
Abstract
This study proposes an improved random forest algorithm for an educational resource course recommendation network based on boundary value for the problems of low accuracy of educational resource recommendation network in universities, including weak ability to deal with boundary value, and poor adaptability in the face of complex educational environments and diversified user needs, the use of this network can be recommended for better educational resources. The research findings demonstrate that the algorithm error value of the improved random forest algorithm is better in the analysis of the matrix, the algorithm has the best algorithmic performance when the number of forests is 300, at the same time in the system test the algorithm can be smooth and safe through the test, the system in the home page resource recommendation and network performance, the improved algorithm test is good, the uploading and running time is less than 1 s, and the memory accounted for less than 40%. Algorithm model threshold at 0.10 and 0.15, the accuracy trend is the same as the threshold 0.05, while the larger the threshold the higher the accuracy. It can be seen that the improvement of the random forest algorithm can improve the accuracy rate of the current course recommendation, and at the same time, it can complete the course recommendation of the current educational resources, which has certain research significance for the research in this direction.
Introduction
The safe recommendation of educational resources in colleges and universities holds significant importance in the digital era, which is not only related to the efficient use of educational resources, but also to the safe recommendation of educational courses (Alvarez et al., 2020). With the improvement of informationization level in colleges and universities, recommender systems become a key technology to optimize the allocation and management of resources in colleges and universities (Wang, 2023). The digitization and networking of higher education resources have gained significant momentum in the educational sector, but in the face of massive online course resources, students and teachers face challenges in swiftly locating high-quality courses tailored to their requirements, which makes the research on recommendation systems for higher education resources particularly important. Although recommender systems have made progress in other fields, they still face the problems of data sparsity, insufficient boundary value processing, dynamic changes in user preferences, and insufficient utilization of multidimensional data in the realm of higher education resource recommendation. Existing researches are fruitful, but the solutions to these problems are still imperfect. Therefore, this research explores a method to improve the robustness and accuracy of the system by introducing a boundary value improvement strategy to better adapt to diverse college education scenarios (Faqihi et al., 2020). Random Forest (RF) is a powerful machine learning tool with the ability to handle large-scale data and complex features (Chapman et al., 2020). However, in the context of educational resource recommendation, the emergence of boundary value cases may lead to the performance degradation of traditional RF algorithms, thus affecting the accuracy of recommendation results. Based on this, this research proposes a set of strategies for boundary value improvement, which enhances the adaptability of the RF algorithm to boundary values by optimizing the key steps such as feature selection, node division, and decision voting. Meanwhile, it provides a new idea for the algorithm optimization of recommender system, and improves the reliability and accuracy of recommender system in practical applications.
This research is divided into four sections, the first section is an overview of domestic and international research, the second section is the construction of the model of the current research method, the third section analyzes the performance of the research content through experiments, and the fourth section is a summary of the article.
Aiming at the problems of insufficient accuracy, weak ability to handle boundary values, and poor adaptability to complex environments in the recommendation network of higher education resources, an innovative RF algorithm based on boundary value improvement is proposed. By constructing a three-layer secure recommendation system including user module, resource publishing module, and total resource management module, secure access and intelligent recommendation of educational resources are achieved. This algorithm significantly improves recommendation accuracy and robustness in sparse data and boundary sample scenarios by optimizing feature selection, node partitioning, and decision voting mechanisms. Grounded in the verification of the MOOOCubeX dataset, the experiment shows that it outperforms traditional approaches in key indicators like accuracy and recall. At the same time, the system has the characteristics of fast response and low memory consumption, providing a practical and feasible technical solution and practical reference for personalized and secure recommendation of higher education resources.
Literature Review
RF algorithm as one of the current commonly used algorithms is often used in a variety of data classification problems due to its unique algorithmic features. Veerabhadraswamy et al. (2021) considered that sensors usually undergo numerical variations in data analysis, which leads to less accurate sensors. Therefore, a forest algorithm based method for classification of sensor regions is proposed. By this method, it is possible to categorize the sensor data. The results of the study show that the use of this method can improve the current classification accuracy of the sensor. Shao et al. (2021) believe that the coefficient value of the field crops can determine the current crop evapotranspiration, but how to get the accurate coefficient value is crucial, so based on the RF algorithm to build a data regression evaluation model, the use of the model can be evaluated on the data of the crop. The findings of the study showed that using this method can improve the accuracy of coefficient classification of crops. Calhoun et al. (2020) concluded that in the control of hypoglycemia, repeated measurements can deal with the different linear relationships between blood glucose data, so an RF algorithm model for repeated measurements of diabetes data was proposed, which is able to measure the information of the current data frequently. The findings demonstrate that using the new model can accurately classify the categorical change data of nighttime blood glucose and reduce the risk of blood glucose . Chen et al. (2020) introduced two-layer Fuzzy Multiple RF in order to solve the problem in speech emotion recognition. The experimental findings demonstrate that the recognition accuracy of this scheme is 1.39%–7.64% and 4.06%–4.30% higher compared to back propagation neural network and RF, respectively. The experimental results show that the mobile robot can track six basic emotions in real time.
