
Abstract
The mining industry is increasingly adopting intelligent systems to address challenges such as declining ore grades, rising operational costs and sustainability demands. This study presents a Proximal Policy Optimisation (PPO)-based truck dispatching model designed to enhance operational efficiency in open-pit mining. Addressing two key research gaps – limited integration of dispatching features and underutilisation of advanced reinforcement learning (RL) algorithms – the proposed model incorporates 19 critical features and is evaluated against the conventional Fixed Schedule (FS) method. A discrete event simulation environment was developed to emulate an open pit case study with heterogeneous trucks and shovels. The PPO model demonstrated convergence within 3.5 h and outperformed the FS baseline across multiple key performance indicators, including a 5.7% increase in total production, 4.2% improvement in plant delivery, and 13.2% higher truck utilisation. Compared to widely used RL algorithms in this domain, the PPO approach achieved faster convergence despite handling a more complex feature set. These findings highlight the potential of PPO as a robust and scalable solution for intelligent dispatching, offering practical benefits for Mining 4.0 initiatives.
Introduction
The mining industry is undergoing a transformative shift as it confronts various challenges – declining ore grades, rising energy costs and increasing pressure to reduce environmental impact (Igogo et al., 2021). In response, the sector is embracing Mining 4.0, a digital revolution that leverages automation, artificial intelligence and real-time data analytics to enhance efficiency and sustainability (Hazrathosseini and Moradi Afrapoli, 2023c). A critical component of this evolution is intelligent truck dispatching, which directly influences operational costs, productivity and carbon emissions (Hazrathosseini and Moradi Afrapoli, 2023b). Traditional dispatching methods, often reliant on static heuristics, struggle to adapt to the dynamic nature of mining operations, leading to inefficiencies in fuel consumption, fleet utilisation and route optimisation (Hazrathosseini and Moradi Afrapoli, 2023a; Khorasgani et al., 2020; Zhang et al., 2020). Therefore, adopting intelligent solutions for truck dispatching is essential to meet the evolving demands of modern mining, enabling adaptive, data-driven decisions that optimise resources, reduce emissions and drive sustainable productivity.
Reinforcement learning (RL) has emerged as a transformative solution, enabling dispatching systems to learn and improve continuously by interacting with their environment. Unlike conventional approaches, RL-based systems can dynamically adjust to real-time variables – such as fluctuating demand, equipment breakdowns and weather disruptions – while optimising for key performance indicators (KPIs) like fuel efficiency, production output and emissions reduction (De Carvalho and Dimitrakopoulos, 2021; Hazrathosseini and Moradi Afrapoli, 2025; Huo et al., 2023; Matsui et al., 2023; Zhang et al., 2020). Recent advancements in deep RL and multi-agent systems have demonstrated significant results compared to conventional methods, including: 5.56% increase in ore production (Zhang et al., 2020), 10–30% lower greenhouse gas emissions (Huo et al., 2024), controlling the grade fluctuating of the ore flow (Qiu et al., 2023), and 47% improvement in cash flow (De Carvalho and Dimitrakopoulos, 2023). These figures underscore RL's potential to revolutionise truck dispatching, bridging the gap between theoretical advancements and practical mining applications.
Over the past five years, numerous researchers have explored the application of RL to develop intelligent truck dispatching solutions. However, as will be discussed in further detail in section ‘Literature review’, a notable research gap exists concerning the comprehensiveness of truck dispatching features addressed within the models developed in the existing literature. Specifically, Hazrathosseini and Moradi Afrapoli (2024) conducted a critical review of previously published articles on RL-based fleet management systems in open-pit mines. Their study introduced a five-feature-class scale, incorporating 29 widely used dispatching features. Their findings revealed that 60% of these features were unaddressed in prior research, indicating substantial potential for improvement in the underlying algorithms.
An additional research gap is evident in the less frequent consideration of alternative RL algorithms, such as Proximal Policy Optimisation (PPO). Existing intelligent dispatching systems have predominantly utilised Deep Q-learning Network (DQN) and Double DQN (DDQN), often without exploring the efficacy of other viable approaches. Consequently, this study aims to address these two identified gaps: the oversight of essential dispatching features and the overuse of certain RL algorithms. To achieve this, the present research is guided by the following three objectives:
To develop an RL-based truck dispatching system incorporating a more comprehensive set of features than those currently addressed in the existing literature. To leverage PPO, an algorithm that has been less explored in the relevant literature. To quantitatively assess the operational efficiency of the developed system within an open pit mine case study against a conventional industry baseline, specifically the Fixed Schedule (FS) strategy, utilising common KPIs such as total production, material delivery to the plant, waste dump delivery, plant feed grade, truck fleet utilisation, and queuing times at shovels.
Literature review
The foundational concept behind intelligent dispatching is the shift from rule-based systems to data-driven decision-making frameworks. In response, researchers have developed intelligent models using RL techniques. Zhang et al. (2020) introduced a multi-agent framework to dispatch large-scale heterogeneous fleets using DQN. Their environment used centralised learning with decentralised execution, allowing individual trucks to act autonomously while sharing knowledge through a global experience buffer. Their approach improves productivity by 5.56%, reduces queuing and shovel starvation, and demonstrates robustness to fleet changes. De Carvalho and Dimitrakopoulos (2021) addressed the challenge of dynamic truck dispatching in mining complexes under operational and geological uncertainties. The authors proposed a DDQN framework integrated with a simulator to optimise dispatching decisions while managing stochastic factors like truck/shovel failures, variable cycle times, and ore grade uncertainty. Their approach, tested in a copper-gold mining complex, demonstrates 12–16% higher copper recovery and 20–23% higher gold recovery compared to baseline methods, while reducing queue times and improving fleet utilisation.
