
Abstract
Knowledge graphs from text have garnered substantial interest across various domains due to their potential to facilitate efficient information retrieval and knowledge exploration. However, knowledge graph generation from textual sources presents unique challenges, particularly in the Islamic domain, where primary sources of knowledge are texts in Arabic, which exhibit complex linguistic and cultural nuances. This article presents a comprehensive methodology for generating a knowledge graph from the hadith corpus. Hadith, a fundamental resource in the Islamic domain, stands as one of the primary sources of Islamic legislation, encompassing the sayings, actions, and silent approvals of the Prophet Muhammad. Leveraging Natural Language Processing techniques, we systematically extract, annotate, and interlink semantic entities and relationships from the hadith corpus, extend the SemanticHadith ontology for entity organization, and compute textual similarities to establish semantic connections. We generate a comprehensive knowledge graph by applying these methods to six hadith collections, facilitating efficient information retrieval and knowledge exploration in the Islamic domain. This is an essential step towards annotating and linking the hadith corpus to allow semantic search to support scholars or students in creating, evolving, and consulting a digital representation of Islamic knowledge. The SemanticHadith knowledge graph is freely accessible at http://www.semantichadith.iknex.com/.
Keywords
Introduction
In the current landscape of abundant data and information, structured representation of knowledge has become crucial for efficient information retrieval and utilization across diverse domains. Knowledge graphs (KGs), with their graph-based organization of entities and relationships, have gained significant attention for their ability to revolutionize information management and retrieval (Chen et al., 2020; Wang et al., 2017). Although KGs have been widely adopted in fields such as biomedicine (Shang et al., 2021), education (Dietze et al., 2013), and cultural heritage (Marden et al., 2013), their application to religious domains, particularly Islamic knowledge, remains under-explored. Generating KGs from textual sources poses distinct challenges, especially in domains characterized by complex linguistic and cultural nuances such as those found in Islamic texts. Our preliminary work has demonstrated the potential of KGs to represent Islamic knowledge (Basharat et al., 2016).
The Islamic knowledge domain, rooted in the Quran and the sunnah of the Prophet Muhammad, presents a vast repository of textual resources that remain under-represented in the semantic web ecosystem (Brown, 2008). Among these resources, the hadith—narrations of the Prophet’s sayings, actions, and approvals—constitute a vital source for understanding Islamic teachings and jurisprudence (Hasan, 1994). While prior studies have addressed specific subdomains, such as prophetic medicine (Al-Rumkhani et al., 2016), chain-of-narrators representation (Azmi & Badia, 2010), and thematic categorization (Altammami et al., 2021), these efforts often operate in isolation, lacking a unified semantic framework. Similarly, ontological models (Harrag, 2014; Jaafar & Che Pa, 2016) and WordNet-like linguistic resources (Alkhatib et al., 2017) frequently suffer from limited interoperability and interdisciplinary applicability. Our previous work, SemanticHadith, addresses part of this challenge by systematically modeling the structure of hadith and narrator chains (Kamran et al., 2023). However, the absence of comprehensive semantic representation for hadith texts continues to hinder their seamless integration into the broader semantic web landscape, limiting effective exploration and retrieval of Islamic knowledge. Overcoming these limitations remain critical to advancing the accessibility and interconnectedness of Islamic knowledge resources.
This study addresses the broader challenges of hadith modeling by introducing a comprehensive methodology for generating a KG from the hadith corpus. By leveraging advanced natural language processing (NLP) techniques, such as named entity recognition (NER) and relationship extraction, our methodology enables a granular understanding of entities, narrators, and their semantic relationships. Tools like spaCy and transfer learning models tailored to Classical Arabic are employed, alongside preprocessing techniques such as diacritic normalization, tokenization, and morphological analysis, to address the linguistic diversity inherent in Arabic texts. However, our methodology operates under several assumptions, including a reliance on standardized textual sources in Classical Arabic and expert validation to resolve ambiguities. Limitations such as linguistic diversity, regional dialects, and varying levels of authenticity across hadith collections remain challenges for accurate semantic modeling. Despite these limitations, the proposed approach significantly advances the representation of Islamic knowledge by integrating principles of linked data and external KGs, such as Wikidata and DBpedia, enabling connections between Islamic studies and fields like history, linguistics, and cultural studies. Such integration is critical for fostering interdisciplinary research and making Islamic knowledge resources accessible to a wider audience. Unlike traditional approaches, which rely on keyword-based searches and static indexing, this framework provides dynamic interlinking of entities and thematic contexts. For instance, a thematic query like “charity” retrieves not only narrations that explicitly mention giving or donations but also those addressing related topics such as the virtues of helping neighbors, assisting the poor, and the prohibition of hoarding wealth. These connections, enabled by semantic relationships within the KG, go beyond traditional keyword searches by uncovering indirect but meaningful links between narrations. This granularity and interconnectedness enable researchers, students, and educators to explore Islamic texts systematically and intuitively. The inclusion of external knowledge sources further enhances interdisciplinary research, bridging Islamic studies with fields such as linguistics, cultural studies, and history.
The SemanticHadith ontology and KG provide practical benefits that cater to diverse audiences. Scholars and researchers can use the framework to perform advanced semantic queries, uncovering patterns and relationships within the corpus that were previously difficult to identify. Educators and students benefit from interactive tools that facilitate thematic exploration or the creation of tailored pedagogical resources. The ontology’s scalability and expert-validated mappings enhance its reliability, making it a valuable resource for both rigorous academic study and public engagement. By integrating state-of-the-art NLP technologies with domain expertize, this framework enables an accessible, interactive, and context-rich exploration of Islamic knowledge.
We present the SemanticHadith ontology version 2.0.1, an enhanced iteration that builds upon the foundation of version 1.0.1. This updated ontology expands the modeling of entities and topics within hadith texts, enabling a more nuanced understanding of Islamic teachings. By formalizing this extensive knowledge repository and interlinking its components, the ontology supports new avenues for research, discovery, and synthesis within the Islamic knowledge domain. This emphasis on comprehensive semantic modeling highlights the importance of integrating various textual resources, including Quranic commentaries that heavily rely on hadith corpora for interpreting Quranic verses. Such integration enriches the exploration of Islamic knowledge, fostering a deeper understanding of the interconnectedness across different facets of Islamic teachings. Through this work, we aim to address challenges in knowledge acquisition and semantic content creation, particularly for applications dependent on advanced semantic technologies. By adopting a semantic perspective, the framework facilitates more effective search and discovery of concepts and relationships within hadith texts.
Background Context and Motivation
In Islamic tradition, hadith serves as a vital source of knowledge, offering narratives of historical events from the life of Prophet Muhammad, interpretations of Quranic verses, and elaborations of essential Islamic concepts. Second only to the Quran, the hadith corpus significantly influences Islamic jurisprudence and understanding. Each hadith consists of two primary components: the matan (narration content) and the sanad (chain of narrators). The sanad, presented as a chronological list of narrators, is instrumental in assessing the authenticity of a hadith, as scholars evaluate the integrity of the chain to determine its reliability. The expansive nature of the hadith corpus presents challenges in managing its intricate relationships and concepts. Beyond the primary texts, a substantial body of supplementary literature, including commentaries and biographical records, adds layers of complexity. Navigating these resources requires not only identifying narrators and texts but also a deeper comprehension of the relationships across both the hadith and the Quran, such as which hadith elaborate specific Quranic verses or share thematic similarities.
Historically, the study of Islamic knowledge has relied on unstructured textual resources, making systematic exploration and analysis arduous. Despite its critical role in shaping Islamic thought, the hadith corpus remains underutilized within the semantic web ecosystem. Advances in semantic modeling and KG construction present transformative opportunities for organizing and linking Islamic texts. Expanding beyond canonical hadith collections to include Quranic commentaries (tafsir), biographies of narrators, Islamic jurisprudence (fiqh), and classical scholarly works could foster a more comprehensive understanding of Islamic tradition. Moreover, multilingual KGs would make these resources accessible to diverse audiences worldwide, addressing linguistic and cultural nuances to enhance inclusivity. Cross-domain integration with datasets from fields such as history, sociology, and science offers the potential for interdisciplinary research, uncovering novel insights into the influence of Islamic knowledge on global history and culture. Future research should also prioritize the development of intuitive tools, such as AI-driven reasoning systems and natural language search interfaces, to empower scholars, students, and the general public in engaging seamlessly with Islamic KGs. These directions highlight the potential for semantic modeling to advance Islamic studies by combining traditional knowledge with modern computational methods, offering unprecedented opportunities for exploration, education, and cross-disciplinary collaboration.
Importance of Hadith
Understanding the significance of hadith requires integrating principles of Quranic understanding and the science of exegesis (tafsir), as Quranic verses often depend on hadith for contextualization and elaboration. Tafsir relies heavily on authentic hadith to clarify historical contexts, reasons for revelation, and essential concepts not immediately apparent from the Quranic text. For example, comprehensive commentaries such as Tafsir al-Tabari frequently reference hadith to elucidate meanings. Adhering to these principles is critical for producing accurate interpretations of the Quran (Philips, 2002).
Need for Formalized Semantic Modeling
Navigating Islamic knowledge—spanning Quranic texts, hadith literature, and tafsir—presents significant challenges. For instance, a student seeking to explore the connections between verses in Surah Ibrahim may instinctively turn to hadith literature for explanations, supplemented by renowned tafsir such as Tafsir al-Tabari. Figure 1 illustrates this scenario and highlights the necessity for structured knowledge modeling tailored to Islamic texts. By organizing Quranic verses and related hadith explanations within a KG framework, scholars and learners can systematically explore the intricate links between primary and secondary sources.

Motivational Scenario—Connecting primary and secondary Islamic knowledge sources.
Hadith complements the Quran by elaborating on its verses and providing practical guidance. Over centuries, thousands of commentaries have been produced in various languages, all of which rely on hadith to interpret Quranic teachings. Formalizing this extensive repository through semantic modeling and KG generation promises to unlock new avenues for research and synthesis. In Figure 2, we provide an example from both the Quranic and hadith texts, highlighting the same entities and topics. This visualization of linking of shared entities and topics across Quranic and hadith texts, emphasize the interconnected nature of Islamic knowledge and the importance of a unified framework.

Motivational Scenario 2—Connecting themes, topics, people and places in the Quran and hadith.
