
Abstract
This manuscript reports on two connected studies designed to examine the effectiveness of mobile-assisted pronunciation instruction in Second Language (L2) Chinese learning, focusing on both phonetic development and the psychological factors that influence such development. The first study employs a 16-week quasi-experimental design comparing HanPhonic-integrated instruction with traditional teacher-led phonetic teaching. The second study builds upon the first by exploring how psychological need satisfaction, specifically autonomy, competence, and relatedness as defined by Self-Determination Theory (SDT), relates to phonetic learning outcomes. A total of 70 learners of Chinese as a second language participated in the study. Phonetic performance across pre-, post-, and follow-up assessments was analyzed via linear mixed-effects and piecewise growth-curve models. Additionally, exploratory association analyses were conducted to examine the relationships between psychological need satisfaction and phonetic learning outcomes. Results indicated that the experimental group demonstrated significant phonetic gains and exhibited sustained improvement at the follow-up stage compared to the control group. Consistent with the Speech Learning Model (SLM), structured integration of perceptual training and production practice was associated with continued perception-production development. From an SDT perspective, autonomy and competence were primarily associated with immediate learning gains, whereas relatedness was linked to variation in follow-up performance, suggesting temporally differentiated motivational associations. These findings contribute to theoretical understandings of L2 phonetic development in mobile-assisted contexts and provide implications for the design of theory-driven, technology-enhanced pronunciation instruction.
Plain Language Summary
Mobile apps are increasingly used to support second language pronunciation learning, but there is limited evidence on whether they help learners maintain progress over time. This study examined how a mobile application, HanPhonic, supports the long-term development of pronunciation in learners of Chinese as a second language. Seventy learners participated in a 16-week teaching programme. One group learned pronunciation with the support of HanPhonic, while another group received traditional teacher-led instruction. Learners’ pronunciation was assessed at several points during and after the programme to examine both improvement and retention. The findings showed that learners using the mobile app achieved better pronunciation outcomes than those in the traditional classroom. More importantly, their progress was more stable over time. Although some decline occurred after instruction ended, learners who used HanPhonic retained their pronunciation skills better and showed a slower loss of learning gains. The study also explored learners’ learning experiences to understand why the mobile app was effective. Different aspects of the learning experience supported learning at different stages. Feeling in control of learning supported early improvement, feeling capable was linked to short-term progress, and feeling socially connected helped sustain improvement over time. Overall, the study suggests that mobile-assisted pronunciation learning can support both immediate improvement and long-term development. It also highlights the importance of designing pronunciation learning tools that encourage learner engagement, confidence, and continued participation.
Keywords
Introduction
Despite rapid digitalization and globalization reshaping Second Language (L2) education, phonetic acquisition, fundamental to effective communication and cross-cultural confidence, remains a persistent challenge for learners worldwide (Li et al., 2025). Accurate pronunciation and fine-grained perceptual sensitivity constitute the core dimensions of phonetic competence and underpin successful L2 interaction. However, many L2 learners experience systematic difficulties in perceiving and producing target-language phonetic features due to first-language (L1) transfer effects (Flege, 2005). These challenges are particularly salient in tonal language learning, where learners from non-tonal language backgrounds often struggle to perceive and produce lexical contrasts encoded through pitch variation, which in turn leads to persistent errors in both perception and production (Deng & Lin, 2017).
Traditional L2 phonetic instruction has typically relied on teacher modeling and repetitive drills. These approaches are constrained by limited instructional time and large class sizes. Such conditions restrict opportunities for individualized feedback and make it difficult to accommodate learners’ diverse perceptual and articulatory needs (Li et al., 2025). In response, mobile and digital technologies have been increasingly used to supplement phonetic instruction, offering learners more exposure, flexibility, and opportunities for practice beyond the classroom. However, existing research has often emphasized technological affordances rather than theoretically grounded instructional design (Sinyagovskaya & Murray, 2021). As a result, many digital tools remain technology-driven, with limited attention to how phonetic learning processes unfold or how learner engagement and motivation are sustained over time (Yang et al., 2023).
From a second language acquisition perspective, phonetic development is widely understood as a dynamic process involving the interaction between perception and production. The Speech Learning Model (SLM) posits that learners’ ability to establish new phonetic categories depends critically on perceptual accuracy, which in turn shapes subsequent production (Flege, 2005). Complementing this cognitive account, research in educational psychology highlights the role of learner motivation and engagement in supporting durable learning outcomes. Self-Determination Theory (SDT) emphasizes that autonomy, competence, and relatedness are essential psychological needs that influence learners’ persistence, effort, and quality of engagement during learning activities. Despite their relevance, these theoretical perspectives have rarely been integrated into empirical research on technology-enhanced phonetic instruction, particularly in ways that account for both learning outcomes and motivational dynamics.
Moreover, much of the existing literature on digital phonetic instruction has relied on short-term or cross-sectional designs, which limits our understanding of how phonetic gains are retained and how learning-related patterns or associations may evolve over time. Longitudinal evidence is needed to examine not only immediate improvements but also the durability of phonetic competence and the changing roles of perceptual, productive, and motivational factors as learning progresses. This gap is especially pronounced in the context of Mandarin phonetic instruction, where tonal perception and production pose sustained challenges and where learner motivation may play a critical role in continued practice and refinement.
In the field of L2 phonetic learning, existing research often focuses on single instructional methods or short-term effects, with a lack of systematic exploration into long-term learning processes and motivational factors. To address these gaps, the present study adopts a theoretically informed perception-production framework that integrates insights from the Speech Learning Model (SLM) and Self-Determination Theory (SDT) within a mobile-assisted instructional context. Using a longitudinal quasi-experimental design, the study compares the effectiveness of two instructional approaches: a HanPhonic-integrated perception-production model and traditional teacher-led phonetic teaching. Additionally, the study examines how learners’ psychological needs, specifically autonomy, competence, and relatedness as outlined by SDT, affect phonetic learning outcomes. The two studies are closely linked, together providing a comprehensive analysis of both instructional methods and motivational factors, exploring their combined effects on L2 phonetic acquisition. The first study employs a quasi-experimental design to compare the phonetic development and follow-up performance of learners in a 16-week intervention, while the second study builds on the first by exploring the influence of psychological needs on phonetic learning trajectories. Through this combined cognitive-motivational perspective, the study aims to provide empirical evidence and pedagogical insights for the design of learner-centered, theory-driven digital tools in L2 phonetic instruction.
Literature Review
The Role of SDT in L2 Learning
Given its focus on intrinsic motivation and psychological needs, SDT has been widely applied in L2 education, particularly in face-to-face instructional settings (Ryan & Deci, 2017, 2024). Prior research has consistently shown that autonomy, competence, and relatedness play central roles in shaping learner engagement in classroom-based L2 learning (Rezaee, 2011). When these needs are satisfied, learners tend to demonstrate greater initiative, persistence, and sustained effort in academic tasks (Hsu et al., 2019; Shi et al., 2025; Wang et al., 2025); when they are not, learners are more likely to experience disengagement, isolation, and reduced willingness to participate.
This motivational dynamic is especially salient in L2 phonetic learning, where challenges arising from negative L1 transfer and perceptual difficulty may undermine learners’ sense of competence and confidence. In such contexts, SDT highlights the relevance of competence and autonomy in shaping engagement and learning processes. Competence is supported through clear and targeted feedback, while autonomy is enabled through learner control over practice opportunities. For example, repeated tonal errors without meaningful feedback, reflecting insufficient competence support, may gradually reduce learners’ willingness to continue phonetic practice.
Despite its explanatory potential, SDT-informed research on technology-integrated L2 instruction remains limited. Recent empirical studies have nevertheless begun to illustrate the relevance of SDT in AI-and GenAI-supported language learning contexts (Park & Derakhshan, 2026; Pan & Wang, 2025; Wang, 2026). For instance, Wu and Wang (2025) showed that autonomy, competence, and relatedness jointly shaped Chinese college students’ flow experience in GenAI-assisted informal English learning, highlighting the motivational affordances of intelligent technologies beyond formal classrooms. Similarly, in robot-assisted language learning environments, J. Zhang and Yan (2025) found that positive psychological traits such as grit and enjoyment significantly predicted learner engagement from an SDT perspective.
However, much of the existing literature has tended either to focus exclusively on online learning environments or to examine broad higher education contexts without addressing discipline-specific domains such as phonetics (Chiu, 2022). This gap is particularly pronounced in L2 phonetic instruction, where real-time interaction and personalized feedback-central to SDT’s emphasis on autonomy and competence-are essential yet remain insufficiently explored in technology-enhanced settings. Consequently, empirical evidence on how SDT-related psychological needs are associated with phonetic development in digital or mobile-supported L2 learning contexts remains scarce.
