
Abstract
The challenge of reconstructing three-dimensional (3D) models from images lies in how to infer a complete 3D structure with detailed geometry from two-dimensional (2D) images. However, single-view reconstruction requires only one image to reason about the 3D shape, demonstrating significant application potential. Yet, most existing methods rely on fully supervised learning approaches, which demand large amounts of labeled data. To alleviate this issue, semi-supervised learning strategies have been proposed to reduce the dependence on annotated data, offering a more efficient solution for single-view 3D reconstruction. We propose a semi-supervised single-view 3D point cloud reconstruction framework that employs a teacher-student paradigm to leverage limited labeled data together with abundant unlabeled samples. To address the modality heterogeneity between 2D images and 3D point clouds, a Heterogeneous Feature Attention Mechanism is designed to align cross-modal features and embed image cues into 3D spatial structures, preserving both geometric and appearance information. Moreover, a Self-Attention Decoder captures global dependencies and salient regions, enabling fine-grained structural recovery. Our model demonstrates outstanding performance on both the ShapeNet dataset and the Pix3D dataset, achieving an L1-Chamfer distance (CD) value of 5.60
Keywords
Introduction
Single-view three-dimensional (3D) reconstruction is an important research topic in the field of computer vision, aiming to infer and reconstruct the corresponding 3D structure from a single two-dimensional (2D) image. This task holds significant application value in various practical domains such as augmented reality, robotic navigation, and medical imaging (Gerbaud et al., 2024; Liu et al., 2024; Wu et al., 2024). In recent years, the development of deep learning has greatly advanced progress in single-view 3D reconstruction. Triplane Meets Gaussian Splatting (Zou et al., 2024) achieves high-quality and efficient 3D reconstruction by integrating explicit point clouds with implicit triplane features, while leveraging Transformer and differentiable Gaussian point cloud rendering. Gamba (Shen et al., 2025) proposes an end-to-end Mamba-based efficient Gaussian point cloud generation method, which significantly improves reconstruction speed while maintaining accuracy.
Despite the remarkable progress that single-view 3D reconstruction has achieved in recent years under the impetus of deep learning (Ding et al., 2025a, 2025b; Jin et al., 2024; Melas-Kyriazi et al., 2023; Szymanowicz et al., 2024), this task still faces numerous challenges. First, there exists a highly complex and nonlinear mapping relationship between 2D images and 3D structures, which makes it difficult for models to capture complete and stable geometric correspondences during the learning process (Jin et al., 2024). Second, the spatial information carried by a single image is inherently limited, lacking both depth and multi-view constraints, which often leads to uncertainty and ambiguity in the reconstructed 3D results (Szymanowicz et al., 2024). This issue becomes particularly pronounced when dealing with fine structural details or occluded scenes. Third, acquiring large-scale and high-quality 3D annotated data is extremely costly, requiring not only complex acquisition devices and labor-intensive annotation processes but also being constrained by the diversity and precision of the data, which severely restricts the broader adoption and application of supervised learning methods (Melas-Kyriazi et al., 2023). In summary, how to alleviate modality discrepancies, enhance geometric consistency, and improve the representation of fine details under limited annotation conditions remains a central challenge in single-view 3D reconstruction research.
In the field of 2D image classification, semi-supervised learning (SSL) has already demonstrated excellent performance by combining a small amount of labeled data with a large quantity of unlabeled data (Vanyan & Khachatrian, 2021). This approach effectively alleviates the reliance on large-scale annotated datasets by mining the latent information within unlabeled data, thereby reducing annotation costs while maintaining high accuracy. It provides new opportunities for single-view 3D reconstruction, reducing the dependence on labeled data while still achieving high precision. We introduce the SSL paradigm into point cloud-based single-view 3D reconstruction, thereby improving the reconstruction quality of models in 3D reconstruction tasks.
Our main contributions are summarized as follows:
We propose a single-view semi-supervised point cloud reconstruction method. With a teacher–student architecture, it effectively leverages limited labeled data together with large-scale unlabeled data, improving the structural consistency and stability of single-view reconstruction; In this method, we design a heterogeneous feature attention mechanism for 2D–3D feature alignment and a decoder architecture integrated with self-attention to model cross-modal interactions and global dependencies, thereby enhancing 3D structure recovery capability; The L1 Chamfer distance (CD) value on the ShapeNet dataset is 5.60
Related Work
Deep Learning for 3D Reconstruction
3D reconstruction is an important research direction in computer vision, with the goal of reconstructing the 3D structure of objects from 2D images. Existing approaches can be broadly divided into two categories: Explicit representations and implicit representations.
Explicit representation methods mainly include three forms: Voxels, meshes, and point clouds. In voxel-based methods, 3D-R2N2 (Choy et al., 2016) employs a 2D convolutional network to encode 2D images into low-dimensional embeddings, processes the embeddings with 3D LSTM, and then decodes them into voxel grids through a 3D convolutional network. CIGNet (Gao et al., 2023) integrates category priors and intrinsic geometric relationships, utilizing reconstruction and refinement modules to generate progressively detailed 3D reconstruction results. However, the memory and computational cost of voxel-based methods grow cubically with resolution, which severely limits the achievable output resolution (Tiong et al., 2022; Xie et al., 2019, 2020a; Yagubbayli et al., 2021). In mesh-based methods, Pixel2Mesh (Wang et al., 2018) employs a mesh deformation network to capture semantic information from 2D images and gradually deform an initial ellipsoid into the target shape. Std-Net (Mao et al., 2021) combines an autoencoder with a topology-adaptive graph convolutional network, enabling the reconstruction of diverse objects with complex topologies. However, mesh-based approaches often struggle to represent internal or irregular structures (Wen et al., 2022a; Yang et al., 2023; Zhang et al., 2024). In point cloud-based methods, PSGN (Fan et al., 2017) effectively addresses the permutation invariance problem of point clouds by adopting CD and Earth Mover’s Distance as loss functions. Part-Wise AtlasNet (Yu et al., 2022) employs a generator–discriminator framework and introduces adversarial loss to enhance global semantic consistency. Such point cloud-based methods usually offer the advantages of low memory consumption and strong detail representation (Afifi et al., 2020).
Implicit representation methods, on the other hand, establish continuous 3D representations through neural radiance fields (NeRFs) and differentiable rendering. NeRF (Barron et al., 2021; Hong et al., 2023; Lin et al., 2023; Metzer et al., 2023; Mildenhall et al., 2021; Yu et al., 2021) achieves high-quality 3D reconstruction by minimizing the discrepancy between synthesized images and real images. Recent studies (Jun & Nichol, 2023; Nichol et al., 2022; Poole et al., 2023) further integrate diffusion models for single-view 3D model generation. 0-1-to-3 (Liu et al., 2023b) leverages a stable diffusion model to perform novel view synthesis conditioned on relative camera poses. 1-2-3-4-5 (Liu et al., 2023a), an improved version of Zero-1-to-3, extracts 2D features from multi-view images and constructs a 3D cost volume with camera poses to infer geometric structures. Wonder3D (Long et al., 2024) fuses image and text embeddings with camera parameters to produce consistent multi-view representations and employs a novel fusion algorithm to reconstruct high-fidelity textured meshes.
