
Abstract
Chinese characters, which form an ideographic writing system, have shown distinctive features in the neurocognition of their reading. This paper gives a comprehensive review of five main issues of Chinese reading, which are (1) the relationship across written forms, sounds, and meanings during the neurocognitive processing of Chinese reading, (2) the involvement of structural and linguistic units, such as strokes (笔画), radicles (部件), components (偏旁), whole characters (整字), and words (词), in character reading, (3) the influence of attentional conditions on character reading, (4) the activation of Chinese characters from non-character input, and (5) the influences of readers’ linguistic experiences on character reading. We summarize that the reading of Chinese characters involves dynamic integration of multi-channel information and multiple levels of processing units, which, as compared with alphabetic writing systems, rely more on form-to-meaning semantic processing, while its form-to-phonology non-semantic processing is greatly influenced by para-linguistic context.
Introduction
Chinese characters, as the writing system that has the longest history of independent development and the largest population of users, have received intensive attention and research over time. However, only in recent decades has the neurocognition of Chinese reading drawn the attention of international researchers. This paper will give a comprehensive review of five main issues regarding the neurocognitive aspects of Chinese reading.
Before moving on to the main issues, we first need to put the features of Chinese characters in the perspective of cognitive neuroscience. By far, most neurocognitive studies have focused on modern Chinese characters, which are known as an ideo-phonographic-symbolic (意符-音符-记号) and morphemic-syllabic (语素-音节) system, and are represented with square-shaped characters (方块字) with complicated internal spatial structures (Qiu, 1988). Each of these three features has neurocognitive meanings.
 , to using ideographs
(意符) within characters, for example, 炮, and modern ideographs are usually existing characters, which indicates that Chinese characters have undergone dramatic symbolic processes (Zang, 2007).
, to using ideographs
(意符) within characters, for example, 炮, and modern ideographs are usually existing characters, which indicates that Chinese characters have undergone dramatic symbolic processes (Zang, 2007).
This feature has two meanings in cognition. First, it means that the Chinese characters have a deep orthography: hardly any rules can be used to associate the structural writing units (the character itself or the radicals or components that form characters) with sounds. By contrast are alphabetic writing systems, such as Dutch, Italian, and Spanish, which have shallow orthography, while the orthography of English is deeper than these systems but still shallower than Chinese characters (Schwartz et al., 2007). The deepness of orthography in the cognitive processing of Chinese characters means that sub-lexical processing, which is well-known in the previous research of alphabetic writing systems, may not apply to Chinese reading. Or, in other words, Chinese readers may rely less on orthography—sound correspondences (colloquially known as phonics) to access words (Shu and Zhang, 1987). The lack of orthography—sound correspondences, though, may be beneficial for the orthographic and phonological mechanisms in character reading to be studied separately, which has been very difficult for alphabetic writing systems (Yang, 2015).
Second, Chinese radicals and components have the potential to activate meanings directly. Semantic components (义符) within a character structure can function as promptings and classifiers for the meaning of the whole word. There have been extensive philological studies on the semantic function of these character components (e.g. Gong, 2013). We will give a review of the studies on the corresponding cognitive mechanism in the next section.
In cognitive processing this feature in the first place means that the association of Chinese characters and Chinese is on the level of whole syllables, which is of a larger grain size than most other writing systems in the world. Most other writing systems associate their basic writing units with phonemes. For instance, English associates graphemes with English phonemes, while Chinese Zhuyinfuhao (注音符号) and Korean Hangul associate letters with onsets and rhymes. Regarding grain sizes, Chinese characters are most similar to Japanese Kana (假名), although Kanas do not represent morphemes or meanings.
The number of syllables in modern Chinese (about 1,200) is relatively small in the world (considering that there are up to 10 times more syllables in Dutch) (Chen et al., 2002). Since readers have no need to distinguish so many syllables in Chinese, it has been suggested that the cognitive processing of Chinese characters may not need to activate that much phonological or phonetic information (Perfetti and Zhang, 1995). We will give a review in more detail regarding this issue.
Moreover, Chinese characters are directly associated with morphemes. All the alphabetic writing systems lack of this type of correspondence. Hence, regarding the heavily debated question of whether whole words can be accessed without the activation of alphabets, we will show that Chinese reading may provide a largely different answer, as the retrieval of morphemes during Chinese reading has to rely on the whole characters.
Review of the reading processes of Chinese characters
Taking the above-mentioned three features of Chinese characters into consideration, it can be inferred that the core issue of Chinese reading processing is the access and retrieval of information at different processing levels, namely the orthographical (written form), phonological (sound), and semantic (meaning) levels.
Two critical issues follow this core issue. The first issue is whether the activation of meanings from character orthography is necessarily mediated by the activation of sounds. The phonological mediation hypothesis states that mediation by sound is necessary (Perfetti and Zhang, 1995), while the orthographic autonomy hypothesis states that mediation by sound is not necessary, which means that when the shapes of characters activate meanings in human minds, corresponding phonological activation can be absent (Han and Bi, 2009; Zhou and Marslen-Wilson, 1999a). The second issue is whether the activation of sounds from character orthography must be mediated by meanings. This question is usually phrased as whether a non-semantic route exists. If it exists in Chinese reading, the claim is that the reading of Chinese characters involves the activation of sounds from character orthography without the activation of the corresponding meanings. In other words, it means that Chinese readers can read sounds from characters without meanings (Weekes and Chen, 1999). These two issues, especially the former, have also been under long-term debate in studies on alphabetic readings (e.g. Perfetti and Bell, 1991; Rayner, 1993). However, the three distinctive features of Chinese characters as introduced above give rise to the possibility of alternative answers.
Furthermore, as they involve complicated internal structures in the square-shaped characters, Chinese characters may differ from alphabetic writing systems regarding the structural units as processing targets (Han et al., 2008; Zhou and Marslen-Wilson, 1999b). The specific research questions consider whether strokes (笔画), radicals (部件), components (偏旁), whole characters, words, and even larger or smaller analytical units are psychologically realistic processing units. Follow-up questions focus on whether the sounds and meanings of radicals can be retrieved and whether phonological and semantic components are distinguished during character reading.
Beside these classical questions, new questions have also been raised in recent years.
The first research hotspot is how the reading of Chinese characters varies under different attentional conditions. Reading is usually a task carried out consciously, for example, reading aloud, reading comprehension, etc. However, people can also come across characters without awareness, be required to neglect specific characters, be asked to read the same characters repeatedly, etc. These various attentional contexts are receiving increasing research interest (e.g. Biederman and Tsao, 1979; Zhang et al., 2012). Moreover, proficient Chinese readers sometimes can even unconsciously “read out” characters from non-character inputs. We will review recent studies that have investigated these character- related illusions or allusions (e.g. Chen et al., 2014; Thierry and Wu, 2004, 2007).
