
Abstract
Clinical psychological science combines multiple measurement traditions, which can create hidden translational gaps in which mismatches in methods and constructs go unnoticed. Here, I discuss reliability as an example of a hidden gap between disciplines, drawing from my own career adapting experimental cognitive tasks for clinical research and the personal challenges of confronting methods limitations. Now, as the field moves toward within-person (e.g., idiographic) approaches, researchers face potential new gaps as they adapt measures from experimental and individual differences research. Bridging these gaps will require even broader multidisciplinary collaboration and awareness of the boundaries between methods.
Keywords
Modern clinical psychological science is a chimera of disciplines, glommed together around the common goal of understanding, predicting, and ultimately addressing mental disorders. Many high-level frameworks that guide clinical psychology represent a landscape of disciplines that combine across different measurement methods and analytic approaches. The National Institute of Mental Health Research Domain Criteria (RDoC), for example, is based on the premise that research on mental disorders must integrate across levels of analysis from genetics to neural mechanisms to behavior (Cuthbert & Insel, 2013). Because clinical psychological science must include an understanding of adaptive mechanisms and their disorder, researchers’ work therefore involves the constant integration of models and paradigms from basic science.
Yet even as this integration expands scope, it can obscure key translational gaps in which methods, concepts, and best practices do not align cleanly across disciplines. These gaps are often hidden behind shared terminology and familiar paradigms, where they quietly constrain the questions researchers can ask, the inferences they can draw, and the robustness of the science.
In this article, I focus on measurement reliability as a hidden translational gap—a single term whose meaning shifts as the field moves focus from basic mechanisms to individual differences and now, toward dynamic and idiographic methods. Idiographic methods focus on the measurement and analysis of intraindividual differences, or differences that occur within a single individual over time (Molenaar, 2004). I describe how my own experience of this measurement gap shaped my scientific trajectory and how such gaps arose from the history of the field’s measurements. And as the field’s science expands to include new analytic and data-collection methods, it is critical to be aware of new and emerging translational gaps and develop a better shared understanding of what makes a measure meaningful.
A Retrospective on Reliability and Small Effects
I entered graduate school in clinical psychological science in the mid- to late 2000s, in the middle of an information revolution. A ubiquitous global internet, enabled by social media and personal digital devices, was rapidly expanding the reach of many psychological-research methods. This meant that an enthusiastic graduate student with some programming skill could build software, connect it to the open internet, and collect data from large samples across the world at very little cost. I took advantage of the moment and began running experiments with thousands of participants using remotely administered cognitive assessments.
Because I was particularly interested in specific and dissociable mechanisms that might underlie common mental disorders, my work required methods translated from experimental psychology. As a conscientious early psychologist, I made sure that any experimental task that I programmed worked: that is, between-conditions effects replicated in both direction and magnitude. But in experiment after experiment, cognitive information processing rarely explained any appreciable variance in symptoms or psychiatric risk, even in my very large samples. Explaining 1% of the variance in symptoms was the best case (Germine & Hooker, 2011) and could not provide the basis of an explanatory framework for mental disorders.
As an early adopter of remote-assessment technology, I assumed the problem was me. Perhaps it was a limitation in my programming skills or the uncontrollable and therefore problematic behavior of my participants, who were likely drunk and watching porn (this radical multitasking hypothesis was proposed by a very skeptical senior colleague). Over time, my file drawer of tiny, hard-to-publish effect sizes became a file cabinet. All of this led to a crisis of confidence that I could fail to make progress even with so much data available to me.
At the same time, psychological science was going through its own period of introspection. As open-data practices and larger samples became widespread, reproducibility concerns dominated conferences and major journals, including concerns about power (Button et al., 2013) and effect sizes too large to be credible (Gelman & Carlin, 2014). These culminated in an article from the Open Science Collaboration (2015) estimating that only about a third of results from psychological science might be reproducible. Even in cases in which significant effects were replicable, information-processing differences rarely accounted for substantial amount of variance in illness risk or symptom expression (Cyders & Coskunpinar, 2011; Enkavi et al., 2019; Paulus & Thompson, 2019), especially in large samples that were less vulnerable to Type M error (Gelman & Carlin, 2014).
