
Abstract
Objectives
The classification of Acute Lymphoblastic Leukemia (ALL) from peripheral blood smear images using Convolutional Neural Networks (CNNs) has achieved expert-level accuracy. However, the computational and memory requirements of CNNs pose a barrier to their deployment in resource-constrained clinical settings and low-income countries. To bridge this gap, we propose NeurALLNet, a memory-efficient convolutional spiking neural network (SNN) augmented with Squeeze-and-Excitation channel attention for the multi-class classification of ALL subtypes.
Methods
NeurALLNet leverages sparse, event-driven temporal computation with an ultra-compact architecture of approximately 0.3M trainable parameters. The model was trained and evaluated on a primary dataset of ALL peripheral blood smear images, and its clinical generalizability was rigorously validated on an unseen external cohort of 3,242 images without retraining. We conducted hardware profiling on CPU and GPU platforms, alongside ablation studies and Grad-CAM visual explanations, to evaluate deployment viability and interpretability.
Results
NeurALLNet achieved a test accuracy of 98.16% on the primary dataset, with a bootstrapped 95% Confidence Interval (CI) of [0.9663, 0.9939]. On the external validation cohort, it yielded an accuracy of 96.02%, with a robust 95% CI of [0.9534, 0.9667]. The architecture requires a memory footprint of 1.35 MB, achieving single-image inference latencies of 454.67 ms on a standard CPU and 11.24 ms on a GPU. Ablation studies confirmed that the attention mechanism is critical to the network’s discriminative power, and Grad-CAM visualizations verified that predictions are grounded in clinically relevant morphological features.
Conclusion
Compared to recent state-of-the-art ensemble and hybrid CNNs that require millions of parameters, NeurALLNet delivers competitive diagnostic accuracy while reducing the computational footprint by orders of magnitude. By providing this precision within a 1.35 MB envelope, NeurALLNet offers a scalable, energy-efficient digital health intervention suitable for portable Lab-on-a-Chip devices and point-of-care diagnostics worldwide.
Keywords
Introduction
Acute Lymphoblastic Leukemia (ALL) is a rapidly progressing malignancy of the lymphoid lineage, characterized by the uncontrolled proliferation of immature lymphocytes in the bone marrow, peripheral blood, and other tissues, frequently leading to bone marrow failure and systemic complications. 1 It is the most common cancer in children, accounting for approximately 75 to 80% of all childhood leukemias worldwide, and imposing a substantial global health burden. 1 According to the Global Burden of Disease Study, leukemias collectively accounted for approximately 573,000 new cases and 341,000 deaths in 2023. 2 The urgency of early and accurate diagnosis cannot be overstated: timely intervention in pediatric ALL can yield five-year survival rates exceeding 90% in high-income settings, whereas diagnostic delays and limited access to treatment in low- and middle-income countries (LMICs) reduce survival to below 40%. 3 Indeed, a delay of more than six months before referral to an oncologist is among the most statistically significant predictors of decreased overall survival. 4 Current diagnostic practice relies on the manual microscopic examination of peripheral blood smears and bone marrow aspirates by trained hematopathologists. This is a process that is labor-intensive, inherently subjective, and susceptible to inter-observer variability and examiner fatigue, particularly in high-volume clinical environments.5,6 These limitations underscore the urgent need for reliable, automated diagnostic tools capable of augmenting clinical workflows.
In response to the limitations of manual diagnosis, deep learning approaches, particularly Convolutional Neural Networks (CNNs), have demonstrated remarkable success in the automated classification of ALL from microscopic blood smear images, often matching or surpassing expert-level performance.7,8State-of-the-art CNN architectures have achieved classification accuracies exceeding 95% on benchmark datasets.9–11 However, CNN-based models are computationally intensive, requiring high-end Graphics Processing Units (GPUs) that consume substantial power alongside stable electricity supply and specialized cooling infrastructure. 12 These hardware dependencies render such systems impractical for deployment in rural clinics and resource-constrained settings in LMICs. 13 Recent parallel efforts to democratize medical AI have actively targeted these computational bottlenecks through various optimization strategies, including parameter-efficient fine-tuning of vision foundation models for endoscopic segmentation 14 and decoupled knowledge distillation for lightweight radiographic diagnosis. 15 While these methods successfully compress spatial feature extraction, Spiking Neural Networks (SNNs) offer a fundamentally different, biologically plausible, and highly energy-efficient alternative by leveraging temporal sparsity. 16 However, SNNs have historically lagged behind CNNs in classification accuracy and have not been adequately explored for hematological imaging.17,18 Bridging this residual performance gap while preserving the extreme energy efficiency of SNNs remains a critical, unaddressed challenge in digital health.
To address these gaps, we propose NeurALLNet, a memory-efficient convolutional spiking neural network augmented with Squeeze-and-Excitation channel attention for the multi-class classification of ALL subtypes. Often referred to as the third generation of artificial neural networks, SNNs process information through discrete, time-dependent events called spikes, closely mimicking the event-driven communication of biological neurons.
16
By integrating an attention mechanism into this sparse, asynchronous computation paradigm, NeurALLNet successfully overcomes the accuracy limitations that have historically hindered SNNs in complex medical imaging tasks.19,20 This architecture is specifically designed to bypass the steep hardware requirements of conventional deep learning, enabling accurate, real-time diagnostic inference directly on low-power edge devices and paving the way for scalable deployment in resource-constrained clinical settings. Our key contributions include: • We propose NeurALLNet, a refined, memory-efficient convolutional spiking neural network architecture for ALL subtype classification using only ∼0.3M trainable parameters and a minimal footprint of 1.35 MB, achieving real-time inference latencies on both CPU and GPU hardware. • We integrate a Squeeze-and-Excitation (SE) attention mechanism into the spiking domain, enabling adaptive channel-wise recalibration across temporal spike steps, validated by an ablation study showing a • We provide a comprehensive robustness analysis evaluating model resilience under Gaussian noise, salt-and-pepper noise, Gaussian blur, random occlusion, rotation, and systematic illumination variation. • We rigorously validate our model’s clinical generalizability by evaluating it on a completely unseen external dataset of 3,242 images, reporting bootstrapped 95% Confidence Intervals (CIs) to ensure statistically sound deployment metrics for digital health applications.
The remainder of this article is organized as follows. The Related Work section reviews CNN-based leukemia detection, SNNs in medical imaging, and attention mechanisms; the Methods section describes the dataset, preprocessing pipeline, NeurALLNet architecture, and evaluation protocol; the Results section presents the classification, external validation, efficiency, ablation, interpretability, and robustness findings; and the Discussion and Conclusion contextualize the deployment implications, limitations, and future directions.
Related work
This section reviews prior work on CNN-based leukemia detection, spiking neural networks in medical imaging, and attention mechanisms, positioning NeurALLNet within the broader landscape of efficient and clinically deployable diagnostic AI.
CNNs for leukemia detection
Convolutional Neural Networks have become the dominant paradigm for automated ALL detection from peripheral blood smear images over the past decade. Early benchmarking studies established the viability of classical architectures such as AlexNet, VGG16, VGG19, and ResNet50 for leukemia microscopy, demonstrating that deep hierarchical feature extraction could reliably discriminate lymphoblasts from normal lymphocytes.10,21 For instance, recent research utilizing a dedicated ResNet-50 deep learning approach has provided a robust benchmark for pediatric ALL classification by leveraging strong residual learning backbones. 22 Subsequent transfer-learning studies refined these results considerably; approaches employing modified VGG16 architectures have demonstrated that lightweight transfer-learning can yield highly competitive blast cell discrimination, 23 while fine-tuning EfficientNet-B3 and DenseNet-121 yielded test accuracies ranging from 95.92% to 98.57%. 11 Furthermore, recent innovations specifically targeting efficient CNN design in this diagnostic domain, such as hybrid CNNs integrated with morphological context blocks, have successfully balanced rigorous spatial feature extraction with more manageable computational overheads. 24 Most recently, in 2025 and 2026, researchers have pushed CNN architectures to their absolute performance limits. Bairwa et al. integrated an Xception network with Gated Recurrent Units to achieve 99.69% accuracy, 25 while Muhammad et al. employed an EfficientNet-B7 backbone paired with explainable AI techniques. 26 Other contemporary approaches include hybrid involutional-convolutional networks, 27 dimensionality-optimized ensemble classifiers, 28 and cognitive attention-based MobileNetV4 architectures. 29 Despite yielding near-perfect classification accuracies, a persistent and critical limitation of these state-of-the-art approaches is their staggering computational overhead. Architectures such as EfficientNet-B7 and Xception carry tens of millions of parameters, demanding GPU-class hardware, consistent power supply, and specialised cooling infrastructure. 30 Even highly optimized models such as MobileNetV4 still require nearly three million parameters. 29 This parameter inflation imposes an acute deployment barrier in rural clinics and low-resource settings, precisely the environments where automated haematological diagnosis is most needed. This stark contrast motivates the exploration of alternative architectures that prioritise extreme efficiency without sacrificing diagnostic fidelity.31,32
SNNs in medical imaging
Spiking Neural Networks have attracted growing interest in medical imaging as an energy-efficient alternative to conventional deep learning, leveraging their event-driven, spike-based computation to achieve substantially lower power consumption on neuromorphic hardware. 33 Across imaging modalities, SNN-based methods have demonstrated competitive results: hybrid SNN-CNN architectures have achieved 97.50% accuracy in brain tumour classification from MRI 34 ; a Deep CNN with Hierarchical SNN (DCNN-HSNN) has been validated on histological tissue and dermatological datasets for multiclass classification 35 ; and lightweight SNNs employing surrogate-gradient backpropagation have been applied to multi-class brain tumour tasks with as few as 1.78 million parameters, underscoring the feasibility of compact spiking architectures for clinical imaging. 34 In neuroimaging, SNN-based frameworks such as NeuCube have been explored for multimodal brain activation data, while eye-gaze-guided Spiking Transformers have shown efficiency gains in biomedical image analysis tasks including segmentation and denoising. 36 Energy benchmarks consistently favour SNNs: event-driven computation reduces power consumption by an order of magnitude or more compared to GPU-resident CNN inference, making SNNs uniquely viable for edge and battery-constrained deployments.37,38 Despite this breadth of application, the use of SNNs for haematological imaging remains virtually unexplored. Existing works in leukemia detection are dominated entirely by CNN and transformer-based approaches; to the best of our knowledge, no prior study has applied an SNN architecture to the multi-class classification of ALL subtypes from peripheral blood smear images, as corroborated by recent reviews of SNNs in biomedical imaging.33,39 This absence represents a significant and clinically relevant gap, given the diagnostic imperative for both fine-grained subtype differentiation and energy-efficient deployment in low-resource settings.
