
Abstract
In recent years, machine learning (ML) models have become the top prediction options in agriculture, cybersecurity, healthcare, and finance, among other fields. ML models have assisted in the study of numerous disorders in medical research. Early diagnosis and health schedule management may prevent severe heart disease in many people. This study uses national government repository data to apply ML models to early heart disease detection. This research also introduces two novel models based on swarm intelligence, called ACOKNN (ant colony optimization with K-nearest neighbors) and ACOWNNBoost (ant colony optimization with weighted K-nearest neighbors), to improve heart disease early detection models. The suggested models pick features using ant colony optimization with traditional k-nearest neighbor and weighted k-nearest neighbor with XGBoost. The suggested models are evaluated with two datasets of varying capacity, and results are compared to various ML techniques based on precision, accuracy, recall, F1 score, and receiver operating characteristic area under the curve score. The investigation shows that the suggested model achieved 92% and 98% accuracy with Dataset-1 and 92.6% and 98.6% with Dataset-2.
Keywords
Introduction
One of the most essential organs in the human body is the heart. Essentially, it controls blood flow throughout the body. Heart irregularities can exacerbate pain in other areas of the body. Any condition that affects the heart's regular function is considered a heart disease. Blood from the heart reaches various body parts, pumps hormones and other essential chemicals, receives deoxygenated blood, transports metabolic waste products to the lungs for oxygenation, and controls blood pressure (American Heart Association, 2020; World Health Organization, 2020). The primary means of preventing heart-related ailments is a healthy lifestyle and early detection. Heart disorders often replace cardiovascular diseases (CVDs). It is most often associated with blockages or restrictions of blood vessels, which can lead to a heart attack, a stroke, or chest discomfort. Heart illnesses include other cardiac problems, such as disorders affecting the heart's muscles, valves, or rhythm. In contrast, machine learning (ML) is crucial in determining whether a person has heart disease or not. Clinical information will be easier to gather if clinicians can anticipate these events. Coronary artery disease (CAD) is primarily misdiagnosed as heart disease. Hypertension, excess triglycerides, excessive cholesterol, and other harmful behaviors increase heart disease risk (World Health Organization, 2020). It has been reported that specific symptoms include disorder in sleep, a sudden increase or drop in heart rate, also termed as irregular heartbeats, regular swelling in the legs, and excess weight gain, such as 1–2 kg per day or week (American Heart Association, 2020). In the near future, these symptoms can lead to a heart attack since they mimic various illnesses, such as those seen in the elderly.
The availability of hospital patient records and study data has increased over time. Patient data can be obtained from numerous open sources, and research can be undertaken to identify conditions before they become fatal using various computer technologies. Medical industry professionals recognize the importance of ML and artificial intelligence (AI). By using models based on ML techniques, the diagnosis process can be simplified, and conditions can be categorized, as well as their outcomes predicted. The use of ML methods simplifies the analysis of historical and present genetic data. It is possible to train models using ML to forecast knowledge pandemics and examine medical data more thoroughly, thereby improving the accuracy of predictions (Hastie et al., 2009; Melillo et al., 2013; Shalev-Shwartz & Ben-David, 2014).
Heart disease should not be taken lightly. It appears that men are more likely than women to develop heart disease, according to a report published by Harvard Health Report (Bharti et al., 2021). The risk of suffering a heart attack at some point in one's life is almost twice as high for men as for women. Even after accounting for established risks such as increased cholesterol, high blood pressure, unbalanced body mass index, diabetes, and low or very high physical activity, the greater risk remained (Bharti et al., 2021; Kadhim & Radhi, 2023). These are the different risk factors that increase a patient's chances of acquiring CVD.
In contrast, removing or improving these elements reduces the risk. This view implies a causal relationship between the risk factor and the disease, suggesting that the risk factor precedes the disease (the concept of anteriority). Correction of the factor will reduce the incidence of the illness (the concept of reversibility) (Kadhim & Radhi, 2023). Naturally, it must be recognized in several groups and provide a reasonable physio-pathological explanation for the condition. A heart disease risk factor is described as a factor that raises the patient's risk of acquiring a CVD when exposed to it (Shao et al., 2014). The relevance of the risk factor is characterized by the degree of relationship with the illness (represented as the relative risk found in exposed patients compared to unexposed subjects) and the progressive association (parallel to the risk factor).
Some datasets may provide better results and be more useful when they have different characteristics. This study, therefore, aims to combine categorization and feature selection to achieve a more accurate diagnosis of heart disease by using a combination strategy. Ant colony optimization (ACO) is employed in this study due to its proven reliability and effectiveness in solving complex optimization problems, particularly in cardiac disease prediction. Although more recent algorithms such as red fox optimization, reptile search algorithm, and crayfish optimization exhibit promise, they lack the extensive empirical validation and robustness required for critical medical applications (Jindal et al., 2021). The efficient search engine of ACO manages high-dimensional healthcare datasets with efficiency, constantly adjusts to changing solution spaces, and strikes a balance between exploration and exploitation. Guided by the no-free-lunch theorem, which states that no algorithm is universally optimal, this study introduces two hybrid approaches: the ACOKNN method, which combines ACO with K-nearest neighbors (KNN), and ACOWNNBoost, which integrates weighted KNN (WKNN) with ACO and XGBoost. These techniques enhance the accuracy, generalization, and robustness of predictive modeling by leveraging complementary capabilities. The proposed models are being tested and compared with traditional KNN and also previously published models.
To proceed with the research work, three important hypotheses are made, and the remaining part of the work tries to address these aspects: H1: Proposed ACO improves feature selection quality because its modified probability function ensures smoother exploration and avoids local optima. H2: Hybridization of ACO with KNN and WKNN + XGBoost yields higher accuracy, since swarm-based feature reduction eliminates irrelevant attributes while ensemble learning enhances generalization. H3: Generalization across multiple datasets is feasible, as shown by consistent improvements using multiple datasets.
The remainder of the text is broken into the following sections: Section 2 discusses several existing studies and their conclusions. Section 3 discusses the methods and materials used for the models' implementations, such as descriptions of datasets, pre-processing of datasets, ML models, and so on. Section 4 illustrated the proposed models. Section 5 addresses experiment outcome analysis and compares it with previous research. Finally, Section 6 concludes the article and outlines its future scope.
Related Studies
To improve data categorization accuracy, many medical investigators have tried different approaches. Identifying potential patients and improving diagnostic accuracy will be enhanced by categorization techniques that provide more accurate results. ML algorithms with swarm intelligence and simple ML algorithms can be categorized as studies in this area. A study published by Jindal et al. (2021) utilizes University of California, Irvine Machine Learning (UCI) repository datasets for training and testing support vector machine (SVM) algorithms to predict cardiac diseases, employing models such as convolutional neural networks (CNNs), decision trees (DTs), linear regressions, and SVMs. Using DT-based feature selection approaches, opinion mining predicts heart disease with fewer characteristics and more accurate experimental outcomes (Tasnim & Habiba, 2021). The study of Kavitha et al. (2021) proposes unsupervised rough set algorithms to improve the results of online opinion text clustering. Even though current methods of classifying liver disorders are accurate enough for practical applications, they still need to be improved.
The central concept of the study (Rani et al., 2021) is to utilize several classification algorithms to forecast liver disease. Several methods were used in this study, including logistic regression (LR), KNN, and SVMs. Comparison of the categorization system is based on accuracy scores and confusion metrics. There is evidence to suggest that LR can be used to predict liver disease. In the study of Amin et al. (2019), the researchers employed a distinctive methodology devised to enhance the accuracy of heart disease prediction using data mining algorithms. The study introduced prediction techniques that leveraged multiple features, incorporating six classification algorithms: DT, KNN, SVM, Naive Bayes, LR, and neural network (NN). The experimental findings revealed that identifying the most suitable data mining model and crucial factors significantly enhanced the prediction of heart disease, and validated the efficacy of the proposed approach.
Any categorization in terms of feature selection is essential. Later, swarm algorithms were proposed, and these were proven to be effective for feature selection. There is some research in the literature that uses swarm algorithms to classify cardiac disease. Behera et al. (2023) explored the SVM model for heart disease prediction and proposed a hybrid model using a swarm intelligence algorithm called particle swarm optimization (PSO). The obtained results were compared with those of simple SVM, and it was found that PSO with SVM performed better than simple SVM. Cherian et al. (2020) propose a hybrid swarm intelligence approach that combines PSO and the lion algorithm with an NN. Before applying the models, the authors applied the PCA technique to reduce the dimensionality of the dataset. After that, they applied both models one by one and compared the results of the models. Manikandan et al. (2023) have used an unsupervised ML algorithm to predict heart disease. They employed a two-fold clustering algorithm and subsequently proposed a hybrid algorithm that utilizes PSO to optimize the number of clusters, thereby increasing efficiency. Asadi et al. (2021) applied a random forest (RF) algorithm for predictions and then proposed a hybrid PSO with an RF model to find the optimal and diverse DTs. The comparative study conducted by the authors suggests that the hybrid model outperformed the simple RF model. Altae and Ehsani Rad (2023) applied extreme learning machines (ELM), simple SVM, and a DT for early heart disease prediction. After analyzing the results of the SVM and DT, they proposed a new hybrid model by combining PSO with each of them and comparing the results. They found that PSO with ELM has outperformed other models.
