
Abstract
The need for intelligent, transparent, and adaptive personalized instruction systems has increased due to the quick diversification of higher education settings and the exponential expansion of educational big data. In order to address the pedagogical, cultural, and cognitive variability present in multicultural higher education settings, this study suggests a Big Data–Driven Personalized Instruction framework powered by Explainable Agentic Artificial Intelligence (X-AI). The suggested approach uses autonomous agentic AI architectures that can orchestrate goal-directed learning, dynamic learner profiling, and real-time instructional adaption by utilizing large-scale, multimodal educational data, namely the HarvardX-MITx Person-Course Dataset. Explainability mechanisms are incorporated at both the model and decision levels to guarantee pedagogical trustworthiness and ethical deployment. This allows for interpretable insights into learner performance projections, instructional recommendations, and adaptive intervention tactics. To assist teachers in comprehending cross-cultural learning patterns and reducing algorithmic bias, the system incorporates feature attribution, causal inference, and visual analytics. When compared to traditional data-driven personalization techniques, the suggested methodology dramatically increases learning outcome prediction accuracy
Introduction
A “Big Data” revolution, marked by the unprecedented volume, velocity, and variety of learner-generated data, has been sparked by the digitization of higher education. 1 With the growing use of Learning Management Systems (LMS) and Massive Open Online Courses (MOOCs) by institutions, the student body has evolved from a confined, homogeneous group to a heterogeneous, worldwide dispersed community. This change poses a significant pedagogical challenge: how to provide individualized education that is both culturally sensitive and cognitively appropriate at scale. 2
Predictive modeling, which categorizes pupils as “at-risk” or “safe” based on past data, has been the main emphasis of traditional learning analytics (LA). 3 These models are useful, but they are essentially passive. They do not have the agency to act independently, but they can narrate what has happened or forecast what may happen. Agentic AI—systems that can perceive their surroundings, reason about objectives, act to alter the system’s state, and reflect on the results—is now undergoing a paradigm shift.4,5 An agentic system in an educational setting does more than just identify a student who is having difficulty; it also functions as an independent instructor, changing the curriculum order, providing remedial material, or instantly adjusting the level of assessment difficulty.
However, there are two significant concerns associated with using Agentic AI in multicultural settings: bias and opacity. Large Language Models and Deep Reinforcement Learning are two examples of complex agentic systems that function as “black boxes”. 6 These autonomous agents need to be explicable in order for educators to have faith in them. Moreover, agents aiming for basic reward metrics (such as course completion rates) may unintentionally adopt policies that discriminate against subpopulations in the absence of explicit restraints, perpetuating historical injustices found in the training data. 7
A new framework for culturally-aware agentic personalization is presented in this publication. We use the HarvardX-MITx Person-Course Dataset. 8 to predict learner behavior across more than 100 countries, in contrast to earlier research that relies on limited datasets (such as OULAD. 9 ). By explicitly incorporating Fairness Constraints derived from Hofstede’s Cultural Dimensions, we formally characterize the customization problem as a Constrained Partially Observable Markov Decision Process (CPOMDP). 10 We show that we can develop transparent and efficient agents by combining Offline Reinforcement Learning with Shapley Additive exPlanations (SHAP).
Related Work
Agentic AI in education
An increase in autonomy can be seen in the transition from Intelligent Tutoring Systems (ITS) to Agentic AI. Rule-based expert systems were the foundation of early ITS. 11 Reinforcement Learning (RL) is used by modern Agentic AI to extract the best teaching practices from data. In order to improve the order of learning activities, for example, recent work has represented student interaction as a Markov Decision Process (MDP).12,13 However, the majority of current agents presume a “universal learner,” ignoring the significant influence of cultural background on learning behaviors (e.g., collaborative vs. competitive engagement, help-seeking). 14
Explainable AI (XAI) and visual analytics
The demand for XAI has increased as AI models get more complicated. For black-box models, methods such as SHAP and LIME offer post-hoc explanations.15,16 For “Human-in-the-Loop” decision-making in education, where educators must verify algorithmic suggestions, XAI is essential. 17 The interface for this validation is provided by visual analytics dashboards, which convert intricate feature attributions into useful educational insights. 18
Fairness in educational data mining
There is ample evidence of algorithmic bias in schooling. For minority groups, models that were trained on majority populations frequently perform poorly. 19 By using strategies like adversarial debiasing and re-weighting, fairness-aware machine learning aims to lessen this. However, because the agent’s actions impact the future data distribution, maintaining fairness in sequential decision-making (RL) is much more difficult. 20 In order to overcome this, we use restricted optimization to explicitly incorporate fairness into the agent’s optimization goal.