Meanwhile the recommendation analysis of educational resources is also the focus of current research, Wu et al. (2020), in order to solve the challenges of educational resources construction, proposed a semantic recommendation framework for educational resources based on the semantic web and pedagogy. The knowledge structure of domain ontology description is constructed, ontology technology and resource description framework are utilized for the description of resource-user combinations, and pedagogy-based inference rules are formulated. The results of the study show that the framework can recommend different learning materials based on different learning performances and can be used as a guide for instructors and resource designers. Salman and Soliman (2023) in order to investigate the students’ perceptions of online education for MBA and DBA, to assess its quality, and to explore the practical implications used a quantitative descriptive survey method and computed a speed factor to screen the valid responses. The findings of the study showed that students had higher satisfaction with online education and better perceptions of university support, instructor–student communication and course design. Han (2023) proposed an analysis method for learning behavior logs grounded in the theory of learner behavior analysis to solve the problem of personalized recommendation of resources in online learning platforms. The findings demonstrate that the clustering effect of the personalized recommendation method is effectively improved by modeling learner behavior through VSM, realizing learner group division based on learner behavior, and further evaluating and optimizing learner group division. Sun et al. (Sun et al., 2022). To improve the research on education big data, this paper comprehensively combs through and deeply explores the three major aspects of education data analysis. The findings demonstrate that the application of big data technology in education provides strong data support for the development of education, which can effectively predict the analysis, identify learners’ behavioral patterns, and match learners’ needs.
Li et al. (2024a). proposed a novel combination of machine learning methods for automatic labeling of Open Educational Resources (OERs) in response to the labor-intensive problem of re-labeling OERs when the classification standard changes. The results of the study show that, although fully automated operation is not feasible, the most general-purpose model achieves non-expert level results with a small number of labeled examples, and close to expert level with a large number of examples. We have publicly released pre-trained models that provide practical guidance for adapting OER to new classification criteria. Although the method can achieve recommendation and labeling analysis of OER, the security of OER cannot be effectively guaranteed, so the study proposes to improve the RF algorithm to enhance the security performance of OER recommendation. Albadarin et al. (2024) In order to explore the application of artificial intelligence (AI) in the recommendation of OER, a systematic overview method is proposed, and the results of the study show that learners use the AI as a virtual assistant to improve writing and language skills and facilitate directed and personalized learning; and educators use it to improve productivity. However, overuse may have negative impacts and it is recommended that training, support, and guidance be provided, and that ongoing research be conducted to refine and enhance the use of AI in education. It can be seen that the recommendation effect of educational resources can be significantly improved through AI, but the data security protection of resources needs to be further explored, so the study uses the improved RF algorithm to improve the recommendation security of educational resources. Zhang et al. (2025). proposed a hybrid educational resource recommendation model that integrates knowledge graphs and adaptive RFs. This study utilizes knowledge graphs to construct a semantic relationship network for educational resources, enhancing the interpretability and diversity of recommendations, while dynamically adjusting the weights of decision trees and node splitting strategies through adaptive RF algorithms. The experimental results show that the accuracy and recall of the model on public datasets reach 0.87 and 0.84, respectively, which are superior to traditional collaborative filtering and benchmark RF methods. The study summarized the advantages of this architecture in dealing with the complexity of educational scenarios, and pointed out the current problems and future research directions. Compared to the educational resource recommendation framework based on the semantic web and pedagogy proposed by Wu et al. (2020). Compared with Li et al. (2024a).'s research on automatic annotation of OER, this study focuses more on the universality and adaptability of system architecture, but does not delve into resource security and annotation automation.
In summary, current research mainly focuses on the application and limitations of the RF algorithm in various fields, to reveal the common shortcomings of the algorithm in handling boundary samples and sparse data, and provide a direct algorithm optimization basis for introducing boundary value improvement strategies in research. The second part of the research focuses on the existing research on educational resource recommendation systems, to illustrate that although current recommendation systems have made progress in personalization, interpretability, and other aspects, they face significant gaps in security guarantees and adaptability to complex educational scenarios. Some traditional research lacks a university education resource recommendation method that can simultaneously handle high sparsity, fuzzy boundary data, and has a secure mechanism. Meanwhile, for the recommended use of educational resources, there are still many problems, so this study proposes a new method based on the improved RF algorithm for the recommendation of educational resources for colleges and universities.
Design and Research on Secure Recommendation Network of Educational Resources in Colleges and Universities Based on Improved RF Algorithm