In this study of Jovanovic et al. (2024), recurrent NNs (RNNs) are used to anticipate time series in order to detect abnormal cardiovascular rhythms in ECG readings. The proposed algorithm outperforms existing techniques and achieves excellent accuracy by applying metaheuristic algorithms for hyperparameter optimization. Further investigation reveals that long short-term memory (LSTM) networks with attention mechanisms included outperform RNN models with an accuracy of 99.83%. These findings underscore the importance of utilizing cutting-edge ML techniques to enhance healthcare applications and emphasize the need for ongoing innovation and improvement in this field. The study yields good accuracy, but this is mainly due to the images, which require more computational resources, as well as proper balancing of the dataset.
Using metaheuristic optimization algorithms such as PSO, firefly algorithm, genetic algorithm, whale optimization algorithm, and sine cosine algorithm, this study of Petrovic et al. (2024) focuses on utilizing AI for early detection of CVD. These techniques improve the accuracy of identifying abnormalities in ECG signals by optimizing RNNs. The error rate dropped from 0.006837 to 0.002486 when attention layers were added to NNs. The paper, however, acknowledges several limitations, including computational constraints and a lack of method comparisons. To improve AI-driven cardiovascular diagnostics, future studies should fill in these gaps and investigate more extensive medical applications. Based on the findings of the above literature, some factors are found to be missing in the above studies. Most studies combined the ML models with PSO, an evolutionary algorithm used for continuous problems. The main benefit of the PSO is its fast convergence rate; however, it may get stuck in a local optimum.
The study of Guo et al. (2025) presented a deep learning-based framework to enhance the diagnosis of myocarditis, a complex cardiac inflammatory disorder that is frequently challenging to identify with standard imaging techniques. The research tackled two significant issues in medical image classification: data imbalance and initialization sensitivity. This was achieved by combining CNNs with an improved data augmentation approach utilizing generative adversarial networks (GANs) and a mutual-learning artificial bee colony (ML-ABC) algorithm for weight optimization. The suggested model successfully combined realistic images of the minority class and improved feature learning for better convergence and stability. The Z-Alizadeh Sani myocarditis dataset showed that the framework did a better job of classifying data than traditional CNN and hybrid models, with an accuracy of 90.8%. The results confirmed the efficacy of integrating data augmentation with metaheuristic optimization to improve diagnostic precision and reliability in predicting heart diseases.
Sasirekha et al. (2025) proposed an effective Internet of Things (IoT)-based framework for predicting heart disease using a weight-updated trans-bidirectional LSTM–gated recurrent unit (Trans-Bi-LSTM-GRU) network that was improved with a new hybrid chameleon electric fish swarm optimization (HCEFSO) algorithm. The HCEFSO merges the chameleon swarm algorithm and electric fish optimization (EFO) to make the process of choosing features and tweaking parameters faster and less likely to get stuck in local optima. Three benchmark datasets—Heart Failure Clinical Records dataset, UCI Heart Disease, and CVD datasets were used to test the model. The system combines physiological data acquired by IoT devices with deep learning and optimization to make diagnoses that are both accurate and up-to-date. The suggested model attained an accuracy of 97.36% on Dataset-2, surpassing current models such as CNN-BiLSTM, fuzzy-LSTM, and EFO-based variations. The research confirmed that integrating IoT-enabled data collection with metaheuristic optimization substantially improves the precision, resilience, and scalability of cardiac disease prediction systems.
Research Gaps
By analyzing the existing studies, the following research gaps are found: Limited exploration of swarm intelligence techniques beyond PSO: While many studies have combined ML models with swarm intelligence, most focus on PSO. Other swarm intelligence techniques, such as ACO, remain underexplored in the context of heart disease prediction. Focus on individual models over hybrid models: Many studies evaluate individual models, such as SVM, DTs, or LR, rather than creating robust hybrid models that combine the strengths of multiple algorithms. The potential of integrating ACO with techniques like KNN or WKNN has not been thoroughly investigated. Feature selection strategies: Effective feature selection is critical for improving classification accuracy. While some studies have used PCA or DT-based feature selection, the literature lacks exploration of swarm-based feature selection methods like ACO for heart disease datasets. Generalization across datasets: Most studies evaluate models on specific datasets, such as the UCI repository, without addressing the challenge of generalizing results across diverse datasets with varying characteristics. Emphasis on accuracy without comprehensive evaluation metrics: Although accuracy is frequently reported, comprehensive evaluation metrics such as F1 score, precision, recall, and receiver operating characteristic area under the curve (AUC-ROC) are not consistently applied in the studies. It hinders the holistic evaluation of the models’ effectiveness. Clinical relevance and interpretability: Existing studies focus primarily on improving prediction performance. However, they often overlook the importance of clinical interpretability, which is crucial for adoption in real-world healthcare applications. Comparison with baseline and advanced models: While hybrid models are proposed in several studies, their performance is often not rigorously compared to baseline and other state-of-the-art models using standardized benchmarks. Underutilization of ensemble techniques: Although ensemble methods like RF have been explored, their integration with swarm intelligence remains limited. The potential of combining advanced ensemble techniques like XGBoost with swarm optimization is underutilized.
Author's Contribution
To address the limitations of the existing models, this article will contribute as follows: A modified ACO method is presented in which feature inclusion probability is computed based on sigmoid-transformed pheromone functions rather than traditional pheromone-heuristic products. Adaptations such as these improve recall to subtle variations in pheromone levels, reduce premature convergence, and improve the selection of discriminative features, which improve the predictive accuracy of models, addressing a major gap in the literature. Development of two novel hybrid models: ACOKNN (ACO + KNN) and ACOWNNBoost (ACO + WKNN + XGBoost), which combine swarm-based feature selection with strong classification/ensemble capabilities. Demonstration of model generalization across two datasets of varying size and attributes, unlike many prior studies restricted to a single dataset. Comprehensive performance evaluation using multiple metrics (accuracy, precision, recall, F1 score, and AUC-ROC), ensuring a holistic view of effectiveness rather than relying solely on accuracy.
Methods and Material
Dataset Description and Standardization
To generalize the results, two datasets are considered for this study. The first dataset is taken from the open source repository Kaggle for ML (https://www.kaggle.com/datasets/johnsmith88/heart-disease-dataset?resource = download). There are 1,025 patient records with 14 clinical and demographic details, such as age, sex, type of chest pain, resting blood pressure, serum cholesterol, fasting blood sugar, resting ECG results, maximum heart rate reached, exercise-induced angina, ST depression, number of major vessels, thalassemia, and a binary target label that shows whether or not heart disease is present. The structured style of the dataset and the medically relevant variables make it good for binary classification tasks like finding heart disease, testing models, and exploring healthcare analytics (Heart Disease Dataset; Maini et al., 2021). Figure 1 shows the description of the attributes and their type.
