
Abstract
We introduce VARM, variant relationship matcher strategy, to identify pairs of variant products in e-commerce catalogs. Traditional definitions of entity resolution are concerned with whether product mentions refer to the same underlying product. However, this fails to capture product relationships that are critical for e-commerce applications, such as having similar, but not identical, products listed on the same webpage or share reviews. Here, we formulate a new type of entity resolution in variant product relationships to capture these similar e-commerce product links. In contrast with the traditional definition, the new definition requires both identifying if two products are variant matches of each other and what the attributes are that vary between them. To satisfy these two requirements, we developed a strategy that leverages the strengths of both encoding and generative AI models. First, we construct a dataset that captures webpage product links, and therefore variant product relationships, to train an encoding large language model (LLM) to predict variant matches for any given pair of products. Second, we use retrieval-augmented generation-prompted generative LLMs to extract variation and common attributes amongst groups of variant products. To validate our strategy, we evaluated model performance using real data from one of the world’s leading e-commerce retailers. The results showed that our strategy outperforms alternative solutions and paves the way to exploiting these new types of product relationships.
Introduction
Entity resolution (ER) 1 is an important task in data integration whose goal is to determine whether two mentions refer to the same real-world entity. Industry practitioners and academic researchers have, for long, devised techniques to address ER in various domains, e.g., resolving social media handles 2 and resolving products in e-commerce. 3 While ER usually refers to exact ER, wherein two mentions are deemed to match each other if and only if each and every attribute of said mentions agrees with each other, data integration in e-commerce entails addressing subtle but nontrivial versions of the basic ER task. Still, this traditional definition of ER fails to capture product relationships that are critical for e-commerce catalogs.
As illustrated in the e-commerce site screenshot in Figure 1A, highly related products, but not identical products, are listed on the same webpage to facilitate the search. These consolidated webpage listings allow customers to look at the common product attributes while being able to easily choose amongst the different product variations, given by the variation attributes, such as color or size. Identifying these kinds of product relationships not only improves e-commerce listings, but it can also be exploited for many other applications, such as review sharing or search deduplication. To capture this notion, we formulate a new type of ER task for variant product relationships.

Variant product relationships in e-commerce sites.
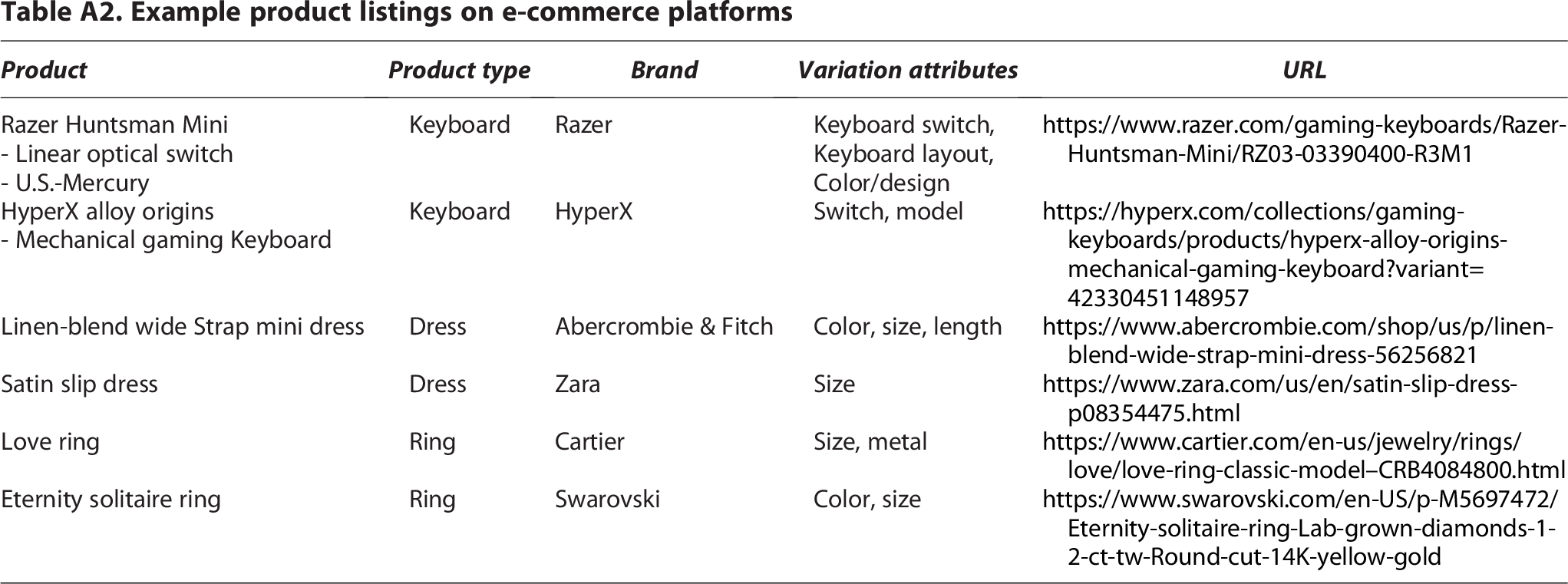
This new definition of variant products imposes additional considerations since it can vary across product types or even brands. For example, color and size are adequate variation attributes for clothing products, but for drinks, the difference between products is their flavor or sugar content, or diagonal screen size for Televisions (Appendix Fig. A1). Moreover, even for products of the same type, the specific variation attributes may change depending on the specific brand, such as keyboards from HyperX brand vary by switch and model, whereas keyboards from Razer have keyboard switch, keyboard layout, and color/design for variation attributes (Fig. 1B, Table A2).