Second, the way Chinese characters are visually processed is found to be related to readers’ linguistic and learning experiences. Reading differs from language in that it requires explicit learning in order to attain it. Hence, it is worth investigating what information can be retrieved by beginning learners during character reading, whether native children differ from Chinese-as-a-second-language learners in character reading, and how learners may differ from proficient readers in character processing. Also, Chinese characters can be used to write different languages (e.g. Japanese, which can be written with Kanji), or used in parallel with other writing systems. There are readers who can read aloud Chinese characters in different linguistic varieties (e.g. bi-dialectals of Standard Chinese and another Chinese dialect). There are also bi-literal bilingual readers (e.g. Chinese English bilinguals) and bi-literal monolingual character users (e.g. Japanese readers who use Kana and Kanji in parallel and Chinese readers who use Chinese characters and pinyin in parallel). How these linguistic-literacy backgrounds influence the processing of Chinese characters will be reviewed.
Cognitive and neurological pathways for the reading of Chinese characters
It has been found that the mental pathways involved in the reading of Chinese characters are basically congruent with those used for alphabetic writing systems (Weekes et al., 2006), as shown in Figure 1.
Plaut et al.’s (1996) triangular reading model (a) and Weekes et al.’s (2006) reading model for Chinese characters.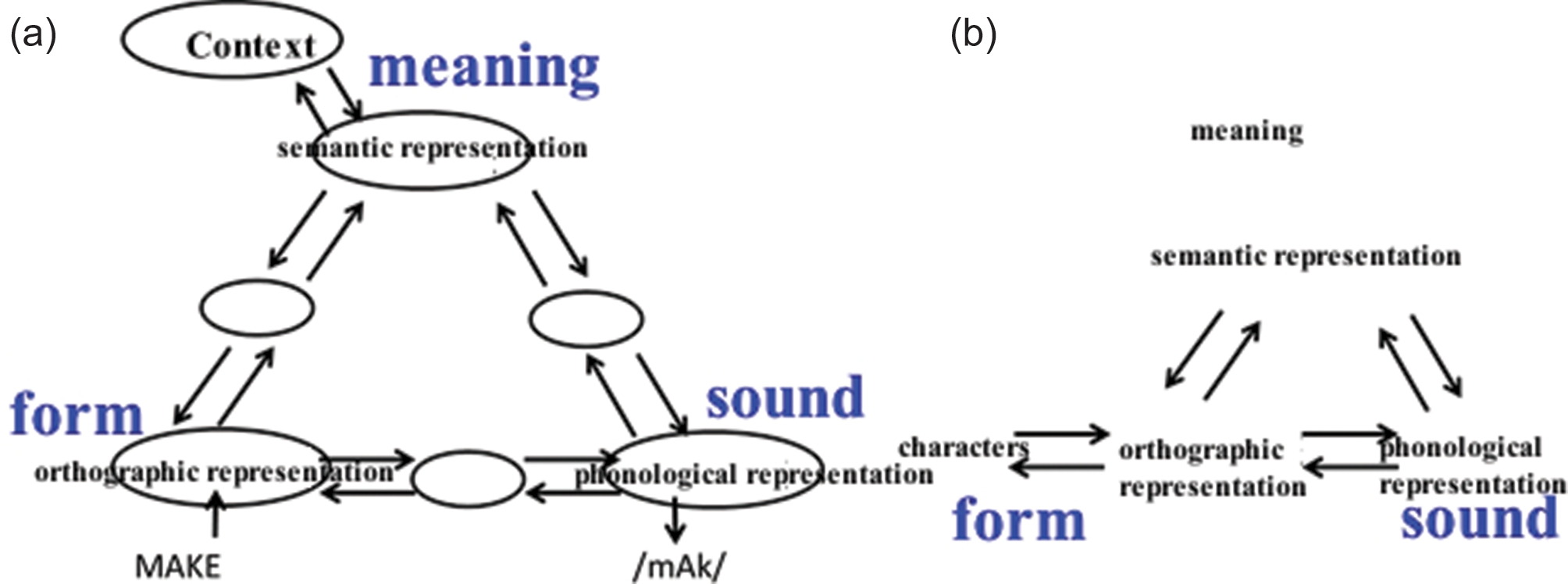
Weekes et al. (2006) have provided a widely accepted model for the reading of Chinese characters: one direct pathway and one indirect pathway each link written forms to sounds, and so do written forms to meanings. In this model, written forms can activate meanings via the activation of sounds, but mediation via sounds is not necessary; similarly, written forms can activate sounds via the activation of meanings, but mediation via meaning is not necessary either. Supporting evidence can be summarized as follows.
Supporting evidence for the direct link between written forms and meanings (namely the semantic route) mainly comes from patients with deep dyslexia. These patients can understand Chinese written words, but make extensive pronunciation errors (Law, 2004; Yin and Butterworth, 1992), which means that they can access meanings from written forms but have difficulty in accessing the sounds. It is claimed that these patients suffered lesions in their non-semantic route and can only rely on their semantic route to read.
There is also evidence from healthy readers. An experimental study showed that, if the reader, before seeing the target character (e.g. “午,” pronounced as wu3 in standard Chinese), sees an orthographically related character (orthographic prime, e.g. “牛,” pronounced as niu2 in standard Chinese) or a phonologically related character (phonological prime, e.g. “五,” also pronounced as wu3 in standard Chinese) flashing over his or her eyes (masked priming), the reader would read aloud the target character more quickly (facilitated). However, if the task is not reading aloud but lexical decision (deciding whether the target character is an existing word), there would be only semantic priming, for example, with “念,” nian2, read, priming “读,” du2, read (Shen and Forster, 1999). Similarly, the semantic priming of Chinese characters in lexical decision holds even when the between-stimuli interval is as short as 57 ms, while the phonological priming of Chinese characters only happens with a longer between-stimuli interval (e.g. 200 ms; Zhou, 2000). These findings suggest that, when the reading task only requires access to the character meanings, readers can skip the activation of character phonology and directly activate semantic information from written forms.
Further evidence for the early neglection of character phonology comes from an eye-tracking experiment. Replacing target characters with phonological incongruent but orthographically similar characters (e.g. replacing “搏,” bo2, fight, with “傅,” fu4, instructor) in a paragraph would only increase the total fixation time (a late eye-tracking indicator) but not the first fixation time (an early eye-tracking indicator). This finding indicates that Chinese readers tend to neglect character phonology in their initial visual processing of characters (Wong and Chen, 1999).
Supporting evidence for the direct link between written forms and sounds (namely the non-semantic route) mainly comes from another type of patient, those who have surface dyslexia (Yin and Butterworth, 1992). These patients are featured with relatively intact abilities in auditory dictation and reading aloud, but severe lesions in spoken and written picture naming. They would make homophone errors in dictation and written picture naming, such as mistaking kuwan4 (Cantonese), “裙,” skirt for kuwan4 (Cantonese), “群,” group (Law and Or, 2001), which indicates that they have difficulties in distinguishing homophone characters. Moreover, one patient can read aloud Chinese characters, but cannot name pictures (Law et al., 2004). Hence, these Chinese surface-dyslexia patients can access sounds from written forms, but have difficulties accessing written forms from meanings. It is claimed that these symptoms are due to lesions to their semantic route, so that they can only rely on the limited form-to-phonology correspondence and the non-semantic route to process Chinese characters.