Other examples of hadith explicitly explaining Quranic principles, demonstrating the interconnectedness of the two sources of Islamic knowledge include:
Quranic Verse: “O you who have believed, when you rise to [perform] prayer, wash your faces and your forearms to the elbows and wipe over your heads and wash your feet to the ankles …” (Surah Al-Ma’idah, 5:6) Hadith: The Prophet provided a practical demonstration of wudu: “Whoever performs ablution as I do, and then prays two rak’ahs without allowing his thoughts to wander, will have all his past sins forgiven.” (Sahih Bukhari, 159) This expands on the Quranic verse by illustrating how to perform wudu properly and its spiritual benefits.
Quranic Verse: “The believers are only those who, when Allah is mentioned, their hearts become fearful, and when His verses are recited to them, it increases them in faith.” (Surah Al-Anfal, 8:2) Hadith: The Prophet defined Iman succinctly: “Iman is to believe in Allah, His angels, His books, His messengers, the Last Day, and to believe in divine decree, both its good and its bad.” (Sahih Muslim, 8)
Efforts to model and publish Islamic knowledge as linked data have predominantly focused on the Quran, while the hadith corpus remains relatively under-explored. Existing research spans various aspects of hadith, including thematic categorization (Altammami et al., 2021), jurisprudential classification (Hakkoum & Raghay, 2015; Harrag, 2014), and linguistic analysis (Dukes et al., 2010; Farghaly & Shaalan, 2009). For instance, Fairouz et al. (2020) modeled hadith commentaries, while Jaafar and Che Pa (2016) concentrated on concepts within Arabic hadith texts. Similarly, Alkhatib et al. (2017) proposed a WordNet-like linguistic resource, and Azmi et al. (2019) provided a comprehensive review of computational techniques applied to hadith literature.
Despite this diversity, the field remains fragmented. While works such as Dukes et al. (2010) explored syntactic and morphological annotations for Arabic texts, and Al-Khalifa et al. (2010) proposed semi-automated ontology construction for Quranic verses, these efforts lack integration into a unified semantic framework. Farghaly and Shaalan (2009) highlighted the under-representation of Islamic textual resources in Arabic NLP tools, whereas Hakkoum and Raghay (2015) focused narrowly on ontologies for Islamic jurisprudence. More recent contributions include Altammami et al.’s annotated Arabic-English corpus for hadith (Altammami et al., 2020) and their work on text segmentation (Altammami et al., 2019) and ontological modeling (Altammami et al., 2021). Additionally, association rule mining techniques have been employed for jurisprudential ontology (Harrag, 2014), similar to the framework proposed by Al-Arfaj and Al-Salman (2014) to create an ontology from Arabic texts. Automated parsing and classification tools have further contributed to the field. E-Narrator (Azmi & Badia, 2010) focused on parsing hadith text and generating graphical representations of narrator chains. Building on E-Narrator, HadithRDF (Baraka & Dalloul, 2014) extended this approach by developing an ontology-based system for assessing isnad authenticity based on scholarly rules. Data mining techniques for indexing hadith collections by Aldhlan et al. (2010) and Naji Al-Kabi et al. (2005) and social network analyses of narrators by Saeed et al. (2022) further illustrate the diversity of computational approaches.
However, these advancements primarily address isolated challenges, such as narrator chains or thematic categorization, and fall short of providing comprehensive, multilingual, and publicly accessible KGs for hadith. While they contribute important foundational work, they lack integration into broader frameworks that can dynamically interlink entities and themes across multiple domains. The lack of standardized numbering schemes, inconsistent citation practices, and varying levels of authenticity hinder dataset unification. Moreover, the linguistic complexity of Arabic—encompassing regional dialects, intricate morphology, and the layered structure of sanad (chain of narrators) and matan (narration content)—adds to the difficulties of semantic modeling. Nevertheless, emerging computational techniques, such as NLP, NER, and similarity computations, hold promise for addressing these challenges. By formalizing and interlinking the vast hadith corpus, researchers can pave the way for a more structured, dynamic, and accessible repository of Islamic knowledge.
Recent work has also begun to explore the use of large language models (LLMs) in Islamic and humanities studies, particularly for tasks such as semantic similarity, question answering, and explainable text analysis. These approaches demonstrate the potential of LLMs to capture contextual and semantic nuances in religious texts beyond surface lexical similarity (Almarzoqi & Alsuhaibani, 2025). Mosa (2025) proposes a hybrid KG–transformer framework focused on narrator disambiguation, combining structural properties of transmission networks with contextual language modeling to resolve name ambiguity in isnad chains. Shafie et al. (2023), through the KASHAF system, address hadith information retrieval by integrating KG querying with semantic-similarity classification to support the retrieval and grouping of related narrations.
These studies address well-defined subtasks within the hadith domain, such as narrator identity resolution and retrieval based on semantic similarity. In contrast, SemanticHadith 2.0 focuses on ontology-driven, text-based KG construction across multiple collections, with expert-validated similarity links integrated directly into the graph to support explainable querying and structured exploration rather than task-specific classification or disambiguation.
NLP Techniques for Processing Hadith Text
The complex structure and linguistic richness of hadith texts demand advanced NLP techniques for effective semantic modeling. Existing methods provide a solid foundation for extracting entities and relationships, which we adapt and fine-tune to meet the specific challenges posed by the hadith literature. Preprocessing steps such as text normalization (e.g., standardizing variations in Arabic script), diacritical mark removal, and sentence tokenization ensure uniformity across the corpus. Domain-specific tools, such as Arabic tokenizers, are employed to accommodate the intricate morphology of the language. Segmenting hadith into sanad (chain of narrators) and matan (narrative content) further supports targeted semantic analysis and enhances downstream tasks, such as entity extraction and relationship mapping. Previous work, such as Azmi et al. (2019) and Bounhas (2019), have emphasized the importance of creating multilingual hadith resources for tasks like NLP, information retrieval, and knowledge extraction. Building on this, we adapt and extend preprocessing workflows to ensure high-quality input for our entity extraction and modeling pipelines.
NER plays a central role in extracting key entities such as narrators, locations, and thematic concepts within hadith. Prior studies, such as Salah and Zakaria (2018), have used NER to extract narrators and associated events, demonstrating the technique’s ability to support semantic representations in hadith. However, the complexities of Arabic—including its variable word order, rich morphology, and diacritical marks—necessitate the use of domain-adapted NER systems. For instance, custom models trained on datasets like CANERCORPUS enable more precise entity extraction in this domain. These approaches ensure consistent linkage of entities, such as narrators like “Abu Huraira,” to their corresponding nodes in the KG, improving semantic accuracy. In our work, we fine-tune existing NER models to better align with the specific challenges of hadith literature, incorporating domain-specific annotations for narrators, prophets, crimes, and holy books. This adaptation is critical to overcoming the limitations of general-purpose NER systems when applied to religious texts.
Similarity computations have been extensively employed to identify semantically or contextually related narrations in hadith and Quranic texts. Huang et al. (2018) used cosine similarity in combination with embedding-based techniques to link related hadith, particularly paraphrased or overlapping narrations, demonstrating the utility of vector-based approaches in clustering narrations with shared meanings. Their work highlighted the potential of cosine similarity for semantic alignment but also noted challenges in capturing more nuanced relationships, such as contextually related but textually dissimilar narrations. Similarly, Basharat et al. (2015) explored similarity computations in the context of Quranic verses, comparing different similarity metrics, including cosine and Jaccard similarity. Their study emphasized the importance of embeddings in semantic similarity, showcasing their effectiveness in clustering narrations by themes or topics. However, they also observed that metrics such as cosine similarity alone may struggle to capture deeper thematic relevance in complex texts. In a more recent study, Alshammeri et al. (2021) applied embedding techniques using Siamese networks to detect relationships between Quranic verses and hadith. Their work advanced the use of pre-trained language models to generate embeddings for Arabic religious texts, illustrating the effectiveness of modern NLP tools for capturing semantic overlap. These methods enabled the automatic clustering of narrations by shared topics, further enriching the interconnectedness within Islamic texts.
Collectively, these studies underscore the utility of similarity computations in Arabic text analysis while highlighting challenges that arise due to the linguistic and contextual complexity of religious texts. Techniques like cosine similarity are foundational in these efforts but often require adaptations or complementary methods to fully capture thematic and contextual relationships within large collections of narrations.
Methods
In this section, we outline our approach to generating a comprehensive KG from the hadith corpus, encompassing several key stages. Figure 3 provides the overview of this framework. The process begins with data selection and acquisition, ensuring the inclusion of relevant hadith collections. This is followed by a description of our custom knowledge extraction methodology, which involves NLP techniques for entity recognition and extraction from textual sources. Subsequently, we discuss conceptual knowledge modeling and formalization, wherein we establish a structured framework to organize and represent the extracted entities systematically. Next, we describe our methodology for similarity computation and the interlinking of hadith narrations. This involves quantifying textual similarities to identify and establish semantic connections, further enriching the structure and utility of the KG. Finally, we outline the integration of external data sources and the final generation of a linked KG. Detailed explanations of each stage are provided in Sections 3.1 to 3.7.

Overview of the SemanticHadith knowledge graph construction framework. The key stages of the framework include Data Selection and Acquisition, NLP-based Custom Knowledge Extraction, Conceptual Knowledge Modeling and Formalization, Similarity Computation and Interlinking of hadith, SemanticHadith Knowledge Graph Enrichment, which encompasses Knowledge Graph Generation and Interlinking with the LOD Cloud, and Endpoints and Applications. NLP = Natural Language Processing; LOD = Linked Open Data.
This study operates under a set of clearly defined assumptions that guide its methodology and scope. First, the textual representations of the hadith corpus are assumed to be standardized and faithful to their original compilations, minimizing concerns about variations across different print editions or translations. Second, the corpus is treated as linguistically uniform, adhering to Classical Arabic for NLP tasks. While this approach facilitates processing, it is acknowledged that certain classical forms and regional dialects inherent to historical narrations may not be fully captured. Third, the authenticity of the selected hadith collections is assumed based on the authority of their compilers; individual evaluations of narrations’ authenticity (e.g., weak or fabricated narrations) fall outside the scope of this study. Finally, expert validation serves as the gold standard for resolving ambiguities in named entities and relationships, ensuring the semantic accuracy and reliability of the resulting KG.
