
Abstract
Introduction
Throughout the past decade, the capabilities of large language models have dramatically increased. 1 Such models are a type of artificial intelligence trained to ingest and generate humanlike text. 2 Prominent examples include ChatGPT (OpenAI), Google Gemini (Google LLC), Meta (Meta Platforms Inc), and Claude (Anthropic).
In medicine, large language models have been adopted to perform a wide range of tasks such as assisting with clinical documentation, performing medical image analysis, and drug discovery.3–5 Multiple investigators have also assessed large language models that have been developed to answer medical questions (eg, Med-PaLM 2 by Google).6–8 An additional area where large language models may benefit patients and physicians is in triaging after-hours emergencies for outpatient specialties. 9
Among outpatient specialties, the retina field has several common patient emergencies that benefit from early recognition and treatment, including retinal detachment and endophthalmitis. 10 Importantly, mismanaged patient emergency telephone calls can lead to vision loss and blindness on 1 end of the spectrum or unnecessary clinic visits on the other. These calls also require meaningful human resources and represent a source of potential medicolegal risk. 11
The current analysis sought to determine the ability of 4 prominent large language model–based AI chatbots (ChatGPT-4o, Google Gemini, Meta, and Claude), programs designed to simulate conversation with users, to accurately diagnose and triage retina patient emergencies as compared with humans.
Methods
The study was performed in concordance with the Declaration of Helsinki. Institutional review board approval was not required because no protected patient information was collected or used. The study was conducted between May 2024 and November 2024 at Retina Consultants of Texas (Houston, TX, USA).
Review of Emergency Call Logs
To determine the most common reasons for after-hours emergency de-identified patient telephone calls to Retina Consultants of Texas, the date of the call, patient message (anonymized), and call center staff comments were analyzed. The calls were categorized into either “medical emergency” or logistics-related (such as appointment confirmations and prescription refills). Those that were categorized as a “medical emergency” were subcategorized based on patient symptoms. For patients reporting multiple symptoms, each was logged individually.
Simulated Emergency Scenarios
Based on a review of the patient emergency calls, 10 simulated patient telephone calls of varying medical urgency (Table 1) were created to mirror the most frequently reported retina emergencies. Cases consisted of 2 parts: 1) a first-person patient account of their symptoms and 2) a brief clinical history including the patient’s age, sex, and ocular history. The cases were reviewed by 3 retina specialists (H.A., K.C.F., and C.C.W.).
Diagnosis and Follow-Up Recommendation for Each Simulated Case.

Abbreviation: AMD, age-related macular degeneration.
Assessment of Diagnostic and Triage Accuracy
The 10 scenarios were presented to 4 large language models chatbots (ChatGPT 4-o, Google Gemini, Meta, and Claude), 3 vitreoretinal surgery fellows (F.B., first-year fellow at Wills Eye Hospital; V.C., first-year fellow at Associated Retina Consultants; L.K., first-year fellow at Bascom Palmer Eye Institute), and 3 certified ophthalmic technicians with on-call experience. All respondents were asked to assume the scenario was an on-call, patient telephone call being received outside of standard working hours (7:00 pm). Respondents were required to provide the single best diagnosis as well as to classify follow-up as 1) “immediate attention” (same day evaluation in clinic or emergency department), 2) “urgent follow-up” (next 1-2 days), or 3) “routine follow-up” (as scheduled/next available, assuming no worsening of symptoms).
Diagnosis and follow-up recommendations were graded for each chatbot and human respondent. Each scenario was graded for the correct diagnosis and follow-up recommendation; therefore, 20 total points could be achieved for the 10 cases, per respondent. Proportions of correct responses were analyzed using the Fisher exact test. Statistical analysis was performed using StataSE 17 (StataCorp LLC). A P value of <.05 was considered statistically significant.
For the large language models (and the human responders), the same prompt was given to prevent biases (Supplement 1). Each scenario was presented 3 separate times to each chatbot to assess reliability and agreement between answers. A new chat was opened (within the same account) to present the cases in triplicate to each large language model. For each chatbot, “agreement” was defined as the same response given across the 3 repeated prompts (intraplatform agreement). For humans, “agreement” was defined as all respondents in a cohort providing the same response for a given diagnosis or follow-up recommendation (intracohort agreement).
