
Abstract
Pretrained transformer models have demonstrated excellent performance on complex tasks. To improve their inference efficiency, recent studies have introduced the multi-exit mechanism, which enables early exiting through multiple intermediate classifiers. However, the deep architectures of pretrained transformers cause severe gradient conflicts during multi-exit fine-tuning, leading to degraded shallow-exit accuracy and reduced early-exit efficiency. To address this issue, we propose Separate Reverse, a multi-exit training strategy specifically designed for pretrained transformer models. The method iteratively integrates reverse iterative optimization and hierarchical knowledge distillation from deeper to shallower exits, maintaining pretrained parameter integrity, enhances the representation capacity of shallow exits, and coordinates gradient updates across exits to achieve a balanced optimization between shallow and deep classifiers. Experiments on multiple GLUE benchmark datasets using BERT demonstrate that our method significantly improves shallow-exit accuracy, maintains main-exit performance, and accelerates inference for simple samples by a large margin.
Introduction
In recent years, pretrained transformer-based models have achieved remarkable breakthroughs in natural language processing, computer vision, and multimodal tasks (Cambria & White, 2014; Chen et al., 2024; Treviso et al., 2023). Owing to their powerful contextual modeling capabilities and scalability, transformer models have become core components of many intelligent systems (de Barcelos Silva et al., 2020; Xu et al., 2023). However, deploying these deep models in complex scenarios still faces significant challenges, including high computational cost and inference latency, which are particularly pronounced in industrial vision and monitoring tasks with strict real-time requirements (Aghajanyan et al., 2023; Yi et al., 2025). Therefore, reducing computational overhead while maintaining model performance has become a critical research direction in model optimization.
Recent studies show that input samples differ greatly in task difficulty, leading complex samples to demand more computation and simple ones to incur redundant inference (Laskaridis et al., 2021; Rahmath et al., 2024). To address this issue, the multi-exit mechanism introduces exit classifiers at different depths of the model, constructing a multi-exit transformer architecture that enables dynamic inference depending on the complexity of each sample (Schuster et al., 2022). As illustrated in Figure 1, a sample can exit early when the output confidence exceeds a predefined threshold, avoiding computation in subsequent layers. By adjusting the confidence threshold (a predefined value indicating sufficient prediction reliability for early exiting), computation can be dynamically controlled while maintaining accuracy, allowing adaptation to devices with varying computational capabilities without retraining. In this work, we investigate multi-exit transformer models for efficient inference optimization. This mechanism (Chen et al., 2023; Xin et al., 2020; Xu et al., 2025) significantly improves inference efficiency while maintaining overall performance.
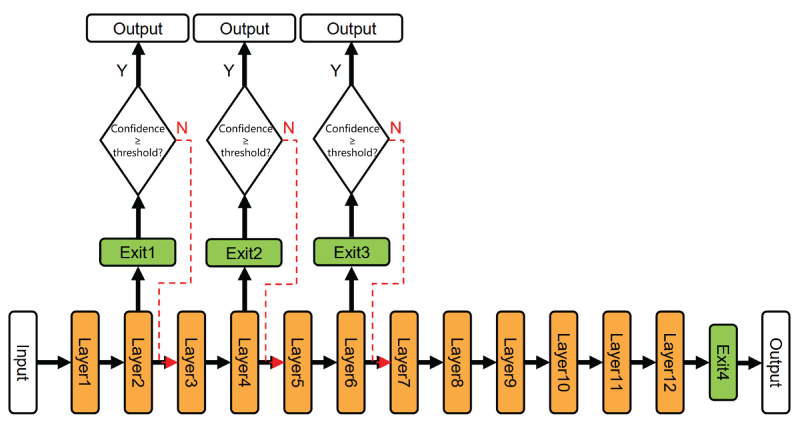
Multi-exit model inference.
However, applying multi-exit mechanisms to pretrained transformer models presents several challenges. First, since multiple exits share the same backbone network, the gradients from different exits are often inconsistent, leading to gradient conflicts that degrade shallow-exit performance and weaken the acceleration benefit of early exiting. Second, unlike conventional neural networks, transformer parameters exhibit strong structural consistency and semantic coherence derived from large-scale pretraining. Existing multi-exit training strategies for general networks (e.g., branch-wise, Huang et al., 2017, and separate, Lattanzi et al., 2023) can alleviate gradient conflicts but may disrupt this parameter coherence, causing shifts in intermediate feature distributions and a decline in overall model accuracy. To address this, many existing multi-exit transformer studies adopt a two-stage training strategy (Xin et al., 2020, 2021): first fine-tuning the backbone model, then freezing the backbone parameters and training only the exit classifiers. Although this approach avoids gradient conflicts, shallow exits—typically composed of a pooling and a linear layer—lack sufficient discriminative capacity. Moreover, the backbone layers of transformers are optimized to extract deep semantic representations to support the final classifier rather than serve intermediate exits, which further limits shallow exit performance (Ji et al., 2023).
In summary, while two-stage and separate strategies partially alleviate gradient conflicts, they fail to balance parameter integrity and exit capacity. Building upon these insights, we propose Separate Reverse, a multi-exit training strategy specifically designed for pretrained transformer models. The method maintains parameter integrity, enhances the representation capacity of shallow exits, and coordinates gradient updates across multiple exits to achieve balanced optimization between shallow and deep layers. Inspired by the two-stage and separate paradigms, Separate Reverse employs a reverse iterative training process from deep to shallow layers, where pretrained parameters are first fine-tuned as a whole and the branch exits are subsequently initialized and trained according to predefined exit positions (i.e., the transformer layers at which intermediate exit classifiers are placed). In each iteration, the previously trained model serves as a teacher, and hierarchical knowledge distillation is applied to mitigate gradient conflicts and catastrophic forgetting, thereby ensuring shallow exit performance while preserving the accuracy of the main exit. Experimental results demonstrate that this strategy significantly improves shallow exit accuracy, maintains main-exit stability, and accelerates inference on simple samples.
This paper makes the following key contributions:
We identify the limitations of existing multi-exit training strategies for pretrained transformer models, particularly their inability to preserve pretrained parameters and maintain balanced performance across exits. We develop Separate Reverse, a new multi-exit training strategy that enhances shallow exit capacity while coordinating optimization between exits through hierarchical knowledge distillation to alleviate gradient conflicts and catastrophic forgetting. We implement and evaluate our approach on transformer-based models, demonstrating significant improvements in shallow exit accuracy, stable main exit performance, and substantial inference speedup under various confidence thresholds.
Recent studies on transformer inference optimization can be broadly categorized into model compression and architectural optimization. The former focuses on reducing model size and computation cost, while the latter modifies network structures to achieve adaptive computation.
Model Compression
Model compression aims to accelerate inference by reducing parameters and computation. Two mainstream approaches are parameter pruning and knowledge distillation.
Pruning removes redundant or less important parameters to create sparse transformer models. Liu et al. (2022) show that pruning overparameterized models often outperforms training small models from scratch. For example, oBERT (Kurtic et al., 2022) applies second-order information to guide nonstructured pruning, which theoretically preserves accuracy with reduced computation (Liao et al., 2020). However, hardware inefficiency limits the speedup from unstructured pruning, driving research toward structured pruning, where parameters are removed in a layer- or head-wise manner. Michel et al. (2019) analyze the impact of removing entire attention heads on model accuracy.
Knowledge distillation, on the other hand, transfers knowledge from a large teacher to a smaller student model (Gou et al., 2021). DynaBERT (Hou et al., 2020) performs layer-wise distillation to derive flexible subnetworks, while Liu et al. (2022) align teacher–student representations across multiple semantic levels for richer supervision. However, these methods still compute all layers for every input and cannot dynamically adapt to varying computational budgets without retraining, leading to redundant computation across diverse devices.
Multi-Exit Mechanism
Architectural optimization focuses on enabling early exiting to adaptively reduce computation. Although deeper transformers extract richer features, many samples can be correctly classified with shallow representations (Rahmath et al., 2024). Multi-exit transformers (Xin et al., 2020) add lightweight classifiers after intermediate feed-forward network (FFN) layers, allowing early termination for simple inputs (Gao et al., 2023).
Schuster et al. (2022) design adaptive exit confidence criteria to mitigate accuracy loss from early termination, while Tang et al. (2023) exploit feature saturation to decouple encoder–decoder computation for further efficiency. Bajpai and Hanawal (2024) propose an online learning method to determine exit points dynamically, and BADGE (Zhu et al., 2023) introduces a block-wise bypass mechanism comparing consecutive exit predictions. FastBERT (Liu et al., 2020) further integrates self-distillation to balance accuracy and latency through adaptive inference delay.
