
Abstract
Research exploring correlates of, precursors to, and consequences of psychological disorders has often relied on designs wherein both predictor and outcome are measured by self-reports. In this article, coauthored by a clinical psychologist (C. E. Fairbairn) and a data scientist (N. Bosch), we offer information surrounding an evolving class of machine-learning models as these inform an expanding measurement tool kit in clinical-psychological science. Specifically, we note the development of deep-learning applications for image analysis, language analysis, and the analysis of physiological time-series data, reviewing implications of these advances for measurement in behavioral research. We weigh strengths and limitations of these automated methods in comparison with self-reports, including the specific form of error likely yielded via each (random vs. systematic), with the aim of fostering a replicable, sustainable, and reputationally strong field of clinical-psychological science.
The science of clinical psychology has long been a science of self-reports (Frances & Widiger, 2012; Garcia & Gustavson, 1997; Grove & Tellegen, 1991). From DSM-based diagnoses to depression inventories, basic research exploring psychological health and dysfunction has relied heavily on participant reporting of experience (American Psychiatric Association, 2013; Beck et al., 1988; Hathaway & McKinley, 1951; Sobell & Sobell, 1992). In a field uniquely interested in internal subjective state, an emphasis on reported experience is unsurprising, as self-reports can at times reflect the most appropriate and direct means of assessment (G. W. Allport, 1961; Garcia & Gustavson, 1997; Lilienfeld & Fowler, 2006). Yet reliance on survey-based assessment extends widely within clinical-psychological science, encompassing constructs ranging from behavior to physiology to automatic cognitive processes to events in the distant past—domains in which self-reports are susceptible to both random and systematic forms of error (Baldwin et al., 2019; Nisbett & Wilson, 1977; Schwarz, 1999; Widom & Shepard, 1996). In a field in which such error can translate into the prolongation or even exacerbation of suffering among individuals in distress, matching construct to method of measurement in a manner that minimizes bias emerges as a central concern.
In the current article, we bring into conversation the fields of computer science and clinical psychology with the aim of introducing an expanding measurement tool kit for behavioral researchers of psychopathology. We review not only the strengths and utilities of questionnaire- and interview-based measures but also the limitations of self-reports when employed for use as a primary method of assessment across construct domains. A class of representational machine-learning models is introduced, and specific applications of this model class are illustrated and reviewed as these facilitate the measurement of key constructs of interest for psychosocial researchers. Specific concerns are noted relevant to the pervasiveness of self-report assessment, particularly the potential for false-positive effects from “common-methods bias.” Finally, we weigh strengths and limitations of automated, 1 self-report, and other measurement approaches as they relate to the broader goal of fostering a replicable and robust field of clinical-psychological science.
Self-Reports in Clinical-Psychological Science
Clinical psychology is a science that is uniquely concerned with the experience of the individual (Garcia & Gustavson, 1997). Participant self-reports offer notable advantages for studying psychological constructs, including their informational richness, causal force, and sheer practicality (Paulhus & Vazire, 2007). This method of measurement has the potential to tap into the expansive body of knowledge humans carry surrounding themselves and their own functioning, a knowledge base that can extend to not only external characteristics but also internal thoughts and feelings (Vazire, 2010). In the study of psychopathology more specifically, self-reports arguably hold particular value in that they have the potential to capture the form of suffering that lies at the core of what we seek to understand. As clinical researchers, we are interested not only in understanding reality, as it exists in truth, but also in understanding each participant’s unique experience of that reality (Frances & Widiger, 2012; Garcia & Gustavson, 1997; Lilienfeld & Fowler, 2006). Is there a truly “objective” measure of whether life is worth living? Isn’t it arguably the individual’s own subjective sense of self-esteem, hopelessness, and/or well-being that concerns people singularly? An interview- or questionnaire-based measure might not capture such experiential processes in a manner free of error. Yet arguably, when it comes to the measurement of such intrinsically experiential constructs, no other measure is likely to do better.
Reflecting the field’s commitment to subjective assessment, self-report measures have had a prominent place within clinical psychology. With a few exceptions (Hathaway & McKinley, 1951), such measures primarily take the form of direct, closed-ended questionnaire- or interview-type items, requiring the explicit reporting of symptoms and experiences by patients and, further, the subsequent patient- or interviewer-mediated translation of these experiences according to a predefined scale or fixed set of response options (American Psychiatric Association, 2013; Beck et al., 1988; Sobell & Sobell, 1992). For the purposes of this article, we conducted a review aimed at quantifying more precisely the prevalence of self-reports in clinical-psychological science, systematically coding measure type employed in empirical research published in three highly ranked clinical-psychology outlets during the years 2021 to 2024: Clinical Psychological Science, Journal of Consulting and Clinical Psychology, and Journal of Psychopathology and Clinical Science (preregistration: https://osf.io/cvnk8). Of 546 studies included in this review, 87% (k = 477) tested primary study aims using at least one closed-ended questionnaire or interview-style self-report. At the level of the measure, 71% (n = 969) of measure codes assigned in our review reflected closed-ended reports. Regarding the assessment target for these self-report measures, results indicated that self-reports were employed for assessing a wide variety of domains of human experience, from behavior to past events to physiological sensations (see Fig. 1), reflecting a broad commitment to self-reports for measuring phenomena well beyond the inherently subjective.
