
Abstract
Since it was first used in 1997, the term “big data” has been popularized; however, the concept of big data is relatively new to medicine. Big data refers to a method and technique to systematically retrieve, collect, manage, and analyze very large and complex sets of structured and unstructured data that cannot be sufficiently processed using traditional methods of processing data. Integrating big data in rare diseases with low prevalence and incidence, like systemic sclerosis is of particular importance. We conducted a literature review of use of big data in systemic sclerosis. The volume of data on systemic sclerosis has grown steadily in the recent years; however, big data methods have not been readily used. This inexhaustible source of data needs to be used more to unleash its full potential.
Introduction
Technologies such as genomics, proteomic, and other -omics, electronic medical records, and patient-reported health information have produced large amounts of data, from various populations, cell types, and disorders. However, analysis of this surfeit of data is a challenging task. The data must be integrated and analyzed to produce models or concepts about physiologic function or mechanisms of pathogenesis. Many data are publicly available, allowing researchers anywhere to search for markers of specific biologic processes or therapeutic targets for specific diseases or patient types. 1 International Committee of Medical Journal Editors (ICMJE) issued a proposal that would require authors of clinical trials to make de-identified patient data publicly available after a 6-month embargo period, with the intention of increasing transparency and reproducibility of the trial results, and facilitating large-scale secondary analyses by external researchers. 2 As of 1 July 2018, manuscripts submitted to ICMJE journals that report the results of clinical trials must contain a data sharing statement and clinical trials that begin enrolling participants on or after 1 January 2019 must include a data sharing plan in the trial’s registration. These initial requirements do not yet mandate data sharing, but investigators should be aware that editors might take into consideration this statement during editorial decisions process. 3 Although many issues must be addressed before data sharing will become the norm including very rigorous data privacy laws in Europe, ICMJE remains committed to this goal.
The term big data has been popularized over the past decade. It is a method and technique to systematically retrieve, collect, manage, and analyze very large and complex sets of both structured and unstructured data that cannot be sufficiently processed using traditional methods of processing data. Traditional methodologies include spreadsheet programs such as Excel; however, new technologies and techniques can analyze the data more efficiently and effectively. Data with many cases (rows) offer greater statistical power, while data with higher complexity (columns) may lead to a higher false discovery rate. As such, big data challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy, and data source. Big data is described by the following attributes: volume (large amount of data), variety (heterogeneity of relevant features), and velocity (rapid accumulation). Other attributes that have later been attributed with big data are veracity (the ability of data to faithfully represent its subject) and value (Figure 1). The term “big data” was first used in 1997 in a paper by Michael Cox and David Ellsworth from National Aeronautics and Space Administration (NASA), describing the problem they had with visualization of large data sets. 4 Although the term has been utilized for some time in business and engineering, the concept of big data is relatively new to medicine and has important implications for rare disease.
Big data attributes.
Big data analysis in clinical medicine
Contemporary medical research involves deductive reasoning, starting with a general theory and a hypothesis to studies testing conceptual models. Inductive reasoning and pattern recognition, in contrast, begin with observations and builds to specific conceptual models or creates tools that have utility in informing decisions. The key is to test the consistency of the results and ensure the validity of the conclusions. Validation of findings becomes an essential component of the research, as broad-based investigations include many different analyses. Big data analytics has helped improve healthcare by providing personalized medicine and prescriptive analytics, clinical risk intervention and predictive analytics, waste and care variability reduction, automated external and internal reporting of patient data, standardized medical terms and patient registries and fragmented point solutions. Some areas of improvement are more aspirational than actually implemented. The level of data generated within healthcare systems is not trivial. Due to practical limitations of randomized control trials (RCTs), there are many important clinical questions that are never addressed in this highly regulated setting. With the adoption of mHealth, eHealth, wearable technologies, and web applications, the volume of data will continue to rapidly increase and provide the opportunity for patient-centered research. Properly captured and interrogated electronic health record data, imaging data, patient-generated data, sensor data, and other forms of difficult-to-process data will provide the opportunity to supplement missing information from RCTs. There is even a greater need for such environments to pay special attention to quality, as big data is often referred to as “dirty data.” Unfortunately, we need to be fully aware that human inspection at the big data scale is impossible, and there is a desperate need in health service for intelligent tools for accuracy and believability control and handling of information missed. Furthermore, getting data into the big data platform can be difficult as different scales and variety of data can overwhelm data specialists unprepared in this sort of area. While extensive information in healthcare is now electronic, it fits under the big data umbrella, as most is unstructured and difficult to use.
