
Abstract
This study presents a real-time, context-adaptive advertisement (ad in short) recommendation framework that dynamically updates user context and utilizes a multistage ranking and filtering pipeline to deliver highly relevant and personalized ads. Contextual ads contribute to better conversion rates and play a significant role in e-commerce. In contrast, non-contextual ads engender frustration among advertisers and users: commercialization efforts frequently prove ineffective due to poor user engagement, as evidenced by high ad-skipping rates. The current practices in digital advertising involve non-contextual and irrelevant ads, which result in poor conversion rates. To address this problem, this article explores semantically enriched and context-aware recommender systems, aiming to align ads with user interests. The proposed framework investigates various components, including a user context extractor (UCE), recommender system, ads database, ads ranker, and ads filter. This study also explores how high-quality and relevant content, along with clickable advertising, contributes to improving customer relationships and reducing ad avoidance. During contextual augmentation, ads that become relevant and engaging are projected to have increased click-through rates in a real-world application. Customer engagement and satisfaction would also increase due to a reduction in ad fatigue and the delivery of relevant content. Furthermore, it can curb ad avoidance because users will gladly respond to ads that suit their interests. Businesses make higher conversions because the more relevant recommendation means greater user interaction. The proposed framework combines a UCE, an ad database, a ranking mechanism, and a filtering module to deliver real-time, personalized recommendations. Evaluated using a k-nearest neighbor-based model, the system achieved improved precision (from 0.8275 to 0.9283), recall (from 0.4628 to 0.5201), and normalized discounted cumulative gain (from 0.9906 to 0.9915). These gains demonstrate that integrating fine-grained, dynamic user context substantially enhances recommendation quality and user engagement, offering a scalable foundation for intelligent, adaptive advertising systems. This research contributes toward the future development of an AI-enabled advertising strategy, with an emphasis on dynamic ad targeting that goes hand in hand with personalization and thus improved conversion rate.
Keywords
Introduction
Advertising convinces people to buy things, while consumer behavior is how people decide what to buy and use. 1 The primary goal of advertising worldwide is to gain valuable consumers by shaping their understanding, mindset, and shopping habits. People worldwide can become successful by using billboards, television, newspapers, advertisements (ads) on the internet, movies, videos, and magazines to promote themselves or their ideas. These tools help them reach many people and achieve their goals.2,3 Online ads have become a notable revenue model for businesses, surpassing print and other forms of advertising. Online ads can be delivered or recommended to viewers based on the user’s location data, user profile, implicit and explicit feedback, and keywords supplied. 4 While this study focuses on ad recommendation, context-aware recommender systems (CARSs) have broad applications across various industries. In artificial intelligence (AI), they enable more responsive and human-centered decision making, as seen in adaptive learning environments and smart assistants. In data management, context-driven systems help filter, prioritize, and personalize content in real time, reducing information overload. Industries such as health care can leverage these systems to personalize treatment recommendations based on patient history and real-time vitals, while the financial sector can use them for personalized investment suggestions and fraud detection based on user behavior. The generalizability of context-aware architectures makes them foundational to the next generation of intelligent systems.
The recommendation system presents the user with relevant things based on their preferences. It handles a variety of user and item-related data. Several e-business associations, movie sites, e-libraries, articles, news, video sites, and social forums use recommendation systems. 5 As a result of the widespread use of the internet, recommender systems have grown in importance. Based on the user’s profile, a recommender system can forecast whether a particular user would like an item. 6 The recommender system takes different parameters, for example, profile information, web history, statistical data, and geographical data, as input and, based on these parameters, recommends items that are hypothetically relevant to the user. 7 The recommender system employs various techniques and models to identify user favorites for recommendation tasks. These techniques are categorized as content-based recommendation systems, collaborative filtering-based recommendation systems, and hybrid recommendation systems. 8
Content-aware recommender systems accept input in the contextual information form and give additional recommendations. 9 Holiday recommender systems, movie recommender systems, and similar applications need more information than items and user information. The need for contextual information is desired. For example, a traveling recommender system recommends different vacation packages based on weather conditions. 10 CARSs go beyond standard ones by utilizing context information such as time, location, and user action to comprehend user conditions and their impact on user preferences. Incorporating context information into recommender systems increases the utility of these systems by enhancing the relevance of potential suggestions about changing user demands. 11 Context can be categorized into two types: static context and dynamic context. In a static context, the attributes and structure of the context remain unchanged over time. Dynamic contexts are the second kind, where the characteristics or organization of the context can change over time. This might lead to removing some contextual characteristics from the system when they become outdated. Conversely, the system can incorporate new attributes that handle newly relevant scenarios. 12
Figure 1 presents the two categories of contexts and the subtypes of each category. Both types are further categorized as fully observable, partially observable, and unobservable. In observable, the structure of all relevant contextual attributes is known to the recommendation system. Over time, these features and their combination remain the same. Similarly, the relevant contextual attributes are partially known to the recommendation system in the partially observable. It might only be familiar with a portion of the relevant contexts generally. Nevertheless, the structures and values of these contexts typically remain stable over a long period. In unobservable, the recommendation system relies on hidden knowledge to derive contextual attributes rather than having direct access to a clear understanding. In such scenarios, the fundamental structure of hidden attributes continues over time. 13
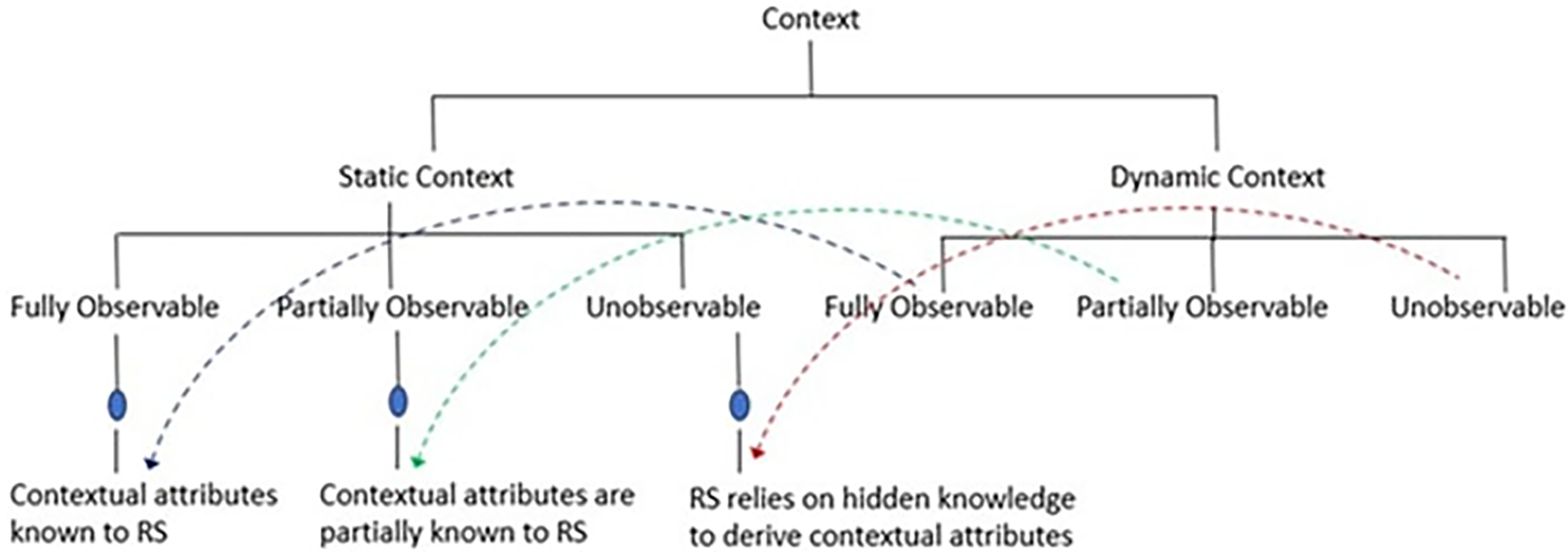
Types of user context. RS, recommendation system.
