
Abstract
Representation learning is critical for multimodal methods; traditional consistency-based multimodal methods always constrain the disagreements among different modality embeddings or predictions as an extra regularization. However, these methods may appear to cause performance degeneration in open environments. This is mainly attributed to the interference of asymmetric information, that is, different modality information exists divergence, whereas consistency regularization prefers to simply minimize the divergence rather than optimal classifiers. Therefore, it is unsafe to directly use consistency regularization. To this end, we propose modality-specific subspace learning (MSSL). It learns the modality-specific subspace representations by treating modality divergence and consistency separately. In particular, MSSL is a semi-supervised framework that maps different modality feature embeddings into shared and independent subspaces. The shared subspace applies reliable consistency regularization by measuring intermodality structural similarities. The independent subspace uses a discriminative modality-separation network to emphasize modality complementary information. Finally, labeled instances from different modalities are classified with weighted predictions over concatenated embeddings. Consequently, MSSL improves both the single modal and ensemble classification results and acquires more robust mapping among different modalities. Empirical studies show the superior performance of MSSL on real-world datasets.
Introduction
Multimodal methods aim to fuse information from multiple correlated sources. This improves classification accuracy and strengthens intermodality correlations. As a result, multimodal learning has attracted increasing attention and has been applied in many areas, such as healthcare (Ma et al., 2015), recommendation (Liu et al., 2019), and information retrieval (Liu et al., 2017; Yang et al., 2024b). Formally, the basic assumption behind existing approaches is that each modality has sufficient information for classification on its own. Following this idea, previous consistency-based methods (Brefeld et al., 2006; Farquhar et al., 2005; Yang et al., 2018b) enforced consistency among modalities. The constraints were applied at different levels, including models, features, and predictions. For example, co-regularization style methods (Brefeld et al., 2006; Yang et al., 2018b) aimed to improve single modal performance via constraining the predictions or similarity matrices of unlabeled multimodal data. In contrast, canonical correlation analysis (CCA)-style methods (Andrew et al., 2013; Wang et al., 2016b; Xie et al., 2020) built cross-modal connections by minimizing embedding discrepancies. Consequently, consistency principles improve not only single-modality performance but also cross-modal relationships, supporting tasks such as classification and retrieval. In consequence, the consistency principle can not only improve the performance of single-modal models, but also build relationships among modalities for applying in tasks such as classification and retrieval. However, in open environments, multimodal data often contains asymmetric information. Each modality may provide both shared and independent parts, and the independent parts cause inconsistency. Traditional consistency constraints suppress these inconsistencies, which interfere with joint optimization (Nie et al., 2022; Wang & Zhou, 2013; Yang et al., 2024a). As a result, such methods may fail and even suffer from performance degradation.
Therefore, robust consistency and diversity regularizations are vital. Robust consistency constraint aims to reduce the influence of asymmetrical instances, thus to achieve more reliable consistency. For example, Muslea et al. (2003) considered single-track teaching, which employed predetermined strong modality to assist weak modality; Yang et al. (2019b) developed robust consistency regularization to eliminate interference from inconsistent instances. On the contrary, the diversity measure aims to highlight the modal complementary information, that is, the independent information. Similar to heterogeneous ensemble learning (Zhou, 2009), different modal models can be considered as various basic classifiers, and a diversity measure can improve the voting results in the PAC-learning framework (Li et al., 2012). Therefore, Wang et al. (2017) and Yang et al. (2019a) combined both consistency and diversity constraints on different modal predictions to encourage diversity for improving the final classification performance. However, these methods measure both the consistency and diversity in the single subspace embeddings or label prediction distribution; it is difficult to learn the shared and independent information simultaneously in reality.
To address this problem, we propose modality-specific subspace learning (MSSL), which explores both consistency and diversity within a unified framework. Specifically, MSSL designs feature embedding networks for each modality. The embeddings are mapped into two subspaces: shared and independent. Shared subspaces capture information consistent across modalities. Independent subspaces capture complementary information, which may appear inconsistent. For classification, we concatenate the shared and independent embeddings of labeled data. The shared subspace is regularized with reliable consistency, while the independent subspace is refined by an modality-separation discriminator. Therefore, MSSL can effectively learn more discriminative embeddings for each modality in return. To summarize, the main contributions of our work are: We establish a unified semi-supervised multimodal deep learning framework, MSSL, which effectively learns modality-specific embeddings to capture both consistency and diversity. We develop related reliable metrics, that is, reliable consistency on shared subspace aims to acquire different modal correlated information, and diversity metric on independent subspace aims to learn distinguishable information for better classification. As a result, MSSL can be effectively applied to reliable multimodal representation learning. We conduct extensive experiments on real-world datasets, and our results demonstrate the superior performance.
Related Work
This paper focuses on exploring reliable, consistent, and complementary information simultaneously, and realizes it by measuring modal-specific embeddings for different modalities. Therefore, our work is related to the following two aspects: traditional multimodal methods and reliable multimodal methods.
Multimodal learning improves performance by leveraging heterogeneous multisource data, in which modal consistency is one of the important principles. Most multimodal methods make full use of unlabeled data by constraining the consistency of different modal predictions, and improve the performance of tasks such as classification and clustering. For example, Brefeld et al. (2006) considered the consistency of different modal predictions, which took the aligned modal predictions of unlabeled instances as the pseudo information; Wang et al. (2013a) proposed to utilize the consistency of manifold structure among different modalities, and applied it on multimodal clustering. On the other hand, feature consistency constraints can build cross-modal relationships and improve the performance of tasks such as retrieval and captioning. For example, Hotelling (1936) proposed the CCA method, which maximized the correlation between two modal representations in a shared subspace, thus to acquire correlated feature representation; Andrew et al. (2013); Ngiam et al. (2011) combined deep learning techniques to learn more discriminative feature embeddings; and Zhen et al. (2019) introduced intra-modal and inter-modal consistency measures to improve cross-modal retrieval tasks. Therefore, correct alignment among modalities is a prerequisite for the success of multimodal approaches. However, multimodal data has asymmetric information in an open environment, and both the feature and prediction consistency are interfered with. Consequently, the traditional co-regularization method is even worse than single modality, as shown in Table 1.
