
Abstract
This paper discusses our work conducting reader studies with prototypical reading interfaces designed in the context of funded Digital Humanities (DH) research projects. We discuss our conceptual and methodological approaches and contemplate which methods have been most productive in advancing our understandings of reading practices and interfaces. To situate this discussion, we first contemplate ways in which reading and new reading interfaces have been conceptualized by audiences within and beyond academia through the period of the emergence of digital environments for reading, and consider the merits of nuanced approaches that acknowledge the diversity of readers and reading practices.
Introduction
This paper discusses our work over the past six years conducting reader studies with prototypical reading interfaces designed in the context of funded Digital Humanities (DH) research projects. We discuss our conceptual and methodological approaches and contemplate which methods have been most productive in advancing our understandings of reading practices and interfaces. To situate this discussion, we first contemplate ways in which reading and new reading interfaces have been conceptualized by audiences within and beyond academia through the period of the emergence of digital environments for reading, and consider the merits of nuanced approaches that acknowledge the diversity of readers and reading practices.
A user study goes viral: Popular perspectives on reading in the digital age
In a video uploaded to YouTube in October 2011, a child is shown navigating a touch screen and then interacting with a magazine. Popular science writer Ferris Jabr has described the scenario thus: ‘a one-year-old girl sweeps her fingers across an iPad's touchscreen…. She appears to pinch, swipe and prod the pages of paper magazines as though they too were screens. When nothing happens, she pushes against her leg, confirming that her finger works just fine’ (Jabr 2013). The problem is not with her finger, it is with the failed interface of the magazine.
The girl's father, Jean-Louis Constanza, who goes by the YouTube name ‘UserExperiencesWorks’, summarizes the gist of the video in its title: ‘A Magazine Is an iPad That Does Not Work’. ‘Technology’, he writes, ‘codes our minds. Magazines are… impossible to understand, for digital natives’ (Constanza 2011). His conclusions are not particularly well supported by the evidence offered. At one point when the child appears to be pinching, for example, she is clearly pulling at a tipped-in advertising piece. And even were a reader to transfer the haptic processes of engaging with a familiar reading interface to another on initial interaction, this does indicate that the second interface would be impossible to understand for that reader given additional exposure. Nevertheless, the image of a child apparently confusing iPad and magazine struck a chord with YouTube viewership. Within two months of its upload, the video had nearly two million views and presently the number is approaching four and a half million.
The question of how reading may be changing in view of various emergent technologies for knowledge mobilization clearly is a compelling one, within and beyond the academy, as the reception of the video suggests. Since the public uptake of the internet, and before, claims have been made that we are seeing a significant shift in our cognitive processes as a consequence of our interaction with digital, multimodal, and global communications environments. Prensky (2001), for instance, among the most widely cited on the subject, refers to those who were born into the world of home-based personal computers as ‘digital natives’, and ascribes to them innate abilities to navigate the currents of digital and social data that flow through the internet. These individuals are presumed to stand in opposition to ‘digital immigrants’, who must throw off the biases of print media in order to succeed (although they seldom accomplish this goal, according to Prensky, without retaining some kind of ‘accent’). Notably, our YouTuber, Jean-Louis Constanza, characterizes his young girl as such a digital native.
The notion of the existence of a digital divide along the lines of age, based on the idea that early exposure to particular media leads to greater fluency with those media, remains a common framing in the context of discussions about the contemporary challenges of teaching, learning, and scholarship within and beyond higher education. Sometimes the argument is nuanced, as Bayne and Ross (2007) observe, by alternative terminologies: ‘Net Generation’ (Oblinger 2003), ‘Digital Generation’, ‘Technological Generation’ (Monereo 2004), ‘Millenials’ (Strauss and Howe 2000), and so on. All such framings share obvious shortcomings: the essentialistic enterprise of categorizing readers as possessing certain traits in accordance with age, for example; the over-simplistic reduction of our understanding to a raw binary opposition; and, as Bayne and Ross (2007) rightly point out, the troublesome nature, in the case of the digital natives/immigrants framing, of a racialized discourse that depends for its ‘comprehensibility and effectiveness on a culturally specific, and racist, understanding of the character of immigrants [and natives]’ (Bayne and Ross 2007).