Attention mechanisms in neural networks
Attention mechanisms have become a standard tool for boosting the discriminative capacity of deep learning models by directing computation toward pathologically relevant image regions. In CNN-based leukemia classification, their impact has been well-documented: a CBAM–VGG19 hybrid achieved 98.73% accuracy on ALL bone marrow images, outperforming DenseNet121, InceptionV3, MobileNetV2, and the vanilla VGG19 baseline 40 ; Squeeze-and-Excitation blocks integrated into ResNet50V2 have delivered consistent accuracy improvements of 5–10% in brain MRI and bone tumour analysis 41 ; and multi-attention EfficientNetV2S models employing transfer-learning fine-tuning have been applied directly to blast cell discrimination in blood smear images.42,43 The integration of attention into SNNs, by contrast, is an emerging and considerably less mature research direction. Because spike-based information is binary and temporally sparse, attention mechanisms originally designed for continuous-valued CNNs cannot be transplanted directly without modification. Recent work has begun to address this: the Spiking Attention Neural Network (Sa-SNN) proposes a Spiking Efficient Channel Attention (SECA) module that performs local cross-channel interaction via convolution without dimensionality reduction, yielding meaningful performance gains with minimal parameter overhead 44 ; the BIASNN framework integrates biologically inspired attention with Leaky Integrate-and-Fire neurons, achieving over 95% accuracy on standard benchmarks while retaining ultra-low power consumption 45 ; and SpikeAtConv couples spiking convolution with spike-compatible attention for energy-efficient neuromorphic vision. 46 However, none of these attention-augmented SNN architectures have been evaluated on haematological imaging tasks. To date, no work has combined SNNs with an attention mechanism for multi-class ALL subtype classification, which is a critical gap given the clinical need to balance fine-grained diagnostic specificity with energy-efficient, edge-deployable inference. The present study directly addresses this gap.
Summary of related work
Summary of recent related work and comparison with the proposed NeurALLNet.
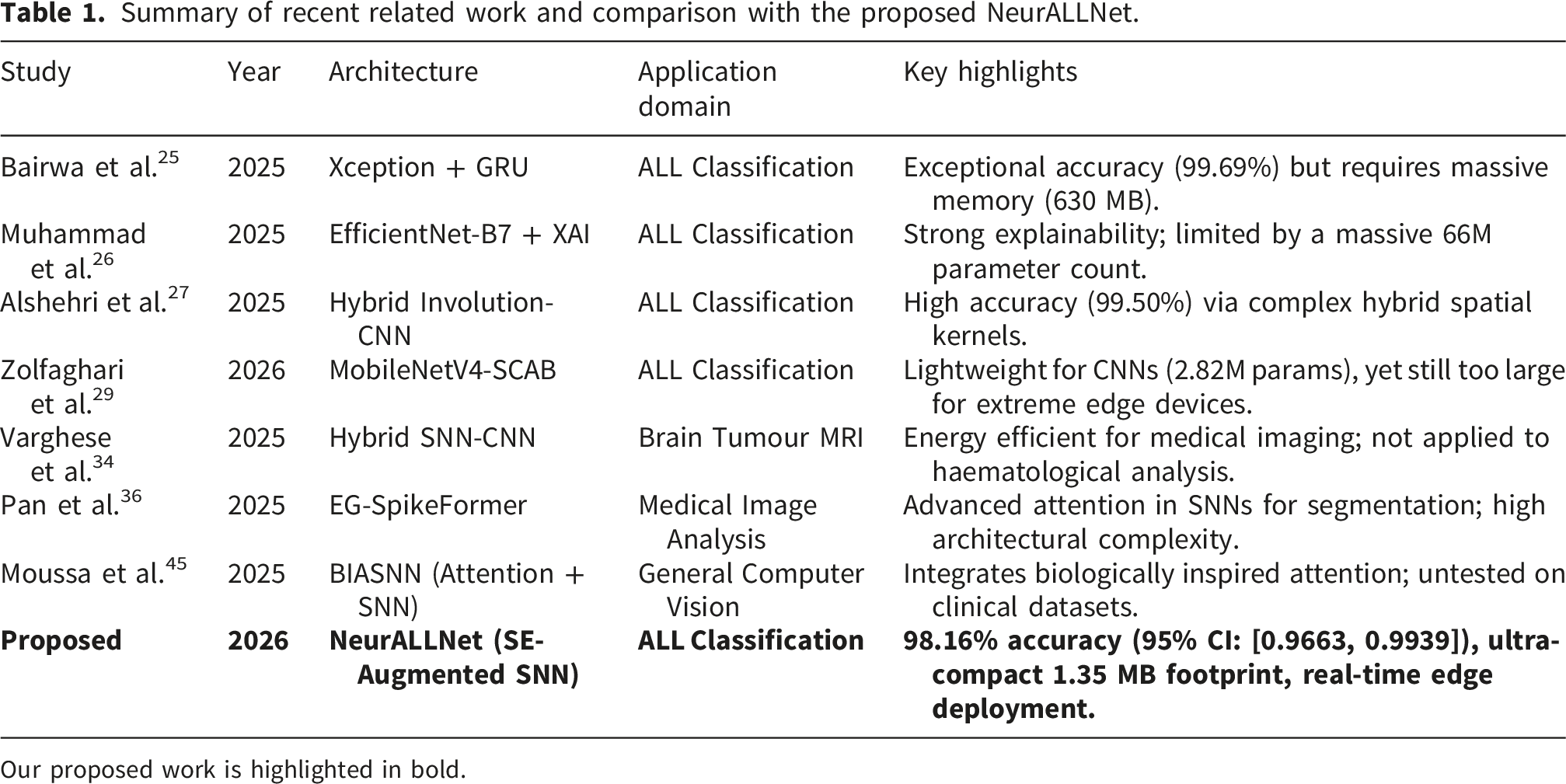
Our proposed work is highlighted in bold.
Methods
This section presents the methodological foundation of NeurALLNet, beginning with a high-level visual overview of the end-to-end framework in Figure 1. The pipeline illustrates the progression from clinical input and preprocessing through the core spiking neural network mechanisms, culminating in the final ALL subtype classification optimized for low-power edge deployment. The end-to-end clinical and computational pipeline of the proposed NeurALLNet framework. (A) Clinical Input: Microscopic peripheral blood smear images undergo preprocessing to standardize inputs. (B) NeurALLNet Core: Static RGB inputs are processed over a T = 4 temporal window via direct coding, depthwise separable convolutions, Squeeze-and-Excitation attention, and event-driven Leaky Integrate-and-Fire (LIF) spiking neurons. (C) Clinical Output and Deployment: The ultra-compact 1.35 MB model outputs one of four ALL diagnostic categories and is designed for real-time, low-power inference on edge hardware such as mobile devices or Lab-on-a-Chip platforms.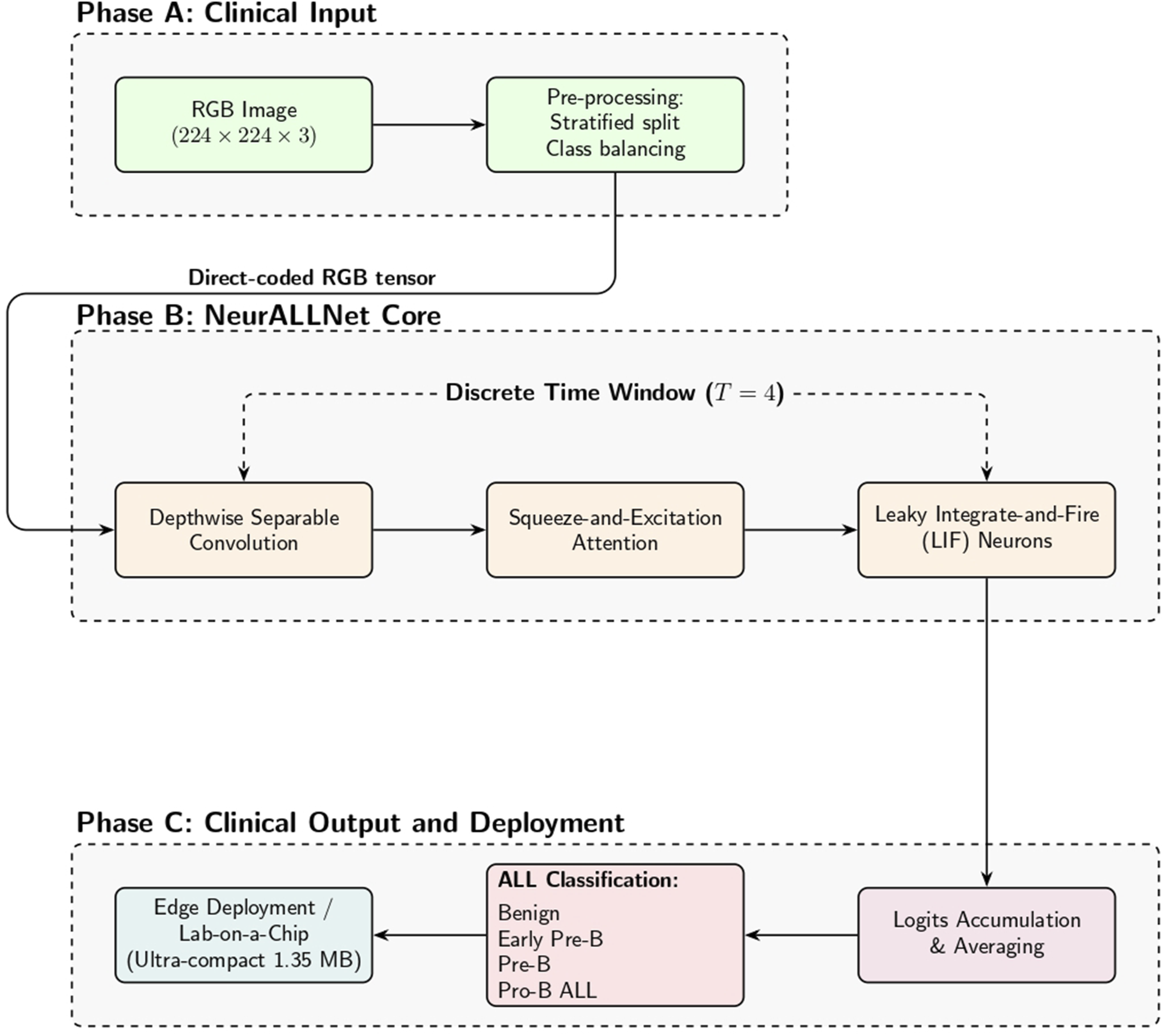
Problem formulation
The automated classification of Acute Lymphoblastic Leukemia (ALL) from microscopic images can be formulated as a supervised discrete-time spatial-temporal mapping problem. Let
Unlike conventional artificial neural networks that process static spatial tensors, our proposed spiking architecture integrates over a discrete temporal window
Dataset & preprocessing
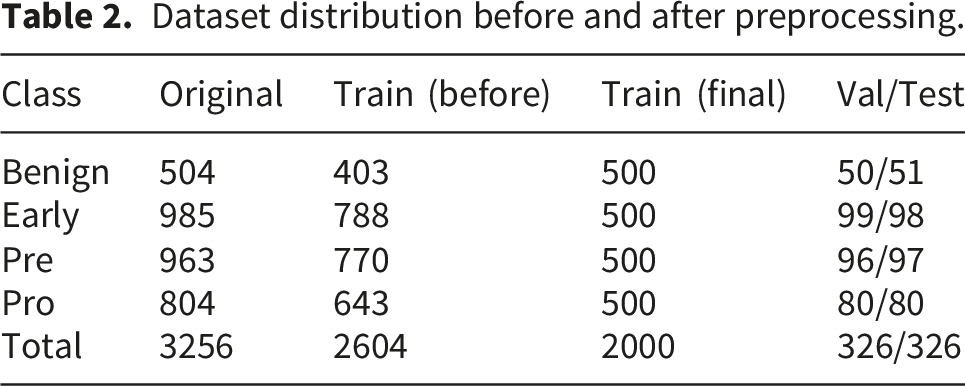
In this retrospective computational study, conducted on Kaggle between January and March 2026, we utilized the publicly available Acute Lymphoblastic Leukemia (ALL) Image Dataset. 47 The primary clinical peripheral blood smear images were originally collected at the Bone Marrow Laboratory of Taleqani Hospital, Tehran, Iran. The dataset comprises 3,256 peripheral blood smear (PBS) images obtained from 89 individuals suspected of ALL, including 25 healthy subjects (benign cases) and the remaining diagnosed with malignant ALL subtypes.
Dataset distribution before and after preprocessing.
NeurALLNet architecture
