
Abstract
Digitalization has created unprecedented freedom of choice in music consumption, highlighting intra- and interindividual differences in everyday listening behavior. To shed light on the factors involved in natural music choices, the present study collected 1,631 music-listening sessions from 110 participants over 14 consecutive days using smartphones for both passive and active ambulatory assessments. We obtained smartphone-sensed music-listening records and experience-sampled mood states, along with Big Five personality traits from traditional surveys. Using multilevel regressions, we predicted momentary music choice in terms of musical valence and energy from concurrent mood states, enduring personality traits, and their interactions. As preregistered, we expected to replicate past findings on mood-congruent music choice and associations between personality and music choice, as well as theory-based interaction effects. However, our models showed that mood and personality accounted for only a small fraction of variance in music choice, with one significant effect indicating that people in more activated mood states chose more energetic songs. Beyond that, our models showed no effects for chosen musical valence and energy. We discuss design-related factors (e.g., operationalization and ecological validity) and outline future avenues for smartphone-based research, with particular emphasis on the role of situational context in everyday music choice.
Introduction
From stationary record players to portable cassette, CD, or MP3 players and now Internet-based streaming on smartphones – technological advancements have fundamentally changed how people engage with music. This transformation has lifted previous restrictions on choice and mobility, enabling listeners to access a virtually limitless library of songs anytime and anywhere (Bull, 2005; Kuch & Wöllner, 2021; North et al., 2004). In line with the rise of music streaming, the quantity and diversity of music consumption have increased within and across listeners (Datta et al., 2018; IFPI, 2019), re-emphasizing personality scientists’ longstanding objective to understand the factors involved in intra- and interindividual differences in music choices (e.g., Knobloch & Zillmann, 2002; Rentfrow & Gosling, 2003). Drawing on the traditional uses and gratifications approach, findings suggest that music serves important functions such as mood regulation (e.g., DeNora, 1999; Lonsdale & North, 2011; Schäfer et al., 2013). Accordingly, momentary mood states, which directly reflect listeners’ current affective needs, may be involved in the musical choices people make (e.g., Greb et al., 2019; Knobloch & Zillmann, 2002). At the same time, enduring personality traits may shape these choices more indirectly, for instance, by predisposing individuals toward certain regulatory tendencies (see Connor-Smith & Flachsbart, 2007). Building on these assumptions, the current study adopts a preregistered, multilevel approach to examine momentary mood-music associations, while simultaneously accounting for enduring personality traits and their interplay with mood. Aiming to generalize past findings to natural music-listening behavior and to gain new insights, we leverage the digital, ecologically valid nature of music listening and examine smartphone music-listening records.
Mood States and Music Preferences
To understand the variability in music choices in everyday life, listeners’ momentary mood states provide a particularly promising starting point. In contrast to fully fledged emotions, mood refers to longer-lasting and lower-intensity affective states that are primarily experienced as shifts in subjective feelings and are not necessarily accompanied by physiological responses (Gross, 1998; Larsen, 2000). According to Russell’s (1980) circumplex model, affective states such as mood can be described along two dimensions: valence (i.e., pleasantness, with higher values indicating more positive and lower values more negative affect) and arousal (i.e., activation, with higher values indicating greater activation). Together, these dimensions define affective categories such as happiness (i.e., high valence and arousal) or sadness (i.e., low valence and arousal; Watson & Tellegen, 1985).
This two-dimensional framework can be used not only to describe listeners’ current mood but also to characterize the affective properties of music, typically operationalized as musical valence and energy, with energy corresponding to the arousal dimension (see Spotify, 2023). With its ability to express and elicit various affective states (e.g., Eerola & Vuoskoski, 2012; Juslin & Laukka, 2004; Lundqvist et al., 2009), music is a popular tool by which listeners maintain or modify the valence and arousal of their mood states (e.g., DeNora, 1999; Lonsdale & North, 2011; Saarikallio & Erkkilä, 2007; Schäfer et al., 2013; Sloboda & O’Neill, 2001). Hence, the music people choose to play may reflect their current mood, sparking researchers’ interest in mood-dependent music choices. Those past studies have primarily focused on music-choice behavior during low-valence, low-arousal mood states (e.g., sadness) and have reported both mood-incongruent and mood-congruent patterns of choice.
According to Mood Management Theory (Zillmann, 2015), researchers have assumed that individuals in negative states are driven to seek pleasant experiences and would therefore choose songs with positive valence. From a mood regulation perspective (see Naragon-Gainey et al., 2017), such mood-incongruent music choices may serve as a disengagement strategy by shifting listeners’ attention away from the negative mood (Miranda & Claes, 2009; Saarikallio & Erkkilä, 2007). While a few studies found support for mood-incongruent music choices (Knobloch & Zillmann, 2002; Tahlier et al., 2013), most studies reported mood-congruent patterns of music choice.
More specifically, a larger body of research has found evidence for mood-congruent music choices, particularly during negative mood states (e.g., Chen et al., 2007; Lee et al., 2013; Taruffi & Koelsch, 2014). Several researchers also observed mood-congruent choices at the positive end of the valence spectrum and for the arousal dimension (Friedman et al., 2012; Greb et al., 2019; Randall & Rickard, 2017; Thoma et al., 2012; Yang & Liu, 2013). In light of the Mood Management Theory, mood-congruent music choice is theoretically more challenging to explain because negative music can heighten negative mood states (e.g., Hunter et al., 2010; ter Bogt, Canale, Lenzi, Vieno, & van den Eijnden, 2021) rather than maximize pleasure (Zillmann, 2015). However, such choices may serve different mood-regulation functions (see Naragon-Gainey et al., 2017 for an overview of regulatory strategies). People in negative states may choose matching songs to enact adaptive engagement strategies such as problem-solving, acceptance, positive reappraisal, or as a proxy for social support (Chin & Rickard, 2012; Miranda & Claes, 2009; Saarikallio & Erkkilä, 2007). For example, the lyrics of low-valence songs may provide information relevant to solving a distressing situation (Saarikallio & Erkkilä, 2007; Van den Tol & Edwards, 2015) or offer a sense of social sharing akin to interpersonal relationships (Lee et al., 2013; Taruffi & Koelsch, 2014; Van den Tol & Edwards, 2015). However, listening to mood-congruent negative music may also serve non-adaptive regulation strategies such as venting or aversive cognitive perseveration (e.g., rumination), preventing listeners from disengaging from negative states (Miranda & Claes, 2009; Saarikallio & Erkkilä, 2007).
Taken together, these findings position mood regulation as a potential mechanism underlying momentary music selection, making mood states a key focus for understanding within-person variability in music-listening behavior.
Personality Traits and Music Preferences
Beyond these momentary processes, enduring personality traits may provide a broader dispositional context that shapes how individuals engage with and select music over time. Personality science has long focused on interindividual differences in the music people prefer, on average, and on how these relate to listeners’ stable dispositions (see Rentfrow & Gosling, 2003). From the perspective of person-environment transactions, music listening can be understood as a navigation mechanism by which individuals select or modify their auditory environments to align with their dispositions (Buss, 1987; Rauthmann, 2021; Swann, 1987). In this sense, music may serve functions related to identity expression or everyday regulation, suggesting that personality traits could be associated with systematic differences in music preferences (Chamorro‐Premuzic & Furnham, 2007; Vella & Mills, 2017).