This chapter focuses on the construction of the current RF algorithm and the safe recommendation network of educational resources in colleges and universities, and a new model of the safe recommendation network of educational resources is constructed by analyzing the functions and procedures of the network system, as well as using the RF algorithm for the improvement of weighting and boundary values.
Secure Recommendation Network Design for Educational Resources in Colleges and Universities
Higher education resources security recommendation network system is mainly divided into three main modules, the user module, also known as the front-end module, is mainly to realize the front-end user's program to use (Ao et al., 2020). The second module is the educational resources publisher module, which mainly carries out the background resource release and reception, course management and so on for the users in colleges and universities. The last module is the total resource management module, which mainly manages applications such as users, resource publishers, and courses in the secure referral network. The schematic diagram of its three modules is shown in Figure 1.
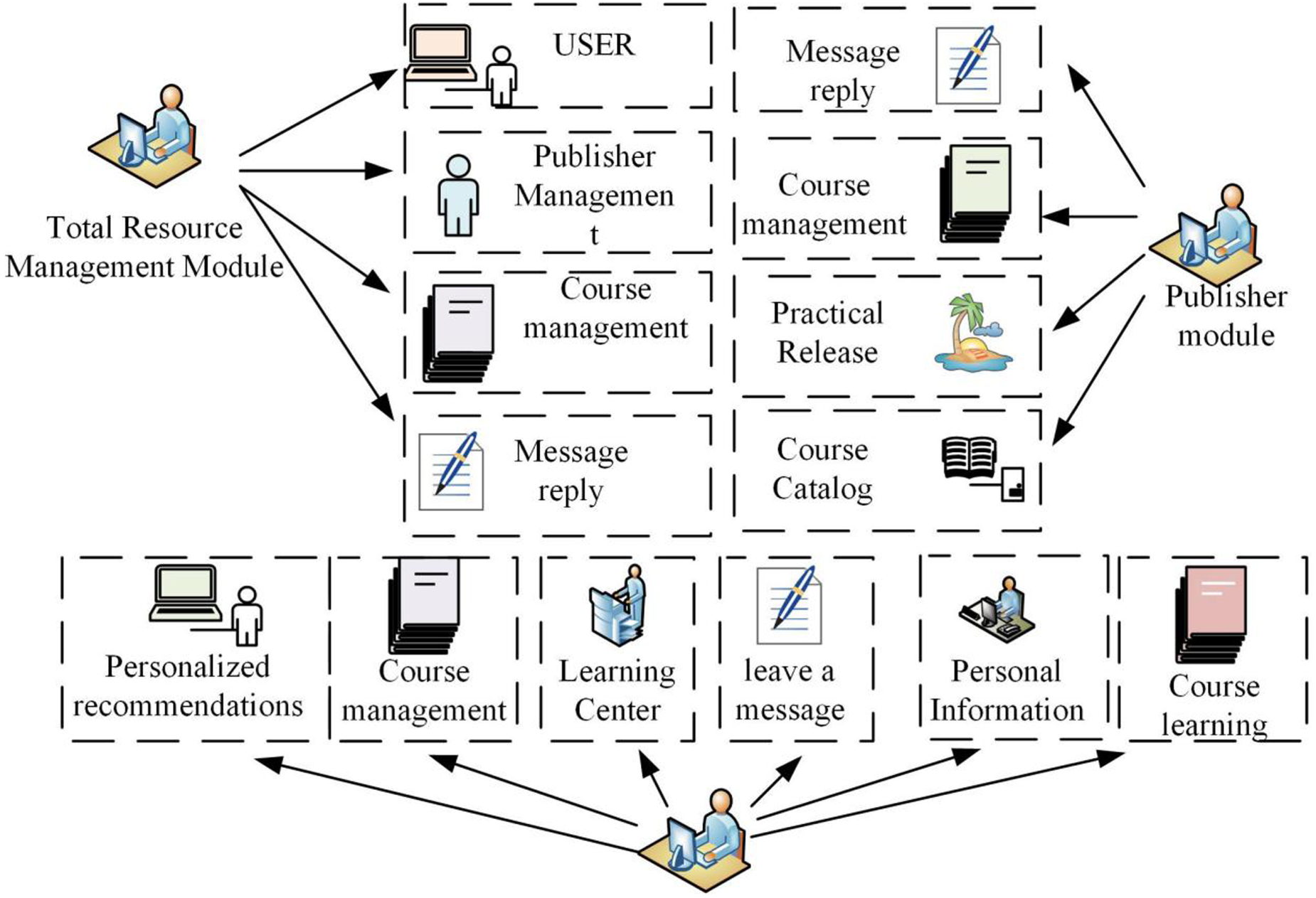
System module schematic diagram.
In Figure 1, the college network security recommendation network system of the three modules, respectively on different background procedures for control, the front-end user module can be personalized management, self-courses on college courses, and the learning center for recommendation and management, at the same time practical analysis of the course can be achieved when the course rating analysis and message feedback. The total resource management module can manage the users and the background to analyze and process the user's message information and arrange the current program directory table. The publisher module is able to manage the published information, analyze and process the college courses, and finally reply to the message information of the current users.
A data management and user resource sharing network platform for security is essential, if the platform in the use of the lack of security will cause the user's data leakage and a series of security problems, so in the design of the platform system need to pay attention to some of the stability and security of the system, increase the privacy of the current system of access to the system, in the test of user data and user verification Can enhance the reliability and security of the current system, such as in the login interface to increase the user verification information, such as fingerprints, passwords, facial recognition, etc. (Cai et al., 2020). Therefore, in view of the current system requirements were analyzed and designed for the three modules of the system, the user module can be used to enter the education security recommendation platform through code scanning and other verification operations, the functions of the platform can be used for user login, resource sharing, resource search, data viewing and other operations, personal information data management, course selection, and personalized design and other interfaces. As shown in Figure 2 for the user module main system operation and use of the process.
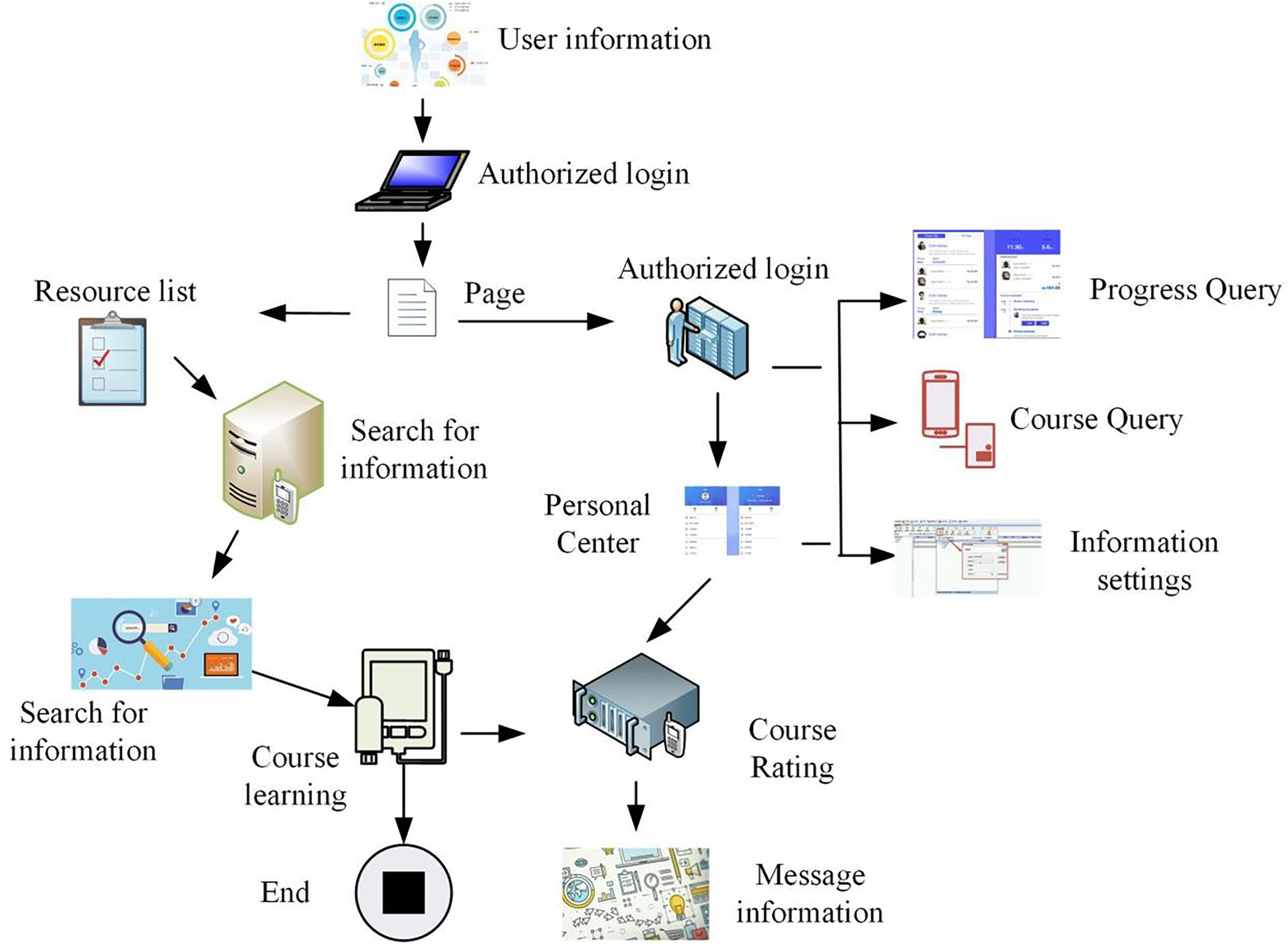
Main system flow of user module.
As shown in Figure 2, the user module enables users to conveniently browse, select, and study recommended courses. The main functions of the user module include user login and authentication, personalized recommendation, course learning and management, course evaluation and feedback, and personal information management. The operation process of the user module is mainly that the user logs into the system through authorization and the system verifies the user's identity. The system then recommends relevant courses based on the user's historical data and preferences. Then the user browses the list of recommended courses and selects the one he is interested in to study. Finally, the user enters the course learning page and starts learning the selected course, and the user evaluates and comments on the course after completing the course. The user can choose to exit the system after completing the operation (Zhu et al., 2022). Educational resources publisher module is mainly able to publish and manage the current class schedule and some information data. As shown in Figure 3 for its basic operation process.
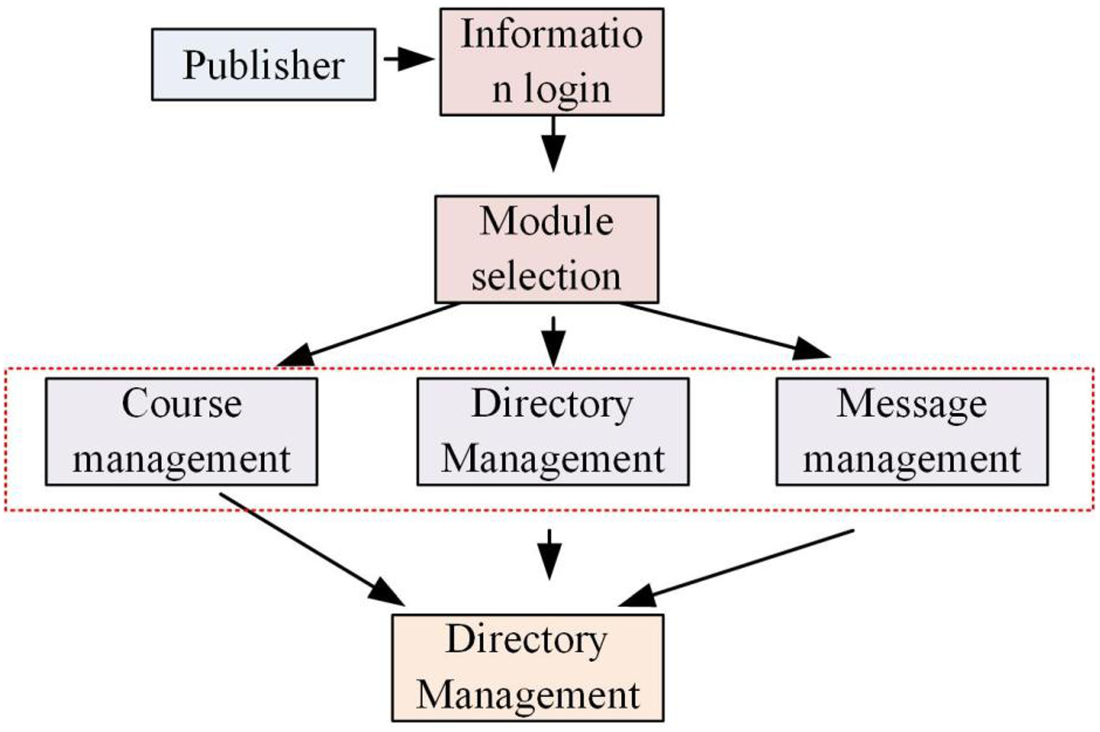
Resource information release process.
In Figure 3, the resource publisher, like the user, needs to be authorized to log in first, such as their fingerprints, passwords, and other information, after logging in and selecting the three program modules in the main program, to manage the course management is mainly to publish some course information data, modify the current course information, and publish some course tasks, etc. The catalog management module is mainly used to add and modify the current course list. Message management is to deal with the messages left by users and to receive the tasks issued by the current course. But at the same time, due to the college courses are more, the classification is more detailed, so each publisher's data management is different, at the same time, the release management data information of each college and major is different. The total resource module is the highest level module among the three modules, as shown in Figure 4 for the total resource management module flow diagram.
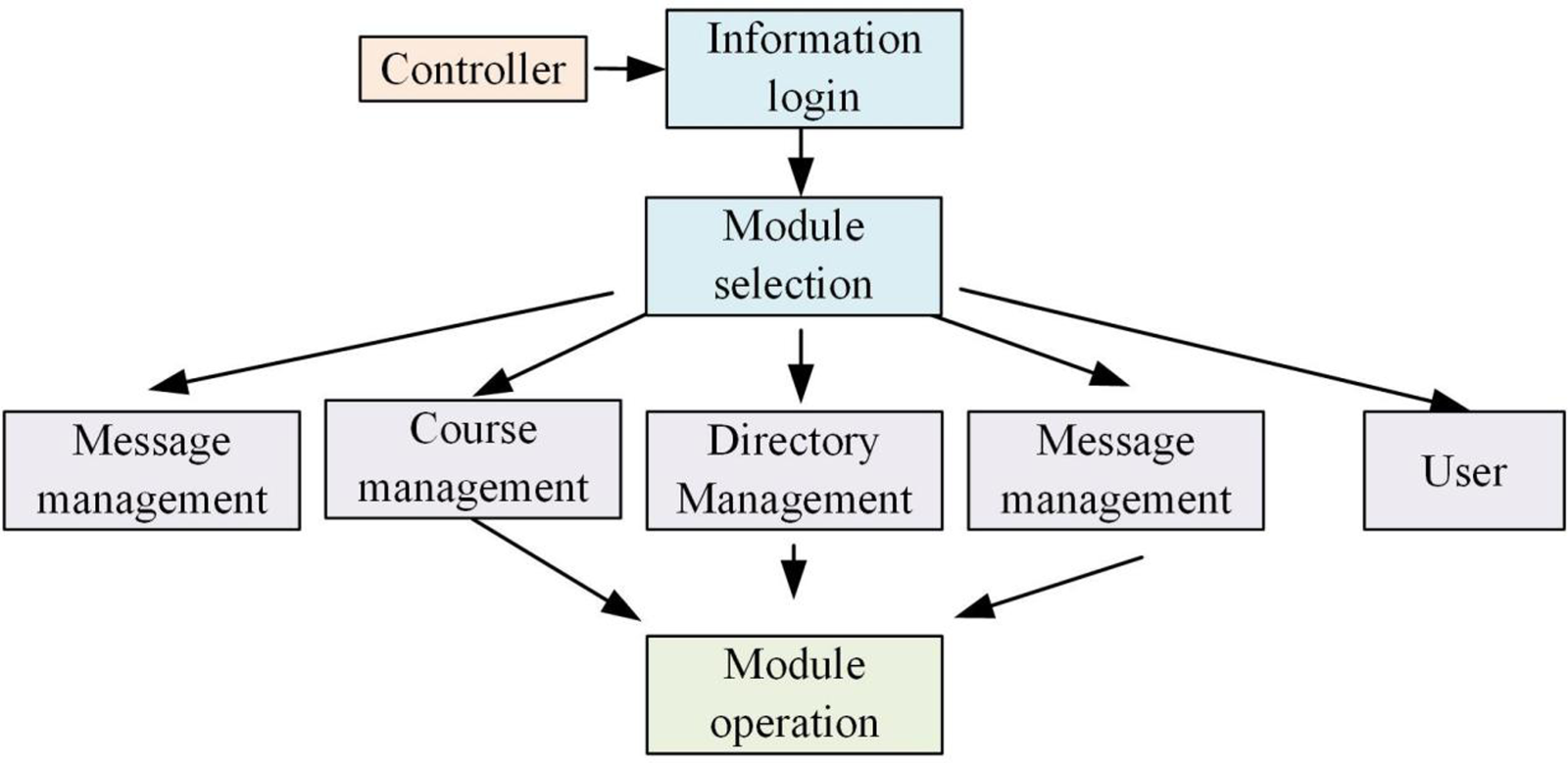
Total resource management process.
In Figure 4, the total resource management also uses authentication to log in, and the total resource manager is able to make choices in course management, user management, publisher management, catalog management, and message management. It can modify the current user information and publisher information, and correct data errors in a timely manner. The total resource management can manage all the courses of the entire university, and can delete or modify some published and unpublished courses, while the message management is to interactively analyze some of the current user experience and improve the user experience. Finally, in the entire university security network system platform, the high-performance data platform is the basis for guaranteeing the normal extraction and use of current data. Therefore, an online safety recommendation database model based on current data information is built to include the above data information for timely use and update.
After completing the construction of the relevant framework of the system, how to recommend better and better quality educational resources for the users becomes a new problem in the construction process of this system, so the improved RF algorithm is added to the system. In the algorithm firstly, the data matrix is built for courses and users as shown in Equation (1) (Li et al., 2022).

