
Abstract
Commercial market research firms provide information on advertising variables of interest, such as brand awareness or gross rating points, that are likely to contain measurement errors. This unreliability of measured variables induces bias in the estimated parameters of dynamic models of advertising. Consequently, advertisers either under- or overspend on advertising to maintain a desired level of brand awareness. Monte Carlo studies show that the magnitude of bias can be serious when conventional estimation methods, such as ordinary least squares and errors in variables, are employed to obtain parameter estimates. Therefore, the authors have developed two new approaches that either reduce or eliminate parameter bias. Using these methods, advertisers can determine an unbiased optimal advertising budget, even if advertising variables are measured with error. The application of these methods to estimate the extent of measurement noise in empirical advertising data is illustrated.
American corporations spend millions of dollars on advertising their products and services. In 1996, the total outlay on advertising in the United States was approximately $180 billion, a sum that exceeded the gross domestic product (at purchasing parity) of 85% of the nations of the world, including some developed countries such as Switzerland, Hong Kong, and Singapore. Given the magnitude of advertising spending, it is important for firms to be able to determine accurately the advertising budgets needed to achieve the desired goals (Lehmann and Winer 1997, pp. 318–19). The subject of budget determination has been covered extensively in the literature over the past four decades, from the pioneering work of Dorfman and Steiner (1954) to recent developments in marketing and management science (see the review article by Feichtinger, Hartl, and Sethi 1994). Using currently available techniques, the optimal advertising budget—one that maximizes profit—is determined by empirically estimating the elasticity of the sales–advertising relationship (e.g., Lehmann and Winer 1997, p. 336). However, this budget may be under- or overstated if the estimated parameters are biased because of the unreliability of the advertising data.
Previous research has investigated parameter bias resulting from temporal aggregation (Clarke 1976), misspecification of dynamic lags (Bultez and Naert 1979), and parameter uncertainty (Aykac et al. 1989) but has not analyzed the problem of noisy variables in dynamic advertising models. This leads us to investigate the impact of unreliable measurements when estimating dynamic models of advertising competition. The objective of this article is to develop new approaches that reduce or eliminate parameter bias due to the unreliability of advertising data (e.g., awareness and gross rating points [GRPs]).
To accomplish this objective, we propose two new estimators: denoised least squares (DLS) and modified Kalman filter (MKF). The DLS estimator uses recent developments in wavelet theory (Donoho and Johnstone 1994, 1995) to denoise the observed data and then applies ordinary least squares (OLS) to this denoised data to obtain parameter estimates. The MKF estimator is based on Kalman filtering theory (see, e.g., Harvey 1994) to model jointly the presence of measurement errors and the dynamics of advertising response. We then compare these models' performance with that of the commonly used OLS (e.g., Erickson 1995) and errors-in-variables (EIV) estimators (Fuller 1987) in terms of parameter bias as well as advertising budget and profit implications. We see in simulation studies that OLS and EIV estimates are substantially biased and that this bias leads to under- or overstating the optimal advertising budget and profit. Thus, neither approach adequately estimates parameters of dynamic models when data are noisy. However, DLS significantly reduces parameter bias compared with OLS and EIV estimates, and MKF eliminates the bias asymptotically. When the measurement noise level is low to moderate (i.e., noise-to-signal ratio < 20%), both DLS and MKF are equally effective. In contrast, for large measurement noise levels, MKF provides an asymptotically unbiased estimate when errors are normal.
For two reasons our results lead us to recommend DLS over MKF for general use. First, DLS is better than the commonly used OLS, and the ideas behind it are easy to communicate to managers because it is related to the familiar OLS method. Second, wavelets are theoretically known to be well suited for analyzing aberrant time series (i.e., cycles, discontinuities, and sharp jumps), which commonly appear in advertising data (e.g., periodic rise and decay of awareness, discontinuous nature of on-and-off pulsing media schedules, jumps due to advertising copy replacement). However, when data are extremely noisy we recommend using the asymptotically unbiased MKF estimator.
We illustrate the use of the DLS and MKF estimators by analyzing real advertising data for a major cereal brand. Empirically we find substantial measurement noise in this advertising data, especially in the awareness scores, which emphasizes the need for using better estimators. We also show how advertisers can assess the extent of measurement noise in empirical data, which thus enables them to influence appropriately the pricing of market research information (Sarvary and Parker 1997).
