
Abstract
Diffusion models have demonstrated impressive performance in text-to-image generation and image editing. However, in instruction-based image editing, they often encounter two challenges: (1) inaccurate localization of the editing targets and (2) unintended modifications in nontarget regions. These issues stem from the global processing of diffusion models due to attention mechanisms. To address these limitations, we conduct a systematic analysis of attention maps under editing instructions and design localization instructions to obtain the desired attention. We propose Instruction Attention Maps (IAM)-Edit, a localized image editing framework that explicitly decouples an editing pipeline into two stages: region localization followed by region-aware editing. Specifically, to localize the editing region, a mask is generated by clustering patches of self-attention maps and combining them with the focal points of cross-attention maps under the editing instruction. To preserve nonediting regions, we apply an attention modulation method that adjusts cross-attention weights at each denoising step based on the generated mask, enabling the denoising process to focus on the editing region. Experiments show that IAM-Edit outperforms state-of-the-art methods both qualitatively and quantitatively.
Introduction
Text-to-image diffusion models (Balaji et al., 2022; Podell et al., 2023; Ramesh et al., 2022; Rombach et al., 2022; Saharia et al., 2022; Xue et al., 2023) have made remarkable progress in image generation. Trained on large-scale visual and textual data, these models can accurately model the relationship between text and image, thereby enabling the generation of high-quality images from textual prompts. Image editing extends the capabilities of generative models by enabling direct modifications of images, thereby improving their applicability to real-world scenarios such as personalized content creation, product design, medical imaging, and virtual try-on systems. However, image editing methods based on Stable Diffusion (Rombach et al., 2022), such as Prompt-to-Prompt (P2P) (Hertz et al., 2022), require both source and target prompts, which must be structurally aligned. In contrast, InstructPix2Pix (IP2P) is a pioneering model in instruction-guided image editing (Brooks et al., 2022), which performs image editing based solely on natural language instructions, thereby simplifying the editing pipeline. Moreover, cross-attention maps in IP2P exhibit strong implicit localization capabilities (Guo & Lin, 2024; Li et al., 2024). During denoising, the key nouns in the editing instruction align spatially with their corresponding image regions via a cross-attention mechanism. This alignment enables the model to effectively encode the semantics of the instructions and conduct region-specific edits. However, when dealing with complex images containing multiple objects, diffusion models’ global processing can lead to unwanted modifications. This influences not only the target region but also other objects that are semantically or visually connected to it, as shown in Figure 1.

Recent studies have sought to enhance IP2P’s capabilities in local editing. Methods such as ZONE (Li et al., 2024) and WYS (Mirzaei et al., 2024) locate editing regions by capturing feature differences during the denoising process. However, these feature differences can be unreliable in complex scenes, leading to two characteristic limitations, as shown in Figure 2. When the feature differences are too small, the estimated region may become overly constrained, resulting in only slight changes between the original and edited images (Figure 2, WYS column). Conversely, IP2P often produces overexpanded edits due to the lack of an explicit editing region, causing unwanted modifications in nonediting regions (Figure 2, IP2P column). Importantly, even with an explicit mask (e.g., ZONE derives a mask from the difference between early and late cross-attention maps), the region-restricted editing and foreground–background composition may still fail to induce a faithful change within the target region, leading to unsuccessful results (Figure 2, ZONE column). These observations suggest that the key difficulty lies not only in obtaining a mask from denoising differences, but also in how the editing instruction guides the model during denoising—that is, how attention maps respond to the instruction to support instruction-aligned localization. Therefore, a research gap remains: existing methods lack an explicit view of how editing instructions shape attention maps during denoising, which makes it difficult to obtain an instruction-aligned editing region.