Explicit methods rely heavily on large-scale annotated 3D data, making it difficult to scale them to complex and diverse scenarios. Implicit methods often adopt self-supervision or weak supervision, but they usually require a large number of multi-view images along with camera pose information, which leads to poor performance under conditions with limited viewpoints. These shortcomings highlight that achieving high-quality single-view 3D reconstruction with limited annotations and restricted viewpoints remains an urgent challenge to be addressed.
Semi-Supervised Deep Learning
The core challenge of SSL lies in how to effectively leverage large amounts of unlabeled data for training under the condition of limited labeled data. Existing methods can generally be divided into two categories: Entropy minimization (Grandvalet & Bengio, 2004; Lee, 2013; Pham et al., 2021; Zoph et al., 2020) and consistency regularization (Berthelot et al., 2019a, 2019b; Gong et al., 2021; Miyato et al., 2018; Xie et al., 2020b). Entropy minimization methods originate from self-training, with the core idea of assigning pseudo-labels to unlabeled data and combining these pseudo-labels with manually annotated data for further training. Consistency regularization assumes that the predictions of unlabeled data should remain unchanged under different perturbations. Therefore, data augmentation is often introduced to expand the training distribution, thereby improving the generalization ability and robustness of the algorithm. Common augmentation techniques include random flipping, geometric transformations, and image contrast adjustments. Meanwhile, more sophisticated augmentation strategies also exist, such as Cutout (DeVries & Taylor, 2017), which achieves effective perturbation by randomly masking local regions.
In the task of single-view 3D reconstruction, there has already been preliminary exploration of the feasibility of semi-supervised paradigms. The study in Yang et al. (2018) was the first to achieve 3D reconstruction with limited annotated data, and it introduced additional camera poses to mitigate issues of pose invariance and viewpoint consistency. Subsequently, Semi-Supervised Soft Rasterizer (Laradji et al., 2021) adopted a Siamese network structure and incorporated image silhouettes as part of the unsupervised loss, thereby improving reconstruction performance. SSP3D (Xing et al., 2022) proposed a semi-supervised 3D reconstruction framework that relies solely on single-view images. By introducing explicit shape priors, a shape discriminator, and a prototype shape prior module, it achieved voxel-based 3D generation.
Although the aforementioned methods have validated, to varying degrees, the potential of SSL for 3D reconstruction, most existing research has focused on voxel or mesh representations, while semi-supervised 3D reconstruction based on point cloud representations is still in its early exploratory stage. Given the advantages of point cloud methods in memory efficiency and geometric detail representation, this direction holds significant research value and application potential.
Method
As shown in Figure 1, the SS3D framework consists of two training phases: A pretraining phase and a semi-supervised teacher–student phase. In the first phase, the model is trained on a labeled dataset
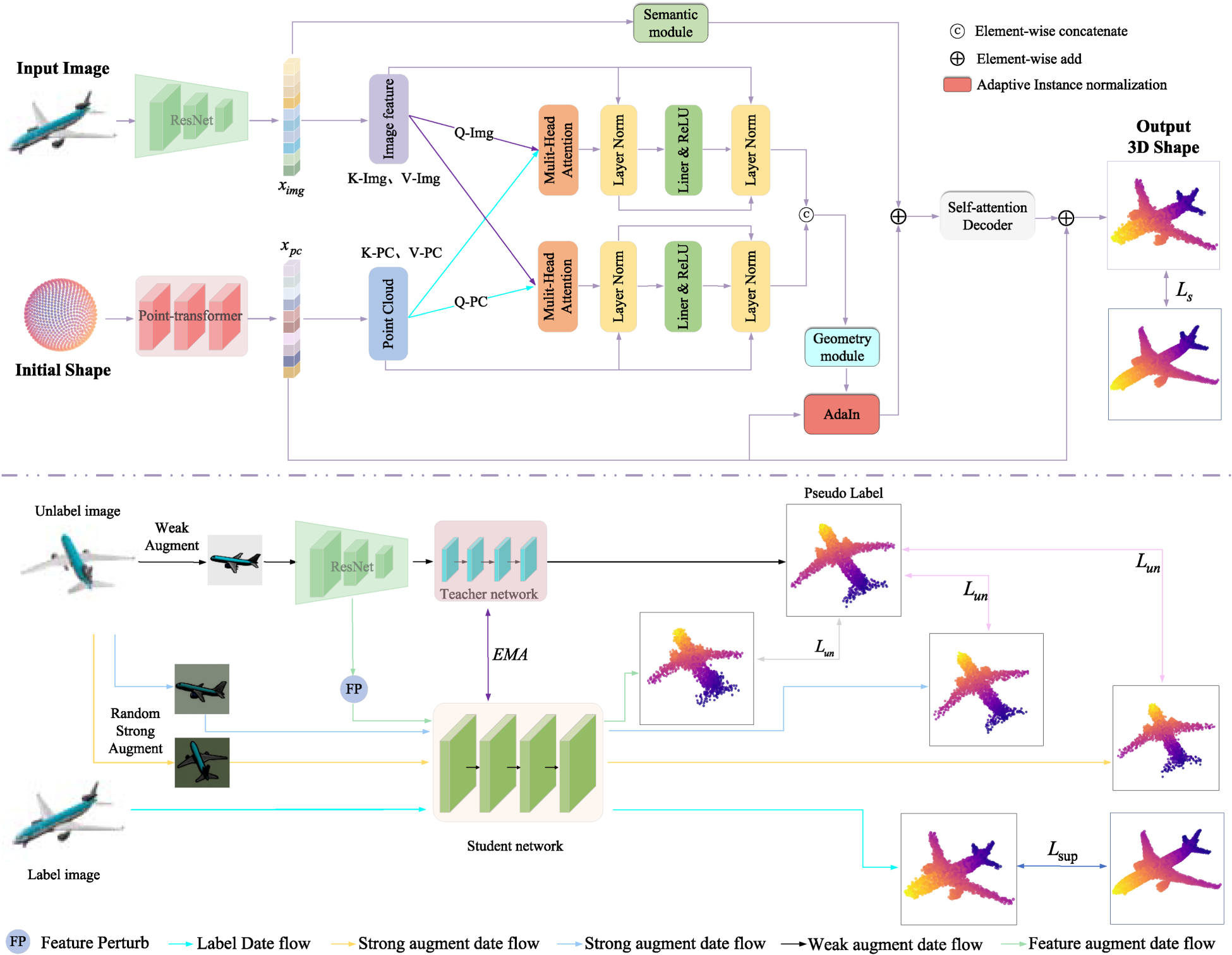
Illustration of the SS3D framework. It consists of two phases: In the pretraining phase, a spherical shell point cloud with 1024 points is used to train the network, achieving effective alignment between images and point clouds and obtaining an initialized model. In the semi-supervised teacher–student phase, the teacher and student networks share the same architecture as the model in the pretraining stage. The teacher network generates pseudo-labels based on weak augmentation, while the student network learns through strong augmentation and feature perturbation. The teacher weights are continuously updated through EMA, thereby improving the accuracy and robustness of 3D reconstruction.
Next, we first introduce the pretraining phase (Section Pretraining Phase), then explain the semi-supervised teacher–student framework (Section semi-supervised teacher–student framework), and finally describe the design and optimization of the loss functions (Section Loss Function Design and Optimization).
As shown in Figure 1, SS3D is composed of four main modules: an image encoder, an attribute flow encoder, a shape-matching transformer, and a self-attention decoder. Recent studies have shown that hybrid deep learning models that combine structures such as CNNs and Transformers exhibit strong feature representation capability and robustness in complex tasks. For example, Kumar et al. (2025) employed a hybrid model integrating ResNet-50 and a Transformer in an internet of things security scenario, demonstrating the effectiveness of this type of architecture for feature extraction. Therefore, we use a pretrained ResNet-50 in the image encoder to extract visual features, adopt PointTransform in the attribute-stream encoder to extract point cloud features, and establish cross-modal associations between image features and point cloud features. Building on this, the shape-matching transformer further integrates geometric and semantic information, progressively deforming and refining the initial point cloud to obtain a geometric representation that better aligns with the target structure. Finally, the self-attention decoder models global dependencies on top of the fused features, thereby generating high-precision 3D point cloud outputs.
Since single-view input lacks depth information, 3D reconstruction often suffers from the problem of different 3D structures sharing the same 2D projection. To alleviate this issue, it is common to introduce an initial point cloud prior to feature extraction. Afifi et al. (2020) proposed using a uniformly distributed spherical point cloud as the initial shape to improve the accuracy of point cloud generation. Therefore, we employ a spherical shell point cloud consisting of 1024 points as the initial input to more comprehensively cover the object surface, thereby enhancing the capacity to capture geometric features. The initial point cloud is composed of uniformly sampled points on a spherical shell; it contains neither the geometric nor semantic information of a specific object, but serves as a structurally neutral geometric initialization. A self-attention-based point cloud encoding module is directly applied to model inter-point geometric relationships, so that, guided by image features, geometric deformation and structural refinement are progressively carried out.
Attribute Flow Encoder. The attribute flow encoder is designed to achieve cross-modal fusion between image features and point cloud features, providing both geometric and semantic support for subsequent shape matching and decoding. The attribute-stream encoder receives image features from the image encoder, as well as geometric features obtained by feeding the initial point cloud into a PointTransform-based encoder. While the image features contain rich appearance and semantic information, the point cloud features provide geometric priors of the object, and their combination establishes the foundation for cross-modal fusion. Through a heterogeneous feature attention mechanism, correspondences between image and point cloud features are established, enabling modality alignment and information interaction. Subsequently, the Geometry Module extracts geometric information from the fused features and generates shape adjustment parameters
Heterogeneous Feature Attention. Cross-modal interactions are employed to establish associations between images and point clouds, thereby improving the quality of the reconstructed 3D models. Unlike traditional cross-attention mechanisms with one-way feature input, heterogeneous feature attention adopts a symmetric dual-branch design to realize bidirectional representations of point cloud features and image features. The query



