-choice stroke-related questions were randomly selected from national medical licensure, residency training, and professional qualification examination banks.
Additionally, a set of open-ended stroke-related questions was compiled to reflect the most common concerns encountered by patients and caregivers. These questions were derived from publicly accessible sources, including official websites of national stroke associations, online patient education portals, and commonly raised topics on social media platforms, as well as open-source Chinese medical dialogue datasets (https://github.com/Toyhom/Chinese-medical-dialogue-data). Questions identified from social media platforms were included because they reflect real-world concerns and information needs frequently expressed by stroke survivors and family caregivers in everyday care contexts. In addition, clinical nurses from a tertiary hospital were consulted to supplement the set with questions frequently encountered in routine stroke care. Then, two experienced nurses, each with over eight years of clinical experience in stroke care, independently reviewed and manually screened these collected questions to eliminate duplicates. From the screened pool, 30 questions were randomly selected for final evaluation question set.
2.4. RAG system implementation
The RAG system was locally deployed using RAGFlow, an open-source RAG platform. Raw stroke-related documents underwent an initial data cleaning step to remove irrelevant information, formatting errors, and textual noise (e.g., metadata, headers, footers, or unrelated content). The cleaned documents were then chunked into segments, each with a maximum length of 500 characters, which was chosen to preserve semantic completeness while maintaining sufficient retrieval granularity. These chunks were subsequently vectorized using the BGE-M3 (BAAI General Embedding - Multilingual, Multi-granularity, Multi-function) 23 embedding model. To enhance retrieval precision, RAGFlow’s native hybrid retrieval strategy was employed, which combines dense semantic vector search with robust full-text keyword search directly within Elasticsearch. To optimize both recall and precision in our retrieval process, we implemented a retrieve-and-rerank strategy. The Top-8 retrieved candidates were then passed to a cross-encoder re-ranking model, namely bge-reranker-v2, which scored and re-ordered the candidate chunks based on their contextual relevance to the query. Finally, the top 5 most relevant document chunks were selected to construct the prompt context for the downstream generation. At the end of each answer, the system showed the corresponding references. This made it easy for users to find out where the information came from. The embedding and re-ranking models were deployed as independent services, accessed via dedicated API endpoints throughout the pipeline.
2.5. Model selection and LLM configuration
GPT-4o (OpenAI), Claude3.7 (Anthropic), and Qwen3-8b (Alibaba) were selected as the LLMs for their robust language capabilities and general availability. All model interactions were conducted through standardized API calls provided by the respective platforms. All responses were generated in Chinese. For all large language models evaluated in this study, a standardized prompt was applied. The prompt instructed the following:
You are an experienced stroke expert, providing accurate, comprehensive, and easy-to-understand guidance on stroke prevention, acute treatment, nursing and care, rehabilitation, and long-term support. You are speaking to patients or family caregivers without a medical background. Your responses should be empathetic, practical, and clearly worded, avoiding technical jargon while ensuring that essential medical concepts are conveyed correctly.
All models were configured with consistent decoding parameters: temperature was set to 0.6, and both frequency and presence penalties were fixed at 0.3. The maximum token limit was set to 800 tokens. These settings were selected based on pilot trials to balance generation quality and readability. Prompt templates were standardized across models and conditions to avoid bias. All responses were generated offline and stored for expert evaluation.
2.6. Evaluation
To evaluate the performance of different LLMs in both zero-shot and RAG settings, we conducted a structured comparison across three state-of-the-art models: GPT-4o, Claude3.7, and Qwen3.
First, to objectively evaluate the model’s accuracy, an additional set of 150 single-choice and 34 multiple-choice stroke-related questions was randomly selected from national medical licensure, residency training, and professional qualification examination banks. Each question consisted of five answer options, and the responses were compared to the correct answers from national licensure and professional exam question banks to compute the accuracy rates. For multiple-choice questions, responses were considered correct only if all correct options were selected.
Then, three clinical experts (two senior nurses and one physician with over eight years of relevant clinical experience) independently assessed 30 open-ended stroke-related questions across four dimensions: accuracy, relevance, completeness, and understandability, using a standardized 5-point Likert scale (1 = very poor, 5 = excellent). To reduce evaluation bias, a blinded assessment procedure was adopted. Information regarding model identity and generation condition (Zero-shot or RAG) was concealed from the evaluators. Responses for each question were anonymized and presented in a randomized order using a standardized format. The experts independently assessed each response without access to information regarding its source. The evaluation questions and detailed definitions of the Likert 5-point rating scale are provided in Appendix A Table A.2.
