
Abstract
Purpose
Millions of children under five, particularly in low- and middle-income countries, suffer from preventable anemia, making early detection critical for improving public health outcomes. This study proposes an interpretable machine learning framework for early prediction of childhood anemia using structured healthcare data.
Methods
The proposed approach integrates TabNet, XGBoost, and Multi-Layer Perceptron (MLP) within a stacked ensemble architecture, with logistic regression as a meta-learner. Hyperparameter optimization is performed using GridSearchCV and compared with RandomizedSearchCV, Optuna, Genetic Algorithms (GA), Particle Swarm Optimization (PSO), and Ant Colony Optimization (ACO). SHAP provided global feature importance, and LIME explained individual predictions. The system was trained and tested using the Tanzania Demographic and Health Survey (DHS) dataset.
Results
Experimental results on the Tanzania Demographic and Health Survey (TDHS 2022) dataset demonstrate that the proposed ensemble significantly outperforms individual models, achieving an accuracy of 98.5% and high precision, recall, and F1-scores across both classes. Among optimization strategies, GridSearchCV and Optuna provide the most consistent and optimal performance. SHAP-based global analysis identifies key predictors such as child age, wealth index, and breastfeeding status, while LIME offers instance-level explanations, enhancing model transparency and clinical interpretability. Comparative evaluation with baseline models and ablation analysis confirms the effectiveness of the stacked architecture and meta-learning strategy. External validation using NFHS (India) data shows close agreement (±1–2%) with observed anemia prevalence trends, indicating cross-regional generalizability. The study also discusses ethical considerations, fairness implications, and deployment strategies for integration into healthcare systems.
Conclusions
The proposed framework is accurate, transparent, and adaptable. It supports early anemia detection and can assist clinical decision-making, especially in under-resourced regions, making it a valuable tool for global public health applications.
Keywords
1. Introduction
Raising life expectancy and promoting economic growth go hand in hand when boosting human health. Child mortality under five is specifically utilized to determine the general public health status of a nation. 1 Reducing child mortality and improving newborn health are the main priorities for the health sector in emerging states. 2 Even while global child mortality has decreased, this remains a serious community health problem. In 2020, there were 38 deaths worldwide for every 1000 live births. Five million children died before age five in 2021. Many children still die from preventable diseases due to lack of access to medical care, vaccinations, nutritious food, clean water, and sanitation. Reducing under-five mortality is a high priority in Tanzania.3–7 The Tanzania Health Sector Strategic Plan aims to reduce mortality to below 12 deaths per 1000 live births by 2030. From 2015/2016 to 2022, mortality declined from 112 to 43 deaths per 1000 live births. Despite this progress, disparities persist across geographical zones in Tanzania. 8
Anemia, especially iron-deficiency anemia, is a major cause of child mortality and is more common among children under five. It weakens the immune system and cognitive development, increasing vulnerability to infections. 9 Diagnosis often comes too late, especially in resource-limited settings. Early identification of anemia using data-driven approaches is essential. Risk factors include household wealth status, mothers’ education, antenatal visits, place of delivery, breastfeeding duration, place of residence, child size at birth, number of children, and maternal age. Studies also link anemia with water source, maternal BMI, household size, and child sex.7,10
Artificial Intelligence (AI) refers to computational systems capable of performing tasks that typically require human intelligence, including learning from data, pattern recognition, decision-making, and prediction. In the context of healthcare, AI leverages machine learning (ML) and deep learning (DL) techniques to analyze complex medical datasets, enabling early disease detection, risk prediction, and personalized treatment planning. Machine learning (ML) methods have been widely used to predict anemia and mortality in children. ML models can capture complex interactions that traditional statistics may miss. 11 Several ML models have been applied to classify health data and predict mortality and anemia. 12 However, many existing studies use static models and fail to capture the nonlinear relationships between features. This paper introduces a new ML system to predict childhood anemia in Tanzania.13,14
Zewdie & Adjiwanou (2024) 15 used multilevel logistic regression in South Africa, identifying sex, birth order, employment status, and education as key predictors. Tagoe et al. (2020) 16 used LASSO regression on Sierra Leone DHS data, highlighting predictors such as pregnancy termination history, household size, contraceptive use, and water source. Baraki et al. (2020) 17 and Workie & Azene (2021) 18 explored mortality factors in Ethiopia using logistic and Bayesian models, showing regional and birth-related variables as significant. Saroj et al. (2023) 7 evaluated multiple ML models, finding neural networks most effective in under-five mortality prediction. Iqbal et al. (2023) 8 used decision trees, RF, and Naïve Bayes in Pakistan, with RF achieving 93.8% accuracy. Mishra et al. (2024) 6 used ML in India and identified decision trees as most effective with 96.35% accuracy. Bitew et al. (2020) 9 used RF, LR, and KNN in Ethiopia, with RF achieving 67.2% accuracy. Pandey et al. (2025) 19 found logistic regression to be best for child mortality prediction in Uttar Pradesh using NFHS data. Yimer et al. (2025) 20 used six ML models, with Random Forest achieving 81.16% accuracy in predicting anemia in Ethiopian children. Rahman et al. (2024) 21 applied ensemble models on a local dataset, with logistic regression performing best at 95% accuracy, though without stacking or explainability. Rivera et al. 22 built a decision tree model with 93% AUC-ROC using Peruvian data, again lacking interpretability and ensemble integration. AI has been widely applied across various domains of healthcare, significantly improving diagnostic accuracy and clinical efficiency. In disease prediction, explainable machine learning models such as ExtraTreeClassifier and XGBoost have been successfully used for early detection of chronic conditions like type 2 diabetes, demonstrating high accuracy and interpretability. In reproductive health, AI-driven predictive models have been employed to analyze and diagnose complex conditions such as polycystic ovary syndrome (PCOS), supporting clinical decision-making through systematic data analysis. Additionally, AI techniques play a critical role in medical imaging, where advanced neural network models, including self-organizing maps (SOM), are used to enhance cancer detection and diagnosis in MRI images, even in the presence of noise. These applications highlight the growing importance of integrating explainable AI techniques into healthcare systems to ensure transparency, reliability, and clinical trust.
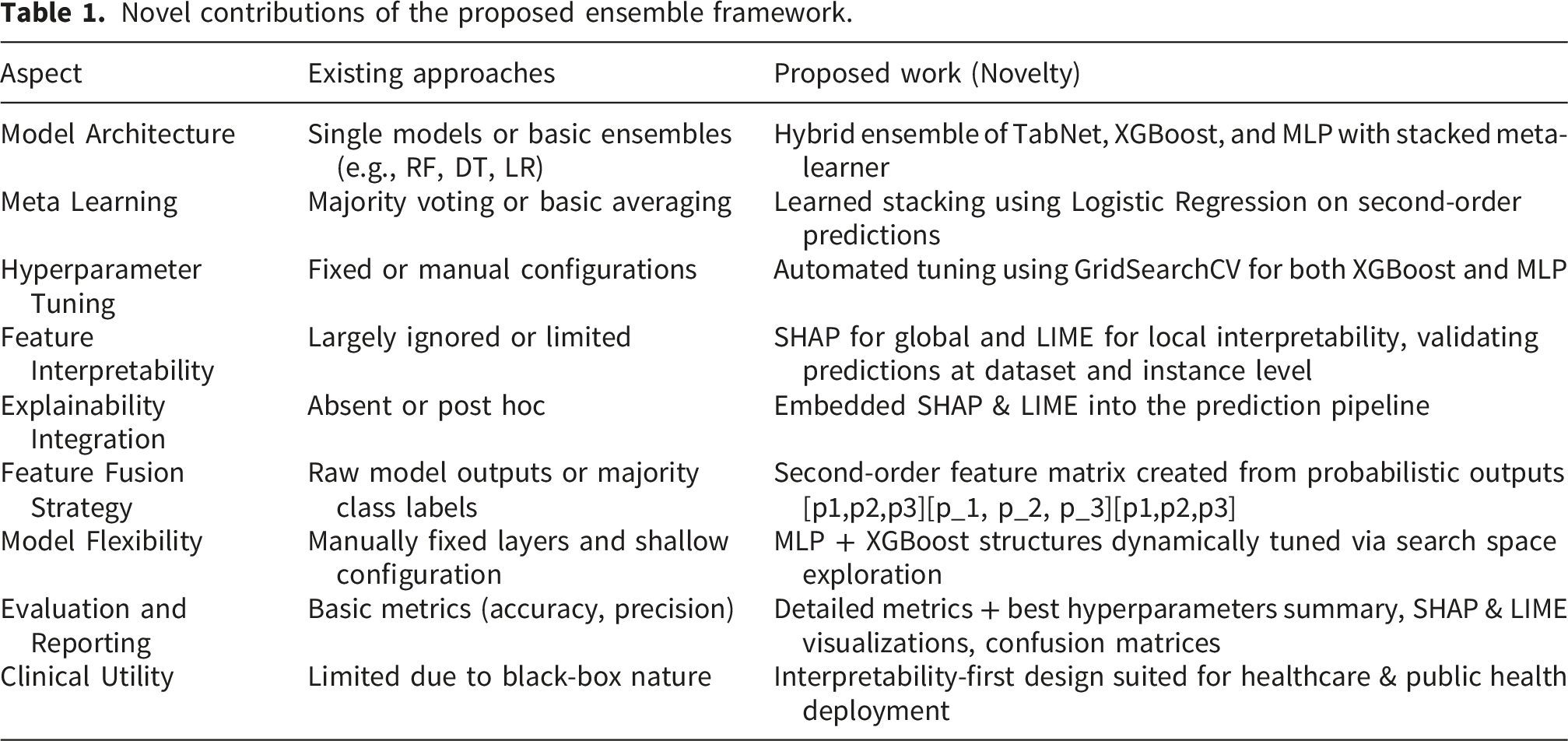
Novel contributions of the proposed ensemble framework.