Such models enable flexible tradeoffs between accuracy and efficiency by adjusting exit thresholds (Rahmath et al., 2024). However, gradient conflicts arise during fine-tuning—parameters are jointly optimized under multiple exit losses with inconsistent directions, degrading shallow classifier performance and diminishing the expected acceleration. Moreover, when few samples exit early, the overhead of shallow classifiers leads to redundant computation. Existing works rarely address these gradient conflicts, limiting the optimization potential of multi-exit transformers.
Challenges of Multi-Exit Transformers
In this section, we first describe the gradient conflict problem in multi-exit transformer models and analyze its impact on the accuracy of different exits. We then summarize existing training strategies and discuss their limitations in pretrained transformer models, which motivates the method proposed in the next section.
Execution Mechanism and Gradient Conflicts of Multi-Exit Transformers
The architecture of multi-exit transformer, as illustrated in Figure 2, consists of a backbone transformer network and several branch classifiers. The backbone includes an embedding layer and

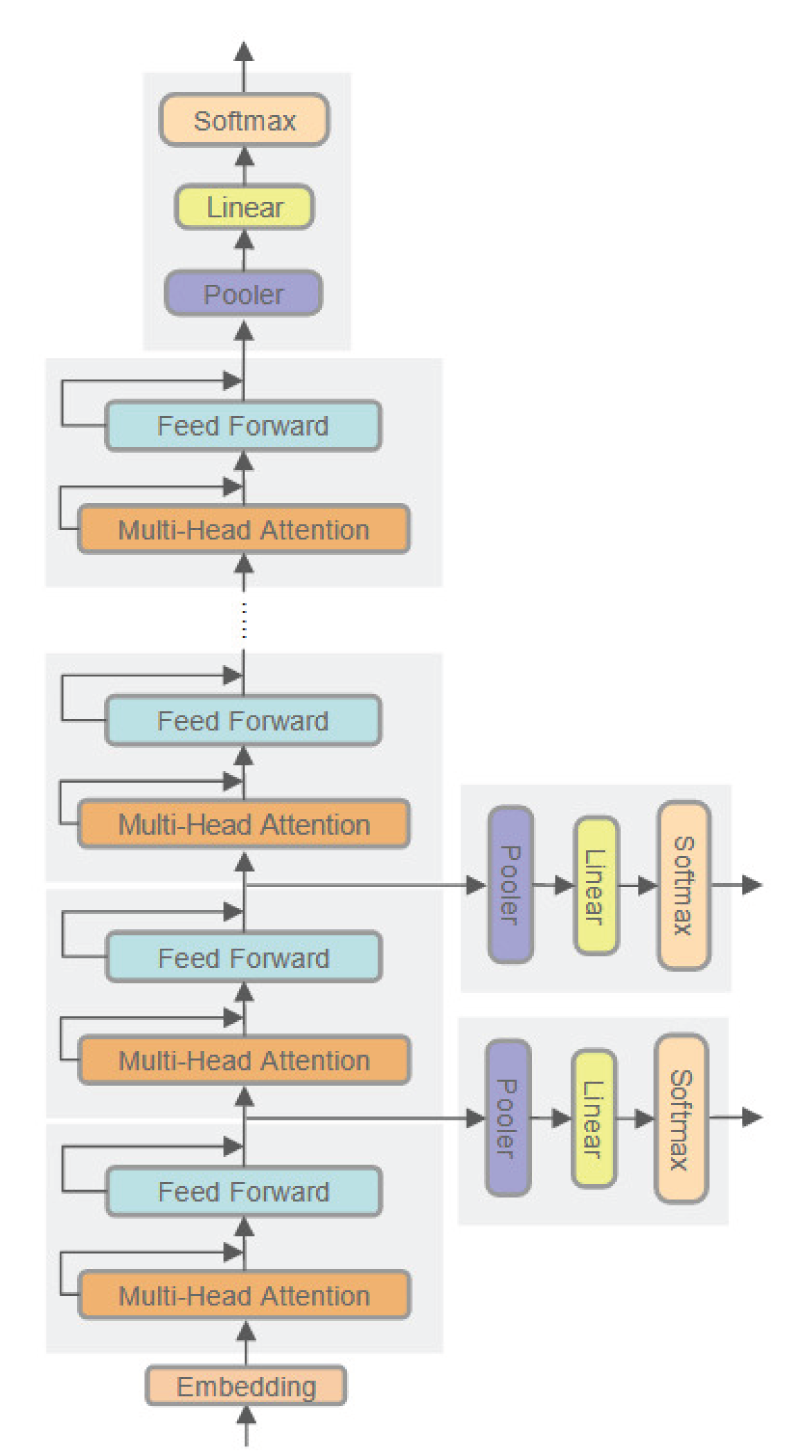
Architecture of the multi-exit transformer.
Each branch module performs early classification through a pooling layer, a linear layer, and a softmax layer, forming multiple exit classifiers. The final output layer of the transformer is treated as the main exit. Assuming there are

For classification tasks, following prior multi-exit studies, the exit confidence is defined as the maximum logit value of the softmax output. The inference follows a confidence-based rule:



However, this joint training strategy causes the shallow layers of the model to receive gradient signals from multiple exit classifiers. Since the gradient directions of different exits are not always consistent, this may lead to suboptimal optimization.
To verify this hypothesis, we constructed a multi-exit BERT (Devlin et al., 2019) by adding three intermediate exit classifiers at the second, fourth, and sixth layers of the original BERT model, as shown in Figure 2. Using the recognizing textual entailment (RTE) dataset from the GLUE benchmark (Wang et al., 2018), we trained the model jointly with a batch size of 8 and a learning rate of
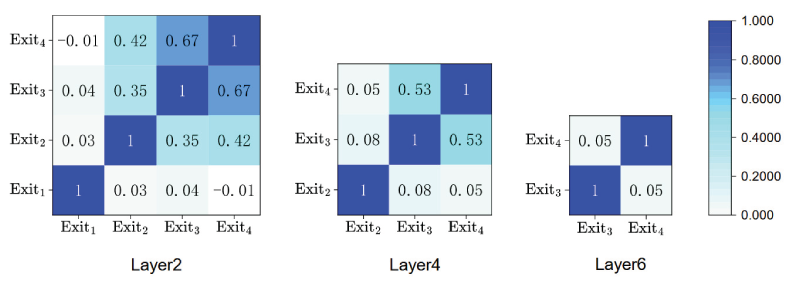
Cosine similarity between gradients of different exit classifiers.
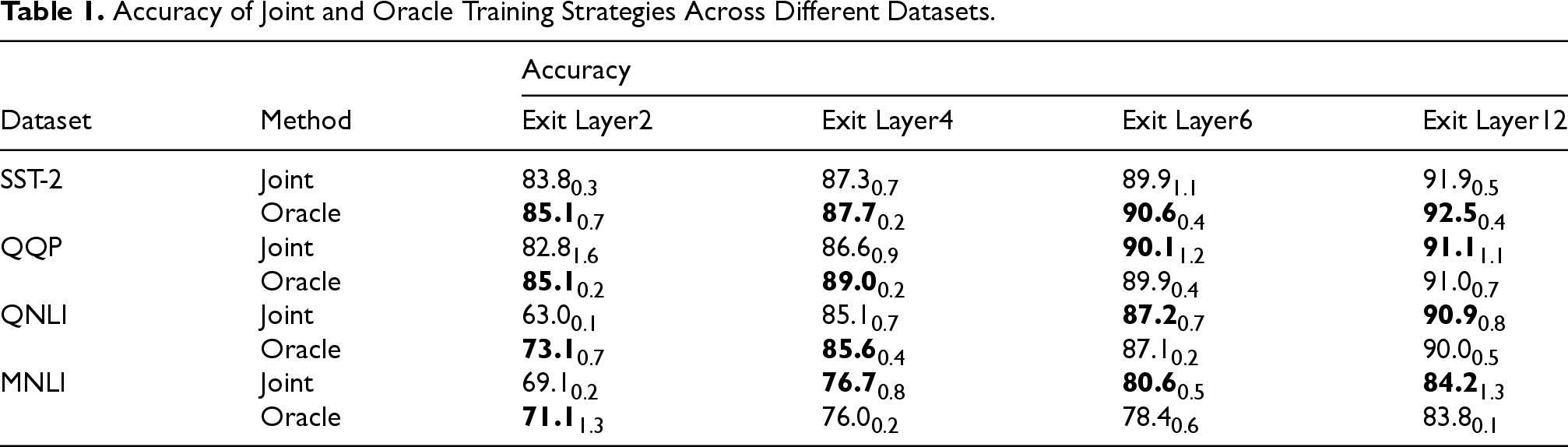
The results indicate that the gradient directions between shallow and deeper exits are largely inconsistent, with average cosine similarities approaching zero. To examine the impact of these gradient conflicts on model accuracy, we compared the joint training strategy with an Oracle training strategy on several GLUE datasets. The Oracle strategy trains truncated BERT models independently with 2, 4, 6, and 12 layers, avoiding gradient conflicts while preserving the full representational capacity of each exit. As shown in Table 1, the Oracle strategy consistently outperforms joint training at shallow exits across all datasets, with the accuracy gap reaching up to 16.0% on QNLI. These results demonstrate that gradient conflicts in joint training significantly degrade the performance of early exits.
