
Abstract
Introduction
Narrative evaluations are crucial components of medical education, offering valuable information about students’ performance. However, the quality of narratives is often variable. Faculty development interventions to improve narrative evaluations can be time-intensive, and clerkship directors cannot mandate faculty participation. To address this challenge, this study implemented a time-efficient faculty development intervention that used the validated Narrative Evaluation Quality Instrument (NEQI) as a feedback tool to improve the quality of narrative evaluations.
Methods
Eighty-nine faculty from the Ambulatory Clerkship at UT Southwestern and the Pediatrics Clerkship at McGovern Medical School were randomized to either a control group, which received no feedback on their narrative evaluations, or an intervention group, which received an educational module on enhancing narrative evaluations using the NEQI, along with individualized NEQI data via email. Pre and post NEQI scores were compared between both groups.
Results
While no significant differences in pre and post NEQI scores were found between the two groups and subgroup analysis of faculty who completed the educational module also showed no statistically significant change, the module demonstrated feasibility across the two clerkships. Results revealed a positive trend toward greater specificity in narrative comments.
Discussion
The lack of measurable change in NEQI scores may be attributed to the timing of the educational module or limited opportunities for direct student observation. Future research should explore the use of artificial intelligence-assisted scoring and standardized templates to prompt more detailed and actionable narrative evaluations. Clerkship directors need support for faculty education and development of novel interventions to improve the quality of narrative evaluations. Our study demonstrated that simply emailing feedback and an invitation for an asynchronous learning module did not result in measurable improvement in narrative quality.
Introduction
As medical education has shifted towards a competency-based approach, narrative evaluations have become increasingly essential. The qualitative assessment of learner performance provides valuable insights into student performance that numerical scores cannot convey. In clinical settings, the information contained offers important feedback to help trainees give context to their performance and identify areas for improvement.1-3 Additionally, narrative evaluations serve to assess the learners, determine readiness for promotion, and contribute significantly to the Medical Student Performance Evaluation (MSPE), a key document factored by residency program directors when selecting candidates to interview.4-8 As such, narrative comments have the potential to serve as an essential handoff between undergraduate (UME) and graduate medical education (GME).
Despite their importance, narrative evaluations often fall short of their potential. Many are vague, overly generic, and describe personal attributes rather than observed behaviors or competencies.6,9-11 This in turn affects the MSPE, which consequentially can be a source of implicit bias and variable interpretation.6,8 Students prefer narrative feedback that is specific, tailored to their individual performance, actionable, and grounded in actual patient encounters.12,13 Narrative evaluations often lack this level of specificity and fail to include concrete examples or clear suggestions for improvement.6,14 These limitations not only reduce the usefulness of feedback for learners but also diminish areas for improvement in UME to GME handoff.
Clerkship directors (CDs) face additional challenges in ensuring consistent, high-quality narrative evaluations. Narrative comments are typically written by a wide range of faculty across diverse clinical sites, leading to inconsistencies. Faculty also face competing priorities in patient-care settings, and in addition to finding the time to write meaningful comments, they perceive they have insufficient contact with learners to generate thoughtful narratives.15,16 Faculty development efforts have emerged as a key strategy to improve the quality, specificity, and usefulness of narrative evaluations.8,17,18 However, while faculty development has shown promise, it is often labor-intensive, and participation is usually voluntary.17-19 As a result, CDs may lack the resources or authority to mandate training or enforce standards across all evaluators.
A valuable resource that supports evaluation quality and faculty development is the narrative evaluation quality instrument (NEQI).17,20 The NEQI is a validated tool that scores evaluations across three domains: the number of performance domains commented on, the specificity of comments, and their usefulness to trainees.17,20,21 As such, this tool provides a quantitative assessment of qualitative information, offering a standardized approach to evaluate narrative comments. Each domain is scored on a scale of 0–4, for a total possible score of 12; a score of 7 or above is considered moderately useful to the trainee. The NEQI thus provides a means to convert qualitative data into a structured, quantifiable format, facilitating a more consistent evaluation of narrative quality.