Two typical limitations in localized instruction-based editing: overly constrained regions (WYS) and overexpanded edits affecting nonediting regions (IP2P/ZONE).
Motivated by this gap, we conduct a systematic investigation of the interaction between editing instructions and the attention mechanism throughout the denoising process. We further introduce Instruction Attention Maps (IAM), which refer to all attention maps generated under editing instructions during denoising. We design localization instructions to generate specific attention maps, enabling the model to support three types of edits: change, add, and remove. In self-attention maps, pixels with similar visual features tend to aggregate, forming patches that effectively localize all instruction-referenced objects. Meanwhile, the cross-attention maps of key nouns assign high attention weights to focused points within the editing region. To compensate for the global processing of diffusion models and prevent overediting, all tokens’ cross-attention maps are constrained within the editing region based on the identified patches and focal points.
Based on the above findings, we propose IAM-Edit, a localized image editing method based on instruction attention maps, which is designed to preserve the integrity of nonediting regions while adhering to instruction semantics. In particular, IAM-Edit performs both localization and edit application by first identifying the editing region and then restricting edits to that region. Our contributions are summarized as follows: We introduce IAM, referring to the self-attention and cross-attention maps generated under editing instructions during the denoising process, and propose IAM-Edit, a training-free localized image editing method. We design an efficient mask generation method, which converts different types of instructions into localization instructions and leverages both self-attention and cross-attention maps to locate the editing region. We propose an attention modulation method that focuses token-wise cross-attention on the editing region, reducing unwanted changes in nonediting regions while preserving instruction-attention consistency. Based on extensive experiments and user studies, IAM-Edit achieves superior performance in both localization accuracy and content preservation compared to state-of-the-art methods.
Text-Guided Image Editing
Text-guided image editing methods can be classified into three categories: training-free methods (Brack et al., 2024; Cao et al., 2023; Hertz et al., 2022; Mokady et al., 2023; Patashnik et al., 2023; Tang et al., 2024; Tumanyan et al., 2023; Wang et al., 2023), fine-tuning methods (Feng et al., 2024; Gal, Alaluf, et al., 2022; Ruiz et al., 2022; Wei et al., 2023), and training-based methods (Brooks et al., 2022; Fu et al., 2024; Huang et al., 2024; Ren et al., 2024; Sheynin et al., 2024; Zhang et al., 2023). Training-free methods include P2P (Hertz et al., 2022), which perform image editing by manipulating cross-attention layers. Null-text Inversion (Mokady et al., 2023) reconstructs images by optimizing null-text embeddings, thus enabling the application of P2P to real image editing. PnP (Tumanyan et al., 2023) performs image-to-image translation by manipulating spatial features and their self-attention within the diffusion model (Rombach et al., 2022). Pix2pix-zero (Parmar et al., 2023) discovers editing directions in the text embedding space while preserving image structure through cross-attention maps. MasaCtrl (Cao et al., 2023) improves local consistency by converting self-attention into mutual self-attention. Fine-tuning methods such as Textual Inversion (Gal, Alaluf, et al., 2022) and DreamBooth (Ruiz et al., 2022) fine-tune pretrained diffusion models to associate a unique identifier with a specific subject. Training-based methods, including IP2P (Brooks et al., 2022), utilize GPT-3 (Brown et al., 2020) and Stable Diffusion (Saharia et al., 2022) to synthesize training data, thereby constructing conditional diffusion models for instruction-driven image editing. Emu Edit (Sheynin et al., 2024) enhances editing precision through task embeddings and multitask joint training. SmartEdit (Huang et al., 2024) and MGIE (Fu et al., 2024) incorporate multimodal large language models (MLLMs) to address complex image editing tasks. Compared with training-based or fine-tuning methods, training-free methods do not require updating model parameters, thereby significantly reducing deployment costs.
Localized Image Editing
Early local editing methods relied on user-provided masks (Avrahami et al., 2022; Lugmayr et al., 2022; Nichol et al., 2022; Yang et al., 2023) or the use of pretrained models (Kirillov et al., 2023) for mask prediction (Yu et al., 2023), which increases operational complexity and time costs. Current research focuses on the automatic identification and manipulation of target regions. DiffEdit (Couairon et al., 2023) and WYS (Mirzaei et al., 2024) generate masks by computing the difference between noise maps with and without text guidance. Cross-attention maps have recently shown significant value in local editing tasks. DPL (Wang et al., 2023) addresses the “attention leakage” problem by optimizing the word embeddings of nouns in the source prompt, ensuring that cross-attention maps remain focused on the target regions. ZONE (Li et al., 2024) captures the differences in cross-attention maps at the beginning and end stages of the denoising process. LEDITS++ (Brack et al., 2024) combines cross-attention maps with noise guidance vectors to generate masks. Other studies integrate cross-attention maps with intermediate features to identify editing regions. LIME utilizes semantic information from intermediate U-Net (Ronneberger et al., 2015) features and combines it with cross-attention scores to determine the editing area. LPM (Patashnik et al., 2023) clusters the self-attention map at specific timesteps and combines them with cross-attention maps to label each patch, identifying the final editing area. Compared to LPM (Patashnik et al., 2023), which clusters self-attention maps during the denoising process guided by the image caption, directly clustering self-attention maps guided by editing instructions can more effectively capture semantic information. In our method, we leverage IAM to perform localized image editing.
Instruction Attention Maps
InstructPix2Pix
For an image

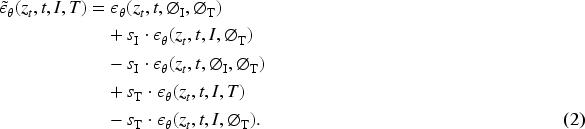
In IP2P (Brooks et al., 2022) and related models, each layer of the U-Net (Ronneberger et al., 2015) incorporates an attention mechanism. Editing instructions are encoded into text embeddings and integrated with image features through cross-attention mechanisms:
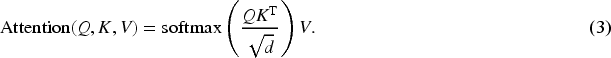

Self-attention arises when
To better capture instruction semantics, we define two types of instruction-aware attention maps derived from the above attention mechanism. The Instruction Self-Attention Map (ISAM) aggregates self-attention tensors across layers, heads, and timesteps:
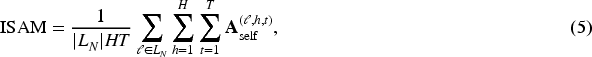
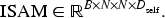
Similarly, the Instruction Cross-Attention Map (ICAM) is defined as:
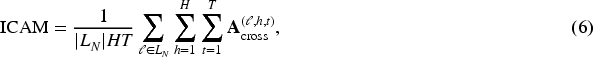
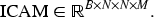
Finally, the IAM are defined as:

The text condition
IP2P employs the editing instruction as the textual condition for denoising, whereas LPM (Patashnik et al., 2023) is conditioned on the image caption. As a result, self-attention maps in IP2P evolve in accordance with the instruction semantics as the diffusion process progresses. We perform principal component analysis (PCA) dimensionality reduction to analyze self-attention maps across different timesteps. Specifically, for a self-attention representation at spatial resolution
To summarize self-attention information over time, we average self-attention maps from selected timesteps to obtain ISAM. ISAM is reshaped into per-location vectors and clustered by
In Figure 3(a), birds that are not present in the original image gradually emerge in the self-attention maps as the timestep increases (e.g., additional highlighted regions appear at