Accuracy of Joint and Oracle Training Strategies Across Different Datasets.
To improve exit performance, several gradient-conflict-free training strategies have been proposed, as shown in Figure 4. Branch-wise (Huang et al., 2017) trains each exit sequentially from shallow to deep, freezing parameters shared with previous branches and updating only branch-specific parameters and the classifier. Separate (Lattanzi et al., 2023) is similar but does not freeze shared parameters, treating each exit as an independent submodel. While these methods are effective for training conventional deep networks from scratch, they disrupt the coordination among pretrained parameters in transformer-based models, altering intermediate feature distributions and fragmenting pretrained knowledge.
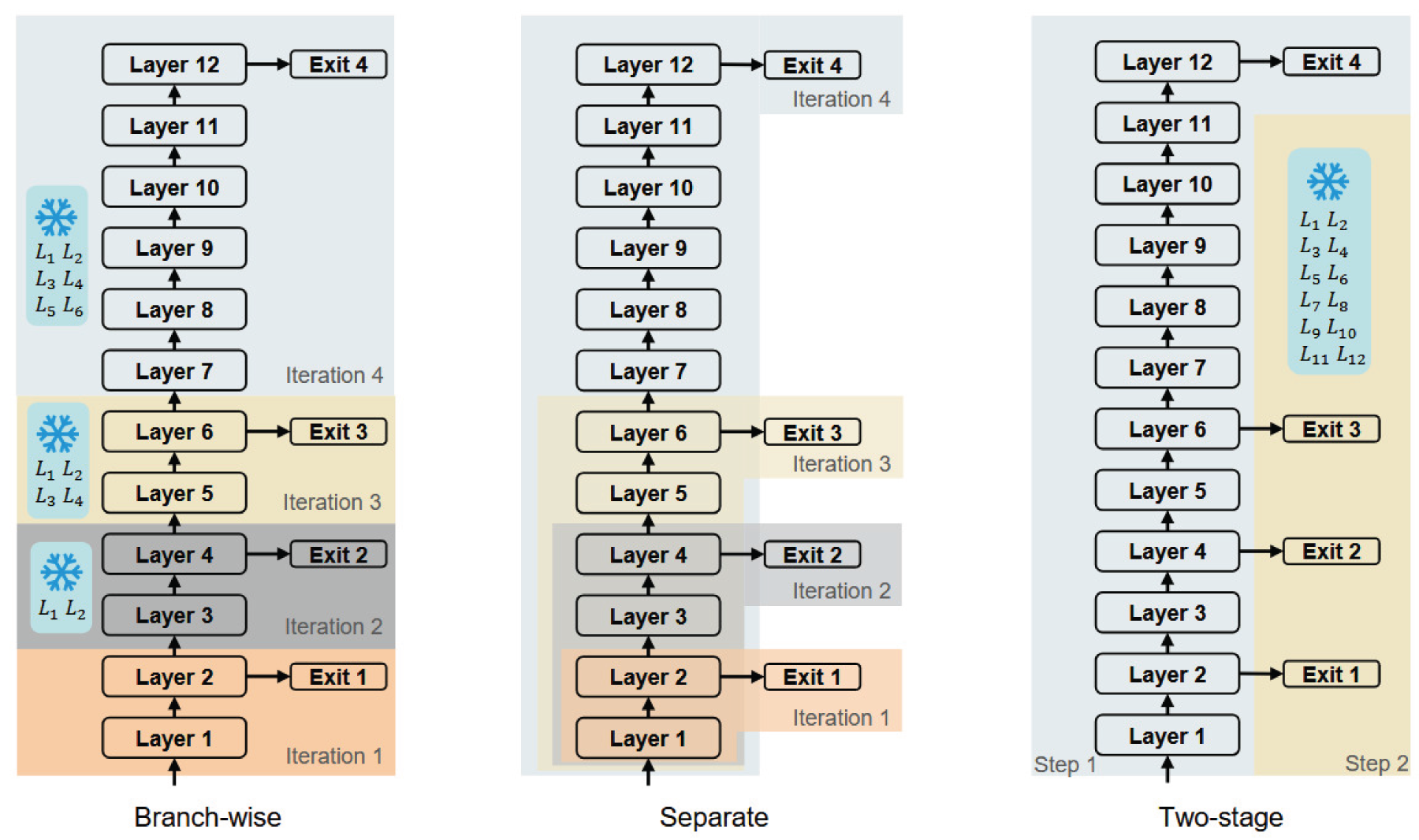
Multi-exit training strategies.
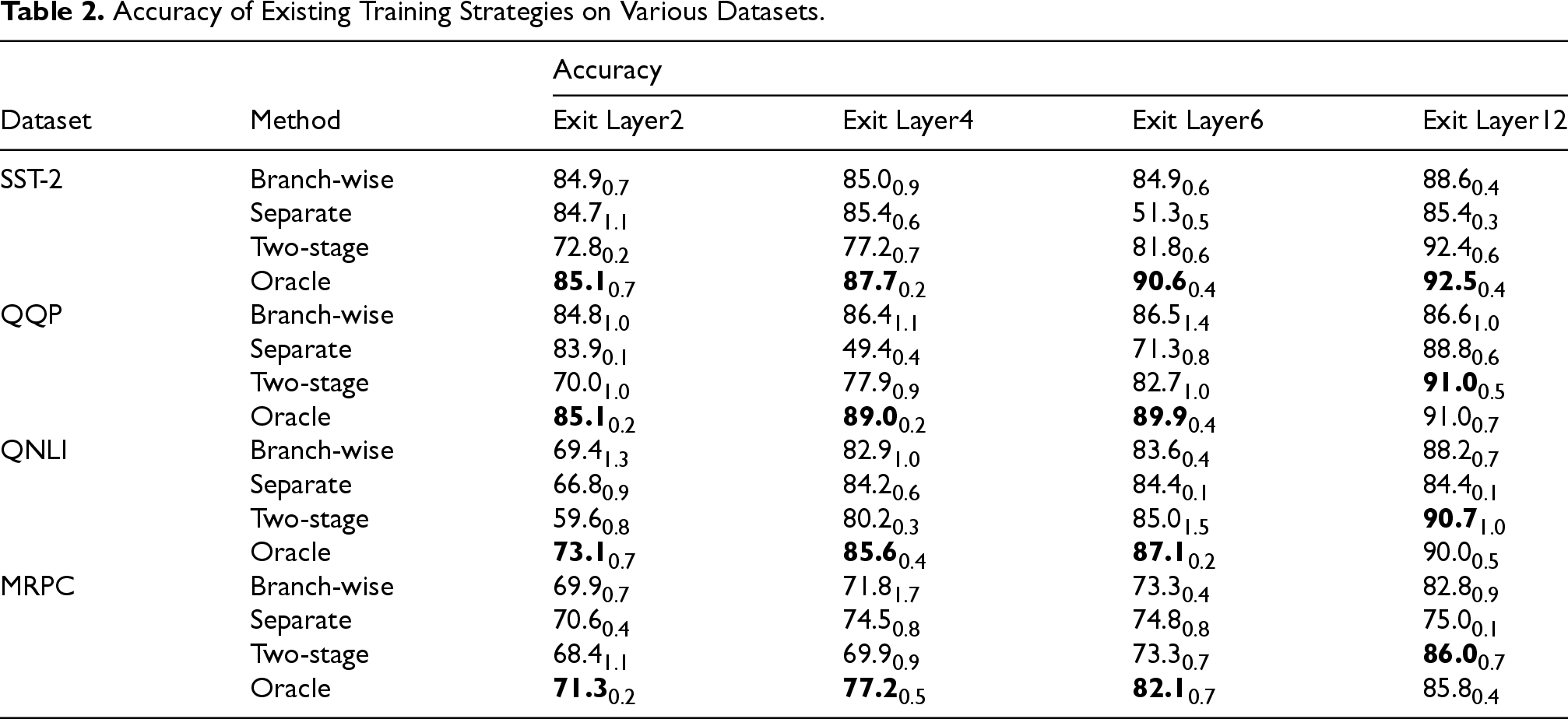
Experimental results in Table 2 show that branch-wise achieves near-Oracle performance at the shallowest exit, as the input embeddings maintain their original distribution. However, it suffers substantial accuracy degradation in deeper exits, with minimal improvement as model depth increases; for SST-2 and QQP, accuracy plateaus between exit layers 4 and 6. Separate shows similar trends and suffers from catastrophic forgetting: for SST-2, the sixth exit reaches
Accuracy of Existing Training Strategies on Various Datasets.