2.7. User testing and evaluation
To evaluate the usability and user experience of the system, a formal task-based usability study was conducted. The best-performing model identified in the prior quantitative assessment was selected for interaction with the participants in a real-world setting, using the same standardized prompt as in the evaluation phase. Stroke survivors and caregivers were recruited from the Neurology Department of a tertiary hospital. Twenty patients and family caregivers were recruited to participate in the user testing of our system. Participants interacted with the system through a text-based chat interface. After a short introduction to how to use the system, they were invited to pose 5–10 questions based on their care-related concerns. They then completed a brief structured questionnaire assessing the usability and user loyalty of the RAG-based assistant in stroke support scenarios, using the System Usability Scale (SUS) 24 and Net Promoter Score (NPS). 25
2.8. Statistical analysis
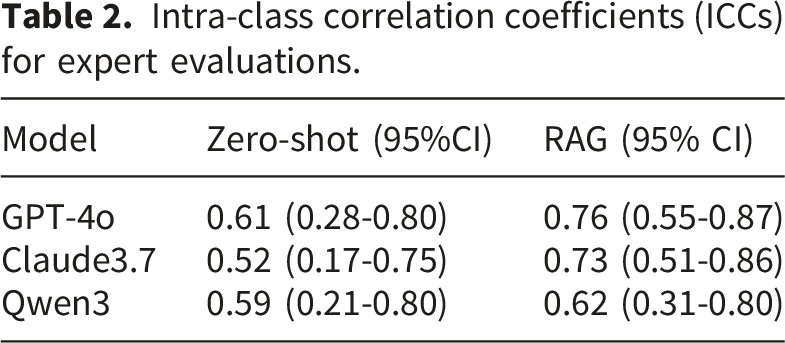
All statistical analyses were performed using Stata 18.0. As the data did not follow a normal distribution, group comparisons were made using the Wilcoxon signed-rank test for paired samples. To address clustering by rater and question, the unit of analysis was established at the question level, with scores averaged among clinical experts for each question and model condition. We calculated intra-class correlation coefficients (ICCs) to evaluate the agreement between experts. 26 A p-value < 0.05 was considered statistically significant.
2.9. Ethical considerations
This study was approved by the Institutional Review Boards of Fudan University School of Nursing (IRB#2023-4-7). This research was conducted in accordance with the ethical principles of the Declaration of Helsinki. All participants provided written informed consent prior to participation.
3. Results
3.1. Model’s accuracy on closed-ended questions
Across the closed-ended questions, RAG configurations consistently achieved higher accuracy than zero-shot across all three models.
In the single-choice questions, the accuracy of RAG responses was improved relative to Zero-shot for all three models: GPT-4o improved from 78.67% (118/150) to 82.00% (123/150), Claude3.7 from 78.00% (117/150) to 84.47% (127/150), and Qwen3 from 79.30% (119/150) to 82.00% (123/150).
In the multiple-choice questions, the performance gain with RAG was even more pronounced. GPT-4o answered 25 questions correctly (73.53%) with RAG, compared to 18 (52.94%) in the Zero-shot setting. Similar improvements were observed for Claude3.7 (58.82% to 67.65%) and Qwen3 (64.71% to 73.53%), further demonstrating the benefit of knowledge-augmented generation in handling complex clinical queries (Figure 2). Performance of LLMs on single-choice and multiple-choice questions under zero-shot and RAG settings.
3.2. Expert evaluation of response quality
Expert evaluation of response quality for LLMs under zero-shot and RAG configurations.