Our proposal is NeurALLNet, a memory-efficient convolutional spiking neural network architecture. We employ direct coding for input encoding, passing static RGB images straight to the spiking network. Temporal spike-based computation is realized by processing the continuous pixel values over T = 4 discrete time steps.
The network relies heavily on depthwise separable convolutions to drastically lower the number of trainable parameters. Given an input tensor 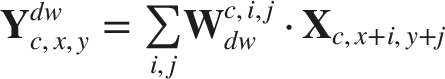
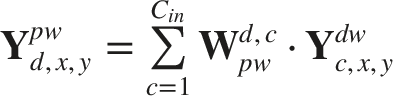
This decomposition lowers the parameter cost to K2 ⋅ C in + C in ⋅ C out , saving a significant amount of memory.
Every feature extraction stage incorporates a Squeeze-and-Excitation (SE) attention mechanism to enhance channel-wise feature representation. Global Average Pooling (GAP) first summarizes global spatial information for an intermediate feature map 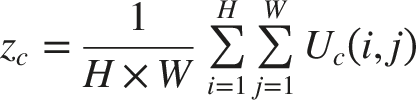
A gating mechanism is then applied to generate channel attention weights 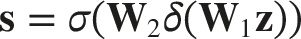
Temporal spiking behavior is introduced by Leaky Integrate-and-Fire (LIF) neurons. The sub-threshold membrane potential dynamics of the LIF neuron at layer l and time step t are governed by: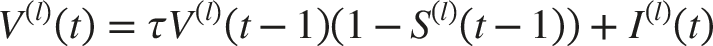
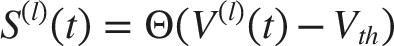

Training configuration, augmentation, and reproducibility
To ensure full experimental reproducibility, the model was implemented using the PyTorch deep learning framework in conjunction with the SpikingJelly neuromorphic library, and all training was executed on an NVIDIA T4 GPU. Experiments were conducted using a globally fixed random seed of 42 to guarantee deterministic weight initialization, data splitting, and bootstrap sampling. The network was trained using a memory-efficient batch size of 16 for a maximum of 50 epochs. An early stopping criterion was implemented with a patience of 5 epochs, monitoring validation accuracy to halt training and prevent overfitting. Optimization was performed using the Adam optimizer with an initial learning rate of η0 = 0.001, modulated by an exponential decay schedule η epoch = η0 ⋅ 10−epoch/20, alongside a standard Cross-Entropy loss function.
To improve the model’s robustness and generalization, a comprehensive spatial data augmentation pipeline was applied exclusively to the training partition prior to inference. This pipeline consisted of random rotations (up to ± 20°), random affine transformations (up to 20% spatial translation and 20° shear), random resized cropping (scaling between 80% and 100% of the image area), and random horizontal flipping.
Because the Heaviside step function Θ(⋅) used for spike generation is non-differentiable everywhere except at the threshold (where it is infinite), standard backpropagation fails. We bypass this using surrogate gradient learning. During the backward pass, the derivative of the spike function is approximated using the Arctangent (ATan) surrogate gradient: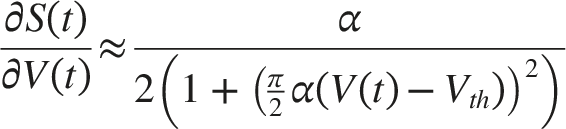
Evaluation metrics
Model performance was quantified using standard multi-class classification metrics computed from the confusion matrix. Let TP, TN, FP, and FN denote the number of true positives, true negatives, false positives, and false negatives, respectively, for a given class under a one-versus-rest formulation. The primary performance measures used in this study are defined as follows:



For the multi-class setting, class-wise precision, recall, and F1-score were first computed independently for each diagnostic category. Macro-average metrics were then obtained by taking the unweighted mean across all classes, whereas weighted-average metrics were computed by weighting each class-specific score by its support. To quantify statistical uncertainty, we additionally report bootstrapped 95% Confidence Intervals (CIs) for the primary evaluation metrics using 10,000 resampling iterations with replacement.
Results
This section reports NeurALLNet’s diagnostic performance, external generalization, computational efficiency, ablation behavior, visual interpretability, and robustness under common image perturbations.
Classification performance
The classification performance of NeurALLNet was evaluated on the held-out primary test set containing 326 images. The model demonstrated strong generalization capability with a raw test accuracy of 98.16% (95% CI: [0.9663, 0.9939]) and a test loss of 0.0938.
Exact metrics and bootstrapped 95% confidence intervals on the primary test set.
