
Abstract
The Selection and Placement of Students to be Sent Abroad for Graduate Studies (YLSY) scholarship program is implemented by Türkiye to develop qualified human resources and foster scientific advancement. Based on this objective, the present study aims to evaluate the effectiveness of the program by identifying the factors that influence the academic success of scholarship recipients and examining the results from a multidimensional perspective. To achieve a comprehensive evaluation, An exploratory sequential mixed method was employed. In the qualitative phase, semi-structured interviews were conducted with scholarship recipients, and the data were analyzed through content analysis to determine key needs and challenges. Based on these findings, four success prediction models were developed in the quantitative phase using different machine learning algorithms. The models were designed to predict academic success in terms of indexed article, other article, citation, and project. The indexed article model trained with a boosted decision tree algorithm achieved an accuracy rate of 77.4%, while the other article model trained with a decision jungle algorithm reached 71.1%. The citation model, also using a boosted decision tree, reached 81.6%, and the project model trained with a support vector machine achieved the highest performance with 84.3%. These findings demonstrate the potential of data-driven approaches in forecasting academic success and offer valuable insights for enhancing scholarship programs. Future research should test the generalizability of these models across disciplines and examine their integration into digital decision support systems to improve program impact and efficiency.
Plain Language Summary
In Türkiye, the YLSY scholarship program is implemented to train qualified human resources and support scientific development. In this study, the effectiveness of the program was analyzed by determining the factors affecting the academic success of the scholarship holders and evaluating the program outputs from different perspectives. In the qualitative phase of the research conducted with exploratory sequential mixed method, semi-structured interviews were conducted and basic needs and challenges were revealed with content analysis. Four machine learning-based success prediction models were developed in the quantitative phase with the findings obtained. The models were designed to predict academic success in terms of indexed article, other article, citation, and project. The highest accuracy rate of 84.6% was obtained in the project success model developed with the a support vector machine. The findings show the potential of data-driven approaches in increasing the effectiveness of scholarship programs.
Introduction
Economic prosperity, knowledge production, and innovation capacity are fundamental drivers of societal development, and their advancement is closely linked to improvements in the quality of education, particularly at the higher education level. The increased rate of progress and development in society depends on the qualified knowledge possessed at the higher education level, where qualified human resources are trained. Therefore, the faculty members who will educate these students must be highly knowledgeable and visionary. It is an important responsibility of states to provide faculty members with this competence and train them in line with needs (Çakmak, 2008; Devlet Planlama Teşkilatı, 1988).
One such mechanism is the YLSY scholarship program, initiated by the Ministry of National Education (MoNE) under legal regulations in 1929 (Aktekin & Tekben, 2019). This program aims to train a qualified workforce capable of meeting Türkiye’s needs in academia and public institutions. As part of the program’s long-standing history, the country aims to send students abroad to receive postgraduate education and later integrate their expertise back into the national system. However, despite its long history, questions remain about the effectiveness and impact of this scholarship program.
This study aims to fill this gap by providing a comprehensive analysis of the YLSY program using machine learning techniques to predict and evaluate the effectiveness of the scholarship program, ensuring that public investments are used efficiently. In accordance with these objectives, the study seeks to address the following research questions:
To contextualize these questions, relevant literature is reviewed below.
Countries obtain many different benefits in subjects such as science and education quality, international competition, culture, art, and economy through international education (DEİK, 2013). Scholarship programs, which provide financial opportunities to ensure the development of the country by supporting students in completing their higher education abroad, are the public investments aimed at cultivating highly qualified individuals who can contribute to national research ecosystems, innovation capacity, and institutional development when return. Consequently, such programs have increasingly attracted scholarly attention, particularly in relation to their effectiveness, sustainability, and measurable outcomes.
Comparative studies on international scholarship schemes demonstrate that governments employ diverse models to both send students abroad and attract international talent. For instance, China has pursued an expansive internationalization strategy by simultaneously supporting outbound student mobility and positioning itself as a destination for international students. Existing research has examined both the structural characteristics of Chinese scholarship opportunities (Latief & Lefen, 2018) and the academic and professional trajectories of students funded to study abroad (Fang et al., 2022). Similarly, the King Abdullah Scholarship Program of Saudi Arabia has been analyzed in terms of its contributions to participants’ cultural capital, academic integration, and intercultural communication, particularly within the U.S. higher education context (Alqahtani, 2014; Taylor & Albasri, 2014). In the Latin American context, the Becas Chile Scholarship Program has been framed as a knowledge-building mechanism that strengthens national research capacity through international academic mobility (Munoz-Garcia & Chiappa, 2017). While these studies collectively underscore the strategic value of international scholarships, much of the existing literature evaluates program success through descriptive indicators such as participation rates, destination countries, or self-reported experiences. Fewer studies systematically interrogate academic success outcomes, such as research productivity, article impact, or project participation, which are central indicators of return on investment in public scholarship schemes. This gap has prompted a growing interest in data-driven approaches to scholarship evaluation and candidate selection. Recent studies have begun to employ quantitative techniques to optimize scholarship allocation and predict student success. For example, Asriyanik and Pambudi (2023) addressed the quota allocation challenges regarding the Kartu Indonesia Pintar program by conducting classification-based selection models, while Irfan et al. (2023) reported high predictive accuracy in student selection processes using the model they developed.
Parallel to these quantitative studies, qualitative research has emphasized the importance of understanding scholars’ lived experiences, challenges, and support needs. Balyer and Özcan (2022) highlighted the necessity of incorporating beneficiaries’ perspectives to evaluate program effectiveness beyond numerical indicators. Similarly, narrative and case-based studies have revealed the critical role of academic supervision, peer support, and orientation processes in shaping scholars’ adaptation and post-return integration (Kara & Çalık, 2022). These findings suggest that academic success is a multidimensional construct, influenced not only by individual capability but also by institutional, social, and policy-related factors. Despite these advances, the literature remains methodologically fragmented, with qualitative and quantitative approaches largely treated in isolation. This separation limits the development of comprehensive evaluation frameworks capable of both explaining and predicting scholarship outcomes. Addressing this limitation, Vanchinkhuu and Shin (2023) explicitly call for mixed-method approaches that integrate qualitative insights with predictive analytics in the evaluation of international education programs. In recent years, a growing body of research has examined the potential of machine learning and artificial intelligence applications in higher education to predict educational outcomes such as student performance, learning engagement, and self-efficacy (Chen et al., 2025; Marengo et al., 2025; Yılmaz et al., 2024). In parallel, mixed-methods approaches have gained increasing importance, particularly in areas such as inclusive and equitable instructional design, offering integrated frameworks for evaluating teaching and learning processes (Soicher et al., 2024). Moreover, systematic analyses of AI- and ML-based evaluation studies provide a more objective understanding of the impacts and opportunities associated with educational technologies (Matos et al., 2025). Taken together, these recent trends position the methodological framework of the present study at the intersection of machine learning applications and mixed-methods evaluation design.
Within this context, the Turkish YLSY scholarship program represents a particularly underexplored case. This program has been run for many years with the aim of meeting Türkiye’s need for highly qualified human resources by the Ministry of National Education. First legalized with Law No. 1416 on “Students to be Sent to Foreign Countries,” which came into force on April 16, 1929, and was directly integrated into higher education policies with the Higher Education Law No. 2547, enacted in 1981. When current data is taken into account (Ministry of National Education (MoNE), Directorate General for Higher and Overseas Education, 2022), approximately 1,000 scholarship recipients are sent each year to abroad. According to the YLSY 2014 to 2023 Term Report (T.C. Ministry of National Education, Directorate General for Higher and Overseas Education, 2024), a total of 6,492 students were eligible to receive scholarships under this program in the last 10 years. Of these students, 52% were sent abroad for postgraduate education on behalf of universities and 48% on behalf of public institutions. The largest number of scholarship recipients were sent to the United Kingdom (2,410), the United States (936) and Germany (323), respectively. Although there was a decrease in the number of scholarship recipients in 2021 to 2022, when the COVID-19 pandemic was effective, there was an increase in the number of scholarship recipients in 2023. Although the program has operated for nearly a century and constitutes one of Türkiye’s most significant human capital investments, empirical studies examining its academic effectiveness remain scarce. Existing research has primarily relied on small-scale qualitative investigations, which suggest that the program contributes positively to scholars’ academic development but faces challenges related to institutional reintegration and utilization of returned scholars’ expertise (Aktekin & Tekben, 2019; Balyer & Özcan, 2022). Moreover, there is a notable absence of studies that systematically link participants’ experiences to quantifiable academic outcomes, such as publications, citations, and project involvement. For example, Aktekin and Tekben (2019) conducted the study where data was collected in a semi-structured form, it was concluded that the 1416 scholarship program made a significant contribution to the academic development of scholars, but the contribution of scholars to their places of duty should be increased.
Building on these gaps, the present study advances the literature by adopting an exploratory sequential mixed-method design that integrates content analysis of scholarship recipients’ experiences with machine learning-based prediction models of academic success. By operationalizing success through multiple research productivity indicators and embedding predictive modeling within a policy evaluation framework, the study contributes conceptually and methodologically to the scholarship on international education programs. In doing so, it responds directly to calls for analytically grounded, data-driven, and policy-relevant evaluations of state-sponsored scholarship schemes.
Method and Implementation
During this transition process, quantitative method measurement tools are developed based on the analysis of the data obtained as a result of the qualitative analysis, and the data collected with these tools are then analyzed (Creswell & Plano Clark, 2018). In this context, the study first collected the opinions of individuals receiving education under the scholarship program through qualitative analysis. Subsequently, quantitative analysis was conducted based on the needs identified through these opinions. Within the scope of quantitative analysis, machine learning models were developed to predict the article, project, and citation success status of scholarship candidates who will benefit from the scholarship program if they are included in the scholarship program.
Qualitative Research Method
The qualitative research method produces holistic results within the framework of an inductive analysis approach that examines a problem in-depth and addresses all its aspects and has gained scientific recognition by being supported by data from various areas of expertise (Costa, 2023; Fraenkel et al., 2012). Different models are used in qualitative research, and one of them is the phenomenology model. In the phenomenology model, which is based on the description of phenomena, people’s perceptions of events and the meanings they attribute to them are discussed (Fraenkel et al., 2012; Yıldırım & Şimşek, 2016). The most important purpose of this model is to understand personal experiences (Van Manen, 2007). In this study, qualitative analysis and phenomenology pattern was used because the interviews will be conducted by focusing on the subjective experiences of people who completed their postgraduate education at universities in a country other than Turkey between 2013 and 2021 within the scope of the YLSY scholarship program. Qualitative analysis in the research was carried out in three stages, as Data Collection, Content Analysis and Validity, Reliability, and Trustworthiness, as presented in Figure 1.
Stages of the qualitative analysis process.
Data Collection
Study Group
To collect the qualitative data for the study, a purposive sampling method was used to form the study group. Purposive sampling is based on selecting samples that have the importance of the purpose. This situation provides the opportunity for in-depth study (Suri, 2011). In order to benefit from this advantage of the method, in this study, the study group was formed with 67 academic scholar participants who were supported by the YLSY scholarship program for postgraduate education abroad between 2013 and 2021. Twenty-one of the academic scholars are women, and 46 are men. Among the participants in the interview, 7 were scholars who completed their master’s degree, 25 who completed their doctoral education, 32 who completed their master’s and doctoral studies, and one who worked as academic staff.
