
Abstract
Emotion recognition models are used to determine the thoughts, feelings, and emotions of humans from facial visuals. The enormity of facial expressions makes it challenging to extract emotions from face images. The main focus of this research is to extract emotions from facial images and emotional speech using deep learning models. In previous research, proposed methods suffer from issues like performance degradation caused by poor layer selection as well as poor accuracy. In the proposed model, data is gathered, and preprocessed to improve the image's quality for more accurate emotion recognition. The region extraction is carried out using a faster Recurrent-convolutional neural network (R-CNN) and the standard Resnet-101. Then, a pretrained model is created using the standard combination of the ResNet-101 and GoogLeNet model for feature extraction. To classify emotions accurately, an activational attention layer coupled deep learning model (ALNN-EmR model) is proposed using the bald hawks-based deep convolutional neural network (bald hawks-deep CNN) in this research. In the proposed model, the features are acquired using the ResLeNet model designed by concatenating the ResNet-101 and GoogLeNet features. Using the ResLeNet features, the proposed activational attention layer coupled deep learning model (ALNN-EmR) recognizes the emotions, where the weights and biases of the model are successfully adjusted using the bald hawk optimization (BHO). The proposed ALNN-EmR model is implemented and the effectiveness is revealed through the emotional speech and video-based data analysis.
Keywords
Introduction: Background
Sentiment analysis (SA) is a method for more accurately determining consumer views toward a certain subject, product, or issue. SA can be performed on different types of data such as written content, images, audio, and video (Alsayat, 2022; Moung et al., 2022). In addition to texts and audio, images also include valuable emotive semantics since they have a wealth of visual data that may be used for a variety of important tasks (Zhang et al., 2020). Automatic sentiment identification is beneficial for many applications, including business analysis (Wang et al., 2016) and psychological care (Xu et al., 2020b; Yadav et al., 2018), as it is vital to understand individual behavior. Social photos are more appealing and intuitive than words; users of social media submit social photographs to the Internet due to the prevalence of image-capture technology (Perez-Gomez et al., 2020). The focus network is commonly used for obtaining discriminative text and visual features in various studies (Chakraborty et al., 2020; Huang et al., 2018; Shin et al., 2016), highlighting how effective it is in this task (Xu et al., 2020a, 2020b, 2020c). However, the words spoken in a video retain a sequence and are extremely related due to the speaker's changing concepts, co-references, and discourse structure. The contextual information of other utterances is very useful for classifying utterances (Poria et al., 2017). In addition to offering services to users, event recommendations in event-based social network (EBSN) also assist users in planning offline gatherings, making it easier for users to have face-to-face interactions. Therefore, to increase the effectiveness of personalized event recommendations in EBSN, the user needs to consider carefully how to combine the offline social relation of the event with the online social relation of the group (Cao et al., 2018).
Three types of focus have been given to the sentiment analysis of images in recent years. The first kind separates the low-level visual aspects from the input photographs (such as colors, shapes, and texture) to derive the emotional findings (Li et al., 2012; Machajdik and Hanbury, 2010; Yanulevskaya et al., 2008). The second kind of work uses mid-level feature features, which are constructed on top of low-level characteristics and include elements like environment and facial expressions (Borth et al., 2013; Chen et al., 2014; Mistry et al., 2016; Yuan et al., 2013), to describe the input photos. A deep neural network utilized in the third kind of technique to extract high-level features is the CNN, which has seen significant success since the development of deep learning algorithms (Xu et al., 2020a, 2020b, 2020c). Deep learning-adapted models start to appear at the right time when neural networks mature (Chen et al., 2019; Creamer, 2017; Pan and Wu, 2019; Ren et al., 2018; Rosa et al., 2018; Xu et al., 2019; Xu et al., 2020a, 2020b, 2020c; You et al., 2016). Many attempts have been made to determine sentiments from visual content. Facial expressions are frequently used as visual cues to infer moods and forecast emotions in close-up facial images, which is where the majority of optical SA research is concentrated (Barrett et al., 2019). Strongly emotive images and videos can reinforce the viewpoint expressed in the text and have a viral impact on the viewership. Understanding the emotion conveyed in visual content can significantly improve social media communication and allow for a wide range of uses in entertainment, education, and advertising (Chen et al., 2014). Most businesses announce news on Saturday, Sunday, or even Friday nights immediately after the stock market closes so that people have time to process the positive or negative news and remember it to improve their perception of the company. However, the day-of-week effect is hardly ever taken seriously when generating sentiment indices (Ren et al., 2018).
Extending the visual method to images with more complicated compositions, such as those with several objects and background elements, has also been attempted (Hassan et al., 2022). Processing and analyzing multimodal data brings opportunities and challenges, in contrast to single-modal SA. Early multimodal works largely consist of handcrafted components (Xu and Zhao, 2020). However, handcrafted features frequently produce less-than-ideal results since they are occasionally produced with insufficient human skill and are unable to adequately represent the high abstractions of sentiment (Zhu et al., 2022). Despite the positive performance of the existing multimodal sentiment analysis, there are still two important problems that need to be fixed (Xu et al., 2020a, 2020b, 2020c). Even though numerous efficient identification algorithms have been put into place in the past, the recognition rate is typically unsatisfactory because of built-in drawbacks such as light, stance changes, noise, and occlusion (Huang et al., 2019). Recent years have seen the publication of several facial expression recognition (FER) research publications, but the fusion approach of the FER model has received less attention. For the most part, they combined many feature representations or used only one feature representation (Islam et al., 2018; Moung et al., 2022; Shengtao et al., 2019). In contrast to real-world applications, the majority of the investigated FER models were created and evaluated using photos that were gathered in a controlled environment (images without obstruction, noise, or recorded at an ideal angle). Similar emotional tendencies are frequently expressed in images with similar topological settings, and this overlapped information can be retrieved as relations and aids in the development of the relational network (Murtaza et al., 2019; Xu et al., 2020a, 2020b, 2020c).
Motivation for Research
The emotions of the facial expression are recognized by various deep learning techniques. In state-of-the-art methods, the emotions are recognized from audio or visual emotions, which also cause some challenges. The challenges obtained from the state-of-the-art methods are high computational overhead that lowers the performance and generates an extended error rate. The depth review of the state-of-the-art methods is discussed below.
1.1.1 Existing Methods and Review
The section below discusses reviews of the emotion recognition model; Moung et al. (2022) introduced an ensemble classifier for classifying facial images into seven attitudes. This technique detected negative emotions while having high-level features that allowed for rapid convergence but low performance. An attention-adapted heterogeneous relational model was introduced by Xu et al. (2020a, 2020b, 2020c) to do multimodal sentiment classification using both the social relations and the content information. The approach offered precise correlations between the image and the text, but it had a high error rate and was extremely computationally intensive. Zhang et al. (2020) developed a new method for sentiment analysis of images termed multidimensional extra evidence mining that combines sample-refinement and cross-modal emotional semantic mining. Lowered the danger of over-fitting and increased real-time speed when processing huge amounts of data, however multidimensional evidence performed poorly across classifiers. Xu et al. (2020a, 2020b, 2020c) developed an original model called social relations-guided multiattention systems to encompass both the multilayer visual components of a single image and the connections across numerous social images. This model is used to do visual sentiment analysis. This method efficiently extracted the image sentiments using the little network data available, but it has network inconsistency. Zhou et al. (2020) hierarchically provided cross-modal interactions for visual-textual evaluation of sentiment. This approach had information loss but was able to achieve high convergence with little noise and a low error rate. An image-text interaction network was created by Zhu et al. (2022) for multimodal sentiment analysis. Although complementary information improved the accuracy of prediction performance, the region-word pair's low gate value was not well aligned. Images of natural disasters have been shown to evoke people's thoughts and attitudes, the newly created concept of visual sentiment evaluation was the main focus of Syed Zohaib Hassan et al.'s study (Hassan et al., 2022). Even if the choice of visual features was important in multimedia analysis, the image complement of visual attributes helped visual sentiment analysis. Ahmed Alsayat introduced an ensemble machine-learning model of language that develops an LSTM network while making use of an improved word embedding technique for sentiment analysis (Alsayat, 2022). While this technique was able to lessen computing complexity, it might not have been very successful in reducing variation across the parts of the models, which could have led to less reliable outcomes. In DTL-I-ResNet18, the authors focused on building the dense upper layers of the Deep CNN model. In this article, the model produced better accuracy while targeting the feature layer selection. The drawback was that the developed model failed to test their effectiveness in varied emotional intensities that matched real-world emotions. In our research, we addressed the aforementioned challenges by designing spatial and channel attentional layers for generating the facial features that would support the deep CNN for more accurately recognizing the emotions and the testing has been validated from emotional speeches and facial visuals. Issa et al. (2020) developed a one-dimensional convolutional neural network for recognizing the emotions from the audio samples. The model automatically recognized the particular emotion from their speech, but the performance of the model was degraded, failing to extract the features properly. Mehendale (2020) identified a two-part convolutional neural network for face emotion recognition that suffered from computational complexity that affected the model performance. Serengil and Ozpinar (2020) used a hybrid deep neural network framework for recognizing facial emotions, which failed to predict all facial emotions. Jain et al. (2020) implemented a deep learning-based support vector machine for classifying human emotions, which was easy to train and the mapping of the input high dimensional data was more accurate when compared with other neural networks. The major challenges of this method were that the voice emotions were not recognized accurately. Li et al. (2018) introduced multichannel EEG signals with different bands, frequencies, and channels for recognizing human emotions from non-physiological signals. However, the different phonetic intonation and facial expressions of several people with true emotions were not validated accurately. Lee et al. (2011) developed a hierarchical binary tree approach for recognizing the speech emotions that suffered from computational complexity. Rajesh and Nalini (2020) implemented a deep recurrent neural network for musical instrument emotion recognition that failed to recognize the emotions from music. Ali et al. (2022) used a sparse auto-encoder (SAE) neural network for recognizing the emotions from speech that suffered from a huge training time that affected the model accuracy.