Preliminary Investigations: (1) Unlabeled Data May Improve Performance, yet it is Unsafe. For Example, LU
/LUC Only Performs Better Than L
on Partial Criteria; (2) Traditional Co-regularization Method may Reduce the Performance. For example, CoReg Performs Worse Than Img/Text on Both Datasets.
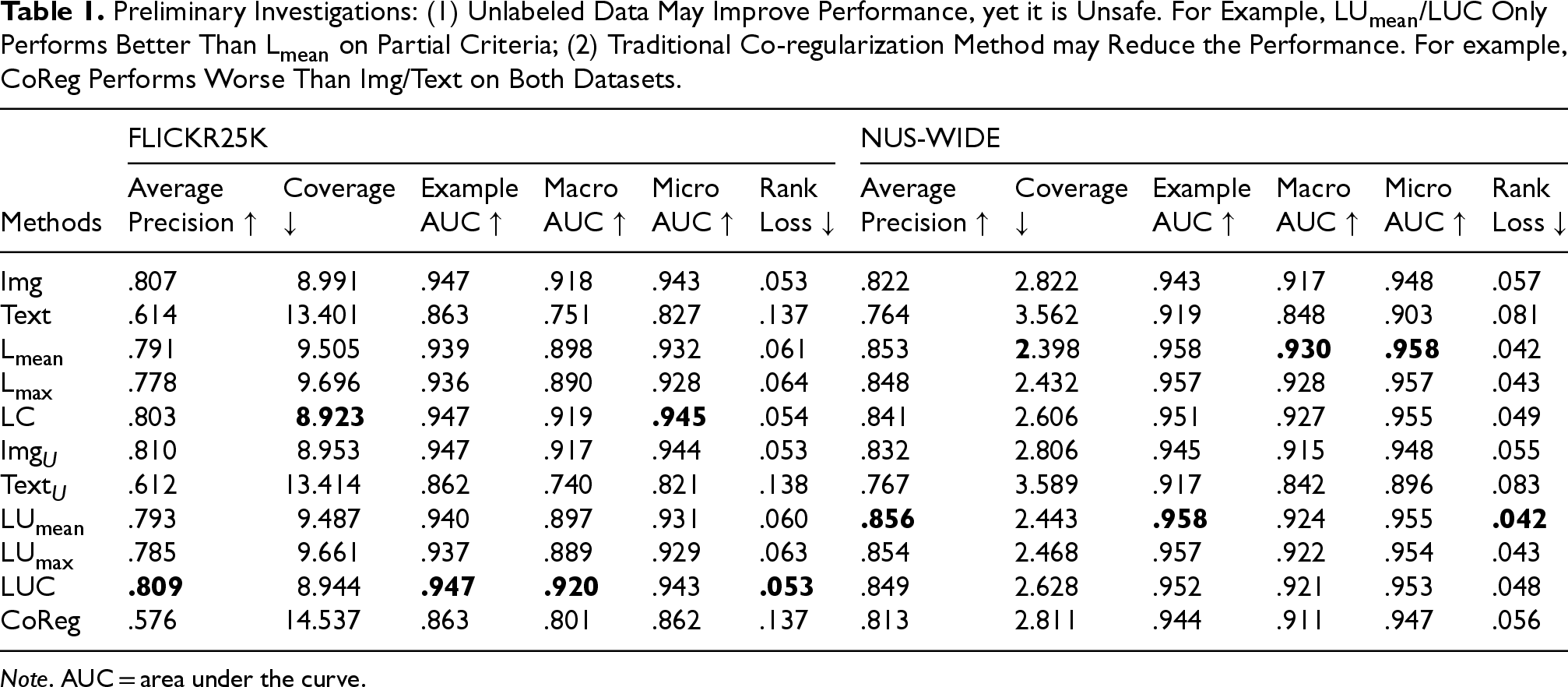
Preliminary Investigations: (1) Unlabeled Data May Improve Performance, yet it is Unsafe. For Example, LU
Note. AUC = area under the curve.
Therefore, reliable multimodal learning is researched to eliminate the inconsistency. Robust consistency regularization is first utilized for eliminating the divergent instances. For example, Iwata and Yamada (2016) proposed probabilistic latent variable models for inconsistent multimodal anomaly detection, which assumed that nonanomalous instances are generated from a single latent vector; Yang et al. (2018b) calculated modal weights using square root loss to eliminate inconsistent instances. However, previous methods focus on removing inconsistent outlier instances, let alone considering divergence comprehensively. To solve this problem, Wang et al. (2017) attempted to combine exclusivity and consistency terms to make complementary representations with a common indicator; Yang et al. (2019a) combined prediction divergence and robust consistency metric to build a reliable multimodal network. Nevertheless, these methods always concentrate on the measurement of single subspace embeddings or prediction distributions for different modalities, which makes it difficult to learn consistent information and local independent information among modalities.
Our method differs clearly from several related approaches. For example, CMML (Yang et al., 2019a) mitigates modality insufficiency with instance-level attention and balances consistency with diversity, but it does not explicitly separate shared and modality-specific subspaces. EXMV (Wang et al., 2017) combines consistency and diversity constraints at the prediction level, yet it lacks a unified representation framework. DSCMR (Zhen et al., 2019) learns a common representation space for cross-modal retrieval and enforces global alignment, but it ignores local inconsistencies and modality-specific information. In contrast, our MSSL explicitly disentangles shared and independent subspaces, filters globally inconsistent instances, and integrates modality separation, reliable consistency, and weighted classification into a unified framework.