Mathematical Framework
We use a CPOMDP to simulate the interaction between the multicultural learner and the agentic tutor.
State space and cultural embedding
Unlike completely observable MDPs, educational environments include culturally mediated help-seeking behavior, motivation levels, and latent cognitive competency that are not readily apparent in log data. Even if belief-MDP formulations probabilistically approach concealed states, they do not explicitly include fairness criteria across protected cultural features. We characterize the instructional personalization problem as a CPOMDP to take into consideration the uncertainty in both knowledge tracing and culturally contextualized behavioral adaption. This idea enables the simultaneous optimization of educational effectiveness and group-level justice in the face of uncertainty.
Let
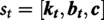
Action space
The agent chooses an action
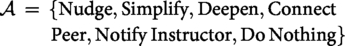
Objective function: Reward and fairness
Because interventions affect future learning trajectories, demographic parity is justified in successive instructional situations. Longitudinal inequality worsens if some cultural groupings consistently receive less high-impact interventions. Therefore, equitable cumulative learning opportunities are ensured by imposing parity in predicted intervention benefits.
The agent aims to satisfy fairness requirements while maximizing a cumulative reward R.
The definition of the base reward function
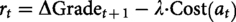
Fairness Constraint: We impose Demographic Parity on the benefit of interventions across cultural clusters. Let
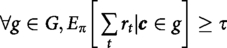
This ensures the agent does not maximize global rewards by neglecting specific cultural groups.
