
Abstract
Background:
Event-related potentials (ERPs) provide implicit feedback and error-correction signals that are valuable for brain–computer interfaces (BCIs). However, models trained on source-domain subject data are vulnerable to inter-subject variability and acquisition noise, which substantially degrades generalization to unseen subjects.
Objective:
We propose a multi-view contrastive learning domain generalization (MVCLDG) method to improve cross-subject generalization in ERP recognition by jointly exploiting discriminative feature extraction and domain-invariant representation learning.
Methods:
MVCLDG employs a multi-view feature-extraction module that fuses raw electroencephalography with phase information derived from the Hilbert transform via multi-scale inception blocks, thereby capturing both amplitude and phase features. The model then applies domain-alignment and contrastive-learning constraints to reduce distributional discrepancy across domains, compact within-class representations, and enlarge between-class separability. The approach was evaluated on a public Error-Related Negativity (ERN) dataset and a self-collected semantic–syntactic violation dataset; performance was assessed in cross-subject settings, and ablation and visualization analyses were conducted to probe the contributions of components and neurophysiological interpretability.
Results:
MVCLDG outperformed baseline and representative domain generalization methods in cross-subject ERP recognition without requiring additional target-domain adaptation. Ablation experiments confirmed the effectiveness of each component. Eigen-Class Activation Maps visualizations indicate consistency between the model-attended electrodes and known neurophysiological scalp patterns, supporting both the model’s generalization mechanism and its biological interpretability.
Conclusions:
MVCLDG offers an effective strategy for integrating phase-aware multi-view feature mining with contrastive domain generalization, yielding improved and interpretable cross-subject ERP recognition. The method advances the feasibility of ERP-based closed-loop BCIs that generalize across users.
Impact Statement
This study introduces a novel multi-view contrastive learning domain generalization (MVCLDG) framework. By integrating raw electroencephalography (EEG) with Hilbert-transformed EEG as complementary views, MVCLDG captures joint amplitude–phase features and, via multi-view contrastive learning, extracts domain-invariant representations. Together, these mechanisms improve cross-subject generalization by integrating discriminative feature mining with domain-invariant representation learning. In addition, we constructed a Chinese semantic–syntactic violation event-related potential (ERP) dataset, thereby addressing a critical gap in language-related ERP resources. This work not only provides new directions for improving cross-subject ERP recognition but also lays the groundwork for generalizing ERP-based closed-loop brain–computer interfaces across users.
Introduction
Brain–computer interfaces (BCIs) establish a direct communication pathway between neural activity and external devices by decoding brain signals into executable commands (Chaudhary et al., 2016). This technology enables the use of neural signals in applications such as neurorehabilitation, rehabilitation engineering, and emotion recognition (Nicolas-Alonso and Gomez-Gil, 2012). Owing to the noninvasiveness, cost-effectiveness, and high temporal resolution of electroencephalography (EEG) (Holz et al., 2013), most BCI systems are developed based on EEG signals.
The performance of traditional EEG-based BCI systems relies heavily on the user’s long-term training and ability to adapt, a process that is typically slow and inefficient. The core challenge is that such systems lack an efficient intrinsic feedback and correction mechanism, preventing them from optimizing in real time using error signals, as occurs in motor learning. ERPs are phase-locked EEG responses elicited by specific stimuli, characterized by a high signal-to-noise ratio and distinct features (Polich, 2007). When users perceive an error generated by the BCI system, the brain automatically produces specific ERP components, such as error-related negativity, without requiring any overt behavioral response. This neural response, which reflects the brain’s intrinsic mechanisms for conflict monitoring and error detection, offers a transformative opportunity for BCI systems to achieve closed-loop adaptive correction (Mak and Wolpaw, 2009).
With the rapid progress of deep learning, the adoption of deep neural networks in EEG analysis has opened new avenues for ERP research. Compared with conventional approaches, models such as EEGNet and Lightweight Multi-Dimensional Attention Network, which integrate convolutional neural networks (CNNs) and attention mechanisms, have demonstrated superior performance in ERP recognition (Miao et al., 2023; Lawhern et al., 2018). However, these general-purpose EEG model architectures remain limited in addressing two challenges that are specific to ERP signal recognition:
Insufficient feature extraction: Compared with conventional EEG signals, valid ERP trials are shorter in duration, and informative content is often concentrated within a specific post-stimulus interval. Moreover, ERP signals exhibit phase-locking and waveform-specific properties. Generic architectures, such as EEGNet, primarily rely on spatial–temporal convolutions of raw EEG signals and fail to explicitly model and efficiently integrate ERP-discriminative features, including phase-related information and peak density. High inter-subject variability: ERP signals exhibit substantial variability across individuals, which arises from differences in signal noise, cognitive state, and fatigue level. Such variability leads to feature distribution shifts between the source and target subject domains, thereby reducing the generalization performance of classification models trained on source subjects. Although models such as EEGNet demonstrate strong performance on within-subject data, their architectures are not explicitly designed to extract domain-invariant representations shared across subjects, which limits their generalization capability when confronted with cross-subject distribution shifts.
To overcome the limitations of existing ERP recognition methods in feature extraction and inter-subject variability, we propose a multi-view contrastive learning domain generalization (MVCLDG) approach that extracts domain-invariant features from two complementary views: raw EEG signals and Hilbert-transformed EEG (HT-EEG) signals. The main contributions of this work are as follows:
We use raw EEG signals and HT-EEG signals as two input views to integrate phase information with amplitude information, thereby addressing the limitation of insufficient feature extraction in existing methods. We develop the MVCLDG model for multi-view EEG signals, incorporating a multi-scale spatiotemporal feature extraction module and a contrastive learning-based domain-invariant feature extraction module to enhance cross-subject recognition performance. We conduct an experiment involving the recognition of sentences with semantic and syntactic violations to construct the violation dataset, thereby addressing the lack of Chinese semantic–syntactic recognition datasets and further demonstrating the practical effectiveness of our recognition algorithm. We analyze the effectiveness of the MVCLDG model by visualizing intermediate features and identifying task-relevant domain-invariant ERP components.
Related Work
ERP signal analysis
Extensive research on ERP detection has primarily focused on developing effective recognition algorithms (Lotte et al., 2007). Traditional approaches, such as support vector machines (Müller et al., 2018) and linear discriminant analysis (Lotte et al., 2007; Krusienski et al., 2008), have been widely applied in ERP analysis. These methods classify samples by constructing high-dimensional feature spaces, showing particularly strong performance on small datasets. However, as dataset size increases and user diversity grows, these traditional methods often suffer from performance degradation, especially in scenarios characterized by pronounced individual differences. To overcome these limitations, researchers have developed advanced algorithms. For instance, xDAWN-based methods enhance ERP features to improve the signal-to-noise ratio, thereby increasing classification accuracy (Barachant et al., 2012; Rivet et al., 2009). In addition, Riemannian geometry–based ERP classifiers exploit geometric representations to capture the intrinsic structure of the data, demonstrating promising results on complex datasets (Barachant et al., 2012; Congedo et al., 2017).
With the rapid advancement of deep learning, significant progress has been achieved in pattern recognition and feature engineering (LeCun et al., 2015). Deep neural networks, particularly convolutional neural networks, have been extensively used to extract temporal and spatial information from EEG signals, yielding remarkable results (Craik et al., 2019; Roy et al., 2019). Classical architectures such as Deep ConvNets employ deep spatiotemporal convolutional layers for EEG feature extraction (Schirrmeister et al., 2017). Building on this foundation, EEGNet introduced separable convolutions to design a compact yet efficient network, which has achieved excellent results across multiple experiments and has become a benchmark model in EEG processing (Lawhern et al., 2018). Subsequently, EEG-TCNet reduced the number of trainable parameters, enabling greater efficiency on resource-constrained devices (Ingolfsson et al., 2020). Eduardo et al. further proposed EEG-Inception, which integrates the Inception module from computer vision and achieved significant improvements in ERP recognition (Santamaría-Vázquez et al., 2020).
Despite these advances, unresolved challenges remain in ERP research, which continue to limit the performance of recognition tasks using such data. We focus on two key challenges:
Compared with conventional EEG signals, ERP signals offer a higher signal-to-noise ratio but a substantially shorter effective duration, which requires efficient extraction of discriminative features within a limited temporal window. However, existing methods have not sufficiently leveraged the rich phase information, specific waveforms, and other attributes embedded in ERP signals. ERP signals also exhibit pronounced cross-subject variability, arising from differences in noise levels, cognitive states, fatigue, and physiological conditions. Such factors cause domain shifts when models trained on source subjects are applied to target subjects, thereby substantially impairing generalization performance.
Multi-view learning
Multi-view learning (MVL) aims to exploit complementary information provided by different views of the same phenomenon. In MVL, data are typically represented as multiple views that integrate different modalities or feature sets (Zhang et al., 2020a). MVL was initially applied to multimedia data, which commonly originate from heterogeneous sources such as text, video, and audio or are characterized by multiple representations (e.g., time-domain and frequency-domain features) (Zhang et al., 2020b; Li et al., 2022; Tang et al., 2020). Existing studies indicate that fusing diverse views to leverage complementary information can improve model accuracy (Tao et al., 2020; Tang et al., 2023). This benefit has been demonstrated across tasks. For example, in text classification, the Multimodal Bitransformer model fuses textual and visual views to leverage image features associated with accompanying text (Kiela et al., 2020). In the image domain, Tian et al. proposed a multi-view contrastive learning framework called Contrastive Multiview Coding, which learns compact representations for raw images and optical flow to maximize the mutual information between different views of the same scene (Tian et al., 2020).
Recently, several studies have extended MVL to EEG signal analysis. Ye et al. constructed temporal and spectral views of EEG signals and exploited their complementarity to mine additional positive pairs, thereby improving contrastive learning performance (Ye et al., 2022). An et al. proposed an amplitude-temporal dual-view fusion method for temporal-feature learning in automatic sleep staging (An et al., 2024a). Zhao et al. investigated the relationship between temporal and time–frequency views and developed a self-supervised multi-view representation learning framework for sleep-stage classification (Zhao et al., 2024). However, existing multi-view approaches in the EEG domain have not been extended to ERP recognition. A robust view-generation and fusion strategy tailored to ERP signals is still lacking.
Domain generalization
Owing to the pronounced inter-subject variability in EEG signals, numerous studies have applied domain generalization (DG) approaches to cross-subject classification tasks. These approaches aim to learn domain-invariant representations from source domains and exploit neural networks to capture shared inter-subject features, thereby improving classification performance (Santamaría-Vázquez et al., 2019). Within existing DG research, Pan et al. employed prototype learning to extract domain-level feature prototypes, which were then used to predict outcomes for new subjects, achieving promising results in zero-shot learning (Pan et al., 2023; An et al., 2024b). Domain-adversarial neural networks (DANNs), which learn domain-invariant representations through adversarial training between a discriminator and a generator, have also demonstrated substantial utility in DG tasks. Li et al. introduced the bi-hemisphere DANN, which incorporates one global and two local domain discriminators to extract emotion-discriminative features specific to each hemisphere (Li et al., 2021b). More recently, contrastive learning has been applied to DG tasks. Shen et al. developed a CNN-based contrastive learning framework that outperformed existing DG methods in cross-subject emotion recognition, thereby demonstrating the effectiveness of contrastive learning strategies in DG, particularly in cross-subject scenarios (Shen et al., 2023).
As an unsupervised learning paradigm, contrastive learning seeks to derive more discriminative feature representations by maximizing similarity between positive pairs while simultaneously minimizing alignment with negative pairs. Contrastive learning has demonstrated strong performance across multiple domains, including computer vision (Chen et al., 2020), natural language processing (NLP; Devlin et al., 2019), and bioinformatics (Li et al., 2021a; Liu et al., 2021). Initial applications of contrastive learning in the EEG domain typically adopted frameworks originally designed for computer vision or NLP. A representative example is the work of Mohsenvand et al., who adopted the Simple Framework for Contrastive Learning of Visual Representations (SimCLR) framework (Chen et al., 2020) to model similarities among multiple augmented views of the same raw EEG data (Mohsenvand et al., 2020), achieving favorable performance across several downstream tasks, including sleep stage classification, clinical anomaly detection, and emotion recognition.