In Equation (1), assuming that the number of users as m and the number of courses as n, then

In Equation (2), T denotes the size of the set of user samples, then the course size at this point is represented by Equation (3) (Lin et al., 2020).

In Equation (3), Y indicates the size of the course set, when there are more users and courses the dataset matrix becomes larger, which can lead to the matrix due to larger data and make the solution more difficult, so the use of sparser matrices for spatial and computational reductions by adding discrete divergence calculations, as shown in Equation (4).
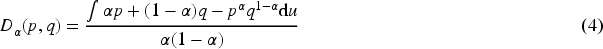
In Equation (4),

In Equation (5),

In Equation (6),
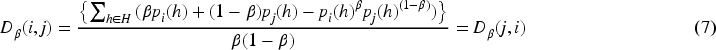
In Equation (7), the parameter size is the same as the above equation, when the value of the difference between the two courses varies less, one can define these two formulas as the same similarity, at this time the similarity calculation formula is shown in Equation (8).

In Equation (8),

In Equation (9), I denotes a kind of course, and

In Equation (10),
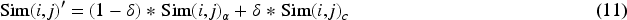
In Equation (11), it represents the formula for the change of similarity after the increase of weights. When the given course i is able to calculate the similarity between other courses and the given course, then the prediction formula at this time is shown in Equation (12).

In Equation (12), u denotes the user, i and j denote two courses, and k denotes the number of courses with the same similarity. The size of similarity and rating can recommend the popular courses. Secondly, in order to solve the current user experience in the course recommendation problem, through the use of RF algorithm feature data for screening in order to reduce the randomness of the user in the course selection, such as what the user will choose what course according to their own preferences, and then it is difficult to ensure the accuracy of the user's recommendation, so in the RF algorithm using a weighted approach to the calculation of the boundary value. Meanwhile, the accuracy function is set in the weighting calculation to get the accuracy formula as shown in Equation (13).

In Equation (13),

In Equation (14), k denotes the number of samples for the second training of the sample, n denotes the number of times the training was performed, u denotes the size of the weights, T denotes the correct number of classifications, and
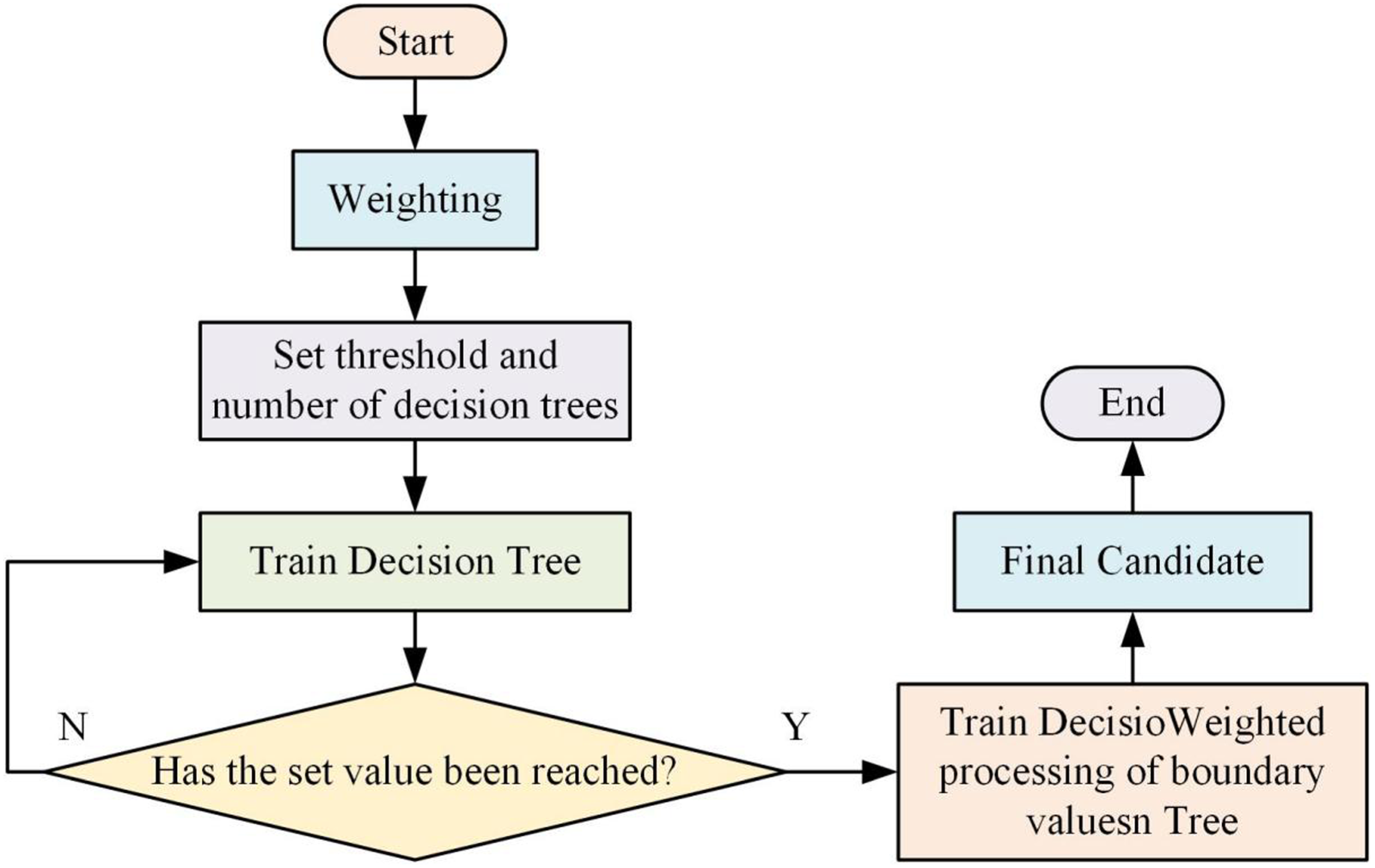
Weighted random forest (RF) algorithm flow.
As shown in Figure 5, the threshold of the algorithm and the number of decision trees are set at the beginning of the weighting process, the initial data training set is imported, and the decision trees are built by randomly selecting the training, and then the number of the calculated decision trees is judged to determine whether it reaches the set threshold or not, and if it does not reach the threshold, the decision trees continue to be built, and when it reaches the threshold, the weighting process is carried out to get the final candidate project, and the algorithm is ended. Through the forest algorithm to improve the weighting, while adding the course similarity calculation to complete the entire system to improve the RF algorithm to build, as shown in Figure 6 for the current system algorithm flow diagram.
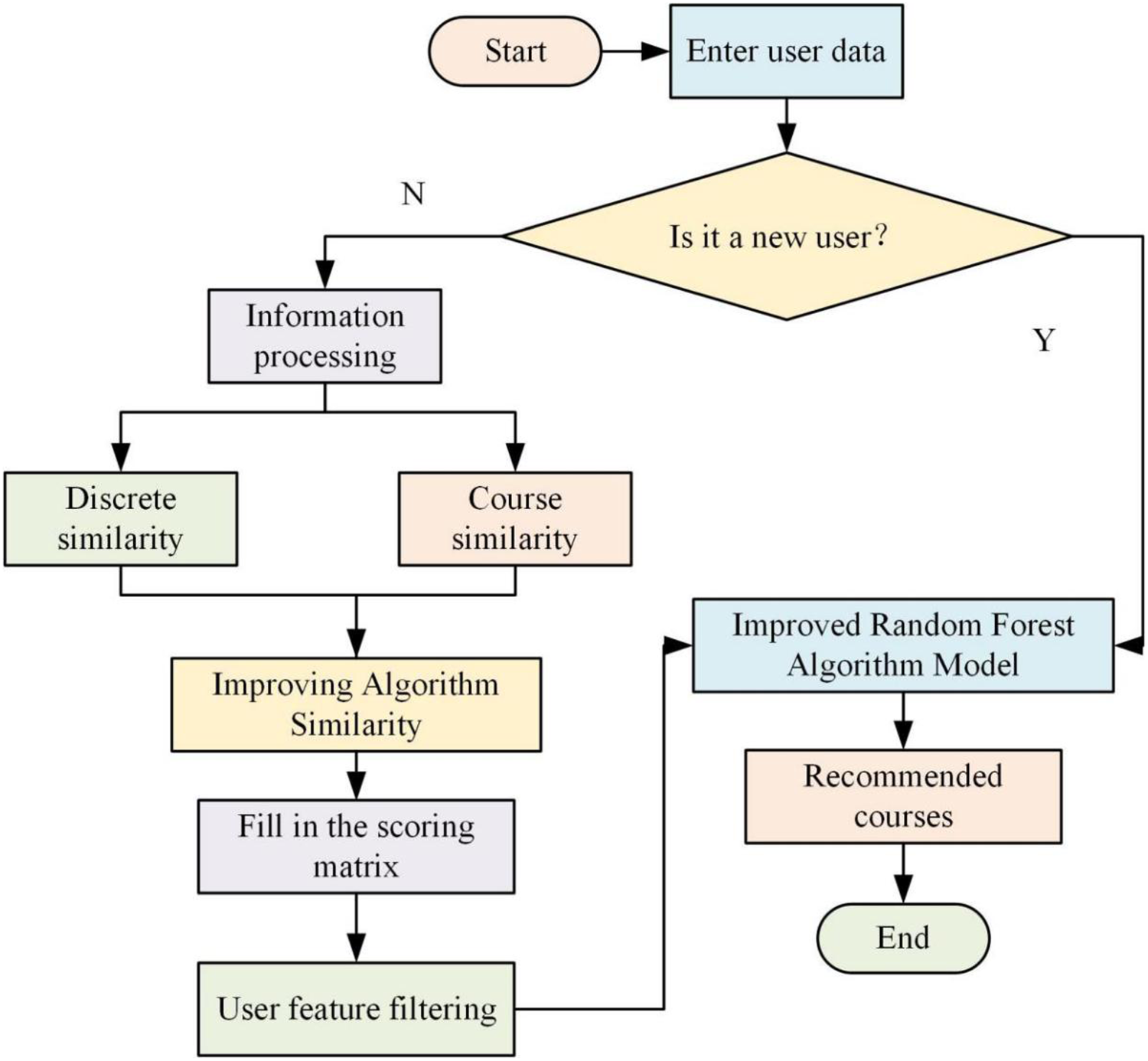
System algorithm operation process.
As shown in Figure 6, when the system is running, first of all, the user's information is input, to determine whether the current user is a new user if it is, then carry out the weighted processing of the improved algorithm, after processing to get the new recommended courses to end the algorithm. If not, then the processing of information, through the calculation of different similarity to get the current candidate course feature data information, and then improve the algorithm of the weighting process to get the final recommended courses, the end of the algorithm. The improved RF algorithm first preprocesses the data, including data cleaning, feature selection and normalization. Then in the feature selection stage, important features are screened by calculating feature importance and setting a threshold, while the threshold is adjusted by cross-validation to optimize the feature set. In the node division stage, an impurity threshold is set to control the depth of tree growth, and the threshold is adjusted to optimize the depth of the tree through experimentation. In the decision voting stage, the voting threshold is set and adjusted by validation set. During model training, key parameters are adjusted through cross-validation. In the experimental validation part, public datasets are selected for comparative experiments to analyse the model performance changes under different threshold settings, and finally the improved RF algorithm is integrated into the university educational resources recommendation system for system testing and user feedback collection to further optimize the system performance. Threshold selection strategy, which involves calculating the importance score of each feature using RF algorithm. According to the distribution of feature importance scores, a threshold is selected to filter out the important features. A threshold is also set to stop further segmentation of a node when the impurity of the node is lower than the threshold. And the threshold can be optimized using grid search or random search. Finally, in RF, each decision tree classifies the samples. By setting a threshold, it is decided how many proportions of decision trees need to agree with a certain classification result in order to take it as the final prediction. Equation (15) is the formula for the root mean square (RMS) value.