Example variant products identified by VARM.
Example product listings on e-commerce platforms
In practice, identifying variant product relationships imposes two main challenges. First, one has to establish if a given pair of products are variations of the same entity variant match or different products mismatch. Supervised methods based on encoding large language models (LLMs) are the current state of the art to establish if two products are identical exact match, but it comes at the cost of collecting extensive labeled datasets for model training,4,5 which are not readily available for variant matching, unlike exact matching. Second, one has to determine the variation attributes for the relevant set of variant products. While it could also be described as a supervised task, this would require learning thousands of variation attribute labels since they can vary by product type or brand, further increasing the need for labeled training data and the overall complexity of the task.
Here, we introduce a new strategy for variant relationship matching, VARM, that leverages the respective strengths of generative and encoding LLMs to overcome the challenges of identifying this new kind of product relationship. First, to capture variant product information, we construct a dataset that captures variant product pair relationships given by products listed on the same webpage, which we used to train an encoding LLM to predict variant match relationships. Second, we use generative LLMs to predict variation attributes for groups of variant products, without requiring training data or being limited to a fixed set of variation attribute labels. To further provide the generative model with e-commerce information, we used a retrieval-augmented generation (RAG)6,7 by providing context about products from similar product types and brands. Overall, this work presents the following main contributions:
We introduce the novel variant product identification task. We formulate a novel method to identify variant products, capitalizing on the information present in e-commerce webpages. We develop a strategy that uses the synergistic properties of encoding and generative LLMs to accurately predict variant matching products and variation attributes. We validate the model on three relevant datasets from e-commerce services.
Related Work
Given that ER has been a topic of research for more than half a century, almost all major approaches of machine learning have been applied to solve it, including supervised and unsupervised approaches. 8 More recently, the focus has shifted to deep learning, including bespoke neural networks, 9 pretrained language models 4 and most recently, generative AI.10–12 None of these works address variant matching, which is the focus of this work. Narayan et al. 10 show that GPT3 can perform ER when provided with few-shot task demonstrations (in-context learning); Peeters and Bizer 11 show that the addition of entity matching rules to the prompt can help boost ChatGPT’s matching quality; and Peeters and Bizer 12 use GPT4 to provide explanations alongside match/mismatch predictions along with automatically dividing mispredictions into easy-to-understand error classes. More importantly, Peeters and Bizer show that despite recent advances, fine-tuning on sufficient labeled data can still outperform the best (zero-shot) generative AI ER results. Following this result in our work, we fine-tune pretrained LLMs to generate variant match labels, and to address the more challenging task of predicting variation attributes, we exploit world knowledge inherent in generative AI models.
