
Abstract
Generative artificial intelligence (AI) models will increasingly replace humans in producing output for a variety of important tasks. While much prior work has mostly focused on the improvement in the average performance of generative AI models relative to humans’ performance, much less attention has been paid to the significant reduction of variance in output produced by generative AI models. In this article, we demonstrate that generative AI models are inherently prone to the phenomenon of “regression toward the mean”, whereby variance in output tends to shrink relative to that in real-world distributions. We discuss potential social implications of this phenomenon across three levels—societal, group, and individual—and two dimensions—material and non-material. Finally, we discuss interventions to mitigate negative effects, considering the roles of both service providers and users. Overall, this article aims to raise awareness of the importance of output variance in generative AI and to foster collaborative efforts to meet the challenges posed by the reduction of variance in output generated by AI models.
Keywords
Introduction
Traditional artificial intelligence (AI) based on logical optimization algorithms will yield identical solutions given the same input conditions and is generally limited to certain well-defined tasks. The recent advent of generative AI models (Anthropic, 2023; Chowdhery et al., 2023; OpenAI, 2022, 2023; Touvron et al., 2023a), learned from large bodies of observed data, has fundamentally advanced the field by generating AI output within any specific, concrete context and thus allowing for heterogeneous solutions. This is particularly well illustrated in the case of chatbots equipped with large language models (LLMs), such as ChatGPT (Open AI, 2022), which attracted more than 100 million users in the first two months after its launch.
Before generative AI models become widely accepted as standard tools for performing tasks important to human society, it is essential that we understand and carefully evaluate the output of such models. While previous work has mostly focused on the improvement in the average performance of generative AI models relative to human performance (Guo et al., 2023; Klang and Levy-Mendelovich, 2023; Kung et al., 2023; Liu et al., 2023), much less attention has been paid to the significant reduction in the variance of the output produced by such models. In this article, we demonstrate that generative AI models are inherently prone to the phenomenon of “regression toward the mean”, whereby output variance tends to shrink relative to that in real-world distributions. We illustrate this problem with two simple empirical examples: the prediction of individual earnings in the USA and the generation of abstracts for scientific papers.
We consider this tendency of variance reduction in generative AI output to be a logical result of the essential tension between the need to improve average prediction quality and the necessary simplification of infinite real-life situations into finite data (albeit in enormous amounts) that generative AI models can learn and represent.
Following this, we explore the potential social implications of this phenomenon across three levels—societal, group, and individual—and two dimensions—material and non-material. Specifically, we emphasize four key aspects: (1) creativity and innovation; (2) stereotypes and statistical discrimination; (3) knowledge and information; and (4) individual identity. Finally, we explore potential interventions to mitigate these effects, considering the roles of both service providers and users. In summary, our objective is to alert researchers to the tendency of variance reduction in the output of generative AI and how it may impact society in order to raise awareness and contribute to the development of potential solutions.
Two examples illustrating variance reduction
We illustrate the phenomenon of variance reduction in the output of generative AI models with two examples. In both examples, we simulate real-life uses of generative AI models by providing prompts for certain tasks. In the first example, we ask ChatGPT to generate a numerical prediction of an American individual's income based on varying levels of sociodemographic information. In the second example, we ask ChatGPT to generate an abstract from inputs with varying levels of information. Both examples clearly show the tendency of regression toward the mean, or alternatively, the reduction of variance, in generative AI output.
Example 1: Numerical prediction
We begin with numerical prediction of income, a key indicator of economic well-being in American society. We examine distributions of individual-level incomes predicted by ChatGPT under varying input conditions and compare them with the actual observed distribution. For this exercise, we tasked ChatGPT with predicting person-specific 2004 income data for 6041 individual respondents in the sample of the National Longitudinal Survey of Youth 1979 (NLSY79) (Rothstein et al., 2019), using increasingly detailed individual information at each level: basic demographic information in Level 1, including age, race, and gender; the further addition of occupational information in Level 2; and the addition of past income data from 1994, 1996, 1998, 2000, and 2002 in Level 3.
We present the results in Figure 1(a). When only basic demographic information (Level 1) is used, the variance in the model's output is significantly less than that of the actual data. This occurs because all sample units sharing the same basic demographic characteristics are given essentially the same mean-centered responses under these conditions. Only when sufficient individual-level contextual information is provided, as in Levels 2 and 3, does the model begin to capture greater variance at the individual level. Although the output still regresses toward the mean in Levels 2 and 3, the combination of means across various conditions becomes more reflective of real-world variance as the conditions become more detailed and person-specific.