Subsequently, the dot product between the queries (


Equations (1)–(5) describe the process of the heterogeneous feature attention mechanism. To further enhance the expressive power of the model, we adopt a multi-head attention mechanism (set to 8 heads), where each attention head independently learns relationships in different subspaces. The concatenated results are then fused through a linear mapping, yielding richer cross-modal representations. Finally, the features of the current modality are updated using the information propagated from the other modality, as shown in equations (6) and (7).


After the heterogeneous feature attention, we introduce a feedforward network composed of a single linear layer and a ReLU activation function to enhance the nonlinear expressive capability of the features. By applying residual connections and normalization, the cross-modally updated features are combined with the feedforward outputs, thereby producing more precise and stable representations, as shown in equations (8) and (9).
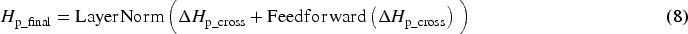
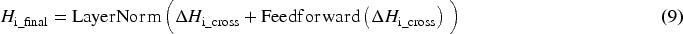
In the Geometry Module, the features

In the Semantic Module, the extracted image features are first compressed into an attribute encoding


In this equation,
Shape-Matching Transformer. A spherical-shell point cloud containing 1024 points is used as the input, and the corresponding point features are output to guide the progressive deformation and reconstruction of the point cloud. We introduce Point-transformer as the core unit of the shape-matching transformer. Point-transformer can dynamically model relationships between points within local neighborhoods, thereby enhancing the flexibility and accuracy of point cloud feature representations. For clarity, we denote the point features output by Point-transformer as
The shape-matching transformer takes the geometric features

Subsequently, the geometrically modulated point features are fused with the semantic feature

Self-Attention Decoder. Traditional MLP decoders for point clouds usually rely on local feature mappings, making it difficult to effectively model global contextual relationships, which in turn limits their performance on complex geometric structures. Moreover, due to the absence of a feature selection mechanism, MLPs often lack adaptability across different semantic regions, leading to insufficient detail recovery. In contrast, the self-attention mechanism can compute global correlations between points and adaptively adjust the distribution of feature weights, thereby capturing long-range dependencies and strengthening the modeling of critical geometric and semantic regions. Although self-attention was initially overlooked in early studies due to its computational complexity and risk of overfitting, its advantages have since been validated with the advent of more efficient attention variants and carefully designed architectures. Therefore, we introduce self-attention modules into the decoder as a replacement for the traditional MLP structure, enabling global feature aggregation and context-aware point cloud decoding, ultimately producing more refined and consistent 3D reconstruction results.
Specifically, we adopt a multi-head self-attention mechanism to capture global context and inter-feature relationships, combined with layer normalization to enhance the generalization ability of the model. In this module, the point cloud feature vector

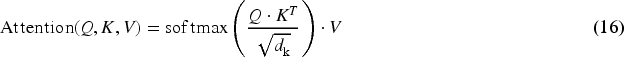
In this equation,

In the second stage, based on the pretrained teacher model, the student model performs SSL under the teacher’s guidance. As shown in Figure 2, we introduce perturbations simultaneously at both the image level and the feature level to expand the perturbation space and enhance the granularity of the supervisory signals. Compared with applying perturbations only at the image level, this approach provides the student model with richer and more effective supervisory signals, helping it better understand and learn complex patterns within the data.
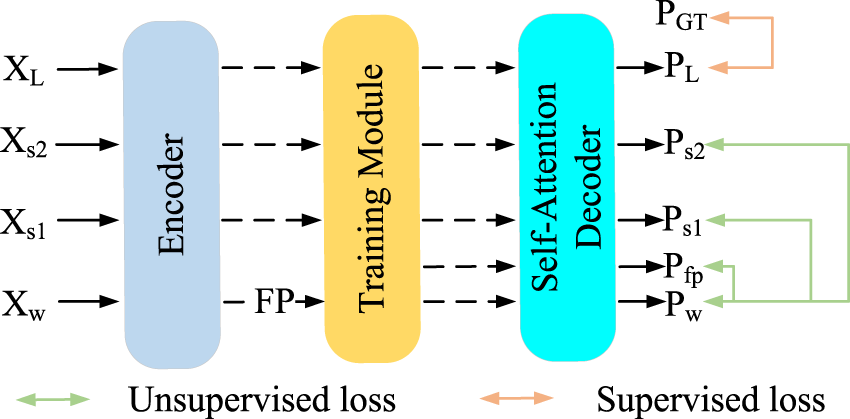
Feature perturbation method. “FP” denotes feature perturbation, the green line represents the unsupervised loss, and the orange line represents the supervised loss.
In the semi-supervised teacher–student framework, after the teacher model converges during the pretraining phase, it generates pseudo-labels for unlabeled samples to supervise the training of the student model. The student model is initialized with the weights of the teacher model and is designed with three training branches, using the unlabeled dataset

At the same time, the input image undergoes two different strong data augmentations, producing strongly perturbed images