Two-stage training (Xin et al., 2020, 2021) splits the process into two steps: first, the backbone transformer model is trained using pretrained parameters; then, intermediate exits are added, the backbone and original classifier are frozen, and only the new exits are trained. This approach effectively avoids gradient conflicts while leveraging pretrained knowledge and is widely adopted in multi-exit pretrained transformer architectures. However, as the exit modules in transformers typically consist of only a pooler and a linear layer, the shallow exits have limited representational capacity, resulting in accuracies lower than Oracle and sometimes even below Separate, as shown in Table 2.
The key challenge addressed in this work is how to train multi-exit transformer models without gradient conflicts, while maintaining pretrained parameter integrity and ensuring sufficient capacity in shallow exit classifiers.
To address gradient conflicts, this section proposes a multi-exit training strategy for pretrained transformer models, integrating the advantages of the two-stage and separate strategies. The training proceeds iteratively: the base model is first fine-tuned to preserve pretrained parameters, after which exit classifiers are initialized and trained from deep to shallow at predefined layers. In this paper, an exit refers to a lightweight classifier attached to an intermediate layer, and the terms “exit” and “exit classifier” are used interchangeably. During each stage, the model from the previous iteration serves as a teacher, and layer-wise knowledge distillation guides updates to mitigate catastrophic forgetting. Unlike conventional separate training from shallow to deep, our method reverses the order and is thus termed Separate Reverse.
Model Fine-Tuning and Exit Configuration
To maintain parameter integrity, this section first fine-tunes the original pretrained transformer models, similar to the two-stage strategy, ensuring optimal performance at the main exit. The main exit output is defined as:


After fine-tuning, multiple exit classifiers are inserted into intermediate layers, transforming the model into a multi-exit transformer structure. Each exit shares the same architecture as the main classifier, consisting of a pooling layer followed by a linear projection. In this work, three shallow exits are added at layers 2, 4, and 6, as illustrated in Figure 1.
To ensure the performance of intermediate transformer classifiers, we follow a separate training strategy, jointly training each classifier with its corresponding model layers while keeping the embedding layer frozen, as shown in Figure 5. Independent training ensures that gradients only affect the relevant layers, allowing shallow layers to focus on feature extraction without interference from multiple gradients. Compared to the two-stage strategy that trains only classifier parameters, this approach better enhances the capacity of shallow exits. However, separate training suffers from catastrophic forgetting, and after training the main exit, further training of intermediate exits can overwrite shallow layers, degrading the main exit’s accuracy.
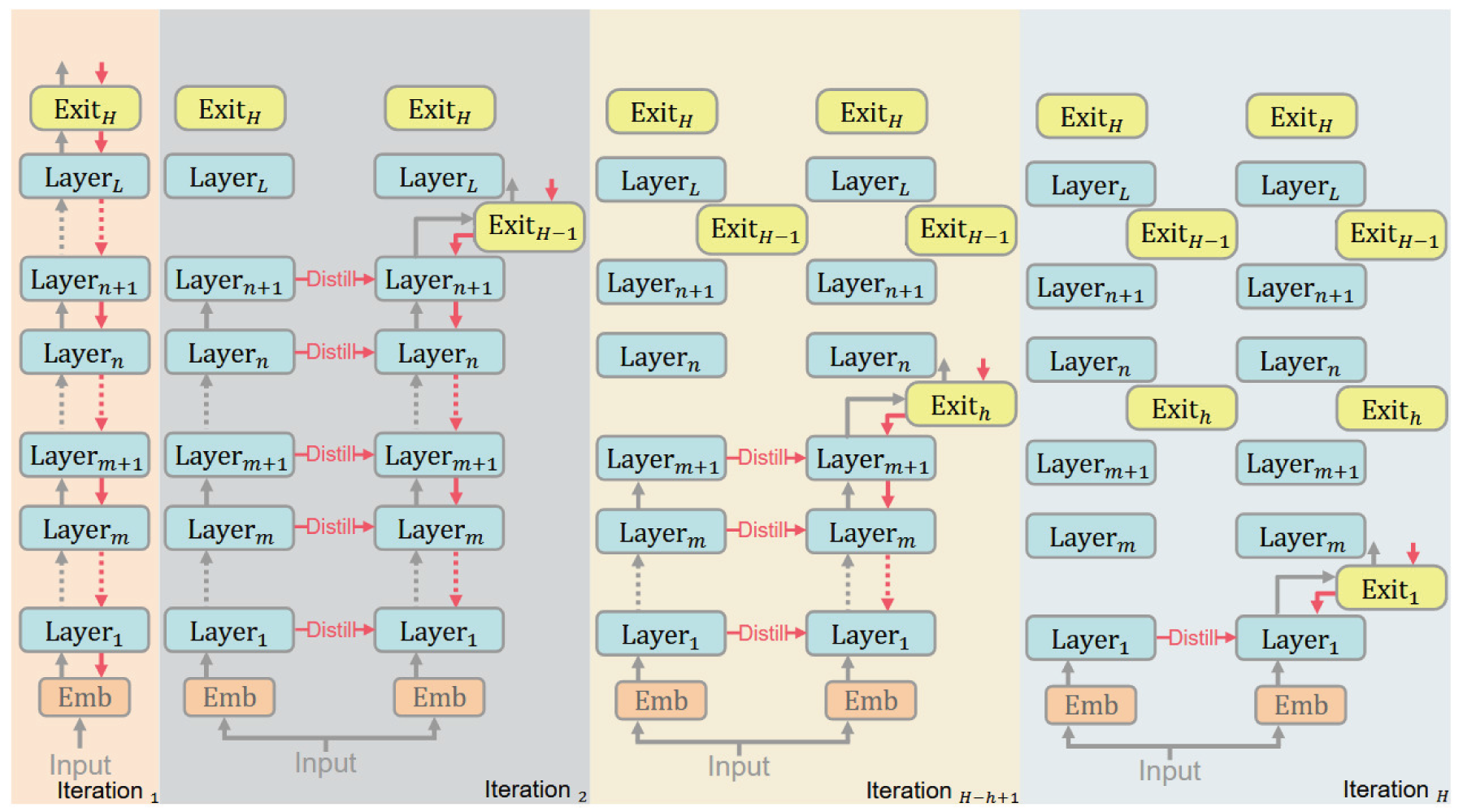
Illustration of Separate Reverse training.