In another effort, De Carvalho and Dimitrakopoulos (2023) proposed an actor-critic RL framework to integrate short-term production planning with dynamic fleet management in mining complexes under geological and operational uncertainties. The method employs two RL agents: the first optimises shovel allocation to mining fronts, while the second assigns material destinations and truck numbers, leveraging a simulator to forecast material flow and update orebody models using real-time sensor data. Tested in a copper mining complex, the approach achieved a 47% improvement in cash flow compared to static baseline strategies by dynamically adapting to equipment failures, grade variability and production targets. Huo et al. (2023) proposed another approach to optimise truck fleet dispatching in open-pit mining, targeting reductions in greenhouse gas emissions and improvements in operational efficiency. Using tabular Q-learning in a hypothetical mining environment, their method dynamically adjusted truck routes and schedules based on real-time factors like payload, traffic and maintenance needs. The results showed a 30% reduction in emissions and a 55% increase in correct material deliveries compared to traditional fixed-schedule dispatching. Matsui et al. (2023) presented a real-time dispatching algorithm utilising Dueling DQN to optimise autonomous haulage truck operations in open pit mining. Their model, simulated in an environment replicating autonomous truck behaviours and accounting for vehicle interactions, demonstrated superior performance compared to industry-standard methods. The experimental results highlighted a 15–20% increase in transportation efficiency and a decrease in fuel consumption. Qiu et al. (2023) proposed a dynamic multi-objective evolutionary algorithm for optimising truck scheduling in open-pit mining, focusing on real-time ore blending and operational efficiency. The study incorporated tabular Q-learning to minimise ore grade fluctuations at crushing stations while maximising production and reducing fuel consumption. Results demonstrated that the proposed method outperforms traditional approaches, achieving better control over grade stability and improving scheduling efficiency.
Huo et al. (2024) developed a smart dispatching solution for mining haul truck fleets using a DDQN approach to improve operational efficiency and reduce greenhouse gas emissions. They simulated a hypothetical open pit mine environment to compare the performance of their model with conventional methods. The results demonstrated that their solution increased productivity at least by 27%, reduced emissions per unit production by 10–30%, and effectively handled operational disruptions, such as fleet size changes and shovel grade variations. Hazrathosseini and Moradi Afrapoli (2025) developed an intelligent rule-based decision-making system for preliminary truck dispatching in open pit mines using a modified Q-learning algorithm. Compared to a conventional rule-based system, the proposed solution achieved 10 times fewer incorrect dispatches, 4% fuel savings, a 10% reduction in queuing time, and a 14% increase in ore production. The study highlighted the system's ability to handle unforeseen scenarios and its potential as an upper-stage solution in multi-stage intelligent dispatching frameworks. Recently, Noriega et al. (2025) developed a real-time truck dispatching system for open-pit mining using DDQN. They created a discrete event simulation model to train the system, accounting for uncertainties in equipment cycles and production targets. The results showed that their DDQN-based solution outperformed traditional heuristics, achieving higher productivity, better adherence to ore quality targets, and improved fleet utilisation while integrating production indicators and traffic rules like no-overtaking constraints.
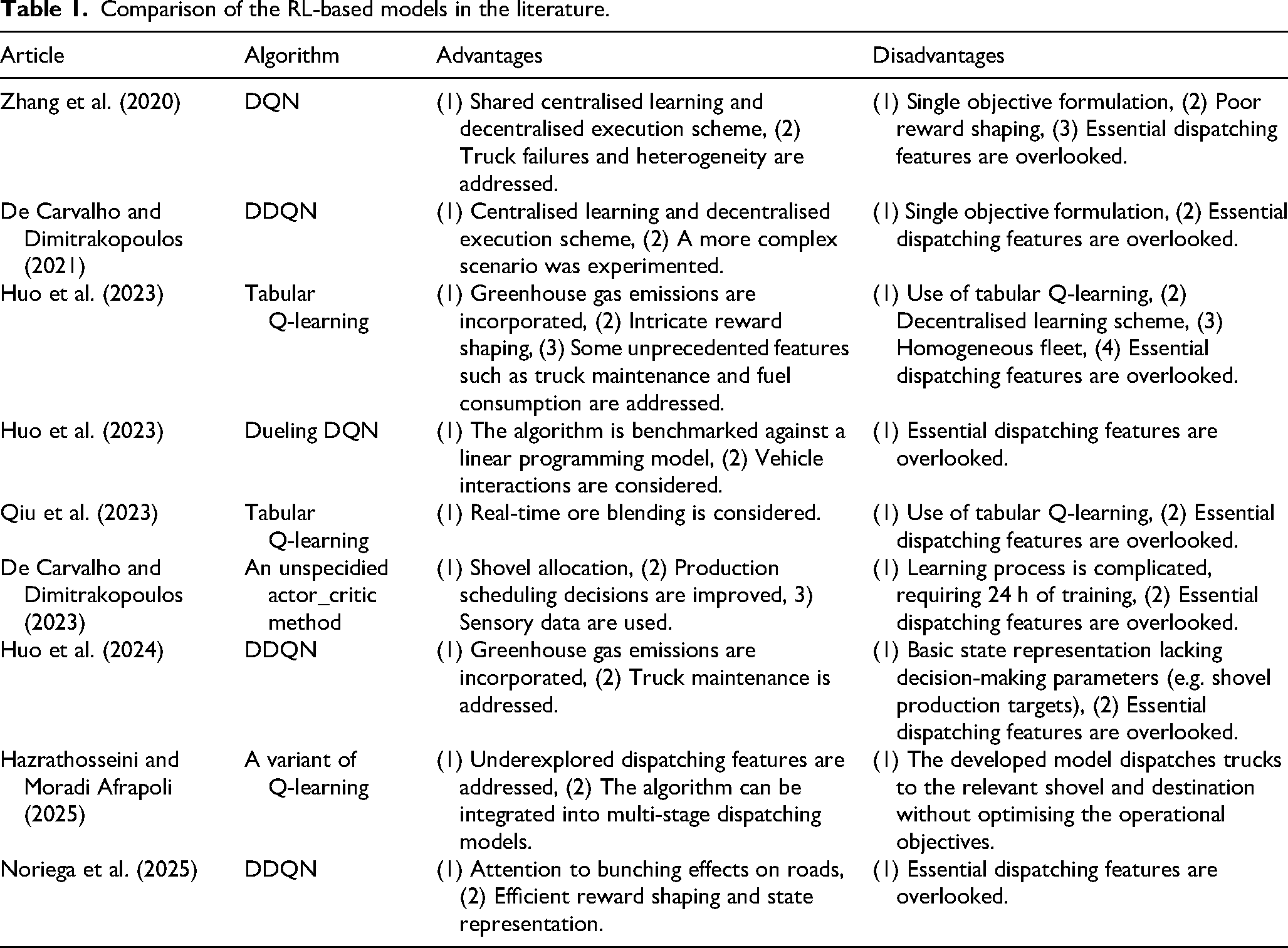
Table 1 offers a comprehensive overview, meticulously detailing the advantages and disadvantages associated with previously developed RL-based dispatching systems. Through this analysis, two distinct research gaps become particularly noticeable. Firstly, there is a consistent oversight of essential dispatching features in existing models, as highlighted by Hazrathosseini and Moradi Afrapoli (2024). Secondly, a prevalent reliance on specific value-based algorithms, such as DQN and DDQN, is observed, often to the exclusion of exploring alternative and potentially more suitable algorithms like PPO, an actor-critic method. This research initiative aims to address these two identified gaps directly by developing a more comprehensive truck dispatching algorithm that leverages PPO, an algorithm that remains relatively underexplored in this specific application domain.