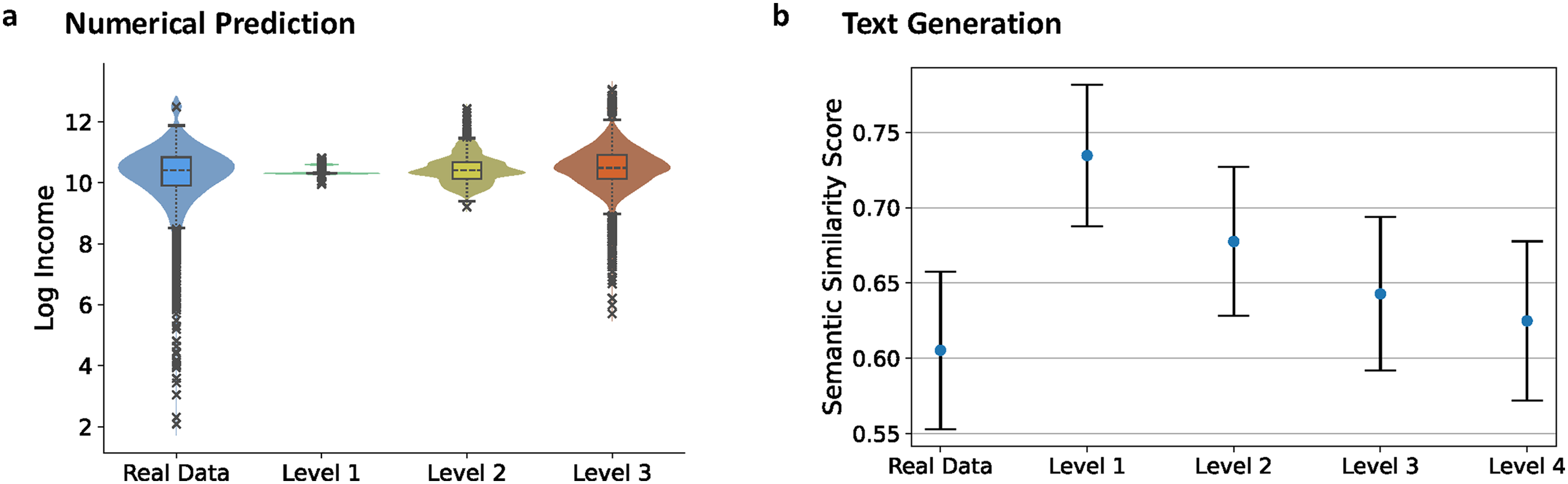
(a) Distributions of the logarithm of 2004 income for real-world data and ChatGPT-predicted data, conditioned on different levels of information in the National Longitudinal Survey of Youth 1979 dataset. (b) Means and standard deviations of semantic similarity scores for real-world data and ChatGPT-generated paper abstracts, conditioned on different levels of information from arXiv.
In general, these numerical results confirm the presence of a reduction of variance in the output of generative AI models.
Example 2: Text generation
For the second test, we turn to text generation. Although textual data lack a direct representation of mean and variance, we can assess diversity by examining semantic similarity between texts. Specifically, for each text, we use the Sentence-BERT model (Reimers, 2019) to generate its semantic vector and compute the average cosine distance between that vector and the vectors of all other texts in the corpus. We then compute the similarity score by averaging the average cosine distance across all texts, with a higher similarity score indicating greater semantic similarity and thus lower diversity within the corpus.
We randomly sampled 2000 scientific paper abstracts from the ArXiv dataset (Clement et al., 2019) and compared the diversity of the original data corpus with those of corpora regenerated by ChatGPT when varying the levels of input information. We used four levels of input information for abstract generation with ChatGPT: the subject of the article in Level 1; the title of the article in Level 2; a summary of the abstract in Level 3; and the full abstract in Level 4 with ChatGPT asked to refine it.
We present the results in Figure 1(b). We observe that only when the full abstract is provided does the diversity of the generated content approach that of real-world data. In contrast, the generated corpora exhibit diminishing diversity (i.e. higher semantic similarity) at lower input levels, confirming the presence of regression toward the mean in text generation.