The training process is divided into two phases. First, in the pretraining phase, we train the teacher model on the labeled dataset
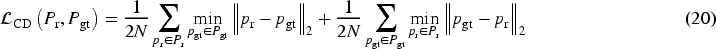
where,
To ensure the orthogonality of

The total training loss in the pretraining phase is expressed as:

In the second phase, the student model is optimized using supervised and unsupervised losses. The teacher model does not participate in backpropagation or gradient updates; however, its parameters are iteratively updated via an EMA of the student model parameters to generate more stable pseudo-label supervision signals. For supervised data, we use the loss function shown in Equation (20). For unlabeled data, the following loss function is used:
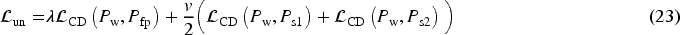
where,
Finally, the loss function of the student model is defined as follows:

Through joint training with both supervised and unsupervised losses, the model can effectively leverage labeled and unlabeled data, thereby significantly improving the accuracy of 3D model reconstruction.
Datasets and Experimental Setup
Datasets. In our experiments, we use the ShapeNet (Chang et al., 2015) and Pix3D (Sun et al., 2018) datasets. For ShapeNet, we select nine categories and randomly split the training set into labeled and unlabeled data according to a 20% labeling ratio. Pix3D is a publicly available dataset that provides precise alignment between real images and 3D models. From Pix3D, we select eight categories and randomly choose 10% of the training set as labeled data, with the remaining samples treated as unlabeled data. Model performance is evaluated using the L1-CD defined in equation (20).
The experimental environment is configured as follows: on the software side, we use Python 3.7.9, the PyTorch deep learning framework, and CUDA 11.7; the operating system is Ubuntu 20.04. The hardware setup includes an Intel(R) Gold 6134 CPU @ 3.20GHz
Comparative Experiments
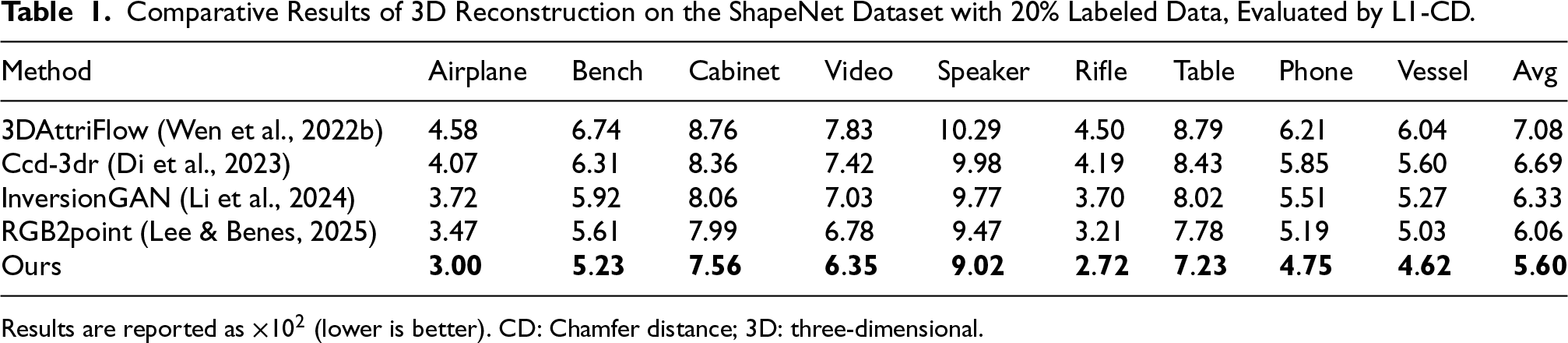
We evaluate reconstruction accuracy on the ShapeNet dataset using the L1-CD metric. To ensure both relevance and fairness in evaluation, we make appropriate adjustments to the comparison methods so that they better align with the task requirements of this study. The comparison methods include 3DAttriFlow (Wen et al., 2022b), Ccd-3dr (Di et al., 2023), InversionGAN (Li et al., 2024), and RGB2point (Lee & Benes, 2025).
As shown in Table 1, our method outperforms existing mainstream approaches on the L1-CD metric, demonstrating higher 3D reconstruction accuracy. Our method achieves the L1-CD value of 5.60
Comparative Results of 3D Reconstruction on the ShapeNet Dataset with 20% Labeled Data, Evaluated by L1-CD.
Comparative Results of 3D Reconstruction on the ShapeNet Dataset with 20% Labeled Data, Evaluated by L1-CD.
Results are reported as
A further analysis of the results across different categories shows that SS3D achieves lower errors in every category, with particularly noticeable improvements in categories with complex structures (such as Airplane and Vessel). This further demonstrates that SS3D exhibits stronger generalization ability and accuracy in fine-grained reconstruction across different categories.
Qualitative comparison on ShapeNet. As shown in Figure 3, we present a visual comparison of our method with four approaches: 3DAttriFlow (Wen et al., 2022b), Ccd-3dr (Di et al., 2023), InversionGAN (Li et al., 2024), and RGB2point (Lee & Benes, 2025) on the ShapeNet dataset. In terms of generating high-quality 3D models from a single image, our method is able to more finely restore object shapes and preserve richer geometric details compared with these four methods, thereby significantly improving both the visual quality and the accuracy of the reconstruction results.

Visualization results on the ShapeNet dataset with 20% labeled data.
The SSL strategy adopted in SS3D shows significant advantages in effectively leveraging unlabeled data. Compared with fully supervised methods that rely entirely on labeled data, the semi-supervised approach better captures the latent structure and distribution characteristics of the data, thereby improving the model’s generalization ability and robustness. At the same time, we introduce a heterogeneous feature attention fusion mechanism, which effectively alleviates the modality mismatch between images and point clouds, further enhancing the model’s geometric representation ability and stability.
As shown in Table 2, we evaluate the 3D reconstruction performance of our model on the ShapeNet dataset using 1%, 10%, and 20% of labeled data. The results indicate a consistent downward trend in L1-CD as the proportion of labeled data increases. The lowest value of 5.60
Comparative Results of 3D Reconstruction on the ShapeNet Dataset under Different Proportions of Labeled Data, Evaluated by L1-CD.
Results are reported as
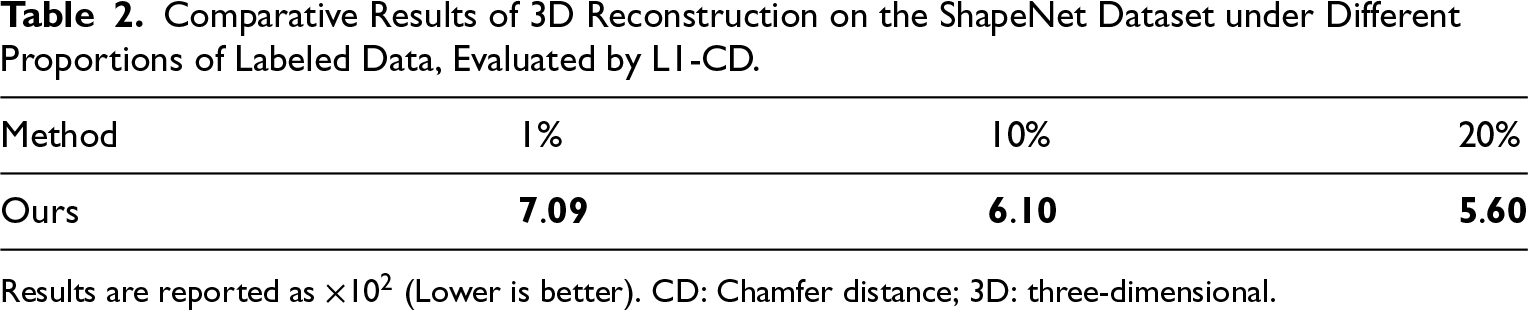
As shown in Figure 4, we conduct a visual analysis of the reconstruction results under different proportions of labeled data. The results demonstrate that as the amount of labeled data increases, the point clouds generated by the model gradually exhibit more complete and detailed geometric structures. This observation is consistent with the quantitative results in Table 2, where the L1-CD distance continuously decreases as the labeling ratio increases.