Comparison of the RL-based models in the literature.
Methodology
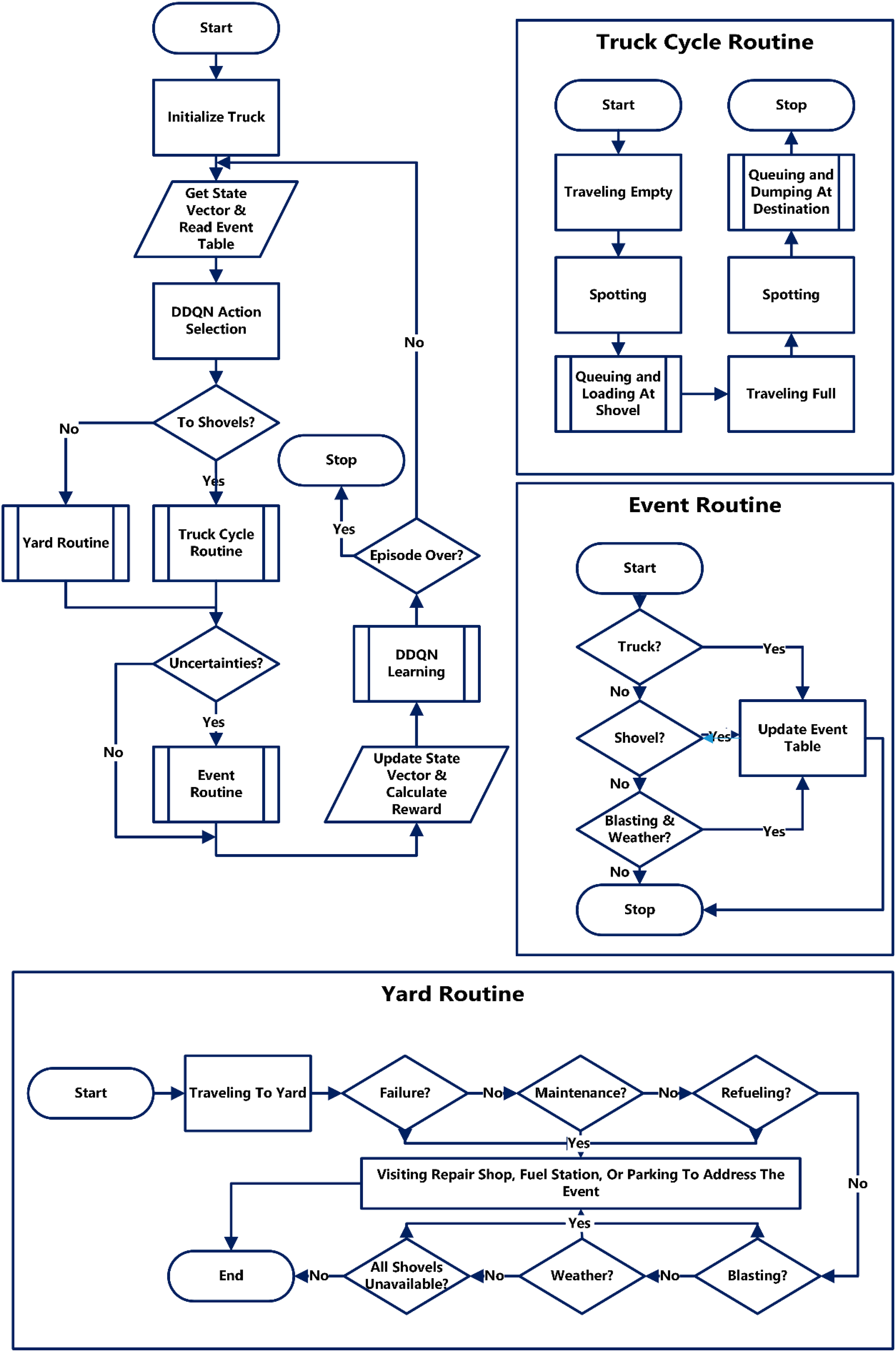
Figure 1 illustrates the methodological flowchart for the intelligent truck dispatching model developed in this study. First, an array of technical dispatching features is selected to be included in the model with a view to fill research gaps. Then, a simulated open pit mining environment is created using Python®. This simulated environment serves as the training platform for the truck agents, enabling them to gain experience and knowledge through interactions within this virtual setting. The environment incorporates the technical dispatching features identified as research gaps earlier. In the next step, an underexplored variant of RL algorithms, known as PPO, is implemented, providing the framework for training the truck agents. Once the training process is complete, the developed intelligent model is evaluated by benchmarking it against a baseline in the subsequent section to provide valuable insights into the effectiveness and potential benefits of the proposed model.