Beyond binaries in the study of reading practices
Choudhury and McKinney (2013) analyse discourses about digital media, the internet, and the adolescent brain in the scientific and lay literature. In response to questions about whether digital reading environments are changing the brain, they note that neuroscience can be used to support these fears, and yet, the same kinds of evidence are used to challenge such fears and reframe them in positive terms. They argue that we need to move beyond the poles of neuro-alarmism and neuro-enthusiasm. Ultimately, in understanding contemporary reading practices we would do well to eschew notions of digital literacy as a revolution in literacy practices resulting in rifts between particular kinds of readers. A more productive approach is to view the onset of digital literacy as an evolution, taking place with both continuities and extensions of traditional print-literacy practices, in line with Bolter's early notion of remediation, or McLuhan's idea that the content of any new medium is an older medium. Digital literacy does not stand in opposition to print; rather, it is part of a continuum in technologies for knowledge diffusion across which we can observe signs of the remaking of old relationships under new conditions of digital and global, networked cultures (Dobson and Willinsky 2009; Dobson and Miller 2014).
To return to the question of scholarly reading, and in keeping with notions outlined above, Tenopir et al. (2009) found great variety in reading practices for information seeking in a study of university faculty from all major academic disciplines: participants of all work responsibilities and ages reported that they read articles for many purposes and locate them by many methods and sources (p. 148). Electronic sources and formats, the researchers conclude, have not replaced print, nor has the web replaced library or personal subscriptions (p. 148). That said, reading articles online, several studies (including the aforementioned) suggest, has become the most common way for researchers in all major disciplines to keep abreast of their respective fields.
Ultimately, in the contemporary moment, as ever, readers are fluent with all sorts of reading interfaces and genres. And this extends beyond information seeking practices in scholarly settings to people's leisure and daily activities, whether those activities include reading signs while commuting, deciphering labels on products, sorting mail (print or digital), reading text in the context of gaming or other video environments, reading billboards, menus, graffiti, and so on. As literacy researchers who carried out studies of reading practices even before the public uptake of the internet have noted, everyday reading practices are highly fragmentary and highly varied, and they always have been (e.g. Sharon 1973). Sustained, continuous reading that may be most valued in the academy doesn't comprise the bulk of reading most people do and it never has. Even people for whom sustained continuous reading is a regular enterprise necessarily spend much of their daily reading time interacting with text in a variety of spaces beyond books and journals. Readers, in short, are versatile, and, to turn technological determinism on its head, emergent experimental environments for reading, scholarly and otherwise, reflect that versatility.
Understanding readers in digital humanities interface design
Building on such perspectives in the context of our studies with readers of experimental reading interfaces in the digital humanities, we have sought to establish an understanding of readers that is nuanced and reflective of the diversity of people who read and their reading contexts. From the start we have preferred the term ‘readers’ to ‘users’, although we use both, because our disciplinary focus in the humanities is on reading, and many of the interfaces with which we work are aimed at augmenting reading environments or offering different perspectives — ‘rich prospects’, to use Ruecker's term (Ruecker et al. 2011) — on textual data for professional humanities readers. The term ‘user’, we feel, is reductive, devaluing the participant, the reading interface, and the texts to which those interfaces may allow access.
Through the past six years we have conducted studies with readers of a range of experimental browsing interfaces in the context of four funded projects: PlotVis (Dobson, Project Lead); The Mandala Browser (Ruecker and Sinclair, Project Leads); Simulated Environment for Theatre (SET; Roberts-Smith, Project Lead) and Implementing New Knowledge Environments (INKE; Siemens, Project Lead). Figure 1 gives a sense of the chronology of our work and the range of prototypical interfaces involved.