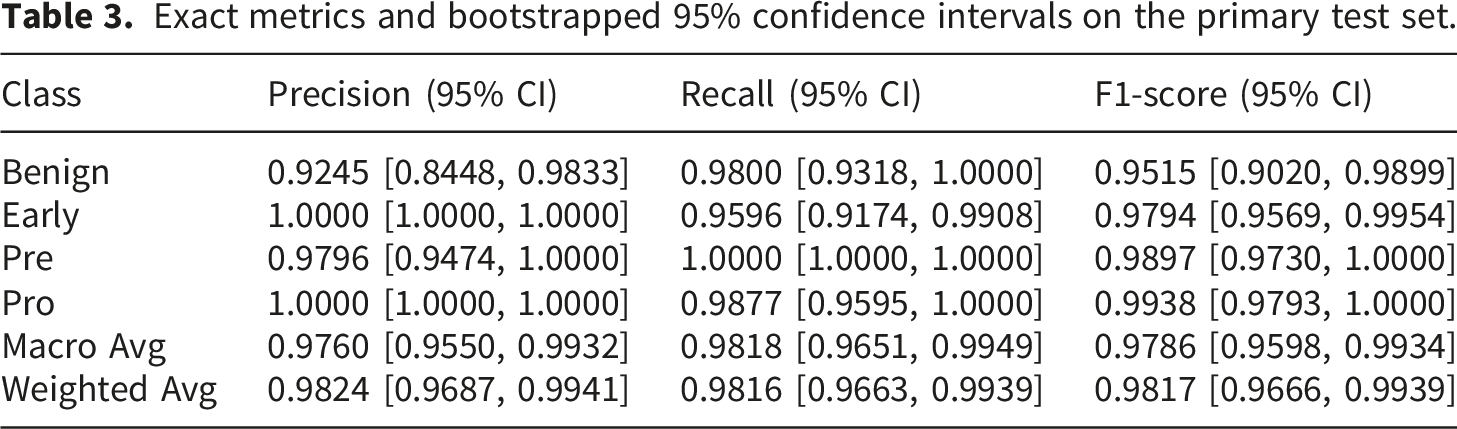
In every category, the model consistently performs well. No Pre cases were misclassified, as evidenced by the remarkable perfect recall of 1.0000 (95% CI: [1.0000, 1.0000]; 96/96 correctly classified samples). The Early class also demonstrated high sensitivity in identifying early-stage ALL cases, exhibiting a precision of 1.0000 (95% CI: [1.0000, 1.0000]), which indicates zero false positives for this sensitive category during bootstrap variations. Furthermore, Figure 2 illustrates the training and validation loss and accuracy over the 20 epochs, confirming stable convergence and effective learning dynamics without significant overfitting. Training and validation loss and accuracy over 20 epochs. The convergence curves demonstrate stable learning dynamics and effective generalization without significant overfitting.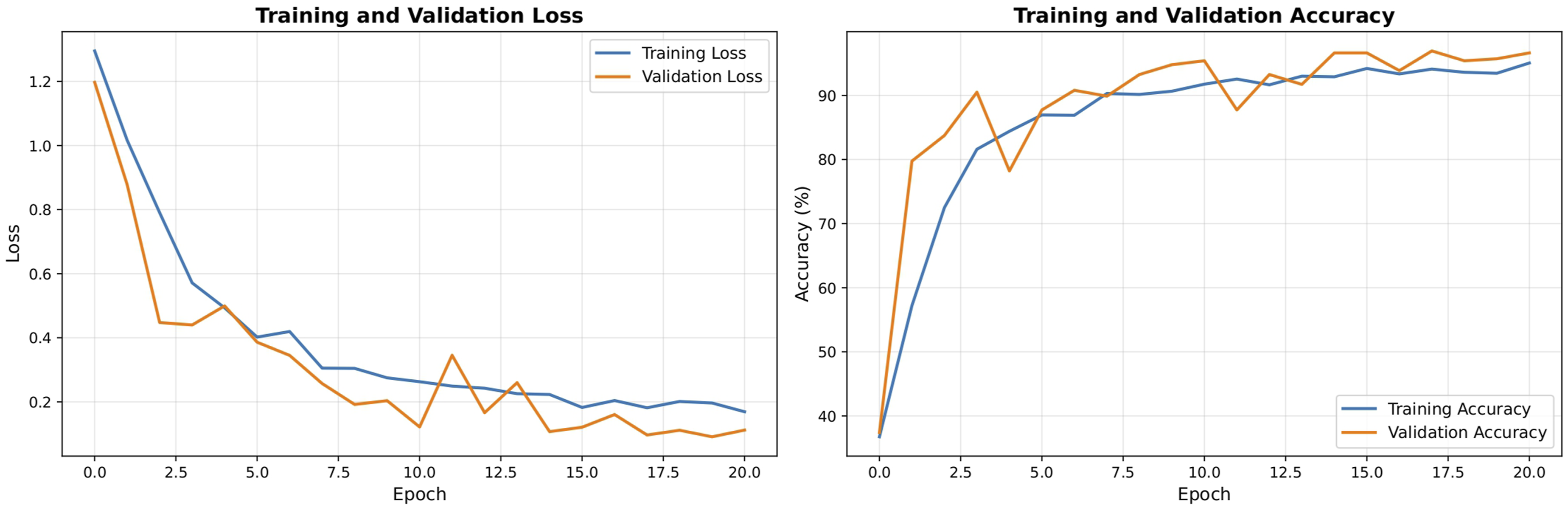
The confusion matrix for the test set is shown in Figure 3. The matrix confirms strong class-wise discrimination by showing that the vast majority of predictions fall along the main diagonal. While four Early cases were incorrectly identified as Benign, resulting in false negatives, the overall false negative rate remains remarkably low. Improved feature regularization or class-aware loss functions could be explored in future research to further minimize these borderline misclassifications. Confusion matrix of the proposed NeurALLNet model on the test set.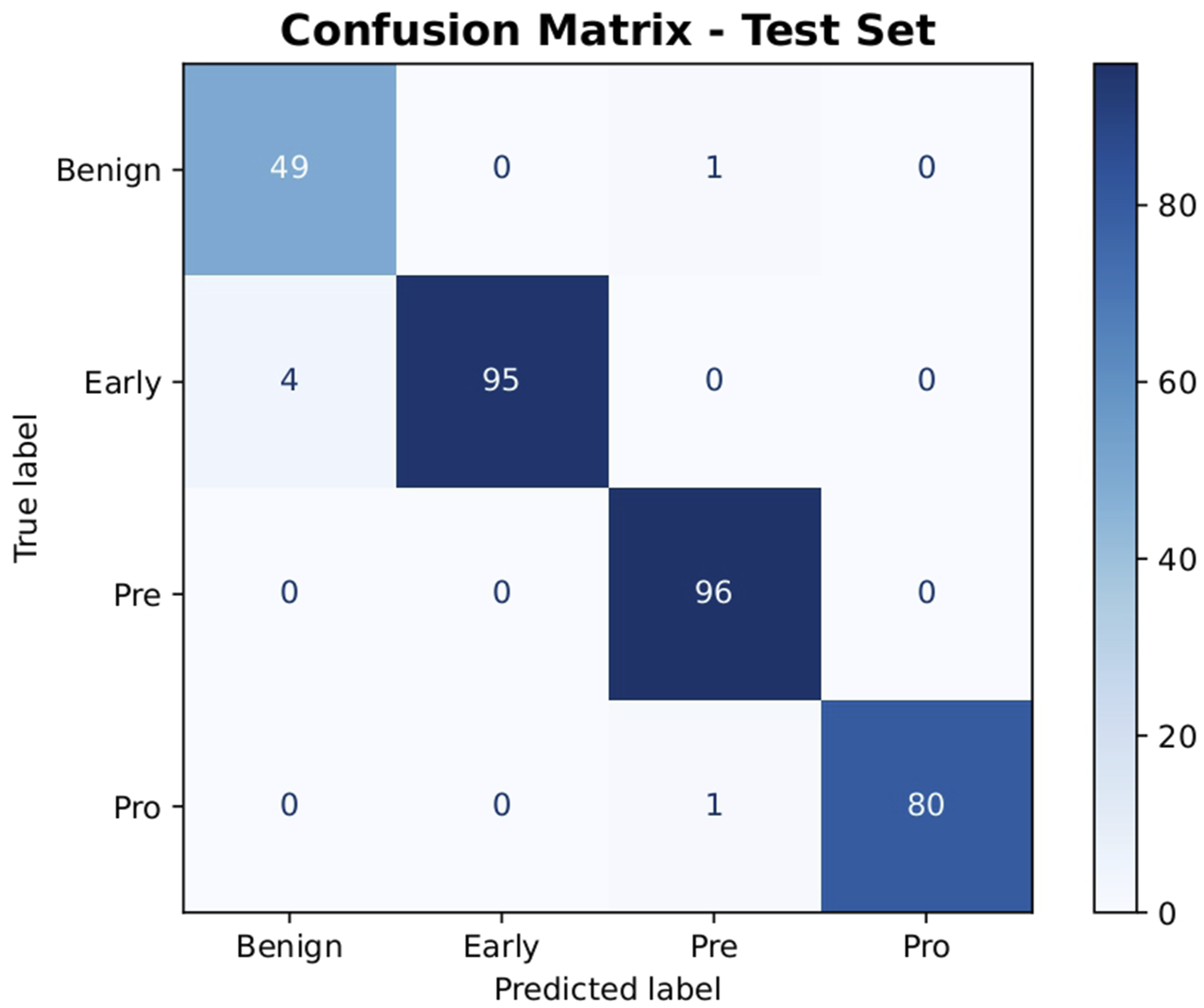
External validation
To ensure the robustness and generalizability of NeurALLNet across different clinical imaging conditions, we evaluated the trained model directly on a completely unseen external dataset containing 3,242 samples. This dataset was sourced from a distinct multicenter study by Hosseini et al., 31 which compiled peripheral blood smear images from multiple hospitals in Tehran, Iran. The external cohort captures inherent clinical heterogeneity, as the images were acquired using various standard laboratory microscopes and camera configurations following routine clinical staining protocols. Crucially, the diagnostic label taxonomy of this external cohort perfectly aligned with our internal Taleqani Hospital dataset. The external cases mapped directly onto our four target classes (Benign, Early Pre-B, Pre-B, and Pro-B ALL), meaning no complex label harmonization or data preprocessing was required to reconcile the two datasets. NeurALLNet was evaluated on this external cohort strictly in its original state, without any fine-tuning, retraining, or domain adaptation.
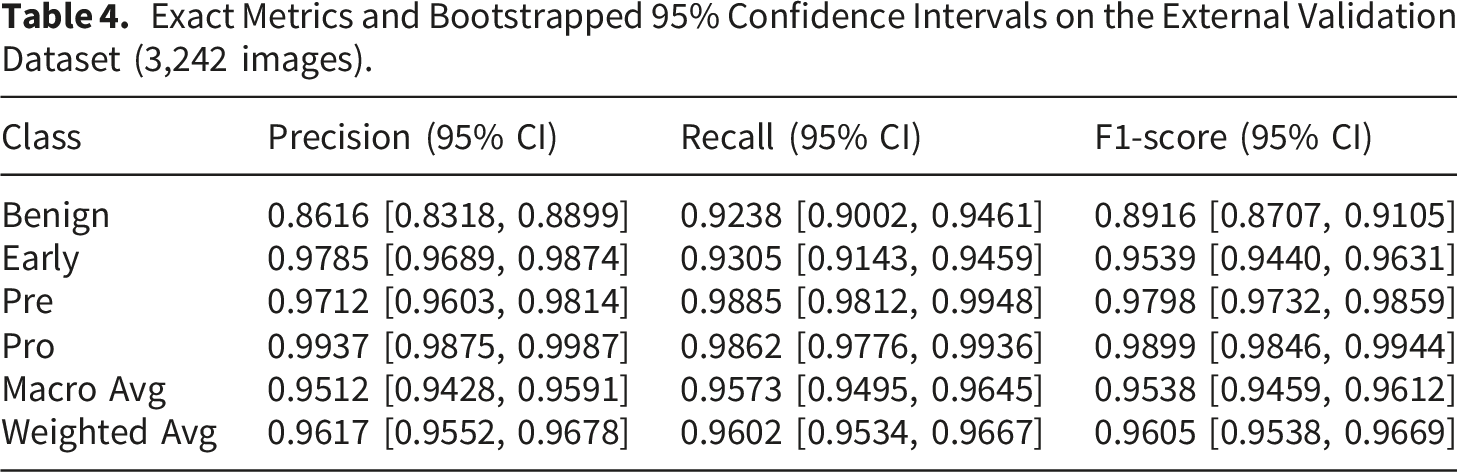
Exact Metrics and Bootstrapped 95% Confidence Intervals on the External Validation Dataset (3,242 images).