The article is organized as follows. We first formulate a Nerlove–Arrow model of advertising competition to investigate analytically the effect of parameter bias on optimal advertising spending and profit. Then we describe the existing OLS and EIV estimators and propose the two new approaches. We next report our findings based on simulation studies as well as on an empirical example. Finally, we summarize the contributions of the proposed methods and provide guidelines for their use.
Competitive Dynamic Advertising Model
We consider a simple model of advertising competition between two firms, 1 in which each firm invests in advertising to build its own goodwill. To illustrate the efficacy of our estimators (to be developed in the next section), we use Tapiero's (1979) formulation of advertising competition to build goodwill, though, alternatively, we could use the Lanchester model (see Kimball 1957) as Erickson (1992), Chintagunta and Vilcassim (1992), and Fruchter and Kalish (1997) do. We derive the open-loop Nash equilibrium solution to obtain the steady-state optimal advertising spending level for both firms and then investigate the effect of parameter bias on optimal advertising spending and profit.
We thank two anonymous reviewers for their suggestion to consider the role of competition.
Nerlove–Arrow Model of Advertising Duopoly
Consider the extension of Nerlove and Arrow's (1962) model, in which firm i, i = 1, 2, invests in advertising at rate ui(t) to build a stock of goodwill, Gi(t), at time t. The evolution of their goodwill is described by the following differential equation:
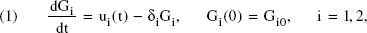
where δi is the forgetting rate and Gi0 is the initial goodwill value for firm i. Suppose that a firm's sales are proportional to the share of goodwill. Furthermore, assume that each firm maximizes the discounted profit over the planning horizon T:
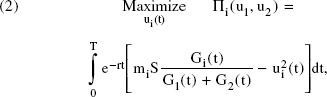
where m i is the margin for firm i, S is total market sales, and r is the discount factor. For the sake of simplicity, we assume that both firms have the same discount factor. Note that the advertising spending in Equation 2 is measured in GRPs and not in dollars. To capture diminishing returns, the cost of buying GRPs is assumed as a convex function u2, which is commonly used in the literature (see, e.g., Erickson 1991; Tapiero 1979).
To solve the non–zero-sum differential game described by Equations 1 and 2, we first define the Hamiltonian for firm i:
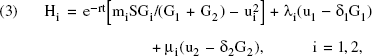
where λi and μi are Lagrange multipliers for firm i. We then obtain the open-loop Nash equilibrium solution in which the optimal advertising is a function of time only. This open-loop solution is meaningful from a budgeting standpoint because an advertiser has to commit to a media plan to facilitate the buying of media time and space in advance (for an account of media planning and buying practices, see Abe 1997). However, this solution may not be useful in deciding the best competitive response, which requires a closed-loop solution that is a function of the competitive spending strategy. In the next subsection we obtain expressions for optimal advertising spending and profit in terms of model parameters r, δi, and mi.
Optimal Advertising Spending Level and Profit
After maximizing the Hamiltonians in Equation 3 with respect to ui, we obtain open-loop solutions, ui*(t). These solutions constitute optimal advertising time paths that satisfy the following dynamic system for both firms i ≠ j, i, j = 1, 2 (for details, see Tapiero 1979, p. 912):

with initial Gi(0) = Gi0. Observing Equation 4, we find it interesting that each firm's optimal advertising spending depends on the other firm's goodwill, even though the two firms' goodwill dynamics are not interrelated.
In the steady state, all time derivatives vanish. Hence we can set the right-hand side of each part of Equation 4 to zero to obtain the equilibrium quantities ūi* and Γi as follows:

Because each firm's sales are assumed to be proportional to the share of goodwill, the total market sales are proportional to total goodwill. That is, we assume that S = k(G1 + G2), where k is a constant of proportionality. This enables us to simplify Equation 5 further, and the resulting expression for the optimal equilibrium advertising spending by firm i, in terms of model parameters, is
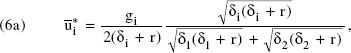
where gi (= mik) is a constant. Analogously, the profit πi = miSGi/(G1+ G2) - u2i can be written as
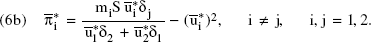
Effects of Parameter Bias on Optimal Advertising Spending and Profit
If we suppose the difference between the estimated
In general, parameter bias due to measurement errors in variables is ubiquitous in marketing research. In particular, commercially available advertising data such as awareness, attitude, recall, and GRPs are likely to contain measurement errors. Given the effects of parameter biases on advertising spending and profit, it is important for advertisers to be able to control measurement errors systematically. To achieve this goal, we propose two new methods to remove noise from advertising data.