Nevertheless, the non-semantic route of Chinese character reading may be split into two sub-routes: one directly associates sounds with the whole written forms (direct route), while the other relies on the correspondence between sub-lexical features and the structural components of Chinese characters. The latter is similar to the sub-lexical route for alphabetic reading, which makes use of the relation between graphemes and phonemes (Jared et al., 1990; Rubenstein et al., 1971; Seidenberg et al., 1984). As for Chinese characters, the discussion on the sub-lexical route mainly relies on the correspondence between the phonological components (声旁) and the character pronunciations.
The major findings can be classified as regularity effects (Seidenberg et al., 1984) and family consistency effects (Glushko, 1979). Regarding regularity effects, for instance, a Chinese Alzheimer’s patient could read characters that contain phonological components that are homophones of the whole characters (e.g. huang2, “蝗,” locust, which is homophonic of its phonological component huang2, “皇, ” emperor) relatively well, but showed more difficulties in reading inconsistent characters (e.g. cai1, “猜,” guess, which is not homophonic of its historical phonological component qing1, “青,” bluish green). Family consistency effects were also found for this patient. He could read characters that share the same phonological component and are consistent in their pronunciation (e.g. huang2, “蝗,” locust, huang2, “煌,” bright, and huang2, “凰,” phoenix) better than characters that share the same phonological component but carry different pronunciations (e.g. qing1, “清,” clear, jing1, “精,” clear, cai1, “猜,” guess). This indicates that suffering from damage to his character-semantic representations and whole-character memories, this patient can use sub-character (sub-lexical) phonological components to infer the pronunciation of characters (Bi et al., 2007; Han et al., 2005). Similar effects have also been found with healthy Chinese readers in reading reaction-time data (Shu and Zhang, 1987; Yang et al., 2009; Zhou et al., 2003), involving N170 and P200 event-related potential (ERP) components (Lee et al., 2007), as well as with computational simulation (Chen and Peng, 2004; Xing et al., 2004; Yang et al., 2009). Thus, it is clear that the sub-lexical route is used in Chinese reading.
However, it is worth noting that the use of the sub-lexical route in Chinese reading is modulated by character frequency. For instance, the number of radicals would only influence the reading of low-frequency characters, and not the reading of highly frequent characters (Peng and Wang, 1997). Also, the reading costs of highly frequent characters are more influenced by the number of homophones, while the reading costs of low-frequency characters are more influenced by the probability of their orthography (Chen et al., 2013). These findings indicate that Chinese readers rely more on the direct route to process highly frequent characters, but make more use of the sub-lexical route to process low-frequency characters.
The reading processing of Chinese characters differs from that of alphabetic writing systems in the dependence of the above-mentioned processing routes, which can be associated with neurological pathways in the readers’ brains. There are three major aspects of differences, summarized as follows (see also Figure 2). Neurological differences involved in the reading of Chinese characters and alphabetic writing systems. Adapted from Principles of Neuroscience (Kandel, 2013), with labels added. 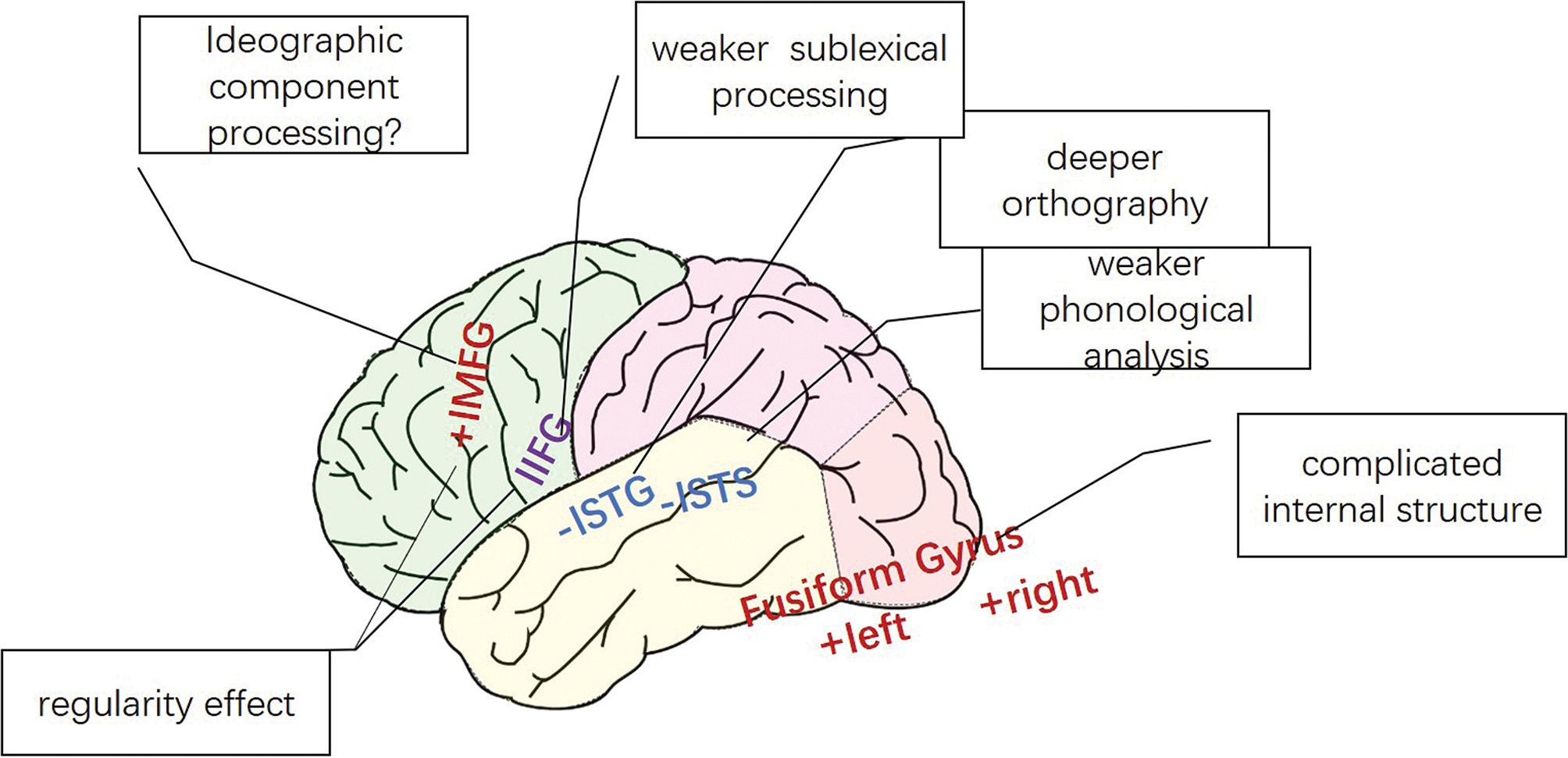
First, Chinese characters require more intensive visual-spatial analysis. The orthographic processing of alphabetic writings is commonly found located in the left fusiform gyrus. However, the reading of Chinese characters by Chinese-native readers in addition activates the right fusiform gyrus (Peng et al., 2004; Tan et al., 2000, 2001). The reason for this difference can be inferred by taking the neurological correlates of orthographic processing of Korean Hangul and Japanese Kana into consideration. Hangul and Kana both take squared shapes and correspond to syllables, similar to Chinese characters. However, only Hangul has similar internal structures to Chinese characters, which require complicated visual analysis. It is found that the reading of Hangul characters by Korean native readers involves similar right fusiform activation to that of Chinese reading (Yoon et al., 2005), but the reading of Kana by Japanese native readers only activated the left fusiform gyrus, like in the Indo-European alphabetic writing systems (Maurer et al., 2008). Hence, we can infer that the involvement of the right fusiform gyrus in the reading of Chinese characters (as well as Korean Hangul characters) is related to the analysis of complicated spatial structure within the characters.