In my late graduate and then postdoctoral years, I began collaborating more broadly with researchers in behavioral genetics and individual differences. From these expert collaborators, I learned how between-person reliability imposes a hard limit on how much variance could be explained in a particular characteristic. Between-person reliability (including internal consistency and test-retest) refers to how consistently a measure distinguishes between individuals in a population. A simple first approximation for calculating this kind of reliability in cognitive tasks is by looking how much scores calculated from two halves of a task correlate with each other (with a correction applied). The maximum correlation between any two measures cannot exceed the geometric mean of their reliabilities (Spearman, 1904). Once I understood this, I began calculating the reliability of every single cognitive task I had ever used. I discovered that cognitive tasks that used difference scores or residuals—mainstays of experimental psychology—had reliability that was consistently and sometimes considerably lower than traditional neuropsychological measures (Passell et al., 2019). The more specific the mechanism, the less reliable the resultant scores were (Hedge et al., 2018).
The graph in Figure 1 is about as close to a Eureka! moment as I have ever come in my career. It shows the association between attention-bias scores (a type of difference score) calculated from two halves of an emotional dot-probe task. Scores from the two halves were not correlated at all (Xu et al., 2025). Variations between people were indistinguishable from noise.
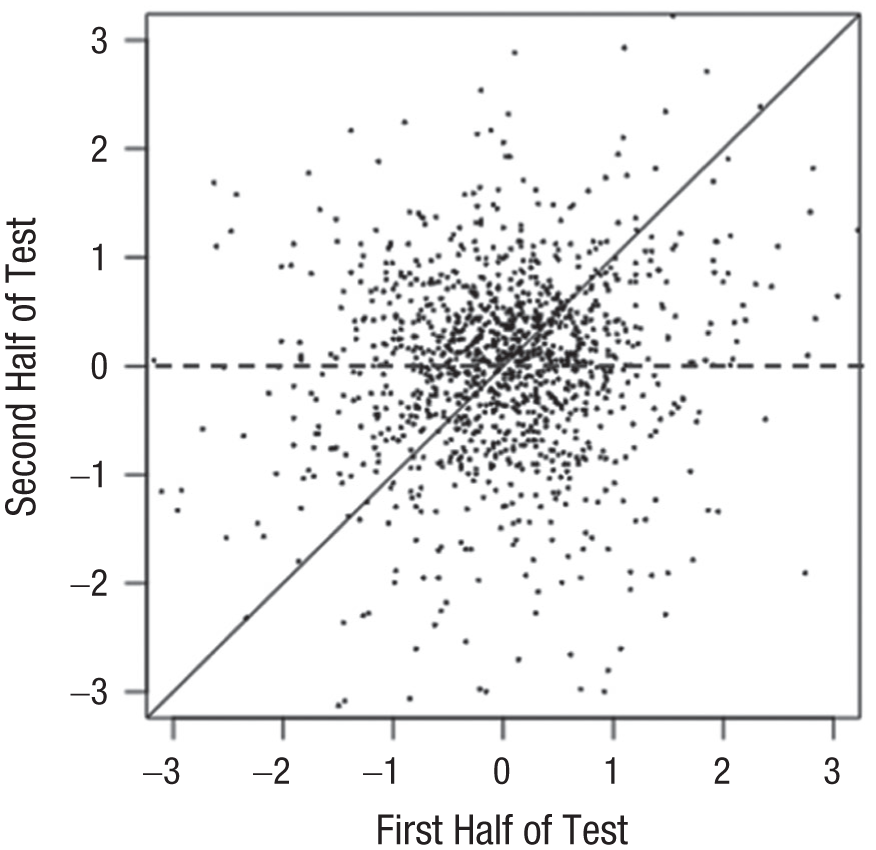
Association of scores calculated from two halves of an emotional dot-probe task.
There is clarity in finding absolutely nothing. The hardest part of a research career, for me, is when you find just enough of something to stay invested but not enough to have confidence—like the 1% variance explained that plagued my graduate years. But this was, truly, unequivocally, a total absence of signal. How could this be? To understand why, I take a brief segue into how the field’s measurement approaches developed and the translational gap that has still not been bridged.
A History of Cognitive Measurement
By looking at the history of how psychologists measure information processing, one can identify at least two broad traditions that shape current approaches. The first tradition emerged from experimental psychology and psychophysics, basic science disciplines aimed at understanding the mechanisms that characterize human behavior, in general. This tradition focused on tasks and paradigms that elicit discrete, more or less objective, and precisely measurable responses to specific stimuli or changes in stimuli. In this approach, mechanisms can be inferred based on the difference in responses between two or more tasks or conditions. These tasks often relied on careful stimulus control and precise measurement of responses. The experimental tradition also assumed that any two reasonably healthy people were roughly equivalent to each other, and in early psychophysics, this was adequately represented by a reasonably affluent German man (Fechner, 1860; Wundt, 1874). Any differences between people were treated as noise, and the most robust paradigms were those in which all participants differed in the same way and to approximately the same degree, with little variance between people. The cognitive revolution of the mid-20th century further reinforced the centrality of such information-processing models, further integrating them with neuroscience and computational models of the mind that formed the basis of modern cognitive psychology (Miller, 2003).