Notations
Suppose there are
Preliminaries
In this section, we present the performance of traditional multimodal methods on real multimodal data to verify whether inconsistent data affects the performance. Table 1 records the results of real-world multimodal datasets, that is, FLICKR25K (Huiskes & Lew, 2008) and NUS-WIDE (Chua et al., 2009). The comparison methods include: (1) we train each modal classifier separately with labeled data, denoted as “Img/Text,” then use max/mean voting to acquire ensemble results, denoted as “L
It is notable that performance across modalities varies. For example, in FLICKR25K, the gap between image and text is large, whereas in NUS-WIDE it is relatively small. We observed several notable phenomena: On FLICKR25K dataset, models using concatenated features perform better than the ensemble methods, that is, LC and LUC perform better than L Semi-supervised methods may improve in single modality, yet their overall performance is worse than the supervised methods on some criteria, that is., coverage, macro area under the curve (AUC), and micro AUC. The phenomenon owes to unlabeled data, which may introduce additional label or structural noise. Traditional co-regularization method performs even worse than single modality on some criteria, that is, average precision (AP), macro AUC, and micro AUC. This is attributed to the interference of inconsistent instances in cross-iterative training.
Therefore, we should design a reliable semi-supervised multimodal model, which can safely utilize the multimodal data, highlight the consistent and divergent information, rather than use the consensus constraint directly. As a result, the model acquires more reliable feature representation for each modality.
In this section, we will introduce the proposed MSSL in detail. Consistency-based methods are often disturbed by inconsistent multimodal instances. These inconsistencies fall into two types: global inconsistency (e.g., mismatched image–text pairs in Figure 1(a)) and local inconsistency (e.g., mismatched blocks in Figure 1(b)). Therefore, MSSL aims to carefully consider these issues by hierarchically measuring inconsistency. First, MSSL computes correlations between feature embeddings of different modalities. A relatively high threshold is applied to filter out globally inconsistent instances. Next, the selected embeddings are mapped into shared and independent subspaces. The shared subspace captures consistent representations, while the independent subspace learns divergent features specific to each modality. Thereby, we can make full use of multimodal consistent information and highlight the modal complementary information in return. With the learned discriminative feature representation, the model can improve the performance of each modality steadily and construct robust relationships between modalities.

Illustration of the inconsistent multimodal instances: (a) globally inconsistent instance; (b) locally inconsistent instance; and (c) consistent instance.
The detailed algorithmic process is shown in Figure 2. First, each modality is encoded by a separate network (e.g., convolutional neural network for images and deep neural network for text). The resulting embeddings
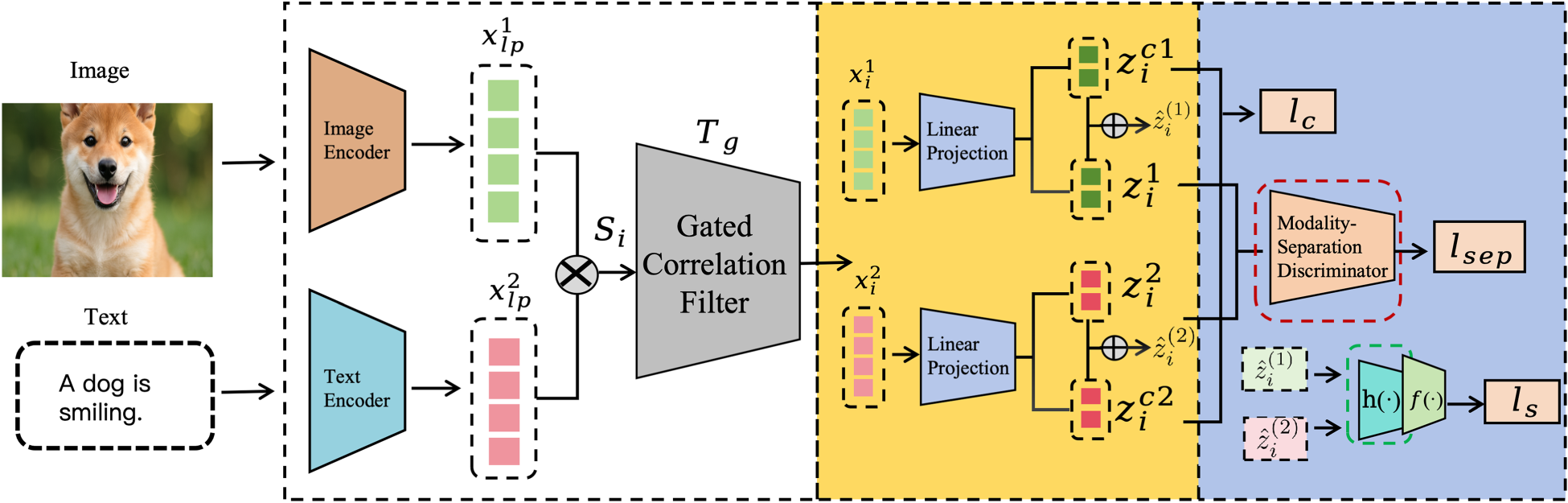
Illustration of the proposed MSSL. MSSL inputs two different modal feature embeddings into the gated correlation module, which aims to exclude globally inconsistent instances. Then each selected modal embedding maps to a shared and independent subspace, which aims to find local consistent and divergent information. Different modal independent embeddings are input to the modality-separation network, thus to learn complementary information with divergent representation, and shared embeddings are constrained by reliable structure consistency. MSSL also combines additional weighting networks for weighted ensemble prediction using each modal’s concatenated features. Consequently, MSSL acquires a more discriminative representation for each modality. Note. MSSL = modality-specific subspace learning.
We first analyze the objective function of each module, then provide the overall objective function.