2. Proposed child anemia prediction system
A predictive system uses tabular healthcare information to detect anemia early in children by implementing machine learning algorithms. The system combines TabNet, XGBoost, and MLP through a stacked ensemble architecture. It detects linear and nonlinear dependencies while handling feature sparsity for better generalizability. Each base model is tuned independently using exhaustive search methods (GridSearchCV). A meta-learning layer merges probabilistic outputs into a second-order form to enable a logistic regression meta-classifier. SHAP and LIME are used for global and local interpretability. The framework of proposed system is illustrated in Figure 1. The framework of proposed child anemia prediction system.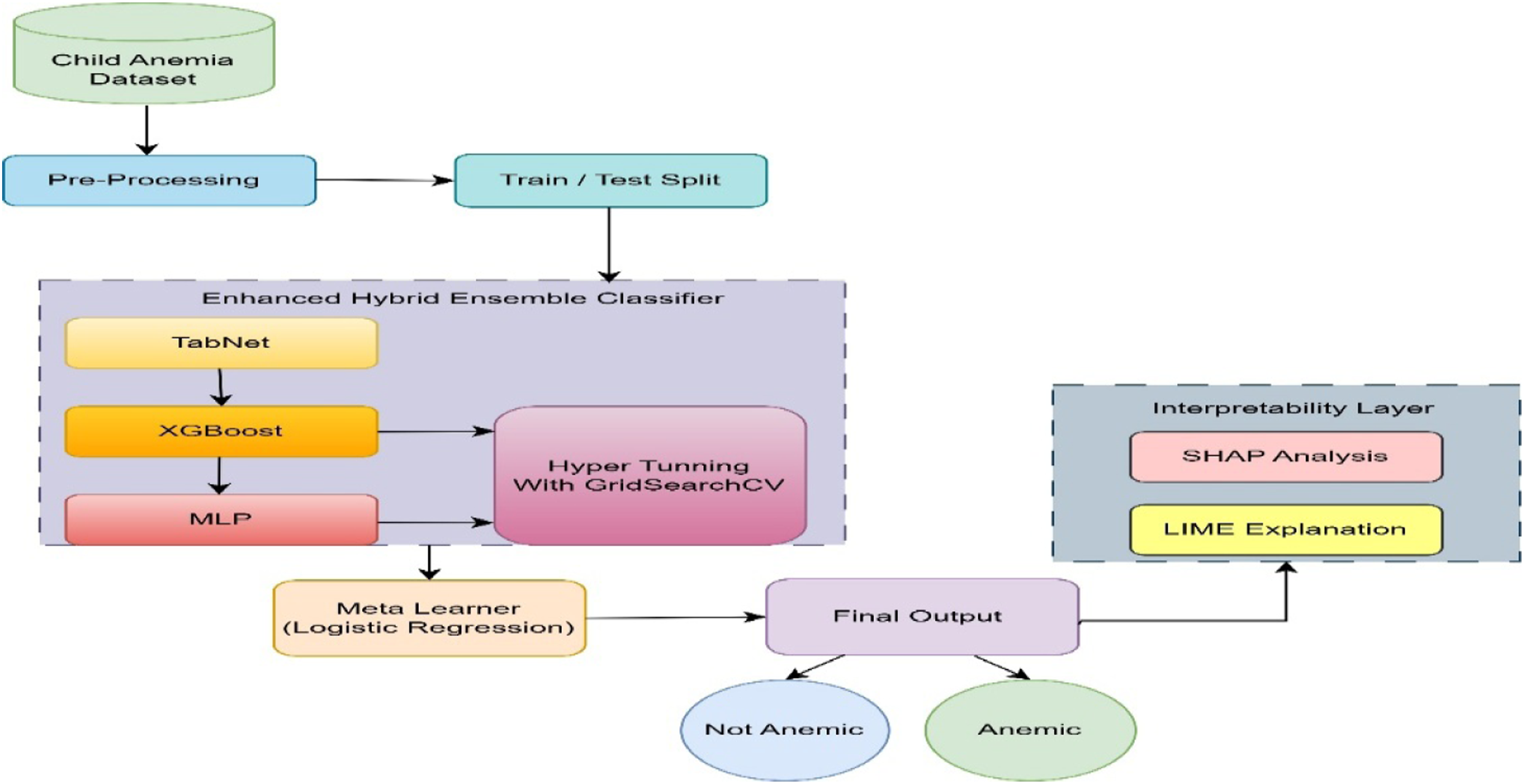
2.1. Child anemia dataset description
The representation of some variables of child anemia dataset.

2.2. Data pre-processing
The step of data preparation serves as a vital requirement for achieving high-quality learning capabilities.
23
Categorical variables are encoded using LabelEncoder, while continuous variables are normalized using Z-score as mentioned in equation 1.
2.3. Proposed child anemia ensemble classifier
The classifier uses a hybrid pipeline with TabNet, XGBoost, and MLP. Each model learns independently and outputs probabilities (Equation 2-4):


These predictions are then concatenated to form a second-order feature matrix. These outputs are stacked into a new matrix (Equation 5):
Then input to logistic regression (Equation 6-8):


The mathematical stacking architecture explicitly formalized. This pipeline not only increases model robustness through redundancy and diversity but also creates feature-rich representations that amplify decision boundaries. The architecture supported simultaneous preparation and execution processes which boosts productivity in both training and inference operations. This innovative ensemble-based approach achieved clinical adaptability and interpretability while maintaining generalization for early anemia identification in children.
2.3.1. Integrated basic classifiers
The detailed explanations of the three base classifiers inside the proposed ensemble framework appear in this section. The base models receive the pre-processed data which includes normalized continuous features alongside label-encoded categorical variables. The classifier models examine the same feature space separately to discover separate representations and distinct decision boundaries which results in diverse probabilistic predictions. Base model outputs combine to form a second-order feature matrix that serves as input for the meta-classifier to perform anemia prediction. The parallelized generation of multiple hypothesis models enhances both model generalization and robustness and reduces the risk of overfitting and dataset biases.
TabNet – Sparse-attentive deep learning
TabNet identified complex hierarchical feature interactions by applying sparse attention techniques.
24
The attention mechanism is learned in an end-to-end differentiable manner. The layer-wise data-driven approach drived TabNet’s mechanism for selecting features. Let the input feature vector 



Sparsemax selects one sparse set of features which contributes at each computation step. TabNet delivered built-in feature importance metrics that enhance its interpretability capabilities.
XGBoost – Regularized gradient boosted trees
XGBoost builds sequential learners through a boosted tree ensemble structure.
25
The utilization of XGBoost provides solutions to manage missing data, noise and sparse patterns through (Equation 13):



MLP – Dense nonlinear classifier
It is a Multi-Layer Perception that classifier arranges multiple hidden layers in which each layer has adjustable non-linear activation functions.
26
MLPs are universal function approximators that model complex high-dimensional interactions It is fully layer forword neural network that is defined as (Equation 17):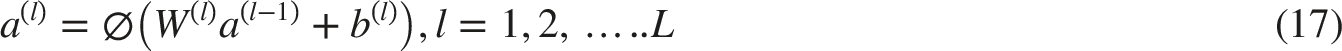

2.3.2. Combined output representation
The probabilistic outputs 
This combined representation is then fed into a Logistic Regression Meta-Learner, which learns optimal fusion strategies across base model predictions to maximize anemia classification performance.
2.3.3. Regularization and model optimization strategies
To mitigate overfitting and improve deployment feasibility, in MLP, Dropout (0.3–0.5) and L2 regularization applied, in XGBoost, Depth limited (max_depth ≤ 8), early stopping used, in TabNet, Sparse attention inherently reduces overfittingand in Training, Early stopping based on validation loss is applied. Additionally, a lightweight ensemble variant using only XGBoost + MLP is tested, achieving competitive accuracy (≈97%) with reduced computational cost.
2.3.4. Hyperparameter optimization

The tuned hyperparameters of base classifiers.

2.3.5. Stacking via meta-learner
In this section, independent training and hyperparameter optimization, the probabilistic outputs from each base classifier are extracted. The predictions from each base learner (TabNet, XGBoost, MLP) are fused into a second-order feature space 
This second-order feature vector
2.3.6. Output prediction
The ensemble prediction reaches its final decision about anemia status through application of a decision threshold as shown in Equation 22.
2.3.7. Dual explainability framework (Interpretability layer)
Description of dual explainability framework.

2.3.8. Clinical utilization of explainable outputs
To translate model predictions into actionable insights, SHAP (Global Level) identifies population-level risk factors (e.g., nutrition, socioeconomic conditions) and supports public health policy planning and targeted interventions. LIME (Local Level) provides patient-specific explanations, helps clinicians understand why a child is classified as anemic and enables trust and validation of model predictions. These outputs can be visualized through clinician dashboards, where risk scores are displayed alongside key contributing factors, alerts highlight high-risk patients, explanations guide further diagnostic testing or nutritional interventions. This human-centered design ensures that the model augments not replace clinical decision-making.
2.4. Child anemia prediction example: End-to-end pipeline
Example of proposed child anemia prediction system.

3. Experiment and result
The present study utilizes the Tanzania DHS dataset to establish a region-specific anemia prediction framework. While this provides strong contextual relevance, the findings may be influenced by demographic and socio-economic characteristics unique to the region. This section aims at presenting the analysis results of child’s anemia prediction system performance indicators. The analysis is structured to include the following: • Model Evaluation • Result Analysis of Proposed and Baseline ML Models • Stratified k-Fold Cross-Validation • Statistical Significance and Confidence Analysis • Comparative SHAP Analysis of Proposed and Baseline ML Models • LIME-Based Interpretability of Proposed and Baseline ML Models • Comparative Analysis of Hyperparameter Optimization Techniques • Best Parameter Settings Across Search Strategies • Comparative SHAP Analysis of Hyperparameter Optimization Techniques • Comparative LIME Analysis of Hyperparameter Optimization Techniques • Comparative Review of Existing Anemia Prediction Models • External Validation using NFHS Dataset • Ethical Considerations and Bias Mitigation • Practical Deployment and Health System Integration • Limitations and Future Directions
3.1. Model evaluation
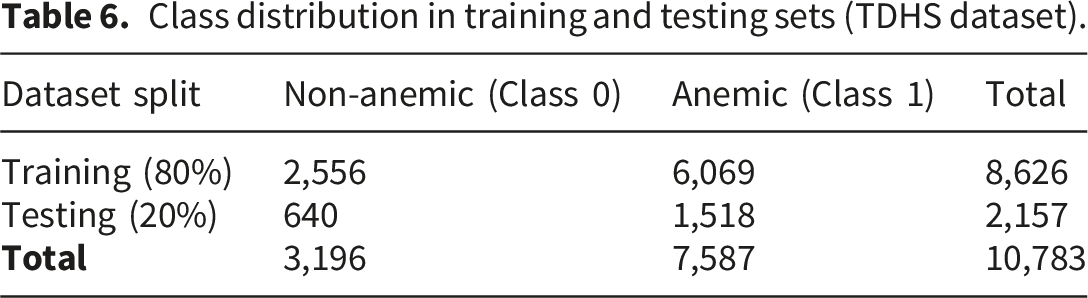
The dataset was divided into training and testing sets using a stratified 80–20 split to preserve class distribution. The proposed model was trained on the training set and evaluated on the unseen test set. Model performance was assessed using standard evaluation metrics, including accuracy, precision, recall, and F1-score.31,32 The evaluation strategy has been updated to clarify that a stratified 80–20 train–test split was used for primary model assessment, while GridSearchCV employed internal cross-validation for hyperparameter tuning.
