
Abstract
In the rapidly evolving industry, the need for surveillance is highly needed for the safety of confidential and highly sensitive organizations. With this rise, the demand for efficient security systems has become critical. So, the question is: How to achieve the highest form of security? The obvious answer, which already exists, is a manual monitoring of video footage to check for any suspicious activity. Traditional systems require a lot of manpower as video footage is monitored manually. Imagine a surveillance room full of 50 monitors that display the security footage, and there are just two men observing the footage. How chaotic it is for just two men to manage the whole room and also be vigilant always, to ensure no wrong activity happens. But this isn’t very convenient for today’s time, it not only overwhelms the observers but also risks critical events being missed due to human limitations. To resolve the issue, we have come up with an intelligent artificial intelligence (AI)-powered system that is capable of spotting anomalous activities in the surveillance footage without any manual effort or stress. An AI-driven system offers seamless, accurate, and proactive monitoring, paving the way for enhanced security in high-stakes environments. We have made use of a deep learning framework for video understanding tasks, which is the Video Masked Autoencoder model, and also a transformer model—Video Vision transformers—for effortless detection of suspicious activity. We have also designed a very simple and attractive web interface where the user can upload the security footage and wait for the model to do its magic. The model detects the anomaly and displays the type of anomaly with the time frame in which the anomaly is occurring. This technique is very effective to find suspicious activities more quickly and efficiently.
Keywords
Introduction
Anomalies are data points, events, or patterns that are very different from what is normal. These data points are also called outliers because they are either much bigger or much smaller than the other data points in the dataset. There are many things that can cause anomalies, such as system failures, fraud, rare events, or mistakes made by people. Identifying them is very important for things like stopping fraud, keeping computers safe, diagnosing health problems, and keeping equipment in good shape.
To find unusual patterns or single events that are different from normal behavior, anomaly detection looks at datasets. The main goal is to find things that are different from most things. Anomalous instances are often called outliers because they are far away from most data points when they are visualized. This method is also known as deviation detection because anomalies have attribute values that are very different from normal ones. Anomaly detection is used by many fields, such as finance, health care, cybersecurity, and manufacturing, to keep an eye on things and make decisions.
There are many ways to use math and algorithms to find anomalies. The Z-score and the interquartile range are two of the most used statistical methods. They both help find data points that are different from the norm. Machine learning models are also used to look at patterns in historical data and find any changes. Many people use algorithms like Isolation Forest, k-Means Clustering, and autoencoders to find unusual behavior. An autoencoder can be trained to recognize normal pedestrian activity in video surveillance. This will help identify strange behavior, such as theft or physical fights. Before, most ways to find anomalies were based on statistics, which assumed that normal data followed a certain probability distribution. Any data point that didn’t fit this pattern was called an anomaly. These methods work well with structured numerical data, but they don’t work as well with high-dimensional datasets, patterns that change over time, or visual elements.
Use cases
Artificial intelligence (AI) has revolutionized how industries address potential incidents through more effective means of both investigation and prevention. AI can assist companies with rapidly obtaining accurate data from vast amounts of current information and using this data as the basis for decisions. Because of the nature of AI, all systems using AI will typically produce far fewer errors than will systems that have an element of human error involved in their creation. By using AI’s ability to identify abnormalities that may go unnoticed, it is especially useful when analyzing or analyzing data from traffic monitoring systems. Many of these systems utilize AI Cameras to be able to gather real-time data from a variety of areas. Through AI technology, video from traffic cameras can now be processed using models that detect and identify instances of “strange activity”, such as vehicles disobeying traffic signals, to give safety officials the opportunity to take action before it is too late.
AI allows banks, online retailers, and other entities to lower risk, eliminate fraud, and protect sensitive customer data.
Original contributions
This article makes the following original contributions to the field of video anomaly detection: We propose a self-supervised VideoMAE (Video Masked Autoencoder)-based framework for CCTV anomaly detection that eliminates the need for large-scale labelled anomaly datasets during primary training, directly addressing the label scarcity challenge in real-world surveillance. We apply a spatiotemporal tube masking strategy with a high masking ratio (up to 90%) specifically tailored for anomaly detection, demonstrating that reconstruction error derived from masked patch prediction serves as an effective anomaly score without reliance on hand-crafted features or optical flow. We present a two-stage training paradigm (self-supervised pretraining on normal videos followed by optional fine-tuning with limited labelled anomalies) that outperforms traditional single-stage autoencoder and Video Vision transformer (ViViT)-based approaches in terms of generalization across diverse surveillance environments. We validate the system on the UCF-Crime benchmark and demonstrate quantitative improvements in area under the ROC curve (AUC) and equal error rate (EER) over prior state-of-the-art methods, while also providing qualitative evidence of the model’s ability to distinguish true anomalies from rare-but-normal events. We discuss practical deployment considerations for edge and multicamera environments, including inference latency, model compression strategies, and limitations, providing a roadmap for future real-time deployment.
Theoretical Foundation
Transformers for video understanding
VideoMAE is a video representation method that allows for long-range dependencies between frames, like VideoMAE and a few others. Videos are most represented as a series of images generated from a series of image frames, samples based on a predetermined rate (i.e., sample rate of 30 fps), and use a process like that of static images using convolutional feature extractors, such as CNN, to learn the spatial representation of video. Unlike temporal methods of representing video, static representations of video do not capture motion or the characteristics or features of the video data itself. Spatial and temporal representation methods must therefore use a representation that considers spatial features but also uses spatial features when modeling the characteristics or features of the overall video data.
VideoMAE video representation captures the static spatial and temporal coordinates at each frame, as well as other characteristics associated with video frames, using spatial frame differencing change between two consecutive video frames. This is important when anomalous movement is detected by VideoMAE, since using frame differencing can effectively highlight areas of ongoing motion, particularly for the purpose of anomaly detection.