Integrating big data could shorten development timelines, improve cost-effectiveness of drug development pipeline, improve the success rate of diagnostic discovery to guide more accurate clinical decision-making (identifying diagnostic, prognostic, or therapeutic response–predictive biomarkers) and improve therapeutic tools.
Drug repositioning is a great example how development timelines could be shortened. It refers to the identification of new indications from existing drugs and the application of the newly identified drugs to the treatment of diseases other than the drug’s intended disease. Thalidomide is a well-known example. The drug was originally developed as a sedative by the German pharmaceutical company Grünenthal in 1957. Not long after the drug was introduced to alleviate morning sickness in pregnant women, it was found to cause serious birth defects, leading to its withdrawal from the market. In the ensuing decades, several research groups found that thalidomide possesses anticancer activity and in 2006, it received US Food and Drug Administration (US-FDA) approval for the treatment of multiple myeloma in combination with dexamethasone. 5
Big data analysis in systemic sclerosis
With each passing year, big data has taken on a larger role in medicine and more specifically, in rheumatology. The value of big data–driven medical research is huge, especially in areas such as epidemiology, genetics and therapeutics, and ranges from relatively basic analysis (such as determining disease incidences in a given population) to more complex studies (efficacy of new drugs in a real-world setting, large-scale genetics research). With regard to long-term benefits of using big data in rheumatology, the greatest achievement is that there will be more patient data. This is of particular importance as there are some rare diseases with low prevalence and incidence, like systemic sclerosis (SSc).
SSc is an autoimmune connective-tissue disorder characterized by micro-vascular damage, immunologic impairments and tissue fibrosis, which results in organ dysfunction due to deposition of collagen and other matrix substances within the skin and internal organs. 6 SSc can be further examined in the context of skin fibrosis, into limited cutaneous SSc (lcSSc) and diffuse cutaneous SSc (dcSSc). 7 Subtypes of SSc present with varying clinical features, have different responses to therapy, and end up with different outcomes, hence are often analyzed separately. However, skin involvement can change over time, which presents the challenge of using cross-sectional big data. In addition, these two subtypes can be further divided by different organ involvement and autoantibody subsets. The prevalence of SSc in Split-Dalmatia County, Croatia, has been estimated at 156 cases/million. 8 Population of Croatia is roughly 3.4 million adults and therefore by extrapolation, there are about 530 patients with SSc. Consequently, in a small country like Croatia, subtype analysis done on a national level would still be underpowered due to sample size, not allowing any concrete conclusions.
Materials and methods
We undertook a search using the Medline, EMBASE, Cochrane Library, and ACR/EULAR meeting abstracts. We searched using the following keywords: SSc OR scleroderma OR autoimmune diseases OR rheumatic diseases and big data. We limited our search to English language and included studies in SSc using big data analysis.
Results
A total of 196 articles were identified using the above search (Figure 2). After removing duplicates, 192 abstracts were included in the abstract review. Of the remaining seven articles, four were excluded based on review of full article. Reasons for exclusion: SSc mentioned only as an example of a disease without new treatment options in the past half a century, two general review articles without any SSc data, reference to electronic medical records review and real-world evidence as “big data.” Bibliography of relevant articles did not identify any additional articles. Finally, three articles fulfilled all the search criteria.
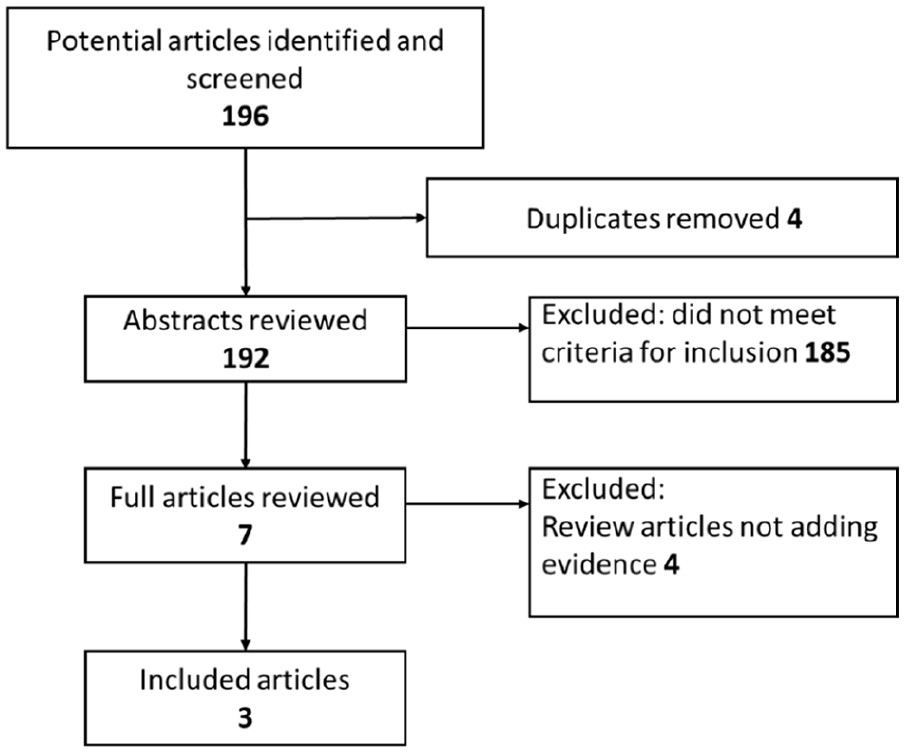
Flow diagram of review process.