The incorporation of context into recommendation algorithms poses a considerable problem in the creation of context-aware recommendation systems. Contextual information, including a user’s location, time of activity, or mood, is essential for customizing recommendations to meet individual needs. Two principal solutions have been developed to tackle the difficulty of integrating such context. The initial technique is context-driven search and querying, which depends on contextual information gathered from people or sensors observing their surroundings. This information may encompass GPS data, ambient circumstances, or behavioral patterns. The system uses contextual data to perform focused database searches, identifying objects relevant to user queries and contexts. To offer nearby open restaurants, a restaurant suggestion system might consider a user’s location and the current time. This method focuses on using explicit context to improve search and ensure highly relevant results. 14
Understanding user preferences across different scenarios is the goal of the second technique: contextual preference elicitation and estimation. This method explores the impact of context on the variability of user decisions. A music recommendation system can personalize its recommendations based on what the user is doing, for example, working, exercising, or relaxing. The learning process for this strategy uses explicit feedback (e.g., ratings) and implicit feedback (e.g., click patterns). Sophisticated machine learning (ML) techniques or changes to recommendation algorithms are often used in this approach to infer and predict contextual preferences. Recommendation systems can provide customized, situation-specific suggestions that evolve using this method, which dynamically maps user preferences and context. 15
The goal of both contextual methods is better, more relevant recommendations, achieved through the efficient use of contextual information. However, their creation necessitates precise handling of data acquisition, user privacy, and computational efficiency to ensure that context-aware recommendation systems are useful and maintain user trust. Effective use of contextual information produces significant recommendations across multiple areas. However, irrelevance and lack of context in most ads result in low conversion rates. Annoying irrelevant ads cause users to skip, avoid, or close content overloaded with ads. Effective recommendations require solutions for problems like data redundancy, information overload, and contextual repetition. This study examines how enriched, fine-tuned contextual information affects relevancy and conversion rates.
Context-aware advertising has proven successful for user engagement and ad relevance on platforms like Google, Facebook, and TikTok. High click-through rates (CTR) and conversions result from the targeted nature of ads based on user behavior, location, and browsing history. Inspired by past accomplishments, this study proposes a framework for an intelligent recommendation system to deliver personalized and relevant ads, improving user experience.
A framework for an intelligent recommender system, focused on better user experience via personalized, relevant ads, is proposed in this study. It is built from six main parts; a key one is the user context extractor (UCE), collecting data like browsing history, search queries, and demographics. These data allow the recommender system to locate relevant ads within the ads database. The ads ranker prioritizes selected ads based on relevance to user preferences and performance data. In addition, this ads filter shows users only relevant ads that fulfill specific criteria. To enhance both ad relevance and user experience, the system continuously monitors and refines its performance using CTR, conversion rate, and precision. This research develops an adaptive ad recommendation system that uses real-time user interactions for continuous relevance updates, unlike prior studies, which relied solely on static contextual information. This study investigates the impact of dynamically fine-tuned user context on the accuracy and effectiveness of online ad recommendation systems. The central assumption is that incorporating enriched and continuously updated contextual information—such as temporal signals, location attributes, and user interaction history—into the recommendation process can yield statistically significant improvements in key performance metrics (precision, recall, F1-score, normalized discounted cumulative gain [NDCG], and accuracy) while also enhancing user engagement and mitigating ad fatigue.
The proposed system’s performance results demonstrate how much recommendation systems perform better with greater user context. The precision increased from 0.8275 to 0.9283, revealing that the positive predictions were more accurate. In the same way, the recall increased from 0.4628 to 0.5201, indicating that the model was now better able to recognize significant items in the dataset. The precision and recall-balancing F1-score increased slightly from 0.5936 to 0.5943, indicating improved performance. Additionally, the NDCG score increased from 0.9906 to 0.9915, indicating improved ranking quality. These findings demonstrate the value of augmenting richer context by improving the recommendations’ relevance and accuracy and gaining a comprehensive understanding of the user’s preferences and behaviors.
The key novelty of this work lies in its real-time contextual adaptation, where user context is continuously updated, combined with a multistage recommendation pipeline that incorporates a dedicated ranking and filtration layer. Unlike prior models that treat context statically, our system dynamically adapts to shifting user behavior, offering fine-grained, situationally aware ad recommendations.
The rest of the article is organized as follows: Section “Literature Review” discusses the literature review. Section “Methodology” discusses the proposed method and materials. Section “Results Analysis and Discussion” presents the results and discussion of results. Section “Ablation Study: Evaluating Contextual Components” provides the conclusion and future work.
Literature Review
Advertising is a form of communication that aims to convince potential consumers to engage with or purchase a particular product, service, or idea. It is a critical component of contemporary commerce, acting as a conduit between businesses and consumers and serving as a cornerstone of marketing strategies. Advertising is a nonpersonal, frequently paid form of communication persuasively conveyed by identifiable sponsors through various media outlets and channels. 4 Among advertising methods, print advertising is one of the oldest and most persistent. This category covers ads printed on physical media such as newspapers, periodicals, and journals.
Print advertising targets specific demographics based on the readership profiles of these publications. Key print advertising formats include newspapers, magazines, direct mail, and brochures. Newspapers offer broad, immediate dissemination; magazines target specialized demographics. Direct mail provides personalized messaging to specific recipients, while brochures give detailed product/service information in a user-friendly format. Print advertising continues to hold value in certain contexts, especially when targeting audiences that value detailed, credible, and physical content, even with the rise of digital media.
Despite this, rapid technological progress has significantly changed the advertising industry. The internet and the rise of digital platforms have allowed advertising strategies to evolve, leveraging global reach and precise targeting via online media. The internet’s advertising prowess allows businesses to efficiently and interactively reach massive audiences. Online advertising uses various methods such as display, search engine marketing, social media, and video ads to engage users in the digital spaces they frequent. Internet advertising’s growth has dramatically reshaped the way consumers and marketers engage. Unlike traditional, one-way advertising, online advertising fosters a two-way dialogue between brands and consumers. Buyers might share content, offer immediate feedback, and become advocates. Until then, marketers can leverage data analytics for user behavior monitoring, campaign effectiveness evaluation, and real-time strategy optimization. 16
Online advertising allows businesses to reach and influence buyers from all over the world, influencing their buying decisions. 4 Companies frequently utilize internet advertising to promote their products and services, but it is challenging for advertisers to make online advertising more effective in generating positive client responses. Context-aware computing adapts according to its place of use, the collection of adjacent persons and objects, as well as changes to those objects over time. 14 Context-awareness is a technique for adapting a system configuration based on the existing situation. CARSs use contextual information, for example, time, weather, and location, to predict user preferences. However, users’ preferences can change over time due to changes in their environment or the following trends. Users can save time by tuning parameters manually with the adaptive system. Users, for example, prefer to listen to soothing music while driving yet aggressive music while exercising. Adaptive systems detect the user’s current situation and adjust the settings accordingly. 17
Recommender systems are advanced software tools and methodologies intended to offer consumers personalized recommendations for items most likely to be of interest to them. These systems have become essential to numerous digital platforms, assisting users in navigating various options in sectors such as e-commerce, streaming services, and online content curation.
7
Recommender systems endeavor to improve the user experience and simplify decision-making processes by examining user preferences and behavior. The applications of recommender systems are extensive and varied, encompassing a wide range of domains. For example, they help users decide what products to buy, music to listen to, movies and TV shows to watch, and even online or news articles to read. Across all scenarios, recommender systems seek to solve information overload by providing personalized suggestions that match each user’s preferences and needs.
18
User ratings are the most common and a crucial part of the transaction data that recommender systems use.
19
There are two principal methods for obtaining these ratings:
Explicitly, in which users actively provide feedback by rating items or composing reviews. Implicitly, systems infer user preferences from behaviors such as browsing history, views, purchases, or time spent engaging with specific content.
Over the years, a wide array of recommendation methods have been designed for different needs and situations. Six main categories typically encompass these methods; examples include CARSs and constraint-based recommendation approaches. 20 When recommending complex products/services with specific user preferences or constraints, constraint-based approaches are superior. Financial services, for instance, use these systems to tailor investment advice to a user’s financial goals, income, and risk tolerance. In the same way, users could apply constraint-based techniques to search for and filter consumer electronics based on technical details, financial limitations, and preferred brands. Accurate and reliable recommendations are generated by these systems using structured data and rule-based logic. CARSs personalize recommendations by considering the user’s context. Contextual information includes user attitude, location, time of interaction, and device.
By explicitly modeling context in their recommendation algorithms, these systems improve understanding of user needs. 21 Multiple approaches are used by CARSs to effectively harness context. Such a service, for example, might play high-energy tracks while you exercise and calming tracks in the evenings. Collaborative, content-based, and hybrid filtering techniques ensure that these systems give contextually appropriate recommendations. 22 AI, ML, and natural language processing are increasingly integrated into recommender systems, making them more sophisticated. These developments allow systems to predict user behavior more effectively, deliver more accurate and context-specific recommendations, and achieve a more thorough understanding of user preferences. Recommender systems will continue playing a crucial role in boosting user satisfaction and engagement, thanks to ongoing innovation fueled by the rapid rise of digital technologies.