Empirically, numerous studies have linked the Big Five personality domains to preferences for broad musical styles (e.g., Greenberg et al., 2022; Rentfrow & Gosling, 2003) and granular audio characteristics (e.g., Dobrota & Reić Ercegovac, 2015; Sust et al., 2023). However, the theoretical specificity of these associations varies considerably across traits. For Openness, links to aesthetic engagement, curiosity, and cognitive explorations provide a clear conceptual basis for preferences for more complex, unconventional, and sophisticated forms of music (De Raad, 2000; Goldberg, 1990; John & Srivastava, 1999). Consistent with this interpretation, Openness has been associated with preferences for music characterized by lower (i.e., more negative) valence, slower tempo, and lower energy (Anderson et al., 2021; Dobrota & Reić Ercegovac, 2015; Sust et al., 2023; Vuoskoski & Eerola, 2011), which may reflect a preference for more intellectually or aesthetically stimulating listening experiences that were previously related to Openness (Chamorro‐Premuzic & Furnham, 2007; Vella & Mills, 2017). For the remaining Big Five domains, reported associations with music preference are sometimes inconsistent, partially overlapping, and their theoretical interpretation is not clearly defined. For example, Conscientiousness has been associated with preferences for higher valence and lower energy in music (Anderson et al., 2021; Greenberg et al., 2022; Qiu et al., 2019). Extraversion has been linked to preferences for music with higher tempo, energy, and valence (Anderson et al., 2021; Dobrota & Reić Ercegovac, 2015; Qiu et al., 2019; Sust et al., 2023; Vuoskoski & Eerola, 2011). Agreeableness has been related to preferences for higher valence and lower energy (Anderson et al., 2021; Sust et al., 2023; Vuoskoski & Eerola, 2011), whereas Neuroticism has been associated with preferences for music characterized by lower valence and, in some cases, higher tempo and energy (Anderson et al., 2021; Qiu et al., 2019; Vuoskoski & Eerola, 2011).
Although these findings could be discussed in terms of “trait-congruent” music preferences, they are not always trait-specific, and the mechanisms linking personality traits to specific musical characteristics remain unspecified. Furthermore, a meta-analysis by Schäfer and Mehlhorn (2017) reported small effect sizes and considerable heterogeneity in associations between Big Five domains and music preferences, suggesting that personality accounts for only a limited portion of variance in music listening. Moreover, personality traits primarily capture between-person differences in average preferences, whereas music-listening behavior in everyday life varies substantially within individuals over time. Previous work indicates that between-person differences explain only 20% of the variance in momentary music choices, highlighting the importance of fluctuating listener states (Greb et al., 2019; Greb, Steffens, & Schlotz, 2018). Personality traits may therefore play a less direct role overall, but they could moderate how individuals respond to their fluctuating states, placing them within a broader mood-based framework of music choice.
Personality as Moderator of Mood-Congruent Music Preferences
Integrating personality traits into a mood-based account of music choice may help reconcile the contradictory empirical findings regarding mood-congruent and -incongruent music preferences. Rather than assuming a single, universal pattern of mood-music associations across persons, this perspective suggests that the direction and strength of mood-music associations may depend on stable individual differences. In other words, personality traits may predispose individuals to translate their momentary mood states into music selection in different ways through distinct mood-regulatory strategies (e.g., Miranda & Claes, 2009; Saarikallio & Erkkilä, 2007).
A large body of research suggests that individuals differ systematically in how they regulate their emotions and cope with affective experiences, and that these differences are associated with the Big Five personality traits (Barańczuk, 2019; Carver & Connor-Smith, 2010; Connor-Smith & Flachsbart, 2007). In particular, the domains of Openness, Conscientiousness, Extraversion, and Agreeableness have been linked to a greater tendency to engage in adaptive, engagement-focused strategies, including problem-solving, positive reappraisal, or seeking social support. In contrast, Neuroticism has been associated with a higher likelihood of disengagement-oriented strategies, such as avoidance or distraction (Barańczuk, 2019; Carver & Connor-Smith, 2010; Connor-Smith & Flachsbart, 2007).
Applied to music listening, these individual differences in regulatory tendencies may translate into systematic variation in how mood states are reflected in music choices across different individuals. For example, individuals who tend to engage with their affective experiences may be more likely to select music that is congruent with their current mood, using it to process or make sense of their feelings. In contrast, individuals more prone to disengagement strategies may be more likely to select mood-incongruent music to distract from or counteract their current state. From this perspective, personality traits may moderate the within-person association between momentary mood and music choice.
Assessing Momentary Music Preferences
Music-listening behavior fluctuates dynamically throughout the day, making it methodologically challenging to assess music choices. Most past studies on overall or momentary music preferences relied on self-report questionnaires (e.g., Rentfrow & Gosling, 2003; Taruffi & Koelsch, 2014) or reactions to musical excerpts presented without context or after mood induction in laboratory settings (e.g., Chen et al., 2007; Greenberg et al., 2022; Knobloch & Zillmann, 2002). However, self-reports of music preferences are prone to biases such as socially desirable responding or memory limitations, which can be especially problematic when reporting contextual variations in a high-frequency behavior like music choices (Baumeister et al., 2007; Stein et al., 2013). Preferences among musical excerpts, on the other hand, are constrained by the sample of songs provided by researchers, which is typically limited to very popular, artificially manipulated, or unreleased tracks, thereby offering fewer choices than the natural music market (Greenberg & Rentfrow, 2017).
For an ecologically valid assessment of music preferences, researchers must investigate music choices as they naturally occur in listeners’ everyday lives. While collecting behavioral data in the field has long been practically infeasible (see Furr, 2009), the digitalization of music consumption has made digital devices like smartphones ideal tools for investigating music-listening behavior “in the wild.” Besides radios, smartphones are the most widely used devices for playing music (IFPI, 2019). Furthermore, they can collect real-time data on people’s thoughts, feelings, behaviors, or environments through active and passive ambulatory assessments (see Conner & Mehl, 2015).
First, smartphones can administer the experience sampling methodology by actively prompting participants to complete short, repeated questionnaires at various occasions throughout the day (Larson & Csikszentmihalyi, 2014; Wrzus & Neubauer, 2023). Previous studies have used this form of in-situ self-report assessment to explore momentary music choices in relation to contextual factors such as mood states (Greb et al., 2019; Randall & Rickard, 2017). They repeatedly asked participants to rate the musical properties of the song they were listening to at the time. These experience samplings were either randomly triggered (Greb et al., 2019), which, however, is not very efficient because people are exposed to music in only about 40% of randomly sampled moments throughout the day (Juslin et al., 2008; North et al., 2004; Sloboda et al., 2001), or they occurred whenever participants used a specially developed music player app (Randall & Rickard, 2017). However, this approach captured only participants’ subjective experiences, which may not always align with the objective characteristics of their selected music because the perception of musical emotion, in turn, depends on listeners’ personality traits and current mood states (Hunter et al., 2011; Vuoskoski & Eerola, 2011).
Beyond experience sampling, smartphones provide a more objective way to collect music-listening data in the field via smartphone sensing, that is, the passive collection of smartphone usage data via custom research applications (short: apps, Harari et al., 2016, 2017; Wrzus & Mehl, 2015). Sensing apps can access a smartphone’s system logs, including music-listening records, and unobtrusively collect music choices in everyday life, thereby serving as a digitally mediated behavioral observation. In contrast to experience-sampled self-reports, smartphones’ digital listening records provide continuous, more granular information about selected songs. In addition, tools from music information retrieval (see Downie, 2003) allow researchers to automatically represent songs from listening records in terms of various intrinsic musical characteristics derived from their audio recordings (e.g., Sust et al., 2023; Yang & Liu, 2013). These technical audio characteristics range from basic physical parameters (e.g., tempo, pitch) to more complex aggregated features (e.g., valence, energy) learned via machine learning algorithms, which can validly represent the emotionality of music (e.g., Eerola et al., 2009; Vidas et al., 2026). While first studies have started to objectively assess and represent overall preferences displayed in natural music-listening behavior on smartphones (Sust et al., 2023, 2026) or streaming platforms (Anderson et al., 2021), they considered only summary metrics, ignoring the potential of longitudinal listening records for uncovering intra-individual fluctuations in daily music choices.
The Present Study
In this naturalistic study, we investigated music choices made in everyday life and their relation to fluctuating mood states and enduring personality traits. We applied an intensive longitudinal sampling design and collected 1,631 music-listening sessions from 110 participants over 14 consecutive days. Using smartphone sensing, we obtained the music-listening records from participants’ private phones. We extracted their momentary music choices based on the songs they played at a given moment and represented them in terms of the two computationally derived audio characteristics of musical valence and energy. In addition, we administered event-triggered experience samplings to capture the valence and arousal of participants’ mood states during the respective music-listening sessions and an online survey to assess participants’ Big Five personality traits. To account for intra- and interindividual fluctuations in these multi-method data, we analyzed them within a multilevel regression framework that predicted the valence and energy of momentary music choices from mood states, personality traits, and their respective interactions. Consistent with our preregistration, we tested hypotheses regarding (a) mood states, (b) personality traits, and (c) their interaction. Importantly, while hypotheses concerning mood states are based on the theoretical reasoning above, hypotheses concerning personality traits are grounded in prior empirical findings, given the limited theoretical specificity of trait-music links.
