
Abstract
Differential privacy (DP) is a mathematical definition of privacy that can be widely applied when publishing data. DP has been recognized as a potential means of adhering to various privacy-related legal requirements. However, it can be difficult to reason about whether DP may be appropriate for a given context due to tensions that arise when it is brought from theory into practice. To aid policymaking around privacy concerns, we identify three categories of challenges to understanding DP along with associated questions that policymakers can ask about the potential deployment context to anticipate its impacts.
Social Media
Differential privacy is a state-of-the-art framework for releasing data summaries while controlling privacy risk to individuals. But prior policy adoptions have led to controversy for reasons not discussed in the lit. We outline key sociotechnical considerations for policymakers.
Key Points
Differential privacy is a state-of-the-art framework for protecting individuals’ privacy when releasing data summaries. Under differential privacy, statistical noise is added to data tabulations to obscure individual people’s information while maintaining high-level patterns in the data.
Differential privacy can be applied in a wide range of contexts from a technical perspective. However, adopting differential privacy for policy has led to controversy. Assessing how appropriate it is for a given situation requires considering a host of sociotechnical considerations.
We identify three challenges to reasoning about differential privacy: first, it is naturally at odds with some common understandings of privacy. Second, it can be difficult to estimate its impact on downstream factors like utility of and trust in the data. Third, differential privacy deployments require implementation and analysis workflows likely to be unfamiliar to many practitioners, calling for strategic planning around how to minimize disruption.
We provide a series of questions policymakers can ask about a use case to help overcome challenges in reasoning about differential privacy. Our aim is for these questions to also help policymakers promote privacy protection, knowledge production, transparency, and trust when making decisions about differential privacy.
Introduction
For the 2020 census, the U.S. Census Bureau updated their technical approach to maintaining confidentiality of responses to be based on differential privacy (DP) (Dwork et al., 2006), a state-of-the-art framework based on a mathematical definition of privacy protection. This change was philosophical as well as technical: rather than advocating a specific process for obfuscating individuals’ data, DP defines a standard for functions (i.e., algorithms) applied to data. For concreteness, imagine an algorithm that takes in census counts to compute population totals by race in a geographic region. At a high level, the algorithm is differentially-private if we expect its outputs to be similar regardless of whether any particular individual's information is included in the input.
Algorithms often inject statistical noise into analyses to achieve DP. Random noise is drawn from a specified probability distribution (e.g., Laplace or Gaussian [Dwork & Roth, 2014]) controlled by a privacy loss parameter, ɛ, also called the “privacy loss budget.” The privacy loss budget controls a tradeoff between the strength of privacy protections and accuracy of estimates: smaller privacy loss budgets mean we expect to add more noise, so privacy protection is stronger, but accuracy is lower.
Despite DP's mathematical rigor, the Census Bureau's adoption of DP was met with backlash and debate (Nanayakkara & Hullman, 2022), both in the popular media and scholarly writing. Many have questioned its necessity given its implications for downstream analysis of census data. One might question whether DP should be applied in other policy contexts. Technically speaking, DP can be applied in a wide range of contexts, but may be a poor fit in light of various social considerations. For example, the protections it offers—which are rigorous, but narrow—may not align with the privacy needs of data subjects (those who contribute their information) in a particular setting. Or, costs it imposes in terms of training analysts to adapt their workflows to constraints imposed by DP may not outweigh its benefits. At the same time, DP has been advocated for policy: in addition to being used by the Census Bureau, who is bound by Title 13 confidentiality requirements, researchers have suggested DP's promise for adhering to requirements outlined in the Health Insurance Portability and Accountability Act (HIPAA) (Ficek et al., 2021) and the General Data Protection Regulation (GDPR) (Cummings & Desai, 2018). Most recently in the U.S. context, a White House executive order 1 named DP as a potential means of advancing trustworthy artificial intelligence.