These findings suggest that when generative AI models such as LLMs are used for content creation without information-rich prompts, the output may lack the diversity and uncertainty typically associated with human generation.
Why does variance reduction occur in generative artificial intelligence output?
We consider variance reduction in generative AI output to be an inevitable result of a fundamental paradox in generative AI, with average accuracy being the main objective of such models.
A paradox in generative AI
One fundamental cause for the reduction of variance in generative AI output lies in the paradox between the infinite heterogeneity of human phenomena and the finite data (albeit in enormous amounts) that generative AI models can learn from and represent.
There are good reasons to believe in irreducible variability, that is, infinite heterogeneity, at the individual level for almost all human phenomena (Xie, 2013). Such variability may originate from either nature—gene-based biological differences that give rise to evolution (Darwin et al., 1859; Mayr, 1982)—or nurture—social situations (Galton, 1889) where individuals face different environments, such as the family, neighborhood, social network, and have different accumulative life-course experiences.
In contrast, the capabilities of generative AI models are bound by design. Their objective is to extract generalizable patterns from a finite—albeit vast—amount of training data, aiming to approximate real-world distributions as effectively as possible for any given input. To enhance generalizability, this process inevitably abstracts away residual individual-level variability that lies outside the modeled distribution (Kandpal et al., 2023), leading model outputs to regress toward average patterns with reduced variance.
Average accuracy as the main objective
In addition to the inherent limitations posed by the capacity of generative AI models in representing real-life variance, commonly employed accuracy-oriented decoding strategies further amplify the phenomenon of variance reduction.
Consider the process of language modeling with AI model Mθ, where the task is to recursively predict the next token until the end of the sequence. Given the preceding context x, for each possible next token yi in the vocabulary, the model computes an unnormalized score zi. These scores are then converted into probabilities using the following softmax function:

During training, p
During decoding (inference), the model needs to sample one token for the exact predicted next token. Instead of sampling from this learned p
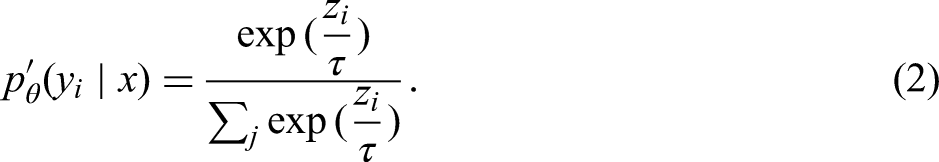
In practice, to achieve more stable average accuracy, the temperature τ is typically set between 0 and 1. For example, the default temperature for models like LLaMA (Touvron et al., 2023a, 2023b) is often configured to values below 1. A lower temperature reduces randomness in the output by concentrating the probability mass on the most likely tokens. In the extreme case, setting τ = 0 corresponds to greedy decoding, where the model always selects the token with the highest probability.
Building on this, many models further incorporate additional techniques such as top-p sampling (Holtzman et al., 2020) and top-k sampling (Fan et al., 2018). These methods restrict the sampling process to the most probable tokens based on a cumulative probability threshold (p) or a fixed number of top tokens (k), ensuring that the model generates frequently observed results.
All of these decoding strategies capitalize on high probabilities for generated results, thereby amplifying the variance reduction in AI-generative outputs. Although these approaches improve the stability of outputs, they come at the cost of sacrificing the diversity that AI models are capable of expressing.
Recovery of variance with fine-grained contexts
In the previous section, we discussed how variance reduction is an inevitable outcome of the capacity limitations of AI models and their primary focus on probabilistically accurate predictions. In this section, we demonstrate how refining user input contexts can increase between-context variance, thereby partially recovering the overall variance.
To directly analyze numerical variance under different levels of context granularity, we consider AI output Y to be a numerical prediction outcome. Nevertheless, the concept can be generalized to other types of AI generation. Suppose an input context c. We compare two possibilities, the original context c = c0 and a further differentiated context c ∈ C = {c1, c2, …, cn}, which collectively represent possible specific versions of c. We then examine how this refinement impacts the variance of output Y.
