
Abstract
Objective:
With the advent of artificial intelligence (AI), new diagnostic tools have emerged, potentially offering more consistent and accurate detection. This study aimed to systematically evaluate the diagnostic performance of AI in identifying pressure injuries (PIs).
Approach:
This systematic review and meta-analysis was conducted following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines and was registered in Prospective Register of Systematic Reviews (CRD 42024618716). Comprehensive literature searches were performed across PubMed, Embase, IEEE, Cochrane, arXiv, and ACM databases for studies published up to November 2024. Two independent reviewers screened studies, extracted data, and assessed methodological quality using the QUADAS-AI (Quality Assessment of Diagnostic Accuracy Studies–Artificial Intelligence) tool. Statistical analyses were performed using R 4.3.3, RevMan 5.4, Stata 17, and Meta-Disc 1.4.
Results:
A total of 16 studies met the inclusion criteria, among which 12 provided 147 2 × 2 confusion matrices for quantitative synthesis. The meta-analysis showed a pooled sensitivity of 0.77 (95% CI: 0.76–0.77), specificity of 0.92 (95% CI: 0.92–0.92), and an area under the summary receiver operating characteristic curve of 0.928 (SE = 0.0079), indicating high diagnostic accuracy. Methodological quality was generally fair, but most studies were retrospective and lacked external validation.
Innovations:
This study applied the QUADAS-AI tool for quality assessment and conducted subgroup analyses by PIs stage, algorithm type, and region to offer a nuanced understanding of AI diagnostic performance.
Conclusions:
AI-based systems demonstrate promising diagnostic accuracy in detecting PIs, with high sensitivity and specificity.
INTRODUCTION
Pressure injuries (PIs) are localized damages to the skin and underlying soft tissues, typically resulting from compression between bony prominences and external surfaces or medical devices. These injuries represent a significant clinical concern in hospitals and long-term care facilities globally. 1 Epidemiological data indicate that approximately 12.9% of patients admitted to acute care hospitals in Australia and New Zealand present with PIs, while 7.9% of patients develop PIs during hospitalization. 2 Meanwhile, multinational clinical studies conducted across surgical centers in China, South Korea, and other countries have demonstrated that the incidence of intraoperative PIs ranges from 4.1% to 41.75%. 3 The impact of PIs extends beyond patient discomfort, significantly affecting mortality rates and health care cost. 4 Systematic reviews have established that patients with PIs face approximately twice the mortality risk compared with those without such injuries. 5 In addition, PIs are classified into six stages based on the severity and depth of tissue loss: Stages 1–4, unstaged, and deep tissue. 6 Severe pressure ulcers (stage III and above) are associated with higher health care costs. 7 Early diagnosis of PIs and prompt intervention are therefore essential to prevent disease progression and facilitate timely recovery. 8
Xu Zhang, PhD

Current diagnostic approaches for PIs rely primarily on visual assessment by clinical nurses. While clinical practice utilizes approximately 40 risk assessment scales (e.g., Braden, Waterlow, Norton 9 ) for predicting PIs development risk, these tools do not assist in diagnosing existing wounds or determining their stage. In addition, the accuracy of visual diagnosis is highly dependent on the professional knowledge and experience of nurses, which can easily lead to errors in diagnosis and staging. 10 This limitation has prompted the exploration of more objective and consistent diagnostic technologies. In recent years, artificial intelligence (AI) has emerged as a promising solution in nursing practice, with increasing applications in diagnosis, complication management, prognosis prediction, and relapse assessment.11,12 Specifically, AI algorithms have demonstrated potential for enhancing the diagnostic accuracy of PIs through standardized image analysis and pattern recognition capabilities.
Currently, the two main types of AI techniques applied to diagnose PIs and their staging are machine learning (ML) and deep learning (DL). ML recognizes and classifies dermatological diseases by manually extracting and selecting features by experts. 13 Common algorithms include logistic regression, support vector machines, and least absolute shrinkage and selection operator methods. 14 Liu et al. developed an ML-based algorithm capable of rapidly determining PIs stages and reporting impressive accuracy values of 0.98, 0.97, 0.95, and 0.95 for stages I through IV, respectively. 15 DL, representing the most recent evolution of ML, learns to recognize patterns and features from extensive datasets without requiring manual feature extraction. DL automatically processes and assimilates complex data characteristics through multilayer neural networks to identify and classify skin conditions. 16 Prominent DL algorithms in PIs assessment include convolutional neural networks, deep convolutional neural networks, and deep neural networks. 14 Tusar et al. developed an algorithmic model based on You Only Look Once version 8, which measured different stages of PIs and achieved an accuracy of 0.9 for deep tissue damage in PIs. 11
Despite several systematic reviews and meta-analyses examining AI applications in PIs management, significant limitations persist in the current literature. Pei et al. 17 and Zhou et al. 18 conducted systematic reviews and meta-analyses focusing exclusively on AI for PIs prediction rather than diagnostic performance assessment. While Dweekat et al. 19 summarized the contribution of ML in the field of PIs and explained its potential to intervene at various stages of PIs, the literature included in this systematic review was all published before July 2022. Given the rapid advancement of AI algorithms, updated analyses incorporating recent publications are essential to accurately assess the current state of AI-based PIs diagnosis. Furthermore, methodological considerations necessitate reassessment of previous studies. The QUADAS-AI (Quality Assessment of Diagnostic Accuracy Studies–Artificial Intelligence), a quality assessment tool specifically for AI diagnostic-type studies, was proposed by Sounderajah et al., 20 suggesting that quality assessments in earlier reviews may require updating. Finally, many researchers have developed algorithms to quantify the diagnostic performance of different stages of PIs 21 ; however, there is a lack of quantitative cross-sectional comparisons of the effectiveness of multiple AI algorithms for diagnosing PIs at different stages. Therefore, this study aims to evaluate the diagnostic accuracy of AI algorithms in PIs detection based on published data through a systematic literature review and meta-analysis. Subgroup analyses will be used to compare the following: (1) the accuracy of AI algorithms in diagnosing PIs across different regions; (2) the accuracy of AI algorithms in diagnosing PIs at different stages (stages 1–4); and (3) the accuracy of AI algorithms developed using different types of technologies (ML, DL, and other algorithm types) for diagnosing PIs, thereby providing evidence-based guidance for clinical application.
