
Abstract
The rapid development of generative artificial intelligence (gen-AI) confronts the social sciences in the Global North and South with uncertainties along a spectrum between hopes for previously unimagined, leapfrogging potentials and fears of unprecedented risks that deepen divides. Lack of empirical data made it difficult to comprehend the situation and how to respond to it. To remedy this predicament, it is necessary to obtain empirical data to understand the extent and the ways in which these innovations are being used in research, teaching, and learning. This article compares evidence from pioneering surveys in Denmark and Mexico, of how gen-AI is used and perceived by faculty and students at institutions within these two strongly contrasting countries. The comparison reveals distinct patterns of usage by country, academic status, and gender. Normative assessments among respondents vary across different research phases and tasks in which gen-AI is deployed. Open survey items suggest uncertainty about gen-AI’s ethical and methodological suitability and a contrast between faculty emphasis on regulation and student prioritization of training. The comparison of the two data sets aims to provide a foundation for reflection and discussion about normative frameworks, facilitative initiatives, and collective interventions at this historical juncture of enormous methodological innovation.
Keywords
Introduction
How does generative artificial intelligence (gen-AI) affect the process and practices of social research? How widely is it being adopted, or rejected or ignored? Through what kind of methodological innovations? For what purposes, and by whom? Does its usage, perception, and evaluation differ among social researchers in the Global North and South? Does it facilitate leap-frogging development, amplify digital divides, exacerbate epistemic inequities, or something in-between? This article aims to explore these questions in order to provide empirical grounding for debates about the opportunities and risks associated with its usage. The immense uncertainty caused by gen-AI’s tsunami-like arrival lends urgency to such questions, to which we wish to offer here, as a modest step, a few empirical data-based observations.
Generative Artificial Intelligence (gen-AI) tools, defined technically as systems that learn patterns from databases and Large Language Models (LLM) to produce texts, images, videos, and code, have existed for several years but it is only since recently that they have gained an unprecedented momentum in academia (Ooi et al., 2025). A key turning point came in November 2022, when the U.S. company OpenAI launched ChatGPT, a chatbot whose release accelerated the adoption of these technologies in scientific research (Qasem, 2023). Soon after, international journals reported cases where ChatGPT was listed as a co-author (Peres et al., 2023). At the same time, other studies highlighted the challenges human reviewers face in distinguishing between human-written and ChatGPT-generated abstracts (Gao et al., 2023).
Since then, new gen-AI tools have emerged and quickly gained popularity. These include Gemini, Microsoft Copilot, and DeepSeek for text generation; Midjourney and DALL-E 3 for visual content creation; and GitHub Copilot for code development, to mention just a few examples. The increasing adoption of these tools in academic research has sparked intense debates about their benefits and risks, their scope and limitations, as well as about fundamental issues such as transparency, scientific accountability, misinformation, and bias inherent in these technologies (Bail, 2024; Benbya et al., 2024; Davidson, 2024; Davidson and Karell, 2025; Davis and Sloane, 2026; Giray et al., 2024; Ivanov, 2025; Pilati et al., 2024; Sok and Heng, 2023; United Nations Educational, Scientific and Cultural Organization, 2023; Zlotnikova et al., 2025). All of this has been accompanied by discussions on how (if at all) to regulate the development and application of AI algorithms and tools (Dabis and Csák, 2024; Fecher et al., 2025; Goyanes et al., 2025; Law and McCall, 2024; Scherer, 2015; Yeung and Lodge, 2019).
Despite the relevance of these discussions, there is not enough systematic, data-driven empirical research on the use of gen-AI in scientific, notably social research, and most of it comes from wealthier countries, such as Denmark (Andersen et al., 2025; compare discussion in Bhat et al., 2024; Bhullar et al., 2024; Feng, 2024; Galjak and Budić, 2025; and, more related to education, e.g. Benavides-Lara et al., 2025; Chao-Rebolledo and Rivera-Navarro, 2024). In their recent study, Mohammadi et al. (2026) bemoan that “there remains a lack of systematic academic studies that examine the use of Gen AI tools across disciplines in both research and teaching, particularly from international perspectives” (p. 2). Given the growing debate about the scope and ethical use of gen-AI, it is essential to generate more evidence, especially around key questions such as: Whether and to what extent is gen-AI used in research processes? In what specific ways is it integrated into the research process? How do these methodological innovations affect the ways in which research is being conducted? What specific potential risks and opportunities loom in these various evolving types and modes of usage? And how should academic institutions approach (e.g. promote, restrict, or regulate) the use of gen-AI in teaching and research activities?
In the case of the social sciences, such questions take on particular relevance because of their objects of study, the nature of their methods, their approaches to analysis and the populations being focused on. Unlike in the exact natural sciences, where the use of gen-AI can focus on the automation of calculations or the programming of models, in the social sciences their understanding and application of such technologies can have implications for the production, interpretation, and validation of knowledge about social phenomena. The generation of texts, the analysis of qualitative and quantitative data, as well as the synthesis of information and critical assessment, are fundamental processes in social research. The incorporation of gen-AI tools raises crucial questions about originality, methodological transparency, possible biases in scientific production and, in general, the ethics of the research processes. Moreover, given that the study of social dynamics involves the analysis of specific discourses, narratives, and contexts, the use of gen-AI in these areas may influence the way in which findings are constructed and communicated. This makes it even more urgent to understand how these technologies are adopted and what implications their use has for the future of the social sciences and societies themselves.
It cannot be assumed merely from the outset that gen-AI will spread around the globe in a single fashion. The global accounting firm PricewaterhouseCoopers (2017) estimated that by 2030 only 15% of the projected $15.7 trillion value boost from AI would go to the developing countries of the Global South due to lower expected adoption rates. If past technologies can serve as an indicator, the diffusion may be global, but not uniform. Digital technologies have been adopted, regulated, and transformed in diverging ways across countries and locales, and their impacts varied just as much (for Latin American countries, see Herzog et al., 2002). As the social shaping of digital technologies unfolds between the poles of domination and participation, social actors have a leverage that can shrink through inaction or expand through imagination and active involvement (Schulz, 2011; Schulz and Costa, 2025; for older technologies, see Ellul, 1954; Feenberg, 1999; Marcuse 1964). Gen-AI integration in knowledge production intensifies the question of “plural epistemologies” and how scholarship from the Global South can overcome dependency, marginalization, and what Santos (2014) calls “epistemicide.” How is the latest technology adopted and impacting an unequal field? In their recent bibliometric study, Xu and Thien (2026) concluded that “multilingual, regionally diverse studies are needed to address the current Global North bias” that they revealed in their review (p. 16). It is thus pertinent to conduct research that can foster debates in sites not limited to the Global North but also in the Global South. This is way we want to help opening the pathway to nuanced cross-regional research by exploring a set of available data samples.
Although the principal reason for comparing survey results from academic populations in Denmark and Mexico is their ready availability, there are also several other aspects that make this particularly useful. A chief contrast is the state of development between Denmark, which is considered to be one of the most developed countries of the Global North, and Mexico, which is classified as a developing country from the Global South. The gap between both countries is measured by major empirical indicators such as GDP per capita (US$ 71,852 vs US$14,158; World Bank [WB], 2025), Gini Index (29.3 vs 42.5; WB, 2025), Human Development Index (0.962, ranking 4th vs 0.789, ranking 81st; United Nations Development Program, 2025), Global Innovation Index (57.1, ranking 10th vs 30.4, ranking 56th; World Intellectual Property Organization, 2025), and population share of AI users (38.7% vs 3%; United Nations Economic Commission for Latin America, in Spanish: Comisión Económica para América Latina y el Caribe, 2025). Denmark represents a digitally cohesive society where infrastructure, policy, and digital literacy converge to make online services universal and inclusive. Mexico, on the other hand, reflects a hybrid reality: strong digital adoption in urban and middle-class contexts, but persistent gaps in rural and marginalized communities that mirror and sometimes exacerbate broader social inequalities. Another mayor difference relates to language: academic researchers in Denmark use primarily globally dominant English and their Mexican counterparts primarily Spanish or a mix of Spanish and English in instances such as translation for publication. Thus, language and the national settings of the institutions, in which the surveys took place, contrast strongly. Yet, the faculty and doctoral students of the survey population are not representative of their country’s general population. It shall be emphasized that no claims are made about any generalizability for either country nor for the country categories, geographic regions, or linguistic groups. The strength of the convenience sample is to provides unique data points for exploring gen-AI use in a nuanced way across all research phases and for dozens of discernable research tasks.
This article seeks to contribute to an empirical basis for reflection and discussion about normative frameworks, facilitative initiatives, and collective interventions in the Global North and South. It does so by comparing empirical evidence from convenience samples available through two recent surveys among academic populations at institutions in Denmark and Mexico. In the following sections, we first explain the methodological fundamentals of this comparative study, including its limitations. We then describe and discuss the main findings, including the similarities and differences between the respondents in both countries, and according to academic status and gender. Finally, the conclusion presents suggestions for broadening debates and developing future research in the Global North and South.
Methodology
This article compares evidence from pioneering surveys conducted in Denmark and Mexico on the use, peer perception, and valuation of gen-AI in research and teaching practices. These are among the first of their kind in Europe and Latin America respectively (cf. Álvarez-Herrero, 2024, for a first survey among university students with one open-ended question related to gen-AI). The research group formed by Jens Peter Andersen, Lise Degn, Rachel Fishberg, Ebbe K. Graversen, Serge P.J.M. Horbach, Evanthia Kalpazidou Schmidt, Jesper W. Schneider, and Mads P. Sørensen is based principally at Aarhus University in Denmark. It developed the questionnaire for a survey conducted at all Danish universities, including all disciplines. Its findings were reported in Andersen et al. (2025). The research group formed by Oscar Fontanelli, Ligia Tavera Fenollosa, Markus S. Schulz, Danay Quintana Nedelcu, Mauricio I. Dussauge Laguna, and Jackeline Alba Udave is based at the Facultad Latinoamericana de Ciencias Sociales (FLACSO) in Mexico. In order to allow for a systematic comparison across the two countries, it mostly replicated the questionnaire from Denmark, translating it into Spanish, while adding questions related to teaching, and adapting it in two steps. This included a pre-pilot test to adjust the survey to a different institutional setting. Its findings were reported in Fontanelli et al. (2025).
Although the English and Spanish questionnaires are largely comparable (see Appendix A and the discussion below with reference to Table B1), there are also limitations that warrant discussion. Most importantly, the survey populations were quite distinct. Whereas the Danish survey covered the entire academia of a whole country, the Mexican survey focused on the academic community of one institution specialized in the social sciences. While the Mexican survey cannot be generalized to the social sciences of the whole country, it has achieved within a 3.8 times shorter time-span during which it stayed open a 4.8 times higher response rate. The survey in Denmark was conducted during the 34 days between 22 January and 26 February 2024. It yielded a response rate of 8.6% completed questionnaires from a total of 29,498 invitations to all faculty and doctoral students across all disciplines at all Danish universities. The Mexican counterpart was conducted during the 9 days between 25 March and 2 April 2025. It yielded a response rate of 41.4% from the 370 invitations to all faculty and students at FLACSO, one of Mexico’s leading social sciences research institutions.