Localized image editing via instruction attention maps.
We categorize editing instructions into three types: “remove,” “change,” and “add.” The “change” instructions are further divided into the replacement of semantically related objects and the replacement of semantically unrelated objects. We then analyze two key properties of ICAM—globality and focus—to understand the impact of different instruction types.
Globality
The globality of ICAM is analyzed from both semantic and structural perspectives.
Semantically, each token in the instruction interacts with the other tokens, resulting in cross-attention maps that are inherently interconnected.
Structurally, the tokens

The top row presents the editing instruction. (a) Original image. (b) Editing result after altering the cross-attention map of
However, the globality can lead to overexpanded edits, with modifications extending beyond the editing regions. We restrict the cross-attention weights of all tokens within the editing region, ensuring that the editing remains confined to the editing region.
Focus
We argue that instruction semantics directly influence the focal points of ICAM. This effect on the attention distribution of target tokens can be summarized as follows.
Remove instructions: When an object is removed, the cross-attention maps suppress attention in the corresponding region. The attention weight of the token of this object significantly decreases, exhibiting a defocusing effect. As shown in Figure 5(a), the attention weight of the deleted object (“bee”) decays, and the model dynamically reconfigures its attention distribution. Consequently, the corresponding region is no longer attended to in the cross-attention map. Add instructions: When adding an object, the focal points of the cross-attention map for this token concentrate on the area where the target object is about to appear. As shown in Figure 5(d), the added object (“sunglasses”) exhibits a strong focus in the cross-attention map. This indicates that the attention mechanism effectively guides the model to the target region where the new object is to be generated. Change instructions: In object replacement tasks, the focal points of the cross-attention map depend on the semantic similarity between the target and original objects—including their visual features such as shape, color, or texture. When the two objects are semantically related (e.g., “replacing a dog with a cat”), the model tends to balance attention across comparable candidates. As a result, the cross-attention map fails to focus on the editing target. For example, in Figure 5(b), the cross-attention map does not properly focus on the “bee.” In Figure 5(e), attention is misdirected to the headscarf instead of the clothes. In contrast, when replacing semantically unrelated objects (e.g., “replacing an apple with a lightbulb”), the model can allocate attention without ambiguity, allowing the cross-attention map to focus on specific areas. In Figure 5(c), the cross-attention map correctly focuses on the “bee,” and in Figure 5(f), it attends to the “clothes,” aligning well with the instruction.

The visualization of the cross-attention maps of the target tokens under different semantic instructions. The original image is on the far left, with the cross-attention maps of specific tokens under different instructions on the right. (a) Corresponds to a remove instruction: “Remove the bee.” (d) Corresponds to an add instruction: “Give her sunglasses.” (b) and (e) Represent replacing objects with semantically similar objects, with (b) having the instruction “Change the bee to a bird,” and (e) having the instruction “Change her clothes to a dress.” (c) and (f) Represent replacing objects with semantically unrelated objects, with (c) having the instruction “Change the bee to granada,” and (f) having the instruction “Change her clothes to a car.”
Therefore, we convert different types of editing instructions into localization instructions by formulating them as replacements of the object with a semantically unrelated one.
Framework of IAM-Edit
Given the initial editing instruction
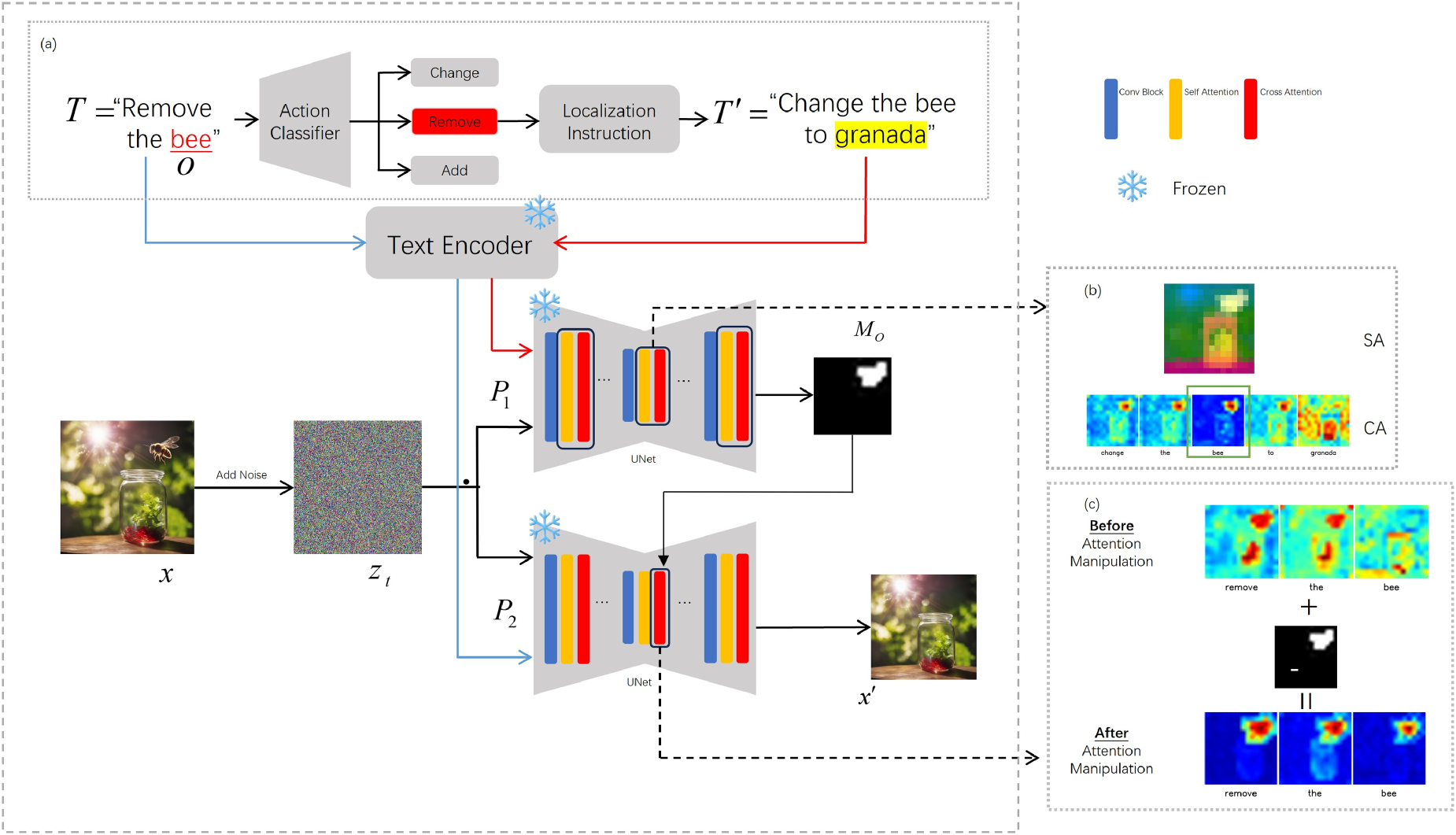
Framework of IAM-Edit. IAM-Edit is designed for instruction-based localized image editing. IAM = instruction attention maps.
We convert
At each timestep, we modulate the cross-attention maps of all tokens in