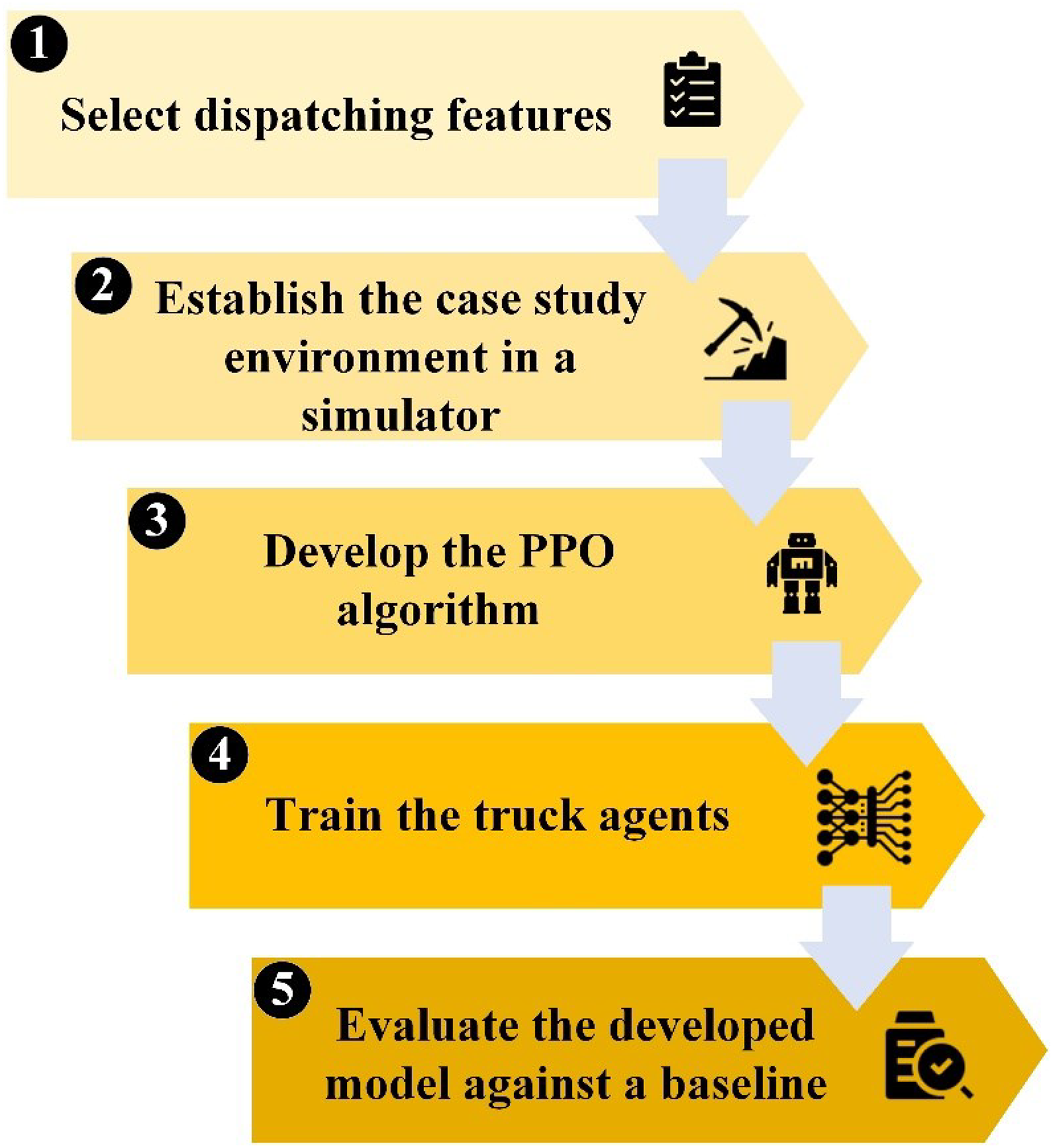
Summary of the methodology.
Dispatching features
Section ‘Literature review’ highlighted the imperative for developing more comprehensive dispatching algorithms capable of integrating a broader array of essential features. Specifically, analysis of prior research indicated that only 12 out of 29 identified features had been addressed in existing studies, leaving a significant portion unexamined. To bridge this gap, the current study selects and incorporates 19 key features. In other words, an effective truck dispatching model for open pit mining must consider a wide range of operational features to reflect the complexity of real-world environments. More specifically, geological uncertainties can affect ore accessibility and quality, so accounting for these in the model helps minimise disruptions. Ore grades determine whether material should be sent to a waste dump or a processing plant, making grade awareness crucial. Block sequences influence the extraction order, and incorporating this ensures optimised shovel and truck allocation. Operational constraints such as shovel refuelling, shovel movement, shovel failure and shovel maintenance are also critical – refuelling is inevitable, movement causes delays, and failures or maintenance can significantly affect productivity.
Given the diversity of equipment, shovel heterogeneity and truck heterogeneity must be reflected, as capacities and speeds vary across units. The model should also support truck scalability, allowing the number of active trucks to change based on demand. Truck failure and maintenance need to be modelled to avoid dispatching to unavailable trucks and to reroute as needed. Likewise, truck refuelling, which contributes notably to idle time, must be planned intelligently. Weather conditions and blasting activities introduce external disruptions, requiring the model to reroute trucks or halt operations when necessary. Beyond operational logistics, the model must align with production objectives. These include ore production targets, which ensure trucks are dispatched to meet output goals; ore processing targets, which maintain a steady flow to processing plants; and processing plant head grade, which ensures consistent ore quality for efficient recovery. Lastly, waste production targets must be respected to adhere to scheduling constraints and stripping ratios. Collectively, these features ensure the dispatching system is robust, adaptive and aligned with mine-wide operational goals. By integrating these features into an intelligent dispatching model, this research aims to contribute a more holistic dispatching framework.