METHODS
This systematic review and meta-analysis was registered in Prospective Register of Systematic Reviews (PROSPERO, CRD 42024618716). All methodological procedures strictly adhered to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses of Diagnostic Test Accuracy guidelines (Supplementary Table S1) 22 and Meta-Analyses Of Observational Studies in Epidemiology 23 reporting standards, as well as the rigor checklist for AI in health care and clinical research. 24
Search strategy
Two researchers (X.Z. and Y.G.) independently conducted a comprehensive literature search across six electronic databases: PubMed, Embase, IEEE Xplore, Cochrane Library, arXiv, and ACM Digital Library. The search encompassed all literature published from database inception through November 2024 examining the diagnostic accuracy of AI applications for PIs. The search was conducted using a combination of subject terms and free terms, and was adapted to the characteristics of each database. In addition, manual search and literature tracing were also conducted to collect research literature that met the requirements based on the search results. The results of the literature screening process conducted by the two researchers were then compared. In instances where a consensus could not be reached, the disputed literature was to be submitted to a third researcher for adjudication. The English search terms include “artificial intelligence,” “diagnosis,” “performance,” and “pressure injury”. The complete search terms and strategies for all databases are provided in Supplementary Table S2.
Eligibility criteria
We established precise inclusion and exclusion criteria before the literature search to ensure methodological rigor and relevance to our research question. Studies were included if they met all of the following criteria: (i) Published diagnostic studies evaluating AI applications for PIs assessment. (ii) Utilized established clinical diagnostic criteria as the reference standard, including the European Pressure Ulcer Advisory Panel (EPUAP), 25 National Pressure Injury Advisory Panel (NPIAP), 26 Pan Pacific Pressure Injury Alliance (PPPIA), 8 or histopathological confirmation, or utilized validated PIs datasets. (iii) Studies that reported AI performance metrics. (iv) Published in English or Chinese with full-text accessibility.
Studies were excluded if they met any of the following criteria: (i) Nonprimary research publications (case reports, conference abstracts, reviews, letters, commentaries, editorials). (ii) Studies focusing solely on image processing techniques without diagnostic classification (e.g., image segmentation, wound measurement). (iii) Studies where the original text was not available or relevant data were not available.
Data extraction
Two researchers independently screened the eligible studies based on the predefined inclusion and exclusion criteria. Following the screening process, relevant data were extracted from each study using a standardized data extraction form. Data extraction included first author’s name, year of publication, country, sample size, gold standard, internal validation type, external validation, algorithms’ architecture, and assessment metrics for diagnostic efficacy. When discrepancies arose between data extracted by two researchers, these would be submitted to a third researcher for adjudication.
Risk-of-bias assessment
The risk of bias for each included study was evaluated using the QUADAS-AI tool. 20 Two researchers independently performed the assessments, and any disagreements were resolved through arbitration by a third senior reviewer. The tool comprises four domains: Patient selection, Index test, Reference standard, and Flow and timing. The first three domains also incorporate an evaluation of clinical applicability. Each domain was rated as having a high, low, or unclear risk of bias.
Statistical analysis
Statistical analysis was performed using R 4.3.3, RevMan 5.4, Stata 17, and Meta-Disc 1.4 software. The quality of the included studies was assessed and corresponding graphs were generated using RevMan 5.4 software. Data were analyzed using R 4.3.3, Stata 17, and Meta-Disc 1.4 software. First, the presence of heterogeneity due to threshold effects was examined by plotting summary receiver operating characteristic (SROC) curve scatter plots and Spearman correlation analysis. Should the scatter plot exhibit a pronounced “shoulder-arm” morphology with a correlation coefficient of p value exceeding 0.05, this indicates the presence of a threshold effect in the research. Subgroup comparisons are then conducted by calculating the area under the SROC curve (SROC-AUC). Conversely, if no threshold effect is present, heterogeneity attributable to nonthreshold effects is assessed through Cochran’s Q test and I2 value. Unless substantial evidence indicates homogeneity of effects across studies of varying methodological quality, data synthesis uses a random-effects model. 27 Finally, the risk of publication bias was assessed using Deeks funnel plot, and the sources of heterogeneity were explored through subgroup analyses, with three subgroup analyses. (i) study region (Asia, Europe, North America); (ii) stage of PI (stages 1–4); and (iii) type of AI algorithms (ML, DL, and other algorithms).
RESULTS
A total of 214 articles related to the research topic were initially retrieved from various databases. After removing duplicates, 199 unique records remained. An additional 23 articles were identified through manual searches and reference tracking. Following a rigorous multistage screening process based on predefined inclusion and exclusion criteria, 16 high-quality studies were ultimately included in the review,28–43 with 12 undergoing meta-analysis.28–31,34,36,37,39–43 Supplementary Table S3 summarizes the listings extracted from the included studies. A total of 147 2 × 2 confusion matrices on diagnostic performance were provided. The screening process and results of the literature are presented in the Preferred Reporting Items for Systematic Reviews and Meta-Analyses flow diagram (Fig. 1).