The Role of the SLM in L2 Phonetic Learning
Learners face challenges in L2 acquisition that extend beyond speech production, including difficulties in perceiving and identifying target-language sounds (Burri, 2023). The SLM posits a close perception-production relationship, suggesting that learners’ ability to discriminate L2 sounds based on fine-grained acoustic cues directly influences the accuracy of their production (Flege, 2005). This linkage has been consistently documented, with perceptual limitations frequently associated with persistent production errors (Burri, 2023; Flege, 2005).
The revised Speech Learning Model (SLM-r) further introduces the notion of phonetic synchrony, referring to the parallel development of perception and production-particularly relevant for sounds that partially overlap with learners’ L1 phonological systems (Flege & Bohn, 2021). Central to SLM-r is the process of phonetic category formation, which holds that successful L2 phonetic acquisition depends on sufficient, high-quality input and learners’ capacity to establish new L2 categories while maintaining distinctions from existing L1 categories.
Recent research indicates that L2 phonetic acquisition is highly sensitive to the quality of auditory input (Chen et al., 2025; L. Zhang & Shi, 2021). However, natural communicative environments often involve phonetic ambiguity, background noise, and rapid speech, conditions that can disrupt auditory perception and constrain learners’ ability to fully utilize input and output opportunities (Bi et al., 2025). These challenges are particularly pronounced in tonal language learning, where tonal contrasts rely on subtle pitch differences that are highly susceptible to contextual interference. For example, fast speech may obscure fine tonal cues and hinder the formation of stable phonetic categories (Chodroff, 2025).
Although implicit exposure and meaning-oriented instruction contribute to communicative fluency in real-world contexts, they offer limited opportunities for controlled exposure to specific phonetic contrasts and do not effectively address mismatches between perception and production (L. Zhang & Shi, 2021). From an instructional perspective, these insights suggest that teaching approaches explicitly integrating perception and production may be more effective than traditional imitation-based phonetic instruction, particularly for supporting accurate phonetic category formation.
Face-to-Face Tonal Phonetic Instruction: Pedagogical Strengths and Constraints
Face-to-face phonetic instruction is inherently interactive, centering on reciprocal feedback and guidance exchanged between teachers and learners (Li et al., 2025; Liu, 2019). This interaction is particularly important for tonal language features. Teachers may render tone contours visually explicit through gestures or provide articulatory cues to help learners differentiate sounds such as aspirated /ph/ and unaspirated /p/. Through a combination of demonstration and focused explanation, instructors highlight fine-grained phonetic distinctions, while learners imitate and receive immediate corrective feedback on errors such as tonal mispronunciations or consonant confusions. This real-time exchange allows learners to obtain clarification promptly, aligning with the SLM’s emphasis on strengthening perception-production links through timely input and correction.
Despite these pedagogical advantages, face-to-face phonetic instruction also entails notable constraints. It places high demands on teachers’ ability to consistently detect subtle phonetic deviations and provide individualized corrective feedback (Burri, 2023). Moreover, large class sizes restrict opportunities for personalized instruction, making it difficult to address learners’ diverse phonetic needs. Some learners may require intensive tone practice, while others struggle with segmental contrasts, yet such individual differences are often challenging to accommodate within conventional classroom settings. These constraints raise questions about whether alternative instructional approaches can not only enhance immediate phonetic performance but also support sustained learning over time, particularly in contexts where individualized feedback is limited (Liu, 2019; Yang et al., 2023).
Technology-Enhanced Phonetic Learning in Tonal Languages
In tonal languages such as Chinese, pitch variation plays a central role in distinguishing lexical meaning, a feature that poses persistent challenges for many L2 learners. Da and Zheng (2018) highlighted the potential of emerging digital technologies to strengthen learners’ perceptual and productive phonetic skills and to support interaction at the phonetic level. Subsequent studies have explored specific software-based tools. Chen et al. (2025) employed Audacity to enhance tone perception training, while L. Zhang and Shi (2021) applied Praat to visualize phonetic contrasts influenced by L1 transfer. Within similar instructional frameworks, Deng and Lin (2017) demonstrated that comparing learner productions with native-speaker models can facilitate error detection, although Deng (2020) noted that perceptual training remains underemphasized despite its importance within SLM-based learning.
Beyond individual software applications, other studies have examined technology-supported pronunciation instruction in broader instructional contexts. Watanabe et al. (2020) reported that the “ST Lab” system enabled remote pronunciation teaching to achieve outcomes comparable to face-to-face instruction, yet individual learner differences, which are known to play a critical role in learning processes, were not explicitly examined. Sinyagovskaya and Murray (2021) proposed an augmented reality-based pronunciation tool integrating visual and auditory cues, but the study offered limited theoretical grounding in frameworks such as SLM or SDT, constraining the interpretability of its pedagogical effects. As a result, few studies have directly compared technology-supported phonetic instruction with traditional teacher-led approaches within the same instructional context, leaving questions about their relative effectiveness unresolved.
More recently, an emerging line of research has shifted attention toward AI- and robot-assisted language learning (RALL). These studies conceptualize intelligent agents not merely as delivery platforms, but as interactive partners capable of providing adaptive feedback and sustained practice opportunities. A recent meta-analysis by Y. Wang et al. (2026) reported a robust positive effect of robot-assisted instruction on L2 learners’ speaking skills, indicating that intelligent systems can effectively support oral development across a range of instructional contexts. This evidence suggests that AI-supported approaches may hold particular potential for phonetic learning, where repeated practice and fine-grained feedback are essential for category formation and stabilization.
Nevertheless, most existing research on technology- and AI-assisted pronunciation instruction has focused on short-term learning outcomes, such as immediate post-test gains. Far less attention has been paid to the durability of phonetic development or to how learning trajectories evolve once formal instruction ends. In addition, although intelligent systems are often assumed to enhance learner engagement, relatively few studies have systematically examined the motivational processes underlying technology-supported phonetic learning. In particular, little is known about how learners’ psychological experiences-such as autonomy, competence, and relatedness-interact with AI-supported instructional designs to shape phonetic development over time.
Taken together, prior research suggests that while technology- and AI-enhanced approaches offer promising tools for supporting L2 phonetic learning, important gaps remain. There is a clear need for longitudinal, theory-driven investigations that examine not only whether AI-supported instruction improves phonetic performance, but also how such improvements are sustained and what psychological associations may underlie their effectiveness. Addressing these issues is especially critical for L2 Chinese phonetic instruction, where stable perception-production coupling and sustained learner engagement are central to successful learning outcomes.
The Present Study
This study focuses on L2 Chinese phonetic learning and examines the effectiveness of a mobile-assisted perception-production instructional approach in comparison with traditional teacher-led phonetic instruction. Grounded in the SLM and SDT, the study adopts a longitudinal quasi-experimental design to investigate both phonetic learning outcomes and development over time, including follow-up performance. In addition, drawing on SDT, the study explores how learners’ autonomy, competence, and relatedness are associated with phonetic development in a mobile-assisted learning context. The following research questions guide the investigation:
Guided by the above three research questions, we designed two interconnected, sequential studies. Study 1 employs a quasi-experimental design to address RQ1 and RQ2 by comparing the effectiveness and long-term durability of mobile-assisted perception-production instruction against traditional phonetic teaching. Study 2 builds on Study 1 to address RQ3 by exploring how autonomy, competence, and relatedness from Self-Determination Theory correlate with and moderate learners’ phonetic learning trajectories. Together, the two studies provide an integrated cognitive–motivational account of mobile-assisted L2 Chinese phonetic learning.
Study1: A Controlled Teaching Experiment on the Outcomes of Phonetic Learning for L2 Learners
This study employed a 16-week quasi-experimental longitudinal design to examine the effects of a HanPhonic-supported perception-production instructional approach on L2 Chinese phonetic learning. Participants were assigned to either an experimental group or a control group following eligibility screening, and phonetic performance was assessed at three time points: pre-intervention, post-intervention, and follow-up. This design was intended to capture both immediate instructional effects and the durability of phonetic learning over time.
To enhance internal validity, several controls were implemented. First, participants were assigned to groups using a randomized procedure after eligibility screening to ensure comparability at baseline. Second, standardized instructional materials and equivalent instructional content were used across groups. Third, the same instructor taught both the experimental and control groups, following a consistent teaching schedule and curriculum framework. Instruction was conducted during regular curriculum hours to minimize novelty effects and scheduling-related biases.