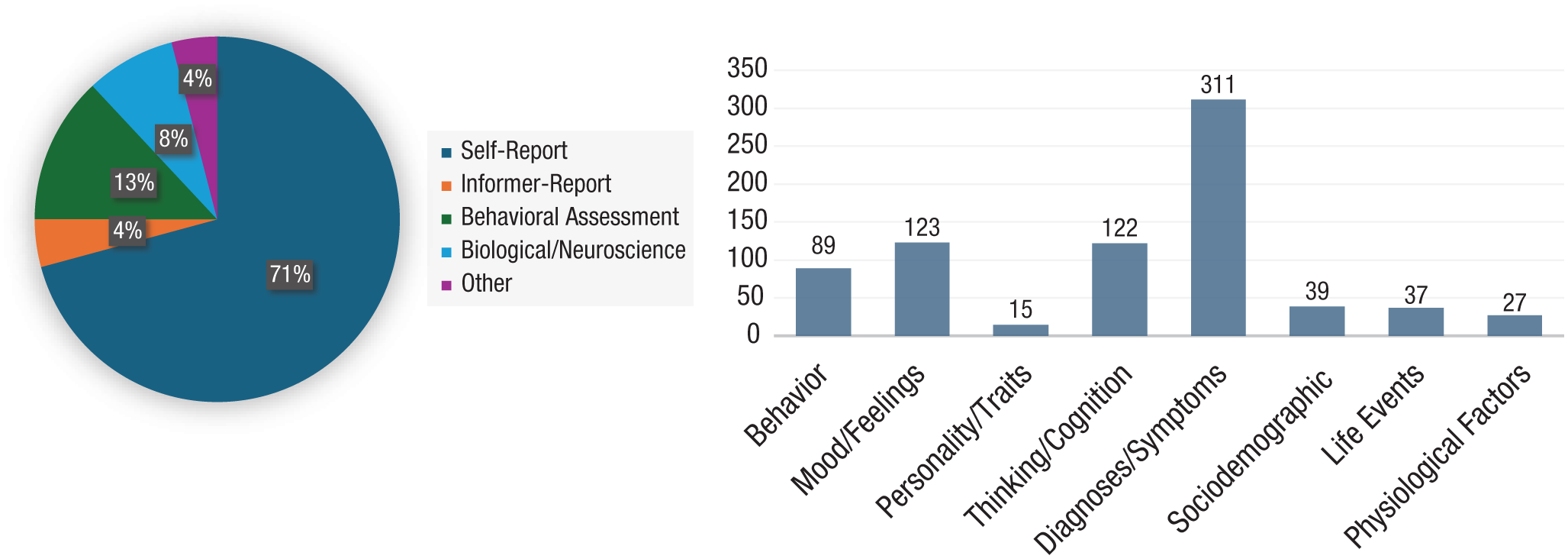
Review of measure types employed in highly ranked clinical-psychology outlets between 2021 and 2024. A literature review was conducted for all empirical articles published in the journals Clinical Psychological Science, Journal of Consulting and Clinical Psychology, and Journal of Psychopathology and Clinical Science from July 1, 2021, to July 1, 2024. All articles were assessed for study type (experimental vs. correlational), measure type, and construct coded in tests of primary study aims. Primary aims were determined according to language employed by articles’ authors or if the authors did not indicate the primacy of individual aims over others, according to the order in which aims/hypotheses were presented in the article. A random sample of 10% of studies was double-coded by a second rater blind to the original rater’s codes (κ = .80). A total of 386 correlational and 160 randomized studies were identified and coded for this search. (Left) Proportion of measure type at the level of the assessment. (Right) Constructs assessed specifically within the measure-type category of self-report. Overlapping codes were permitted—for cases in which a given assessment met criteria for more than one measure type or construct, it is represented in each. For the purposes of this review, “self-report” assessments are defined as closed questionnaire- or interview-style assessments in which participants self-report according to a predefined set of categorical or numerical responses. Questionnaire or interview assessments involving open-ended response options that required no immediate categorization are listed under “other” measure type. Review procedures and hypotheses were preregistered at OSF (see https://osf.io/cvnk8).
Important, although acknowledging their strengths, behavioral researchers have long raised concerns surrounding the potential fallibility of self-reports (F. H. Allport, 1927; Baumeister et al., 2007; Nisbett & Wilson, 1977; Schwarz, 1999). Congruence between contemporaneous and retrospective measures of major life events is markedly low (Baldwin et al., 2019; Widom & Shepard, 1996), participants’ self-assessments of their own skills/performance consistently yield inflated results (Dunning et al., 2004), and regarding internal experience, the automaticity of many domains of human cognition can limit participants’ ability to accurately report (Nisbett & Wilson, 1977). Misreporting is especially widespread for items that touch on socially sensitive topics: To offer just two examples, studies have estimated that only 52% of abortions (Fu et al., 1998) and 30% to 70% of drug use (Hilario et al., 2015; see Tourangeau & Yan, 2007) are reported in survey measures.
Regarding the study of psychopathology more specifically, characteristics of clinical contexts, populations, and the assessments themselves have the potential to exacerbate self-report bias. Regarding clinical assessments, these measures are particularly likely to involve socially sensitive topics—including items assessing self-harm, trauma, and substance use—and so are especially vulnerable to misreporting (Kelly, 1998; Tourangeau & Yan, 2007; Yeater et al., 2012). Beyond the assessments themselves, clinical contexts can be linked with the perception of secondary gains surrounding measurement outcomes, leading to substantial concern surrounding underreporting or overreporting on clinical measures (Berry et al., 1991; Rees et al., 1998; Schretlen, 1988). Finally, clinical populations comprise individuals exhibiting diverse levels of functioning, with specific forms of psychopathology being defined in part or in whole by skill deficits that would substantially affect self-reports. These include deficits along domains core to accurate reporting, including impaired verbal expression, impaired attention, lack of insight, and propensity toward deceit (Ditzer et al., 2023; Lilienfeld & Fowler, 2006; Williams et al., 2008). In sum, although self-reports are widely employed in clinical psychology, clinical psychology is arguably a discipline that should be uniquely concerned with the biases associated therewith.