Mine environment
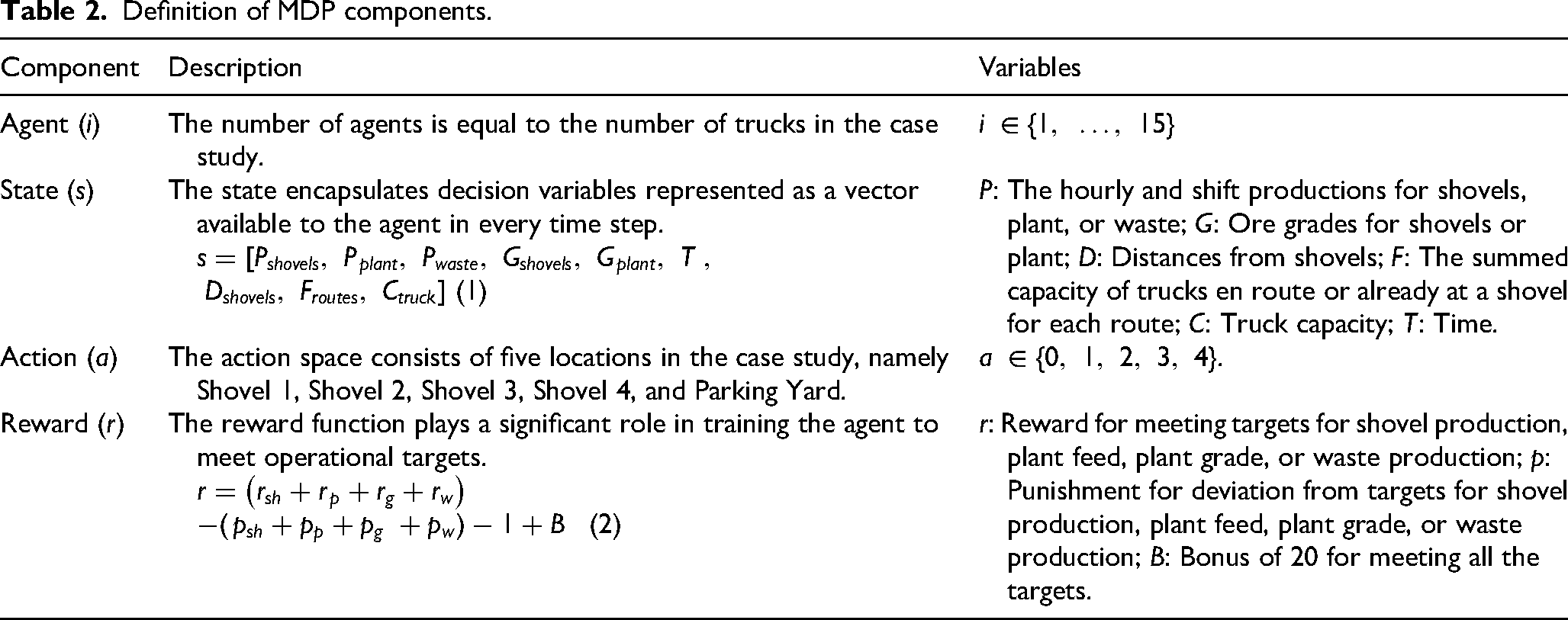
A ‘mine environment’ denotes a simulated environment emulating the conditions and complexities encountered in mining operations. The environment can be modelled as a Markov Decision Process (MDP), where the decision-making agent learns to optimise long-term operational efficiency. The MDP is formally defined by: a set of states (
Definition of MDP components.
The environment needs to provide a simulator in order that the truck agents interact within. The simulation model used in this study is designed based on an open pit mine case study encompassing 4 heterogeneous shovels, 15 heterogeneous trucks of two types, and 1 parking yard embedded with a fuel station and a repair shop (Figure 2). Discrete event simulation was employed as the paradigm for modelling the mining environment using the logic depicted in Figure 3. The simulation initialises each truck with attributes, then iteratively evaluates actions based on a dynamic event table reflecting uncertainties and maintenance needs. A PPO agent determines optimal dispatch (to a shovel or yard) using a state vector, executes the action, and updates the event table if uncertainties or maintenance criteria are met. The truck's state and a computed reward are stored in PPO's replay memory for learning, with the simulation continuing until a 12-h shift duration is completed, implemented in Python® using SimPy®.
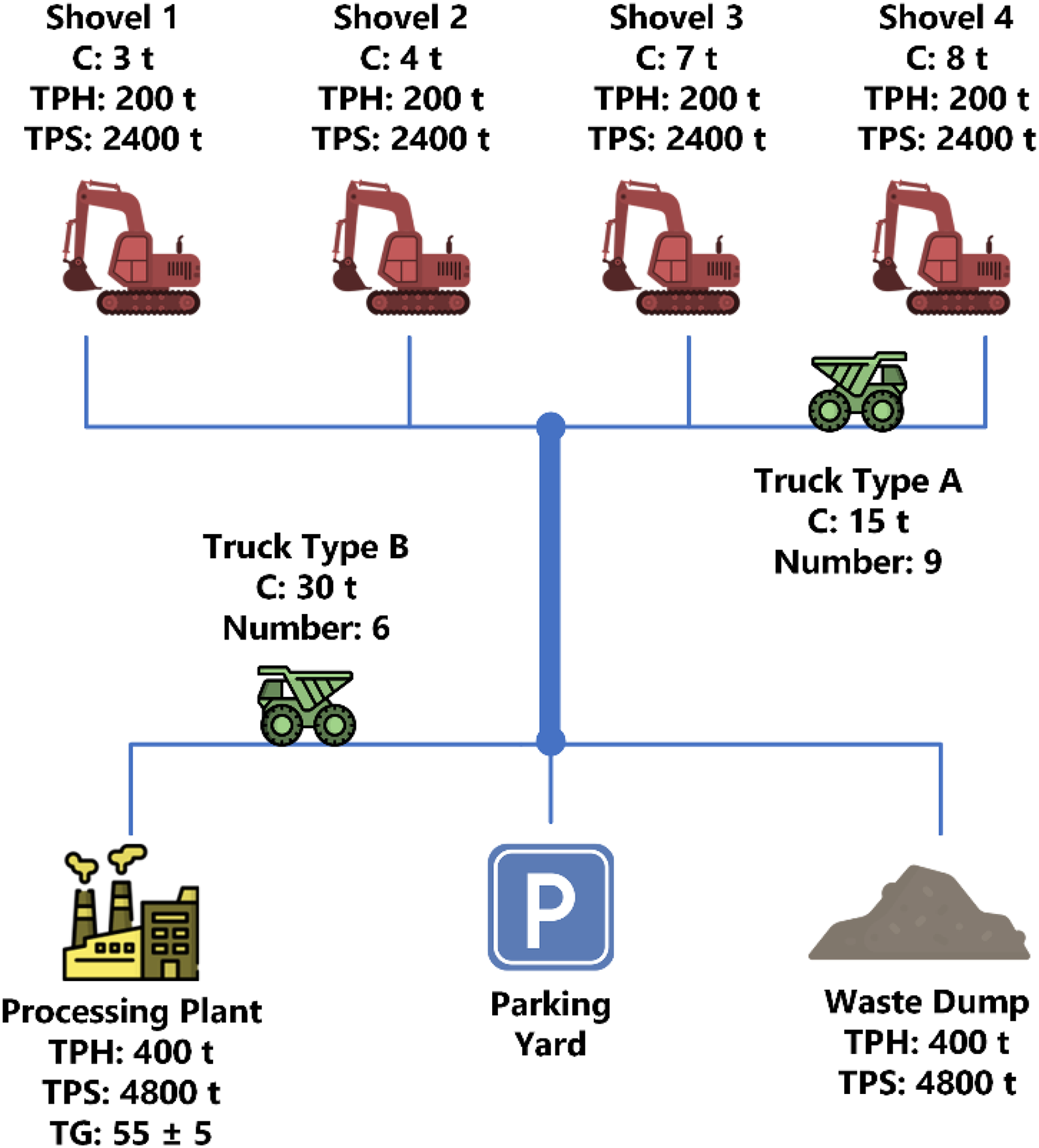
The open pit mine case study.
The simulation model.
PPO
PPO is an RL algorithm introduced by Schulman et al. (2017) as a more practical alternative to Trust Region Policy Optimisation (TRPO) (Schulman et al., 2015). It belongs to the class of on-policy, actor-critic methods and has become a cornerstone in modern deep RL due to its balance of efficiency and empirical performance across a wide range of tasks (Gu et al., 2022). PPO operates by optimising a clipped surrogate objective function that constrains the policy update to remain within a trust region, thereby preventing large, destabilising updates. Specifically, the algorithm maximises the following objective (equations (3)):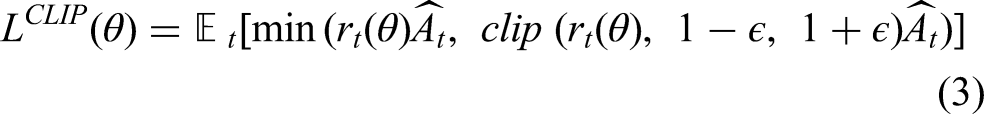
Where,
The PPO algorithm coded in Python® was used to train truck agents for dispatching in the mining environment developed earlier named as the MineEnvironment class. The pseudo code for this algorithm is detailed in Table 3. The PPO algorithm consists of three main parts: (1) Hyperparameters, (2) The PPOAgent class and (3) The episodic training part. The hyperparameters were initially chosen based on the values recommended by Schulman et al. (2017) and were subsequently refined through iterative trial-and-error tuning to better suit the specific characteristics of the dispatching environment. Regarding the PPOAgent class, the agent's neural network consists of a shared feature extractor with multiple dense ReLU layers, followed by dual output heads: an actor generating a softmax probability distribution over dispatching actions (e.g. assigning trucks to shovels or dump sites) and a critic estimating state values