For the purpose of equivalency, we will include from the Danish survey only the subset of respondents who identified themselves as belonging to the social sciences, that is the responses from 362 professors and 145 doctoral students. From the Mexican survey, we will disregard the 99 respondents at the MA level and also those seven doctoral student respondents who had not been familiar with the concept of gen-AI and were hence not asked to complete the survey. The Mexican subset of respondents that is thus subject to this comparison includes 24 full-time professors and 30 full-time doctoral students. While the Danish subset offers the advantage of an 8.6 times greater number of respondents, the Mexican subset has the distinction of very high response rates (45.5% among its doctoral students and 66.7% among its professors). In the analysis, we will pay particular attention to comparing the responses from professors and doctoral students not only because of their different weight in the two country subsets but also because of the younger cohort’s allegedly greater interest in gen-AI use (cf., e.g. Kotsier, 2023; SalesForce, 2023; Tsai, 2023).
Apart from basic questions about academic and demographic characteristics, the common parts of the questionnaires covered three main aspects: one’s own use of gen-AI in the research process, the perception of such use among peers, and the usage’s normative evaluation. Within each aspect, five phases of the research were distinguished: idea generation, research design, data collection, data analysis, and writing and publication. Within each of these phases, 5–10 questions asked about the gen-AI usage for a specific research task. A table with these questions and their corresponding research tasks and phases is included in Appendix B. Open questions about the evaluation of gen-AI and institutional demands complemented the quantitative items and the exploratory function to provide respondents with opportunity for non-standardized input (see Appendix B). Issues of translatability, contextual adaptation, and equivalency are addressed below when discussing specific results (for general discussion, see, e.g. Behr and Shishido, 2016). In sum, the surveys seek to provide relevant empirical information to document and analyze how gen-AI is being used (or not) in academic research, to contribute to the debate on its ethical, responsible and transparent use, as well as to develop guidelines or principles that help regulate and enhance its application in academic activities.
While we acknowledge that our comparison of the Danish and Mexican experiences faces important limitations, the use of a largely common survey instrument, the focus on equivalent populations, and the similar novelty of the topic for both countries’ research environments make for a sensible comparison. We wish to emphasize that our aim is not to deliver statistical generalizations but to open pathways for exploring the implications of new gen-AI technologies in academic contexts around the world.
Results
This section presents a systematic comparison of the survey results from Denmark and Mexico. Diagrams will help to visualize it. The section is structured according to these key questions:
- How does the gen-AI usage, perception, and valuation of gen-AI differ between Denmark and Mexico?
- How does gender impact usage, perception, and valuation of gen-AI in Denmark versus Mexico?
- How does academic status impact usage, perception, and valuation in Denmark versus Mexico?
- How does the valuation pattern of gen-AI usage across different research phases and research tasks compare between Denmark and Mexico?
Figures 1 and 4 include error bars. These depict aggregated proportions, such as overall frequencies and usage by research phase. In these cases, a concise representation of within-sample variability aids interpretation without sacrificing readability. We deliberately avoid extending error bars to all figures because most of the other visualizations display much more detailed task-level patterns and multiple subgroup comparisons simultaneously. Additionally, the Danish and Mexican samples differ significantly in size, and the Mexican subsamples become relatively small when disaggregated by academic status, gender, or specific research tasks. Under these circumstances, the corresponding confidence intervals would become disproportionately wide and visually dominant, which would limit rather than enhance interpretability. More importantly, systematically including error bars throughout the manuscript could create a misleading impression of inferential precision and statistical comparability that is not justified given the non-probabilistic, non-equivalent, and temporally displaced nature of the samples. Therefore, error bars are selectively included as descriptive aids rather than inferential tools.
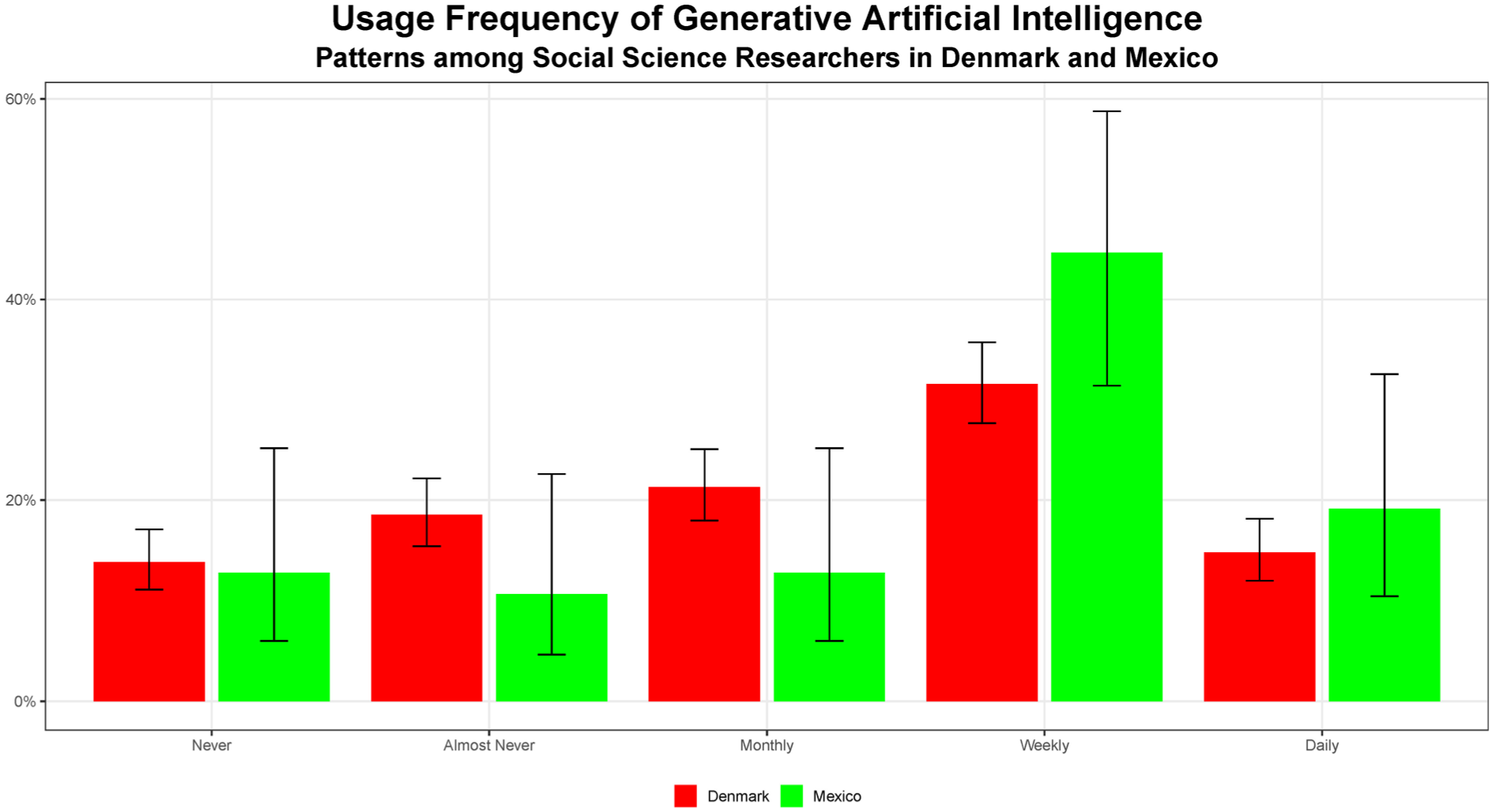
Gen-AI usage frequency patterns. Error bars show Wilson 95% confidence intervals for within-sample proportions; they do not imply population-level inference.
At its most fundamental level, the comparison examines the basic usage frequencies of gen-AI that social science researchers (i.e. here defined as doctoral students and professors) in the two surveys report. This is depicted in Figure 1. In both surveys, the researchers had choices to report their own usage ranging from “never” to “almost never,” “monthly,” “weekly,” and “daily.” The results follow largely the shape of a bell curve, except that the Mexican respondents chose “almost never” slightly less often than “never” or “monthly.” The peak is at the weekly usage. Almost 45% of the Mexican respondents and over 30% of the Danish report gen-AI use in their research practice on a weekly basis. Almost 15% of the Danish and almost 20% of the Mexican respondents report an even daily gen-AI use. Only 14% in Denmark and 13% in Mexico report having never used gen-AI.
What could be unexpected is that the more intense usage frequencies reported from Mexico are considerably higher than those from Denmark. The reverse could have been expected in light of Denmark’s much higher per capita income, higher ranking in the Human Development Index, more developed infrastructure, and more inclusive digital culture. Yet, given the high education level, national economic variables may be expected to be less relevant. Moreover, the Mexican institution, at which the survey was conducted, is a leading research center, thus not to be expected to mirror country-wide averages. Thus, it would be interesting to extend this survey to cover the full spectrum of the country’s universities, including those in remoter rural areas.
At least as important a factor could be the time lag between the two surveys. In many research areas, a year difference would hardly register but in this case of a rapidly spreading technology, this could explain this difference fully too. A coming iteration of the Danish survey would provide second datapoints that could be connected by a timeline and thus allow an estimate of the magnitude of this factor.
A comparison of weight-coded scores for Gen-AI usage intensity (range: 0–360, based on: daily = 360; weekly = 60; monthly = 12; almost never = 2; never = 0) showed the Danish faculty (70.4) and doctoral students (86.9) reporting lower average usage intensities than the Mexican faculty (87.1) and doctoral students (108.3). If those who reported unfamiliarity with the concept gen-AI were counted as never users, then the score for Mexican doctoral students would drop to 83.1, that is slightly below the score for Danish doctoral students, though still well above Danish professors. Although the error margins prevent claims of statistical significance, the differences suggests that after a year’s time lag, the respondents in the Mexican sample did at least not score much lower than their Danish counterparts.
The obvious limitations related to the response rates have been discussed above. Here, it could be hypothesized that never-users might have been less inclined to participate in such a survey compared to intensive users. However, the very high response rate among the respondents in Mexico sets a ceiling to the extent of such a possible bias for its part of the comparison.
Figure 2 expands on the previous by disaggregating the responses from professors and students. This disaggregation serves as control for any potential impact stemming from the two country cohorts’ differential composition. To recall, whereas the Mexican sample is almost equally balanced between the two status groups, the Danish sample has 2.5 times more doctoral students than professors. Yet, as we can see here in this Figure 2, the same pattern is consistent between faculty and students both among the intensive users and the never-users. Most notably, the doctoral students report in both countries markedly higher gen-AI usage at the more intense weekly and daily usage levels than the professors. Correspondingly, they are less represented amongst both countries’ never-users. The oddity of the Mexican faculty deviating from this pattern in the “almost never” category would disappear if the rather very small counts for the “never” and “almost never” categories were to be combined. Assuming that professors are on average older than doctoral students, we can see here also the generational impact discussed above.