In the context of cross-subject EEG recognition, Shen et al., inspired by inter-subject correlation studies (Hasson et al., 2004; Dmochowski et al., 2012), proposed a CNN-based contrastive learning framework designed to extract domain-invariant features. Without relying on extensive external data, their method achieved state-of-the-art performance in cross-subject emotion recognition (Shen et al., 2023). Deng et al. proposed the multi-source contrastive learning transfer model, which leverages contrastive learning to capture interindividual variability and incorporates domain adaptation and multi-domain feature learning to enhance model generalization across subjects (Deng et al., 2024). Zhi et al. introduced a supervised contrastive learning-based domain generalization network for cross-subject motor imagery and motor execution decoding, which extracts both domain-invariant and class-relevant discriminative representations from multiple EEG frequency bands (Zhi et al., 2025). Collectively, these studies further underscore the potential of contrastive learning in cross-subject EEG signal recognition.
Methods
In this section, we present the proposed MVCLDG framework, as illustrated in Figure 1. First, the Hilbert transform is applied to the raw ERP signals to obtain HT signals, thereby capturing richer feature information. Next, we design an efficient dual-path, multi-scale spatiotemporal convolutional module to learn class-related information from both the raw EEG and HT-EEG views. Contrastive learning is then performed on the dual-view and fused-view features. The subsequent subsections provide a detailed description of each component.
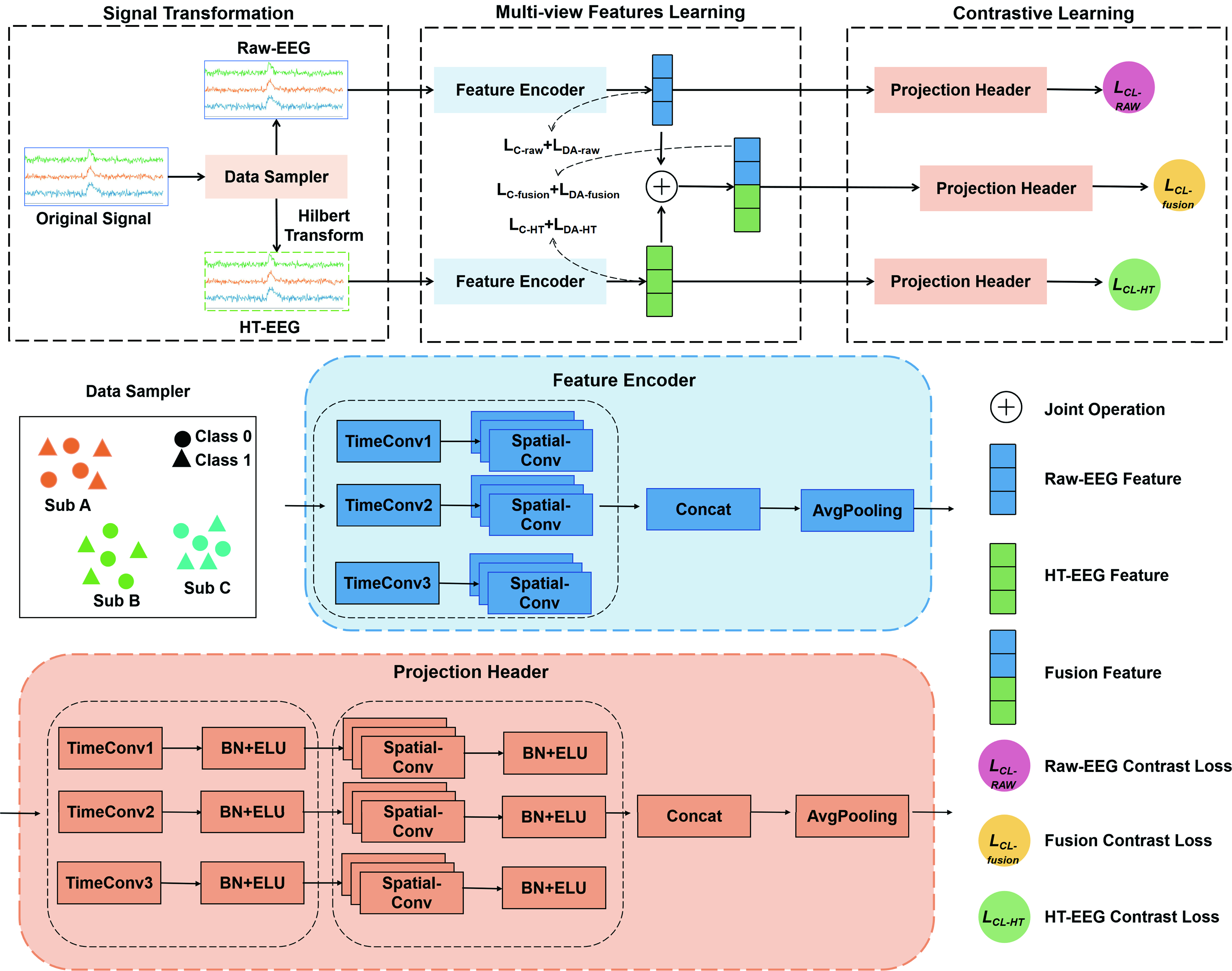
An overview of the MVCLDG architecture, which comprises three main components: the signal processing block, the feature encoder, and the contrastive learning block. The signal processing block generates mini-batches from the raw signals for contrastive learning and applies the Hilbert transform to Raw-EEG to construct the HT-EEG view. The feature encoder extracts spatiotemporal representations from both views. Subsequently, the contrastive learning block learns domain-invariant representations. Finally, the network is jointly optimized using three objectives: the classification loss (
Signal transformation
ERP exhibits phase-locking, that is, under specific stimulus conditions, participants’ EEG responses show a high degree of phase consistency (Helfrich and Knight, 2019). Given the importance of phase information for ERP recognition, we exploit phase as one of the bases for constructing multi-view representations. When using phase information, reliance on phase-synchronization indices (e.g., phase-locking value and phase-lag index) can overly simplify the information and may yield suboptimal performance (Moon et al., 2018; Wang et al., 2019). Therefore, we use both raw EEG and HT-EEG as two complementary input views to the network so as to exploit phase information more fully.
The Hilbert transform is a widely used method for extracting phase information from raw EEG. A two-view architecture enables us to retain amplitude information from the raw EEG while simultaneously deriving phase information from the HT-EEG view (Kim and Im, 2024). Specifically, the Hilbert transform is a mathematical operation that maps a real-valued signal to a signal that is orthogonal to the original. For a real-valued signal x(t), the Hilbert transform H(x(t)) is defined as:
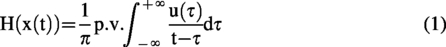

H(x(t)) is a complex-valued signal whose real part corresponds to the original signal x(t), while the imaginary part corresponds to the Hilbert-transformed signal (denoted here as x’(t)). The magnitude and argument (phase) of the complex signal H(x(t)) correspond to the instantaneous amplitude and phase, respectively, thus both amplitude and phase information of the original EEG signal are preserved. Unlike other approaches (e.g., wavelet transforms) that require a predefined time window, the Hilbert transform is data driven and computationally efficient, rendering it suitable for the real-time constraints of online BCI systems. By employing the Hilbert transform, our CNN is expected to capture both amplitude and phase features from EEG data, thereby improving the model’s capacity to extract class-discriminative features.
Multi-view contrastive learning domain generalization
Dual-view feature encoder
The ability of an EEG feature encoder to extract discriminative representations underpins robust performance in cross-subject scenarios. Motivated by the multi-branch design of Inception blocks, we design a dual-view feature encoder to learn discriminative representations. Specifically, the encoder comprises two parallel sub-encoders—one for the raw EEG view and one for the HT-EEG view. Each view is processed by a base feature encoder with an identical Inception-style architecture; the two independent extraction paths preserve view-specific information.
The dual-view design allows the model to retain amplitude information from the raw EEG while exploiting phase information provided by the HT-EEG view. In an Inception module, the input from the previous layer is routed through parallel paths consisting of multi-scale convolutions and pooling operations to produce features, which are subsequently concatenated into a single output. In MVCLDG, the raw EEG and HT-EEG views correspond to one another and are processed by parallel, Inception-like feature-extraction paths operating at the view level. Concretely, the feature-extraction pipeline comprises two EEG inputs (raw EEG and HT-EEG), parallel input paths, and a subsequent filter-wise concatenation stage. The Hilbert transform converts the real-valued raw EEG into a complex signal whose real part corresponds to the original waveform and whose imaginary part encodes the Hilbert-derived signal. We split the complex signal into two real-valued inputs: the raw EEG (real part) is used directly, and the HT-derived imaginary part is converted to a real representation (e.g., by taking the analytic signal’s imaginary component) to serve as the HT-EEG input. Each base feature encoder processes its respective raw EEG or HT-EEG input to produce output feature maps. Output feature maps from the two input paths are concatenated along the depth dimension; after this filter-wise concatenation, the depth dimension is effectively doubled.
Each base encoder comprises a multi-scale temporal convolutional block followed by a spatial convolutional block to extract spatiotemporal features. In the multi-scale temporal block, multiple branches are set up in parallel, each corresponding to a different temporal kernel size. Each branch employs a 2D temporal kernel of a different size—specifically (1, T/2), (1, T/4), and (1, T/8)—to capture both transient events and rhythmic oscillatory patterns. Each branch produces D feature maps. Following the temporal convolutions, depthwise separable convolutions are applied to learn spatial patterns across EEG channels. To aggregate spatial information across input channels, 2D convolutional kernels of size (C,1) are employed; channel grouping and weight constraints (cf. EEGNet) are used to promote spatial feature disentanglement. The outputs of the three branches are downsampled in time via average pooling with kernel size (1,4) and stride (1,4). All output feature maps are concatenated along the depth dimension to form the feature representation f, where
Domain-generalization module
To improve cross-subject performance, our model incorporates a domain-generalization module that learns class-related, subject-invariant features from ERP signals, thereby enhancing robustness to individual variability. The domain-generalization module comprises two components: a domain-alignment component and a contrastive-learning component, both intended to address distributional discrepancies between domains. The domain-alignment component minimizes distributional differences among source subjects, while the contrastive-learning component facilitates learning of domain-invariant representations.
The domain-alignment component is specifically designed to mitigate intersubject distributional variability. Unlike domain-adaptation approaches, which align source and target distributions using target data, domain generalization aims to achieve robustness without access to target-domain samples. Consequently, we perform alignment across pairs (or groups) of source subjects: the rationale is that representations that are invariant to source-domain perturbations are more likely to generalize to unseen target subjects (Zhou et al., 2023). To realize domain alignment, we integrate the Deep Correlation Alignment (CORAL) loss into our framework to align second-order statistics across distributions. Deep CORAL promotes domain-invariant feature extraction by aligning the covariance matrices of the learned feature representations. Let
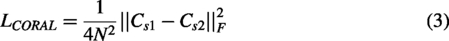
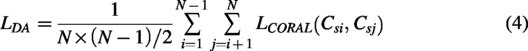
Contrastive learning aims to obtain domain-invariant representations by pulling together representations of samples from the same class (positive pairs) while pushing apart representations from different classes (negative pairs) in the latent space. To this end, a feature projection head is inserted between the base encoder and the contrastive loss to better shape representations for downstream prediction. The projection head architecture popularized by SimCLR (a nonlinear Multi-Layer Perceptron (MLP)) is widely used because it helps the base encoder learn improved representations. However, because ERP datasets are relatively small, MLP-based projection heads tend to be over-parameterized and prone to overfitting. Motivated by modular architectural design, we implement the projection head using convolutional units analogous to those in the base encoder. The projection head comprises two stages: (1) multi-scale temporal convolutions with kernels (1,T/8), (1,T/16), and (1,T/32) and (2) a depthwise (channel-wise) convolution stage with kernel size (2D,1) to model relationships across channels. This design reduces parameter count while preserving spatiotemporal feature extraction capacity. Each convolutional stage is followed by batch normalization (for feature standardization), an ELU activation (for nonlinearity), and appropriate regularization (e.g., dropout) to mitigate overfitting. After projection, features are vectorized so that inner products in the projection space can be used to measure similarity. The projection head is discarded after training; at inference time, we use only the feature encoder and the classifier. In deployment, only the feature encoder and classifier C are used for ERP recognition.