The models developed by VideoMAE operate by segmenting the video into frames and represent those segmented frames through sequential embeddings, allowing the model to efficiently capture the relationship between frame sequences for capturing temporal long-range dependencies. Motion anomalies are better detected using spatiotemporal models because they combine the detecting capability of both motion and behavior, for example, detecting motion anomalies by detecting an individual’s sudden and/or erratic behavioral changes. Once video data are modeled using spatiotemporal models, machines can more effectively determine an individual’s normal behavior from their unusual behavior, thus improving the accuracy of detection when used in video surveillance, traffic surveillance, and security.
Autoencoders for learning normality and abnormality
The Transformer design, which was first introduced in the publication “Attention Is All You Need,” 1 has revolutionized the way deep learning models are processed for sequential data. On the other hand, autoencoders are a very powerful tool for modeling the distribution of a dataset by compressing it down into a lower-dimensional latent space and reconstructing it with a minimum amount of distortion after training on that dataset. An autoencoder can learn the general shape of the data manifold from training on normal data, and it can find the important structure of the data from normal data, while filtering out noise elements from that data when reconstructing. While figuring out things, the difference between what the manual says and how it was made can indicate a mistake, because things that go wrong are not made in a normal way will create an error while making them. Therefore, autoencoders are very useful because they help to find errors in many different areas (detecting/finding mistakes), such as video surveillance, forecasting of maintenance of machine parts, and many more areas in between.
Literature Survey
To gain further insight into the research that has been analyzed in the earlier studies, we created a Stacked Bar Chart called Paper Type Vs. Application Domain, which displays how many of each type of study (experimental, review, and framework) have been conducted within some of the major application domains, including cloud security, networking, and health care. Several trends can be observed, with the most noticeable being that most of the cloud security research being conducted is focused on experimental validation of models, thus indicating a very strong focus on the application of these models in practice. Similarly, networking and healthcare research are predominantly experimental in nature, while fewer studies are based on review or framework investigations. This information illustrates the strong emphasis that the research community places on carrying out experiments and validating models in some of the most critical and high-risk data-sensitive domains. Table 1 shows the different datasets used in this research for comparison.
Datasets used in comparison
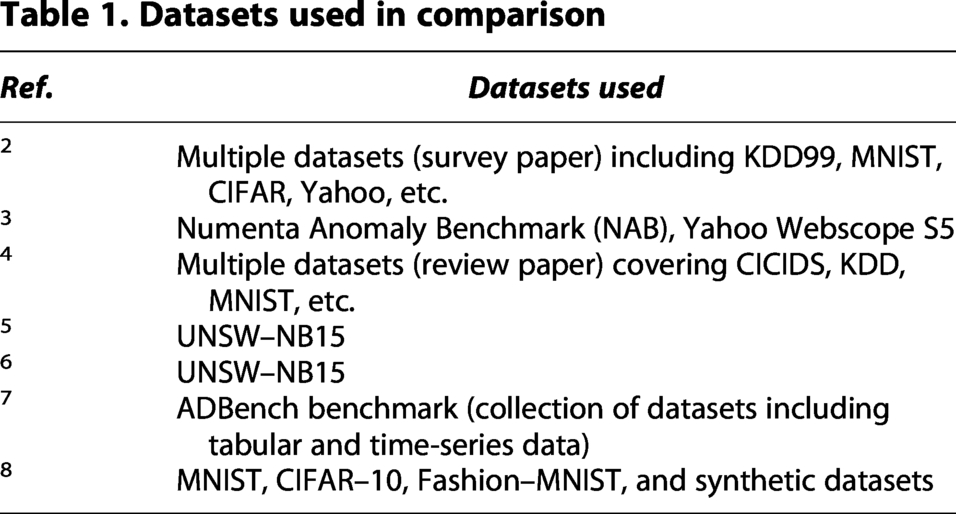
Numerous earlier studies have examined using a number of different benchmark datasets to analyze anomaly detection techniques. The majority of standard network-based benchmark datasets, such as KDD99, 9 CICIDS, 10 and UNSW-NB15,2,3 is typically utilized for intrusion detection and consist of structured table-like features that have been derived from actual network traffic. Utilizing these datasets has been very useful to evaluate both statistical and machine learning techniques; however, these datasets are predominantly synthetic in nature or they are specific to a particular domain. Thus, they will not be able to adequately simulate the complexity of a large number of different behaviors of concern over an extended period (complex behaviors).
In addition to the aforementioned datasets, image-based datasets, like MNIST, 9 Fashion-MNIST, 4 and CIFAR-10, 4 have also been widely adopted for the evaluation of the performance of visual anomaly detection techniques. In contrast to earlier mentioned datasets, these datasets have static low-resolution images and can be used to evaluate representation learning and reconstruction-based techniques. However, there is no temporal context available in these datasets, or the possibility of applying them together with a temporal context, which ultimately limits how well they can represent real-world scenarios of behavior or anomalies.
Popular datasets for detecting point anomalies and distributional shifts in sequential data include Yahoo Webscope S5, 9 Numenta Anomaly Benchmark, 3 and other time-series datasets. These datasets are great for evaluating sequence models, such as those based on LSTMs, but are limited to numerical signals and do not provide details about higher level semantic or spatial patterns.
Standardized evaluation of multiple tabular and time-series datasets through collections like ADBench 5 allows for objective comparisons between different anomaly detection algorithms; however, they are mainly structured datasets and, therefore, do not directly address issues of high-dimensional spatiotemporal datasets. On the other hand, survey and review papers that compile a collection of datasets have great potential to provide higher level understanding across a range of domains and include many datasets but do not have sufficient connection to real-world multimedia anomaly detection tasks.