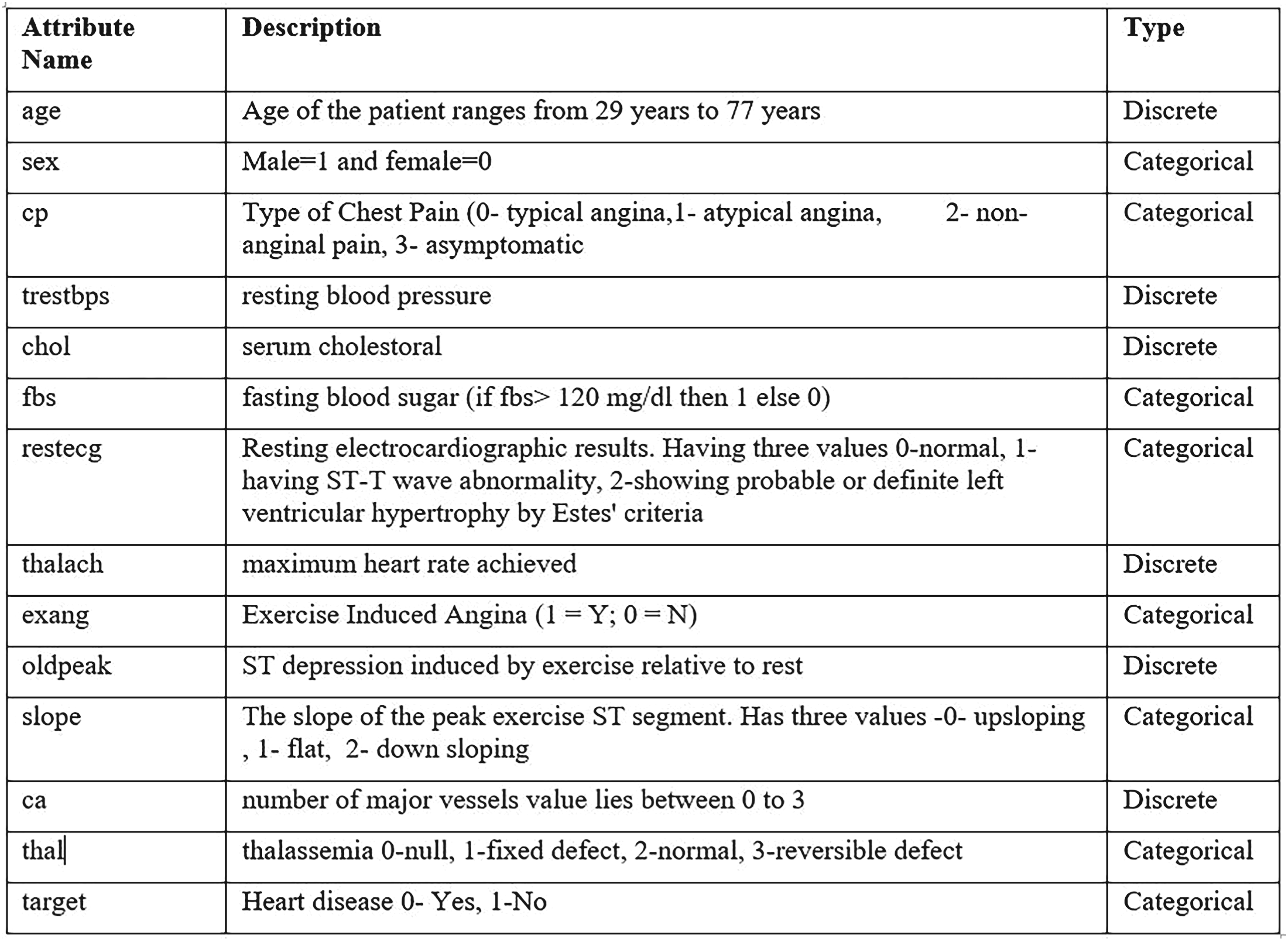
Description of Dataset-1.
The second dataset is also an open-source dataset, containing a collection of patient information from Framingham, Massachusetts (https://www.kaggle.com/datasets/aasheesh200/framingham-heart-study-dataset). The dataset comprises 15 attributes and 4,240 records. The attributes include demographic factors (like age and sex), behavioral indicators (like smoking status and cigarettes per day), medical conditions (like hypertension and diabetes), vital measures (like systolic/diastolic blood pressure, body mass index, and glucose levels), treatment status, and the binary target variable TenYearCHD, which shows whether a patient developed coronary heart disease within the next decade. The dataset's extensive array of risk indicators renders it particularly advantageous for binary classification tasks, cardiovascular risk modeling, and comparative analyses of ML algorithms in healthcare analytics (Framingham Heart Study dataset). Figure 2 shows the description of the attributes and their type.
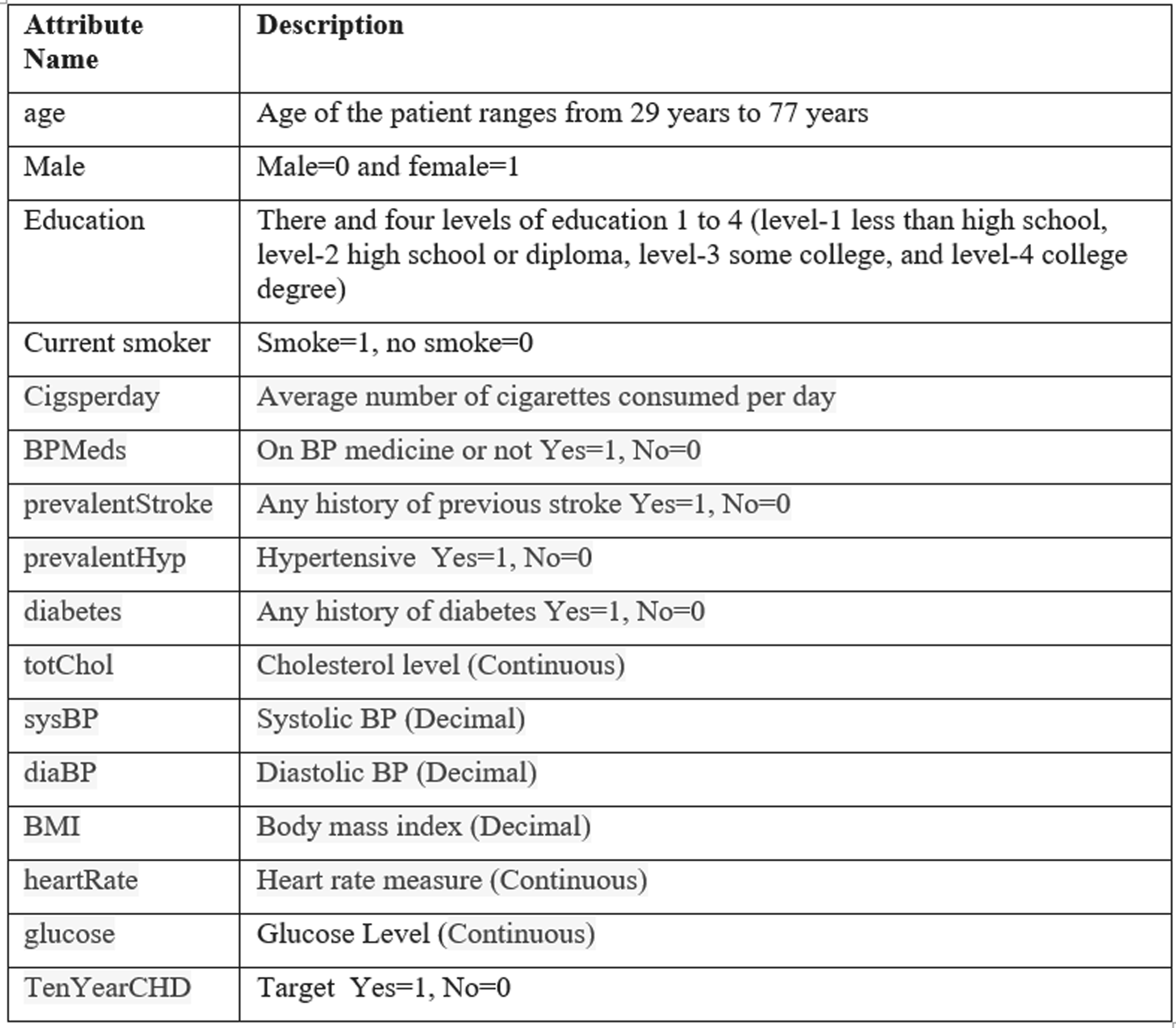
Description of Dataset-2.
After reading the dataset, feature scaling is used to normalize the features of both datasets (Janosi et al., 1988). This normalization process ensures that all features have similar scales and ranges.
Equation (1) is used to standardize the features


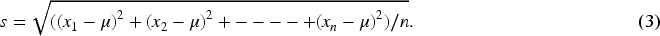
After normalization, the Dataset-2 (Framingham) was found unbalanced and also with missing values in some features, such as cigsperday, BPMeds, totChol, and so on. To handle that, the data distribution of attributes was evaluated. If it is normally distributed values, mean impotent are used; otherwise, the median is used. If the feature is categorical, then mode is utilized to handle missing values.
PSO is a population-based stochastic optimization technique inspired by bird flocking. It seeks the optimum answer by iteratively altering the locations of a population of particles in a search space depending on their own neighbors’ best placement. PSO is commonly used to solve optimization problems in various fields. KNN is a non-parametric classification technique that finds the majority class among a sample's K closest neighbors in the feature space to identify its class. KNN is an instance-based learning system that is simple but effective for classification and regression applications (How to use the sklearn.preprocessing.StandardScaler function in sklearn ). The purpose of integrating PSO with KNN is to use PSO to optimize the parameters or hyperparameters of the KNN algorithm. The parameters to be optimized include the number of closest neighbors (k) or other KNN algorithm-specific characteristics. The search is led toward the area of the parameter space that offers higher performance for the KNN method by repeatedly modifying the particle placements in the PSO algorithm (Barges & Thabet, 2023). The PSO optimization method aims to identify parameters that maximize the fitness function, thereby demonstrating optimal KNN algorithm performance for a specific task (Hu et al., 2023). The PSO algorithm searches the parameter space for the optimum combination of parameter values that results in the best KNN algorithm performance (Kooshari et al., 2024). There are two main phenomena PSO uses for finding out the best solution: first updation of velocity by equation (4) and update position using equation (5). The PSO generally has one main drawback, namely a fast convergence rate, because it can get stuck in local optima.