Developing an enhanced KG begins with the careful selection and acquisition of relevant data. Building on the SemanticHadith ontology and KG from prior work (Kamran et al., 2023), this study broadens its scope while maintaining continuity. The same six authoritative hadith collections—Sahih Bukhari, Sahih Muslim, Sunan Abi Dawood, Sunan Ibn Majah, Sunan An-Nisai, and Jami At-Tirmidhi—sourced from the Islamic Urdu Books Website, 1 were utilized. Collectively known as the Kutub al-Sittah, these collections, comprising 34,458 hadith, are widely regarded as the most authentic compilations in Islamic tradition. Each narration includes the original Arabic text alongside Urdu and English translations.
To ensure platform compatibility, all textual data were standardized into Unicode format using Python’s
NLP-Based Custom Knowledge Extraction
The NLP methodology for entity extraction in developing the SemanticHadith ontology v2.0.1 is pivotal in accurately identifying and extracting relevant entities from the hadith corpus. Our approach ensures precision and comprehensiveness in entity extraction by leveraging a combination of custom-trained NER models and expert-validated noun dictionaries.
Our approach employs a customized NER pipeline to extract entities from the hadith corpus, enabling the extension of the SemanticHadith ontology. The process begins with a modified version of the CANERCORPUS dataset (Salah & Zakaria, 2018), enriched with domain-specific entities such as prophets, angels, holy books, and crimes, ensuring alignment with the semantic characteristics of hadith texts. The customized dataset includes 14 entity classes relevant to the hadith corpus, with a total of 57,763 labeled entities. Linguistic preprocessing steps, including diacritic removal, orthographic normalization, and tokenization, address the structural challenges of Arabic text, ensuring consistent and accurate entity extraction.
The NER model is trained using the spaCy NLP library and pre-trained embeddings from the CAMeLBERT-CA NER model. We fine-tuned it for the hadith domain. The dataset is split into an 80–20 ratio for training and validation. Training stabilizes at 10 epochs, achieving high precision, recall, and F1-scores for frequently occurring entity classes such as Persons, Prophets, and Allah, while rare entity classes (e.g., crimes and natural objects) show lower recall due to limited representation in the dataset.
To ensure alignment with the ontology and to standardize entity mappings, noun dictionaries are employed, accounting for variations in Arabic morphology and transliterations. This methodology includes expert validation to review annotations and ensure that extracted entities are accurate and contextually relevant. Further details of the methodology, including dataset customization, hyper-parameter optimization, and model evaluation metrics, are discussed in Section 4.
Conceptual Knowledge Modeling and Formalization
During this stage, we conceptualize and design a formal ontology structure as described in Section 5. We follow an iterative approach in ontology engineering, where the knowledge model evolves as formalization progresses. The methodology encompasses seven steps, including determining the scope of the ontology, enumerating important terms, and defining classes, hierarchies, properties, and facets. The scope of the ontology is defined based on competency questions (CQs) formulated from the findings of the NLP module. Additionally, existing ontologies are reused, and vocabularies such as Schema.org, DBpedia, and Wikidata are leveraged to ensure interoperability and standardization. The ontology design incorporates key entities and relations relevant to hadith literature, such as
Similarity Computation and Interlinking of Hadith
Our study initially explored the use of cosine similarity and pre-trained Arabic sentence transformers to identify similar hadith within Sahih Bukhari and other selected collections, including Sahih Muslim, Ibn Maja, Sunan Abi Dawood, and Nisai. This approach was informed by prior successful applications of semantic similarity computations for Quranic verses (Alshammeri et al., 2021) and hadith literature (Huang et al., 2018). The asafaya BERT base Arabic model, implemented in the Transformer library, was employed to encode Arabic hadith texts into numerical representations, facilitating the computation of cosine similarity scores between pairs of hadith. The process involved preprocessing hadith texts to remove diacritics, punctuation marks, and stop words, ensuring uniformity in representation. Cleaned texts were then encoded into embedding vectors, and a cosine similarity matrix was computed to quantify similarity between all pairs of hadith. Initial thresholds for similarity were derived using a small dataset of expert-identified similar pairs, which served as a benchmark for evaluating the suitability of this approach for larger datasets.
However, significant challenges were encountered in applying this methodology to the complete Sahih Bukhari corpus, including issues with inflated similarity scores due to shared narrator chains (sanad) and difficulty capturing thematic or contextual relevance. As a result, we concluded that the approach was not sufficiently refined to reliably identify similar hadith across the corpus. Consequently, we relied exclusively on the expert-provided similar hadith pairs for interlinking within the SemanticHadith KG. Further details on the similarity computation process, challenges encountered, and expert validation are provided in Section 6.
SemanticHadith KG Enrichment
This section describes the processes involved in the enrichment of the SemanticHadith KG. It covers the KG generation itself and its interlinking with external Linked Open Data (LOD) resources.
KG Generation
The KG-generation module of our methodology involves aligning the domain and concepts in the data with the ontology classes, automatically translating the hadith records and the entities recognized by our NLP module into Web Ontology Language (OWL) individuals, incorporating data as data properties, and establishing semantic relationships based on object properties and mapping rules. To transform entities extracted by our NLP pipeline into a resource description framework (RDF)-based KG, we utilize the OntoRefine tool (Ontotext AD, 2022) along with our SemanticHadith ontology (Kamran et al., 2023). Both the SemanticHadith ontology version 2.0.1 and the KG are publicly available on a GitHub repository. 2 GitHub’s issue-tracking system will serve as a platform for communication regarding the maintenance and future development of the ontology.
KG Interlinking With LOD Cloud
For linking with external KGs such as DBpedia (Becker & Bizer, 2008) and Wikidata (Vrandečić & Krötzsch, 2014), we utilized automated interlinking tools like LIMES (Ngomo et al., 2021) and OntoRefine (Ontotext AD, 2022). Expert validation was employed to ensure the accuracy of the discovered links and resolve any conflicts or ambiguities. As a result, substantial interlinking was achieved with external KGs, including DBPedia, 3 Wikidata 4 and QuranOntology (Hakkoum) vocabularies, thereby enhancing the interconnectedness of the SemanticHadith KG.
However, the reconciliation of links posed challenges with some tools due to their limited compatibility with Arabic data. Nonetheless, we successfully linked significant entities such as prophets, places, and tribes with at least three external KGs: DBpedia, Wikidata, and QuranOntology. For other entities like animals, topics, plants, and events, we devised an automated approach to establish similarity between entities found in the QuranOntology KG by querying the graph and obtaining all instances of each category.
Expert validation was crucial to verify the discovered links and identify any potential conflicts, duplicates, or ambiguities. We found
Expert Validation
The dataset preparation, annotation, and ontology development processes were supported by domain experts selected based on specific criteria to ensure accuracy and relevance throughout the evaluation process. They possessed graduate-level qualifications and a foundational understanding of relevant disciplines. Additionally, the experts demonstrated a working knowledge of Islamic studies, particularly regarding the Quran and hadith, to provide domain-specific insights. Proficiency in both Arabic and English was essential to facilitate accurate linguistic evaluation and ensure consistency during text processing. They also had experience with semantic annotation and a strong understanding of entity categorisation, particularly in the context of Islamic knowledge representation.
Three domain experts were engaged to ensure the accuracy and domain relevance of the research, contributing to various aspects of the study. They guided the development of the extended SemanticHadith ontology by advising on entity definitions, relationships, and thematic categorizations to capture the complexity of the corpus. The experts annotated key entities such as prophets, angels, crimes, and holy books, refining these annotations to align with semantic and linguistic goals while excluding irrelevant labels. They also created dictionaries for named entities like people and locations, addressing variations in Arabic naming conventions to support entity extraction. To validate extracted entities, the experts cross-referenced identified entities with corresponding hadith passages, reviewing a random sample of 100 instances from each collection. Additionally, they provided insights into challenges encountered during similarity computations, such as distinguishing contextually similar but semantically distinct narrations and addressing paraphrased hadith versions. This collaborative effort ensured the dataset and ontology were accurate, contextually grounded, and semantically robust.
Endpoints and Applications
A persistent triple store holds the graph data and interacts with other components through a SPARQL endpoint. The SemanticHadith KG was uploaded to the triple store by Virtuoso, enabling query capability through the SPARQL endpoint available at http://www.semantichadith.iknex.com/sparql.
NLP Methodology for Entity Extraction
The extraction of entities from the six canonical hadith collections is a crucial step in the development of the extended SemanticHadith ontology. This section describes our NLP methodology, which combines custom-trained NER model with expert-validated noun dictionaries to identify and extract entities relevant to our ontology accurately. There are many off-the-shelf NER models, such as CAMeLBERT-CA (Inoue et al., 2021). However, they are not very accurate for Arabic in hadith text. Hence, we need for custom NER model specifically trained on the target domain. Custom NER models can be trained on a specific corpus of text to improve the accuracy and performance of the model (Alshammari et al., 2023(@). Hence, we used modified CANERCORPUS (Salah & Zakaria, 2018) to train our NER model. Our implementation along with modified corpus is available at https://github.com/nigar-azhar/SemanticHadithNLP.git.
Dataset Preparation
To build a domain-specific NER model for extracting meaningful entities from the hadith corpus, we utilized the CANERCORPUS dataset (Salah & Zakaria, 2018) as the foundational resource. This dataset, known for its extensive coverage of Arabic texts and entity annotations, served as a robust starting point for our research. However, to ensure alignment with the unique semantic and structural characteristics of the hadith domain, we applied significant modifications in collaboration with domain experts.
Customization and Annotation
The original CANERCORPUS dataset was adapted to include additional entities specific to the hadith corpus. These customizations aimed to enhance the alignment of the dataset with the extended SemanticHadith ontology, which includes entities relevant to the selected six collections. These modifications include:
 ), Bible (
), Bible ( ), Injeel (
), Injeel ( ), and Zabur (
), and Zabur ( ) were not previously identified as named entities. Similarly, in the angels category, entities such as Jibreel (
) were not previously identified as named entities. Similarly, in the angels category, entities such as Jibreel ( ) and Mikail (
) and Mikail ( ) were annotated to reflect their frequent mentions in the hadith corpus.
) were annotated to reflect their frequent mentions in the hadith corpus. ), and numerical expressions (NUM, e.g., 70 /
), and numerical expressions (NUM, e.g., 70 /  )—were removed or replaced to streamline the model’s focus.