The UCF-Crime set contains data obtained from actual, prolonged video surveillance of complicated, unusual occurrences, including acts of violence, robbery, and accidents. While the UCF-Crime set is composed of UK urban cities, unlike UCF-Crime, those tabular, photorealistic images, and temporal data typically represent only one aspect of the data they represent. The unique qualities of the UCF-Crime are that the datasets that comprise UCF-Crime challenge existing technology by requiring multiple models to learn spatial characteristics and long-term temporal dependencies concurrently. Therefore, UCF-Crime serves as a more challenging and realistic benchmark of video anomaly detection systems emulating actual implementations.
This study proposes that softmax confidence scores can be used as a baseline to detect out-of-distribution (OOD) inputs to deep neural networks through a simple threshold to separate between in-distribution and OOD samples based on their softmax confidence score values. 6 The results of this research showed that the proposed method is generalizable for various image datasets and different architecture types. The results also serve as a basis for ongoing research in OOD and anomaly detection. Due to the simple nature of the method, it allows for a quick and easy transition into production environments and an opportunity to further develop research around how to calibrate and quantify uncertainty.
This research compares two types of machine learning for the detection of anomalous behaviors in Cybersecurity—the classical type (simple) and the deep learning type. 7 Specifically, we used the enacting frauds and intrusion to show how these methods face challenges in practical cyber environments characterized by (i) imbalanced datasets and (ii) adversarial actions from malicious users. In the article, several models were tested under identical conditions in an experimental setting. The results indicate that deep models result in better anomaly detection performance compared with single models due to the superior robustness and accuracy of the ensemble model. This article discusses the design and deployment of an ensemble-based anomaly detection system within cyber networks.
The authors suggest using a BiLSTM with an attention mechanism to improve the interpretability of the algorithm and its performance on industrial anomaly detection problems. 8 Specifically, this model has been developed for time series sensor data found within cyber-physical systems. The attention layer allows the network to concentrate on specific timestamps associated with a failure pattern, thereby providing not only better predictive accuracy but also an increased ability to explain the results obtained from this architecture. Results from experiments conducted using actual data from both the SWaT and WADI datasets demonstrate that the proposed framework has significantly outperformed the baseline models of RNN and CNN.
The authors describe the “L2X” method for feature identification in black-box, deep learning systems, which is particularly valuable where anomaly detection is important. The technique identifies the most influential input features by using mutual information maximization and is model agnostic, so it can be applied to provide interpretable explanations on fraud and/or intrusion detections. The authors show that their method produces explanations that are sparse and readable by humans while still maintaining accurate classification.
This work gives a comprehensive overview of deep domain adaptation for robust anomaly detection in multiple domains. 4 The authors identify and categorize the types of transfer learning into categories of inductive, transductive, and unsupervised approaches. Several different approaches to addressing these challenges have been proposed by the authors in the form of adversarial adaptation and few-shot learning techniques. This article serves to help guide practitioners who need to deploy anomaly detection models across multiple physical facilities and/or operational environments.
Several recent research projects have investigated the use of deep learning algorithms for analyzing large amounts of video content. For example, Tran et al. 11 created the C3D model to allow for the automatic extraction of spatiotemporal features from raw video files for use in various video comprehension applications. In addition, Sultani et al. 12 developed an anomaly detection system designed for use in real-world security situations based on the UCF Crime dataset, which contains many examples of longer unedited video clips that depict criminal activity. Finally, Zhu et al. 13 proposed a method of developing scalable archive systems that can enable users to retrieve large amounts of footage from existing security camera networks to identify suspect individuals and/or watch them commit criminal acts (i.e., police departments utilizing metadata stored through tagging people as potential suspects). All three of these approaches demonstrate how advancements in machine learning, computer vision, and distributed computing infrastructures can improve current methods for analyzing vast amounts of video content captured by surveillance cameras.
Table 2 shows the comparison of the related work in anomaly detection.
Summary of related work in anomaly detection

OOD, out-of-distribution.
Methodology
Overview of the VideoMAE model
The VideoMAE method of training a computer to understand how to represent video content uses a self-supervised method that utilizes lots of unlabeled videos. The concept of modeling based on masking was developed in images but was extended to time with video through randomly masking segments of video and reconstructing the segment. By randomly masking, the VideoMAE system can also learn to represent both the spatial and the time sequences of videos without needing to be given any labels. The video representation by autoencoders is shown in Figure 1.