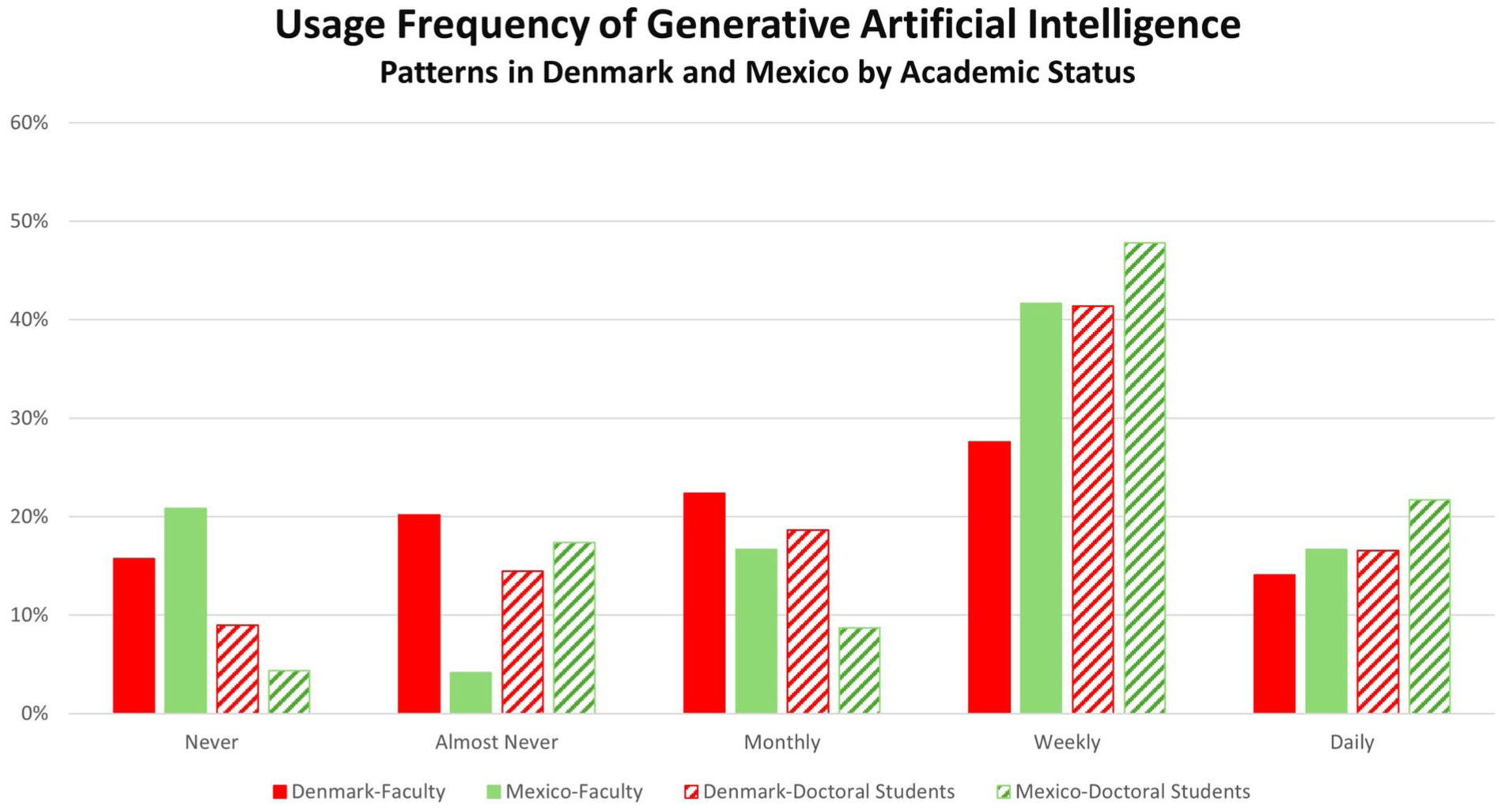
Gen-AI usage frequency patterns by academic status.
Figure 3 allows us to consider the impact of gender on gen-AI usage. We can see here a distinct pattern between men and women, though it should be noted that the sample size is too small for producing detailed interpretations, particularly for non-binary gender. Within the group of the most intensive (i.e. daily) users, the rates are about the same across women and men respondents from both countries. The strongest contrast, however, is at the weekly usage level, at which the female respondents in the Danish survey are represented at over 2.5 times the rate as their counterparts from Mexico. At this weekly usage level, Danish women are represented also with a noticably higher rate than their male counterparts, while the reverse applies less pronouncedly to the Mexican respondents. Among the never-users, Danish women are represented with the lowest rate. Non-binary gender is omitted here due to the small sample sizes.
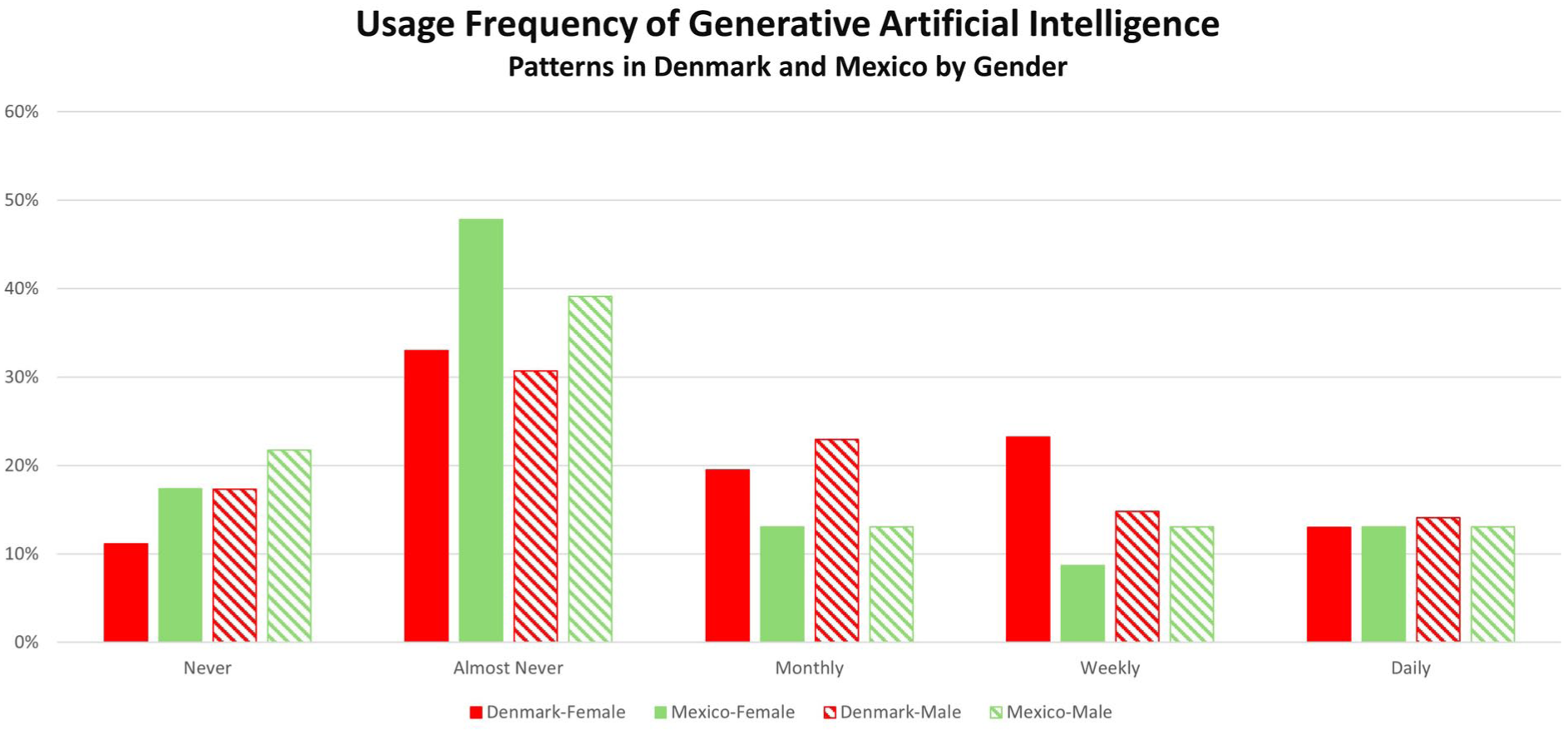
Gen-AI usage frequency by gender.
Figure 4 shows the usage frequence pattern by the five research phases of idea generation, research design, data collection, data analysis, and writing and publication. We can see strong similarities between the Danish and Mexican respondents, except for the phase of research design, for which the respondents in Denmark report considerably higher usage than their counterparts in Mexico.
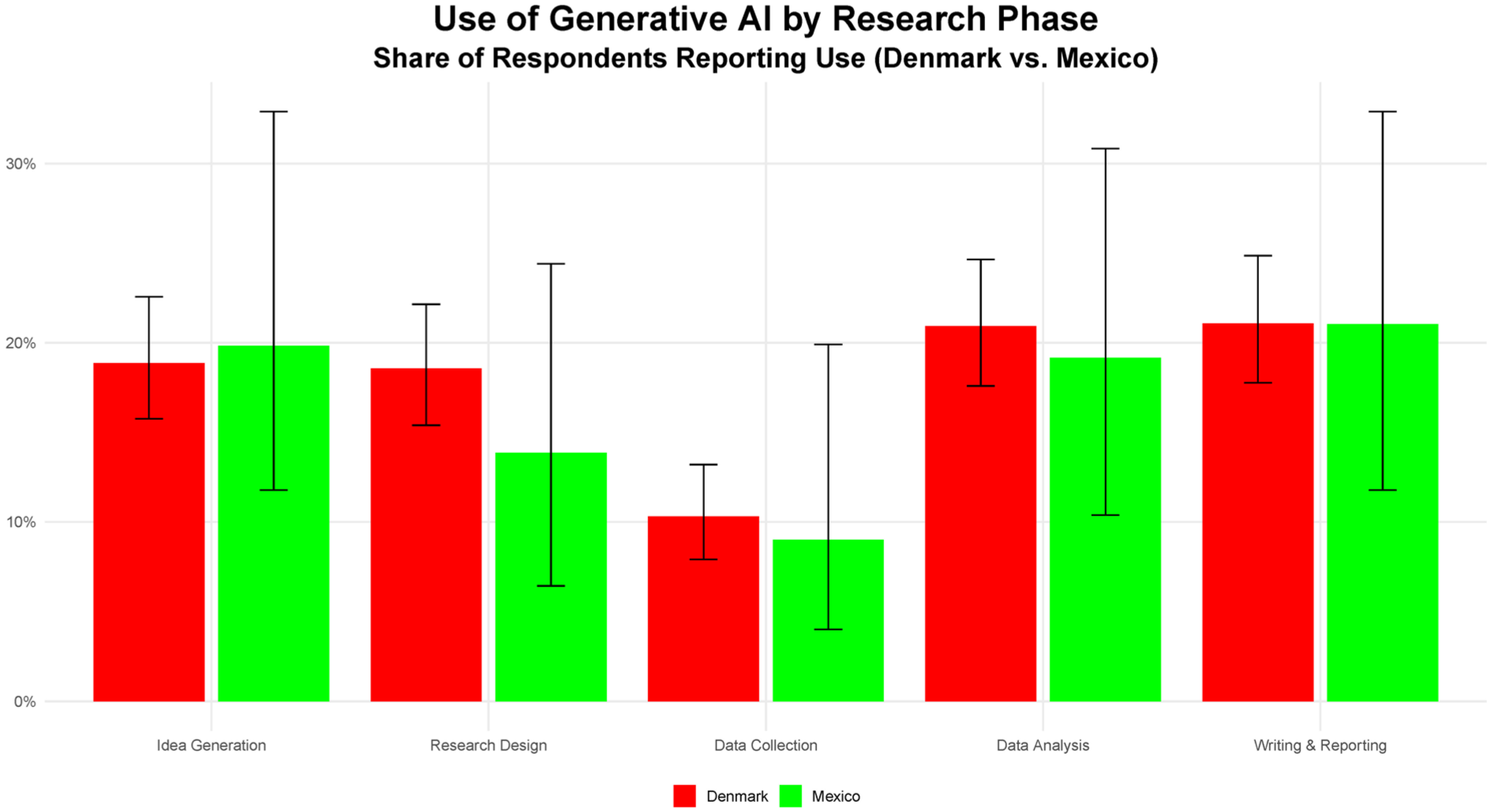
Gen-AI usage by research phase. Error bars show Wilson 95% confidence intervals for within-sample proportions; they do not imply population-level inference.