Results
In total, 563 emergency on-call telephone calls were recorded between May 2024 and September 2024 (Figure 1). The 3 most common concerns were flashes and floaters (n=89, 15.8%), eye pain (n=88, 15.6%), and postintravitreal injection symptoms (n=62, 11.0%).
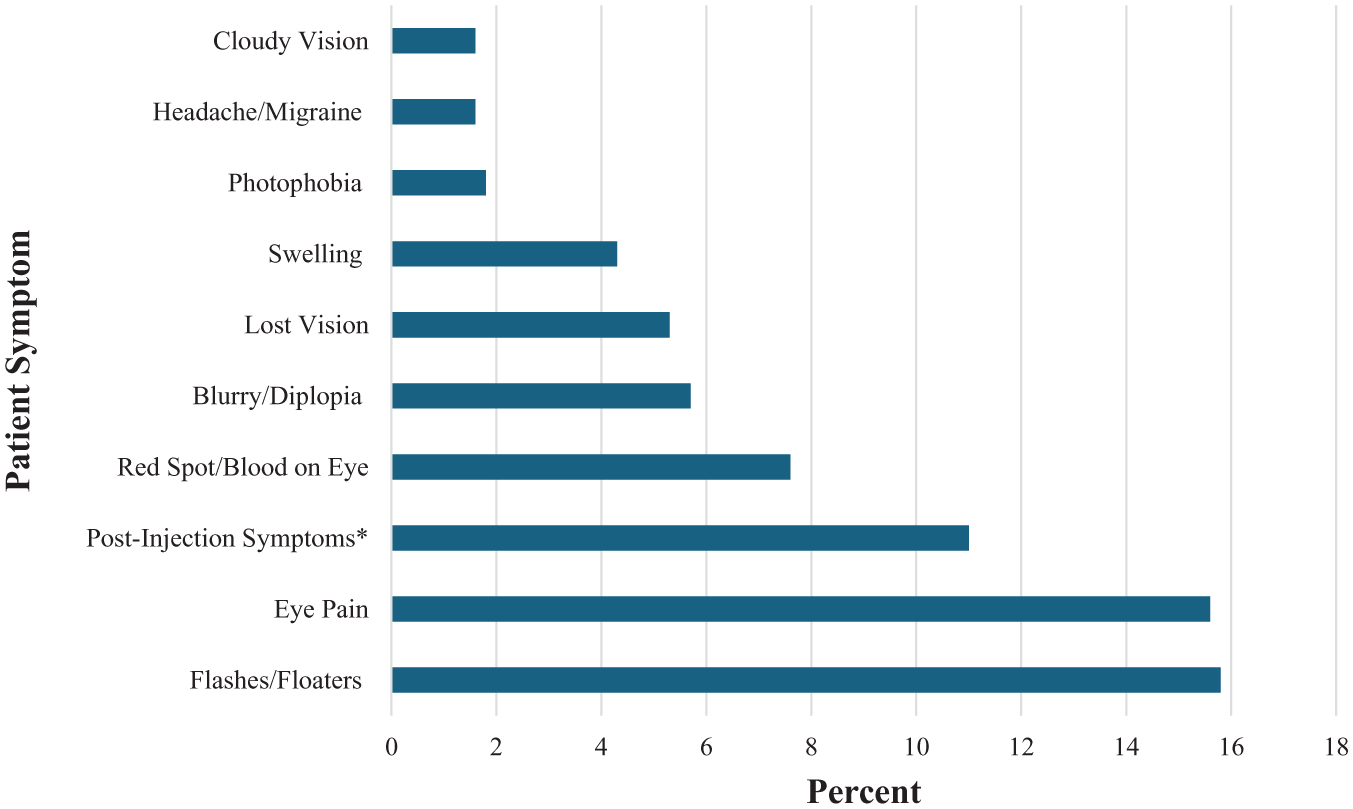
The most common symptoms prompting patient emergency calls.