Contrastive losses
The MVCLDG framework defines loss functions for the raw EEG view, the HT-EEG view, and the fused view. For each view, three objectives are jointly optimized: the classification loss
The classification loss is the cross-entropy loss, which minimizes the discrepancy between predicted and ground-truth labels. For a batch of N samples, the cross-entropy loss is defined as:

Here
To construct effective batches for contrastive learning, we employ a stratified sampling strategy. Let the source domain consist of n subjects. For each subject, k samples are randomly and uniformly selected from each of the C experimental classes, resulting in a total batch size of N = n × C × k. This design ensures strict class balance within each batch and avoids sample duplication. The proposed strategy mitigates potential bias caused by class imbalance and encourages each batch to encompass diverse intersubject variations, thereby facilitating the learning of domain-invariant representations.
Following the batch construction strategy described above, positive and negative sample pairs for contrastive learning are formally defined. A positive pair is formed by two projection vectors
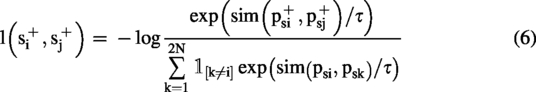
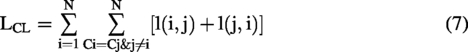
In the above formula,
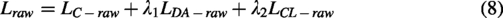
The weight coefficients
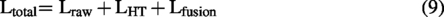
By jointly optimizing these objectives, the model converges toward representations that are both class-discriminative and domain-invariant.
Experiments and Results
This section evaluates the effectiveness of the proposed method on two ERP classification datasets, including one collected in-house. The experimental setup and results are described in detail.
Datasets
Dataset I (feedback error-related negativity)
In the Kaggle-ERN dataset, EEG signals were recorded from 26 healthy participants using 56 electrode channels placed according to the extended 10–20 system, at a sampling rate of 600 Hz (Margaux et al., 2012). During the experiment, participants were presented with a 6 × 6 matrix containing 36 alphanumeric characters to elicit P300 responses (Krusienski et al., 2008). This dataset is designed to identify neural responses associated with erroneous selections by analyzing post-feedback EEG signals. Each participant completed 340 trials. The median number of error-feedback trials was 115.5 (range: 20–199), whereas the median number of correct-feedback trials was 237.5 (range: 141–320), yielding a median error-to-correct trial ratio of 0.51 (range: 0.06–1.41). No demographic information (e.g., age or gender) is available in this public dataset. Prior to analysis, EEG data were band-pass filtered between 1 and 40 Hz using an Finite-Impulse Response (FIR) filter in EEGLAB (Delorme and Makeig, 2004), and then down-sampled to 128 Hz. EEG trials corresponding to correct and incorrect feedback were extracted from the [0,1.25]s time window following feedback presentation and used as features for a binary classification task.
Dataset II (Chinese semantic–syntactic violation ERP)
The Chinese semantic–syntactic violation ERP (CSSV-ERP) dataset was collected in-house. EEG signals were recorded from 12 healthy participants using 64 electrodes placed according to the 10–20 system, at a sampling rate of 500 Hz. As illustrated in Figure 2, Chinese sentences were presented to participants one word at a time. Each word was displayed for 400 ms (stimulus), followed by a 100 ms blank screen (fixation). Participants completed the task under three conditions (Zhu et al., 2022): (1) correct sentences (CORR), that is, well-formed subject–verb–object sentences; (2) local syntactic violation (SYN-P), in which a degree adverb that normally modifies an adjective is erroneously inserted before the object noun, rendering the phrase syntactically ill-formed; (3) semantic violation (SEM), in which the object conflicts with the verb’s selectional restrictions. This dataset aims to probe participants’ cognitive processing of grammatical and syntactic violations by analyzing EEG signals recorded after participants’ button presses. In BCIs that select characters by detecting users’ cognitive responses, semantic processing (N400) can serve either as an additional control signal or as a monitoring indicator of the appropriateness of system instructions. Each participant completed a total of 192 trials, with 64 trials per stimulus category. The final sample consisted of 10 males and 2 females aged 22–26 years, all of whom held a bachelor’s degree. Thirteen participants were initially recruited for this study. One participant was excluded due to excessive EEG artifacts, accounting for more than 25% of the total trials. Before analysis, EEG recordings were band-pass filtered between 0.1 and 60 Hz using an FIR filter in EEGLAB. Independent component analysis was applied to remove ocular and muscular artifacts, and the data were re-referenced to TP9 and TP10. After preprocessing, a median of 68.5 correct trials (range: 54–63), 61.5 semantic violation trials (range: 48–64), and 61.5 syntactic violation trials (range: 47–63) were retained per subject. EEG segments corresponding to semantic and syntactic violations were extracted from the [−0.15, 1] s time window relative to the critical word onset (first object noun position) and used as features for a multi-class classification task, with baseline correction applied using the −150 to 0 ms interval. Detailed information about the CSSV-ERP dataset can be found in the dataset card (Table 1).
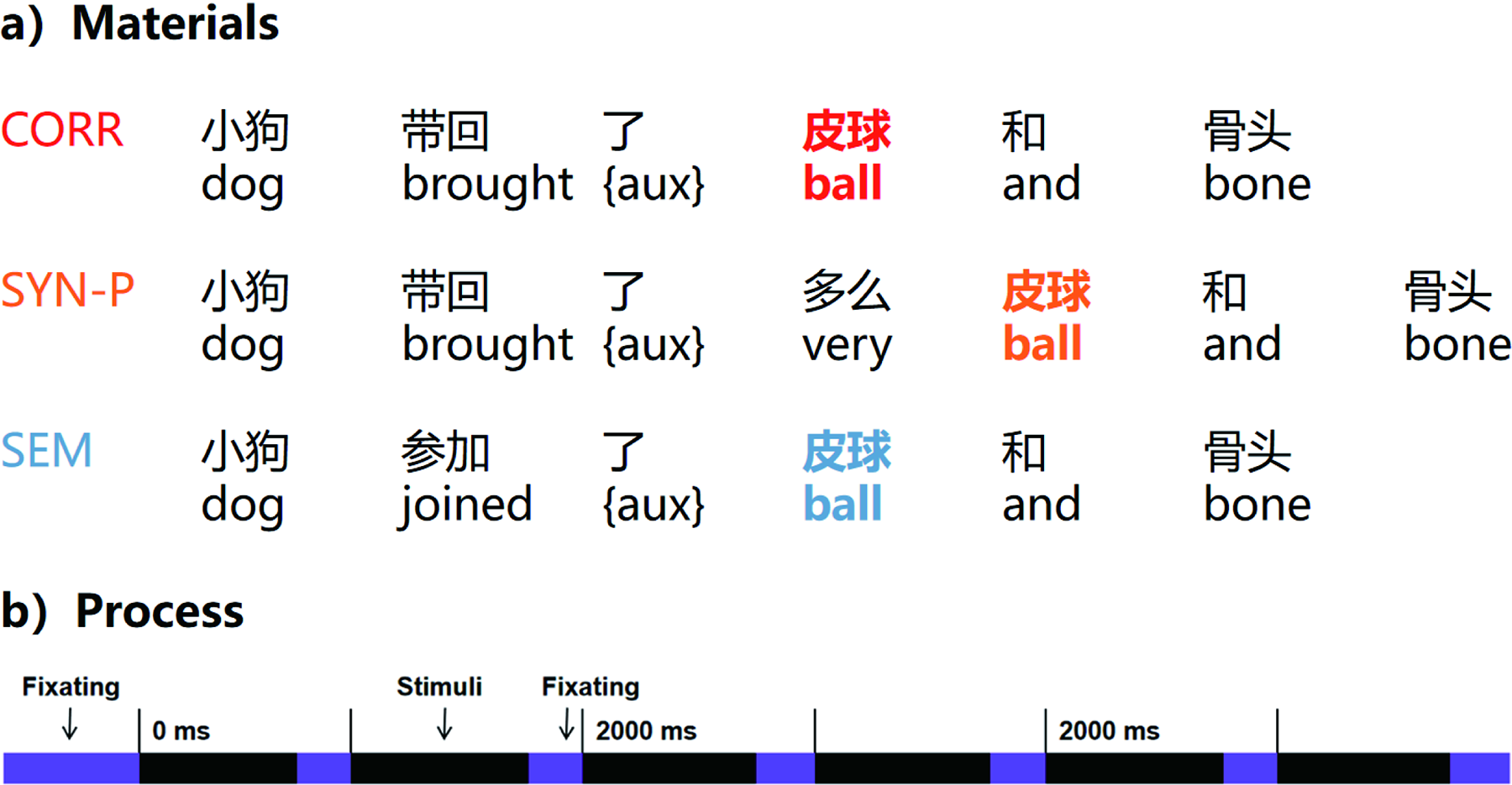
Example stimuli from the semantic–syntactic violation paradigm.
Dataset Card for Chinese Language Event-Related Potential Dataset

EEG, electroencephalography; ICA, independent component analysis.
Experiment details
Network settings
The code was implemented in PyTorch (Paszke et al., 2019) and evaluated on an NVIDIA RTX 5000 GPU. The training objective combined cross-entropy loss, domain-alignment loss, and contrastive loss. The maximum number of training epochs was set to 100. The learning rate was selected via grid search from the set {1e-3, 1e-4, 1e-5}, with 1e-3 yielding the best performance. Similarly, the dropout rate was chosen from {0.1, 0.25, 0.5} and set to 0.5. During training, each mini-batch was required to include samples from every class of each source subject; therefore, the batch size was determined by the number of source-domain subjects and stimulus categories (batch size = number of source subjects × the number of stimulus categories × 2). The Adam optimizer was used for optimization, and early stopping was applied to reduce training time and prevent overfitting. The loss weighting coefficients
Comparison models
To validate our method, we compared it with standard deep-learning baselines and representative domain-generalization techniques. For deep-learning baselines, we used EEGNet (Lawhern et al., 2018), EEG-Inception (Santamaría-Vázquez et al., 2020), EEG-Conformer (Song et al., 2023), and HiReNet (Kim and Im, 2024): EEGNet was chosen for its established role as a compact benchmark architecture for EEG, while EEG-Inception adapts Inception-style multi-scale parallel convolutions to EEG data. EEG-Conformer integrates convolutional architectures commonly used in EEG analysis with transformer-based modeling. Building upon a ResCNN backbone, HiReNet incorporates raw EEG signals and their Hilbert-transformed counterparts as dual inputs. For domain generalization methods, we evaluated Mixup (Zhang et al., 2018), maximum mean discrepancy (MMD) (Li et al., 2018b), invariant risk minimization (IRM) (Arjovsky et al., 2020), meta-learning for domain generalization (MLDG) (Li et al., 2018a), DANN (Ozdenizci et al., 2020), and SelfReg (Kim et al., 2021). Mixup performs convex interpolation between randomly selected sample–label pairs to synthesize training examples, thereby regularizing the decision boundary and improving cross-subject robustness. MMD minimizes distributional discrepancy between source domains in an Reproducing Kernel Hilbert Space (RKHS), encouraging domain-invariant latent representations without access to target data. IRM enforces a shared classifier across domains that depends only on features exhibiting a stable causal relationship with labels, thus mitigating spurious EEG artifacts. MLDG splits source domains into “meta-train” and “meta-test” partitions and uses bi-level optimization to promote rapid adaptation to unseen domains. DANN employ a domain-adversarial training framework to learn subject-invariant representations across individuals. SelfReg incorporates contrastive and other regularization terms during self-supervised pretraining to align cross-domain feature distributions while preserving discriminative information.