Two types of instructions can be used as localization instructions. For change instructions on the semantically unrelated object, the cross-attention map
Given
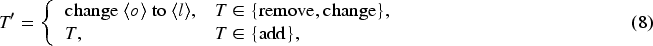
To define the selection rule for the unrelated replacement word
Candidate filtering. Construct a candidate pool Embedding and similarity. For each Unrelated replacement. Select the least similar candidate:

This yields an “unrelated”
We obtain the cross-attention map of
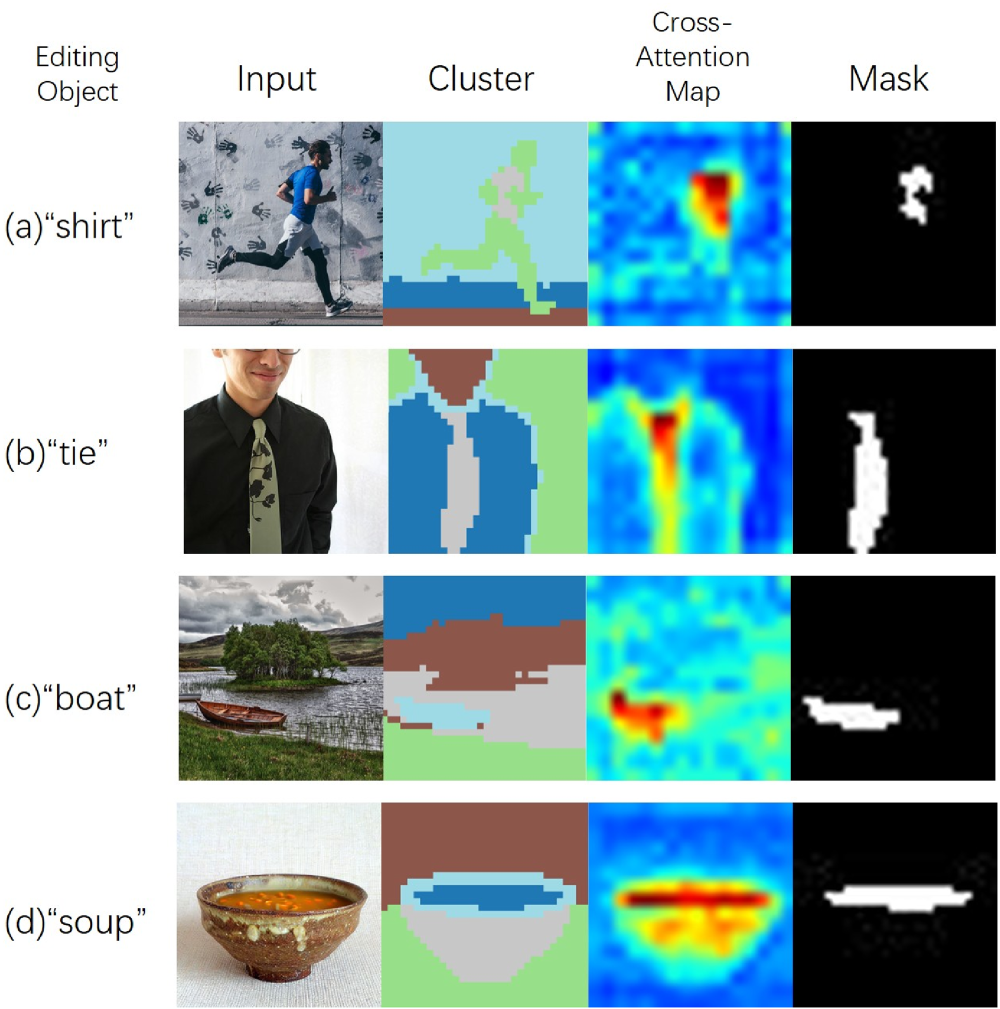
Mask generation. We perform clustering on the self-attention map and combine it with the cross-attention map of the editing object to determine the editing region. From left to right: editing object, input image, clustering result of the self-attention map, cross-attention map of the editing object, and the mask of the editing object.
We then apply