Methodology
Measurement Instrument
HanPhonic is a WeChat-based mobile application integrated with iFLYTEK’s streaming speech-recognition API. The system automatically analyzes learners’ pronunciation by extracting multiple acoustic features, including fundamental frequency (F0) contours for tonal realization, segmental duration, and formant trajectories. These features are compared against native-speaker reference models to generate an overall pronunciation score and to identify specific phonetic errors, such as tonal deviations and segmental inaccuracies, which are presented to learners through visual and textual feedback.
In the present study, HanPhonic served two analytically distinct functions. First, it functioned as a standardized measurement instrument for both the experimental and control groups during the pre-intervention, post-intervention, and follow-up assessments. The same scoring algorithms, reference models, and feedback criteria were applied across all three testing occasions to ensure measurement consistency over time. Second, for the experimental group only, HanPhonic was used as an instructional and practice platform throughout the 16-week intervention. During this period, learners engaged in perception-based tasks, production exercises, and system-generated review activities within the app, thereby operationalizing the perception-production instructional approach. Importantly, while the instructional activities varied across groups, the assessment procedures remained identical for both groups at all testing points, allowing for valid longitudinal comparisons of phonetic learning outcomes.
To minimize potential instrumentation bias, the scoring algorithm, acoustic reference models, and evaluation criteria were fixed across all assessment points and were not adjusted during the intervention period. Assessment procedures were identical for both groups, and no adaptive scoring functions were activated during testing sessions.
To further address the potential risk of measurement contamination arising from the dual role of HanPhonic as both instructional and assessment tool, several additional precautions were taken. Although the same item pool was used across pre-, post-, and follow-up assessments to maintain comparability, item presentation was randomized at each testing occasion to reduce immediate recall and order effects. Because both groups were exposed to identical assessment procedures and interface conditions, any familiarity effects would be expected to influence both groups in a comparable manner.
In addition, supplementary analyses were conducted to examine potential item-repetition effects, with results indicating stable patterns across conditions. Nevertheless, it is acknowledged that the use of a shared platform for both instruction and assessment may introduce familiarity or interface-related effects that cannot be entirely ruled out.
Participants
The study was conducted at a public university in Zhengzhou, Henan Province, China. A total of 142 international students enrolled in a Chinese language program were invited to complete a screening questionnaire, from which 116 valid responses were obtained. Based on predefined inclusion criteria: (a) aged between 19 and 22 years, (b) no prior systematic training in Chinese phonetics, and (c) residence in China for less than 1 year, 70 eligible participants were selected for inclusion in the experiment.
The participants were randomly assigned to either an experimental group (n = 35) or a control group (n = 35). Randomization was implemented using a computer-generated sequence and stratified by learners’ L1 backgrounds to ensure baseline comparability across groups. In the experimental group, HanPhonic was integrated into both in-class instruction and after-class practice as part of the perception-production instructional approach. The control group received traditional teacher-led phonetic instruction and used HanPhonic exclusively for assessment purposes.
A repeated-measures design was adopted, with phonetic performance assessed at three time points: a pre-intervention assessment (February 24, 2024), a post-intervention assessment (April 28, 2024), and a follow-up assessment (June 2, 2024). The follow-up assessment was included to examine phonetic performance at the follow-up stage after the instructional period. Across all three measurement occasions, HanPhonic functioned as a standardized assessment instrument for both groups.
All participants provided written informed consent prior to participation and were informed of their right to withdraw at any time without penalty. The study was approved by the institutional Human Research Ethics Committee (REC) and conducted in accordance with its ethical guidelines.
Data Collection Procedure
Data were collected at three time points across a 16-week instructional period, with HanPhonic serving as the standardized assessment instrument. Both the experimental and control groups received the same weekly 90-min phonetics course taught by the same instructor, ensuring consistency in instructional time, curriculum coverage, and teacher involvement.
At the pre-intervention stage, participants in both groups completed an initial pronunciation assessment using HanPhonic. Prior to testing, standardized instructions were provided to ensure that all participants understood the assessment procedures and were able to operate the application independently. This assessment established baseline phonetic performance for subsequent comparisons (Table 1).
Study Timeline and Assessment Schedule.

Following the 16-week instructional period, both groups completed a post-intervention assessment administered via HanPhonic. During the intervention, the experimental group had used HanPhonic for preview activities, in-class perception and production tasks, and post-class consolidation exercises, whereas the control group had received conventional face-to-face phonetic instruction only. The post-intervention assessment employed the same item pool as the baseline assessment, with items presented in a randomized order to reduce potential practice effects.
Approximately 5 weeks after the completion of instruction, a follow-up assessment was conducted to examine follow-up phonetic performance following the follow-up stage. During the interval between the post-intervention and follow-up assessments, no new instructional content was introduced in either group. However, both groups engaged in structured review activities focusing on previously learned material. The experimental group engaged only in system-generated review activities within HanPhonic, and the control group participated in teacher-led review sessions of equivalent duration, both of which were limited to consolidation of previously learned material. The follow-up assessment drew on the same item pool as the previous tests, with item order again randomized.
All assessment data were exported from HanPhonic, screened for completeness, and processed using Excel prior to statistical analysis. To ensure full ethical compliance, the study design minimized potential harm to participants through multiple safeguards: all data collection procedures were non-invasive, consistent with standard educational research protocols, and strictly confidential. All personal information was anonymized and stored securely to prevent unauthorized access or disclosure. For participants, the intervention offered structured, personalized phonetic practice that supported their Chinese language learning progress. Informed consent was obtained from all participants prior to data collection; each participant received a detailed written statement outlining the study’s purpose, procedures, potential risks and benefits, and their right to withdraw at any time without penalty. All participants provided voluntary written consent before any study procedures, and all activities were conducted in full compliance with the ethical guidelines approved by the REC.
Data Analysis
Reliability analysis of the phonetic assessment scores indicated strong internal consistency, with a Cronbach’s alpha of .864 and a corrected item-total correlation (CITC) of .761, supporting the suitability of the instrument for group comparisons and longitudinal analysis. All assessment data were screened for completeness, cleaned, and coded prior to statistical analysis. All analyses were conducted using RStudio.
To examine the immediate effects of instructional approach on L2 Chinese phonetic learning outcomes (RQ1), a linear mixed-effects model (LMEM) was fitted using the lme4 package. Phonetic performance served as the dependent variable, with instructional group (experimental vs. control) and time (pre-intervention, post-intervention, follow-up) specified as fixed effects. Participant-level random intercepts were included to account for within-subject dependence arising from repeated measurements. This modeling strategy is well suited to longitudinal data and allows for the estimation of group differences while controlling for individual variability. In addition, planned contrasts were conducted to examine changes between specific time points (post-intervention vs. pre-intervention; follow-up vs. post-intervention), with corresponding confidence intervals reported to facilitate interpretation of temporal changes.
To further explore patterns of change across phases, a piecewise growth curve model (PGCM) was additionally estimated using the nlme package. This model was intended as an exploratory analysis to provide a descriptive account of potential differences between the instructional phase and the post-instructional phase. However, given that only three measurement occasions were available, each segment was effectively estimated based on two time points, which may limit the stability of slope estimates. Therefore, the PGCM results should be interpreted with caution and are presented as supplementary to the primary mixed-effects analysis.
To further assess the potential influence of repeated exposure to the same item pool, supplementary robustness checks were conducted. Specifically, exploratory analyses were performed using subsets of assessment items that were less likely to be memorized or explicitly practiced during the instructional period. The overall pattern of results remained consistent, suggesting that the observed group differences were unlikely to be solely attributable to repeated item exposure or test familiarity. Nevertheless, as no independent outcome measure was included, these findings should be interpreted with appropriate caution.
Results
Descriptive Statistics
Table 2 presents the descriptive statistics for both groups across the three assessment points. At the pre-intervention stage, the experimental and control groups demonstrated comparable baseline performance (experimental: M = 1.771, SD = 0.731; control: M = 1.629, SD = 0.770), indicating no meaningful initial differences in phonetic proficiency.
Results of Descriptive Statistics for Test Scores of the Experimental and Control Groups Across Three Assessments.