Following this rationale, our primary research question concerned the role of mood states. We expected to replicate the mood-congruent music choices observed in most prior studies across both mood dimensions, based on natural music-listening behavior (
Our second set of hypotheses concerned the role of personality traits. We expected to replicate past findings on overall music preferences (
Finally, our third set of hypotheses targeted the interaction between momentary mood states and enduring personality traits. Based on mood-regulation research, we hypothesized that personality traits would moderate the relationship between mood states and music choices in everyday life (
Method
The present study was conducted as part of the PhoneStudy research project (https://phonestudy.org) at LMU Munich. It integrated three data-collection modalities, namely smartphone sensing, experience sampling, and online surveys. All procedures have received approval from the ethics committee of the Department of Psychology at LMU Munich under the title “Moody Life” and adhered to the General Data Protection Regulation (GDPR). Before data collection, all participants provided their written informed consent, which they could withdraw at any time during the study without giving a reason.
Transparency, Openness, and Reproducibility
This study is based on data collected during a large-scale empirical project that included various self-reported and behavioral measures. Here, we focus our report on the procedures and measures relevant to the present research question and give a full account of all collected measures in the online supplemental material (OSM; see Chapter S1) in our OSF project: https://osf.io/rptjx. Thereby, we follow the Journal Article Reporting Standards (JARS) for quantitative research proposed by the American Psychological Association (APA).
The theoretical background, hypotheses, data preprocessing procedures, and formal analyses reported in this manuscript were preregistered under https://osf.io/7j5e3. We made this registration after initial data collection but prior to accessing the raw self-report and smartphone-sensing data. Due to practical challenges encountered during data preprocessing, we had to make some modifications to our preregistered analysis protocol, which are detailed throughout the methods section and elaborated further in our OSF project.
This OSF project also contains datasets of our processed variables, including codebooks, which allow readers to reproduce our multilevel analyses. In line with GDPR regulations, the underlying raw data can only be accessed on LMU Munich’s local servers under an individual legal agreement due to the privacy-sensitive nature of our data. We also provide the Python and R code for data preprocessing and analysis, along with a read-me detailing the purpose and sequence of the scripts. More information for reproducing our software environments is available in the “Statistical Software” section below.
Procedures
Our data collection took place between May and November 2020 in Munich, Germany. We recruited participants with the help of student researchers, using university mailing lists, social media, and personal contacts. To be eligible for participation, subjects had to be over 18 years old, be fluent in German, and, for technical reasons, be the sole user of a smartphone running on the Android operating system. As for compensation, participants received an individual personality profile in addition to either 10 EUR or 4 h of course credit, unless they chose to donate their data.
Participants were first invited to an onboarding survey in which they received information about the study’s aim and scope. After providing informed consent, they installed the Android-based smartphone sensing app PhoneStudy on their private phones and completed a second round of informed consent within the app (i.e., granting access permissions). For the following 14 days, the PhoneStudy app unobtrusively logged smartphone usage data, including participants’ music-listening records (see Chapter S1 of our OSM for details and Table S1.1 for an overview of all logged data). In addition, the app administered experience samplings (ES), asking participants to report their current mood states. ES were scheduled in an event-triggered manner and appeared with a five-second delay each time participants opened a music app – as defined by an app categorization by Stachl et al. (2020) – on their smartphones. We chose this procedure to create a timely contingency between mood reports and music-listening behavior. In a concluding reactivity check, participants reported, on a rating scale from 1 to 5, that their music-listening behavior had been not at all to barely influenced by the event-triggered ES on average (M = 1.38, SD = 0.62). Additional ES were administered each morning, but these were not relevant to the current research question (see Chapter S1 of OSM for details). Beyond these two forms of ambulatory assessment, participants completed two online surveys – one at the beginning and one at the end of the 14-day study period – that included demographic questions, a personality inventory, and other psychological measures (see Table S1.3 of our OSM).
Sample
We aimed to obtain the largest possible sample size given the time constraint imposed by our data collection schedule described above. The resulting convenience sample initially contained smartphone-sensing data from 476 participants. However, not all of them had listened to music on their smartphones or participated in our ES (either due to non-compliance or a misconception of our sampling schedule 2 ), as discerned in Table S2 of our OSM. Hence, during preprocessing, we had to exclude 363 participants with fewer than four valid music-listening sessions. We defined valid music-listening sessions as completed ES instances (i.e., where both mood items were answered) surrounded by a 30-min window where (a) music was played for at least 1 minute and (b) at least one played song had available song-level information (i.e., musical valence and energy) from Spotify. com. Furthermore, we removed two participants with zero variance in either of our two mood items across the ES and one participant who had not completed the personality measure. These exclusions resulted in a final sample of 110 participants with sufficient data in all measures relevant to our hypotheses. Please note that we adapted some of our preregistered exclusion criteria to preserve a reasonably large dataset without compromising data quality. We provide more details on the data exclusion pipeline and our deviations from the preregistration in our OSM (see Table S2).
The final sample comprised 74 women (67%) and 36 men (33%). Participants’ ages ranged from 18 to 57, with an average of 23 years (SD = 6.5), and the sample was skewed towards higher education (78% with A-levels and 16% with a university degree).
Measures
Self-Report Measures
Mood States
The PhoneStudy app captured participants’ mood states via ES. In line with previous studies (e.g., Schoedel et al., 2023), we used two single-item measures to assess participants’ mood in terms of valence and arousal, the dimensions of the circumplex model of affect (Russell, 1980). The items asked participants to report their current emotionality and level of activity at the time of the ES (see Table S1.2 for the item wording). Responses were made on a bipolar six-point rating scale, ranging from very negative (1) to very positive (6) for valence and from very inactive (1) to very activated (6) for arousal.
Personality Traits
Descriptive Statistics of State- and Trait-Level Measures
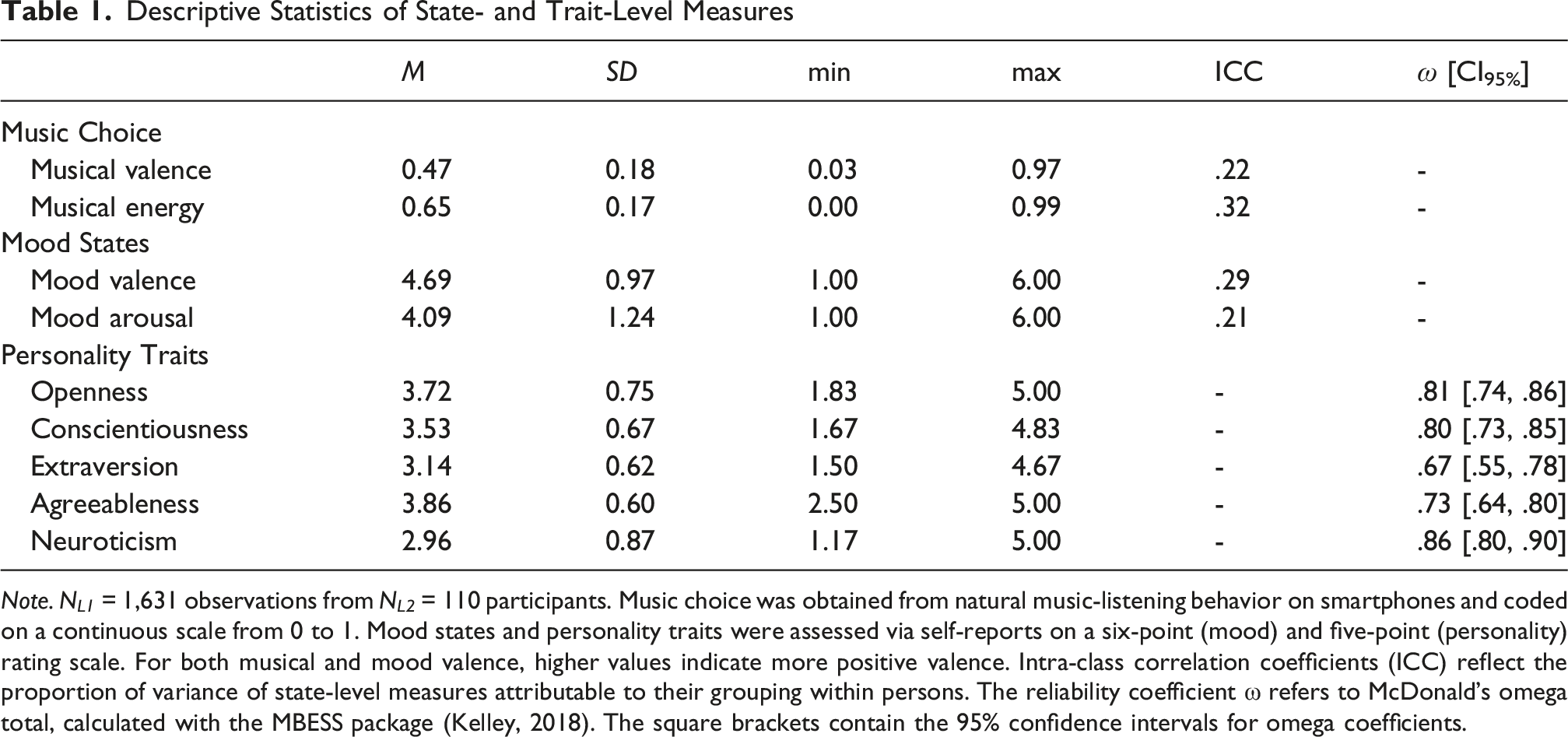
Note. N L1 = 1,631 observations from N L2 = 110 participants. Music choice was obtained from natural music-listening behavior on smartphones and coded on a continuous scale from 0 to 1. Mood states and personality traits were assessed via self-reports on a six-point (mood) and five-point (personality) rating scale. For both musical and mood valence, higher values indicate more positive valence. Intra-class correlation coefficients (ICC) reflect the proportion of variance of state-level measures attributable to their grouping within persons. The reliability coefficient ω refers to McDonald’s omega total, calculated with the MBESS package (Kelley, 2018). The square brackets contain the 95% confidence intervals for omega coefficients.