Second, the reading of Chinese characters relies less on the non-semantic route. Besides what has been discussed in (2), neurological evidence has shown that the left superior temporal sulcus, which is known to be a critical part of the network responsible for phonological processing, tends to be less activated during the reading of Chinese characters, as compared with the reading of alphabetic writings (Tan et al., 2005). This may be a neurological adaptation to the ideographic feature of Chinese characters as well as to the larger grain size of Chinese orthographic–phonological relation.
Finally, the reading of Chinese characters involves weaker sub-lexical activation as compared with alphabetic readings, which also uses a different neurocognitive mechanism. The reading of Chinese characters does not activate the left superior temporal gyrus, which was found to be more activated with shallow orthographies (Paulesu et al., 2000). It also showed weaker activations of the left inferior frontal gyrus (BA44/45), which was found to be associated with sub-lexical processing and regularity effects. However, the reading of Chinese characters activates the left medial frontal gyrus more than alphabetic readings, which some researchers claim to be relevant to the processing of ideographic structural components within characters (Siok et al., 2004; Tan et al., 2000, 2001, 2005) . These differences regarding the left frontal gyrus indicate that Chinese reading makes use of different phonological integration mechanisms as compared with alphabetic reading.
Taken together in this section, orthographies, sounds, and meanings of Chinese characters can activate each other in reading. The activations from written forms to sounds and meanings during reading mainly rely on whole-word correspondence, but they can also make use of the information provided by the phonological and ideographic components at the sub-character level. Chinese readers can integrate information from different routes to achieve the goal of reading, and their neurological network has adapted to the specialties of Chinese characters.
Processing units of character reading
As noted in the previous sections, Chinese characters have complicated internal structures. The basic structural units of Chinese characters include strokes (笔画) and radicals (部件). Accordingly, the cognitive research of processing units has also focused on strokes and radicals, especially radicals. Radicals … are structural units of characters which are made of strokes, can be used independently, and have the function to form Chinese characters (由笔画组成的, 能独立运用的, 具有组配汉字功能的构字单位). (Shao, 2007)
Radicals can refer to two types of units, namely level-1 radicals (一级部件) and level-2 radicals (二级部件; National Language Commission, 1998). On the one hand, level-1 radicals are the result of splitting characters once, which in many cases correspond to the meanings or sounds of the characters and, hence, approximate phonological or ideographic structural components (偏旁). For example, the character xiang3, “想,” think can be split into two level-1 radicals, “想=相+心,” which represent the sound and meaning of this character, respectively. About 80% of modern Chinese characters are phonograms (形声字; Fu, 1991). On the other hand, level-2 radicals are the smallest splitable structural units of characters, which cannot be split further except for getting split into strokes. They are sometimes called logographemes in the English literature and are also called mo4ji2bu4jian4, “末级部件,” last-grade radicals in the Chinese literature (Fu, 1991; Su, 1995), which in many cases are not associated with meanings or sounds. For example, the character xiang3, “想,” think can be split into three level-2 radicals, yielding “想=木+目+心.”
Regarding sub-character structural units, it has been verified that strokes, radicals, and components each have independent influence on character reading.
Regarding strokes, characters with repeated strokes are easier to recognize. However, characters with more complicated strokes (e.g. zi3, “子,” son) are not more difficult to recognize than characters with the same number but less complicated strokes (shi2, “十,” ten), which indicates that strokes are the smallest processing units of character reading and that the internal structures of strokes are not analyzed during character reading (Zhang et al., 2002). With the number of level-2 radicals controlled, the number of strokes alone can influence the processing costs of character reading. For instance, zhi3, “只,” only and “sheng1, “声,” sound both have two radicals, but zhi3, “只,” only has less strokes than sheng1, “声,” sound, and Chinese readers read out the former faster than the latter (Peng and Wang, 1997).
Similarly, with the number of strokes controlled, the number of level-2 radicals alone can influence the processing costs of character reading as well, although this effect only applies to low-frequency characters. For instance, the following two low-frequency characters, pan2, “爿,” (quantifier) for shops and yao2, “爻,” hexagrams both have four strokes, but the former is structured with only one radical, while the latter is made of two. Chinese readers also read out the former faster than the latter (Peng and Wang, 1997).
While the above-mentioned findings were based on level-2 radicals, findings on level-1 radicals or actually phonological and ideographic components also show that they play critical roles in character reading. As discussed in the previous section, regularity effects in character reading indicate that the reading processing involves the activation of phonological components (声旁) within characters (Bi et al., 2007; Chen and Peng, 2004; Chen et al., 2013; Han et al., 2005; Lee et al., 2007; Li and Wang, 2016; Peng and Wang, 1997; Tan et al., 2001; Xing et al., 2004; Yang et al., 2009).
Also, if preceded by an exposure to a priming character (e.g. cai1, “猜,” guess) that contains a phonological component (e.g. qing1, “青,” bluish green), which is homophonic to the target character (e.g. qing1, “轻,” light), the reading of the target character would be facilitated (Zhou and Marslen-Wilson, 1999b). This effect persists even if the phonological component (e.g. qing1, “青,” bluish green) does not sound identical to the whole character (e.g. cai1, “猜,” guess). The findings indicate that when Chinese readers read phonogram characters, the sounds of the phonological components are activated independently of the whole character’s pronunciation.