Given the well-documented forms of bias linked with subjective assessment, why has clinical psychology so often turned to self-reports, including to measure constructs well beyond those that might be considered inherently experiential? One possible answer to this question is the lack of perceived alternatives available within the field. Although biological researchers have recourse to brain scans and biological assays, objective assessment options available to psychosocial researchers have historically been relatively sparse. Regarding the measurement of behavior, direct assessment has often relied on the application of human-based coding systems (Bakeman & Gottman, 1997), an endeavor that can consume hundreds and sometimes thousands of hours for a single-participant sample (e.g., Ekman et al., 2002). Regarding the measurement of context, no established systems currently exist for the objective assessment of participants’ everyday environments (Ariss et al., 2025; Rauthmann et al., 2014). Studies of personality/traits have sometimes sought to address issues of subjective bias via informant reports, a practice that can yield valuable information yet is associated with its own form of subjective bias (McDonald, 2008). Finally, although physiological data can often be valuable, the output from physiological sensors is often highly complex, and thus links between such sensor output and underlying psychological processes have been difficult to disentangle (e.g., the relationship between skin conductance and stress; Dawson et al., 2007). In sum, in many cases, researchers in clinical-psychological science have turned to self-reports because it has been challenging to conduct adequately powered, affordable, and interpretable research using other methods. Yet with the advent of new machine-learning-model types, automated measurement options available to behavioral researchers are likely to rapidly expand, resulting in a substantially more diverse tool kit of methods for use in psychological science. In this article, coauthored by a behavioral researcher with a doctorate in clinical psychology (C. E. Fairbairn) and a machine-learning researcher with a doctorate in computer science (N. Bosch), we offer a cross-disciplinary perspective on these methodological developments.
Machine Learning
Machine learning is a branch of data science in which algorithms learn to make predictions directly from patterns observed in data without requiring explicit programming. In contrast to conventional statistical approaches, wherein the relationship between variables is first theorized and then imposed on the data by the researcher (e.g., linear relationship between predictor and outcome), machine-learning models learn relationships directly from observed patterns in the data themselves. Machine-learning models in fact undergo an explicit “training” stage, wherein a model is exposed to observations (“training data”) and subsequently learns associations in the context of these data. Machine-learning models tend to be exceptionally flexible and well suited to capturing complex associations, including nonlinear relationships and interactions among multiple predictors, especially when the shape of associations is unknown or too complex to be prespecified. Thus, machine-learning models can have particular utility when applied to data that might be characterized as unstructured or organic in nature (e.g., text from webpages, speech in audio recordings, or image data), a data type that often yields highly complex data sets in which the number of features (i.e., predictors) is large and patterns are best recognized through an understanding of multiple variables and variable interactions (e.g., how pixels work together to represent an object in an image; Adjerid & Kelley, 2018; Tay et al., 2022).
Many in psychology are familiar with the enthusiasm (even “hype”) that surrounds the field of machine learning. Yet less well understood is its larger history, including roots spanning back more than 80 years (McCulloch & Pitts, 1943) and particularly relevant, the rapid rate of progress that has distinguished the years since 2012 (Holzinger et al., 2018; Maclure, 2020). The field has in fact seen epochs characterized by highly divergent levels of success and public enthusiasm, encompassing periods of intense acceleration and also lackluster progress (Norvig & Russell, 2021). According to many, progress in machine-learning application had reached a plateau in the years before 2012, with automated systems failing to reach human performance levels across a variety of key task domains. However, within the past decade, a subclass of representational machine-learning models known as “deep learning” experienced a resurgence (LeCun et al., 2015), ultimately heralding an era of unprecedented progress for artificial-intelligence (AI) 2 application.
Deep-learning methods were proposed by LeCun and colleagues in the 1990s, although it took nearly 2 decades and the introduction of fast graphical-processing units for the promise of these methods to be realized (LeCun & Bengio, 1995; see Norvig & Russell, 2021). Deep-learning methods are characterized by multiple hierarchically organized structural levels, each of which constitutes a “layer” of representation for pattern decomposition (LeCun et al., 2015). Whereas traditional machine-learning models required sophisticated “feature engineering” of raw data into high-level, semantically meaningful units by the programmer before analysis, deep-learning methods were unique in that they could automatically detect patterns in low-level raw data itself, leading to programs capable of detecting patterns at a complexity level not previously possible. In 2009, deep-learning methods achieved high accuracy on a standard speech-recognition task (Grove et al., 2000; Mohamed et al., 2011), and several years later, in the context of the widely publicized ImageNet competition, a deep-learning-based program nearly halved error rates for image recognition (Krizhevsky et al., 2012). This period also gave rise to developments in methods for controlling model complexity, increasing the likelihood that results of complex models would generalize to new data sets (e.g., regularization; Tian & Zhang, 2022). Finally, this epoch ultimately gave rise to the advent of generative AI—a form of deep learning model capable of creating original content. Reflecting these developments, the years since 2012 have sometimes been referred to as the “AI Spring,” marking a period of notable growth for the field of machine learning: AI publications increased 20-fold between 2010 and 2019, error rates for image-based object detection improved from 28% in 2010 to 2% in 2017, and language-based question-answering accuracy had exceeded that of humans by 2019 (Norvig & Russell, 2021; see also the AI Index website, aiindex.stanford.edu).
Clinical-psychological researchers were quick to recognize the potential of machine-learning methods for identifying people at risk for negative mental-health outcomes (Dwyer et al., 2018; Walsh et al., 2017; Yarkoni & Westfall, 2017) and for matching patients to clinical interventions (Delgadillo & Gonzalez Salas Duhne, 2020; Webb et al., 2020). The question of machine-based prediction is not one that is new in clinical-psychological research as, for decades theorists and researchers have pondered the relative utility of “mechanical” (e.g., algorithmic, numbers-based/automatic) versus clinical (e.g., human/subjective) prediction of mental health (Grove et al., 2000; Meehl, 1954). In the present day, machine-learning methods have gained attention through their application in studies seeking to predict clinically relevant outcomes using standard survey data types (Belsher et al., 2019; Kuo et al., 2024; Passos et al., 2016; Vieira et al., 2022; Walsh et al., 2017; Yarkoni & Westfall, 2017) and in some instances, their lackluster performance and/or problematic application (Christodoulou et al., 2019; Jacobucci & Grimm, 2020; Jacobucci et al., 2021).