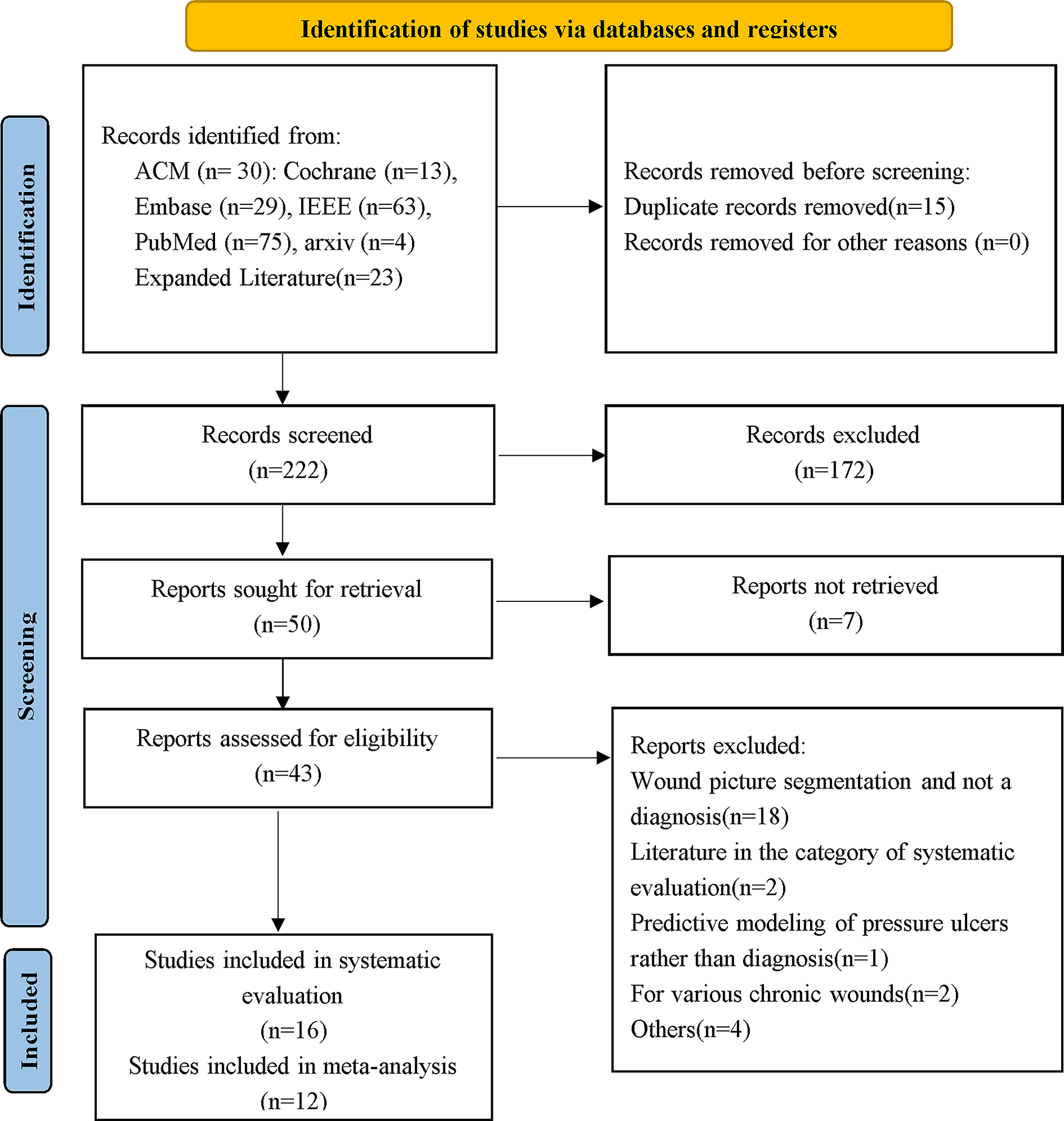
Flowchart of literature screening. The flowchart illustrates the process of identifying and screening studies, from database searches to the final selection of studies meeting the eligibility criteria.
Basic characteristics and quality assessment
The basic characteristics of the 16 included studies are summarized in Table 1. Four studies were conducted in China,33,34,40,41 three in Turkey,28,42,43 two each in the United Kingdom,29,38 Japan,30,36 and South Korea,31,37 with one study each from Greece, 32 Italy, 35 and the United States, 39 indicating a broad international distribution.
Basic characteristics of included studies
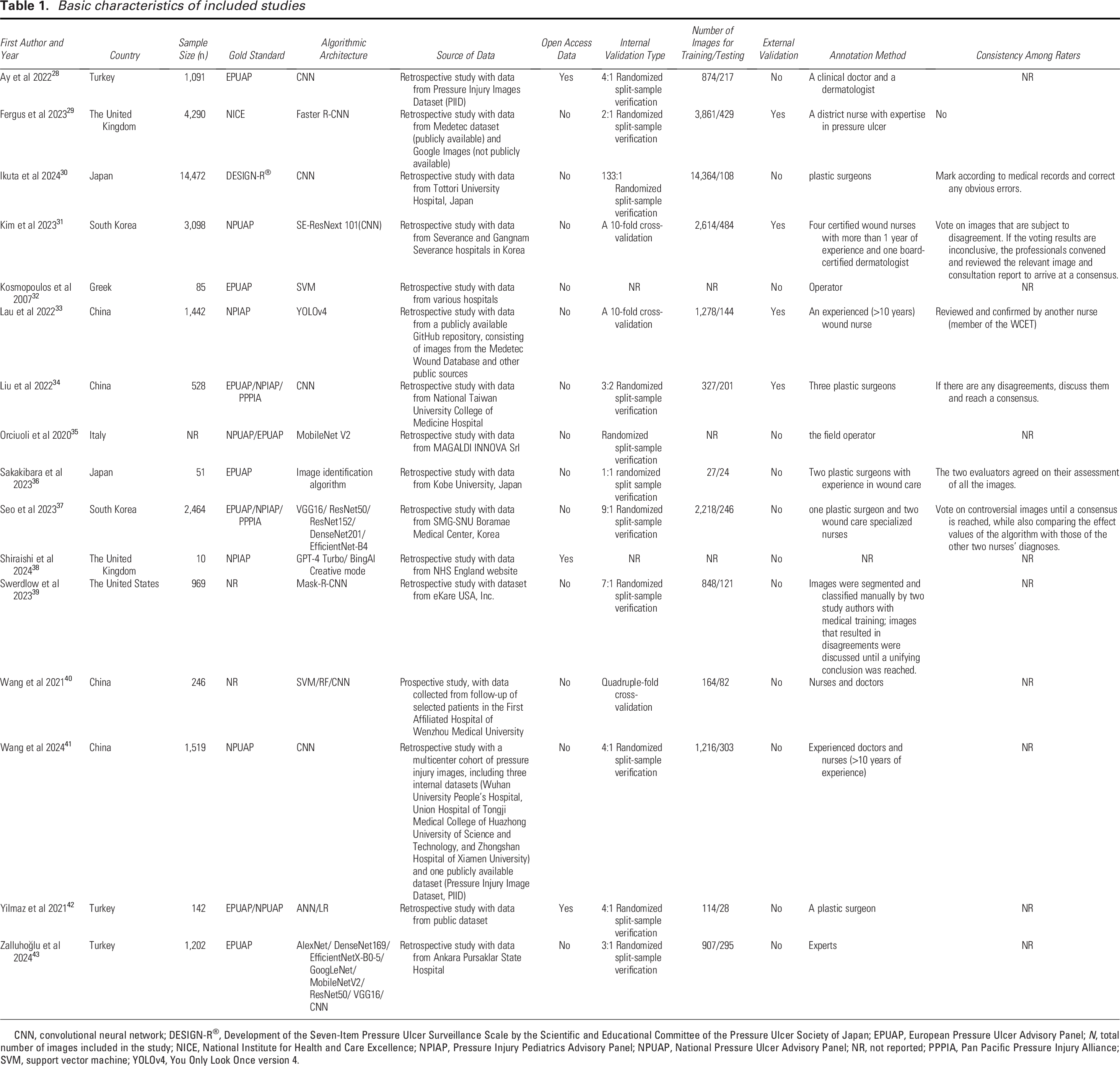
CNN, convolutional neural network; DESIGN-R®, Development of the Seven-Item Pressure Ulcer Surveillance Scale by the Scientific and Educational Committee of the Pressure Ulcer Society of Japan; EPUAP, European Pressure Ulcer Advisory Panel; N, total number of images included in the study; NICE, National Institute for Health and Care Excellence; NPIAP, Pressure Injury Pediatrics Advisory Panel; NPUAP, National Pressure Ulcer Advisory Panel; NR, not reported; PPPIA, Pan Pacific Pressure Injury Alliance; SVM, support vector machine; YOLOv4, You Only Look Once version 4.
Reliable diagnostic reference standards were used in 14 studies,28–35,37,38,41–43 whereas two studies39,40 did not clearly define the reference standard. Regarding internal validation methods, 11 studies28–30,34–37,39,41–43 utilized random splitting of data, two adopted 10-fold cross-validation,31,33 one used fourfold cross-validation, 40 and two did not specify the method.32,38 Only four studies conducted external validation.29,31,33,34