Finally, the major of the researches used facial images or videos for emotion recognition, while a few researches had focused on speech for emotion recognition. The drawback of the existing methods was that the model accuracy was affected due to the higher training time, inappropriate features, redundant features, and computational complexity of the model. Finally, the challenges are summarized as follows:
The challenge of handling uncertain images is difficult because it requires a long computation time to identify the emotions, which makes this process slow and steady. The challenge of simultaneously identifying emotions in several images is the most difficult. The challenging aspect of the research is that the classifier's error rate is high and extracted deep learning feature execution time may be lengthy. Implementing the activation module in deep CNN has issues since it actively demands the model to properly categorize, perform in social streams, and interpret for emotion recognition.
Motivation Summary
To overcome these limitations, we proposed an ALNN-EmR model to predict the emotions accurately from video with better performance. In our proposed method an activational attention layer coupled deep learning model (ALNN-EmR) classifier with an optimized attention module is used to quickly categorize the emotions from both the facial and speech. Further, to support the detection accuracy, the ResLeNet descriptor has been proposed for extracting the features from the input video that not only considers the facial expression but also extracts the speech-based emotions. Furthermore, the redundant features are effectively handled through the usage of the feature selection for which the BHO algorithm is used. Moreover, the model accuracy has been improved by presenting dimensionally reduced facial features that overcome the curse of computational complexity. Furthermore, the training is managed effectively through designing the BHO algorithm for tuning the classifier hyperparameters that promoted the convergence rate.
The main objective of this research is to classify the emotions in the face image using the ALNN-EmR model and overcome the issue of performance degradation and poor accuracy in existing methods. Preprocessing enhances the image's quality to enhance emotion recognition. The region of extraction is then carried out using faster R-CNN hybridization and the standard Resnet-101 hybridization. Then, a hybridized pre-trained model named ResLeNet was proposed using the standard hybridization of the Resnet-101, and the GoogLeNet model was used for feature extraction. Once the features have been collected, an activational attention layer coupled deep learning model (ALNN-EmR) classifier with an optimized attention module is used to quickly categorize the emotions visible in the image. The following are the contributions to the research:
The proposed bald hawk optimization is developed by the standard hybridization of a bald eagle (Alsattar et al., 2020) and Harris hawk (Elgamal et al., 2020) algorithm that successfully combines the traits of hunting with different chasing styles of Harris hawk merged with the bald eagle search algorithm for improving time complexity and provided faster convergence. The ALNN-EmR classifier is developed by the combination of channel and spatial level attention in deep CNN for efficiently recognizing the emotions present in the image with higher accuracy. The BHO algorithm tunes the weights and biases of the classifier to get better results.
The remaining portions of the manuscript are divided into five sections: Section 2, which reviews the proposed method for emotion recognition, Section 3, which discusses the results of the proposed ALNN-EmR method with experimental data, Section 4 describes the achievement of the proposed model, and Section 5, which covers-up the conclusion of the manuscript.
Materials and Methods
Proposed Methodology for Emotion Recognition Model
The goal of this research is to use the ALNN-EmR model with a BHO-deep CNN classifier to identify the emotions captured in the image. In the beginning, the input image from the database is gathered, and preprocessing is done to improve the image quality for better emotion recognition. After preprocessing, the region extraction from the image is performed using the ResLeNet model, which is developed by combining ResNet-101 and faster R-CNN. ResNet-101 is a CNN that is 101 layers deep. Object detection is performed using the deeper R-CNN faster. It creates region proposal networks (RPN) and produces region suggestions for fast R-CNN to use in object detection. The pre-trained ResNnet-101 helps in reducing the error rate and faster R-CNN can perform the quickest iteration. Hence faster convergence with a reduced error rate is obtained using the combination of ResNet-101 and Faster R-CNN model. Then, the feature extraction is done for extracting the features, which helps in the reduction of the large number of pixels of the image and is efficiently performed by using a pre-trained model developed by the combining Resnet-101, and GoogLeNet model. GoogLeNet is a CNN that is 22 layers deep. The feature extraction is performed efficiently using this model and the extracted features are fed forward to the ALNN-EmR classifier in which the CNN learns and concentrates more on the vital information using attention modules as opposed to acquiring unhelpful background information and detects the emotions present in the image. The research's significance depends on the developed ALNN-EmR model that uses the BHO algorithm, which is created using standard BEO and HHO (Alsattar et al., 2020; Elgamal et al., 2020). BHO aids in tuning the classifier's weights and bias, which increases convergence and shortens training time. Figure 1 displays the methodology's diagrammatic depiction.