New Estimators to Control Measurement Errors
We first state the model structure and describe the commonly used OLS and EIV estimators. We then develop two new estimators to control measurement errors in dynamic models.
Model Structure
Let Ait be the awareness measure for goodwill variable Git, and let xit denote the GRPs that serve as a measure of spending rate uit. The model, which includes measurement errors in advertising variables, is


and

where i = 1, 2, and t = 1, …, T Equation 7 states that observed = true + error as in Morrison and Silva-Risso's (1995) study. All error terms (ε1t, ε2t, v1t, v2t, η1t, η2t)′ are independently distributed normal random variables with zero means. (We relax this assumption subsequently to enable estimation of various pattern of correlation among error terms when we develop the MKF.) Equation 8 is a discrete-time version of Equation 1, because empirical observations are made at discrete points in time (e.g., weekly, monthly). In addition, the error term εit makes Equation 8 a stochastic difference equation. It can be interpreted as a perturbation of the dynamic model in Equation 1 induced by various factors, such as misspecification of the functional form or the number of lags. Thus, Equation 8 can be viewed as a first-order stochastic approximation to the true dynamics of advertising response.
In the next two subsections we describe the OLS and EIV estimators. We suppress the subscript i because the goodwill dynamics of the two firms are not directly interrelated and the estimation approaches hold for multiple firms.
OLS Estimator
If we let zt be the lagged awareness At - 1, the linear regression model for Equation 8 is

where εt ∼ N(0, σε2.) for t = 1, …, T. This model ignores the presence of measurement errors (vt, ηt)′. The resulting 2 × 1 vector of parameters, Θ = [(1 - δ),β]', is estimated by OLS as
EIV Estimator
The previous OLS estimates will be biased if regressors in X are measured with errors, that is, if either σ2 or σ2v is not zero. Therefore we use the maximum likelihood estimator, which incorporates the presence of measurement errors, to estimate the unknown parameters (see Fuller 1987, Theorem 2.3.1):

where Mxx = X'X/n, Mxy = X'A/n,
Note that the estimator
DLS Estimator
In this subsection we develop a new estimator based on wavelet theory (see Donoho and Johnstone 1994, 1995). We first explain the idea of denoising data by using wavelets and then describe what a wavelet is, the denoising procedure, and the proposed DLS estimator. The aim is to extract a signal from noisy empirical data. To this end, we first transform the noisy data (signal plus noise) into a set of numbers called the wavelet coefficients. Large wavelet coefficients represent the signal, whereas small coefficients capture noise. By applying a thresholding scheme that “kills” (sets to zero) the small wavelet coefficients (noise), it is possible to recover the noise-free signal. (The interested reader can find a more detailed introduction to wavelets in Hubbard 1996.)
Wavelets
A wavelet is a little wave localized on a compact support that decays quickly to zero everywhere else. Two well-known examples, Haar and Daubechies wavelets, are given in Figure 1. Wavelets theory has been applied successfully to problems in speech recognition, medicine, and image processing (see Aldroubi and Unser 1996; Hubbard 1996; Prasad and Lyengar 1997). One remarkable feature of wavelets is that they are good building block functions for a variety of smooth as well as nonsmooth signals (i.e., sharp bumps, discontinuities, and periodic cycles). This property is especially useful in the context of advertising data because media spending patterns are like square waves of on-and-off pulses (e.g., Mahajan and Muller 1986; Winer 1993), awareness patterns exhibit periodic rise and fall (Zielske 1959), and advertising copy replacement induces sharp jumps (Pekelman and Sethi 1978).