Mathematically, we first project each modal feature to a low-dimensional space, that is, 
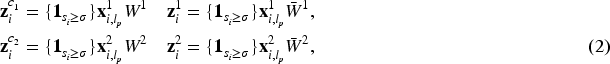
To highlight the divergence between various modal independent information, we can distinguish it by divergent measures. Without any loss of generality, we refer to the modality-separation network (Goodfellow et al., 2014). Specifically, let 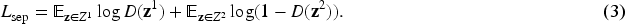
The importance of each modality may vary across instances, especially in the presence of local inconsistencies. Previous methods often used mean or max voting, which ignores this variability. Thus, MSSL turns to utilize an extra weight mechanism to automatically learn the weights for different modalities. The weight mechanism can be formulated as follows:

The loss can be separated into two parts: classification loss and consistency regularization. With the calculated weights, the classification loss can be denoted as:

Beyond traditional consensus regularization, we also minimize inter-modal discrepancies, inspired by Zhen et al. (2019). This encourages embeddings to produce more reliable mappings, as formulated below:
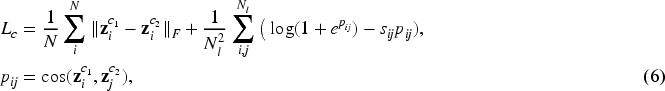
In conclusion, combining equations (3), (5), and (6), we generate the whole formulation as:

For optimizing MSSL, we sample a mini-batch at each iteration, and calculate the objective according to equation (7). The model parameters are updated via the Adam optimizer (Kingma & Ba, 2015). With the learned model, we conduct inductive learning. The procedure of training the MSSL model can be summarized as Algorithm ??.

To validate the soundness of our optimization in equation (7), we provide two concise analyses: (i) a convergence guarantee for the modality-separation module under a two-time-scale update, and (ii) an upper bound showing that subspace separation does not increase task risk under mild conditions.
Modality-Separation Under TTUR
Let
TTUR convergence
Under the above conditions, the ascent–descent iterates
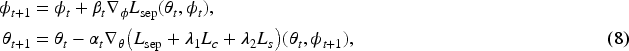
With
Implication
Updating the separator faster than the encoder/fusion yields stable optimization under TTUR; our update schedule thus aligns with the convergence guarantee.
Let
(Risk gap bound)
Let 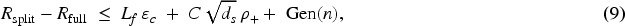
Couple predictions with and without separation and bound their loss difference via Lipschitz stability of
Implication
The bound shows separation is risk-nonincreasing when
Datasets and Compared Methods
Most of the existing large-scale multimodal datasets focus on the two-modal multilabel classification with image–text pairs. Therefore, we first experiment on two public datasets, that is, FLICKR25K (Huiskes & Lew, 2008) and NUS-WIDE (Chua et al., 2009). FLICKR25K consists of 25,000 images collected from the Flickr website, each image is associated with several textual tags. The text for each instance is represented as a 1386-dimensional bag-of-words vector. Each point is manually annotated with 39 labels. NUS-WIDE contains 260,648 web images, and each image is associated with textual tags. Each point is annotated with 81 concept labels, and we select the 21 most frequent concepts as (Yang et al., 2019a). The text is represented as a 1000-dimensional bag-of-words vector. We also experiment on one real-world complex article dataset, that is, WKG Game-Hub (WKG in simplify; Yang et al., 2018a) consists of 25,694 image–text pairs collected from the Game-Hub of “Strike of King” with 54 concept labels. The text is represented as a 512-dimensional vector using Chinese BERT (Cui et al., 2019).
For the comparison method. First, we adopt an ablation study to verify the effectiveness of each module. Specifically, we define three different varieties of MSSL: (1) no modal separation module, denoted as MSSL-S; (2) no weight module, denoted as MSSL-W; and (3) no reliable consistency module, denoted as MSSL-R. Moreover, we compare MSSL with the state-of-the-art multimodal method: Co-trade (Zhang & Zhou, 2011), WNH (Wang et al., 2013a), SLIM (Yang et al., 2018b), ICo-train (Guo & Wang, 2019), EXMV (Wang et al., 2017), CMML (Yang et al., 2019a), M3DN (Yang et al., 2018a), and TagCLIP (Lin et al., 2024). For multilabel classification, we treat each label independently, that is, for each label, we train a corresponding classifier using different modalities.
Moreover, MSSL can also obtain shared subspace embeddings, so in addition to classification tasks, we also utilize shared subspace representations for cross-modal retrieval. Therefore, we compare MSSL with six state-of-the-art cross-modal method: CCA (Hotelling, 1936), LCFS (Wang et al., 2013b), JFSSL (Wang et al., 2016a), DCCA (Andrew et al., 2013), VSE++ (Faghri et al., 2018), and DSCMR (Zhen et al., 2019).
Implementation Details
All experiments are implemented in PyTorch and conducted on a single NVIDIA RTX 3090 GPU with 24 GB memory. The image encoder is ResNet-18 pretrained on ImageNet, while the text encoder is a three-layer fully connected network. Unless otherwise specified, the embedding dimension of the shared subspace is set to
For each dataset, we randomly select
Multilabel Classification
We first give the multilabel classification results. Single modal and ensemble results are listed in Tables 2 to Table 4. The notation “N/A” means a method cannot give a result within 60 h. The best performance for each criterion is bolded. The single modal performance of some traditional methods has not been improved, and the ensemble effect is even worse than single modality, for example, Co-Trade, WNH, and ICo-train on most criteria. The performance is due to the drawbacks of the direct consistency principle. The methods considering both the divergence and consistent constraints, that is, EXMV and CMML, are much better than traditional multimodal methods. Meanwhile, CMML performs better than EXMV on all criteria of both public datasets, which is attributed to CMML utilizing the reliable consistent constraints to eliminate the inconsistent instances. MSSL is superior on most criteria. It is notable that MSSL achieves the best performance on both single modality and ensemble results in most performance measures, except the ensemble results of coverage/AP on FLICKR25K/NUS-WIDE datasets. In ablation experiments, we found that results decrease after removing either the module, except the AP on the NUS-WIDE dataset, which validates the effectiveness of weighted ensemble and modality-specific subspace learning.