Methods
Our variant relationship matching, VARM, strategy can be largely divided into two main tasks (Fig. 2): (1) variant match prediction and (2) identification of variation attributes.
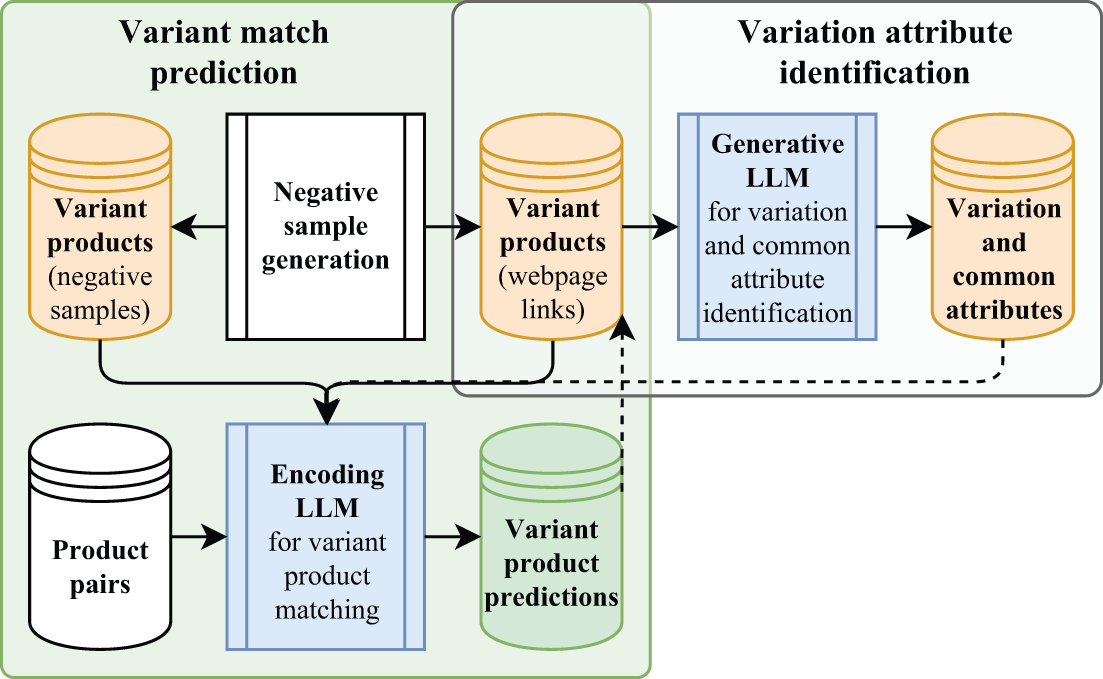
VARM strategy schematic. The variant product relationships present in webpages are exploited to construct a dataset with matching variant product pairs, which are then augmented to generate negative or mismatched examples for encoding LLM training. The groups of variant products are also used to predict variation attributes using a generative AI that can also take RAG product information in the prompt. The trained models can be used to predict variant product relationships and attributes for any new pair of products. LLM, large language model; RAG, retrieval-augmented generation; VARM, variant relationship matcher.
Variant match prediction
Each product
DistilBERT was chosen as the encoding model given its competitive performance on product entity tasks,4,12 but the strategy generalizes to alternative model choices. The model has 66 M parameters, distilled from a 110 M parameter teacher model, with 12 hidden layers, or transformer blocks, and 768 attention heads.13,14 Given a pair of products, the product attributes from both products are first concatenated and tokenized into a single sequence of text tokens to enable early fusion.