Development of Data Collection Tool
The questions in the interview form were created by taking into account the questions created during the literature review and the problems and expectations experienced in the interviews with scholars who studied abroad within the scope of the 1416 overseas education scholarship. While there were nine open-ended questions in the first version of the form, as a result of the meeting held with the participation of the project team and four experts from the General Directorate of Higher Education and Overseas Education of the Ministry of National Education, one question was eliminated due to the similarity of the two questions. The finalized interview form includes the eight open-ended questions listed below. Before data collection, the interview form was piloted with three scholarship holders to ensure clarity and sequencing. Minor wording revisions were made accordingly. To ensure methodological rigor, qualitative validity and reliability were established through credibility, transferability, dependability, and confirmability criteria (Yıldırım & Şimşek, 2013). These questions:
What are the strengths of the 1416 education scholarship program?
What are the weaknesses of the 1416 education scholarship program?
If you had the opportunity, what would you like to change in the 1416 scholarship program? Why?
In your opinion, which mechanisms work adequately/insufficiently in the program?
What kind of additional mechanisms do you think need to be implemented in the program?
What are the threats posed by the weaknesses of the 1416 education scholarship program?
What would you suggest to improve the 1416 education scholarship program?
What are the opportunities offered by the 1416 education scholarship program to scholars?
Data Collection Process
In the study, interviews were held with 67 scholars. Individual interviews were conducted during the data collection process, either face-to-face or online, depending on the participants’ convenience. Additionally, the interviews were recorded with the consent of the participants. During the interviews, the introduction and warm-up stages were first carried out, and for this purpose, the participants were asked questions about their postgraduate education process and what they experienced. The audio recordings obtained from these interviews were transcribed, and the resulting texts were used for analysis.
Qualitative Data Analysis
Content analysis was employed to systematically examine the qualitative data obtained from semi-structured interviews. Content analysis enables the identification of patterns, meanings, and relationships within textual data through a structured and rule-based process (Prasad, 2008). In line with qualitative research principles, a human-coded, inductive approach was adopted, allowing themes to emerge directly from participants’ responses rather than being imposed a priori (Neuendorf & Kumar, 2016). The analysis followed a multi-stage coding procedure. First, all interview recordings were transcribed verbatim. During the initial coding phase, six members of the research team independently reviewed the transcripts to become familiar with the data. Open coding was then conducted, whereby meaningful units of text were labeled to capture key ideas, experiences, and challenges expressed by the participants. To enhance coding consistency, the research team jointly discussed sample responses prior to full-scale coding, and trial coding was conducted on selected experts as part of coder training.
In the second stage, the first two interview questions were coded independently by all six coders. The resulting codes were compared during consensus meetings, where overlapping codes were merged, ambiguous labels were refined, and a shared coding language was established. Through this iterative comparison process, preliminary categories were generated. In the final stage, related categories were systematically clustered into higher-order themes by examining conceptual similarities and relationships among codes. This iterative and collaborative process ensured that themes were firmly grounded in the data and reflected participants’ shared perspectives rather than individual interpretations.
Validity, Reliability, and Trustworthiness
To ensure the trustworthiness of the qualitative findings, the study adopted established criteria for qualitative rigor, namely credibility, transferability, dependability, and confirmability (Yıldırım & Şimşek, 2013). Credibility was strengthened through investigator triangulation, as multiple researchers participated independently in the coding and analysis process. In addition, participant diversity was intentionally ensured to capture a wide range of experiences related to the scholarship program. Transferability was supported by providing thick descriptions of the research context and participants, and by incorporating direct quotations from the interview data to allow readers to assess the applicability of findings to similar contexts. Dependability was addressed by maintaining consistency in the data collection process; all participants were asked the same semi-structured interview questions in the same order, and the analytical procedures were applied systematically across the dataset. Confirmability was ensured through inter-coder agreement procedures. The coding of the first interview question was independently conducted by multiple coders, and inter-coder reliability was calculated using Miles and Huberman’s (1994) formula, resulting in an agreement rate of 81.3%, which exceeds the recommended threshold of 80% for qualitative reliability. For the remaining questions, coding was performed by two researchers, followed by consensus discussions until full agreement was reached on codes and themes. Additionally, all interviews were recorded via video conferencing to prevent data loss and to allow for repeated review during analysis. After completing the qualitative analysis, some of the resulting themes indicated which dimensions of academic achievement would be more suitable for measurement in the quantitative phase. In this context, quantitative variables related to academic achievement were determined by considering the themes that directly contributed to the preference for quantitative measurement. This relationship between the qualitative findings and the academic achievement variables used in the quantitative phase is summarized in Table 1.
Dimensions of Academic Achievement Determined Based on Qualitative Findings.

Quantitative Research Method
In this context, activities within the scope of quantitative analysis were carried out within the framework of the CRISP_DM method. This model, which was introduced in a 1999 project, aims to make data mining projects less costly, more reliable, more repeatable, more manageable and faster (Wirth & Hipp, 2000). In the research, within the scope of this method, data collection, data preprocessing, model development, evaluation, and selection steps were applied. As a result of these steps, machine learning models were developed that predict the success of scholars according to four criteria. The methodological workflow of the quantitative analysis are presented in Figure 2. Specifically, the dataset was first cleaned and transformed through editing, handling of missing/outlier values, feature generation, and discretization techniques. Multiple machine learning algorithms, including Averaged Perceptron (AP), Bayes Point Machine (BPM), Logistic Regression (LR), Support Vector Machine (SVM), Locally-Deep Support Vector Machine (LDSVM), Neural Network (NN), Boosted Decision Tree (BDT), Decision Jungle (DJ), and Decision Forest (DF), were trained to predict four types of academic success. The models were then evaluated using performance metrics such as accuracy, precision, recall, and F1-score.
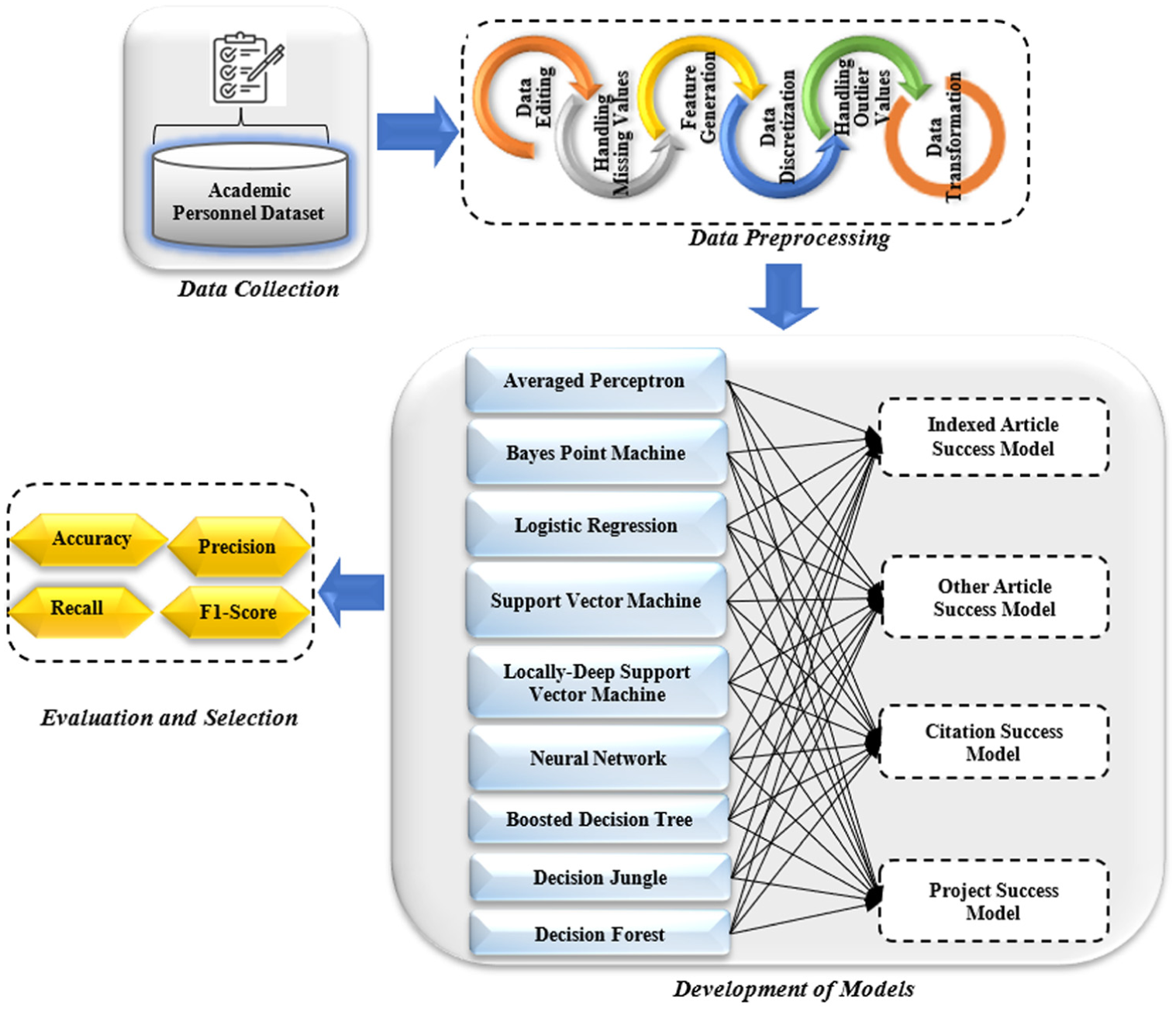
Stages of the quantitative analysis.
Data Collection
The initial phase of the machine learning workflow involves defining the target study population and designing the instruments for data acquisition.
Study Group
The research group, evaluated within the scope of quantitative analysis, comprises a total of 664 academic staff scholarship participants.
Development of Data Collection Tool
The questionnaire used in this study was developed through a formal, multi-step scale-development process within the TÜBİTAK Project 122G002. Specifically, a 34-item pool was generated from the literature and qualitative findings, reviewed by eight domain experts, refined to a 26-item, five-factor structure, and piloted with six YLSY scholars. Validity and reliability were then established using independent samples for EFA (n = 200; KMO = 0.833; Bartlett χ2 = 3,248.00; variance = 66.69%) and CFA (n = 200; χ2/df = 2.88; RMSEA = 0.079; CFI = 0.93), with satisfactory reliability and convergent/discriminant validity (Cronbach’s α = .85; CR = 0.82–0.89; AVE ≥ 0.50). The full methodological report, including item generation, expert review documents, pilot results, and complete EFA/CFA statistical tables, has been published under the same project and is publicly accessible (see Göl et al., 2023). The scale questions within the scope of quantitative analysis in the developed form and the variables corresponding to the questions are presented in Table 2.
Questionnaire Items and Corresponding Variables Used in the Quantitative Analysis.

Data Preprocessing
At this stage, the data obtained through structural form was made suitable for the development of models. Data editing, data discretization, handling missing values, feature generation, handling outlier values, and data transformation processes were applied in the data preparation and preprocessing steps to obtain the variables to be used in the development of the models.
Data Editing
In this step, various data editing operations were carried out for Undergraduate_GPA, ALES, Country_Master, Country_PhD, and Official_Language attributes. The answers given by the participants to the question “What is your undergraduate graduation average?” in the survey form varied. Some participants reported their GPA score in the 100-point system, and some participants reported their GPA score in the 4.00-point system. Therefore, in order to transform the attribute values into a single scale, GPA scores in the 4.00-point system were converted into GPA scores in the 100-point system. The formula used for this is given in Equation 1.