In equation (15),

In equation (16),
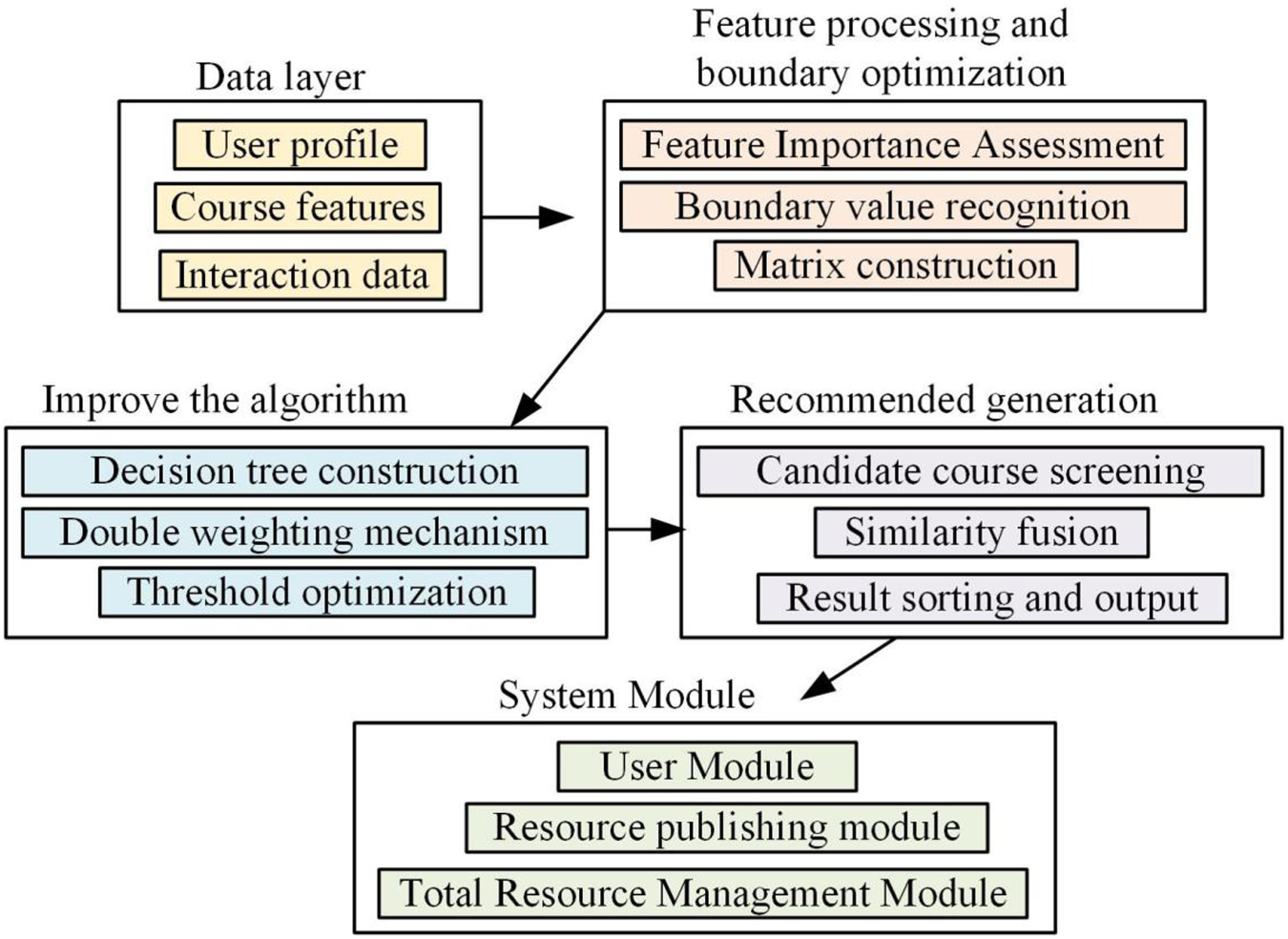
Framework diagram for research use.
From Figure 7, it can be seen that the proposed university education resource security recommendation network based on boundary value improved RF algorithm consists of a data layer, feature processing layer, algorithm core layer, recommendation generation layer, and system application layer. The data layer integrates user profiles, course features, and historical interaction behaviors, constructs a user course rating matrix, and introduces dispersion calculation to address high sparsity. The feature processing layer calculates feature importance through RF, and optimizes feature selection and node splitting strategies by combining boundary value recognition and double weighting mechanism. The core layer of the algorithm adopts a second-order weighted RF, and sets feature thresholds, node splitting thresholds, and voting thresholds during the decision tree construction process to enhance adaptability to boundary samples. The recommendation generation layer is based on a weighted similarity fusion method to screen candidate courses and generate a personalized recommendation list. The system application layer will embed improved algorithms into a three-layer secure recommendation system that includes a user module, a resource publishing module, and a total resource management module, to achieve secure access control and intelligent resource recommendation.
In order to validate the current use of the RF algorithm on the security of educational resources in colleges and universities, the accuracy of the algorithm is compared with the RMSE and the absolute error of the mean in the algorithm. The test dataset uses the open learning data of courses from Harvard University and MIT on the web platform, and each record is tested for interactive attributes, while each record is represented as an interactive change between the current user and the course. The size of the dataset is about 100,000 records covering 50 different course attributes, including user ratings, course categories, study duration, user behavior logs, and so on. The number of decision trees is set to 300, the maximum depth is set to 20 layers, and the minimum number of sample splits is set to 2. The experimental dataset used in the study is the publicly available MOOOCubeX dataset, which covers nearly 100,000 interaction records generated between approximately 5000 college students and 200 interdisciplinary courses between 2016 and 2020. It includes more than 50 dimensional features such as explicit user ratings, video viewing duration, homework completion rate, and other implicit behavioral logs. The constructed user course interaction matrix has a sparsity rate of up to 92%, effectively simulating the challenges of data sparsity and boundary sample processing in real educational recommendation scenarios. This dataset is a publicly available research resource that can be used for repeated experiments and comparative studies (https://mooc.acemap.cn). After cleaning, encoding, and standardization preprocessing, the data is divided into an 80% training set and a 20% testing set in chronological order to ensure the timeliness and reliability of model predictions. The algorithmic model of this research is compared to other current algorithmic models in this direction, such as programable Programable Computer Controller (PCC), Kullback-Leibler divergence Collaborative Filtering (KLCF) mode, and RF algorithmic model for different sparsity levels. The performance comparison is shown in Figure 8.
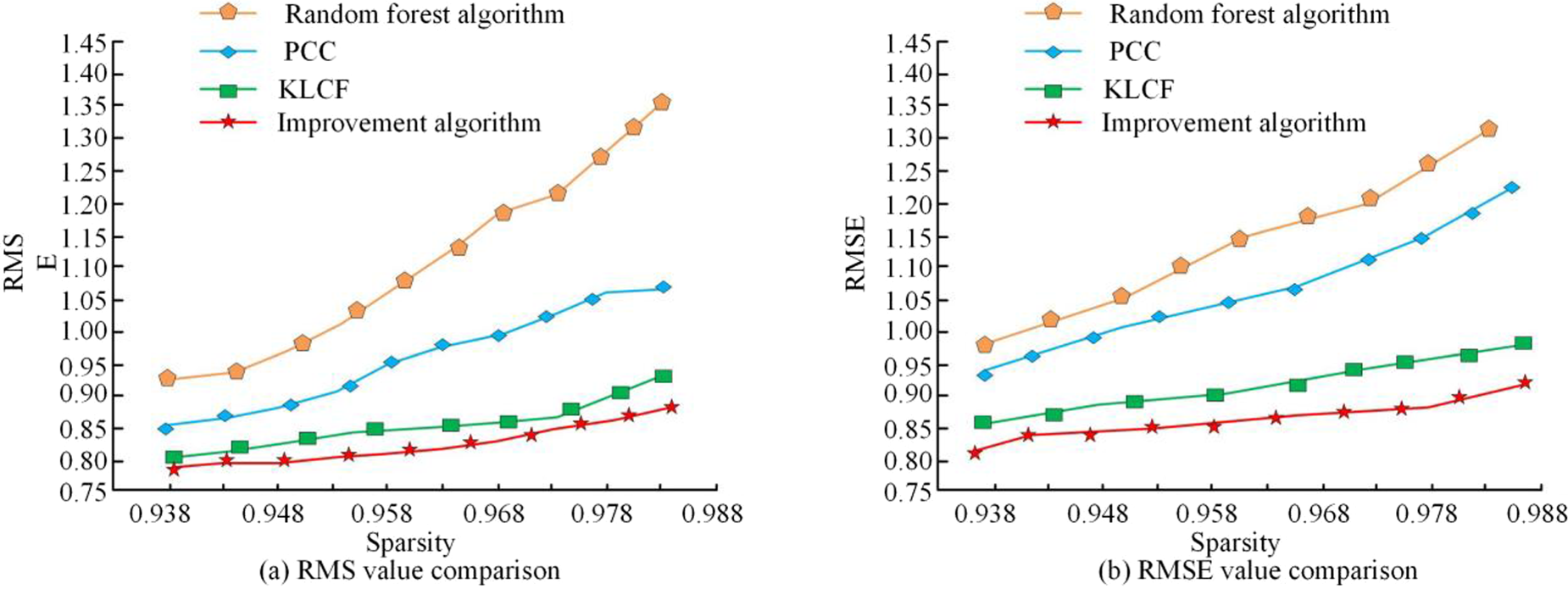
Error comparison of different models.
As shown in Figure 8(a), the RMSE of different data models increases with the increase of sparsity, but in the comparison of several algorithms, the improved RF algorithm has the smallest change in the RMSE value, and at the same time the change trend of the RMSE value is relatively slow, which indicates that the improved RF algorithm can handle the sparsity of the current model data very well. Meanwhile, in Figure 8(b), all the models make the mean absolute error (MAE) rise as the sparsity rises, but the change in the error value of the improved RF algorithm is relatively small compared to several models, and at the same time, its error value is also the lowest. This shows that the algorithmic error value of the Improved RF algorithm performs better in the analysis of matrices. In order to compare the accuracy changes of the current algorithm models, several models are set to different thresholds and an accuracy comparison is obtained that is shown in Figure 9.