For the original context c0, the variance in output Y is formulated as Var(Y | c0). When the context is refined into a set of fine-grained contexts C, we treat c as a random variable taking values in C. The total variance of Y across these refined contexts can be decomposed as follows:
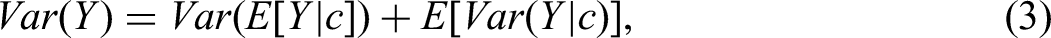
Refining c0 into C introduces heterogeneity across the specific contexts, as the expected values E[Y | c = c1], E[Y | c = c2], …, E[Y | c = cn] are likely to differ, contributing to a typically large between-context variance term, Var(E[Y | c ]). At the same time, fine-grained contexts typically result in a small increase in within-context homogeneity, leading to a reduction in the expected within-context variance, E[Var(Y | c)], relative to Var(Y | c0). However, this reduction is typically small and insufficient to counterbalance the increase introduced by the between-context variance. As a result, the total variance tends to increase with context refinement. This explains our empirical results that providing AI models with more fine-grained contexts leads to outputs with higher variance.
Social implications
We acknowledge that the social impact of reduced variance encompasses a wide range of issues, which cannot be exhaustively discussed in this article. As an illustration, we focus on several selected aspects that we consider particularly important. Of course, future research can extend our limited discussion to other topics.
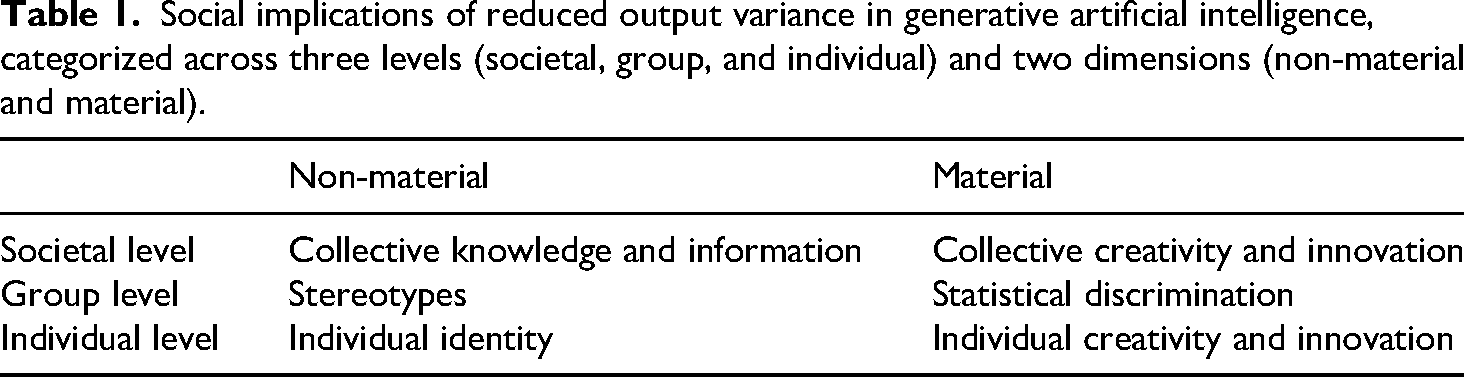
We organize our discussion of the social implications of reduced variance in output generated by generative AI according to three levels—societal, group, and individual—and two dimensions—material and non-material. The three levels correspond to distinct aspects of variance reduction: (1) the societal level: overall variance reduction in total distribution; (2) the group level: the compression of individual characteristics into group-level averages; and (3) the individual level: the loss of individual uniqueness due to an individual's characterization through parameterization. The material dimension emphasizes tangible outcomes such as creative output, innovation, and decision-making processes, whereas the non-material dimension primarily focuses on aspects such as opinions, values, preferences, and other intangible human attributes.
An overview of the discussion is provided in Table 1.
Social implications of reduced output variance in generative artificial intelligence, categorized across three levels (societal, group, and individual) and two dimensions (non-material and material).
Societal level
The reduction in output variance of generative AI can lead to a decline in overall diversity across various domains for a society as a whole. The potential negative impacts can be either non-material, involving collective knowledge and information, or material, involving collective creativity and innovation.
Collective knowledge and information
Collective knowledge and information refers to the shared repository of facts, concepts, perspectives, and cultural practices maintained within a human society. As generative AI becomes an increasingly mainstream tool for knowledge and information acquisition (Baidoo-Anu and Ansah, 2023; IBTimes UK, 2024; Lo, 2023), its inherent tendency toward variance reduction raises the possibility of narrowing this collective knowledge resource. Compared to traditional methods of information acquisition, generative AI increases the likelihood that individuals will encounter similar, homogenized narratives. This can discourage the exploration of less common or minority perspectives, limiting exposure to diverse viewpoints. As highlighted in prior work (Peterson, 2025), this trend risks suppressing long-tail information and progressively curtailing the richness of our shared knowledge compared to the broader breadth of historical knowledge.