Recent study has explored the potential of the Google search engine to collect and merge large series of patients with systemic autoimmune diseases (nearly 400,000 patients) reported in the PubMed library, with the aim of obtaining a high-definition geoepidemiological picture of each diseases. Using a big data analysis of 31,585 SSc patients revealed unbalanced gender ratio with more than five females affected per one male. Mean age at SSc diagnosis (time of fulfillment of classification criteria) was 51 years. Further analysis has differentiated mean age at onset (first non-Raynaud feature attributable to SSc) was 46.6 (range: 44.6–50.5) years and mean age at study entry (current age) was 55.3 (range: 54.6–56) years. 9
Bragazzi et al. 10 performed a nation-wide epidemiological survey relying on a large database, using big data analysis methods to dissect not only the relationship between SSc and depression but also the impact of depression on SSc in terms of mortality. Data-mining technique was used to extract a homogeneous SSc population from a 400,000-member chronic disease registry and compare to age- and sex-matched controls. The overall population comprised of 15,141 subjects with a female/male ratio 4.5:1. The proportion rate of depression among SSc patients was significantly higher than in healthy controls (16.2% vs 10.9%) and this proportion was even higher in female SSc patients and of low socioeconomic status. SSc was found to be an independent risk factor for depression with an odds ratio (OR) of 1.55 (95% confidence interval (CI) 1.29–1.88, p < 0.0001). However, depression was not found to have a significant impact on the SSc patient’s survival rate with a hazard ratio (HR) of 1.06 (95% CI: 0.80–1.42). Importantly, if mental health influences patient participation in structured data collection significant selection bias could result.
Watad et al. 11 mined Clalit Health Services, major Israeli health organization (public and semi-private) delivering healthcare services to about 4.4 insured subjects to obtain a cohort of SSc patients, properly age- and sex-matched with controls to compare the prevalence of psoriasis (PsO). Overall, 1.3% cases of PsO were diagnosed and a statistically significant difference in PsO cases, with 1.2% among controls and 1.9% among SSc patients. SSc diagnosis was an independent risk factor for PsO plus SSc patients with PsO had a significantly higher mortality rate.
Discussion
In our literature research, we identified only three articles that addressed big data methods in SSc. There is a lot of real-world evidence addressing epidemiological data. According to a large, population-wide assessment of two claim databases in United States, SSc has a prevalence of 0.05%. 12 Analyzing SSc distribution transversely over various geographic areas and ethnic cohorts may help advance our understanding of the contrasting genetic and environmental underpinnings. 13 SSc is characterized by several unmet needs and one of them, probably the most important, is the difficulty to make a right and timely diagnosis. Delay in diagnosis can have a significant life-changing or life-shortening consequences for SSc patient. Early SSc detection and differentiation from other connective-tissue disorders are essential for proper disease management.
The body of evidence linking depression and SSc is based on several small studies and the wide range of the epidemiological findings warranted further research to clarify the complex and multifactorial relationship between SSc and mental health. Smaller studies reported depression to affect anywhere between 36% and 65% of SSc patients. 14 High prevalence of depression among SSc patients portray the importance of the analysis by Bragazzi et al. 10 on the impact of depression on survival. Although depression did not significantly impact survival, concomitant PsO was associated with a higher mortality rate.