)—were removed or replaced to streamline the model’s focus.
The linguistic structure of Arabic posed unique challenges for text processing. Preprocessing steps were applied to normalize text and ensure consistency across the training data:
The customized dataset includes 14 entity classes relevant to the hadith corpus, such as
Statistical Overview of the Customized Dataset.

We trained a custom NER model using the spaCy NLP library to extract entities from the Arabic hadith corpus. This model was fine-tuned using transfer learning techniques on the customized dataset prepared for this study. The training process included a series of steps to optimize the model’s performance and evaluate its effectiveness across domain-specific entities.
Training Setup
The training data was split into an 80–20 ratio for training and validation. The NER model was initialized using pre-trained embeddings from the CAMeLBERT-CA NER model. 5 The model is trained on classical Arabic texts. We fine-tuned it further for our domain-specific tasks using the following parameters during training:
The model’s performance was evaluated using precision, recall, and F1-score for each entity class. To summarize overall performance, three types of averages—micro, macro, and weighted—were calculated:
The model’s performance stabilized at epoch 10, with minimal improvements observed in subsequent epochs. Some rare entity classes, such as
The Summary of the Precision, Recall, and F1-Score for Each Entity Class at Epoch 10.
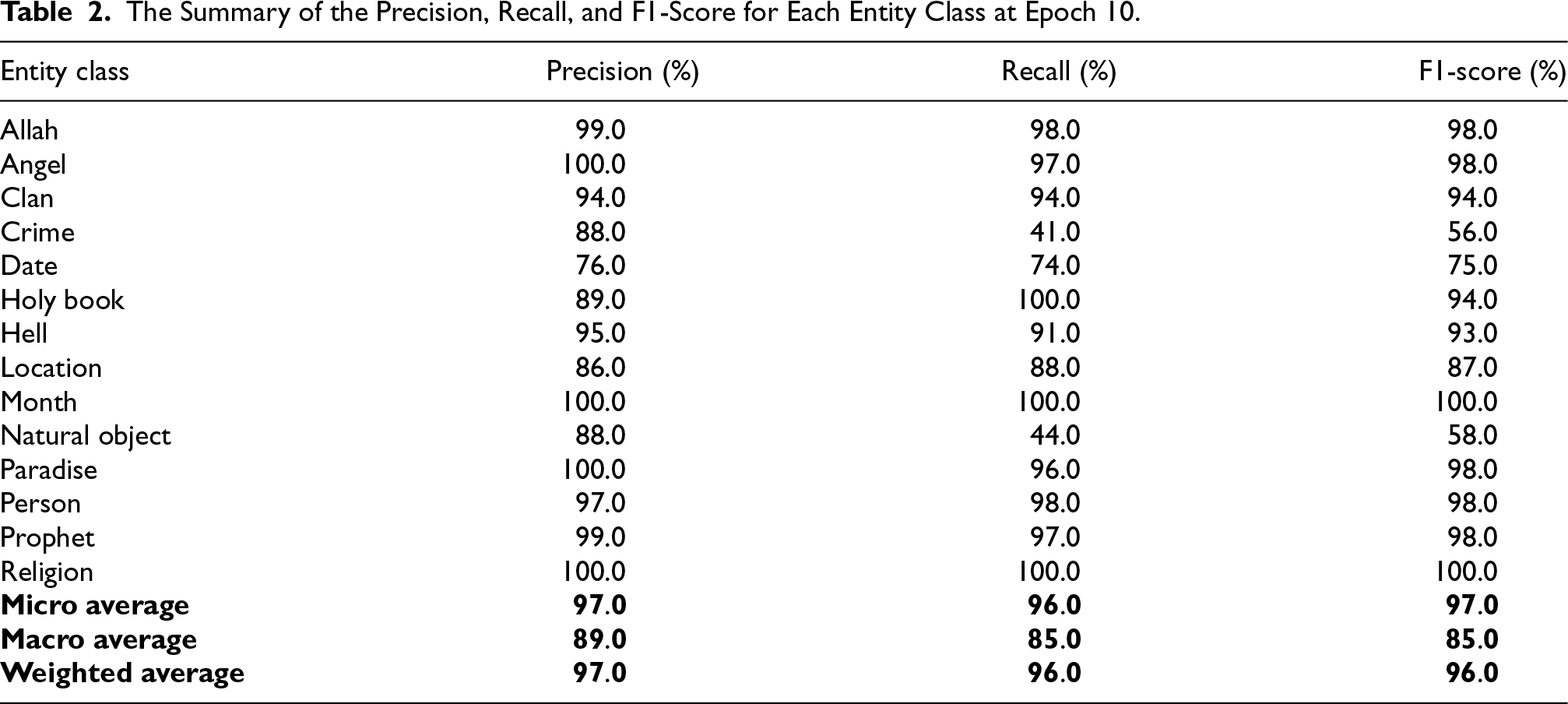
The Summary of the Precision, Recall, and F1-Score for Each Entity Class at Epoch 10.
The training pipeline, implemented using spaCy and the seqeval library, is fully reproducible. Scripts, annotated datasets, and performance logs are included in the Supplemental Material to support further research and model adaptations.
The entity extraction process utilized the trained NER model to analyze the hadith corpus across all six collections. For each passage, the model identified spans of text corresponding to entities such as persons, locations, events, and thematic topics, categorizing them into predefined classes like angels, prophets, clans, crimes, and others, based on the extended SemanticHadith ontology.
To address variations in entity representation and ensure consistent mapping, noun dictionaries were developed in collaboration with domain experts. These dictionaries included: Instance ID: a unique identifier for each entity aligned with the ontology, English variations: common transliterations and spellings in English, and Arabic variations: variants in Arabic script accounting for morphology and diacritics.
For example, the Clans class in the ontology includes an instance for “Quraysh,” represented as follows: Instance ID: English variations: Quraysh and Quraish Arabic variations:

When the NER model identified an entity (e.g., Quraish), the noun dictionary was used to map it to the corresponding ontology instance (
For each hadith collection, the extraction process generated a file for each entity class. These files listed the identified instances along with their corresponding Hadith IDs. For example, in the Clans class within Sahih Bukhari,

An expert reviewed these results by cross-referencing the identified entities with the corresponding hadith passages. For instance, in hadith number seven from Sahih Bukhari, the expert verified that the entities Romans, Jews, Quraysh were correctly identified and appropriately mapped to their ontology instances. This process was repeated for a random sample of 100 instances from each collection. No discrepancies were reported during this validation phase, confirming the reliability of the mapping process.
Our NLP methodology effectively extracted specific entities, such as prophets, pious caliphs, and the wives of Prophet Muhammad, by leveraging dictionaries and predefined mappings. However, accurately mapping general person names to corresponding ontology instances remains a significant challenge. In particular, shared names among multiple individuals in Islamic tradition, coupled with the variability in Arabic naming conventions—such as the use of familial relations, titles, and honorifics—complicate systematic linking of names to ontology instances.
For example, the name Zainab ( ) refers to multiple prominent figures in hadith literature:
) refers to multiple prominent figures in hadith literature:
Zainab bint Jahsh ( Zainab bint Muhammad ( Zainab bint Abi Salamah (
 ): A wife of Prophet Muhammad, also known as Umm al-Masakin.
): A wife of Prophet Muhammad, also known as Umm al-Masakin. ): The Prophet’s eldest daughter.
): The Prophet’s eldest daughter. ): A stepdaughter of the Prophet.
): A stepdaughter of the Prophet.
Such diversity confuses automated tools, especially when references lack explicit details, like whether Zainab refers to Zainab bint Muhammad or another individual. Currently, the system uses predefined dictionaries to map explicit names to ontology instances accurately. However, ambiguous references or uncommon terms, like Umm al-Masakin, are flagged for manual review or excluded to avoid errors.
To address this, we suggest a crowdsourcing framework for expert validation as a future enhancement. In this framework, ambiguous names extracted from hadith texts would be presented to domain experts alongside relevant contextual information, such as the full hadith passage and a list of potential ontology matches. For example, when encountering Zainab in a hadith, experts could determine whether it refers to Zainab bint Muhammad or another individual such as Zainab bint Jahsh based on the passage’s context and thematic content. This iterative validation process would systematically reconcile ambiguities, expanding the dictionaries and improving the system’s ability to handle complex naming conventions. Incorporation of expert validation would significantly enhance the reliability of entity mapping in the SemanticHadith ontology, particularly for shared names and cases involving contextual or cultural nuances.
In the following subsections, we provide a comprehensive account of the design and development process of the SemanticHadith ontology.
Conceptual Knowledge Modeling
We follow an iterative approach in ontology engineering, where the knowledge model evolves as we formalize our representation. To model the results from Section 4, we follow the Ontology Development 101 methodology (Noy et al., 2001) to design the SemanticHadith ontology consisting of seven steps: (1) Determine the scope of the ontology, (2) Enumerate important Terms, (3) Reuse existing ontologies, (4) Define classes and their hierarchies, (5) Define the class-slot properties, (6) Define the facets of the slots, and (7) Create instances. See Sections 5.2 to 5.6 for the detailed ontology design and development process. It is worth noting that the SemanticHadith ontology presented in this paper builds upon the foundation laid in our previous work (Kamran et al., 2023), extending and refining the ontology to encompass a broader range of concepts, entities, and relationships within hadith texts.
Scope of the Ontology—CQs
As this work is an extension of SemanticHadith 1.0, we intentionally reuse the original set of CQs to ensure continuity and comparability between ontology versions. While the CQs remain structurally similar, their realization in SemanticHadith 2.0 differs substantially. This is due to the introduction of text-driven KG generation, NLP-based entity and relation extraction, and similarity-based interlinking across hadith texts. Consequently, the contribution of this work lies not in redefining information needs, but in enabling these needs to be addressed through automated and scalable methods rather than manual curation. The original formulation of these CQs is described in detail in our prior work on SemanticHadith 1.0 (Kamran et al., 2023).
Building on this foundation, and informed by the findings of our NLP module, we define the scope of the SemanticHadith ontology through a set of CQs that characterize the types of queries the ontology and the resulting KG are expected to support. Table 3 presents these CQs together with their corresponding CQ archetypes. Following the framework proposed by Ren et al. (2014), the CQs are mapped to 12 generic question patterns, providing a structured view of the query capabilities enabled by the ontology.