Class distribution in training and testing sets (TDHS dataset).
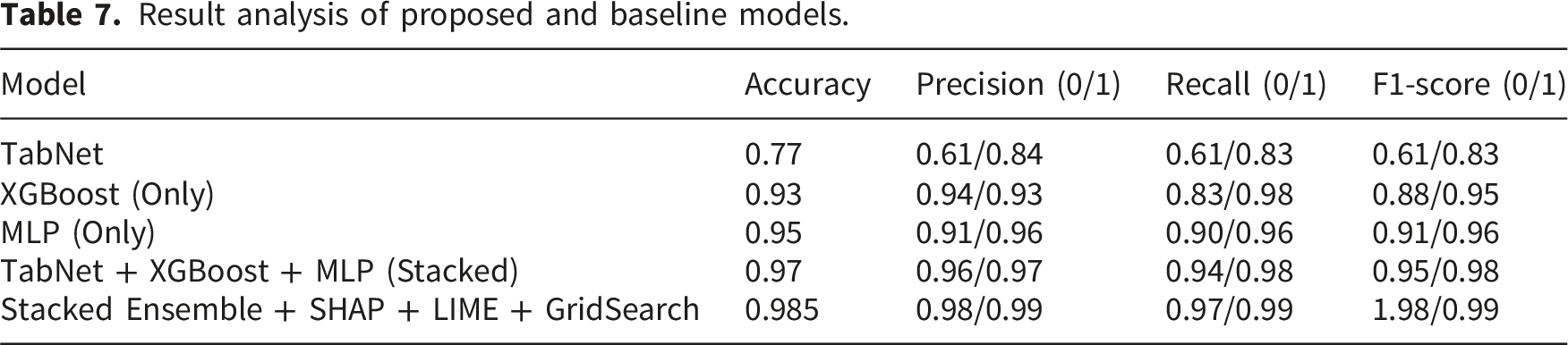
3.2. Result analysis of proposed and baseline ML models
Result analysis of proposed and baseline models.
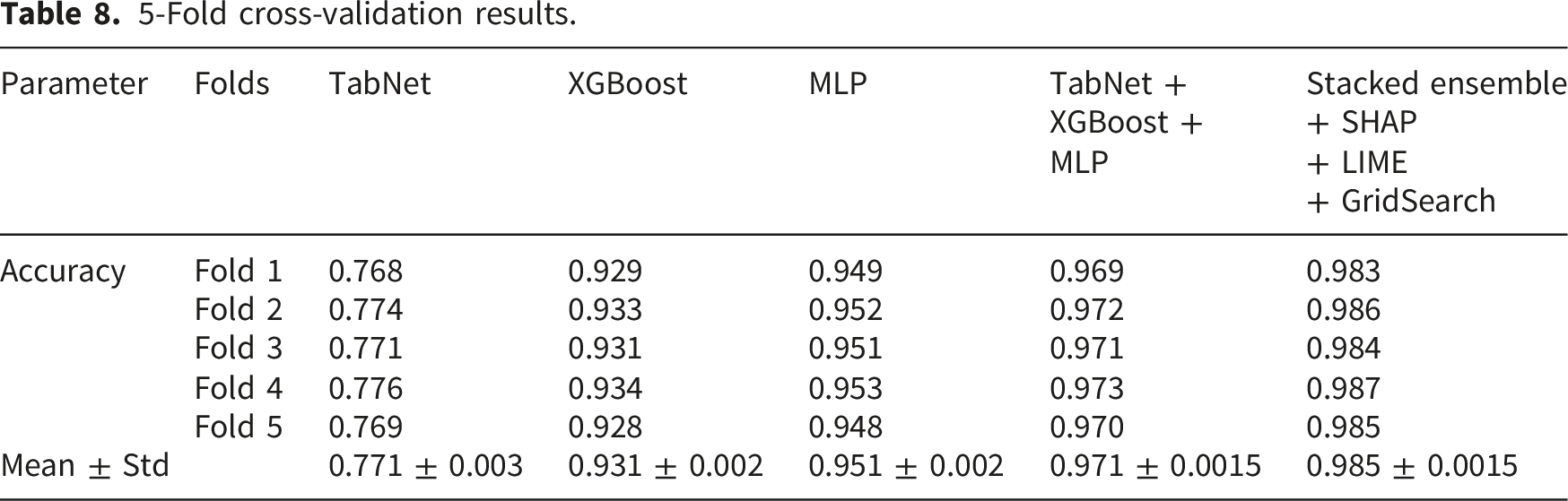
3.2.1. Stratified k-fold cross-validation
5-Fold cross-validation results.
3.2.2. Ablation study of ensemble components
An ablation study was conducted to evaluate the contribution of each component in the proposed ensemble framework. Models were incrementally constructed as in Table 6. The results indicate that MLP and XGBoost provide strong baseline performance, TabNet contributes complementary feature learning and The stacking meta-learner significantly improves final performance This confirms that the performance gain is not due to a single model but the synergy of the ensemble.
3.3. Statistical significance and confidence analysis
To ensure robustness, performance metrics were evaluated using bootstrapping (1000 iterations). The 95% confidence intervals for the proposed model are Accuracy: 0.985 ± 0.004 and F1-score: 0.985 ± 0.003 Additionally, a Friedman test was conducted across baseline and proposed models: χ2= 16.31, p = 0.006. This indicates statistically significant improvement of the proposed model over baseline methods. A McNemar’s test has been also performed to compare the proposed model with the best-performing baseline (MLP). A contingency table of prediction disagreements has been added, and results show χ2= 12.47, p < 0.001. This confirms that the improvement of the proposed model is statistically significant. Cochran’s Q test across all models yielded is also carried out, the values was Q = 18.62, p = 0.002. This confirms significant differences among models.