Additional information can be gained through network biology, also referred to as systems biology. The purpose of this field is to understand organisms or cells as a whole at various levels of functions and mechanisms, and it is facing the challenge of analyzing big molecular biological data and huge biological networks. 15 Wealth of high-throughput gene expression data collected on SSc can now be analyzed in aggregate to gain mechanistic insight into the disease by systems biology approach. Mahoney et al. 16 applied these methods to three independent SSc skin data sets to identify the genes that were consistently associated with the intrinsic subsets, show the relationship between these genes using a gene–gene interaction network, and place the genetic risk loci in the context of the intrinsic subsets. Franks et al. 17 introduced a novel machine-learning classifier as a robust accurate intrinsic subset predictor. Lofgren et al. 18 performed an integrated, multi-cohort analysis of SSc transcriptome data across seven data sets and identified the SSc skin severity score (4S) that significantly correlated with modified Rodnan skin score (mRSS). Furthermore, it was suggested that 4S could be used to distinguish treatment responders prior to mRSS change. These studies demonstrate the value of analyzing gene expression data from multiple studies. Taroni et al. 19 performed a meta-analysis of gene expression data from skin biopsies of patients with SSc treated with five therapies: mycophenolate mofetil, rituximab, abatacept, nilotinib, and fresolimumab. This framework allowed comparisons of different trials and ask if patients who failed one therapy would likely improve on a different therapy, based on changes in gene expression. Genes with high expression at baseline in fresolimumab non-improvers were downregulated in mycophenolate mofetil improvers, suggesting that immunomodulatory or combination therapy may have benefited these patients. Further analyses of these data from SSc studies are likely to continue to provide insight into disease pathology, thus allowing us to develop better and more targeted therapies for SSc. 20
Marquez et al. used a cross-disease meta-analysis of genome-wide association study (GWAS) and Immunochip data from 37,159 patients with seropositive autoimmune disease that included 3477 patients with SSc. The analysis identified eight loci associated with SSc that have not been previously reported, including locus rs10931468 located within the NAB1 gene that has not been previously associated with any of the diseases analyzed. Furthermore, investigation of proteins encoded by pleiotropic genes identified 13 potential repositionable drugs for SSc. 21 It should be noted that GWAS studies are not without limitations, as genome-wide sequencing can lead to type-I errors especially in rare disease like SSc, where the sample size is not large enough. 22
Big data analysis challenges in SSc
The use of big data in healthcare has raised significant ethical challenges ranging from risks for individual rights, privacy, and autonomy to transparency and trust. Previous studies have indicated that people have very little understanding, and there are concerns about how organizations are using big data. 23
It is possible that there are over expectations regarding big data, especially in rare diseases such as SSc. The benefits about real-world data from non-organized sources, can provide evidence beyond clinical research studies and can generate new hypothesis, however cannot support casual conclusion or generate evidence for decision-making. Real-world data from an organized source, instead, can assess care and health outcomes in routine clinical practice and can inform about application of evidence. Big data analysis could help uncover the potential evidence that remains hidden to date.
In 2014, Big Data Sjögren Project Consortium, an international, multicenter registry was designed to take on “high-definition” picture of main features of primary Sjögren’s syndrome (SS), also a rare systemic autoimmune disease, with a prevalence less than 0.1%. By January 2016, 8417 patients were included in the database across five continents (20 centers) and after exclusion of 107 patients, an analysis provided first evidence of a strong influence of geolocation and ethnicity on the phenotype of SS at diagnosis. 24 Subsequent analysis on 10,050 patients confirm the strong influence of immunological markers on phenotype, portraying greater influence for cryoglobulinaemic-related markers in comparison with Ro/La autoantibodies and antinuclear antibody. 25 In January 2019, the project was running in 24 countries and included 11,421 patients thus, multiplying by six the largest number of patients in an international registry. 26 The data provided thus far may guide physicians in designing a specific individualized management of patients with primary SS.
Recently, European League Against Rheumatism (EULAR) published essential issues and provided a framework for the use of big data in rheumatic and musculoskeletal disorders recognizing the tremendous opportunities that can be unlocked by expansion of big data. 27 However, there is an unmet need to establish a strategy to promote national and international registries in SSc. The next phase should be to harmonize existing data, and anticipate needs and identify outcomes for future research. In case of treatment, registries should be established as early as possible, during development of potential biomarkers of disease pathogenesis. Most importantly, the data needs to capture all patients and be compatible across registries using international standards for semantic interoperability.
The principal challenges in SSc diagnosis and treatment include:
Lack of diagnostic criteria.
Specific clinical multidisciplinary standardized management due to heterogeneity of the diseases.
Persistent comorbidities, and physical and cognitive changes during disease course, which may influence research participation.
Effective and safe therapies that can induce remission and delay comorbidities, improving long-term prognosis.
Conclusion
The volume data on SSc is low and for this reason, specific technology for big data analysis is desperately needed to move the field forward. The SSc research community should be interested in learning about and implementing these new methods. This review article will hopefully inspire interest in this promising field. Big data is a great potential yet to be leveraged in SSc. This inexhaustible source of knowledge needs to be used to unleash its value because it is not merely the size of data, but the quality and nuances of the data elements that can guide discovery.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.