Supplementary Figures S1 and Figure S2 provide the results of the risk-of-bias evaluation of the included studies. In terms of image selection for PIs diagnosis, seven studies were deemed high risk and eight had unclear risk. Clinical applicability in this domain was unclear in nine studies, possibly due to the reliance on publicly available image databases without clear inclusion and exclusion criteria. For the index test domain, 10 studies demonstrated a high risk of bias, while clinical applicability remained unclear in eight, largely due to the absence of external validation. Regarding reference standards, 14 studies were judged to have low risk, and two were of unclear risk. In the domain of flow and timing, seven studies had low risk, seven were unclear, and two were high risk.
Pooled diagnostic performance of AI algorithms for PI detection
In this study, the overall Spearman correlation coefficients and subgroup-specific correlation coefficients were calculated to assess the presence of a threshold effect. As shown in Supplementary Table S4, the combined Spearman correlation coefficient across all studies was –0.068 (p = 0.416), indicating no evidence of a threshold effect. However, subgroup analysis revealed significant threshold effects in two cases: PIs stage 4 (correlation coefficient = –0.547, p = 0.002) and studies using other types of algorithms (correlation coefficient = –0.943, p = 0.005).
Table 2 and Supplementary Table S4 present the meta-analysis results. The pooled sensitivity of AI algorithms for diagnosing PIs was 0.77 (95% CI: 0.76–0.77), with substantial interstudy heterogeneity (I2 = 88.5%, χ2 = 1271.6, p < 0.001). The pooled specificity was 0.92 (95% CI: 0.92–0.92), also demonstrating high heterogeneity (I2 = 91.7%, χ2 = 1761.06, p < 0.001). The combined positive likelihood ratio (LR+) was 9.87 (95% CI: 8.62–11.31), and the negative likelihood ratio (LR−) was 0.26 (95% CI: 0.23–0.29). The pooled diagnostic odds ratio was 40.86 (95% CI: 33.75–49.46). The area under the SROC-AUC was 0.928, with a standard error of 0.0079 (Fig. 2A).