3.4. Comparative SHAP analysis of proposed and baseline ML models
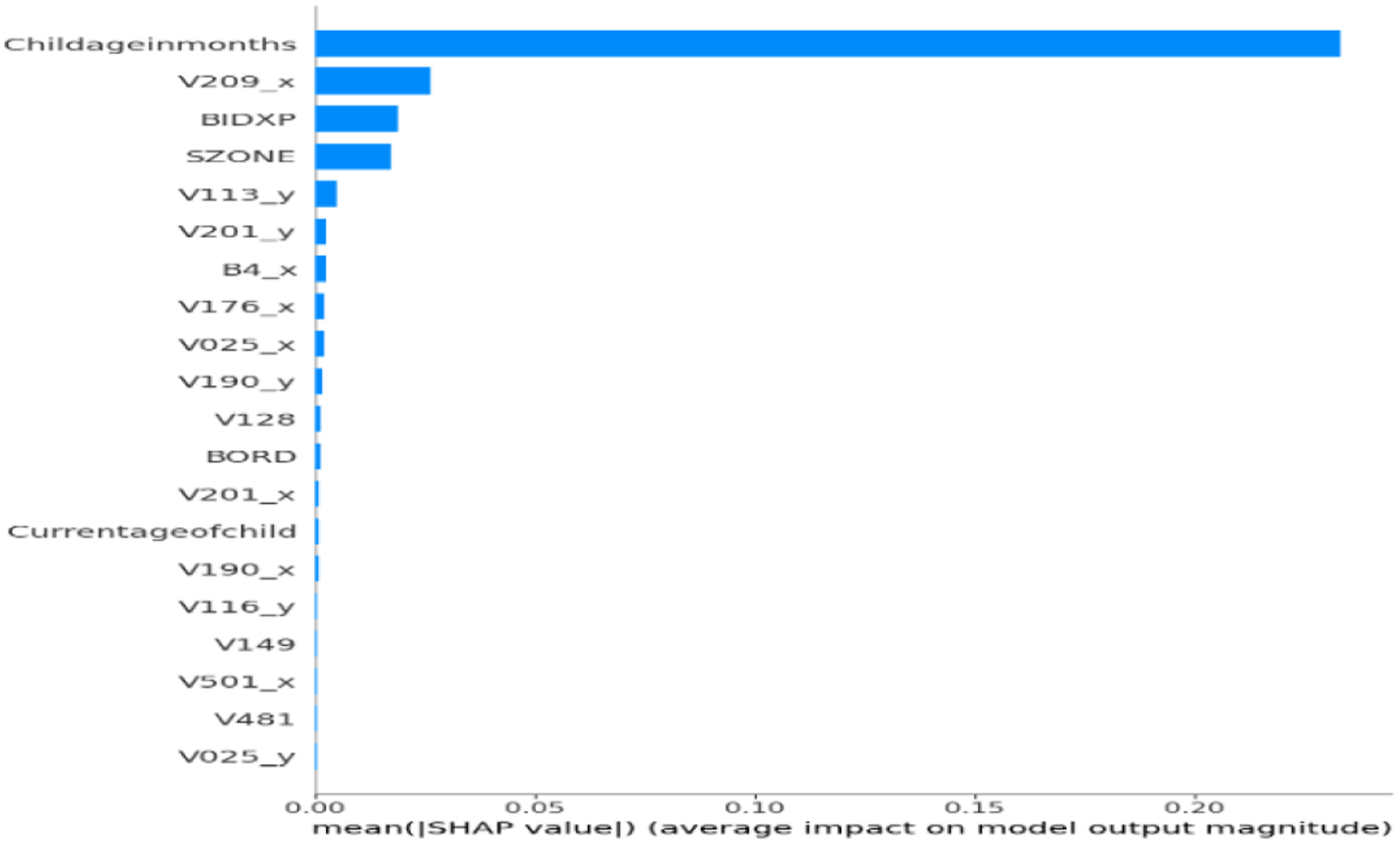
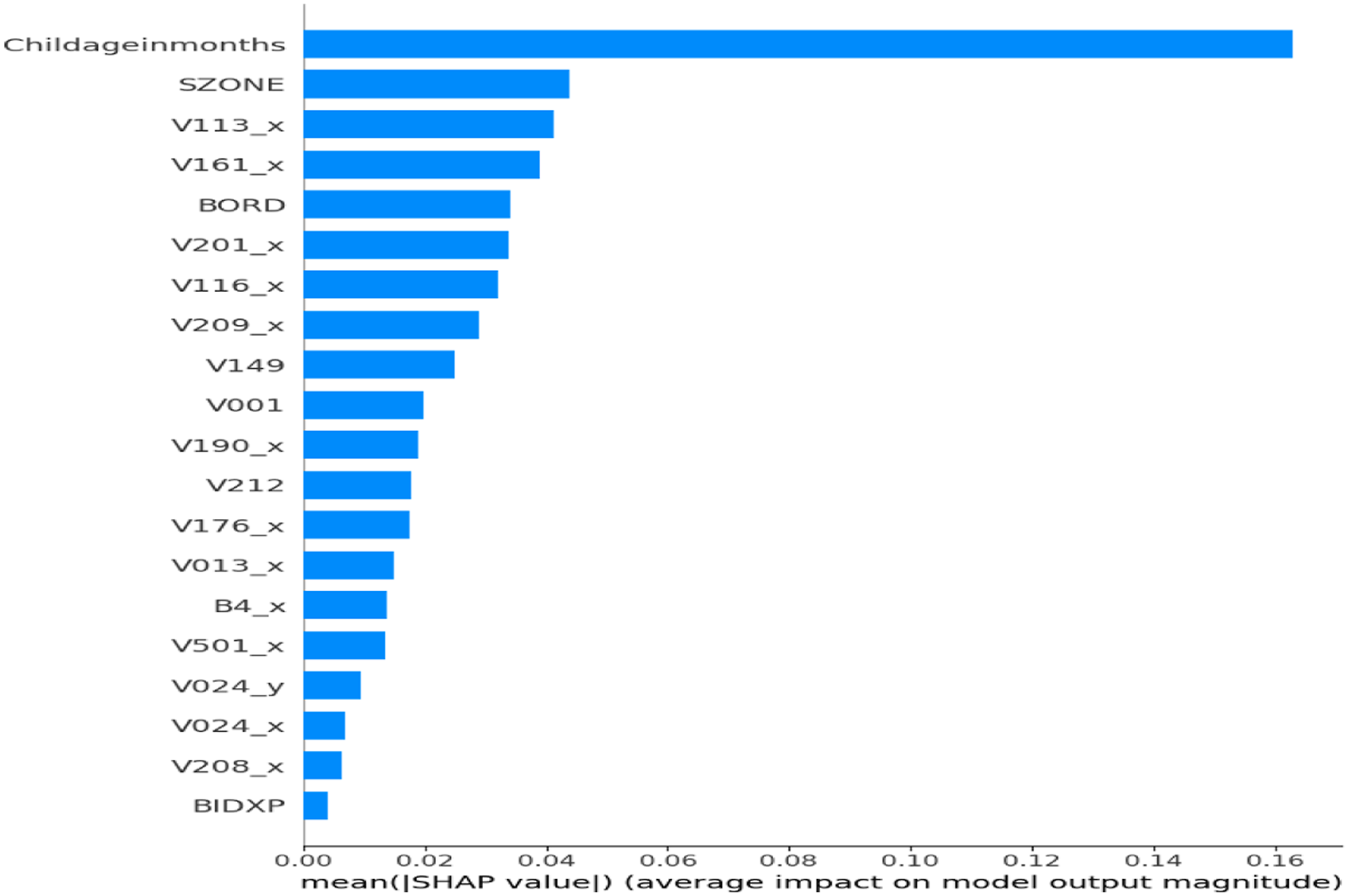
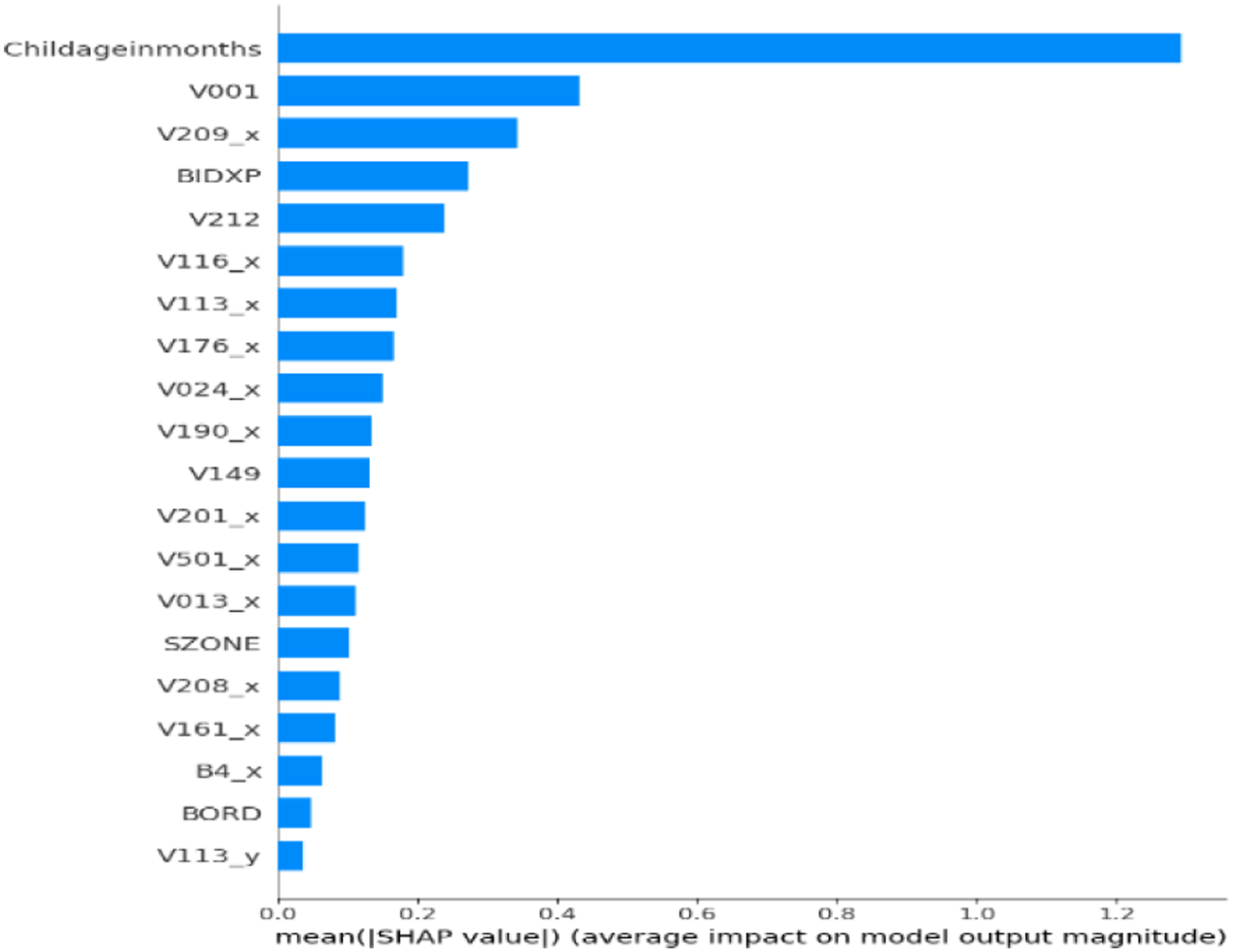
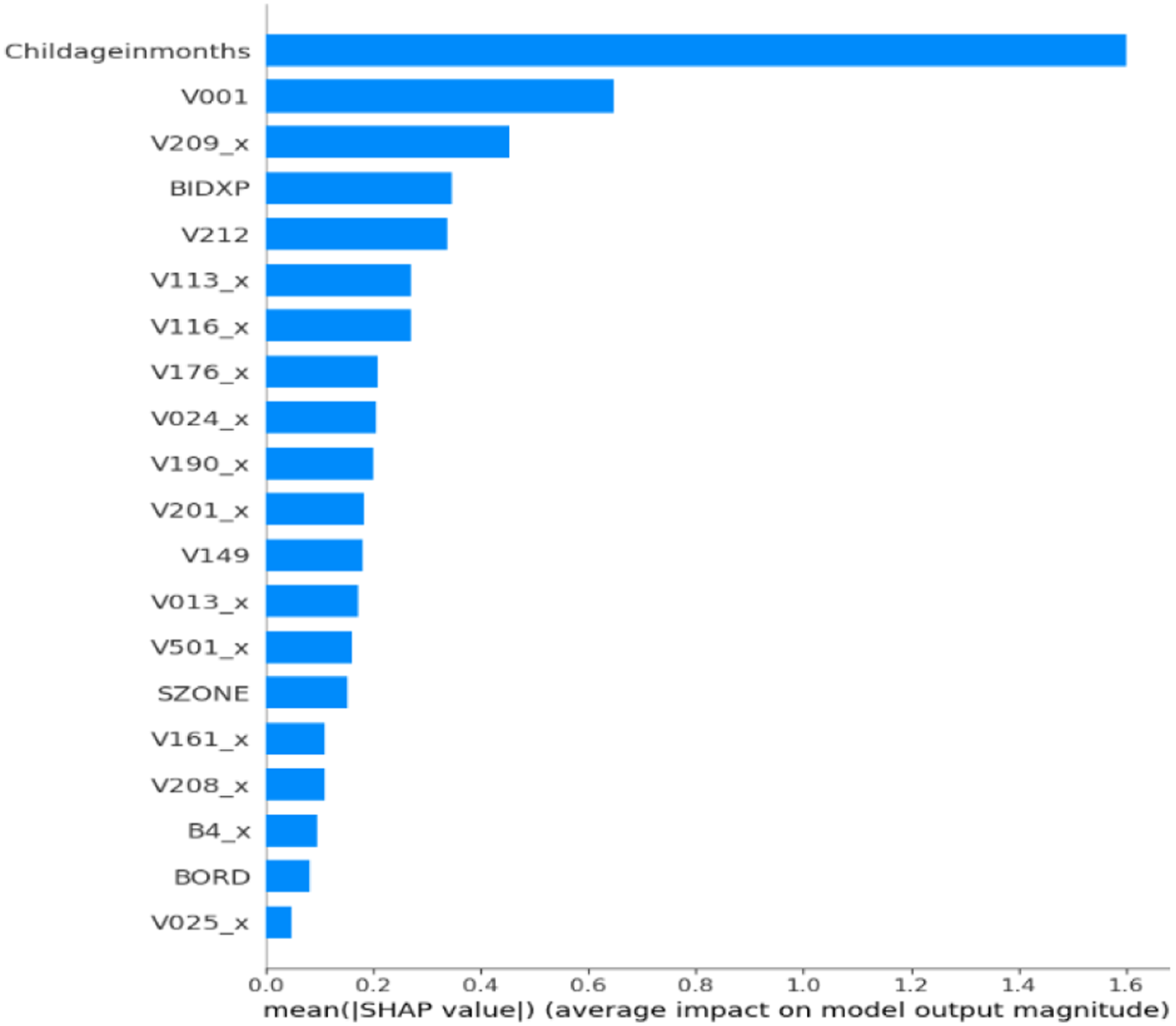
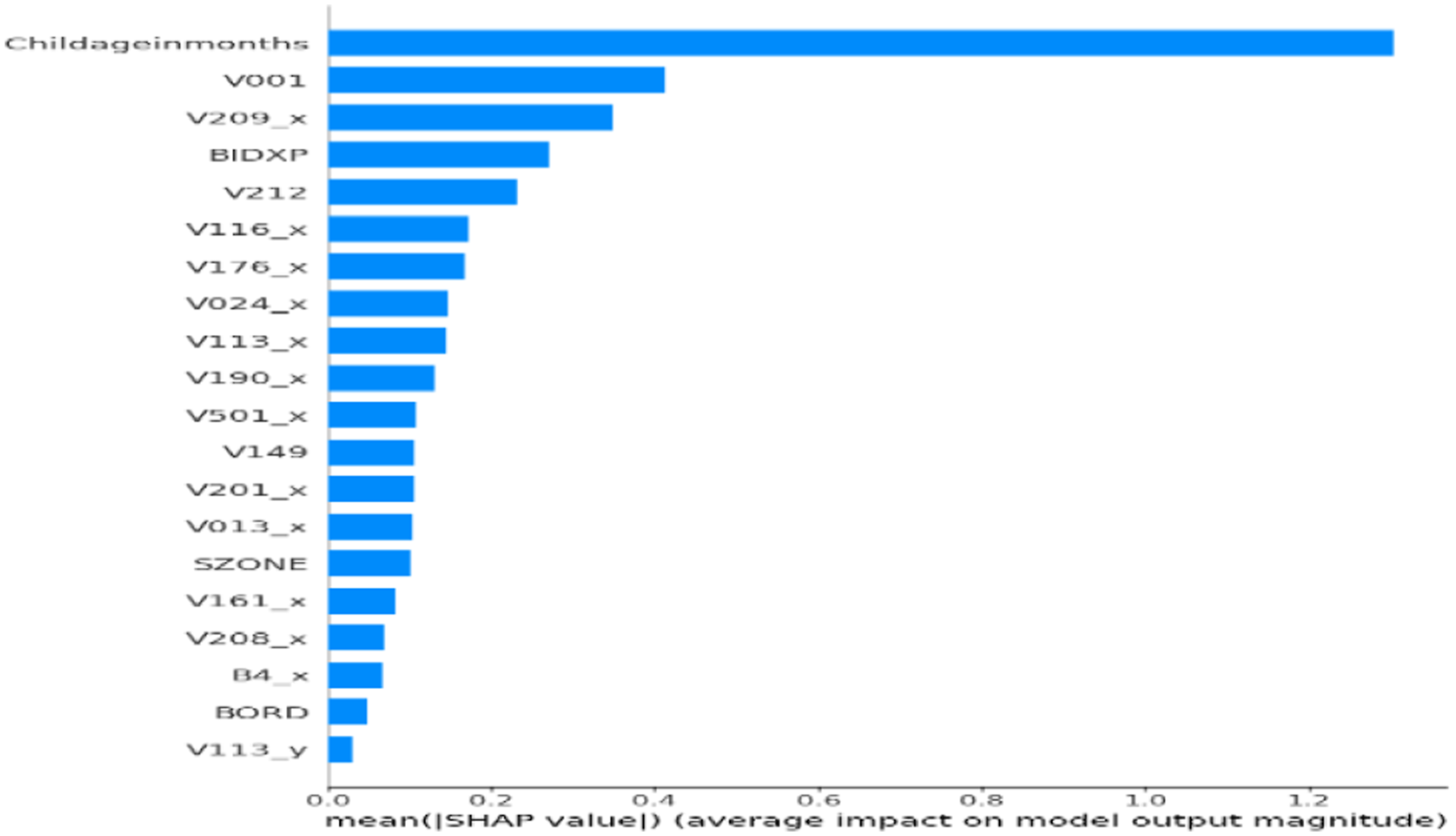
To ensure clinical relevance and model transparency, SHAP was applied to the final ensemble classifier to assess global feature importance. The SHAP plot (Figure 2) showed that Childageinmonths was the most influential predictor of anemia status. Other key features included V001 (Cluster Number) and V209_x (Breastfeeding status), along with BIDX, V212, V116_x, V113_x, V190_x, and V024_x. SHAP validated that the model aligns with medically relevant features. Figure 3 showed that TabNet prioritized Childageinmonths, followed by V209_x, BIDX, SZONE, V113_y, V116_y, and V190_x. Lower SHAP magnitudes were observed for Currentageofchild, V481, and V025_y, confirming TabNet’s focus on maternal and environmental indicators. Figure 4 confirmed MLP’s emphasis on Childageinmonths, along with V209_x, BIDX, and sanitation variables. Figure 5 showed XGBoost’s emphasis on V001, V190_x, and V212, highlighting its strength in capturing socioeconomic hierarchies. The SHAP output for the unoptimized ensemble (Figure 6) showed a wider spread of feature importance, with consistent prominence of Childageinmonths and V001. The ensemble combined diverse insights from TabNet, MLP, and XGBoost, enhancing interpretability and diagnostic confidence. SHAP confirmed that features like child’s age, region, and maternal behavior are critical to accurate prediction. SHAP feature importance