Behavioral Music-Listening Measures
The PhoneStudy app provided smartphone-sensing data on a wide range of smartphone usage behaviors (see Table S1.1 for an overview), including participants’ music-listening records. The app created time-stamped logs whenever participants listened to music stored locally on their smartphones or streamed through them. To extract momentary music-choice variables from these music logs, we followed the framework by Schoedel, Sust, et al. (2026) and implemented the preprocessing pipeline shown in Figure 1. Preprocessing Workflow for Extracting Momentary Music Choice Variables from Smartphone-Sensed Music-Listening Records.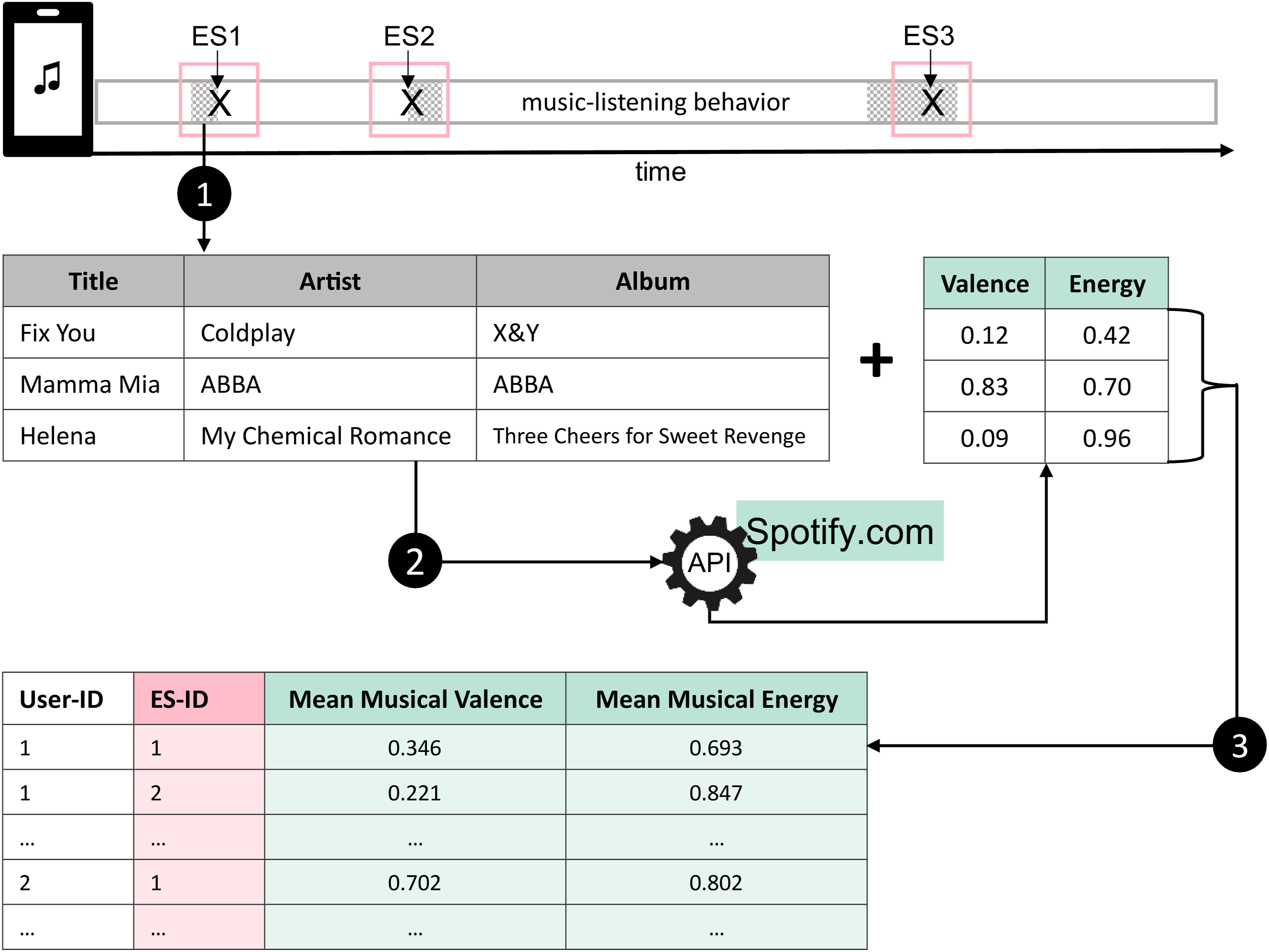
Data Enrichment
The sensed music logs specified the title, artist, and album of the songs participants played, but lacked psychologically meaningful information about their intrinsic musical attributes. Hence, to describe participants’ song choices, we enriched the raw logs with song-level information using Spotify’s Track API 3 (Application Programming Interface). We visualize this workflow in steps 1 and 2 of Figure 1. For each song, we retrieved two audio characteristics computed from the song’s audio recording (Spotify, 2023). These audio characteristics reflect the songs’ musical valence and energy, mirroring the valence and arousal dimensions used to assess participants’ momentary mood states (Russell, 1980). According to Spotify (2023), musical valence captures the positivity conveyed by a song, with values closer to 1.0 indicating greater positivity (e.g., cheerful) and values closer to 0.0 indicating greater negativity (e.g., sad, angry). In contrast, the musical energy represents the perceived intensity of a song, with values ranging from 0.0 to 1.0. Songs with higher values sound faster, louder, and noisier. Recent research has demonstrated that these features show good validity and align well with human ratings of musical affect (Vidas et al., 2026). We assigned both audio characteristics to the corresponding songs in our music logs, but could not enrich all entries because some contained non-musical tracks (e.g., podcasts), had incorrect song information (e.g., typos in the song title), or were not available on Spotify. We provide further details on the song-level data enrichment in Chapter S3 of our OSM.