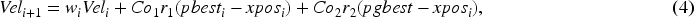

ACO is a meta-heuristic algorithm inspired by ant foraging behavior. The notion of pheromone trails underpins ACO. In the wild, ants leave pheromones on the ground as they travel, which act as a sort of communication, guiding other ants to food sources (Wu et al., 2023). Similarly, with the ACO algorithm, while investigating a probable solution, artificial ants leave pheromone trails on the problem space. The pheromone trail updating equation and the probabilistic solution selection equation are the two primary equations in the ACO first pheromone trail update and second probabilistic solution selection. After each repetition, the pheromone trail update equation is employed to update the pheromone trail shown in equation (6). Its goal is to encourage the courses adopted by ants that have discovered excellent solutions while also evaporating the pheromone trails over time (Verma et al., 2021).

The probabilistic solution selection equation calculates the likelihood that an ant will choose the next solution based on pheromone trails and a heuristic value (Maithani & Verma, 2023). It enables ants to make choices based on information acquired via pheromone trails and problem-specific expertise. Equation (7) gives the probability,

The objective of this section is to discuss the framework used to develop the final solution, which is an ML approach for predicting early heart disease. Figure 3 shows the flowchart of the proposed framework. After reading the dataset, it is split into training and test data. A total of 1,024 entries are in the Dataset-1 with 14 attributes, and 4,000 + records with 15 attributes were in Dataset-2. In Dataset-2, some attribute values were missing, that in Dataset-2 that were also handled as a pre-processing step. The feature scaling is used after splitting the dataset into the training data to normalize the features of the dataset. This normalization process ensures that all features have similar scales and ranges. The KNN ML model is applied to the dataset, and performance metrics are calculated. After applying KNN, all results are recorded, and the integration of PSO with KNN is used to optimize the parameters or hyperparameters of the KNN algorithm. The parameters to be optimized include the number of closest neighbors (K) or other KNN algorithm-specific characteristics. The PSO method seeks to collect parameters that maximize the fitness function, showing the optimal KNN algorithm performance for a particular patient's data. The PSO algorithm searches the parameter space for the optimum combination of parameter values that result in the best KNN algorithm performance. The PSO generally has one drawback that, because of the fast convergence rate, it sometimes gets stuck in the local optima. To improve the results and also find the global solution, two new algorithms are proposed: ACOKNN and ACOWNNBoost. Also, the modification is done in the traditional ACO approach, where standard ACO calculates the likelihood of feature selection directly from the pheromone trail and heuristic data, usually relying on feature relevance or cost. The proposed method, on the other hand, uses a sigmoid transformation of pheromone values, which are scaled by the evaporation factor, to figure out the probability of including features. This change makes the probability transitions smoother, helps explore the feature space more effectively, and reduces the likelihood of quickly converging to poor subsets. Because of this, the algorithm can better find combinations of features that improve the performance of the classifier, which immediately leads to more accurate predictions when it comes to finding heart disease.
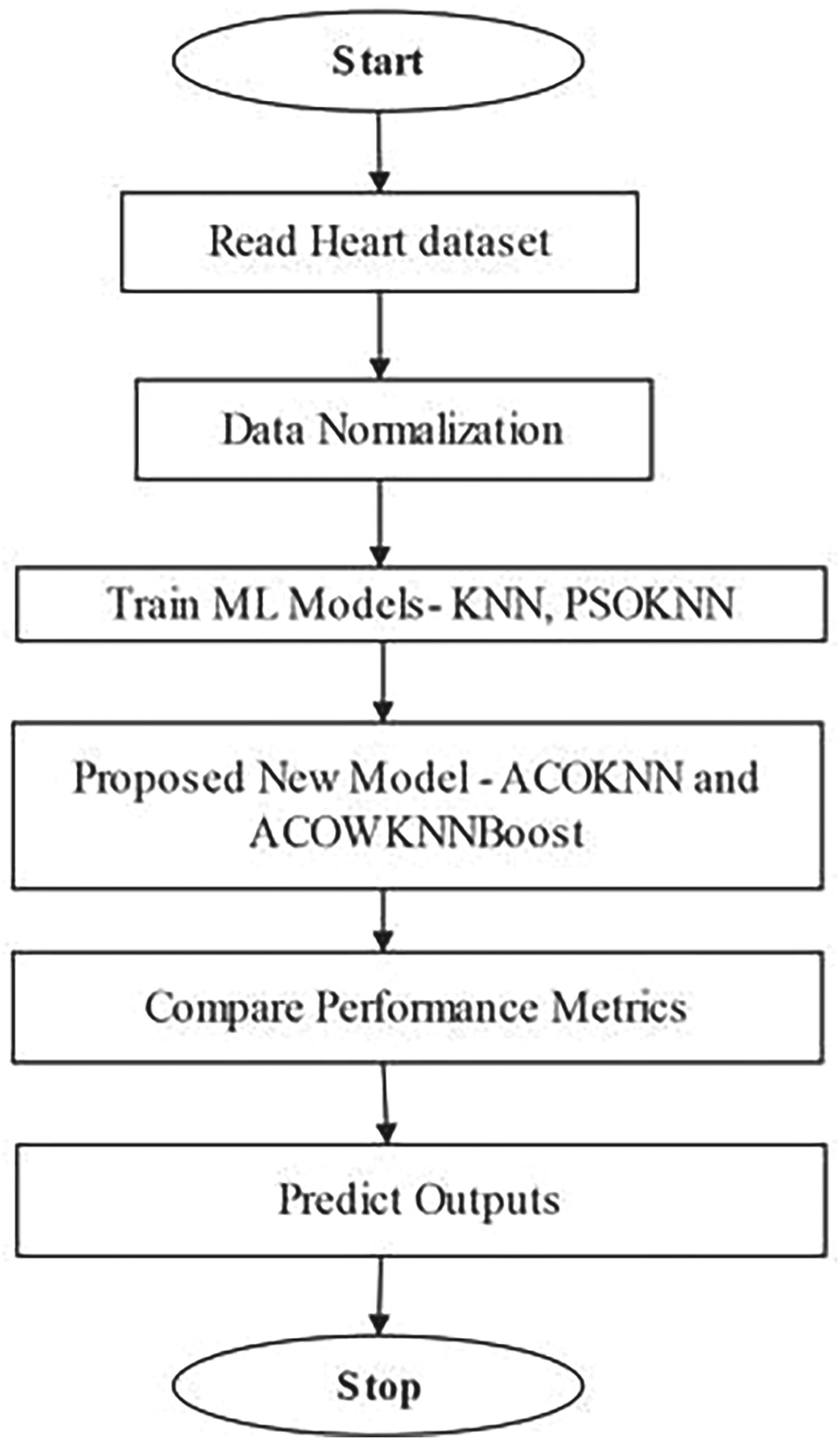
Flow diagram of the proposed framework for early heart disease prediction.
This proposed algorithm is a combination of the optimization algorithm ACO and the ML classifier KNN. This method uses the local search capabilities of KNN to make educated judgments based on the information stored in the pheromone trails by merging ACO and KNN. The KNN component aids in introducing the concept of similarity or distance between solutions, enabling the ants to evaluate neighboring options more efficiently. Proposed algorithm steps are shown in Algorithms 1 to 3. Algorithm 1 shows the steps of the model proposed with ACOKNN. Steps 1 and 2 represent the reading of the dataset and splitting it into train and test with a 70:30 ratio. Steps 4 to 9 are calling each algorithm, starting from KNN, till the proposed ACOKNN, and printing its performance, respectively.
Model
Model

Algorithm 2 represents the proposed ACOKNN algorithm from stop Step 1 to 3, three arrays are initialized: pheromone matrix, best_sol, and best_fitness. Where the pheromone matrix represents the pheromone on each feature and is initialized to 0.5. Step 4 defines the number of iterations. Steps 5 and 6 create the solutions and fitness list for each iteration. Steps 7 to 37 calculate the fitness value by using algorithm third and update the best solution and best fitness. After that, the pheromone matrix is updated. After the completion of all the iterations, the best solution is returned by an algorithm.
This section proposes another model called ACOWNNBoost. The model is designed by combining the ACO with the WKNN and XGBoost ML model. WKNN is a variation of the KNN algorithm that assigns different weights to the nearest neighbors when making predictions. These weights are based on the distances between the query point and its KNN. When making predictions, the goal is to give more influence to closer neighbors and less influence to farther ones. First, calculate the distance between the query point (denoted as Q) and each data point in the training set using the Euclidean distance. Let's denote the distance between the query point Q and the ith data point as
Let 
In the context of classification problems, the process involves assigning a class label to a given query point Q. This assignment is determined by considering the majority class among the KNN of Q, with the influence of each neighbor being weighted according to their respective distances. A weighted voting strategy may be used, whereby the class label that each neighbor votes for is influenced by its respective weight. In regression tasks, the prediction of the query point Q is determined by calculating the weighted average of the target values of its KNN. The calculation of the weighted average is represented by the following equation:
ACOKNN


fit_aco

ACOWNNBoost

WNN

cal_weights

The implementation of the proposed framework is done on Windows 10 using Python 3.6 on PyCharm IDE. All four models were trained and tested on two datasets to receive more generalized results. The list of parameters, such as the number of particles, iterations, value of ants, and so on, is listed in Table 1 for all the proposed models. The objective function in the study measures the classification accuracy (or any other optimization target such as F1 score, AUC, etc.) by evaluating the quality of the feature subset or hyperparameters selected by the optimization algorithms. Equation (10) defines the objective function taken for the models. The goal is to maximize 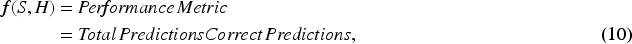
List of Parameters Used at the Time of Evaluation.