plot for proposed hybrid ensemble (TabNet + XGBoost + MLP+GridSearch). SHAP feature importance plot for TabNet classifier. SHAP feature importance plot for MLP classifier. SHAP feature importance plot for XGBoost classifier. SHAP feature importance for the unoptimized hybrid ensemble (TabNet + XGBoost + MLP).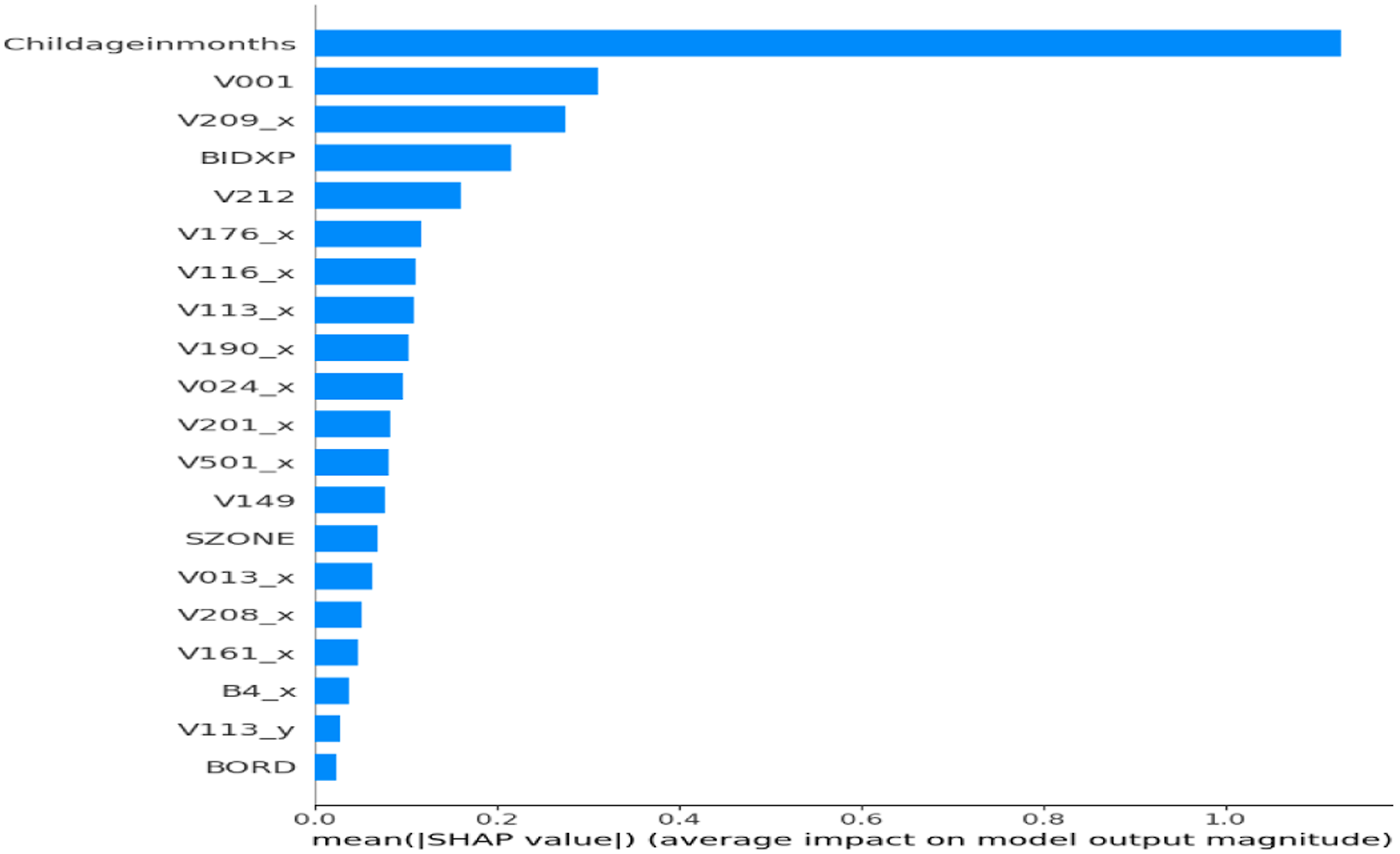
3.5. LIME-Based interpretability of proposed and baseline ML models
To provide localized model transparency, LIME was used to explain individual predictions of anemia status. It builds surrogate models to show how specific features contribute to classifications, which is crucial in healthcare. The optimized ensemble (Figure 7) showed strong alignment between medical reasoning and model logic, with key features like Childageinmonths, V209_x, and V113_x influencing decisions. TabNet explanations (Figure 8) emphasized Childageinmonths and V113_x, with sparse, focused contributions. MLP (Figure 9) highlighted Childageinmonths and V190_x, though sometimes overemphasized less effective features. XGBoost (Figure 10) showed local impact from V001, V113_x, birth index, and child age, confirming regional and sanitation sensitivity. The unoptimized ensemble (Figure 11) still prioritized Childageinmonths and V209_x, though with less ranking stability. LIME validated the system’s contextual and clinical interpretability, reinforcing its trust and usefulness in real-world pediatric screening. Lime explanation for the proposed optimized ensemble model. Lime explanation for the TabNet model. Lime explanation for the MLP model. Lime explanation for the XGBoost model. Lime explanation for the unoptimized hybrid ensemble (TabNet + XGBoost + MLP).