Training procedure
This study focuses on cross-subject domain-generalization scenarios for deep models. To assess effectiveness and generalization, we adopt the leave-one-subject-out (LOSO) protocol. In each LOSO round, data from one subject are held out as the test set, and data from all remaining subjects are pooled as source data; the pooled source data are split into 80% training and 20% validation subsets. All trials from any given subject were strictly confined to either the training, validation, or test set, thereby preventing subject-level information leakage. After training for the maximum number of epochs, the model achieving the best performance on the validation subset is selected for final testing on the held-out subject. We report the average cross-subject test performance across all LOSO rounds.
Results
We adopted the LOSO scheme, in which data from one subject were used for testing, while data from all other subjects were used for training the classifier, in order to evaluate the proposed method. The LOSO procedure resembles real-world cross-subject applications, where the model is trained on available data and validated on unseen test subjects. Since the number of target samples is much smaller than that of nontarget samples, the area under the Receiver Operator Characteristic (ROC) curve (AUC) was selected as the evaluation metric for binary classification. The AUC results on Dataset I and Dataset II are presented in Tables 2 and 3, respectively. For the three-class classification task on Dataset II, the one-vs-rest strategy is used to compute the multi-class AUC.
Classification Performance (Area Under the ROC Curve) on Dataset I (ERN)
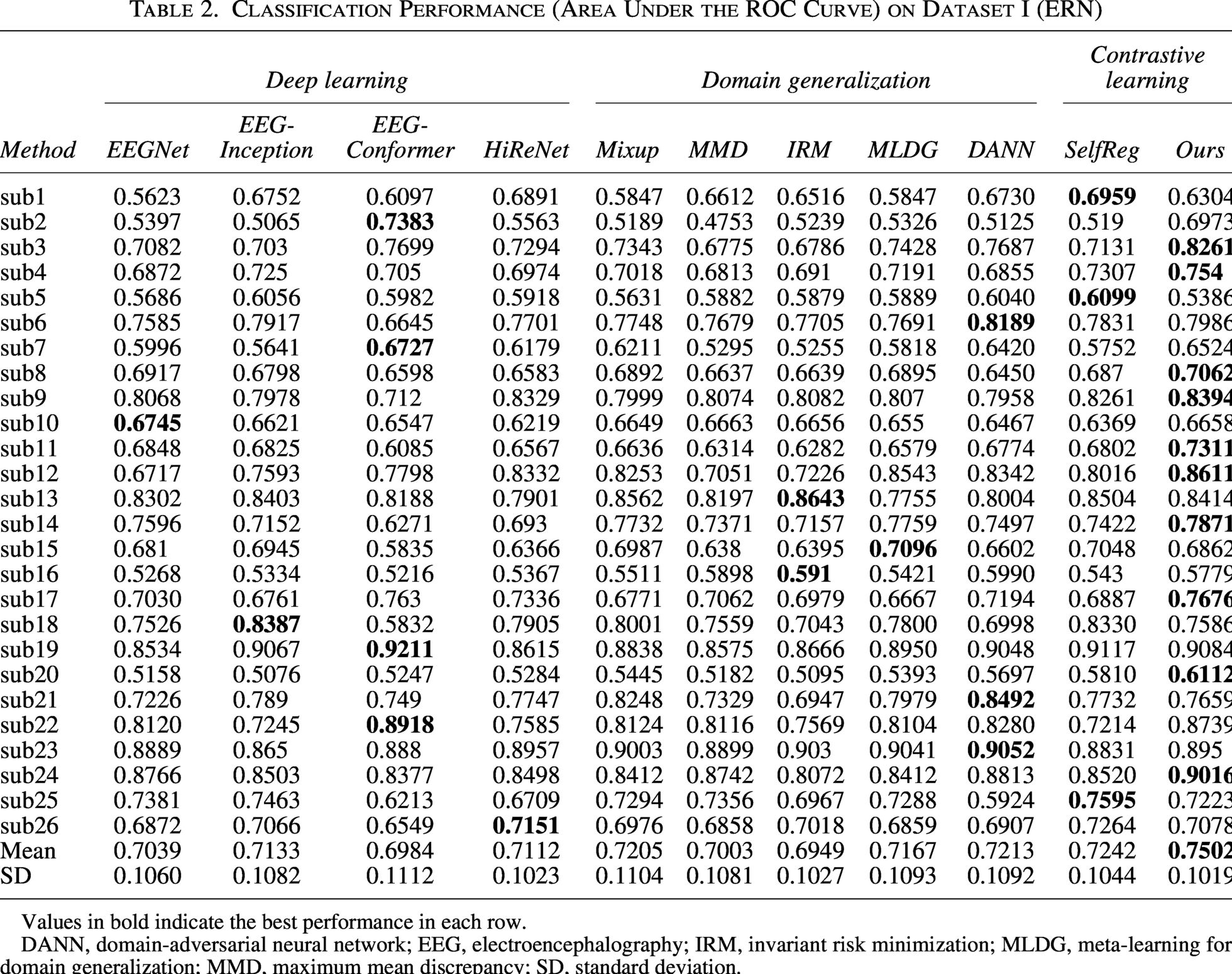
Values in bold indicate the best performance in each row.
DANN, domain-adversarial neural network; EEG, electroencephalography; IRM, invariant risk minimization; MLDG, meta-learning for domain generalization; MMD, maximum mean discrepancy; SD, standard deviation.
Classification Performance (Multi-Class Area Under the ROC Curve; Macro-F1) on Dataset II (Chinese Semantic–Syntactic Violation Event-Related Potential)
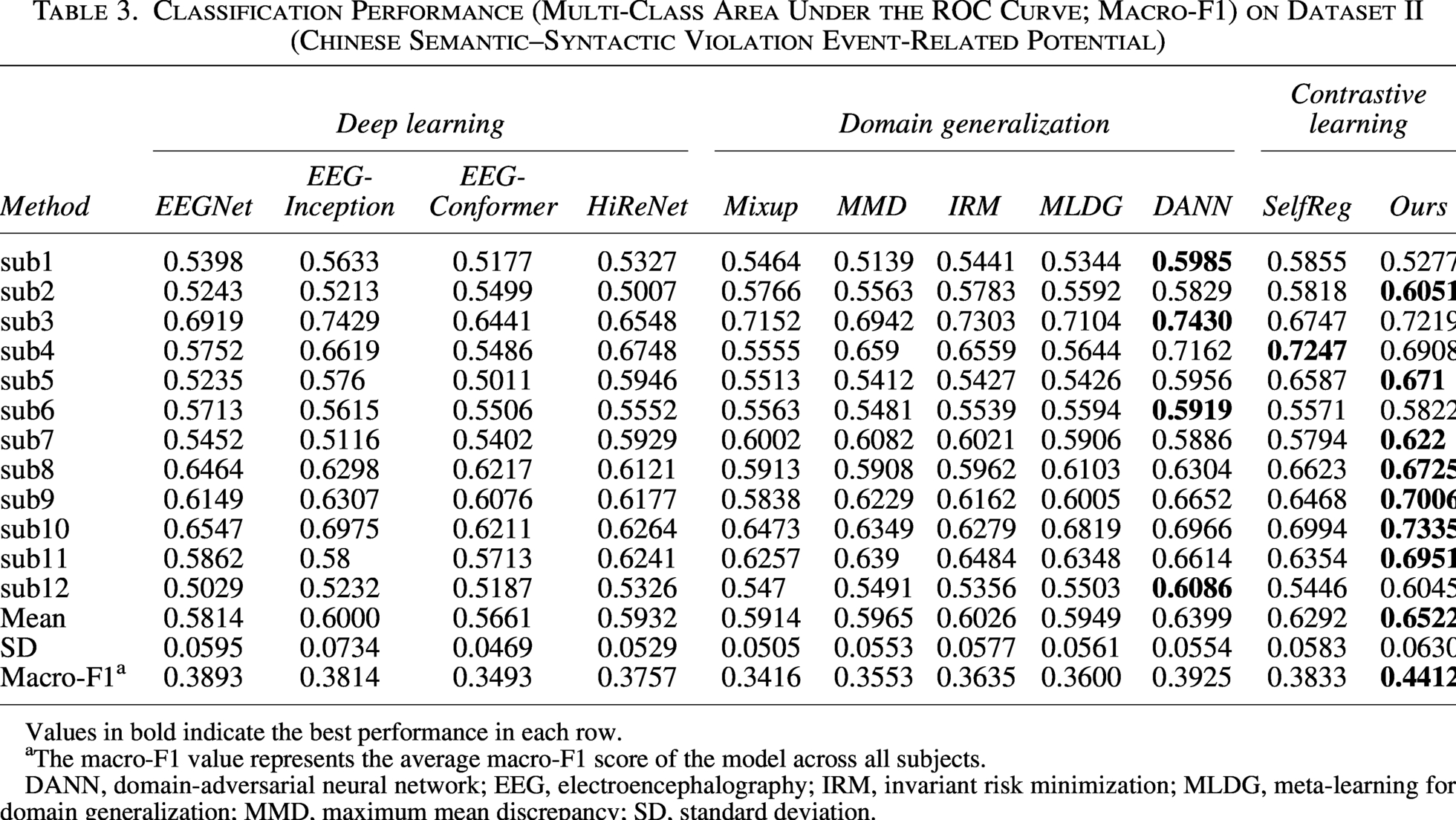
Values in bold indicate the best performance in each row.
The macro-F1 value represents the average macro-F1 score of the model across all subjects.
DANN, domain-adversarial neural network; EEG, electroencephalography; IRM, invariant risk minimization; MLDG, meta-learning for domain generalization; MMD, maximum mean discrepancy; SD, standard deviation.
In Dataset I, the AUC values of the deep learning methods EEGInception and EEGNet were 0.7133 ± 0.1082 and 0.7039 ± 0.1060, respectively, demonstrating their ability to capture the spatial and temporal representations of ERP signals. By exploiting phase information derived from the Hilbert transform, HiReNet achieves an AUC of 0.7112 ± 0.1023. EEG-Conformer, which is based on a Transformer architecture and is optimized for modeling long-range dependencies, shows limited effectiveness on short-duration ERP signals, yielding an AUC of 0.6984 ± 0.1112. The Mixup and MLDG methods achieved AUCs of 0.7205 ± 0.1104 and 0.7167 ± 0.1093, respectively, outperforming the standard deep learning baselines and indicating that they can better learn domain-invariant features. MMD and IRM tend to perform poorly on small-sample datasets. Among the domain generalization methods, DANN achieves the highest performance, with an AUC of 0.7213 ± 0.1092. MMD enforces alignment of feature distributions across domains; under limited-sample conditions, this can over-regularize the learned representations and collapse class-specific structure, thereby blurring class boundaries. IRM is particularly vulnerable when sample sizes are small: high variance in domain-wise risk estimates can destabilize optimization and cause the model to converge to poor local minima. The contrastive learning–based approaches, SelfReg and MVCLDG, further improved the results, yielding AUCs of 0.7242 ± 0.1044 and 0.7502 ± 0.1019, respectively. Notably, MVCLDG achieved the highest average AUC of 0.7502 ± 0.1019, and paired-sample t-tests demonstrated a statistically significant performance improvement over existing methods (p < 0.05). This suggests that our method can extract essential domain-invariant representations more effectively through contrastive learning. Moreover, the reduced variance observed in contrastive learning methods indicates lower sensitivity to specific domain shifts. Overall, these experiments confirm the superiority of the proposed algorithm on public ERP datasets.
On our self-collected Dataset II, standard deep learning models remained suboptimal: Although EEGInception (AUC = 0.6000 ± 0.0734) outperformed EEGNet (AUC = 0.5814 ± 0.0595), both were surpassed by specialized domain generalization algorithms and our proposed approach. Owing to the smaller size of this dataset, the performance of EEG-Conformer degrades markedly. In domain generalization algorithms, the aforementioned drawbacks of MMD and IRM on small-sample datasets are once again manifested. MVCLDG achieved the highest average AUC of 0.6522 ± 0.0630 and the highest average macro-F1 score of 0.4412 ± 0.0644, representing an improvement over the strongest baseline method, DANN (AUC = 0.6399 ± 0.0554), and an even larger advantage compared with standard deep learning models. Importantly, this performance gain was achieved while maintaining relatively high stability.