KNN = K-nearest neighbors; PSO-KNN = particle swarm optimization and K-nearest neighbors; ACOKNN = ant colony optimization with K-nearest neighbors; ACOWNN = ant colony optimization with weighted nearest neighbors.
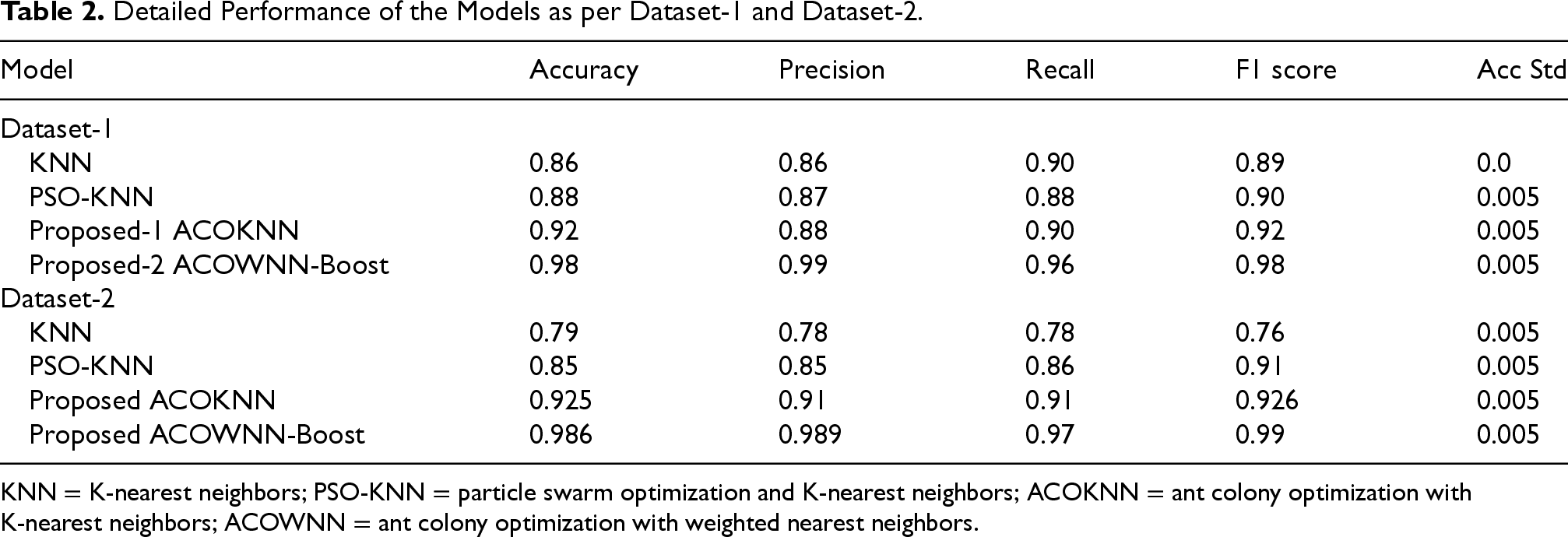
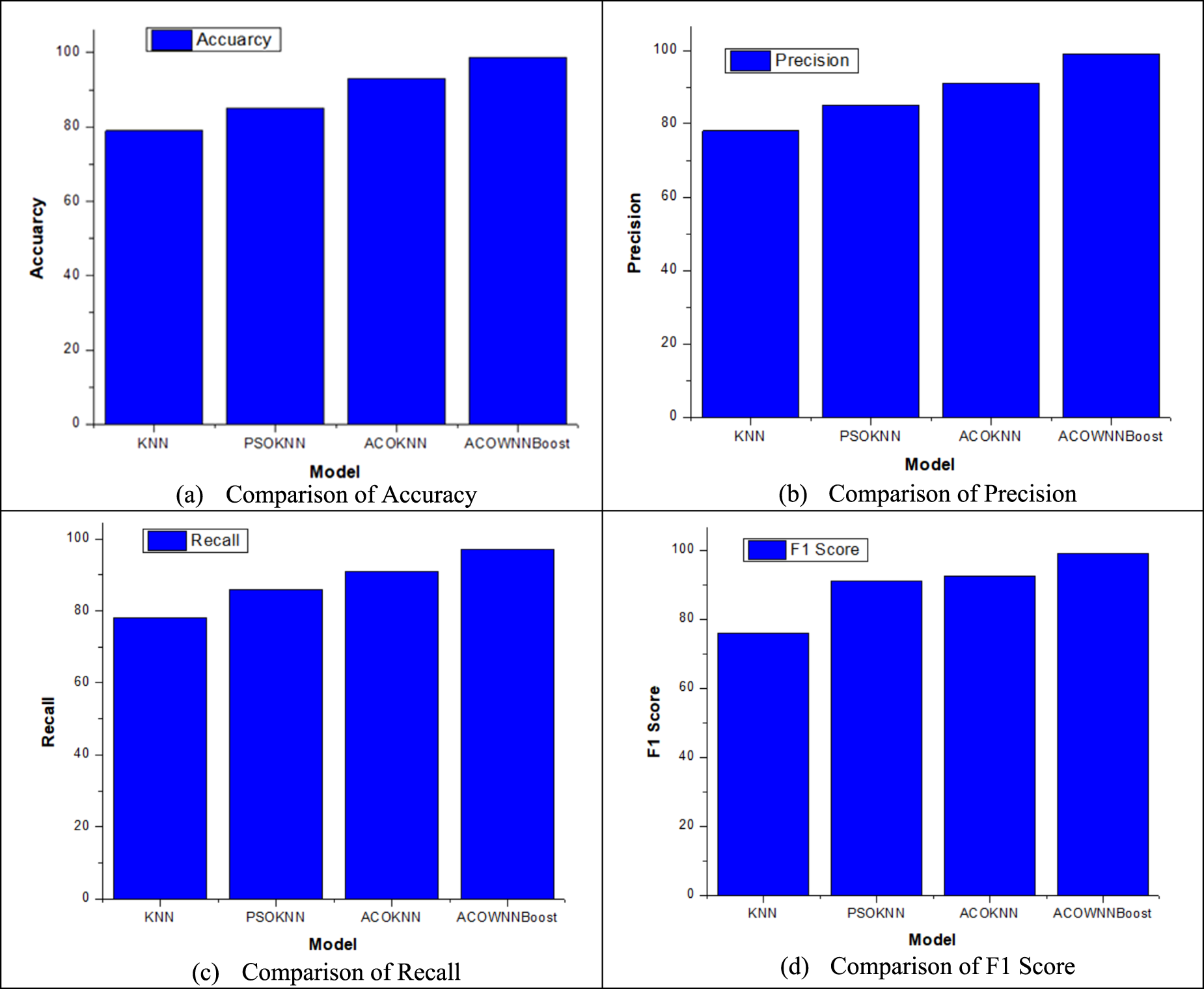
The first step in the examination was to look at Dataset-1, which had 1,024 instances and 14 attributes taken from the national government repository. This dataset was used to test the suggested hybrid frameworks’ capacity to make accurate predictions and stay stable over time. Table 2 and Figures 4 and 5 show how the four models—KNN, PSO-KNN, ACOKNN, and ACOWNNBoost—compare on the main metrics of accuracy, precision, recall, F1 score, and AUC-ROC.