15
The two product descriptions are separated by a
To capture variant product relationships, a labeled dataset was generated capitalizing on the positive variant product links present in webpage listings and variation groups and synthesizing negative samples by leveraging the positive links (see dataset details below). Model weights were fine-tuned to perform the variant product matching task in a supervised fashion by minimizing the cross-entropy loss function of a linear classification layer using this dataset. The training regime was limited to a single epoch with Adaptive Moment Estimation optimization and a
Variation attribute identification
For a set of products in a given variation group, we formulated the variation attribute estimation of VARM as a “Text-to-Text” task inspired by the recent success of generative AI.18–20
Specifically, the input is structured as an instruction that encapsulates the text attributes for all the products belonging to a given variation group. Therefore, for each given variation group, we have a set of products 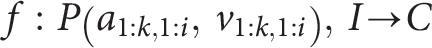
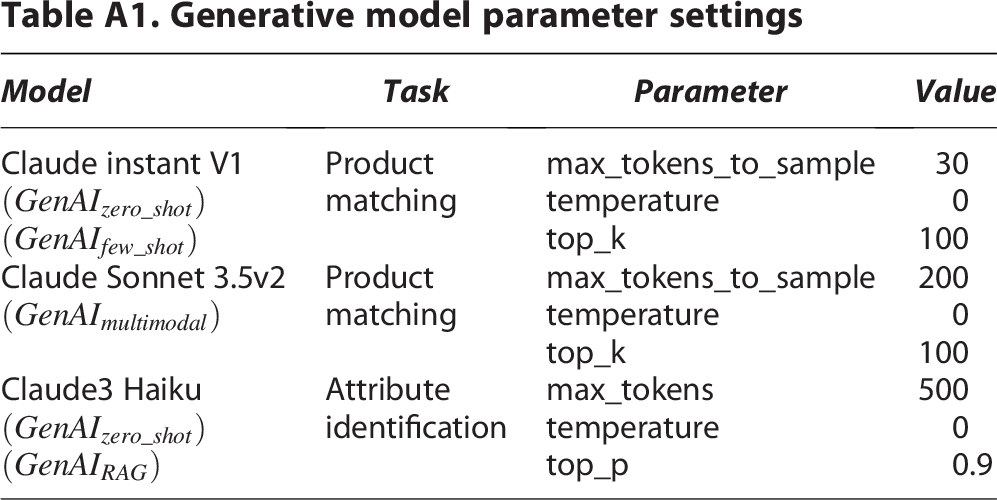
We formalize the model as both a zero-shot and few-shot learner utilizing an off-the-shelf LLM, Claude3 Haiku 21 (see parameters settings in Appendix Table A1). The zero-shot formulation implicitly assumes that LLMs have been trained on massive amounts of language data and thus possess contextual understanding, given a correctly engineered prompt.20,22 For prompt engineering we combined chain-of-thought and instruction techniques to predict all attributes labels for a given variation group.23,24 To mitigate the impact of this assumption, we provide product-relevant information as part of the prompt using RAG. 7 For a given product pair of certain product type and brand, information about variation attributes is retrieved online from the webpage-linked products dataset. For the specific product type or brand, variation groups with products belonging to the same product type or brand were filtered, then the associated variation attributes were collected and structured into a list of unique variation attributes to be included in the prompt.
Generative model parameter settings
The detailed prompt provided to the model is structured as follows:
*Variation attribute identification prompt*
You are an expert on products. The following list of products are the same entity but variations of each other. Some of the descriptors are unique to each product and some other are different across them. The attributes can be descriptors or keywords within the descriptor.
<if RAG:><Usual different attributes for {product_type} products are {product_type_variation_attributes}. Usual different attributes for brand products are {brand_variation_attributes}.>
Below are the products’ descriptions:
{variation_group_products}
You need to complete the following tasks.
Compare the details in the all products above and determine the attributes that are common and different across the products.
If an attribute is “different,” it cannot be “same.”