The impact of social network contextual data (location, time, actions, preferences) on recommender system performance was studied by Ebadi et al. 23 The quality of recommendation models was analyzed in relation to contextual dimensions, with a focus on the importance of location, covering both physical (coordinates) and virtual (IP addresses) contexts. Likewise, 24 introduces a method for creating user guidelines on battery-saving actions in electric vehicles; this is done by merging overall suggestions with vehicle-specific details to produce context-aware recommendations. A public dataset was used to test the methodology, and the findings underscore the need for well-timed, accurate direction.
Jeong et al. 25 similarly investigated CARS assessment, introducing a novel dataset partitioning method based on CARS category classification. Unlike traditional systems, this evaluation uses novel techniques, features, and datasets, ignoring contextual factors. In, 26 the authors developed a graph convolution machine (GCM), which is an architecture for CARS. Context-aware graph convolutions on the user–item graph are applied by the GCM to enhance user–item embeddings; prediction scores are then derived from these refined embeddings. Experiments using real-world datasets show that this algorithm is more effective than collaborative filtering and the current best-performing CARS algorithm.
Chiang et al. 27 presented a new recommendation system that adapts to users’ changing preferences by using context and attention processes. The system uses two attention methods: the contextual item attention module and the multi-head attention module. The context for each attention technique is derived from the users’ most recent interaction items. The contextual item attention module records the contextual data, changing user choice patterns and item significance. The multi-head attention module increases user variety and adjusts to shifting user preferences. By modeling the depiction of the contextual item(s) with extratemporal information of objects, the recommendation performance is improved.
Yoon et al. 28 developed a real-time tourism recommendation system (R2Tour). The system responds to changing circumstances and makes customized travel recommendations based on visitor profiles and contextual data. R2Tour’s recommendation performance was verified using data from Jeju Island tourism sites and six ML models. A micro-F1 of 0.773, a macro-F1 of 0.415, and an accuracy of 77.3% were obtained from the experiment. Since R2Tour can train tourism trends based on situational information, it can suggest new tourist destinations and adjust in real time to changing circumstances. When installed in cars, it might be recommended for nearby tourist destinations. In, 29 the authors focused on personalized recommendations in marketing, specifically in delivering individualized, dynamic, and ongoing recommendations for ads. The traditional approaches of using supervised learning with past data are yielding decreasing returns, leading to the need for a new technique. The technique proposed in the article is based on reinforcement learning techniques, specifically contextual bandits.
L. Guo et al. 30 suggested a strategy recommender system for online advertising, including their proposal on the Taobao display advertising platform. The system recommends which optimization techniques will help based on the advertiser’s optimization goals. The authors observed how advertisers use different recommended advertiser-specific advertising techniques to deduce which individual indicators and performance criteria the authors should prefer in their ads. They utilized contextual bandit algorithms to use this knowledge and increase the adoption of the recommendations. An experiment with Taobao online auction data reported that the proposed algorithms maximize marketer adoption of their tactics. Table 1 summarizes the research on CARSs.
Summary of contextual data used in recommendation systems a

This table summarizes the contextual data considered by various recommendation systems and the corresponding methods used.
CD-CARS, cross-domain context-aware recommender systems.
The literature demonstrates the effort made to improve the accuracy and performance of recommender systems by utilizing contextual data. Everything from location, preferences, and the current environment determines what should be recommended at that time. In addition, more sophisticated methods such as matrix factorization and graph convolutions, which are themselves pairs of operations that can be repeated multiple times to learn increasingly refined patterns or states along with other ML architectures, have been designed to capture fine-grained user behavioral preferences synergistically underpinning recommendation systems. Nowadays, progress in this field and adding recent methods in conjunction with a better understanding of what users want will inevitably result in more sophisticated, powerful recommendation systems.
Issues and challenges with recommender systems
A variety of challenges increasingly undermines the effectiveness of recommendation systems. The essential problem is showing an ad without destroying the viewing experience. More choices mean a greater number of alternatives available, which can be confusing and overwhelming to users. The implementation of these technologies has raised questions regarding the privacy of users as well as biased recommendations. Information security must be strengthened to mitigate these concerns, and systems must become impartial. One cannot make recommendation systems accurate without developing new computer programs and managing information quickly. We need better tools for this, as the information at hand is gathered from various sources. The following problems limit the performance of the recommender system, and they are considered in the proposed work.
Cold start: A cold-start problem arises when there is not enough data about some new user or item in the case of a recommendation system. With an entirely new item, there are fewer impressions for user feedback to come back from, creating challenges in the system finding accuracy and confidence within its recommendation process until more data are obtained.
37
Data sparsity: We will use data sparsity when client input cannot provide enough information for a recommendation system model to work well. That might be because some consumers are bad at giving feedback, or it could mostly be due to the cold-start problem. This means that if there are not enough data, it can reduce the diversity and accuracy of recommendations, leading to a decrease in its capacity to produce an extensive collection of thoughts corresponding with user preference/interest.
35
Scalability: The more a recommendation system grows, the more it will meet new computational challenges that may block performance. This type of management also drives the need for more processing power. This can slow down computations and response times, leading to a drop in the throughput and efficiency of recommendation algorithms. This can in turn reduce the system’s ability to make correct and recent recommendations at a fast pace, which ultimately affects the user experiences.
38
Methodology
Figure 2 presents the structure of the proposed system. The schematic diagram shows six main components of the proposed system for providing relevant ads to the viewers/users. The system exploits the fine-tuned real-time contextual information associated with both viewers and items. The UCE component is responsible for gathering the user’s contextual information, which is then used by the recommender system to search for relevant ads in the ads database. The ads ranker further ranks the selected ads. Moreover, the ads filter component filters out ads that do not meet certain criteria. Finally, the filtered and ranked ads are displayed to the user by the recommender system component. Context in recommender systems can be categorized by observability and temporal behavior.
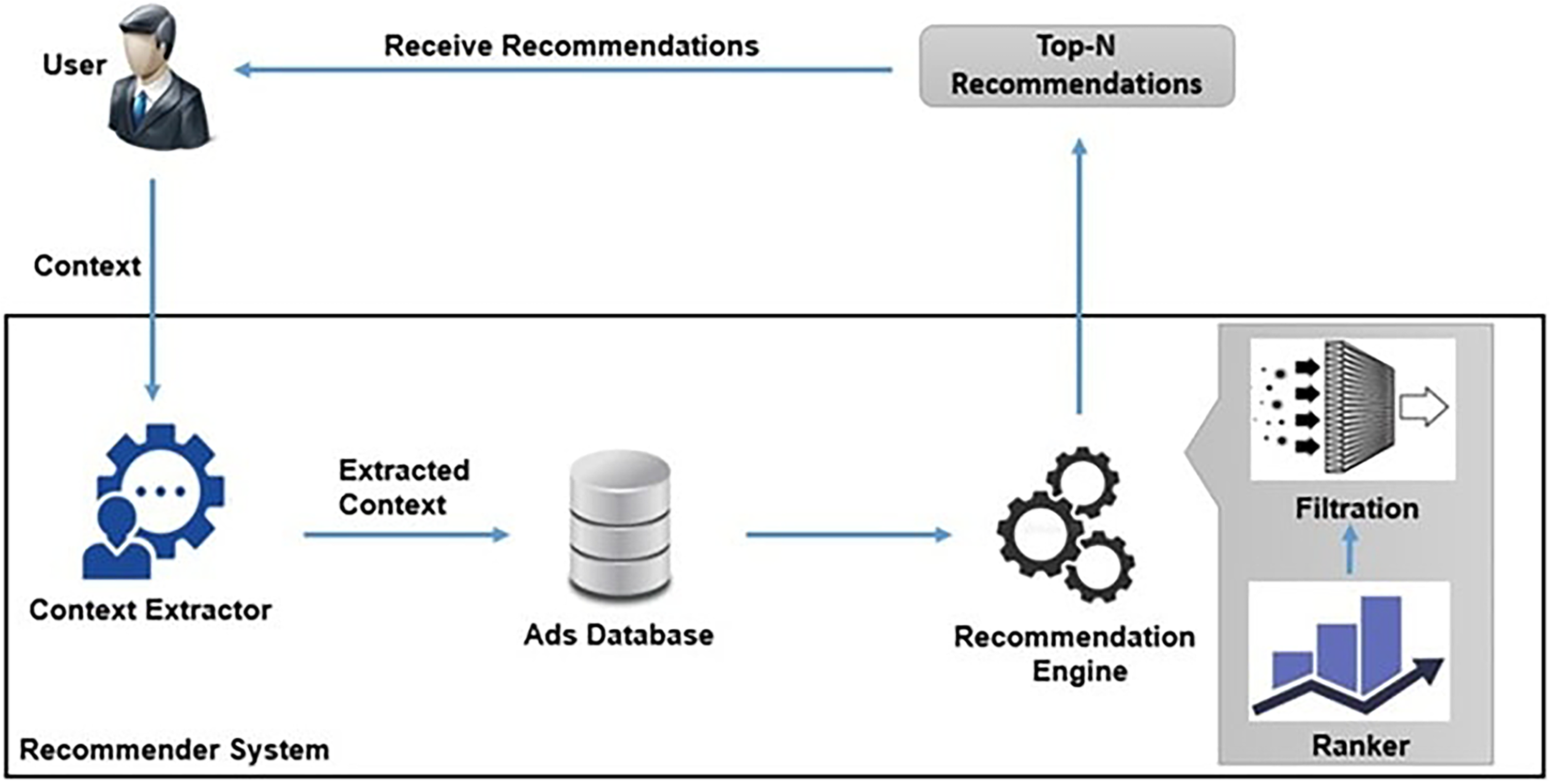
Proposed system architecture.