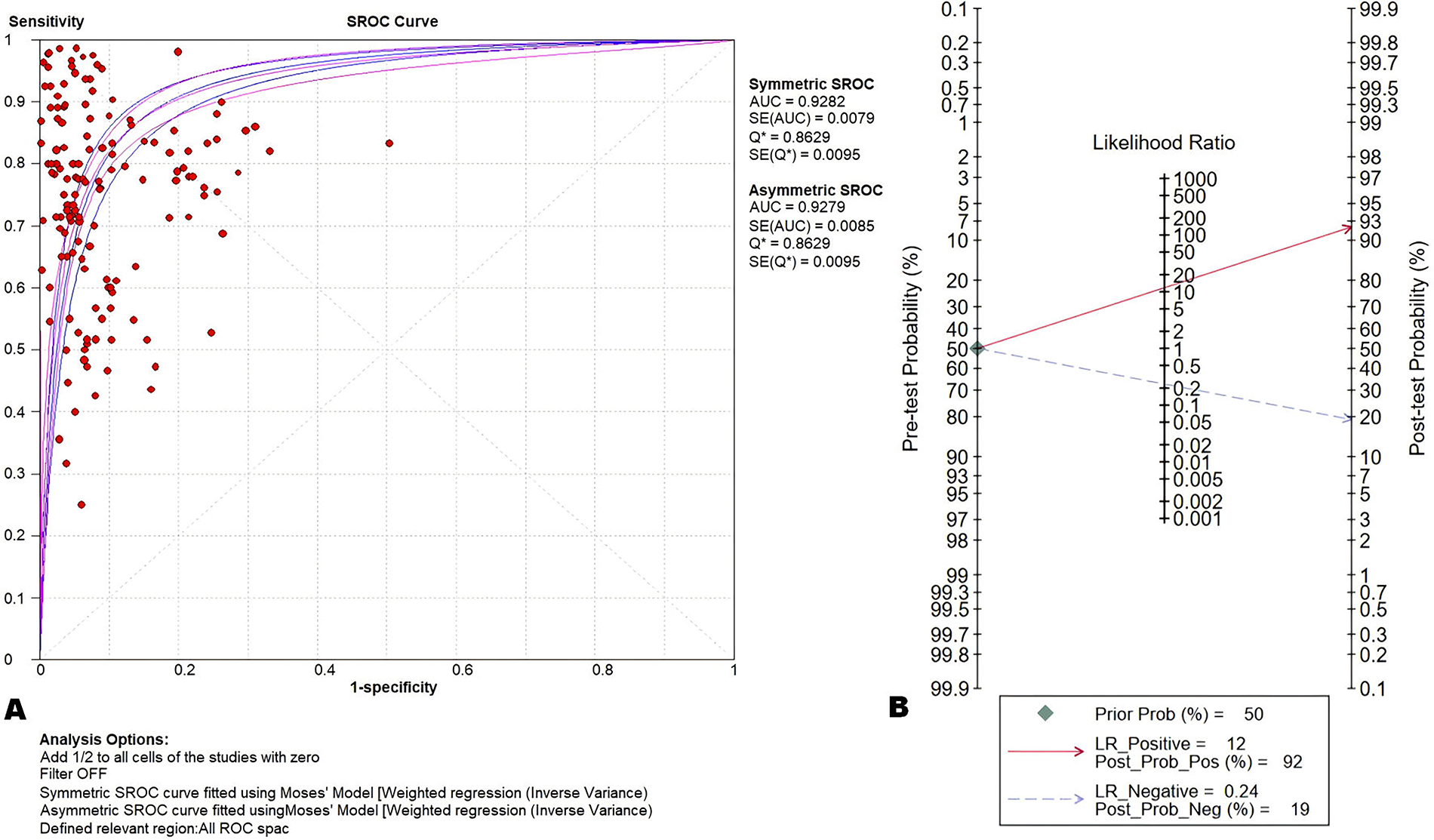
Overall effectiveness of the 12 studies.
Results of combined analysis of artificial intelligence for diagnosis of pressure injuries
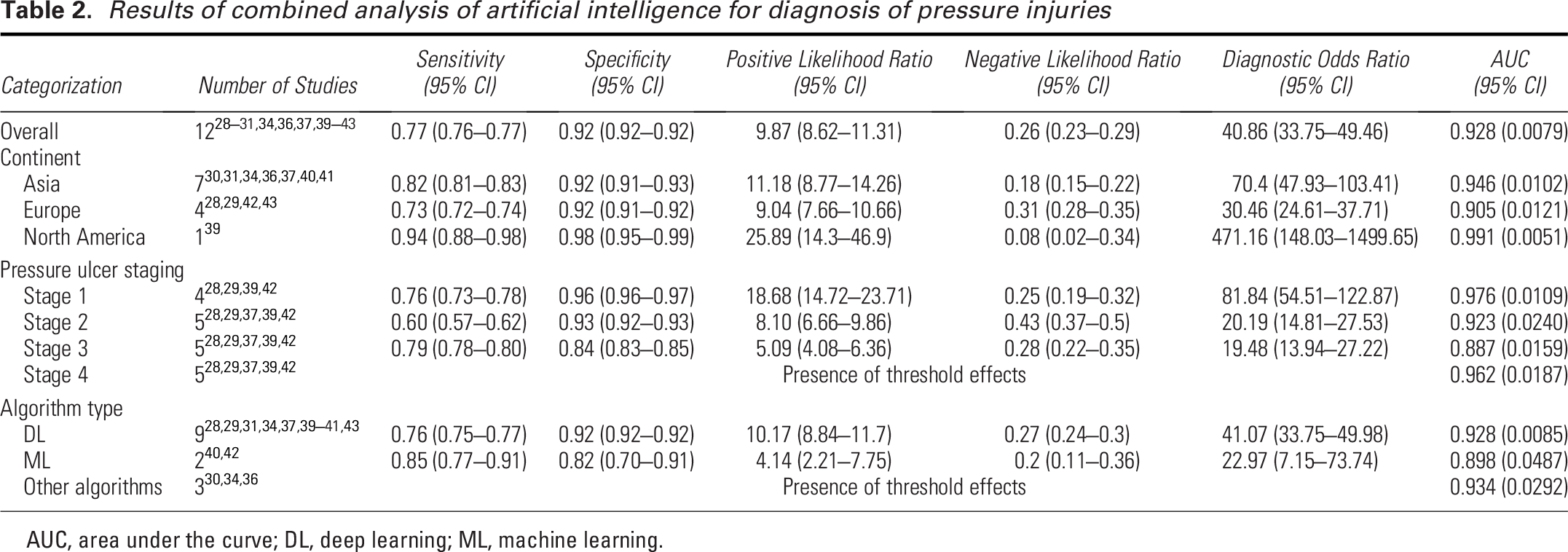
AUC, area under the curve; DL, deep learning; ML, machine learning.
Figure 2B demonstrates the results of the analysis of the Fagan plot, from which it can be seen that the LR+ of the current diagnostic tests performs well and is suitable for confirmatory diagnosis in high-prevalence populations. However, the LR− suggests insufficient exclusionary power and needs to be combined with more test results in clinical confirmation. Supplementary Figure S3 demonstrates the results of the funnel plot analysis, and the significant result of Deeks test (p < 0.05) indicates that there is a statistical asymmetry in the funnel plot, which suggests a possible publication bias. This may occur because studies reporting higher AI diagnostic sensitivity are more likely to be published, leading to high overall estimates. Supplementary Figures S4-S7 present the crosshair plots summarizing all confusion matrices as well as the crosshair plots for individual subgroups.