Visualization results on the ShapeNet dataset under different proportions of labeled data.
Specifically, when the labeling ratio is only 1%, the model can roughly recover the overall contour of the input image, but the point cloud is relatively sparse, and local details exhibit omissions and distortions. For example, the backrest of a bench appears uneven, the surface structure of a cabinet is incomplete, the shape of table legs is blurred, and the edges of airplane wings are irregular. When the labeling ratio is increased to 10%, the density and geometric integrity of the point cloud improve significantly: the corners of the cabinet become clearer, the connections between table legs are more reasonable, and the wing structures of airplanes become more stable. With a further increase to 20% labeled data, the reconstruction results align closely with the ground truth in both geometric structure and point cloud distribution. For instance, the bench backrest is straighter, the cabinet edges are well defined, the connections between tabletops and legs are precise, and the overall airplane structure is complete, showing strong detail recovery and global consistency. Finally, although the performance improvement for certain categories is relatively small, this also reflects the robustness and consistency of SS3D in handling different types of 3D shapes. In contrast, some supervised methods may perform well on specific categories but poorly on others, leading to greater fluctuations in overall performance.
As shown in Figure 5, we present visualization results of the ShapeNet dataset from different viewing angles. The generated 3D models exhibit high completeness in overall geometric structures, with the main contours of objects clearly represented across all perspectives. For example, the wings, fuselage, and tail fins of airplanes are consistently reconstructed from different viewpoints; furniture objects such as tables and bookshelves not only preserve reasonable overall frameworks but also achieve good restoration of local details; the outlines of vessels and phones are also clear and complete, demonstrating the model’s adaptability to diverse categories. In addition, the point clouds are uniformly distributed overall, without noticeable collapse or large voids. In summary, these results indicate that our method captures macro-level geometric shapes while maintaining strong cross-view consistency and robustness.

Visualization results of three-dimensional (3D) reconstruction on the ShapeNet dataset from different viewpoints.
The quantitative comparison results on Pix3D are shown in Table 3. We compare our method with Ccd-3dr (Di et al., 2023), InversionGAN (Li et al., 2024), and RGB2point (Lee & Benes, 2025) on the Pix3D dataset, using the L1-CD metric as the evaluation criterion.
Comparative Results of 3D Reconstruction on the Pix3D Dataset with 10% Labeled Data, Evaluated by L1-CD.

Results are reported as
As shown in Table 3, our method outperforms existing mainstream approaches on the Pix3D dataset in terms of the L1-CD metric, achieving higher 3D reconstruction accuracy. Specifically, our method attains an L1-CD value of 6.29
Qualitative comparison on Pix3D. As shown in Figure 6, we present visual comparison results between our method and Ccd-3dr (Di et al., 2023), InversionGAN (Li et al., 2024), and RGB2point (Lee & Benes, 2025) on the Pix3D dataset.

Visualization results on the Pix3D dataset with 10% labeled data.
From the Figure 6, it can be observed that although Ccd-3dr and InversionGAN are able to generate the rough shapes of objects, their point cloud distributions are noticeably sparse, with severe losses of local details, such as incomplete table legs, blurred sofa armrests, and indistinct geometric boundaries. RGB2point shows some improvement in maintaining overall shapes, but it still suffers from fractures and collapses in local structure reconstruction, particularly in slender parts such as table legs. In contrast, our method consistently demonstrates clearer geometric structures and more uniform point cloud distributions across reconstruction results of different furniture categories. It effectively restores both object contours and local details, with overall results highly consistent with the ground truth.
In summary, SS3D outperforms existing methods on both the ShapeNet and Pix3D datasets. Even under conditions with limited labeled data, the model achieves lower L1-CD through cross-modal fusion enabled by the heterogeneous feature attention mechanism and the semi-supervised teacher–student framework. Moreover, it demonstrates higher accuracy in maintaining global structures and restoring local details. The experimental results show that SS3D possesses excellent robustness and generalization ability across different categories and data scenarios, fully validating its effectiveness and advantages in single-view 3D reconstruction tasks.
In this section, we verify the effectiveness of the heterogeneous feature attention mechanism, the semi-supervised teacher–student framework, and the self-attention decoder.
Impact of the heterogeneous feature attention mechanism. To evaluate the effectiveness of the heterogeneous feature attention mechanism in 3D model generation, we design a comparative experiment with an experimental group (using the mechanism) and a control group (without the mechanism). Both models are trained under identical conditions, and L1-CD is used as the evaluation metric for comparison.
As shown in Table 4, when the heterogeneous feature attention mechanism is not introduced, the average L1-CD values on the ShapeNet and Pix3D datasets are 6.20 and 6.88, respectively. After incorporating the heterogeneous feature attention mechanism, the L1-CD values decrease to 5.60 and 6.29, respectively, resulting in significant improvements in reconstruction accuracy. This indicates that the heterogeneous feature attention mechanism enables more effective fusion of features from different modalities, thereby enhancing the precision of 3D reconstruction.
Comparative Results of 3D Reconstruction on the ShapeNet Dataset Under Different Proportions of Labeled Data, Evaluated by L1-CD.