Figure 5 expands on the previous by showing side by side how self-reported usage contrasts with the perceived usage of one’s peers. Most notable here is that in both Mexico and Denmark the reported own usage is much lower than the perceived usage of peers across all five phases of the research process. The consistent pattern that respondents perceiving their peers’ use of generative AI tools in academic activities to be more than their own aligns with prior self–other discrepancies in AI-related attitudes, such as those documented by Purcell et al. (2026). Unlike Purcell’s focus on generic “others” in AI-mediated communication contexts, the Mexican survey pertained to colleagues within the same institution or with recent collaborators, that is relationships in which respondents could plausibly observe actual behavior. Strikingly, this perception gap was nearly identical in both the Mexican and Danish samples. This suggests that the self–other discrepancy is robust across domains and persists even when “others” are close colleagues, highlighting its significance for understanding technology adoption norms in academia. This finding should be considered in the construction of future surveys and when interpreting data on self-reported usage.
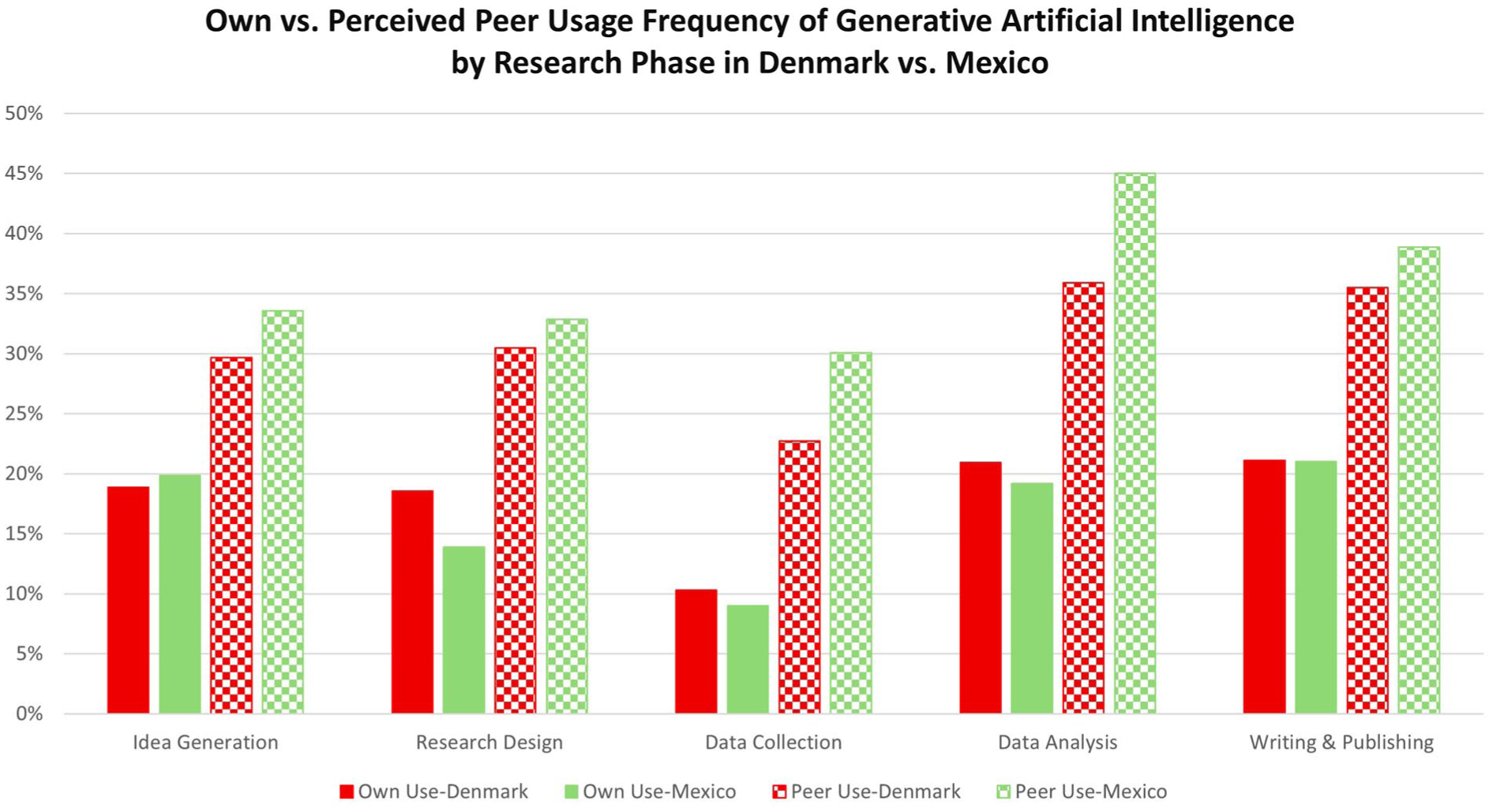
Own vs. perceived Gen-AI usage frequency by research phase.
The following five diagrams will show how the respondents to the two surveys evaluate the deployment of gen-AI for accomplishing specific tasks within the five distinct research phases of idea generation, research design, data collection, data analysis, and writing and publication. The evaluations by faculty and doctoral students are depicted separately. In their respective questionnaires, the respondents were asked to select their assessment among seven options, ranging from “excellent” to “very problematic” with the term “neutral” in the center and unlabeled gradation buttons in between them, plus the non-evaluative option “unable to answer” (on this latter option see the discussion below). For the purpose of comparison, the seven evaluative options are re-coded as scores ranging from −3 for “very problematic” to +3 “excellent.”
Figure 6 presents the normative assessment of gen-AI usage for five distinct tasks in the initial research phase of idea generation. These research tasks include assistance in identifying research gaps, relevant literature, and potential collaborators; in summarizing or analyzing existing literature; and in proposing new hypotheses. Approval or disapproval is by no means uniform, but varies strongly between different research tasks. In four of the five items, there is full agreement in the evaluative direction between students and professors from both countries, with variance only in the intensity of approval or disapproval. Gen-AI assistance in identifying research gaps and in proposing new hypotheses is seen by all four subgroups as negative, with the Danish respondents assessing it arguably more negative than their Mexican counterparts. In contrast, help in identifying relevant literature and summarizing or analyzing existing literature is considered among all four subgroups to be net-positive. The only disagreement is between the Mexican students assessing gen-AI help in identifying potential collaborators as something negative, whereas the Danish students assess it as positive. In contrast, the Danish faculty assess it much more positively than the Mexican faculty.
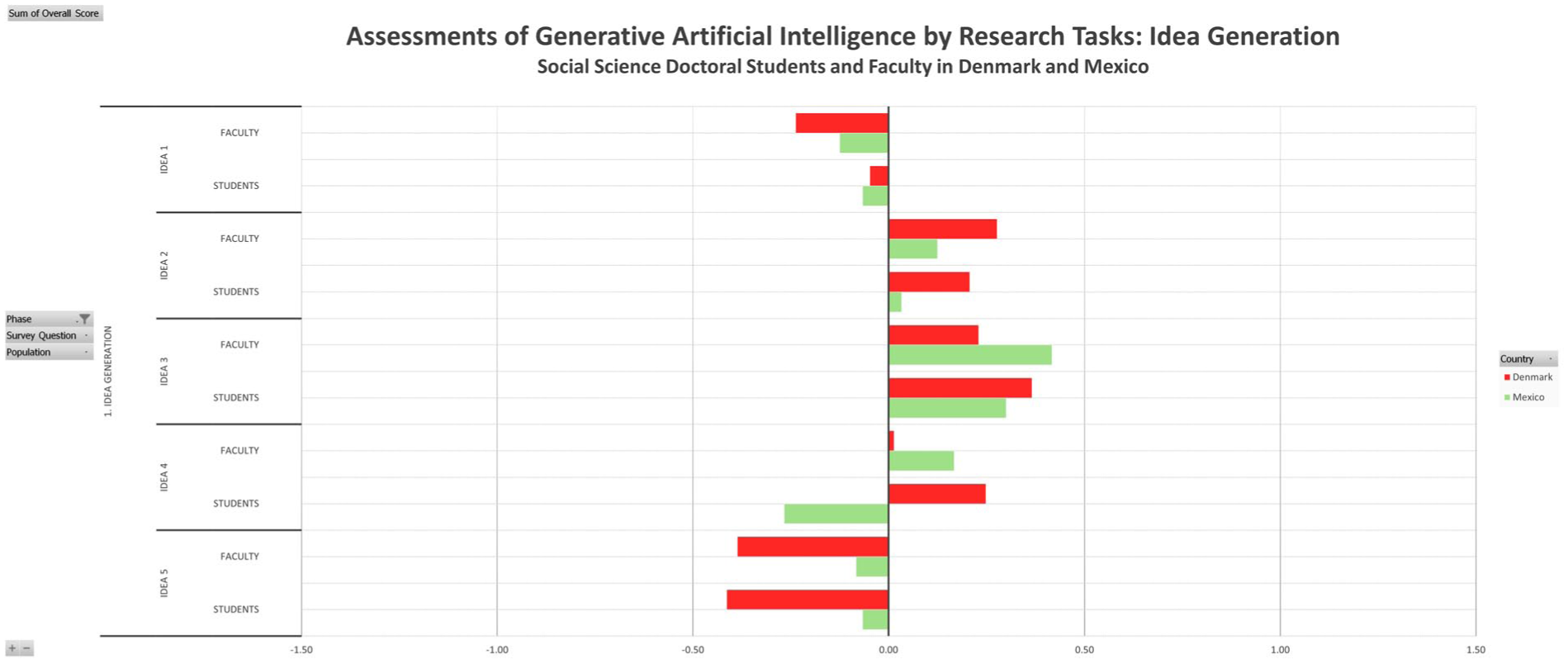
Idea generation.
