
Abstract
Following the early achievements in the U.S. space program, expectations (and demands) for future success became high, and the “achieve big things” mantra was largely replaced with “build reliable systems.” The approach to build reliable systems has been based on a combination of using a standardized set of building blocks and system reliability prediction methods. The demand to build reliable systems is certainly noble, but the aforementioned methods would form a trap that freezes technology to largely 1960s capability with support from a misused methodology that would further penalize any departure from the deemed-reliable building blocks. This article will frame the technical problem and resulting perils of imposing a probability of success requirement on a newly developed space system and provide a basis to discontinue the practice.
BACKGROUND
The history of electronics reliability prediction dates back to World War II as thoroughly described in. 1 The demand for reliable systems that were to be procured accordingly required reliability prediction methods as a precursor to establish the requirement. With electronic parts considered the weakest links in the chain based on the failure rates of vacuum tubes, MIL-HDBK-217 2 was drafted so that a reliability prediction approach would be available to support the imposition of reliability requirements. The convenience of predicting reliability using only parts lists and high-level representations of the system architecture would form a convenient and straightforward process to provide the highly valued probability of success and to impose a system requirement. As long as the traditional parts were used, any design could be sold to the government with a high-reliability declaration. Furthermore, the requirement could justify arbitrary actions by a contractor to increase the resulting Ps at extra cost, but with no actual benefit. In general, parts or handbook-based Ps estimates have never predicted actual system life-success rates. This is elaborated in numerous references with a pointer to physics of failure-based approaches that are not plagued by outdated notions about electronic parts.3–7
A List of Part Numbers Cannot Be Used to Predict System Reliability
Even with some detailed top-level information about the electronics design, part numbers are not sufficient or necessary to predict system reliability. First, part numbers do not in general specify the manufacturer or manufacturing location, and thus a part number is not sufficient to characterize the reliability of an individual part. Even with the same manufacturer and location, the reliability would be different in general in different time frames, particularly if the part is not manufactured under the same statistical process controls across the different time frames. More importantly, even with accurate reliability estimates for individual parts, parts cannot be used to determine system reliability, which leads to Theorem 1.
Of course, for practical purposes, the infinite part of this is not important, and the ultimate point is that part failures would only account for a very small percentage of ways the system can fail. Furthermore, for the limited history of on-orbit part failures (a small percentage of mission failures and anomalies) within NASA over recent decades, the parts did not fail due to a predicted failure mechanism represented accurately in a handbook but rather because of a gap or hole in a given MIL-SPEC, a handling or overtest issue, or a radiation event (or accumulation of events). While some handbooks, such as 217PLusTM8 include factors to account for events of that nature, they do not provide an accurate enough prediction to use to impose a requirement, and they do not distinguish the reliability of parts with common part numbers manufactured by two manufacturers with comparable quality practices. Most such handbooks indicate reliability credits for older technology parts or base them on the extensiveness of screening, suggesting that reliability can be screened into parts that were otherwise not reliable or less reliable (in fact, there is no established correlation between screening and field reliability). Last (but not least), it has long been established that parts in general are not the weak link in the chain. 9
The Notion That Imposing Ps Requirements Always Yields Good Results Is False
Most reliability engineers understand at least part of the fallacy of some handbook approaches for reliability prediction such as incorrect constant failure rate assumptions, 10 differences among part reliabilities of the same part number from different manufacturers, and so forth. Likewise, any user of MIL-HDBK-217 knows that the handbook itself states that it should not be used for absolute reliability prediction and that it should never be placed onto a contract (MIL-HDBK-217F NOTICE 2, 28 Feb 1995: THIS HANDBOOK IS FOR GUIDANCE ONLY—DO NOT CITE THIS DOCUMENT AS A REQUIREMENT). 