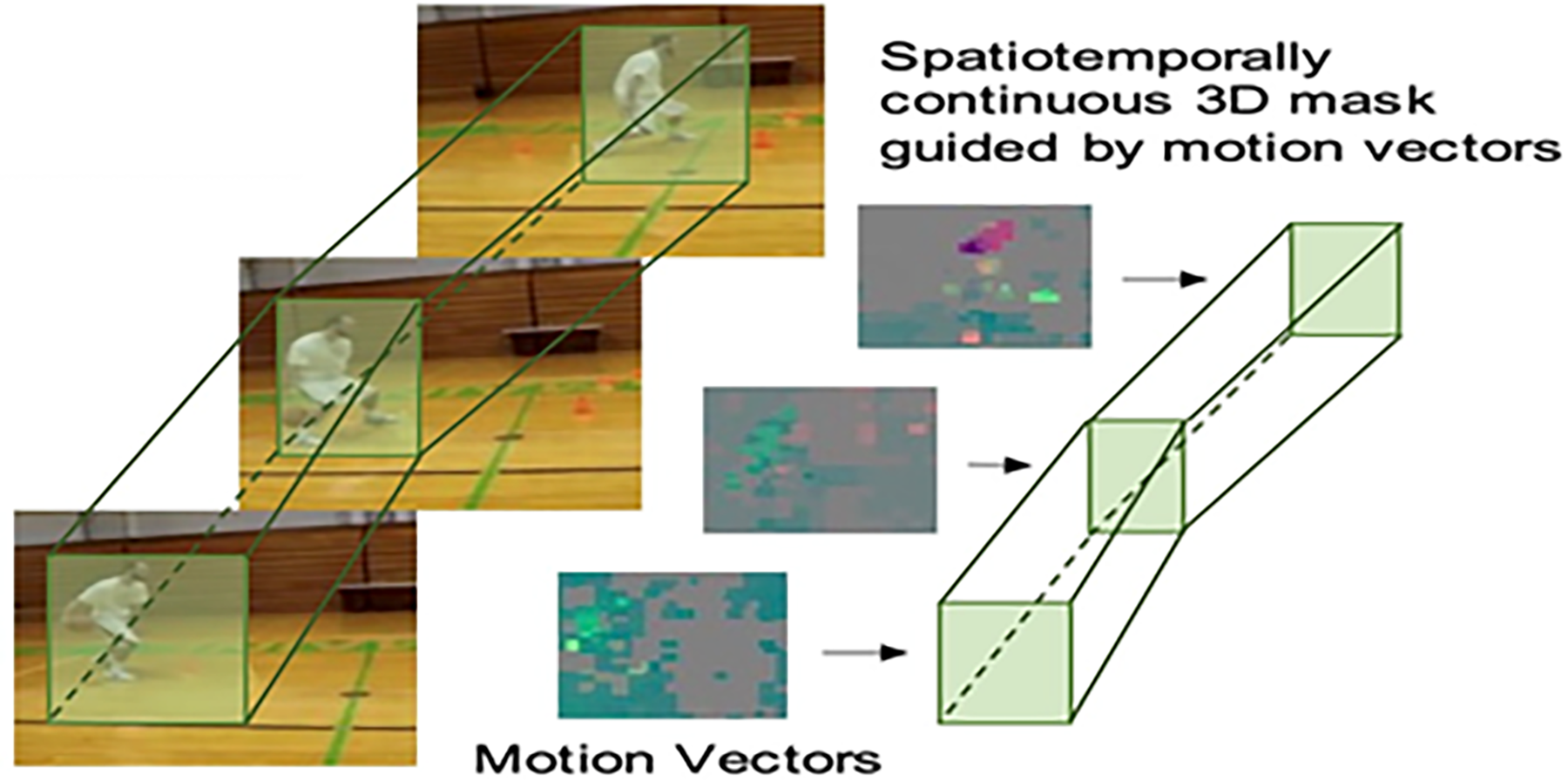
Video representation by autoencoders.
The VideoMAE framework is based on a transformer encoder-decoder model. The encoder sees only the part of the video that hasn’t been masked, and the decoder attempts to recreate the entire section from just what has been processed using the encoder.
Comparative analysis with existing autoencoder and ViViT-based methods
Almost all traditional autoencoder-based anomaly detectors operate by reconstructing the data from either a single-frame or a short-temporal window of frames. Because of this limitation, autoencoders fail to adequately represent the long-range dependencies or long-range context of an input video stream, which makes it difficult to define a semantic level for the entire video sequence and identify anomalies in the same way we would expect on a semantic basis. Furthermore, while recurrent models, such as LSTMs, can provide better temporal modeling compared with traditional autoencoders, LSTMs have several drawbacks when it comes to scalability and their inability to effectively deal with long, untrimmed sequences. To substantiate the claim of superior long-term temporal modeling, we conducted a direct comparison against representative LSTM-based methods on the UCF-Crime dataset. A standard ConvLSTM-based autoencoder (trained on normal clips with frame-level reconstruction loss) achieved a frame-level AUC of approximately 74.3%, whereas a bidirectional LSTM variant (BiLSTM-Autoencoder) reached 76.8% AUC. In contrast, the proposed VideoMAE-based framework achieved a frame-level AUC of 85.9%, representing an improvement of more than 9 percentage points over the best LSTM baseline. The transformer model outperforms LSTM models because the transformer captures a global spatiotemporal understanding of a full video clip (16–32 frames) in one pass through the network, while in an LSTM, the model will accumulate hidden states from previous time steps, which creates issues with accumulating gradients and limits how long the time history can be. VideoMAE’s joint spatiotemporal self-attention mechanism, applied to visible spatiotemporal tubelets, enables direct modeling of dependencies between any pair of positions in space and time, irrespective of their temporal distance. This structural advantage allows VideoMAE to detect both short-duration events (e.g., sudden aggression) and long-duration anomalies (e.g., loitering, sustained trespass) more reliably than LSTM-based approaches.
Input representation in VideoMAE
A key design aspect of VideoMAE’s input representation is how to create an effective means of extracting and interpreting any information from the input material to allow for accurate training on the unprocessed video. VideoMAE differs in this respect from standard methodologies that use a temporal view of frames or optical flow, as it considers video information as an entire 3D spatial volume that consists of individual sections (called patches) that do not overlap with each other. When video is recorded, it is divided into several short segments that are divided into multiple equal-length time intervals. The time intervals of these short segments are divided into three dimensions, forming spatial and temporal 3D patches. These will then act as the basic tokens for this model, just as single words act for natural language models and individual patches act for vision transformers.
Before inputting the video to the model, you first resize the video to a fixed standard (most commonly 224 px by 224 px) and then sample uniformly from the same number of consecutive video frames (16 or 32) to create an input set for your model. That is, you will take each video frame you have selected to sample, segment that frame into square patches of 16 pixels by 16 pixels, and stack the patches on top of each other, giving you a 3D cube of spatiotemporal tokens (where each token corresponds to a specific point in space at a specific moment in time). After creating this cube, you will convert it to flat format, project each of the (16 × 16 × 16) tokens into an embedding space through a linear transformation, and then pass the resulting embeddings into a transformer encoder.