To this point, the most widely cited machine-learning applications in clinical psychology have often centered around the use of machine learning as an analytic/predictive tool applied to a standard set of predefined measures—for example, predicting suicide risk on the basis of survey responses. However, some of the most powerful machine-learning-model types currently available to researchers require both massive training data sets rich in instances (e.g., observations; Adjerid & Kelley, 2018; Bahri et al., 2024; Hestness et al., 2017) and reliably measured predictors (Jacobucci & Grimm, 2020), a group of attributes unlikely to characterize even the largest of survey studies. Thus, the application domain for which machine learning is best suited arguably diverges from that for which it has to date received the most attention in clinical-psychological science: not in transforming the manner in which researchers analyze constructs of interest but rather by transforming the manner in which researchers measure these constructs to begin with. Put differently, in light of recent advances in deep-learning applications, machine learning may prove most revolutionary for psychological science not as a novel analytic technique applied to existing data sets but, rather, as a method for reimagining these data sets from the ground up.
With the advent of deep learning and enhanced regularization, machine-learning models have demonstrated strengths in three key application areas with implications for measurement in clinical-psychological science: (a) speech transcription and language understanding/analysis, (b) analysis of images, and (c) recognition of patterns in complex time-series data. Below, focusing on these three areas of application, we review impactful automated-measure developments relevant to behavioral scientists. In the context of this review, we focus on specific content domains high in observability/externality (Vazire, 2010). Specifically, our review focuses on measures of social processes, behavior, and situation/context. Of note, this review is not intended to be comprehensive—in light of the pace of progress in the field, such a reference would be dated immediately upon publication—but is rather aimed at offering a broad overview of key advances relevant for psychosocial/behavioral researchers. For a summary of core domains of progress and associated publications and tools, see Table 1. A narrative summary of selected research is provided below.
A Noncomprehensive Review of Machine-Learning Applications Relevant for Behavioral Researchers in Clinical-Psychological Science

Note: Studies reflect a mixture of application (in which a preexisting model/tool is applied) and validation (in which a model is trained and/or its accuracy is assessed) studies and studies integrating elements of both. “Ground truth” reflects the metric used to validate and train automated measures. In cases in which models were unsupervised, no ground truth is listed. The above review focuses on automated models that might offer alternatives to closed-ended reports and therefore does not cover applications of machine learning to strictly biological constructs (e.g., genetic or neuroscientific data). We focus here on the measurement of constructs high in externality/observability. Machine learning has also been applied to data derived from external indicators of internally experienced state- and trait-level constructs (e.g., emotion, cognition, personality, symptoms). For a noncomprehensive review of these applications, see the Supplemental Material available online.
Regarding language, within the past several years, machine-learning algorithms have emerged capable of understanding speech at high accuracy; novel programs avoid common transcription errors observed in earlier iterations and are now also capable of identifying changes in speakers in social exchange (PoornaPushkala et al., 2022). Advances in speech recognition have come hand in hand with advances in language analysis. Recent automated tools are capable of the rapid analysis and categorization of large quantities of unstructured written text, a data type that previously posed formidable analytic challenges for human coders. These developments have yielded a subfield of machine-learning application often referred to as “natural language processing” (NLP). NLP has been employed for the analysis of various features of language, from broad emotional tone (e.g., positive, negative, neutral) to the content and structure of speech (e.g., pronoun usage, beliefs on a specific topic). These advances in both spoken-language transcription and language analysis have packed a powerful one-two punch for the examination of social processes in clinical research, having been employed successfully for the assessment of expressed empathy (Xiao et al., 2015), alliance (Goldberg et al., 2020), stereotyping (Nicolas et al., 2022), and therapist fidelity and effectiveness (Althoff et al., 2016; Atkins et al., 2014). In even more recent developments, large language models (e.g., ChatGPT)—a deep learning application based in generative AI—have been leveraged to analyze the content and form of social communication. Trained on text corpora of unprecedented size, large language models have been successful in detecting characteristics of social media posts, such as sentiment, expressed emotion, and offensiveness, with high accuracy levels (Rathje et al., 2024).
In the domain of image analysis, machine-learning models have been developed with accuracy levels that exceed that of humans for the recognition of elements in videos and photographs (e.g., object and face recognition; LeCun et al., 2015; Norvig & Russell, 2021). Such algorithms can be used for the swift and accurate detection of a variety of elements of the physical environment, from the level of overall lighting (e.g., dim, bright) to the position of objects in the physical surroundings to the nature of activities being performed to the size and composition of social groups. Leveraging these advances, tools for image analysis have been applied to photographs and videos taken by participants in everyday life to identify context-level drivers of psychological disorder and disorder symptoms, including setting-level predictors of heavy drinking (Ariss et al., 2025; see also Redmon, 2016). Also in the realm of image analysis, machine-learning models have been employed for the examination of a range of social processes, including socially expressed emotions (e.g., smiles) and affiliative behaviors (e.g., physical proximity). Regarding the latter of these, algorithms have been developed with high accuracy for recognizing human body position and posture from images (Cao et al., 2019). Such posture-detection algorithms have been employed for a variety of purposes, including for the analysis of factors affecting changes in physical proximity (i.e., social distance) among participants in social exchange from video recordings (Gurrieri et al., 2021).