Variable Extraction
To capture participants’ momentary music choices in close temporal proximity to their self-reported mood states, we matched the song-level enriched music logs with the ES instances (see Figure 1). Because the PhoneStudy app triggered ES questionnaires whenever participants opened a music app, we had preregistered to aggregate music choice (i.e., the audio characteristics of played songs) over a 30-min window following the event-triggered ES. However, this rationale failed because participants often started songs through the controls banner on their smartphone’s lock screen 2 , not opening their music app at all or only later to search for a specific song or to stop the music. Hence, many ES instances were preceded but not followed by music-listening behavior. To accommodate this data structure, we adapted our preregistered extraction strategy and defined music-listening sessions as 30-min time windows surrounding an ES instance (i.e., 15 minutes before and after an ES). This definition was sufficiently broad to capture some music-listening behavior but narrow enough to still assume a timely contingency between music choices and self-reported mood states. Within these music-listening sessions, we removed songs played for less than 20 seconds (i.e., skipped songs) and aggregated the two audio characteristics across all unskipped songs using a weighted arithmetic mean based on each song’s playtime. The resulting variables represented participants’ momentary music choices in terms of the musical valence and energy of the songs they played. However, as noted above, Spotify’s audio characteristics were not available for all tracks in our music logs, and songs without audio characteristics were not included in the weighted arithmetic mean. We did not impute missing song-level values because they reflect unavailable external annotations rather than missing observations in our dataset and stem from heterogeneous causes (e.g., unmatched songs or non-musical content; see above), making them unsuitable for reliable estimation based on other songs within a session. In total, for 74% of music-listening sessions, audio characteristics were available for all songs listened to, while in the remaining sessions, the availability of song-level data ranged from 8% to 94% of songs played (M = 69%, SD = 17%).
Data Analysis
For the regression analyses, we first adjusted extreme outliers (>|M +/− 3SD|) in the music choice variables to the value three standard deviations from the respective mean (see Winsorizing according to Ghosh & Vogt, 2012) to eliminate the influence of potential inaccuracies in our logging data. Apart from that, we did not exclude or adapt any outliers or influential cases.
To account for the hierarchical two-level structure of our data (i.e., music-listening sessions nested within participants), we applied multilevel regression modeling (MLMs) to test our hypotheses (Bates, Mächler et al., 2015; Kuznetsova et al., 2017). As preregistered, we computed one model for each of the two audio characteristics representing participants’ chosen songs (i.e., musical valence and energy). Both models simultaneously estimated the within-person effects of mood states (H1), the between-person effects of personality traits (H2), and the cross-level interaction effects between mood and personality (H3) on momentary music choices (see Barr et al., 2013; Bates, Kliegl et al., 2015). More precisely, the MLMs contained both dimensions of self-reported mood (i.e., valence and arousal) and their interaction as Level-1 predictors, the Big Five personality domains as Level-2 predictors, and the cross-level interaction between each personality domain and the mood state focal to the respective hypothesis (i.e., mood valence for the musical valence model in H3.1-5a, mood arousal for the musical energy model in H3.1-5b). Because mood states could manifest within as well as between persons, they were within-person centered, and their person means were reintroduced as additional Level-2 predictors as recommended by Enders and Tofighi (2007). All Level-2 predictors (i.e., personality traits and aggregated mood states) were grand-mean centered. After initially running the preregistered random-intercept-random-slope models, we removed the random slopes to avoid problems of singular fit (i.e., variance estimates near zero; Bates, Kliegl, et al., 2015). We provide our final model equations in Chapter S4 of our OSM.
To estimate the effect size of the combined predictors, we determined the models’ marginal R 2 (m) , which indicates the proportion of the criterion variance explained by all fixed effects (Rights & Sterba, 2019). Furthermore, we computed fully standardized versions of the two MLMs specified above to obtain standardized regression coefficients as effect-size estimates for the single predictors (Lorah, 2018). In these models, we z-standardized all variables and – after standardizing – person-mean centered Level-1 predictors. In addition to the preregistered MLMs, we calculated beta regression mixed models as robustness checks, which we report in our OSM (see Chapter S7).
We applied a conservative α = .005 to determine the significance of our hypotheses. We derived this alpha level by correcting the default of .05 for multiple testing. Applying the Bonferroni correction, we divided alpha by the maximum number of tests across our higher-order hypotheses, which were 10 tests for H2 and H3. Because we had preregistered the directionality of our hypotheses, we used one-tailed p-values to determine the statistical significance of the predicted effects 4 . P-values for all other effects that were not part of our hypotheses were purely exploratory and, hence, reported in a two-tailed manner. The p-values presented in our results tables below are tagged accordingly.
Statistical Software
The API call from Spotify. com was conducted in Python (version 3.8.6, Python Software Foundation, 2021), while all other steps of analysis were conducted in the statistical software R – version 4.2.1 for data preprocessing on an RStudio Server and version 4.1.2 for descriptive and multilevel analysis in a local R environment (R Core Team, 2022). To preprocess our raw logging data on the RStudio Server, we used the packages tidyr (version 1.2.1; Wickham & Girlich, 2022) and dbplyr (version 2.2.1; Wickham et al., 2023). We also provide an Excel file listing all R packages installed on the RStudio server in our OSF project. For the locally conducted multilevel modeling, we employed the packages lme4 (version 1.1-31, Bates, Mächler, et al., 2015) and lmerTest (3.1-3, Kuznetsova et al., 2017) as well as r2mlm (version 0.3.2, Shaw et al., 2020) to determine marginal squared Rs. For reproducibility, we used the package management tool renv (version 0.16.0, Ushey, 2022) for our local data analyses and provided a complete list of all installed R packages in a renv.lock file in our OSF project.
Results
Descriptive Statistics
Within- and Between-Person Correlations Between State- and Trait-Level Measures

Note. Each cell contains Pearson correlation coefficients (first row) and their 95% bootstrapped confidence intervals (second row). For correlations among state measures (i.e., music choice & mood states), coefficients below the diagonal are means of within-person correlations (with Fisher’s z-transformation used for pooling), and coefficients above the diagonal are between-person correlations (i.e., correlations between person-means of the respective states). Coefficients in bold font represent correlations whose CIs do not contain zero. For musical and mood valence, higher values indicate more positive valence.
The intra-class correlation coefficients (ICCs) in Table 1 indicate that 22% (for musical valence) and 32% (for musical energy) of the total variance of music choices was attributed to the grouping of music-listening sessions within persons. At the same time, music choices varied substantially within individuals, confirming the multilevel structure of our data.