to stabilise training. The select_action method ensures operational feasibility by masking invalid actions (e.g. unavailable routes) and applying a numerically stable softmax to sample valid actions, enhancing decision-making efficiency in constrained environments. Experience transitions (state, action, reward, next state) are stored in a replay buffer (memory) and sampled in mini-batches for training, where the compute_gae function computes Generalised Advantage Estimation (GAE) to balance bias and variance in reward signals – critical for handling sparse, delayed rewards in dispatching. During training (train_step), the agent optimises the policy using a clipped surrogate objective to prevent destructive updates, while a critic loss refines value predictions and entropy regularisation encourages exploration. The replay method orchestrates batch sampling, GAE calculation and multi-epoch updates, ensuring robust policy refinement. The episodic training phase of the PPO-based truck dispatching algorithm begins with the initialisation of the simulation environment and learning agent. Specifically, an instance of the custom-designed MineEnvironment is created to emulate the operational dynamics of an open pit mine, while a PPOAgent instance is initialised to learn optimal dispatching policies. At the start of each training episode, the environment is reset to a predefined initial state. Subsequently, multiple truck agents are instantiated as parallel simulation processes, each interacting with the shared MineEnvironment and PPOAgent. This parallelism enables realistic modelling of concurrent truck operations and facilitates efficient data collection for policy learning. The shared architecture ensures that all agents contribute to and benefit from a centralised learning process, promoting coordinated behaviour across the fleet.
The PPO algorithm.

Training
The PPO-based truck dispatching algorithm was trained for 3.5 h over 100 episodes using an NVIDIA® A100 GPU on the Google Colab® platform (Figure 4). On average, each truck completed approximately 45 haulage cycles per episode. Given a fleet size of 15 trucks and a maximum achievable reward of 23 per truck (as defined in equation (2)), a cumulative reward of 15,525 was established as the minimum reward target. The learning process demonstrated convergence after approximately 90 episodes, with total episodic rewards peaking at 20,000 – well above the defined target threshold. In terms of operational metrics, the total material produced stabilised just above 15,000 tonnes, with each shovel contributing an average of 3800 tonnes, thereby exceeding the per-shovel production target. Material deliveries to both the processing plant and the waste dump plateaued around 7500 tonnes, aligning with their respective minimum thresholds. Notably, the plant feed grade exhibited marked stabilisation in the final episodes, suggesting the algorithm's capacity to maintain consistent ore quality. Additionally, truck fleet utilisation remained steady at approximately 91%, attributed to reduced queuing times at shovels following policy convergence.