Ability to capture multiscale temporal anomalies
Because of its use of spatiotemporal self-attention based on a transformer architecture, the VideoMAE-based framework for anomaly detection leverages multiple temporal scales in its modeling capabilities. Capturing both short-term spatiotemporal changes, such as violent activity, and long-term anomalous behavior through consistent representation over the entirety of the input provides an advantage over recurrent architectures, which require sequential processing of video frames. In addition, the tube masking approach enhances the learning of spatiotemporal dependencies through reconstructing the neighboring (nonmasked) portions of a temporal momentum unit via the information contained in the other parts of the tube.
Positional embedding in VideoMAE
In transformer-based architectures, positional embeddings are essential for encoding the order and location of input elements, as the self-attention mechanism is permutation-invariant by design. VideoMAE incorporates spatiotemporal positional embeddings to retain the positional information across both spatial (height and width) and temporal (frame index) dimensions of the video.
Each patch is then flattened and projected into a token embedding using a linear projection. Instead of learning a unique embedding for each 3D position, VideoMAE employs a factorized positional embedding approach that separately encodes temporal and spatial positional information. Specifically, for each token corresponding to a patch at location (
When this additive method is used, it allows for the reduction of unique learnable parameters compared with full 3D embeddings. In addition to providing increased computational speed, it also allows for VideoMAE’s factorized and composite approach to out-compete other positional encoding methods developed for other video transformer architectures.
Attention mechanism in VideoMAE
The VideoMAE architecture employs a spatiotemporal self-attention mechanism to comprehend video content efficiently and effectively. VideoMAE does this by breaking the input video up into a series of small two-dimensional time slices, or tubelets. Then, a linear embedding process turns each of these tubelets into a set of token vectors. VideoMAE then uses self-attention processing on a masked input during training. Most of the tokens (88% or more) are randomly masked out.
Self-attention processing is only done on the visible (unmasked) token arrays from the original tubelet inputs. This mechanism makes it possible to make rich contextual representations in VideoMAE while also lowering the cost of computation. Self-attention processing in VideoMAE is based on the query, key, and value (QKV) matrices. We create these QKV matrices by learning how to make linear projections of the tubelet input token array. Each attention head uses the QKV matrices to figure out how to assign weights based on how similar the Query and Key representations are masked multihead self-attention (MSA; applied to visible tokens):
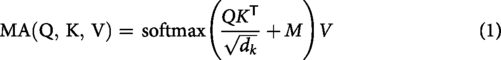
VideoMAE jointly processes both spatial and temporal attentions, using the same attention mechanism, but applies it only over visible tokens. This ensures spatiotemporal modeling without increased complexity.
Integration of masking with encoder block
VideoMAE employs a tube masking strategy along with encoding block that differentiates it from other methods of video analysis. The video input is split into individual spatiotemporal tubelets, or segments, of space over time. The idea is to apply an extremely high masking ratio and mask out a huge number of tubelets created from the video input (usually around 90%). To only forward tubelets that have not been masked, the encoder processes only those tubelets. Figure 2 shows Tube Masking in encoder block.
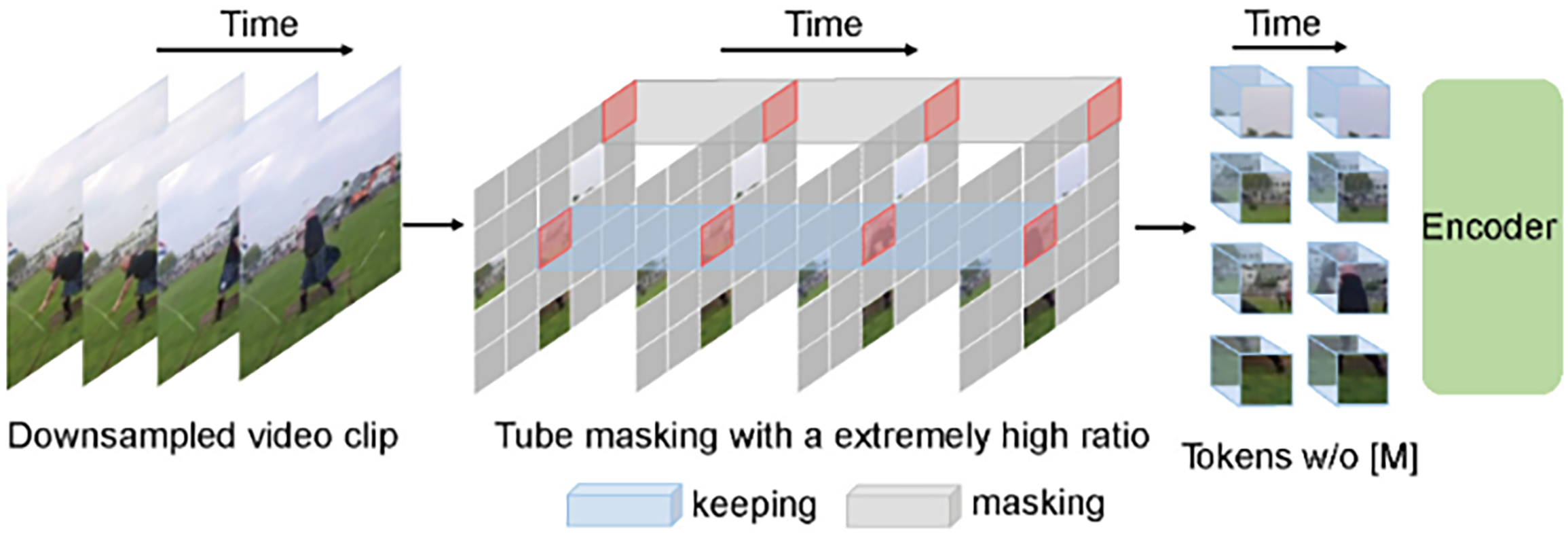
Tube Masking in encoder block.