2 Nonetheless, the ease in using such prediction methods based on the plethora of available tools, combined with the almost euphoric interest of government customers demanding such numbers, has sustained the original approach or variants thereof for decades, supported by the notion that even though the numbers might be “conservative” [sic], the enforcement of such requirements promotes better practices. Of course, this is under the reasonable sounding (but entirely misguided) assumption that the features, requirements, and products that lead to higher predicted reliabilities in the handbooks all lead to actual higher reliability. In fact, other than elements of fault tolerance (such as redundancy), there is no connection of such things to reliability of systems. This is particularly the case with MIL-SPEC grading (or no grading at all—COTS or custom) of EEE parts. Even those features that have a direct alignment with reliability such as failure rate levels have no practical connection to field failures of parts since parts in general are not used at their maximum rated values in any type of well-designed system. In practice, most electronic parts in space operate in temperature-controlled environments far more benign than, for example, automotive environments. What this approach has done is create a self-fulfilling prophecy that involves choosing parts based on their outdated notions of reliability, forming the predictions, and confirming the reliability of such parts. Then, when in most cases, the parts work reliably in the field, even if not consistent with the predictions, the approach is considered validated. The element that is not recognized is that the design and testing form the recipes for field performance and not the parts. On the occasion where on-orbit failures and major anomalies are attributed to parts, there is no recognition that the parts failed due to a phenomenon that was not in the model or otherwise predicted accurately with the model. The primary such causes in NASA missions over the past several decades are (1) reliance on low-volume MIL-SPEC parts that are subject to occasional manufacturing flaws not captured in the particular MIL-STD or MIL-PRF documents, (2) overtesting parts prior to launch or overstress in the circuit without test-as-you-fly verification prior to launch, or (3) cumulative radiation effects, most commonly single event effects that degrade the part or circuit in general. But more importantly, outside of this mischaracterization of part reliability, parts are rarely the weak point in the system, so the use of parts to characterize a system’s reliability would at best be considered a poor academic prediction.
Adherence to MIL-SPEC Is Often the Cause of Failures
Notably, one of the most recent part failures to occur in a major NASA mission (the Soil Moisture Active Passive, or SMAP, radar transmitter) with a serious effect on the mission involved an apparently well-manufactured MOSFET, radiation hardness assured (RHA) to levels well above the mission environment, that was subjected to circuit effects (voltage spike) that combined with single event effect spikes in the South Atlantic Anomaly to regularly exceed the rated voltage of the Metal Oxide Semiconductor Field Effect Transistor (MOSFET), ultimately causing gate rupture. Since only RHA numbers were used to address radiation and the circuit was not tested as flown, the phenomenon was not captured in ground testing prior to launch. In another example, the Satélite de Aplicaciones Científicas (SAC)-D satellite observatory 11 DC/DC converters were overtested prior to launch using the standard approach to “screen-in reliability,” resulting in latent failures for many of the DC/DC converters. The Solar Dynamics Observatory and LandSat-8 missions both experienced severe capacitor degradation due to a longstanding periodic manufacturing flaw that was not observable in the particular MIL-SPEC testing. The causes in these cases are all represented in one or more of the three categories above, and none align with reliability predictions from any handbook. In the approaches used in each of these cases, the part selection and usage approach were aligned with handbook-based reliability prediction, and in all cases, the approach either caused or contributed to the failure or otherwise did nothing to prevent it. But more importantly, the handbooks largely penalize modern high-volume, statistically process-controlled manufacturing and encourage old technology, lot-controlled, small-volume manufacturing, using a “screen-in reliability” approach. In many cases, the parts that are encouraged are largely obsolete with lead times that approach or exceed a year with high costs and minimum order quantities, all of which combine together to make many projects unimplementable under reasonable budget and time constraints.
Life Predictions Using Handbook-Based Ps Are Meaningless
There is real harm in customers using a formal Ps requirement to ensure some operational life of the system being acquired. Unless actual demonstrated lifetimes for a satellite (or subsystem or component) are available, the developer will resort to a handbook method in a misguided approach to showing compliance with a misguided requirement. Often, it is less capable, older, slower, larger, and heavier (“Dinosaur”) parts that are used to make the Ps exceed some arbitrary number. Without a specific Ps-based lifetime-reliability requirement, designers and project managers are able to make engineering-based cost-schedule-weight-power-performance-risk trades, resulting in a better delivered system.