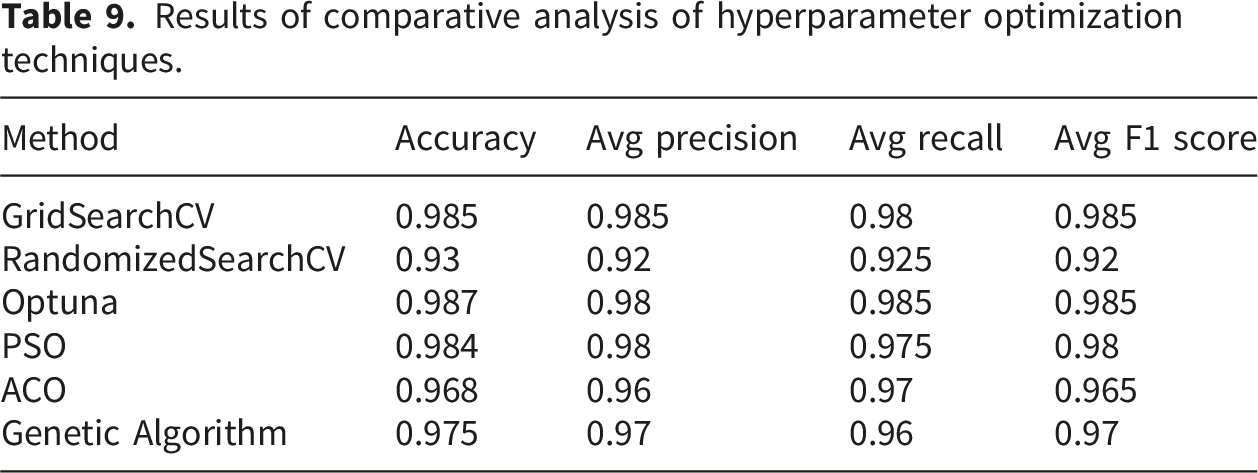
3.6. Comparative analysis of hyperparameter optimization techniques
Results of comparative analysis of hyperparameter optimization techniques.
3.7. Best parameter settings across search strategies
Best parameters settings across search strategies.

3.8. Comparative SHAP analysis of hyperparameter optimization techniques
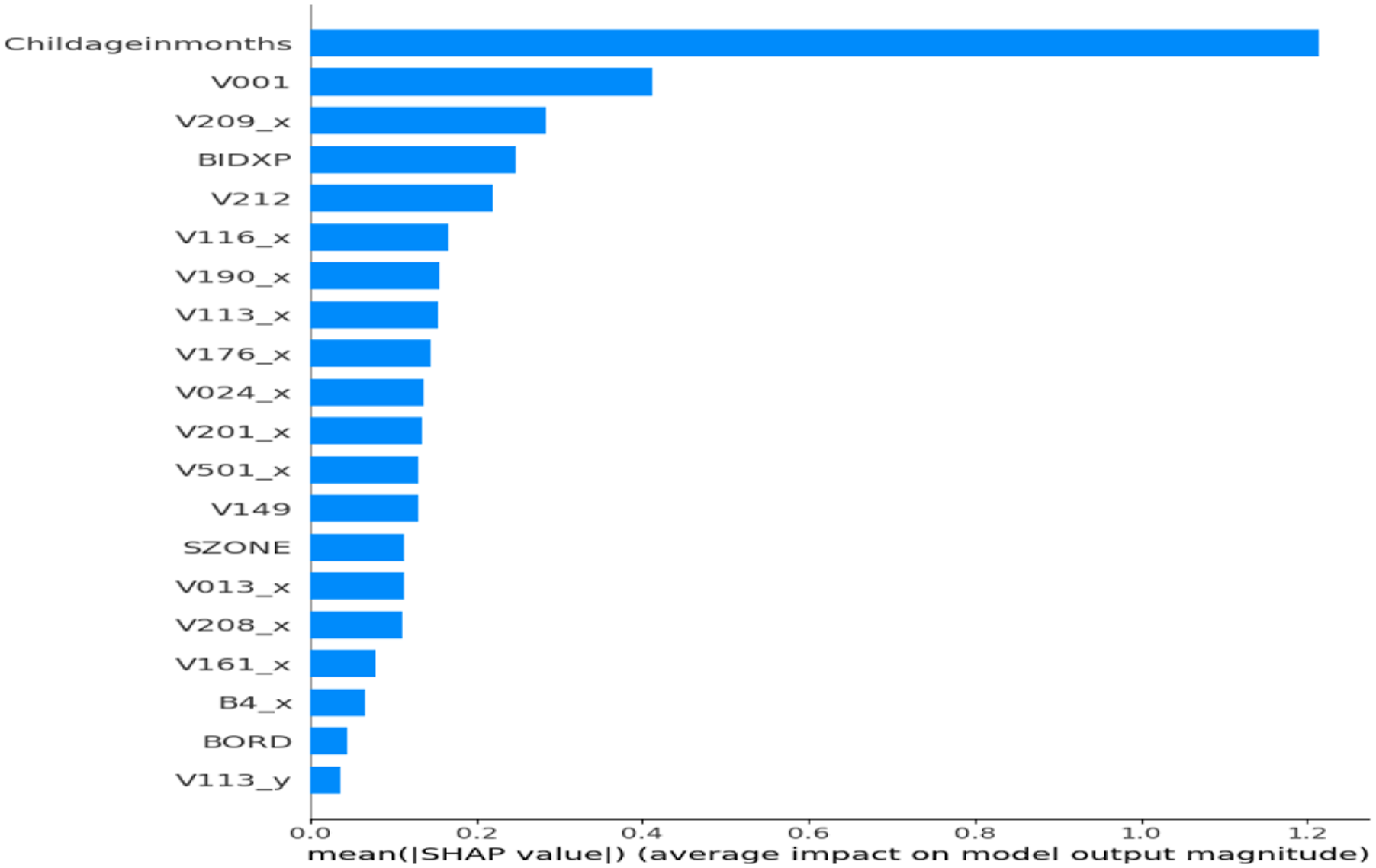
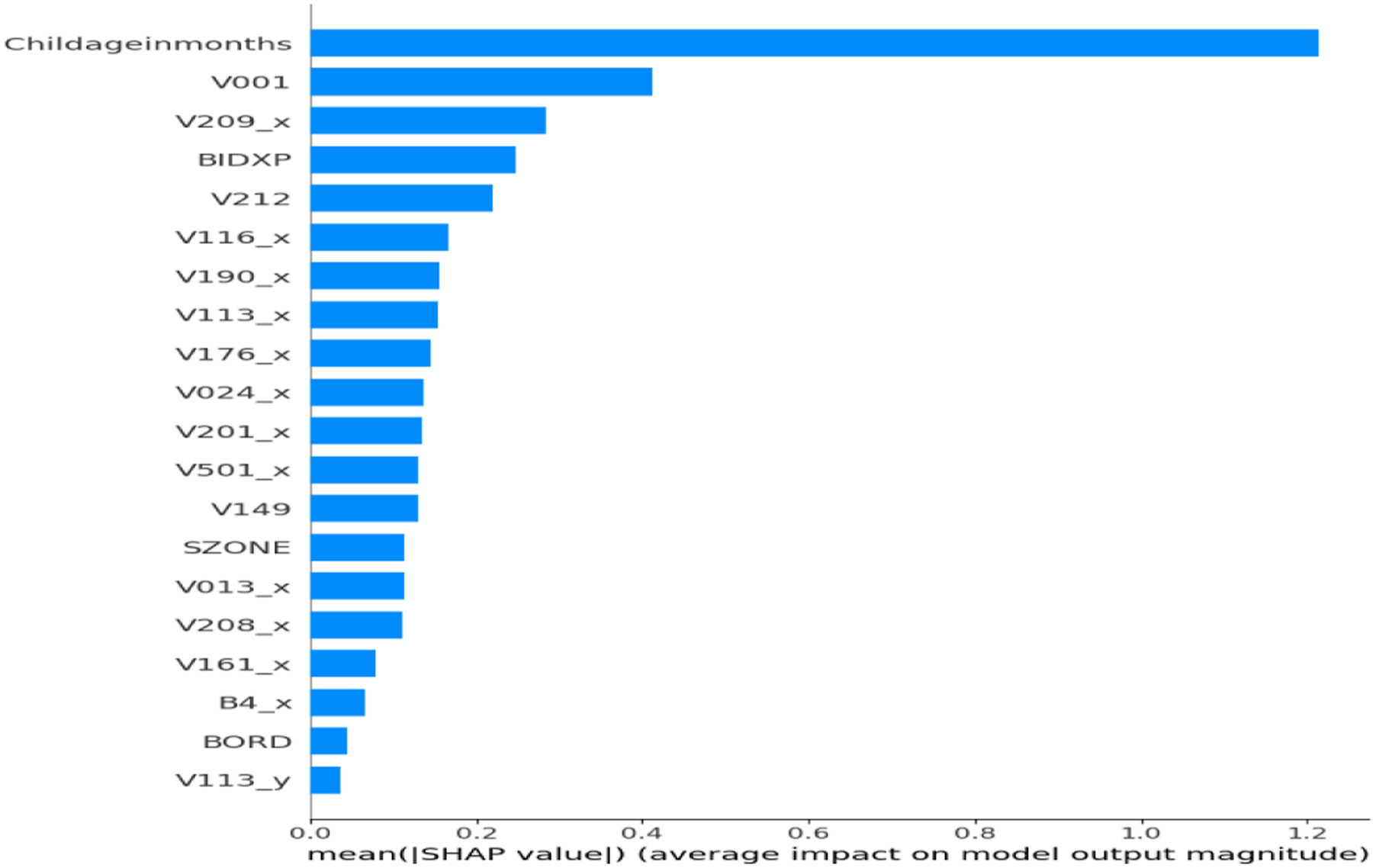
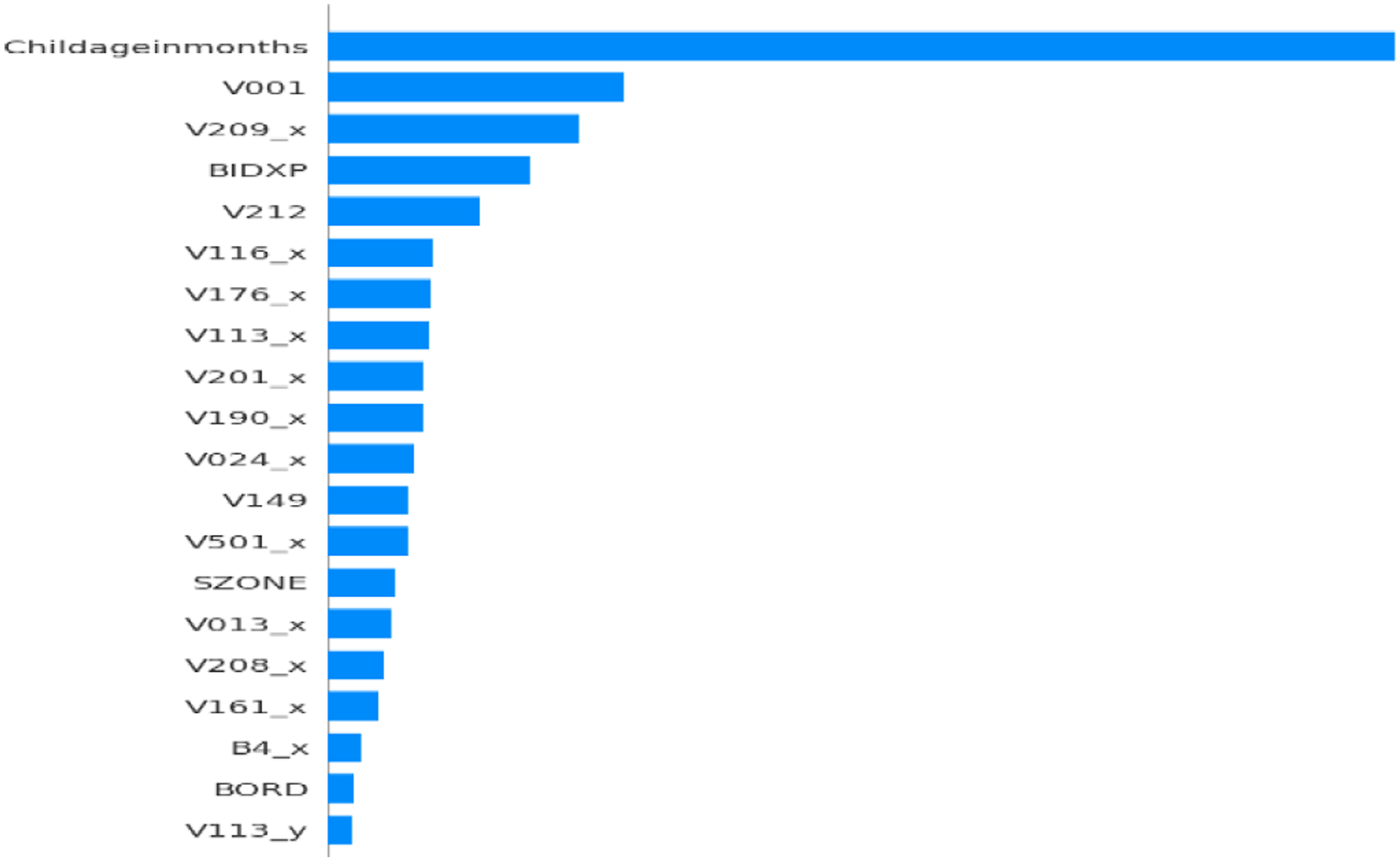
SHAP was applied with different optimizers (GridSearchCV, Optuna, PSO) to interpret the stacked model combining TabNet, XGBoost, and MLP. SHAP plots (Figures 12–16) highlight key features based on average importance. Top contributors included Childageinmonths (older children less likely anemic), V113_x (water source), V209_x (breastfeeding status), V190_x (wealth index), and V212 (number of children). These features consistently influenced predictions—e.g., higher wealth index reduced anemia risk. The results align with clinical and epidemiological insights. This is the first time SHAP has been used to explain a stacked ensemble combining deep, tree, and dense models in anemia prediction—enhancing interpretability without sacrificing accuracy. Shap feature importance plot for TabNet + XGBoost + MLP + Optuna model. Shap feature importance plot for TabNet + XGBoost + MLP + RandomizedSearchCV