Comparative Results of 3D Reconstruction on the ShapeNet Dataset Under Different Proportions of Labeled Data, Evaluated by L1-CD.
Results are reported as
As shown in Figure 7, we compare visualization results on the ShapeNet dataset under conditions with and without the heterogeneous feature attention mechanism. From the figure, it is evident that incorporating the heterogeneous feature attention mechanism allows the model to achieve superior performance in both overall structural reconstruction and detail restoration.
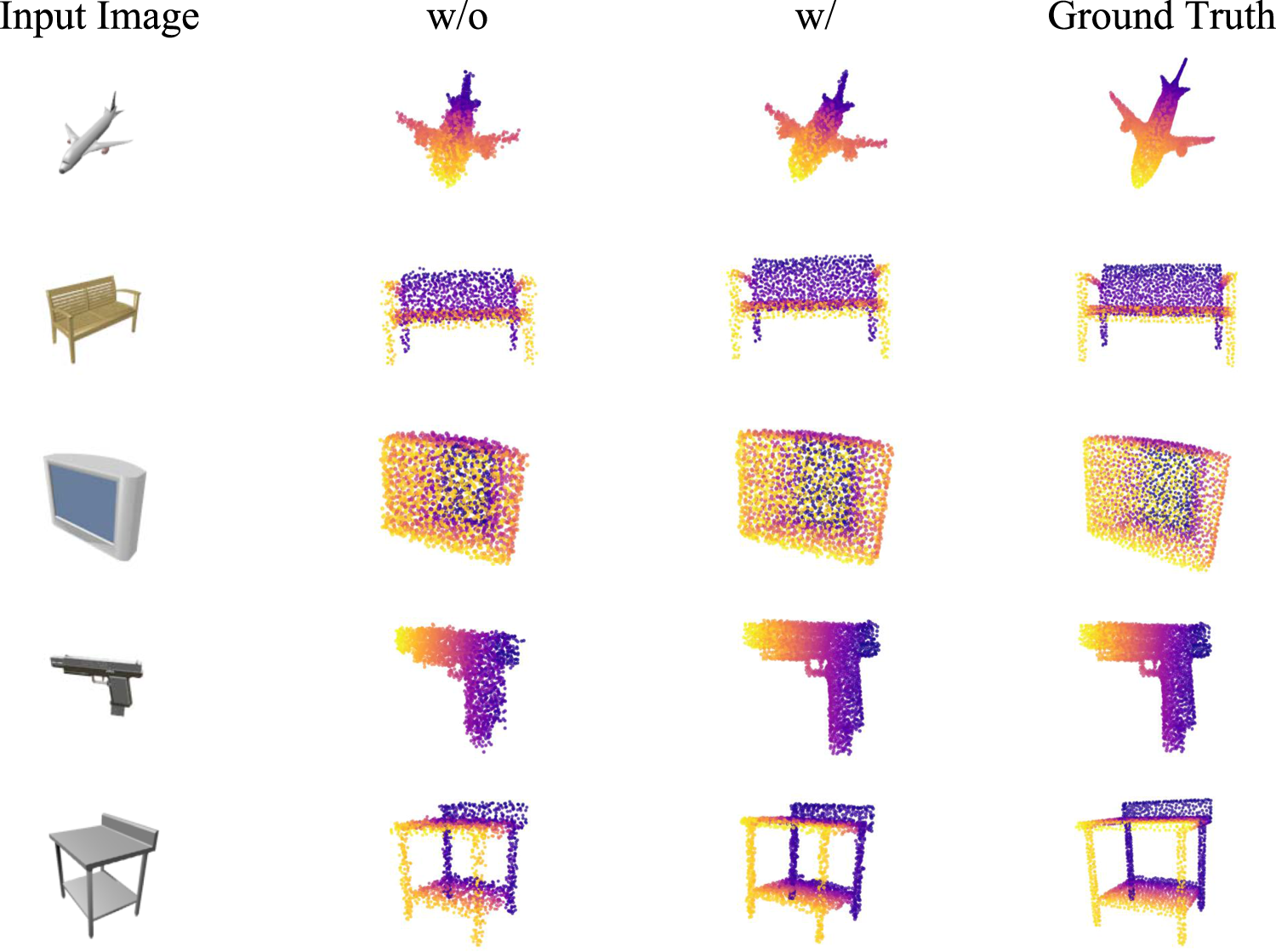
Visualization results on the ShapeNet dataset with and without the heterogeneous feature attention mechanism.
Specifically, for complex geometric structures such as airplanes and chairs, the model without the heterogeneous feature attention mechanism produces point clouds with blurred edges and local missing regions, such as sparse and unclear contours around the wings and chair backs. In contrast, after introducing the heterogeneous feature attention mechanism, the point cloud distribution becomes more uniform, geometric boundaries are clearer, and the overall shape remains highly consistent with the ground truth. For regular objects such as videos, the model with the heterogeneous feature attention mechanism more accurately restores planar structures and straight edges, better preserving geometric regularity and consistency compared with the model without the mechanism. For categories with rich local details, such as pistols and tables, the mechanism likewise enhances the detail-level performance of point clouds, resulting in clearer and more accurate geometric structures.
In summary, the results in Table 4 and Figure 7 corroborate each other. The heterogeneous feature attention mechanism effectively enhances the model’s feature fusion capability, achieving complementary and reinforced information exchange, thereby improving geometric completeness and detail accuracy in 3D reconstruction. This mechanism not only alleviates the limitations caused by insufficient single-modal feature representation but also strengthens the model’s reconstruction ability for complex structures and fine local details.
Impact of the semi-supervised teacher–student framework. To verify the effectiveness of the semi-supervised teacher–student framework in 3D model reconstruction, we design a comparative experiment. We set up an experimental group using the semi-supervised teacher–student framework and a control group without it. The experimental group is trained with 20% of the ShapeNet dataset and 10% of the Pix3D dataset, while the control group does not employ the teacher–student framework. Under otherwise identical training conditions, both models are trained and evaluated using L1-CD as the metric to measure the accuracy of the generated results.
As shown in Table 5, on the ShapeNet dataset, the control group without the semi-supervised teacher–student framework achieves an average L1-CD value of 5.77. After introducing the semi-supervised teacher–student framework, the value decreases to 5.60, representing an error reduction of about 2.95%. On the Pix3D dataset, the L1-CD value decreases from 6.94 to 6.29, corresponding to an error reduction of approximately 9.36%. These results demonstrate the effectiveness of the semi-supervised teacher–student framework in improving 3D reconstruction quality.
Comparative Results of Single-view 3D Reconstruction on the ShapeNet and Pix3D Datasets with and without the Semi-supervised Teacher–student Framework, Evaluated by L1-CD.