The primary goal of this pilot study was to determine whether the NEQI could serve as a practical and scalable feedback intervention to help faculty improve the quality of their narrative evaluations. We hypothesized that the NEQI may offer a sustainable solution for improving narrative feedback without requiring extensive additional time or mandatory participation in faculty development workshops. The study aimed to evaluate the utility of the NEQI in supporting CDs as a resource-efficient tool to guide faculty in writing clearer, more specific, and useful evaluations, and to assess the overall quality of narrative comments provided by faculty preceptors.
Methods
This multi-institutional study examined narrative evaluations written by faculty for students on the Ambulatory Clerkship at UT Southwestern (UTSW) and the Pediatrics Clerkship at McGovern Medical School (MMS), UTHealth Houston, using an adapted version of the NEQI. The study took place from January 2024 to March 2025.
The NEQI Adaptation
Investigators adapted only the “Performance Domains Commented On” section to match the clinical competencies more closely on UTSW and MMS’s student evaluation forms (Figure 1). Specifically, overall performance, clinical skills, prepares for and participates in patient care activities, fund of knowledge, and written and/or oral skills were removed and replaced with history taking and physical exam skills, oral presentation skills, documentation, patient communication skills, and receiving and applying feedback. We also developed a set of criteria for the specificity and usefulness domains to provide more consistency when scoring. For the specificity domain, qualifiers were defined as adjectives used to describe the student (“student was professional”); evidence was defined as a general description (“student showed professionalism by calling consultants”); example was defined as a specific encounter (“student showed professionalism by remaining calm and communicating well with a cardiology fellow during a rapid response.”). For the usefulness domain, a 0 was defined as minimal information and vague; a 2 was defined as commenting on at least 2 domains with at least 1 piece of evidence but only encouraging student to continue same behavior; a 4 was defined as giving suggestions for student growth. Modified narrative evaluation quality instrument (NEQI)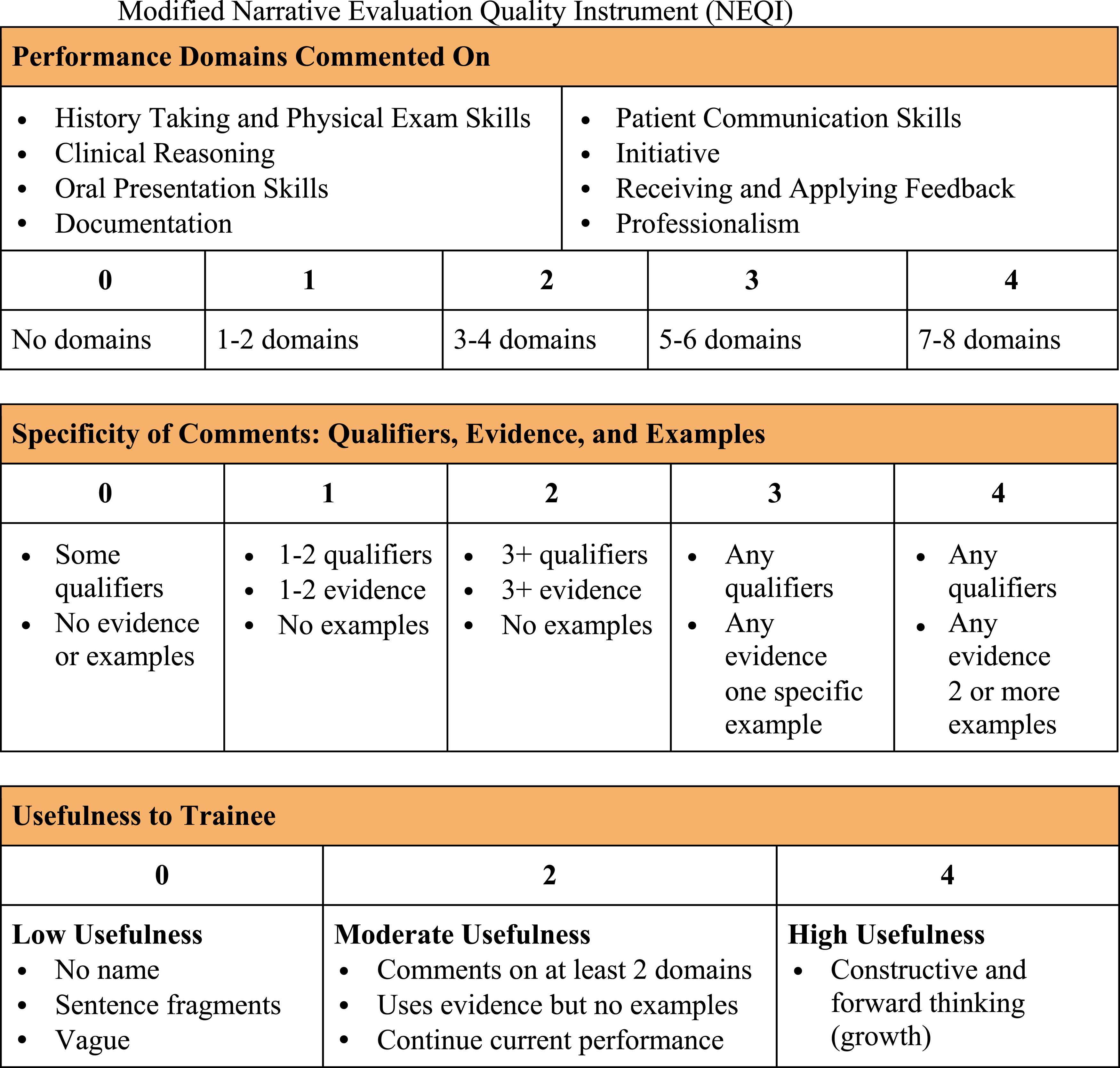