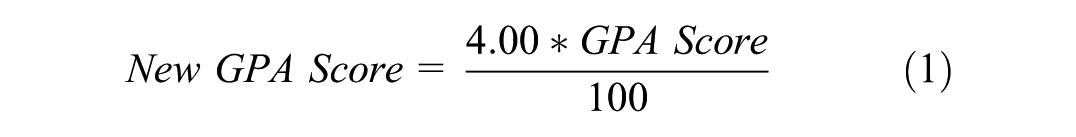
Similarly, there were differences in the answers given by the participants to the question, “What is your ALES score for applying for the 1416 education scholarship?” While some participants wrote their ALES score values calculated in the 100-point system, some participants reported their LES exam scores calculated in the 80-point system. For this reason, LES scores in the 80-point system were converted to ALES score type using Equation 2.
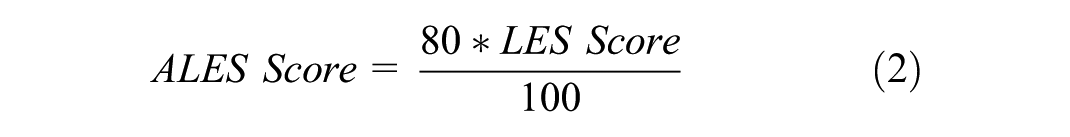
Finally, in this step, the data in the Country_Master, Country_PhD, and Official_Language attributes were edited and standardized. All answers were checked, uppercase and lowercase inconsistencies were eliminated, spelling errors were corrected, and thus data inconsistency was eliminated.
Data Discretization
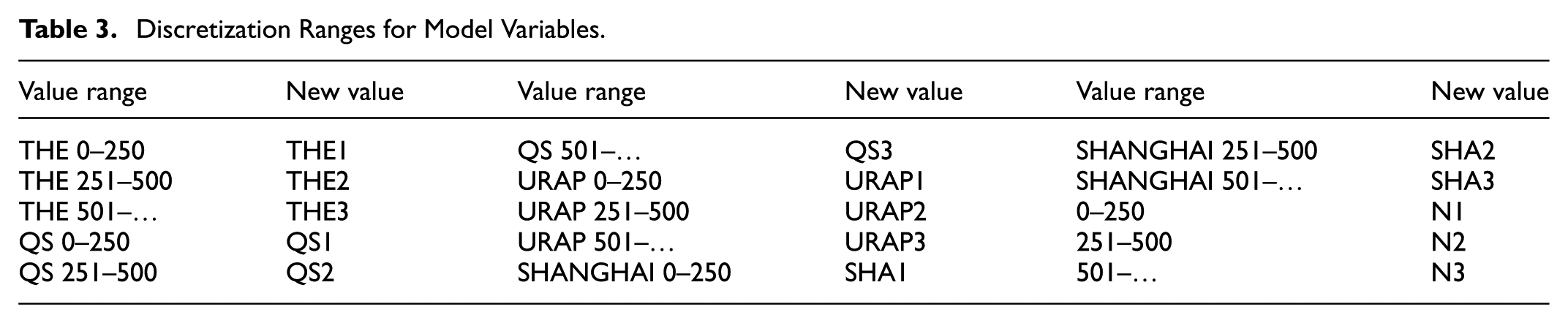
Data discretization, one of the basic preprocessing technique, is a data reduction method that converts numerical attributes into discrete or nominal attributes (Garcia et al., 2012). The answers given by the participants for the “University_Ranking” attribute vary within the scope of THE, SHANGAI, QS, URAP, and ARWU international university ranking indicators. For example, one participant answered this question as THE-226, while another participant answered this question as SHANGAI-901. Some participants reported only the ranking without specifying the type of indicator (N1, N2, and N3). For this reason, the answers to this question were discretized and shown in Table 3.
Discretization Ranges for Model Variables.
Handling Missing Values
When there is no value in an observation, this situation is called missing value. Missing data problems, which are frequently encountered when working with large data sets, may occur due to coding errors, unanswered situations, or sometimes intentionally. Since this problem will negatively affect the results, data analysts are required to find a solution using the necessary techniques (Zhang, 2015). In this study, there were various attributes with missing values due to the participants not answering some questions. There are missing values in 288 samples in the “Department_of_Graduation” attribute in the dataset. On the other hand, since many participants did not have an interview exam when they applied for the scholarship or did not remember their exam scores, there are 375 missing values in the attribute “Interview_Exam _Score.” Two attributes were removed from the data set due to the high number of missing values.
There are 4 missing values in the “Undergraduate_GPA” attribute and 19 missing values in the “ALES” attribute. Since these two attributes are numeric attributes, missing values were completed by replacing them with the average value. There are 51 missing values in the “University_Ranking” attribute. Since this attribute is categorical, missing values are completed by replacing them with the mode value.
Feature Generation
The feature generation process, also known as feature engineering in the field of machine learning, is the addition of a new dimension to the data set by creating new attributes from existing attributes (Kamath & Choppella, 2017; Sarkar et al., 2018). In this step, one input variable and four output variables were generated by using the existing variables. First of all, since English is the academic language at the international level, the “Official_Language_English” input variable was generated depending on the “Official_Language” attribute values. This attribute consists of “Yes” and “No” values. On the other hand, the study aims to predict whether the scholarship program will be beneficial for academic staff participants who will go abroad with the scholarship program in the future. To develop supervised machine learning models, attributes representing the benefits seen by participants were needed as output variables. In this study, it was aimed to estimate four attributes of the participants. For this purpose, the “Number_of_Indexed_Articles,”“Number_of_Other_Articles,”“Number_of_Projects,” and “Number_of_Citations” attributes were used to generate these attributes, respectively. Table 4 lists the transformation rules applied to the raw dataset to generate meaningful features that are used as input to machine learning models.
Feature Generation Rules.

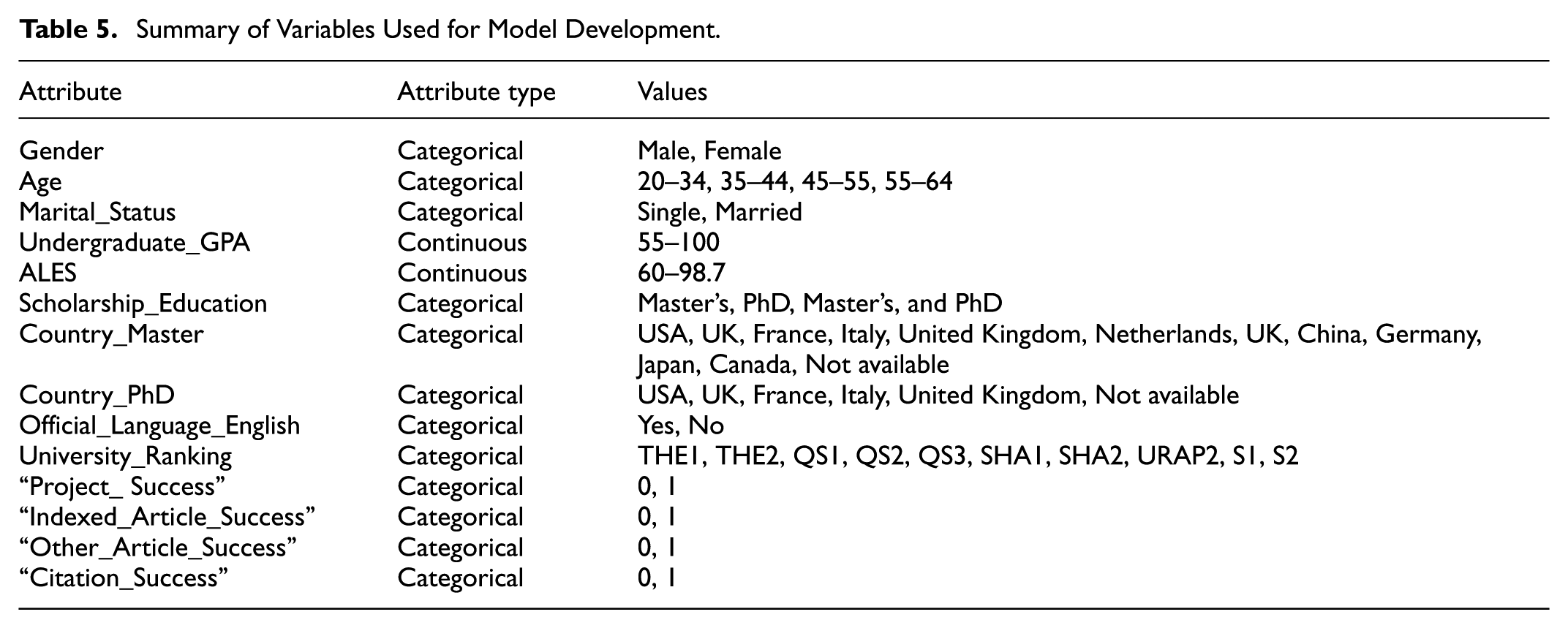
As a result of this step, Table 5 summarizes the distributional features and statistical properties of the resulting features.
Summary of Variables Used for Model Development.
In this study, academic performance (articles, citations, projects) was measured using a binary classification system. Academics were coded as “present” if they had at least one academic output, and “absent” if they had no output. The aim of this approach is to make the results easier and more understandable for policymakers.
Handling Outlier Values
Outliers are patterns in the dataset that do not fit the general situation. In order to ensure the solution accuracy of the analysis, these values must be determined and eliminated by data cleaning methods (Singh & Upadhyaya, 2012). For this purpose, the outlier value should be identified to reveal a data sample that is significantly different from other samples (Park, 2023). In this study it was determined that there were outliers in the “ALES” and “Undergraduate_GPA” qualifications. To eliminate these outliers, the lower and upper outlier values of the two attributes were equalized to the lower and upper threshold values. During equalization, the percentile value of the upper threshold was set as 90, and the percentile value of the upper threshold was set as 10.
Data Transformation
In this step, the normalization method, one of the data transformation methods, was applied to the numerical values “ALES” and “Undergraduate_GPA.” The normalization method ensures that the attributes take values within a common scale. In this study, the values of the two attributes were transformed to be in the [0–1] value range through the MinMax normalization process given in Equation 3. This method is based on subtracting the smallest value of the X feature from each value and dividing it by the X range, where X′ is the normalized data and Xi is the input data.