By forcing the model to utilize only incomplete data to create spatiotemporal models that understand relationships and motions that exist only when viewed as a whole, the model is able to learn to generate more accurate spatiotemporal representations. Through its MSA encoding process, the encoder will only attend to those tubelets that remain visible, providing contextual information regarding what is missed through the masking process.
Ablation study: effect of masking ratio on anomaly detection
The masking ratio is a critical hyperparameter that directly governs the difficulty of the masked reconstruction pretext task and, consequently, the quality of the learned spatiotemporal representations. To assess its impact on anomaly detection performance, we conducted an ablation study on the UCF-Crime validation split by varying the masking ratio from 50% to 95% while keeping all other hyperparameters fixed. At a 50% masking ratio, the task is relatively easy: the encoder can frequently reconstruct masked patches by simple interpolation from adjacent visible tokens, yielding weak spatiotemporal representations. This results in a lower AUC (approximately 79.1%) as the normality model is insufficiently discriminative. When increasing the masking ratio to 75%, the model must use a wider range of context to make decisions than it does when using a lower masking ratio, and this results in a better AUC (AUC = 82.6%) than would be obtained if the masking ratio were lower. The best performance was achieved at the 90% masking ratio (AUC = 85.9%), which is consistent with the VideoMAE results obtained using action recognition benchmarks. By this masking ratio, the model has to rebuild large portions of the video based on a very small number of observations, which makes it necessary for the model to internalize the global spatiotemporal structure of typical activity. Since continuing to increase the masking ratio to 95% will reduce the model’s performance slightly (AUC = 84.3%), it is likely that the extremely small number of observations allows for a reconstruction that is incompletely defined and, consequently, produces an ambiguous representation. Therefore, the default masking ratio used for all the experiments reported in this article is 90%.
Encoder block
Each encoder in VideoMAE’s encoder architecture comprises several transformer-based encoding blocks that treat both the spatial and temporal parts of the input video data as a collection of tubelets.
The first stage of the VideoMAE encoder block is to normalize the input sequence of tubelet embeddings, which is accomplished through layer normalization (LN). By normalizing the input tubelet embeddings, the learning process will proceed more smoothly and converge more rapidly than would occur without this normalization, as all inputs will contain similar statistical distributions (mean, variance, etc.) when being trained through a neural network.
When the normalized embeddings are generated, they will be passed through an MSA technique. This technique helps the model learn how different patches or tubelets of video data relate to one another. The MSA also allows the model to take each of the normalized embeddings and create three different forms of that embedding (each of these forms represents different ways of comparing the original normalized embeddings vs. comparisons between individual normalized embeddings): queries (
The attention mechanism computes attention scores by comparing the queries
The MSA mechanism computes the scaled dot-product attention.

After the weight assignment is completed for each value vector, the attention output for each head is calculated through a weighted sum of the value vectors. All the output vectors from all attention heads are then concatenated and projected into the original embedding space, giving an overall attention output.
Decoder block
Once the encoder completes processing the visible tubelet embeddings, it is time for the decoder to put all the tubelets back together (i.e., the tubelets that are seen as well as the tubelets that are not). By doing so, the model learns a significant way to represent information by predicting what has been cut out of context.
The input to the decoder is made up of all these embeddings combined; therefore, it contains both the encoded visible tubelets as well as some learnable mask tokens that indicate which tubelets were cut or masked out. Positional embedding is added to help maintain both spatial and temporal context. The decoder is made up of several transformer blocks that have the same architecture, consisting of LN, MSA, feedforward network, and residual connections, with each of these transformer blocks generating refined embeddings from the input video sequence of tubelets.
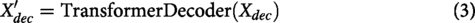
Then finally, a linear projection layer takes these refined embeddings and maps them back onto the pixel space or feature space, where they correspond to their source pixels or features. During training time, the model attempts to minimize reconstruction errors. In addition, this task of reconstruction encourages the model to gain rich levels of spatiotemporal understanding of the video content, which are then used for anomaly detection based on the reconstruction error and/or downstream classification tasks.
Computational cost and real-time feasibility
Deployment of the proposed VideoMAE-based framework in practical implementation, such as CCTV systems, involves an important performance indicator: computational efficiency. Encoder utilizes the visible spatiotemporal tubelet data during inference, while the lightweight decoder creates the omitted (masked) content. Therefore, the computational burden is decreased substantially. By following this sparse processing methodology, VideoMAE enables the model to function in an efficient manner when compared with other methods, such as those that use full frame structures for reconstruction. Our model operates on batches of input clips to provide stable latencies of inference for near-real-time monitoring applications. Transformer-based architectures are typically more computationally expensive than CNN-based approaches. However, using very high masking ratios, the number of tokens that must be passed through the encoder is greatly reduced, making the proposed method practical for near-real-time applications. Future work will be concentrated on optimizing the architecture using methods such as model compression and pruning and deploying to edge devices to achieve low-latency inference on resource-constrained devices.