Figure 7 illustrates the effectiveness of our method in generating the mask for the editing region of
To enable localized image editing, we modulate the cross-attention maps so that the model modifies only the editing region while keeping other regions unchanged.
In each timestep of
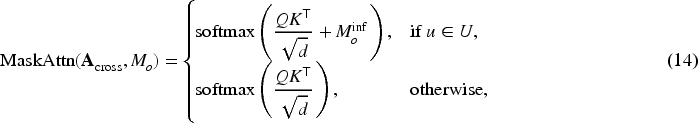
The index set of the tokens in
We define the attention modulation mask as:

Then we perform
As shown in Figure 8, after modulation, the new cross-attention map of each token concentrates on the editing region, ensuring that the editing occurs only within
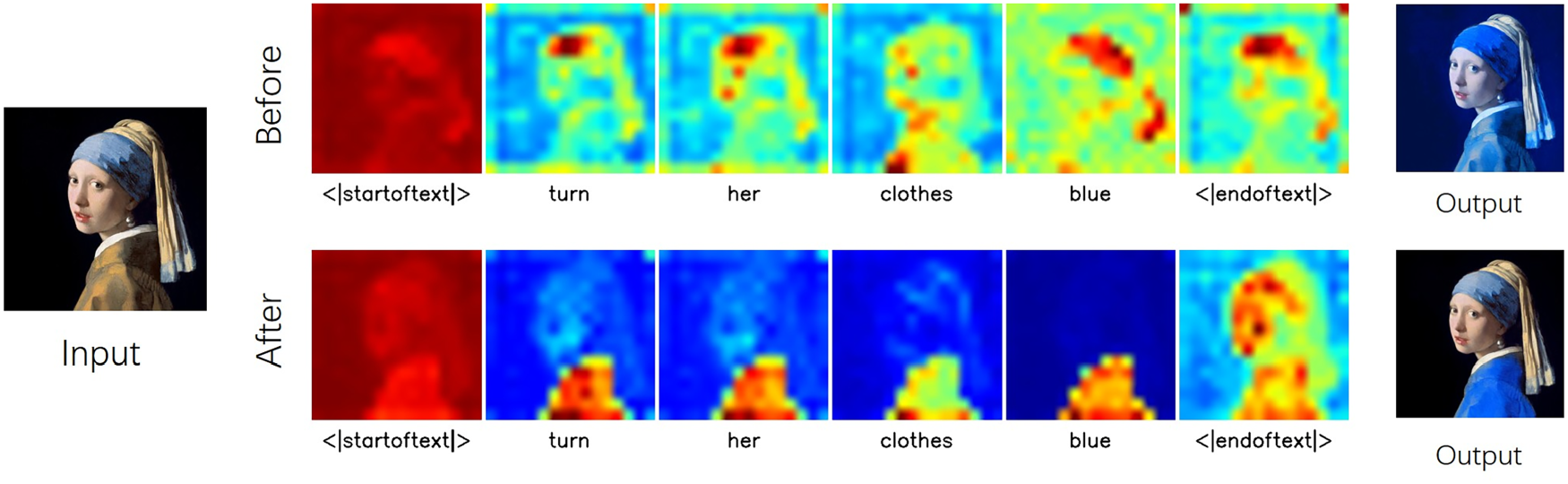
Cross-attention maps before and after the application of attention modulation. Restrict the cross-attention scores of all tokens in the instruction to the editing region, with the modulated cross-attention maps shown in the second row.
Experimental Settings
Baseline
Five image editing methods are used to evaluate IAM-Edit: LEDITS++ (Brack et al., 2024), IP2P (Brooks et al., 2022), MagicBrush (Zhang et al., 2023), WYS (Mirzaei et al., 2024), and ZONE (Li et al., 2024). LEDITS++ is an inversion-based image editing method. IP2P is the base model for instruction-based image editing methods. MagicBrush fine-tunes IP2P using a large-scale, manually annotated dataset. WYS determines the editing mask by leveraging the absolute difference between the image-and-instruction-conditioned noise and the image-only noise in IP2P.
ZONE determines the editing mask from the difference between the first and last cross-attention maps, and further incorporates SAM (Kirillov et al., 2023) to refine the mask. The resulting mask is then dilated, and its boundaries are refined using fast Fourier transform. Finally, the edited image layers are composited onto the original image at the pixel level, producing the final result.
Datasets
We evaluate IAM-Edit on three representative benchmarks: PIE-Bench (Ju et al., 2023), ZONE_testset (Li et al., 2024), and OIR-Bench (Yang et al., 2024). Table 1 summarizes the dataset composition and sample counts. PIE-Bench contains 700 instruction-driven editing samples and groups them into 10 editing tasks, covering: (1) object addition, (2) object removal, (3) object replacement, (4) attribute/color change, (5) material/texture change, (6) style transfer, (7) background change, (8) scene/layout change, (9) spatial/position change, and (10) quantity/number change. ZONE_testset contains 100 images grouped into three action types (add/change/remove). OIR-Bench consists of 308 text–image editing pairs, including 208 single-object pairs and 100 multiobject pairs. We define IDLE-Bench (Instruction Driven Local Editing Benchmark) as the union of these three datasets, resulting in 1,108 samples in total. For a unified evaluation protocol, we standardize each sample into a consistent set of fields: source image, editing instruction, and editing object; prompts and masks are used when available from the original benchmark.
Dataset Composition Used in this Paper.