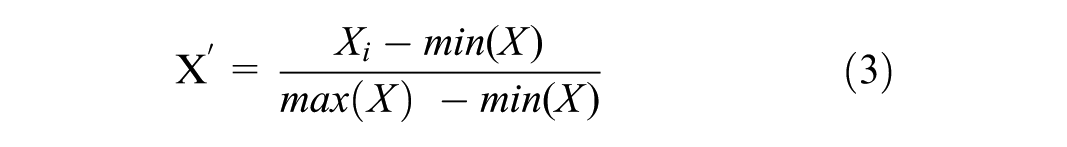
Development of Models
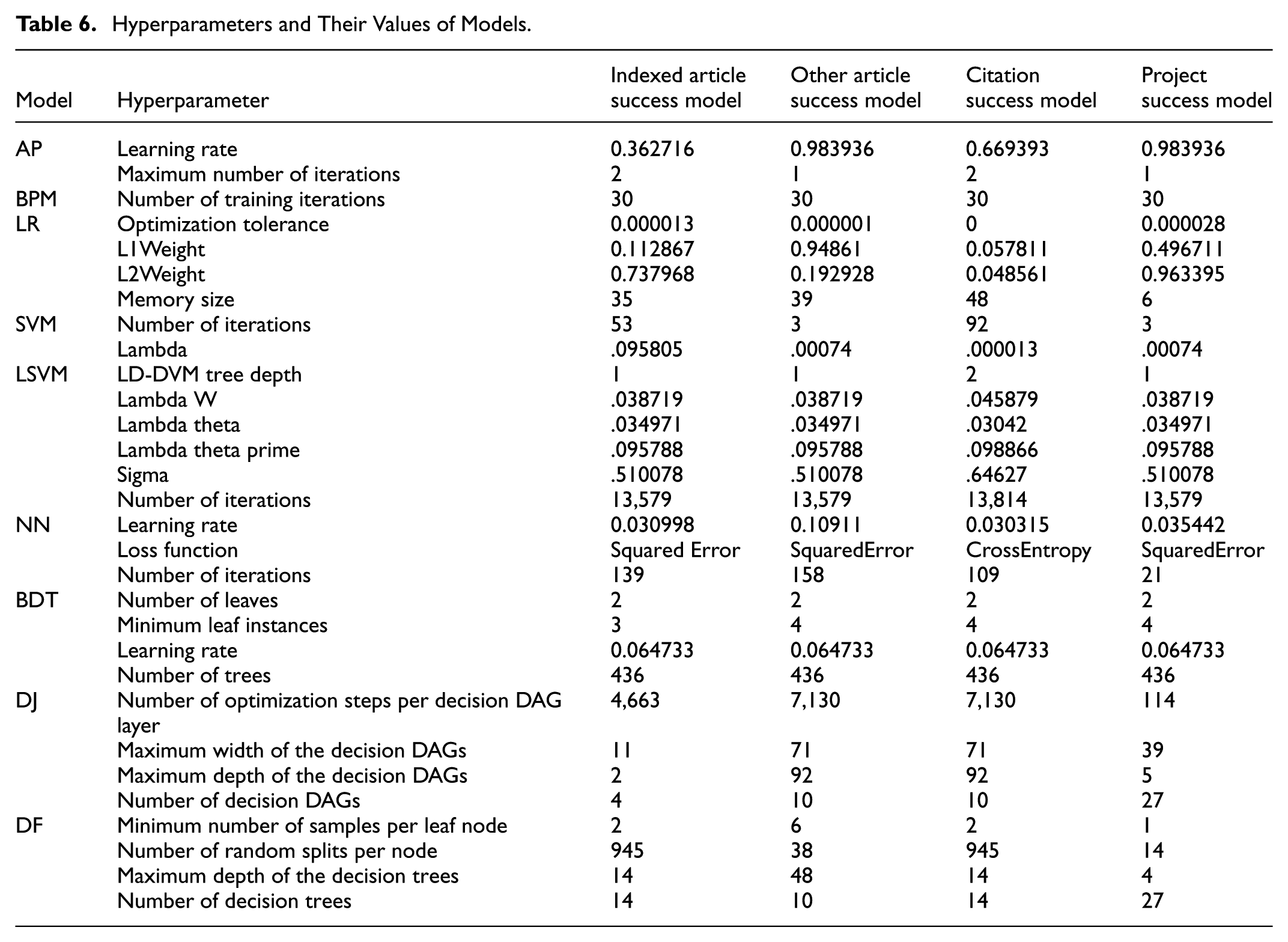
At this stage of the study, within the scope of quantitative analysis, it was aimed to develop four classifier models, namely the Indexed Article Success Model, Other Article Success Model, Citation Success Model, and Project Success Model, which will predict the success of academic staff scholarship candidates who applied to the international scholarship program. For this purpose, nine machine learning algorithms, which are two-class classifiers, were used for each model. Thus, a total of 36 models were developed. The training and testing phases of the models were carried out in the Microsoft Azure Machine Learning Studio environment. In developing the models, 50% of the dataset was used as training and 50% as test dataset. In training the models, model parameters were determined using the “Tune Model Hyperparameter” module. The parameter sweeping mode in the module was set to Random sweep. The maximum number of runs on random sweep was set to 500. During random sweep optimization, model performance was evaluated on the validation set using accuracy, and the hyperparameter configuration yielding the best validation performance was selected. Optimum hyperparameter values for each model are presented in Table 6.
Hyperparameters and Their Values of Models.
Random sampling was used for dataset partitioning. Within this partitioning process, the hyperparameter tuning process was performed using only the training data, which was partitioned into training and validation subsets by Azure Machine Learning Studio. Model performance was evaluated on the validation subset using an accuracy metric, and the best configuration was selected. The test data was not included in the hyperparameter optimization and model selection processes and was only used to evaluate the final performance.
Although classical statistical significance levels (e.g., p-values) are not directly applicable to machine learning models, SHAP values provide an interpretable alternative by quantifying the relative contribution of each variable to model predictions.
Findings
Research Question 1
As a result of the content analysis carried out within the scope of qualitative analysis, eight themes were obtained: The themes, codes and frequencies determined by the team based on the answers to the interview questions are presented in Table 7. The themes are detailed below.
Themes, Codes, and Frequencies Identified in the Qualitative Analysis.

Strengths of the Program
This theme captures the positive aspects of the YLSY scholarship program as experienced and perceived by participating scholars. These strengths demonstrate the program’s potential to make a meaningful contribution to scholars’ development and to the broader goals of higher education and research capacity building in Türkiye. One of the most commonly mentioned aspects was “Code1.” Scholars emphasized how studying abroad broadened their academic horizons, improved their research skills, and immersed them in a global academic culture. Another frequently cited advantage was the “Code2” and “Code3,” which offered participants the chance of “Code4” in academic positions upon their return. One participant commented: “Position which promises permanency… In general, I think it is a good thing that our position is certain.” These aspects were seen as valuable in fostering inclusivity and ensuring career continuity. “Code5” are also appreciated by participants. Participants also mentioned “Code6” as a strength of the program and the potential for “Code7,” which they believed enriched both their professional lives. These findings suggest that the YLSY program plays a significant role in equipping scholars with the competencies and experiences needed for academic careers while also fostering a sense of belonging to a global academic community.
Weaknesses of the Program
This theme focuses on scholars’ critical reflections regarding the structural and procedural shortcomings of the YLSY scholarship program. A frequently cited concern was the “Code8,” which refers to scholars’ perceptions that scholarship amounts are standardized and do not sufficiently account for differences in country-, city-, and cost-of-living conditions, leading to financial strain in high-cost destinations. As one participant stated, “The current scholarship amount may be sufficient at a basic level, but it does not provide comfortable living conditions … in countries with high living and health insurance costs.” (Participant 1). Overall scholars consistently expressed that the current system does not adequately account for variations in the cost of living, leading to financial hardship for those studying in more expensive locations. Another major weakness was the “Code9” such as ministry of national education, Higher education council, and attaché offices. This gap was seen as a root cause of inefficiencies throughout the program process, from pre-departure to post-return. The “Code10” also drew criticism. Participants questioned the fairness and transparency of the evaluation, with some describing the interviews as subjective or inconsistent. As one scholar commented, “It felt more like a formality than a real assessment of our academic potential.” Post-return challenges were also significant. Many participants reported “Code11” including delays in placement or temporary assignments unrelated to their expertise. “Code12” was a source of frustration, particularly for scholars trained in specialized disciplines. These mismatches often led to underutilization of skills and reduced motivation. One participant mentioned “… What should he do at …. University? There is no lecturer or department with a doctorate on drones at …. University ….” Finally, scholars described “Code13.” One participant reflected, “That is, because it is already very difficult to get accepted from departments and from a good university. In other words, it is difficult to find a teacher in that subject, in the subject they want.”
Points Suggested to Be Changed
One of the most emphasized suggestions (Code14) concerned the lack of coordination between institutions involved in the scholarship process. Participants indicated that insufficient coordination created uncertainties and inefficiencies throughout different stages of the program. As one participant stated, “I think you have a lack of coordination. In other words, there is a lack of coordination between institutions. If I had the chance, I would want to change it.” Overall, scholars emphasized that improving institutional coordination was a critical area for change in order to ensure a more coherent and effective implementation of the scholarship program. A second recurring suggestion (Code15) concerned the need for more systematic communication and guidance mechanisms both before and after scholars’ time abroad. Participants emphasized the importance of regular updates, mentorship, and structured channels for receiving guidance and feedback in order to reduce uncertainty and improve preparedness throughout the scholarship process. One participant remarked, “The university needs to check its students and those who go abroad from time to time. I think the university should hold meetings. This problem will be eliminated if the places where students will go are determined in advance.” Revisions to “Code16” were also strongly recommended. Participants advocated for clearer guidelines regarding academic appointments, improved transparency in placement processes, and ensuring that placements align with scholars’ academic backgrounds. “Reorganizing the employment methods of returnees ….” Closely related to this was the call for that “Code17,” including mechanisms to request reassignment if initial placements do not match the scholar’s qualifications or research interests. One participant mentioned “If the university doesn’t accept us when we return, it would be nice if we were at least given a second choice. So, it was scary for us to be dragged into uncertainty there.”“Code18” and the “Code19,” as these were perceived as sources of inconsistency or inefficiency. Furthermore, several scholars suggested that the program include more personalized planning for placement so “Code20.” One said: “When we return, if the university’s appointment criteria are met, we will be appointed as faculty members without any equivalence requirement.”
Adequacy of Existing Mechanisms
This theme captures scholars’ perceptions regarding the effectiveness and sufficiency of the current mechanisms embedded in the YLSY scholarship program. The most frequently mentioned issue was “Code21.” Several scholars reported that counseling services were either insufficient or ineffective, particularly after departure. One participant stated, “Counseling doesn’t actually work very well. As none. There is a communication gap after going abroad.” However, not all views were negative. Another participant noted, “This is about counseling … This is changing. Definitely. This must be it.” Developing a predictive support model tailored to scholars’ evolving needs abroad may contribute to a more proactive and functional counseling framework. The second most frequently mentioned issue was related to “Code22.” Participants noted significant limitations, particularly in terms of staffing and capacity. One participant recalled, “I remember that the number of people working in the education consultancy was quite small, and our number was close to 200. As such, it was not possible for one person to reach 200 people. This reflects a structural gap in human resources ….” Another significant concern was the “Code23.” Participants highlighted the lack of systematic follow-up during their time abroad. A participant emphasized this gap by stating, “Secondly, let me say that the follow-up of the student is carried out. The student should not be abandoned.” This underscores the need for an active and responsive monitoring mechanism that maintains regular contact with scholars and addresses emerging issues promptly. Further concerns were raised regarding the “Code24.” In addition, participants pointed to weaknesses in “Code25,” which can result in misaligned expectations and planning gaps. Lastly, a few participants highlighted the “Code26,” suggesting that existing digital tools for managing the scholarship process are underutilized or poorly integrated.
Suggestions for Additional Mechanisms
This theme reflects scholars’ forward-looking recommendations for mechanisms that do not currently exist within the structure of the YLSY scholarship program but are considered essential for improving its long-term effectiveness. Similar to the previous theme on the adequacy of existing mechanisms, the most frequently emphasized need was for a more robust “Code27.” One participant stated, “There is no structure where you can receive any kind of academic or psychological support ….” This highlights the pressing need for institutionalized systems that go beyond logistics and address holistic support for scholars throughout the scholarship lifecycle. Another area identified for improvement was the “Code28.” Participants argued that better monitoring would help institutions remain informed of scholars’ progress and challenges while abroad, enabling more timely support and accountability. A further significant area of suggestion centered on the “Code29.” The comments reflected a broader expectation that the scholarship program align more closely with national priorities and institutional needs. One participant emphasized this by stating, “In general, determining what the country needs, in which areas of technology the universities need progress, and sending scholars abroad to fill those gaps in advance.” Participants also proposed “Code30,” noting that a proactive and consistent exchange of information is essential for aligning expectations, fostering a sense of inclusion, and ensuring smooth academic reintegration. In a similar vein, the “Code31” was also highlighted as a crucial step to reduce institutional fragmentation and ensure alignment between individual scholar training plans and broader academic strategies. Finally, some scholars stressed the need for “Code32,” as current procedures related to diploma recognition and academic standing were viewed as ambiguous or inconsistent.