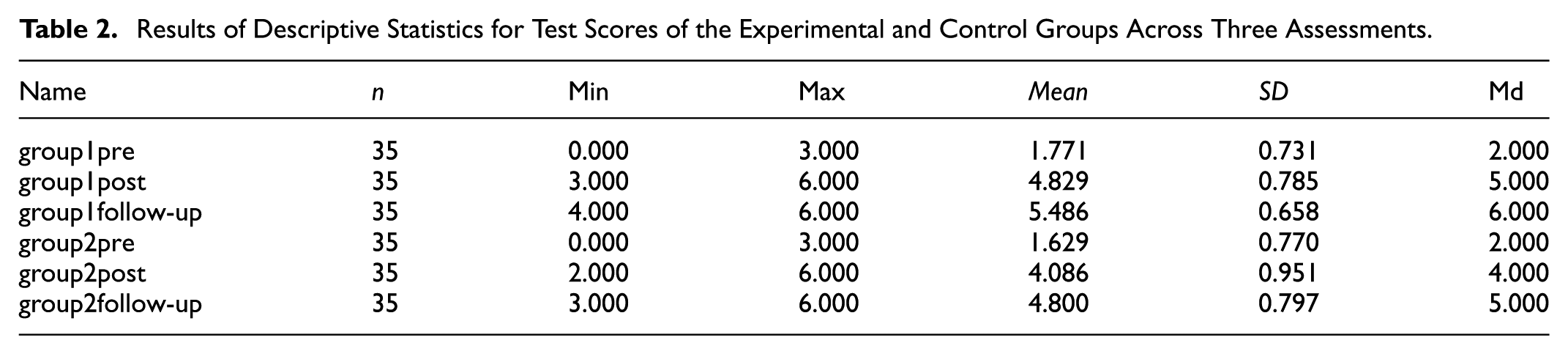
Following the 16-week instructional period, the experimental group achieved higher post-intervention scores than the control group (experimental: M = 4.829, SD = 0.785; control: M = 4.086, SD = 0.951). A similar pattern was observed at the follow-up assessment, where the experimental group continued to outperform the control group (experimental: M = 5.486, SD = 0.658; control: M = 4.800, SD = 0.797). These descriptive trends suggest a potential instructional advantage for the HanPhonic-supported perception-production model, particularly in post-intervention performance and follow-up performance.
Linear Mixed-Effects Model Results for Follow-Up Performance
To further examine group differences at the follow-up stage and to control for prior performance, an additional linear mixed-effects model was fitted with follow-up scores as the dependent variable and instructional group, pre-intervention scores, and post-intervention scores specified as fixed-effect predictors (Table 3).
Estimation Results of the Linear Mixed-Effects Model for the Chinese Phonetic Teaching Experiment.
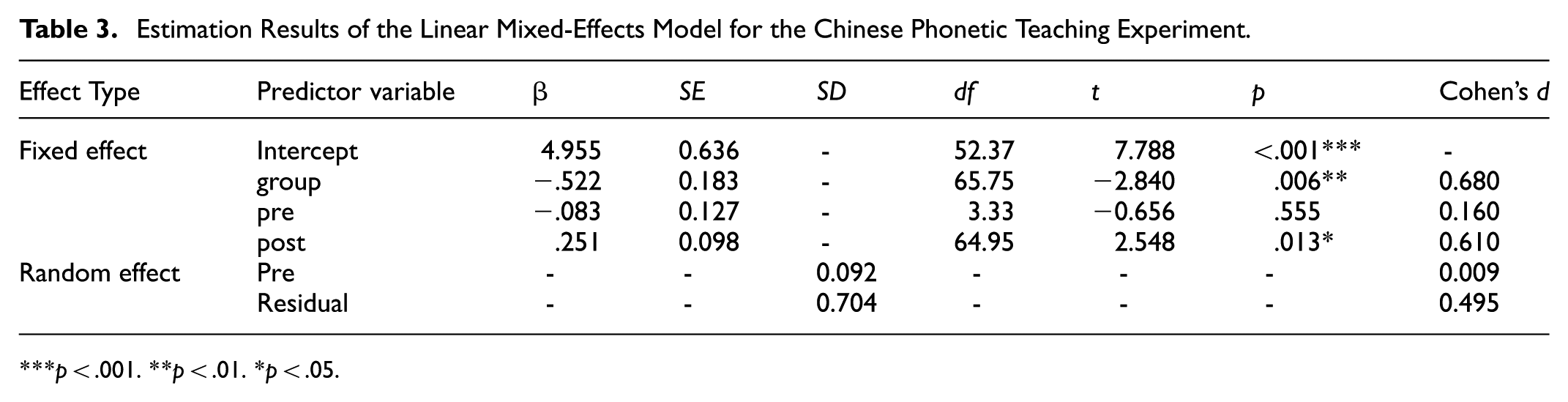
p < .001. **p < .01. *p < .05.
The fixed-effect intercept was 4.955 (SE = 0.636, t = 7.788, p < .001), representing the expected follow-up score for the control group when other predictors were held at their reference levels. A significant effect of instructional group was observed (β = −.522, SE = 0.183, t = −2.840, p = .006), indicating that the control group scored significantly lower than the experimental group at the follow-up assessment. The corresponding effect size (Cohen’s d = 0.680) falls within the medium-to-large range, suggesting a substantively meaningful group difference in follow-up phonetic performance.
Pre-intervention assessment scores did not significantly predict follow-up performance (β = −.083, SE = 0.127, t = −0.656, p = .555; Cohen’s d = 0.160), indicating that baseline phonetic proficiency was not associated with subsequent follow-up outcomes after accounting for other predictors. In contrast, post-intervention assessment scores significantly predicted follow-up performance (β = .251, SE = 0.098, t = 2.548, p = .013; Cohen’s d = 0.610), with higher post-intervention scores associated with better follow-up performance.
Model diagnostics indicated that residuals were approximately normally distributed and showed no evidence of heteroscedasticity. The random intercept variance was small (variance = 0.009, SD = 0.092), suggesting limited between-participant variability beyond fixed effects. The model accounted for 58.3% of the variance in follow-up performance (conditional R2 = .583), with fixed effects explaining 32.7% (marginal R2 = .327). The intraclass correlation coefficient was low (ICC = .017), indicating minimal clustering at the participant level.
Piecewise Growth Curve Model
The following results from the piecewise growth curve model should be interpreted as exploratory, given the limited number of measurement occasions. Table 4 presents the parameter estimates from the piecewise growth curve model. The intercept, representing baseline phonetic performance, was estimated at 1.771 (SD = 0.137, t = 12.879, p < .001). The group effect at baseline (Group2) was not statistically significant (β = −.143, SD = 0.195, t = −0.734, p = .465), indicating comparable initial performance between the experimental and control groups.
Piecewise Growth Curve Model Parameter Results.
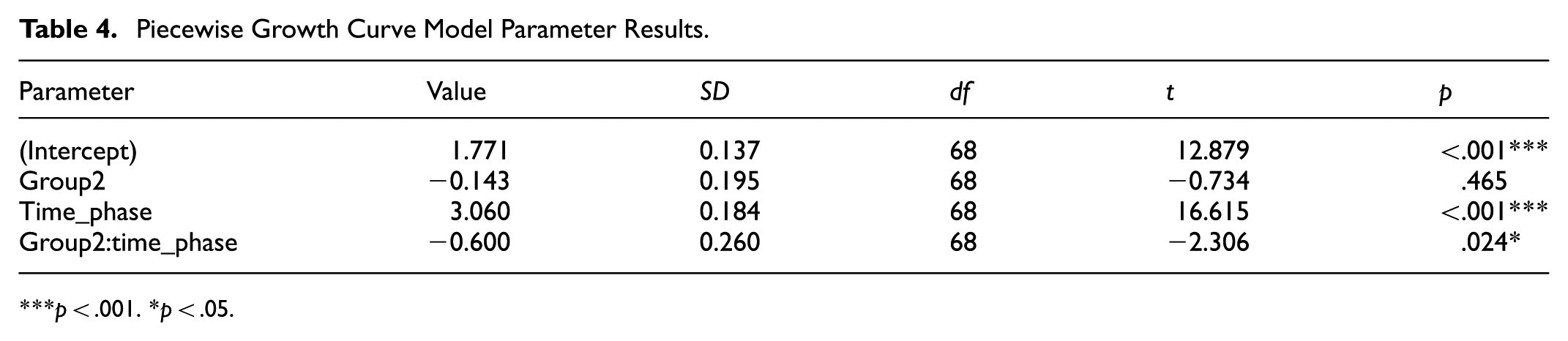
p < .001. *p < .05.
The time_phase parameter, capturing overall change across measurement phases, was positive and statistically significant (β = 3.060, SD = 0.184, t = 16.615, p < .001), reflecting a general increase in phonetic performance over time. Importantly, the negative interaction coefficient (β = −.600, p = .024) confirms that while both groups improved, the control group exhibited a significantly shallower growth trajectory compared to the experimental group.