Establishing Interrater Reliability
Four investigators (JC, VG, RA, BC) scored the evaluations. Study members used an automated Excel spreadsheet containing the specific rules for scoring discussed above when scoring evaluations to improve consistency. The intraclass correlation coefficient (ICC) was calculated on Statistical Package for the Social Sciences (SPSS) using two rounds of a pilot sample of 10 evaluations from UTSW and MMS. The ICCs for each round were 0.892 (95% CI 0.772-0.949) and 0.840 (95% CI 0.720-0.916), respectively, both demonstrating strong reliability.
The Intervention
This study was approved as exempt by the UT Southwestern Medical Center Human Research Protection Program (UTSW: Y2-23-0316) and was approved by the Committee for the Protection of Human Subjects at UTHealth Houston (MMS: HSC-MS-23-0688). Inclusion criteria included clinical faculty with teaching appointments for the Ambulatory Clerkship at UTSW and the Pediatrics Clerkship at MMS who submitted medical student evaluations during the study period were eligible (85 at UTSW and 30 at MMS). Exclusion criteria were faculty who do not participate in medical student evaluations directly (i.e. due to prior existing doctor-patient relationship) or had resigned prior to scoring of the pre-intervention evaluations. Both institutions granted waivers of informed consent, and as such an email with a Letter of Information was sent to all faculty who could voluntarily opt-out of participation. Investigators (AO, PH) not involved in scoring evaluations randomly assigned participants to a control group and an intervention group. All narrative evaluations were de-identified of student and faculty names before their release to three investigators scoring narrative evaluations, who were also blinded to participant groups. Evaluations were divided into two sets. One set was scored by one investigator, and the other was scored by two investigators who met to resolve any differences to determine a single score.