Competency Questions Mapped to CQ Archetypes/Patterns as Identified by Ren et al. (2014).

Competency Questions Mapped to CQ Archetypes/Patterns as Identified by Ren et al. (2014).
CE
In addition to reusing concepts from established ontologies, we extend our SemanticHadith ontology, building upon the foundation laid in our previous work (Kamran et al., 2023). This extension involves refining and expanding the ontology to encompass a broader range of concepts, entities, and relationships within hadith texts. To ensure maximum interoperability and leverage existing standards, we reuse concepts from established ontologies while designing the ontology for the hadith source. This approach involves obtaining a list of important terms from hadith, which is informed by a high-level analysis of data from the six prominent hadith collections as elaborated in Section 3.1 as well as the entities and relations from the results of our NLP pipeline. We then design an ontology to model these terms as concepts and relations, providing axioms for formally expressing their meaning. Our design process includes a review of scientific literature and existing standards, particularly focusing on ontologies in the Islamic domain, such as those based on hadith (Azmi & Badia, 2010; Baraka & Dalloul, 2014).
We draw inspiration from existing vocabularies such as the Semantic Quran vocabulary (Sherif & Ngonga Ngomo, 2015) and Quran ontology (Hakkoum & Raghay, 2015) to model certain concepts within our ontology, including the Quranic verses, geographical and divine locations, divine events, historical groups and people cited, topics in hadith texts. These vocabularies provide comprehensive coverage of numerous concepts mentioned in the Quran and can be leveraged in the future for extracting additional entities from hadith.
In our ontology, we reuse classes and properties from the following established vocabularies: DCMI Metadata Terms (Dublin Core) (DU Board): This standard ontology is utilized for representing metadata, with terms from this vocabulary employed to describe the metadata of the SemanticHadith ontology. Schema.org (Guha et al., 2016): Curated primarily by search engine operators, the Schema.org vocabulary enhances search engine results, making it a valuable resource. It includes concepts such as schema:Event, schema:Place, and schema:Person. DBpedia (Becker & Bizer, 2008): DBpedia provides structured information extracted from Wikipedia projects as a central component of open KGs. It includes entities related to various events and places. Wikidata (Vrandečić & Krötzsch, 2014): A collaborative project, Wikidata serves as a free and open knowledge base that can be queried and edited by humans and machines alike. It includes information about events and places.
To reuse these vocabularies, we created sub-classes and sub-properties to some of the existing concepts from http://schema.org. For instance, we have integrated the
Ontology Design
Figure 4 shows the conceptual model for the SemanticHadith ontology. Here, we summarize the key entities and relations we chose to include in the conceptual design model of the SemanticHadith ontology version 2.0.1. The ontology design can easily be extended further by adding more concepts as the knowledge model matures.

Conceptual model of the SemanticHadith ontology version 2.0.1.
In this section, we provide an overview of the key entities and relations incorporated into the SemanticHadith ontology version 2.0.1, expanding upon the foundational concepts outlined in the original SemanticHadith ontology.
Additionally, the ontology incorporates the following relations:
Based on the list of significant terms identified through the analysis of hadith structure and data examination, we develop classes to represent objects with independent existence in the SemanticHadith ontology. Table 1 in the Supplemental Material presents the terms designated as classes in the ontology. Following a top-down approach, we initially define classes such as
Object properties denoting relationships or links between instances are defined for each class based on the available data. Table 2 in the Supplemental Material describes the object properties in detail. These properties establish connections between various entities in the ontology, facilitating the representation of complex relationships between different elements. Additionally, Table 3 in the Supplemental Material outlines the data properties defined in the SemanticHadith ontology version 2.0.1. Data properties provide detailed information about instances, such as attributes and characteristics. Moreover, links to well-known similar or related hadith are established using the property of the
Modeling Decisions
In refining the SemanticHadith ontology, we made strategic design decisions to enhance its expressiveness and semantic clarity:
These design decisions aim to capture the intricacies of the domain while maintaining semantic coherence and consistency within the ontology structure. By refining class relationships based on domain knowledge and logical inference, the SemanticHadith ontology evolves to better represent the complex relationships and attributes inherent in hadith literature and Islamic history.
The last step in the Ontology101 methodology is to create instances for the classes of the ontology (Noy et al., 2001). Our KG-generator automatically generates these individuals for our data, assigns the corresponding values to each data property for the individuals, and then establishes the relations or links between the individuals. To provide clarity on how entities and relationships are represented, Figure 5 shows the hadith class in Protégé, detailing its connections to narrators, locations, and thematic topics. This visualization demonstrates the structured nature of the ontology and its ability to capture semantic relationships within hadith texts. As depicted in Figure 6, the hadith text undergoes semantic annotation with ontology classes, facilitating enhanced comprehension and semantic querying capabilities.
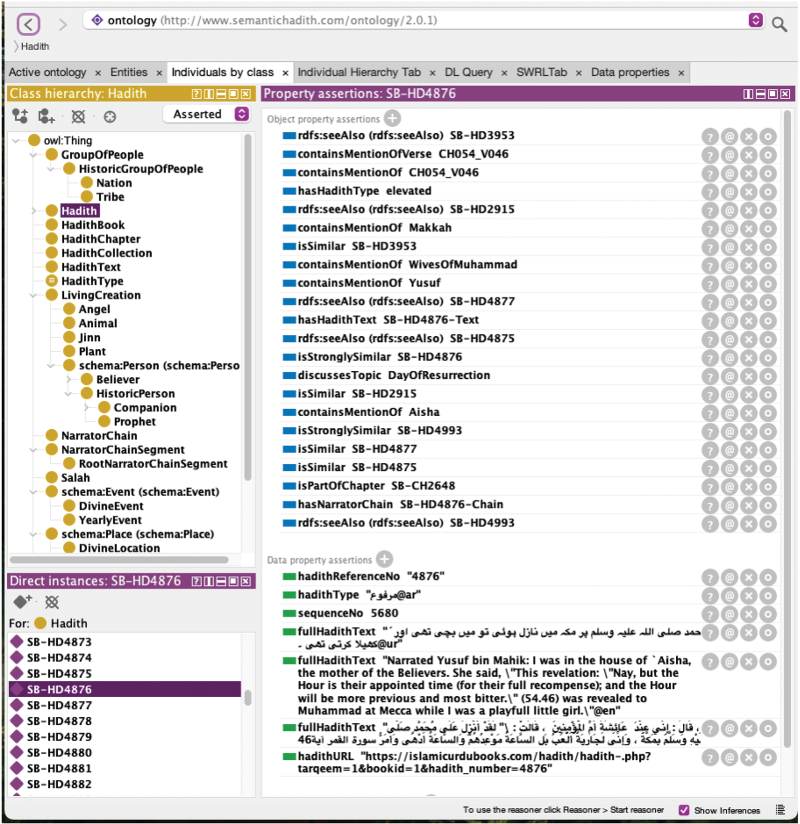
Ontology class :Hadith with property assertions for hadith instance SB-HD4876 in Protégé.
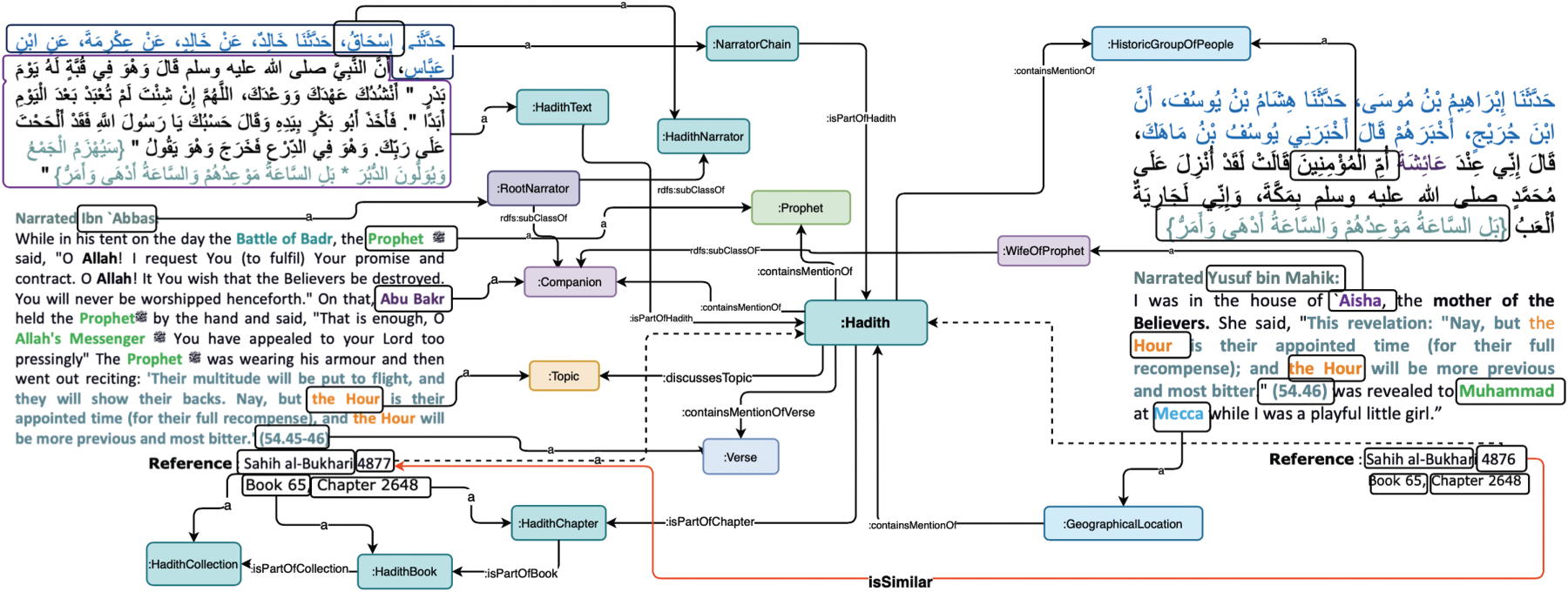
Semantic annotation of hadith text with SemanticHadith ontology.