An effective advertising system has a set of different yet interrelated elements, as depicted in Figure 2. The UCE acts as central to relevance by acquiring critical user data such as browsing history, search queries, and demographic information. The recommender system can then use this information to search through the ads database to find ads applicable to a given user scenario. Ranking factors that target relevancy, user experience, and ad performance to ensure the quality and relevance of the ads. Enforcing legal compliance and respecting user preferences naturally lead to a better-performing process. Based on their behaviors and the algorithms used, users are shown a selection of relevant personalized ads, thus enhancing the user advertising experience. This procedure aims to improve the user experience by bringing relevant ads of interest to them while also increasing the success rate of the ads for the sellers.
In a mathematical model, shown in the following equation form, we need to consider numerous factors that influence relevancy and computational power to analyze the impact of fine-tuned context on the relevancy of ads. Here, a structured approach to building such a model is presented. The contextual features are represented by (C), where C = c1, c2, …, cn. Each ci represents a specific contextual feature (e.g., user location, time of day, user preferences, browsing history). Similarly, ad relevancy is presented by (R). Where R is the relevancy score of an ad for a given context. R is a function of the contextual features: R = f(C). The computational power is presented by (P), where P presents the computational power required to process the contextual features. P is a function of the number and complexity of the contextual features: P = g(C). The incremental relevancy is presented by IR, where IR is the increase in relevancy due to the addition of a new contextual feature.
Computational role of components
The proposed ad recommendation framework relies on a pipeline of components that work together to extract, process, and apply user context for personalized ad delivery. Each component plays a distinct computational role, contributing to the overall accuracy and relevance of the system. The following outlines how user context is operationalized, how relevance scores are computed, how ads are ranked, and how inappropriate or low-quality ads are filtered out.
User Context Transformation into Features
The UCE collects raw contextual data from multiple sources, such as device type, location, time of day, recent browsing history, and demographic details. These raw data are cleaned, normalized, and encoded into structured features. Categorical attributes (e.g., device type, city, time slots) are one-hot or label encoded, while numerical features (e.g., session length or ad interaction frequency) are normalized or standardized. The final output is a feature vector that represents the user’s situational context in a format suitable for ML models or similarity computations.
Relevance Score Calculation
The recommender system takes as input the user feature vector and ad metadata (e.g., category, campaign timing, audience targeting rules). A relevance score is computed using a weighted combination of context-aware matching functions. Specifically, three aspects are assessed:
User–ad interaction history (e.g., click frequency or dwell time). Contextual compatibility (e.g., time-sensitive or geo-relevant ads) and behavior-pattern match (e.g., repeated ad themes for users with similar past behavior).
A composite score is calculated using a learned linear or neural scoring function:
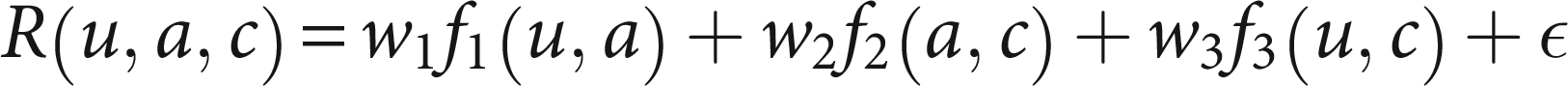
To optimize the scoring function parameters w1, w2, and w3, a systematic data-driven tuning strategy was employed. The process began with a grid search over a bounded parameter space using a step size of 0.1 to identify a coarse region of promising values. This was followed by fine-tuning through cross-validation on the training set, where performance was assessed using F1-score and NDCG. The final weights were chosen based on the configuration that achieved the highest average performance across folds. Table 2 presents the complete set of hyperparameters used in the framework, including their respective search ranges and the final selected values. The choice of k = 15 in the k-nearest neighbor (KNN) model was determined empirically through cross-validation. Initial experiments evaluated k values ranging from 1 to 50 using precision, recall, and NDCG on the validation set. It was observed that smaller values of k (e.g.,
Hyperparameters used in the proposed framework with bounds and selected values
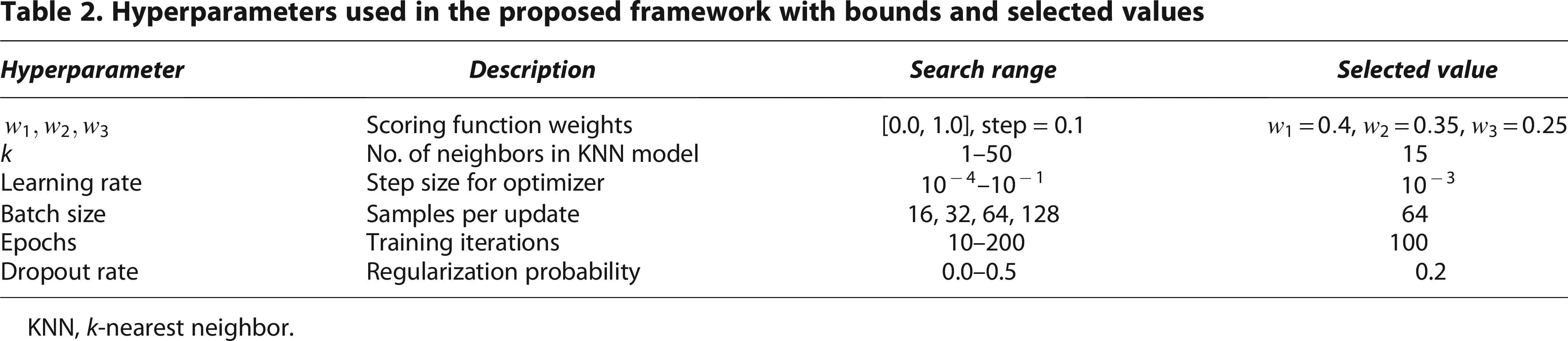
KNN, k-nearest neighbor.
Table 2 summarizes all hyperparameters used in our framework, along with their search ranges and the final selected values. The choice of
Rationale for model selection
The core ranking mechanism in the framework is based on a KNN ranker, chosen for its balance of efficiency, interpretability, and adaptability. First, KNN aligns naturally with recommendation tasks by leveraging user–item similarity directly, eliminating the need for extensive model training and enabling computational efficiency in real-time, dynamic advertising environments. Second, compared with more complex black box models, KNN offers greater interpretability, as the influence of neighbors on each recommendation is transparent and can be easily communicated to business stakeholders. Third, the framework’s contextual design incorporating user profiles, temporal information, and location attributes integrates seamlessly with distance-based similarity measures, allowing the ranker to dynamically adapt to evolving user contexts. Finally, pilot experiments demonstrated that while more complex models such as gradient boosting or deep neural networks provided only marginal gains, they introduced significant training overhead and reduced transparency. For these reasons, KNN was selected as the most effective compromise between accuracy, scalability, interpretability, and adaptability for real-time context-aware ad recommendation.
Ad Ranking by the Ads Ranker
Once the recommender system computes the relevance scores for a set of candidate ads, the ads ranker component sorts them in descending order of predicted effectiveness. In addition to the relevance score, the ranker considers historical performance metrics such as average CTR, conversion rate, and user engagement time. Advanced implementations may incorporate learning-to-rank algorithms (e.g., XGBoost rank or LambdaMART) to learn optimal ranking from user feedback data. Ads with higher expected utility, based on both real-time context and historical success, are prioritized for final delivery.
Filtration of Ads by the Ads Filter
Before displaying the ranked ads to the user, the ads filter evaluates each ad against a set of content quality, ethical, and user preference constraints. This step ensures that inappropriate, repetitive, or poorly rated ads are excluded. The filter logic includes rules such as blocking adult or sensitive content for underage users, eliminating ads already shown recently, and rejecting those below a quality threshold (e.g., low-resolution, clickbait language). This ensures that only high-quality, diverse, and contextually aligned ads are finally presented to the user, enhancing both relevance and user trust.