Collective creativity and innovation
Variance is essential to fostering collective creativity and driving innovation in society. Research on functional diversity suggests that diverse groups often outperform teams composed solely of the highest-performing individuals (Burton et al., 2024; Hong and Page, 2004, 2012; Page, 2008). This is because high-performing individuals often have similar characteristics, which can limit the range of perspectives and solutions within the group. Generative AI models, while capable of producing highly accurate and effective ideas according to past experiences and accepted standards due to their training on vast datasets, generate outputs that are relatively homogeneous. As a result, individuals who rely heavily on these models tend to think “in a box” rather than “out of the box”, and their outputs are at risk of having a high degree of similarity to those of other “high-performing” contributors who are also relying on generative AI. When large numbers of people depend on the same AI models for creative tasks—such as idea generation, refinement, or decision making—there is a risk that, despite the model's high performance, this uniformity could reduce functional diversity among individuals, potentially stifling collective creativity and innovation at a societal level.
Group level
Secondly, the reduction in the output variance of generative AI leads to the compression of individual characteristics into group-level averages, which can further result in the reinforcement of group-level stereotypes, a non-material implication, and statistical discrimination, a material implication.
Stereotypes
A stereotype can be viewed as an oversimplified, or compressed average, representation of the (assumed) distribution of the characteristics of a group of people (Kanahara, 2006). Stereotypes can be associated with race/ethnicity, gender, occupations, and various demographic categories, potentially negatively impacting individuals in socially disadvantaged groups (Fiske et al., 2018; Spencer et al., 2016; Steele and Aronson, 1995). The variance reduction inherent in generative AI, which tends to suppress within-group variability and gravitate toward group-level average representations, can further reinforce existing stereotypes (Bianchi et al., 2023; Zhou et al., 2024). In language-based applications, LLMs are widely used for information retrieval and content generation (Xie et al., 2024; Zhao et al., 2023; Zhuang et al., 2023), yet their outputs can embed and perpetuate stereotypes when describing individuals (Abid et al., 2021; Ferrara, 2023; Gallegos et al., 2024; Kotek et al., 2023; Liu et al., 2024). For instance, gender biases in LLM-generated reference letters have been documented (Wan et al., 2023), with phrases like “Kelly is a warm person” and “Joseph is a role model” reflecting stereotypical gender associations. In multimodal applications, generative tools for audio, image, and video can “bring to life” content from textual descriptions (Croitoru et al., 2023; Goodfellow et al., 2020), but they also risk perpetuating stereotypes. For instance, research has shown that widely used text-to-image models often amplify demographic stereotypes: for example, prompts like “Ethiopian man with his house” consistently generate depictions focused on poverty, with little variation (Bianchi et al., 2023). As generative AI models become increasingly prevalent across these tasks, the risk of reinforcing group-level stereotypes and biases continues to grow, potentially exacerbating existing inequalities.
Statistical discrimination
Statistical discrimination is a material implication of the group-level stereotyping discussed above: for example, when such stereotyping informs the actions of employers. Consequential decision making based on group characteristics such as race, gender, or age, rather than individual attributes, can potentially result in systemic unfair treatment. Statistical discrimination can be illegal under certain circumstances (e.g. gender-based labor market discrimination) (Dickinson and Oaxaca, 2009). When generative AI is applied to decision making, variance reduction impairs the user's ability to evaluate individuals based on their unique characteristics, increasing the risk of defaulting to group-level attributes (Hacker et al., 2024). For example, in employment or lending decisions, generative AI may rely on summary statistics that reflect and amplify group-level differences across observed attributes in the training data. Such practices could potentially perpetuate existing inequalities and unfairly disadvantage certain demographic groups.
Individual level
Thirdly, the reduction in the output variance of generative AI can lead to indifference to individuals due to the loss of individual residuals, affecting both individual identity, a non-material implication, and individual creativity and innovation, a material implication.