There are multiple ontology editors available. Among these widely used ones have been comprehensively compared by Alatrish (2013). For this research, we selected Protégé version 5.5.0 (S. University) for its extensibility, UTF-8 support for Arabic data, and compatibility with tools like Jena and XML. The hadith: prefix was adopted for the vocabulary, while established vocabularies such as Schema.org (Guha et al., 2016) and DublinCore (Initiative et al., 2012) were reused to ensure interoperability. Equivalence relations with DBpedia (Becker & Bizer, 2008) and Wikidata (Vrandečić & Krötzsch, 2014) enhanced linkage with external datasets. According to the classification by Partridge et al. (2020), we decided to opt for top-level ontologies such as
Integration challenges included reconciling structural and semantic differences between SemanticHadith and external ontologies. Structural alignment issues were resolved by reusing external classes where possible and introducing custom subclasses linked through
Identification of Similar Hadith
One of the pivotal objectives of our study is to identify similar hadith within the six canonical hadith collections. To achieve this, we employed pre-trained Arabic sentence transformers to encode Arabic hadith texts into numerical representations, facilitating the computation of cosine similarity scores between pairs of hadith. This process has been used successfully for Quranic verses (Alshammeri et al., 2021; Basharat et al., 2015) as well as proposed for hadith (Huang et al., 2018).
Encoding and Similarity Calculation
The hadith texts were preprocessed to remove diacritics, punctuation marks, and stop words, ensuring uniformity in representation. These cleaned texts were then encoded using pre-trained sentence transformers, generating embedding vectors for each hadith. We used the asafaya bert base Arabic model, an NLP model implemented in the Transformer library, using the Python programming language (Safaya et al., 2020). Subsequently, a cosine similarity matrix of dimensions
Discrepancy in Similarity Bins
During the computation of cosine similarity scores for the complete Sahih Bukhari corpus, a significant discrepancy was observed between the similarity distributions of the expert-annotated dataset and the full corpus. The similarity matrix, comprising all unique pairs from the
The similarity bins for the expert dataset (shown in Table 4(a) and Figure 7(a)) revealed 19,877 hadith pairs in the highest similarity bin (0.9–1.0). However, the same bin in the complete corpus (as shown in Table 4(b) and Figure 7(b)) contained 1,042,332 pairs, which is an order of magnitude larger. Similar discrepancies were observed in other bins, with the complete corpus yielding significantly higher counts of pairs with moderate to high similarity scores, compared to the expert dataset.
Distribution of Hadith Pairs Across Similarity Bins in Sahih Bukhari.

Distribution of Hadith Pairs Across Similarity Bins in Sahih Bukhari.
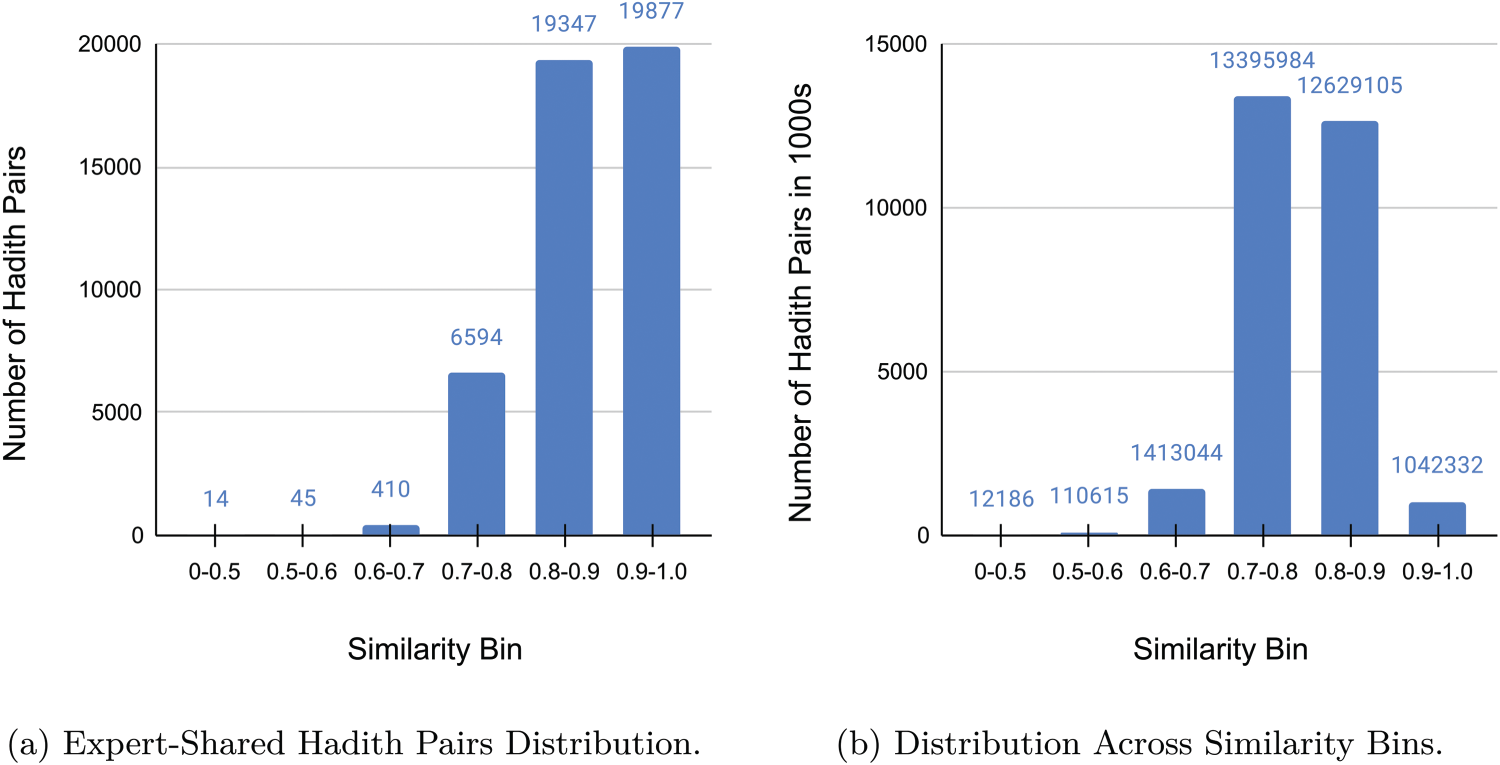
Distribution of hadith pairs across similarity bins in Sahih Bukhari for expert-shared pairs and complete corpus.
We engaged domain experts to validate 100 randomly selected hadith pairs from the top similarity bins (0.7–0.8, 0.8–0.9, and 0.9–1.0) to assess the accuracy of the similarity computation and understand discrepancies in the results. The hadith pairs were selected using a stratified random sampling strategy from the top similarity bins, ensuring representation across different hadith collections. This approach provides a more balanced basis for expert validation of similarity scores.
The experts used two primary criteria to evaluate the pairs. First, they assessed textual similarity (matan) by determining whether the similarity score reflected genuine overlap in wording, meaning, or structure. A high degree of similarity in matan was required for pairs to be classified as similar. Cases where similarity scores were inflated due to shared narrator chains (sanad) rather than genuine textual overlap, were considered as false positives. Second, experts considered contextual and thematic relevance, going beyond textual similarity to identify hadith pairs addressing related topics or events. Even when the matan differed significantly, pairs were classified as relevant if they shared meaningful thematic or historical connections.
The experts helped us identify reasons for the discrepancy in actual and expected results with concrete examples. For example, pairs like Sahih Bukhari 3398 and Sahih Bukhari 3415 involved subset relationships, where one hadith encompassed a shorter segment of another. In such cases, the shared matan warranted classification as similar despite differences in length or additional context in the longer narration. This difference in textual length resulted in a lower similarity score. Another issue arose with pairs like Sahih Bukhari 52 and Sahih Bukhari 2051, which shared overlapping matan but scored moderately (0.67656) due to differences in sanad. Additionally, thematic connections were observed in pairs like Sahih Bukhari 69 and Sahih Bukhari 4341, where little to no overlap in matan existed hence scoring low in similarity score, yet the hadith were deemed similar by the experts because they addressed related topics within Islamic tradition.
The validation process highlighted significant challenges with the automated similarity computation. Many high-scoring pairs were identified as false positives, primarily due to inflated scores caused by overlapping sanad rather than genuine matan similarity. This discrepancy highlights a limitation in the current methodology, and future work will aim to address this issue by focusing solely on the textual content (matan) of hadith to mitigate the impact of overlapping narrator chains (sanad). Additionally, several valid pairs fell outside the top similarity bins, demonstrating that cosine similarity metrics alone were insufficient to capture the multifaceted nature of hadith similarity. For example, thematic connections were observed in pairs where the matan showed little to no overlap, further emphasizing the limitations of a purely automated approach.
Furthermore, the sheer scale of the similarity matrix, encompassing over 2 million unique hadith pairs in Sahih Bukhari alone, made manual validation impractical. Given these challenges, we decided to rely solely on the expert-annotated dataset for this phase of the study. The expert dataset, which includes carefully validated hadith pairs, was integrated into the SemanticHadith KG to ensure the accuracy and reliability of the relationships represented.
Integration Into KG
Ultimately, we chose to map only the hadith pairs from the expert dataset into our KG. However, through consultation with experts, we augmented these mappings by adding a “strongly similar” property for pairs falling into the top similarity bin (0.9–1.0 cosine similarity). This additional property enhances the representation of highly similar hadith pairs within the KG, providing a more nuanced understanding of their relationships. Moving forward, our efforts will focus on improving and identifying similar hadith pairs for all collections considered in our study. By extending our analysis to encompass other collections such as Sahih Muslim, Ibn Maja, Sunan Abi Dawood, and Nisai, we aim to enrich the KG with a comprehensive representation of textual similarities across diverse sources of hadith literature. In the current implementation, only expert-validated similarity pairs from Sahih Bukhari are integrated into the KG. This decision was made to ensure semantic reliability and to avoid propagating similarity links that have not been reviewed in a religiously sensitive domain. Other hadith collections, including Sahih Muslim, Ibn Majah, Sunan Abi Dawood, and Sunan An-Nisai, are included in the KG with their structural, entity, and topic information; however, similarity-based interlinking for these collections has not yet been implemented. References to similarity integration for additional collections, therefore, describe planned future extensions rather than contributions realized in this study.