Results are reported as
As shown in Figure 8, we compare visualization results on the ShapeNet dataset under conditions with and without the semi-supervised teacher–student framework. From the overall effect, it is evident that after introducing the teacher–student framework, the generated point clouds show significant improvements in both global structural consistency and local geometric detail.
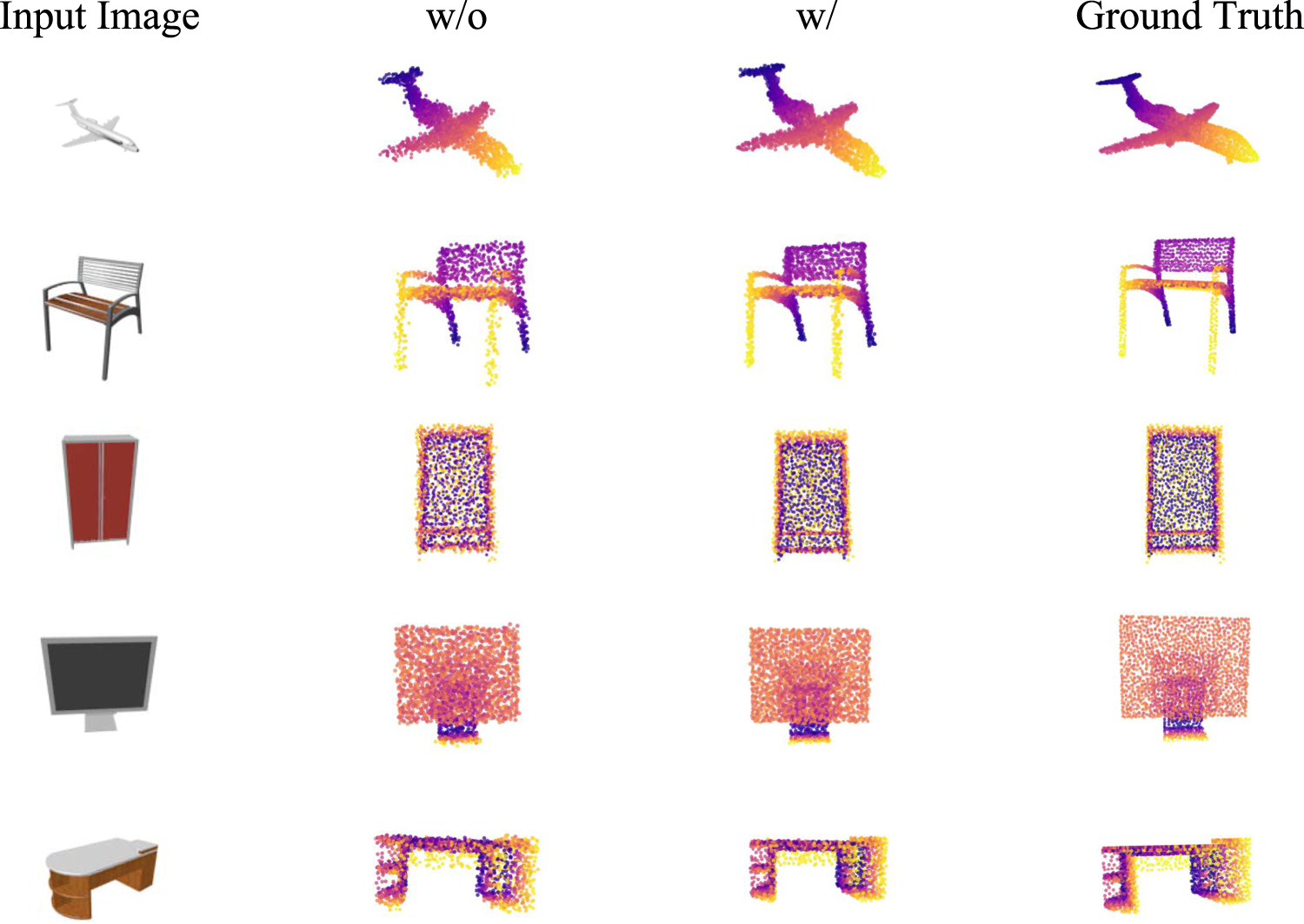
Visualization results on the ShapeNet dataset with and without the semi-supervised teacher–student framework.
Specifically, for complex categories such as airplanes and chairs, the model without the semi-supervised teacher–student framework produces point clouds with blurred geometric structures and incomplete local details, such as sparse distributions and unclear edges around airplane wings, or incomplete backrest structures in chairs. In contrast, after introducing the semi-supervised teacher–student framework, the 3D model point clouds become more uniformly distributed, with clearer edge contours, and the overall shape is highly consistent with the ground truth. For objects such as cabinets and videos, the reconstruction results without the framework show sparse and scattered point clouds, whereas incorporating the teacher–student framework produces outputs with better planar structures and straighter edges. For objects like tables, which include curved surfaces and numerous details, the teacher–student framework also improves the capture of corners and curved shapes, making both the overall structure and local details more closely aligned with the real point clouds.
The experiments demonstrate that the semi-supervised teacher–student framework can fully leverage unlabeled data. By generating pseudo-labels for unlabeled samples through the teacher network and guiding the student network under conditions of strong augmentation and feature perturbation, the model is able to reconstruct 3D models that are highly consistent with the ground-truth point clouds, even under limited labeled data conditions.
Impact of decoder type. To verify the effectiveness of the self-attention decoder, we compare the performance of a MLP decoder and a self-attention decoder on the ShapeNet and Pix3D datasets.
As shown in Table 6, on the ShapeNet dataset, the average L1-CD value using the MLP decoder is 5.92, while with the self-attention decoder it decreases to 5.60, representing an error reduction of about 5.41%. On the Pix3D dataset, the average L1-CD value with the MLP decoder is 6.55, whereas with the self-attention decoder it drops to 6.29, a reduction of approximately 3.97%. These results indicate that the self-attention decoder outperforms the MLP decoder on both datasets, capturing geometric details in complex scenes more effectively. The MLP decoder relies on layer-by-layer nonlinear mappings, with its expressive power primarily reflected in the combination of local features, making it difficult to sufficiently model the global dependencies among different points in 3D shapes. In contrast, the self-attention decoder dynamically models long-range dependencies in point clouds through the attention mechanism, enabling the network to more accurately reconstruct complex 3D structures and thereby achieve consistent improvements in overall reconstruction quality.
Comparative Results of Single-view 3D Object Reconstruction on the ShapeNet and Pix3D Datasets using Different Decoders, Evaluated by L1-CD.

Results are reported as
As shown in Figure 9, when using the MLP decoder, the generated results show clear deficiencies in detail representation. For example, the point cloud distribution in the wing regions of airplanes is sparse, with incomplete edges; the outer contours of videos appear relatively rough; and models of other categories generally exhibit problems such as missing local details and blurred boundaries. In contrast, the results produced with the self-attention decoder are closer to the ground truth in both overall structure restoration and local detail performance. They preserve geometric boundaries more clearly and better capture the semantic consistency of objects. This demonstrates that the self-attention decoder can effectively model the global dependencies of point clouds, thereby improving the structural completeness and detail accuracy of 3D reconstruction.
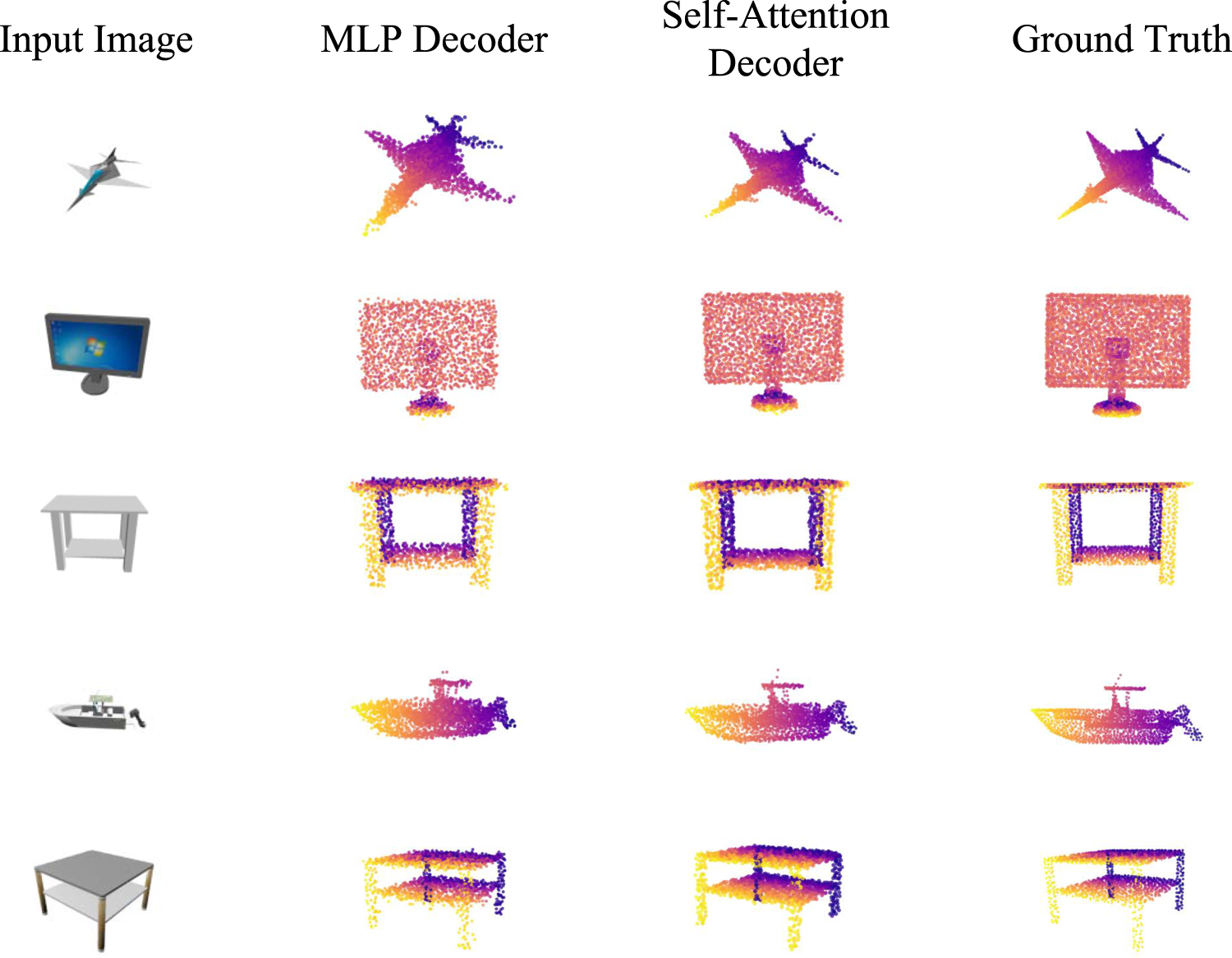
Visualization results on the ShapeNet dataset using different decoders.
The experimental results show that the decoder architecture has a critical impact on the performance of 3D reconstruction. Compared with the traditional MLP decoder, the self-attention decoder achieves superior performance in 3D model reconstruction tasks. This finding provides a valuable reference for the design of decoders in future 3D reconstruction models.
As shown in Table 7, we compare 3DAttriFlow, Ccd-3d, RGB2Point, and our proposed SS3D in terms of parameter count, inference time, GPU memory footprint, and computational cost (floating-point operation (FLOPs)) under a batch size of 1. The results indicate that, compared with 3DAttriFlow, our method uses more parameters but achieves shorter inference time and lower computational complexity, demonstrating higher generation efficiency. Compared with Ccd-3dr and RGB2Point, our method shows clear advantages in parameter count, inference speed, memory usage, and FLOPs. These findings suggest that our method attains good computational efficiency while maintaining strong modeling capability, achieving a favorable balance between performance and resource consumption.
Limitation Analysis
Although our model achieves strong performance in cross-modal feature fusion and semi-supervised 3D reconstruction, certain limitations remain. As shown in Figure 10, in complex geometric regions such as airplane tail fins and vessel hull edges, the reconstruction results still exhibit blurred details compared with ground-truth point clouds. This indicates that the model has slight shortcomings in capturing fine details and restoring edge structures. In addition, as shown in Table 7, compared with 3DAttriFlow, SS3D increases the number of parameters by 44.2% and the GPU memory footprint by 5.2%, which imposes certain limitations on its deployment in resource-constrained or real-time application scenarios.
Model Efficiency Comparison: the Number of Parameters, Inference time, GPU Memory usage, and Floating-Point Operations (FLOPs).