Subgroup analysis
Table 2 show the results of subgroup analyses according to region, with a combined sensitivity of 0.94 [95% CI (0.88–0.98)] in North America being higher than in Asia [0.82, 95% CI (0.81–0.83)] and Europe [0.73, 95% CI (0.72–0.74)]. However, there was only one study in North America, a relatively small sample size. In contrast, the sensitivity of Asia included seven studies with higher confidence, and in addition to this, the combined specificity of all three regions was greater than 0.9. Figure 3 demonstrates the SROC-AUC results of subgroup analyses performed in the three different regions, with an SROC-AUC of 0.946 in Asia ([SE] = 0.0102), an SROC-AUC of 0.905 in Europe ([SE] = 0.0121), and an SROC-AUC of 0.991 in North America ([SE] = 0.0051). Overall, the efficacy of using AI to diagnose PIs was better and more consistent in Asia.
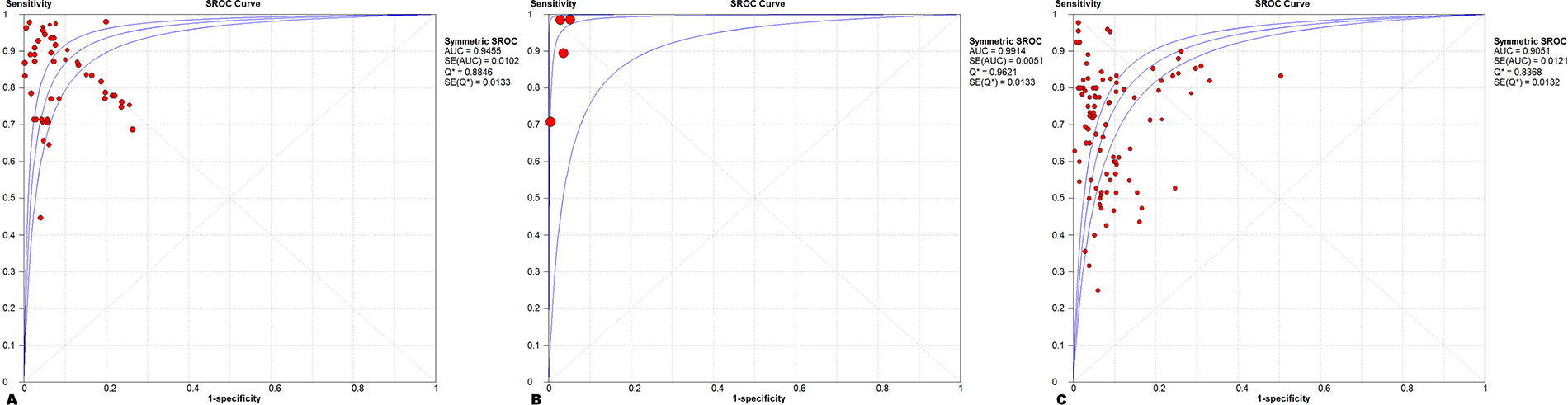
sROC AUC in different regions.
For the results of the subgroup analysis of the efficacy of AI in diagnosing different stages of PIs (Table 2), the combined sensitivity was 0.79 [95% CI (0.78–0.80)] for stage 3, 0.76 [95% CI (0.73–0.78)] for stage 1, and 0.60 for stage 2 [95% CI (0.57–0.62)], and overall, the sensitivity of AI to diagnose stage 3 was higher than the other two stages. In contrast, the combined specificity was 0.96 [95% CI (0.96–0.97)] for stage 1, 0.93 [95% CI (0.92–0.93)] for stage 2, and 0.84 [95% CI (0.83–0.85)] for stage 3, and AI diagnosis of stage 3 performed poorer than the other two stages in terms of specificity. As the threshold effect at the time of merging in the studies was included in stage 4, only the values of the AUC were merged and analyzed and compared (Fig. 4), with an SROC-AUC of 0.976 ([SE] = 0.0109) for stage 1, 0.923 ([SE] = 0.0240) for stage 2, 0.887 for stage 3 ([SE] = 0.0159), and 0.962 ([SE] = 0.0187) for stage 4. Stage 1 had the highest SROC-AUC value.

sROC AUC with different pressure injury staging.
In the subgroup analysis of algorithm-type classification, according to Table 2, the sensitivity of the DL algorithm to diagnose PIs was 0.76 [95% CI (0.75–0.77)], which was smaller than that of the ML algorithm of 0.85 [95% CI (0.77–0.91)]; however, the specificity of the DL algorithm was 0.92 [95% CI (0.92–0.92)] greater than 0.82 [95% CI (0.70–0.91)] for ML algorithms. For the other types of algorithms, there is a threshold effect when merging, so only the values of AUC were merged, analyzed, and compared; according to Fig. 5, the SROC-AUC for the DL algorithm was 0.928 ([SE] = 0.0085), for the ML algorithm was 0.898 ([SE] = 0.0487), and for the other types of algorithms was 0.934 ([SE] = 0.0292).