To rigorously assess the performance gains of MVCLDG, paired-sample t-tests were conducted to compare it against each of the 10 baseline models. To account for errors arising from multiple comparisons, all p values were adjusted using the Holm–Bonferroni correction, and statistical significance reported throughout the article is based on the corrected values. In addition, we report the mean AUC differences (
Pairwise Statistical Comparisons Between Multi-View Contrastive Learning Domain Generalization and Baseline Models on Dataset I
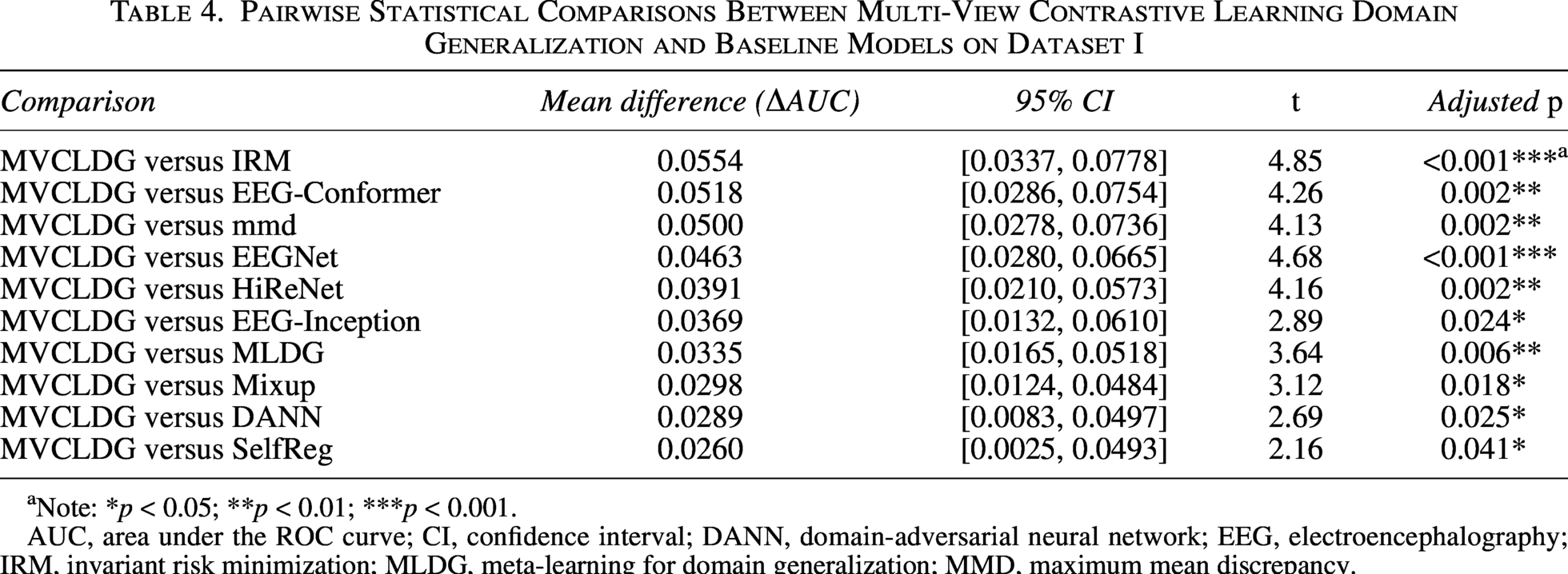
Note: *p < 0.05; **p < 0.01; ***p < 0.001.
AUC, area under the ROC curve; CI, confidence interval; DANN, domain-adversarial neural network; EEG, electroencephalography; IRM, invariant risk minimization; MLDG, meta-learning for domain generalization; MMD, maximum mean discrepancy.
Pairwise Statistical Comparisons Between Multi-View Contrastive Learning Domain Generalization and Baseline Models on the Dataset II
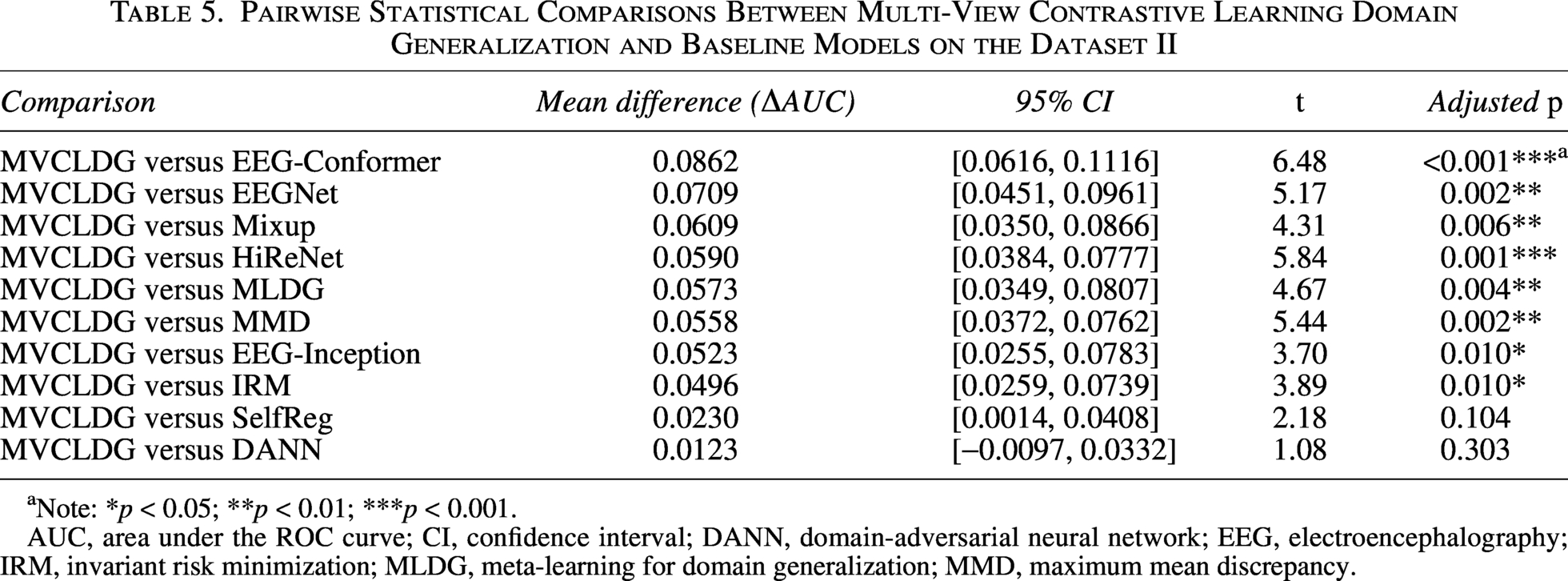
Note: *p < 0.05; **p < 0.01; ***p < 0.001.
AUC, area under the ROC curve; CI, confidence interval; DANN, domain-adversarial neural network; EEG, electroencephalography; IRM, invariant risk minimization; MLDG, meta-learning for domain generalization; MMD, maximum mean discrepancy.
The results indicate that on the Dataset I, MVCLDG significantly outperforms all 10 baseline methods (corrected p < 0.05), with mean AUC improvements ranging from 0.026 to 0.055. On Dataset II, MVCLDG achieves statistically significant improvements over 8 of the 10 baselines. Notably, when compared with the strongest competitors, DANN and SelfReg, the average differences remain positive; however, their 95% confidence intervals include zero, and the corrected p values do not meet the significance criterion. This outcome highlights the inherent difficulty of obtaining further gains on this more challenging task.
To evaluate the performance of MVCLDG on the CSSV-ERP test set, we aggregated the LOSO test results across 12 subjects to construct the aggregated confusion matrix shown in Figure 3.
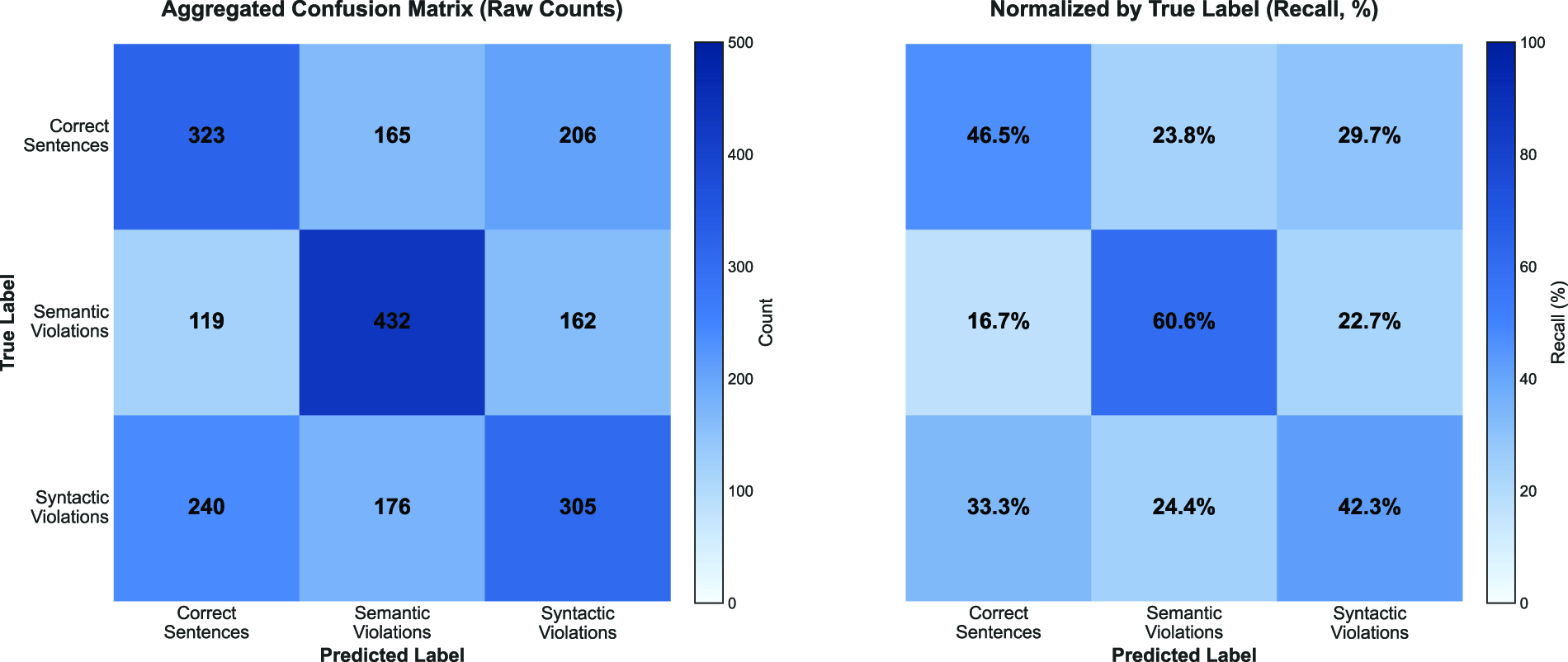
Aggregated confusion matrices of the MVCLDG model on the CSSV-ERP test set across 12 subjects under the leave-one-subject-out (LOSO) evaluation protocol. The left matrix shows the raw classification counts, while the right matrix presents recall rates normalized by the true classes for the three-class classification task. CSSV-ERP, Chinese semantic–syntactic violation event-related potential; MVCLDG, multi-view contrastive learning domain generalization.