Multilevel Models
Fixed Effects for Multilevel Models Predicting Music Choice From Personality Traits, Mood States, and Their Interactions
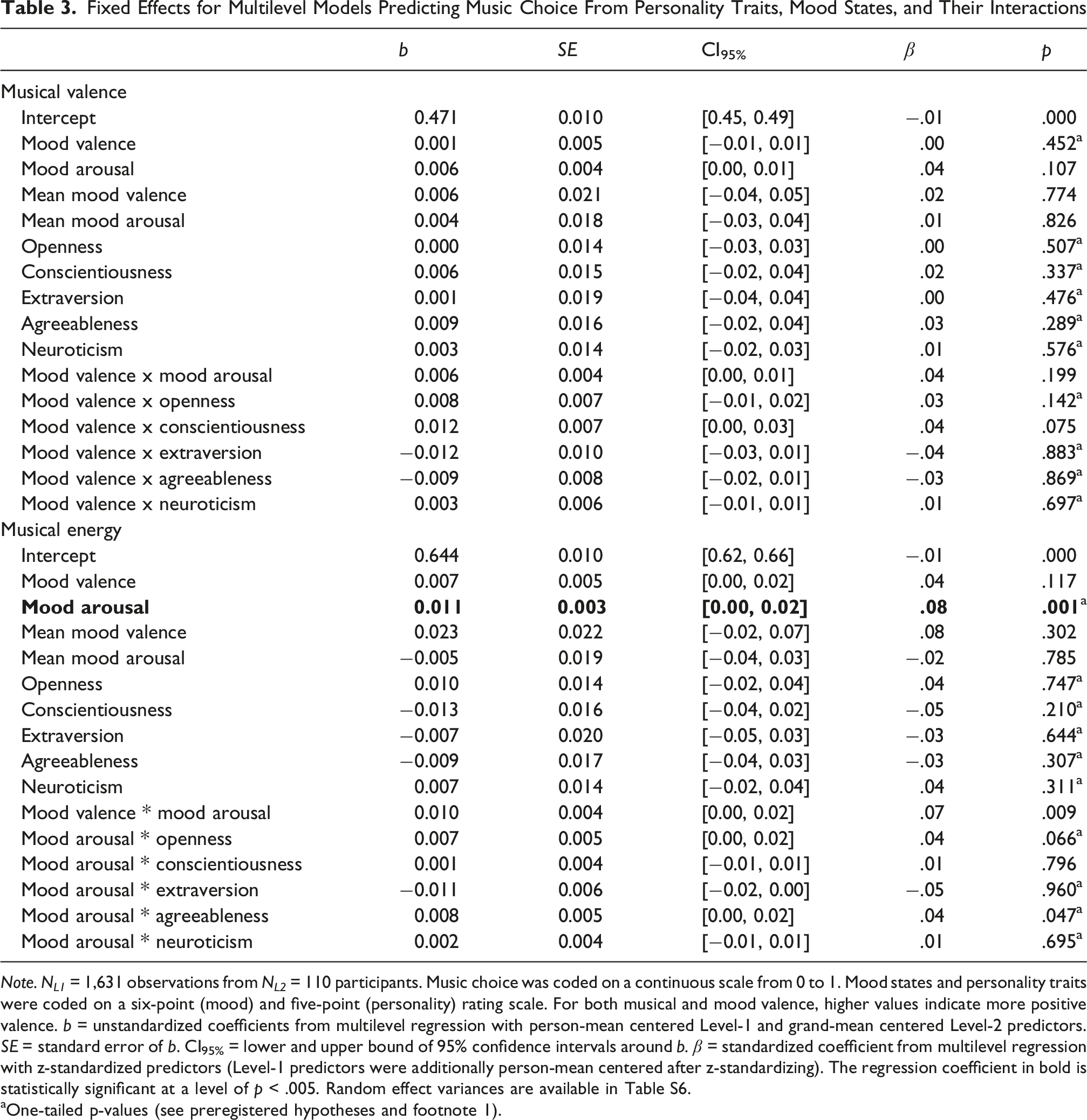
Note. N L1 = 1,631 observations from N L2 = 110 participants. Music choice was coded on a continuous scale from 0 to 1. Mood states and personality traits were coded on a six-point (mood) and five-point (personality) rating scale. For both musical and mood valence, higher values indicate more positive valence. b = unstandardized coefficients from multilevel regression with person-mean centered Level-1 and grand-mean centered Level-2 predictors. SE = standard error of b. CI95% = lower and upper bound of 95% confidence intervals around b. β = standardized coefficient from multilevel regression with z-standardized predictors (Level-1 predictors were additionally person-mean centered after z-standardizing). The regression coefficient in bold is statistically significant at a level of p < .005. Random effect variances are available in Table S6.
aOne-tailed p-values (see preregistered hypotheses and footnote 1).
For musical valence, Table 3 shows that none of the 15 included (and 10 preregistered) associations were statistically significant at the level of p < .005, leading us to reject all hypotheses for this criterion variable. In more detail, neither mood states (see H1a), personality traits (see H2.1a-2.5a), nor their interactions (see H3.1a-3.5a) appeared to be related to the musical valence of songs listened to. In line with this lack of effects, the overall proportion of variance explained by the MLM’s fixed effects on musical valence was very small, as suggested by a marginal R 2 (m) of .01.
For musical energy, the results in Table 3 indicate that only one of the 15 included (and 10 preregistered) associations was statistically significant at p < .005. The Level-1 predictor mood arousal was positively related to musical energy (b = 0.01, p = .001), consistent with the directionality expected in hypothesis 1 (see H1b). The unstandardized regression coefficient implies that, within individuals, a one-point increase in self-reported mood arousal relative to a person’s average arousal level (on a scale from 1 to 6) is associated with an average increase of .01 in the energy level of the music they choose (ranging from 0 to 1) if all other predictors are kept constant. Mood arousal also exhibited the largest effect size (i.e., standardized coefficient) with β = .08, hinting at the superiority of this Level-1 variable compared to other state- and trait-level predictors. Because no other predictor reached statistical significance, all other hypotheses regarding the musical energy criterion were rejected. In particular, none of the Big Five personality domains (see H2.1b–2.5b) exhibited significant relationships with chosen musical energy, and for Openness (see H2.1b) and Extraversion (see H2.3b), the beta coefficients even ran counter to our expected directionality. Similarly, personality traits did not interact significantly with mood states (see H3.1b-3.5b), falsifying our third hypothesis.
Despite the significant Level-1 predictor, mood states and personality traits only explained a very small fraction of the variance in chosen musical energy as implied by a marginal R 2 (m) of .02. Thus, while mood and personality were more informative about the musical energy than about the musical valence of played songs, both aspects of music choice were not well explained by our predictors.
Discussion
The present study employed a longitudinal multimethod design to examine the music people select on a moment-to-moment basis on their smartphones. We extracted listeners’ momentary preferences for musical valence and energy from smartphone-sensed music-listening records and predicted them from experience-sampled mood states, self-reported personality traits, and their interaction. Based on theoretical reasoning and previous empirical findings, we expected to replicate mood-congruent associations with affective valence and arousal (H1) and established associations with the Big Five personality domains (H2). Furthermore, we assumed that personality traits would moderate the association between mood states and music choice (H3).
However, our multilevel regression models showed that mood states and personality traits accounted for only a small proportion of the variance in music choice. For musical valence, none of the mood and personality predictors or their interactions were statistically significant, leading us to reject all hypotheses for this outcome. For musical energy, only the predictor mood arousal exhibited a significant, albeit small, effect, indicating that people preferred more energetic music when in more activated mood states, consistent with our second hypothesis on mood congruence (H1b). Apart from this effect, all remaining hypotheses had to be rejected for the musical energy outcome. Please note that, given the observational nature of the data, no conclusions about causal direction can be drawn.
Taken together, our findings suggest that music choice was largely unrelated to mood states, except for a small positive association between listeners’ arousal and the musical energy of their chosen music. Such a congruence effect has previously been reported for the arousal dimension of mood (Greb et al., 2019; Randall & Rickard, 2017; Thoma et al., 2012; Yang & Liu, 2013) and may indicate that music is used to maintain rather than regulate arousal levels (i.e., to energize or relax), which is consistent with engagement strategies of mood regulation. However, we could not replicate the mood congruence effects for the valence dimension that have repeatedly been reported in prior research (Chen et al., 2007; Ferwerda et al., 2015; Friedman et al., 2012; Greb et al., 2019; Lee et al., 2013; Randall & Rickard, 2017; Taruffi & Koelsch, 2014; Thoma et al., 2012).
A similar pattern emerged for personality. The Big Five domains were largely unrelated to music choice, which contrasts with previous findings linking personality to preferences for broader musical styles (e.g., Greenberg et al., 2022; Rentfrow & Gosling, 2003) and technical audio characteristics (e.g., Anderson et al., 2021; Dobrota & Reić Ercegovac, 2015; Sust et al., 2023). At the same time, our results align with meta-analytic evidence suggesting that these associations are generally small (Schäfer & Mehlhorn, 2017) and may be difficult to detect in naturalistic settings. In line with the small or absent main effects, we also found no evidence that personality traits moderated the association between mood states and music choice. This differs from our theoretical assumptions based on coping literature (e.g., Barańczuk, 2019; Carver & Connor-Smith, 2010) and previous findings (Ferwerda et al., 2015; Taruffi & Koelsch, 2014), and may suggest that such interaction effects do not generalize to natural music-listening behavior.
Design Considerations in Mood-Music Research
The present findings raise the question of why previously reported associations between mood and music choice were largely absent in our study of natural music-listening behavior. In this regard, differences in how mood–music associations have been studied in prior research may help explain the observed pattern and highlight broader design considerations for future research.
First, differences in how affect was operationalized may have contributed to the absence of mood-congruency effects. Unlike many previous studies that focused on discrete affective categories such as sadness (e.g., Chen et al., 2007; Friedman et al., 2012; Taruffi & Koelsch, 2014), we assessed mood and music using the dimensional circumplex model of affect (Russell, 1980). Because we modeled valence and arousal separately, we could not distinguish between specific affective states such as sadness and anger. If mood congruence occurs primarily for specific affective categories rather than for negative mood more generally, this operationalization may have attenuated effects. Moreover, we treated positive and negative valence as opposite ends of a single dimension, whereas some approaches treat them as independent (e.g., Tellegen et al., 1999), and some prior studies in the field focused solely on negative valence (e.g., Chen et al., 2007; Lee et al., 2013). Although prior research has also reported mood-congruent effects using dimensional measures (e.g., Greb et al., 2019; Randall & Rickard, 2017; Thoma et al., 2012; Yang & Liu, 2013), these differences suggest that the way mood is conceptualized and operationalized should be a conscious design decision and may be usefully compared across approaches in future studies.