Dataset Composition Used in this Paper.
Metrics
CLIP-I (Radford et al., 2021) is used to quantify the visual consistency between the original and edited images. DINOv2 image similarity (Oquab et al., 2023) is used to assess the degree of spatial structure preservation during the editing process, serving as a measure of the stability in nonedited areas. LPIPS score (Zhang et al., 2018) is used as a perceptual metric to evaluate the retention of high-level semantics and details between the edited image and the original image. CLIP-T (Gal, Patashnik, et al., 2022) is used to measure whether the image modifications before and after editing align with the editing instructions. The higher the scores of CLIP-I, DINO-I, and CLIP-T, the better the model performs in terms of semantic consistency, spatial structure preservation, and instruction execution accuracy. A lower LPIPS score indicates higher perceptual similarity.
Implementation Details
We use the IP2P (Brooks et al., 2022) implementation from the Diffusers library on the HuggingFace platform. IP2P is a latent diffusion model for instruction-based image editing, and we employ the Euler ancestral sampler with 100 denoising steps (Karras et al., 2022). During the mask-generation phase, self-attention and cross-attention maps are collected from all timesteps. Based on parameter studies, the number of clusters for the self-attention maps is set to 5. During the image-generation phase, we modulate cross-attention maps at all timesteps. The image guidance scale
Hyperparameters and Configurations
All IP2P-based methods (IP2P, MagicBrush, WYS, and ZONE) share the same IP2P backbone, the same number of denoising steps, the same guidance scales, and the same fixed random seed as in our Implementation Details.
For
Hyperparameter Selection Protocol
Unless otherwise specified, we start from the default/recommended settings of the original implementations. For the method-specific hyperparameters in IAM-Edit, we determine a unified setting based on the ablation results reported in the Supplemental materials, and keep the same setting across all benchmarks and all compared methods to ensure reproducibility and fairness. In particular, we choose
Qualitative Evaluation
Figure 9 shows qualitative examples of various editing tasks. We adopt a fixed protocol for qualitative comparison and select six representative image–instruction pairs from IDLE-Bench that cover the three operation types (“change,” “add,” and “remove”). The “change” category further includes multiregion editing, object replacement, large-area editing and style transfer. For each example, LEDITS++ follows its original paper settings since it is not IP2P-based, whereas all remaining methods share the same IP2P backbone, denoising steps, guidance scales, and random seed. Figure 9 shows, from left to right, the input image, the results of LEDITS++, IP2P, MagicBrush, WYS, ZONE, our IAM-Edit, and the editing mask predicted by IAM-Edit. The change edits in LEDITS++ are implemented by adding or removing objects, which does not fully capture the semantics of the change instructions, resulting in incomplete modifications or inaccurate localization. In Figure 9, column “LEDITS++,” rows (c), (d), (e), and (f) all show localization errors, such as no modification between the original and edited images in row (c), blurred edits in row (d), and incorrect edits in rows (e) and (f).
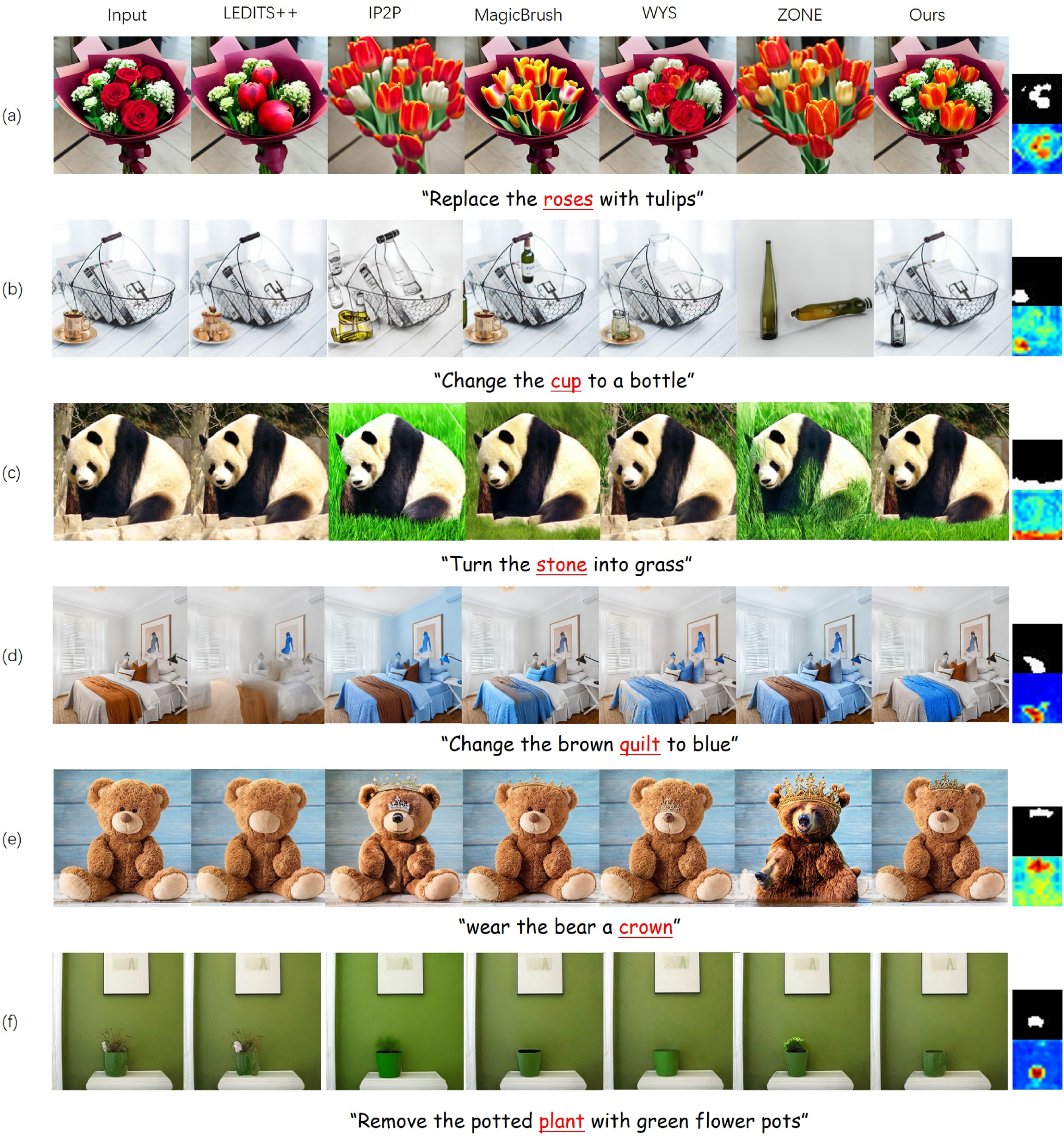
Qualitative comparison. We tested IAM-Edit on different tasks: (a) multiregion editing, (b) single-region editing, (c) large-area editing, (d) style change, (e) add, and (f) remove. The editing results of IAM-Edit are compared with the state-of-the-art methods. From left to right: input image, LEDITS++ (Brack et al., 2024), IP2P (Brooks et al., 2022), MagicBrush (Zhang et al., 2023), WYS (Mirzaei et al., 2024), ZONE (Li et al., 2024), and IAM-Edit. The last column shows the editing region mask obtained by our method and the cross-attention map of the editing object. All editing instructions are displayed below the image. IAM = instruction attention maps.
IP2P and MagicBrush often produce to overexpanded edits, even though they can localize the editing area based on the instructions. In Figure 9, columns “IP2P” and “MagicBrush,” row (b) shows the basket being modified into a “bottle,” and row (d) shows multiple areas turning blue in addition to the blanket.
WYS suffers from inaccurate localization, occasionally leading to cases where the image remains unedited. For example, in Figure 9, column “WYS,” row (a), the image shows no visible change.
ZONE still exhibits overexpanded edits. In Figure 9, column “ZONE,” row (b), the entire image is modified, making the result appear as if it were generated directly from the edit instruction.
We compare the masks generated by WYS, ZONE, and IAM-Edit in Figure 10. WYS relies on noise differences to generate masks, which struggles to handle visually similar objects (e.g., different types of flowers). While ZONE successfully locates the area of “rose,” it only locates one flower. During rose generation, the mask dilation is uncontrolled, extending into nonedited areas, leading to overexpanded edits, as shown in Figure 9, column “ZONE,” row (a).