Figure 1 illustrates the model-predicted growth trajectories for the experimental and control groups. At baseline (Time Point 0), predicted outcomes for the two groups were similar. At subsequent time points, the experimental group exhibited a steeper increase in predicted scores than the control group, consistent with the significant Group × Time interaction observed in the model.
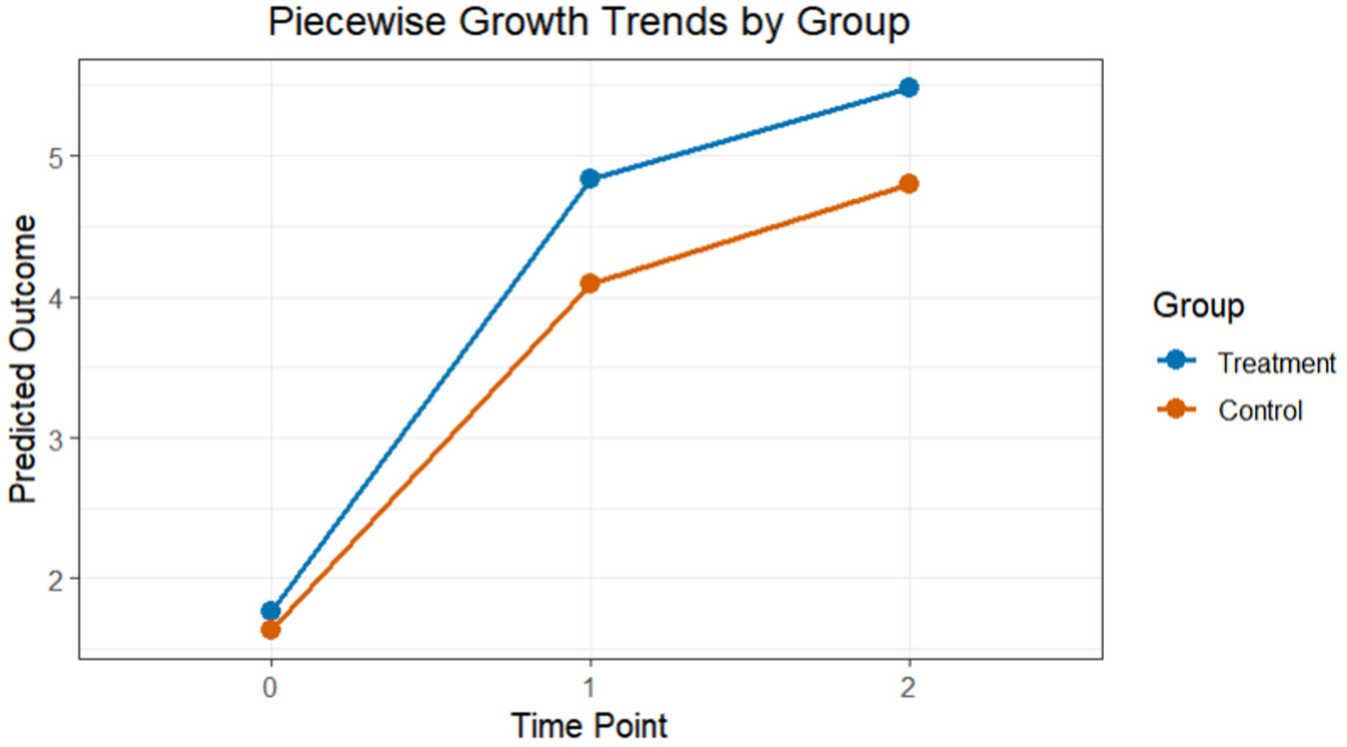
Piecewise growth trends by experimental and control groups.
Study 2: Psychological Needs and Learning Associations
To further explore the psychological associations underlying the instructional differences observed in Study 1, this component of the research examined whether the three basic psychological needs proposed by SDT, autonomy and competence, and relatedness-were associated with learners’ phonetic learning outcomes, and whether they varied across instructional conditions. Rather than functioning as an independent experiment, Study 2 builds directly on the instructional context of Study 1 by focusing on learners’ motivational experiences during the intervention period.
Guided by RQ3, Study 2 adopted a correlational and exploratory analytical approach. Measures of autonomy, competence, and relatedness were collected from participants in both the experimental and control groups following the instructional phase. These SDT-related variables were examined in relation to learners’ phonetic performance to assess their associations with short-term learning gains and longer-term outcomes. By situating motivational factors within the same instructional framework as Study 1, this analysis aimed to clarify how psychological needs may help explain individual differences in phonetic development observed under technology-supported and traditional instructional conditions.
Importantly, Study 2 does not seek to establish causal relationships between psychological needs and phonetic outcomes. Instead, it examines patterns of association between SDT constructs and learning performance, thereby providing a theoretically grounded interpretation of the instructional effects identified in Study 1. This approach allows for a more nuanced understanding of how mobile-assisted phonetic instruction may interact with learners’ motivational experiences to support phonetic development over time.
Methodology
Participants
Immediately after the follow-up assessment in Study 1, all 70 participants from the experimental and control groups completed the SDT questionnaire. Administering the questionnaire at this stage allowed learners to form relatively stable evaluations of their autonomy, competence, and relatedness based on their full instructional experience, while minimizing potential reactivity or measurement contamination during the intervention period.
All participants who completed Study 1 were invited to take part in this phase of the research, and response rates were identical across the experimental and control groups. Participation was voluntary, and respondents were informed that their questionnaire responses would be used solely for research purposes and would not affect their course grades or assessment outcomes. All procedures were conducted in accordance with REC approval.
Instrument
Autonomy, competence, and relatedness were assessed using an adapted version of the three-dimensional SDT scale reconstructed by Du et al. (2020), which was originally based on the Basic Psychological Needs Scale developed by Sheldon and Niemiec (2006). Minor wording adjustments were made to ensure contextual relevance to L2 phonetic learning, such as referencing pronunciation practice, classroom interaction, and learning support during phonetic instruction. These adaptations were intended to enhance contextual fit without altering the conceptual meaning of the original items.
The scale consists of three subscales: autonomy, reflecting learners’ perceived volition and self-directed engagement in phonetic learning; competence, capturing learners’ perceptions of effectiveness, progress, and mastery in pronunciation tasks; and relatedness, measuring learners’ sense of support and connection with peers and the instructor during the learning process. The scale comprised nine items in total (RQ1–RQ9), with three items assigned to each subscale: autonomy (RQ1–RQ3), competence (RQ4–RQ6), and relatedness (RQ7–RQ9). To enhance measurement transparency, Table 5 provides detailed descriptions of the nine SDT-related items, including their corresponding dimensions and example content.
Description of the SDT Measurement Items.
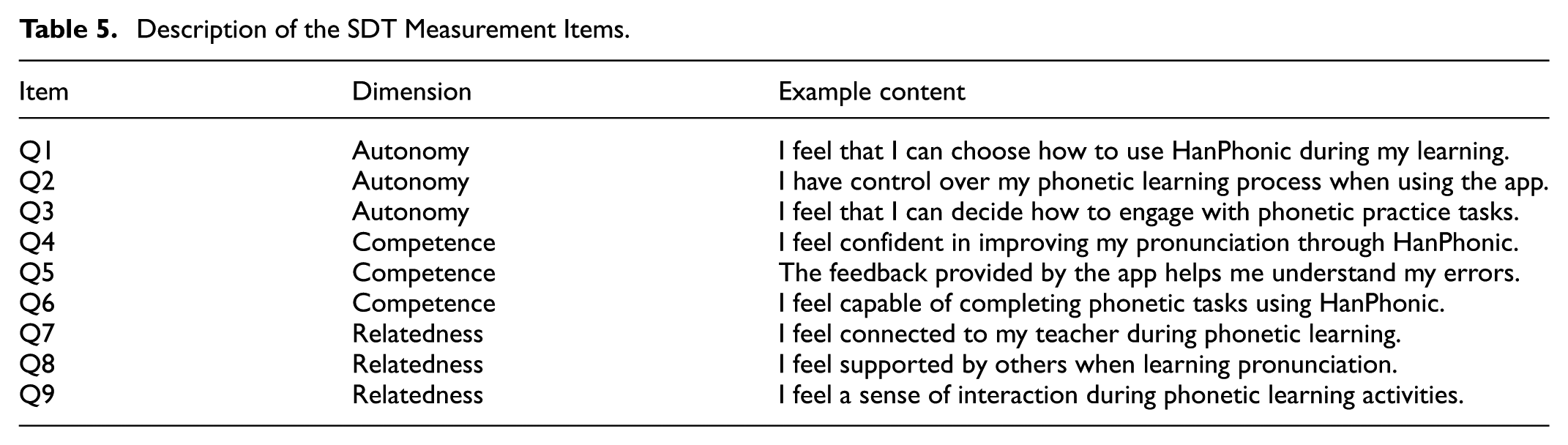
All items were measured on a seven-point Likert scale (1 = strongly disagree to 7 = strongly agree). Internal consistency and item-level diagnostics (e.g., item–total correlations) were examined prior to subsequent analyses. Du et al. (2020) reported that this adapted SDT scale demonstrated good construct validity (χ2 = 40.36, df = 24, χ2/df = 1.68; RMSEA = 0.070; GFI = 0.940; CFI = 0.970), with standardized factor loadings 0.65 and an overall Cronbach’s α of 0.86. In the present study, reliability analyses again indicated satisfactory internal consistency. Cronbach’s α indicated acceptable internal consistency for each subscale (autonomy: α = .86; competence: α = .88; relatedness: α = .81), as well as for the overall scale (α = .89).