Second, beyond differences in how affect was operationalized, the way affective musical characteristics were measured may also help explain the lack of effects. Whereas previous studies often relied on participants’ subjective ratings of the emotionality of the songs they listened to (e.g., Greb et al., 2019; Randall & Rickard, 2017), we used technical audio characteristics derived from the songs’ recordings via music information retrieval (Spotify, 2023). This approach offers advantages in terms of objectivity and comparability (Greenberg & Rentfrow, 2017), and such audio characteristics have been shown to align well with average human ratings of musical affect (Vidas et al., 2026). At the same time, however, they do not capture how individual listeners subjectively perceive the emotional qualities of music. Such perceptions are known to vary as a function of mood and personality (Hunter et al., 2011; Vuoskoski & Eerola, 2011), and music may derive its emotional impact partly from autobiographical memories or personal meaning associated with it (Juslin et al., 2014; Taruffi & Koelsch, 2014; Van Goethem & Sloboda, 2011). If mood-congruent music choice depends on subjective interpretation rather than objective acoustic properties, our approach may have obscured such effects. These considerations suggest that the choice between objective and subjective measures of musical affect represents another important design decision in music-mood research.
Third, the ecologically valid nature of our study design may also have influenced the results. Unlike many prior studies that relied on controlled listening experiments with mood inductions (e.g., Chen et al., 2007; Friedman et al., 2012; Lee et al., 2013; Thoma et al., 2012), we assessed naturally occurring music-listening behavior in everyday life. In this context, both music and mood tended to be relatively neutral. Participants predominantly listened to songs with moderate valence and slightly elevated energy (e.g., “Viva La Vida” by Coldplay), consistent with previous findings on smartphone-based music listening (Sust et al., 2023), and their reported mood states were similarly low in intensity. Compared to the more extreme stimuli (e.g., prototypically sad vs. happy songs) and induced affective states typically used in laboratory settings, this restricted range may have reduced the likelihood of detecting mood-congruency effects. Thus, findings from experimental paradigms may not fully generalize to natural listening contexts (see also Greenberg & Rentfrow, 2017). Although experience-sampling studies have also reported such effects in everyday settings (Greb et al., 2019; Randall & Rickard, 2017), self-reported music choices differ conceptually from the fully behavioral parameters obtained in our study, as discussed above. Taken together, these considerations highlight the importance of studying music-listening behavior in naturalistic settings and underscore the need for further research “in the wild” that directly captures behavior, complementing laboratory-based approaches. An ecologically more valid perspective may also yield new insights into behaviors beyond music listening and help re-evaluate findings in personality psychology more broadly, as repeatedly called for in the past (e.g., Baumeister et al., 2007; Furr, 2009).
Finally, the temporal structure of our experience-sampling design may have contributed to the lack of findings in our study. In contrast to previous studies that assessed mood immediately before music listening (e.g., Chen et al., 2007; Greb et al., 2019; Lee et al., 2013; Randall & Rickard, 2017), our event-triggered sampling occurred when participants opened a music app, which could happen before, during, or after music listening (see footnote 1). This led us to aggregate music choices over a time window surrounding each experience-sampling instance. As a result, our analyses conflated potential effects of mood on music choice with effects of music listening on subsequent mood states. Given that music itself can influence affect (e.g., Eerola & Vuoskoski, 2012; Juslin & Laukka, 2004; Lundqvist et al., 2009) and may even return mood to more neutral levels (Randall & Rickard, 2017), these opposing processes may have canceled each other out, reducing observable associations. This highlights the importance of carefully conceptualizing and temporally aligning measurements to disentangle the different processes underlying mood–music associations in future research. In particular, future studies using temporally structured sampling designs (e.g., with more uniform time intervals between observations) are well-suited to examining lagged or cross-lagged dynamics between mood states and music choices, thereby helping to more clearly position music within mood-regulation research (for an outlook on the application of such models on sensing data, see Schoedel, Sust, et al., 2026).
Taken together, our study represents a novel integration of several emerging methodological approaches to studying music listening in everyday life and underscores the value of considering these design features in future research on music and mood and beyond.
Within-Person Variability and Situational Context in Music Choice
Beyond design-related considerations, the present findings may also reflect more general characteristics of music-listening behavior in everyday life. In particular, the overall patterns observed in our data, together with prior research on music preferences, suggest several assumptions about which factors may play a role in music choices.
A key consideration in this context is the within-person variability of our data. Musical choices varied substantially within individuals over time, whereas only a relatively small proportion of variance was attributable to differences between individuals. This pattern aligns with prior experience-sampling studies of music listening, which reported comparable intraclass correlations and found that momentary variables, such as mood states and contextual factors, rather than stable traits, were the primary predictors of music choice (Greb et al., 2019; Greb et al., 2018; Randall & Rickard, 2017). Given this within-person variability, it is not surprising that relatively stable constructs, such as personality, show weak associations with music-listening behavior in everyday contexts (see also Schäfer & Mehlhorn, 2017). More generally, this pattern aligns with recent developments in personality science that emphasize the importance of intraindividual processes and within-person variability (e.g., Baumert et al., 2019; Kuper et al., 2021). Hence, these findings underscore the value of focusing more strongly on such processes and suggest that the role of stable personality traits may be more limited in highly variable, real-life contexts than is often implied by research based on aggregated self-reports or laboratory paradigms.
These considerations further suggest that momentary influences may play a more prominent role in music choice. While we focused on mood states as a theoretically relevant momentary predictor, given the well-established link between emotion and music (e.g., Eerola & Vuoskoski, 2012; Schäfer et al., 2013), the observed effects were small or absent, pointing to other momentary factors in music selection. Theories of person-environment transactions emphasize that understanding behavior requires considering not only attributes of the person (e.g., mood or personality) but also those of their situation (e.g., Funder, 2006, 2009; Rauthmann, 2021).
Natural music listening is embedded in such situational contexts, defined, for example, by ongoing activities, the current location, or one’s social company, all of which may shape the types of music selected (Juslin et al., 2008; North & Hargreaves, 1996; Sloboda et al., 2001; Sloboda & O’Neill, 2001). Consistent with this perspective, previous research has shown that both objective situational cues (e.g., location, activity) and subjective situation characteristics (e.g., perceived sociality or duty) are associated with music choices in everyday life (Behbehani & Steffens, 2021; Greb et al., 2019; Greb et al., 2018; Randall & Rickard, 2017). Situations may thereby impose specific affordances that shape listening behavior, as different listening situations have been associated with different uses of music (Greb et al., 2018; North et al., 2004; Randall & Rickard, 2017; Volokhin & Agichtein, 2018). More specifically, music serves a variety of functions, such as providing background noise, supporting physical activities, or simply affording aesthetic enjoyment, which are closely tied to situational demands and, in turn, require different types of music (Chamorro-Premuzic et al., 2010; Getz et al., 2012; Greb et al., 2018; Vella & Mills, 2017).
Whether mood plays a role in music choice may depend on the current situation and the function music is intended to serve, with mood becoming more relevant when music is actively used for the function of mood regulation. But even in those cases, situational affordances may give rise to more flexible mood-based regulation that does not follow a fixed pattern. Instead, individuals may flexibly select music to either match or counteract their current mood, depending on situational demands. For example, listeners in negative mood states may sometimes choose congruent music to process their feelings and, at other times, select incongruent music to distract themselves, depending on whether the situation allows for engagement or calls for disengagement (see situational coping; e.g., Carver & Scheier, 1994). In other situations, when music serves non-mood-related functions, situational affordances may constrain the expression of mood, consistent with the concept of situational strength (Cooper & Withey, 2009; Mischel, 1977; Snyder & Ickes, 1985). In support of this reasoning, Greb et al. (2019) found that the uses of music listening mediated the association between mood states, situational variables, and music choices.