The following algorithm and corresponding flowchart illustrate the procedural flow of the proposed context-aware ad recommendation system. While the pseudocode details the logic and operations in a stepwise manner, the flowchart (see Fig. 3) provides a visual summary of the system pipeline, covering the key stages from context extraction to ad filtration and delivery.
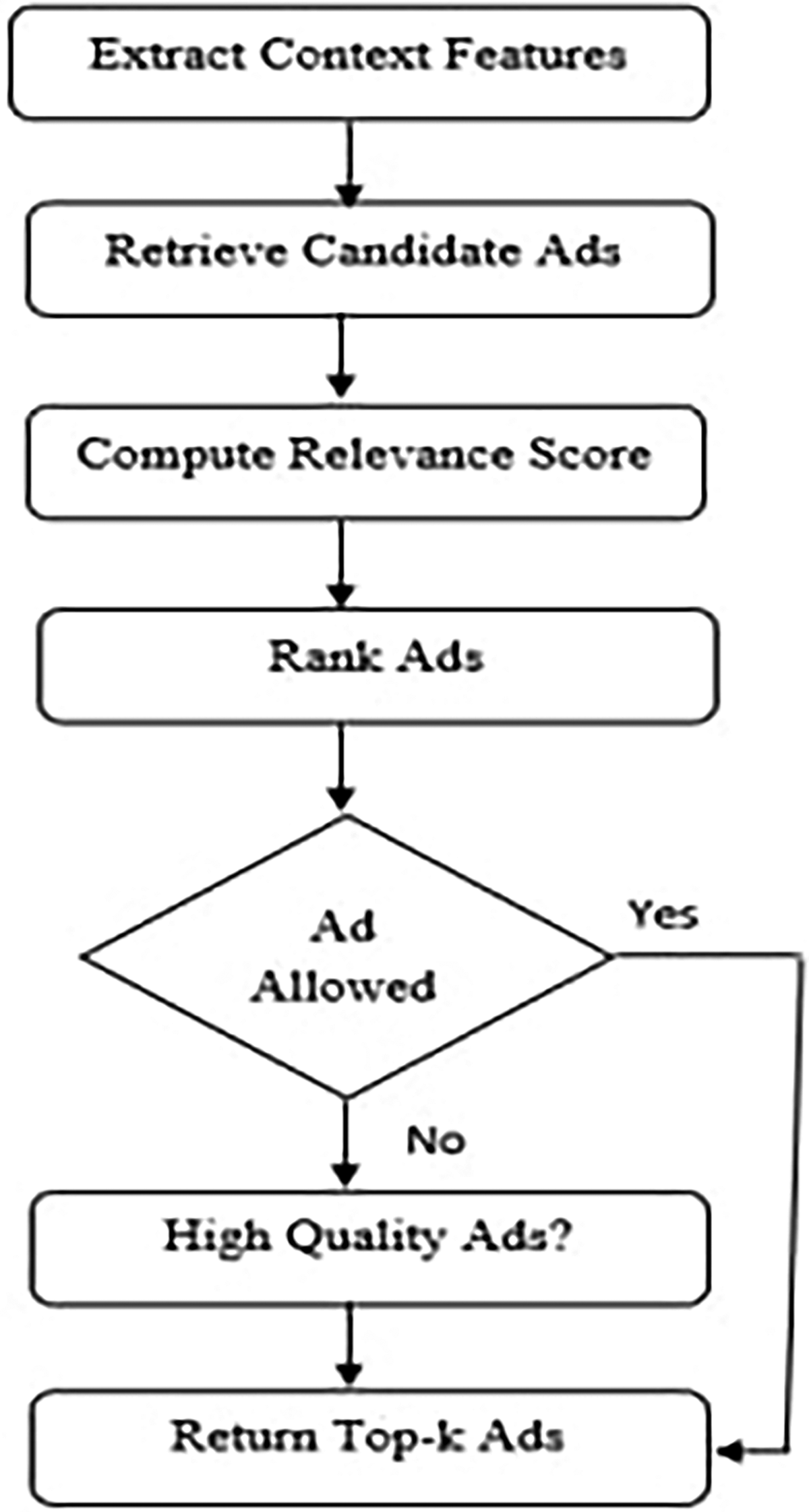
Structure of proposed system.

Each block in the flowchart aligns with a corresponding operation in the pseudo code, ensuring clarity in understanding how components such as the context extractor, ad ranker, and filter operate within the system.
Interpretability analysis
To improve transparency and address interpretability concerns, we performed an additional feature importance analysis using SHAP (SHapley Additive exPlanations). The SHAP values provide a global understanding of the marginal contribution of each contextual feature to the weighted scoring function. Our results show that w1 (user profile context) contributes the most to recommendation relevance, followed by w2 (temporal context), while w3 (location context) has a smaller but consistent contribution. For instance, SHAP summary plots indicate that user profile attributes dominate recommendation outcomes, whereas temporal context refines personalization and prevents temporal drift. To complement this, we also generated local explanations with LIME (Local Interpretable Model-agnostic Explanations) for sample users, which revealed how individual contextual signals influenced the ranking of ads. These interpretability results not only validate the correctness of the weighting strategy but also provide stakeholders with actionable insights into why specific ads were recommended. To provide a clearer overview of the computational pipeline, Figure 4 presents the end-to-end flow of the proposed framework, from context extraction to final ad delivery.
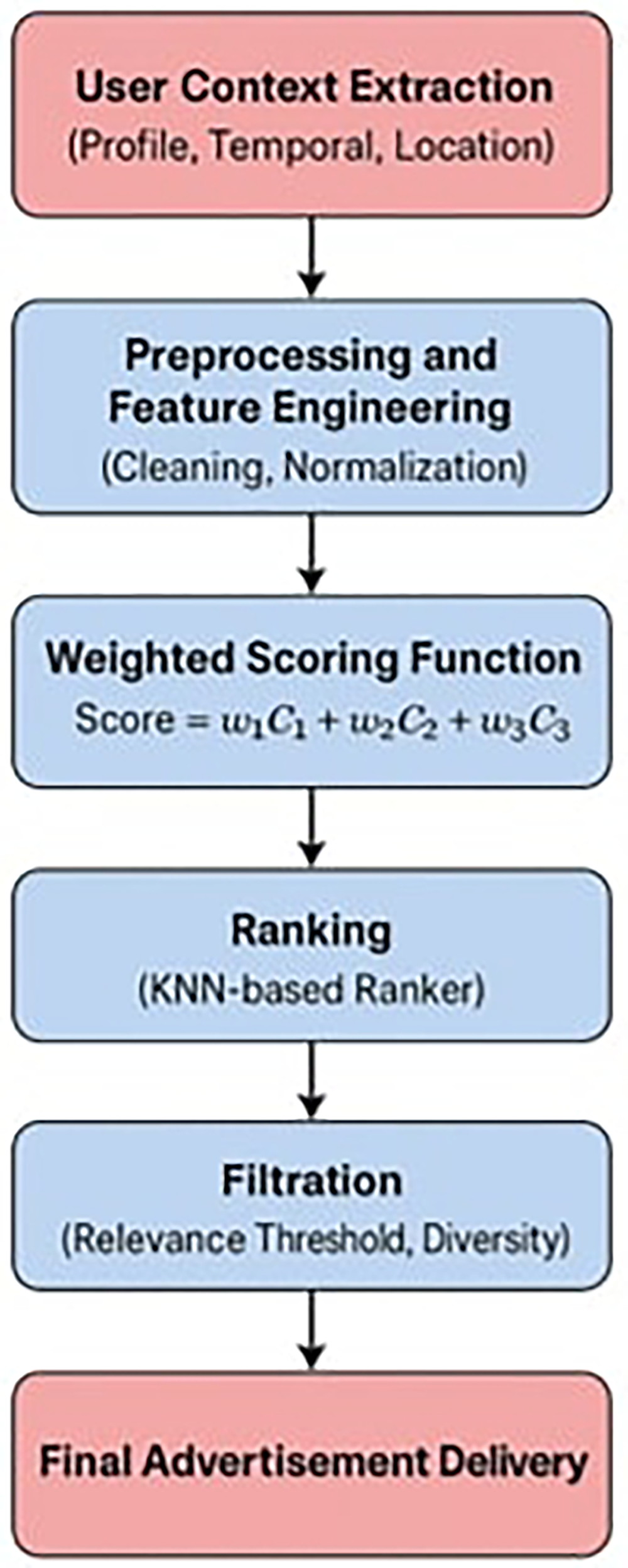
End-to-end flowchart of proposed system. KNN, k-nearest neighbor.