Unfortunately, many of the sociotechnical trade-offs that policymakers must grapple with when considering DP remain underdiscussed, in part because of DP's newness as a practical intervention. In this paper, we discuss contextual considerations relevant to decisions about adopting DP. Our discussion is organized into three categories of cognitive and sociocultural challenges arising from DP's abstract and mathematical nature, drawing on observations of past DP deployments. First, given the myriad ways privacy can be conceptualized, DP is naturally at odds with some common understandings of privacy. Second, while a goal of privacy-related policy decisions is often to balance privacy needs against the value of data for downstream analysis and decisions, it can be difficult to estimate the impact DP will have on subsequent data use as well as associated trust (in the data among data users, and in the data collection process among data subjects). Third, DP deployments require implementation and analysis workflows that are likely to be unfamiliar to many practitioners, calling for strategic planning around how to minimize disruption.
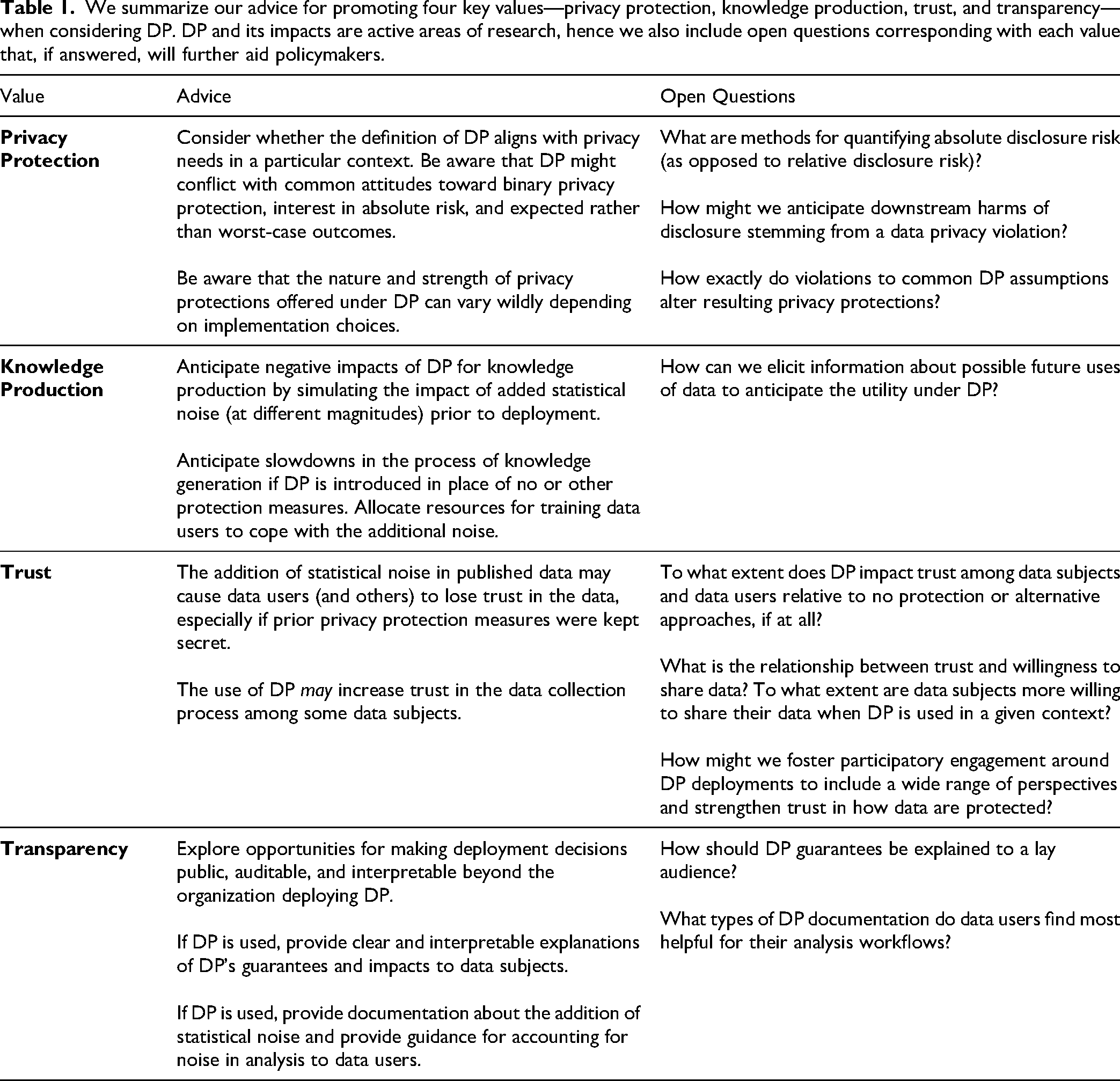
We provide a series of questions policymakers can ask about specific contexts to help overcome aforementioned challenges and guide them toward contextually-appropriate recommendations about the use of DP. Our recommendations are intended for policymakers deciding whether to implement DP where previously no technical privacy protections existed or to determine whether to replace an existing approach with DP. We summarize our advice and open questions in Table 1.