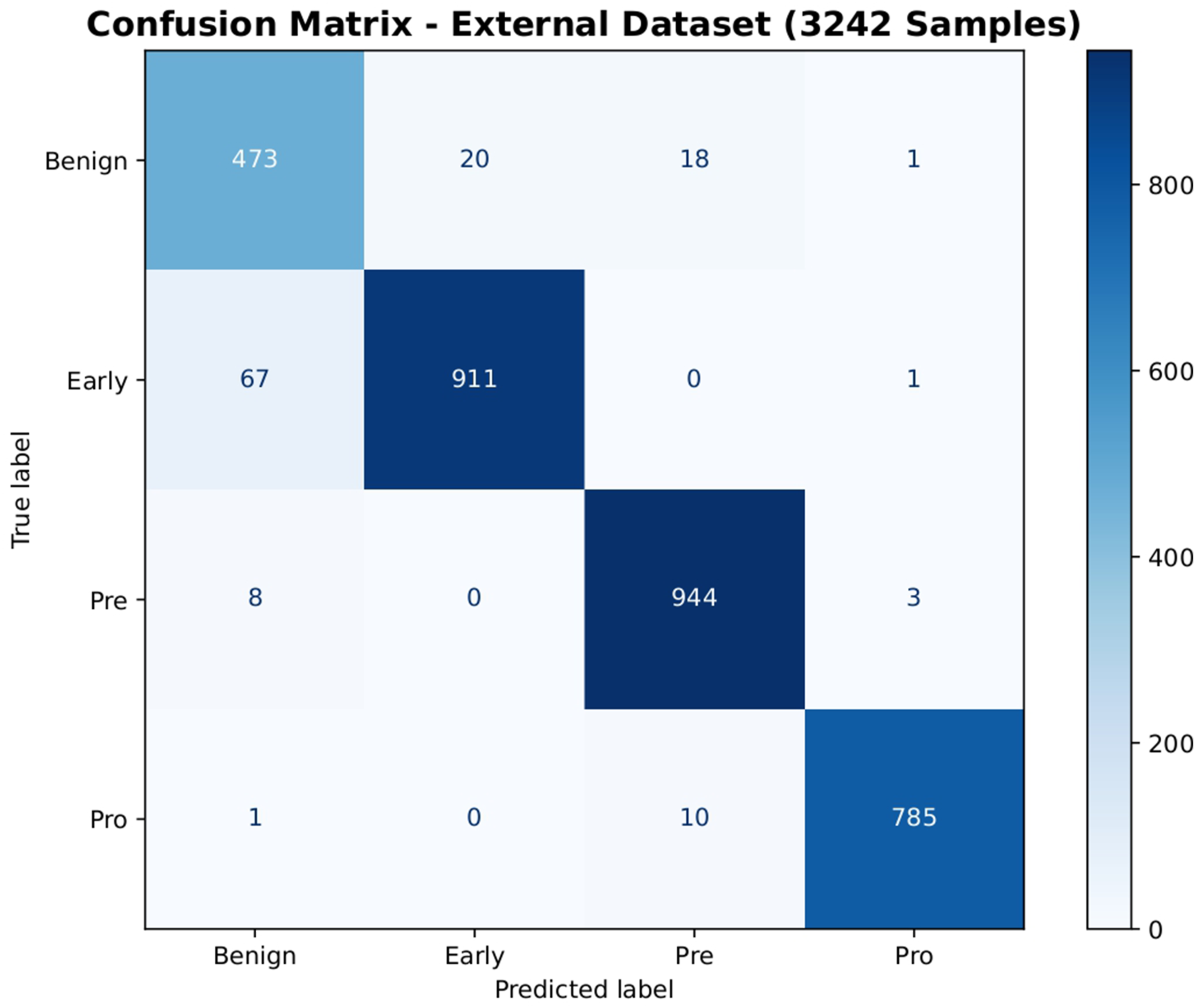
Confusion matrix of the NeurALLNet model on the unseen external validation dataset (3,242 samples), demonstrating high generalization capability without retraining.
Efficiency and computational performance
To validate the deployment viability of NeurALLNet in resource-constrained environments, such as rural clinics operating on edge devices, we benchmarked the computational footprint of the network across both CPU (single-thread execution) and GPU platforms.
The network requires only 336,544 parameters, translating to a highly compact model size of just 1.35 MB at FP32 precision. Inference on a single image over T = 4 time steps requires a mean latency of 11.24 ms on the GPU and 454.67 ms on the CPU. While a ∼455 ms CPU latency may bottleneck high-framerate live-feed video analysis, it is highly acceptable for the automated evaluation of static peripheral blood smear slides, where localized fields of view are processed sequentially. For future edge deployments requiring strictly sub-100 ms CPU latencies, standard model optimization techniques such as INT8 quantization could be readily applied. Under maximum batch loading, throughput scaled to 185.2 images per second on the GPU. These hardware profiling results, including the single-image inference latency distribution and throughput scaling across varying batch sizes, are visually summarized in Figure 5. Hardware profiling of NeurALLNet. The left panel shows the single-image inference latency distribution, while the right panel illustrates throughput scaling across different batch sizes.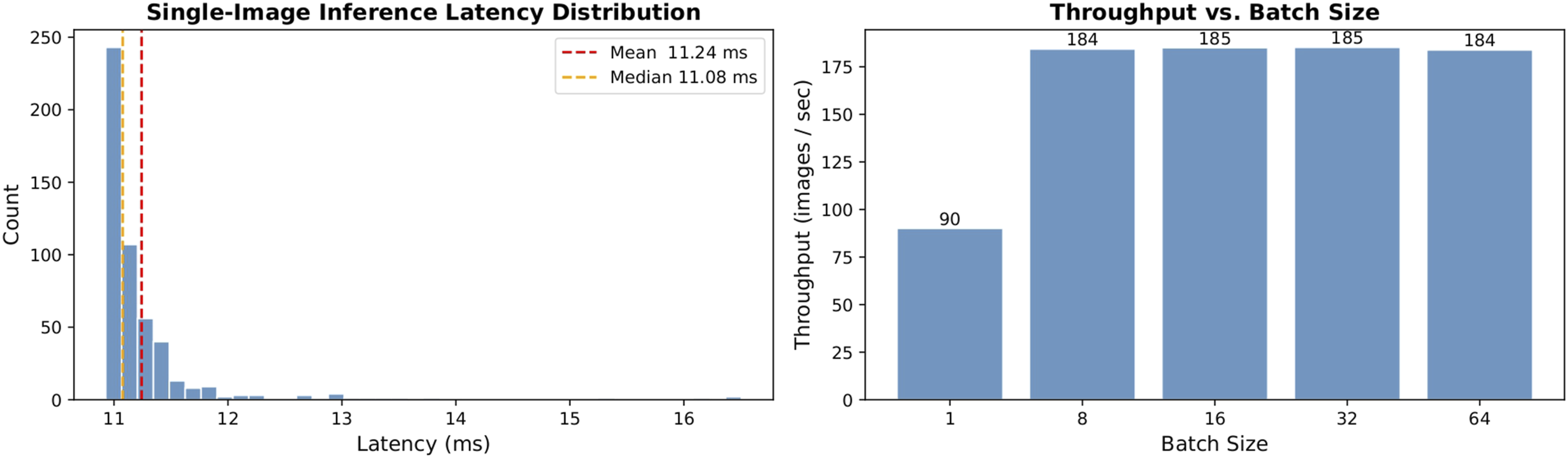
Crucially, memory footprint measurements indicated a peak allocated GPU memory of only 171.83 MB. On the CPU, the delta process RAM during inference was approximately 53.5 MB. While our current computational benchmarking was conducted in standard CPU and GPU environments, these highly compact memory metrics strongly align with the theoretical hardware constraints of mobile embedded systems and microcontrollers. This suggests a strong potential for future Lab-on-a-Chip integration, where conventional CNNs typically fail due to thermal limits and memory bottlenecks. To definitively confirm real-world edge deployment readiness, future work will necessitate direct hardware profiling of the NeurALLNet architecture on target embedded hardware, such as ARM-based microprocessors and dedicated neuromorphic accelerators.
Ablation study
Ablation study results showing the impact of architectural modifications on classification performance.
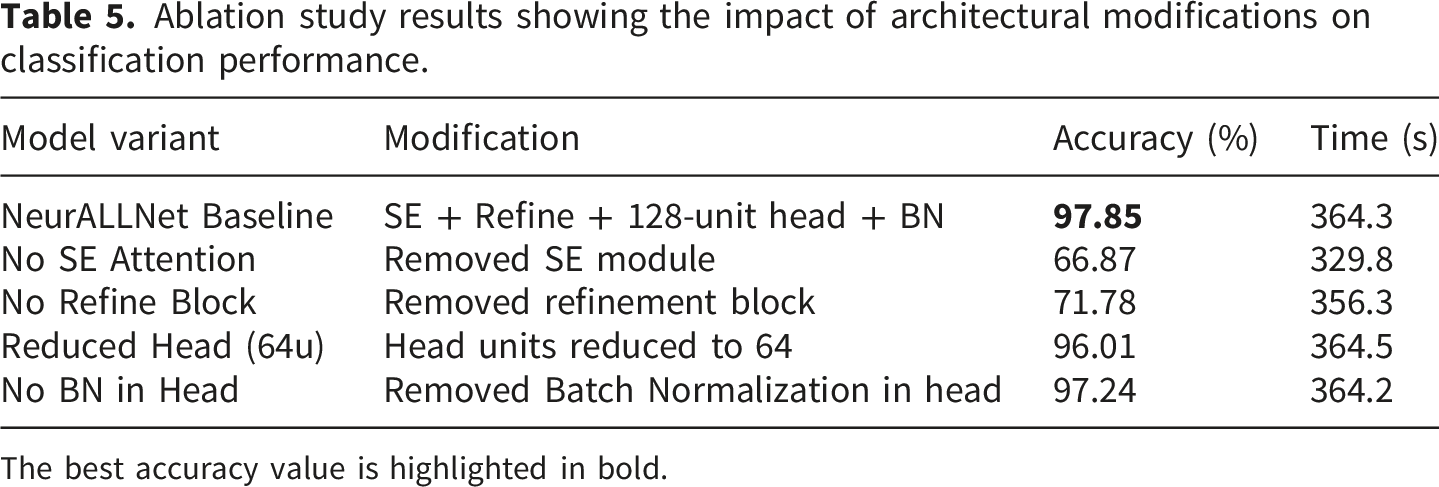
The best accuracy value is highlighted in bold.