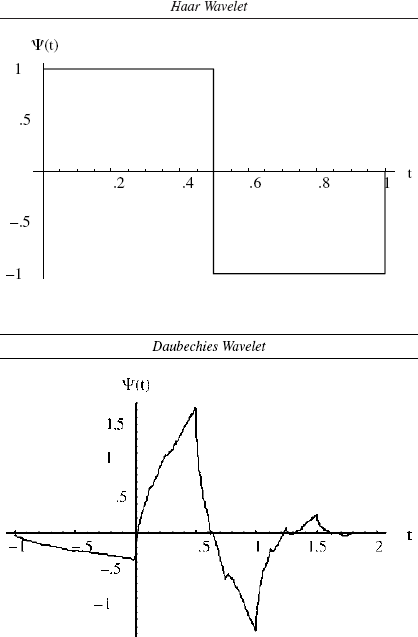
Some Examples of Wavelets
Denoising
Consider the observed GRPs sequence (x1, …, xT)′ in Equation 7b. A vector of wavelet coefficients, w, is obtained by applying the discrete wavelet transform to the noisy data vector x = (x1, …, xT)′ as follows:

where W is a T x T matrix whose elements depend on the specific wavelet (e.g., Haar or Daubechies) used as the filter. These wavelet coefficients are contaminated with measurement noise induced by the noisy data x. To remove the noise, we adopt Donoho and Johnstone's (1994, 1995) hard thresholding scheme:

where τ is a threshold. In Equation 12, the wavelet coefficient wt (in absolute magnitude) that is smaller than the threshold τ is killed, whereas the larger coefficient is retained because it contains the signal. The resulting wavelet coefficient

Here
DLS Estimator
In this approach, we first apply the previous denoising procedure to both the dependent and independent variables. We then fit the denoised data with the classic regression model, and we define the resulting estimator as the DLS estimator,
MKF Estimator
This subsection develops a new estimator based on Kalman filtering theory (e.g., Harvey 1994). The proposed estimator is referred to as an MKF, because we allow the independent variable in the standard Kalman filter to be a random variable due to the presence of measurement errors. In other words, we extend the standard Kalman filter to the case of stochastic regressors. Furthermore, the MKF estimator can estimate the correlation between measurement errors as well as the inertia in managerial spending decisions, 2 which we model next.
We thank two anonymous reviewers for suggesting these two extensions.
Adopting Dekimpe and Hanssens's (1995) approach, we model inertia in spending decisions as a first-order autoregressive, AR(1), process:

In Equation 14, by suppressing i, we obtain a constant spending pattern (ut = ut − 1 =… = u0) if ϕ = 1 and γ = σa = 0; a random walk (i.e., the persistence effect, as described by Dekimpe and Hanssens [1995]) if ϕ = 1, σa ≠ 0, and γ = 0; a random walk with a trend if ϕ = 1, σa ≠ 0, and γ ≠ 0; and a simple AR(1) if |ϕ| < 1 and σa ≠ 0 regardless of γ. Analogous to Equation 8, Equation 14 is to be viewed as a first-order stochastic approximation to the true temporal spending decisions.
To obtain the MKF estimates, we first express the set of Equations 7, 8, and 14 in a state-space form and then maximize the resulting likelihood function. As in Naik, Mantrala, and Sawyer's (1998) study, we determine the state-space form by deriving the observation and transition equations (see Appendix B for details). For each firm, the observation equation is

where

where ũt = ϕut − 1, and (εt, at)′ are normally distributed with mean zeros and covariance matrix Q2 × 2.
The previous state-space form expresses all error terms in the observation Equation 15, which thereby enables the estimation of correlation among error terms (εt, at, vt, ηt)′ by properly specifying off-diagonal elements of the covariance matrix H4 × 4. For example, we can estimate the correlation between measurement errors in awareness and GRPs, ρvη, by parameterizing the elements (3, 4) and (4, 3) in the matrix H4 × 4 with a proper range constraint. The section “An Empirical Example” illustrates this process.
To obtain the likelihood function of the parameter vector θ = (β, δ, ϕ, γ, σ, σ2a, σ2, ση2, ρvη, μ0)′, we first consider the joint density, g(Y; θ), of the observed advertising data Y = (Y1, …, YT)′, where Yt = (At, xt)′, At is the awareness score, and xt is the GRPs per week. We then decompose the joint density as a product of the conditional density and the marginal density; that is, g(Y; θ) = f(YT|IT– 1) g(Y1, …, YT– 1; θ). Here f(YT|IT– 1) denotes the conditional density of observing YT given the information set IT- 1. The information set contains the history of all information until the realization of advertising data Yt in the current period; that is, It–1 = (Y1,…, Yt–1)′. We recursively apply this decomposition so that the likelihood function, L(θ; Y), can be expressed as follows:
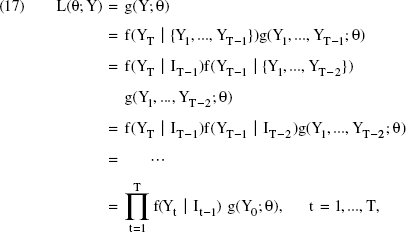
where the initial density g(Y0) is assumed to be normal with mean μ0. Appendix C shows that the conditional density f(Yt|It − 1) is normal for all t and the conditional moments can be expressed as recursive closed forms.