Any faculty member teaching in the Pediatrics Clerkship at MMS or the Ambulatory Clerkship at UTSW who did not opt-out were eligible for the study. Initially, 89 evaluations from unique faculty members (59 at UTSW, 30 at MMS) were available for scoring in the time window of the study and thus were randomized to the study, 45 in the control group and 44 in the intervention group (Figure 2). After the intervention, 66 evaluations from the same group of faculty members were available for scoring (43 at UTSW, 23 at MMS). The drop in number of evaluations available was due to some faculty members not teaching and therefore not submitting evaluations during the time period. Thus, total of 33 paired evaluations were conducted in both the control and intervention groups. Flow diagram of the participant randomization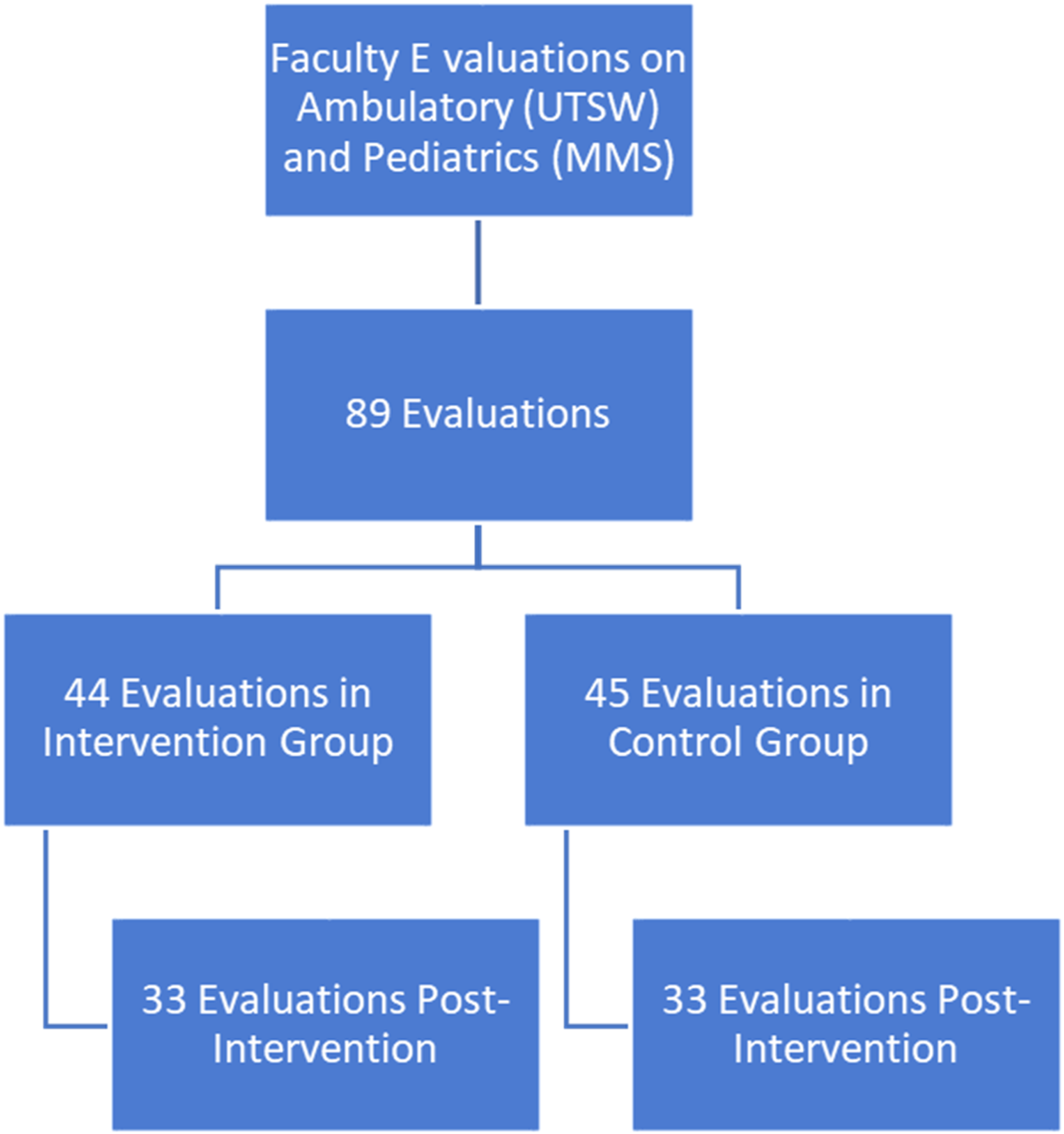
Faculty Demographics
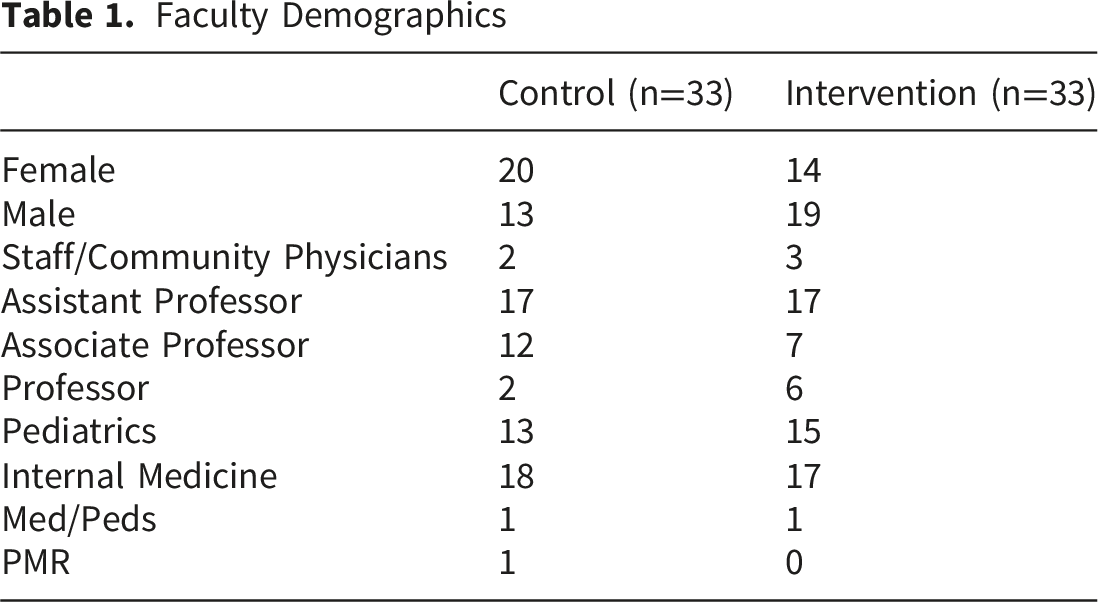
Investigators used the NEQI to score baseline evaluations pulled from both clerkships at the start of the study. The control group did not receive any feedback regarding their evaluations or the NEQI tool itself. The intervention group received an email with a link to an asynchronous, educational module developed by study investigators which oriented learners to the NEQI and demonstrated how to use it to improve the quality of narrative comments. The module began with a low-scoring narrative