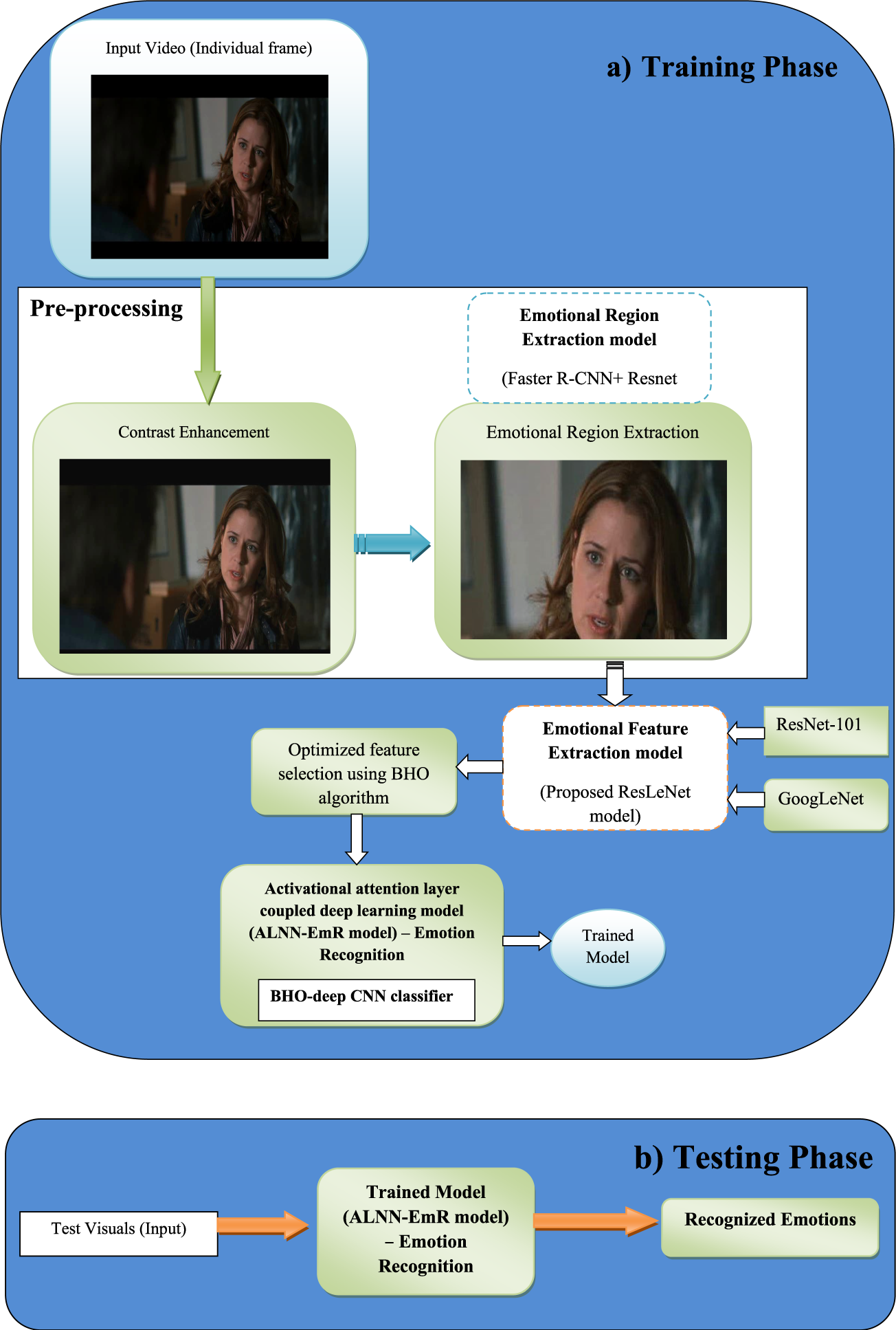
Block diagram of ALNN-EmR model: (a) training and (b) testing.
The input for the recognition of emotion is gathered from the AFEW and RAVDESS datasets and is mathematically denoted as
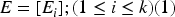
2.2.1 AFEW-VA Dataset (AFEW-VA)
The AFEW-VA dataset consists of 600 difficult video clips that have each frame annotated with 68 different face cues and extremely precise levels of valence and arousal.
2.2.2 RAVDESS Dataset (RAVDESS)
There are 7,356 files totaling 24.8 GB in the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), which is available online. Moreover, 24 professional actors, 12 male and 12 female, are recorded in the database vocalizing two sentences that are lexically similar in an impartial North American accent.
The preprocessed video data is converted into keyframes to improve the image quality, and the contrast is improved for the input frames. Unwanted regions are removed and the informative regions are retrieved as a region of interest (ROI) through the combination of R-CNN and ResNet.
To locate and extract areas of an image that are pertinent to emotions or affective content, emotional region extraction methods are used that generally combine many techniques or models. The objective is to identify and isolate particular areas of an image that contain expressive or emotional clues. In this research, both ResNet and Faster R-CNN are combined to extract the emotional regions. It is a technique that makes use of the Faster R-CNN algorithm for object and region recognition as well as the ResNet architecture for feature extraction. With this method, emotional areas or ROIs in images that are important to feelings or affective content are extracted.
2.3.1 Faster R-CNN
An efficient object detection method called faster R-CNN may also extract ROI. To create region proposals and categorize items inside those regions, it combines a region proposal network and a CNN. Here is a high-level description of how Faster R-CNN performs ROI extraction,
An input image is used as the starting point of the process, which is then run through multiple layers of convolution to extract valuable properties. These layers begin by learning lower-level visual attributes and work their way up to higher-level ones. The RPN creates region proposals, which are potential bounding boxes around picture objects, using the information from the convolutional layers. The RPN generates region proposals at various scales and places using anchor boxes, which are predefined boxes of various sizes and aspect ratios. To retrieve fixed-size feature maps from the convolutional layers, the RPN generates region suggestions. Region of interest pooling or cropping is the term used to describe this technique. It makes sure that the extracted sections are of a consistent size and can be fed into the network's later levels. The network's many branches are fed with the fixed-size feature maps that were obtained from the region of interest pooling. One branch uses object classification to assess whether there are objects in each region, while the other uses bounding box regression to improve the region suggestions and pinpoint the objects precisely. Using the results of the bounding box regression, the region suggestions are improved. Then, non-maximum suppression is used to remove redundant or overlapping region proposals, preserving just the strongest ones. The remaining region suggestions are taken into account as the ROI retrieved from the image after the non-maximum suppression. These areas match possibly interesting objects. An efficient and popular approach for object detection and ROI extraction is faster R-CNN. It is suitable for jobs that call for exact localization and identification of objects in an image because of its capacity to develop accurate region recommendations and classify objects inside those regions.
2.3.2 ResNet-101
ResNet is a CNN based on the residual network. To solve the gradient disappearance issues brought on by the depth of the network, it can skip the middle layer and connect the higher layer to the lower layer directly. ResNet versions can be separated into two groups. One is the Basic Block-based shallow network, like ResNet-18 and ResNet-34, while the other is the Bottleneck-based deeper network, like ResNet-50 and ResNet-101. ResNet-101 comprises four major layers with a total depth of 101 and some bottles in each layer. For all three of the mentioned architectures, the input size is 224 × 224, and the first convolution layer (7 × 7, 64 Stride 2) and the final three layers are fixed. As more internal convolution layers are added, the deep network's depth is modified.
Emotional Feature Extraction Using ResLeNet Model:
Emotional feature extraction extracts the features from images using the proposed ResLeNet model that are pertinent to emotions or affective content by combining several approaches or models. The objective is to comprehensively and robustly capture and portray emotional cues or traits using the ResLeNet model that is developed through concatenating the GoogLeNet and ResNet. Emotional feature extraction, as used in image analysis, is the process of extracting emotional information from images by combining several feature extraction models. To facilitate further analysis or classification, these attributes are then employed to indicate the emotional content or characteristics of the images. The ResNet-101 and GoogLeNet architectures are combined in this research's feature extraction process to extract emotional data from images. This method combines the advantages of both models to completely and effectively collect and convey emotional content. Resnet-101 mainly focused on personal emotional state accompanied by the individual unique activities of the emotions. GoogLeNet focuses on the facial recognition and emotional calculation of various scenarios under poor lighting and low-resolution images. Hence, the ResLeNet features are developed through the concatenated features of ResNet-101 and GoogleLeNet to identify the emotions accurately. The dimension of ResLeNet features is
2.4.1 GoogLeNet
GoogleNet's architecture comprises 22 deep CNN layers, although there are only 4 million parameters as opposed to 60 million in AlexNet. In the first three boughs, convolution layers with 1 × 1, 3 × 3, and 5 × 5 kernel sizes are employed. By combining two intermediary branching in the input channels with a window size of 1 × 1, the complexity of the frame can be reduced. All four boughs are properly cushioned such that the inputs and outputs are of the same height and width. After connecting each bough's output, the last inception block is built. There are over 6.8 million factors in it. Each of the nine starting blocks of the GoogLeNet design has six convolutional layers, three levels of 1 × 1, 3 × 3, and 7 × 7 convolutional layers, four layers of maximum pooling, two layers of normalization layers, average pooling, and a fully connected (FC) layer. Rectified linear unit (ReLU), the activation function, is used by all convolutional layers, and drop regularization is used by the FC layer.
2.4.2 Resnet-101
The texture features are acquired using Resnet and the architecture explanation is presented in Section 2.4.2. The features acquired using the proposed ResLeNet are subjected to the feature selection for handling the course of dimensional reduction.