Threats
This theme reflects participants’ perceptions of the potential risks that could undermine the long-term success and sustainability of the YLSY scholarship program. Participants expressed concern that “Code33,” especially those in technical fields, may lead to resignation and pursuit of international opportunities after completing their studies. One participant noted, “Here’s a problem. For example, those who find their way, especially those in technical sciences, can resign and leave.” This was perceived as a loss of national investment and talent. The issue of “Code34” was also identified as a major threat. Factors such as poor adaptation, lack of support, or academic challenges may contribute to dropout or delay. As a participant stated, “These factors include not completing the training on time. The biggest threat is on these students.” In some cases, “Code35” was observed upon their return. One participant described this by saying, “So, after all, the student cannot be happy with teaching after coming here. He cannot do his work properly.” Another critical concern was “Code36.” Stress, lack of academic guidance, or poor topic selection were cited as factors that hinder scholarly quality. A participant remarked, “Because of this stress and lack of control, students can study very absurd subjects. Actually, it’s not very up to date.”“Code37” where they are employed was seen as another barrier to long-term academic contribution. One scholar noted, “Maybe it could be something in terms of feeling like you belong to the institution or contributing something to that institution.” Lastly, “Code38” was mentioned, particularly during the initial transition abroad. One participant commented, “Here’s what I said at the beginning. When you first go there, this is a ridiculous security problem due to the lack of coordination. This is an important thing so ….”
Suggestion for Improvement
This theme includes participants’ proposals for improving the overall implementation, sustainability, and impact of the YLSY scholarship program. The most frequently emphasized areas for improvement were “Code39” and “Code40.” One participant stressed the importance of the former by stating, “… people who will go there should be informed in advance, … perhaps the experiences of those who return can be shared with them.” This comment highlights the perceived need for pre-departure orientation to enhance scholars’ academic preparedness and psychological readiness. Concerns about scholars’ reintegration upon return were also prominent. “Code41” and “Code42” were both noted as critical to ensuring continuity in scholars’ career paths and optimal use of their expertise. These suggestions point to the need for proactive institutional engagement throughout the scholarship cycle. At the selection stage, “Code43” was proposed to ensure that highly qualified and motivated individuals are selected. As one participant commented, “An effort could be made to send more qualified people.” This indicates a concern for maintaining the program’s merit-based integrity. Further, “Code44” was mentioned as a strategy to ensure that scholars have clearly defined goals and institutional alignment before beginning their studies. Finally, “Code45” reflects a broader call for strategic foresight in national academic planning. One participant noted, “… institutions need to work in coordination and clearly state what is needed according to long-term plans.” This underscores the relevance of predictive models in shaping the scholarship program’s future direction and aligning it with national development priorities.
Opportunities
This theme highlights the broad range of benefits that scholars perceive as outcomes of their participation in the YLSY scholarship program. The most frequently cited benefit was the “Code46.” One participant reflected, “As I said, I think the most important thing is that it provides that academic culture for us as scholars.” A closely related benefit was the “Code47,” which provided not only financial relief but also allowed scholars to focus entirely on their academic goals without the stress of tuition fees and living expenses. As one participant explained, “So you don’t think about tuition fees. Your salary is deposited …” Participants also highlighted the “Code48” they were able to build during their studies abroad, noting that collaborations with international researchers significantly enriched their academic perspectives and opened new avenues for future cooperation. In terms of personal growth, scholars emphasized “Code49” as a key outcome of their time abroad. Other positive outcomes mentioned include the “Code50,” such as conferences and workshops, which helped scholars stay current in their fields and gain visibility within the global academic community. Finally, the “Code51” itself was regarded as valuable, not only for academic reasons but also for the life experience it provided.
Building on the qualitative findings of Research Question 1, the second phase of the study aimed to explore whether predictive models could be developed to evaluate the effectiveness of the YLSY scholarship program. In line with the exploratory sequential mixed method design, the qualitative phase served as the foundation for shaping the structure and content of the subsequent quantitative analysis. Themes and codes identified through in-depth interviews were systematically examined to inform the selection of input and output variables for predictive modeling. In the following section, the results of the quantitative analysis addressing Research Question 2 are presented.
Research Question 2
Predictive Modeling Results
This section presents the results of the machine learning–based predictive models developed to analyze multiple academic success outcomes of YLSY scholars. Separate classification models were constructed for four success dimensions as indexed article success, citation success, project success, and other article success.
Four performance criteria (formulations are given in Equations 4–7) were used to evaluate the performances of 36 machine learning models developed within the scope of quantitative analysis. For each predictive model, the target variable represents a binary academic success outcome with two classes: “0” (successful) and “1” (unsuccessful). In this study, the “successful” class is treated as the positive class, while the “unsuccessful” class is treated as the negative class. In this situation, TP is the number of “successful” samples predicted as “successful,” and TN is the number of “unsuccessful” samples predicted as “unsuccessful” by the model. FP is the number of samples predicted as “successful” when the actual value is “unsuccessful,” and FN is the number of samples predicted as “unsuccessful” when the actual value is “successful.”
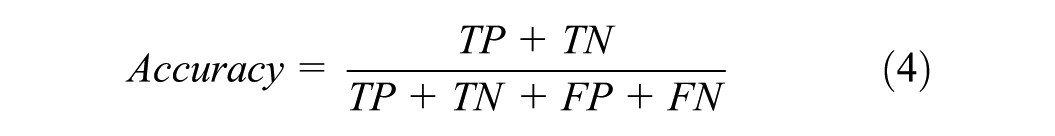

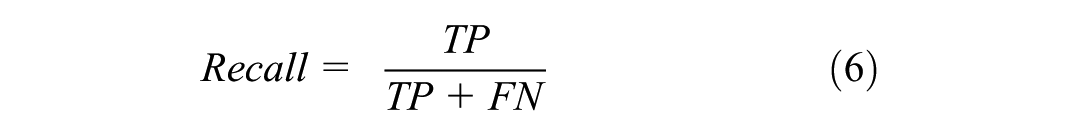
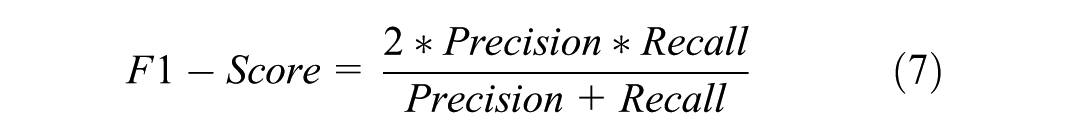
TP, FP, FN, and TN values, as well as accuracy, precision, recall, F1-Score, and AUC values of the nine classifier models developed to predict the indexed article success of scholarship candidates are given in Figure 3. When the figure is examined, it was concluded that the highest accuracy and precision values with values of 0.774 and 0.826, respectively, were obtained with the BDT model, the highest recall value was obtained with the DJ model with 1.000, and the highest F1-Score value was obtained with the BDT model and DJ model with a value of 0.853, and the highest AUC value was obtained with LR model and BDT model with a value of 0.715.
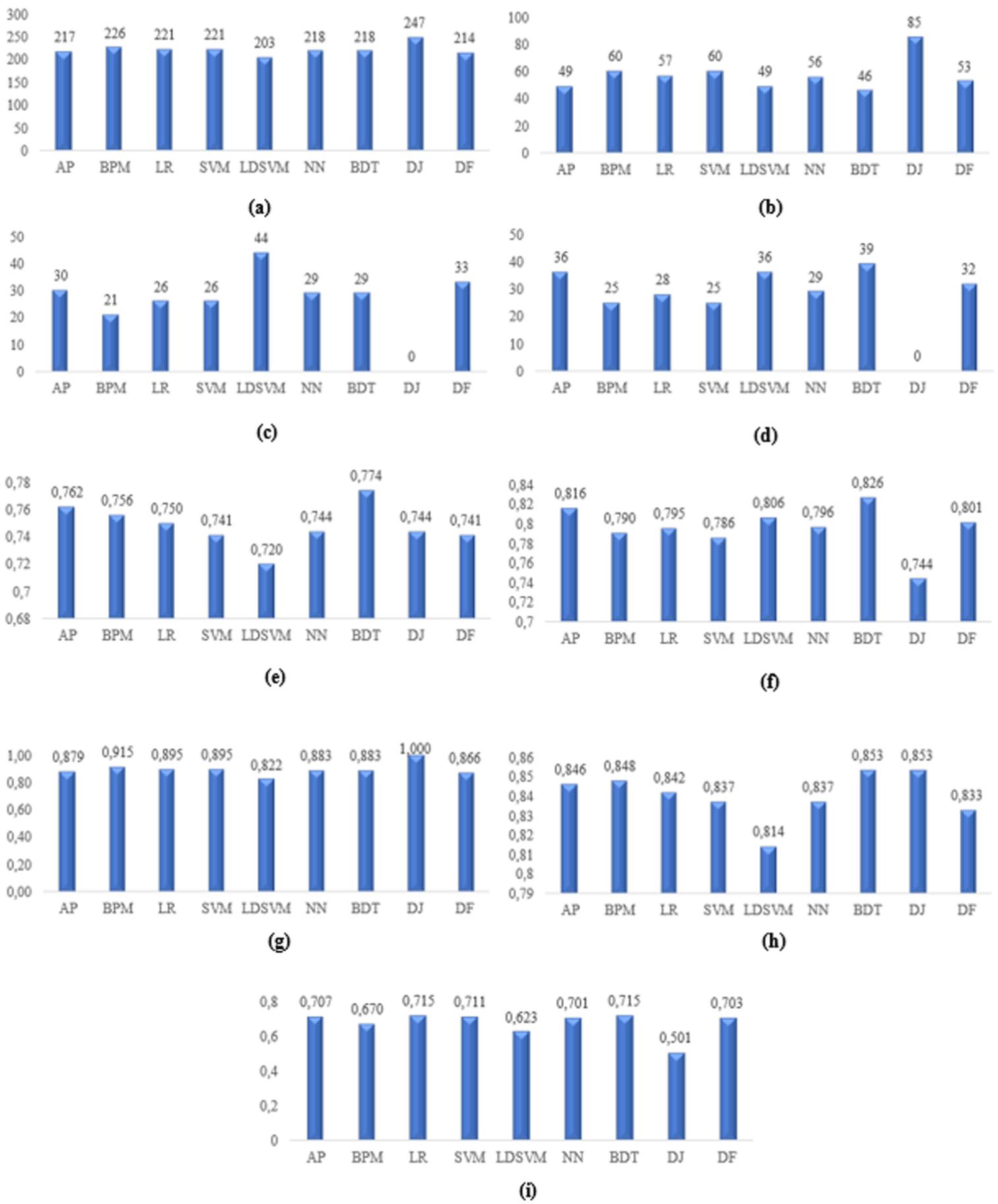
Performance criteria values of indexed article success models: (a) TP, (b) FP, (c) FN, (d) TN, (e) Accuracy, (f) Precision, (g) Recall, (h) F1-Score, (i) AUC.
These findings indicate that the indexed article performance within the YLSY program follows a systematic and predictable pattern, rather than a random one. The successful performance of the model suggests that the variables included in the analysis capture significant determinants of academic productivity in terms of indexed outputs.
As shown in Figure 4, the DJ model provided the best prediction performance in terms of accuracy and precision performance measures, with values of 0.711 and 0.735, respectively. The best recall value was achieved by AP with a value of 0.970, and the highest F1-Score value was achieved by the DF model with a value of 0.819, and the highest AUC value was obtained with LDSVM model and DJ model with a value of 0.575.