In addition, item-level diagnostics were conducted to examine the quality of the SDT scale in the present sample. Item-total correlations were calculated for each subscale, and all items showed acceptable correlations with their respective subscale scores (r > .30), except for one relatedness item (RQ9), which exhibited a substantially lower item-total correlation and an inconsistent response pattern relative to other relatedness items. No reverse-coded items were included in the scale. Given the observed ceiling effect for one relatedness item (RQ3) and the anomalous behavior of RQ9, supplementary analyses were conducted excluding these items from the relatedness subscale. Reliability estimates for each subscale remained acceptable (Cronbach’s α > .70 for autonomy, competence, and adjusted relatedness), indicating that the overall measurement quality was not substantially compromised.
Data Analysis
Subscale scores were computed by averaging the corresponding items within each dimension (autonomy: RQ1-RQ3; competence: RQ4-RQ6; relatedness: RQ7-RQ9). Data analysis was conducted in three sequential steps to examine psychological need satisfaction and its associations with phonetic learning outcomes.
First, independent-samples t tests were performed to compare the experimental and control groups on autonomy, competence, and relatedness. This preliminary analysis provided an initial assessment of whether the two instructional conditions differed in learners’ perceived satisfaction of basic psychological needs.
Second, within the experimental group, Pearson correlation analyses were conducted to examine associations between autonomy, competence, relatedness, and phonetic learning gains, calculated as the difference between post-intervention and pre-intervention assessment scores. This step explored whether higher levels of psychological need satisfaction were related to greater improvement in phonetic performance among learners who engaged with the mobile-assisted instructional approach.
Third, to address RQ3, a conditional process analysis was conducted using the lavaan and semTools packages in R. In these models, observed frequency of HanPhonic use was treated as the predictor variable. Observed frequency of HanPhonic use was derived from system log data recorded during the 16-week intervention period. Specifically, usage frequency was operationalized as the total number of completed practice sessions per learner within the application. Each session corresponded to a completed perception-production task sequence. This measure reflects learners’ engagement with the instructional platform during the intervention phase. Descriptive statistics indicated moderate variability in usage frequency across participants. Given that HanPhonic use was only meaningful within the experimental condition, subsequent analyses were conducted within the experimental group to avoid confounding with group membership. Autonomy, competence, and relatedness were specified as association variables, and phonetic learning gain was entered as the outcome variable. Each SDT dimension was additionally examined as a moderator to assess whether the strength of associations between HanPhonic use and phonetic outcomes varied as a function of psychological need satisfaction.
Parameter estimates were obtained using a bias-corrected bootstrap procedure with 5,000 resamples. Importantly, given that psychological variables were measured after the follow-up assessment, the analyses do not establish temporal or causal relationships but should be interpreted as exploratory associations. All model assumptions, including residual normality, homoscedasticity, multicollinearity, and overall model fit, were evaluated prior to interpretation.
To assess the robustness of the findings, key analyses were re-estimated using the adjusted relatedness subscale excluding the identified problematic items. The overall pattern of results remained substantively unchanged, suggesting that the reported associations were not driven by item-level anomalies or ceiling effects.
Results
Group Differences in Psychological Needs
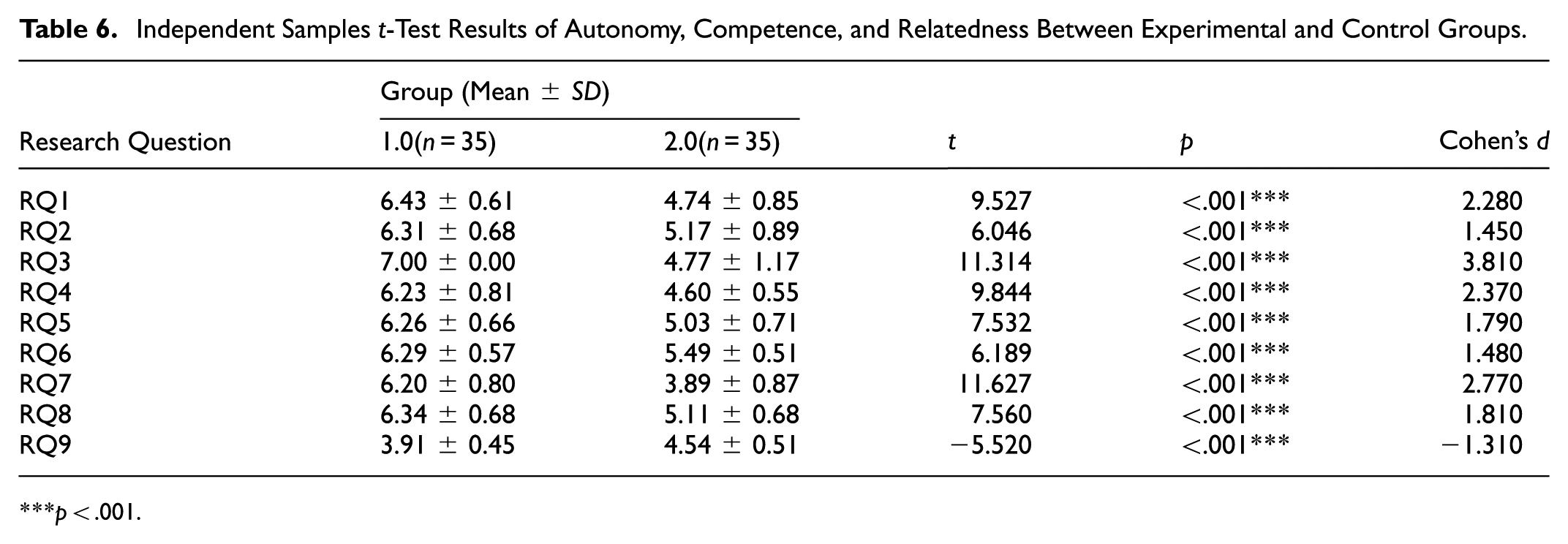
Independent-samples t tests were conducted to compare autonomy, competence, and relatedness between the experimental and control groups. As reported in Table 6, the experimental group scored significantly higher than the control group on autonomy (t = 9.527, p < .001, Cohen’s d = 2.28) and competence (t = 6.046, p < .001, d = 1.45), both reflecting large effect sizes. Significant group differences were also observed for overall relatedness (t = 11.314, p < .001, d = 3.81).
Independent Samples t-Test Results of Autonomy, Competence, and Relatedness Between Experimental and Control Groups.
p < .001.
The relatively large effect sizes observed for psychological need satisfaction should be interpreted in light of the bounded scale range, the homogeneity of the sample, and the limited within-group variability, which may contribute to inflated standardized mean differences. In particular, RQ3 reached the upper scale boundary (7.00 ± 0.00) for all participants in the experimental group, indicating a potential ceiling effect that may have amplified item-level effect size estimates. Importantly, the overall pattern of group differences remained consistent at the construct level. Supplementary analyses excluding the ceiling item (RQ3) and the anomalous item (RQ9) yielded consistent results, indicating that the observed group differences were not driven by item-level distortions.
At the item level, most relatedness items followed the same pattern, with higher mean scores observed in the experimental group. However, one item (RQ9) showed a reversed trend, with the control group reporting higher perceived peer support (t=−5.520, p < .001, d=−1.310).
Taken together, these results indicate that learners in the HanPhonic-supported perception-production condition reported higher levels of autonomy and competence and generally higher relatedness compared with learners receiving traditional phonetic instruction.