Optimized Feature Selection Using BHO Algorithm
The features extracted using the ResLeNet descriptor are subjected to the feature selection that helps to minimize the curse of the data dimensionality, which further minimizes the computational complexity of the model. The feature selection is supported through the deployment of the BHO algorithm within the ResLeNet. The feature selection relieves the model from redundant features that might cause overfitting, leading to longer training times, and poorer model performance. The BHO-based feature selection helps in searching and evaluating the best relevant features and also maximizes model performance. The dimension of the selected features is denoted as
ALNN-EmR Model: Activational Attention Module-Based Deep CNN for Emotion Recognition
The ALNN-EmR consists of a BHO-deep CNN classifier constructed with one fully connected layer, one max-pooling layer, four fully connected attention modules, and four convolutional layers. The four convolutional layers’ feature maps are 64, 128, 256, and 64, respectively, with filter sizes of 5 × 5,5 × 5, 5 × 5, and 3 × 3. Specifically, a convolutional and attention module is employed after each convolutional layer to utilize the spatial and channel attention techniques. To conserve more information and improve the stability of the network, utilize one max-pooling layer with a filter of 2 × 2 modules after the last convolutional attention. The max-pooling layer's outputs are finally flattened and supplied to the fully linked layer.
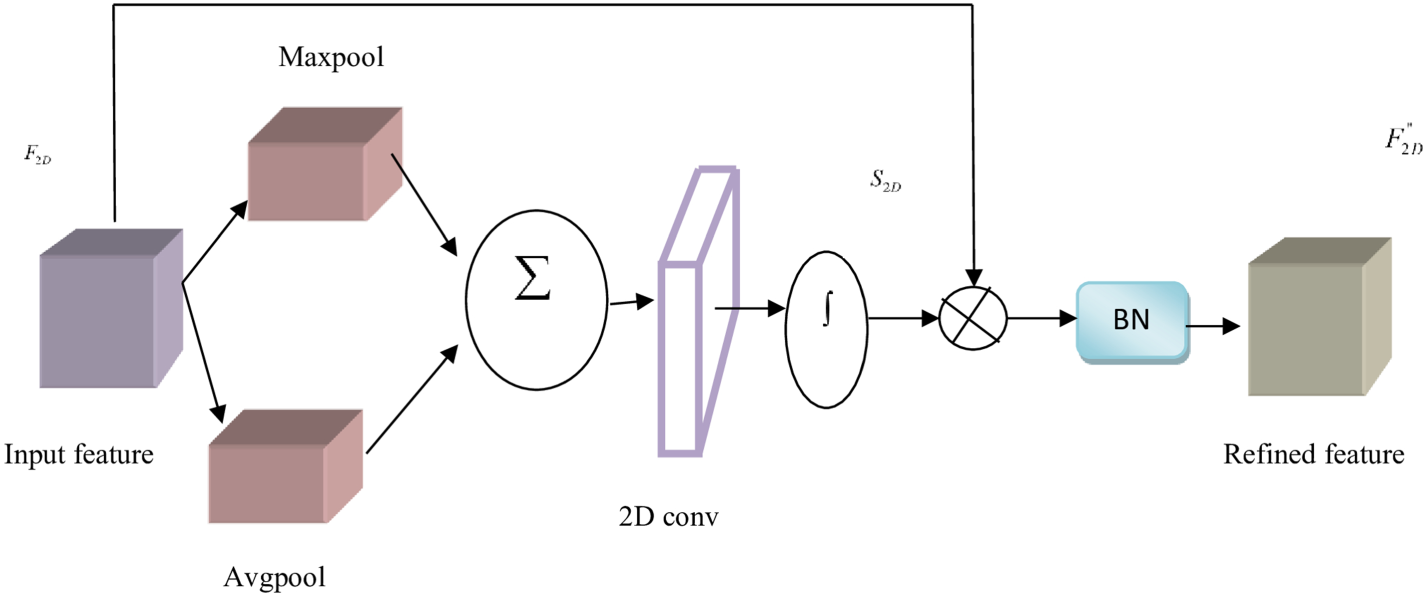
Channel-Level Attention
The channel-level (CL) attention module is used to create the channel-wise attention map from the 2D convolution maps of features. This attention map assists in recalibrating the channel's weights, allowing the model to focus on the useful elements of the input. Two more 2D layers of convolution are included in this module for obtaining channel data from the feature maps particular to each channel. The channel aspects of the input feature map are compressed to efficiently calculate the CLattention. The channel data is kept the same, but the feature map's geographic and temporal dimensions are reduced. The resulting squeezed feature map is then sent through two different 2D convolutional layers to extract spatial and temporal data for each channel. The results from these convolutional layers are used to generate the CL attention map. Figure 2 depicts the CL attention module's organizational structure. The attention map is first obtained using adaptive learning, and the feature map
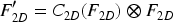
Channel-level attention model.
where
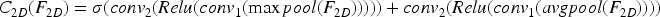
Using the 2D convolution feature map, the spatial-level (SL) attention module creates the spatial-wise attention map. The spatial attention module seeks out valuable spatial regions in feature maps whereas the CL attention module emphasizes educational channels. Spatial attention works in conjunction with channel-level attention to help the model find the informative bits. Figure 3 depicts the SL attention module's organizational structure. The refined feature map
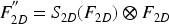
Spatial-level attention module.
where
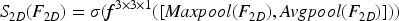
The proposed BHO algorithm is developed by the hybridization of the bald eagle and Harris hawk algorithm that successfully combines the traits of hunting with different chasing styles of the Harris hawk and is merged with the bald eagle search algorithm for improving time complexity and providing faster convergence.
Motivation: The hunting habits of bald eagles served as the inspiration for the development of the new meta-heuristic optimization algorithm known as Leukos (bald eagle). The bald eagle initially chooses a search space for finding the food for which the bald eagle gradually lowers the flying altitude, dives down quickly, and effectively catches the prey. At this attempt, if the bald eagle fails in hunting, the energy of the eagle is wasted massively. For managing the energy distribution, the chasing and hunting traits of hawks is intergrated that promotes the selection of the search space and successful food preying without energy loss. The three stages of the include the search space selection, search, and swooping.
Mathematical model of the proposed bald hawk optimization: The following part discusses the mathematical model for the bald hawk optimization behavior.
(1) Solution representation: The optimization is employed for selecting the best solution. In terms of feature selection, the redundant features are selected and in terms of the classifier training, the hyperparameters of the classifier are selected using the optimization. The solution for feature selection is represented as, (2) Fitness measure: The best solution is declared based on the maximal fitness measure that corresponds to minimal mean square error (MSE). The feature combination and the hyperparameters of the model corresponding to the maximal model accuracy is chosen as the best feature set and best hyperparameters of the model. For performing the solution selection, the solutions undergo updated at the end of each iteration and the following are the three phases of the solution update. (3) Solution update at the end of iteration: The solutions are updated based on the three phases described below. Selecting space phase: The eagle selected the optimum location for search based on the equation represented below.
Searching space phase: During this phase, the eagle moves in different directions inside the previously established spiral area in search of prey. Additionally, mathematics states that the location chosen for the optimum swoop and prey hunt is,
Final phase: The eagle hunts in only one direction, using less energy and taking more time, moving from the best viewing prey position. At this stage, the behavior of the hawk attacking strategies is combined with eagle to decrease time complexity. It used a variety of chasing techniques, including both hard and soft approaches, to capture its prey. The main technique employed by Harris hawks (unicinctus) for capturing prey is the surprise pounce, sometimes known as the seven-kill strategy. This clever tactic involves many hawks working together to simultaneously attack from several angles and converge on a discovered escape rabbit outside the cover. The attack may be quickly finished by killing the unsuspecting prey in a matter of seconds, but occasionally, depending on the prey's evasion skills and habits, the seven kills may involve numerous short, swift dives close to the prey over several minutes. The dynamic nature of the situation and the prey's evasion techniques can influence the Harris hawk's pursuit behavior. A member of the group assumes command of the pursuit when the top hawk (leader) kneels at the target and flees. This is a switching approach. These switching behaviors can be observed in several circumstances because they aid in confusing the escaping rabbit. The main advantage of these combined tactics is that the discovered rabbit will become more susceptible as the Harris’ hawks fatigue from pursuing it. Additionally, the confusion prevents the escaping victim from regaining its defensive capabilities. The fatigued rabbit is finally unable to escape the besieging squad as one of the hawks, usually the most capable and knowledgeable one quickly captures it and distributes it with the other party members. The proposed equation is modeled as
(4) Declare the best solution: Once the solution is defined, the update is repeated for the maximal iteration and the final solution representing the selected features and classifier hyperparameters corresponding to the maximal fitness is declared as the best solution

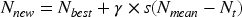
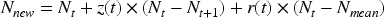
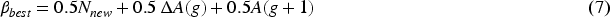
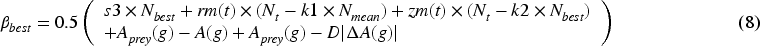
The results of the proposed ALNN-EmR model for emotion recognition are discussed in this section.