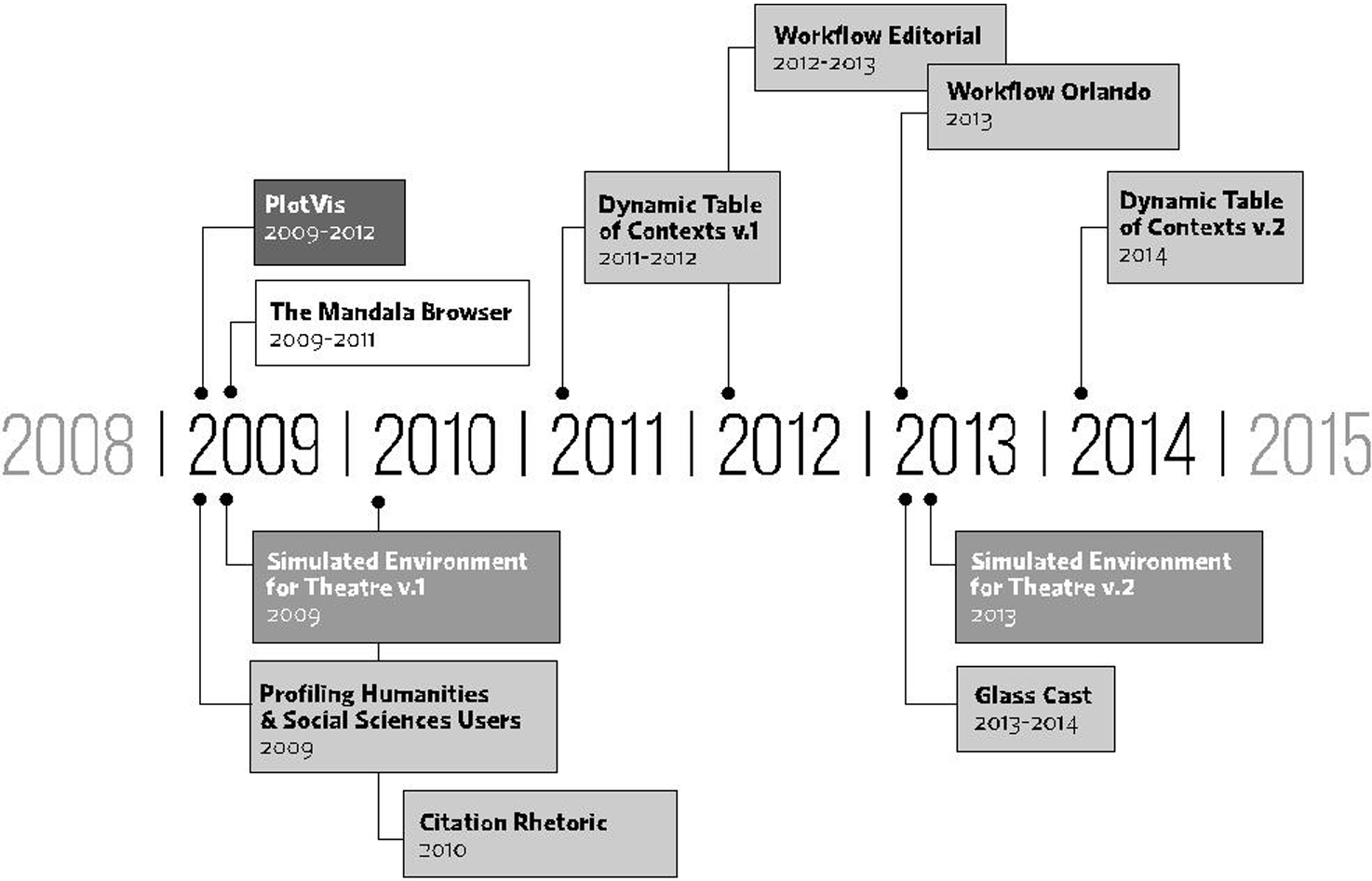
A chronology of reader studies with experimental interfaces.