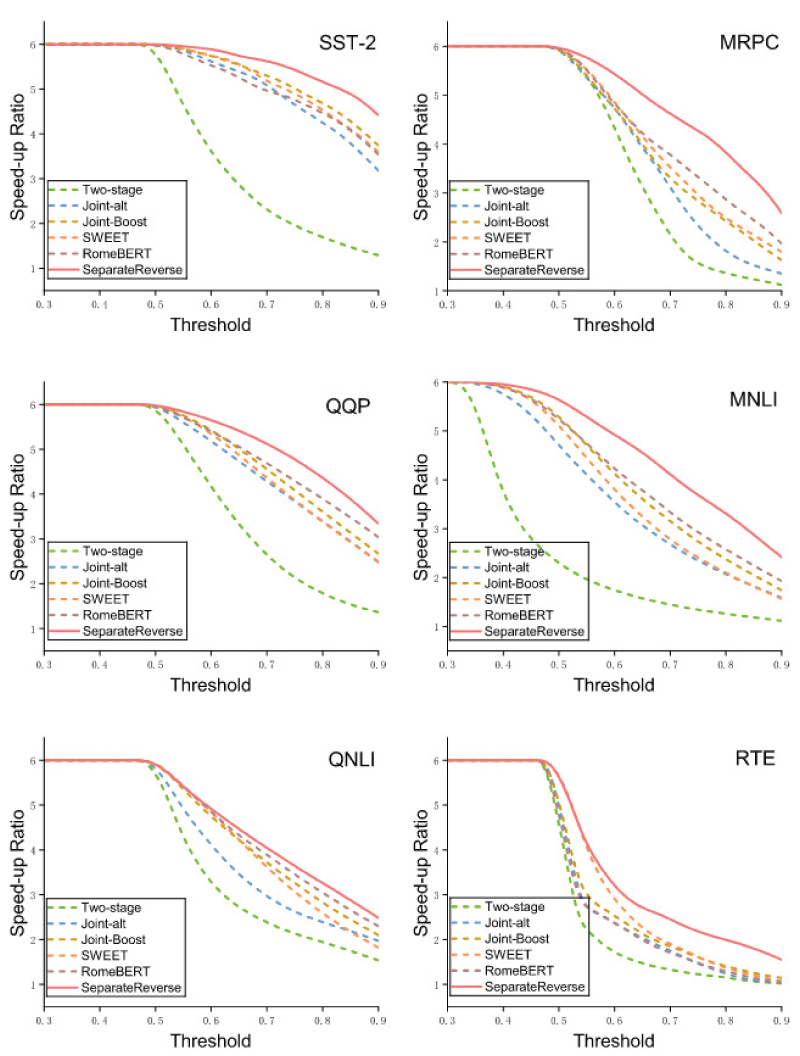
Speed-up ratios of multi-exit BERT under different thresholds.
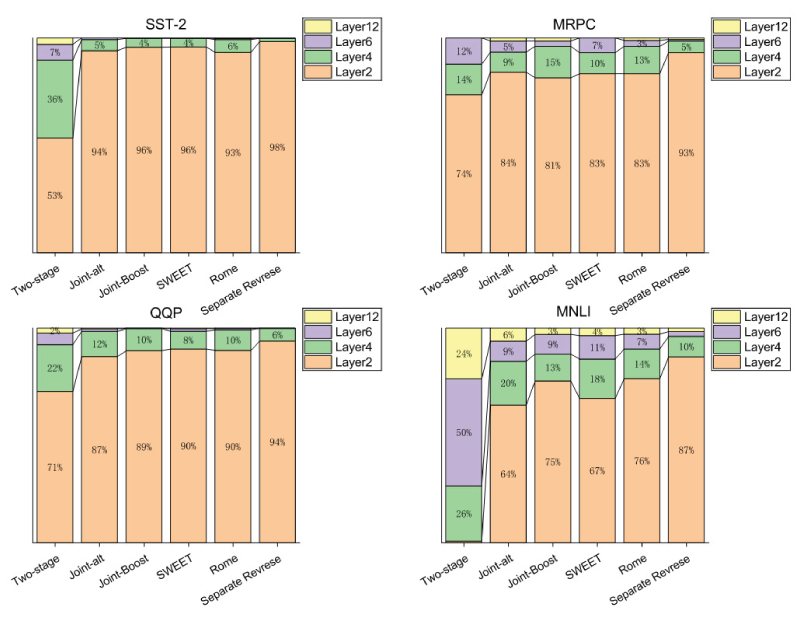
Proportion of samples exiting at each layer (threshold
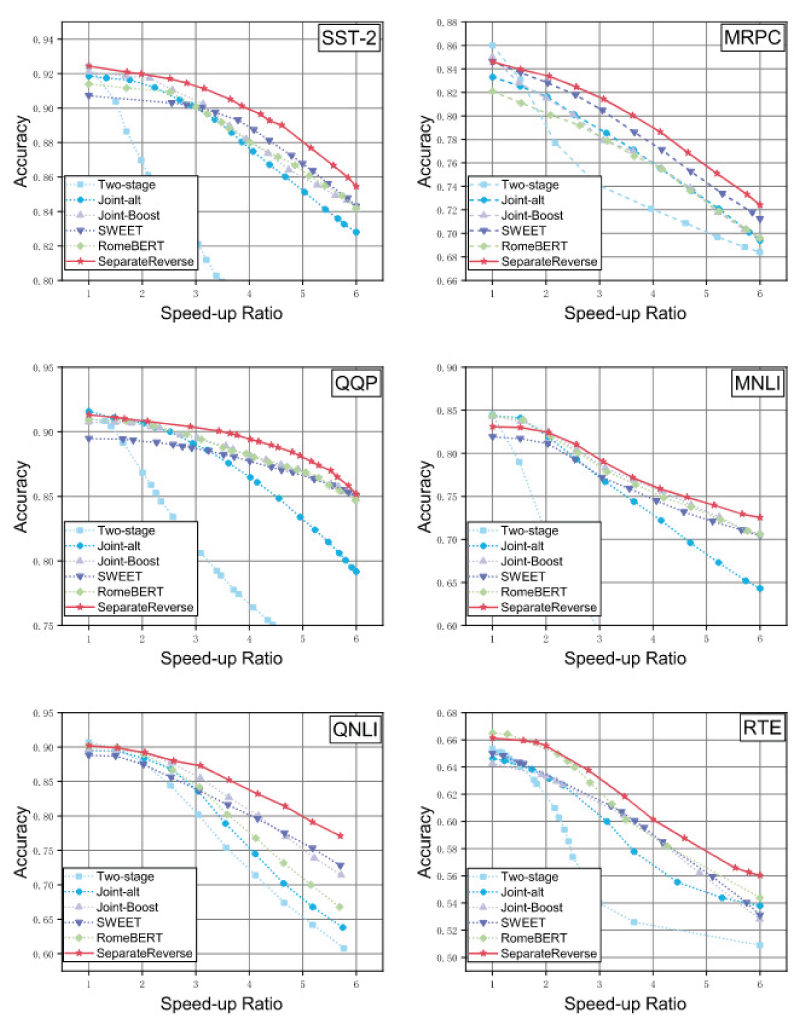
Speed-up curves of multi-exit BERT under different training strategies.
To address this, hierarchical knowledge distillation is employed, using the model itself as a teacher and training the exit classifiers from deep to shallow. First, the main exit is trained, after which the model parameters contain only the knowledge learned from the main exit. Then, the model is copied as a teacher, and during training of the next shallow exit, the teacher supervises shallow layer updates to prevent forgetting main exit knowledge. Next, after training, the model parameters contain knowledge from both the main and current exit. The old teacher is discarded, and the current model is copied as the new teacher to supervise the following exit. Finally, this process is repeated for all intermediate exits from deep to shallow, ensuring that knowledge learned from each exit is preserved, avoiding catastrophic forgetting, improving shallow exit performance, and maintaining the accuracy of deeper exits.
Formally, during training of the 

The distillation loss for the 



This section presents the experimental analysis of the proposed Separate Reverse training strategy for pretrained transformer models. We first introduce the datasets and evaluation metrics, followed by a description of the baselines and experimental settings. Finally, we report the results of applying the Separate Reverse strategy to the BERT model, compare them with existing studies, and further investigate the contributions of individual components through ablation studies and analysis of the performance balance coefficient.
Experimental Setup
Dataset and Metrics
We evaluate the performance of the BERT model on classification tasks, selecting six representative classification datasets from the GLUE Benchmark. Table 3 provides the statistical information for these datasets. Specifically:
Dataset Statistics.
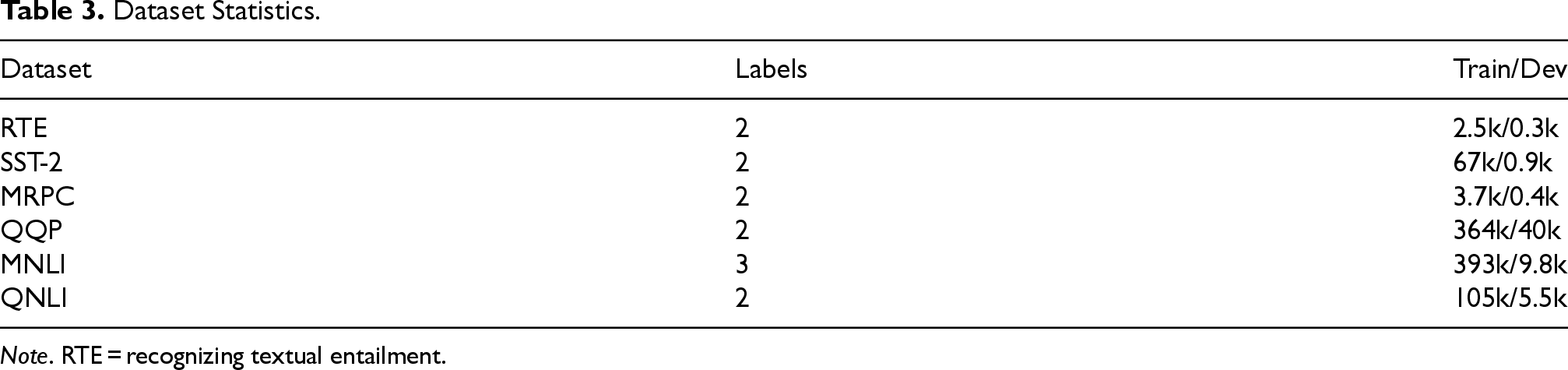
Dataset Statistics.