Individual identity
Individual identity refers to a person's subjective self-assessment that distinguishes them from others, including personal characteristics, preferences, social categories, attitudes, and values. When generative AI reduces variance by compressing representations into group averages, individual residuals—traits that set individuals apart but that are either not parameterized in or not input as prompts into AI models—are essentially discarded. While the residual variance in AI-generated outputs is random and algorithmic, real human residuals reflect fixed, meaningful attributes that may carry deep personal and social significance. For instance, religious beliefs, political views, and personal preferences are inherently individualistic and may not be fully captured or represented by AI models, despite being very important to people in real life. This systematic indifference to person-specific opinions, preferences, and values in generative AI outputs can subtly erode individual identity over time. As individuals interact with AI-generated content, their beliefs and opinions may be influenced, shaped, or even homogenized, resulting in a gradual loss of individuality. Alternatively, some people may find AI-generated content unsatisfactory and stop using AI for content generation as a result of this.
Individual creativity and innovation
The impact of variance reduction in generative AI on individual creativity can be viewed from both positive and negative perspectives. On the positive side, generative AI, when applied appropriately, has the potential to enhance individual creative output. Studies have shown that generative AI can benefit individual creativity in specific contexts (Gao and Wang, 2024; Lee and Chung, 2024; Si et al., 2024). We know, for example, that it can help people avoid making both factual and stylistic errors. On the negative side, however, the ease of obtaining high-quality results can discourage individuals from striving for extraordinary breakthroughs. Historically, major cultural, intellectual, artistic, or scientific advancements have often been driven by the “out of the box” ideas of extraordinary individuals (Cole and Cole, 1972; Sawyer and Henriksen, 2024).
While generative AI serves as a convenient tool that directs users toward high-quality (yet standardized) results, there is a risk that individuals may lose the motivation for independent thought and original creativity. As a result, the potential for groundbreaking innovations could diminish, leaving society with an abundance of high-quality yet routine creations.
Mitigation
Having examined the potential social implications of variance reduction in generative AI, we propose a set of mitigation strategies—centered on variance preservation and caution in use—as summarized in Table 2. Although there is no universal solution for countering the tendency of variance reduction in generative AI output, we aim to provide actionable insights for service providers and users.
Mitigation strategies for meeting the challenges associated with variance reduction in generative artificial intelligence, categorized by roles (service providers and users) and their focus (variance preservation and caution in use).
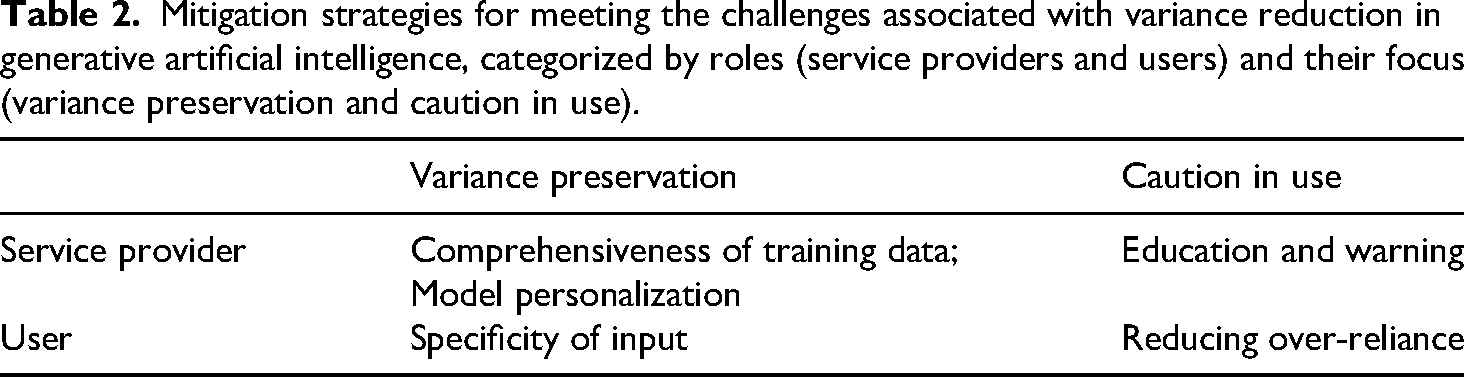
Service providers
Comprehensiveness of training data
Service providers are encouraged to ensure that training data used in generative AI models are comprehensive and representative of diverse demographics, cultures, knowledge domains, and perspectives. This diversity in training data is crucial because generative AI models can only produce relevant and accurate content when they are sufficiently trained on data that encompass the corresponding knowledge and perspectives. Without such coverage, models struggle to reflect underrepresented information, regardless of how precisely users craft their inputs. For example, research has shown that the performance of LLMs in processing knowledge from low-resource languages often falls behind their performance in English, primarily due to significant gaps in the availability of training data (Huang et al., 2023; Jin et al., 2024). Similarly, state-of-the-art LLMs struggle with local cultural knowledge, such as understanding Basque culture (Etxaniz et al., 2024). Therefore, assembling comprehensive training datasets serves as a critical foundation for enabling generative AI models to preserve variance in their outputs.