Finally, specific types of psychophysiological data can manifest as dense time series, featuring individual series spanning thousands or even millions of observations and characterized by complex temporal fluctuations (i.e., Big Data in the “temporal” sense; Adjerid & Kelley, 2018). In such data, parsing signal from noise—recognizing meaningful temporal fluctuations—has represented a challenge for conventional statistical methods relying on theory-derived models (Dawson et al., 2007; Fairbairn & Bosch, 2021). Automated methods have been developed that can quickly extract hundreds of over-time features from such time-series data (e.g., slope, number of peaks, cyclical elements; Christ et al., 2018). These extracted features can be entered into machine-learning algorithms to yield models capable of accounting for complex interactions between over-time processes in a manner not possible using conventional analytic approaches (Fairbairn & Bosch, 2021). When larger data sets are available for model training, deep-learning methods reduce this two-step process into a single stage, directly learning features from over-time patterns in the data set itself and so being capable of more flexibly extracting patterns uniquely predictive in the data set versus constrained by a predefined set of features. Machine learning has been employed to analyze and extract a range of behavioral indicators from such time-series data, including everyday activities and eating behaviors from accelerometer data (Ordóñez & Roggen, 2016; Thomaz et al., 2015), sleep duration and sleep stage from multisensor data (Boe et al., 2019), and alcohol-use episodes from sweat-based sensors (Didier et al., 2023; Fairbairn & Bosch, 2021; Fairbairn et al., 2020, 2025).
In sum, progress in the field of machine learning over the past decade has been rapid, giving rise to new methods well suited to the recognition of complex patterns in unstructured data. These novel methods have limitations, including the potential for bias and lack of transparency, and accuracy levels vary across applications (see Weighing Risks and Benefits section below). Machine learning has nonetheless yielded automated tools for assessing a range of constructs in clinical-psychological science, including through the analysis of speech, photographs, video, and physiological data. However, researchers in clinical psychology have tended so far to approach cautiously, with uptake rates for many of these methods not keeping pace with progress even as these tools exceed the accuracy of human coders. We next consider these novel tools in the context of the current measurement landscape of clinical research, giving specific consideration to the type of error linked with various measurement options and the potential for false-positive effects associated therewith.
Selecting a Method of Measurement: Common-Methods Bias and False-Positive Effects
As the field of machine learning was transformed by applications of deep learning, psychological science meanwhile underwent a transformation of its own. Often referred to as the “replicability movement,” the past several decades have witnessed a sharp rise in concern surrounding the prevalence of false-positive findings in psychological science (Open Science Collaboration, 2015) paired with awareness of the prevalence of research practices in the discipline that invite such outcomes (John et al., 2012; Simmons et al., 2011). Engagement with the replicability movement in clinical-psychological science was somewhat delayed from its initial inception in the field at large (Tackett et al., 2017). Nonetheless, and driven in part by concern surrounding low reliability of clinical diagnoses (Frances & Widiger, 2012), awareness surrounding harm linked with false-positive effects has increased among researchers of psychopathology (Miller et al., 2025; Tackett et al., 2017, 2019). Highlighting the importance of both direct and conceptual replications, the movement brought to the fore potential reputational damage and also lost time and resources linked with false-positive findings (Francis, 2014; Gelman & Loken, 2013; Simmons et al., 2011). In a field in which such wasted resources might translate to the prolongation of suffering among individuals in need, the stakes of such false-positive effects in clinical psychology might be considered especially high. Thus, clinical scientists have advocated for vigilance surrounding research methods that might systematically inflate associations, including methods employed for the initial measurement of constructs.
Although concern has risen among clinical-psychological researchers surrounding false-positive findings, discussion has been ongoing in various psychological subdisciplines concerning potential inflationary effects associated with self-reports (Bagozzi & Yi, 1991; J. R. Edwards, 2008; Francis, 2014; Podsakoff et al., 2012). The process of responding to a self-report measure is a complex social-communicative act that relies on the functioning of multiple discrete stages of cognitive processing, including question interpretation, memory retrieval, judgment formation, and response selection (Nisbett & Wilson, 1977; Tourangeau, 1984). In moving through these stages, participants engage with self-reports not simply as a means of information transfer but, rather, as a process for social communication, influenced by all of the interpretative challenges involved therein (Schwarz, 2007). Such a process requires participants to not only interpret the literal meaning of the question but also to make inferences surrounding the questioner’s intent, including integration of a given question with other questions and with additional contextual information offered in the assessment context (Schwarz, 1999). Thus, self-reports can be influenced by a range of factors beyond the content targeted by the question itself, from participants’ state- or trait-based self-reflective capacity (Andrews & Herzog, 1986; Knäuper et al., 1997) to their response style (Couch & Keniston, 1960) to the order and phrasing of questions (Schwarz et al., 1991) to the letterhead a given survey was printed on (Norenzayan & Schwarz, 1999) to architectural and structural features of the setting in which reporting takes place (Chaikin et al., 1976). Given cognitive and communicative challenges evident in many clinical populations and the sensitive and (sometimes) cognitively taxing nature of some clinical-assessment contexts, the potential for influence by such extraneous factors can run particularly high in the study of psychopathology. The type of error linked with such measures might be systematic in nature, leading to significant associations linked not only with underlying constructs but also with the manner in which these constructs were measured (Campbell & Fiske, 1959).
Variability in measured constructs can be divided into three discrete elements: variability in the true underlying construct, random error variance, and systematic error variance. In the examination of relationships between multiple variables, significant correlations can emerge attributable to not only shared variation in the underlying constructs but also shared systematic forms of error linked with the method of measurement (see Fig. 2). This type of error covariance, often referred to as “shared-methods bias” or “common-methods bias,” has long been documented across various psychological subdisciplines as a major factor influencing results of behavioral research (Campbell & Fiske, 1959; J. R. Edwards, 2008; Podsakoff et al., 2003). As observed by Campbell and Fiske (1959), measures that use the same method to measure different constructs will often produce more similar results than do measures that assess the same construct using different techniques. In light of the ubiquity of questionnaire and interview methods and the specific systematic forms of error associated therewith, concern has been particularly high surrounding potential effects of common-methods bias as these relate to self-reports (Bodner, 2006; Podsakoff et al., 2012). In hypothetical terms, common-methods bias might either magnify (inflate) or diminish observed effects, depending on the size of the true underlying correlation in relation to the size of shared systematic forms of error. However, when examined with respect to studies employing self-report methods in psychology, observed effects of common-methods bias have been overwhelmingly inflationary. A mega-analysis of 233 bivariate correlations from 59 meta-analyses estimated common-methods inflation rates ranging from 120% to 160%, depending on the specific domain of methods overlap (shared reporter vs. shared time point; Podsakoff et al., 2024).