evaluation and guided learners through each NEQI domain, demonstrating how to build upon and enhance the narrative step by step. The module could be completed in approximately 20 minutes; it was shared via Canvas Catalog and OneDrive to participating faculty at both institutions. Participants in the intervention group received periodic email reminders to complete the module over the course of one month. Participants in the intervention group also received a personalized email from a non-scoring investigator providing feedback on their baseline evaluation NEQI score. The email contained a breakdown of their baseline NEQI score (their score in each domain and their overall score), a link to access the learning module, and a copy of the NEQI chart for reference. The email did not include written, individualized suggestions or targeted recommendations beyond the general guidance provided in the module. After the deadline to complete the learning module, investigators scored the second set of de-identified evaluations. Two-sided t-tests were conducted using SPSS (v. 29.0) for the paired pre- and post-samples to determine significance.
Results
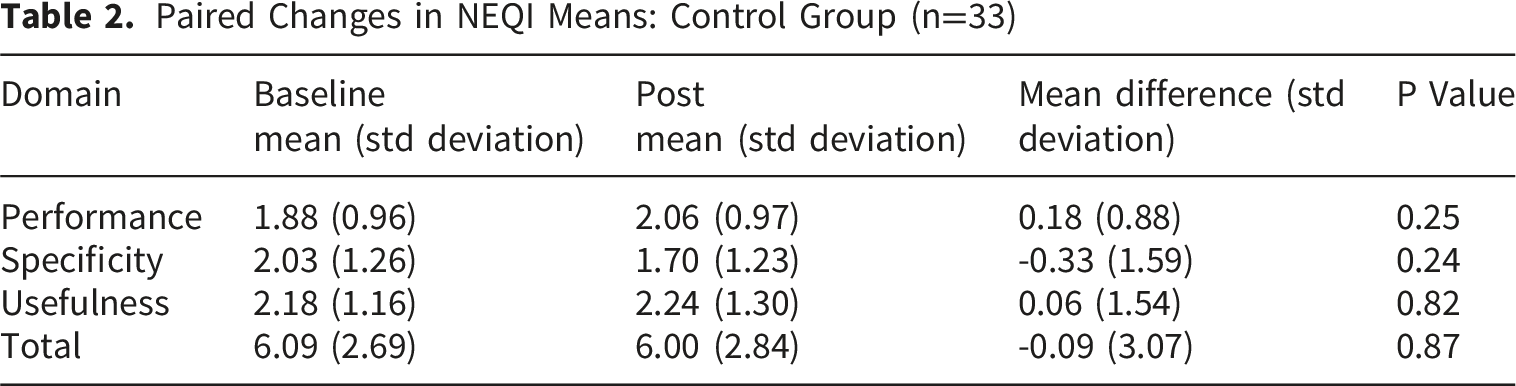
Paired Changes in NEQI Means: Control Group (n=33)
Paired Changes in NEQI Means: Intervention Group (n=33)
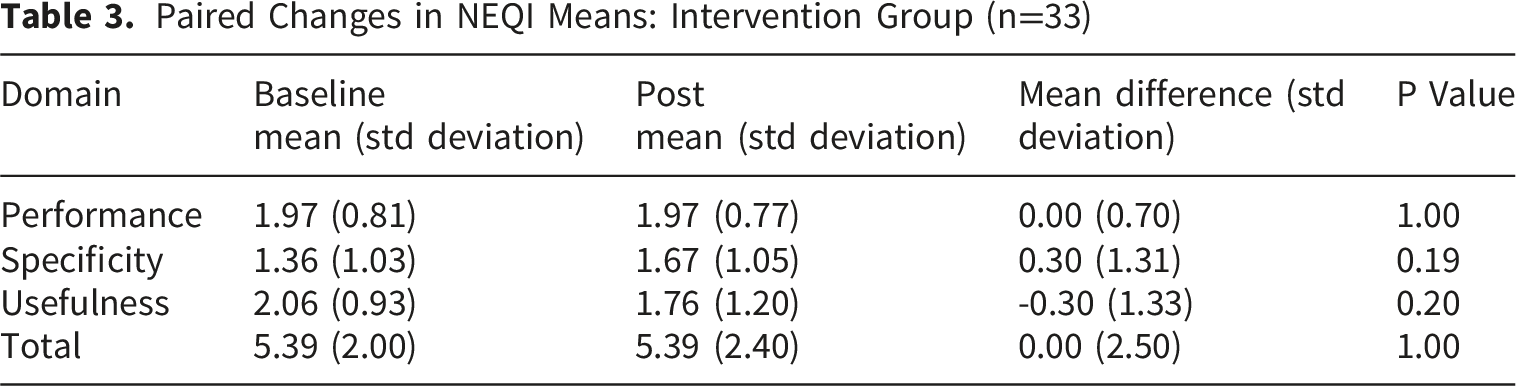
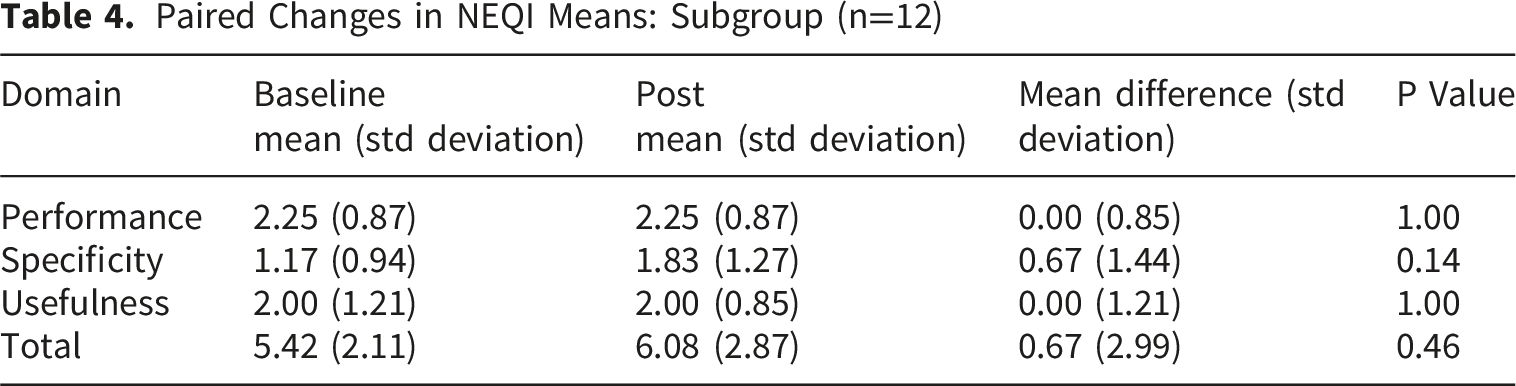
Paired Changes in NEQI Means: Subgroup (n=12)
Discussion
This study has several strengths. As a multi-institutional and multi-clerkship study, we had a diverse sampling of faculty across multiple specialties, practice settings (inpatient and outpatient), and academic ranks (experience). Investigators who assigned NEQI scoring were blinded to participants, thus minimizing the risk of evaluator bias. We demonstrate how a validated tool from the existing literature can be adapted to fit individual institutional needs. This pragmatic approach allows educators to build upon previous findings to improve their evaluation process. The lessons we learned in reaching high interrater reliability such as developing specific criteria and creating an automated process show how others can best utilize the tool at their institutions. A limitation of our study was the small number of evaluations available, with only one pre- and post-intervention evaluation scored per faculty member. While generalizability evidence suggests that at least three narrative evaluations with the NEQI are needed to generate a dependable estimate of an individual’s narrative quality, 22 we intentionally narrowed the scope to reflect the pilot nature of the study and to ensure feasibility for the investigators. Accordingly, our use of a single evaluation per time point likely reduced statistical power and reliability and may have attenuated our ability to detect any differences.