Methods
We adhere largely to a qualitative paradigm in our studies with prototypical reading interfaces, entailing work with small groups of participants and collection of rich data through observation and interview approaches — a method that we feel aligns well with the humanistic tradition of critical interpretation. In this regard, our approach might be associated with the sort of work that Schnapp and Presner (2009) describe as ‘second wave’ DH work insofar as it is ‘qualitative, interpretive, experiential, emotive, and generative in character’ (Schnapp and Presner 2009). Although, like Hayles (2012), we find categorizations such as ‘first’ and ‘second’ generation limiting in many respects, the ‘second wave’ description of Schnapp and Presner appeals, beyond methodological alignment, because we are particularly interested in work with readers that yields what we describe as ‘generative’ feedback.
Levels of feedback
To this end, we identify three levels of feedback and we seek to develop instruments and approaches that will elicit all three levels. In increasing order of importance, for our purposes, the levels are as follows:
Functionality
Interface challenges and merits; wish lists.
Proof of concept
Evidence of the feasibility of the design approach for the proposed problem.
Generative
Insights that transcend exploration of the ideas instantiated in the prototype, shedding light on conceptual, theoretical and methodological issues in DH.
These levels are a modification of Ruecker's levels of feedback:
What are the bugs?
Is this instantiation of the concept reasonable?
Is the concept worth pursuing? (Ruecker, 2014)
In the context of industry, Ruecker notes, the priority may be reversed — finding bugs may be key and users may not be given opportunity to offer other types of feedback. In DH settings, however, prototypes typically serve as vehicles for advancing a theoretical position or for ‘conveying an argument about designing interfaces’ (Galey and Ruecker 2010); hence, conceptual feedback is particularly important.
We have here identified ‘generative’ feedback as unique in our taxonomy of levels. The notion of generative feedback is, of course, not new in the context of design literature on prototyping. Brown (2009), for example, describes the importance of iterative testing with low-fidelity prototypes with a view to obtaining a form of generative feedback:
Prototypes should command only as much time, effort, and investment as is necessary to generate useful feedback and drive an idea forward…. The goal of prototyping is not to create a working model. It is to give form to an idea to learn about its strengths and weaknesses and to identify new directions for the next generation of more detailed, more refined prototypes. (p. 91)
In Brown's framing, however, the enterprise of ‘giving form’ to ideas instantiated in the prototype remains key. In our own framing, generative feedback moves beyond the prototype altogether: it is the type of feedback that may invite one to step away from the ideas instantiated in the prototype and consider the broader context, such as the values inherent in, say, a disciplinary approach to knowledge and knowledge mobilization as evidenced by the responses of readers. We will offer examples in the next section.
Timing of studies
A final observation on the timing of studies is warranted. We have conducted studies at all stages of the development process, from conceptualization through levels of prototyping (low fidelity to alpha). In reflecting on the last six years of work, we note that in the case of studies in the context of projects where the design team is situated in a different location than the reader studies team, ‘testing’ with alpha prototypes is most often requested, regularly at the end of a funding cycle. In the case of projects in which design and reader studies teams are one in the same, or substantially overlapped, we have completed most of our studies pre-prototype or with low-fidelity prototypes.
Readers and experimental interfaces
In the next section we offer three examples of studies we have conducted with experimental reading interfaces through the past few years — one with PlotVis and two with INKE prototypes — with particular attention to feedback we found most productive.
PlotVis: A study in reader preparedness
PlotVis is one outcome of Dobson and colleagues’ research aimed at expanding approaches to conceptualizing story structure in secondary school and junior-level college courses (e.g. Dobson 2006; Dobson et al. 2011). In such settings, linear forms of plot graphing that situate time on the x axis and the fortunes of the hero or the disposition of action on the y axis dominate (models such as Freytag's Pyramid). We pondered how we might move beyond the Cartesian graph in representing narrative structure so as to better reflect the complexity of story, including new forms such as e-Literature. In interviews, Canadian writer Alice Munro has conceptualized her own writing process as that of identifying a story kernel around which she layers scenes. The metaphor that comes to mind in considering Munro's configuration is the armillary sphere. Canadian writer Carol Shields also forwards a three-dimensional metaphor, conceptualizing story as a ‘subjunctive cottage’ that readers might enter and wander about at will (Shields 2001). Such conceptualizations of story structure suggested a 3D visualization approach and so this was a challenge for the team.