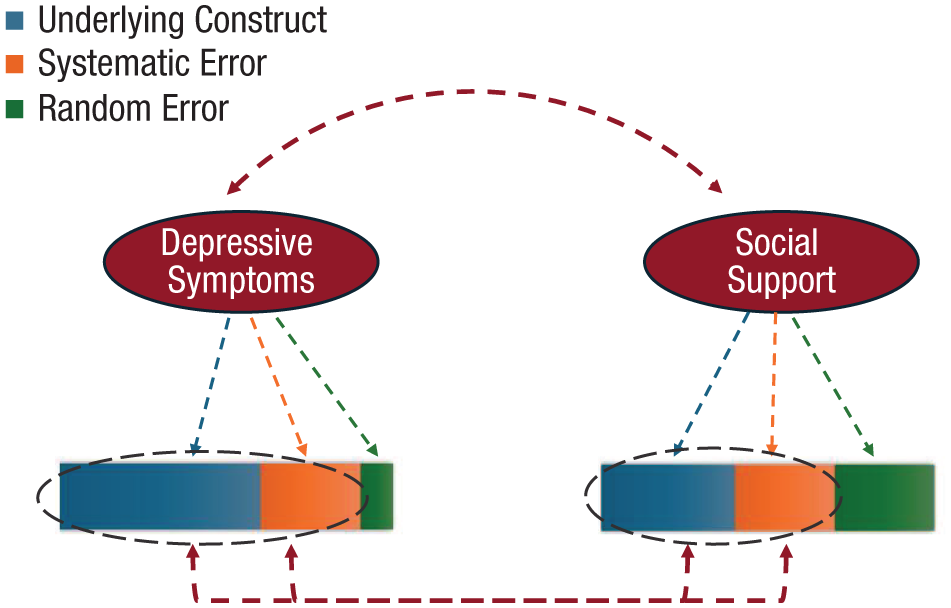
Example of common-methods effects on correlations between measured constructs in clinical-psychological science. Variability in measured constructs can be divided into three elements: variability in the true underlying construct, random error variance, and systematic error variance. In the examination of relationships between multiple variables, significant correlations can emerge attributable to not only shared variation in the underlying constructs but also shared systematic forms of error linked with the method of measurement (see also Podsakoff et al., 2024). Negative affect represents one contributor to common-methods effects in self-report studies, influencing participants’ reports of not only their internal subjective state but also others’ behaviors, past events, and attitudes.
Clinical psychology is notable as a subdiscipline in which discussion of common-methods effects has been relatively scarce, yet the potential for bias linked with these effects runs high. Several factors point to a potentially outsized influence of common-methods bias in clinical psychology, including the ubiquity of self-report assessments and the amplification of specific drivers of common-methods effects in clinical-assessment contexts. Regarding the latter of these, factors that have been established or theorized as potential contributors to common-methods bias include participants’ affective states (Watson et al., 1987), social-desirability concerns (A. L. Edwards, 1957), implicit theories (Eden & Leviatan, 1975; Nisbett & Wilson, 1977), consistency motifs (Podsakoff & Organ, 1986; Schmitt, 1994), and response style (Baumgartner & Steenkamp, 2001). In light of the (often) sensitive nature of clinical assessment and the characteristics and deficits observed in clinical populations, each of these elements has the potential for amplification in research on psychopathology. Specifically, pronounced state- or trait-level affect (e.g., depression) has long been proposed as a source for common-methods effects, often leading individuals to respond to all self-report items in an affect-consistent manner, including items extending well beyond mood to include current events, behaviors, and attitudes (Thoresen et al., 2003; Watson et al., 1987). Furthermore, self-report items in clinical investigations are especially likely to trigger social-desirability concern (e.g., sensitive items; Tourangeau & Yan, 2007), potentially leading individuals to respond to items in a manner most likely to cast themselves in a positive light, irrespective of item content (A. L. Edwards, 1957). Third, in light of the perceived urgency and centrality of mental-health problems among many clinical samples, studies of psychopathology may be especially likely to concern topics surrounding which participants have their own fully crystallized lay theories (i.e., “My drinking and my marital stress are related”), leading to self-report studies that reflect primarily the prevalence of these implicit theories rather than true underlying relationships (Schleider et al., 2015). In addition, in clinical-assessment contexts, cognitive resources available for processing individual items in self-reports may at times be diminished (Bruijnen et al., 2019; Robinson et al., 2006), leading participants to rely more heavily on consistency motifs and/or a specific response style (Podsakoff & Organ, 1986; Schmitt, 1994). Finally, beyond these established contributors to common-methods bias, the (real or perceived) instrumental consequences associated with clinical-assessment contexts might yield drivers of common-methods bias unique to the field, including malingering and (related but less widely discussed) distress broadcasting (Berry et al., 1991; Rees et al., 1998; Schretlen, 1988), each of which might lead participants to report symptoms broadly across domains in a manner that artificially inflates associations yet fails to capture true underlying links.