Associations Between Psychological Needs and Learning Outcomes
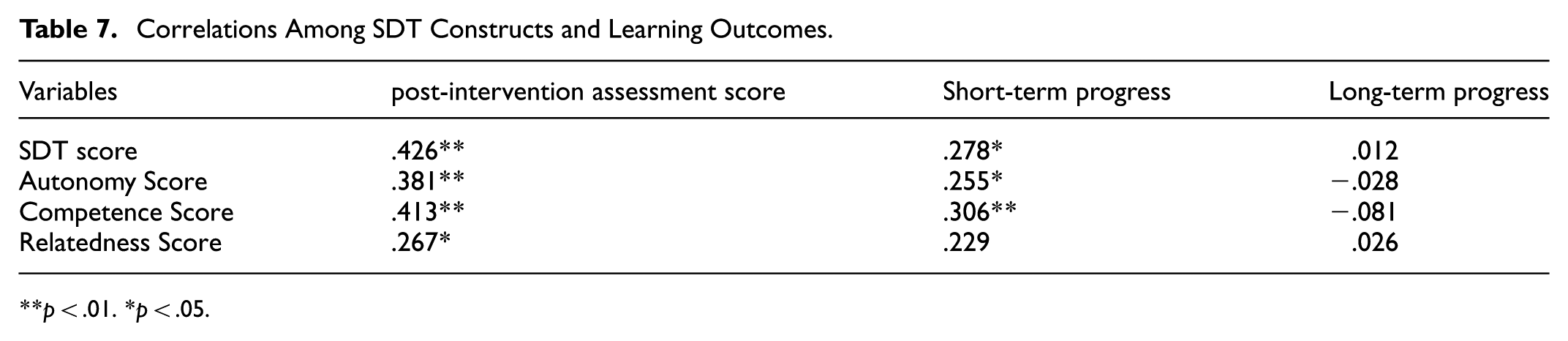
Pearson correlation analyses were conducted for the experimental group to examine associations between psychological need satisfaction and phonetic learning outcomes (Table 7). The total SDT score showed a significant positive correlation with post-intervention phonetic performance (r = .426, p < .01), indicating that higher overall satisfaction of autonomy, competence, and relatedness was associated with better post-test outcomes.
Correlations Among SDT Constructs and Learning Outcomes.
p < .01. *p < .05.
At the dimension level, both autonomy and competence were significantly correlated with short-term learning gains, operationalized as the difference between pre-intervention and post-intervention scores (autonomy: r = .255, p < .05; competence: r = .306, p< .01). In contrast, neither autonomy nor competence was significantly associated with delayed performance, and relatedness did not show significant correlations with either short-term gains or delayed performance.
Overall, the correlation results indicate that autonomy and competence were associated with immediate phonetic improvement following the intervention, whereas no significant associations were observed between the SDT variables and delayed performance in this analysis.
Although relatedness was not significantly correlated with delayed performance, subsequent moderation analyses suggest that it may condition the relationship between instructional engagement and sustained phonetic progress rather than exerting a direct effect.
Moderating Effects of Psychological Needs
The conditional process model demonstrated acceptable overall fit according to commonly recommended criteria, with a Comparative Fit Index (CFI) and Tucker-Lewis Index (TLI) both exceeding 0.90, a Root Mean Square Error of Approximation (RMSEA) below 0.08, and a Standardized Root Mean Square Residual (SRMR) below 0.08. These indices indicate that the model provided an adequate representation of the relationships among HanPhonic use, psychological needs, and phonetic learning outcomes. Exploratory conditional association analyses were conducted using the lavaan and semTools packages with 5,000 bias-corrected bootstrap samples.
Autonomy significantly moderated the association between classroom use of HanPhonic and immediate phonetic learning gains. The interaction term was positive and statistically significant, indicating that the relationship between HanPhonic use and short-term progress varied as a function of learners’ autonomy levels. Simple slope analyses showed a significant positive association between HanPhonic use and immediate gains at higher levels of autonomy, whereas this association was not significant at lower autonomy levels.
Relatedness emerged as a significant moderator of sustained phonetic progress. The interaction between HanPhonic use and relatedness was statistically significant for delayed performance over time, indicating that learners with higher perceived relatedness demonstrated stronger delayed performance in relation to HanPhonic-supported instruction.
Competence did not significantly moderate the relationship between HanPhonic use and either immediate or sustained phonetic progress. Although competence was positively associated with short-term gains in earlier analyses, its interaction terms with HanPhonic use did not reach statistical significance in the exploratory conditional association analyses.
Taken together, the conditional process analyses indicate that the associations between HanPhonic use and phonetic learning outcomes differed across psychological need dimensions and across learning phases, with autonomy moderating immediate gains and relatedness moderating longer-term performance.
Discussion
RQ1: Instructional Effects of the Perception-Production Model
Addressing RQ1, Study 1 compared a perception-production instructional model supported by HanPhonic with traditional phonetic teaching using a longitudinal design grounded in the SLM. Results from the linear mixed-effects model showed that learners in the experimental group achieved higher scores than those in the control group at both post-intervention and follow-up stages, suggesting a potential instructional advantage. However, these findings should be interpreted with caution. The shared use of HanPhonic for both instruction and assessment may introduce familiarity or test-specific effects.
From an SLM perspective, L2 phonetic learning is constrained by learners’ existing L1-based perceptual categories, which limit their ability to discriminate non-native phonetic contrasts (Flege, 2005). Effective phonetic instruction therefore requires sustained perceptual training that helps learners attend to language-specific acoustic cues. The perception-production model implemented in this study directly addressed this requirement by systematically integrating perceptual discrimination tasks with production practice across instructional phases.
Specifically, learners in the experimental group engaged in structured listening activities targeting tonal contrasts prior to class, followed by guided pronunciation practice with real-time acoustic feedback during instruction, and focused review of acoustically challenging items after class. This coordinated design may have supported learners’ attention to fine-grained acoustic cues, such as pitch contour differences, while providing opportunities for corresponding adjustments in articulation. In contrast, traditional phonetic instruction relied primarily on teacher modeling and repetition, providing limited opportunities for explicit perceptual training. As a result, learners in the control group were more likely to continue relying on L1 perceptual filters, which have been shown to impede accurate discrimination of Mandarin tonal contrasts, particularly for learners from non-tonal language backgrounds (Flege et al., 1999).
A core assumption of SLM is the bidirectional relationship between perception and production, whereby improvements in perceptual accuracy facilitate more accurate production, and production-based feedback further refines perceptual sensitivity (Flege & Bohn, 2021). The performance advantage observed in the experimental group at follow-up may indicate that such a perception-production cycle was associated with the development of more stable L2 phonetic representations. Rather than reflecting short-lived performance gains, the perception-production model may have supported more durable phonetic development.
The present findings suggest that SLM principles can be operationalized in digital instructional environments through scalable and individualized instructional design. Whereas traditional classrooms face constraints in delivering continuous, learner-specific phonetic feedback, HanPhonic’s automated acoustic analysis and visual feedback tools may provide structured opportunities for perception-production practice across instructional stages. In this sense, the perceived effectiveness of the perception-production model may relate not only to its theoretical alignment with SLM, but also to its potential to translate phonetic theory into technology-mediated teaching practices.
RQ2: Delayed Performance and Developmental Trajectories
However, these trajectory-based interpretations should be approached with caution, as they are derived from exploratory analyses based on only three measurement points and may be sensitive to potential ceiling effects observed at the follow-up stage. Addressing RQ2, the present study examined whether the instructional advantages observed during the intervention continued to be evident during the post-instructional review phase. Importantly, both groups demonstrated continued improvement from post-test to follow-up, indicating that the delayed assessment reflects not only prior learning but also ongoing consolidation and practice effects during the review period. Results from the piecewise growth curve model revealed a significant Group × Time interaction, suggesting that learners in the experimental group exhibited a more favorable developmental trajectory during the post-instructional phase compared with those in the control group. Although both groups demonstrated substantial improvement during the instructional phase, their developmental trajectories diverged following the completion of formal instruction, with the experimental group showing more sustained phonetic performance during the review phase.
This pattern can be interpreted through the lens of memory consolidation research, which emphasizes the role of repeated retrieval and feedback in stabilizing newly acquired knowledge (Sinyagovskaya & Murray, 2021). Learners in the experimental group engaged in recurring perception-production cycles throughout the intervention, including preview listening activities, in-class articulatory practice supported by immediate feedback, and post-class review of persistent phonetic errors. Such cycles align with principles of spaced retrieval practice, which has been shown to strengthen delayed performance by reinforcing memory traces at optimally distributed intervals (Cook, 2010).