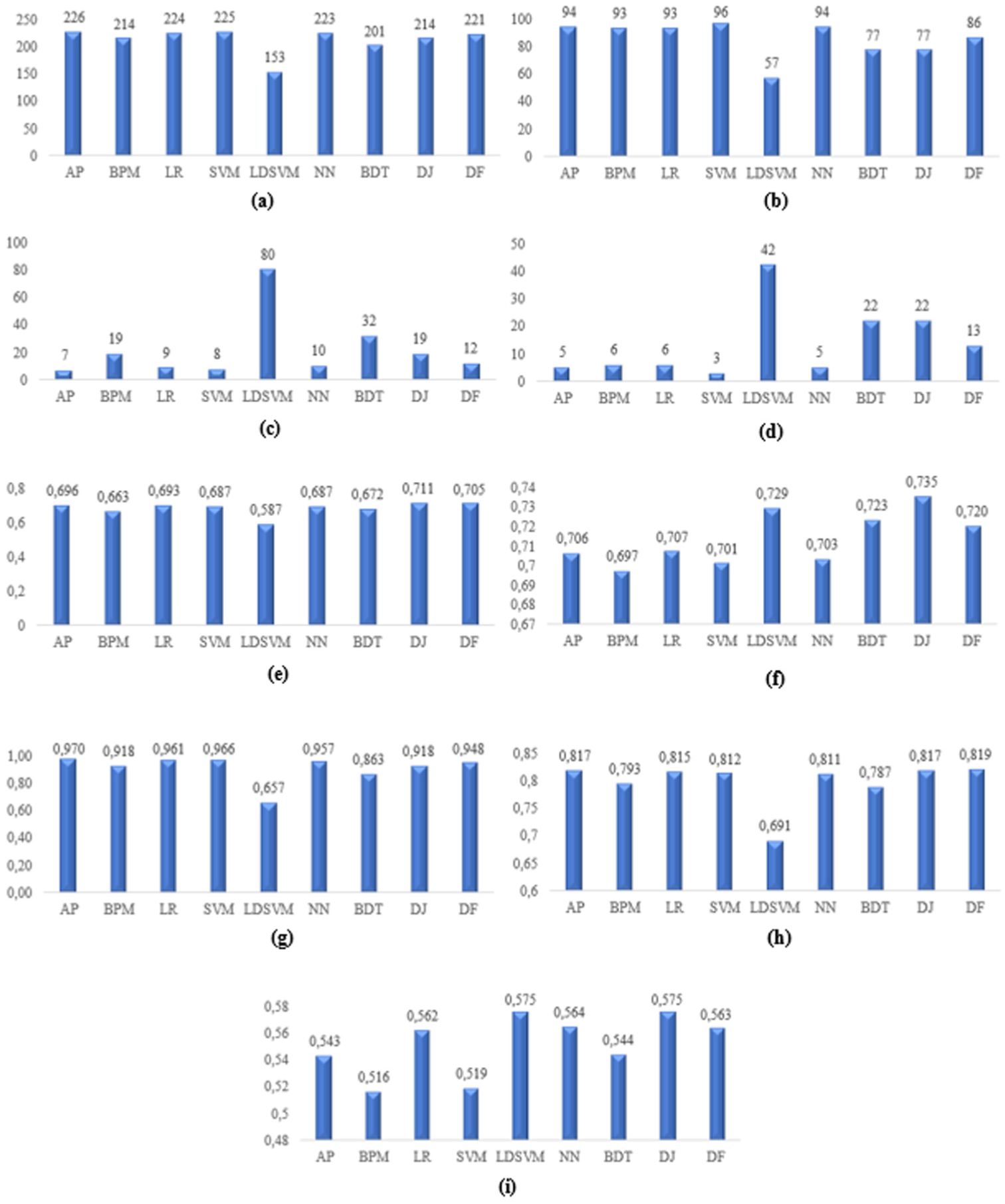
Performance criteria values of other article success models: (a) TP, (b) FP, (c) FN, (d) TN, (e) Accuracy, (f) Precision, (g) Recall, (h) F1-Score, (i) AUC.
These findings indicate that the other article outcomes are structured and can be successfully predicted. This suggests that academic output across broader article categories is also influenced by similar systematic factors.
As shown in Figure 5, the BDT model showed the best prediction performance, excluding recall, and the LDSVM model showed the lowest prediction performance, excluding precision value. While the accuracy, precision, and F1-Score values obtained with the BDT model were 0.816, 0.831, and 0.832, the highest recall value was reached with the DJ and DF models, with a value of 0.965, and the highest F1-Score value was achieved by the BDT model with a value of 0.891, and the highest AUC value was obtained with BDT model with a value of 0.711.
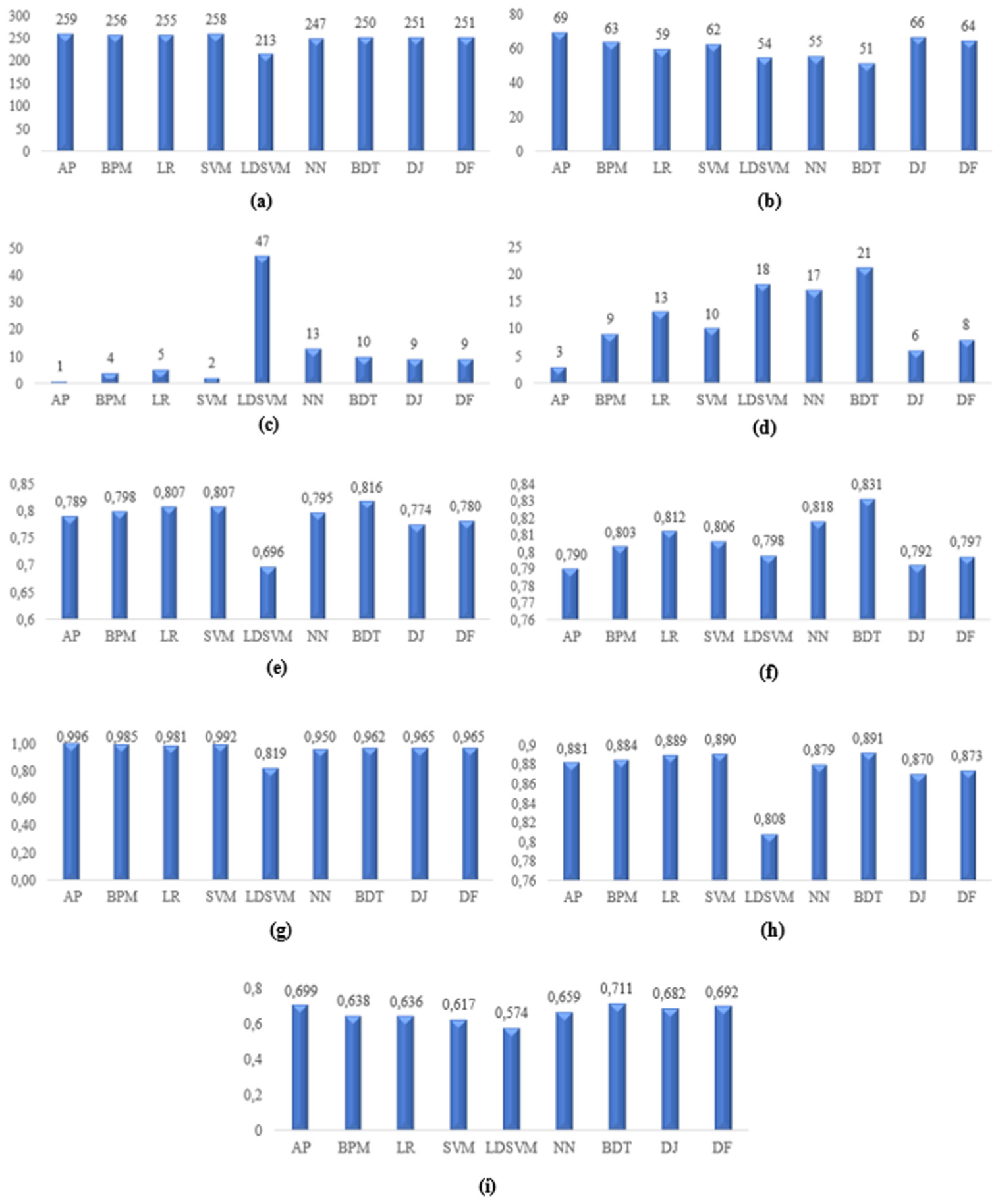
Performance criteria values of citation success models: (a) TP, (b) FP, (c) FN, (d) TN, (e) Accuracy, (f) Precision, (g) Recall, (h) F1-Score, (i) AUC.
These findings indicate that the citation success model, the performance regarding citation outcomes demonstrates that academic achievement improves in a consistent and explainable manner. This finding supports the view that the program contributes to measurable academic impact.
As shown in Figure 6, participation in research projects can be meaningfully predicted, indicating that research engagement follows a systematic and predictable pattern rather than occurring randomly. When the model performances are examined, the NN model achieved the highest accuracy (0.846), while the LDSVM model demonstrated the highest precision (1.000). The highest recall value was obtained with the DJ model (1.000), and the highest F1-Score was achieved by the SVM model (0.879), and the highest AUC value was obtained with SVM model with a value of 0.566.
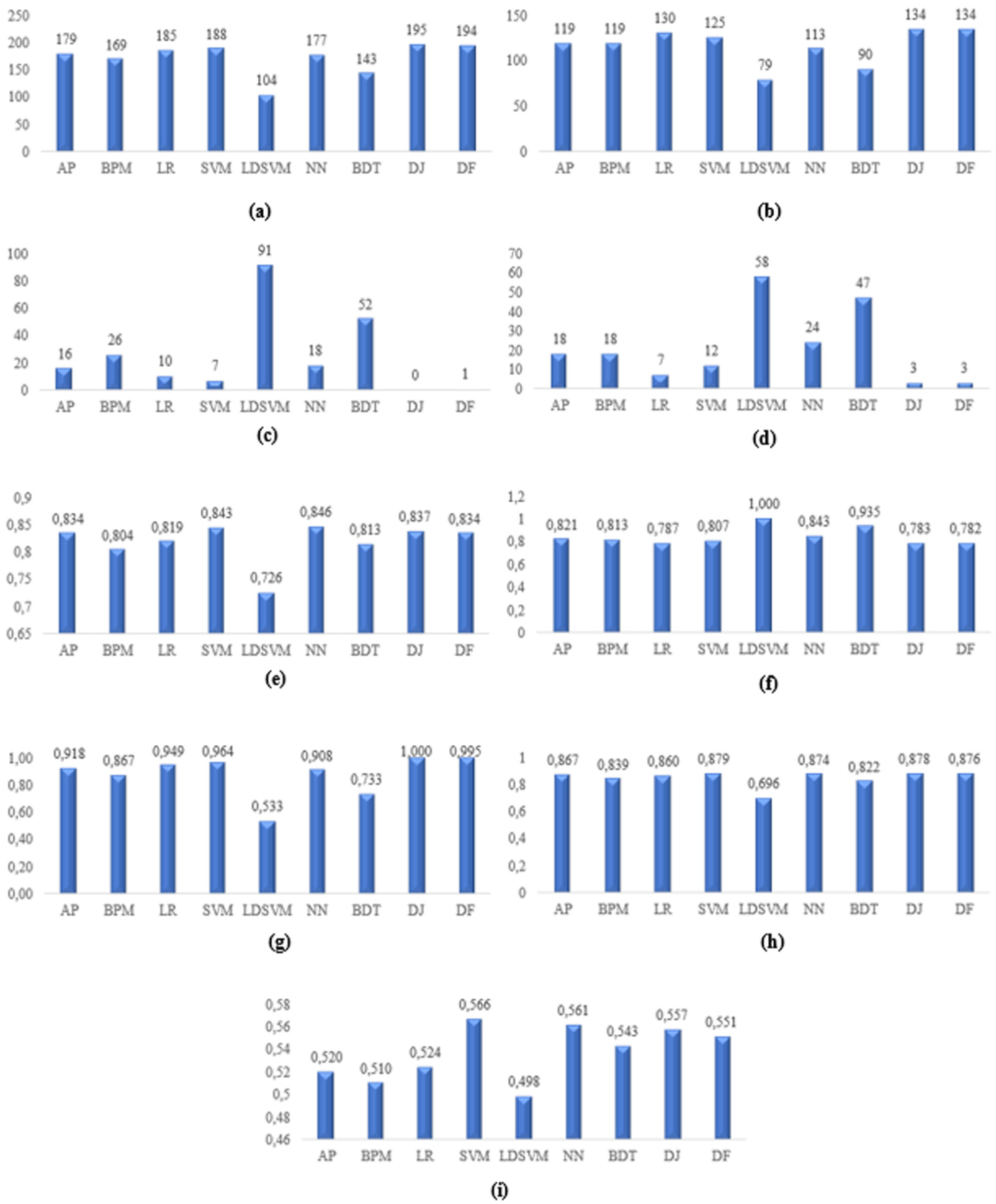
Performance criteria values of project success models: (a) TP, (b) FP, (c) FN, (d) TN, (e) Accuracy, (f) Precision, (g) Recall, (h) F1-Score, (i) AUC.