Figure 7 shows the assessment of gen-AI usage for seven distinct tasks in the second research phase of research design. All four subgroups converge in their assessment of Gen-AI assistance to “suggest a structure for a research project,” “refine or edit the language of research proposals” and “the content of research proposals.” On the other hand, all subgroups perceive assistance to “design research methodology” and “develop theoretical models or conceptual frameworks” as clearly negative. Two exceptions are striking: Danish students disagree with the other three subsets in assessing the assistance in “drafting parts of a research proposal” as something positive, while Mexican students disagree with the others in a positive assessment of “help design research techniques, such as experiments or surveys”
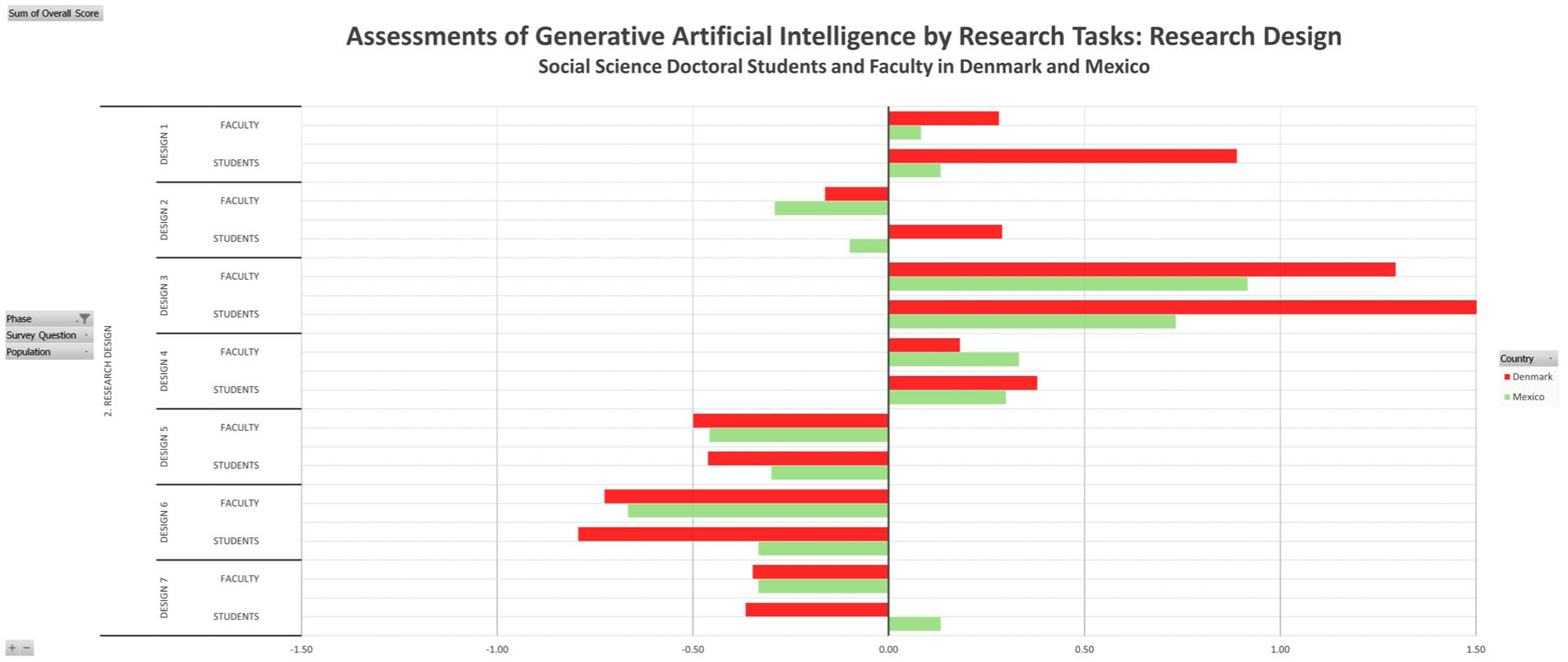
Research design.
Figure 8 presents the assessment of gen-AI usage for the five distinct tasks in the third research phase of data collection. All four subsets assess assistance in “formulating survey or interview questions” and to “transcribe and summarize recordings of interviews, workshops, or focus groups” as positive. Yet they assess “suggest experimental parameters” and “identify ethical issues in research” as negative. The assessment of assistance to “generate synthetic data sets” hovers around neutral, with Danish faculty scoring it slightly negative, while the other three subgroups score it slightly positive.
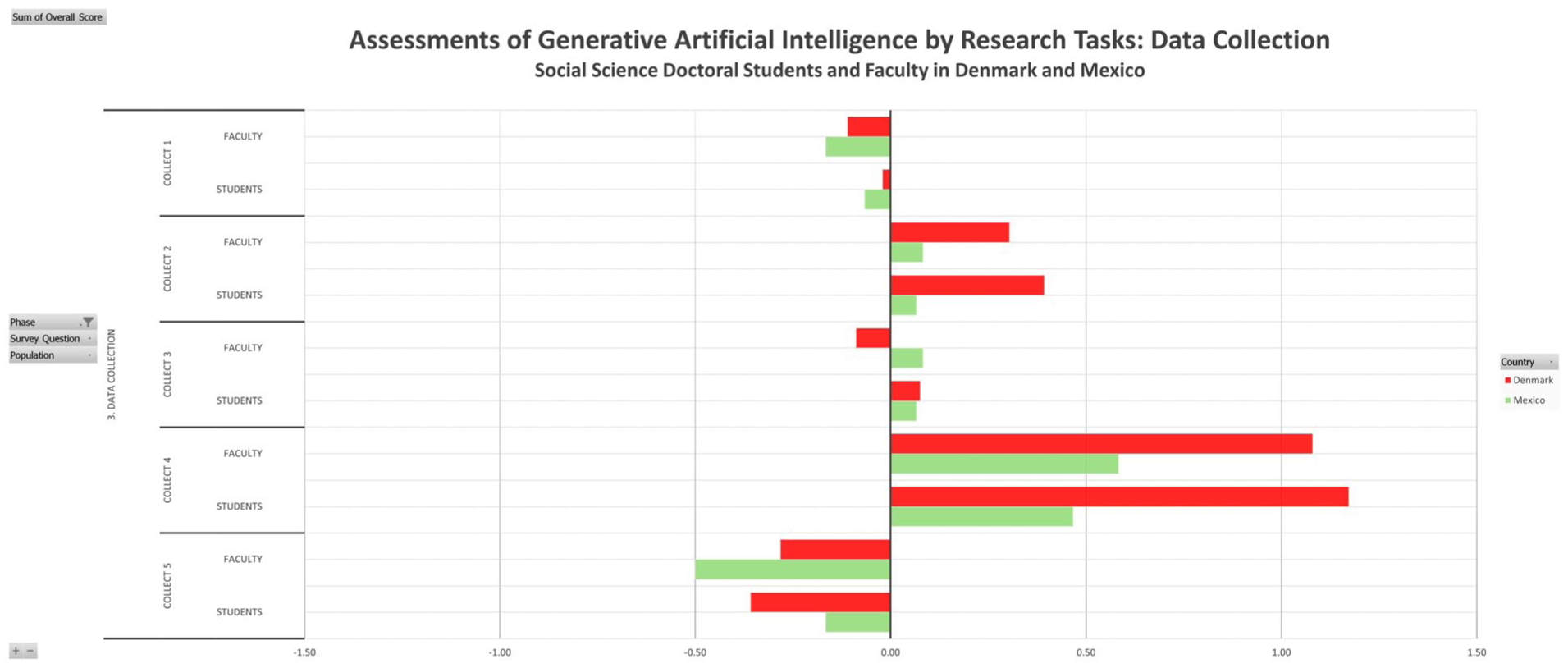
Data collection.
Figure 9 shows the assessment of gen-AI usage for tasks in the fourth research phase of data analysis. These include “create or edit code for data analysis (e.g. in R, Python, SPSS, STATA or other),” “create or edit code to perform simulations,” “support statistical data analysis,” “help interpret results,” “help pattern recognition in data,” “help generate models,” and “create or modify figures for reports, presentations or publications,” “help clean data,” and “help identify trends in the data.” Most notably, none of research tasks in this phase are scored negatively by any of the four subgroups.
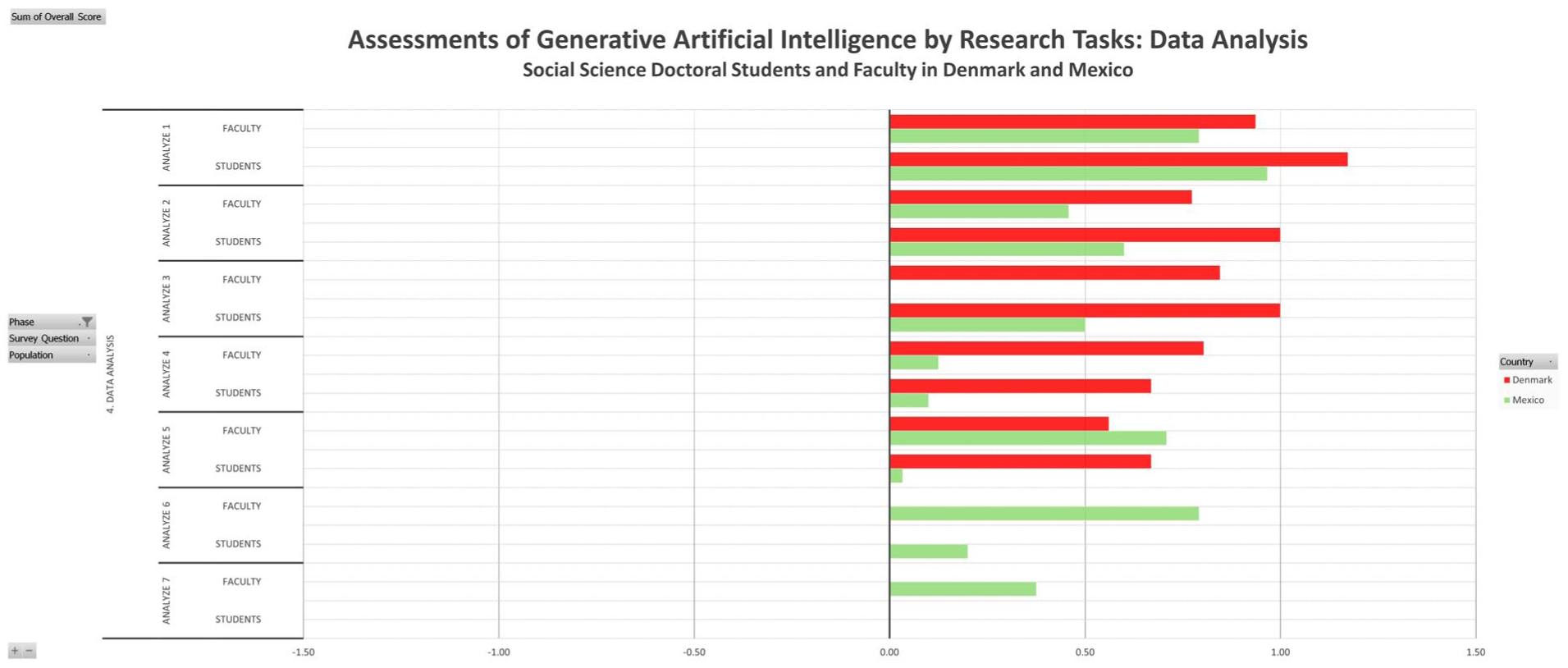
Data analysis.