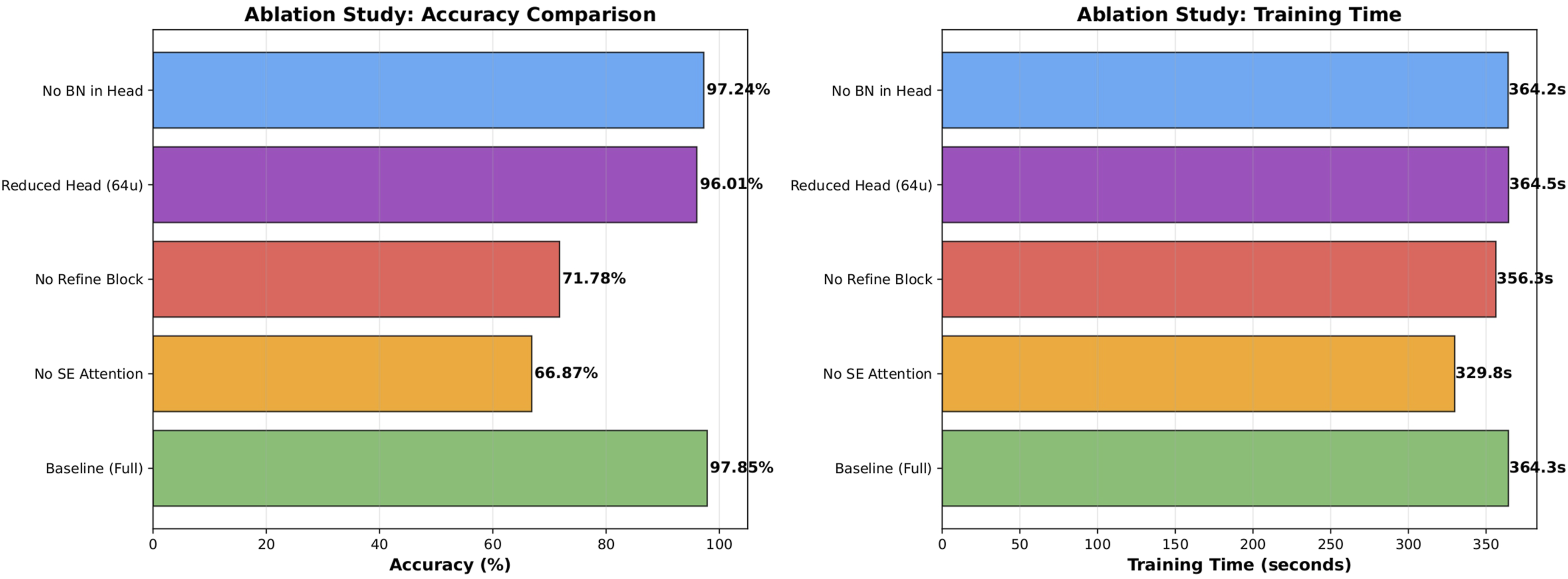
Ablation study results illustrating the critical impact of the Squeeze-and-Excitation (SE) attention module and refinement block on overall accuracy and training time.
As shown in Table 5, the full baseline configuration achieves the highest classification accuracy, confirming the effectiveness of integrating both the SE attention mechanism and the refinement block. The most significant performance degradation occurs when the SE module is removed, where accuracy drops sharply to 66.87%. This substantial decline highlights the critical importance of channel-wise attention in adaptively recalibrating feature responses across temporal spiking steps, acting as a primary driver of the model’s discriminative capacity. Removing the refinement block also results in a considerable decrease in accuracy to 71.78%, demonstrating that the additional depthwise separable convolution and spiking transformation meaningfully enhance high-level feature representations prior to classification.
In contrast, reducing the classifier head size and removing Batch Normalization cause only marginal performance drops. This indicates that the backbone feature extraction and attention mechanisms contribute far more significantly to overall performance than minor modifications in the classifier design. The combined integration of these structural enhancements yields the optimal balance between accuracy and efficiency.
Visual explanations
To enhance the interpretability of the proposed spiking neural network, Grad-CAM visualizations were generated for each class. Specifically, we targeted the final pointwise convolutional layer within the refinement block (mapping 384 to 256 channels) immediately preceding the global average pooling layer. Since spiking neurons rely on surrogate gradients during backpropagation, the visualization pipeline was carefully adapted to ensure reliable gradient flow. This was achieved by temporarily forcing the model into training mode to activate the Arctangent surrogate gradient, while keeping all Batch Normalization layers strictly in evaluation mode to maintain stable statistics for single-sample inference. Crucially, rather than utilizing sub-threshold membrane potentials, the visual explanations were derived from the direct spatial output activations of the targeted convolutional layer. Because NeurALLNet processes information over T = 4 discrete time steps, we captured the activations and their corresponding gradients at each independent step. Temporal fusion was then performed by averaging (computing the mean) the gradients and activations across the temporal dimension. Following this aggregation, global average pooling was applied to the temporally averaged gradients to compute channel-wise importance weights, which were subsequently combined with the averaged activation maps to produce the final class-specific localization heatmaps.
The resulting Grad-CAM maps, presented in Figure 7, consistently demonstrate that the model concentrates on biologically meaningful regions of the microscopic images, particularly around the cell nucleus and the boundary between the nucleus and the cytoplasm. For the Benign class, attention is distributed across well-defined nuclei with regular morphology, whereas for Early and Pre stages, the heatmaps intensify around enlarged or morphologically irregular nuclei. In the Pro class, the model focuses strongly on dense nuclear regions and abnormal chromatin structures, reflecting advanced pathological characteristics. Importantly, the attention regions align with clinically relevant morphological cues rather than background artifacts, providing strong visual evidence that NeurALLNet learns discriminative cellular structures rather than spurious correlations. Grad-CAM visual explanations for each ALL diagnostic class. The heatmaps (overlaid on the original images) confirm that NeurALLNet focuses on clinically relevant morphological features, such as abnormal chromatin structures and enlarged nuclei, rather than background artifacts.
Robustness analysis
To assess the practical robustness of the proposed model under real-world perturbations, we conducted a comprehensive evaluation on the held-out test set using the best-performing checkpoint. The analysis encompassed noise-based distortions (additive Gaussian noise, salt-and-pepper noise, and Gaussian blur), structural transformations (random occlusion and in-plane rotation), and systematic light intensity variations. Crucially, these synthetic perturbations were selected to mathematically proxy the physical acquisition challenges common in clinical hematology workflows. Specifically, Gaussian blur simulates focus drift during rapid slide scanning; additive Gaussian and salt-and-pepper noise approximate sensor artifacts and image compression degradation during telepathology transmission; occlusion mimics slide preparation artifacts such as stain precipitates or overlapping cellular debris; and systematic light intensity variations reflect instability in microscope illumination or inconsistent smear thickness.
Results indicate a clear dichotomy in resilience patterns. Under low-level Gaussian noise (σ2 = 0.01), performance remained stable; however, accuracy declined sharply as variance increased. Salt-and-pepper noise produced severe degradation even at low corruption levels, reflecting a high sensitivity to impulse perturbations. Similarly, Gaussian blur substantially impaired classification accuracy, particularly at higher sigma values, underscoring the model’s reliance on high-frequency spatial details and edge information. Figure 8 visualizes the model’s varying resilience under these structural and noise perturbations. Model resilience under various structural and noise perturbations, including Gaussian noise, salt-and-pepper noise, occlusion, and rotation.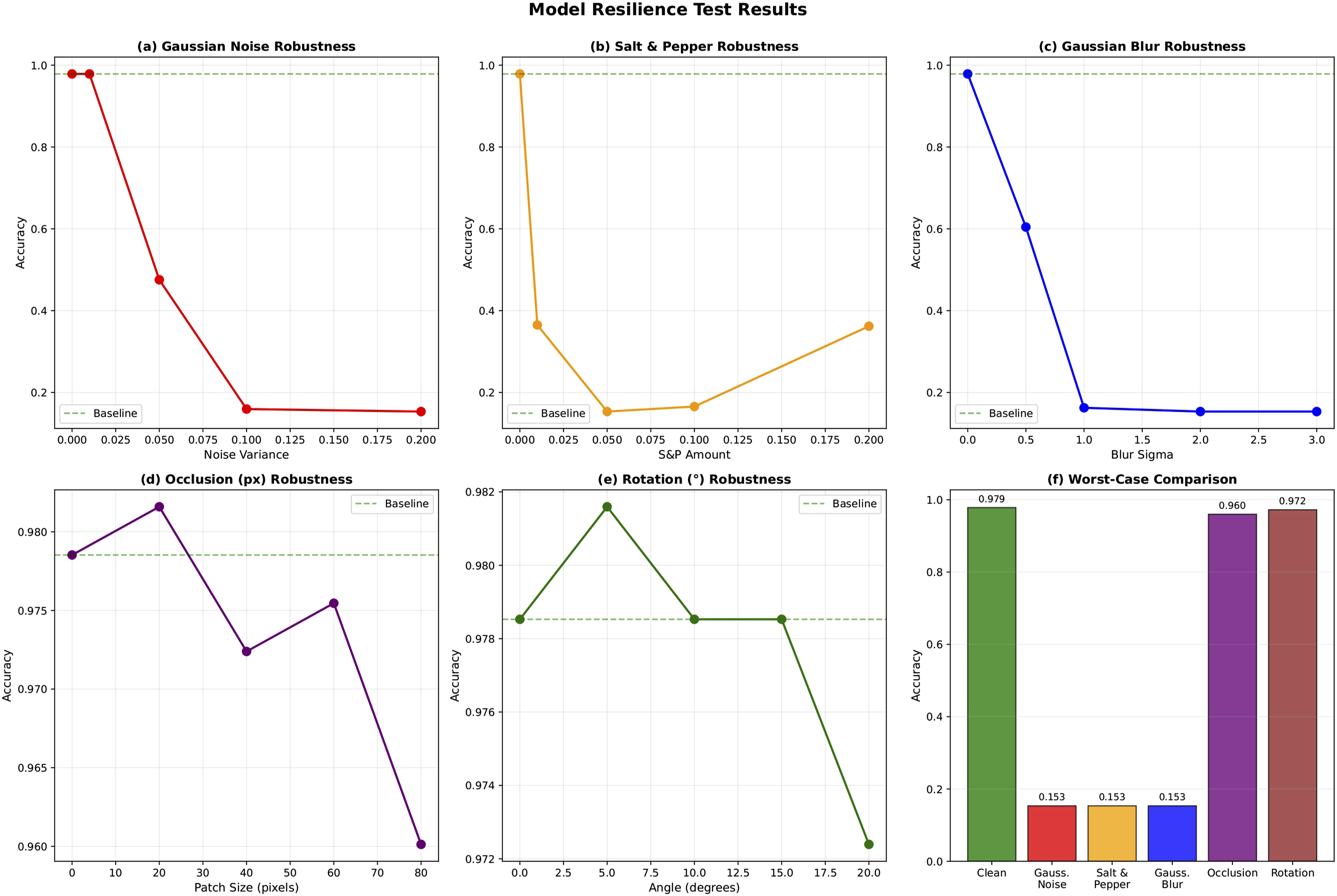
In contrast, robustness to structural distortions was notably strong. Occlusion of up to 25% of the input area resulted in only a minor reduction in accuracy, and smaller occlusions occasionally yielded marginal improvements, possibly due to implicit regularization effects. Rotational perturbations within ± 20° preserved accuracy above 97%, suggesting effective capture of spatial relationships and moderate transformation invariance.