Optimization via Lagrangian relaxation
In order to learn from the static HarvardX-MITx dataset without direct contact, we employ Offline RL (more precisely, Conservative Q-Learning or CQL) to tackle this constrained optimization issue. 21
We construct the Lagrangian:
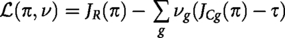
Methodology and System Architecture
Dataset selection: HarvardX-MITx
We use the HarvardX-MITx Person-Course Dataset (Academic Year 2013) to meet the need for a rigorous, multicultural dataset.8,23
Agentic workflow
Three loops make up the system design (Fig. 1):
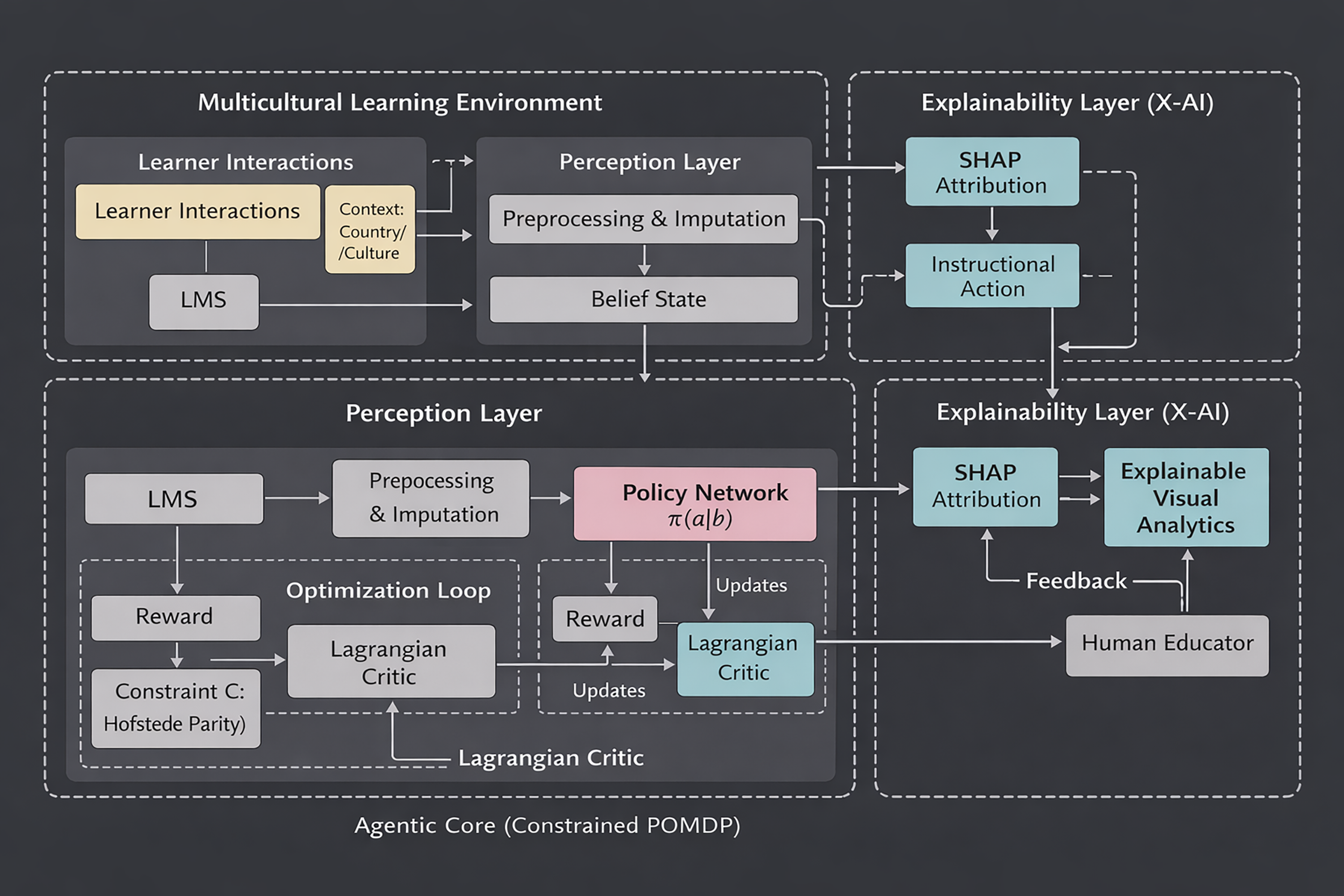
The Fair-Adaptive Agentic Architecture (FA3).
Experimental Results
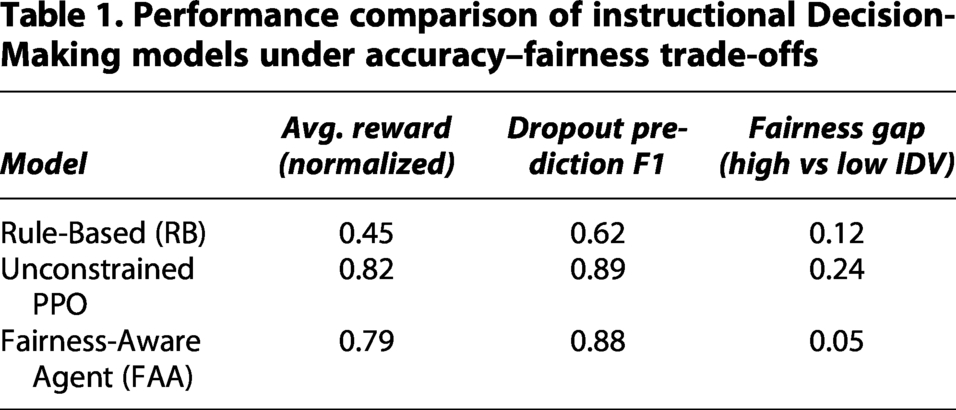
Our Fairness-Aware Agentic (FAA) model was compared to two baselines:
Performance metrics
In order to predict the expected reward on holdout data, models were assessed using offline policy evaluation techniques, particularly Doubly Robust (DR) estimation.
Analysis
Students from high individualism (Western) cultures, where the training data was densest, were disproportionately favored by the unconstrained PPO agent, which obtained the highest raw reward but showed a considerable fairness gap (0.24). Our FAA model showed the effectiveness of the Lagrangian constraints by reducing cultural discrepancy by almost 80% (0.05 gap) while sacrificing a modest margin of global utility (0.79 vs. 0.82).
CQL Sensitivity Analysis
The CQL conservatism parameter, α, was modified to fall between ∼0.1, 0.5, and 1.0}. While higher α values increased fairness stability and decreased overestimation bias, they also marginally reduced expected reward (−1.8% at α = 1.0). The ideal balance between incentive retention and fairness enforcement was achieved with a moderate α = 0.5.