Multilabel Classification Results of two Public Datasets. Three Common Criteria are Recorded. The Best Performance for Each Criterion is Bolded.
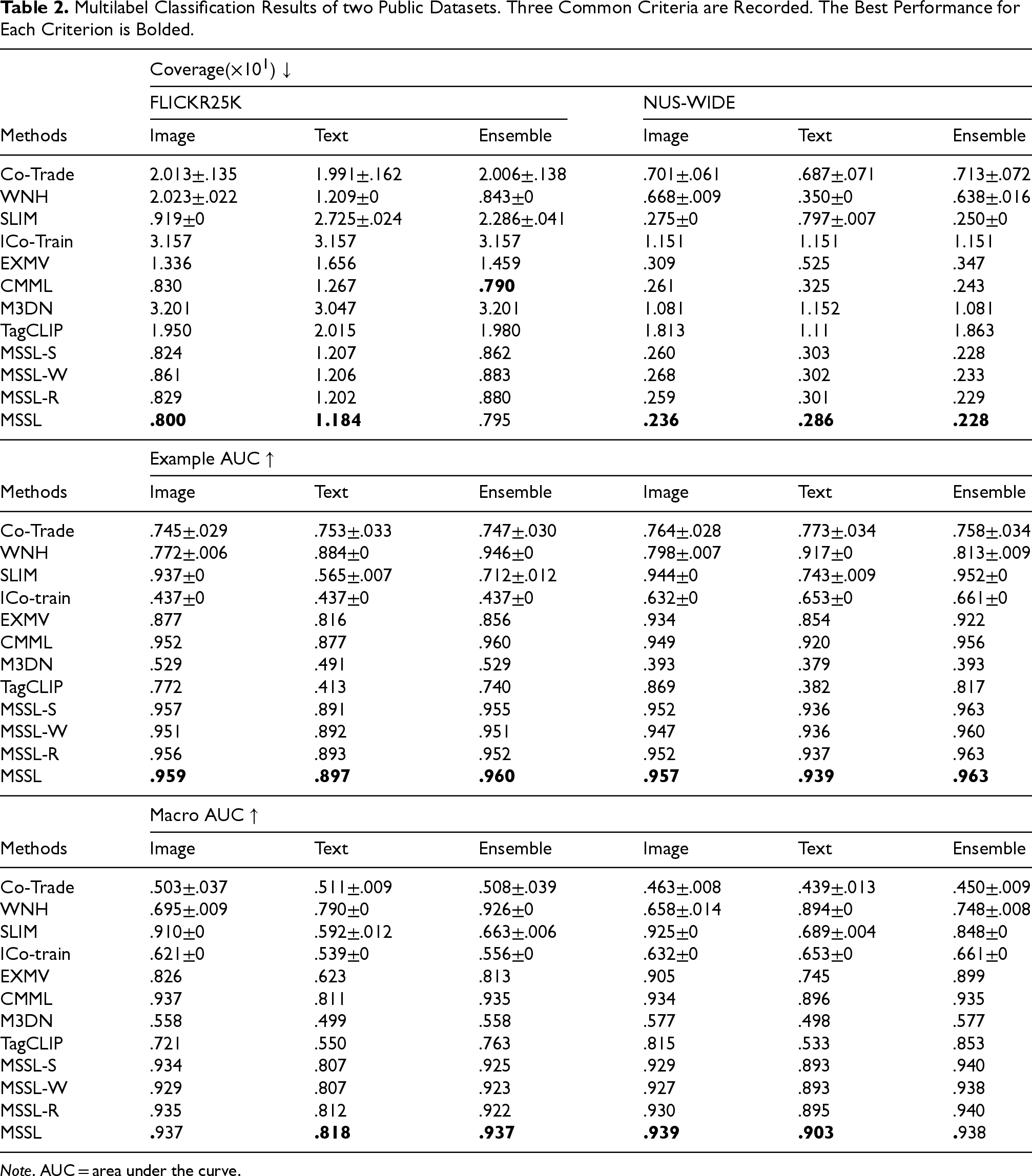
Multilabel Classification Results of two Public Datasets. Three Common Criteria are Recorded. The Best Performance for Each Criterion is Bolded.
Note. AUC = area under the curve.
Multilabel Classification Results on Two Public Datasets. Three Common Evaluation Criteria are Reported. The Best Results for Each Criterion are Highlighted in Bold. The Notation “N/A” Indicates that the Method Could not Produce Results Within 60 Hours.