Respond: “Different:” followed by a list the attributes that are the different across them.
Respond: “Same:” followed by a list the attributes that are same across them.
Respond: “Reason:” explaining why or how attributes are different, for the different attributes.
Do not add an explanation about the output format. Ensure the output is exclusively in JSON format.
Return only a JSON block using double quotes in this format and in this order:
{[“Different”: [“list different attributes”], “Same”: [list same attributes], “Reason”: [Reason why attributes are different]]}
Do not return anything except a JSON. Always begin your output with: “{“
Datasets
The datasets used to develop and evaluate VARM models were 1 :
Results
VARM accurately learns variation matching product relationships from website structure
To validate our VARM strategy, we evaluated the outputs of the different model components under different experimental conditions and compared its performance with state-of-the-art models performing the same tasks.
First, since the webpage-linked products dataset initially contains only positive variation match samples, we generated synthetic samples by shuffling product pairs. We used an informed strategy to generate the negative samples according to types of products and brands (see Datasets section in Methods).
As control, we compared the performance of models trained in this dataset with that of a dataset containing random pair shuffles for negative sample generation. For each experiment we generated 1 M negative samples to generate a label-balanced dataset with 2 M pairs partitioned into 70:30 training:evaluation splits, while ensuring that products from the same variation group would be in a given split.
We fine-tuned encoding LLM models on the aforementioned set of negative samples and the positive labels from the webpage-linked products dataset, starting from an off-the-shelf DistilBERT
2
model or a DistilBERT model pretrained on e-commerce tasks,
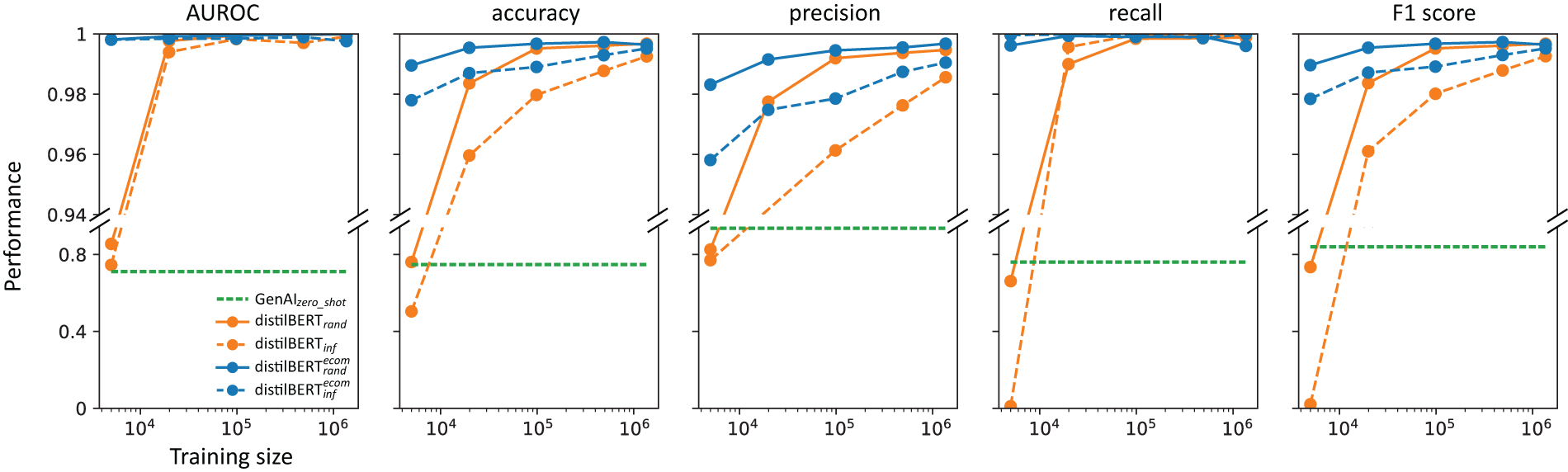
Model performance as a function of training set size on the webpage-linked products dataset. Performance of GenAI model