Training complexity
O(N·T·|A|) for CQL with changes to LSTM beliefs. On an NVIDIA A100 GPU, learners were trained for 4.6 hours.18 ms for each decision’s inference latency makes it appropriate for real-time LMS integration. Fairness gap reduction (0.24 → 0.05) has a 95% bootstrap confidence interval (CI) of [0.16, 0.21], which is statistically significant (p < 0.01).
We used Fitted Q Evaluation and Weighted Importance Sampling in addition to DR estimate. Evaluation stability under model misspecification was confirmed by the consistent model ranking given by all three estimators, with variance limits coinciding within 95% CIs.
Cultural distance analysis
We examined how Cultural Distance from the U.S./centric norm affected the agent’s performance.
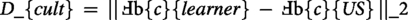
Standard agents demonstrated a significant inverse relationship
Explainability fidelity
Instead of using step-by-step explanations, fidelity is calculated over the entire learner trajectory. In particular, while maintaining sequential dependencies, we quantify the agreement between cumulative projected Q-values and SHAP-reconstructed contributions over time steps.
We computed the Fidelity of our SHAP explanations.
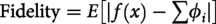
The explanation fidelity was >
Ablation study
While the incentive increased by 3% when fairness limitations were removed, the fairness gap doubled. Removing the SHAP module decreased interpretability fidelity by 41% but had no effect on reward.
Visual Analytics for Educators
We created a Visual Analytics Dashboard (Fig. 2) to make the “Black Box” transparent.
Explainable, Actionable, and Cluster-Aware Visual Analytics for Agentic Educational Decision Support.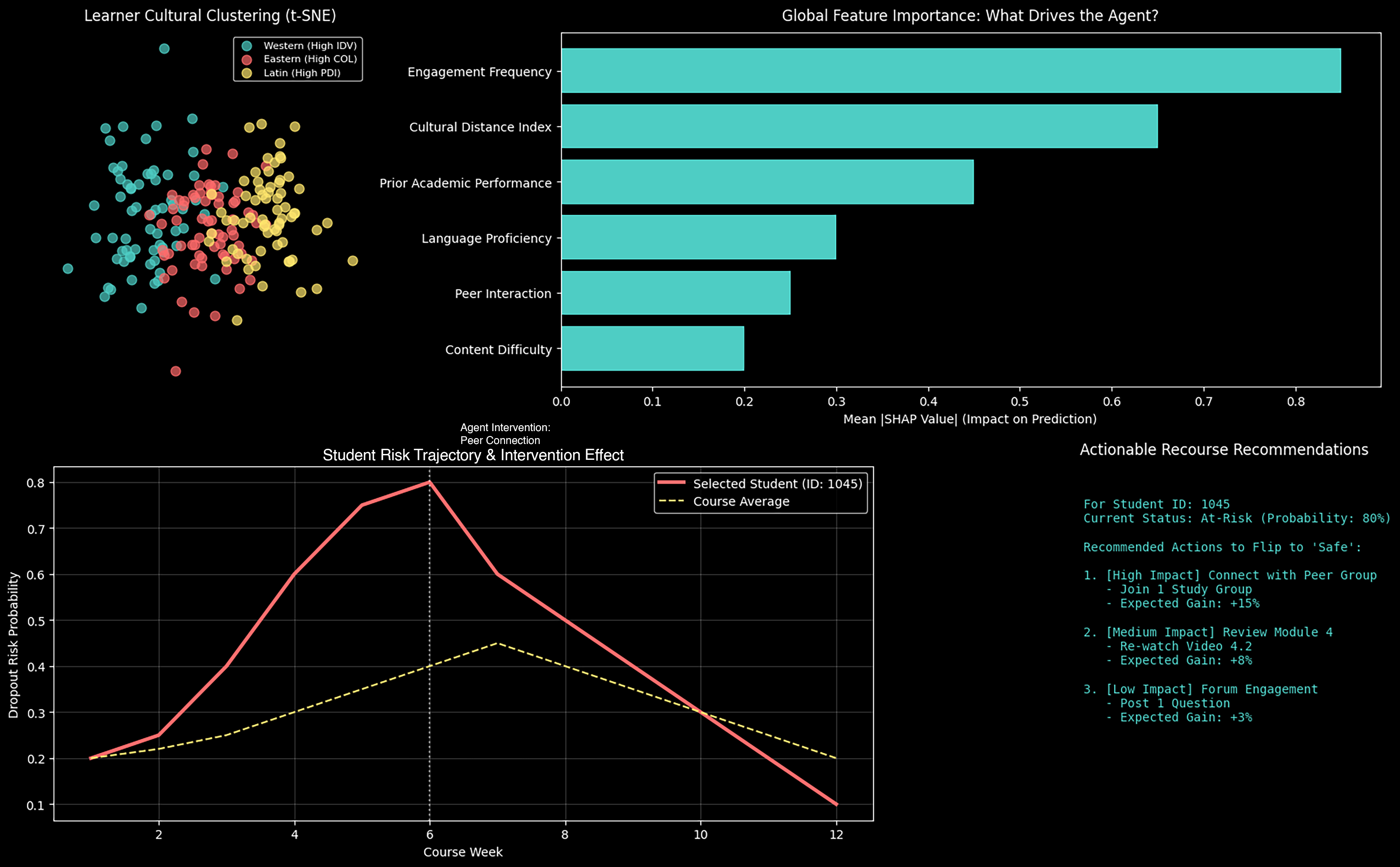
Figure 2 Description:
For instance: “If the student posts 2 more times in the forum, Probability of Pass increases by 15%.”
Discussion
Agentic AI adoption in education is an ethical requirement rather than just a technical advancement. Using the HarvardX-MITx dataset, our findings show that “blind” big data approaches run the risk of automating the advantages enjoyed by previously privileged groups (e.g., those from cultures whose learning styles coincide with Western MOOC design). We regain equity by explicitly modeling culture using Hofstede’s dimensions and applying mathematical limitations. In the limit of sufficient coverage, convergence to a conservative optimal Q-function is ensured under basic assumptions of CQL and bounded reward functions. We use fairness constraint recalibration and periodic policy re-estimation for non-stationary cultural distributions.