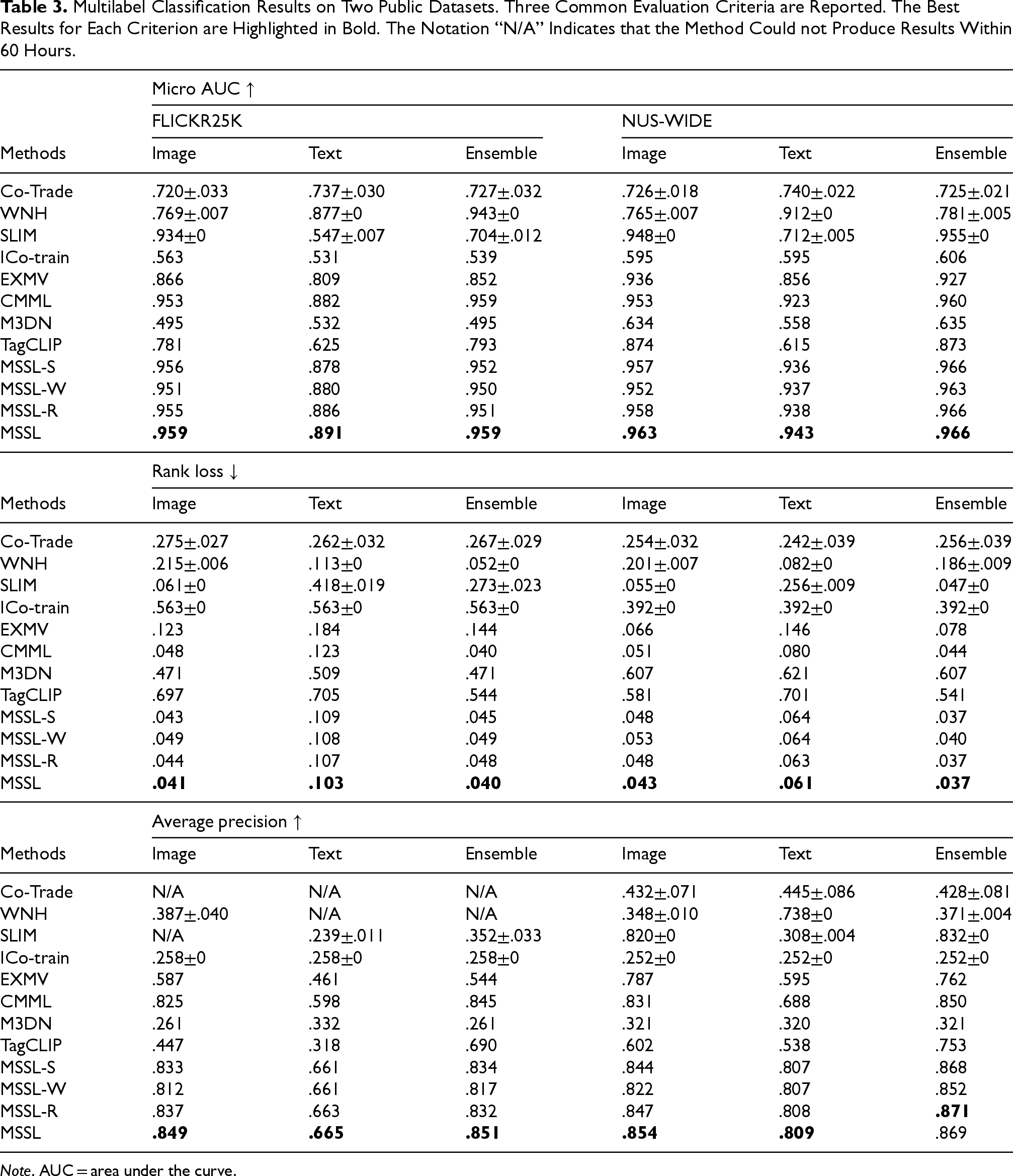
Note. AUC = area under the curve.
Multilabel Classification Results of WKG Game-Hub Dataset. Six Common Criteria are Recorded. The Best Performance for Each Criterion is Bolded.
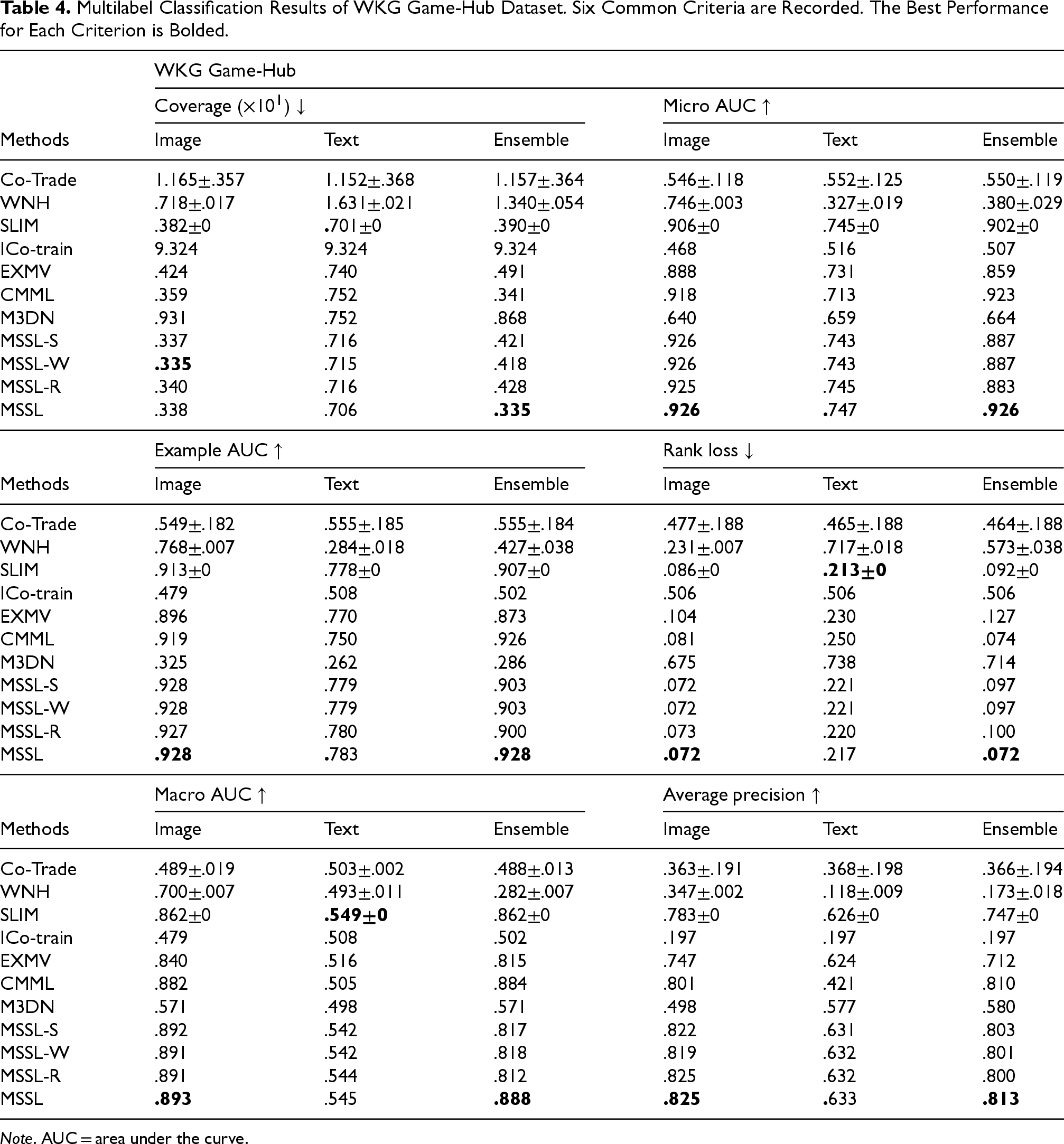
Note. AUC = area under the curve.