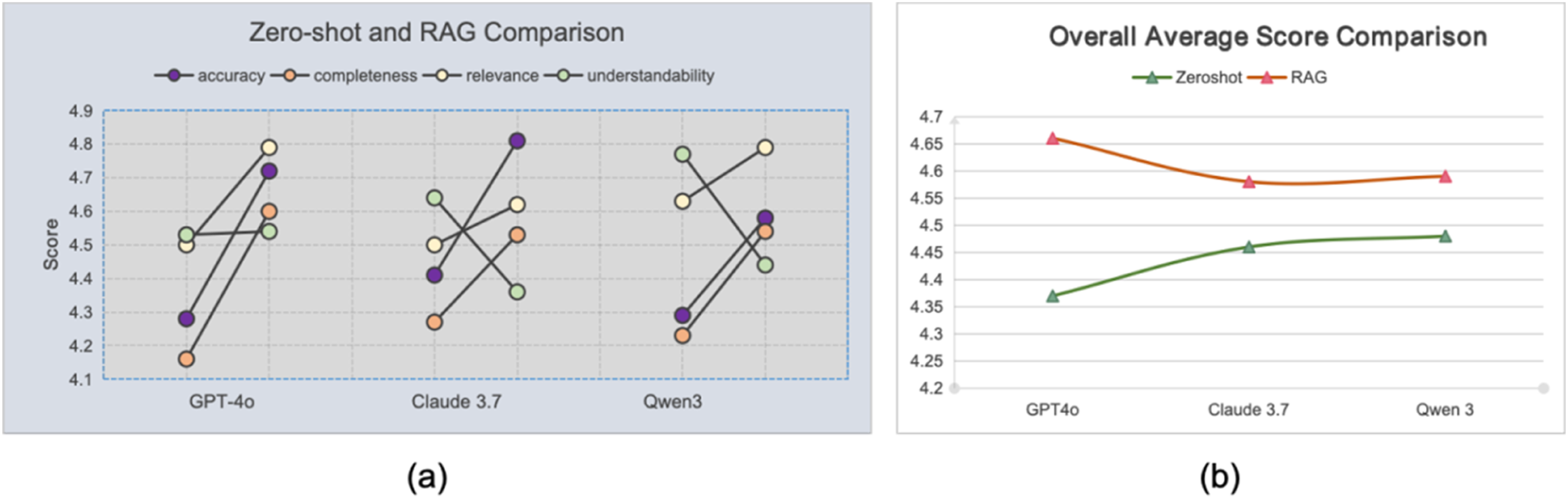
Comparison of zero-shot and RAG performance across three LLMs: (a) Comparison of zero-shot and RAG configurations across four dimensions (accuracy, completeness, relevance, and understandability) for each model; (b) Comparison of the overall average scores for each model under the two configurations.
While the RAG enhancement improved factual accuracy, this did not consistently lead to better understandability. For GPT-4o, the understandability score remained stable, showing no significant change after the RAG enhancement (mean 4.53 vs. 4.54; P=1). The mean score for Claude3.7 dropped from 4.64 (SD 0.57) to 4.36 (SD 0.53) (P< 0.01). Similarly, the score for Qwen3, which had the highest baseline understandability, decreased from 4.77 (SD 0.45) to 4.44 (SD 0.62) (P< 0.01). This made the answers less accessible to a lay audience compared to the more conversational and simplified language used by the Zero-shot models. This result underscores a critical challenge: while RAG excels at improving informational fidelity, it necessitates a sophisticated generation strategy to maintain high understandability for non-expert end-users.
Among the models, Claude3.7 achieved the highest individual scores in accuracy (4.81 ± 0.45) under RAG. However, GPT-4o demonstrated the best overall performance, achieving the highest average score across the four dimensions (4.66) under RAG. Qwen3 achieved the highest overall average score under the Zero-shot configuration (4.48).
3.3. Consistency among expert evaluation
Intra-class correlation coefficients (ICCs) for expert evaluations.
3.4. User evaluation of the RAG-based stroke care assistant
A total of 20 participants were recruited for the usability study, including stroke survivors (n=12) and family caregivers (n=8). Details of user characteristics and usability evaluation are presented in Appendix A Table A.3. Based on the results of the previous evaluation phase, the best-performing model (GPT-4o under RAG configuration) was selected for user testing. All participants were guided on how to interact with the assistant, and then each submitted 5-10 questions reflecting their own caregiving needs. The results from post-session questionnaires indicated a positive user reception. The SUS scores from 20 participants ranged from 65 to 95, with a mean of 82.75 (SD=6.43), corresponding to a “good” usability rating. In addition, the mean recommendation score in the NPS assessment was 8.5(Score range 0-10) Among respondents, 55% (n=11) were promoters (scores 9–10) and 45% (n=9) were passives (scores 7–8); no respondents were detractors (scores 0–6). The resulting NPS was 55, indicating a high level of user satisfaction and a strong willingness to recommend the system.