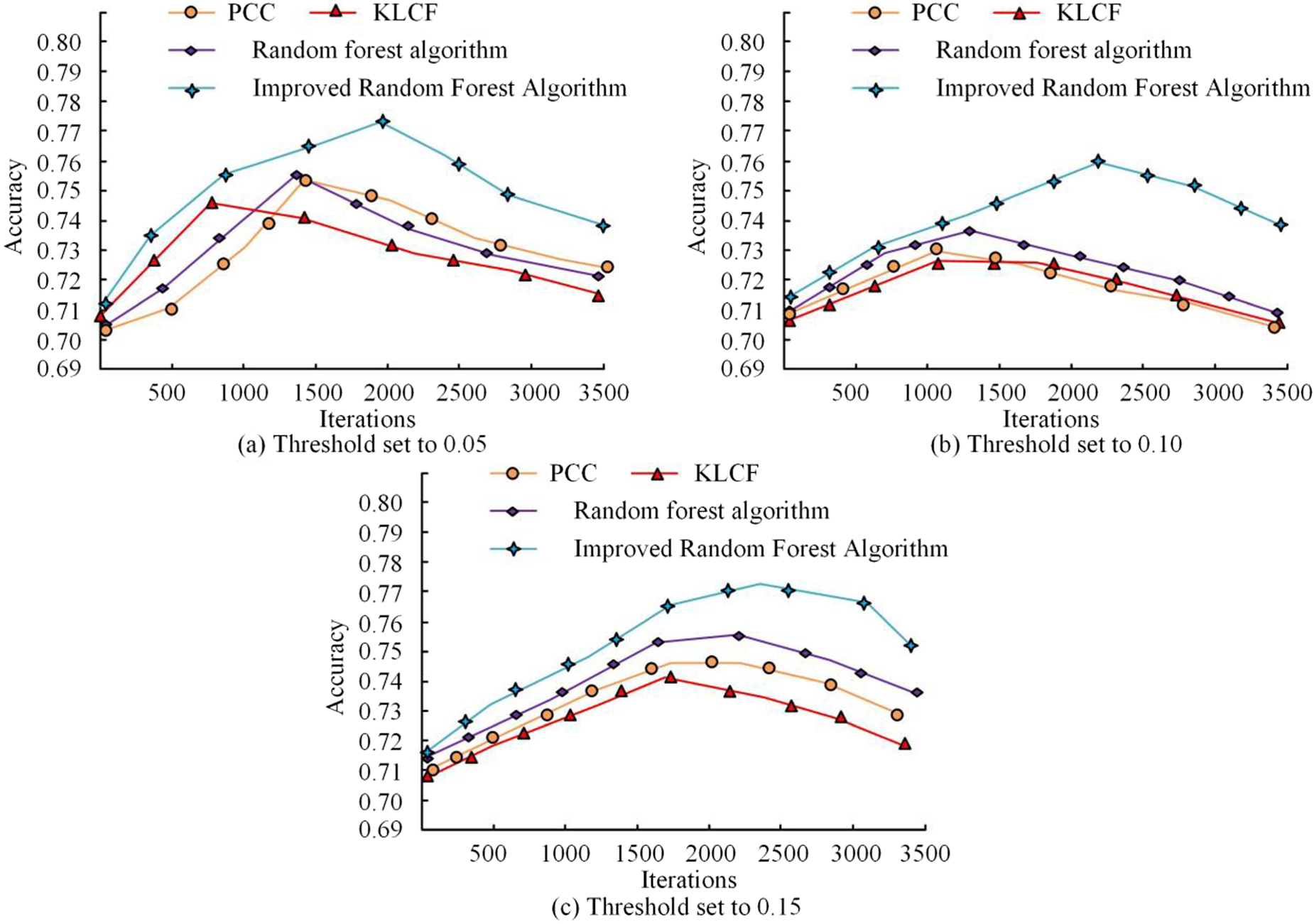
Comparison of accuracy of algorithms with different threshold sizes.
As shown in Figure 9(a), the trend of several algorithms in the threshold value of 0.05, all with the increase in the iteration count and the increase in accuracy, in the iteration count up to a certain number of times, the accuracy began to show a downward trend. Comparison of several models in the improved RF algorithm has the highest value of accuracy, there is a decline in accuracy when the maximum iteration count value of 2000. at the same time, Figure 9(b) and (c) in the different size of the threshold value of 0.10 and 0.15 when the trend of change in the accuracy rate of several models and the threshold value of 0.05 is roughly the same, but the difference lies in the size of the accuracy rate and the iteration count when there is a decline in the accuracy rate of the research. Using the algorithm model has the highest accuracy value and the highest iteration count when there is a drop. This shows that the RF algorithm performs better with different threshold settings for the algorithm with higher accuracy. In order to verify the effect of different RF trees on the algorithm's accuracy change, the algorithm's accuracy change is compared under different RF tree settings, as shown in Figure 10.
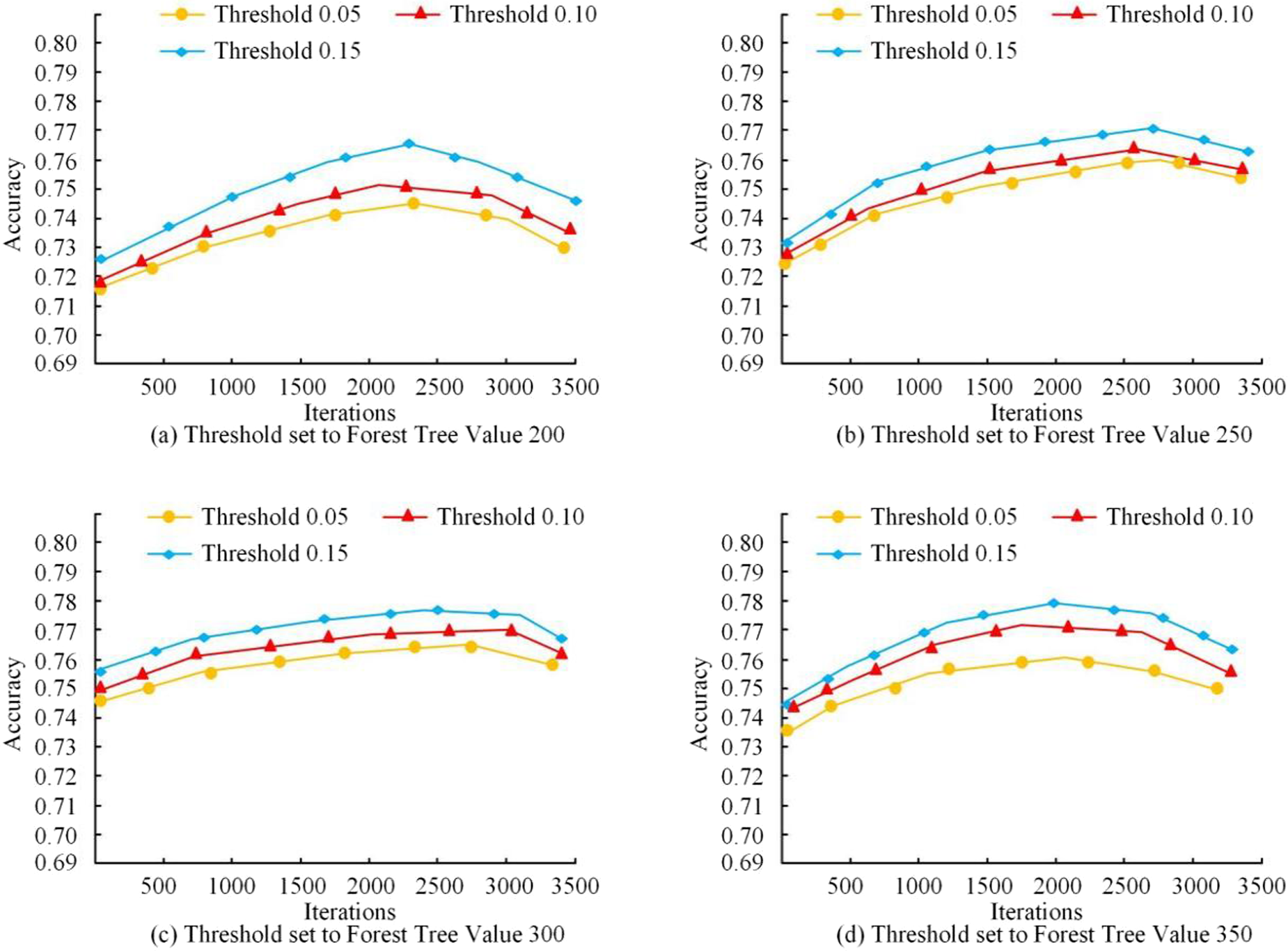
Comparison of accuracy of forest tree numbers with different thresholds.
As in Figure 10, the four graphic comparisons found that when the number of forest trees is 300 the whole algorithm's accuracy change curve is relatively smooth, while the algorithm's accuracy change value size with several other different numbers of accuracy change is relatively high, which shows that in the algorithm to set the size of the number of forest trees to be able to improve the accuracy size of the algorithm, thereby improving the algorithm's performance, as can be seen from the four graphs of Figure 9, the algorithm set the number of tree. From the four graphs in Figure 9, it can be seen that the algorithm can reach a high level of accuracy when the number of trees is set to 300. In order to test the current improved algorithm threshold setting size, will be several different RF-processing methods for the accuracy rate and the number of forest trees comparison, which comparison only use the quadratic weighted RF algorithm and traditional RF algorithm, as well as the experiments of the quadratic weighted and boundary value RF algorithm for comparison, get as shown in Figure 11.
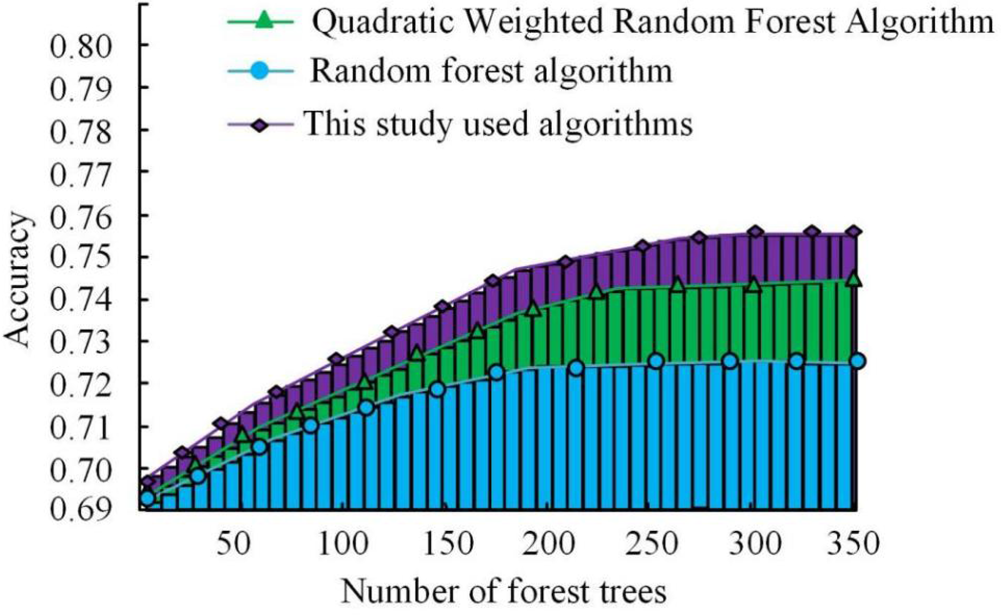
Performance comparison of different improvement methods.
As shown in Figure 11, the accuracy curve of the three algorithms tends to increase with the increase in the number of forest trees, and gradually tends to stabilize when it reaches a certain value. Among them, the accuracy of the RF algorithm tends to a stable state when the number of forest trees is 200, the RF algorithm improved by using edge quadratic weighting gradually tends to a stable change in accuracy when the number of forest trees is 250, and the RF algorithm using quadratic weighting and change in boundary value gradually tends to a stable state when the number of forest trees is 300, while the accuracy rate is 0.75 when comparing the accuracy rate, high RF algorithm 0.72 about 0.03 and high quadratic weighted improved forest algorithm 0.74 about 0.01. This shows that the improved RF algorithm using the methodology of this research performs better. In order to test the feasibility of the current algorithm in the recommendation of educational resources for the college safety network, the data was imported into the web system for resource testing on the home page. It is obtained as shown in Table 1.
Page Data Information Test Results.
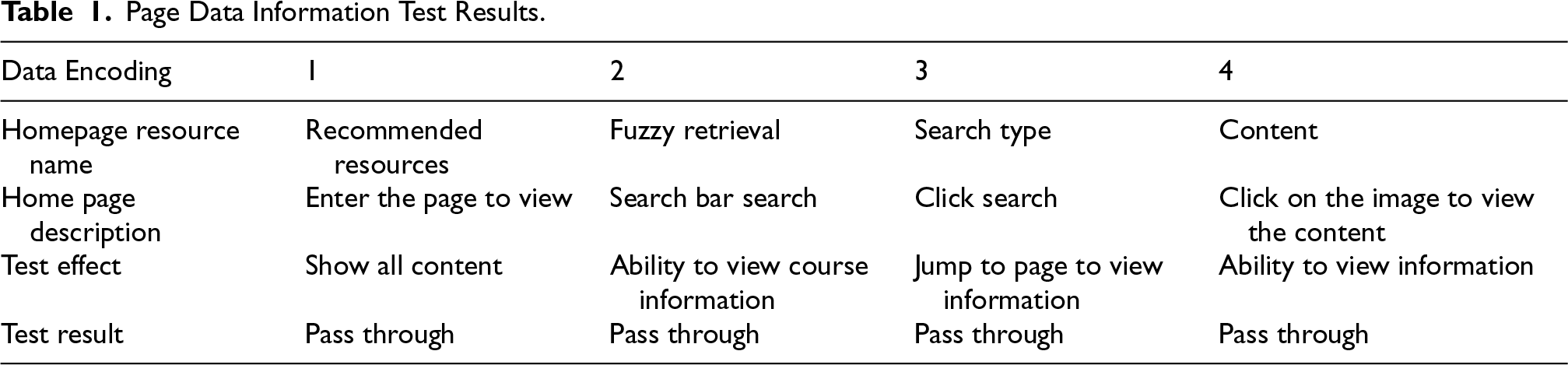
As shown in Table 1, the home page resource recommendation system using the improved RF algorithm is able to perform the expected operation on the current use page, and it can successfully pass and achieve the expected test results when the system function test is conducted, which can be seen that the system can achieve the expected operation effect in the network security recommendation interface. In order to test the performance of the current system to test the current system of several operational items are shown in Table 2.
Network Performance Test Results.