As shown in Table B1 of Appendix B, the Mexican survey had two more questions than the Danish. These two inquired about the use of gen-AI to “help clean data” (coded here as “da6”) and “help identify trends in the data” (coded here as da7). Although they do not have an equivalent in the Danish survey, they are not omitted here from this comparative analysis because of their partial overlap with other questions and their being part of a particular research phase. These two questions are commonly associated with statistical analysis but not exclusively. It may be added that the scores of the responses to the two questions that were omitted from the Mexican survey had the same directionality than the other five question within this cluster about the research tasks of data analysis. Therefore, there is no indication that the variance and additions in questionnaire language here undermined the basis for comparison in any other than most minimal ways.
The greatest variance within the shared evaluative directionality between the two country cohorts appears among the Danish respondents’ much stronger approval for the third item (da3) compared to their Mexican counterparts (0.85 vs 0.01). The strong difference in approval score for this question needs to be understood with regard to the variance between the Danish and Mexican question.
As mentioned above, a note is needed here on the issue of translatability, contextual adaption, and equivalency. Whereas three of the questions were straightforwardly translated (coded here as da1, da2, and da5), two others were paired more loosely. The Danish question about the use of gen-AI “to support statistical analysis” was paired with the Spanish “[a]yudar a interpretar resultados,” which literally means “to help interpret results” (coded here as da3) that is not necessarily only statistical results.
The other Danish question that had only a loose match asked about the use of gen-AI “to help pattern recognition in data” (coded here as da4). It was paired in the Mexican survey with the question about “[a]yudar a generar modelos,” which literally means “to help generate models.”
The second greatest variance among any of the four groups appears between the Danish students’ much stronger approval score for the use of gen-AI in helping to generate presentable figures (da5) than the Mexican students (0.67 vs 0.03). However, Mexican faculty score (0.71) this use even slightly higher than Danish students, while Danish faculty are a bit more reserved (0.56).
Figure 10 presents the assessment of gen-AI usage for the 10 tasks in the final phase of writing and publishing. Agreement between the subgroups’ direction of assessments can be observed for the items #1 “suggest a structure for a research article, book or book chapter,” #3 “proposing a title, abstract or keywords for your article,” #4 “editing a research paper to improve readability and/or language,” #5 “formatting citations and references,” #8 “translating your own text into a different language,” #9”assist in creating (parts of) a presentation for a conference, congress or broadcast event,” and #10 “supporting the creation of summaries or different versions of own texts for a non-specialized audience. Item #2 “assisting in writing parts of a research paper” is scored negative by both Mexican faculty and Danish students, but slightly positive by Mexican students and more clearly positive by Danish faculty. For items #6 “identify the strengths and weaknesses of a manuscript during the peer review process,” and #7 “assist in drafting review reports during the peer review process” the Mexican faculty arrive at mildly positive assessments, while the other three subgroups see it somewhat negative.
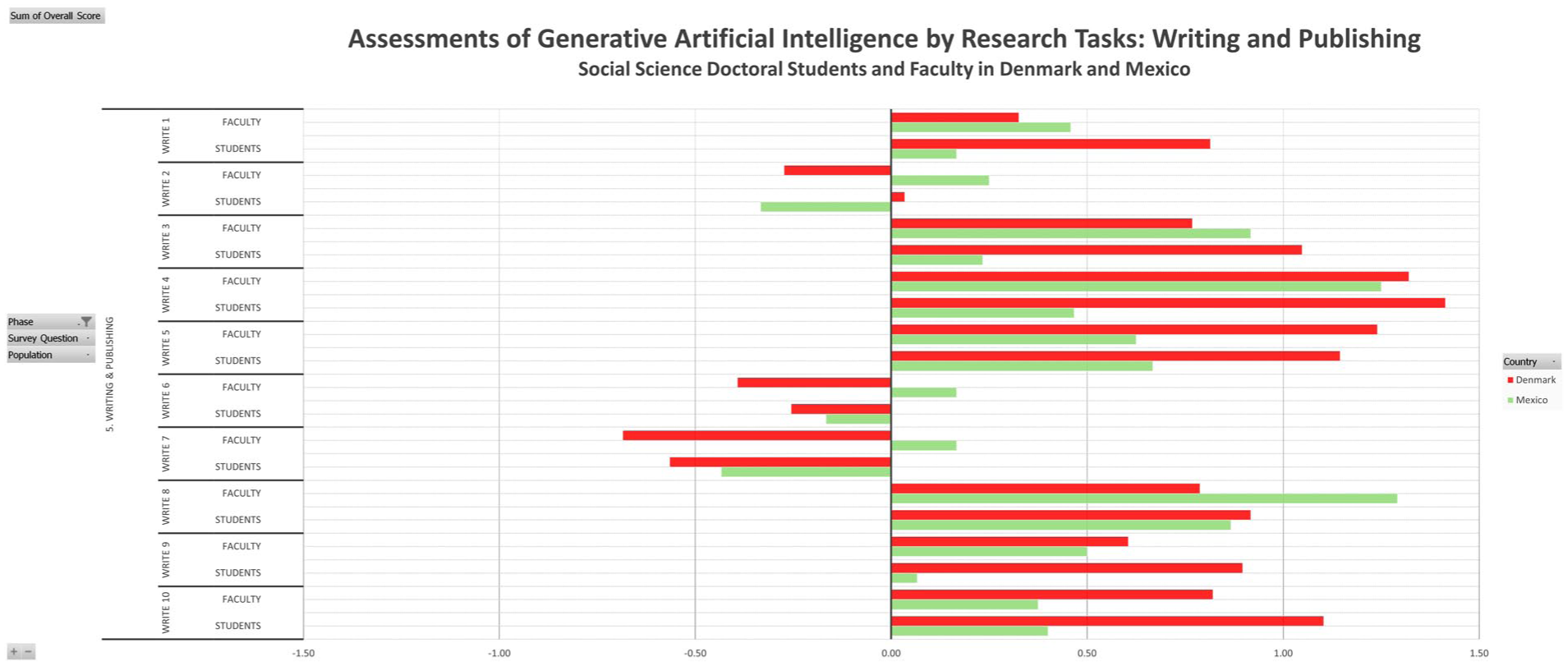
Writing and publishing.
The open questions in both surveys provided additional insights. Danish respondents highlighted concerns for accuracy, trustworthiness, and privacy, though these concerns were expressed across disciplines, and not limited to the social sciences. The Mexican survey included also an open question on institutional expectations. Responses converged on the urgency of establishing clear guidelines, but revealed also a noticeable divergence in orientations. While faculty tended to emphasize regulation, limits, and the risks associated with misuse, students placed greater weight on the need for practical training, ethical guidance, and the development of competencies for effective use. Beyond this divergence, the open responses in the Mexican case indicated how gen-AI is being incorporated into everyday academic practices as a cognitive and technical support tool, particularly in programming, data analysis, and mathematical understanding. At the same time, they reflect an emerging reflexivity among students, who explicitly recognized that these tools should not replace theoretical understanding and warn against treating AI outputs as authoritative. The open sections thus complemented the quantitative findings not only by identifying areas of concern, but also by illuminating how gen-AI is reshaping academic practices, expectations, and institutional demands, thereby pointing to issues for further research.
Implications, further analysis, and limitations
The comparison has revealed commonalities and differences in the knowledge, use, perception, and assessment of gen-AI between the two national groups. Gen-AI use appeared overall higher among the Mexican respondents who completed the questionnaire compared to their Danish counterparts. Yet it needs to be kept in mind that a third of the responding Mexican doctoral students were eliminated from the further analysis due to their prior unfamiliarity with the concept of gen-AI. The actual gap by academic status could be deeper according to the postulate that people who do not know the term are less likely to respond. Among respondents, the overall gen-AI usage frequency does not vary significantly by gender. In any case, the usage frequency results suggest a considerable gap in the diffusion of this emerging technology according to the academic but not the development status.
Overall, the findings show very nuanced patterns of positive and negative evaluations with which agreement exists in the assessment directionality between Danish and Mexican professors and students. The top score among all subgroups comes from the evaluation by Danish students of “refine or edit language of a research proposal (score 1.51). Among the overall most positively assessed gen-AI uses are assistance in the editing of research proposals and papers. These are most enthusiastically embraced by Danish student and faculty respondents (scores 1.41 and 1.31 respectively) as well as Mexican faculty (score 1.25), though only moderately by Mexican students (score 0.47). Among Mexican faculty, the most positively evaluated application is “translation of own text into a different language,” presumably from native Spanish to English as the global academic lingua franca (score 1.29). Among Mexican students, the favorite is the creation or editing of code for data analysis (score 0.97).
By contrast, the greatest skepticism pertains to gen-AI use for certain tasks of designing research, especially “help develop theoretical models or conceptual frameworks” (rd6; scores −0.79, −0.73, −0.67, −0.33 by Danish students, Danish faculty, Mexican faculty, and Mexican students, respectively) but also “help design research methodology” (rd5), and, related to the phase of data collection, “identify ethical issues in research” (dc5) as well as, related to the last phase, for peer review (pub6, pub7). Most striking is the deviation of the positive Mexican faculty response score from the other three subgroups’ rather strong disapproval of the last two mentioned items.
The strongest disagreement between any two subgroups about the evaluation of gen-AI use for a specific research task is the divergence between Danish and Mexican students about “edit[ing] a research article to improve legibility and or language” (pub4; scores 1.41 vs 0.47 with differential rounded to 0.96). The largest disagreement between any two subgroups involving bidirectional responses pertains to “help write reports during the peer review process” (pub7), which Danish faculty evaluated quite negative while Mexican faculty regarded it, within the neutral range, nominally positive (scores −0.69 vs 0.17, with a differential of 0.85).
These disagreements notwithstanding, it is likewise striking that there are also so many convergences. Follow-up research could further explore to what extent the relatively small number of strong disagreements is caused by deeper structural differences or a merely passing experience within a subgroup.
The two independent sample unequal variances test, better known as Welch’s t-test, helps to analyze the differences in assessment scores between the Danish and Mexican samples for each of the research tasks. This test is more appropriate than the standard or Student’s t-test when the two samples have unequal variances and unequal sample size. Although neither the Danish nor the Mexican samples constitute random samples of their respective national academic populations, Welch’s t-test provides a systematic way to assess the magnitude and direction of sample-specific differences in assessment scores across research tasks. In this context, the test is used as an exploratory, model-based comparison tool that evaluates whether observed mean differences are large relative to within-sample dispersion, rather than as a basis for population-level inference. Figure 11 displays the estimated sample effects by research task on a centered scale. Positive values indicate tasks for which Danish respondents evaluated gen-AI use more positively than Mexican respondents, and negative values indicate the reverse. The intervals for the difference in sample effect are indicated by the corresponding horizontal lines.