The money waste, also, often doesn’t end after the satellite is built and launched. Many government programs waste additional money periodically paying contractors to estimate the “remaining life” in a satellite to inform decisions on capability refresh or budget needs. At NASA, for example, long-lived missions like the Hubble Space Telescope (HST) make predictions on the Ps drop-off into the future few years. As pointed out by the National Academies, 12 the 50% Ps for HST always lands about 5 years in the future—this has been true since before launch and for the entire (now 35 years) life of the mission. Clearly, in hindsight, this estimate has been wrong for at least 30 years. If you had a stock advisor who was wrong 30+ years in a row, wouldn’t you find a different one? In the flyout of the NASA Tracking Data Relay Satellite System (TDRSS) constellation, the periodic handbook-based “life remaining” estimates were recently found to be exactly wrong: the predicted long-life one died unexpectedly, and the predicted short-life one keeps on going and going. The silver lining of these events is that the project figured out that they were wasting money on periodic recalculations and stopped doing them.
Ps Requirements Imposition and the Recent History of Spacecraft Reliability and Lifetimes at NASA GSFC
Notably, the practice of imposing Ps requirements on spacecraft is largely within US-government-procured systems, particularly those considered national assets. Furthermore, the specific Ps requirements for the mission or spacecraft are often considered sensitive and not publicly releasable, as is the case for the Joint Polar Satellite System weather satellites, for which such information is redacted in publicly released documents. 13 Even for those projects where the fallacy of Ps has been recognized, new orbital debris mitigation requirements per NASA-STD-8719.14 14 specify requirements for end-of-life (Ps > 90% for assured reentry), which are still plagued by the same problem, albeit with some workarounds and more limited reach throughout the system (e.g., restricted to power system, guidance, navigation, and control, and thrusters needed to reenter the vehicle at mission disposal). Leitner and Hyde 15 and Thomas 16 provide the lifetimes of NASA GSFC-launched spacecraft from 2000 to 2024, along with the mission required, or design lifetimes. Notably, all missions surpassed their required lifetimes with the exception of one subject to a launch failure and an instrument onboard an external host spacecraft that failed shortly after reaching orbit. While the data are not releasable to indicate which missions had Ps requirements, which did not, or what the specific Ps requirements were, suffice it to say that the collection represents a balanced mix of those that did and those that did not impose Ps requirements. Furthermore, the Ps > 90% end of mission Ps requirement was not imposed until 2021 and thus was not generally represented in the data set. Typically, Classes A and B national asset missions have imposed Ps requirements, while Class B missions of more general scientific nature, along with Classes C and D missions, did not impose such a requirement. In either case, the two mission failures that occurred were outside of the Ps modeling regime, and since all the other missions had already met their lifetime requirements or were on target to do so, it is trivial to conclude that the imposition of a Ps requirement or not had no noticeable effect.
What Is the Alternative?
While it is natural when spending $100s of millions or more to procure an essential complex system to have a minimum reliability figure, the reality is that such a number cannot reasonably be calculated for anything but a repeat build. Demonstrated life or demonstrated Ps of flight-proven designs of statistically relevant quantities are one approach to gain confidence. With new developments, the misguided handbook must be set in the dustbin of history and a common-sense, engineering judgment should be engaged. Although reliability can be designed into a system, a specific reliability number cannot, and thus any such requirement is degenerate. The alternative is to apply sound engineering principles, perform a copious amount of testing in a flight configuration, and resolve all problems from the testing or bound the risk for those that cannot be fully corrected with the resources available. Sound risk management based on rigorous risk assessments is essential, but demands for specific absolute reliability numbers provide costly emotional support without technical merit. Reliability tools such as failure modes and effects analysis, fault trees, reliability block diagrams, and probabilistic risk assessments can be valuable tools for characterizing risk and prioritizing assurance activities, but developers and overseers should avoid overquantifying the associated products when planning responsive or proactive actions. There are a few practical requirements that may be applied when specifying a mission lifetime, provided in Table 1 .