At the same time experimental psychologists were characterizing core information-processing mechanisms, a parallel psychometric tradition was developing, aimed at rank-ordering people based on their general cognitive abilities or intelligence. Such approaches for measuring cognitive abilities began as a way of identifying impairment (Seguin, 1866) and later to characterize the range of individual differences across the population (Galton, 1883). Psychometric assessments captured broad cognitive capacities that contribute to real-world functioning—capacities such as naming ability, vocabulary size, and memory span—and relied on paper, pencil, or other simple equipment that could assess many people and at minimal cost.
Psychometric assessment of cognitive ability really took off, however, in the context of military conscription and recruitment in World War I and, later, World War II. As men enlisted in the hundreds of thousands, it was necessary to determine—rapidly, at scale, and in a standardized fashion—who should be assigned to what roles to maximize military efficiency. Military cognitive assessment was entirely for the purpose of differentiating people from each other to identify those recruits who could (or could not) succeed in roles that required superior cognitive abilities (Yerkes, 1921). These approaches, developed to identify how people differed from one another, formed the foundations of modern educational testing, clinical neuropsychology, and behavior genetics. Unfortunately, these same data were later used to justify eugenics-related policies and practices (e.g., Brigham, 1922).
These two traditions were brought together in modern clinical psychological science, which included methods from clinical neuropsychological assessment but also came to rely on cognitive-behavioral models of mental disorders. The use of experimental tasks to test these models grew rapidly when personal computers became widely available in the 1980s and 1990s because these allowed psychologists to deliver highly controlled experimental paradigms with precise measurement of responses in almost any laboratory (Haxby et al., 1993; Schneider, 1988). At that point, experimental methods for capturing information-processing mechanisms took an even more central role. If mental disorders arise from information-processing mechanisms gone awry, this should be measurable based on differences in those same between-conditions comparisons that were used to characterize information processing more generally. The trouble is that much of the time, by design, such between-conditions comparisons are poorly suited for reliably capturing individual differences.
A Reliability Crisis and Widespread Recognition
Awareness of the translational gap between experimental and individual differences research is not new (Stern, 1900). The importance of psychometric reliability as a key metric and prerequisite for construct validity is also not new (Cronbach & Meehl, 1955). Despite this, many experimental tasks have been adapted for measuring clinically relevant individual differences without evaluating whether such translation is appropriate or psychometrically supported. Although concerns about reliability of the dot-probe task were first published 2 decades ago (Schmukle, 2005), the problem of reliability for experimental cognitive tasks has gained attention only more recently (Clark et al., 2022; Enkavi et al., 2019; Green et al., 2016; Hedge et al., 2018; Parsons et al., 2019; Zorowitz & Niv, 2023). Hedge et al. (2018) concluded it was exactly those experimental tasks that had the lowest variability in performance across individuals—making them excellent measures of between-conditions differences—that had the lowest reliability. Their analysis made it clear that many experimental cognitive tasks are poorly suited for measuring individual differences. More broadly, tools developed for studying brains and minds at the group or average level (to capture differences across conditions) could not be applied uncritically to the study of individual differences. The solution, however, is also clear. As Parsons et al. (2019) argued (conveniently in the title, so the message could not be missed) “Psychological science needs a standard practice of reporting the reliability of cognitive-behavioral measurements” (p. 378).
More recently, researchers have explored whether different scoring strategies, such as scores derived from computational modeling, might rescue reliability from paradigms such as the dot-probe task (Hochman, 2025; Price et al., 2019). The translational gap for such tasks thus may be bridgeable, although it remains to be seen whether such strategies can be adapted to provide generalizable and scalable approaches for scoring in clinical research and practice.
Collaborative Jingle
Greater attention to research rigor, reproducibility, open data, and increasing sample sizes has almost certainly contributed to the growing awareness of reliability concerns. But what took so long? One possible factor is a subtle but pervasive jingle that has emerged from two traditions. The jingle fallacy is the mistaken assumption that two constructs are the same because they share a label (Thorndike, 1904). A touch of jingle may help form communities and collaborations around adjacent interests, but it also hides disciplinary boundaries and perpetuates translational gaps.