The MKF estimator,
Simulation Studies
This section presents simulation studies 3 that compare the performance of four estimators, OLS, EIV, DLS, and MKF, in the ability to estimate true model parameters as measurement noise increases. We first describe the simulation settings, and then we discuss our findings.
We are grateful to an anonymous reviewer for the valuable suggestion of using simulated data.
Simulation Settings
We assumed true parameter values of δ1 = .05, δ2 = .10, β1 = β2 = 1, ρ = .1, miS = 1, gi = .1, ϕi = 1, γi = 0, σai = 0 for both firms, and T = 64 observations. Using Equation 6a, we obtained the equilibrium quantities ū*1 = 1.26 and ū*2 = 1.55. The observed advertising data was constructed by using Equation 7b, xit = ū*1 + ηit, for t = 1, …, T, where the ηit were randomly generated from the normal distribution with mean zero and variance ση2. Although the variance of measurement noise was the same for both firms (ση1 = ση2 = ση), the scaled measurement noise, ση/ū1*, will be different for i = 1, 2. The parameter ση was varied from .08 to .2 in increments of .01 for moderate noise levels and was set at .25, .33, .5, and .75 for high noise levels. Consequently, the scaled measurement noise ranged from less than 5% to more than 50% for both firms. At high levels of noise some xit values become negative, and these were replaced by zeros. Finally, goodwill variables were simulated by using Equation 8. Because the average goodwill was about ten times the mean advertising level, the variance of measurement noise of awareness scores in Equation 7a was kept at σεi = 10ση. This simulated data on awareness and advertising spending was used to estimate model parameters (βi, δi), i = 1, 2. One thousand random realizations generated as many different data sets, and we estimated model parameters for each data set by using the four estimators. We computed DLS estimates by using the Haar wavelet to filter GRPs data and Daubechies wavelet order 4 to filter awareness data (see Figure 1). The findings in the next two subsections are based on the average of these 1000 parameter estimates.
Parameter Biases
In Figure 2, Panel A, we present the OLS, EIV, DLS, and MKF estimates of Firm 1's forgetting rate parameter δ1. At zero measurement noise, all four estimates are equal to the true one, δ1 = .05. As measurement noise increases, the estimated parameters tend to depart from the true value. The bias of

PARAMETER ESTIMATES
In Figure 2, Panel B, we present the OLS, EIV, DLS, and MKF estimates of the advertising effectiveness parameter β1. Noting that the EIV estimates are unreasonably large, we scaled them by a factor of 100 so that the four estimates can be plotted together effectively. The patterns of these estimates are essentially similar to those described previously. Because all the results noted also hold for the second firm, the figures for the second firm are not presented here.
Bias in Advertising Spending and Profit
As discussed previously, the estimate of advertising effectiveness may not be equal to its true value, βi = 1 for i = 1, 2. When this is the case, advertising spending is still given by Equation 6a, whereas the profit expression in Equation 6b becomes

EFFECTS OF MEASUREMENT ERRORS
As measurement noise increases, OLS, EIV, DLS, and MKF parameter estimates show upward bias (see Figure 2, Panel A), which leads to a downward bias in advertising spending (see Figure 3, Panel A) and an upward bias in profit (see Figure 3, Panel B). Thus, these simulation findings show that the analytical results (see Appendix A) hold for the case δ1 ≠ δ2. Furthermore, even small parameter biases (e.g., MKF estimates) can have a large impact on the estimated advertising spending and profit, which suggests that the optimal advertising spending and profit are sensitive to the presence of measurement errors.
Overall, we find that both OLS and EIV estimators are substantially biased. The parameter biases result in under- or overstating the advertising budget and profit. Therefore, these existing approaches are not adequate to estimate dynamic advertising models when data are noisy. In contrast, the proposed DLS and MKF estimators outperform them. Specifically, DLS reduces the bias, whereas MKF eliminates it asymptotically. Moreover, when measurement noise is moderate, both DLS and MKF estimate the true parameters equally well. As measurement noise becomes large, the MKF estimate stays closer to the true parameter than does the DLS estimate.
From these results we observe that EIV is outperformed by the other three estimators, and therefore it should not be used to estimate dynamic models when data are noisy. DLS is better than OLS and performs as well as the asymptotically unbiased MKF for low to moderate noise levels (noise-to-signal ratio < 20%). MKF is ideal for higher noise levels. Given these results, we next apply DLS and MKF estimators to real advertising data.