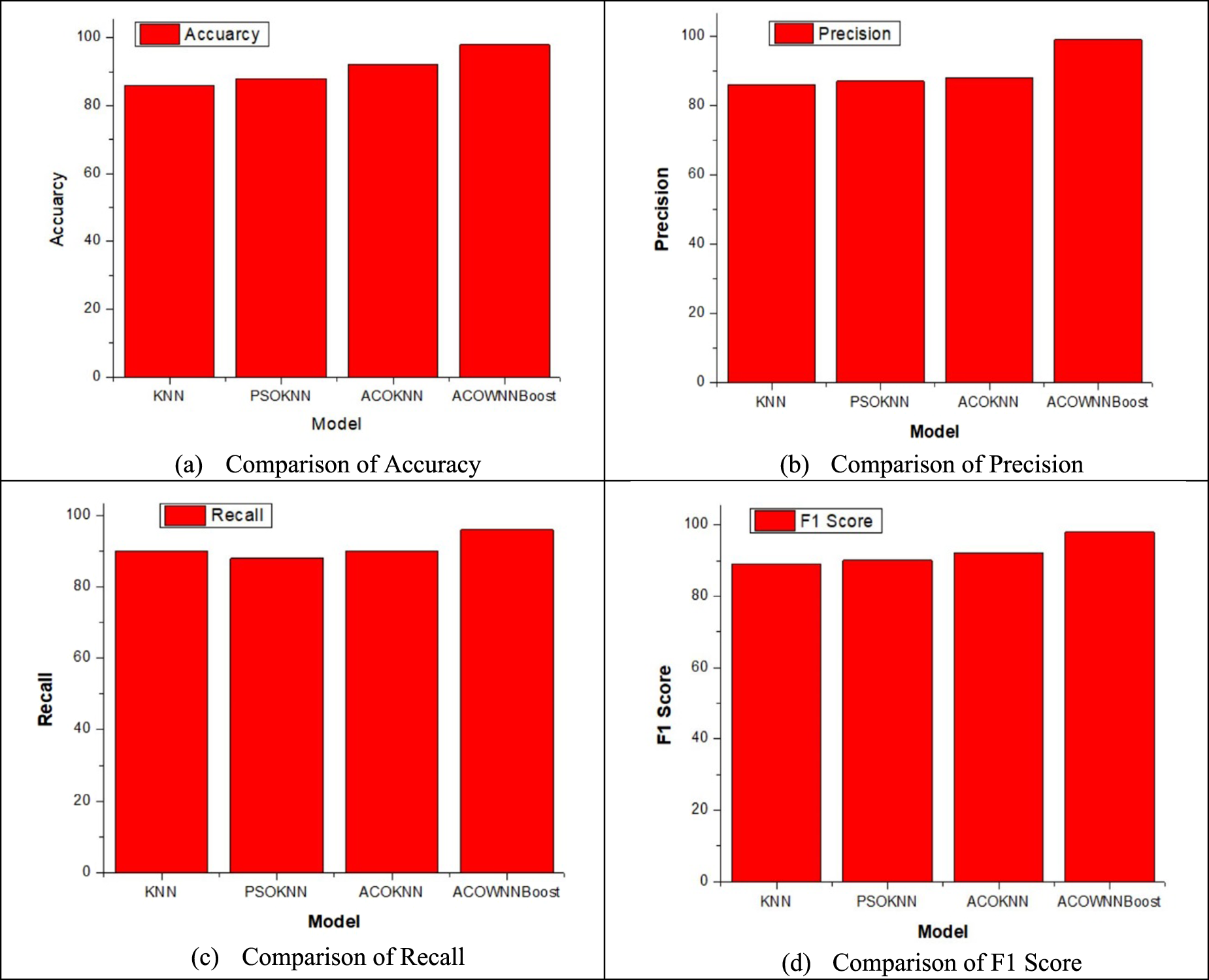
Comparison of various performance metrics for Dataset-1: (a) comparison of accuracy; (b) comparison of precision; (c) comparison of recall; and (d) comparison of F1 score.
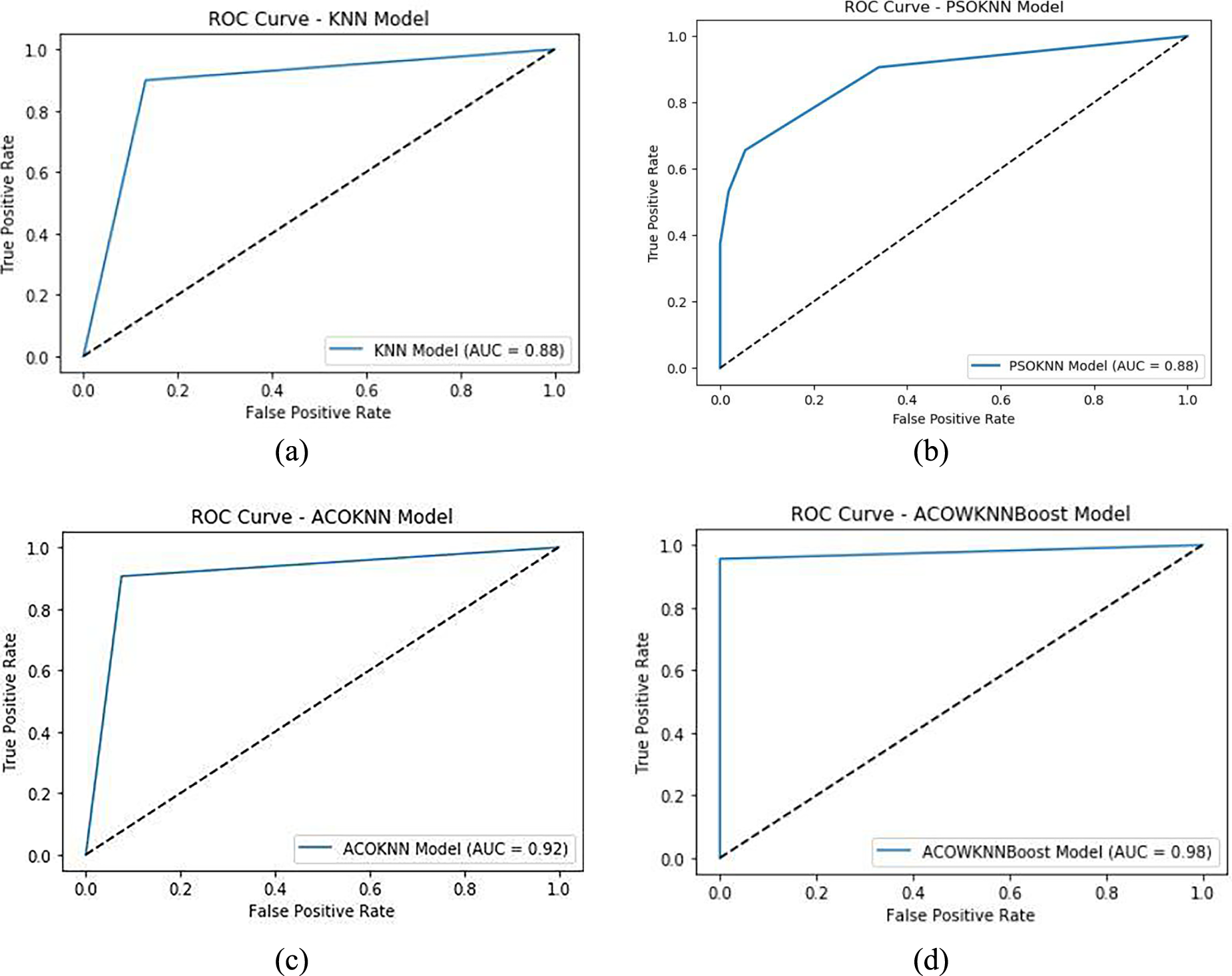
(a) AUC-ROC curve of KNN, (b) PSO-KNN, (c) proposed ACOKNN, and (d) proposed ACOWNNBoost for Dataset-1.
Detailed Performance of the Models as per Dataset-1 and Dataset-2.
KNN = K-nearest neighbors; PSO-KNN = particle swarm optimization and K-nearest neighbors; ACOKNN = ant colony optimization with K-nearest neighbors; ACOWNN = ant colony optimization with weighted nearest neighbors.
The baseline KNN model had an accuracy of 0.86, with intermediate precision and recall. This showed that it was not good at handling high-dimensional and partially correlated features. Combining PSO with KNN raised the accuracy slightly to 0.88. This shows that optimizing neighborhood parameters through swarm behavior helps use features better, but it still has problems with premature convergence to local optima.
The suggested ACOKNN model, which uses ACO-based feature selection with a sigmoid-transformed pheromone probability, greatly improved accuracy to 0.92 and F1 score to 0.92. This enhancement arises from the adaptive pheromone trail updating technique, which facilitates more seamless exploration of the feature space and removes superfluous or weakly associated information. The model's recall of 0.90 shows that it is better at picking up on minority (disease-positive) cases, which is important for medical screening.
The ACOWNNBoost model shows much more improvement by combining ACO-driven feature optimization with WKNN and XGBoost for ensemble learning. This hybrid framework had an amazing accuracy of 0.98 and an F1 score of 0.98, which was better than all the other benchmark models. Weighted neighborhood voting and gradient boosting worked together to make sure that both accuracy (0.99) and recall (0.96) were balanced, which reduced both false positives and false negatives. The AUC-ROC curve in Figure 5(d) shows much better discrimination capacity, with the curve getting closer to one, which means that the classification performance is almost perfect. The results overall show that combining swarm intelligence with ensemble learning in a synergistic way greatly improves the reliability of diagnosis.