model. Shap feature importance plot for TabNet + XGBoost + MLP + Genetic model. Shap feature importance plot for TabNet + XGBoost + MLP + ACO model. Shap feature importance plot for TabNet + XGBoost + MLP + PSO model.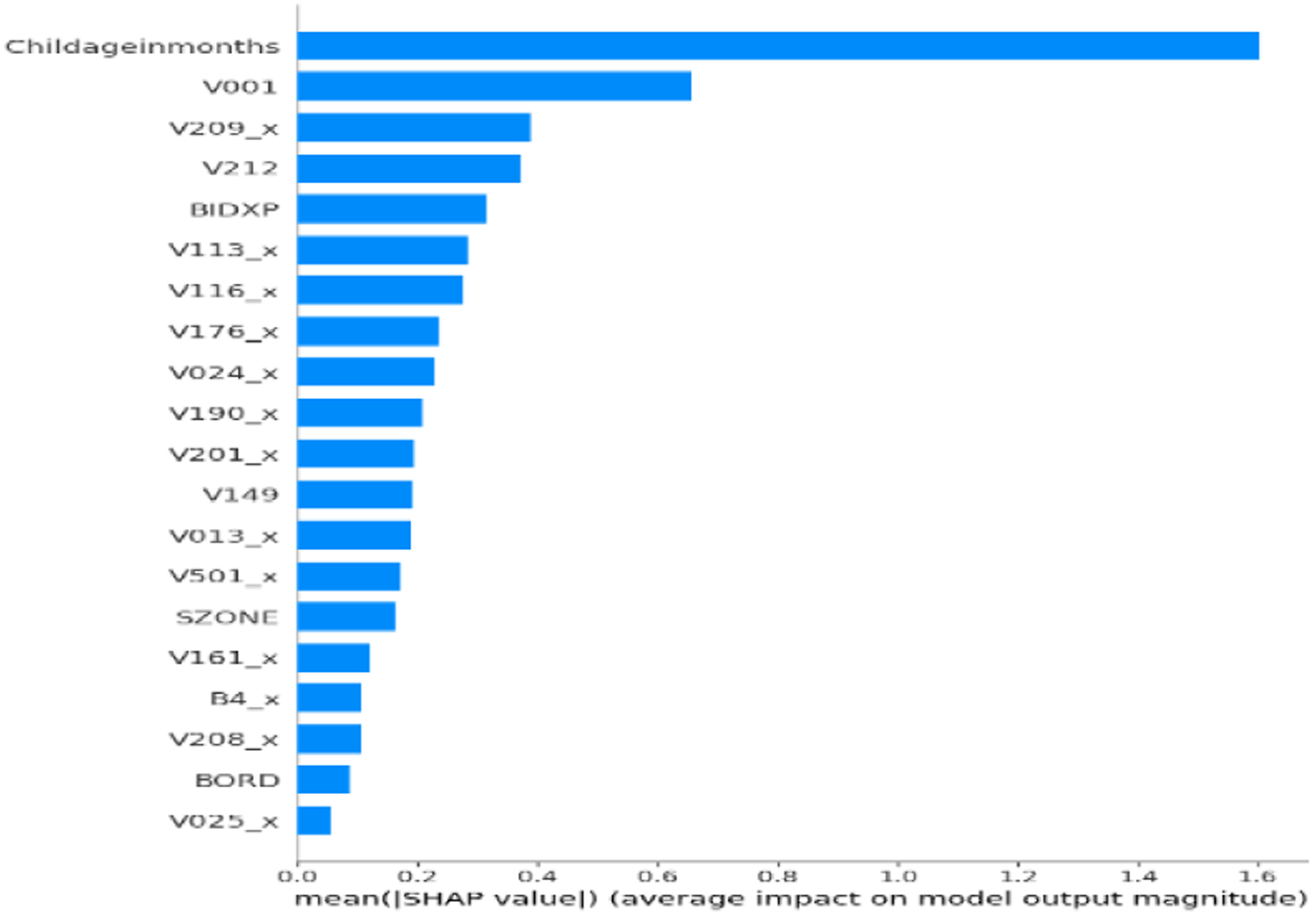
3.9. Comparative lime analysis of hyperparameter optimization techniques
LIME was used to analyze results from models optimized by GridSearchCV, Optuna, GA, ACO, and PSO. In the Optuna-tuned case, LIME showed lower wealth and poor water access influenced the anemic classification. For PSO, Childageinmonths and V209_x (breastfeeding) were key anemia-preventing factors. Each LIME plot (Figures 17–21) used green (supports prediction), red (opposes), and bar length (feature impact). These insights aided in debugging, patient risk understanding, and clinician communication. LIME enables patient-specific explanations, supporting medical decisions that require individualized reasoning. Lime explanation for TabNet + XGBoost + MLP + Optuna model. Lime explanation for TabNet + XGBoost + MLP + RandomizedSearchCV model. Lime explanation for TabNet + XGBoost + MLP + Genetic model. Lime explanation for TabNet + XGBoost + MLP + PSO model. Lime explanation for TabNet + XGBoost + MLP + ACO




3.10. Comparative review of existing anemia prediction models
Comparative results of existing anemia prediction models with proposed system.