Taken together, these considerations underscore the importance of situational context in understanding music-listening behavior. To more fully capture the dynamic interplay among listeners‘ states and traits, situations, uses of music, and music choices, future studies should more explicitly incorporate situational factors into study designs (see Kuper et al., 2026). In this regard, integrating passive and active ambulatory assessment via smartphones offers a particularly promising avenue (Conner & Mehl, 2015). Passive smartphone sensing allows researchers to objectively capture natural music-listening behavior through digital listening records while simultaneously logging contextual information such as location, activity, or social environment (e.g., via GPS, accelerometers, or ambient noise; see Harari et al., 2020; Schoedel et al., 2023). In addition, experience sampling can provide in situ self-reports of concurrent states, subjective perceptions of the situation, and uses of music in close temporal proximity to listening episodes. Together, these approaches offer valuable opportunities to investigate music listening as a dynamic, context-dependent behavior in everyday life.
More broadly, these findings highlight the importance of considering momentary processes and situational context when studying behavior, suggesting that a stronger integration of person-, situation-, and time-varying factors may be beneficial for personality psychology more generally (see Funder, 2006, 2009; Mischel, 1977; Rauthmann, 2021).
Limitations and Outlook
Our study faced several limitations that should be considered when interpreting our findings. First, our initial large sample (N = 476) was reduced to N = 110 due to missing music-listening and experience-sampling data. As a result, our multilevel analyses were likely underpowered according to simulation-based guidelines (Arend & Schäfer, 2019): At α = .05, our design would have provided adequate power (1 − β = .80) to detect small within-person effects (starting at .12), which were central to our study, but only medium-to-large between-person (starting at .30) and cross-level effects (starting at .78). Given our more conservative significance threshold (α = .005) and the unbalanced nature of our data, these estimates should still be interpreted as approximate lower bound for detectable effects. Accordingly, small effects (particularly at the between-person level) may have gone undetected. To obtain a larger sample size, future studies should employ an elaborate pre-screening strategy to include only participants who regularly listen to music on their smartphones (see Greb et al., 2019). Furthermore, studies should improve experience-sampling scheduling and present mood questionnaires whenever participants play music, not only when they open a music app, to avoid missing music-listening instances controlled via the banner on the lock screen. Such a design will also help disentangle the confounding effect of music listening on the mood states discussed above if mood states are consistently sampled prior to music listening and autoregressions are included in the modeling process.
Second, our sample composition may have restricted the generalizability of our results. As is common in university recruitment contexts, our sample consisted mostly of young, female participants drawn from a Westernized, educated, industrialized, rich, and democratic (i.e., WEIRD; Henrich et al., 2010) population. Since music preferences vary by age and gender (e.g., Greenberg et al., 2022) as well as between countries (e.g., Bello & Garcia, 2021), follow-up studies should transfer our study design to more heterogeneous samples, which, however, have to be drawn from populations with sufficient smartphone penetration, possibly excluding certain countries or age groups. While our study’s scope was limited to owners of Android smartphones, users of other operating systems do not appear to differ systematically, according to the literature (Keusch et al., 2020; Schoedel, Reiter et al., 2026).
Third, the timing of our data collection during the COVID-19 pandemic may have further limited the generalizability of our findings. Although our study did not take place during a strict lockdown, several containment measures were still in place and may have affected participants’ everyday lives, including their mobility, social interactions, and opportunities for listening to music (see Mathieu et al., 2020; Steinmetz et al., 2022). In turn, these changes may have influenced both natural music-listening behavior and mood states. For example, reduced mobility due to remote work or online teaching may have reduced mobile music listening on smartphones, whereas restrictions on social activities may have altered the functions and corresponding choices of music listening. Furthermore, the restrictions and broader pandemic context may also have influenced participants’ mood states, potentially dampening affective experiences (see Charles et al., 2021; Zacher & Rudolph, 2021). Accordingly, future research should examine mood states and music-listening behavior under more typical and less restricted everyday conditions.
Finally, we cannot confirm whether participants actively chose (and liked) the music they listened to on their smartphones because music apps offer various editorial, algorithmic, or user-created playlists and allow listeners to select music via the shuffle mode, which they do especially while on the go (Heye & Lamont, 2010). In particular, participants often started playing music without opening their music apps, indicating that they did not search for a specific song but simply played what was on before. In those instances, listeners may not have been invested in their music choice, potentially obscuring mood-congruency effects. Furthermore, automated music recommendations pose a risk of listeners getting stuck in “filter bubbles” (Petridis et al., 2022), that is, overly personalized areas in the recommender space that may limit the intraindividual variance in their momentary music preferences. Hence, researchers should try to distinguish active choices from automatic recommendations when sensing music-listening behavior, for example, by tracking keystrokes or explicitly asking participants about their selection mode in experience samplings.
Conclusion
The present study employed a smartphone-based intensive longitudinal sampling design to investigate momentary music choices in relation to concurrent mood states and enduring personality traits. Based on theoretical reasoning and previous empirical findings, we expected that the musical valence and energy of the selected songs would align with listeners’ valence and arousal states and be related to their Big Five scores, with personality moderating mood congruence. However, our multilevel regression models explained only a small fraction of the variance in music choices, revealing only one significant, albeit small, mood-congruency effect: listeners in more activated states chose more energetic songs. Beyond that, our models failed to replicate mood-congruent momentary music preferences and could not demonstrate personality or interaction effects. Still, the present study introduced an ecologically valid ambulatory assessment approach to studying intra- and interindividual differences in natural music listening behavior, while highlighting key design considerations for research in this area. Extending this approach by incorporating situational contexts may provide a more comprehensive understanding of how music choices unfold in everyday life and help to clarify the relative roles of person-, situation-, and time-varying influences.
Supplemental Material
Supplemental Material - Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits
Supplemental Material for Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits by Larissa Sust & Ramona Schoedel in Personality Science.
Supplemental Material
Supplemental Material - Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits
Supplemental Material for Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits by Larissa Sust & Ramona Schoedel in Personality Science.
Supplemental Material
Supplemental Material - Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits
Supplemental Material for Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits by Larissa Sust & Ramona Schoedel in Personality Science.
Supplemental Material
Supplemental Material - Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits
Supplemental Material for Investigating Everyday Music Choice on Smartphones: The Role of Mood States and Personality Traits by Larissa Sust & Ramona Schoedel in Personality Science.
Footnotes
Author Note
This manuscript was handled by Dr. Sointu Leikas in her role as handling editor for Personality Science.
This study has received approval from the ethics committee of the Department of Psychology at LMU Munich under the title “Moody Life” and adhered to the General Data Protection Regulation (GDPR).
Acknowledgments
We thank the PhoneStudy team at LMU Munich for their continuous and diligent work on the PhoneStudy app, which enabled our research. Special thanks go to Markus Bühner for providing the infrastructure for our research and to Florian Bemmann for technical support during this study. We also thank Florian Pargent for his helpful advice on our multilevel modeling. Finally, we thank our student researchers from the EmPra seminar and thesis students for helping us recruit participants. We also disclose the use of generative AI (ChatGPT version GPT-5.5) to improve the clarity of text passages and refine the argumentation structure. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Author Contributions
LS - conceptualization; data curation; formal analysis; investigation; methodology; project administration; visualization; writing - original draft; writing - review & editing.
RS - investigation; project administration; supervision; writing - review & editing
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by internal funding from the Faculty of Psychology and Educational Sciences at LMU Munich through the Lehre@LMU (2020) program, which funded data collection in the context of seminars and student theses.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
We provide the dataset of aggregated variables, as well as the reproducible code for preprocessing and formal analysis in the project’s OSF repository, accessible under https://osf.io/rptjx. Due to GDPR regulations, the underlying raw smartphone-sensing data can only be accessed on the local servers of LMU Munich under an individual legal agreement, given its privacy-sensitive nature. The analyses reported in this manuscript were preregistered under ![]() , and all deviations from the preregistration are reported in the document “Preregistration_Changes” in the above-linked OSF repository.
, and all deviations from the preregistration are reported in the document “Preregistration_Changes” in the above-linked OSF repository.
Supplemental Material
Supplemental material for this article is available online. Depending on the article type, these usually include a Transparency Checklist, a Transparent Peer Review File, and optional materials from the authors. In addition, the authors provide their Online Supplemental Material (OSM) in their OSF repository (![]() ).
).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.