Mask analysis. We show tasks similar to IAM-Edit: the editing region masks and editing results of WYS and ZONE for Figure 9(a). IAM = instruction attention maps.
IAM-Edit generates the mask of the editing region using attention maps, ensuring accurate edits without affecting unrelated regions. This demonstrates the effectiveness of IAM in improving local editing capabilities.
Quantitative Evaluation
As shown in Table 2, IAM-Edit achieves the best results on the metrics CLIP-I, DINO-I, and CLIP-T, indicating that it not only effectively retains the overall semantics (CLIP-I) and visual structure (DINO-I) of the original image, but it also accurately captures and reflects the semantic intent of the editing instructions (CLIP-T), achieving an effective balance between editing accuracy and visual fidelity. ZONE performs slightly better than IAM-Edit on the LPIPS metric due to its stronger pixel-level statistical consistency. However, as evidenced by the qualitative results, ZONE often produces complete modification of the entire image or incorrect localization, which deviates from the goal of image editing.
Quantitative Comparisons.
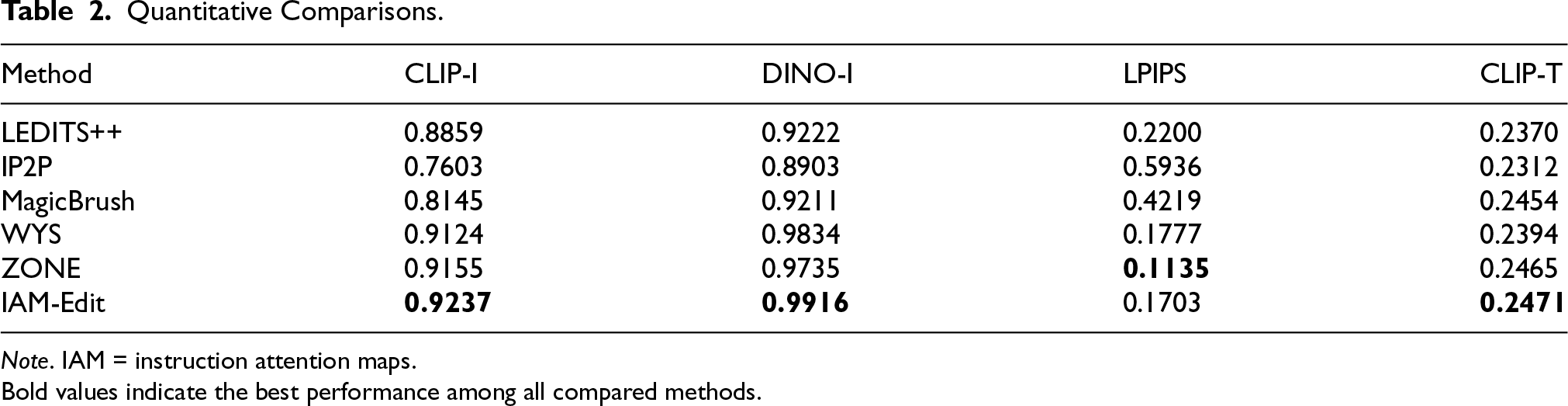
Note. IAM = instruction attention maps.
Bold values indicate the best performance among all compared methods.
User Study
To assess the perceptual quality of localized editing, we conduct a user preference study on 48 image–instruction pairs sampled from IDLE-Bench. The 48 examples are balanced across the three operation types (“change,” “add,” “remove”) and cover both single-object and multiobject edits, as well as large-area and style-change edits. For each example, we generate six edited results using LEDITS++, IP2P, MagicBrush, WYS, ZONE, and our IAM-Edit with the same hyperparameter settings as in the quantitative evaluation.
We recruit five volunteers from diverse academic backgrounds, including computer science and technology, finance, electrical engineering and automation, visual communication design, and business administration. All participants are unfamiliar with the compared methods and are not informed which result is produced by which method. For each question, the interface (see Figure 14 in the Supplemental materials) displays the original image at the top and the six anonymized edited results below it in a randomly shuffled order. The textual editing instruction is shown together with the original image. Participants are asked to select a single image that best satisfies two criteria: (i) alignment with the editing instruction and (ii) preservation of the content and visual quality of nonedited regions. Each participant evaluates all 48 examples, resulting in
We calculate the selection ratio of each method, termed as user preference rate (UPR):