Note. RTE = recognizing textual entailment.
To comprehensively assess both the prediction accuracy and inference efficiency of the multi-exit transformer models, two evaluation metrics are employed: Accuracy and Speed-up Ratio. Their definitions are as follows:


To evaluate the effectiveness of the proposed Separate Reverse strategy, we compare it against a range of representative multi-exit BERT training methods, including both classical multi-exit strategies and recent BERT-specific adaptations. Although our experiments are conducted on BERT with GLUE tasks, the proposed training framework does not rely on BERT-specific components and can be readily extended to other transformer-based models with intermediate exits. The comparative baselines are summarized below:
In our experiments, the multi-exit BERT model is constructed by placing exit classifiers at the second, fourth, and sixth layers of the BERT backbone. All experiments are conducted on an NVIDIA GeForce RTX 2080 Ti GPU server, with training performed on the Train Set and validation on the Dev Set. We adopt the Adam optimizer with a linear learning rate scheduler. To ensure fairness, all compared methods use identical hyperparameter settings, the pretrained BERT weights are obtained from Hugging Face, and the balance factor
Training Parameters for Different Datasets.
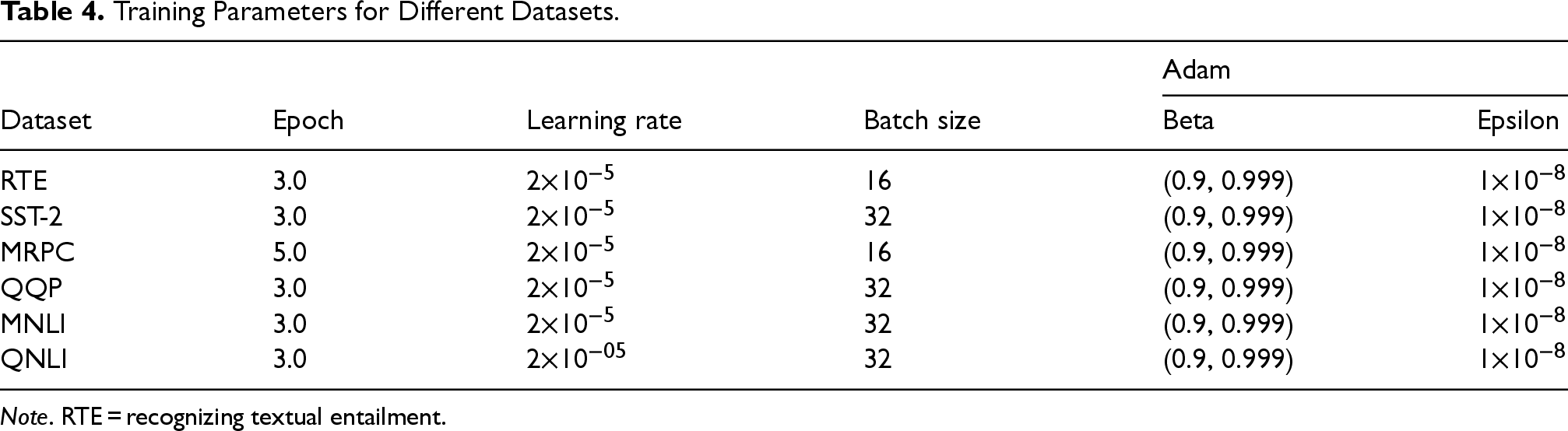
Training Parameters for Different Datasets.
Note. RTE = recognizing textual entailment.
The multi-exit BERT models trained with different strategies are evaluated, and the accuracy of each exit is summarized in Tables 5 to 8. The bold values indicate the best accuracy for each exit on a given dataset, or the highest accuracy excluding the Oracle strategy.
Accuracy of BERT Model’s Layer 2 Exit Under Different Training Strategies.
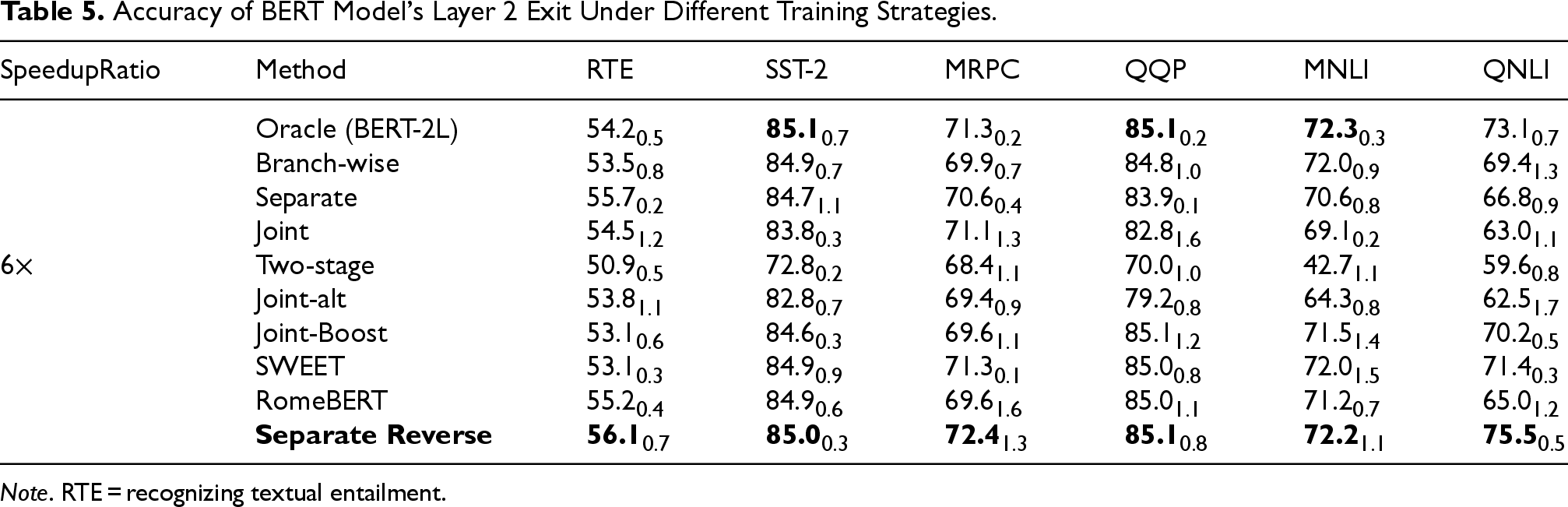
Accuracy of BERT Model’s Layer 2 Exit Under Different Training Strategies.
Note. RTE = recognizing textual entailment.
Accuracy of BERT Model’s Layer 4 Exit Under Different Training Strategies.