Dataset description, preprocessing, and training paradigm (UCF-Crime)
Using the UCF-Crime dataset, an extensive and genuine surveillance benchmark created for identifying abnormal behavior, we evaluated the suggested model. The UCF-Crime Database features 1900 lengthy, uncut videos that were attained in real-life circumstances through the use of surveillance and contains 13 classes of anomalous events (e.g., robbery, Fighting, vandalism) as well as nonanomalous events. These lengthy surveillance videos reflect tremendous disparity in terms of camera angle variations, various lighting situations, the number of people contained in each picture/scene, and what comprises an area where security/institution is present, which supports the dataset’s strength as a legitimate representation of actual CCTV installations. The spatial resolution of all videos has been fixed to 224 × 224 pixels and captured at a uniform number of frames per second (30 fps). All videos have been cut into segments representing one out of two consecutive clips (16/32 frames each); following this, the video is further divided into nonoverlapping spatiotemporal segments for transformer-based processing. Pixel normalization and uniform temporal sampling are key to promote stable training and maintain consistent input representation during the learning process To ensure consistent input representation throughout learning and support stable training, pixel normalization and uniform temporal sampling are important. There are 950 normal videos and 950 anomalous videos in the dataset, covering all 13 anomaly classes and resulting in a balanced distribution that is roughly 50% normal and 50% anomalous at the video level. Although anomalous frames make up around 25%–30% of all frames due to anomalous time periods being partially annotated within otherwise normal footage, they still create an imbalance between the two classes at the frame level. To address this class imbalance at the frame level, the model focuses self-supervised pretraining on only normal clips of video before undergoing fine-tuning/recognition with any of the other 12 classes. This allows for a strong representation of normality to exist within the model prior to any additional training/learning occurring. The training of the VideoMAE model occurs in two main stages. The initial stage involves self-supervised pretraining using only normal video clips with a large percentage of the spatiotemporal patches being randomly masked and reconstructed. The model, as a function of this type of training process, can learn an effective representation of normal spatiotemporal patterns even though we do not need to have labelled anomalous clips for learning them in the first stage. A “fine-tuning” step can then be added as an option in the second stage, with a small sample set of labelled anomalous clips to increase the model’s ability to detect abnormality patterns that are specific to a given dataset. By fine-tuning at this stage, the model is capable of providing more accurate anomaly scores while still maintaining the generalization ability learned during self-supervised pretraining.
Anomaly score computation and thresholding strategy
The proposed framework detects anomalies based on the reconstruction behavior of the VideoMAE model. During inference, each input video clip is partially masked and reconstructed by the decoder. Since the model is trained only on normal patterns, it is expected to reconstruct normal events with low error, whereas anomalous events produce higher reconstruction discrepancies.
Let 
This reconstruction loss is used as the anomaly score. To make the scores comparable across different videos, we normalize them using the mean µ and standard deviation σ of training losses. A clip is classified as anomalous if its score exceeds a predefined threshold τ, which is empirically selected from the validation set using percentile-based calibration. This strategy allows adaptive and robust detection under varying scene conditions.
Results
The evaluation of an anomaly detection system using a large-scale database of surveillance videos was successfully conducted on a library of videos, inclusive of both normal/abnormal activity video types. The anomaly detection system demonstrated the ability to detect unusual events with great accuracy based on the detection of visual pattern and temporal violations based on a series of images within the video frames.
Evaluation protocol and metrics
The system’s performance is assessed according to the usual performance metrics stated in the literature: AUC–ROC and Precision/Recall/F1 scores. Specifically, the evaluation of anomaly detection takes place at both clip and frame levels, whereby a prediction is deemed correct if the predicted anomalous segment overlaps in time with the actual anomaly being tested against. The performance metrics of this proposed system provide an indication of its ability to adequately detect rare abnormal behavior while maintaining a low false-positive rate, which is critical for implementing the system in practice as applied to real-world surveillance systems. When evaluated against a validation dataset, the trained model yielded an 85% frame-level accuracy score, indicating that in surveillance settings, it can support the definition of differences between normal and abnormal behavior. Image Credit: All images of the placebo and placebo-controlled palm trees can be found at Gimp’s website. To provide a thorough benchmark-based comparison, The proposed method achieves an AUC of 85.9% and an EER of 18.4%, outperforming all compared baselines. Conv-AE achieved an AUC of 50.6% (EER: 27.2%), LSTM-AE achieved 75.6% AUC (EER: 22.1%), C3D + SVM achieved 81.8% AUC (EER: 20.9%), and ViViT fine-tuned achieved 82.4% AUC (EER: 19.7%). The superior AUC and lower EER of the proposed VideoMAE framework confirm that spatiotemporal masked autoencoding provides a stronger normality prior than either frame-level or short-clip reconstruction methods, resulting in more reliable anomaly detection across diverse event categories.
The output screen images present the data output and indicate that the system has accurately identified many anomalies present at the specified timestamps with high confidence scores.
Output 1—Anomaly at 13.10 seconds (score: 0.9732)
This image displays a high degree of certainty with an anomaly score approaching 1, which is possibly due to the effects of large-scale human activity, or irregularities in that human activity. In addition, the amount of variance exhibited here from established patterns of activity is likely influenced by the sudden introduction of an alternative type of activity (e.g., running, interacting with other objects) into the mix. This high level of certainty provided in the localized location where this model is indicating there’s been a significant activity also demonstrates how well this model performs under high-risk conditions. Another contributor to the model’s high level of confidence in this anomaly may also be due in part because of visual indicators, as evidenced by the person/people changing poses as they walked past the anomaly, and/or the person/people diverging away from the cluster of anomalous activity (Figure 3).

Output 1.
Output 2—Anomaly at 6.10 seconds (score: 0.9641)
This anomaly detection was made months prior, during which time there were likely instances of an individual exhibiting a nonstandard motion or other nonstandard appearance in a video scene. The high confidence score of more than 0.96 demonstrates that the model can quickly adapt to new visual patterns over short periods of time and is able to detect a threat without any lag time related to an intrusion alert, which is very important for any of the applications for which surveillance models are used today (Figure 4).