Although MVCLDG achieved the best relative performance among all baseline methods, the confusion matrix in Figure 3 still reveals the inherent challenges of this classification task. The model demonstrates a measurable ability to discriminate between semantic and syntactic violations, suggesting that it may capture neural features specific to different violation types. Among the three classes, semantic violations are recognized most reliably, achieving a recall rate of 60.6%. Meanwhile, the model exhibits complex multidirectional error patterns, with confusion between correct trials and syntactic violations being the dominant error type. This phenomenon may arise because the recognition of syntactic violations depends more strongly on contextual and individual factors, rendering their neural patterns more difficult to distinguish from those of correct sentences at the single-trial level. In contrast, direct confusion between semantic and syntactic violations remains relatively low, suggesting that the model may have learned neural representations that differentiate between distinct types of anomalies.
Overall, these findings are consistent with those reported in Santamaría-Vázquez et al. (2020). Since single-trial decisions often fail to achieve the required accuracy, repeated trials are necessary to ensure reliable classification. Although improvements were observed compared with existing algorithms, the current state of research remains insufficient to achieve satisfactory discriminative capability in cross-subject single-trial settings. Furthermore, substantial intersubject variability resulted in relatively high algorithm variance.
Discussion
Ablation study
An ablation study was conducted within our model framework to assess the contribution of each component to overall performance. To ensure a fair comparison, all hyperparameters were kept identical, while specific components or architectural modules were removed or replaced, with the remaining parts of the model adjusted accordingly. Six ablated variants were examined: (a) without the multi-scale temporal extraction module; (b) without raw EEG input; (c) without HT-EEG input; (d) without the contrastive learning loss module; (e) replacing the projection head with an MLP; and (f) using a single-path contrastive loss.
The results in Table 6 highlight several key findings.
Result of Ablation Study on Dataset II
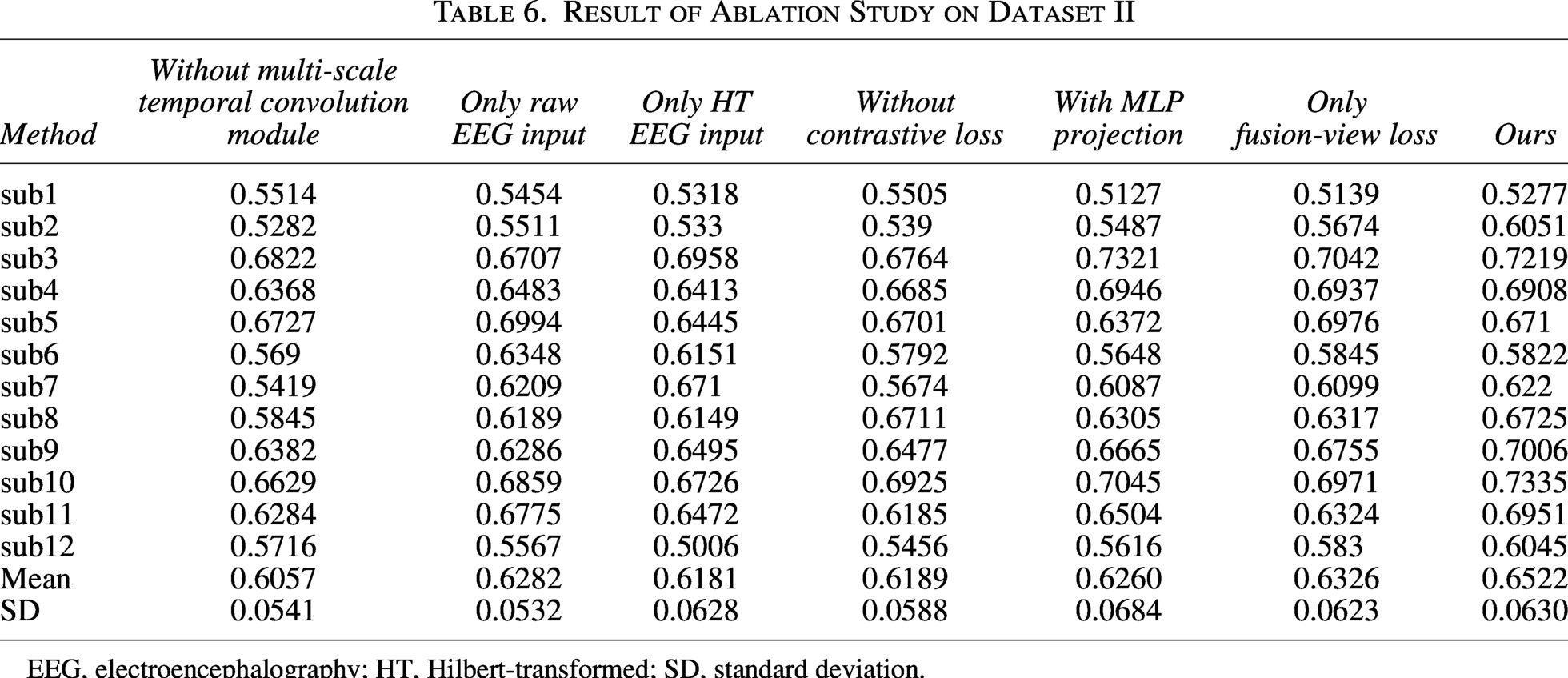
EEG, electroencephalography; HT, Hilbert-transformed; SD, standard deviation.
Multi-scale temporal extraction module: Employing temporal filters of different scales allowed the activation of features across multiple frequency bands, thereby enhancing the model’s temporal feature extraction capacity. Specifically, the AUC achieved by using the single-scale temporal extraction module is 0.6057 ± 0.0541, which lags behind our method by 4.65 percentage points.
Multi-view feature extraction module: Extracting features jointly from raw EEG and HT-EEG enabled the model to leverage critical phase information inherent in ERP signals. The exclusion of raw EEG led to the largest decrease in average multi-class AUC, confirming that the combination of raw and HT EEG inputs is particularly effective. The AUC values obtained using only raw EEG and HT-EEG are 0.6282 ± 0.0532 and 0.6181 ± 0.0628, respectively, which are 2.4 percentage points and 3.41 percentage points lower than our method.
Contrastive learning loss module: Incorporating contrastive loss facilitated the extraction of domain-invariant features during training, improving the model’s performance under cross-subject conditions. Without using the contrastive learning loss, the AUC is 0.6189 ± 0.0588, which is reduced by 3.33 percentage points.
Incep2Incep module with MLP projection: Under conditions with limited EEG samples, replacing the projection head with an MLP considerably increased the number of parameters, thereby raising the risk of overfitting and potentially impairing the ability of contrastive loss to extract domain-invariant features. Using the incep2incep module increases the AUC from 0.6260 ± 0.0684 by approximately 2.62 percentage points.
Multi-path contrastive learning loss: The three-path loss explicitly maintained and regularized the discriminative subspace of each modality, preventing detail loss due to the “fusion bottleneck.” Moreover, the independent losses of raw and phase views acted as a form of soft supervision, reducing the risk of the fusion loss being disproportionately biased toward a single modality. The AUC achieved using only the fused-view loss is 0.6522 ± 0.0630, which is 1.96 percentage points lower than our method.
Overall, our framework integrates modules that enhance feature extraction breadth, improve domain-invariant representation learning, and mitigate overfitting. The ablation experiments collectively demonstrate the contribution of each component and underscore their potential in advancing cross-subject ERP recognition tasks.
Feature distribution visualization
To illustrate the effect of contrastive learning, we present two t-SNE (t-distributed stochastic neighbor embedding) (Com and Hinton, 2008) visualizations of features extracted from subjects by different models. These visualizations help elucidate how the features are separated and clustered in the embedding space. Figure 4 compares the t-SNE projections of the baseline model and our model on the Dataset I training set. With the baseline model, features extracted from EEG signals disperse around distinct cluster centers that largely align with individual subjects (Fig. 4a). Clusters from different subjects that correspond to the same task class lie far apart in the embedding space; for example, features for the same task from Subject 1 and Subject 2 are distant, yet they can be closer to features from different tasks of the same subject.
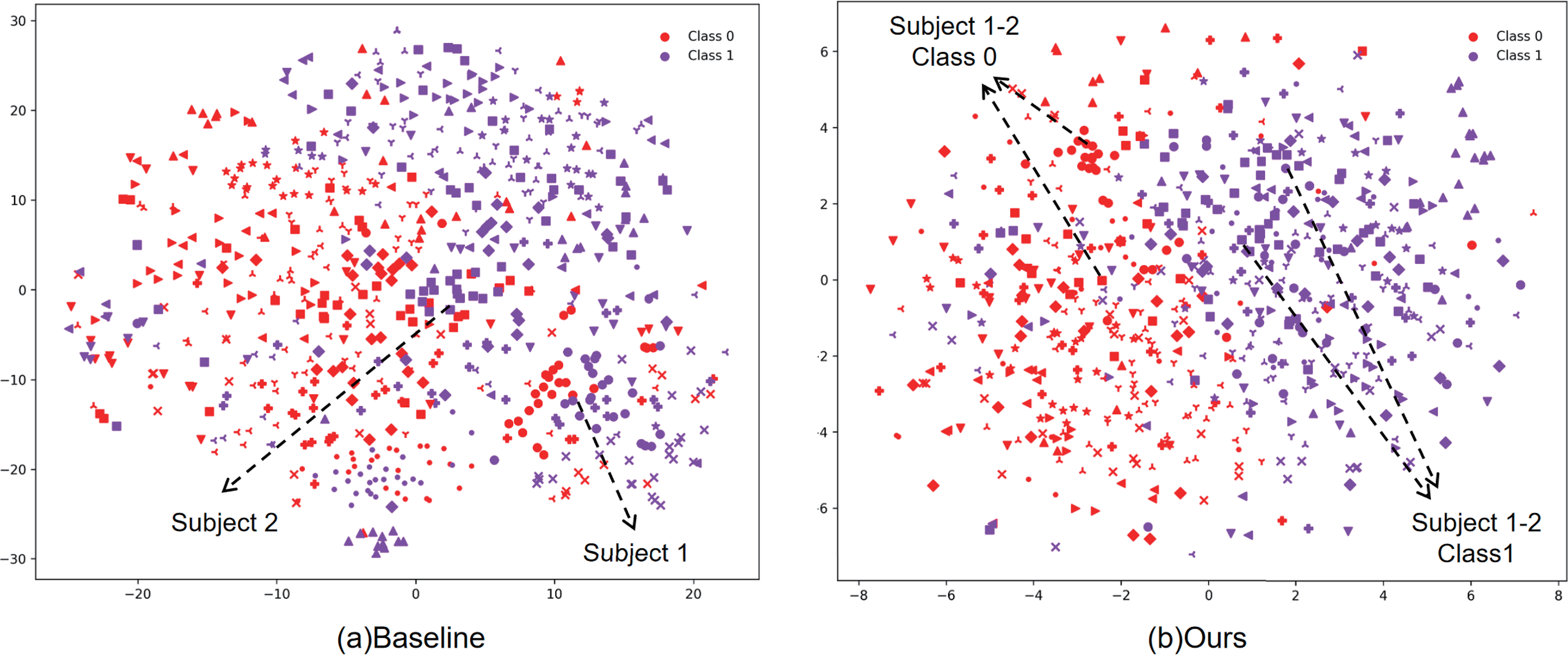
t-SNE visualization of features for
By contrast, MVCLDG yields features with clearer separation across stimulus classes (Fig. 4b). We attribute this to our domain-alignment mechanism together with the contrastive loss, which enlarges interclass differences while reducing intra-class variance. These results indicate that the model effectively learns domain-invariant representations, mitigates intersubject variability without sacrificing class separability, and thereby facilitates cross-subject ERP recognition. Quantitative evidence further substantiates the enhanced feature separability: Our model achieves a separation ratio (defined as the ratio of interclass to intra-class feature distances) of 1.8031, corresponding to a 9.79% improvement over the baseline model (1.6423).
Furthermore, Figure 5 contrasts the t-SNE projections of the baseline and our model on the Dataset I test set. The baseline produces test-sample features that are noticeably more dispersed and lack explicit cross-subject alignment; in contrast, MVCLDG forms tighter within-class clusters, and the concentric arrangement suggests that contrastive learning induces a hyperspherical feature space. Taken together, these t-SNE visualizations confirm that our approach learns features that are both domain-invariant and class-discriminative, and that this generalization extends to unseen test samples.