We summarize our advice for promoting four key values—privacy protection, knowledge production, trust, and transparency—when considering DP. DP and its impacts are active areas of research, hence we also include open questions corresponding with each value that, if answered, will further aid policymakers.
What Is Differential Privacy and How Is It Different From Prior Approaches?
Consider a table of published statistics, such as population counts by race and age group. Aggregating data (e.g., by only publishing statistics over groups defined by race and age) may seem to prevent answering questions about any particular individual, but theoretical computer scientists have proven that any informative statistic necessarily leaks information about the people it describes. 2 DP provides a framework for accounting “privacy loss” incurred with the publication of any given statistic. Specifically, DP is a mathematical standard for the behavior of an algorithm applied to data. It stands in stark contrast to prior approaches. For example, for the 2010 census, the Census Bureau swapped data from carefully-chosen households (Christ et al., 2022). k-anonymity (Samarati & Sweeney, 1998), another technique, stipulates that published tables must have at least k individuals that share each combination of potentially-revealing attributes (e.g., age and race). Though these approaches are simpler to explain and implement, they are vulnerable to attacks that DP protects against. For example, an adversary can identify whether an individual contributed their data in k-anonymous data if they have relevant background knowledge (Machanavajjhala et al., 2007), whereas DP's guarantees are designed to hold regardless of an adversary's prior knowledge (and knowledge they may obtain in the future). We consider an adversary to be anyone who might attempt to deduce individual people's information from published data.
As alluded to earlier, the definition of DP 3 describes how similar we expect an algorithm's outputs to be with the addition or removal of any given person's information. Algorithms satisfying DP are randomized. Specifically, DP ensures that the chances of returning any particular output on input datasets that differ by one person's information are close. We refer the interested reader to Wood et al. (2018) for an in-depth primer on DP.
Differential Privacy Is at Odds With Common Understandings of Privacy
DP equates privacy protection with statistically limiting what can be learned about an individual based on analyses of datasets that include the individual (Dwork et al., 2006). However, privacy is a vast, social concept (Schoeman, 1984) that is difficult to fully capture mathematically (Seeman & Susser, 2024). We summarize four ways in which common societal understandings of privacy are at odds with DP.
DP Provides Non-Binary Protections
DP provides probabilistic guarantees, yet privacy is often conceptualized as binary: one's privacy is protected or not. Using DP means providing partial privacy protection. The mathematical reality that publishing statistics leaks some information about individuals introduces a question of how much privacy loss to permit, which may seem inappropriate to those expecting binary protection.
DP Is Suited to Quantifying Relative Disclosure Risk
DP is suited to quantifying relative disclosure risk: how much more likely it is that an adversary learns a person's sensitive attribute with access to published data relative to without access (i.e., an adversary is x% more likely to correctly guess Alice's race with the data versus without). However, many find it more natural to use absolute disclosure risk for decision-making: the chance of an adversary learning a sensitive attribute with the published data without comparison to any other value (i.e., the adversary has x% chance of correctly guessing Alice's race with the data). Researchers have argued that absolute disclosure risk is the more relevant measure because relative risk can hide important information (Hotz et al., 2022); for example, a large relative increase in risk may not be cause for major concern if absolute risk is very low to begin with. See Reiter (2005) and McClure and Reiter (2012) as cited in Hotz et al. (2022) and Jarmin et al. (2023) for further discussion and specific methods of computing disclosure risk.