The existing prototype, built using the Unity game engine, allows researchers to load an XML-encoded story, select elements of interest, then manipulate the display by yawing, rotating, zooming, panning, and so on. There are five designs currently available, all by Piotr Michura of the Academy of Fine Arts School of Industrial Design in Krakow (Dobson et al. 2011). In this case, however, we focused our reader studies on education and training — without offering participants even low-fidelity prototypes. We were seeking proof-of-concept feedback in introducing secondary and postsecondary students to DH visualization and engaging them in active discussion about the concept of plot in fiction.
One team member, Monica Brown, pointed to what she deemed to be particularly rich conceptual feedback:
During our [PlotVis] reader training sessions we asked participants to come up with their own means of diagramming a narrative [in this case Hemingway's Hills Like White Elephants], an activity we proposed because we wanted to gauge their understanding of visualization going into the study. Many participants drew static diagrams, as we expected they would, but one participant actually drew a three-dimensional model. (Monica Brown)
In the study, participants drew single timelines, multiple timelines and other two-dimensional models, including speech bubbles as in an iPhone chat, where the size of the bubble denoted the importance or intensity of the speech — an interesting signal of how participants’ interactions with a range of media influenced their interpretations of story, and particularly suited to Hills, which consists of a dialogue between two people. The three-dimensional model mentioned above is shown in Figure 2.
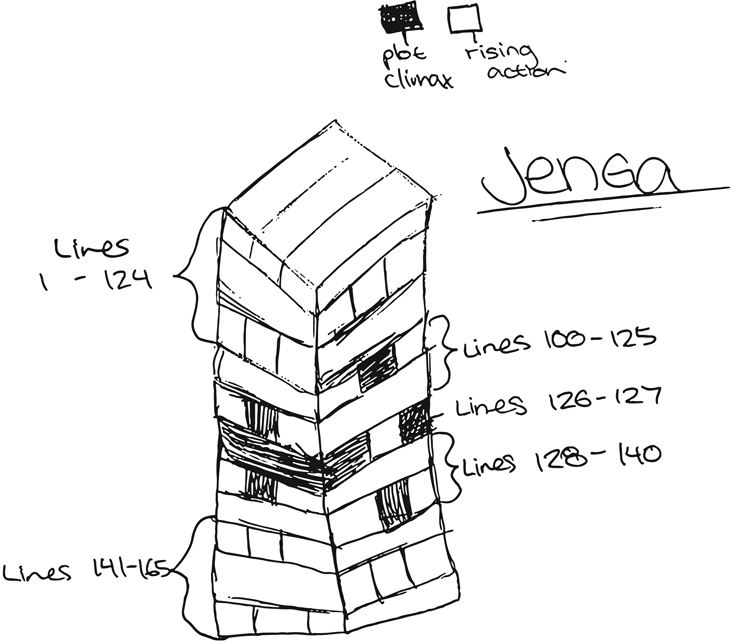
Jenga plot model drawn by a secondary school student.
The student proposed the story should begin at the top of the structure and move toward its base. Shaded blocks in the middle of the structure denote the climactic points of the story, with line numbers identified. In the game of Jenga, players remove one block at a time from a tower of blocks. Each block removed is, in turn, balanced on top of the tower, creating a progressively taller but less stable structure. In terms of its three dimensionality, coupled with the idea that the central shaded blocks are the key — or core — aspect of the story, this Jenga model is perhaps closer to Munro's understanding than Michura's Fibonacci disk design. It is particularly well suited as a model for Hills Like White Elephants, a sparse dialogue that hovers throughout on the verge of breakdown. Such plot models gave us a good sense of reader preparedness to engage with the prototype and also gave us a series of new metaphors to explore. We felt the workshop approach and the absence of an alpha prototype encouraged such rich feedback because participants’ imaginations were not limited by exposure to an existing working model.