Moreover, as shown in Table 4, MSSL also achieves similar performance in real-world complex article classification. MSSL gets the best on all ensemble results over each criterion, although it ranks second in the text results of some criteria, that is, example AUC, and rank loss. The results verify the effectiveness of MSSL and present an interesting direction for multimodal learning. In detail, we need a reliable fusion of multimodal information, that is, on the basis of safely using the consistency among modalities, we need to consider the modal independence to improve the ensemble performance.
Furthermore, we conduct more experiments to explore the influence of parameters
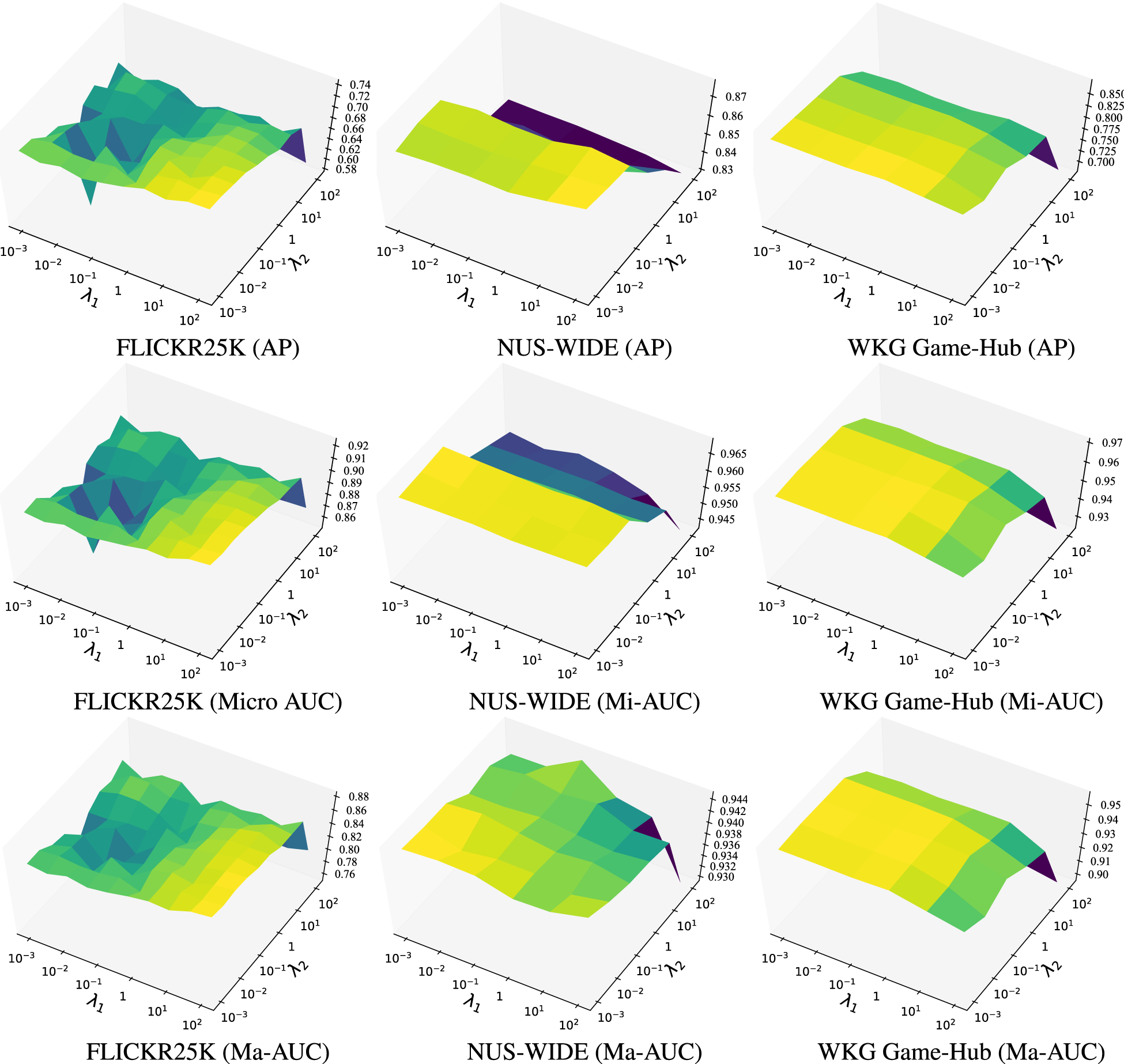
Influence of the parameters
We evaluate our method on the tri-modal IEMOCAP (Busso et al., 2008) using the standard splits and evaluation protocol, and compare against the classic tri-modal baseline HRG-SSA (Ji et al., 2025). We report class-wise accuracies (Happy/Sad/Neutral). As shown in Table 5, our tri-modal variant consistently surpasses HRG-SSA, demonstrating the method’s effectiveness and scalability to multimodal settings.
IEMOCAP Tri-Modal Results. We Report Per-Class Accuracies for Happy, Sad, and Neutral; Best Results are in Bold .

IEMOCAP Tri-Modal Results. We Report Per-Class Accuracies for Happy, Sad, and Neutral; Best Results are in
Note. MSSL = modality-specific subspace learning.
Considering MSSL can effectively eliminate the inconsistent instances. We conduct more experiments, and locate the image–text pairs with the similarity

Examples of inconsistent instances using the reliable consistency gated module from the WKG Game-Hub dataset.