In contrast, phonetic instruction in the control condition was primarily delivered through teacher modeling and repetition within limited classroom time. While this approach may support short-term performance gains, it offers fewer opportunities for individualized retrieval and targeted reinforcement of problematic phonetic features. As a result, learners may rely more heavily on surface-level articulatory routines rather than on consolidated phonetic categories, which may lead to less sustained performance during the post-instructional phase.
The vulnerability of phonetic learning to instability is particularly salient in L2 Chinese, where tonal contours and fine-grained segmental distinctions require sustained perceptual reinforcement to remain stable (Yu et al., 2018). By enabling learners to revisit acoustically unstable items, HanPhonic may provide continued perceptual and articulatory practice opportunities beyond the classroom. This iterative feedback structure may help preserve the integrity of emerging phonetic categories during the post-instructional phase.
The observed differences in post-instructional trajectories may indicate that the HanPhonic-supported perception-production model was associated with more sustained phonetic performance during the review phase. By embedding retrieval, feedback, and spaced review into the instructional process, the model may help support the continuation of phonetic development beyond the formal instructional period.
RQ3: Psychological Correlates of HanPhonic From the Perspective of SDT
Beyond observable performance gains, RQ3 examined the psychological factors associated with phonetic learning in the context of the HanPhonic-supported perception-production model, drawing on SDT.
Autonomy was positively associated with immediate learning gains. Learners in the experimental group reported significantly higher autonomy than those receiving traditional instruction, and autonomy was positively associated with short-term phonetic improvement. Moreover, conditional process analyses showed that the relationship between HanPhonic use and immediate progress was stronger among learners who experienced higher autonomy. From an SDT perspective, this pattern suggests that the perception-production tasks supported by HanPhonic were more effective when learners perceived these activities as self-endorsed rather than externally imposed. Features such as self-paced practice, individualized review, and transparent performance feedback may have enabled learners to experience greater volitional control, thereby transforming structured phonetic training into intrinsically regulated learning behavior (Derakhshan & Park, 2026; Ryan & Deci, 2017, 2024).
Competence also played a prominent role in short-term phonetic development. Learners in the experimental group reported higher perceived competence, and competence showed the strongest association with immediate learning gains. This finding aligns with the nature of phonetic learning, in which progress is often incremental and highly sensitive to feedback. HanPhonic’s real-time error detection, acoustic visualization, and explicit scoring associations likely enhanced learners’ awareness of improvement, reinforcing their sense of effectiveness in mastering challenging phonetic features. At the same time, competence did not moderate the relationship between HanPhonic use and learning outcomes across phases, suggesting that while perceived mastery supports engagement and effort, it does not condition how learners respond to the instructional model over time.
Relatedness exhibited a more nuanced pattern. Although relatedness was not strongly associated with short-term improvement, it significantly moderated follow-up phonetic performance over time. Learners who reported stronger social connectedness demonstrated more stable phonetic outcomes during the post-instructional phase. This finding resonates with SDT’s claim that relatedness plays a key role in sustaining motivation and persistence, particularly once the novelty or external structure of instruction diminishes (Deci et al., 2017). In the context of mobile-assisted learning, relatedness may function less as a catalyst for rapid improvement and more as a stabilizing force that supports continued engagement and consolidation of learning over time.
The results suggest that HanPhonic supports learners’ psychological needs in complementary ways across learning phases. Autonomy and competence primarily facilitate immediate phonetic improvement by enabling self-directed engagement and making progress perceptible, whereas relatedness contributes to the durability of learning outcomes by sustaining motivation beyond the instructional period. This differentiated pattern reflects SDT’s assertion that basic psychological needs jointly underpin high-quality motivation, while exerting distinct influences depending on the temporal dynamics of learning (Deci et al., 2017). By integrating self-paced practice, individualized feedback, and opportunities for socially embedded learning, HanPhonic provides a motivational pathway through which mobile-assisted perception-production instruction can support both short-term performance gains and continued development over time.
Several limitations should be acknowledged. First, although procedural controls and robustness checks were implemented, the dual role of HanPhonic as both instructional and assessment tool may still introduce potential familiarity or platform-related effects. Future research should incorporate independent outcome measures, such as human ratings or alternative assessment instruments, to further strengthen validity. Secondly, the sample size was relatively modest (N = 70), which may limit the generalizability and statistical power of the findings. Therefore, the results should be interpreted with caution and warrant replication in larger and more diverse samples. Finally, the analyses examining SDT-related variables were exploratory and associational in nature. As such, no causal inferences can be drawn, and future studies employing longitudinal or experimental designs are needed to further investigate underlying associations.
Conclusion
This study investigated the effectiveness and motivational correlates associated with the use of the HanPhonic mobile application within the context of digitally mediated L2 pronunciation instruction through two complementary studies. Drawing on the SLM and SDT, the research combined a longitudinal controlled experiment with a process-oriented analysis of psychological needs to provide an integrated account of both learning outcomes and motivational dynamics.
Findings from Study 1 indicated that learners who received HanPhonic-supported perception-production instruction achieved higher scores on the HanPhonic-based assessments at both post-intervention and follow-up stages than those receiving traditional phonetic instruction. However, these findings should be interpreted with caution given the use of a shared platform for both instruction and assessment, which may introduce familiarity or test-specific effects.
Study 2 further clarified the motivational correlates associated with these effects from an SDT perspective. Autonomy and competence were closely associated with short-term phonetic improvement, highlighting the role of volitional engagement and perceived mastery in facilitating immediate learning gains. Relatedness, in contrast, played a more prominent role in supporting delayed performance, underscoring the importance of social connection in sustaining learning beyond the instructional period. Together, these findings illustrate how digital pronunciation tools may influence learning trajectories by supporting different psychological needs at different phases of development.
From a pedagogical standpoint, the results suggest that integrating mobile-assisted tools such as HanPhonic into classroom instruction can help establish a coherent instructional cycle that links perception, production, feedback, and review. By providing individualized feedback and making learning progress visible, such tools may enable teachers to address persistent phonetic difficulties more efficiently while supporting learners’ motivational needs.
Several limitations should be acknowledged. The sample size was relatively modest (N = 70), which may limit the generalizability and statistical power of the findings. Therefore, the results, particularly those from exploratory association analyses-should be interpreted with caution and warrant replication in larger and more diverse samples. In addition, the participant sample was relatively homogeneous, which may further constrain the external validity of the findings. Although bootstrapping procedures were employed to enhance the robustness of the estimates, the psychological association findings should be interpreted with caution. Psychological needs were assessed through self-report measures, and the follow-up period, while sufficient to capture short-term performance, may not fully reflect longer-term stabilization or fossilization processes. In addition, the use of a piecewise growth model with only three measurement occasions may limit the stability of estimated growth trajectories, and potential ceiling effects at the follow-up stage may further constrain the interpretation of developmental patterns.
Furthermore, HanPhonic served both as the instructional platform and as the standardized assessment tool. Although the scoring algorithm and evaluation criteria were fixed across all assessment points to minimize instrumentation bias, the dual role of the platform may introduce familiarity effects. Future research may consider incorporating independent perceptual and production measures (e.g., blind human ratings or transfer-based assessment tasks) to further strengthen external validity and to disentangle potential familiarity or platform-specific effects. The assessment also focused primarily on segmental accuracy and tonal production, without examining broader prosodic or communicative transfer.
Future research could extend this work by involving more diverse learner populations, incorporating qualitative methods to deepen understanding of motivational processes, and tracking phonetic development over longer time spans. Expanding outcome measures to include prosodic features and communicative effectiveness may further illuminate the broader role of mobile-assisted tools in L2 pronunciation development.
Footnotes
Acknowledgements
This work was supported by North China University of Water Resources and Electric Power. The university has no role in the design or implementation of this study. The authors are also grateful to the insightful comments suggested by the editor and the anonymous reviewers.
Ethical Considerations
This study was approved by the Ethics Committee of North China University of Water Resources and Electric Power (Approval Number: NCWUSFS20240515). All procedures performed in this study involving human participants were conducted in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all participants prior to their involvement in the study.
Consent to Participate
Informed consent to participate was obtained from all individual participants included in the study.
Consent for Publication
Informed consent was obtained from all individual participants included in this study.
Author Contributions
All authors listed in the study have materially participated in the research and article preparation. Additionally, they have approved the final version.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the 2025 Henan Provincial Philosophy and Social Science Planning Youth Special Project (2025CJY074) and the 2025 Henan Provincial Higher Education Teaching Reform Research and Practice Project (2025SJGLX113Y).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request.*