Results Analysis and Discussion
In this section, we present the comprehensive results of our study, followed by a detailed analysis of the findings. We used the MovieLens 1M dataset, which is a widely used resource in the field of recommender systems research, sourced from the MovieLens platform, a movie recommendation service. One million movie ratings, accompanied by detailed user demographics (age, gender, occupation) from about 6000 viewers, are available. This dataset also includes information for about 4000 movies, with their corresponding genres and titles. Because of its real-world importance and large size, it is a valuable resource for researching personalized recommendations, overcoming cold-start issues, and developing context-aware recommendation methods. The MovieLens 1M dataset, while facing challenges with sparse data and privacy, continues to be essential for advancing recommendation system capabilities and knowledge in academic and real-world contexts. For model evaluation, the dataset was partitioned into training and testing subsets using an 80/20 split ratio. The training set was used to learn user–item interaction patterns, while the held-out 20% test set was employed exclusively for evaluating generalization performance. To ensure robustness, the splitting process was stratified on user interactions, ensuring each user had representation in both training and testing sets. This is the section where we want to add our findings and implications, highlighting a key component of R spectroscopy, investigating with other studies in the field. The confusion matrix gives a detailed breakdown of a classification model’s performance by comparing predicted labels to the actual ones. The true negatives (TNs) correctly predicted 67,971 instances as negative, which were negative. The false positives model incorrectly predicted 9750 instances as positive, which were negative. Similarly, in the false negatives (FN) case, the model incorrectly predicted 56,039 instances as negative, which were positive. True positives (TP) correctly predicted 47,920 instances as positive, which were positive. Figure 5 presents the obtained confusion matrix.
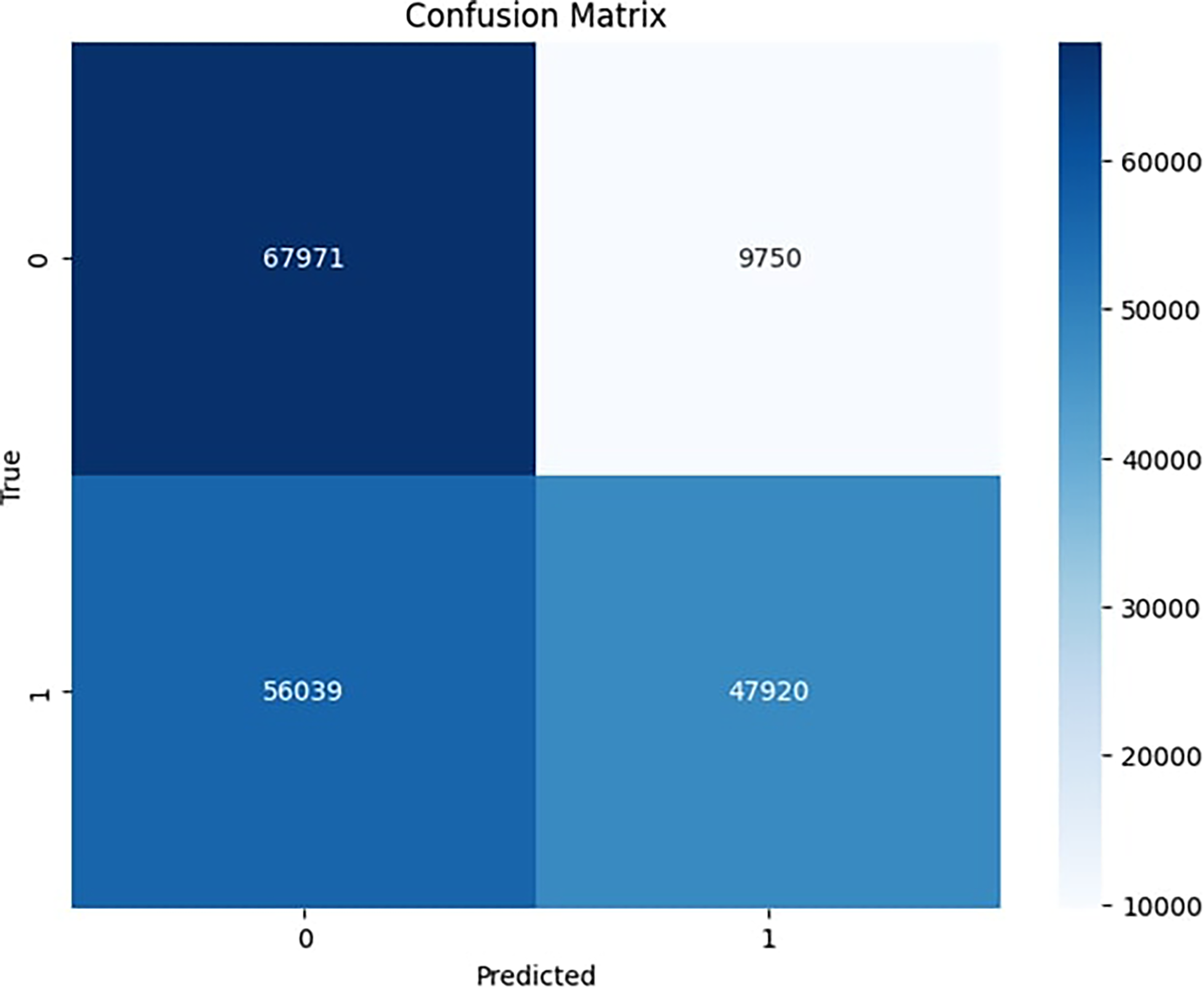
Confusion matrix.
In the confusion matrix, shown in Figure 5, the model has a high number of TN and TP, indicating good performance in identifying both classes correctly. However, the relatively high number of FN suggests that the model could improve in identifying all relevant positive instances. The high number of false positives also indicates room for improvement in avoiding incorrect positive predictions. The confusion matrix thus highlights areas where the model performs well and areas where further refinement is needed to enhance its accuracy and reliability.
Figure 6 presents the obtained results of the performance of the proposed model in various metrics. Precision, at 0.8275, measures the accuracy of the positive predictions, meaning 82.75% of the items identified as relevant were indeed relevant. Recall, at 0.4628, assesses the ability to capture all relevant items, showing that only 46.28% of the actual relevant items were identified. The F1-score, which balances precision and recall, is 0.5936, indicating a moderate harmonic mean of the two. The NDCG, a measure of ranking quality, is exceptionally high at 0.9906, suggesting that the model’s ranking of relevant items is nearly perfect. These results highlight a model with excellent precision and ranking quality but with room for improvement in recall.
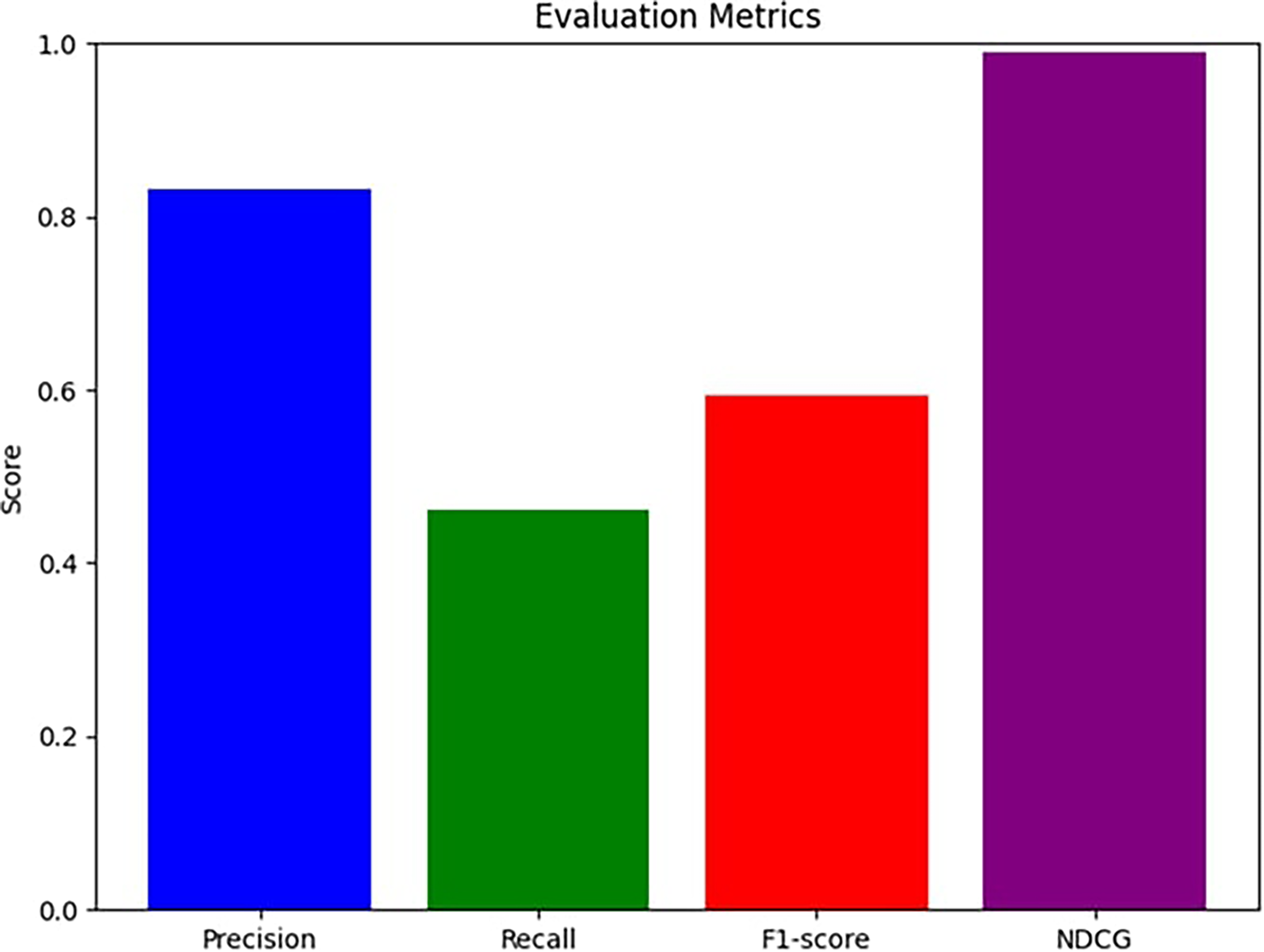
Performance of the proposed model. NDCG, normalized discounted cumulative gain.