Model personalization
Beyond efforts to enhance the representativeness of foundation models, enabling model personalization represents another approach to preserving variance in AI outputs. Typically, generative AI models are aligned with “common” human values and preferences, possibly excluding or underrepresenting certain groups or individuals (Kirk et al., 2024). Personalization offers a potential solution, allowing users to adapt and shape AI models to suit their unique needs and preferences rather than relying on a one-size-fits-all approach. For instance, a LLM could be personalized to align with a user's political inclinations, religious beliefs, and perspectives on various topics, thereby preserving their distinctive identities and contributing to essential variance at the societal level. LLM personalization has been both theoretically explored in research (Kirk et al., 2024) and practically attempted by chatbot services such as ChatGPT, which utilize users’ interaction histories to deliver more personalized responses.
Education and warning
Beyond variance preservation, service providers can also mitigate negative effects through warnings and user education. Existing warnings in generative AI often focus on accuracy issues. For example, ChatGPT displays messages such as “ChatGPT may make mistakes. Please verify important information”, alerting users to potential factual inaccuracies in AI output. We suggest that service providers expand their warnings and educational efforts to also address variance reduction. For instance, they could inform users about the potential for output homogenization (variance reduction), whereby generated outputs may become similar across different users for the same prompted task. In addition, service providers could educate users on how to craft more specific and tailored prompts to generate outputs that better align with their unique needs and perspectives. This approach would enhance both user awareness and engagement, helping to mitigate the negative effects associated with variance reduction.
User
Specificity of input
User attention to the specificity of inputs plays a crucial role in preserving essential variance in AI output. As demonstrated in our empirical experiments and theoretical analysis, when input contexts are sufficiently fine-grained and rich in information, the outputs of generative AI can more closely reflect real-world variance. In other words, while simple or generic inputs tend to produce more homogenized responses, detailed and nuanced prompts can unlock the full diversity potential of generative AI models by introducing heterogeneity as between-context variance. Greater awareness of the need for such specificity at the individual level can not only result in more accurate and relevant answers, but at the societal level it can also help mitigate the reduction of variance in information, perspectives, and creative output.
Reducing over-reliance
Reducing over-reliance on generative AI is another proactive step users can take. While generative AI serves as a powerful and convenient tool for various applications, excessive dependence on it can lead to anchoring bias (Choi et al., 2024; Tversky and Kahneman, 1974), where individuals rely too heavily on the initial output they receive from AI. Over-reliance on AI substitutes for humans’ effort for further exploration and ultimately yields the negative impact of variance reduction discussed earlier. To address this, users are encouraged to engage in independent exploration and critical thinking, ensuring that AI-generated content does not become the sole or dominant source of information or ideas.
Conclusion
The average performance of generative AI has garnered significant research attention and its implications for various aspects of human society have been extensively analyzed. In this article, we move beyond average performance to focus on the often overlooked variance of AI output. We highlight the phenomenon of regression toward the mean in generative AI, wherein output variance tends to shrink compared to real-world distributions. We analyze this phenomenon as a natural consequence of the constraints imposed by AI model capacity and the prediction accuracy objectives of AI applications. We delve into the social implications of variance reduction at the societal, group, and individual levels, as well as across non-material and material dimensions. Finally, we propose potential mitigation strategies to meet the challenges posed by variance reduction in AI output, offering actionable insights for both service providers and users. We aim for this article to draw research attention to the inherent tendency of variance reduction in generative AI and its broader social implications, thereby fostering collaborative efforts to minimize its potential negative impacts.
Footnotes
Contributorship
Yu Xie conceived the idea of this work, analyzed the results, and contributed to the writing of this manuscript. Yueqi Xie conducted experiments, analyzed the results, and contributed to the writing of this manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by the Paul and Marcia Wythes Center on Contemporary China at Princeton University.