An Empircal Example
In this section, we show how advertisers can determine the extent of measurement noise in commercial advertising data. We first briefly describe the advertising data used and then present estimation results.
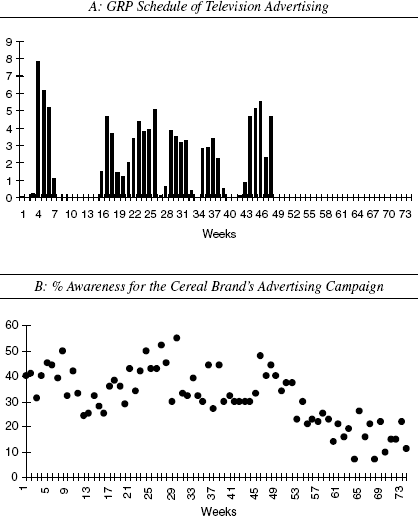
An Advertising Tracking Study
Data
We consider the tracking study of an advertising campaign for a major cereal brand over a period of 74 weeks (for details, see West and Harrison 1997). To illustrate how to determine measurement noise level empirically, we analyze the awareness tracking data for a single firm. The single-firm analysis is appropriate because the goodwill dynamics for the two firms in Equation 1 are not directly interrelated. Figure 4, Panel A, shows the GRPs of television advertising for this cereal brand. Figure 4, Panel B, displays the percentage of survey respondents aware of the brand's advertising during this period. We briefly note here that continuous tracking of advertisements has become the fastest-growing market research technique in the United States (Rossiter and Percy 1997, p. 607), because advertisers are increasingly using such data in advertising decision making. Our proposed methods can complement this desirable development in the practice of advertising.
Estimation Results
DLS estimate of measurement noise level
We first de-noise the GRP data, {xt}, using the Haar wavelet, and the awareness data, {At}, using the Daubechies wavelet of order 2.
4
Then we apply the standard OLS approach to the resulting denoised data, {Ât} and {
We tried different orders of Daubechies wavelet to denoise the awareness and GRP data and obtained essentially similar results. It appears from our experimentation that matching the shape of a wavelet with the underlying data pattern is a reasonable heuristic for deciding which wavelet to use as the filter. Thus, our choice was driven by the fact that the shape of a Haar wavelet resembles the square-wave pattern of pulsing media schedules (see Mahajan and Muller 1986), whereas that of a Daubechies 2 wavelet matches the growth and decay in the awareness data (see Zielske 1959). However, we emphasize that the choice of a specific wavelet or even the filtering approach (e.g., wavelet, spline, smoothing) is not crucial because the resulting estimates across these methods are asymptotically unbiased (see Cai, Naik, and Tsai 1997).
To assess whether the measurement noise level is small or large, we compute the noise-to-signal ratio, which is equal to the standard deviation of noise divided by that of the de-noised signal. For the awareness data, noise-to-signal ratio is
Because the noise-to-signal ratio of awareness data is high, the MKF approach must be considered. For the purpose of comparison, we also obtain DLS parameter estimates (see Table 1). A detailed discussion of the DLS and MKF estimates is given next.
Empirical Estimates from DLS and MKF Estimators
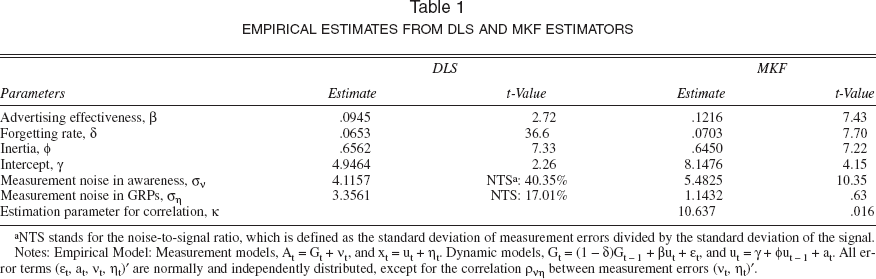
NTS stands for the noise-to-signal ratio, which is defined as the standard deviation of measurement errors divided by the standard deviation of the signal.
Notes: Empirical Model: Measurement models, At = Gt + vt, and xt = ut + ηt. Dynamic models, Gt = (1 - δ)Gt − 1 + βut + εt, and ut = γ + ϕut − 1 + at. All error terms (εt, at, vt, ηt)′ are normally and independently distributed, except for the correlation ρvη between measurement errors (vt, ηt)′.