Illumination variation experiments revealed pronounced asymmetry in tolerance to brightness changes. While moderate brightening led to a manageable decrease, reductions in brightness caused substantial degradation. Extreme lighting conditions confirmed limited resilience, with accuracy remaining well below baseline levels. The performance degradation under these systematic light intensity variations is detailed in Figure 9, which clearly highlights the model’s asymmetric sensitivity to image darkening and the necessity for standardized illumination preprocessing in clinical deployment. Performance degradation under systematic light intensity variations, highlighting the asymmetric sensitivity to image darkening.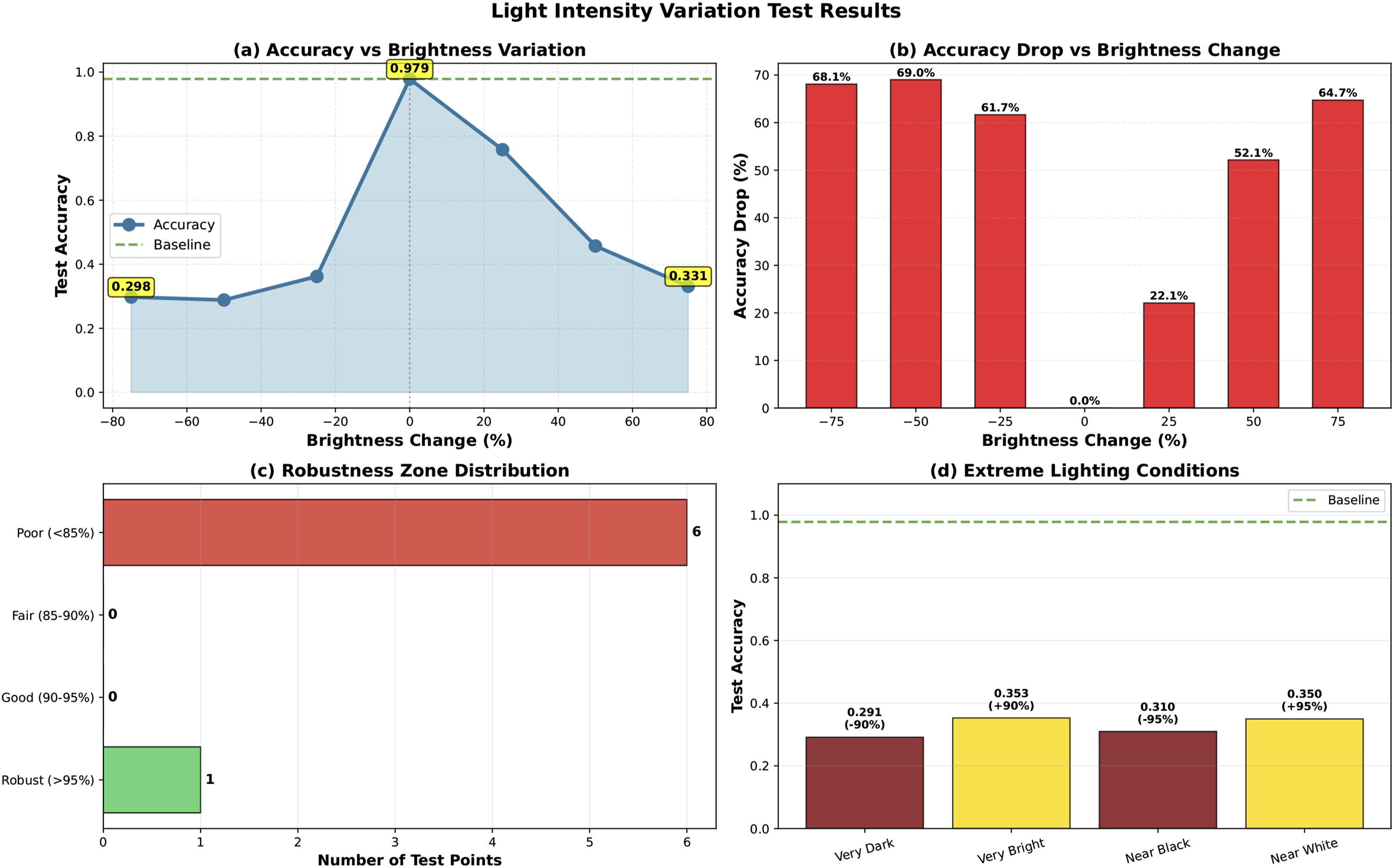
Comparison with the state-of-the-art
Comparison of NeurALLNet with recent state-of-the-art models on the Taleqani Hospital ALL dataset.
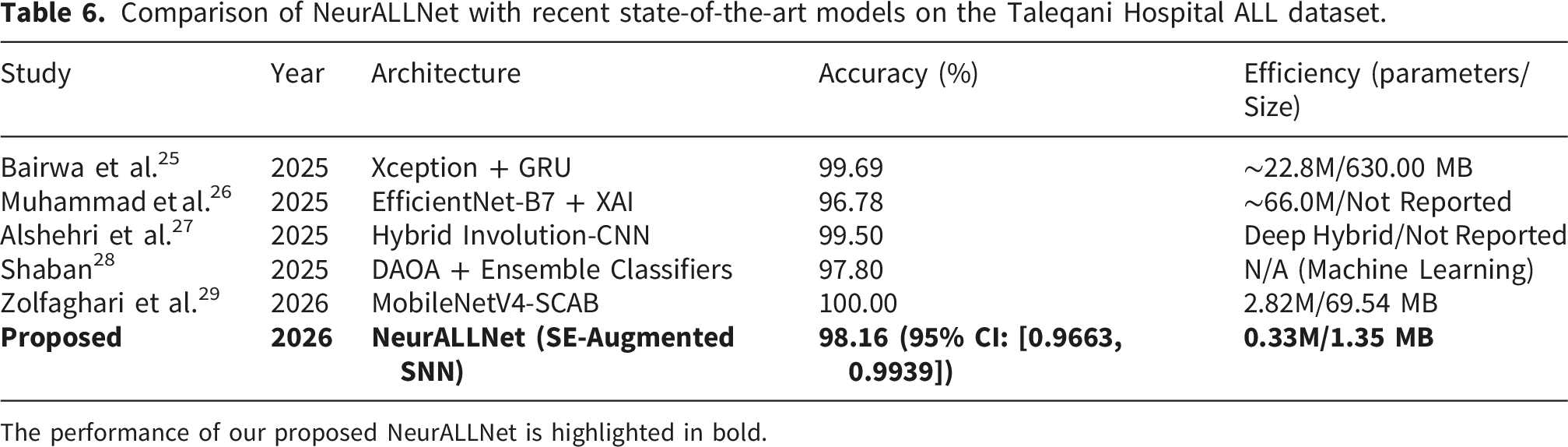
The performance of our proposed NeurALLNet is highlighted in bold.
It is important to emphasize that these comparisons are approximate. Because the underlying studies employ varying data partitioning strategies (sometimes reporting best-case split performance rather than standard cross-validation), differing augmentation pipelines, and distinct preprocessing protocols, this juxtaposition cannot serve as a strictly controlled, head-to-head leaderboard. Rather, this comparison is intended primarily to contextualize the efficiency-accuracy trade-off, demonstrating the viability of ultra-lightweight SNN architectures in a diagnostic domain currently dominated by massive computational networks.
While recent models achieve excellent accuracy, they overwhelmingly rely on massive architectures with extreme memory requirements. For instance, Bairwa et al. 25 reported 99.69% accuracy using an Xception + GRU framework; however, this model requires 630 MB of memory and over 22 million parameters. Similarly, Muhammad et al. 26 utilized EfficientNet-B7, a massive architecture with approximately 66 million parameters, to reach 96.78% accuracy. Zolfaghari et al. 29 introduced the MobileNetV4-SCAB model, attaining up to 100.00% accuracy on specific splits, yet still demanding 2.82 million parameters and a 69.54 MB footprint. Alshehri et al. 27 proposed a complex hybrid involutional-convolutional network yielding 99.50% accuracy, while Shaban 28 achieved 97.80% accuracy using computationally expensive manual feature extraction paired with ensemble machine learning classifiers.