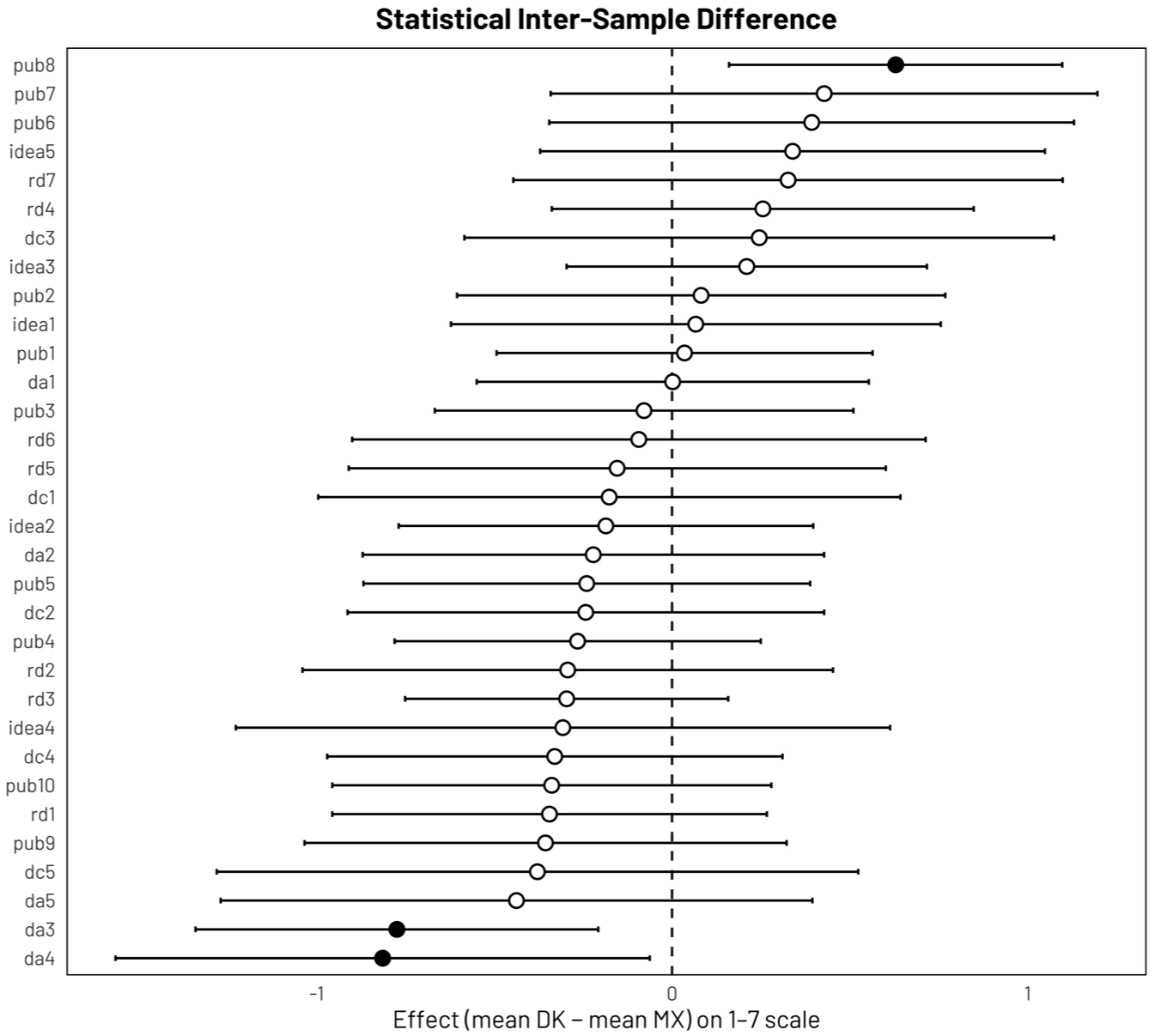
Intersample differences by research tasks. Difference in mean ratings between Denmark 2004 (DK) and Mexico 2025 (MX) with 95% confidence intervals. Black-filled circles indicate statistically significant differences (p < 0.05); white-filled circles indicate non-significant results. The dashed vertical line marks zero difference.
Most striking are the similarities between the results from the two samples and the fact that in the vast majority of paired items the divergences are within the error margins. Only three paired items showed statistically significant differences. The two items with the strongest effect embraced by the Danish side were “help pattern recognition in data” (da4) and “support statistical data analysis” (da3), which were the two items in which the Spanish wording lacked the explicit narrowing to quantitative research and could thus have shaped the effect. The task “translate your own text into a different language” (pub8) showed the strongest effect of any item embraced more strongly by the Mexican side, which could be related to the fact that researchers in Denmark use regularly for their work English instead of Danish, whereas Mexicans face strong trade-offs between writing for a domestic and large Latin American audience in Spanish or a global in English. To control for the effect of composition differential across country samples, Welch’s t-tests was also applied to disaggregated status and country groups, which showed the effect by sample stronger than by status (cf. supplemental Figure 12: Welch’s t-test of Disaggregated Status and Country Groups, provided in Appendix C).
In sum, the Welch-based comparisons reveal pronounced sample-specific differences in selected research tasks within the observed Mexican and Danish samples. These patterns are substantively informative in their own right; however, broader survey coverage based on random sampling would be required to assess whether such differences extend to national academic populations and cross-national survey coordination or iteration to assess the extent timing plays a role.
One aspect that could not be pursued here further is the strong divergence observed in the full set of the Mexican data regarding the differentiated adoption of gen-AI by academic roles, according to which faculty use gen-AI mainly in the final stages of the research process (writing and editing language), while students also use it in the initial stages of literature review and idea generation. This divergence seems to reflect not only the diversity of interests and experience between the two groups, but also the need to design differentiated training processes that respond to the specific needs of each group. Yet, this distinction largely disappeared when the MA students were eliminated from further analysis for the purpose of a more even comparison with the Danish data set. To be sure, there are marked difference between faculty and doctoral students but these are not as strong as with MA students. Hence, next international iterations of this kind of survey should consider including more junior student cohorts too.
The Mexican survey team had pointed to the high frequency of “unable to answer” responses across all phases of the research process as an indication for widespread uncertainty in how respondents evaluate the use of gen-AI (Fontanelli et al., 2025: 273). This appears to be similar to the Danish survey, in which “don’t know”-responses were merged with missing values (Andersen et al., 2025: 4). Informal conversations at the Mexican site revealed hesitation about using a new technology, whose inner working presents itself like a black box. Following Mahr and Weinberger’s (2025) suggestion from a different context, “epistemic friction” is in itself an interesting finding. The data should be analyzed in greater depth and followed up through focus groups to generate deeper insight from the epistemic unease, including the disentanglement of any “ignorance” ascribed to “don’t know” from a cautious “withholding of judgment.” It is necessary to demystify what Subramani (2025) calls “the non-innocence of our knowledge production” (p. 28). There is an apparent need for debate about how to promote responsible and ethical uses of such technologies in the generation of scientific knowledge.
The robust discrepancy between self-reported own use and perceived peer use of gen-AI in both the Danish and Mexican cases along with the low awareness of existing regulations observed in the open question part of the Mexican survey may point to institutional needs for more conversation about gen-AI usage among faculty and students, though institutional involvement should not to hinder, but enhance and guide, the integration of appropriate, productive, ethical, and transparent use of gen-AI.
Conclusion
Gen-AI has unleashed a new wave of methodological innovations in social research, leaving no research phase or aspect unaffected. This comparative study revealed considerable differences and nuanced patterns based on very recent empirical evidence on the usage, perception and assessment among social science doctoral students and faculty researchers across universities in Denmark and at an academic institution in Mexico. Among the many findings of this comparative study, we would like to highlight four central ones, along with further questions these raise.
First, the Danish and Mexican surveys show a wide adoption of gen-AI in the social science research process. Almost half of the Danish and almost two-thirds of the Mexican respondents reported a weekly or daily use. As discussed above, the Mexican cohort’s higher adoption rate may be attributed to the timing and institutional sampling. This calls for survey expansion and iteration in order to cover more institutions in Mexico and to get second data points in Denmark. At the same time, this does demonstrate that factors such as the general economic development status or GDP per capita do not play a role in determining such an outcome as apparently the level of education and institutional setting do here. The fact that Mexican respondents reported (at least) no less gen-AI use in research than their Danish counterparts suggests that Mexican researchers supported by a top institution were able to keep up with the pace of technological development and methodological innovation witnessed in the Global North. The issue of timing points to an acceleration of technological development (broadly described and analyzed by Toffler, 1970; Rosa, 2005), which appears to change the objects and practices of research at such increasing speed that it is bound to outpace established protocols of human-led review processes of academic publishing and the scholarly discourse needed for critical reflection. Will collective debate and the needed research accompany, perhaps even influence the use and norms of use of gen-AI, or will it lag behind?
Second, we find both strong convergences and differences in the types of usage and evaluation of gen-AI between the respondents from the two countries. These point to a compelling need for further research. Even the overestimation of peer-use compared to reported own use is robust across respondent populations and research phases, which we suggest to consider in upcoming survey research.
Third, the pattern of predominantly neutral or positive assessments along with pronounced disapproval of certain applications by both the Danish and Mexican respondents should not ignore the large number of “unable to answer” or missing responses. These can be seen as pointing to a need to building capacity, such as institutional efforts to raise awareness and develop practical training that not only teaches faculty and students about the merely technical use of gen-AI but involves also reflections on its implications for the development of concepts, models, theories, and approaches as well as discussions of ethical principles and academic responsibility.
Fourth, the general lack of knowledge about institutional guidelines or principles for ethical gen-AI use, and the urgency for institutional response to a new phenomenon, became especially apparent in the Mexican survey, which solicited feedback on this issue through an open question. Notably, professors emphasized norm-setting regulations while students prioritized training. This duality of concerns suggests the need to promote practices that combine both approaches and guarantee both integrity in the use of gen-AI and trust from all members of the academic community.
As discussed, the findings of this comparison have numerous limitations. While the Danish survey was undertaken across all of Denmark’s universities, the Mexican survey was focused on one of the country’s leading social science research institutions. The latter approach yielded a multiple times higher response rate but obviously it leaves open how results could differ if the survey could be expanded to other universities across the country, including both metropolitan campuses and rural ones in less prosperous regions. An iteration of the Danish survey could help plot the Mexican responses on a timeline that would help to control for the effect of survey timing. Both would be useful next steps within a broader agenda for survey research.