Model Efficiency Comparison: the Number of Parameters, Inference time, GPU Memory usage, and Floating-Point Operations (FLOPs).
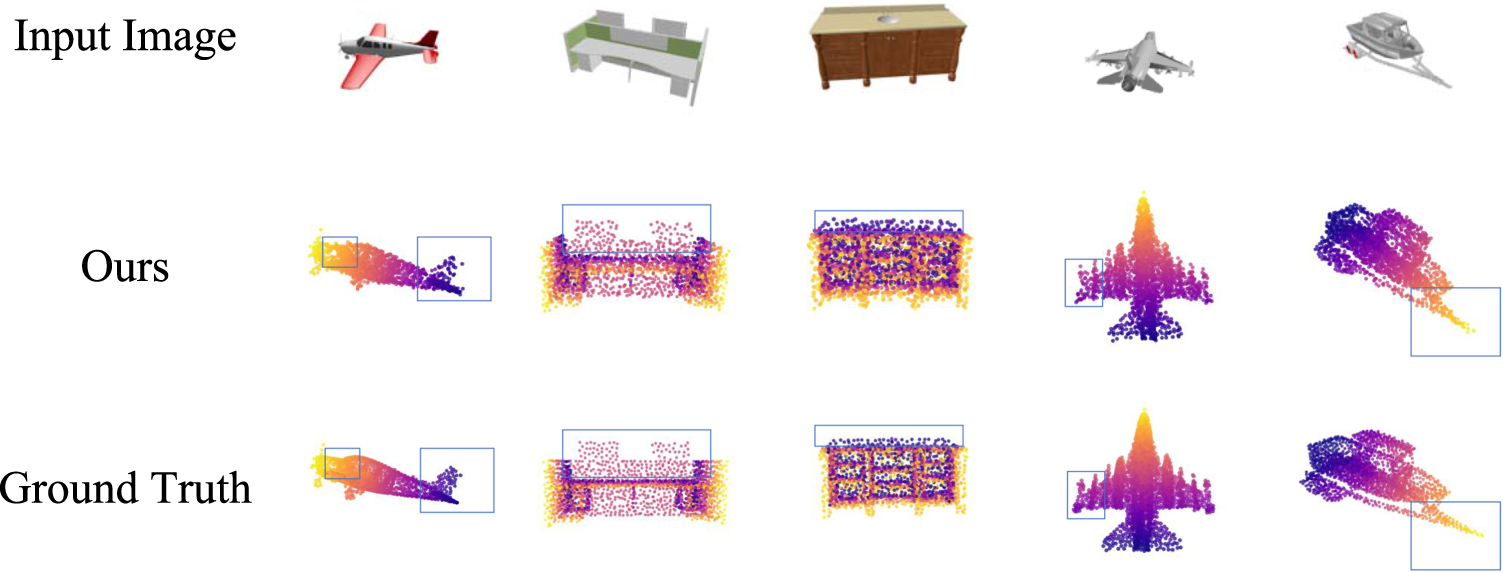
Visualization of limitation analysis results on the ShapeNet dataset.
Therefore, in future work, we plan to explore how to further improve the reconstruction accuracy of the model in complex components and edge regions, thereby enhancing the overall reconstruction quality. We also plan to design a more lightweight cross-modal fusion structure to improve the efficiency and scalability of the model.
We propose a single-view 3D reconstruction method that integrates SSL with a heterogeneous feature attention mechanism, aiming to enhance the model’s reconstruction ability under conditions of limited image information and background interference. Specifically, the heterogeneous feature attention mechanism enables cross-modal fusion of image and point cloud features, strengthening the complementarity of multi-source information. The semantic module and geometric module respectively reinforce global semantic consistency and local geometric structure representation, while AdaIN aligns multi-scale features. Finally, the self-attention decoder effectively captures long-range dependencies, generating high-quality 3D point clouds. Meanwhile, we introduce a semi-supervised teacher–student framework in which the teacher network generates pseudo-labels through weak augmentation, and the student network is optimized under strong augmentation and feature perturbation. An EMA mechanism is employed to steadily update the teacher network weights, improving the reliability of pseudo-labels and further enhancing the stability of overall training. Experimental results show that our proposed method can generate 3D point cloud models with clear structures and rich details, significantly outperforming existing mainstream methods in performance. Overall, the framework of our study provides new insights and directions for future research on cross-modal fusion and semi-supervised 3D reconstruction.
Footnotes
Acknowledgments
This research was funded by the research on 3D Object Detection Technology Based on Narrative Representation, grant number: (No.JJKH20250525KJ).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.