DP Provides Worst-Case Guarantees
DP provides worst-case privacy guarantees by upper-bounding how much we expect the results of an analysis to differ based on the inclusion of any given individual's data. For example, using DP with ɛ = 0.1 for computing population totals might dictate that at most, the chance of a particular count outputted when Alice is represented in the data is 1.1 (eɛ) times the chance of that particular count outputted when Alice is not represented in the data. DP's guarantees hold even assuming an adversary with unlimited computational power and separate datasets to the one being protected. This is why DP is described as aligning with the assumption that potential adversaries will have an increasing amount of both over time.
The notion of making decisions so as to minimize one's maximum loss is familiar in economics, where it is known as the minimax decision strategy. However, often it is preferable to make decisions under uncertainty by choosing an action that is a best response to the most likely outcome (Neumann & Morgenstern, 1944; Savage, 1954).
If the strongest guarantees are unnecessary, but other considerations motivate using DP, it may be useful to consider relaxations of the “pure” DP definition (ɛ-DP), such as (ɛ, δ)-DP (Dwork & Roth, 2014). This definition allows for a “probability of failure” (i.e., δ), representing the chance that the DP guarantee will not hold. Such relaxations often yield gains in accuracy.
DP Does Not Prevent Making Statistical Inferences
DP provides protections against threats like (1) linkage attacks (Dwork & Roth, 2014), where an adversary links data without identifiers, like names, to data with identifiers to re-identify people and learn their sensitive attributes, (2) differencing attacks (Dwork & Roth, 2014), where an adversary computes statistics over subsets of the data to learn a person's sensitive attribute, and (3) membership inference attacks (Shokri et al., 2017), where the adversary's goal is to determine whether a person's data is included in a dataset. DP does not prevent making statistical inferences (Bun et al., 2021) —that is, learning overall patterns about a population—which can lead to apparent privacy violations that rely on making high-confidence guesses about a person's sensitive attribute based on aggregated information (Kenny et al., 2021). For example, if a statistic indicates that the majority of people living in a particular geographic region belong to a certain racial group, an adversary may use this information to guess with high confidence that Alice, an individual living in that region, belongs to the majority racial group. Entirely restricting inferences of this kind would prevent most scientific knowledge production (Bun et al., 2021). However, to those new to DP guarantees, the fact that DP does not prevent inference can seem contradictory. Indeed, conflicts around DP's protections as related to inference were a point of debate in the Census Bureau's DP deployment for the 2020 census (Nanayakkara & Hullman, 2022).
Real-World Impacts of Differential Privacy Are Hard to Estimate in Advance
DP offers an elegant theoretical framework for quantifying the privacy–accuracy tradeoff, but other real-world factors implicated in the tradeoff are more difficult to estimate. We summarize such real-world impacts and offer questions for policymakers that can help them account for these factors when determining DP's appropriateness.
Utility of Data Published Under DP Can Be Difficult to Foresee
In comparison to accuracy, it is much harder to estimate how DP will impact the utility of data. Utility refers to the usefulness of data beyond simply what is captured by quantitative measures of accuracy, such as the usefulness of the statistic for informing policy (Cummings et al., 2024). Utility is difficult to measure because downstream uses of data are potentially vast. Many other analyses may be unknown when the data are published (Hotz et al., 2022). For example, census data are collected for well-defined purposes like reapportionment, but are also used for social science research broadly. Observational data, which are not collected for a particular purpose, may become useful when used in combination with experimental data in a causal inference context (Mann et al., 2023).