We hypothesize a few reasons for the lack of difference in the NEQI scores in the intervention group. As the module was voluntary, the low participation in the educational module could largely explain why there was no difference in scoring. However, our subgroup analysis of faculty who completed the module, though underpowered, also did not show a significant difference in scores. The low participation rate also highlights the difficulties that clerkship directors face when trying to implement voluntary faculty development without incentives or support from leadership. The timing of the educational module may have also contributed. While not specifically measured, based on the timing of the emails and the follow-up evaluations, there was a time gap of several weeks between completion of the educational module and the participants’ subsequent evaluations. By the time the participants wrote their next evaluation, they may not have been primed to think about the NEQI and the educational module. Factors that were not considered in randomization but may have contributed to outcomes include gender (more female faculty in control group), prior training on writing narrative evaluations, and prior experience as a learner receiving narrative evaluations.15,23,24 Finally, educating faculty on how to write narrative evaluations may not matter if their workflow does not include documenting and reflecting on observable behaviors in multiple specific domains of their learners in the first place. In other words, it may not be that faculty do not know how to write an evaluation, but rather they do not have the time or a system in place to prioritize gathering the data needed to observe and remember the specified competencies in a busy clinical environment
While the intervention as tested did not result in significant differences in evaluations, the trend toward more specific comments in the intervention group is promising. The specificity of comments is important for many aspects of residency applications, including the MSPE and structured letters of evaluations (SLOEs). Faculty may also reference their prior evaluations when asked to write an individual recommendation letter to document concrete behavioral examples. These findings shed light on some potential next steps that may increase the usefulness of the NEQI as a tool for improving narrative evaluations that can be investigated in future studies. First, the NEQI could be used to structure evaluator orientation materials, observation tools, and evaluation templates to prompt the specific components needed to achieve higher quality with individualized coaching. Specific observation exercises which parallel the performance domains could be suggested or assigned during the supervisory period. Templated narrative prompts in the evaluation form, rather than blank text boxes, may be more effective in guiding evaluators to include comments on competency domains, provide specific examples and feedback for learner improvement. 25 Next, artificial intelligence may be used to score evaluations using the NEQI, thus relieving time burden, reducing human differences in grading, and allowing multiple opportunities for feedback. These findings could be shared with faculty in longitudinal peer-mentored groups focused on improving faculty teaching skills which could capitalize on the importance of spaced and active learning. 26 These interventions highlight the importance of technology and ensuring the systems of formative and summative assessment are thoughtfully integrated and available for use in clinical settings. Finally, more targeted educational interventions may yield greater benefits. Sessions focusing on portions of the NEQI instead of the overall may lead to more incremental changes in quality of evaluations over time.
Conclusion
Narrative evaluations are essential for learner feedback, competency-based evaluation, and UME to GME handoffs. Narrative evaluations should comment on multiple competency domains, provide specificity, and be useful for learner growth. Programs need to prioritize and provide space for faculty development on gathering and documenting the necessary observations effectively to promote trainee growth and improve learner handoffs. Clerkship directors require institutional support and resources for faculty education and development of novel interventions to improve the quality of narrative evaluations, as our study showed that simply emailing feedback and an invitation for an asynchronous learning module did not demonstrate measurable improvement.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.