As shown in Table 2, when using the current algorithm for system network testing, several just the system performance upload time and running time are less than 1 s, while the network running on the current computer's memory accounted for less than 40%, and at the same time for the test results are shown to pass, which indicates that the use of the algorithm can complete the performance test of the current system in the system testing, which indicates that the algorithm-based network educational resources recommendation can be realized. The study tested the different types of methods for evaluation to get the results shown in Table 3.
Comparison of Test Results of Different Methods of Assessment.
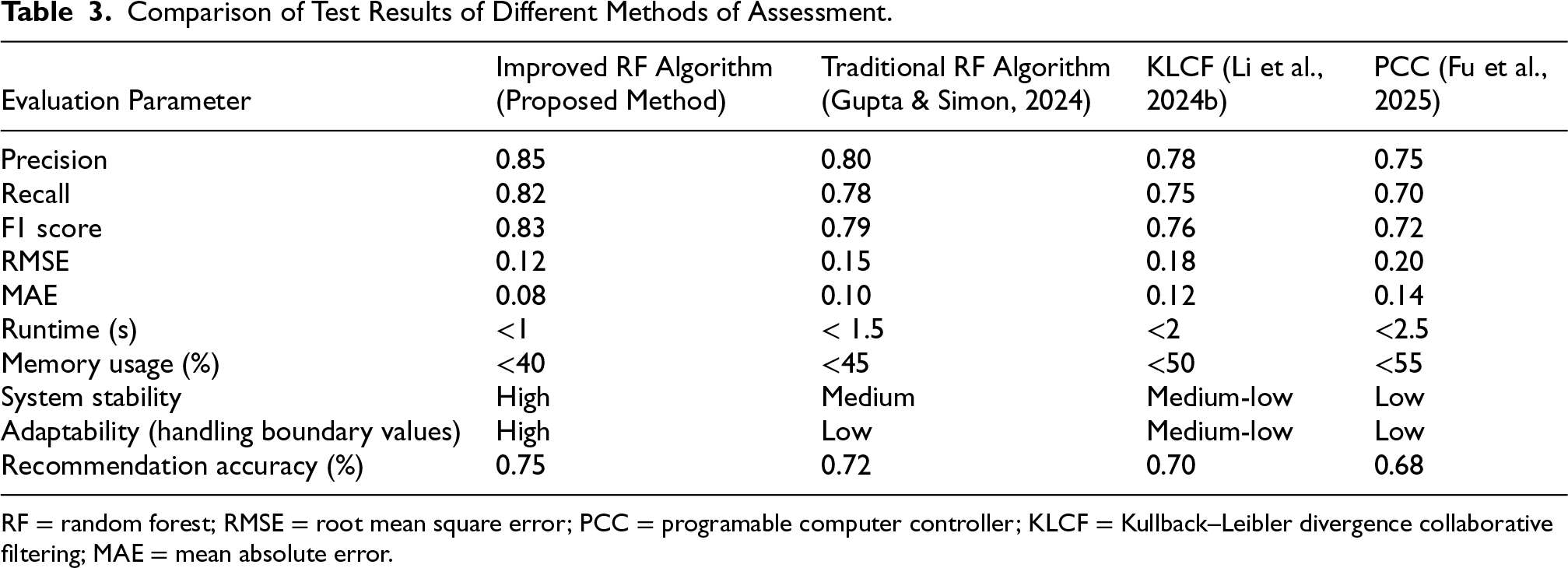
RF = random forest; RMSE = root mean square error; PCC = programable computer controller; KLCF = Kullback–Leibler divergence collaborative filtering; MAE = mean absolute error.
As can be seen from Table 3, the precision rate of the improved RF algorithm in the comparison of different methods can reach the highest in the comparison of several algorithms, with the highest precision rate of 0.85, and at the same time, the recall and F1 value of the improved RF algorithm can reach the highest in the comparison of several algorithms to reach 0.82 and 0.83, respectively, and the error of the improved RF algorithm in the comparison of different algorithms is only 0.12 and 0.08. It can be seen that the error and resource recommendation accuracy of the improved RF algorithm is the best among several algorithms in the comparison of different algorithms. Finally, the performance of the improved RF algorithm reaches the highest in the system adaptability and stability test. This shows that the improved RF Algorithm has a good resource recommendation effect in data testing. The boundary value improvement strategy proposed in the study significantly enhances the processing capability of RFs for sparse data and boundary samples by optimizing feature selection and node partitioning. This directly explains why it outperforms traditional RFs and collaborative filtering models in terms of accuracy, recall, and F1 score. The performance comparison of algorithms under different data sparsity levels is shown Table 4.
Boundary Value Processing Capability Test.