On average, the human cohort (fellows and technicians) was significantly more accurate than the chatbots for both diagnosis (95% vs 76.7%, respectively, P < .01) and management (85% vs 70%, respectively, P = .03) (Table 2). However, there was meaningful variation in accuracy across the 4 chatbots. Diagnostically, the highest-performing chatbots were ChatGPT (90%, P = .4 compared with humans) and Claude (83.3%, P = .11 compared with humans), both of which were noninferior to human graders. Meanwhile, Meta (76.7%, P = .01 compared with humans) and Gemini (56.7%, P < .001 compared with humans) performed significantly worse than the human cohort.
Diagnosis and Follow-Up Recommendation Accuracy Among Humans and Chatbots.
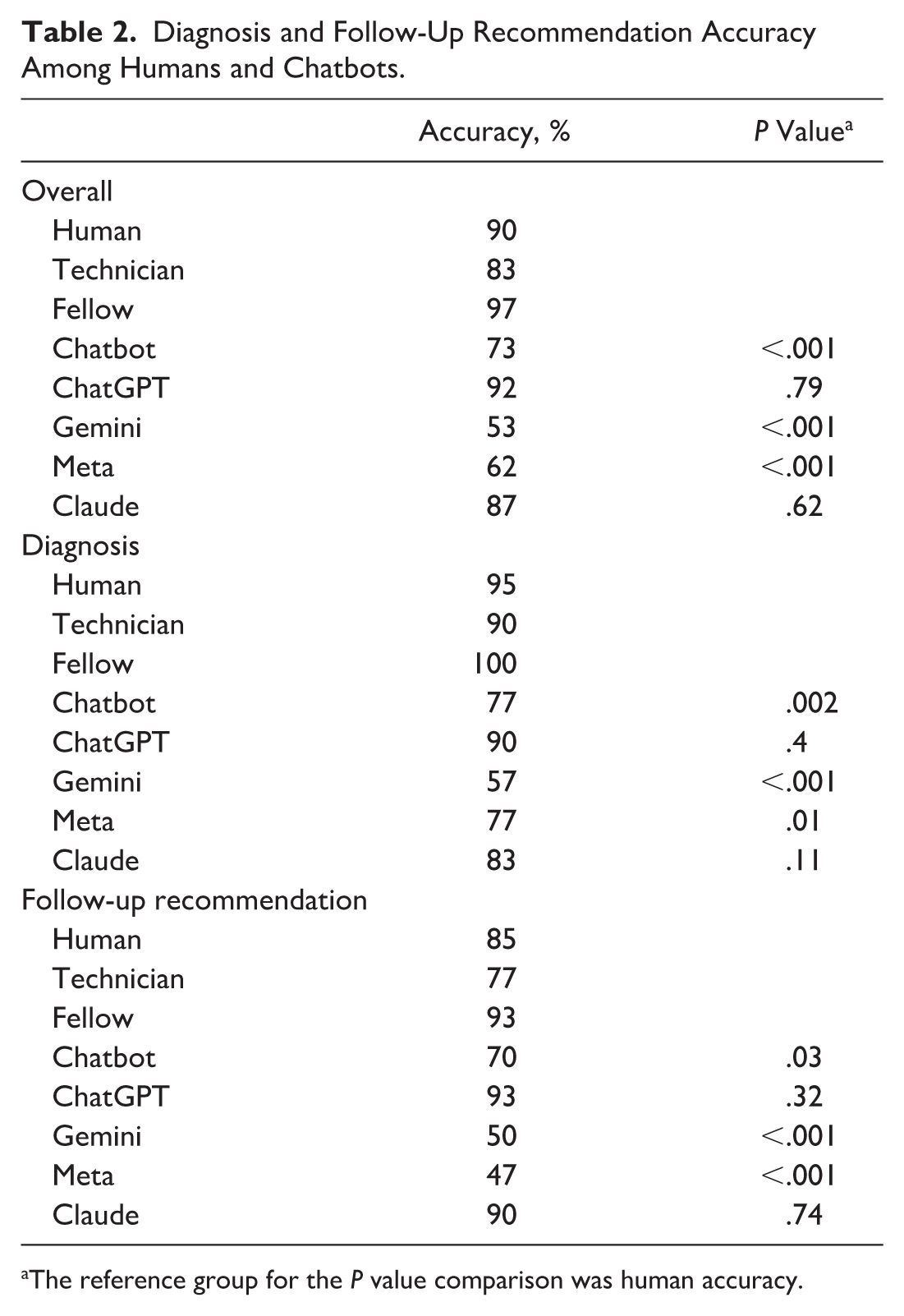
The reference group for the P value comparison was human accuracy.