Experimental Setup
The experiment is carried out in Python on Windows 10 with 8 GB of RAM, and the implementation is assessed using the AFEW-VA and RAVDESS datasets.
Experimental Results
Figure 4 displays the experimental outcomes from the ALNN-EmR model. Separate interpretations are also given to the original image, preprocessing image, ROI image, Resnet-101 image, and output image.

Experimental results of ALNN-EmR model: (a) sample input, (b) preprocessed output, (c) region extraction output, (d) Resnet-101 output, and (e) emotion recognition.
The performance evaluation of the ALNN-EmR model and a detailed analysis of classifier performance at various epochs of 50, 100, 150, and 200 are shown in the section below.
Performance Analysis for AFEW-Va Dataset
Figure 5 displays the evaluation of the ALNN-EmR performance at several epochs, including 50, 100, 150, and 200. When the accuracy of the methods is first tested, the ALNN-EmR in Figure 5a) reaches the values of 93.05%, 93.20%, 93.83%, 93.97%, and 94.37%. Similar to the previous assessment, the sensitivity of the ALNN-EmR is determined, and it produced values of 94.72%, 94.80%, 95.13%, 95.21%, and 95.42% for the TP 90 shown in figure 5b). The specificity ALNN-EmR model is 87.13%, 89.45%, 91.49%, 93.53%, and 94.23% for the TP of 90 shown in Figure 5c.
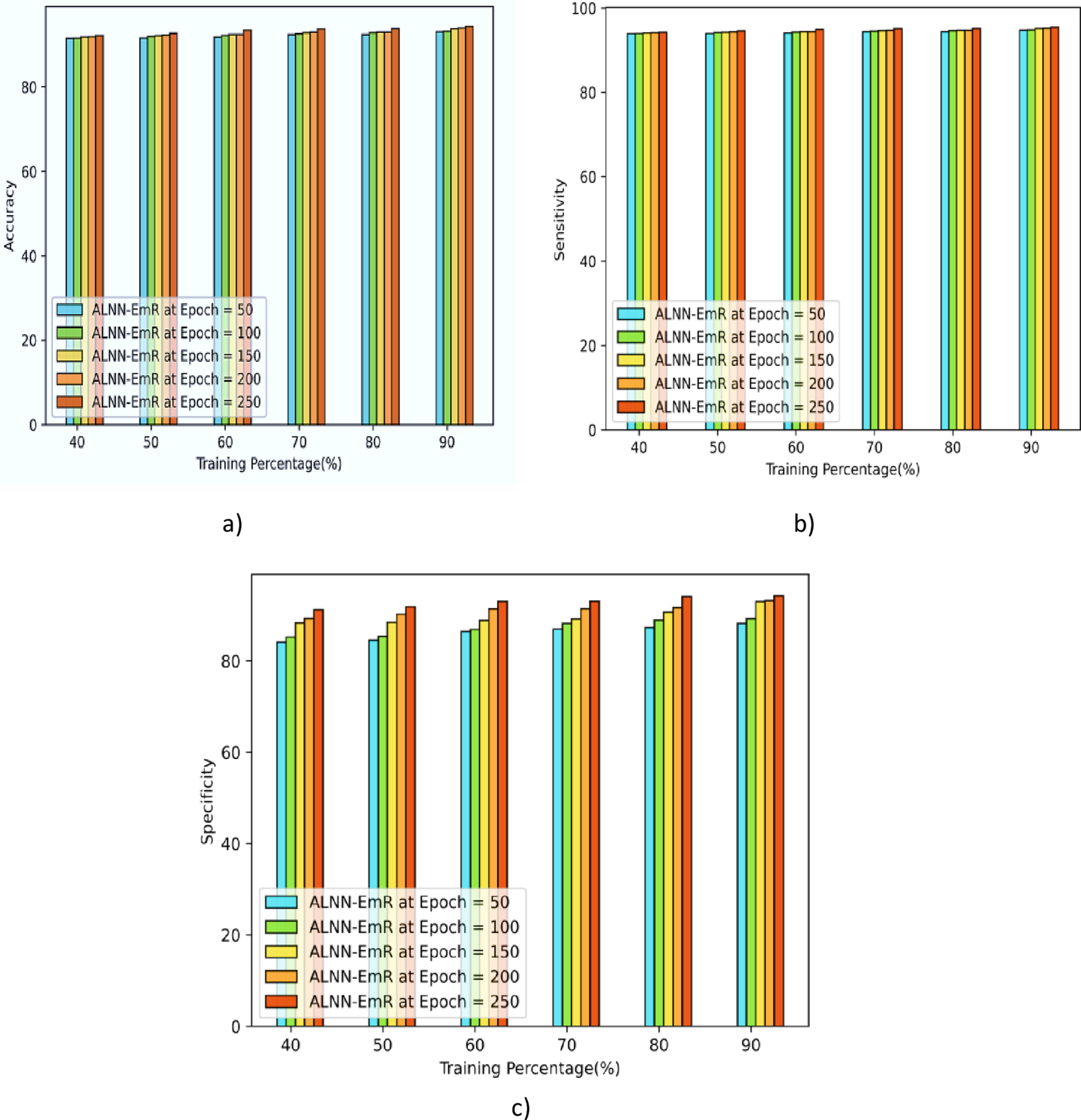
Analysis for dataset-1 with TP: (a) accuracy, (b) sensitivity, and (c) specificity.
Figure 6 displays the ALNN-EmR model performance evaluation for multiple epochs, including 50, 100, 150, and 200. When the accuracy of the methods is first tested, the ALNN-EmR in Figure 6(a) reaches the values of 91.44%, 92.08%, 92.13%, 94.13%, and 94.62%. Similar to this, the sensitivity of the ALNN-EmR is evaluated, and it produces values of 92.66%, 93.00%, 93.03%, 94.08%, and 94.33% for the TP 90 shown in Figure 6(b). The specificity of ALNN-EmR is 84.67%, 89.83%, 90.23%, 91.39%, and 92.32% for the TP of 90 shown in Figure 6c.