4. Discussion
The RAG-based question-answering system evaluated in this study has important clinical value for stroke patients and their caregivers. Throughout the stroke care continuum, from acute hospitalization to rehabilitation and long-term community living, patients and caregivers frequently encounter challenges in accessing accurate, timely health information. Developed as a supplementary patient-centered educational resource rather than a diagnostic or therapeutic tool, the system aims to provide reliable answers to common stroke caregiving questions, improve health literacy, strengthen caregiver confidence, and support informed self-management. To establish the reliability and suitability of the system for its intended users, a multi-stage validation approach was adopted. Model performance was objectively evaluated using standardized stroke-related questions derived from professional examination banks, followed by blinded expert assessment across four dimensions: accuracy, relevance, completeness, and understandability. This was complemented by real-world usability testing involving stroke patients and caregivers using the SUS and NPS. Overall, these evaluation procedures provide preliminary evidence supporting the reliability, usability, and acceptability of the RAG-enhanced approach in stroke patient education.
We systematically compared GPT-4o, Claude 3.7, and Qwen3 under zero-shot and RAG configurations for stroke caregiving. The results demonstrated that RAG-based models generally outperformed their zero-shot counterparts in terms of accuracy, completeness, and relevance. Among the models tested, GPT-4o demonstrated the best overall performance under the RAG configuration, a finding that aligns with previous comparative studies of LLMs in medical RAG applications.27,28 This indicates its compatibility with structured knowledge input and its effectiveness in addressing clinical questions. However, the integration of RAG was not universally beneficial across all evaluation dimensions. Notably, while RAG consistently improved accuracy, relevance, and completeness, it led to a decrease in understandability scores for Claude3.7 and Qwen3. This limitation has also been observed in other medical RAG applications. For example, a recent evaluation of RAG-enabled models for postoperative rhinoplasty patient queries reported that although responses were generally accurate and comprehensive, readability and understandability fell below recommended standards for patient education materials, 29 highlighting persistent challenges in producing patient-friendly outputs even when grounded in authoritative sources. One possible reason is that retrieval augmentation may bring up more specialized or guideline-oriented content from source materials. This content may be clinically accurate, but it can also include technical terms and formal language that are harder for non-experts to understand. This suggests that while retrieval augmentation enhances factual reliability and information richness, it may inadvertently reduce clarity for end users and compromise contextual integration and coherence, especially when responses become denser or more formal. 17
Interestingly, Qwen3 achieved the highest ratings in both relevance and understandability under the zero-shot configuration. One possible explanation is that Qwen3, as a Chinese-developed LLM, may be better aligned with the linguistic and cultural nuances of the Chinese context in which this evaluation was conducted. This alignment may have supported the generation of more contextualized and reader-friendly responses, even without external knowledge augmentation. Moreover, Qwen3 also outperformed GPT-4o and Claude3.7 in the structured multiple- and single-choice question tests under the zero-shot configuration, which may reflect its potential adaptation to the linguistic patterns and item formats of Chinese professional or licensure examination items, from which the test questions were derived. However, this interpretation remains speculative and should be examined in future comparative studies.
Departing from many studies that focus solely on algorithmic performance, we incorporated direct user testing. 30 The usability evaluation of the RAG-based assistant powered by GPT-4o showed a high level of user acceptance. These findings indicate that the assistant has good usability and was generally well-accepted by its target users, including stroke patients and family caregivers, in real-world contexts. Furthermore, during user testing, we observed that when participants phrased questions in a more colloquial or emotionally expressive manner, such as “My mother had a stroke, I’m so worried, how should I help her with limb function exercises?”, the system appeared to generate responses with a more empathetic tone. They were more understandable compared to the answers to standardized questions, such as “How should stroke patients perform limb function exercises”. This observation suggests that an advanced LLM like GPT-4o, within a RAG framework, may support factual accuracy while also appearing to capture and respond to users’ emotional context, adapting its communication style to provide more compassionate and human-centered support in real-world interactions. 31 However, this observation was exploratory and was not assessed using a formal empathy evaluation metric.