This initial comparison of pioneering surveys in Denmark and Mexico provides us with a snapshot of how social science researchers from the two countries use and think about gen-AI during a crucial juncture at which a new technology has exploded onto the scene, disrupting established practices, and beginning to form a new “normal” tool in the study of social phenomena. The convenience sample is drawn from strongly contrasting country contexts but this should not be misunderstood as suggesting representability or generalizability regarding country, country category, or region. However, the nuanced results demonstrate a compelling need for further and expanded research. Will the commonalities continue, perhaps even into a uniformity, or will there be more divergence? What shapes these patterns? It is hoped that this initial comparison can serve as a first baseline for further research. Replications at other universities around the world would allow interesting institutional, national, and regional comparisons.
The debate about gen-AI must take into account the unequal distribution of technological access to avoid reinforcing current social and educational inequalities. It cannot be assumed that the methodological innovations afforded by gen-AI across the different phases and practices of the research process stem from innocent tools in a merely technical production of knowledge, but debate is needed about who controls the underlying algorithms and LLMs, for what purposes, and what kind of oversight? Furthermore, it is important to consider the fact that high quality training opportunities in responsible gen-AI use should be designed to reach all users—both faculty and students—ensuring broad and equitable inclusion. Variations in approval rates across and within research phases point to the need to complement the use of gen-AI with meaningful human intervention. Complementarity rather than substitution should guide decisions about innovative uses, training, and regulation.
While emphasizing the caveat that further time-coordinated cross-national survey research is needed for validation, the comparative analysis of empirical evidence from the surveys on Denmark and Mexico points in the direction of mild optimism that, at least, the social researchers of one of the Global South’s top institutions are quite capable to access and experiment with the new research tools that are fast evolving. This may be interpreted in two ways. On one hand, a Mexican top institution is perhaps simply more akin to and more closely integrated with the Global North than with the Global South at large. On the other hand, these researchers are positioned to adopt Gen-AI and contribute to methodological innovations from a Global South perspective based on their quotidian embeddedness in a peripheralized national setting and their close proximity to lived experiences distinctive of the Global South.
Perhaps it is the peculiarity of this position that can be seen as a chance. Social scientists at institutions without regular access to computers, electricity, and internet lack the basics for testing Gen-AI and might fall further behind in the digital divide. Conversely, the social researchers at a Mexican top institution may have just sufficient access for leapfrogging innovation and overcoming epistemic inequities.
However, the data we compared relate only to the use of gen-AI, not to its control, shaping, or creation. The fact that electronic communication networks allowed a leapfrogging to a certain extent by skipping national fixed phoneline infrastructure through an immediate adoption of mobile usage should not distract from recognizing the digital divide in terms of bandwidth, skill, and usage quality. Yet, phone networks and the classic internet were largely conceived as content-neutral, akin to the system of pen and paper. Content neutrality was already no longer the case with oligarchically owned social media platforms and less so with gen-AI. How ownership and control of gen-AI platforms will interfere with and shape social research practices are crucial research questions.
The comparative analysis of empirical evidence contributes to a knowledge base for urgently needed reflection and debate on what kind of training can help to unleash the benefits of gen-AI in social research and what kind of regulations or guiding principles can help to contains risks and orient ethically responsible usage. How new technology is adopted, used, and shaped is not an inevitable process but can be shaped through research, reflection, and imaginative deliberation. It is crucial that these processes involve both the Global North and the Global South.
Footnotes
Appendix A
Appendix B
The five phases of the research process and the associated tasks.
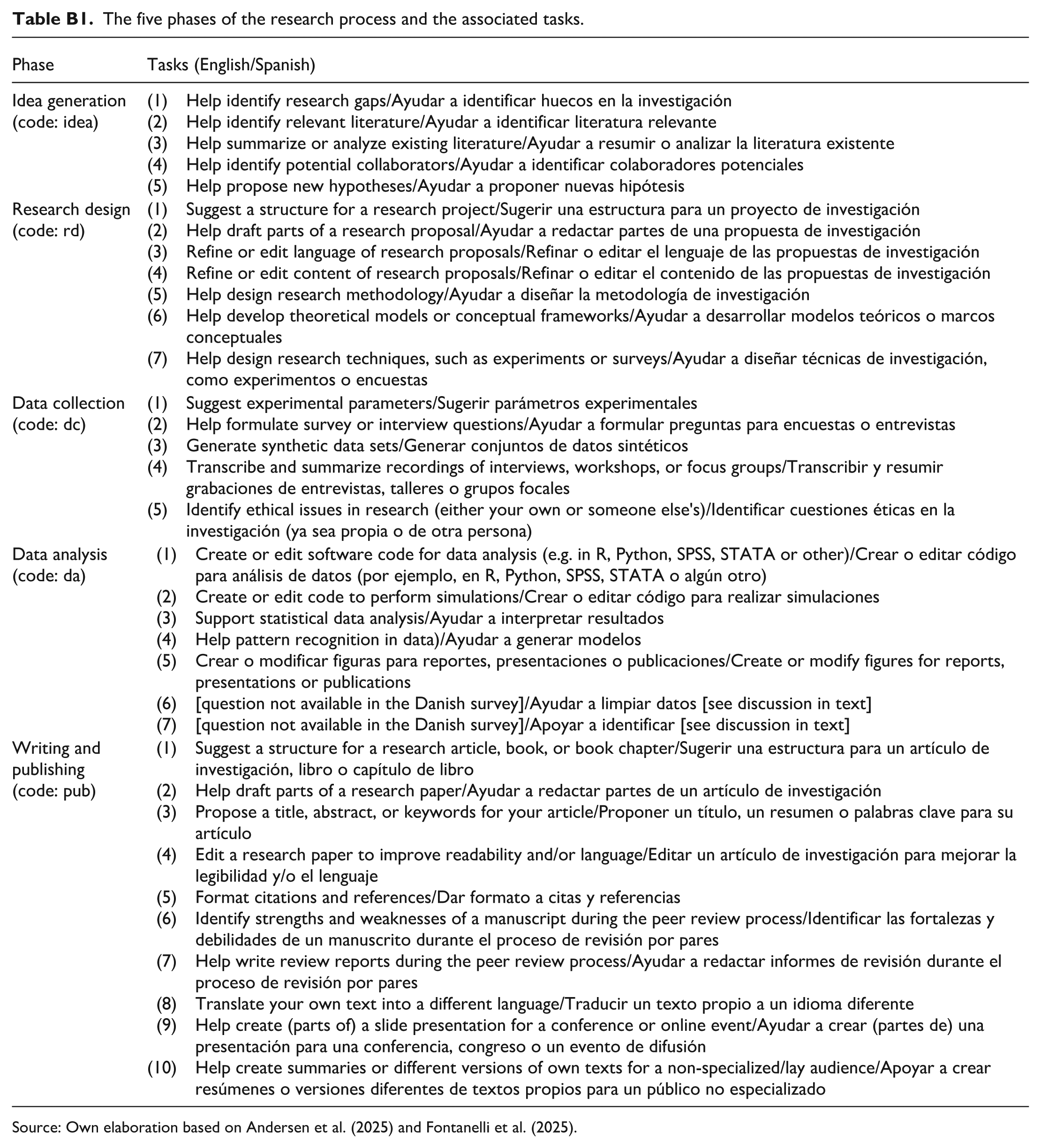
| Phase | Tasks (English/Spanish) |
|---|---|
| Idea generation (code: idea) | (1) Help identify research gaps/Ayudar a identificar huecos en la investigación (2) Help identify relevant literature/Ayudar a identificar literatura relevante (3) Help summarize or analyze existing literature/Ayudar a resumir o analizar la literatura existente (4) Help identify potential collaborators/Ayudar a identificar colaboradores potenciales (5) Help propose new hypotheses/Ayudar a proponer nuevas hipótesis |
| Research design (code: rd) | (1) Suggest a structure for a research project/Sugerir una estructura para un proyecto de investigación (2) Help draft parts of a research proposal/Ayudar a redactar partes de una propuesta de investigación (3) Refine or edit language of research proposals/Refinar o editar el lenguaje de las propuestas de investigación (4) Refine or edit content of research proposals/Refinar o editar el contenido de las propuestas de investigación (5) Help design research methodology/Ayudar a diseñar la metodología de investigación (6) Help develop theoretical models or conceptual frameworks/Ayudar a desarrollar modelos teóricos o marcos conceptuales (7) Help design research techniques, such as experiments or surveys/Ayudar a diseñar técnicas de investigación, como experimentos o encuestas |
| Data collection (code: dc) | (1) Suggest experimental parameters/Sugerir parámetros experimentales (2) Help formulate survey or interview questions/Ayudar a formular preguntas para encuestas o entrevistas (3) Generate synthetic data sets/Generar conjuntos de datos sintéticos (4) Transcribe and summarize recordings of interviews, workshops, or focus groups/Transcribir y resumir grabaciones de entrevistas, talleres o grupos focales (5) Identify ethical issues in research (either your own or someone else’s)/Identificar cuestiones éticas en la investigación (ya sea propia o de otra persona) |
| Data analysis (code: da) | (1) Create or edit software code for data analysis (e.g. in R, Python, SPSS, STATA or other)/Crear o editar código para análisis de datos (por ejemplo, en R, Python, SPSS, STATA o algún otro) (2) Create or edit code to perform simulations/Crear o editar código para realizar simulaciones (3) Support statistical data analysis/Ayudar a interpretar resultados (4) Help pattern recognition in data)/Ayudar a generar modelos (5) Crear o modificar figuras para reportes, presentaciones o publicaciones/Create or modify figures for reports, presentations or publications (6) [question not available in the Danish survey]/Ayudar a limpiar datos [see discussion in text] (7) [question not available in the Danish survey]/Apoyar a identificar [see discussion in text] |
| Writing and publishing (code: pub) | (1) Suggest a structure for a research article, book, or book chapter/Sugerir una estructura para un artículo de investigación, libro o capítulo de libro (2) Help draft parts of a research paper/Ayudar a redactar partes de un artículo de investigación (3) Propose a title, abstract, or keywords for your article/Proponer un título, un resumen o palabras clave para su artículo (4) Edit a research paper to improve readability and/or language/Editar un artículo de investigación para mejorar la legibilidad y/o el lenguaje (5) Format citations and references/Dar formato a citas y referencias (6) Identify strengths and weaknesses of a manuscript during the peer review process/Identificar las fortalezas y debilidades de un manuscrito durante el proceso de revisión por pares (7) Help write review reports during the peer review process/Ayudar a redactar informes de revisión durante el proceso de revisión por pares (8) Translate your own text into a different language/Traducir un texto propio a un idioma diferente (9) Help create (parts of) a slide presentation for a conference or online event/Ayudar a crear (partes de) una presentación para una conferencia, congreso o un evento de difusión (10) Help create summaries or different versions of own texts for a non-specialized/lay audience/Apoyar a crear resúmenes o versiones diferentes de textos propios para un público no especializado |
Source: Own elaboration based on Andersen et al. (2025) and Fontanelli et al. (2025).
Appendix C
Ethical considerations
This article compares data from previously reported surveys, which were following all institutional ethics protocols and are referenced in the article.
Consent to participate
This article compares data from previously reported surveys, which are based on informed consent and referenced in the article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data availability statements are included in the referenced articles, in which the data from the surveys in Denmark and Mexico were first reported.