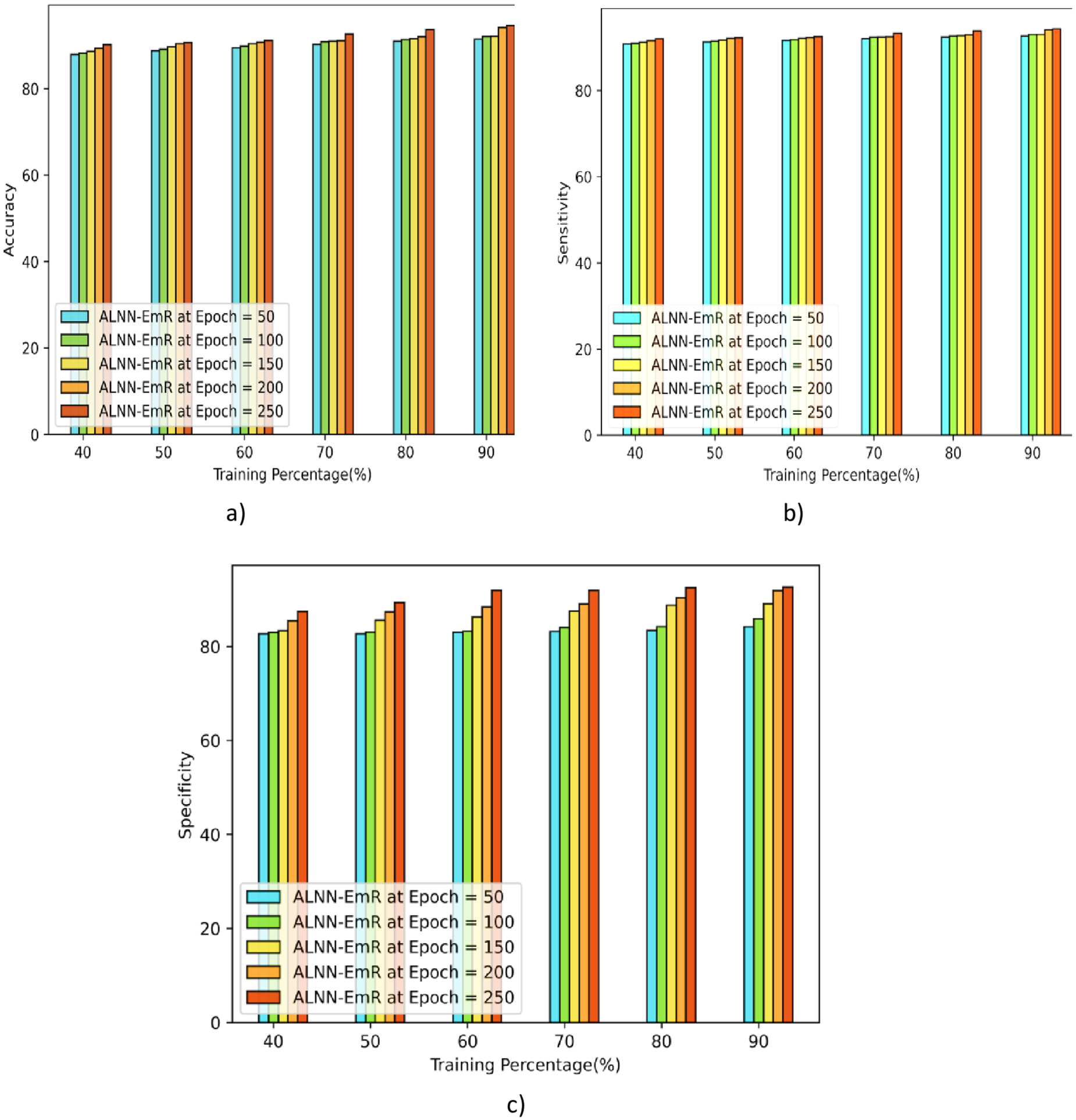
Analysis for dataset-2 with TP: (a) accuracy, (b) sensitivity, and (c) specificity.
K-nearest neighbor (KNN) classifier (Li et al., 2018), decision tree (DT) classifier (Lee et al., 2011), random forest (RF) classifier (Pu et al., 2015), deep-RNN (DRNN) classifier (Rajesh and Nalini, 2020), bald eagle-based deep-CNN (BDNN) (Alsubai et al., 2022), and Harris hawks-based deep-CNN (H2NN) (Ali et al., 2022) are implemented, and the results are compared with proposed ALNN-EmR model.
Comparative Analysis for AFEW-VA Dataset
Figure 7 illustrates the contrasting analysis for the AFEW-VA dataset of the proposed ALNN-EmR. Figure 8(a) measures and displays the accuracy at 90% training, the suggested ALNN-EmR improved by 5.11 over H2NN. Additionally, the sensitivity of the ALNN-EmR improved by 2.88 over H2NN, and the analysis is shown in Figure 7(b)). The ALNN-EmR improved by 0.46 over H2NN at 90%, as seen in Figure 7(c), when the improvement in specificity was finally evaluated. The analysis demonstrates that the ALNN-EmR outperforms the existing approaches.
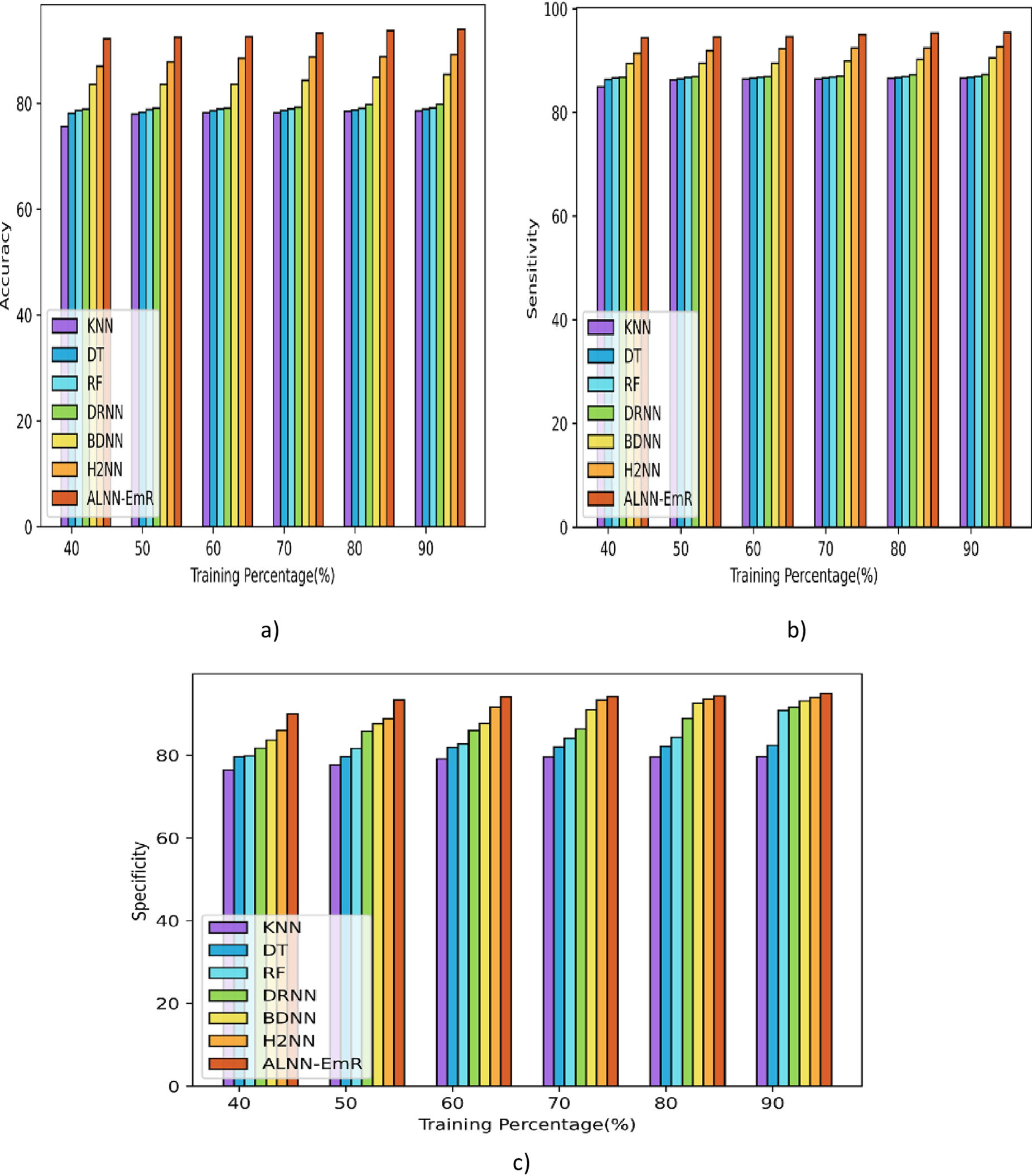
Comparison of ALNN-EmR model using dataset-1: (a) accuracy, (b) sensitivity, and (c) specificity.