Based on interactions with scientists from different disciplines, “reliability” does not always mean the same thing. Researchers trained in the experimental tradition may say a measure is “reliable” (used colloquially) if differences between conditions or tasks are replicable across studies. For folks trained in the psychometric traditions, a task is “reliable” if it captures consistent differences between people over time or across trials. These are different definitions of reliability.
Likewise, the same terms often refer to both general processes and individual variability in those processes. “Face recognition,” for example, describes both the process whereby people’s brains individuate and identify faces and variation in how well different people recognize faces.
Even constructs that refer exclusively to individual differences are often operationalized using a range of different methods, introducing jingle in cases where cross-method generalizability is poor. Impulsivity, for example, can be measured based on objective behavior from cognitive tasks or self-reported behavior from questionnaires. Yet these two methods tend to be poorly correlated, indicating that these two approaches are capturing different underlying constructs (Cyders & Coskunpinar, 2011; Hedge et al., 2020; Strickland & Johnson, 2021). Clinical psychology is especially vulnerable to these cross-method gaps because the field’s constructs are so high-level and challenging to operationalize and rely on commonly used words. Yet modern theoretical frameworks demand such integration across methods, disciplines, and levels of analysis.
At the same, another discipline-spanning translational gap is emerging. As researchers move from cross-sectional methods to dense longitudinal measurement, they carry the field’s jingle of terms and disciplinary assumptions with them into a new dimension of inquiry.
Measurements Across Time
I genuinely believe this is the beginning of an era of substantial progress in clinical psychological science. The same digital devices that enabled scalable assessment across individuals are now being used in labs worldwide to support high-frequency longitudinal measurement, capturing everything from symptoms to cognition, physical activity, and environmental exposures (Germine et al., 2021). Such methods can help characterize the experiences of individuals as they unfold over time and in the real world.
Yet researchers approach another translational gap as the field evolves into a science of dynamic measurement that better incorporates time. The measurement traditions that brought the field here—experimental and individual differences—assume constructs that are relatively stable. Any variation over time is treated as noise, degrading measurement of both between-conditions and between-person differences. Indeed, measures of individual differences are often selected based on high test-retest reliability and discarded if test–retest reliability is low (the approach I argued for in the prior sections). In this new measurement context, researchers risk repeating the same mistake and using measures that are by design poorly suited to their research questions. The field must now identify which measures are inadequate for identifying within-person effects and adopt standard practices, such as evaluation of within-person reliability—or how consistently a measure can quantify differences between time points within an individual. Computing within-person reliability involves methods that may be unfamiliar to many clinical psychological scientists, including application of mixed-effect, multilevel models or other methods developed for partitioning variance in intensive longitudinal or time-series data (Sliwinski et al., 2018).
The Future of Multidisciplinary Clinical Psychological Science
I have argued that clinical psychological science is inherently multidisciplinary and requires that researchers both work across traditional boundaries, such as those between experimental and applied fields, and recognize hidden translational gaps that emerge when those boundaries blur. This becomes even more important as clinical psychological science expands to encompass the complexity of the mind and its disorders as they unfold over time. New frontiers require new expertise to develop new best practices that can ensure scientific rigor.
It is also important to remember that any meaningful understanding of clinical syndromes over time must account for the messy social, environmental, and contextual variables that operate over time. As I write this in the United States in spring 2025, American scientists are working in a political environment that is openly hostile to research on social and environmental determinants of health. This includes factors such as discrimination, poverty, and toxic exposures that can profoundly and disastrously shape people’s lives. The already difficult work of building a multidisciplinary science becomes even harder when one denies that social and environmental contexts exist. My greatest hope is that these concerns are short-lived and that future readers will judge this paragraph as largely a historical footnote. In the meantime, it is even more critical that researchers support and uplift colleagues who are fighting the battle to understand how social and environmental factors contribute to poor mental health, knowing such factors disproportionately affect communities that (to the surprise of no rational scientist) are also disproportionately affected by mental-health disparities. These multidisciplinary collaborations will help identify and overcome translational gaps and ultimately accelerate progress in clinical psychological science toward reducing the burden of mental disorders.
Footnotes
Acknowledgements
Thanks to Jeremy Wilmer, my mentor in individual differences research and longtime friend, who has always been reliable.
Transparency
Action Editor: Alexander Shackman
Editor: Jennifer L. Tackett
Author Contributions