In the context of the PlotVis workshop sessions we were also interested in the capacity of our readers to understand the semantic encoding that would facilitate their interactions with the text, and whether it might be possible to have secondary students themselves encode texts for use with such a prototype as an element of their exploration of short story. To this end, we gave one class of senior secondary students our schema to apply to Hills Like White Elephants. The schema we gave them is PlotVisML, a simple, adaptable schema consisting of five key elements: <action>, <dialogue>, and <narration>, tags for marking up narrative events; and <character> and <object>, tags for marking up narrative agents. We gave a second class cart blanch to develop their own schema with the same story. As we note elsewhere (Grue et al. 2013), the students were not very successful if judged by their ability to generate a consistently coded text that would actually work with PlotVis, which had pragmatic implications for how we would need to proceed (we would need, for example, to include with the prototype a set of marked up texts for use, which was not our preference because we did not want to establish a canon of texts associated with PlotVis). Beyond this, as one member of the research team pointed out, the students’ seeming failure was in itself a productive outcome of the study, a generative moment. In a reflection on the work, Dustin Grue remarked:
I still believe, for example, that the interesting thing… is how ‘poorly’ [they] performed their XML encoding, but it was in this poor performance, the lack of fit between our conceptual (XML) schema and the participant's conceptual (literary) one, that we found interesting results. Students couldn't follow an XML schema to save their lives, but they're not at all ‘bad’ or ‘incapable’: getting students to think about these formal systems highlighted their own subjective experience with the text, mostly by contrast. The example I think of is the group who decided to tag ‘contradictory statements’ in Hills Like What Elephants — how would one do that with a rudimentary tagging system? But in looking at the ‘professional’ (i.e. peer-reviewed Hemingway literature), ‘contradiction’ in Hills is discussed, and excerpts or quotations selected by the professionals also displayed a lot of tagging ‘activity’ from our participants. (Dustin Grue)
DToC: The anxiety of XML encoding
Anxiety around markup has in fact featured in all of our work with prototypes that visualize XML-encoded text, particularly in humanities contexts: this perhaps has to do with the superimposition of an interpretation in a discipline where interpreting is seen as the primary work (in some ways the secondary students were refreshingly unconcerned about the state of their markup).
The Dynamic Table of Contexts (DToC) is a browser that combines tagging of the structure of the text with the tagging of named entities (people, places, organizations, titles). It is a way of combining the Table of Contents with the Index with a view to improved search functionality. The result is a dynamic browsing environment in which readers can see where the materials that interest them are located within the structure of the volume. We completed two studies with the DToC: one with readers of a literary text (Munro's The Love of a Good Woman marked up with PlotVisML) in an early iteration of the prototype, and one with Feminism and Women's Writing, an expository text edited by members of the INKE Modelling and Prototyping team, in a more recent iteration of the prototype.
XML tagging is evidently a metadata overlay on any text. In the case of PlotVisML, this metadata represents a subset of literary theory from which definitions of conceptual or grammatical categories like ‘narration’, ‘character’, or ‘action’ are adopted (all of which were XML tags available to participants in the first reader study). This subset of theory, in turn, sets the boundaries on a reader's options to organize and visualize a literary text on the basis of the XML markup. In many prototypes, this XML metadata is hidden from the user and a rationale behind the subset of literary theory used for the schema is not made available. This, we found, can cause problems for literary scholars, who in their research select from a range of literary and linguistic theories of text structure and meaning as they study a work of literature.
In our study with an early prototype of DToC designed by Milena Radzikowska, one participant, on seeing the ‘XML Markup’ pane, commented, ‘So it's been marked up with XML. Interesting’ (Participant 296). He clicked on the ‘Narration’ tag and viewed the items that appeared in the Table of Contents pane. His immediate, unfiltered reaction to the XML markup as it was presented was: ‘that seems ridiculously broad…. Are those manually marked up?’ His challenge to the prototype was rooted in his own literary theoretical commitments. The idea that ‘narration’ as he understood it could be tagged in XML and represented as unitary concept by the DToC was troubling to him. The difficulty was summed up by another participant in response to the following question, ‘Is there anything you think this browser could help you perceive that you would not have been able to perceive in a different reading environment?’ She moused over the XML Markup pane and said: ‘Well, this seems to me the most relevant section, so whoever puts that together is pretty much the wizard in this Oz’ (Participant 573).