To address the prevalence of common-methods effects in published research in clinical psychology, we return to the results of our journal review. As noted previously, self-reports were the most common measure type in reviewed studies, outpacing the highest frequency alternative measure type by a factor of nearly 6 (see Fig. 1). Most pertinent to the question of common-methods effects, of 386 nonexperimental studies coded, 209 (54.1%) tested primary hypotheses via an analysis that examined relationships between two closed-ended self-report assessments. To assess the extent to which this potential source of bias had received attention, we conducted a search for “common-methods effects” and related terms 3 in these same three journals for the same span of years. This search indicated that in a field in which more than half of the articles rely on a single method type for primary hypothesis tests, none mentioned shared-methods bias in the article abstract, and fewer than 5% (n = 20) mentioned these terms anywhere in the full text. In sum, attention to common-methods effects in clinical-psychological science appears to be low, whereas the potential for bias because of these effects is high. Such a measurement landscape points to the utility of alternative measurement types beyond self-reports. Although such options in the past might have been sparse, automated tools may ultimately represent a game changer for expanding measurement options in clinical-psychological science.
Recommendations for Researchers: Weighing Risks and Benefits
In this article, we urge researchers to reimagine the principal place of machine-learning methods in clinical-psychological research: from a tool useful primarily at the stage of data analysis to one useful also for the initial measurement of constructs. At the same time, it is important to consider these automated measurement tools in the context of their limitations. First, machine-learning models often trade increased accuracy for reduced transparency. Although it is possible to understand machine-learning output in a manner that breaks down which variables in the model were most impactful in determining predictions, such explanatory models typically leave many questions unaddressed, including the exact means by which a variable influenced the outcome and the nature of the relationship (Rudin, 2019). Thus, machine-learning models are poorly suited for use cases in which knowledge of the processes through which a measurement was made is essential (e.g., insurance-coverage eligibility, legal proceedings; Vollmer, 2020). Furthermore, accuracy rates for machine-learning models vary widely across areas of application, often dependent on the size, representativeness, and measurement type reflected in the data set available for model training. These models are typically trained and curated on data sets created by humans and thus often contain biases and representational imbalances, including imbalances along contextual and person-level factors (Belitz et al., 2021; Tay et al., 2022). Compared with conventional (“top-down”) statistical and measurement approaches, data-driven models, such as machine learning, are particularly sensitive to characteristics of training data, and thus, final models will reflect biases and errors contained in data sets used in model training. Finally, machine-learning models have the potential to yield systematic forms of error in cases in which they are misapplied (Jacobucci & Grimm, 2020). Many psychologists lack training in the application of machine-learning methods, and thus, collaboration with data scientists or psychologists who have specifically developed skills in applying these methods may be required to protect against such errors.
Regarding the vulnerability of machine learning to specific inflationary effects described above, a range of measures has been employed as the label (i.e., target or ground truth) used for training and validating machine-learning models, including closed-ended self-reports (see Table 1). Each of these measure types is linked with its own potential measurement errors. To some extent, it seems apparent that machine-learning models may recreate the same measurement errors present in the labels used during training because models are indeed supposed to learn to replicate those labels. However, note that “leakage” of self-report bias into the newly trained automated measure requires that a given source of bias is discernable not only in the self-report measure but also within the predictors (i.e., features) in the machine-learning model. In practice, measurement biases in the labels are due to numerous factors (e.g., various cognitive biases in self-reports), including some that are not present in the features (e.g., unmeasured contextual factors). Thus, effects of common-methods bias are likely to be substantially mitigated if not wholly erased in the context of such automated assessment tools, even those trained on a self-report as ground truth. 4
The question of whether machine-learning methods are relevant to any specific research project is a complex one, requiring consideration of details of both the study itself and the specific automated tool in question. For a framework for approaching this process, see Table 2. In the event a study involves examining relationships between two or more measured variables and one of these variables is already assessed using closed-ended self-reports, then our recommendation is that researchers consider expanding beyond survey methods for measuring the remaining variables. The need for measurement diversification becomes particularly urgent for cases in which the experimental context features elements likely to exacerbate shared-methods effects (e.g., sensitive questions, evaluation/stigma concern, limited cognitive capacity, positive or negative affect) and/or features affecting the validity of self-reports (e.g., perception of secondary gains or punishments, studies targeting primarily automatic processes, populations with low verbal/expressive ability).
Key Questions for Selecting Method of Measurement in Psychological Research

Regarding measures that expand beyond self-reports, a broad range of behavioral, psychophysiological, lexical, and other methods have long been established capable of assessing constructs of interest in psychological science (Bakeman & Gottman, 1997; Dawson et al., 2007; Ekman et al., 2002; Holmqvist et al., 2011). The validity of many such measures was established well before the advent of automated tools for assessment. Regarding the specific choice to apply machine-learning methods for measurement above and beyond these alternative tools, we recommend researchers consider two essential questions in approaching this decision (Table 2): (a) Is transparency surrounding the process of variable creation critical for the specific application in question? and (b) How accurate are current machine-learning models in measuring the identified constructs in representative data? Regarding the former of these questions, although machine-learning-based measures can be replicated via the rerunning of code, more complex model types cannot easily be explained or decomposed into component parts. In basic clinical research, the issue of transparency in measure creation is unlikely to represent a major concern. However, in specific domains of applied clinical science, transparency issues may come to the fore—for example, researchers seeking an indicator of recidivism that might be applied directly in the courts (Rudin, 2019). Regarding the latter of these questions, it is important to consider accuracy metrics in the context of the data employed in algorithm training. Although some machine-learning models can be trained on smaller data sets, more complex tasks require more powerful model types (e.g., deep learning) and thus exceptionally large data sets for model training. Thus, large data sets typically yield higher accuracy metrics. Note that although the size of the data set is often linked with the generalizability of the sample to novel measurement scenarios, this is not always the case. For example, for facial-recognition algorithms, although larger data sets are more likely to feature more faces of different races, many larger early training data sets still involved a remarkably low proportion of non-White individuals (Tay et al., 2022). Therefore, not only the size of the data set but also its diversity and generalizability to the specific use case is relevant for interpreting accuracy metrics. Finally, many automated tools are developing at a rapid rate, particularly in the broad area of deep learning. Therefore, an accuracy metric at a given moment in time is exactly that—accuracy at that moment in time. In the event accuracy metrics fail to meet expectations for a given measure type, it may be worth revisiting the literature in the (near) future to establish the extent to which such performance metrics improve.