Policymakers should solicit information about what kinds of analyses data users plan to conduct, and run simulations accordingly. Policymakers may consider developing a set of “acceptance criteria”—attributes about the published data that should be maintained after DP is applied—alongside data users and other relevant parties to ensure utility downstream, as was done with a recent differentially-private synthetic data release from Israel's National Registry of Live Births (Hod & Canetti, 2024). Finally, policymakers should be aware that estimating downstream utility is a challenge they may face with other approaches as well, and is not unique to DP.
How DP Impacts Trust in Data Collection and Published Data is Not Well Understood
Using DP may increase trust in data collection among data subjects, potentially leading to higher response rates. On the other hand, the explicit addition of statistical noise introduced by DP may rupture a “statistical imaginary” around data being “objective and neutral” (boyd & Sarathy, 2022), leading to a decrease in trust in the fidelity of published data among the broader public and data users. This decrease may be especially salient if data users are used to seeing the data without privacy protection or with forms of protection that are necessarily less visible to uphold the method's integrity (known in computer science as “security through obscurity” [La Cryptographie Militaire, 1883]). In the case of DP applied to the U.S. census—which was previously protected through “invisible” methods like swapping—the addition of DP noise brought attention to the ways in which census data are not “a raw headcount of the public that the Census Bureau simply collects and tabulates” (boyd & Sarathy, 2022). We hold the view espoused by Manski (2020) that encouraging a veneer of “incredible certitude” is ultimately counterproductive to policy and data literacy. Policymakers should nevertheless anticipate how DP may abruptly collide with existing “statistical imaginaries” (boyd & Sarathy, 2022).
Similarly, a growing body of work aims to explain DP guarantees to data subjects (e.g., Nanayakkara et al., 2023; Xiong et al., 2020), with some findings suggesting that explanations of DP may improve trust and increase willingness to share data. In scenarios where data subjects are concerned about past data collection and publication efforts, understandable explanations of privacy measures that are possible under DP may ease their concerns and foster trust in data collection. A risk is, of course, that tensions between DP and common notions of privacy challenge widespread understanding of DP's guarantees.
The Impacts of Violations to Common DP Assumptions Are Not Yet Well Understood
Accounting privacy loss under DP relies on assumptions which are often at odds with needs to keep certain statistics unaffected by noise. For example, state population counts from the 2020 census were held invariant—meaning no statistical noise was added—for legal reasons related to apportionment. 5 The architects of the census DP deployment have noted the unknown privacy impacts of invariants (Garfinkel et al., 2018); in fact, their impact is the topic of ongoing research (Bailie et al., 2023). Beyond theoretical measures of privacy loss, empirical measures can also be useful in understanding the extent to which such violations impact privacy (e.g., Kenny et al., 2021), but such work remains relatively limited and inherently context-specific.
Harms of Disclosure May Be Difficult to Estimate
Real-world harms are harder to estimate than disclosure risk. For example, if an adversary discovers Alice's sensitive attribute, it is difficult to predict with high confidence how they will use this information and what impact it will have on Alice or others. Publicized examples of major harms resulting from leaked data provide partial information about the landscape of risks, such as identity theft. 6 Recent legal scholarship proposes a typology of privacy harms, which include physical, economic, and psychological harms, among others (Citron & Solove, 2022). To account for these possibilities in decision-making, policymakers must be ready to associate them with costs, broadly defined, so they can be formally reasoned about.
How to Effectively Facilitate Participatory Engagement Is Not Yet Well Understood
The decision of whether to adopt DP and under what specifications may benefit from participatory engagement, considering DP impacts a range of parties like data subjects and data users. However, how to foster productive engagement is not obvious. Prior deployments, like that of the 2020 U.S. Census, have demonstrated that different parties arrive at discussions with varied assumptions and epistemic orientations around data (boyd & Sarathy, 2022), which make participatory engagement challenging at best, and a liability for progress at worst (Eyal, 2019).
Deploying Differential Privacy Requires New Analysis Practices and Skills
Applying DP entails making a series of implementation choices. These choices are likely unfamiliar to data curators. Moreover, the statistical noise introduced by DP will change analysts’ typical routines. We present three implementation-related challenges, along with avenues to ensuring smoother DP deployments, both before and after data publication.