Interestingly, phonological components can also activate meanings during reading. For instance, if preceded by an exposure to a priming character (e.g. cai1, “猜,” guess) that contains a phonological component (qing1, “青,” bluish green), which is semantically related to the target character (e.g. zi3, “紫,” purple), the reading of the target character would also be facilitated (Zhou and Marslen-Wilson, 1999b). Similarly, semantic relations between the target words (e.g.“zi3, “紫,” purple) and the priming characters’ (e.g. cai1, “猜,” guess) phonological components (qing1, “青,” bluish green) would also facilitate semantic judgments of the target characters (Marslen-Wilson and Zhou, 2002). Moreover, the activation of the sounds of the phonological components can also mediate the activation of meanings that correspond to these sounds, given that the characters are regular phonographs. For instance, if preceded by an exposure to a priming character (e.g. lü4, “滤,” filter) that contains a regular phonological component (lü4, “虑,” consider) that is homophonic to the character (lü4, “绿,” green), which is semantically related to the target character (e.g. zi3, “紫,” purple), the reading of the target character would also be facilitated (Zhou and Marslen-Wilson, 1999a).
One may infer that reading meanings from phonological components can be explained with a classical philological idea that Chinese characters sharing phonological components also share meanings via these components, which was first proposed by Wang Shengmei (王圣美) in the Song Dynasty as youwenshuo, “右文说” (Zhang et al., 2014). However, we have to note that in these experimental studies, characters with transparent semantic relations between the phonological component and the whole characters (which comply with youwenshuo) were excluded in the material. Hence, we can clarify that these findings mainly represent cognitive mechanisms instead of the historical mechanisms as proposed by youwenshuo, “右文说.”
Parallel phenomena were found regarding the ideographic components (形旁), which were believed to represent the meanings of the characters. For instance, if preceded by an exposure to a priming character (e.g. ping2, “评,” comment) that contains a transparent ideographic component (e.g. “讠,” related to speech), which is shared with and semantically related to the target character (e.g. lun4, “论,” discuss), the reading of the target character would be facilitated. Nevertheless, if preceded by an exposure to a priming character (e.g. zhu1, “诸,” every) that contains a non-transparent ideographic component (e.g. “讠,” related to speech, but not related to the modern meaning of the whole character), which is shared with and semantically related to the target character (e.g. lun4, “论,” discuss), the reading of the target character would instead be inferred (Feldman and Siok, 1999).
Also parallel to the semantic activation by phonological components, ideographic components would activate not only their own meanings, but also their own pronunciations. For instance, if preceded by an exposure to a priming character (e.g. duo3, “躲,” hide) that contains an ideographic component (e.g. shen1, “身,” body), which is homophonic to the target character (e.g. shen1, “深,” deep), the reading of the target character would be facilitated (Zhou et al., 2000).
Hence, both phonological and ideographic components are activated during character reading, but they are treated as similar functions, and both activate both sounds and meanings.
Relative positions of structural units are important for the distinction of similar Chinese characters, which have also been proven to be stored and used for the cognitive processing of characters.
Regarding stroke orders, Chinese characters are usually written from left to right, from top to bottom (Qiu, 1988). Eye-tracking studies found that character readers follow this writing principles in reading as well. Omitting the left-hand or the top side of a Chinese character (namely the parts written first) would introduce more interference to the reader than omitting the right-hand or the bottom side (Yan et al., 2014).
Regarding radical locations, radical priming requires that the corresponding radicals locate at comparable locations (e.g. “躯-枢”) to take effect (Ding et al., 2004). Position-specific radical frequencies (e.g. with “阝” at the right and the left treated separately) influence ERP components earlier than position-independent radical frequencies (e.g. with “阝” at the right and the left considered together; Wu et al., 2012). When deciding whether a character is a real (existing) Chinese character, proficient Chinese readers tend to accept pseudo-characters (假字), which contain wrong but existing radicals at correct positions (e.g. “  ”), but reject non-characters (非字), which contain radicals at wrong positions or non-
existing radicals (e.g. “
”), but reject non-characters (非字), which contain radicals at wrong positions or non-
existing radicals (e.g. “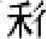 ” or “
” or “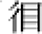 ”). Moreover, regarding the two types of non-characters, readers tend to accept wrong positions (“
”). Moreover, regarding the two types of non-characters, readers tend to accept wrong positions (“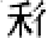 ”) more than non-existing radicals (e.g. “
”) more than non-existing radicals (e.g. “ ”; Peng et al., 2006). These findings verified that proficient Chinese readers are cognitively and neurologically sensitive to the position of radicals.
”; Peng et al., 2006). These findings verified that proficient Chinese readers are cognitively and neurologically sensitive to the position of radicals.
Moreover, although we have verified that phonological ideographic components are treated as similar functions in the cognitive processing of character reading, studies have shown that character readers are still sensitive to the locations of these structural units. An eye-tracking experiment has shown that proficient readers are more focused on the right-hand and lower sides of phonograms, which indicates that they tend to pay more attention to the positions where phonological components are more likely to appear (Chi et al., 2014), following the left-ideo-right-phono (左形右声) and the upper-ideo-lower-phono (上形下声) principles of Chinese orthography (Qiu, 1988).
As given above, strokes, radicals, and components are different levels of processing units for character reading. Nevertheless, it is worth noting again that the Chinese linguistic units corresponding to Chinese characters are mostly mono-syllabic morphemes (only sometimes meaningless syllables), while Chinese linguistic units related to radicals are incongruent (syllables, articulatory positions, rhymes, semantic features, or none), and word-segmentation is not handled within the common orthography of Chinese characters. Hence, neurocognitive studies also work on whether and how multi-character words can be processing units in Chinese reading.
The basic finding in a word is that readers actively combine Chinese characters into words during their reading processing. For instance, an eye-tracking study found that, instead of fixating on each Chinese character within a sentence, readers tend to put their first fixations in the middle of words, and their regressive fixations at the start of words (Yan et al., 2010). Introducing correct word-segmentations with spaces (e.g. “世界各国都受到了金融 危机 的冲击”) reduces the total fixation time on each word, which means the processing gets easier, while introducing wrong word-segmentations (e.g. “世界各国都受到了金融危 机的冲击”) reduces the efficiency of reading (Bai et al., 2011). Marking words in the preview with colors influences the efficiency of reading in a similar way (Liu et al., 2016; Yu et al., 2018; Zhang et al., 2012). These findings indicate that word-segmentation happens automatically during the reading of Chinese characters.
Summarizing this section, the reading processes of Chinese characters involve multi-level neurocognitive analysis of written forms. Different levels of writing units, including strokes, radicals, components, whole characters, and words, function together in character reading.
The influence of attentional conditions on character reading
Most of the above-mentioned studies investigate normal reading comprehension or reading out. However, previous studies have found that different attentional conditions may influence readers’ cognitive processing of Chinese characters.
(1) The first special attentional condition worth noting is related to repetition. If reading the same Chinese character repeatedly (e.g. read “务务务务务务务务务务务务务务务务”), readers may temporarily lose the recognition of the target character. This effect is known as repetition blindness, which is an effect of visual attention, caused by the inhibition of repeated items in short-term memory, and is related to negative brain components and has been found in many other writing systems (see Guo et al., 2008, for a review). In addition to the classical findings, it is also found that the reduction of intervals (Wang and Zhang, 2002) and the increase of speed (Wang and Zhang, 2005) would both strengthen the repetition blindness effect of character reading.