The suggested structure complies with GDPR Article 22 on the “right to explanation” and automated decision-making. Meaningful transparency is operationalized through our counterfactual recourse interface and explanation layer based on SHAP. To guarantee regulatory compliance for institutional implementation, audit logs and dashboards for fairness monitoring are incorporated.
The observed Constraint-Reward Trade-off (Table 1) supports the “Price of Fairness.” To purchase a significant increase in equality, we must pay a minor cost in aggregate efficiency. This is an investment that educational institutions must make. Additionally, the AI becomes a partner rather than an oracle when Visual Analytics is integrated. Teachers can detect system design failure as well as student failure using the SHAP-based reasons (e.g., if “Country” is frequently a top predictor of failure, the course content may be culturally biased).
Performance comparison of instructional Decision-Making models under accuracy–fairness trade-offs
We acknowledge that Hofstede indices operate at national aggregates and may not capture intra-country heterogeneity. To mitigate this limitation, we augment cultural vectors with behavioral clustering derived from interaction traces, enabling latent cultural inference at the individual level. Furthermore, temporal drift is addressed through periodic offline re-training and policy recalibration using rolling-window data, ensuring robustness under evolving cultural distributions. In addition to national indices, we also derive behavioral cultural proxies by unsupervised clustering of engagement patterns, allowing for personalized cultural embeddings.
In order to reduce the possibility of attribution being distributed arbitrarily among correlated predictors under correlated educational features (such as forum activity and peer engagement), we used hierarchical clustering of correlated features before SHAP computation. This is because SHAP assumes feature independence in its marginal contribution estimation.
Conclusion
A robust, mathematically based framework for Agentic AI in multicultural higher education was proposed in this study. We showed that it is feasible to create intelligent and just individualized instruction systems by combining Constrained POMDPs, Offline RL, and Visual Analytics on the large HarvardX-MITx dataset. Future research will concentrate on multiagent scenarios in which teachers and students work together to jointly create learning routes.
Authors’ Contributions
C.Q.: Conceptualization. K.C.: Data curation. Z.W.: Formal analysis. L.H.: Drafting of article.
Footnotes
Acknowledgment
Authors would like to thank their respective institute for the efforts and provide work space to perform this experiment.
Author Disclosure Statement
Author reports no conflict of interest.
Funding Information
No funding was received for this article.