MSSL can also learn shared subspace representation for each modality; thus, we perform cross-modal retrieval to verify the effectiveness. Cross-modal retrieval is performed with two tasks: (1) Image The deep learning-based methods are helpful to improve the performance of traditional methods, for example, DCCA outperforms CCA on all datasets. The label information improves model feature learning, for example, the best two linear methods, LCFS and JFSSL, using deep output features, outperform the unsupervised deep method DCCA on all datasets. MSSL outperforms both the unsupervised methods and the deep learning-based methods on most datasets, except FLICKR25K. The reason is that the label concepts of the FLICKR25K dataset are fine-grained, and the DSCMR deep method additionally considers the interclass/intraclass structure information, thus they are better in
Comparison of Different Real-Valued Cross-Modal Learning Methods on Three Datasets (NUS/FLICKR Denotes NUS-WIDE/FLICKR25K). NDCG@500 is Recorded. The Best Performance is Bolded.
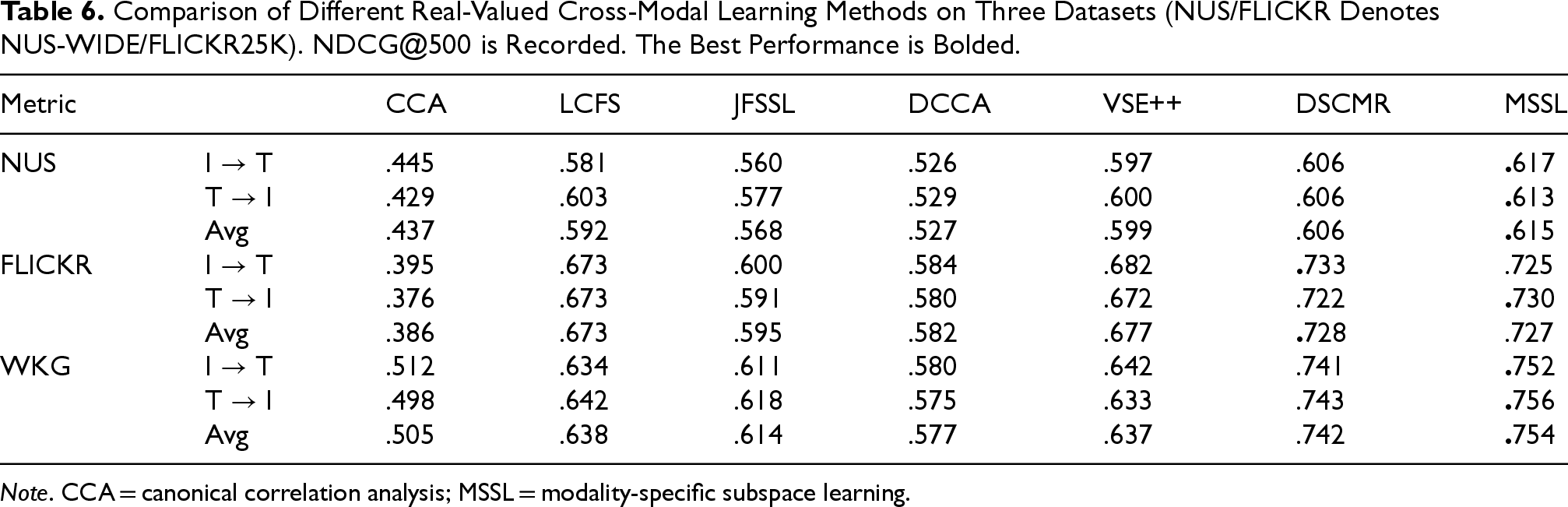
Comparison of Different Real-Valued Cross-Modal Learning Methods on Three Datasets (NUS/FLICKR Denotes NUS-WIDE/FLICKR25K). NDCG@500 is Recorded. The Best Performance is Bolded.
Note. CCA = canonical correlation analysis; MSSL = modality-specific subspace learning.
To explore the quality of cross-modal retrieval, we also analyze the success and failure of cross-modal retrieval examples. Considering that the text modality of NUS-WIKD/FLICKR25K datasets only contains tag information, we give the retrieval examples of our proposed method on the real-world dataset WKG as shown in Figures 5 and 6. In detail, Figure 5 shows the success retrieval results of Correctly retrieved examples usually have simple modal information, for example, images describing game hero label concept (e.g., Li Bai, Di Renjie, and Guan Yu), and text describing skills label (e.g., Assassin). Whereas several retrieved results do not match the true image/text, they are still very relevant to the query information, for example, the retrieved text contains the hero’s name (i.e., the first case in Figure 5 includes “Li Bai” in failure examples), or the retrieved image belongs to the game (i.e., the failure examples of fourth case in Figure 5 belongs to WKG game). Failure examples are usually more complex and require professional judgment. The reasons are: (1) the modal itself has insufficient information and contains lots of noise, which increases the difficulty of retrieval. Meanwhile, the image–text pair correlation of these examples is low as indicated in Figure 4; and (2) the retrieved samples have few training examples, for example, news or other game examples.

Success results on the WKG dataset, we tested our method. Given text/image description as a query, we retrieve the most relevant image/text ranked from left to right.

Failure results on the WKG dataset, we tested our method. Given a text/image description as a query, we retrieve the most relevant image/text ranked from left to right.
In open environments, multimodal data contains both shared and independent information, which often undermines traditional consistency-based approaches. We proposed MSSL, a unified semi-supervised framework that explicitly models both shared and independent information. MSSL integrates three components—modality separation, reliable consistency regularization, and weighted classification. This design expands complementarity at the representation level, enhances ensemble prediction through automatically learned weights, and enforces robust structure-aware co-supervision. Extensive experiments across diverse benchmarks demonstrate that MSSL achieves significant improvements under multiple evaluation criteria.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.