Requirements to Assure High Probability of Meeting a Mission Lifetime
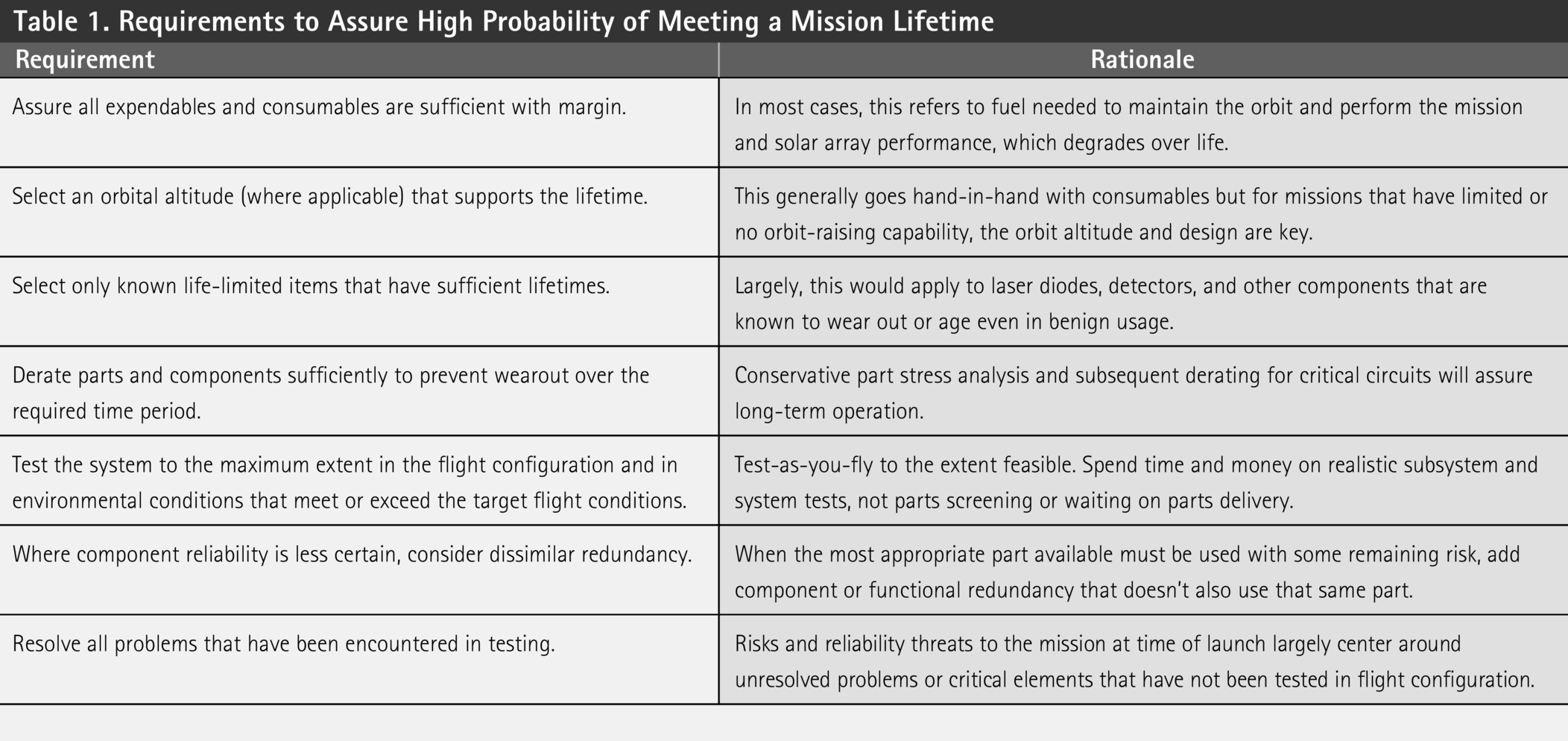
From a reliability perspective, apply ample margins to areas with most uncertainty or least experience, use dissimilar redundancy when practical, and use products well within their rated stress levels. Every project is resource challenged—you must protect the realistic system-level testing that comes at the end, even if this means skipping parts screening and component-level testing at the beginning.
CONCLUSIONS
The space community is a community of tradition and heritage. If systems worked before with the collection of requirements imposed, then such requirements are forever proven to work, and they are thus forever instituted as critical to mission success. However, it is time to take a critical look at all such requirements to delineate among those that are based on sound engineering and clear linkage to the success and those that instill good feelings but lack a sound technical basis. The requirements for a minimum probability of success should be some of the first to go based on a flawed view of how parts contribute to mission success and the subsequent premise that parts are generally the weak link in a complex space system around which reliability is centered.
AUTHORS’ CONTRIBUTIONS
J.A.L.: Conceptualization, methodology, writing, and supervision. T.T.H.: Conceptualization, methodology, and writing. All work is original.
Footnotes
AUTHOR DISCLOSURE STATEMENT
No competing financial interests exist.
FUNDING INFORMATION
No funding was received for this article.