Applying DP Entails Navigating Complex Implementation Choices
Unfortunately, there is little existing guidance for curators making DP implementation choices. For example, DP experts largely consider setting the privacy loss budget to be a “policy question” (Garfinkel et al., 2018). However, this parameter is unit-less and does not directly map to real-world outcomes, making it difficult to reason about even among policy experts. Curators must also make a series of other choices. For example: the “unit” at which protections apply (e.g., the record level or the user level) (Dwork et al., 2019); which variation of DP to use; and the deployment model (such as the central model, where raw data are collected and noise added by the curator, or the local model, where data are noised prior to being sent to the curator [Kasiviswanathan et al., 2011]). Making these choices requires weighing various tradeoffs. For example, the local model affords additional privacy protections—because data subjects never share raw information—but comes at the cost of lower accuracy than the central model. Research to develop interactive interfaces for curators (e.g., Nanayakkara et al., 2022), which would help them make these decisions, is still early stage.
Depending on How DP is Implemented, the Privacy Guarantees Can Vary Wildly
Implementation choices can have profound impacts on strength of privacy protections. Thus, DP can be used to create the appearance of privacy without substantive protections—in other words, “privacy theater” (Smart et al., 2022, Seeman & Susser, 2024, Sarathy, 2022).
These choices should ideally be presented in a format understandable by people with and without technical DP expertise. To enable audiences with technical expertise to perform audits, policymakers may further recommend that source code for the deployment is made public. Making implementation choices public prior to deployment can also enable an organization's competitors or other relevant parties to push back against ill-advised plans. Such was the case when Google's competitors pushed back against their plans to cluster users into granular groups, causing Google to adapt their plan (Steed & Acquisti, 2024).
Analyzing and Interpreting Data Under DP Calls for New Analysis Practices
Analysts can be given access to data either via differentially-private algorithms or through published data products with added statistical noise. In both cases, they will have to cope with changes in their routines. Analysts who are given access to the data via differentially-private algorithms are given access to the data under a total privacy loss budget. With each query for a statistic they wish to compute, they must “spend” some portion of the budget. Once the budget is depleted, they may no longer issue queries. This constraint will reconfigure their typical practices (Sarathy et al., 2023), particularly for exploratory analyses, since they can only make a limited number of queries. Hence, they will need to efficiently allocate their budget across queries while still learning what they need to about the data; research is just beginning to explore how to support these needs (e.g., Nanayakkara et al., 2024). On the other hand, analysts who are given access to DP-noised data products will need to account for how DP noise impacts uncertainty around their findings (Hotz et al., 2022). This may sometimes require the use of new statistical methods. Such changes should be expected to introduce hiccups in workflows and possibly pushback.
Analysts who work with DP-noised data products should also adapt their routines. Policymakers should consider how to communicate the new layer of noise in ways that are interpretable and usable, including documentation that explains the added noise and how to account for it in analyses. For instance, the data may contain seemingly nonsensical values owing to DP noise, like negative counts, causing confusion if not explained well (Garfinkel et al., 2018, Dankar & El Emam, 2013). Policymakers should also consider how to set up feedback loops between analysts and the research community, who is developing techniques for analyzing DP-noised data products and accounting for the additional layer of statistical uncertainty. Interdisciplinary workshops with both data users and researchers can promote feedback loops and help ensure that methods are developed for common use cases. 8
Conclusion
Challenges to understanding DP may prevent policymakers from making informed recommendations about using DP. However, policymakers can more easily anticipate potential impacts and make recommendations that incorporate lessons from prior DP deployments by asking context-specific questions. Moreover, as technical methods of protecting privacy grow in availability and sophistication, guides like ours may support policymakers in making technical privacy recommendations more broadly.
Footnotes
Acknowledgments
We thank danah boyd, Christian Cianfarani, Ryan Steed, and participants of the Privacy Law Scholars Conference—especially Jayshree Sarathy, our discussant—for their thoughtful feedback on an earlier draft of this work.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.