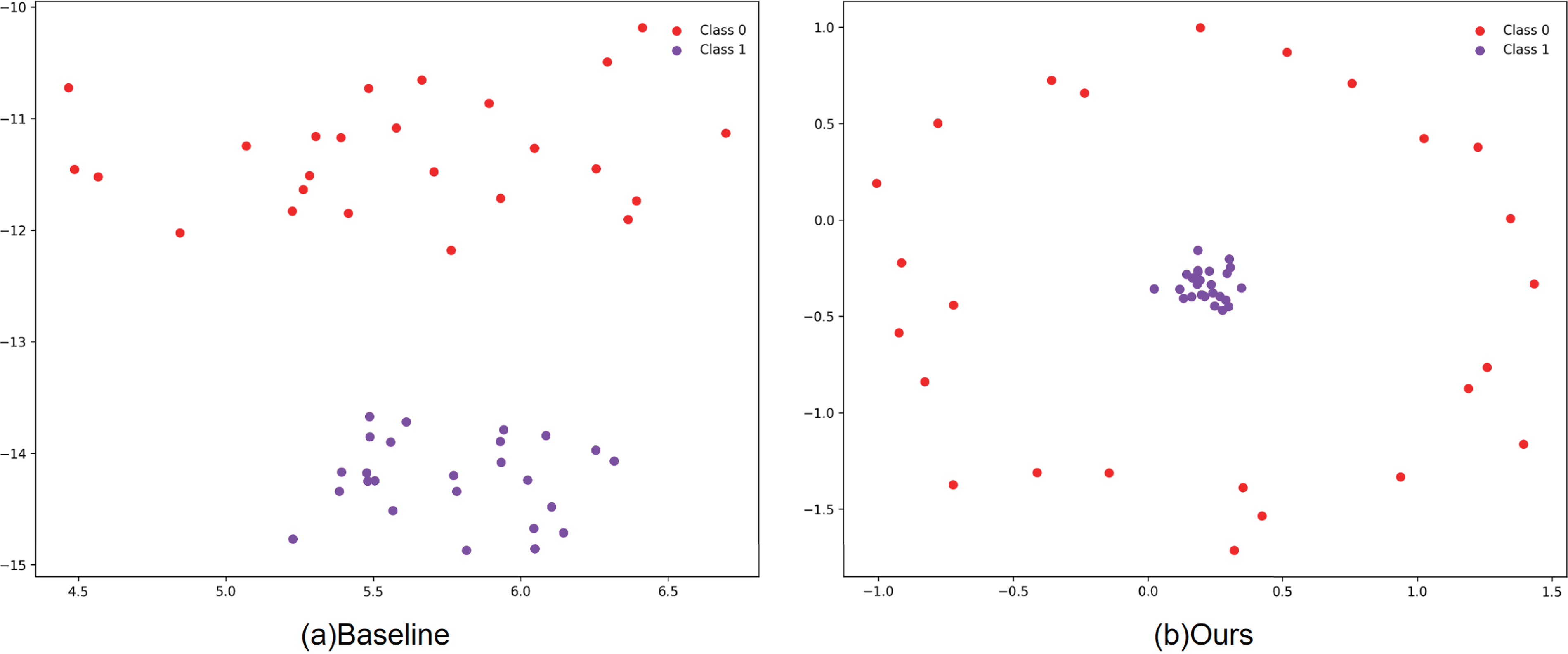
t-SNE visualization of features for
Interpretability
We employed class activation maps (CAM) (Chattopadhay et al., 2018; Selvaraju et al., 2017) to visualize the spatiotemporal activation patterns generated by MVCLDG and validated them against established neurophysiological findings. Among existing CAM methods, Eigen-CAM (Muhammad and Yeasin, 2020) visualizes the principal components of learned features without altering the network architecture or requiring gradient backpropagation, thereby providing a robust and reliable localization of discriminative regions. It has also been shown to outperform alternative approaches in identifying critical areas (Muhammad and Yeasin, 2020). Therefore, we adopted Eigen-CAM as our visualization tool to accurately identify the key features captured by MVCLDG.
We conducted interpretability analysis of MVCLDG on ERN (Dataset I) and semantic/syntactic violation (Dataset II) using the following procedure: high-confidence correctly classified trials were first selected as input, and Eigen-CAM was applied to obtain CAMs
The ERN is an electrophysiological signal closely associated with error feedback. As illustrated in Figure 6, panels A1 and A2 display temporal heatmaps of spatial convolutional features for correct and incorrect feedback trials, with time zero indicating feedback onset. The black dashed line marks the moment of maximum Eigen-CAM response, denoted as the “most salient moment.” The salient moments for correct and incorrect feedback were 0.335 and 0.390 s, respectively. The highlighted regions correspond precisely to two well-established ERN components (Margaux et al., 2012): the pos-ErrP and neg-ErrP. These findings indicate that the discriminative features extracted by MVCLDG align with prior neuroscientific knowledge and effectively capture class-related information.
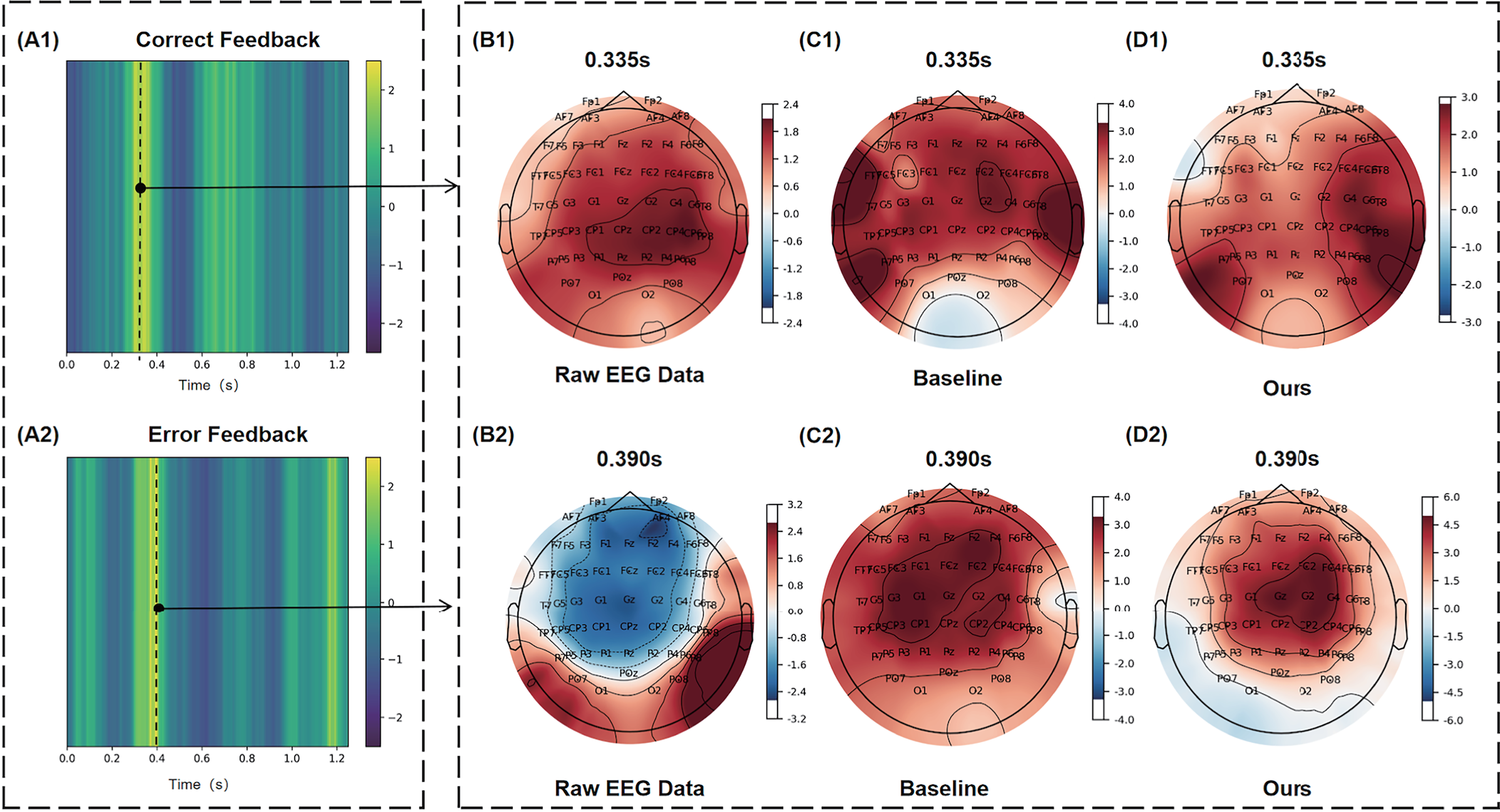
Temporal heatmaps and scalp topographies visualized with Eigen-CAM on Dataset I.
While learning class-relevant representations, MVCLDG simultaneously reduces its focus on task-irrelevant features. Panels B1 and B2 illustrate the scalp topographies of raw EEG data at the salient moments for correct and incorrect feedback trials. Panels C1 and C2, together with D1 and D2, present the temporal convolutional features of correct and incorrect feedback trials visualized from the baseline (MLDG) and MVCLDG models, respectively. Panels B1 and B2 suggest that, at salient time points, the topographies of raw EEG signals offer limited interpretability and fail to directly reveal channel relevance, often necessitating comparisons between target and nontarget conditions to identify informative electrodes. In contrast, CAM-based temporal feature visualizations explicitly highlight the relative importance of individual channels. Panels D1 and D2 display MVCLDG’s spatial feature visualizations at the salient moments. Panel D1 shows that MVCLDG assigns strong importance to channel P7 for correct feedback, whereas panel D2 indicates that Cz plays a dominant role in distinguishing erroneous feedback. The channels highlighted in the visualization exhibit scalp-surface topographic distributions that are consistent with those of brain regions well established in ERN research, thereby supporting the validity of MVCLDG’s spatial feature extraction. Compared with the baseline results in panels C1 and C2, MVCLDG places less emphasis on task-irrelevant regions and greater emphasis on task-relevant ones, underscoring its stronger capability for extracting domain-invariant features.
A semantic/syntactic violation refers to the occurrence in sentence processing when a word or structure violates semantic or grammatical rules. Such violations trigger additional neural resources to process the linguistic anomaly, producing characteristic electrophysiological responses. As illustrated in Figure 7, panels A1 and A2 present temporal heatmaps of spatial convolutional features for semantic and syntactic violation trials visualized by Eigen-CAM, with time zero marking the critical word onset. Because MVCLDG captured a greater number of salient moments in the more complex neural dynamics of Dataset II, the black dashed lines indicate overlaps between well-known ERP components (N400 and P600) and Eigen-CAM highlighted regions, which we refer to as “prior salient moments.” Semantic and syntactic violations were associated with salient moments at 0.374 and 0.595 s, respectively, again capturing features consistent with prior neuroscientific knowledge.