To better understand the dependency of labeled data on model performance, we varied the amount of data used to fine-tune the encoding models. As expected, the performance increases monotonically with training set size. However, fine-tuning a LLM model from scratch,
To prove the validity of VARM’s matching model component for practical e-commerce applications, we tested its performance in a dataset with varied product pairs across e-catalogs and expertly labeled. Given that the example pairs were sampled and not synthetically generated, they represent conditions that could be faced when tackling e-commerce tasks. Testing the generalization performance of the different models showed that all models can accurately estimate variant product relationships. In addition, providing few-shot examples using RAG as part of the instruction,
Still,
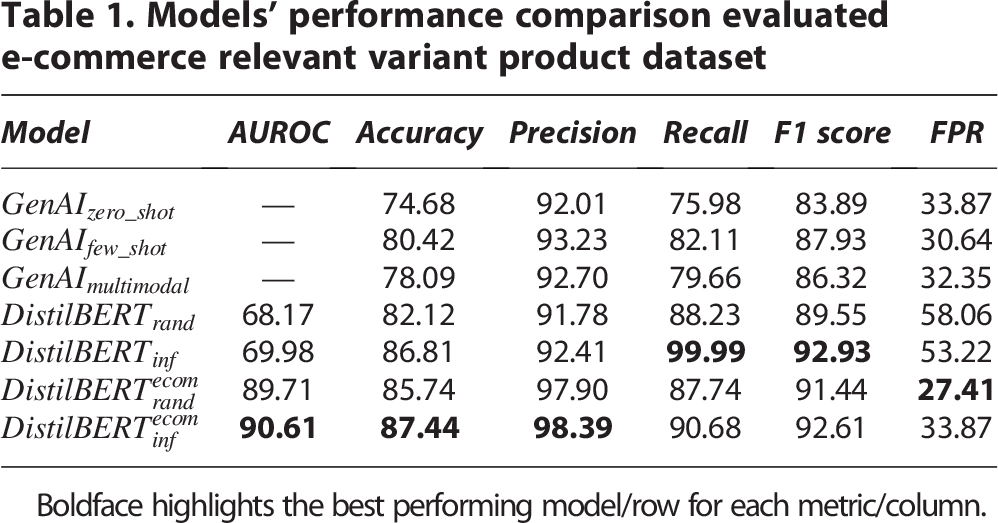
Boldface highlights the best performing model/row for each metric/column.
VARM correctly classifies variation attributes
Identifying attributes that are common or vary across groups of variant products is critical for multiple applications. To assess VARM’s ability to label attributes, we sampled 500 variation groups present in the webpage-linked products dataset where the variation attribute is known. We tested the performance of the zero-shot generative AI model,
To get a quantitative estimate of the performance, we estimated the recall when predicting structured variation attributes to prevent penalizing for additionally found variation attributes that may not have a structured key. As baseline, we define a heuristic model that estimates variation attributes as the structured attributes that vary across more than 90% of the products in the variation group. All models can predict variation attributes above chance, with generative models outperforming heuristic-based methods. Moreover, providing additional context about products in the prompt,
Variation attribute identification performance on the webpage-linked dataset sample
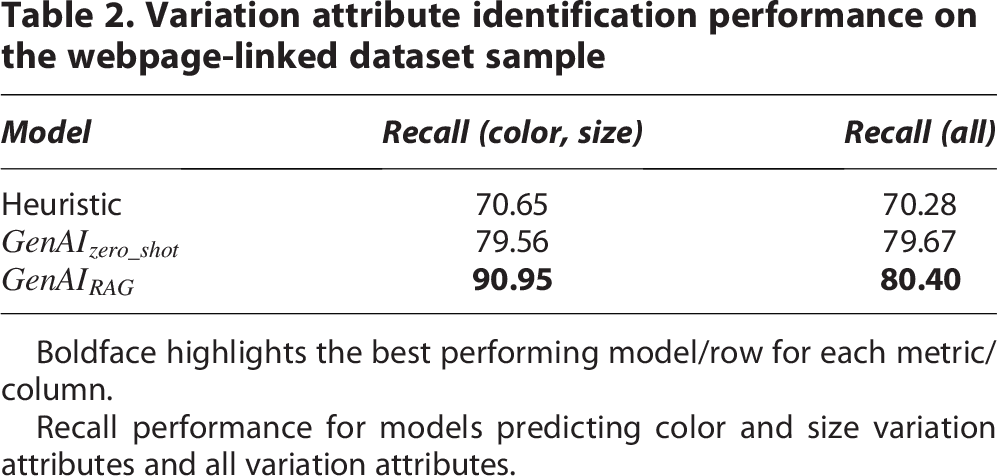
Boldface highlights the best performing model/row for each metric/column.