Challenges and Insights
Several challenges were encountered while identifying similar hadith, including the inclusion of sanad alongside matan in the encoding process. This led to inflated similarity scores for pairs with similar sanad but distinct matan. Additionally, instances where one hadith encompassed a subset of another posed challenges in accurately determining textual similarity. Insights gained from the expert validation process highlighted the importance of considering contextual relevance beyond textual similarity. While not textually similar, certain hadith pairs were deemed relevant due to thematic or historical connections, underscoring the multifaceted nature of similarity in hadith literature.
Based on the findings and insights from the validation process, future efforts will focus on refining the methodology to prioritize textual similarity while accounting for contextual relevance. To mitigate inflated results, future approaches could isolate matan by preprocessing the text to exclude sanad before embedding. Alternative distance measures, such as Euclidean distance (measuring absolute spatial distance) or Manhattan distance (sum of absolute differences in dimensions), could complement cosine similarity by capturing variations in embedding magnitude. These measures could provide additional insights into contextual relationships that cosine similarity alone may overlook. Using LLMs fine-tuned for Islamic texts can provide embeddings that better encode semantic and contextual nuances. Furthermore, integrating hybrid metrics, such as a weighted combination of cosine similarity and contextual relevance derived from LLMs, could better capture the multifaceted nature of hadith relationships. Supervised learning methods trained on expert-labeled data could further refine the thresholds for similarity classification. Additionally, as previously outlined, future work will involve developing a crowdsourcing framework for expert consultation, where hadith pairs meeting a predefined similarity threshold will be reviewed by domain experts. To address potential disagreements or conflicts, mechanisms such as majority voting or weighted input from experienced experts could be explored.
Results and Discussion
This section evaluates the design and implementation of the SemanticHadith ontology and KG, focusing on its logical consistency, scalability, practical applications, and future potential. We also present the metrics of both the SemanticHadith ontology and KG, the formal ontology design requirements, and answers to CQs in addition to the intended applications for this endeavor. A thorough analysis of the ontology’s structure, evaluation outcomes, and scalability adaptations highlights the project’s achievements and identifies avenues for further research.
Evaluation of SemanticHadith
The SemanticHadith ontology version 2.0.1 underwent a thorough evaluation to ensure its accuracy, consistency, and adherence to best practices in ontology design. Key evaluation steps and outcomes are summarized below:
Statistics of the SemanticHadith Ontology and the SemanticHadith Knowledge Graph.

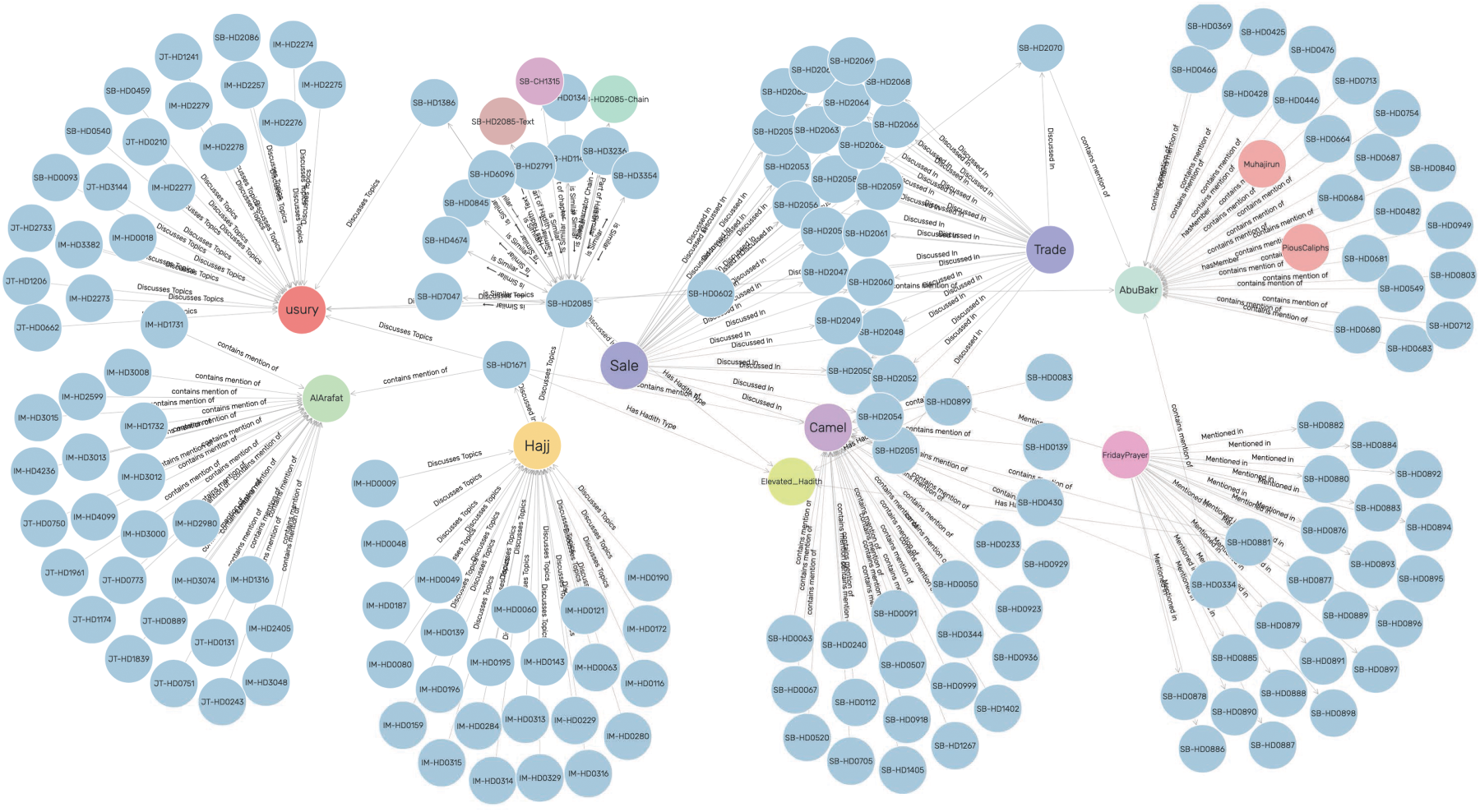
Visualization from the SemanticHadith knowledge graph.
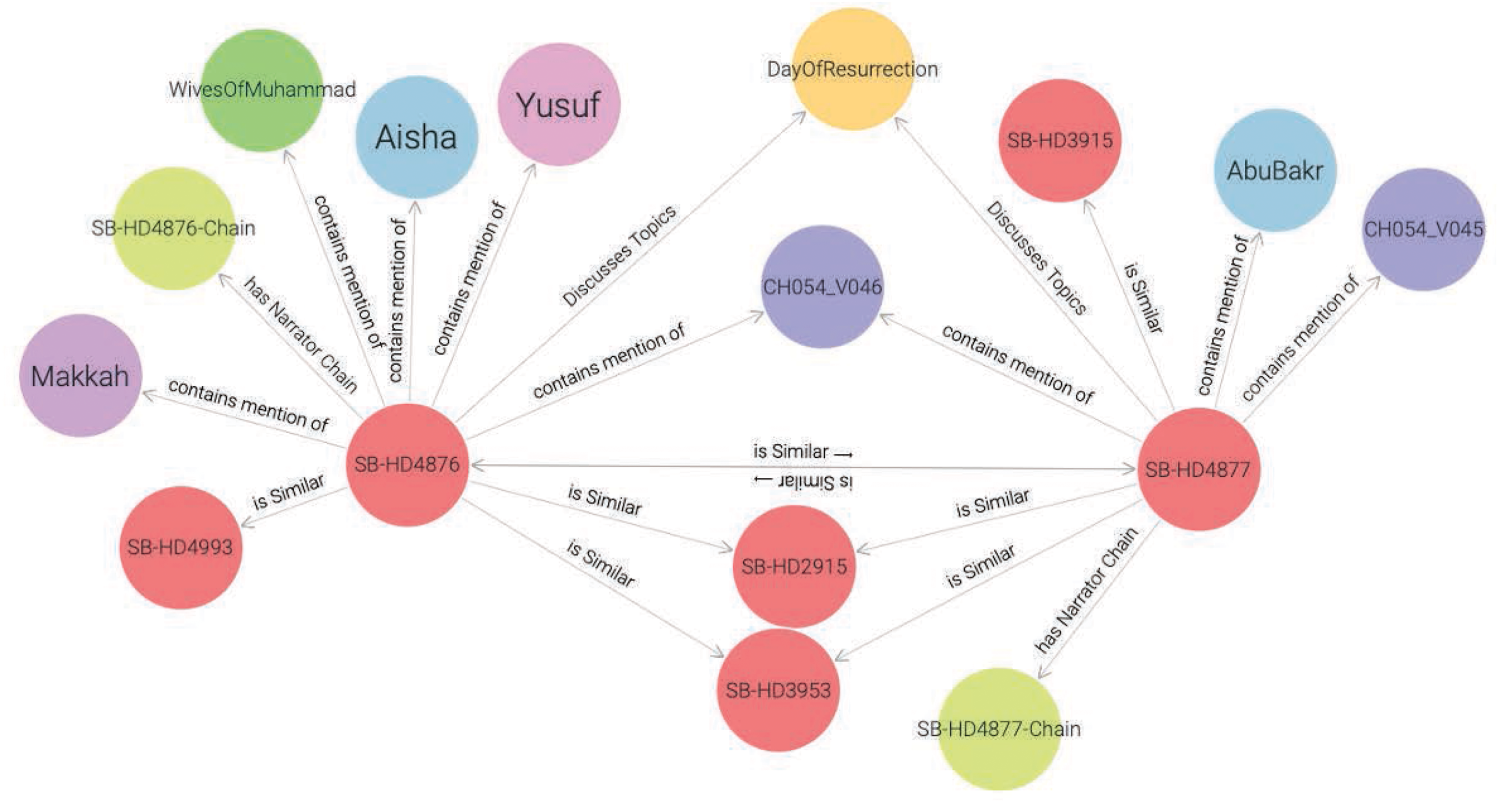
Knowledge graph visualization showing relationships between hadith (
This section outlines the intended usage and potential applications of the SemanticHadith ontology and KG.
Annotation of Additional Hadith Collections
The existing implementation of the SemanticHadith ontology has successfully utilized NLP techniques to annotate hadith texts. While the current focus has been on specific hadith collections, the methodology and infrastructure established can be extended to additional hadith collections. By leveraging NLP technologies, the annotation process can be automated to a significant extent, enabling the efficient annotation of large-scale hadith corpora. This expansion would result in a more comprehensive and interconnected repository of annotated hadith texts, facilitating advanced research and analysis in Islamic studies.