Other considerations may be relevant to the question of whether machine-learning measurement tools warrant consideration. Depending on the research environment and domain of measurement application, machine-learning methods might offer specific advantages beyond other available assessment tools. In some cases, machine-learning tools might offer enhanced accuracy. For example, accuracy for automated object and image analysis now exceeds that of the average human coder (Norvig & Russell, 2021). Advantages might also include that of consistency because automated methods are not reliant on the strength or training of a specific collection of individual human coders on a research team and thus have the potential to “smooth over” rater idiosyncrasies and yield measures with superior psychometric properties (Hickman et al., 2025). Finally, machine learning can often offer pragmatic advantages, facilitating free or (comparatively) low-cost application and/or completing tasks in a matter of seconds that might take a team of human coders months or even years to complete.
Finally, note that although interpretation of automated models may in some cases be facilitated when these algorithms are applied to the measurement of characteristics considered “observable” in nature (e.g., Table 1), these methods have nonetheless been applied to the analysis of a wide range of features beyond the inherently extrinsic. A variety of data sources, from behavior to language to psychophysiology, have long been employed as external markers of internal psychological characteristics, including as measures of personality, cognition, emotion, and psychiatric symptoms. These have included, among many others, eye-tracking measures for the assessment of attentional focus (Ariss et al., 2023; Holmqvist et al., 2011), observer ratings of personality (McDonald, 2008), and facial and prosodic measures of emotion (Bakeman & Gottman, 1997; Caumiant et al., 2025; Ekman et al., 2002; Fairbairn et al., 2015). In such investigations, wherein inherently internal characteristics are inferred via extrinsic/observable cues, a machine-learning model would be considered as acting in a role analogous to the informant in studies employing observer reports of personality, inhabiting a valuable yet singular (often context-dependent) lens for viewing the subjects’ characteristics that reflects one among several potential perspectives (Brunswik, 1956; Tay et al., 2020). For cases in which constructs of interest might be considered inherently experiential and thus reports of internal experience are of central importance, NLP approaches can be applied to unstructured text derived from participants’ written entries or transcribed interview responses, circumventing issues of classification linked with traditional forced-choice self-report items. Thus, automated analysis of both written and spoken text have been used to derive indicators of a range of internally felt subjective experiences. For a selective review of machine-learning applications for the measurement of personality, emotion, cognition, and psychiatric symptoms/diagnoses, see Table S1 in the Supplemental Material available online. Finally, for a compilation of useful resources for psychologists starting out in the domain of machine-learning measurement, including reading recommendations and software packages/tools, see Table S2 in the Supplemental Material.
In sum, the question of whether to integrate novel automated methods for measurement will always be a complex one. Consideration should be given to the specific construct under investigation; potential bias (if any) linked with self-reports; availability of alternative, nonautomated measurement types; and the phase of development of the automated tool. In such circumstances, the draw to favor a flawed yet familiar survey measure can be strong. Yet the specific form of error linked with assessment type is a factor worthy of consideration—whereas error variance linked with automated assessment may in certain cases be sizable, systematic forms of error can result from overreliance on self-reports. Thus, in a field in which, among top journals, 87% of tests of primary study aims rely on closed-ended self-reports and concern surrounding research practices likely to yield false-positive findings runs high, measurement diversity should rank as a priority for the field.
Conclusion
With each major advent in scientific-measurement technology comes the siren song of hope (Borup et al., 2006; Maclure, 2020). From functional MRI to ecological momentary assessment to eye tracking, the arrival of new methods has consistently inspired exaggerated arguments surrounding their utility for psychological research—their ability to offer the long-coveted “window into the soul.” The draw of such inflated visions can be strong, especially in behavioral research, in which “soft” constructs are often of critical interest yet have long posed challenges for objective assessment (Meehl, 1978). Here, in considering the potential for automated methods of measurement, we offer no rose-colored view of the future but, rather, a vision of measures now. We argue that error from machine-learning models is likely to be substantial in some cases and that the exact size and nature of this error for all applications is currently unknown. Yet in a research landscape dominated overwhelmingly by survey methods vulnerable to systematic forms of bias, these new tools may offer clinical scientists a relatively unglamorous but nonetheless precious “lesser of two evils.” By offering a source of error more likely to serve as noise compared with confound, we posit that the past decade of development in automated assessment techniques could ultimately prove a point of inflection for measurement in clinical-psychological research.
In sum, clinical psychology has long been characterized by a focus on self-reports. This emphasis may spring in part from the nature of clinical constructs, which can manifest as inherently subjective in nature. In other cases, reliance on self-reports springs from a lack of viable alternatives for behavioral researchers. Here, we review advances at the intersection of computer science and clinical psychology in which recent developments bid fair to expand measurement tools for researchers of psychopathology, offering paths toward a methodologically varied, replicable, and reputationally sound field of clinical-psychological science.
Supplemental Material
sj-docx-1-cpx-10.1177_21677026251379441 – Supplemental material for Applying Artificial Intelligence to Expand the Measurement Tool Kit in Clinical-Psychological Science: Moving Beyond Self-Reports
Supplemental material, sj-docx-1-cpx-10.1177_21677026251379441 for Applying Artificial Intelligence to Expand the Measurement Tool Kit in Clinical-Psychological Science: Moving Beyond Self-Reports by Catharine E. Fairbairn and Nigel Bosch in Clinical Psychological Science
Footnotes
Transparency
Action Editor: Alexander Shackman
Editor: Jennifer L. Tackett
Author Contributions
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.