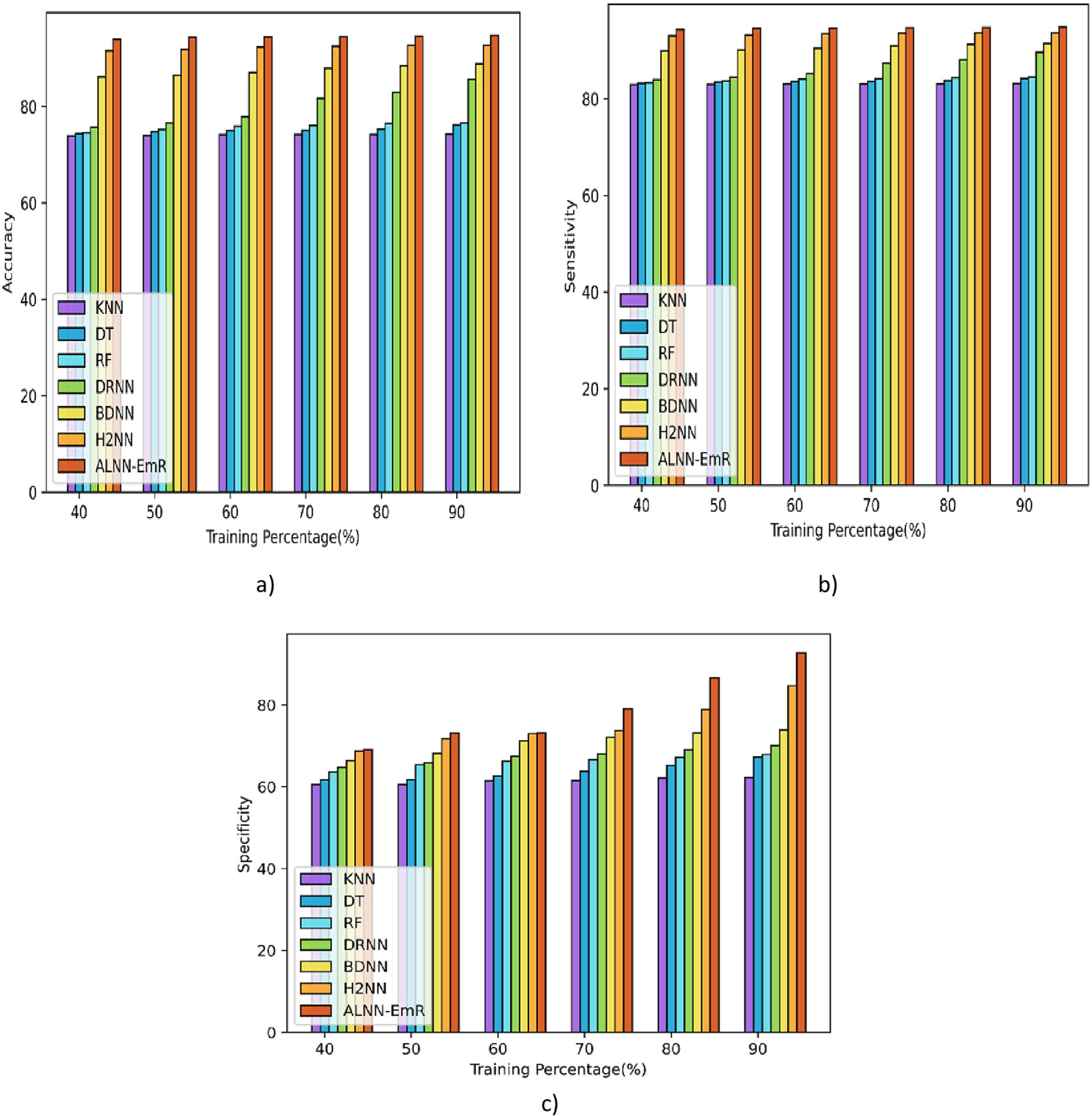
Comparison of ALNN-EmR model using dataset-2: (a) accuracy, (b) sensitivity, and (c) specificity.
Figure 8 illustrates the contrasting analysis for the RAVDESS dataset of the proposed ALNN-EmR. Figure 8(a) measures and displays the accuracy at 90% training, the suggested ALNN-EmR improved by 2.17 over H2NN. Additionally, the sensitivity of the ALNN-EmR improved by 1.24 over H2NN, and the analysis is shown in Figure 8(b). The ALNN-EmR improved by 8.67 over H2NN at 90%, as seen in Figure 8(c), when the improvement in specificity was finally evaluated.
Validation Results
The validation results of the ALNN-Emotional recognition model at 90% of training are demonstrated below. The results of validation accuracy and the loss function are analyzed with the maximum number of epochs as 250, the accuracy rate is found to be 0.97 and the loss function value is obtained as 0.0059 which is explained in Figure 9.
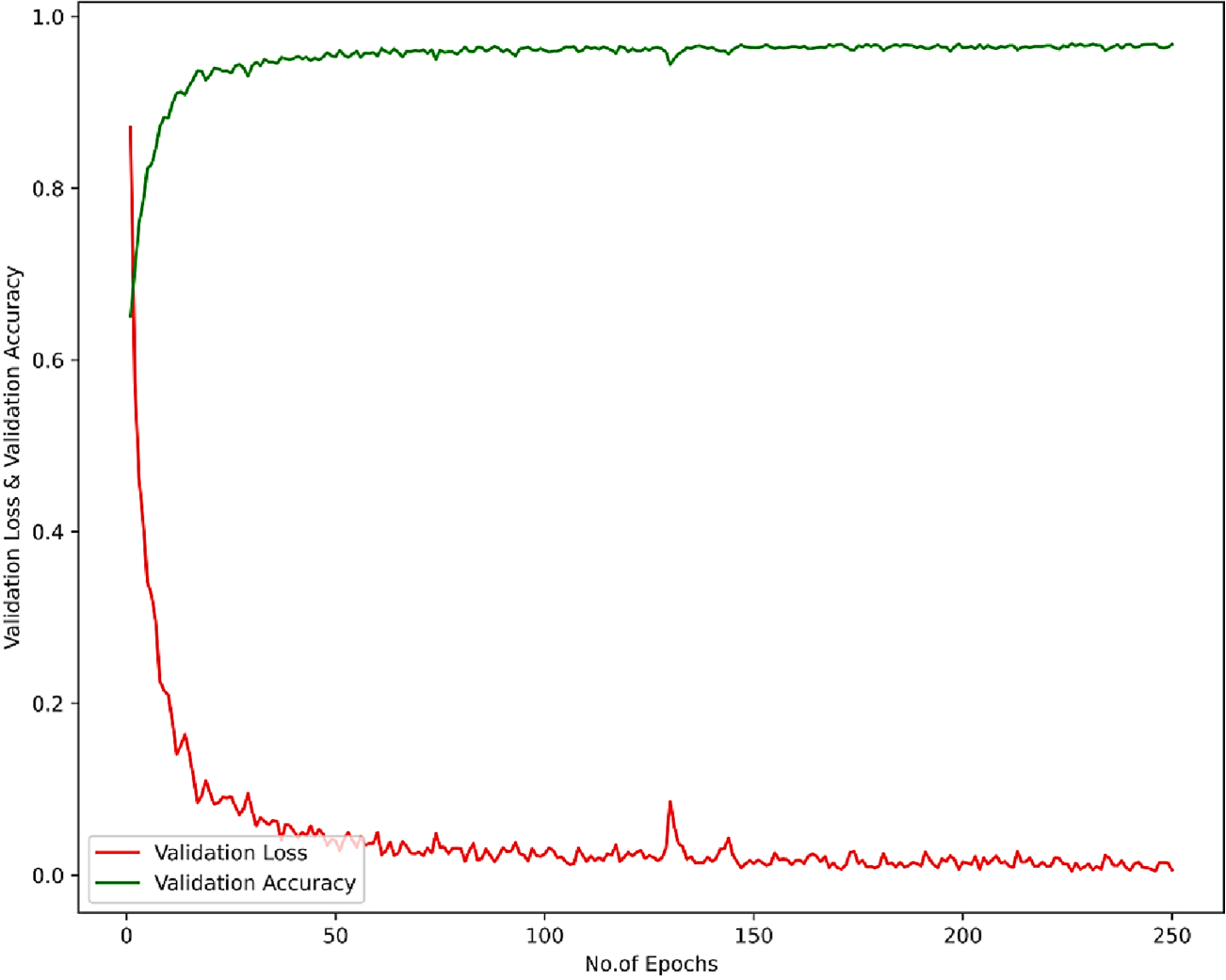
Validation accuracy.
The ablation study manages the performance of the ALNN-EmR model with respect to the feature extraction methods, ResLeNet with existing ResNet-101 and GoogleNet. The accuracy of the ALNN-EmR model using the Resnet feature is 89.35% and the GoogLeNet feature is 92.43%, while using the hybrid emotional features from ResLeNet is 94.00%. The Ablation study proves that the performance of the developed ALNN-EmR model with ResLeNet features attained a higher value of accuracy, which is given in Figure 10.