MKF estimates
Using the maximum likelihood approach (see Appendix C) we obtain the estimates of model parameters, the extent of measurement noise in awareness and GRPs, and the associated standard errors. In Table 1, we present the parameter estimates and t-values. Comparing the DLS and MKF estimates, we find the similarity in the magnitudes of
MKF estimates of measurement noise levels
The MKF estimate of the awareness noise level is
Correlation between measurement errors
To estimate the correlation between measurement errors (vt, ηt), we set the elements (3, 4) and (4, 3) of the covariance matrix H (see Equation 15) to be ρvησvση. We appropriately constrain the value of ρvη, between ± 1 by estimating a parameter κ ∈ (−∞, ∞) such that ρvη, = 2f(κ) − 1, where f(κ) = eκ/(1+ eκ). The estimated
Conclusion
Advertising variables such as awareness, attitudes, recall, or GRPs can be measured only approximately. The unreliability of measured variables induces substantial bias in OLS estimates, and therefore it becomes difficult to discern the true effectiveness of advertising when data are noisy. Consequently, advertisers are likely to either under- or overspend on advertising. It is therefore imperative to account for measurement errors when dynamic advertising models are estimated. Although the existing EIV approach incorporates measurement errors into its estimation procedure, it ignores the dynamic aspects of advertising response, and therefore the bias in EIV estimates persists. Thus, these existing approaches are not adequate to control for measurement errors in dynamic advertising models, and therefore we have proposed two new approaches.
The DLS approach uses wavelet shrinkage to remove measurement noise from the data before OLS is applied to estimate parameters. This approach successfully reduces the parameter bias, as is shown in our simulation studies. The MKF approach jointly models the effects of measurement errors as well as the dynamic aspects of advertising response, eliminating the parameter bias asymptotically. We emphasize that these conclusions are valid when advertisers know the correct functional form, proper lag specification, the issues of temporal aggregation, and the distribution of errors; then our procedures take care of the remaining source of bias: presence of measurement errors.
Both approaches can estimate the extent of measurement noise in commercial advertising data. In addition, the MKF approach provides information on the statistical significance of the noise level. However, the DLS approach does not offer such a significance test. This is because the use of wavelets in statistics is a recent development (e.g., the pioneering article by Donoho and Johnstone appeared in 1994). Consequently, asymptotic theory for DLS estimators covers point estimation (Cai, Naik, and Tsai 1997), and the issue of statistical inference needs further investigation.
Guidelines for Using DLS and MKF Estimators
If no measurement noise exists, the use of OLS is appropriate. In practice, because measurement noise is usually present, we recommend that advertisers routinely use the DLS approach because it will perform better than OLS and enable them to estimate the noise-to-signal ratio. If the noise-to-signal ratio is less than 20%, DLS is as effective as MKF; otherwise, the MKF approach is recommended. In any case, the EIV approach is not appropriate for estimating dynamic models when data are noisy.
Advertisers also can use the optimal MKF approach to estimate the extent of measurement noise in empirical data and can use this information to negotiate the pricing of market research information. We emphasize that this endeavor involves a method-based judgment on the quality of data. Therefore, advertisers and/or market research firms may want to seek a second opinion to cross-check the magnitude of estimates and achieve convergent validity (Brinberg and McGrath 1985, p. 122). The availability of multiple methods to permit such analyses is especially valuable when the underlying theories are quite different. 5 Therefore, DLS plays an important role as a meaningful alternative, especially because we know EIV is biased and is not stable for estimating dynamic advertising models. Thus, in practice, we envisage the use of DLS and MKF approaches in a complementary way.
Sarvary and Parker (1997) show theoretically that two expert opinions are complements rather than substitutes when there is a low correlation between the two sources of information. Here, “expert opinion” is the output from these procedures (DLS, MKF) and the “source of information” is the underlying statistical theory (wavelets, Kalman filtering).
Issues for Further Research
We have focused here on the Nerlove–Arrow dynamics of goodwill formation and the AR(1) model of inertia in spending decisions, consistent with the recent marketing literature (Dekimpe and Hanssens 1995; Naik, Mantrala, and Sawyer 1998). First, future studies may apply the proposed methods to other models of advertising response (e.g., the Lanchester model; see Chintagunta and Vilcassim 1992; Erickson 1991, 1992; Fruchter and Kalish 1997) and managerial spending decisions (e.g., AR[p], ARMA[p,q]). Second, the role of measurement errors in other marketing-mix variables (e.g., price) needs investigation; attraction models provide a useful framework to study this problem (see Cooper and Nakanishi 1988). Third, a significance test for the DLS estimate of measurement noise level is required. Fourth, theoretical properties of MKF estimators when the mean function involves aberrant time series (i.e., cycles, discontinuities, and sharp jumps) need verification. Fifth, the estimation of cointegrated time series models with EIV is an open topic. Sixth, biases due to misspecification of models need investigation (e.g., White 1982).