Phase 2 of testing used Dataset-2, which was the Framingham Heart Study dataset. It had 4,240 records and 15 clinical attributes. This dataset is more diverse and has class imbalance and missing values, which makes it a good test of how well a model works in general and how strong it is. The same four models—KNN, PSO-KNN, ACOKNN, and ACOWNNBoost—were trained and tested again with the same conditions after normalization and imputation. Table 2 shows a summary of the results of the comparisons, and Figures 6 and 7 show them visually.
Comparison of different performance metrics for Dataset-2: (a) comparison of accuracy; (b) comparison of precision; (c) comparison of recall; and (d) comparison of F1 score.
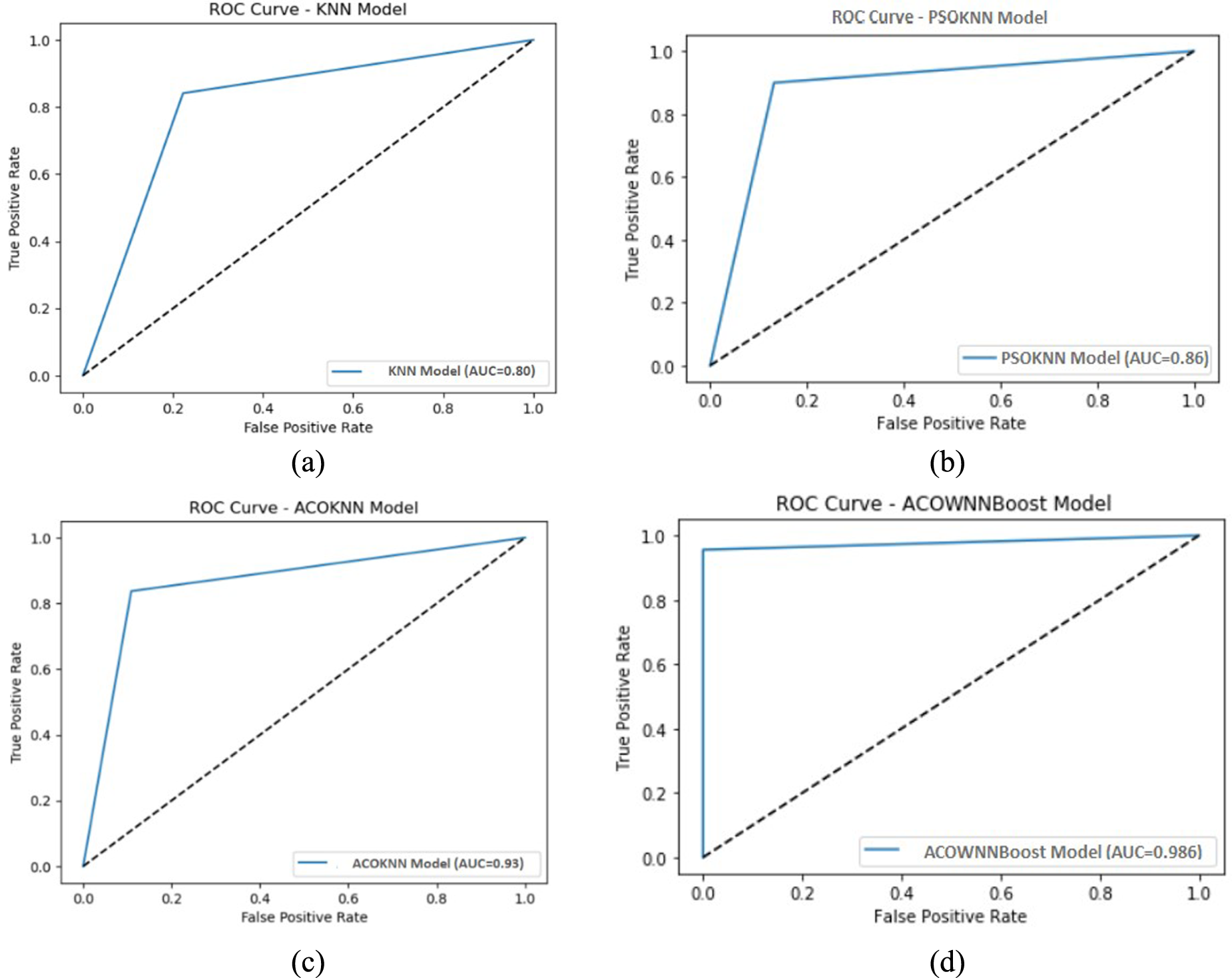
AUC ROC curve of KNN, PSO-KNN, proposed ACOKNN, and proposed ACOWNNBoost for Dataset-2.
The standard KNN classifier got a fair accuracy of 0.79, which shows that it does not work well on imbalanced medical data. The PSO-KNN hybrid raised the accuracy to 0.85, showing that using particle swarm dynamics to tune parameters helps enhance the neighborhood structure but still has problems with premature convergence and redundant features.
The suggested ACOKNN model showed good improvement, reaching an accuracy of 0.925 with a balanced precision and recall of 0.91 each. The pheromone-driven feature selection worked well to get rid of features that were not relevant or were only weakly associated. This made the feature subset smaller and more useful. The smooth sigmoid transformation in the pheromone update process made sure that the exploration was progressive and that overfitting was kept to a minimum. This led to consistently higher F1 scores across folds.
The ACOWNNBoost model had the best overall performance, with an accuracy of 0.986, a precision of 0.989, a recall of 0.97, and an F1-score of 0.99**. The combination of WKNN and XGBoost made it easier to learn from cases in the minority class and found nonlinear feature interactions that single-model baselines missed. The ROC curve in Figure 7(d) rises quickly to the top-left corner, which demonstrates that the model can tell the difference between things quite well.
All of these results show that both proposed models work well on datasets of different sizes and distributions. The small difference in accuracy (standard deviation = 0.005) shows that it is stable and can be reproduced. The ACO-based feature selection and hybrid ensemble technique is strong because the performance is the same from Dataset-1 to Dataset-2. This makes ACOWNNBoost a dependable and scalable system for predicting heart disease early on real-world clinical data.
Using convergence analysis, it has been analyzed how the optimization-driven models converged to see how stable and efficient the search process was during iterative learning. Figure 8(a) and (b) shows how the PSO-KNN, ACOKNN, and ACOWNNBoost models converge for Dataset-1 and Dataset-2, respectively. The shaded areas show the difference between runs, and each curve shows how the objective function (accuracy) changes over time.
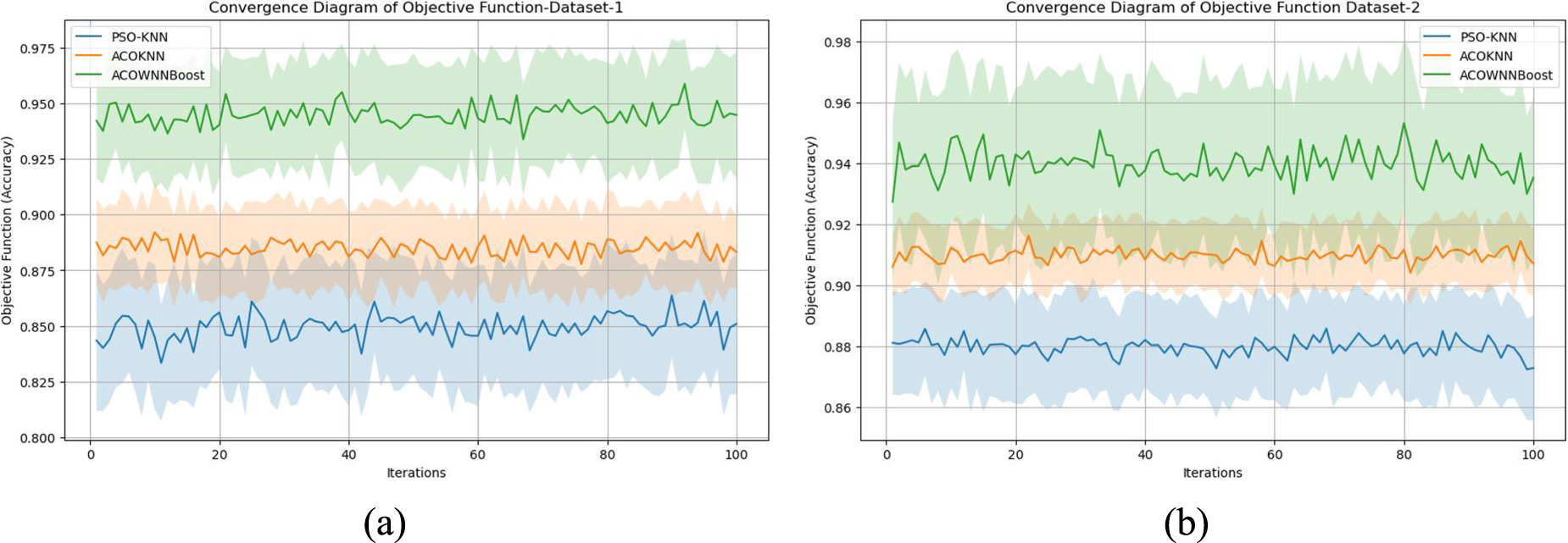
Convergence plot of PSO-KNN, ACOKNN, and ACOWNNBoost models using both datasets.