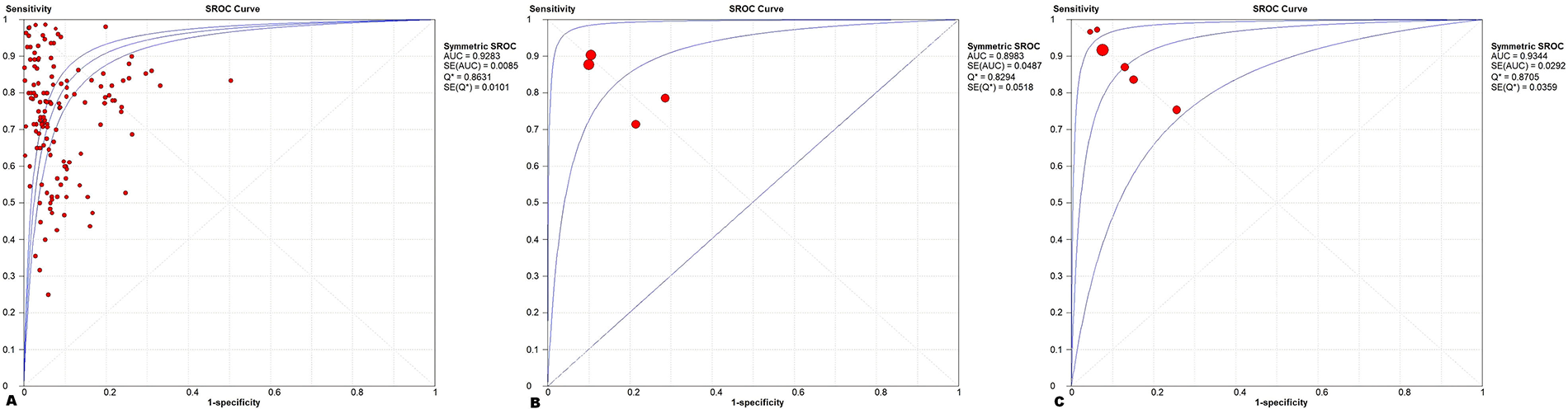
sROC AUC for different algorithm types.
DISCUSSION
PIs remain a major concern for hospitalized patients, with significant implications for patient outcomes and health care costs. 44 While various risk assessment tools exist, their effectiveness is often limited by caregiver expertise and inconsistent diagnostic criteria. 45 Recent advances in AI have introduced new possibilities for assisting in PIs diagnosis. 34 However, previous reviews have primarily focused on predictive modeling or image segmentation, with limited attention to diagnostic performance.46–48 This study fills that gap by systematically evaluating the diagnostic accuracy of AI algorithms for PIs, offering quantitative evidence to support clinical and research applications.
This meta-analysis of 12 studies incorporating 147 2 × 2 confusion matrices demonstrated AI’s robust diagnostic performance in PIs detection, with a pooled sensitivity of 0.77 and a specificity of 0.92, achieving a diagnostic odds ratio of 40.86 and an AUC of 0.93. Significant heterogeneity (Supplementary Table S4) primarily originated from different algorithm types (Supplementary Table S3). However, the discriminatory capacity remained consistent with established AI meta-analyses in oncological imaging 14 (sensitivity 0.88) and musculoskeletal diagnostics. 49 Future investigations warrant standardized external validation protocols and prospective multicenter trials to address algorithmic heterogeneity. The demonstrated diagnostic superiority substantiates AI’s capacity to enhance secondary prevention through elevated early detection rates, thereby enabling timely therapeutic interventions and improved rehabilitation outcomes in PIs management. However, funnel plot analysis revealed statistical asymmetry, suggesting a publication bias toward positive results. Future efforts should promote the preregistration of diagnostic AI studies (e.g., through the PROSPERO platform). According to the QUADAS-AI assessment, methodological flaws in the included studies have impacted the validity and applicability of the meta-analysis. First, significant patient selection bias (seven high-risk, eight unclear risk) and unclear applicability (nine studies) may introduce spectrum bias. By directly including PIs images from databases, challenging cases may be excluded, thereby overestimating diagnostic accuracy. Second, there are certain methodological flaws in the indicator detection domain (10 high-risk studies, 8 studies with unclear applicability). Since most of the included studies lack external validation, this may lead to overfitting, thereby overestimating the performance of the study results in practical applications. Therefore, caution is advised when translating these study results into clinical practice, and future studies should carefully consider the criteria for including images and conduct more external validation studies.
Regional subgroup analyses demonstrated consistent specificity (>0.90) across all geographic regions, with pooled specificities of 0.98 in North America, 0.92 in Asia, and 0.92 in Europe. Although sensitivities varied (0.94 in North America, 0.82 in Asia, and 0.73 in Europe), the overall diagnostic performance remained comparable, potentially due to standardized clinical criteria and similar wound segmentation architectures in AI systems. 50 Meanwhile, the factor of skin color has a relatively low impact on the segmentation of wound parameters (color, size, depth) in the image preprocessing process. 51
The updated NPIAP 25 classification system outlines six PIs categories: stages 1–4, unstageable, and deep tissue injury. Current AI-driven diagnostic studies predominantly focus on stages 1–4 PIs, a research scope mirrored in our subgroup analyses. The evaluation demonstrated superior AUC performance across stages: 0.98 (stage 1), 0.92 (stage 2), 0.89 (stage 3), and 0.96 (stage 4). The AI exhibited higher AUC and superior diagnostic performance for stage 1 and 4 PIs, paralleling clinical caregivers’ accuracy in PIs staging assessments. 52 The diminished diagnostic accuracy for stage 3 PIs in this study appears attributable to two interrelated mechanisms. Primarily, the clinical presentations of these stages demonstrate significant overlap with chronic wound etiologies such as diabetic and arterial ulcers, creating substantial diagnostic uncertainty 53 ; secondarily, the characteristic obscuration of stage 3 wound beds by necrotic tissue or eschar fundamentally compromises depth evaluation, resulting in misinterpretation. 54 The enhanced diagnostic accuracy for stage 1 PIs likely relates to its epidemiological prevalence, where its higher proportion in training datasets enables AI algorithms to optimize diagnostic parameters. 55 Collectively, these findings confirm the clinical value of AI-driven nursing systems in facilitating early-stage PIs detection and intervention. However, there remains insufficient attention to clinically significant unstaged or deep tissue damage, as well as overlapping etiologies of trauma (such as diabetic ulcers and PIs). Future research should focus more on these areas.