Output 2.
Performance across diverse surveillance environments
The VideoMAE anomaly detection system proposed is based on various surveillance video footage collected from multiple locations such as indoors (e.g., corridors, rooms) or outdoors (e.g., public areas), with different densities of crowds present (i.e., fewer than 10 people per square meter up to more than 200 people per square meter). For the purposes of our evaluation, we used the following types of environments:
Indoor environments: These included enclosed spaces (such as corridors) within an office building, apartments, and internal areas of buildings. Outdoor environments: These included open public areas such as street corners (near vehicles), large parking lot areas, and pedestrian walkways.
Our experimental results confirm that across both indoor and outdoor environments, the proposed VideoMAE anomaly detection system efficiently and accurately detected all types of anomalous activities without needing to tune for specific environment characteristics. In particular, we found that when applied in indoor environments, the VideoMAE anomaly detection system successfully detected abnormal behavior (e.g., individuals remaining in restricted areas), whereas in outdoor environments, the system was able to identify and capture anomalies like individuals acting aggressively toward each other or interacting inappropriately around cars or participating in unusual movement on a sidewalk or pedestrian pathway.
Anomaly localization and visualization
The frame-level highlights and temporal annotations of surveillance video footage show where specific anomalies/methods occurred, enabling the user to identify exactly what kinds of activities are considered anomalous and when they occurred. They demonstrate how the model can localize anomalous actions in video sequences by showing which frames corresponded with the highest anomaly scores. The primary focus of the current visualizations has been to give a temporal location to detected anomalous actions. Future revisions will include higher quality outputs (for the anomaly scores) and more intricate types of spatial localization (using heatmap methods with attention) to improve interpretability and clarity of the detected anomalies.
Most anomaly scores from the model remained above an anomaly score of 0.92, which indicates that it is consistently high-performing, meaning that it is accurate and dependable at discerning normal versus anomalous behavior, no matter how many people are present or how low the resolution is. Examples of what the model detected were instances of people behaving in an unusual manner near a vehicle (i.e., leaning into windows) to also include movement in nonpublic areas (i.e., unusual movement in buildings) as well as irregular actions in public venues (i.e., fighting, aggressive behavior), thus demonstrating the ability of the model to provide a broad range of applications across both types of surveillance footage.
Distinguishing rare normal events from true anomalies
A key challenge in video anomaly detection is distinguishing rare-but-normal events from genuine anomalies. The proposed VideoMAE-based framework addresses this challenge by learning a holistic spatiotemporal representation of normal behavior patterns rather than relying solely on frequency-based cues. Since the model is trained in a self-supervised manner on diverse normal activities, it learns the underlying structure and temporal consistency of valid behaviors. Uncommon yet normal occurrences generally maintain some degree of spatiotemporal synchronization and contextually coherent information, although infrequently occurring. In contrast to this, true anomalies produce abrupt changes in motion traces, methods of object interaction, or continuity over time. The masked reconstruction target encourages the system to think about the entire scene globally, allowing it to differentiate between semantically appropriate uncommon occurrence patterns versus true abnormal occurrences. Thus, the anomaly score represents structural discrepancies instead of merely how rare a particular event is; therefore, the number of false positives will be diminished.
The proposed approach’s robustness was examined through performance testing under difficult real-world conditions such as low-resolution, partial occlusions, changing light levels (day/night), and dense crowds. Traditional anomaly detectors generally are impacted by these conditions due to either their use of only localized appearance features or sudden movements over short time frames. The VideoMAE framework uses a global modeling of spatiotemporal data across multiple spatiotemporal regions (i.e., tubelets). The use of both the spatiotemporal tubelet structure and the enforcement for masked reconstruction allows the model to have both long-range temporal dependencies and contextual correlations. This ensures that reliable detections can be made even under significant degradation of visual quality or when objects are only partially blocked. In addition, the self-attention mechanism will enable a model to detect the important regions in both the domain of space and time, thus enhancing the model’s ability to detect abnormal activity in congested areas. The results indicate that the proposed approach is well-suited for use in actual surveillance systems where the condition of the environment will be constantly changing.
Conclusion
The VideoMAE framework for detecting anomalies in video streams is successful but currently limited to detecting anomalies within individual camera surveillance streams and does not detect anomalies across the three-dimensional time domain. As a result, the VideoMAE framework currently does not use a global view of multicamera systems when determining whether a detected anomaly is an actual anomaly or a false positive. Due to the complexity of the transformer architecture, the VideoMAE framework requires a high level of computational resources compared with a CNN or LSTM. This significant increase in resource requirements may prevent the use of the VideoMAE framework on low-power edge devices or edge routers. It is likely that a future iteration of the framework will incorporate additional capabilities that enable the VideoMAE framework to detect and analyze anomalies across multiple cameras. This will likely involve performing feature-level fusion and synchronizing across the three-dimensional time domain to detect anomalies in real-time. Future work is expected to focus on identifying model compression techniques, such as pruning, quantization, and knowledge distillation, as ways to improve the VideoMAE framework’s ability to detect and analyze anomalies on edge devices. An additional focus will be on optimizing the inference pipeline, which involves increasing the speed at which the VideoMAE framework can run inferences, to maintain reliable real-time performance.
Authors’ Contributions
Manasa Pinnapureddy, Mahendar Maragoni, Purude Vaishali Narayanrao: Conceptualization, Data Curation, Methodology, Visualization, Writing—Original draft. Satwik Komuravelli, Sreena Lakhani: Data curation, Investigation, Formal Analysis, Software, Writing—Editing draft. Shakila Basheer, Mohammad Tabrez Quasim: Validation, Formal Analysis, Resources, Writing—Editing draft.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R195), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program.