The divergent trend in chatbot performance was also seen for follow-up recommendation accuracy. ChatGPT (93.3%, P = .32 compared with humans) and Claude (90%, P = .74 compared with humans) were noninferior to human graders, while Gemini (50%, P < .001 compared with humans) and Meta (46.7%, P < .001 compared with humans) again performed significantly worse than humans.
Within the cohort of human graders, fellows, as compared with technicians, had a numerically higher accuracy of diagnoses (100% vs 90%, respectively) and follow-up recommendations (93.3% vs 76.7%, respectively), but these differences were not statistically significant (P = .234 for diagnoses and P = .15 for follow-up recommendations).
Fellows showed the highest rate of agreement (complete agreement on 18/20 diagnoses/follow-up recommendations, 90%), followed by ChatGPT, Gemini, and Claude (16/20, 80%), then Meta (15/20, 75%), and lastly, the technicians (13/20, 65%).
Conclusions
The current study found that the included large language model–enabled chatbots had widely varying abilities in the assessment and triage of emergency after-hours telephone calls from patients of retina specialists. In a pooled analysis, chatbots as a group were inferior to humans in both providing accurate diagnoses and management recommendations for patient-reported retina emergencies. However, subanalysis of the individual chatbots revealed that ChatGPT-4o and Claude were both noninferior to human respondents. This pilot study, therefore, provides initial evidence that with further validation, certain large language models may be useful in assisting physicians with fielding retina patient emergency telephone calls in an after-hours outpatient setting.
Many ocular conditions are time-sensitive and can cause permanent vision loss if not recognized and treated quickly. 10 A large percentage of ocular emergencies are of retinal etiology. 12 As demonstrated by the 563 calls to 1 retina practice over 5 months, emergency calls can pose a substantive resource burden. Given the outpatient nature of retina practice, patients with after-hours emergencies must either be triaged by an on-call team or present to emergency departments that may not be adequately staffed or equipped for comprehensive and accurate ophthalmic diagnosis. 13
The results of the present pilot study suggest that large language model–based applications may be leveraged to aid clinicians in responding to retina emergencies. However, many publicly available large language model chatbots have explicit restrictions on providing medical advice. 14 For example, in the present study, the Gemini chatbot sometimes initially refused to respond to the cases unless given reassurance that the cases were simulated. Despite these restrictions, many prior studies have demonstrated high rates of accuracy among large language models in diagnosing ophthalmic conditions.15–17 As in this work, prior studies have shown significant variations between chatbots in their accuracy in diagnosing cases or answering questions in ophthalmology, with ChatGPT generally outperforming other large language models.18–21
While large language models show promise as clinical tools for both patients and providers, there are several concerns that must be addressed. First, large language models have been demonstrated to “hallucinate,” creating persuasive but incorrect responses. 22 This is especially important to consider for patient-facing applications, where nonexperts such as patients might be unable to identify incorrect responses. Additionally, large language models could also provide different answers to the same prompt when asked multiple times. 23 To assess consistency between responses in the present study, we prompted the large language model chatbots 3 times in separate chats. In the present case, all 4 chatbots demonstrated relatively high rates of agreement (75%-80%), achieving rates between fellows (90%) and technicians (65%).
The present study was limited by the simulated nature of the patient cases used. However, cases were created based on a systematic review of real emergency telephone calls to a large, urban retina specialty practice. Additionally, all cases were developed with nonexpert levels of language, representing a typical patient. An additional consideration is that case selection was limited to the most common symptoms prompting emergency telephone calls. Future studies could evaluate a broader spectrum of patient-reported emergencies.
The large language models’ performance would likely benefit from training prior to deployment, though we opted to use the most common publicly available versions. Lastly, real-time interactions with patients present unique challenges for implementation, which were not addressed here and warrant further study. Nevertheless, the current study highlights the promise of large language models in assisting with the remote care of retina patients in the emergency setting.