The real-world implementation of a RAG-based stroke care assistant depends not only on its technical accuracy but also on a robust governance framework to ensure its long-term safety and trustworthiness. 32 Firstly, given the dynamic nature of stroke guidelines, the knowledge base requires a continuous update process to remain synchronized with the latest clinical evidence. 33 Secondly, guided by the principles of human-centered design, the system must demonstrate contextual adaptability, tailoring its interface and language to diverse use cases, from hospital discharge planning to community rehabilitation. 34 Furthermore, although the underlying RAG framework is transferable across healthcare settings, implementation in other countries or regions would require localization of the knowledge base to reflect local clinical guidelines, healthcare practices, and patient needs. Such localization is essential to ensure the relevance, accuracy, and contextual appropriateness of the information provided. Thirdly, safety assurance needs to go beyond initial testing to include the option of localized, hospital-based deployment to better protect patient privacy and data security. 35 It also needs continuous post-deployment monitoring, which involves tracking retrieval accuracy, detecting outdated content, and flagging high-risk queries for expert review. 36 Ultimately, sustained user trust hinges on algorithmic transparency,34,37 such as the consistent citation of information sources, and a demonstrable responsiveness to user feedback.
There are some limitations. First, inter-rater reliability analysis involved only three experts, resulting in wide ICC confidence intervals; future studies should include larger evaluator panels. Second, we did not formally assess fairness or accessibility across sociodemographic groups with varying health literacy levels, which remains an important direction for future research. Third, usability testing was conducted in a single controlled setting with 20 participants from one center, limiting generalizability and precluding assessment of long-term user behavior changes. Fourth, while RAG improved accuracy and completeness, it occasionally reduced understandability due to longer or more technical responses. Future research should evaluate long-term outcomes in real-world settings and explore strategies to balance readability with factual accuracy.
5. Conclusion
This study shows that combining RAG with LLMs can improve the quality of responses to stroke-related questions. Usability testing further indicated strong user acceptance among stroke patients and family caregivers, supporting the early feasibility of the system’s performance and usability. The trade-off between informativeness and understandability seen in some RAG outputs, on the other hand, shows an important area for future improvement. Continued research is needed to enhance linguistic accessibility and assess long-term clinical benefits in real-world caregiving contexts.
Supplemental material
Supplemental material - Performance and usability of retrieval-augmented large language models for stroke patient and caregiver support
Supplemental material for Performance and usability of retrieval-augmented large language models for stroke patient and caregiver support by Jinxia Rong, Min Liang, Zheyan Wang, Zhixue Ye, Jingjing Luo, Yan Liang in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors would like to thank all the experts who participated in the evaluation for their valuable time and insights, which significantly contributed to the development of this study.
Ethical considerations
This study was approved by the Institutional Review Boards of Fudan University School of Nursing (IRB#2023-4-7).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 72304071), the Medical Science and Technology Project of Zhejiang Province (Grant No. 2025HY0957), and the Nursing Research Fund of the First Affiliated Hospital of Ningbo University (Grant No. H2025YJ002).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The RAG system was locally deployed using the open-source RAGFlow framework, available at: ![]() . The deployment followed the official Docker-based setup instructions provided in the repository, allowing for full reproducibility in a local environment. All other data supporting the findings of this study are available within the manuscript or its supplementary information files.
. The deployment followed the official Docker-based setup instructions provided in the repository, allowing for full reproducibility in a local environment. All other data supporting the findings of this study are available within the manuscript or its supplementary information files.
Contributorship
Jinxia Rong: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Software, Writing- Original draft. Min Liang: Conceptualization, Data curation, Formal analysis. Zheyan Wang: Conceptualization, Formal analysis, Methodology. Zhixue Ye: Data curation, Investigation, Software. Jingjing Luo: Methodology, Supervision. Yan Liang: Conceptualization, Funding acquisition, Methodology, Supervision, Writing – review & editing.
Declaration of generative AI usage
During the preparation of this work, the authors used ChatGPT (OpenAI) to assist with language editing and grammatical polishing. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the published article.
Guarantor
Yan Liang.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.