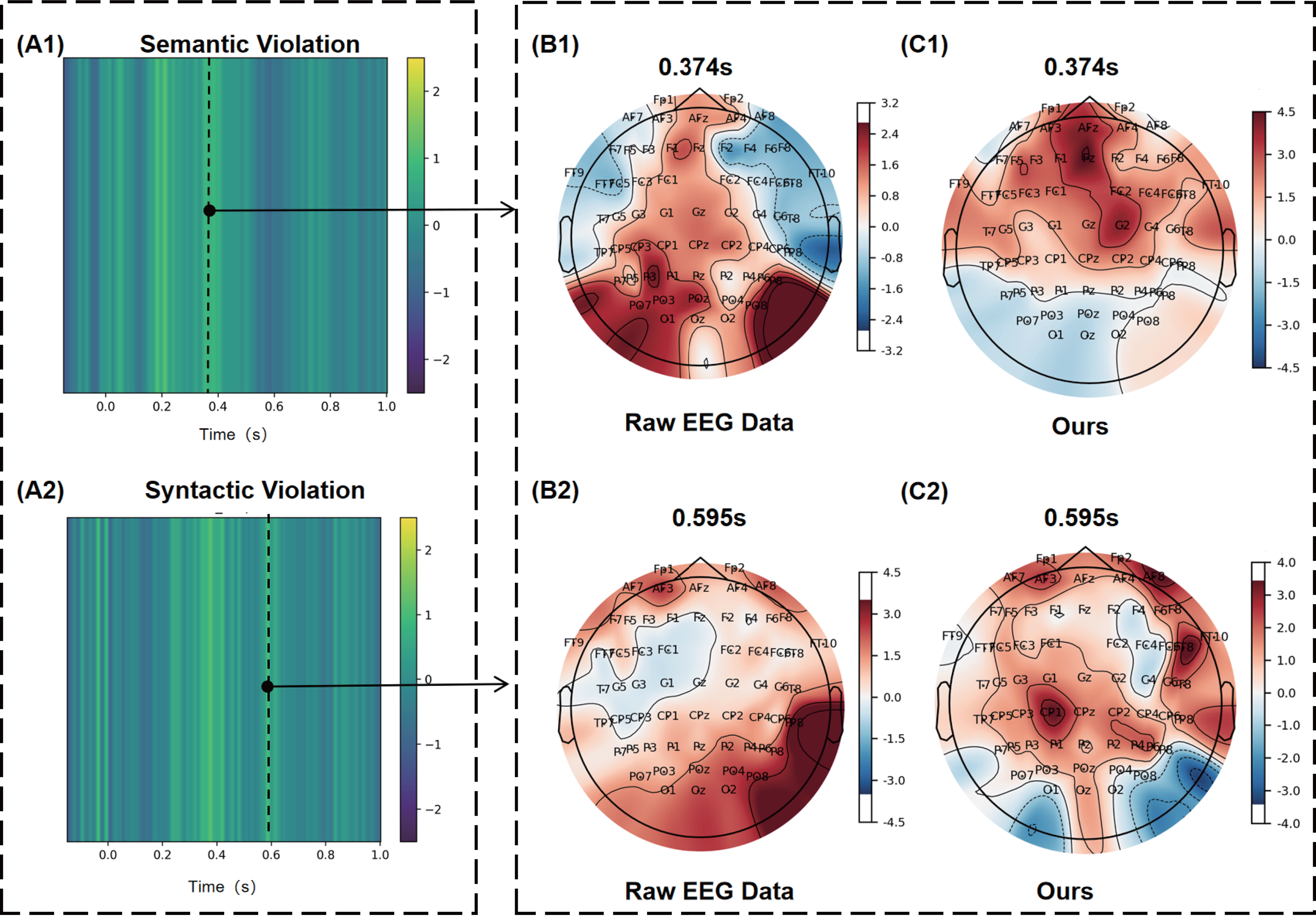
Temporal heatmaps and scalp topographies visualized with Eigen-CAM on Dataset II.
Panels C1 and C2 show MVCLDG’s spatial feature visualizations at the salient moments. Compared with the raw EEG signals shown in panels B1 and B2, panel C1 demonstrates that MVCLDG assigns strong importance to channels Fz and F1 during semantic violations, whereas panel C2 indicates heightened attention to channel CP1 during syntactic violations. The scalp-topographic emphasis on fronto-central (e.g., F1/Fz) and centro-parietal (e.g., CP1) electrodes for semantic and syntactic violations, respectively, is broadly consistent with the canonical distributions of the N400 and P600 components. This indirectly supports that our model learns features whose inferred neural generators align with regions traditionally associated with each process, confirming its ability to capture domain-invariant neurophysiological patterns.
BCI practicality
The number of trainable parameters during training and inference for the proposed method on Dataset I is summarized in Table 7. As a canonical baseline, EEGNet is the most parameter-efficient model among all compared methods. Conventional domain generalization methods do not modify the network architecture; therefore, their parameter counts remain identical to that of the baseline EEG-Inception model. Notably, DANN and contrastive learning–based methods exhibit distinct behaviors between training and inference: DANN removes the adversarial discriminator at inference time, whereas contrastive learning approaches discard the projection head.
Comparison of Model Complexity Across Different Methods
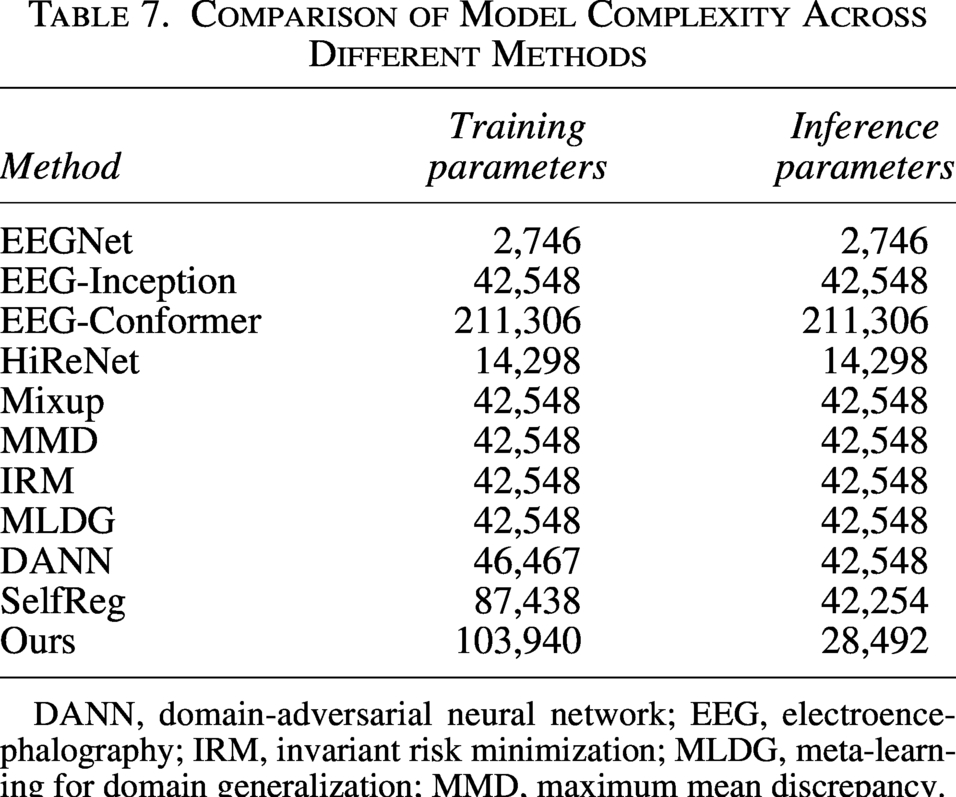
DANN, domain-adversarial neural network; EEG, electroencephalography; IRM, invariant risk minimization; MLDG, meta-learning for domain generalization; MMD, maximum mean discrepancy.
Built upon multi-view contrastive learning, our method achieves a distinctive balance between model capacity and deployment efficiency. During training, an additional projection module termed Incep2Incep is introduced, comprising 57,012 parameters. This module mirrors the encoder architecture while incorporating additional nonlinearity, thereby enhancing feature learning and improving cross-subject generalization. At inference, the projection module is entirely removed, leaving only the encoder and classifier, resulting in a total of 28,492 inference parameters. This design reflects the fact that the projection module primarily serves to structure the feature space during training; once optimization is completed, this role is effectively absorbed by the encoder parameters.
From a practical BCI perspective, this design offers two key advantages. First, the lightweight inference model enables faster response times in real-world closed-loop systems. Second, despite the reduced parameter count during inference, the higher model capacity during training ensures superior classification performance compared with all baseline approaches.
Limitations and future work
This study still has considerable scope for further improvement. First, MVCLDG currently exploits only the raw signal and the Hilbert-transformed signal, without fully leveraging the potential advantages of incorporating multiple views. Future work may focus on exploring additional representative views, such as time–frequency views and amplitude views, to facilitate the extraction of domain-invariant features. Second, MVCLDG is primarily designed for recognizing different stimuli in cross-subject scenarios within a single dataset. However, its effectiveness across datasets and, more broadly, across tasks has yet to be systematically explored and validated. In future work, we plan to directly apply the model trained on the dataset in this study to publicly available ERP datasets with similar paradigms (e.g., applying the model trained on Dataset I to a P300 speller dataset) for cross-dataset validation.
Rehabilitation medicine increasingly acknowledges the value of EEG analysis in supporting patient recovery. Nevertheless, the neurophysiological significance of MVCLDG remains limited. Further investigations leveraging multimodal techniques, such as simultaneous EEG–fMRI acquisition, to more precisely characterize task-related and violation-related brain activity may provide valuable opportunities for real-time monitoring and assessment of rehabilitation progress.
Advancing the clinical translation of the proposed approach represents an important direction for future research. For example, the MVCLDG framework could be integrated into portable EEG systems to facilitate the assessment of post-stroke cognitive function. Patients would perform standardized semantic tasks (e.g., the Dataset II paradigm), while the system analyzes their ERP components and compares them against normative baselines derived from healthy cohorts, thereby providing clinicians with quantitative indicators of cognitive impairment and recovery. A key strength of MVCLDG lies in its cross-subject generalization capability, which allows models pre-trained on large-scale healthy datasets to be directly deployed for new patients, enabling reliable detection without the need for individual calibration. This property is of particular clinical relevance for patient populations with language or motor impairments, for whom active behavioral feedback is difficult or infeasible.
Conclusion
This article presents a multi-view domain generalization contrastive learning framework, MVCLDG, designed to enhance the classification performance of ERP signals in cross-subject scenarios. Our approach leverages both raw EEG signals and Hilbert-transformed signals as complementary views, thereby emphasizing critical phase information in ERP data. It incorporates both view-independent and view-fusion contrastive losses to ensure the learning of discriminative domain-invariant features from different views of the same sample while promoting mutual knowledge transfer between views. The proposed multi-view cross-prediction mechanism yields more discriminative interclass features and more consistent intra-class features for downstream tasks. The effectiveness of the method was validated on both a public ERN dataset and a self-collected semantic syntactic violation dataset, where it outperformed existing domain generalization models. In addition, Eigen-CAM–based visualization analysis indicates that the key spatiotemporal patterns exploited by the model—such as the pronounced focus on the central–parietal Cz electrode in the ERN task—exhibit a high degree of correspondence with the canonical scalp topographic distributions of the associated ERP components. This scalp-level topographic consistency provides neurophysiological support for the effectiveness of the proposed model, demonstrating the potential of the proposed method to advance ERP signal recognition.
Authors’ Contributions
C.C.: Conceptualization, methodology, formal analysis, investigation, writing—original draft, and visualization. L.X.: Investigation. J.Z.: Conceptualization, methodology, writing—review and editing, and supervision. Q.Q.: Methodology, investigation, resources, and writing—review and editing. H.J. and J.L.: Conceptualization, methodology, resources, writing—review and editing, supervision, and funding acquisition.
Footnotes
Ethics Statement
This work involved human subjects in its research. Approval of all ethical and experimental procedures and protocols was granted by the Ethics Review Committee of Shanghai Yangzhi Rehabilitation Hospital under Application No. Yangzhi Lun Shen Zi [2023]036 and performed in line with the Declaration of Helsinki.
Author Disclosure Statement
The authors declare that they have no conflicts of interest.
Funding Information
This work was supported in part by the National Natural Science Foundation of China under Grant 62472319, the Second Round of the “Three-Year Action Plan to Promote Clinical Skills and Clinical Innovation in Municipal Hospitals” Research Physician Innovation Transformation Capability Training Program under Grant SHDC2023CRT001, the National Clinical Key Specialty Construction Project of China under Grant Z155080000004, the Shanghai Research Center of Rehabilitation Medicine (Top Priority Research Center of Shanghai) under Grant 2023ZZ02027, and the Shanghai Disabled Persons’ Federation Key Laboratory of Intelligent Rehabilitation Assistive Appliance and Technology.