Figure 7 presents the performance after augmented context. The results indicate the performance of the model across different metrics. Precision is 0.9283, meaning 92.83% of the items predicted as relevant are indeed relevant, demonstrating high accuracy in their positive predictions. Recall is 0.5201, showing that the model identifies 52.01% of the actual relevant items, indicating room for improvement in capturing all relevant data. The F1-score, which balances precision and recall, is 0.5943, reflecting a moderate harmonic mean of the two. The NDCG is 0.9915, indicating that the model’s ranking of relevant items is nearly perfect. Overall, the model excels in precision and ranking quality but could enhance its recall to improve overall effectiveness.
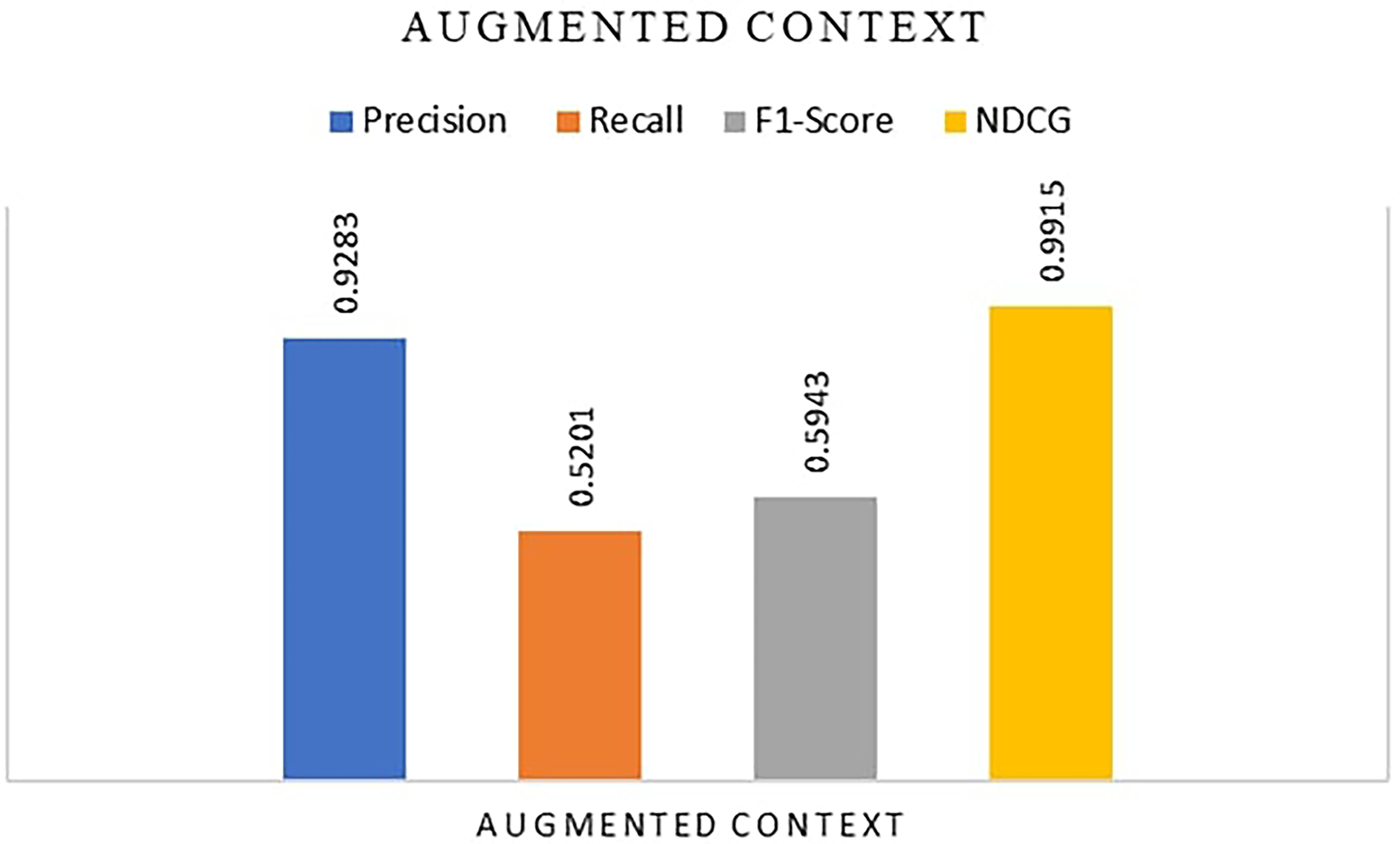
After augmented context.
Figure 8 presents a comparative analysis of both types of contextual information. The comparison of the two sets of results indicates that augmenting richer context significantly enhances the model’s performance. The second set, which likely incorporates richer context, demonstrates superior precision (0.9283 vs. 0.8275) and recall (0.5201 vs. 0.4628), leading to a slightly improved F1-score (0.5943 vs. 0.5936). The NDCG score also shows a slight improvement (0.9915 vs. 0.9906), highlighting better ranking quality. These enhancements suggest that providing richer context allows the model to make more accurate and comprehensive predictions, thus improving its overall effectiveness.