Figure 7 presents the confusion matrix plots of the best-performing models for each prediction task. The results indicate a strong ability of the selected models to correctly identify successful cases across different success criteria. In Figure 7a, corresponding to the Indexed Article Success task, BDT model demonstrates a high number of true positives, indicating effective identification of scholars with indexed article success, while maintaining a moderate level of false positives. Figure 7b shows the DJ model for Other Article Success, where a relatively higher number of false positives is observed. However, the model successfully captures a large proportion of true positive cases, reflecting its high recall-oriented behavior. In Figure 7c, the BDT model applied to Citation Success exhibits a strong balance between true positives and true negatives, suggesting robust discrimination capability with limited misclassification. Finally, Figure 7d illustrates the SVM model for Project Success, which achieves a high number of correctly classified successful cases, although the presence of false positives indicates a tendency to favor sensitivity over specificity.
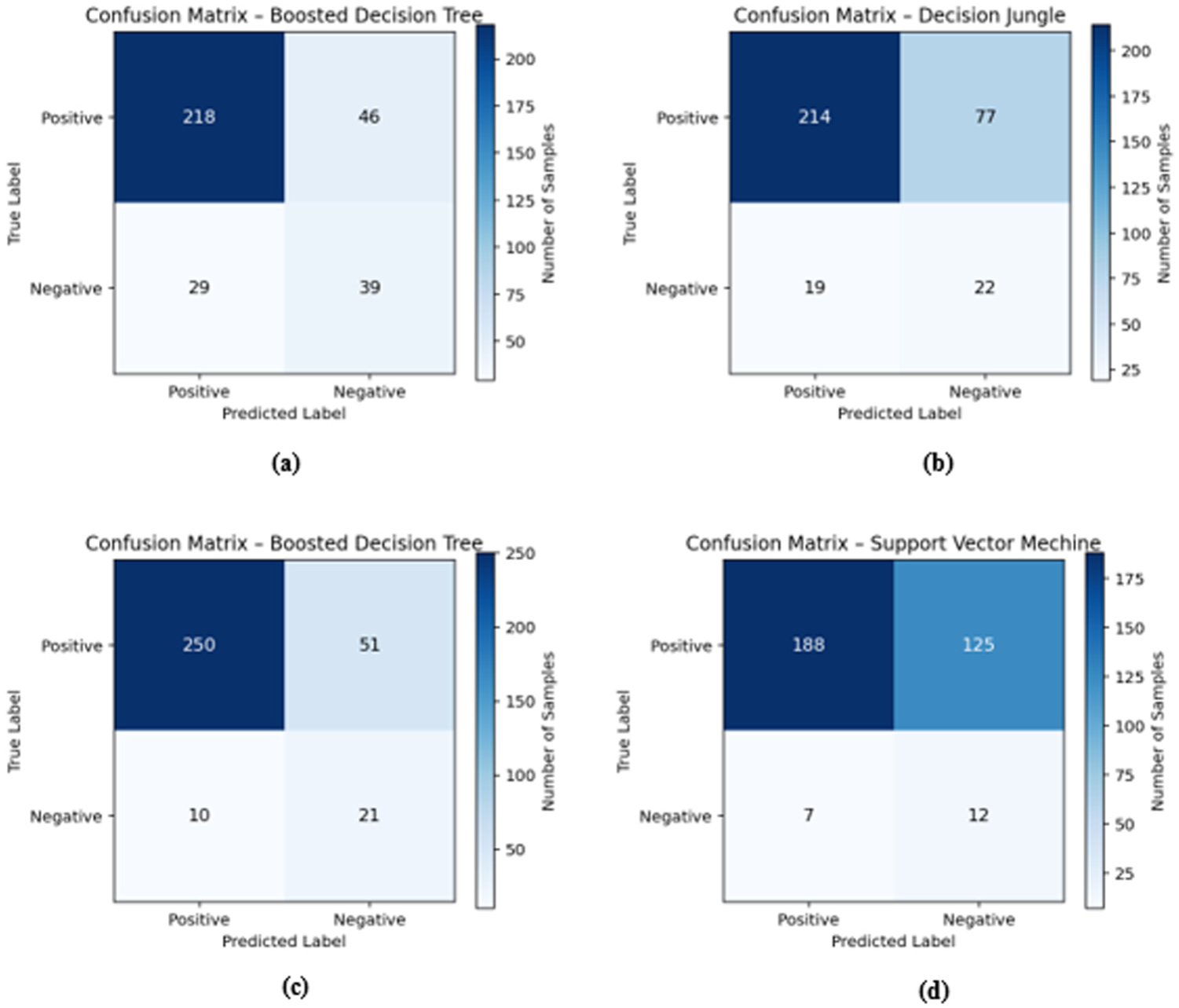
Confusion matrix plots for the best-performing models (a) Indexed Article Success, (b) Other Article Success, (c) Citation Success, (d) Project Success.
Figure 8 presents the Receiver Operating Characteristic (ROC) curves of the best-performing models for each prediction task. The BDT models in Figure 8a and c demonstrate strong discriminatory performance, achieving AUC values of 0.715 and 0.711, respectively, and remain well above the diagonal reference line. In Figure 8b and d, the DJ and SVM models exhibit moderate discriminatory ability with AUC values of 0.575 and 0.566.
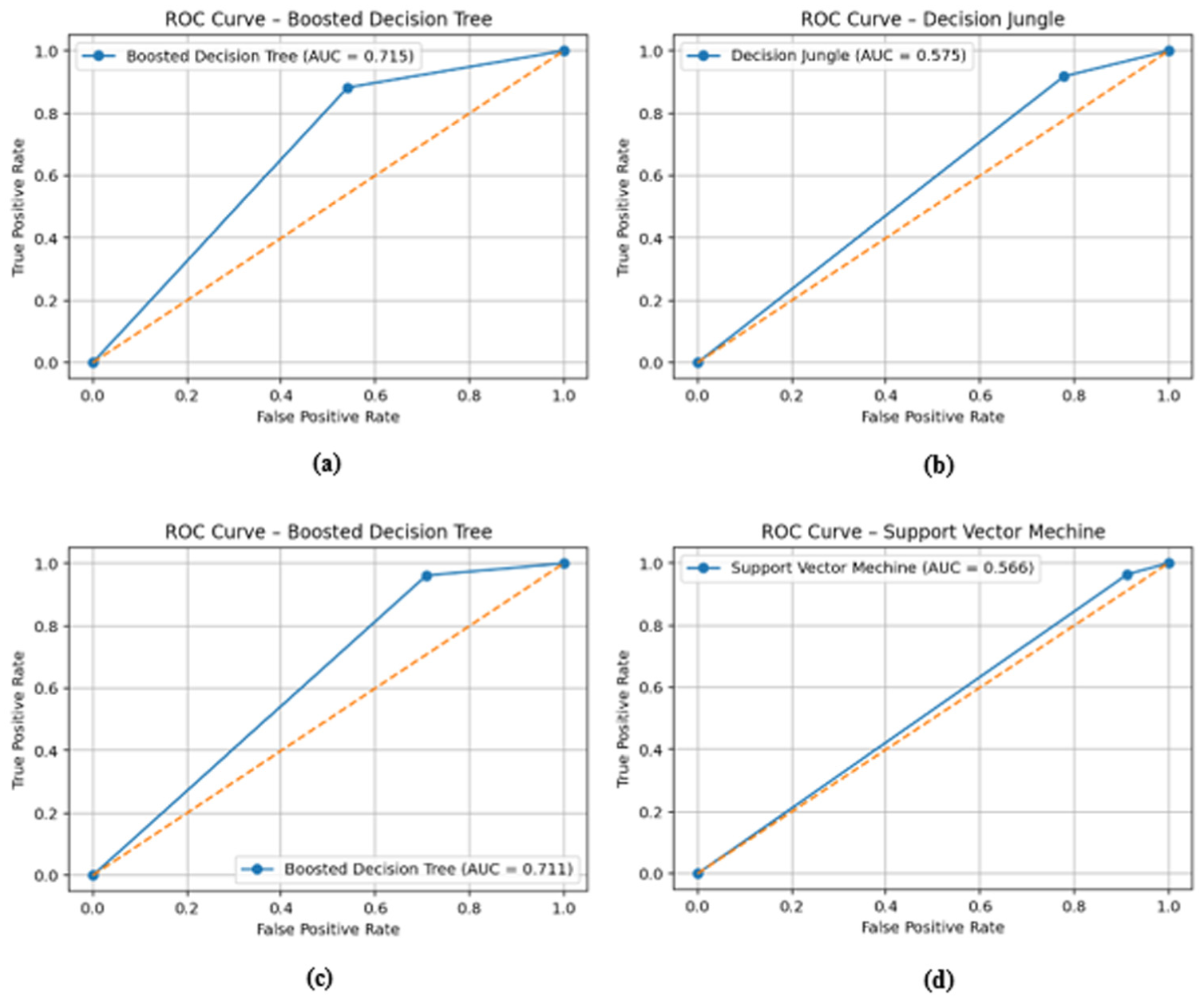
ROC curves for the best-performing models (a) Indexed Article Success, (b) Other Article Success, (c) Citation Success, (d) Project Success.
SHAP-Based Feature Importance Analysis
SHAP (SHapley Additive exPlanations) is an explainable AI method that attributes a model’s prediction to its input features by assigning each feature a contribution value based on Shapley values from cooperative game theory. In other words, SHAP explains how much each variable increases or decreases the predicted probability of success for a given outcome (Marcílio & Eler, 2020; Wang et al., 2024).
To enhance the interpretability of the machine learning–based predictive models, a SHAP (SHapley Additive exPlanations) analysis was conducted for each academic success outcome. SHAP values provide a unified and model-agnostic framework to quantify the contribution of individual input features to the model’s predictions, enabling a transparent examination of how different candidate characteristics influence prediction outcomes.
In this study, mean absolute SHAP values were used to rank feature importance, where higher values indicate a stronger overall impact of a feature on the corresponding success outcome. This approach allows for a consistent comparison of influential factors across different success dimensions, including indexed article success, citation success, project success, and other article success.