More recently, our team conducted a series of reader workshops that sought to secure feedback on Curator Mode, a function of the Dynamic Table of Contexts (DToC) in its present instantiation that allows readers to customize, or ‘curate’, their perspective on a digital text or collection of texts in a number of different ways. Participants took part in focus group and exit interviews and the text they worked with in DToC was Feminism and Women's Writing.
Where in the first study with DToC we thought perhaps the anxiety with the prototype was related to our use of a text marked up with PlotVisML, we found similar anxieties surfaced in the second study with a different text and a different XML schema. Many of the focus group conversations centered around participants’ concerns about whether or not they could use their own tags sets in the DToC rather than the one provided. Participants also wondered in general about how literary critics learn to mark up our texts, even when working in print. Even though they were very interested in using the DToC to read and interact with texts that they had encoded on their own, some of them expressed anxiety about sharing their tag sets with other scholars.
What began to emerge was a pattern of thinking about the DToC that perhaps mirrored the intimacy of a scholar's relationship to print. Not only did participants want to reproduce that relationship — they wanted their own tags sets and their own text collections, and they appeared to want these to remain distinct from the tag sets and text collections of others (this was even true of participants who did collaborative DH work). In terms of metaphor, participants who critiqued the tag set with which they had worked during their session offered comparisons to their encounters with another person's marginalia in a book in order to qualify their evaluations: an interpretive intrusion. Nevertheless, perhaps because these observations emerged out of a broader conversation about literary pedagogy, participants remained thoughtful about the DToC's scholarly implications. As one participant observed:
I keep coming back to the question, ‘How do we learn how to annotate?’ […] It never occurred to me until I did [this workshop]: I learned how to annotate. Like, people actually took time in classes and sat me down and taught me, ‘This is why we highlight this, this is why we underline that, this is why we put a marginal note here’. Is this something everyone learns? And, if so, is this maybe one of the reasons why something like this [the DToC] is both anxiety-producing and exciting?
Again, we noted that the workshop approach was beneficial in eliciting such feedback because it provided readers with the opportunity to apprehend a DH prototype from a number of different perspectives as responses to the concepts instantiated in the prototype were negotiated among group members.
Workflow Editorial and Orlando Edition: Generative feedback with a working prototype
Workflow Editorial Edition was described by many of our participants as project management software. It aims to support and improve the document editing and publication process. Designed by Milena Radzikowska and programmed by Luciano Frizzera, it is derived from the flowchart of activities that an editor can use to manage the movement of a submitted article or other item of text through the stages from acquisition to publication (Frizzera et al. 2013). We worked also with Workflow Orlando Edition, a customization for the document writing and markup process in The Orlando Project, an online cultural history of women's writers in the British Isles.
In a 2013 study with Workflow Editorial Edition we approximated the percentage of feedback falling under each of the feedback categories we mentioned earlier: roughly sixty per cent was related to functionality, thirty per cent to proof of concept. Ten per cent was deemed generative. In this instance our readers had trouble looking beyond the functional limitations of the prototype. That said, they appreciated the design metaphor and our proof-of-concept feedback was overwhelmingly positive.
To encourage conceptual and generative feedback, we added a creative component to the study following the talk-aloud session with the interface, inviting participants to imagine how they might picture their own visual workflow by completing a sketch, should they wish. One individual considered the invitation, took up a pen, and began to draw: ‘It's almost like I would want to do it like… a Rubik's Cube, [where everything to do with particular actors in the process is coded in a different way and] to see connections among those when necessary’ (Participant 2202). Within a moment of commencing his sketch, however, the participant — I'll call him Joseph — stopped, conceding that the enterprise would fail in short order: ‘I have a feeling’, he mused, somewhat gloomily, ‘that that's like me trying to organize things. Like socks in a drawer, it just isn't going to work for very long’. He then changed the subject. The interviewer, however, returned to the Rubik's Cube metaphor at the end of the session and invited Joseph to elaborate. Here is an abridged portion of the discussion:
Interviewer: The Rubik's Cube… the ability to, since these are tiles already, to move things around on the fly, to adapt… such an interface, would that be something?