Enhanced Knowledge Exploration
Integrating NLP annotations into the SemanticHadith ontology opens up new possibilities for knowledge exploration and discovery. Researchers can leverage the KG to gain insights into various aspects of Islamic knowledge, including the relationships between entities, events, and concepts mentioned in hadith texts. By applying semantic querying techniques, users can explore the annotated corpus in depth, uncovering hidden connections and patterns within the data. Furthermore, the KG provides a foundation for the development of advanced semantic search and recommendation systems tailored to the needs of scholars and researchers in the Islamic domain. For example, Figure 10, a GraphDB screenshot, illustrates a query and its results, which capture shared entities (
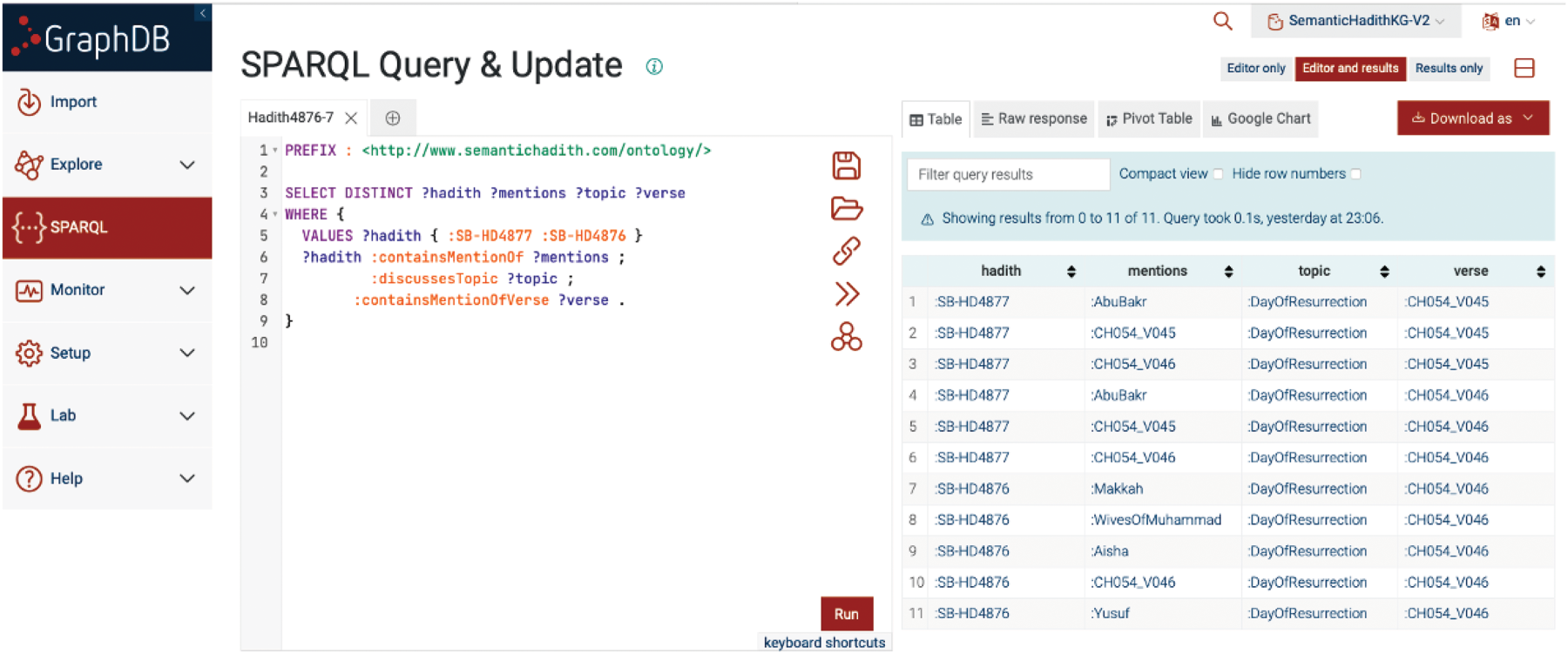
SPARQL query execution and results showing relationships between hadith, entities, and topics in GraphDB.
Beyond the realm of Islamic studies, the SemanticHadith KG holds potential for cross-domain integration with other knowledge domains. The KG facilitates interdisciplinary research and knowledge discovery by linking annotated hadith texts to relevant entities and concepts in external KGs, such as DBpedia and Wikidata. This cross-domain integration opens up opportunities for exploring connections between Islamic knowledge and other fields, including history, philosophy, linguistics, and cultural studies. Researchers across various disciplines can benefit from the enriched semantic annotations provided by the SemanticHadith ontology, enabling them to leverage Islamic knowledge in novel and interdisciplinary research endeavors.
Educational Applications
The SemanticHadith KG serves as a valuable resource for educational and pedagogical applications in Islamic studies. By providing a structured and semantically enriched representation of hadith texts, the KG supports interactive learning experiences, digital scholarship, and curriculum development in academic institutions and educational settings. Educators can utilize the ontology to create customized learning materials, interactive quizzes, and educational tools that engage students with authentic hadith texts in a meaningful and contextually rich manner. Furthermore, the availability of annotated hadith data in linked data format enables learner-sourcing initiatives, where students and scholars contribute to the annotation and enrichment of the KG through collaborative efforts, thereby fostering a culture of knowledge sharing and co-creation within the academic community.
Addressing Scalability Challenges and Existing Limitations
Expanding the SemanticHadith KG to encompass a wide range of Islamic resources, including the extensive hadith corpus and related literature, presents several scalability challenges. These challenges include managing large volumes of data, handling the linguistic and thematic diversity of Islamic texts, and ensuring computational efficiency. Effectively addressing these issues requires managing heterogeneous datasets, maintaining coherence across domains (e.g., tafsir, fiqh, and historical biographies), and verifying the authenticity and contextual relevance of entities and relationships.
One of the primary limitations is linguistic diversity. Historical and regional variations in classical Arabic can result in processing inaccuracies, even with customized NLP tools. Similarly, implicit meanings, contextual nuances, and cultural idioms may not be fully captured, limiting the granularity of the ontology. The inclusion of additional hadith collections or related Islamic texts can further complicate the ontological structure and computational performance. Despite employing advanced NLP techniques, such as transfer learning and pre-trained models, challenges like entity misclassification and relationship extraction errors persist in linguistically complex passages.
To address these challenges, a modular approach to ontology expansion has been adopted, enabling dynamic integration of additional domains while minimizing structural inconsistencies. Validation processes have been enhanced with semi-automated workflows, leveraging advanced machine learning models to assist with initial verification tasks and allowing experts to focus on complex cases. Optimized similarity computations, incorporating clustering techniques and pre-filtering strategies, reduce the computational burden associated with large-scale similarity analysis. For NLP tasks, pre-trained models fine-tuned on domain-specific data (e.g., hadith commentaries and classical Arabic prose) enhance the adaptability of the pipeline, ensuring consistent performance across diverse text genres.
Scalability also necessitates infrastructure improvements. Transitioning to distributed storage systems and adopting scalable architectures, such as cloud-based infrastructures, would support the processing and storage demands of the expanding KG. Federated SPARQL queries could further enhance interoperability by enabling seamless integration with external linked datasets, broadening the scope of interdisciplinary applications.
Moving forward, the SemanticHadith project aims to refine the KG-generation pipeline and expand the scope of annotated data by incorporating state-of-the-art NLP techniques and machine learning algorithms. These advancements will improve annotation accuracy and efficiency, enabling the inclusion of diverse hadith collections and genres. Additional efforts will focus on enriching the ontology with metadata, including provenance information, temporal data, and linguistic annotations, to provide a more comprehensive and contextually rich representation of hadith texts.
To address variations in naming conventions within hadith passages and improve entity mapping accuracy, a crowdsourcing framework for expert validation is under development. This framework will allow domain specialists to reconcile extracted named entities with predefined ontology instances, resolving ambiguities and ensuring reliable mapping based on contextual knowledge and expertize. Collaboration with scholars and domain experts will guide the ongoing evolution of the SemanticHadith ontology, ensuring its relevance and usability in research, education, and broader interdisciplinary contexts.
By combining methodological adaptations, expert input, and technological advancements, the SemanticHadith framework is positioned to meet the challenges of scalability and adaptability while expanding its utility for the comprehensive exploration of Islamic knowledge.
Conclusion
In conclusion, our article presents a comprehensive methodology for generating a KG from the hadith corpus, addressing key challenges in entity extraction, similarity computation, and KG construction. By leveraging NLP techniques, expert validation, and ontology engineering, we have successfully extracted entities, identified similar hadith, and enriched the SemanticHadith KG. We ensured accuracy in entity extraction through meticulous data selection, preprocessing, and custom NER model training, laying the foundation for a robust KG. Identifying similar hadith, facilitated by cosine similarity computation and expert validation, provided insights into textual similarities and thematic connections within hadith literature. Furthermore, our methodology includes conceptual knowledge modeling and formaliszation, ensuring interoperability of the KG. By interlinking with the LOD Cloud and providing an endpoint for SPARQL queries, we enhance accessibility and usability, fostering further research and applications in Islamic studies and related fields. Overall, our study contributes to advancing KG generation from textual sources, particularly in the domain of Islamic knowledge. Our framework facilitates efficient information retrieval and exploration and opens avenues for interdisciplinary research and the development of intelligent applications in religious studies and beyond.
Supplemental Material
sj-pdf-1-swj-10.1177_22104968261431425 - Supplemental material for Semantic Enrichment of Hadith Corpus—Knowledge Graph Generation From Islamic Text
Supplemental material, sj-pdf-1-swj-10.1177_22104968261431425 for Semantic Enrichment of Hadith Corpus—Knowledge Graph Generation From Islamic Text by Amna Binte Kamran, Nigar Azhar Butt and Amna Basharat in Semantic Web
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Competing Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Data Availability
Ontology, Knowledge Graph, ontology documentation, SPARQL Queries corresponding to Competency Questions, MIRO report https://github.com/A-Kamran/SemanticHadith-V2. The implementation of the Entity recognition framework along with the modified corpus is available at ![]() .
.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.