Recall performance for models predicting color and size variation attributes and all variation attributes.
While identifying variation attributes is sufficient to cluster variant products, also extracting common attributes is critical to provide a complete description of the product group. To test VARM’s ability to determine both common and variant attributes, catalog experts evaluated model predictions for both labels on a dataset with 10 variation groups. The evaluation showed that both versions of VARM,
Common and variation attribute identification performance

Boldface highlights the best performing model/row for each metric/column.
Discussion
The recent developments in LLM technology have popularized its use with successful application to a multitude of use cases, including e-commerce tasks. 12 Particularly, encoding LLMs are generally preferred for classification tasks or learning embeddings, while generative AI models are used for text generation tasks like summarizing or translation.12,17,25 In this work, we capitalize on the respective advantages of encoding and generative LLMs to solve a new task for ER aimed at identifying variant matches and variation attributes amongst e-commerce products. While using both encoding and generative models provides higher performance, it also increases design and computational complexity. A promising direction to reduce this complexity would be to also use generative models for ER by leverage generated samples in context learning, 26 which as shown in or few-shot examples aids the model learn this kind of product relationship, and given the rapid progress in the field, they could provide comparable performance to encoding models. 27
Here, we show how we can learn variant product relationships leveraging the information present in website structures. Still, it will be worth exploring in future works how to adjust the granularity of these relationships so it can be applied across e-commerce sectors. For example, jewelry variation attributes could be material type at a coarse level of description, but for jewelry retailers the relevant variation attributes could be finer, such as ring size or gem type. Here, we showed that the strategy used to augment the dataset and generate negative examples was for model performance, suggesting that data augmentation methods could prove useful to define new types of product relationships.28,29
This work expands the traditional definition of ER to identify variant relationships and implements a model to successfully identify these relationships amongst products. While it was only tested in e-commerce catalog applications, the new formulation and model strategy can be directly extended to other areas using ER, such as data curation or customer identification. 30
Authors’ Contributions
Conceptualization—P.H.V., L.W., and P.S.; Data curation—P.H.V.; Formal analysis—P.H.V.; Investigation—P.H.V.; Methodology—P.H.V., L.W., and P.S.; Project administration—P.H.V., L.W., P.S., and B.X.; Software—P.H.V. and Y.C.; Supervision—L.W., P.S., B.X., and C.L.; Validation—P.H.V. and Y.C.; Visualization—P.H.V.; Writing—original draft—P.H.V., L.W., and P.S.; Writing—review—P.H.V., L.W., P.S., and B.X.
Footnotes
Acknowledgments
The authors thank Abhishek Tripathi, Alvaro Quitral, Venessa Tauro, Daniel Marti, Nilotpal Das, Raghavendran Balu, Marian George, and Yi Ren for their assistance accessing resources and insightful feedback.
Author Disclosure Statement
The authors declare no competing interests or conflict of interest.
Funding Information
All work was performed while authors were employed at Amazon on in-house infrastructure. The views expressed in this article are solely the authors’ and may not necessarily reflect Amazon’s viewpoint.