In stark contrast, our proposed NeurALLNet delivers a highly competitive 98.16% accuracy (95% CI: [0.9663, 0.9939]) using only 336,544 parameters, which translates to an ultra-compact model size of just 1.35 MB. This represents a substantial improvement in parameter efficiency, delivering state-of-the-art classification fidelity with less than 2% of the memory footprint of lightweight models such as MobileNetV4-SCAB, and a fraction of a percent compared to Xception or EfficientNet ensembles. Such aggressive optimization proves that diagnostic precision does not have to be sacrificed for efficiency, satisfying the key requirements for deploying AI-driven hematological diagnostics to resource-limited clinics and mobile edge devices.
Discussion
A central contribution of this work is demonstrating that high diagnostic accuracy need not come at the cost of computational tractability. While recent state-of-the-art models evaluated on the same clinical dataset achieve accuracies between 96.78% and 100.00%, they overwhelmingly rely on massive architectures. Examples include EfficientNet ensembles or complex hybrid involutional networks requiring up to 66 million parameters.26,27 Even lightweight benchmarks such as MobileNetV4 require over 2.8 million parameters. 29 In stark contrast, the proposed NeurALLNet achieves a highly competitive test accuracy of 98.16% (95% CI: [0.9663, 0.9939]) with approximately 0.3M trainable parameters. This represents a parameter reduction of over 88% compared to the lightest recent benchmark and over 99% compared to heavy ensembles, effectively delivering competitive ALL subtype discrimination at a fraction of the standard model footprint. Furthermore, our external validation on a completely independent cohort of 3,242 images yielded an accuracy of 96.02% (95% CI: [0.9534, 0.9667]), proving that the architecture generalizes exceptionally well across varying clinical environments without retraining.
The efficiency gain is attributable to three complementary design choices: depthwise separable convolutions, 48 which decouple spatial and channel-wise filtering to reduce the parameter cost; the Squeeze-and-Excitation attention module, 41 which channels representational capacity toward diagnostically relevant features; and the LIF-based spiking mechanism.16,17 Unlike conventional CNNs that rely on energy-intensive Multiply-Accumulate (MAC) operations for continuous-valued spatial activations, NeurALLNet’s LIF neurons communicate via discrete, binary spikes. This event-driven paradigm fundamentally shifts the computational burden from MACs to significantly cheaper Accumulate (AC) operations, commonly referred to as Synaptic Operations (SOPs), which are executed only when a spike is generated. By leveraging this temporal and spatial spike sparsity across our T = 4 integration window, the network minimizes dynamic power consumption. While our empirical hardware profiling reflects execution on standard von Neumann architecture (CPU/GPU), mapping this sparse, binary computation onto dedicated neuromorphic hardware theoretically translates to an order-of-magnitude reduction in active energy footprint relative to equivalent CNN baselines. This distinction underscores that NeurALLNet is not merely a structurally lightweight model, but a fundamentally different, energy-aware computational paradigm. The ablation study results reinforce this interpretation: removing the SE module alone caused a 30-percentage-point accuracy collapse. Together, these results suggest that the efficiency-accuracy trade-off can be substantially mitigated through principled attention-guided design in the spiking domain.
Despite its strong overall performance, the model exhibits pronounced sensitivity to reductions in image brightness. Accuracy remained manageable under moderate brightening (+25%: 75.77%) but degraded sharply under darkening conditions, falling to 36.20% at −25% brightness. This asymmetric response is consistent with the model’s reliance on high-frequency spatial details and morphological edge information to discriminate between ALL subtypes, features that are progressively attenuated as illumination decreases. In practical haematology settings, particularly in resource-constrained clinics where microscope light sources may degrade or lack standardization, lighting inconsistency is a common challenge. 49 From a clinical safety perspective, this asymmetric sensitivity necessitates strict safeguards before edge deployment. We recommend that real-world diagnostic pipelines incorporate automated image quality assessment (IQA) to flag severely under-illuminated smears for manual review prior to model inference. Furthermore, remediation strategies such as Contrast-Limited Adaptive Histogram Equalisation (CLAHE) 50 should be integrated as a fixed, mandatory preprocessing step to normalize luminance distributions, 21 acting alongside aggressive photometric augmentation during training to ensure reliable, illumination-invariant representations.
A notable limitation of our experimental design relates to the provenance and partitioning of the datasets. First, while the primary dataset 47 (sourced from Taleqani Hospital) and the external validation cohort 31 (sourced from multiple Tehran hospitals) represent distinct, peer-reviewed collections, both originate from the same city. Although this provides a stringent test of generalizability across different local clinics, we cannot entirely rule out the theoretical possibility of shared institutional sample preparation protocols or minor patient overlap. Future validation on geographically diverse, international cohorts is recommended to definitively confirm cross-institutional generalizability. Second, because patient-level metadata was not provided by the creators of the primary dataset, our training, validation, and test splits were necessarily image-based rather than patient-based. While this is a recognized constraint in retrospective open-source medical imaging studies, it introduces a theoretical risk of performance inflation due to the potential leakage of patient-specific morphological features or slide-preparation artifacts across the data splits.
Beyond raw accuracy, the clinical value of any diagnostic model is ultimately determined by where it can be deployed. At approximately 0.3M parameters, NeurALLNet is natively compatible with a broad class of low-power embedded platforms. Our hardware profiling confirms a highly compact model size of just 1.35 MB (FP32), requiring a mean single-image inference latency of 454.67 ms on a standard CPU and 11.24 ms on a GPU, with a peak GPU memory allocation of only 171.83 MB. This positions the architecture as a genuine candidate for integration into Lab-on-a-Chip diagnostic devices: compact, portable instruments that combine microscopic imaging, automated cell preparation, and computational classification into a single handheld unit. 32 Because these point-of-care workflows typically evaluate static blood smear captures rather than high-framerate live video, the ∼455 ms CPU latency remains practically viable. Furthermore, applying post-training quantization (e.g., INT8) could further compress the model footprint and accelerate CPU inference times for next-generation portable devices, although recent work on edge-based malaria microscopy shows that quantization alone does not ensure adversarial robustness or clinical safety under targeted attacks. 51 The broader clinical relevance of this design philosophy is reinforced by recent lightweight explainable AI work in cardiometabolic triage, where clinically interpretable models achieved millisecond-scale inference and kilobyte-scale storage requirements without specialized hardware. 52 Such systems have transformative potential in resource-limited settings,3,13 allowing rural clinics to perform on-site ALL classification from a peripheral blood smear without cloud connectivity or specialist hardware.
Conclusion
This study presented NeurALLNet, a memory-efficient convolutional spiking neural network augmented with Squeeze-and-Excitation channel attention for the multi-class classification of Acute Lymphoblastic Leukemia subtypes from peripheral blood smear images. Trained on a balanced partition of the publicly available ALL image dataset, the proposed architecture achieved a test accuracy of 98.16% (95% CI: [0.9663, 0.9939]) and maintained a highly robust external validation accuracy of 96.02% (95% CI: [0.9534, 0.9667]) on an unseen external validation cohort of 3,242 images. Operating with approximately 0.3M trainable parameters, the model requires only 1.35 MB of memory. This achieves CPU and GPU inference latencies well within the requirements for real-time point-of-care diagnostics while reducing the parameter footprint by orders of magnitude compared to recent state-of-the-art deep learning architectures.
The ablation study demonstrated that the SE attention mechanism is the single most influential architectural component, underscoring the critical role of adaptive channel-wise recalibration in the spiking domain. Grad-CAM visualisations confirmed that the model’s predictions are guided by biologically meaningful morphological cues rather than spurious background correlations. While the robustness analysis identified strong resilience to structural distortions, it also revealed sensitivity to severe illumination reduction, motivating targeted preprocessing strategies in future deployments.
The broader implication of this work is that spiking neural networks are no longer constrained to neuromorphic computing benchmarks or generic vision datasets. Critically, this work demonstrates that the integration of attention mechanisms into the spiking domain is not merely additive; it is transformative, enabling compact SNN architectures to overcome the accuracy gap that has historically limited their clinical adoption. As global health systems increasingly demand diagnostic tools that are accurate, affordable, portable, and energy-efficient, attention-augmented SNNs represent a compelling and timely design paradigm for digital health interventions.
Supplemental material
Supplemental material - NeurALLNet: An attention-based spiking neural network for energy-efficient multi-class classification of acute lymphoblastic leukemia
Supplemental material for NeurALLNet: An attention-based spiking neural network for energy-efficient multi-class classification of acute lymphoblastic leukemia by Md Rafsan Hassan, Rejaul Islam Shanto, Umar Hasan, Sifat Momen in DIGITAL HEALTH
Footnotes
Ethical considerations
This study was conducted exclusively using previously published and anonymized secondary datasets. No new participant recruitment, intervention, or collection of identifiable personal information was performed. The original data collection procedures were conducted in accordance with the Declaration of Helsinki and approved by the Iran National Committee for Ethics in Biomedical Research (Primary dataset Approval ID: IR. SBMU.RETECH.REC.1399.735 47 ; External dataset Approval ID: IR. SBMU.RETECH.REC.1400.591 31 ). As the present study involved only the secondary analysis of these de-identified and publicly available datdata, no additional institutional ethics approval or Institutional Review Board (IRB) waiver was obtained.
Author contributions
Funding
The authors received no financial support for the research, authorship, or publication of this article.
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Data Availability Statement
The datasets analyzed during the current study are publicly available. The primary dataset is available as described by Ghaderzadeh et al.
47
The external validation dataset is available as described by Hosseini et al.
31
To ensure full reproducibility of our results, the pre-trained weights of NeurALLNet and the complete source code, including model architecture definitions, training pipelines, and evaluation scripts, is publicly available on GitHub at ![]() .
.
Guarantor
Md Rafsan Hassan.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.