3.11. External validation using NFHS dataset
NFHS vs Model predicted anemia prevalence.
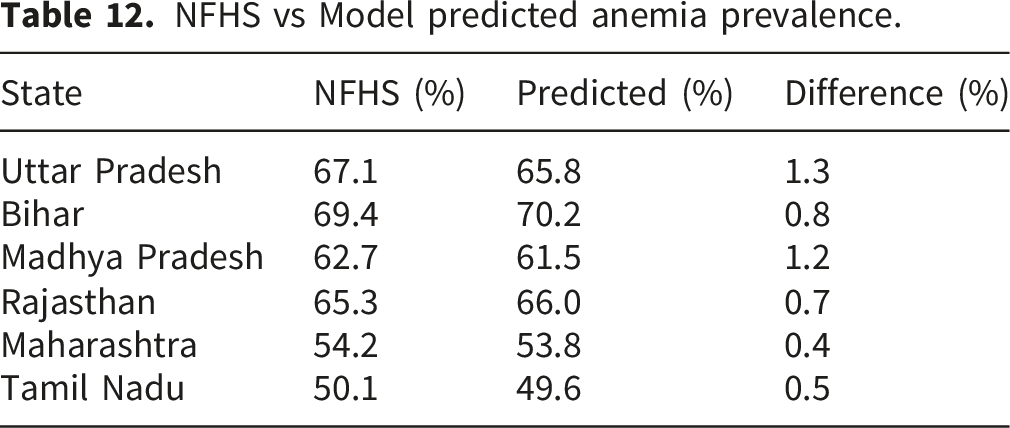
The results show close agreement (±1–2%) between observed and predicted values, indicating that the model captures consistent anemia patterns across regions. This provides evidence of cross-regional generalizability and suggests that the proposed framework is capable of learning transferable health patterns. However, due to the aggregated nature of the NFHS dataset, these findings should be interpreted as indicative rather than definitive.
3.12. Ethical considerations and bias mitigation
The use of demographic and socioeconomic features in predictive healthcare models introduces potential risks of algorithmic bias. Variables such as wealth index, region, and maternal education may inadvertently encode structural inequalities, leading to biased predictions if not carefully monitored. To address this, the proposed framework incorporates the following safeguards: Feature Sensitivity Analysis: SHAP-based evaluation ensures that predictions are not disproportionately driven by sensitive demographic attributes. Subgroup Performance Evaluation: Model performance is analyzed across different population groups (e.g., urban vs rural, socioeconomic strata) to detect disparities. Bias Mitigation Strategy: Features with high bias potential are interpreted cautiously, and model decisions are validated against clinical knowledge rather than purely statistical importance. The findings indicate that medically relevant features such as child age, BMI, and nutritional indicators consistently dominate predictions, reducing reliance on sensitive attributes. However, fairness monitoring remains essential for real-world deployment.
3.13. Practical deployment and health system integration
For real-world applicability, the proposed framework can be integrated into existing Health Information Systems (HIS) and Electronic Health Records (EHR) through a modular deployment architecture: • API-Based Integration: The trained model can be deployed as a REST API, allowing real-time predictions from clinical data inputs. • Data Pipeline Compatibility: The preprocessing pipeline aligns with standard healthcare data formats, enabling seamless integration with structured hospital datasets. • Edge Deployment: Lightweight variants of the model can be deployed on low-resource devices in rural clinics. • Decision Support System (DSS): The model functions as a screening tool, assisting clinicians in identifying high-risk children for further testing.
This integration supports scalable, real-time anemia screening in resource-constrained environments.
3.14. Limitations and future directions
The proposed system has several limitations. First, combining TabNet, XGBoost, and MLP with extensive GridSearchCV tuning leads to high computational complexity, making scalability difficult in low-resource or real-time settings. Second, the model is trained on TDHS data, which, while suitable for Tanzania, limits its applicability to other regions without retraining. Third, although SHAP and LIME provide global and local interpretability, they require expert interpretation, and SHAP is computationally expensive on large datasets. Additionally, strong statistical correlations may cause features like region or wealth index to dominate predictions, potentially overshadowing less frequent yet clinically meaningful features. While this external validation demonstrates promising generalizability, future work will include individual-level validation using DHS datasets from other countries (e.g., Ethiopia, India) to further strengthen cross-population robustness. Lastly, the model uses a static design, analyzing each case individually and failing to capture temporal trends in health status over time. From a fairness perspective, the model is designed to support early screening rather than final diagnosis, thereby minimizing the risk of harmful decisions. The inclusion of explainability mechanisms ensures transparency, allowing clinicians to verify whether predictions are clinically justified rather than demographically biased.38–46
Future work will incorporate formal fairness metrics such as: Demographic Parity, Equal Opportunity and Calibration across subgroups to further strengthen ethical reliability. Although class imbalance was addressed using stratified sampling and class weighting, advanced resampling techniques such as SMOTE or adaptive synthetic sampling were not explored and may be considered in future work to further improve minority class sensitivity. A note has been added acknowledging that further validation using repeated k-fold cross-validation and additional external datasets can be explored in future work. The future research should focus on generalizing the model to other regions by testing it on more datasets like EDHS to evaluate robustness and adaptability. Incorporating temporal models such as LSTM or Transformers can help capture time-based changes in child health. Developing lightweight versions of the model using techniques like compression or knowledge distillation can support deployment on mobile devices or in rural clinics. Future work could also integrate causal inference to study the root causes of anemia, and connect the model with EHR systems to support real-time clinical decision-making. Lastly, automated dashboards visualizing SHAP and LIME results should be built to assist healthcare professionals and non-technical users in understanding predictions. Further, advanced validation techniques such as k-fold cross-validation and repeated sampling can further improve robustness and are considered for future work. To improve deployment feasibility, future work will explore lightweight ensemble architectures and model compression techniques such as pruning and knowledge distillation. A key limitation of this study is the lack of publicly accessible code at the time of submission, which may limit reproducibility. Future work will focus on releasing the full implementation in an open-source repository to ensure transparency and facilitate further research. Additionally, although cross-regional validation using NFHS data has been conducted, further validation using standardized individual-level clinical datasets from multiple countries is necessary to fully establish the robustness and generalizability of the proposed model.
4. Conclusion
An interpretable hybrid ensemble system is developed in this study for quick prediction of anemia in children based on healthcare data. Using TabNet, XGBoost, and MLP as complementary classifiers, the system captures deep feature interactions, logical trees, and nonlinear behavior. GridSearchCV tunes hyperparameters, while SHAP and LIME provide dual-level explanations. The Stacked Ensemble + SHAP + LIME + GridSearch model outperformed all individual models and known ensembles, achieving 98.5% accuracy and excellent F1-scores. The system supports clinical decisions in real-world settings, especially in resource-limited areas, and offers understandable visualizations for healthcare experts. The study also evaluated hyperparameter optimization methods—GridSearchCV, RandomizedSearchCV, Optuna, GA, PSO, and ACO—confirming GridSearchCV as the top performer in medical contexts. This work presents an accurate, interpretable, and robust ensemble model for early anemia detection, aiding efforts to reduce childhood illness and mortality. The integration of fairness-aware modeling and interpretable outputs enhances the ethical reliability and clinical usability of the proposed system, making it suitable for real-world deployment in diverse healthcare settings. Future steps include temporal modeling, real-time clinical integration, and cross-region support for wider public health impact.
Footnotes
Ethical considerations
The study used publicly available, anonymized data from the Tanzania Demographic and Health Survey (TDHS) 2022, obtained with permission from the DHS Program. As per the DHS data use agreement, ethical approval is not required since no human subjects were directly involved and no personally identifiable information is used. The DHS datasets are collected with informed consent and are approved by national ethics review boards in the respective countries.
Consent to participate
The study utilized secondary data that is anonymized and publicly accessible through the DHS Program. No direct involvement of human participants occurred during this research.
Consent for publication
This study does not include any identifiable personal data or images requiring consent for publication.
Funding
This research was funded by the Programme “Research, Innovation and Digitalisation for Smart Transformation” 2021–2027, co-financed by the European Union, under Project No. BG16RFPR002- 1.014-0007 “Center of Competence “PERIMED-2””.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The dataset used in this current study was obtained from the most current and available TDHS 2022 after having been requested by Julius Moinget Loibor from the DHS program website and also getting permission to download the dataset. The study focuses on the childbirths recode (TZBR82SV) file extracting data relevant to child mortality. The TDHS 2022 has collected information from a representative of the country. The dataset link for this study is obtained through the DHS program website (![]() ).
).
Code availability
The code used in this study is currently available upon request. To improve transparency and reproducibility, we plan to release the complete implementation, including preprocessing and model training pipelines, in a public repository (e.g., GitHub or Zenodo) in future work.