As shown in Table 4, as the data sparsity increases from 85% to 95%, the accuracy and recall of all algorithms show a downward trend. However, the improved RF algorithm has the smallest decrease, maintaining an accuracy of 0.70 and a recall of 0.66 at an extremely high sparsity of 95%, and its stability is always better than the comparison algorithm. In contrast, collaborative filtering algorithms exhibit significant performance degradation as sparsity increases. Although traditional RFs outperform collaborative filtering, they still struggle to maintain stable performance in highly sparse environments. This indicates that the boundary value improvement strategy proposed in this article can effectively enhance the algorithm's adaptability to sparse data and improve recommendation robustness in boundary conditions.
This research aims at the current problem of insufficient recommendation of educational resources network in colleges and universities, and builds a recommendation model of educational resources network in colleges and universities based on the improved RF algorithm, which can be used to recommend the educational resources courses by building a network system, the research firstly researches on the recommendation system of the educational resources courses, and then improves the RF algorithm to build a new improved algorithm, and finally validates the feasibility of the research through the testing of the algorithm. Finally, the feasibility of the study is verified by testing the algorithm. The results of the study show that the improved RF algorithm exhibits smaller changes in RMSE and MAE when dealing with different sparsity levels of data models. The algorithmic model thresholds at 0.10 and 0.15 have the same trend of model accuracy change as the threshold of 0.05, while the algorithmic model is able to achieve a higher accuracy rate at different threshold settings and maintains a higher accuracy rate when the iteration count is larger. The RF algorithm with quadratic weighting and boundary value change gradually tends to stabilize when the number of forest trees is 300, and the accuracy rate comparison is 0.75, the high RF algorithm is about 0.03, and the high quadratic weighting improved forest algorithm is about 0.01. In the system test, the home page resource recommendation and network performance, the improved RF algorithm can achieve the expected operation, and the test results are good, and the uploading and operation time are less than 1 s, and the memory share is less than 40%. In a university environment, the recommendation system can be applied to recommend basic courses for new students that are appropriate for their major and stage of study. At the same time, according to the students’ learning progress and preferences, it can recommend advanced courses or expansion courses in related fields. Finally, it helps teachers understand students’ learning needs, optimize course design and teaching content, and encourage students to explore interdisciplinary courses to broaden their knowledge. Comprehensively, the algorithm-based network educational resource recommendation achieves efficient and stable system performance. Although this research has obtained some research results, there are still some defects, such as the course data model used in data analysis is small, and a larger data model will be analyzed subsequently. At the same time, only one dataset was used for performance testing in the study and the generality of the system model needs to be further analysed so more datasets will be tested and analysed in subsequent studies.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.