Figure 9 presents SHAP-based feature importance results using mean absolute SHAP values. For Citation Success (Figure 9a), Education_Level_Doctorate is the dominant predictor (0.751), with a sharp drop to the next variable Age_20–34 (0.140), indicating high concentration around a single feature. In the Indexed Article Success model (Figure 9c), importance is more evenly distributed, with Doctoral_Degree_ABD (0.267) and Doctoral_Degree_YOK (0.250) leading, followed by GPA and language variables. For Other Article Success (Figure 9b), Education_Level_Master’s ranks highest (0.248), with moderate dispersion across academic and demographic characteristics. In the Project Success model (Figure 9d), Undergraduate_GPA emerges as the strongest predictor (0.156), with feature influence spread across multiple variables. Across all models, education level and GPA consistently appear as key predictors.
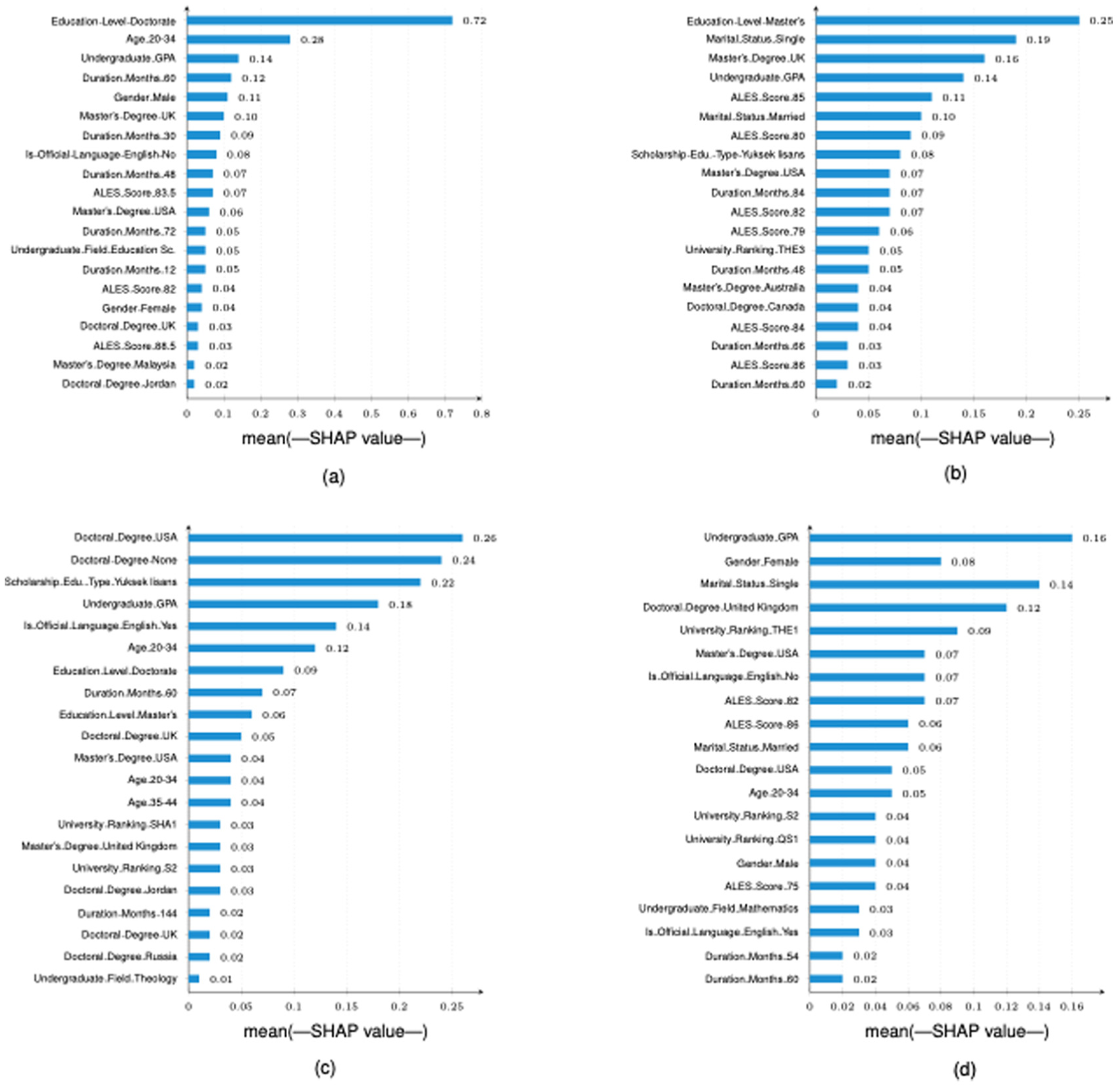
SHAP feature importance analysis for four success metrics. Each panel shows the mean absolute SHAP values (average impact on model output magnitude) for the top features influencing: (a) Citation Success, (b) Other Article Success, (c) Indexed Article Success, and (d) Project Success.
Conclusion
This study aims to evaluate the effectiveness of the YLSY scholarship program and the success of the scholars by developing machine learning-based prediction models. In the study, the input and output variables required to develop prediction models within the scope of quantitative analysis were determined as a result of the qualitative analysis. Qualitative findings informed the development of the quantitative prediction models. The quantitative results indicate that academic success outcomes—such as indexed articles, other articles, citations, and project participation—can be predicted with reasonable performance using machine learning techniques.When the performances obtained from the models are taken into consideration, it is seen that the qualitative analysis reveals critical needs, and meaningful and consistent prediction performance is achieved by the quantitative models developed based on these needs. These findings suggest that machine learning methods may offer useful tools for evaluating scholarship program outcomes. These findings suggest that machine learning methods may offer useful tools for evaluating scholarship program outcomes. In addition, it is thought that these results will shed light on the development of a future decision support system infrastructure that integrates qualitative insights with predictive analytics.
Discussion
An analysis of the themes derived from academics’ qualitative accounts indicates that participants in the YLSY scholarship program experience substantial academic and social gains. Academics consistently emphasized enhanced academic competencies, bilingualism, and intercultural engagement, which emerged as recurring patterns across individual accounts. These gains reflect both formal academic training and broader exposure to international research cultures and academic networks. From a human capital investment perspective in higher education, such outcomes suggest that the YLSY program supports capacity development beyond individual academic advancement. Consistent with the relevant literature, the findings of this study reinforce prior research on the YLSY scholarship program and similar international scholarship schemes, which report positive effects on academics’ professional development, intercultural competencies, and international academic engagement (Aktekin & Tekben, 2019; Haupt et al., 2021; Kaya, 2024; Taylor & Albasri, 2014). These quantitative findings suggest that the program’s core success dimensions exhibit a systematic and partially predictable structure.
However, an examination of the themes related to the weaknesses of the program indicates that, alongside its benefits, the YLSY scholarship program also exhibits structural and institutional limitations. Recurring themes reveal difficulties in securing appropriate academic positions, limited acceptance by host institutions and departments, and mismatches between scholars’ acquired competencies and the roles available to them. These challenges suggest that the benefits of international graduate education may be undermined when post-scholarship employment processes lack clarity, alignment, and institutional support. These patterns are consistent with prior research emphasizing that unclear employment pathways and insufficient institutional support play a central role in weakening the outcomes of international scholarship programs (Aktekin & Tekben, 2019; Öcal, 2012). Similarly, studies have documented that when returning academics are unable to translate their international gains into institutional practice due to policy constraints and limited opportunities, the intended systemic benefits of such programs remain unrealized (Campbell, 2020; Çelik, 2012). Taken together, the findings suggest that the effectiveness of the YLSY program depends not only on the quality of overseas training but also on the extent to which post-return structures enable the integration of individual-level gains into the higher education system. According to the findings of the study regarding program weaknesses and suggested changes, together with insights from the literature, there is a need for mechanisms capable of predicting the adequacy of existing structures, the effectiveness of the scholarship program, and the academic trajectories of scholarship holders. This need points to the importance of policy-oriented models that can support the systematic evaluation of international mobility programs. In line with this assessment, Balyer and Özcan (2022) emphasize that international mobility programs require continuous updating in terms of infrastructure, personnel, and access to data. Furthermore, within the scope of the theme “mechanism sufficient/insufficient,” academics’ accounts highlight the Counseling and Guidance System as a critical institutional mechanism. Consistent with this observation, Shen et al. (2017) identify guidance systems as a fundamental component of effective educational processes. On the other hand, it is seen that the most important code in the theme of “points suggested to be changed in the program” is the suggestion to improve coordination between institutions. Therefore, as stated in the study conducted by Chan (2021), it is important and necessary to create policies that encourage cooperation between institutions and to provide their infrastructure.
The second research question of the study can be addressed within the scope of quantitative analysis. The comparative evaluation of different machine learning algorithms revealed notable performance differences across success dimension. According to the quantitative analysis results, the indexed article success model trained with the BDT algorithm reached the most successful results with an accuracy rate of 0.774, the other article success model trained with the DJ algorithm reached 0.711, the citation success model trained with the BDT algorithm reached 0.816 and the project success model trained with the NN algorithm reached 0.846. Similar algorithms were used by Ahmad and Bakar (2018) and they achieved quite successful results with the prediction models they developed. A hybrid machine learning approach was also proposed in the study conducted by Yang et al. (2020) to examine the mobility of Taiwanese students. The proposed model demonstrated competitive performance, achieving relatively low error rates compared to alternative prediction models. In the study conducted by Mozyrska and Pawluszewicz (2022) to select talented students to be given scholarships, deep learning and particle swarm optimization were used and The results indicated relatively high predictive performance for the applied methods.
Recommendations
As a future direction, the sample group can be expanded to include a wider range of participants. Additionally, the “Advisory and Guidance System” emerged as a critical code across three themes: “Sufficiency of mechanisms,”“Recommendations for additional mechanisms,” and “Suggestions for improvement.” Enhancing communication channels and fostering collaboration among stakeholders are expected to strengthen program outcomes. Furthermore, integrating the machine learning models developed in this study into a centralized database and registration system could enable real-time monitoring of scholars’ academic progress and support data-driven decision-making in future implementations. Future studies may model academic performance indicators as continuous or ordinal variables.
Limitations
The research has some limitations. The study sample group consists of scholars who participated in the scholarship program between 2013 and 2021. Data on scholars other than these years were not included. In addition, nine machine learning algorithms were used in the development of models in the quantitative method, but there are many individual and ensemble algorithms other than these algorithms. Another limitation of the study is that not all algorithms have been tested. Since the use of different algorithms can provide higher prediction accuracies, it may be worth trying in new studies. Academic performance indicators in this study were analyzed in a binary (0/1) format. This may have resulted in a lack of detailed representation of differences among academics with high academic productivity. However, this approach was deliberately chosen to make the results more easily understood, particularly by policymakers and decision-makers. Future studies could model academic performance using continuous or ordinal variables to allow for more detailed assessments.
Footnotes
Acknowledgements
We would like to thank Professor Cemal YILDIZ for his support for this study.
Ethical Considerations
The study was carried out with the permission of the Educational Research and Publication Ethics Committee of the Sakarya University with the decision numbered 02 taken at the meeting numbered 02 on December 8, 2021. The committee authorized the data acquisition for this study. All data were collected and analyzed in compliance with relevant regulations and ethical principles governing research involving human subjects.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article was prepared with the project “Examining the Effectiveness of the Abroad Education Scholarship Under Law No. 1416 and Developing a Policy Document” within the scope of TÜBİTAK 3005 program (Grant Number: 122G002).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
To our regret, these data are part of a larger research project.