Subgroup analysis by algorithm type revealed distinct performance characteristics: DL demonstrated a pooled sensitivity of 0.76 and a specificity of 0.92, while ML showed higher sensitivity (0.85) but lower specificity (0.82). Other algorithm types achieved superior pooled AUC (0.934) compared with both, although with fewer included studies than DL. This result suggests greater diagnostic consistency in DL, whereas ML and other algorithms may exhibit variability influenced by publication bias or random effects during meta-analysis. 56 These findings align with established diagnostic research, particularly Wu et al’s comparative analysis 57 demonstrating comparable accuracy between DL (sensitivity = 0.82) and ML (sensitivity = 0.93) in chronic obstructive pulmonary disease detection, with nonsignificant performance variation. While ML exhibited lower misdiagnosis rates, DL showed superior comprehensive diagnostic performance metrics. Overall, ML demonstrated reduced misdiagnosis rates, and DL exhibited superior comprehensive diagnostic efficacy; however, these comparative performance outcomes require confirmation through rigorously designed prospective clinical studies.
Overall, the high diagnostic accuracy (pooled sensitivity 0.77, specificity 0.92) demonstrates AI’s potential to transform PIs management. First, in triage settings, AI’s high discriminative ability (AUC: 0.98 for stage I, 0.96 for stage IV injuries) enables nurses to rapidly initiate interventions for early-stage injuries to prevent progression, while prioritizing critical cases. Secondly, the high combined specificity (0.92) supports the use of artificial intelligence-assisted diagnosis to enhance efficiency and achieve standardised decision-making. 37 This supports AI-assisted diagnostics for improved efficiency and standardized decision-making. Finally, integration with mobile applications 35 facilitates remote screening, allowing patients to submit images for community nurse evaluation with AI support—enhancing diagnostic throughput in telemedicine workflows despite variable user experience levels. Therefore, in future clinical practice, AI can be integrated into the diagnostic process for PIs to optimize staged diagnosis and improve patient outcomes. For example, after training with PIs datasets and clinical guidelines, the most appropriate AI diagnostic system can be selected and embedded into the hospital system. Nurses can then take photographs and upload them, and the system will provide real-time diagnostic criteria, nursing care recommendations, and prevention guidance (Supplementary Fig. S8). However, widespread implementation is constrained by critical limitations: Prevalent methodological deficiencies in existing research designs, utilization of datasets with ill-defined evaluation criteria, and insufficient external validation across most of analyzed studies. To bridge this gap, future investigations should prioritize rigorous external validation of diagnostic algorithms to ensure clinical applicability and generalizability. In addition, device compatibility is critical, as differences in smartphone/tablet camera quality (e.g., resolution, light calibration) can affect the accuracy of image-based AI, especially in resource-poor settings. Further training needs for health care workers also pose a challenge, including technical proficiency (application operation, standardized image acquisition) and clinical interpretation of AI outputs to avoid overreliance. Furthermore, regulatory and ethical challenges encompass algorithm transparency (concerns about “black boxes”), liability allocation for misdiagnoses, and patient data privacy issues during image transmission. Addressing these issues through adaptive AI design, competency-based training programs, and clear governance frameworks will be key to achieving practical application.
This meta-analysis has the following limitations: (i) Only one of the included studies was prospective in design, with the remainder being retrospective. This limits the strength of the evidence and introduces selection bias. Future studies with larger sample sizes are required. (ii) ML subgroup analyses demonstrated limited statistical power due to insufficient study numbers, resulting in compromised reliability of pooled effect estimates that require validation through dedicated ML-focused meta-analytic approaches. (iii) Heterogeneous reference standards and labeling processes across studies may compromise the validity of pooled accuracy estimates. (iv) Substantial variation in sample sizes could disproportionately influence meta-analysis results, lacking clear mitigation strategies. (v) Among the 16 studies included, only four incorporated external validation. This raises concerns regarding the overfitting and generalization capabilities of AI models in real-world clinical settings, thereby undermining their credibility for application in independent populations. Therefore, the applicability of the findings of this study to different populations and health care settings needs to be further explored through external validation in future studies.
CONCLUSION
The diagnostic efficacy of AI for PIs is high, but there may be risks such as overfitting due to factors such as the timeliness of the databases included in the study and the lack of external validation. This refers to the fact that the data used to train and test the AI models may have been collected over a limited or outdated time period, potentially not reflecting the latest imaging technologies, clinical practices, or patient demographics. To enhance the suitability of AI algorithms for clinical applications, future research should consider external validation or prospective validation with a predefined cutoff to support their implementation.
INNOVATION
This study advances the field by applying the QUADAS-AI tool—a methodological innovation tailored for AI-based diagnostic accuracy studies—to systematically assess the quality of included evidence. It also integrates subgroup analyses across injury stages, algorithm types, and geographical regions, offering a more granular understanding of AI performance variability. By combining rigorous quality assessment with comprehensive subgroup analysis, the study provides a critical foundation for guiding future research and clinical implementation of AI in PIs diagnosis.
KEY FINDINGS
AI systems achieved a pooled sensitivity of 0.77 and specificity of 0.92 in diagnosing PIs, indicating high diagnostic accuracy.
The SROC-AUC reached 0.928, demonstrating strong overall performance across included models.
Subgroup analyses revealed variation in performance by injury stage, algorithm type, and geographic region.
AI-based tools hold promise for early and standardized PIs detection in clinical settings.
Most studies were retrospective and lacked external validation, highlighting the need for higher quality evidence.
AUTHORS’ CONTRIBUTIONS
Y.G. developed the study concept and design, conducted the electronic searches, performed data extraction, and wrote the first draft of this article. Y.G. and X.Z. contributed to data analysis and interpretation, and risk-of-bias assessment. S.A., Y.M., and X.H. assisted with electronic searches and literature screening. X.Z. contributed to the contextualization, critical review, and supervision. All authors have approved the final version of this article.
Footnotes
ACKNOWLEDGMENTS AND FUNDING SOURCES
Research reported in this publication was supported by the National Natural Science Foundation of China (No. 72404014).
AUTHOR DISCLOSURE AND GHOSTWRITING
No competing financial interests exist. The content of this article was expressly written by the authors listed. No ghostwriters were used to write this article.
ABOUT THE AUTHORS
Supplemental Material
Abbreviations and Acronyms
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.