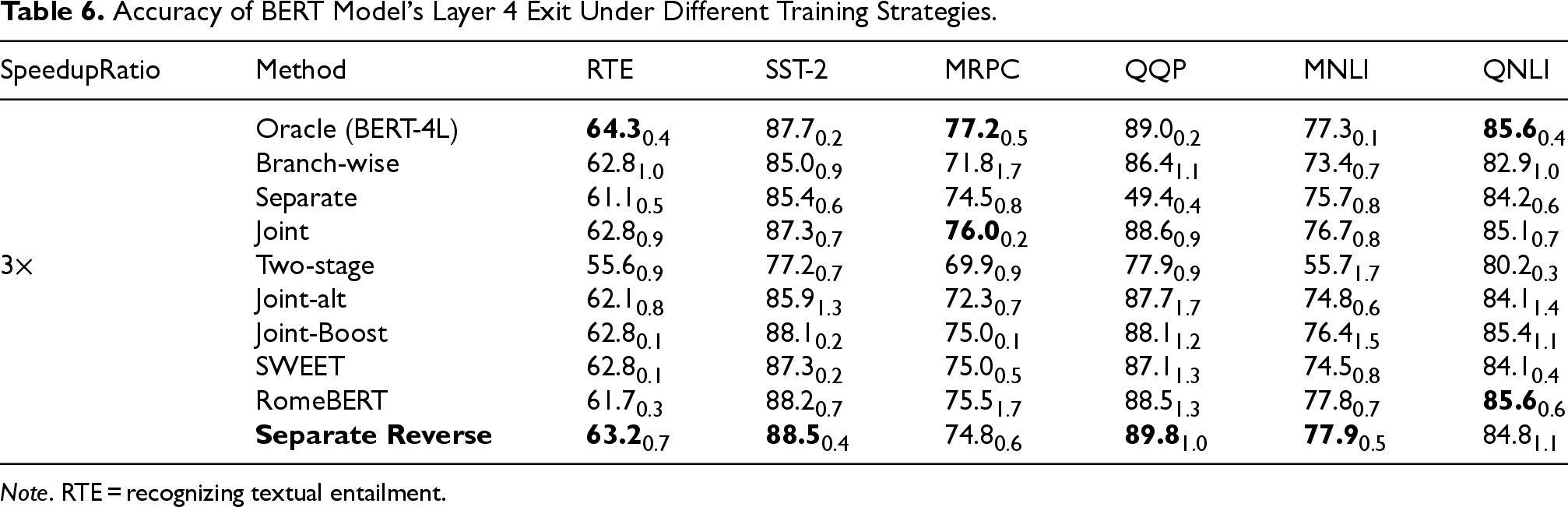
Note. RTE = recognizing textual entailment.
Accuracy of BERT Model’s Layer 6 Exit Under Different Training Strategies.
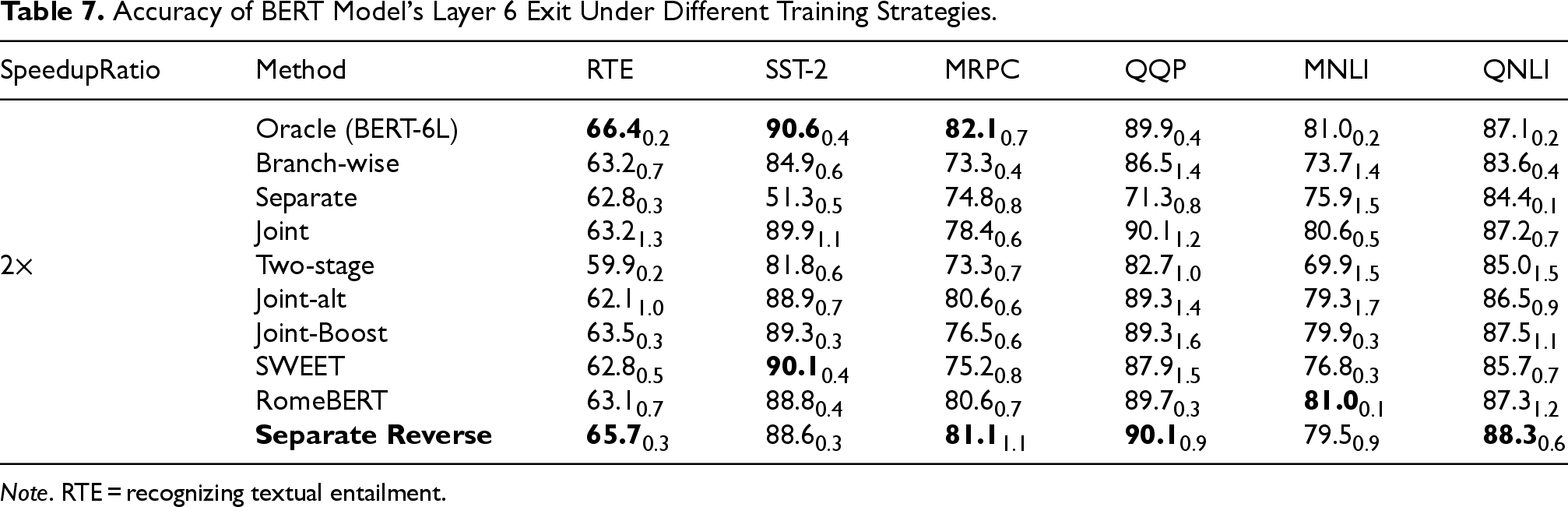
Note. RTE = recognizing textual entailment.
Accuracy of BERT Model’s Layer 12 Exit Under Different Training Strategies.
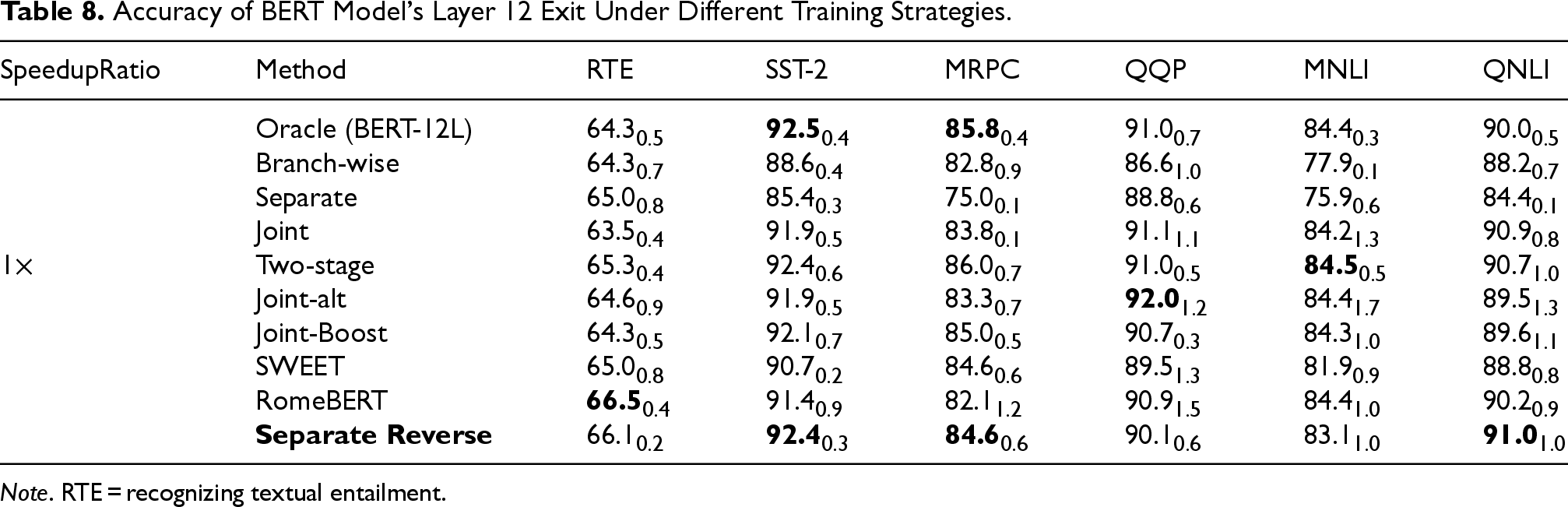
Note. RTE = recognizing textual entailment.
As shown in Table 5, across all datasets, the Separate Reverse training strategy achieves the highest (or second-highest, excluding Oracle) accuracy at the shallowest exit compared with other methods. This demonstrates that Separate Reverse effectively mitigates gradient conflicts and enables shallow exits to approach the performance of the Oracle model. Moreover, Separate Reverse allows shallow layers to retain useful high-level semantic knowledge from deeper layers, sometimes even surpassing the Oracle model’s accuracy at specific exits. Compared to the strongest non-Oracle baselines, Separate Reverse yields consistent gains at shallow exits, ranging from marginal improvements to over 4% on certain datasets, underscoring its effectiveness in mitigating gradient conflicts.