Figure 8(a) shows that the PSO-KNN model converges faster but too soon, stabilizing early around lower accuracy values because it tends to get stuck in local optima. The ACOKNN model, on the other hand, has a smoother and more gradual convergence pattern. This shows that the pheromone-based probabilistic search mechanism has a favorable effect. The adaptive sigmoid transformation employed in pheromone updating lets the ants keep exploring different areas, which helps the algorithm avoid getting stuck in one place and gradually improve its fitness levels.
The convergence profiles for Dataset-2 (Figure 8(b)) show that the ACOWNNBoost model not only has the highest accuracy but also converges more consistently, with very few oscillations. The combination of ACO-based feature selection and XGBoost-driven ensemble refining speeds up the process of finding the best solution while keeping the quality of the solutions the same. The ACOWNNBoost curve's narrow shaded confidence band shows that it is very repeatable and less sensitive to initialization.
The convergence analysis shows that the suggested algorithms have a good balance between exploration and exploitation, and they are more stable than classic PSO-based optimization. The ACOWNNBoost model, in particular, keeps a stable learning path across datasets, which shows that it may be used in real-world heart disease prediction applications because it is scalable, adaptable, and strong.
The performance of the proposed models is compared to several state-of-the-art methods from the literature (Asadi et al., 2021; Cherian et al., 2020; Guo et al., 2025; Manikandan et al., 2023; Sasirekha et al., 2025) that mostly used swarm-based optimization with classical and deep-learning classifiers such as NN, RF, and SVM. These investigations attained moderate accuracy, between 83% and 88%, although they were confined to single-dataset validation and had constrained feature-selection capabilities, hence compromising the generalizability of their models. Recent studies, including Guo et al. (2025) and Sasirekha et al. (2025), have developed sophisticated hybrid deep-learning frameworks (CNN + GAN + ML-ABC and Trans-Bi-LSTM-GRU + HCEFSO) that enhanced diagnostic accuracy to 90.8% and 97.36%, respectively. But both of them used data that was specialized to their field or the IoT and did not include adaptive ensemble learning or lightweight generalization across different clinical datasets.
In contrast, we tested the suggested ACOKNN and ACOWNNBoost models on two different datasets of different sizes to show that they can handle a lot of data and are stable. Table 3 shows that the ACOKNN and ACOWNNBoost models got 92% and 98% correct, respectively, for Dataset-1. This is better than any other benchmark study. The accuracy for Dataset-2 went up even further, to 92.6% and 98.6%, which shows that adaptive pheromone-based feature optimization and the ensemble synergy of ACO, WKNN, and XGBoost both work. The proposed framework also fixes some of the main problems with current methods, like premature convergence, single-dataset dependency, and poor exploration-exploitation balance. It does this by using a multi-dataset, trust-aware, and computationally efficient architecture that has better convergence stability and predictive reliability.
Comparison With Existing Studies.
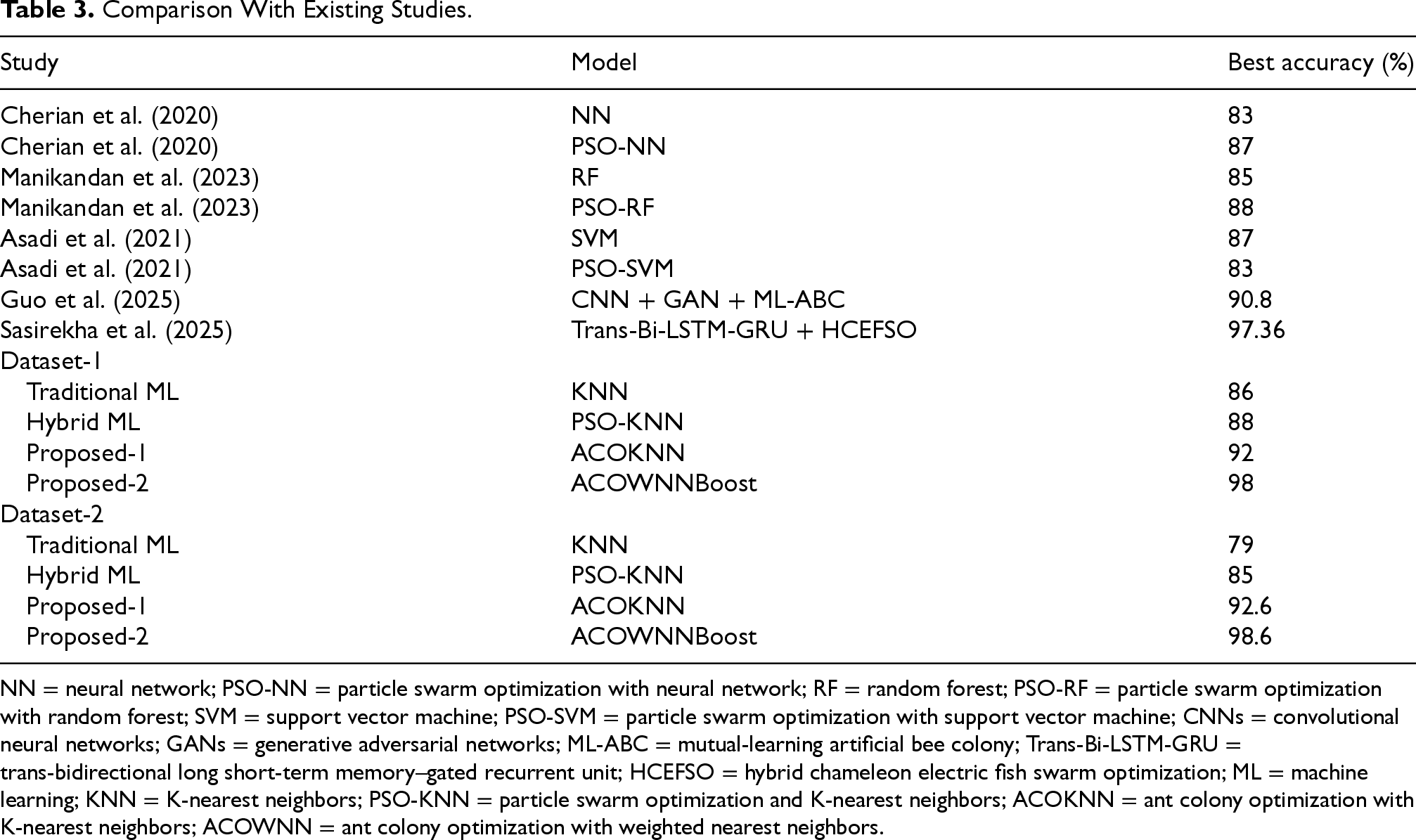
Comparison With Existing Studies.
NN = neural network; PSO-NN = particle swarm optimization with neural network; RF = random forest; PSO-RF = particle swarm optimization with random forest; SVM = support vector machine; PSO-SVM = particle swarm optimization with support vector machine; CNNs = convolutional neural networks; GANs = generative adversarial networks; ML-ABC = mutual-learning artificial bee colony; Trans-Bi-LSTM-GRU = trans-bidirectional long short-term memory–gated recurrent unit; HCEFSO = hybrid chameleon electric fish swarm optimization; ML = machine learning; KNN = K-nearest neighbors; PSO-KNN = particle swarm optimization and K-nearest neighbors; ACOKNN = ant colony optimization with K-nearest neighbors; ACOWNN = ant colony optimization with weighted nearest neighbors.
Heart disease remains one of the leading causes of mortality worldwide, posing a significant threat to millions of lives. Early detection is crucial, as delayed diagnoses can lead to severe consequences, both in terms of health and healthcare costs. Leveraging ML techniques has become crucial in enhancing diagnostic accuracy and efficiency. This study introduced two novel classifiers—modified ACO combined with KNN (ACOKNN) and ACO with WKNN integrated with XGBoost (ACOWNNBoost)—to enhance heart disease prediction. The models were trained and tested on two normalized datasets, and their performance was compared with that of traditional ML models, such as KNN and PSO-KNN. Both proposed models demonstrated superior performance, with ACOKNN achieving an accuracy of 92% and the novel ACOWNNBoost model achieving a remarkable 98% accuracy in heart disease predictions with Dataset-1, 92.5%, and 98.6% with Dataset-2, respectively. Ultimately, all the targeted research questions have been addressed, ranging from the importance of ML in heart disease prediction to the generalization of models using different datasets of varying capacities.
While the proposed study highlights the effectiveness of the proposed models in comparison to baseline methods, it is essential to acknowledge that there may be other state-of-the-art models or recent advances in the field that were not included in this comparison. Future work could explore a statistical view and incorporate additional datasets, including ECG images, to further improve prediction accuracy and expand the scope of heart disease detection methods.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.