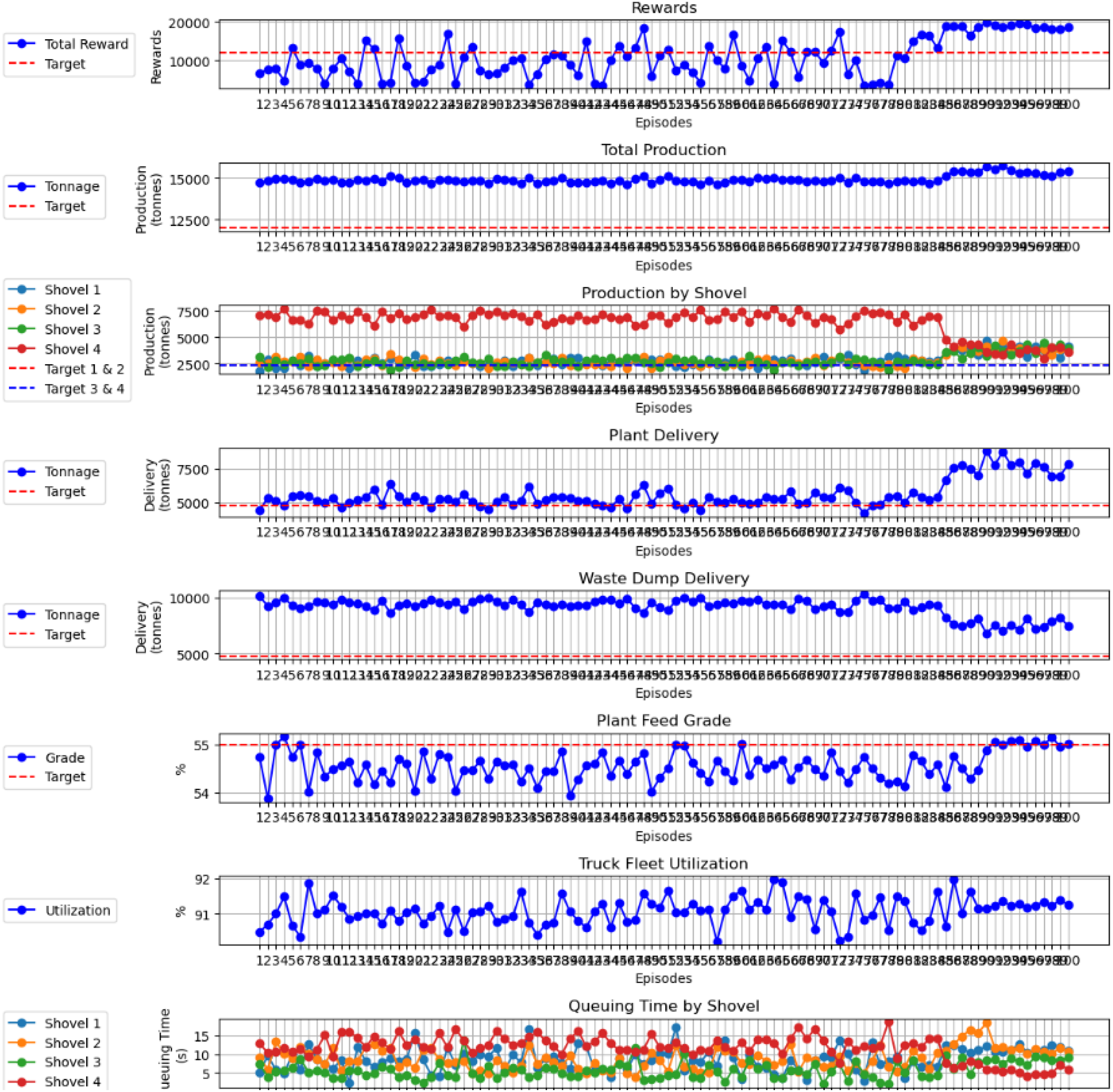
Performance of the developed model over 100 episodes during training.
Results and discussion
The previously developed and trained PPO-based truck dispatching model is evaluated against the FS method, a widely used baseline in open-pit mining operations. This comparative analysis, grounded in a set KPIs, seeks to assess the potential advantages offered by the PPO approach. The FS method represents a traditional dispatching strategy in which truck routes and shovel assignments are predetermined and remain fixed throughout each episode. Under this scheme, each truck consistently follows the same route and loads from the same designated shovel. To ensure a fair comparison, the same simulation environment was employed for both methods, with modifications made to the dispatching logic to implement the FS strategy. Specifically, trucks were grouped and assigned to shovels as follows: trucks 1–4 to Shovel 1, trucks 5–8 to Shovel 2, trucks 9–12 to Shovel 3 and trucks 13–15 to Shovel 4. Both the PPO and FS models were executed over a 30-day simulation period (30 episodes), and their performance was evaluated using KPIs such as total production, plant delivery, waste dump delivery and plant feed grade.
Figure 5 presents a comparative evaluation of the PPO and FS models across six KPIs upon running each model for three times and calculating average values. The results indicate that the PPO approach yielded a total production of 15,350 tonnes, marking a 5.7% improvement over the 14,523 tonnes achieved by the FS method. In terms of ore delivery to the processing plant, PPO averaged 7554 tonnes – an increase of 4.2% compared to the 7251 tonnes delivered under FS. Similarly, waste dump deliveries under PPO reached 7633 tonnes, reflecting a 7.5% gain relative to the 7099 tonnes recorded with FS. While the average ore grade in the plant feed showed only a slight difference between the two methods, PPO demonstrated a modest 0.9% improvement and, more importantly, exhibited greater stability in grade delivery. This consistency is particularly valuable for downstream processing. A key factor contributing to PPO's superior performance is truck fleet utilisation. By significantly reducing idle time at shovel queues – by approximately 30.4% – the PPO model enhanced overall fleet utilisation by 13.2%, reaching an average efficiency of 91.15%. These findings highlight the effectiveness of the PPO-based approach in optimising both operational throughput and resource utilisation.