(2) Note that even when the task does not require character reading, proficient readers would read characters automatically. Chinese characters presented so briefly that the reader does not even notice (e.g. the 57 ms masked primes as described in the first section) can also provide information (Shen and Forster, 1999).
On this basis, the processing of orthographical, phonological, and semantic information during inattentional reading has been studied extensively.
First, when the task only focuses on the forms of characters, only orthographical but not phonological or semantic information would be activated. For instance, in a direction-judgment experiment, readers respond faster to characters with radicals of higher frequencies in the corpus (e.g. “扯,” which contains “止,” a frequent radical) than those of lower frequencies (e.g. “犹,” which contains “尤,” a less frequent radical). This indicates that proficient character readers can automatically extract radicals from whole words. However, the location-specific frequencies of radicals, which as mentioned above can influence conscious reading processing, no longer play a stable role if the task is only to judge the directions of the whole characters, which indicates that even the locational information of radicals is not processed completely in this task (Wu et al., 2015).
Second, when the task does not direct the readers’ attention to recognize the characters, proficient Chinese readers would still automatically read the characters and retrieve orthographic, semantic, and phonological information from the characters. A famous task is to judge the ink colors of characters, which is called the Stroop task (MacLeod, 1991). Classical designs of Stroop experiments usually include semantic conflicts between a character and its ink color, for example, giving the readers a hong2, “红,” red character in yellow, which would interfere with the readers’ color naming and delay the readers’ responses. Also, there are consistent conditions, where the character and the ink color are semantically consistent, for example, giving the readers a hong2, “红,” red character in red, which would facilitate the readers’ color naming. Stroop effects have been confirmed with Chinese character for decades (Biederman and Tsao, 1979; Tzeng and Wang, 1983). However, there are still debates on the processing differences of Stroop tasks between Chinese characters and other writing systems.
The earliest comparison found that American English-Chinese bilinguals showed larger Stroop interference in Chinese than in English (Biederman and Tsao, 1979). However, follow-up studies with nearly identical settings found opposite (Smith and Kirsner, 1982) or equivalent (Lee and Chan, 2000) results. Another study also found a general delay of responses by Chinese readers as compared with German readers in all Stroop conditions, and the delay to the general difficulties was attributed to the general difficulties in the processing of Chinese characters (Saalbach and Stern, 2004). Recent findings further suggest that the readers’ bilingual or bi-dialectal (Wu, 2015) linguistic backgrounds influence the Stroop effects with Chinese characters.
It has been confirmed that the sounds of Chinese characters are also activated in Stroop tasks, similar to the case of alphabetic systems (MacLeod, 1991). However, there are still debates on the tonal activation of Chinese characters. When the segments are consistent and the meanings are irrelevant, tonal-consistent conditions (e.g. a red hong2, “洪,” flood, which is phonologically related to hong2, “红,” red) would facilitate ink naming as compared with tonal-inconsistent conditions (e.g. a red hong1, “轰,” flood, which is also phonologically related to hong2, “红,” red). This finding supports the automatic activation of tones from Chinese characters. However, when the segments are inconsistent, whether tonal-consistent conditions (e.g. a red tu2, “涂,” smear, which has the same tone as hong2, “红,” red) would facilitate ink naming as compared with tonal-inconsistent conditions (e.g. a red guan4, “贯,” penetrate, which is totally irrelevant to hong2, “红,” red) is still under debate (Li et al., 2013; Spinks et al., 2000). Anyway, tonal and non-tonal phonological processing during character reading may involve different processing mechanisms. This claim has also been supported with the lack of tonal effects in masked priming experiments (Lee, 2007) and the dissociation of tonal and syllabic lesions by acquired dyslexia patients (Law and Or, 2001).
Moreover, studies on the neurological correlates of Stroop effects also reveal various differences between Chinese characters and alphabetic writing systems. On the one hand, automatic processing of Chinese characters seems to involve more right-hemisphere activities as compared with alphabetic writing systems. As early as the 1980s, studies found that the English Stroop interference mainly happens in the right view field (RVF), while the Chinese Stroop interference mainly happens in the left view field (LVF). Taking into consideration that the right and left hemispheres of human brains control the opposite sides of human bodies, it can be inferred that automatic reading of Chinese characters involves more right-hemisphere activities (Tsao et al., 1981), which has further been confirmed in neuro-imaging studies (Khateb et al., 2000). On the other hand, regarding conflict detection and resolution, the Chinese Stroop task is also special. Chinese Stroop interference would activate negative ERP components similar to what has been found with alphabetic writing systems, and activate proficient readers’ prefrontal cortex, which is known to relate to conflict resolution (Khateb et al., 2000; Qiu et al., 2006). However, alphabetic Stroop interferences usually increase the activation in the anterior cingulate cortex and temporal parietal lobe, which are known to relate to conflict detection, while Chinese Stroop interference would not increase the activation in these areas, unless performed with special visual tasks. This may indicate that the semantic activation from Chinese character forms is more automatic and involves fewer correspondence rules between the orthography and phonology (Chen et al., 2006).
Finally, Chinese characters are also processed in preview. It is well known that when proficient readers read sentences, they not only see the words they fixate on, namely what is in their foveal view, but also extract information from a less attended scope of view, which is known as the parafoveal view, especially the following part of the target sentence to be read, namely the preview (Rayner, 1998). Information processing in the preview during the reading of Chinese characters has received increasing attention recently.
Words are extracted during preview reading. As noted in the second section, preview processing is sensitive to word boundaries (Liu et al., 2016; Zhang et al., 2012), which indicates that word-segmentation probably starts in the preview. Besides word boundaries, readers also access within-word character order information unconsciously during preview reading. A gaze-contingent display-change experiment showed that switching the within-word orders of characters (e.g. displaying guai1li4, “乖戾,” grumpy as li4guai1, “戾乖”) when they are in preview and changing them back to normal as soon as readers fixate on them would increase the durations of fixation time, although readers would not notice this change (Gu et al., 2015).
However, the activation of orthography in the preview is still incomplete. Another recent eye-tracking experiment using the gaze-contingent display-change paradigm, by introducing a temporary mask in the preview, showed that whether depriving the preview of the coming word (e.g. “政府大力
In contrast, semantic information is largely extracted in Chinese previews. An ERP experiment with the rapid serial visual presentation (RSVP) paradigm showed that lexical semantic violation in the preview within Chinese sentences is related to larger N400 effects, which indicates that character readers can extract semantic information from the preview (Wang et al., 2014).
Moreover, the top-down predictability effect can also interact with preview conditions. The basic finding regarding the predictability effects of Chinese visual sentential processing is that, given the same contexts (e.g. “世界各国都受到了金融
Hence, even when attentional character reading is not required by the task, proficient Chinese readers would still process characters automatically and sometimes even unconsciously. However, the phonological and orthographic activations in this process may not be as complete as attentional reading, which may be beneficial if the task involves phonological or orthographical conflicts. However, the semantic activation of Chinese characters may be more complete and more difficult to inhibit as compared with alphabetic writing systems.