User Preference Rate Calculation Results.

Note. IAM = instruction attention maps.
Bold values indicate the best performance among all compared methods.
In this work, we introduced IAM-Edit, a localized image editing framework built on instruction attention maps (IAM). Conceptually, our contributions are threefold. First, we define IAM by jointly analyzing instruction-aware self-attention (ISAM) and cross-attention (ICAM), and show that these maps encode rich semantics about both the editing instruction and the spatial layout of the image. Second, we propose a localization-instruction mechanism and an attention-driven mask generation strategy that clusters ISAM and combines it with ICAM to automatically recover the editing region without additional supervision. Third, we design a generic attention modulation operator that gates the cross-attention maps of all tokens with the editing mask at every denoising step, thereby constraining edits to the target region while preserving nonediting areas.
Although our instantiation of IAM-Edit uses IP2P as the backbone, the proposed concepts and operators are defined purely at the level of attention maps. As such, they are in principle compatible with a broad family of instruction- or text-guided diffusion models that expose self- and cross-attention tensors, including IP2P variants and other backbones such as SDXL-based editors or MLLM-assisted editing pipelines. We therefore expect that the localization and preservation gains provided by IAM-Edit can transfer to these architectures with minimal adaptation, and we regard a systematic evaluation on additional backbones as an important direction for future work. Extensive experiments and user studies on IDLE-Bench demonstrate that IAM-Edit achieves superior localization accuracy and content preservation compared to state-of-the-art baselines.
Looking ahead, we plan to extend IAM-Edit to other modalities such as video and 3D/NeRF-based editing, and to investigate more efficient implementations of IAM that reduce the computational overhead of attention collection and modulation. Another promising direction is to combine IAM-Edit with learned safety filters and content-aware constraints, enabling controllable yet responsible deployment of localized editing in real-world applications.
Limitations
Our current implementation and experiments focus on IP2P as the underlying diffusion backbone. Consequently, in challenging cases where IP2P itself fails to faithfully render the target object, IAM-Edit may still produce unsatisfactory edits even when the editing region is correctly localized. Moreover, IAM-Edit relies on several key dependencies: (i) it requires access to intermediate self-/cross-attention maps inside the diffusion U-Net, and thus is not directly applicable to pipelines that do not expose attention tensors; (ii) its localization cues depend on token-wise cross-attention under the CLIP text encoder with BPE tokenization, where long or complex instructions and word-to-subword splitting may weaken the focus of target token maps; and (iii) it uses an action classifier and an “unrelated replacement” word selection to construct localization instructions, so misclassification or suboptimal replacement selection may reduce localization reliability in rare cases. In addition, IAM-Edit requires two forward passes and similarity computations during the mask generation phase, which introduces extra inference overhead compared to directly applying IP2P. Exploring more efficient implementations and validating IAM-Edit on a wider range of diffusion backbones are left to the future work.
Supplemental Material
sj-pdf-1-eai-10.1177_30504554261450837 - Supplemental material for IAM-Edit: Localized Image Editing via Instruction Attention Maps
Supplemental material, sj-pdf-1-eai-10.1177_30504554261450837 for IAM-Edit: Localized Image Editing via Instruction Attention Maps by Shucheng Mao, Hua Cheng, Zehong Qian, Yingying Ding, Shibo Luo and Yiquan Fang in The European Journal on Artificial Intelligence
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.