As shown in Tables 6 to 8, Separate Reverse also outperforms most baselines under
To further evaluate the inference acceleration of Multi-exit BERT trained with Separate Reverse, we use the maximum logit at each exit as the confidence score. A sample exits once its maximum logit exceeds a predefined threshold. The threshold is varied from 0 to 1 with a step size of 0.005, and the corresponding speed-up ratios are measured. As shown in Figure 6, when the threshold is very small, nearly all samples satisfy the confidence requirement at the shallowest exit, leading to the highest speed-up ratios for all strategies. As the threshold increases, the exiting criterion becomes stricter, forcing more samples to pass through deeper layers, and the speed-up ratio gradually decreases. Compared with joint optimization strategies, Separate Reverse trains each exit individually in a deep-to-shallow manner, which strengthens intermediate classifiers and enables more samples to exit early under higher thresholds. Consequently, it maintains higher speed-up ratios, particularly in the medium-to-high threshold regime. Figure 7 further illustrates the proportion of samples exiting at each layer when the threshold is 0.6, where Separate Reverse yields a larger share of shallow exits. Figure 8 presents the accuracy under different speed-up ratios. Separate Reverse achieves a more favorable speedup-accuracy trade-off: under the same acceleration constraint, it consistently attains higher accuracy than competing strategies. This improvement stems from reduced gradient interference among exits, which enhances shallow-exit reliability, while hierarchical knowledge distillation preserves the performance of deeper exits. As a result, Separate Reverse maintains competitive performance even at low speed-up ratios.
To evaluate the effectiveness of hierarchical knowledge distillation, this section removes the distillation step and retrains the model. The ablation results are shown in Table 9. Knowledge distillation helps preserve information learned from the main output during intermediate-layer training, thereby maintaining the performance of deeper exits. When distillation is removed, the accuracy of the main exit drops significantly, and in some cases—such as the sixth-layer exits on MNLI and QNLI—the intermediate exits even outperform the main one. This indicates that as shallow exits are trained, model parameters gradually forget deeper knowledge, leading to degraded downstream performance. Introducing hierarchical distillation mitigates this issue by constraining parameter updates under the supervision of the previous iteration, preventing shallow layers from overfitting to intermediate features while forgetting learned semantic knowledge. Overall, removing distillation causes an average main-exit drop of 3.5%–6.8% across datasets, underscoring the critical role of hierarchical knowledge transfer in preventing catastrophic forgetting.
To further examine the effect of the balance coefficient
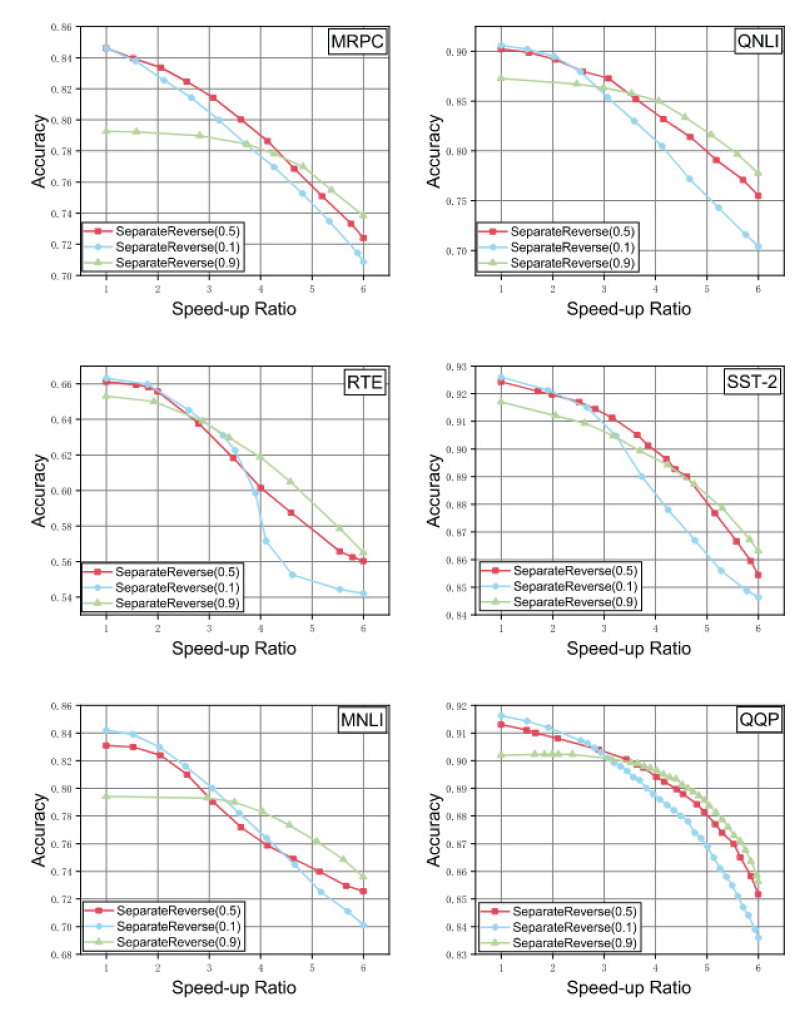
Comparison of Separate Reverse with different balance coefficients.
Ablation Study Results of Hierarchical Knowledge Distillation.
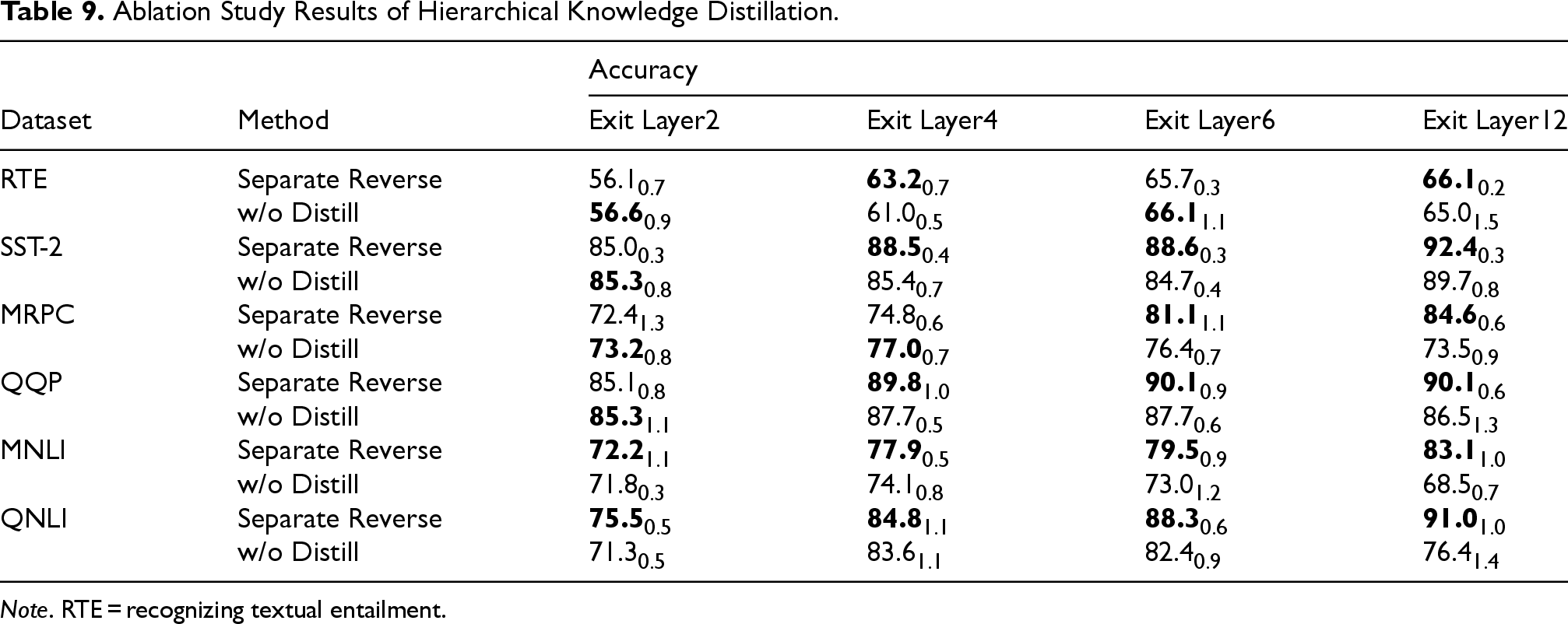
Note. RTE = recognizing textual entailment.
Overall, comparing the speed-up curves for
In this paper, we propose a multi-exit training strategy for pretrained transformer models to mitigate gradient conflicts and improve early-exit performance. The strategy combines the strengths of existing methods, maintaining pretrained parameter integrity while balancing optimization across shallow and deep exits. By coordinating gradient updates with hierarchical knowledge distillation, it enhances the accuracy of shallow exits without degrading the main exit. Experimental results on the GLUE benchmark demonstrate that our approach achieves an effective tradeoff between accuracy and inference speed, enabling efficient early exiting for simpler samples.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Research on Key Technologies of Efficient Cloud-Edge-End Collaborative Computing for Computer Vision in Electric Power System (No. J2024147).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.