The activation of Chinese characters via non-character input
As noted in the third section, proficient readers would process Chinese characters automatically even if they are not required to direct their attention to the characters. It has been proposed that Chinese readers have a visual neurological network always ready to process Chinese characters, even when no characters are present, which involves continuous rest-state communication between the right and left occipital visual areas (Zhao et al., 2011).
One of the non-character triggers for character processing is the Chinese pinyin, which is an alphabetic writing system used to supplement Chinese characters (Standing Committee of the National People’s Congress of China, 2000). It is found that, if preceded by an exposure to a priming pinyin string (e.g. bēizi) that corresponds to a Chinese character string (e.g. bei1zi, “杯子,” cup) that takes a written form similar to the target character (e.g. huai2, “怀,” bosom), the reading of the target character would be facilitated, as compared with an irrelevant target character (e.g. chao3, “炒,” stir-fry) (Chen et al., 2014). This finding indicates that even automatic processing of pinyin strings can activate the corresponding character orthographically.
Moreover, bilingual readers can activate the orthography of Chinese characters via the written forms of their other languages. Thierry and Wu (2004, 2007) found that, when judging whether English words are semantically related, although viewing no Chinese characters in the task, Chinese-native English learners are still influenced by the Chinese characters corresponding to the translations of these words. For instance, for the English word pair “post–mailbox,” the Chinese translations “邮局–邮箱” both contain the character you2, “邮,” mail, while for the English word pair “bath–shower,” the Chinese translations “洗澡–淋浴” do not share any character, and Chinese-native English learners would make semantic judgments on the former faster than the latter. One may argue that this finding is not the result of character sharing but of morphemic sharing (Chinese characters mostly represent morphemes anyway). However, even when the Chinese words are semantically not so transparent in the combination of morphemes, Chinese characters seem to still take effect in the English task. It still takes more time and larger N400 ERP effects for the Chinese-native English learners to judge the pair “train–ham” (火车–火腿) as semantically unrelated than to judge the pair “rabbit–desk” (兔子–书桌), even if the implicit overlap of the Chinese character “火” in the former case is not that transparent in meaning. These phenomena may suggest that Chinese-native second language (L2) learners’ mental storage of foreign written forms are dependent on their storage of Chinese characters, as has been suggested earlier for other cases of L2 learners (Kroll and De Groot, 1997).
Summarizing this section, proficient Chinese readers are always cognitively and neurologically ready to process Chinese characters, and they do not even need to view Chinese characters to start processing.
The influences of readers’ linguistic experiences on character reading
While most studies reviewed above considered proficient Chinese readers, many studies have also involved Chinese readers with special backgrounds, such as children, deaf readers, bilinguals, and bi-literals, and investigated the influences of the readers’ linguistic experiences on character reading processing.
(1) Children are the most common natural group of character learners. Many studies have investigated the change of character processing mechanisms by Chinese children during their learning process. Comparing primary school learners from the second and fifth grades against college students, one study found that the processing errors with pseudo-characters (e.g. “ 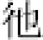 ”) and the two types of non-characters (e.g. “
”) and the two types of non-characters (e.g. “ 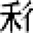 ” and “
” and “ 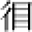 ”) largely reduced with increased duration of schooling. Moreover, processing differences across the pseudo-characters and the two types of non-character also emerge in this process (Peng et al., 2006). These findings indicate that Chinese children’s sensitivities to radicals and the location of character units are gradually developed.
”) largely reduced with increased duration of schooling. Moreover, processing differences across the pseudo-characters and the two types of non-character also emerge in this process (Peng et al., 2006). These findings indicate that Chinese children’s sensitivities to radicals and the location of character units are gradually developed.
(2) Deaf Chinese readers have generally shown more reliance on semantics in character processing. Since deaf readers, as compared with hearing readers, have limited auditory experiences with Chinese speech but comparable visual experiences, it is not surprising that deaf readers differ from hearing readers in the way they acquire literacy (Zan and Liu, 2004). As noted above, cognitive processing for the reading of Chinese characters involves both semantic and non-semantic routes. Adaptive to such linguistic experiences, deaf readers tend to rely more on the semantic route to process Chinese characters (Fang and Zhang, 1998; Feng and Fang, 2003), although the non-semantic route with sounds involved also takes effect (Tan et al., 2003; Zan and Tan, 2004). Deaf Chinese readers may have developed special neurological pathways for reading as well, as they showed even more advantages in the LVF, which may be related to the influence of sign-language experiences (Wang, 1993).
(3) Bilingualism can influence the processing of Chinese characters. Some bilinguals are bi-literal, that is, they can read in two writing systems corresponding to their two languages (e.g. Chinese-English bilinguals), while some other bilinguals are mono-literal, that is, they use the same writing system to write two dialects of the same language (e.g. Chinese bi-dialectals of Standard Chinese and one northern Chinese dialect) or use partially overlapping orthography to write related words of the two languages (e.g. Japanese-Chinese bilinguals who can use Kanji for Japanese and Chinese characters for Chinese, with the two writing systems largely overlapping).
Most studies have been carried out on the former type of bilinguals. On the one hand, L2 learners of Chinese whose native language makes use of another type of writing system can adapt their cognitive mechanism to the complex visual-spatial processing of Chinese. For instance, even beginning Vietnamese-native L2 learners of Chinese can use radicals to code Chinese characters, as they showed the familiarity effect of Chinese radicals in their copying delay of pseudo-characters (Ruan et al., 2016). Although beginning learners cannot activate Chinese characters via pinyin, they would acquire such ability with the improvement of their Chinese achievement (Chen et al., 2017). Even English-native Chinese learners can make use of some Chinese-specific neurological networks, such as medial frontal gyrus (BA9), right occipital lobe (BA18/19), and middle fusiform gyrus (BA39), to read Chinese characters (Perfetti et al., 2007).
On the other hand, native writing systems can be transferred to read Chinese characters, especially regarding the sub-lexical and sub-character aspects. For instance, western learners whose native writing systems are alphabetic would pay more attention to the right-hand and bottom locations within Chinese characters and show writing order effects. In contrast, Japanese and Korean learners, who have experience with square-shaped Hangul or Kana and Kanji, only showed sensitivity to radicals within the up–down-structured (上下结构) characters, while tending to process left–right-structured (左右结构) characters as a whole. Such effects probably can be attributed to the transfer from their native writing systems; for example, Hangul characters are also up–down structured but not left–right structured.
It is widely accepted that bilinguals (including multi-linguals) have integrated mental lexicons, which means that lexical items from different languages are usually co-activated in their mental lexicon and compete for selection (e.g. see Van Heuven et al., 2008). The way such competition happens largely depends on the task and the relative proficiency of the competing languages.