Ultimately, this pilot study demonstrated that humans performed better as a cohort compared with current-generation chatbots in diagnosing and triaging retina emergencies. Importantly, the accuracy of these chatbots was variable, with ChatGPT and Claude achieving noninferior performance compared with human graders. Further research is warranted on the highest-performing large language models to evaluate real-time implementation challenges as well as performance with a broader set of cases.
Supplemental Material
sj-docx-1-vrd-10.1177_24741264251414097 – Supplemental material for Large Language Models Triage of Retina Patient Emergency Telephone Calls: A Pilot Study
Supplemental material, sj-docx-1-vrd-10.1177_24741264251414097 for Large Language Models Triage of Retina Patient Emergency Telephone Calls: A Pilot Study by Rohini Chahal, Flavius Beca, Viet Q. Chau, Lauren Kiryakoza, Mya Abousy, Kenneth C. Fan, Charles C. Wykoff and Hasenin Al-khersan in Journal of VitreoRetinal Diseases
Supplemental Material
sj-docx-2-vrd-10.1177_24741264251414097 – Supplemental material for Large Language Models Triage of Retina Patient Emergency Telephone Calls: A Pilot Study
Supplemental material, sj-docx-2-vrd-10.1177_24741264251414097 for Large Language Models Triage of Retina Patient Emergency Telephone Calls: A Pilot Study by Rohini Chahal, Flavius Beca, Viet Q. Chau, Lauren Kiryakoza, Mya Abousy, Kenneth C. Fan, Charles C. Wykoff and Hasenin Al-khersan in Journal of VitreoRetinal Diseases
Footnotes
Ethical Approval
Institutional review board approval was not required for this study.
Statement of Informed Consent
Patient cases were simulated and therefore no consent was required.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: HA reports Annexon (C), Apellis (C), Ocular Therapeutix (C), Genentech (C), and Regeneron (C); KCF reports Apellis (C), AbbVie/Regenxbio (C), Ocular Therapeutix (C), Genentech (C), and Regeneron (C); CCW reports 4DMT (C,R), AbbVie (C,R), ADARx (C), Adverum (C,R), AffaMed (R), AGTC (C), Alcon (C), Alexion (R), Alimera (C,R), Alkeus (C), Allgenesis (R), AMC Sciences (C), Amgen (R), Annexin (R), Annexon (C,R), Apellis (C,R), Ascidian (R), Asclepix (R), Aviceda (R), Bausch + Lomb (C), Bayer (C,R), Beacon (R), Biocryst (C), Bionic Vision (C), Boehringer Ingelheim (C,R), Chengdu Kanghong (C), Chengdu Origen (R), Clearside (R), Curacle (C,R), Eluminex (R), Emmecell (C), EyeBiotech (C,R), EyePoint (C,R), Genentech (C,R), Gyroscope (R), InGel (C,SO), IONIS (R), IVERIC Bio (C,R), Janssen (C,R), Kalaris (R), Kiora (C), Kodiak (C,R), Kowa (C), Kyoto DDD (R), Kyowa Kirin (R), Merck (C), Nanoscope (C, R), Neurotech (C, R), NGM (R), Novartis (C, R), Oak Bay Bio (C), Ocugen (R), Ocular Therapeutix (C, R), Oculis (R), Ocuphire (C), OcuTerra (C, R), Ollin (C), ONL (C, SO), Opthea (C,R), Osanni (C,SO), Outlook Therapeutics (R), Oxurion (R), Panther (SO), Perceive Bio (R), PolyPhotonix (SO), Ray (C), RecensMedical (SO), Regeneron (C,R), RegenXBio (C,R), RetinAI (C), Roche (C,R), Sandoz (C), Sanofi (C), Santen (C), Skyline (C, R), Stealth (C,R), Sylentis (C), THEA (C), Therini (C), TissueGen (SO), VH401 (C,R), Visgenx (C,SO), Vitranu (SO), Zeiss (C); RC, FB, VQC, LK, and MA have no financial disclosures to report.
C= Consultant | R= Research Support | SO= Stock Options
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability
Data can be requested from the corresponding author.
Supplemental Material
Supplemental material is available online with this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.