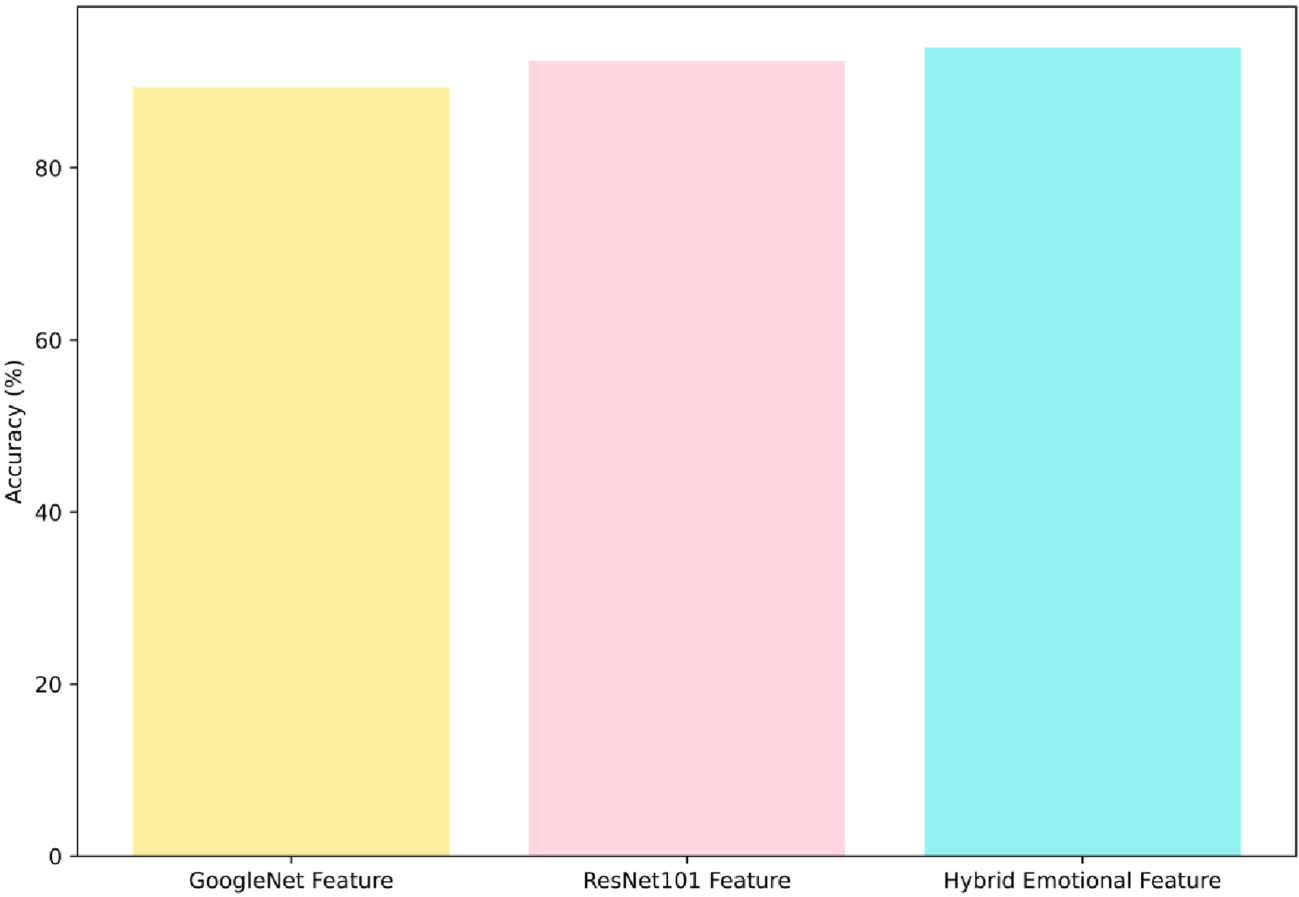
Ablation study of ALNN-EmR model.
Table 1 compares the proposed ALNN-EmR for the emotion recognition model with existing models at 90% of training. The importance of the research relies on the activation layer and coupled attention layer in deep CNN for refining the features for extracting the emotional features from the face and ensuring improved recognition accuracy. When compared to other existing methods the proposed method attains better performance. In the KNN Classifier analysis with the AFEW-VA dataset, the accuracy attained is 78.59%, the sensitivity is 86.61%, and the specificity is 81.68% whereas in the RAVDESS dataset, the classifier attains the accuracy is 74.31%, the sensitivity as 83.18% and specificity as 65.21%. DT classifier analysis with the AFEW-VA dataset the accuracy attains as 78.86%, sensitivity as 86.77%, and specificity is 87.65% whereas in the RAVDESS dataset, the classifier attains the accuracy of 76.18%, sensitivity of 84.25%, and specificity as 67.60%. In RF classifier analysis with the AFEW-VA dataset, the accuracy attains 79.09%, a sensitivity of 86.90%, and a specificity of 87.65% whereas in the RAVDESS dataset, the classifier attains an accuracy of 76.63%, a sensitivity of 84.51% and specificity as 69.50%. DRNN Classifier analysis with the AFEW-VA dataset the accuracy attains as 79.83%, sensitivity as 87.32%, and specificity of 91.17% whereas in the RAVDESS dataset, the classifier attains the accuracy of 85.65%, sensitivity of 89.66% and specificity as 70.89%. In the BDNN classifier analysis with the AFEW-VA dataset, the accuracy attained was 85.47%, the sensitivity was 90.54%, and the specificity was 92.29% whereas in the RAVDESS dataset, the classifier attained the accuracy of 88.87%, the sensitivity was 91.50% and specificity as 74.36%.In the H2NN classifier analysis with the AFEW-VA `dataset, the accuracy attained is 89.21%, the sensitivity is 92.68%, and the specificity is 94.03% whereas in the RAVDESS dataset, the classifier attains the accuracy of 92.72%, sensitivity as 93.70% and specificity as 84.67%, but the proposed ALNN-EMR model is analyzed with the AFEW-VA dataset which attains an accuracy of 94.01%, a sensitivity of 95.43%, and a specificity of 94.47% also in the RAVDESS dataset an accuracy of 94.78%, a sensitivity of 94.88%, and specificity as 92.72%. By this, the proposed method produced better performance when compared with other existing methods.
Comparative Discussion of the ALNN-EmR Model.
Comparative Discussion of the ALNN-EmR Model.
In the KNN classifier, the data is trained without any training period so any data can be added at any time for processing also very efficient and easy to implement but it is complex for large datasets, and the error rate is increased. RF classifier requires more time for data training. In the DT classifier, the data is processed with versatility and interpretability, but overfitting problems occur. Deep RNN classifier requires high computational cost, which suffers from overfitting problems based on data quality. In the BDNN classifier, the computational requirements are high, and for larger networks, the complexity problem occurs. These problems are overcome by the proposed ALNN-EmR method with BHO-deep CNN classifier to accurately identify the emotions, which provides more information about the data and generates accurate results.
The major limitations of the research remained in considering separate descriptors for extracting the features from speech and video input for emotion recognition, which is said to further promote the recognition accuracy of the ALNN-EmR model.
In this research, an ALNN-EmR model is developed using the BHO-deep CNN classifier for classifying emotions. In the beginning, data is gathered, and preprocessing is done to improve the image's quality for more accurate emotion recognition. The region of extraction is then carried out using faster R-CNN hybridization and the standard ResNet-101. Then, the ResLeNet model designed using the standard combination of the ResNet-101 and GoogLeNet model is used for feature extraction. Once the features have been collected, the ALNN-EmR model with an optimized attention module is used to quickly categorize the emotions. The ALNN-EmR attained 94.01%, 95.43%, and 94.47% for accuracy, sensitivity, and specificity using dataset-1 and 94.78%, 94.88%, and 92.72% for accuracy, sensitivity, and specificity using dataset-2, which is more efficient than other techniques. In future, the accuracy of this approach can be considerably increased by extending the model with multimodal input and advanced hybrid classifiers.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.