In conclusion, given the millions of dollars of advertising expenditure, we believe that the potential savings from optimizing the budgeting decision will far outweigh the costs of implementing the proposed methods. We hope that advertisers and market research firms use these approaches to improve their marketing practices.
Footnotes
The Effects of Parameter Bias
This appendix shows the effects of parameter bias on optimal advertising spending and profit. Let α denote the bias in estimating the true forgetting rate δi, so that the estimated parameter
To determine the effect of parameter bias, we examine the signs of
Thus, the estimated advertising spending is understated (overstated) and the estimated profit is overstated (understated) as the positive (negative) parameter bias increases. When δ1 ≠ δ2, the algebraic expressions for
Derivation of the State-Space Form
This appendix shows how to obtain the state-space form, consisting of the observation Equation 15 and transition Equation 16. We suppress the index i for the two firms for the sake of notational simplicity.
To obtain the transition Equation 16, consider the following change of variables:
and
Then we substitute Equations B1 and B2 in model Equations 8 and 14 given in the article, respectively, to get
and
Now lead the Equation B1 by one time period and then substitute Equation B3 in the resulting right-hand side as shown:
Therefore,
Similarly, lead Equation B2 by one time period and substitute Equation B4 in the right-hand side to get
Therefore,
Now substitute Equation B4 into Equation B5 so that the right-hand side is expressed in terms of the new variables. Thus,
This equation is the transition Equation 16 given in the article.
To obtain the observation Equation 15, we substitute Equations B3 and B4 in Equation 7a given in the article. Thus, we get
and thus get
Moments of the Conditional Density f(Y t |I t − 1 )
In this appendix, we show that distribution of Yt given It–1 is normal for all t, then derive the conditional mean and covariance expressions, and finally state the estimation procedure for the MKF estimator.
The observation Equation 15 can be expressed generally as
where
Similarly, the transition Equation 16 can be written as
where
In addition, the error terms ωt and
where
It is important to note that the matrix S arises because the error terms (εt, at)′ are common to both the observation and transition equations (i.e., Equations C1 and C2).
To show normality of Yt|It − 1, we note that both the observation and transition equations (see Equations C1 and C2) are linear in the state variable αt and the error terms (ωt,
Let Ȳt and Ft denote the mean and covariance of Yt|It–1, respectively; that is, Yt|It–1 ∼ N(Ȳt, Ft). To obtain the mean, we take the conditional expectation of the observation equation:
where at|t − 1 denotes the mean of σt given It − 1, which is to be determined. Similarly, to obtain the covariance of Yt|It − 1, we note that
where Pt|t − 1 denotes the covariance of αt given It − 1, which is to be determined. Next, we seek the expressions for obtaining at + 1|t and Pt+1|t after observing data Yt. That is, we determine the mean and covariance of state variable αt + 1 given information until It = Yt ∪ It − 1.
Following the standard filtering literature (Lewis 1986, pp. 122–23), we now write the conditional mean and co-variance of αt+ 1|It as follows:
where Kt = [TPt|t - 1T′ + eSc'][zPt|t − 1z' + cQc']–1 is the Kalman gain factor. These are known as the Kalman filter recursions, which provide the closed-form expressions to update optimally the prior distribution αt|It − 1 after the current information Yt is received.
We initiate the previous recursive process by assuming that a0 has a diffused prior distribution with mean μ0; that is, a0| − 1 = μ0, and P0| − 1 = cI, where c is a large constant. Then we iterate Equation C6 over t = 1, 2, 3, …, T to obtain at + 1|t and Pt + 1|t from the knowledge of at|t − 1, Pt|t − 1, and observed data Yt in period t. Next, we obtain the moments of Yt|It −1 by using Equations C4 and C5. Using the moments of Yt|It − 1, we compute the likelihood function given in Equation 17. Maximizing the likelihood function, we obtain the MKF estimates. We also obtain the standard errors of MKF estimates by evaluating the information matrix at the estimated parameter values (see Harvey 1994, p. 140).