Stroop interferences tend to appear with larger effect sizes when the written form and the naming speech are in the same language (e.g. naming the ink color of a red “蓝,” lan2, blue, in Chinese) as compared with naming in a different language of the written forms (e.g. naming the ink color of a red “蓝,” lan2, blue, in English; Chen and Ho, 1986; Van Heuven et al., 2011). This indicates that crossing the “boundary” between languages can influence automatic reading of Chinese characters. Moreover, a trilingual Stroop study found weaker interferences between Chinese characters and an alphabetic writing system (e.g. English) than between two alphabetic writing systems (e.g. between English and Malay; Van Heuven et al., 2011). This indicates that typological features of the bilinguals’ two (or more) writing systems may play important roles in cross-linguistic reading processing as well.
Regarding the influence of proficiencies, Chinese-English bilinguals with lower English proficiencies as compared with more proficient readers received stronger interferences from Chinese characters when carrying out the Stroop task in English (Chen and Ho, 1986), which means that low-proficiency learners still have difficulties in inhibiting their automatic activations of Chinese characters. Nevertheless, regarding equivalently proficient Chinese-English bilinguals, their linguistic experiences of language acquisition can further modulate automatic activations of Chinese characters, in that early bilinguals showed more difficulties than late bilinguals in inhibiting the interference of Chinese characters during an English ink-naming task (Lu and Tu, 2010; Tu, 2007).
Now we come to the latter type of bilinguals, who use the same writing system for two linguistic varieties. Using the same writing system for two linguistic varieties requires the dissociation of orthography from pronunciation, which can only easily be achieved with an ideographic writing system, such as Chinese characters. This phenomenon is almost specific to Chinese characters and has been less studied.
One of the few studies involves Chinese-native Japanese learners. These learners are influenced by homophonic relations between Chinese characters in judging homophonic relations of Japanese Kanji. For instance, the first syllables of “日本” and “荷物” are homophonic in Japanese, as in “にほん,” nihon, and “にもつ,” nimotsu, which share “に,” ni, but not homophonic in Chinese, as in ri4ben3 and he4wu4, while “非常” and “飛行機” are homophonic in Japanese, as in hijou and hikoki, as well as in Chinese, as in fei1chang2 and fei1xing2ji1. It is found that the former pair is accepted more slowly than the latter, which indicates that Chinese characters (and Kanji) can activate their Japanese and Chinese pronunciations simultaneously (Li, 2011).
Anther special case of mono-literal bilingualism is actually Chinese bi-dialectism. Recent findings have shown that bi-dialectals of Standard Chinese and Jinan Mandarin can better modulate their own attention than Standard Chinese mono-dialectals in Stroop tasks even in Standard Chinese. The bi-dialectals selectively blocked tonal information from interfering characters, which reduced their Stroop interference, and only the bi-dialectals, but not the mono-dialectals, showed Stroop facilitation under congruent conditions (Wu, 2015). Interestingly, it was the bi-dialectals instead of the mono-dialectals who showed more consistent findings as compared to earlier Chinese Stroop studies.
(4) Some languages use two or even more writing systems in parallel, which makes the readers in these linguistic societies bi-literals. In Chinese, pinyin is used supplementary to Chinese characters, while in Korean and Japanese, Chinese characters are still used supplementary to their alphabetic writing systems, Hangul and Kana. The main question is whether the neurological and cognitive pathways for the two writing systems are separate in one brain. There was a Japanese patient who could write Kanji (Chinese characters) but suffered severe lesion in his Kana writing ability. This finding indicates that the neurological pathways for Kanji and Kana may be separate (Sasanuma, 1974). Also, studies of functional networks in bi-literal brains have shown that pinyin reading as compared with character reading involves more activation of the primary motor area (M1), supplementary motor area (SMA), Broca’s area, and Wernicke’s area. Researchers believe that these findings indicate that pinyin reading involves a more direct and sub-lexical route as compared with character reading (He et al., 2003). However, we have shown in the previous section that pinyin strings can activate their corresponding Chinese characters (Chen et al., 2014). Also, the proficiency in using pinyin input in typing has shown facilitatory effects in the visual searching of Chinese radicals (Zhu et al., 2009). These findings suggest that pinyin reading and character reading are closely related and interactive in their cognitive mechanisms.
Conclusion and prospects
Based on three distinctive features of Chinese characters as compared with the other writings systems, we gave a comprehensive review of five main issues of Chinese reading, which are (1) the relationship across written forms, sounds, and meanings during the neurocognitive processing of Chinese reading, (2) the involvement of structural and linguistic units, such as strokes (笔画), radicals (部件), components (偏旁), whole characters (整字), and words (词), in character reading, (3) the influence of attentional conditions on character reading, (4) the activation of Chinese characters from non-character input, and (5) the influences of readers’ linguistic experiences on character reading. Taken together, the reading processing of Chinese characters not only is in accord with the general principles of visual language processing, but also shows unique characteristics. The reading of Chinese characters involves dynamic integration of multi-channel information and multiple levels of processing units, which as compared with alphabetic writing systems, rely more on form-to-meaning semantic processing, while their form-to-phonology non-semantic processing is greatly influenced by the para-linguistic context. The orthographic, phonological, and semantic processing of Chinese characters is influenced by the readers’ attentional conditions, as well as the readers’ long-term linguistic experiences. Character readers, when turning from beginners to skilled readers, develop a mental mechanism that is more and more automatic and ready to process character inputs. They can adjust their visual, linguistic, and attentional neurological networks to different extents, in order to satisfy the need for character processing.
Although there have been extensive findings on the neurocognitive processing of Chinese characters, two major issues may require further investigation. The first issue is how Chinese readers can extract context-pertinent information in contexts that involve multiple orthographical-semantic or orthographical-phonological correspondences, which may involve different fonts (e.g. Li 隶, Cao 草, Xing 行, Kai 楷, or even Zhuan 篆 and Oracles 甲骨文), orthographical variants (e.g. qun2, “群-羣,” group), simplified and traditional Chinese characters (e.g. ai4, “爱-愛,” love), polyphonic characters (e.g. shuai4, lü4, “率”), mono-literal bilingualism (i.e. bilinguals or bi-dialectals who use Chinese characters for two linguistic variants), or bi-literal monolingualism (e.g. Chinese monolinguals who use both pinyin and Chinese characters). The second issue is how linguistic units larger than words are processed in character reading, especially by elite readers who can legendarily read multiple lines in one glimpse (一目十行).
Footnotes
Acknowledgments
I would like to thank Professor Zheng Wei for urging me many times to write and re-write this review article, my student Zeng Xiaoxin for choosing a related topic as her term thesis, which put me under a lot of pressure to read more articles and refine this paper, and the editors of this journal for encouraging the submission of this work.
1.
This review is based on studies that research Chinese readers who do not have special knowledge about the history and evolution of Chinese characters. I can well expect that including researchers or calligraphers who have extensive knowledge of these aspects would show different and more interesting results.