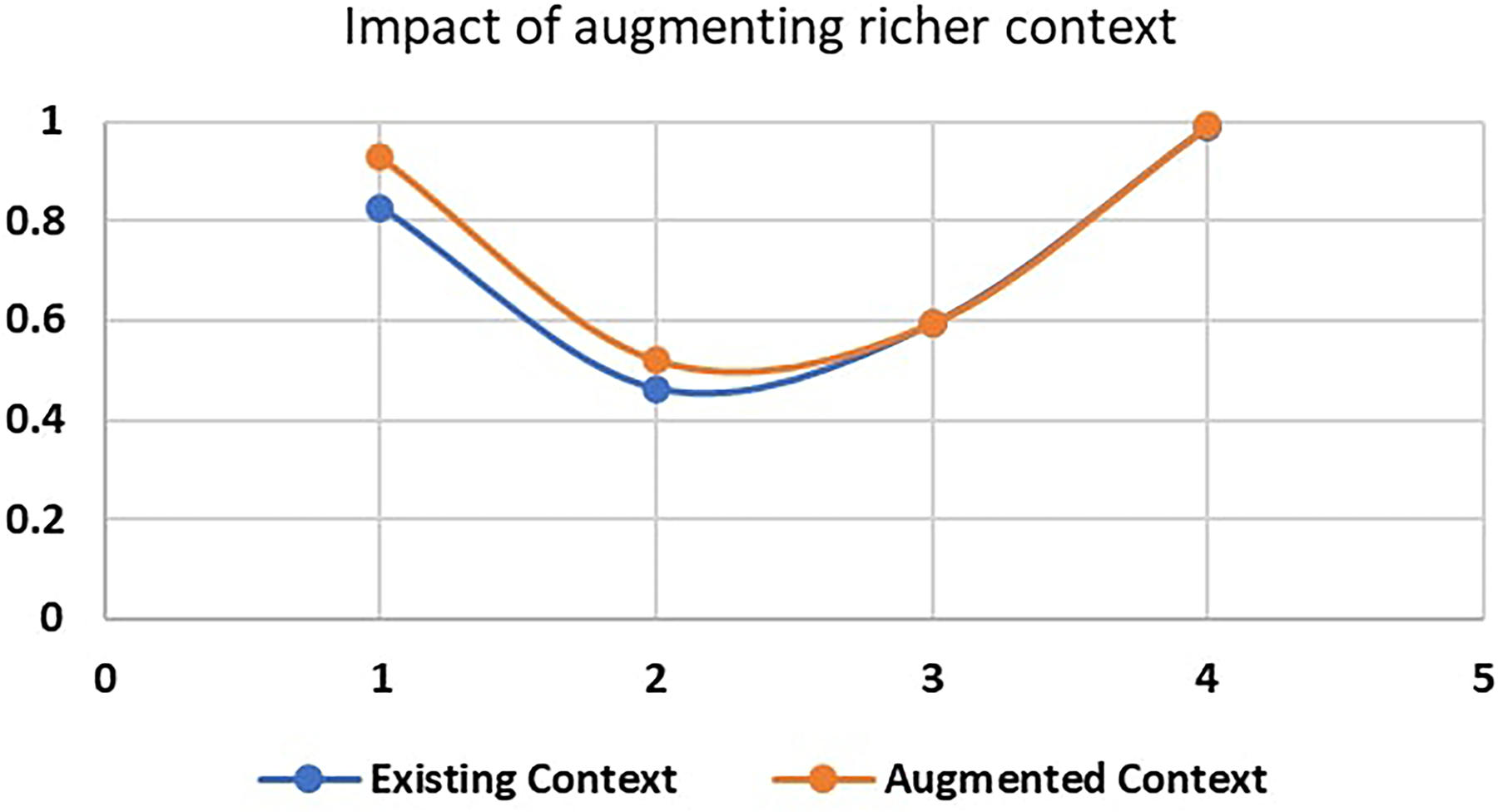
Impact of augmenting context.
Table 3 presents the performance comparison between the baseline and the proposed framework in terms of absolute values as well as percentage gains.
Performance comparison between baseline and proposed framework

NDCG, normalized discounted cumulative gain.
As shown, the proposed framework improves precision by 12.2%, recall by 12.4%, and F1-score by 14.6% while achieving marginal gains in NDCG. To statistically confirm the reported improvements, we conducted additional significance testing. A two-tailed paired t-test was performed between the baseline and proposed framework across all evaluation metrics (precision, recall, F1-score, NDCG, accuracy) using 5-fold cross-validation results. The improvements in precision (p < 0.01), recall (p < 0.05), and F1-score (p < 0.01) were found to be statistically significant. Bootstrap resampling with 1000 iterations further confirmed that the 95% confidence intervals (CIs) of the proposed framework did not overlap with those of the baseline for these metrics. The NDCG improvement, while positive, was not statistically significant (p = 0.21), consistent with the small absolute gain observed. These tests demonstrate that the performance improvements are not due to random variation but represent genuine advances in recommendation quality.
To statistically confirm the reported improvements, we conducted additional significance testing. A two-tailed paired t-test was performed between the baseline and proposed framework across all evaluation metrics (precision, recall, F1-score, NDCG, accuracy) using 5-fold cross-validation results. The improvements in precision (p < 0.01), recall (p < 0.05), and F1-score (p < 0.01) were found to be statistically significant. Bootstrap resampling with 1000 iterations further confirmed that the 95% CIs of the proposed framework did not overlap with those of the baseline for these metrics. The NDCG improvement, while positive, was not statistically significant (p = 0.21), consistent with the small absolute gain observed. These tests demonstrate that the performance improvements are not due to random variation but represent genuine advances in recommendation quality.
Ablation Study: Evaluating Contextual Components
To evaluate the contribution of contextual features in our framework, we performed an ablation study on the MovieLens 1M dataset. Contextual signals were gradually introduced to a baseline KNN ranker (k = 15), and performance was measured using precision, recall, F1-score, NDCG, and accuracy with 5-fold cross-validation. As shown in Table 4, the study began with a baseline that relied only on historical user–item interactions. User profile features were then added, followed by temporal signals, and finally location-based information. Each contextual layer was assigned specific weights to balance its impact within the scoring function.
Ablation study configurations

Performance comparisons across different setups are presented in Table 5. The results indicate consistent improvements as contextual components were added. User profile features led to modest gains in personalization, while temporal signals contributed the largest recall improvement. Location features, although less influential on precision, significantly boosted NDCG, underscoring their value in geo sensitive ad delivery. The full model achieved the best overall performance across all metrics.
Performance metrics (±standard deviation)

While the inclusion of contextual features improves recommendation quality, it also introduces additional computational requirements. As shown in Table 6, the baseline model achieved inference times of around 50 ms per query, while the full model increased to
Computational trade-offs

Cross-dataset generalization potential
Although the proposed framework was primarily evaluated on MovieLens dataset, its design is inherently adaptable to other datasets and domains. This is because the weighted scoring function and multistage ranking pipeline are agnostic to the specific dataset, relying instead on contextual features such as user profile, temporal activity, and location, which are widely available in many recommendation settings. In principle, the same framework can be applied to other domains such as e-commerce, streaming platforms, and location-based services, provided that relevant contextual information is available. However, we also acknowledge that contextual distributions vary across datasets (e.g., different temporal patterns or demographic biases), which may influence performance. To mitigate this, the hyperparameters (w1, w2, w3, k) can be retuned via cross-validation on each new dataset, ensuring adaptability without redesigning the core model. Therefore, while the framework demonstrates strong performance on the evaluated dataset, it also holds promise for robust cross-dataset generalization, which we leave as a direction for future empirical validation.
Privacy and compliance considerations
The integration of contextual information, such as location, time, or user activity, into ad recommendation systems raises important privacy and compliance concerns. Sensitive attributes can potentially expose personal behavior patterns if not properly handled. To address these issues, our framework follows three guiding principles: The integration of contextual information, such as location, time, or user activity, into ad recommendation systems raises important privacy and compliance concerns. Sensitive attributes can potentially expose personal behavior patterns if not properly handled. To address these issues, our framework follows three guiding principles.
First, data minimization ensures that only the contextual attributes strictly necessary for recommendation are collected and processed, while unnecessary identifiers and raw logs are discarded or not persisted to storage, thereby reducing exposure risk and limiting the attack surface.
Second, anonymization and aggregation are applied, so that user identities are anonymized before storage or analysis. Wherever possible, analytics and model inputs operate on aggregated population-level summaries rather than on individual-level traces, preventing reidentification.
Last, the framework adheres to compliance with regulations by following widely accepted data protection principles (e.g., lawfulness, purpose limitation, data minimization, and storage limitation). Its design and deployment are aligned with established regulations such as the General Data Protection Regulation and the California Consumer Privacy Act, thereby ensuring lawful, fair, and transparent processing of user data.
Moreover, privacy-preserving recommendation techniques—such as federated learning, differential privacy, and secure multiparty computation—offer promising directions for future work to further enhance compliance and user trust in context-aware systems. We plan to investigate these methods in future extensions of the framework to enable learning from contextual signals while minimizing raw-data exposure.
Conclusion
This study addressed the challenges of delivering personalized online ads and proposed a context-adaptive recommendation framework that integrates user profiles, temporal signals, and location attributes. The framework, composed of a context extractor, recommender, ads database, ranker, and filter, was evaluated using CTR, conversion rate, gross merchandise volume, and average revenue per user. Results showed that richer contextual modeling significantly improved recommendation quality, with precision increasing from 0.8275 to 0.9283, recall from 0.4628 to 0.5201, F1-score from 0.5936 to 0.5943, and NDCG from 0.9906 to 0.9915. These improvements highlight the potential of context-aware systems to enhance ad relevance, engagement, and conversion, though at the cost of higher computational requirements—manageable with advances in hardware. The framework’s layered design and dynamic user context modeling distinguish it from existing approaches, offering both adaptability and transparency. While effective in advertising, it could also extend to domains such as health care and finance, where contextualized recommendations can drive impactful decision making. Despite these strengths, three key limitations remain. First, the evaluation relied on a single dataset, restricting insights into cross-domain generalization. Second, the weighted scoring function improves interoperability but requires hyperparameter tuning (w1, w2, w3), which may limit scalability in large systems. Third, interoperability tools such as SHAP and LIME provide valuable explanations but introduce computational overhead for real-time deployment. Future work will focus on validating the framework across multiple datasets, automating hyperparameter optimization, and developing more efficient explainability modules, with continued emphasis on privacy, security, and user-centric personalization.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.