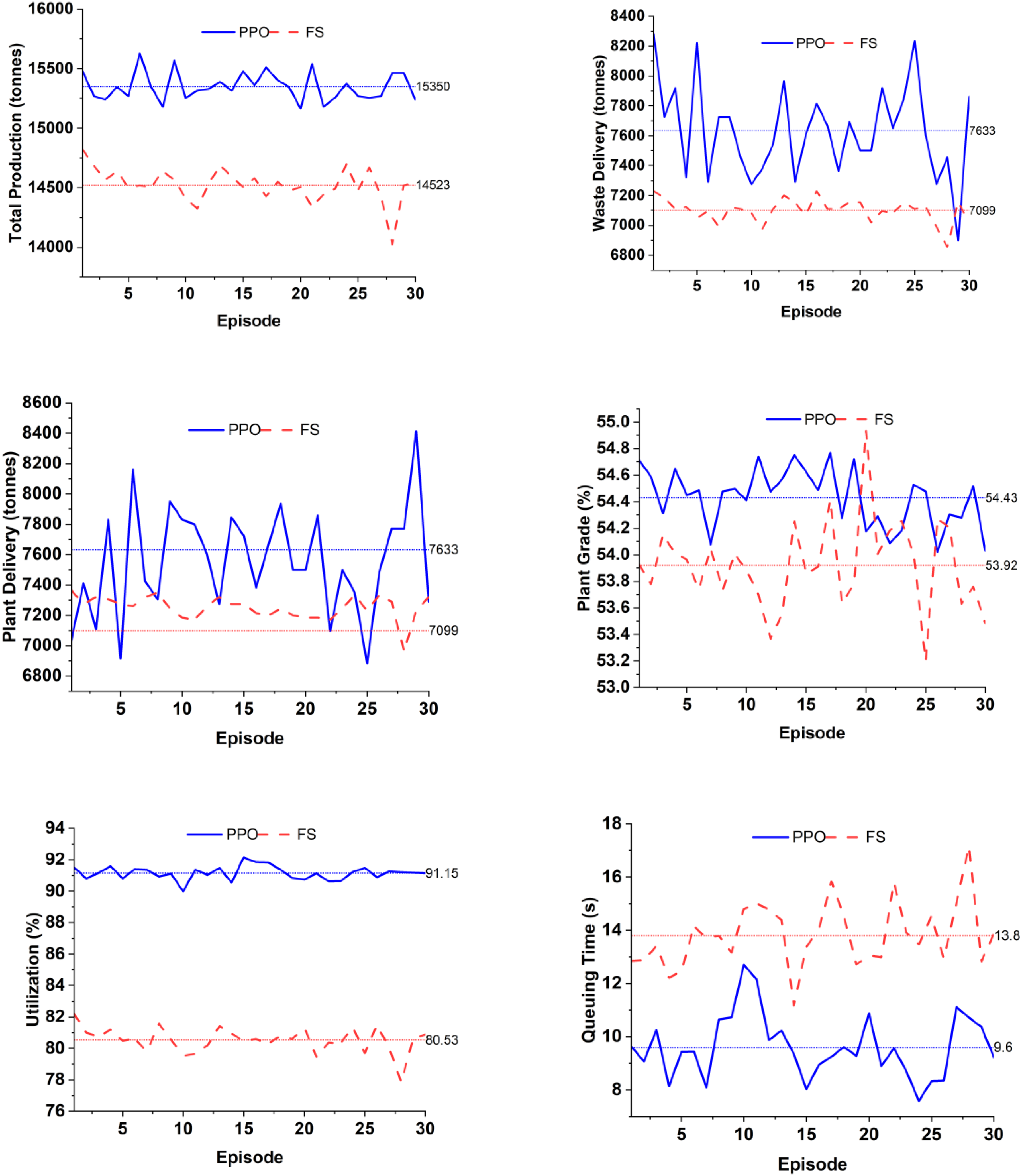
Comparison of PPO and FS in terms of average KPIs after running each model for three times.
The findings validate the potential of PPO as a viable and effective alternative to traditional RL algorithms in mining applications. The integration of a more comprehensive feature set allowed the dispatching agent to make more context-aware decisions, reflecting the complex realities of modern mining operations. The model's ability to converge within 90 episodes and maintain stable performance across multiple operational dimensions highlights its robustness and practical applicability. Notably, the PPO-based model developed in this study, which incorporates a broader set of dispatching features, achieved convergence within approximately 3.5 h. This is slightly faster than the 4-h training time reported for the DDQN-based model by Noriega et al. (2025), despite their model including fewer dispatching features and being trained on the same Google Colab® platform. This comparison suggests that the PPO algorithm may offer improved training efficiency, even when handling more complex input representations.
Conclusion
This study was initiated to contribute to the field of intelligent truck dispatching in open pit mining by integrating a more comprehensive set of 19 operational features – surpassing the narrower scope of prior research – and by implementing the PPO algorithm, moving beyond conventional value-based RL methods. The proposed PPO-based model demonstrated significant improvements over the standard FS approach in KPIs. These included a marked increase in total production, a notable improvement in material delivery to essential destinations, and a superior reduction in truck idle times, which culminated in a high average fleet utilisation. Furthermore, the model provided a critical enhancement in operational consistency, particularly in maintaining ore grade stability, which is vital for processing efficiency. The results highlight the algorithm's sophisticated capacity to adapt to dynamic mining conditions, optimising resource allocation and mitigating inefficiencies. This research confirms that leveraging richer feature representations and modern policy-based RL algorithms can yield profound improvements in mining productivity and sustainability, providing both a valuable academic contribution and practical guidance for the industry's transition towards data-driven, adaptive dispatching systems aligned with Mining 4.0 principles. Future work may explore the scalability of the proposed model in larger mining environments, as well as its integration with digital twin platforms for real-time decision support.
Footnotes
Author contributions
Eyman Hazrathoseyni: conceptualisation, methodology, data curation, investigation, software, writing – original draft. Arman Hazrathosseini: writing – review and editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data is available upon request.