Participant: Now that could work, right, as long as it wasn't too complicated… a certain ability to move things around, to move the parts into different relationships might actually work — to keep the flowchart itself flowing for particular projects.
Interviewer: Is it the connections, you mean, that can be re-thought depending on the project?
Participant: Yes, depending on the project…. What would happen if an experienced chess player were to begin working with this, with a particular kind of memory and a particular way of seeing relationships among things? The architect, probably, would have a different way of seeing, and so on. I come to this as one who works in sentences and works in syntax and semantics in certain ways, and so the metaphors that I'm using, typically, are. Well, even the notion of parsing a sentence into a diagrammatic tree, pattern, or model — I was always intrigued by that kind of parsing, and once I began working with sentences in order to parse them in that way I began to see those patterns more readily. And so I think that probably different kinds of editors with different disciplinary backgrounds would respond to Workflow in different ways.
Here interviewer and participant engage in a process of negotiated understanding that yields important insight into the importance of attending to how reader values — particularly their disciplinary perspectives — influence their understandings. It is a method of interviewing Luce-Kapler (2006) has described as sideshadowing — a ‘talk-aloud’ approach in which interviewer and participant engage in natural dialogue during the session towards negotiated interpretation. As such, it aligns well with user-centered design approaches such as Cooperative Design (Greenbaum and Kyng 1991) or Participatory Design (Schuler and Namioka 1993) — approaches that place users and designers on an equal footing. Reflecting on the negotiation of meaning in such exchanges, research team member Dustin Grue observed the following:
I always felt that the desire for the first type, for functionality, was VERY strong…. I'm actually not sure if I ever really ‘saw’ generative feedback. …and maybe it is the case that generative feedback isn't possible on its own — participants, being participants, just can't be aware that their feedback is generative until it's met with the analysis of the researchers… Eliciting generative feedback, I would say, is tricky, because it plays in between the researcher and participant's behaviours and biases. (Dustin Grue)
Grue's comments align with understandings of the nature of the relationship between participant and researcher in qualitative empirical research in the social sciences. As Meyers (2000) observes, drawing on Munhall (1989), ‘in [the qualitative] paradigm, which rejects both a cause-and-effect construct and universal laws devoid of any sociohistorical context, the separation between researcher and respondent is diminished’. Indeed, beyond a mere diminishment of separation between researcher and respondent, some would go so far as to argue that participants themselves should be counted as members of the research team and recognized as such (Phillips and Zovros, 2013). In this case, Joseph's comments encouraged team discussion about the possibilities of a Rubick's Cube-type workflow, including this design sketch by Ernesto Pena (see Figure 3).

Rubik's Cube Workflow.
The interface implications of understanding readers: Concluding thoughts
It is important to situate this discussion within Digital Humanities interface design, and within a particular subset of visualization projects whereby prototypes typically served as vehicles for advancing a theoretical position or for conveying an argument about designing interfaces. We have found the qualitative approaches described above, along with pre-prototype and low-fidelity prototype work, productive in garnering rich proof-of-concept and generative feedback that might advance projects on conceptual and theoretical levels.
We have also found that the optimal organization of large interdisciplinary DH interface design projects is one in which design and reader studies teams are one in the same or substantially overlapped, which better allows for the sort of iterative work described herein. Finally, we argue for careful consideration of how participants are valued in DH reader studies with prototypical browsing interfaces – as important members of the design process.
Notes on contributor
Teresa M. Dobson is an associate professor in the Department of Language and Literacy Education at the University of British Columbia, Canada. Her research interests include literary education, digital literacy, and digital humanities. Her work in the digital humanities includes collaborating with teams of interdisciplinary scholars in the development of prototypical browsing interfaces for text visualization.